【Python爬虫】Python爬取喜马拉雅,爬虫教程!

一、思路设计
(1)分析网页

在喜马拉雅主页找到自己想要的音频,得到目标URL:https://www.ximalaya.com/qinggan/321787/

通过分析页面的网络抓包,最终的到一个比较有用的json数据包
通过分析,得到了发送json数据包的一个有用的API接口:https://www.ximalaya.com/revision/play/album?albumId=321787&pageNum=2
其中album为主播的ID在页面url中有显示,pageNum为json数据包的“页数”。每个json数据包有30个json数据
(2)设计代码
向服务器发送请求 ----> 得到json数据包 ----> 分析json数据包 ----> 提取json数据包中的有用数据 ----> 存储到本地MongoDB数据库
二、代码实例
代码共分为两部分,执行脚本(ximalaya.py)和配置文件(config_ximalaya.py)
ximalaya.py
1 # -*- coding:utf-8; -*-2 # Author : Bingnan Huo3 # Create : 2018-12-064 import os5 import time6 import json7 import requests8 9 from threading import Thread
10 from datetime import datetime
11 from pymongo import MongoClient
12 from config_xiamalaya import *
13
14 def getWorkTimeNow():
15 '''Acquire work time '''
16 t = datetime.now()
17 year = t.year
18 month = t.month
19 day = t.day
20 hour = t.hour
21 minute = t.minute
22 time_str = "[%s-%s-%s-%s:%s]"%(str(year),
23 str(month),
24 str(day),
25 str(hour),
26 str(minute)
27 )
28 return time_str
29
30 def getJsonData(userID,page):
31 '''Get target server json data'''
32 count = 0
33 pa = {"albumId":userID,"pageNum":page}
34 while(ERROR):
35 if count > 10:
36 return False
37 try:
38 ret = requests.get(url=INDEXURL,params=pa,headers=HEADERS,timeout=30,verify=True,proxies=None)
39 ret.raise_for_status()
40 except Exception as e:
41 count += 1
42 print(getWorkTimeNow(),end='')
43 print(" [INFO] Retry...")
44 continue
45 else:
46 ret.encoding = ret.apparent_encoding
47 return ret.text
48
49 def analyseJsonData(jsonData):
50 '''Analyse json data and save into MongoDB'''
51 if jsonData:
52 client = MongoClient()
53 print(getWorkTimeNow() + " [INFO] Connected to MongoDB!")
54 db = client.ximalaya# Create DataBase
55 print(getWorkTimeNow() + " [INFO] Create new database!")
56 table = getattr(db,TABLENAME)# Create Table
57 print(getWorkTimeNow() + " [INFO] Create new table --> %s" %(TABLENAME))
58 dict_obj = json.loads(jsonData)
59 data = dict_obj["data"]# Json attr data
60 content = data["tracksAudioPlay"]# json content
61 for i in content:
62 tmp_dict = {'序号':None,'名称':None,'Url':None,'源':None,'状态':False,'时长':None,}
63 tmp_dict['序号'] = i['index']
64 tmp_dict['名称'] = i['trackName']
65 tmp_dict['Url'] = "https://www.ximalaya.com" + i['trackUrl']
66 tmp_dict['源'] = i['src']
67 if i['isPaid']:
68 tmp_dict['状态'] = True
69 tmp_dict['时长'] = i['duration']
70 table.insert_one(tmp_dict)
71 print(getWorkTimeNow() + " [INFO] Insert one data!")
72
73
74 def DBStart(dbpath):
75 '''start MongoDB client'''
76 status = os.system("start mongod --dbpath " + dbpath)
77 if not status:
78 print(getWorkTimeNow() + " [INFO] DataBase start!")
79 return True
80 else:
81 print(getWorkTimeNow() + " [INFO] DataBase Failed...")
82 return False
83 def execute(user_id,page):
84 json_data = getJsonData(user_id, page)
85 analyseJsonData(json_data)
86
87 def main():
88 DBStart(DBPATH)
89 for page in PAGECONTIANER:
90 execute(USERID, str(page))
91
92
93
94
95 if __name__ == "__main__":
96 main()
config_ximalaya.py
1 # -*- coding:utf-8 -*-2 # ximalaya.py -- config3 import time4 5 def getUnixTime():6 t = time.time()7 return str(int(t))8 9
10
11 INDEXURL = " https://www.ximalaya.com/revision/play/album"
12
13 ERROR = True
14
15 HEADERS = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:63.0) Gecko/20100101 Firefox/63.0",
16
17
18 }
19 """
20 Cookie:x_xmly_traffic=utm_source%253A%2526utm_medium%253A%2526utm_campaign%253A%2526utm_content%253A%2526utm_term%253A%2526utm_from%253A;
21 device_id=xm_1544076474056_jpc79kg8f1h3u6;
22 Hm_lvt_4a7d8ec50cfd6af753c4f8aee3425070=1544076479;
23 Hm_lpvt_4a7d8ec50cfd6af753c4f8aee3425070=1544076479
24 API : https://www.ximalaya.com/revision/play/album?albumId=321787&pageNum=1
25
26 """
27 COOKIE = {"x_xmly_traffic":"utm_source%253A%2526utm_medium%253A%2526utm_campaign%253A%2526utm_content%253A%2526utm_term%253A%2526utm_from%253A",
28 "device_id":"xm_1544076474056_jpc79kg8f1h3u6",
29 "Hm_lvt_4a7d8ec50cfd6af753c4f8aee3425070":getUnixTime(),
30 "Hm_lpvt_4a7d8ec50cfd6af753c4f8aee3425070":getUnixTime()
31 }
32
33 DBPATH = "D:\\MongoDB\\data\\db"
34
35 TABLENAME = "Test_321787_02"
36
37 PAGECONTIANER = [i for i in range(1,10)]
38
39 USERID = "321787"
三、执行结果
最终的数据插入到了本地的MongoDB数据库
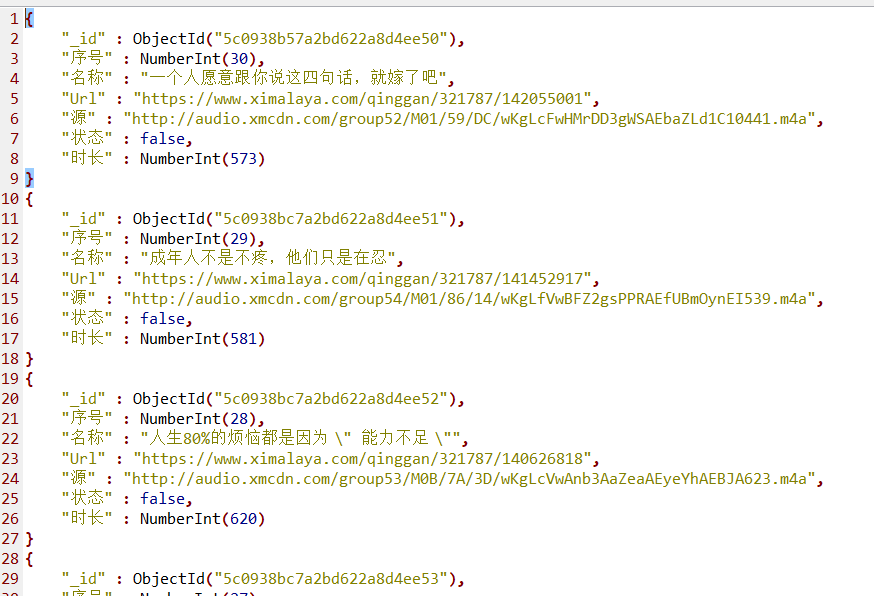
由于MongoDB为NoSQL型数据库,该数据库采用BOSN数据类型(json加强版)进行存储
在RoboMongo中也可以用MySQL数据库的表形式进行显示
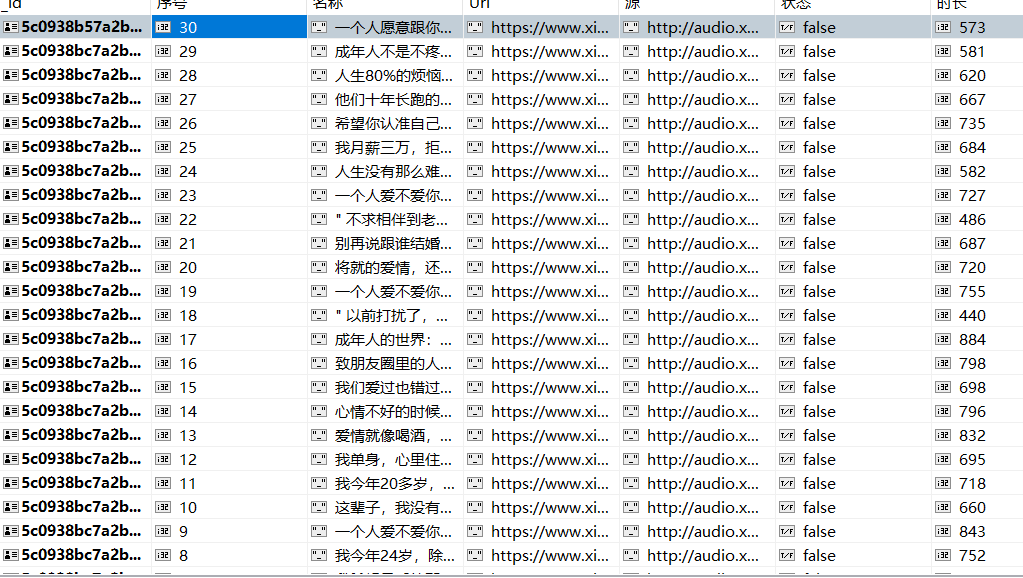
最后:如果你对Python感兴趣,想要学习Python,希望可以帮到你,一起加油!以上是给大家分享的Python全套学习资料,都是我自己学习时整理的:
一、Python所有方向的学习路线
Python所有方向路线就是把Python常用的技术点做整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

二、学习软件
工欲善其事必先利其器。学习Python常用的开发软件都在这里了,还有环境配置的教程,给大家节省了很多时间。

三、全套PDF电子书
书籍的好处就在于权威和体系健全,刚开始学习的时候你可以只看视频或者听某个人讲课,但等你学完之后,你觉得你掌握了,这时候建议还是得去看一下书籍,看权威技术书籍也是每个程序员必经之路。
四、入门学习视频全套
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了。
五、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
**学习资源已打包,需要的小伙伴可以戳这里:【学习资料】
相关文章:
【Python爬虫】Python爬取喜马拉雅,爬虫教程!
一、思路设计 (1)分析网页 在喜马拉雅主页找到自己想要的音频,得到目标URL:https://www.ximalaya.com/qinggan/321787/ 通过分析页面的网络抓包,最终的到一个比较有用的json数据包 通过分析,得到了发送json…...

基于Jmeter的分布式压测环境搭建及简单压测实践
写在前面 平时在使用Jmeter做压力测试的过程中,由于单机的并发能力有限,所以常常无法满足压力测试的需求。因此,Jmeter还提供了分布式的解决方案。本文是一次利用Jmeter分布式对业务系统登录接口做的压力测试的实践记录。按照惯例࿰…...

IDEA常用代码模板
在 IntelliJ IDEA 中,常用代码模板可以帮助你快速生成常用的代码结构和模式。以下是一些常用的代码模板及其使用方法: 动态模板(Live Templates) psvm:生成 public static void main(String[] args) 方法。sout:生成 System.out.println(); 语句。soutv:生成 System.ou…...
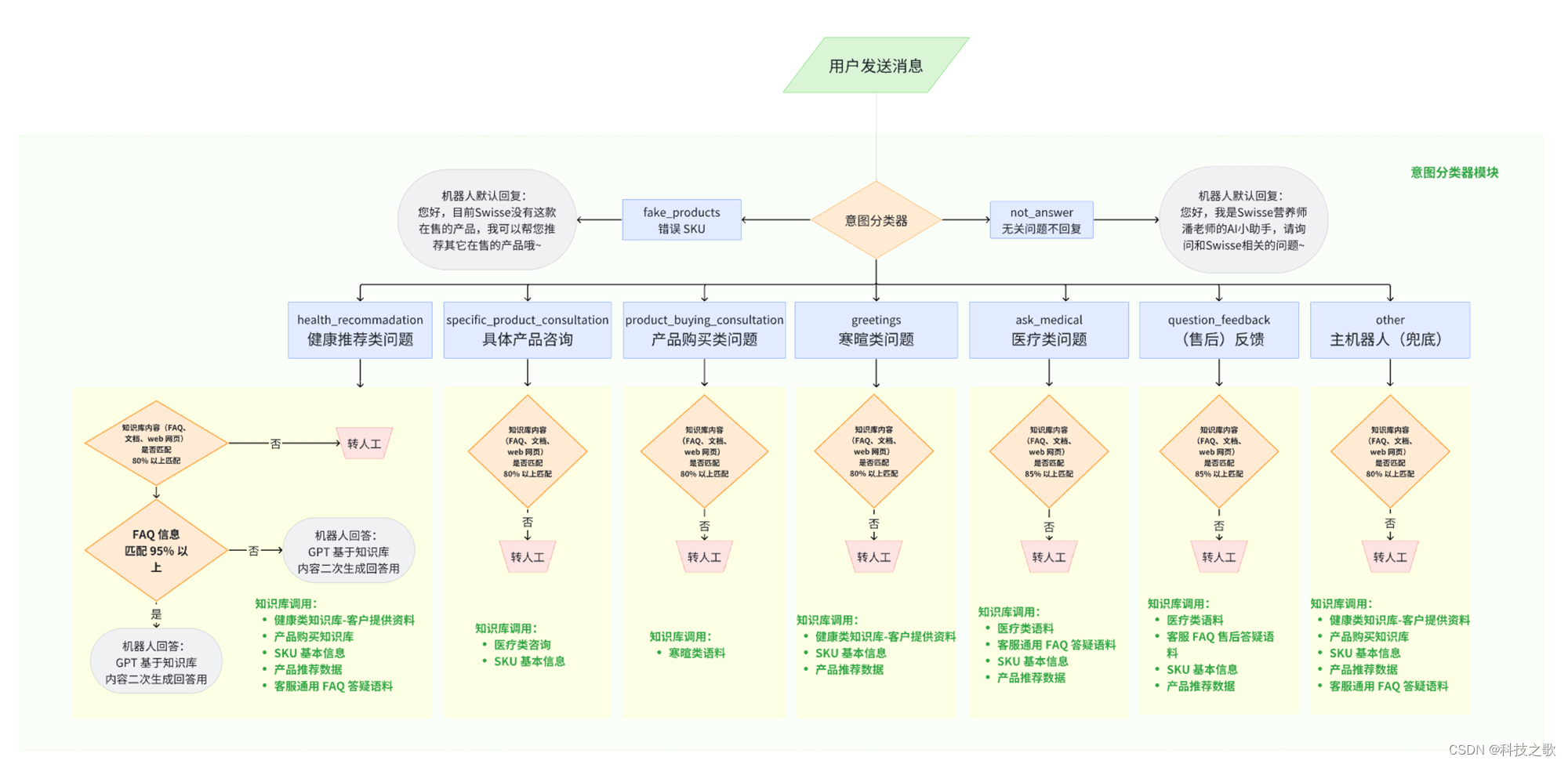
基于大语言模型的多意图增强搜索
随着人工智能技术的蓬勃发展,大语言模型(LLM)如Claude等在多个领域展现出了卓越的能力。如何利用这些模型的语义分析能力,优化传统业务系统中的搜索性能是个很好的研究方向。 在传统业务系统中,数据匹配和检索常常面临…...
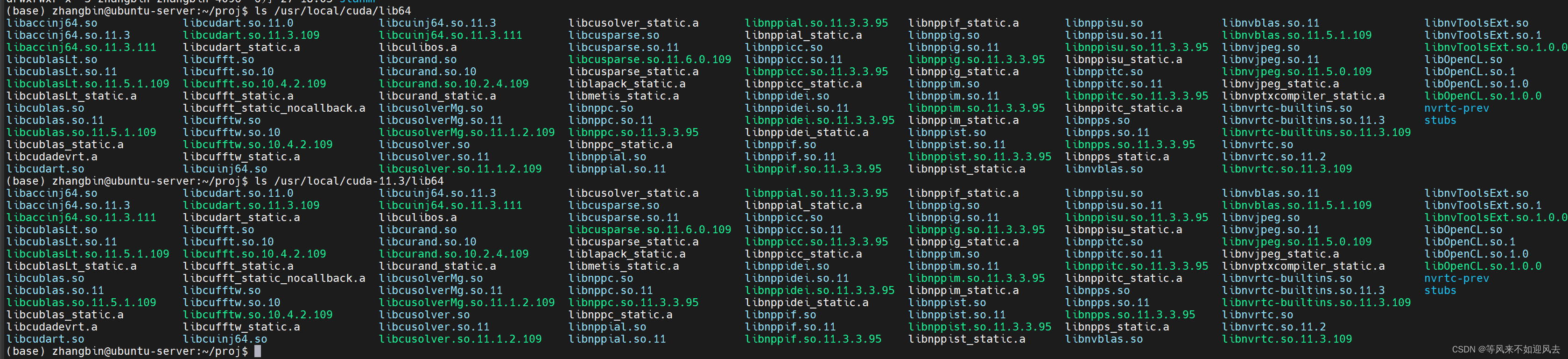
【ai】ubuntu18.04 找不到 nvcc --version问题
nvcc --version显示command not found问题 这个是cuda 库: windows安装了12.5 : 参考大神:解决nvcc --version显示command not found问题 原文链接:https://blog.csdn.net/Flying_sfeng/article/details/103343813 /usr/local/cuda/lib64 与 /usr/local/cuda-11.3/lib64 完…...

深入了解DDoS攻击及其防护措施
深入了解DDoS攻击及其防护措施 分布式拒绝服务(Distributed Denial of Service,DDoS)攻击是当今互联网环境中最具破坏性和普遍性的网络威胁之一。DDoS攻击不仅危及企业的运营,还可能损害其声誉,造成客户信任度的下降。…...

【面试系列】产品经理高频面试题及详细解答
欢迎来到我的博客,很高兴能够在这里和您见面!欢迎订阅相关专栏: ⭐️ 全网最全IT互联网公司面试宝典:收集整理全网各大IT互联网公司技术、项目、HR面试真题. ⭐️ AIGC时代的创新与未来:详细讲解AIGC的概念、核心技术、…...

前端特殊字符数据,后端接收产生错乱,前后端都需要处理
前端: const data {createTime: "2024-06-11 09:58:59",id: "1800346960914579456",merchantId: "1793930010750218240",mode: "DEPOSIT",channelCode: "if(amount > 50){iugu2pay;} else if(amount < 10){iu…...

力扣热100 哈希
哈希 1. 两数之和49.字母异位词分组128.最长连续序列 1. 两数之和 题目:给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 target 的那 两个 整数,并返回它们的数组下标。你可以假设每种输入只会对应一个答案。…...
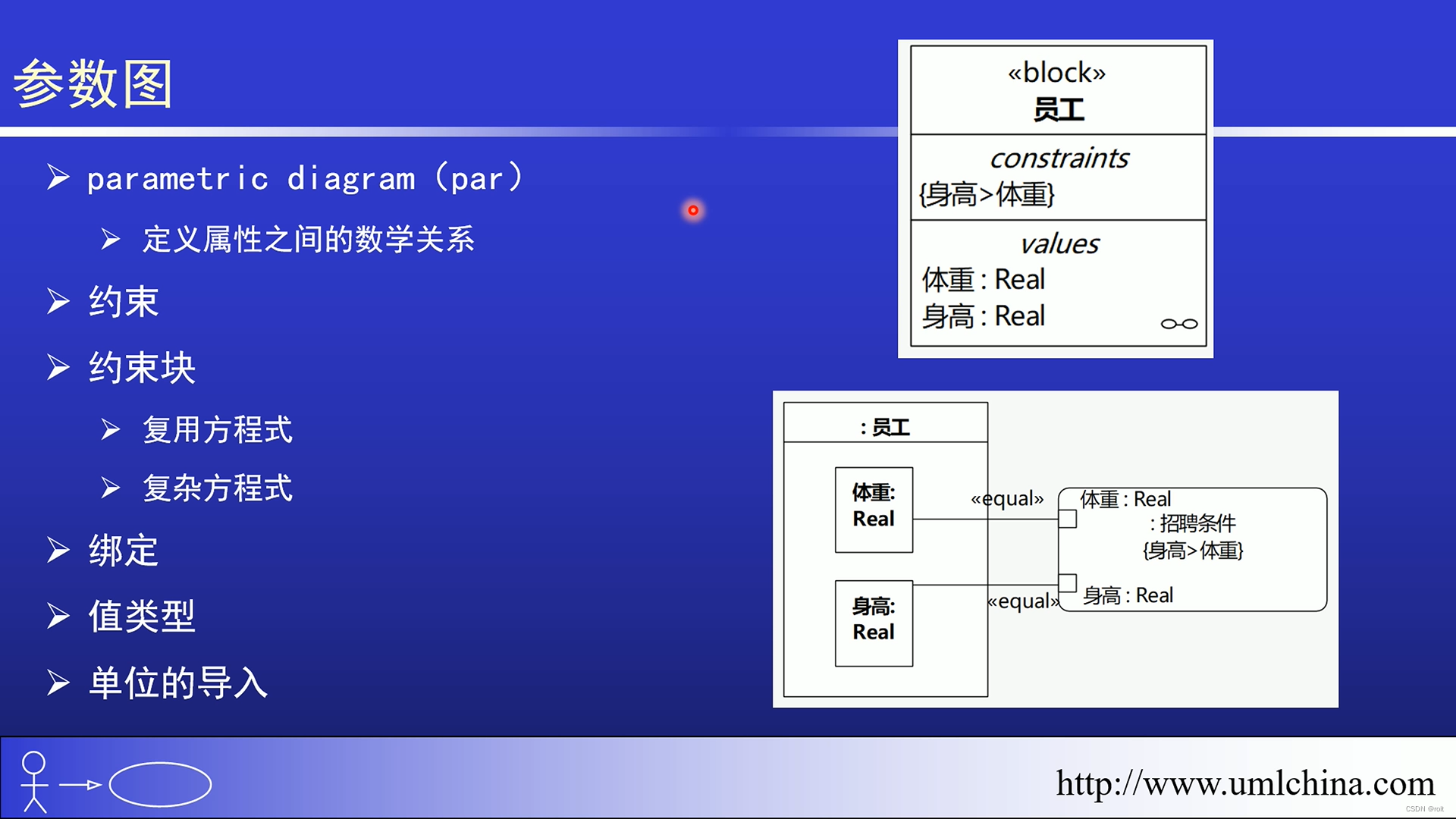
[图解]SysML和EA建模住宅安全系统-05-参数图
1 00:00:01,140 --> 00:00:03,060 这是实数没错,这是分钟 2 00:00:03,750 --> 00:00:07,490 但是你在这里选,选不了的 3 00:00:07,500 --> 00:00:09,930 因为它这里不能够有那个 4 00:00:11,990 --> 00:00:13,850 但是我们前面这里 5 00…...

JavaScript——对象的创建
目录 任务描述 相关知识 对象的定义 对象字面量 通过关键字new创建对象 通过工厂方法创建对象 使用构造函数创建对象 使用原型(prototype)创建对象 编程要求 任务描述 本关任务:创建你的第一个 JavaScript 对象。 相关知识 JavaScript 是一种基于对象&a…...

大二暑假 + 大三上
希望,暑假能早睡早起,胸围达到 95,腰围保持 72,大臂 36,小臂 32,小腿 38🍭🍭 目录 🍈暑假计划 🌹每周进度 🤣寒假每日进度😂 &…...

C语言使用先序遍历创建二叉树
#include<stdio.h> #include<stdlib.h>typedef struct node {int data;struct node * left;struct node * right; } Node;Node * createNode(int val); Node * createTree(); void freeTree(Node * node);void preOrder(Node * node);// 先序创建二叉树 int main()…...

如何在服务器中安装anaconda
文章目录 Step1: 下载 Anaconda方法1:下载好sh文件上传到服务器安装方法2:在线下载 Step2: 安装AnacondaStep3: 配置环境变量Step 4: 激活AnacondaStep4: 检验安装是否成功 Step1: 下载 Anaconda 方法1:下载好sh文件上传到服务器安装 在浏览…...

夸克网盘拉新暑期大涨价!官方授权渠道流程揭秘
夸克网盘拉新暑期活动来袭,价格大涨!从7月1日开始持续两个月,在这两个月里夸克网盘拉新的移动端用户,一个从原来的5元涨到了10元。这对做夸克网盘拉新的朋友来说,真的是福利的。趁着暑期时间多,如果有想做夸…...
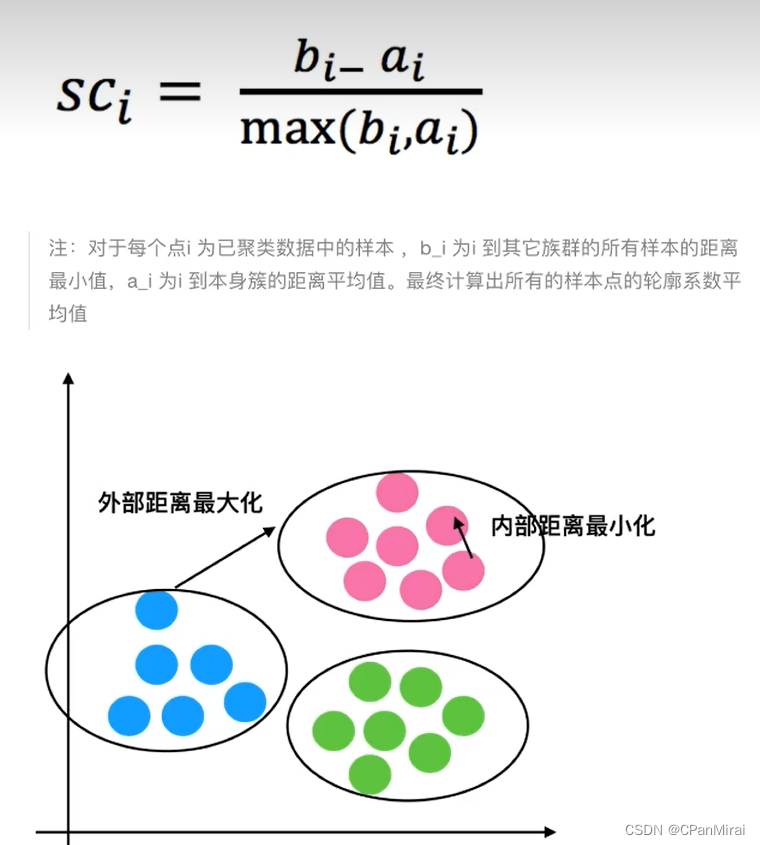
机器学习(三)
机器学习 4.回归和聚类算法4.1 线性回归4.1.1 线性回归的原理4.1.2 线性回归的损失和优化原理 4.2 欠拟合与过拟合4.2.1 定义4.2.2 原因以及解决方法4.2.3 正则化 4.3 线性回归改进-岭回归4.3.1 带L2正则化的线性回归-岭回归4.3.2 API 4.4 分类算法-逻辑回归与二分类4.4.1 定义…...
)
PostgreSQL 基本SQL语法(二)
1. SELECT 语句 1.1 基本 SELECT 语法 SELECT 语句用于从数据库中检索数据。基本语法如下: SELECT column1, column2, ... FROM table_name; 例如,从 users 表中检索所有列的数据: SELECT * FROM users; 1.2 使用 WHERE 条件 WHERE 子…...

linux 控制台非常好用的 PS1 设置
直接上代码 IP$(/sbin/ifconfig eth0 | awk /inet / {print $2}) export PS1"\[\e[35m\]^o^\[\e[0m\]$ \[\e[31m\]\t\[\e[0m\] [\[\e[36m\]\w\[\e[0m\]] \[\e[32m\]\u\[\e[0m\]\[\e[33m\]\[\e[0m\]\[\e[34m\]\h(\[\e[31m\]$IP\[\e[m\])\[\e[0m\]\n\[\e[35m\].O.\[\e[0m\]…...
【紫光同创盘古PGX-Nano教程】——(盘古PGX-Nano开发板/PG2L50H_MBG324第十二章)Wifi透传实验例程说明
本原创教程由深圳市小眼睛科技有限公司创作,版权归本公司所有,如需转载,需授权并注明出处(www.meyesemi.com) 适用于板卡型号: 紫光同创PG2L50H_MBG324开发平台(盘古PGX-Nano) 一:…...

详述乙级资质企业在城市综合管廊与隧道一体化设计中的挑战与机遇
挑战 1. 技术与设计复杂性 城市综合管廊与隧道项目往往涉及复杂的地质条件、地下水位、周边建筑物影响等因素,要求企业具备高水平的岩土工程、结构工程和流体力学等专业知识。此外,一体化设计需要跨学科合作,协调不同系统的兼容性ÿ…...

OpenLayers 可视化之热力图
注:当前使用的是 ol 5.3.0 版本,天地图使用的key请到天地图官网申请,并替换为自己的key 热力图(Heatmap)又叫热点图,是一种通过特殊高亮显示事物密度分布、变化趋势的数据可视化技术。采用颜色的深浅来显示…...

多模态2025:技术路线“神仙打架”,视频生成冲上云霄
文|魏琳华 编|王一粟 一场大会,聚集了中国多模态大模型的“半壁江山”。 智源大会2025为期两天的论坛中,汇集了学界、创业公司和大厂等三方的热门选手,关于多模态的集中讨论达到了前所未有的热度。其中,…...

C++_核心编程_多态案例二-制作饮品
#include <iostream> #include <string> using namespace std;/*制作饮品的大致流程为:煮水 - 冲泡 - 倒入杯中 - 加入辅料 利用多态技术实现本案例,提供抽象制作饮品基类,提供子类制作咖啡和茶叶*//*基类*/ class AbstractDr…...

突破不可导策略的训练难题:零阶优化与强化学习的深度嵌合
强化学习(Reinforcement Learning, RL)是工业领域智能控制的重要方法。它的基本原理是将最优控制问题建模为马尔可夫决策过程,然后使用强化学习的Actor-Critic机制(中文译作“知行互动”机制),逐步迭代求解…...

Golang 面试经典题:map 的 key 可以是什么类型?哪些不可以?
Golang 面试经典题:map 的 key 可以是什么类型?哪些不可以? 在 Golang 的面试中,map 类型的使用是一个常见的考点,其中对 key 类型的合法性 是一道常被提及的基础却很容易被忽视的问题。本文将带你深入理解 Golang 中…...

Java 8 Stream API 入门到实践详解
一、告别 for 循环! 传统痛点: Java 8 之前,集合操作离不开冗长的 for 循环和匿名类。例如,过滤列表中的偶数: List<Integer> list Arrays.asList(1, 2, 3, 4, 5); List<Integer> evens new ArrayList…...
` 方法)
深入浅出:JavaScript 中的 `window.crypto.getRandomValues()` 方法
深入浅出:JavaScript 中的 window.crypto.getRandomValues() 方法 在现代 Web 开发中,随机数的生成看似简单,却隐藏着许多玄机。无论是生成密码、加密密钥,还是创建安全令牌,随机数的质量直接关系到系统的安全性。Jav…...

无法与IP建立连接,未能下载VSCode服务器
如题,在远程连接服务器的时候突然遇到了这个提示。 查阅了一圈,发现是VSCode版本自动更新惹的祸!!! 在VSCode的帮助->关于这里发现前几天VSCode自动更新了,我的版本号变成了1.100.3 才导致了远程连接出…...
)
python爬虫:Newspaper3k 的详细使用(好用的新闻网站文章抓取和解析的Python库)
更多内容请见: 爬虫和逆向教程-专栏介绍和目录 文章目录 一、Newspaper3k 概述1.1 Newspaper3k 介绍1.2 主要功能1.3 典型应用场景1.4 安装二、基本用法2.2 提取单篇文章的内容2.2 处理多篇文档三、高级选项3.1 自定义配置3.2 分析文章情感四、实战案例4.1 构建新闻摘要聚合器…...

HBuilderX安装(uni-app和小程序开发)
下载HBuilderX 访问官方网站:https://www.dcloud.io/hbuilderx.html 根据您的操作系统选择合适版本: Windows版(推荐下载标准版) Windows系统安装步骤 运行安装程序: 双击下载的.exe安装文件 如果出现安全提示&…...