【Redis】Redis 主从复制 + 读写分离
Redis 主从复制 + 读写分离
- 1. Redis 主从复制 + 读写分离介绍
- 1.1 从数据持久化到服务高可用
- 1.2 主从复制
- 1.3 如何保证主从数据一致性?
- 1.4 为何采用读写分离模式?
- 2. 一主两从环境准备
- 2.1 配置文件
- 2.2 启动 Redis
- 3. 主从复制原理
- 3.1 全量同步
- 3.1.1 建立连接
- 3.1.2 主库同步数据给从库
- 3.1.3 发送新写命令到从库
- 3.2 增量同步
- 3.2.1 主从网络断开之后的同步方式
- 3.2.2 repl_backlog_buffer
- 3.2.3 基于长连接的命令传播
- (1)主 -> 从:PING
- (2)从 -> 主:REPLCONF ACK
- 4. 总结
1. Redis 主从复制 + 读写分离介绍
1.1 从数据持久化到服务高可用
Redis 的数据持久化技术,可以解决机器宕机,数据丢失的问题,并没有从根本上解决 Redis 的可用性。我们需要的是解决 Redis 的高可用,减少甚至避免 Redis 服务发生宕机的可能,来从根本上解决数据丢失问题。
如果对 Redis 如何进行数据持久化不是很了解的同学,可以读一下:Redis 数据持久化:AOF和RDB
1.2 主从复制
目前实现Redis高可用的模式主要有三种: 主从模式、哨兵模式、集群模式。这篇文章我们来一起学习主从模式。
Redis 提供的主从模式,是通过复制的方式,将主服务器上的 Redis 的数据同步复制一份到从 Redis 服务器,这种做法很常见,MySQL 的主从也是这么做的。
主节点的 Redis 我们称之为 master,从节点的 Redis 我们称之为 slave,主从复制为单向复制,只能由主到从,不能由从到主。可以有多个从节点,比如1主2从甚至n从,从节点的多少根据实际的业务需求来判断。
1.3 如何保证主从数据一致性?
采取读写分离的模式:
-
读操作:
主、从库都可以执行,一般是在从库上读数据,对实时性和准确性有100%高真要求的部分业务,可以谨慎评估之后读主库; -
写操作:
只在主库上写数据,写完之后将写操作指令同步到从库。

1.4 为何采用读写分离模式?
你可以设想一下,不管是主库还是从库,都能接收客户端的写操作。那么,一个直接的问题就是:如果客户端对同一个数据(例如 k1)前后修改了三次,每一次的修改请求都发送到不同的实例上,在不同的实例上执行,那么,这个数据在这三个实例上的副本就不一致了(分别是 v1、v2 和 v3)。在读取这个数据的时候,就可能读取到旧的值。
如果我们非要保持这个数据在三个实例上一致,就要涉及到加锁、实例间协商是否完成修改等一系列操作,但这会带来巨额的开销,当然是不太能接受的。
而主从库模式一旦采用了读写分离,所有数据的修改只会在主库上进行,不用协调三个实例。主库有了最新的数据后,会同步给从库,这样,主从库的数据就是一致的。
那么,主从库同步是如何完成的呢?主库数据是一次性传给从库,还是分批同步?要是主从库间的网络断连了,数据还能保持一致吗?下面我们来一起学习。
2. 一主两从环境准备
2.1 配置文件
- 创建目录
mkdir -p /data/redis/master/data
mkdir -p /data/redis/slave1/data
mkdir -p /data/redis/slave2/data
- 主配置文件:
bind 0.0.0.0
port 6379
daemonize yes
requirepass "123456"
logfile "/usr/local/redis/log/redis1.log"
dbfilename "pointer1.rdb"
dir "/usr/local/redis/data"
appendonly yes
appendfilename "appendonly1.aof"
masterauth "123456"
- 两个从配置文件:
bind 0.0.0.0
port 6380
daemonize yes
requirepass "123456"
logfile "/usr/local/redis/log/redis2.log"
dbfilename "pointer2.rdb"
dir "/usr/local/redis/data"
appendonly yes
appendfilename "appendonly2.aof"# 从本机 6379 的 redis 实例复制数据,Redis 5.0 之前使用 slaveof
replicaof 8.129.113.233 6379
# 从节点开启只读模式(默认)
replica‐read‐only yes
# 从节点访问主节点的密码,和 requirepass ⼀样
masterauth "123456"
bind 0.0.0.0
port 6381
daemonize yes
requirepass "123456"
logfile "/usr/local/redis/log/redis3.log"
dbfilename "pointer3.rdb"
dir "/usr/local/redis/data"
appendonly yes
appendfilename "appendonly3.aof"# 从本机 6379 的 redis 实例复制数据,Redis 5.0 之前使用 slaveof
replicaof 8.129.113.233 6379
# 从节点开启只读模式(默认)
replica‐read‐only yes
# 从节点访问主节点的密码,和 requirepass ⼀样
masterauth "123456"
2.2 启动 Redis
# 启动主
./redis-server /data/redis/master/data/redis.conf
# 启动从
./redis-server /data/redis/slave1/data/redis.conf
# 启动从
./redis-server /data/redis/slave2/data/redis.conf
3. 主从复制原理
主从复制分两种:主从刚连接的时候,进⾏全量同步;全量同步结束后,进⾏增量同步。
-
全量同步 - 首次配置完成,主从库连接之后;
-
增量同步 - 全量同步结束后
- 准实时同步 - 主从正常运行期间;
- Append增量数据 + 准实时同步 - 主从库间网络断开重连。
3.1 全量同步
主从库第一次复制过程大体可以分为 3 个阶段:准备阶段(即建立连接准备)、主库同步数据到从库阶段、发送同步期间增量指令到从库的阶段。

3.1.1 建立连接
这个阶段的主要作用是建立主从之间的连接,连接成立之后,才能够做数据全量同步。主要包含如下步骤:
-
从节点的配置文件中的 replicaof 配置项中配置了主节点的 ip 和 port ,配置完成之后,从节点就知道要跟哪个主节点进行连接;
-
当连接成功之后,从库开启 replicaof 操作,同时发送
psync指令告诉主库,我准备开始同步了。命令包含了主库的 runID 和 复制进度 offset 两个参数;- runID:每个 Redis 实例启动都会自动生成一个唯一标识 ID,第一次主从复制,还不知道主库 runID,所以参数会默认设置为:?;
- offset:因为第一次复制,没有偏移量,所以默认设置为 -1,这样就默认从第1条指令开始复制;
-
主库收到 psync 命令后根据参数启动复制,使用
FULLRESYNC响应命令,同时带上两个参数:主库 runID 和主库目前的复制进度 offset,返回给从库; -
从库收到响应后,记录下这两个参数。
3.1.2 主库同步数据给从库
-
master 执行
bgsave命令生成 RDB 文件,并将文件发送给从库,从库收到 RDB 文件后保存到磁盘,清空当前 Redis 库中的数据,再将 RDB 文件数据加载到内存中。 -
同时主库为每一个 slave 开辟一块
replication buffer缓冲区记录,用于记录主库生成 RDB 文件后那段时间(那段时间的产生的写命令没有被记录到 RDB 文件中,但是主库又会源源不断的接收到新的请求指令,记录缓冲区是为了保证数据不丢失)产生的所有写指令。
3.1.3 发送新写命令到从库
-
在 主库同步数据给从库 整个初始化工作完成之后,继续执行从
replication buffer缓冲区发送过来的数据,避免数据断层。 -
主数据同步到从库的过程中,主库不会被阻塞,可以正常处理其他任意操作,这也是 Redis 保证高性能的必备条件。
-
replication buffer 缓冲区创建在 master 主库上,存放的数据是下面三个时间内 master 数据的所有写操作。
- master 执行 bgsave 生产 rdb 的期间的写操作;
- master 传输 rdb 文件到 slave 期间的写操作;
- slave 加载 rdb 文件将数据初始化到内存期间的写操作。

三个步骤完成了 Redis 主从的全量复制。这边需要注意的是,Redis 中的通信,无论是主库跟从库之间,还是与客户端之间的数据交互。本质上都是通过分配内存 buffer 来进行的,Master 会先把数据写到 buffer 中,再通过网络发送出去,从而完成数据交互。
RDB 文件作为二进制文件,无论是网络传输还是写入时的磁盘IO,效率都要比 AOF 高很多。同样的,从库进行数据恢复的时候,效率也会高一些。所以我们会选择 RDB 文件做同步而不是 AOF 模式。
3.2 增量同步
3.2.1 主从网络断开之后的同步方式
在网络断开之后或者从实例服务故障恢复之后,主从库会采用增量复制的方式继续同步,而不是全量同步的模式,这样会大大降低开销,提升效率。
增量复制: 就是指网络中断或者从库重启等情况后的复制,只将中断期间主节点执行的写命令发送给从节点,与全量复制相比更加高效。
3.2.2 repl_backlog_buffer
主从库重新连接之后可以实现增量复制。关键就在 repl_backlog_buffer 缓冲区上面。
因为 master 会将写指令操作记录在 repl_backlog_buffer 缓冲区中,并使用 master_repl_offset 记录 master 写入的位置偏移量,slave 则使用 slave_repl_offset 记录读的偏移量。master 新增写操作的时候,偏移量则会增加。从库持续执行同步的写指令后,slave_repl_offset 也会不断增加。一般情况下,这两个偏移量会保持同步,如下图左。
但是网络断开或者从库故障期间,主实例 Redis 一般会收到新的写操作命令,但从实例则暂停执行,所以 master_repl_offset 会大于 slave_repl_offset。如下图右。

需要注意的是,
repl_backlog_buffer并不是如图中显示的貌似无限队列的模式,而是一个类似环形数组,如果数组内容满了,就会从头开始覆盖前面的内容,因为给到的内存空间是有限的。
在主从之间重新连接之后,slave 会先发送 psync 命令给 master,同时将自己的 {runID,slave_repl_offset} 两个参数发送给 master。master 只需要把 master_repl_offset 与 slave_repl_offset 之间的命令同步给从库即可。增量复制的流程类似如下:
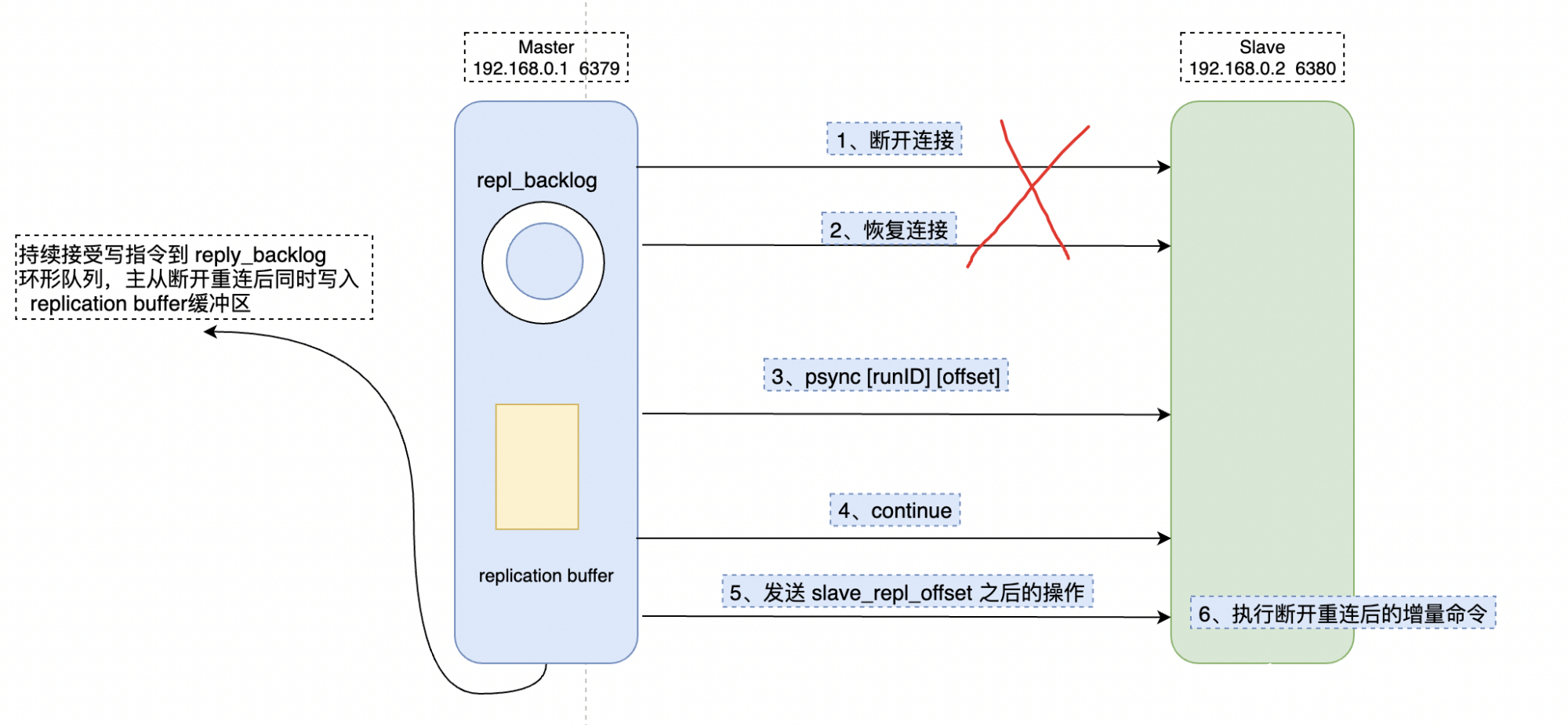
在配置repl_backlog_buffer 的时候,需要综合考虑各种因素,太大了会导致增量执行周期比较长,还不如RDB全量覆盖。太小了有可能从库还没读取到就被 Master 的新写操作覆盖了,那样也只能执行全量复制。
所以我们需要给出一个合理缓冲区size。一般有如下的计算公式共参考:repl_backlog_buffer_size = seconds * write_size_per_second
-
seconds:正常情况下从库断开,到重连主库所需的平均时间,秒为单位。
-
write_size_per_second:主库平均每秒产生的写命令数据量大小。
如:主服务器大约每秒产生 0.5MB 的写指令数据,而断开到重连一般需要 30s,那么缓冲区的大小就是 0.5 * 30s = 15 MB。
但是我们一般会保留一点buffer,比如预留 0.5 倍,那就是 : 1.5 * 15 MB = 22.5 MB 。
3.2.3 基于长连接的命令传播
上面的工作都是为了完成完整复制,那在完成全量复制之后,主从开始进入正常有序的同步了,具体应该怎么做呢?
主从完成全量复制之后,他们之间需要保持连接。当主库收到操作指令的时候,通过这个连接同步给从库,这个过程称之为:基于长连接的命令传播。
为了保证传播的有效性和稳定性,从节点采用心跳机制进行侦测,发送命令:PING 和 REPLCONF ACK。
(1)主 -> 从:PING
每隔指定的时间(比如 1 分钟,可配置),主节点会向从节点发送 PING 命令,侦测从节点有无超时来判断从节点的健康情况。
(2)从 -> 主:REPLCONF ACK
命令执行传播的阶段,从服务器默认会以每秒一次的频率,向主服务器发送命令,将复制的偏移量发送过去。
- REPLCONF ACK <replication_offset>
replication_offset 的属性指的是当前从实例服务器的复制偏移量。
-
从实例发送 REPLCONF ACK 命令对于主要实例,主要有以下作用:
-
检测主从服务器的网络通路是否正常。
-
辅助实现 min-slaves 选项,使用 Redis 的 min-slaves-to-write(少于n个从实例时,拒绝执行写命令) 和 min-slaves-max-lag(主从延迟大于等于n秒时,拒绝执行写命令)两个选项可以防止主服务器在不安全的情况下执行写命令。
-
检测命令丢失, 从节点发送了 slave_replication_offset,主节点会对比 master_replication_offset ,如果不一致,说明从节点数据缺失,主节点会从 repl_backlog_buffer 缓冲区中找到并推送缺失的数据。
-
4. 总结
主从复制的作用一个是为分担读写压力,均衡负载,另一个是为了保证部分实例宕机之后服务的持续可用性,所以 Redis 演变出主从架构和读写分离。
主从复制的步骤包括:建立连接的阶段、数据同步的阶段、基于长连接的命令传播阶段。
数据同步可以分为全量复制和部分复制,全量复制一般为第一次全量或者长时间主从连接断开。
命令传播阶段主从节点之间有 PING(主到从的的探测) 和 `REPLCONF ACK(从到主的ack应答) 命令,这种互相确认心跳的模式保证数据同步的稳定性。
主从模式是比较低级的可用性优化,要做到故障自动转移,异常预警,高保活,还需要更为复杂的哨兵或者集群模式。
相关文章:
【Redis】Redis 主从复制 + 读写分离
Redis 主从复制 读写分离1. Redis 主从复制 读写分离介绍1.1 从数据持久化到服务高可用1.2 主从复制1.3 如何保证主从数据一致性?1.4 为何采用读写分离模式?2. 一主两从环境准备2.1 配置文件2.2 启动 Redis3. 主从复制原理3.1 全量同步3.1.1 建立连接3…...

2023届秋招,鬼知道我经历了什么
仅记录个人经历,充满主观感受,甚至纯属虚构,仅供参考,杠就是你对 本想毕业再写,但是考虑到等毕业了,24秋招的提前批就快开始了,大概就来不及了,正好现在有点时间,陆陆续…...
ChatGPT助力校招----面试问题分享(一)
1 ChatGPT每日一题:期望薪资是多少 问题:面试官问期望薪资是多少,如何回答 ChatGPT:当面试官问及期望薪资时,以下是一些建议的回答方法: 1、调查市场行情:在回答之前,可以先调查一…...

CSS媒体查询@media (prefers-color-scheme:dark)判断系统白天黑夜模式
前言 在最近学习中突然看到了在媒体查询中prefers-color-scheme:dark监听的使用,然后就模仿里边写了个简单例子,代码如下: body {background-color: #f5f5f5;}media (prefers-color-scheme: dark) {body {background-color: #666;}}然后通过…...
运行YOLOv8实现识别
https://github.com/ultralytics/ultralyticshttps://docs.ultralytics.com/环境配置官方环境要求Python>3.7(我是python3.8也是可以用的) environment with PyTorch>1.7.这是ultralyticsCommand Line Interface命令行接口运行输入参数的格式yolo …...
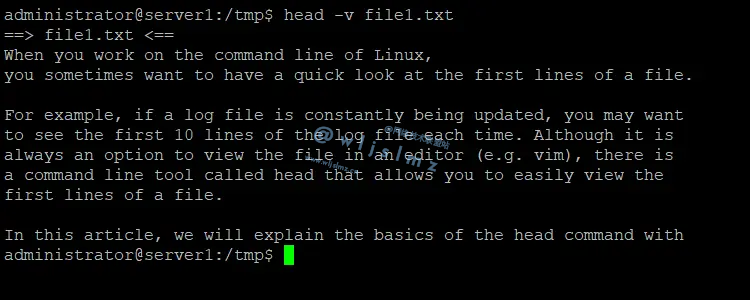
如何在Linux中优雅的使用 head 命令,用来看日志简直溜的不行
当您在 Linux 的命令行上工作时,有时希望快速查看文件的第一行,例如,有个日志文件不断更新,希望每次都查看日志文件的前 10 行。很多朋友使用文本编辑的命令是vim,但还有个命令head也可以让轻松查看文件的第一行。 在…...

Nginx.conf 配置详解
#安全问题,建议用nobody,不要用root. #user nobody; #worker数和服务器的cpu数相等是最为适宜 worker_processes 2; #work绑定cpu(4 work绑定4cpu) worker_cpu_affinity 0001 0010 0100 1000 #error_log path(存放路径) level(日志等级) path表示日志路径&…...

剖析NLP历史,看chatGPT的发展
1、NLP历史演进 1.1 NLP有监督范式 NLP里的有监督任务的范式,可以归纳成如下的样子。 输入是字词序列,中间一步关键的是语义表征,有了语义表征之后,然后交给下游的模型学习。所以预训练技术的发展,都是在围绕怎么…...

20个Python使用小技巧,建议收藏~
1、易混淆操作 本节对一些 Python 易混淆的操作进行对比。 1.1 有放回随机采样和无放回随机采样 import random random.choices(seq, k1) # 长度为k的list,有放回采样 random.sample(seq, k) # 长度为k的list,无放回采样1.2 lambda 函数的参数 …...

Kafka 主题管理
Kafka 主题管理创建主题查看主题修改主题内部主题异常主题删除失败创建主题 创建 Kafka 主题 create : 创建主题partitions : 主题的分区数replication-factor : 每个分区下的副本数 bin/kafka-topics.sh \ --bootstrap-server broker_host:port \ --create --topic my_topi…...
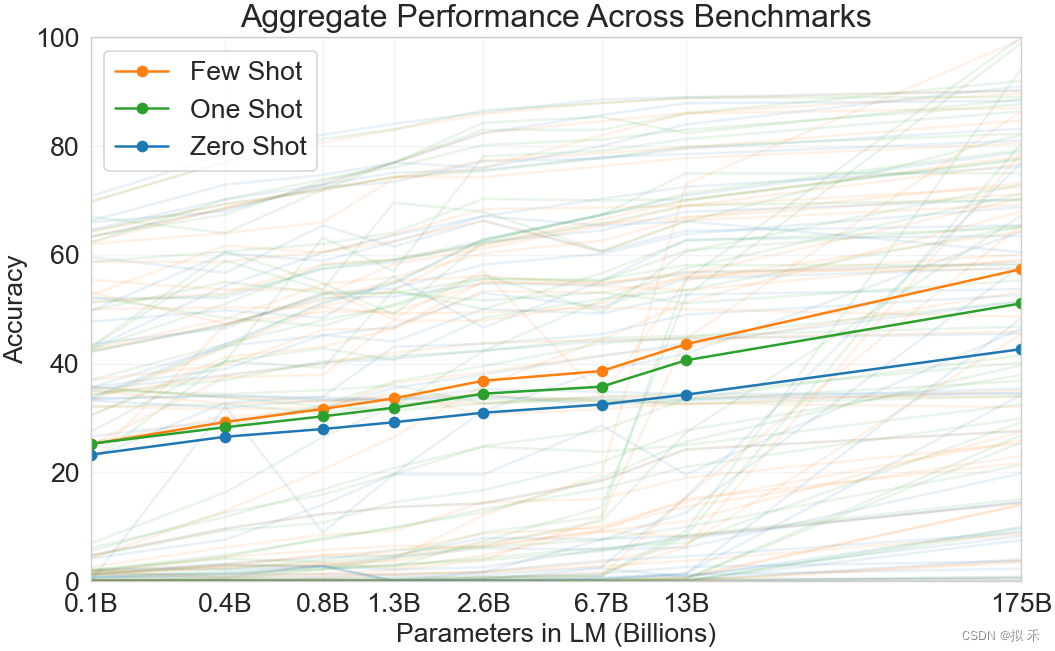
【深度学习】GPT系列模型:语言理解能力的革新
GPT-1🏡 自然语言理解包括一系列不同的任务,例如文本蕴涵、问答、语义相似度评估和文档分类。尽管大量的未标记文本语料库很充足,但用于学习这些特定任务的标记数据却很稀缺,使得判别式训练模型难以达到良好的表现。我们证明&…...

【Vue.js】全局状态管理模式插件vuex
文章目录全局状态管理模式Vuexvuex是什么?什么是“状态管理模式”?vuex的应用场景Vuex安装开始核心概念一、State1、单一状态树2、在 Vue 组件中获得 Vuex 状态3、mapState辅助函数二、Getter三、Mutation1、提交载荷(Payload)2、…...

JPA 之 Hibernate EntityManager 使用指南
Hibernate EntityManager 专题 参考: JPA – EntityManager常用API详解EntityManager基本概念 基本概念及获得 EntityManager 对象 基本概念 在使用持久化工具的时候,一般都有一个对象来操作数据库,在原生的Hibernate中叫做Session&…...
)
英语作文提示(持续更新)
星期(介词on)Monday星期一Tuesday星期二Wednesday星期三Thursday星期四Friday星期五Saturday星期六Sunday星期日月份(介词in)lunar calendar农历on the second day of the second lunar农历初二January1月February2月March3月Apri…...
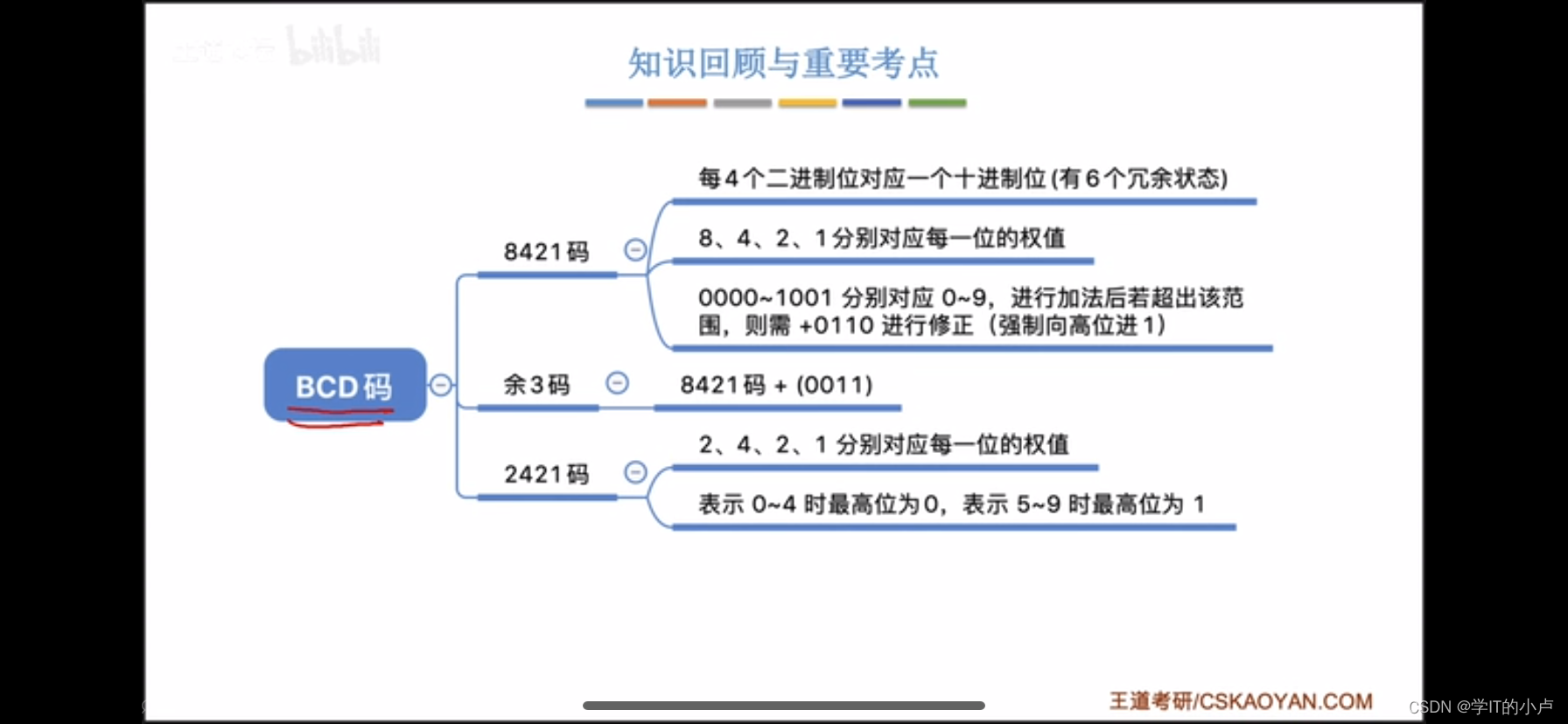
【计算机组成原理】计算机的性能指标、数据的表示和运算、BCD码和余3码
计算机组成原理(二) 计算机的性能指标: 存储器的性能指标: 存储器中,MAR为存储单元的个数 MDR为机械字长也就是存储单元的长度 存储器的大小MAR*MDR n为二进制位能表示出几种不同的状态呢? 2的n次方种不同的状态 CPU的性能指标…...
三天吃透MySQL八股文(2023最新整理)
本文已经收录到Github仓库,该仓库包含计算机基础、Java基础、多线程、JVM、数据库、Redis、Spring、Mybatis、SpringMVC、SpringBoot、分布式、微服务、设计模式、架构、校招社招分享等核心知识点,欢迎star~ Github地址:https://github.com/…...

队列_23约瑟夫问题+_24猫狗收容所
约瑟夫问题 n 个小孩围坐成一圈,并按顺时针编号为1,2,…,n,从编号为 p 的小孩顺时针依次报数,由1报到m ,当报到 m 时,该小孩从圈中出去,然后下一个再从1报数,当报到 m 时再出去。如此反复&#…...

gradle
Gradle环境介绍OpenJDK 17.0.5Gradle 7.6示例代码 fly-gradleGradle 项目下文件介绍如果你的电脑安装了 gradle,可以使用 gradle init 去初始化一个新的 gradle 工程,然后使用电脑安装的 gradle 去执行构建命令。但是每个开发电脑上的 gradle 版本不一样…...

[牛客]链表中倒数第k个结点
使用快慢指针法:两种思路:1.fast先向后走k-1次,slow再向后走1次,然后fast和slow同时向后走,当fast走到最后一个结点时,slow刚好在倒数第k个位置上;2.fast先向后走k次,slow再向后走1次,然后fast和slow同时向后走,当fast走到最后一个结点的后面时(此时为NULL),slow刚好在倒数第k个…...

English Learning - L2 语音作业打卡 双元音 [eɪ] [aɪ] Day14 2023.3.6 周一
English Learning - L2 语音作业打卡 双元音 [eɪ] [aɪ] Day14 2023.3.6 周一💌发音小贴士:💌当日目标音发音规则/技巧:🍭 Part 1【热身练习】🍭 Part2【练习内容】🍭【练习感受】🍓元音 /eɪ/…...
:软件篇之系统工程详解(上篇))
计算机系统基础知识(十七):软件篇之系统工程详解(上篇)
📝 前言 在系统架构设计师的知识体系中,我们学过处理器、存储器、网络协议、数据库、操作系统等具体的计算机技术。但将这些技术组件有效组织起来,设计出一个满足业务需求的完整系统,还需要一套更高层次的思维方式——系统工程。…...

别再让CPU等外设了!用Multi-Layer AHB搭建一个不堵车的片上‘高速公路网’
用Multi-Layer AHB构建片上系统的高效数据通道 堵在早高峰的高架桥上时,你有没有想过——芯片里的数据流其实也面临着类似的拥堵问题?当多个处理器核心、DMA控制器同时争抢总线带宽时,传统的单层AHB架构就像只有两条车道的城市主干道…...

2分钟解决iPhone网络共享问题:Windows用户的免费终极方案
2分钟解决iPhone网络共享问题:Windows用户的免费终极方案 【免费下载链接】Apple-Mobile-Drivers-Installer Powershell script to easily install Apple USB and Mobile Device Ethernet (USB Tethering) drivers on Windows! 项目地址: https://gitcode.com/gh_…...

PEG-PLA-PAMAM-Fe₃O₄ NPs,聚乙二醇-聚乳酸-PAMAM修饰四氧化三铁纳米颗粒,制备方法
PEG-PLA-PAMAM-Fe₃O₄ NPs,聚乙二醇-聚乳酸-PAMAM修饰四氧化三铁纳米颗粒,制备方法PEG-PLA-PAMAM-Fe₃O₄ NPs是一类以四氧化三铁(Fe₃O₄)纳米颗粒为核心,并在其表面构建聚乙二醇-聚乳酸(PEG-PLA…...

如何彻底清理显卡驱动:DDU完整指南解决NVIDIA/AMD/Intel驱动残留问题
如何彻底清理显卡驱动:DDU完整指南解决NVIDIA/AMD/Intel驱动残留问题 【免费下载链接】display-drivers-uninstaller Display Driver Uninstaller (DDU) a driver removal utility / cleaner utility 项目地址: https://gitcode.com/gh_mirrors/di/display-driver…...

目标检测刷榜史:从R-CNN到Faster R-CNN,那些被我们忽略的工程“魔法”与妥协
目标检测进化论:R-CNN系列背后的工程智慧与妥协艺术 当计算机视觉领域还在手工特征时代徘徊时,2014年横空出世的R-CNN系列算法,用深度学习的力量重新定义了目标检测的基准。但鲜为人知的是,这些里程碑式的工作背后,隐藏…...

AI 域名投资价值高吗
我觉得 AI 域名本身它不是顶级域名,是一个国家域名。 这就有点和我们国家的 CN 域名以及一段时间炒的比较火的 IO 域名是一个意思。 一个国家域名在管理中一个最大的问题,就是很多域名的注册修改以及使用都跟国家政策相关。 .ai域名自1995年就已存在&…...
)
ODrive 0.5.6源码编译实战:从环境配置到烧录调试(STM32F4平台)
ODrive 0.5.6源码编译实战:从环境配置到烧录调试(STM32F4平台) 在嵌入式开发领域,ODrive因其出色的FOC(磁场定向控制)算法实现和开源特性,已成为高性能电机控制的热门选择。本文将手把手带你完成…...

AcousticSense AI从零开始:搭建视觉化音频分析工作站完整指南
AcousticSense AI从零开始:搭建视觉化音频分析工作站完整指南 1. 项目介绍与核心价值 AcousticSense AI是一个创新的音频分析解决方案,它将音频处理与计算机视觉技术巧妙结合,让计算机能够"看见"音乐的本质。这个项目的核心思路很…...

KDash高级使用教程:流式日志与资源描述完整指南
KDash高级使用教程:流式日志与资源描述完整指南 【免费下载链接】kdash A simple and fast dashboard for Kubernetes 项目地址: https://gitcode.com/gh_mirrors/kd/kdash KDash是一款简单快速的Kubernetes仪表盘工具,能够帮助用户轻松管理和监控…...