人工智能--图像语义分割

个人主页:欢迎来到 Papicatch的博客
课设专栏 :学生成绩管理系统
专业知识专栏:专业知识

文章目录
🍉引言
🍉介绍
🍈工作原理
🍍数据准备
🍍特征提取
🍍像素分类
🍍模型训练
🍍模型评估与优化
🍈关键技术
🍍特征提取
🍍上采样和下采样
🍍注意力机制
🍍多尺度融合
🍍损失函数
🍉分割方法
🍈基于阈值的分割方法
🍍基本原理
🍍阈值的选择
🍍优点
🍍缺点
🍍应用场景
🍍改进方法
🍈基于边缘检测的分割方法
🍍基本原理
🍍常见的边缘检测算子
🍍优点
🍍缺点
🍍应用场景
🍍改进和扩展
🍈基于区域的分割方法
🍍基本原理
🍍常见的基于区域的分割方法
🍍相似性准则
🍍优点
🍍缺点
🍍应用场景
🍍改进和发展
🍈基于聚类的分割方法
🍍优点
🍍缺点
🍍应用场景
🍈基于图的分割方法
🍍优点
🍍缺点
🍍应用场景
🍈基于深度学习的分割方法
🍍优点
🍍缺点
🍍应用场景
🍉示例
🍈以下是一个使用 Python 和 TensorFlow 实现简单的全卷积网络(FCN)进行自然图像分割的示例。
🍈以下是一个使用 Python 和 TensorFlow 实现简单的 U-Net 模型进行医学图像分割的示例
🍉总结
🍉引言

图像语义分割是计算机视觉领域中的一项重要任务,它旨在将图像中的每个像素分配一个特定的类别标签,从而实现对图像内容的精细理解和划分。
在人工智能的背景下,图像语义分割技术取得了显著的进展。它的应用范围广泛,包括自动驾驶、医学图像分析、卫星图像解译、虚拟现实和增强现实等领域。
🍉介绍
🍈工作原理
图像语义分割的工作过程主要包含以下几个关键步骤:
🍍数据准备
首先,需要收集大量的图像数据,并对这些图像中的每个像素进行类别标注。标注的类别可以是物体类别,如人、车、建筑物等,也可以是场景类别,如室内、室外、森林等。
🍍特征提取
使用深度卷积神经网络(CNN)来自动提取图像的特征。CNN 由多个卷积层和池化层组成。卷积层通过卷积操作来捕捉图像中的局部模式和特征,池化层则用于降低特征图的分辨率,减少计算量并提取主要特征。在这个过程中,图像从原始的像素空间被转换为抽象的特征空间。
🍍编码 - 解码结构:
许多图像语义分割模型采用编码 - 解码的结构。编码部分(通常是一系列卷积和池化层)逐渐降低图像的分辨率,提取高级语义特征。解码部分(通常包含上采样和反卷积操作)则逐步恢复图像的分辨率,将抽象的语义特征映射回像素空间,以实现像素级的分类预测。
🍍像素分类
在特征提取和映射的基础上,对每个像素进行分类。通过在网络的最后一层使用 softmax 函数或其他分类器,为每个像素计算属于不同类别的概率。最终,根据概率分布为每个像素分配一个确定的类别标签。
🍍模型训练
使用准备好的带有标注的图像数据对模型进行训练。通过不断调整网络的参数,使得模型的预测结果与真实的标注尽可能接近。训练过程中,使用损失函数来衡量预测结果与真实标签之间的差异,常见的损失函数如交叉熵损失、Dice 损失等。通过反向传播算法来更新网络参数,优化模型性能。
🍍模型评估与优化
使用验证集或测试集对训练好的模型进行评估,常见的评估指标包括像素准确率、平均交并比(mIoU)等。根据评估结果,对模型进行进一步的优化,例如调整网络结构、超参数,或者使用更先进的技术如注意力机制、多尺度融合等。
例如,对于一张包含汽车和道路的图像,模型会先提取图像中关于汽车和道路的特征,然后对每个像素判断其是属于汽车还是道路的类别,最终实现将汽车和道路在像素级别上进行准确的分割。
再比如,在医学图像中,对肿瘤的分割,模型会学习肿瘤的特征,然后为图像中的每个像素判断其是否属于肿瘤区域,从而辅助医生进行诊断和治疗规划。
🍈关键技术
🍍特征提取
- 特征提取是图像语义分割的基础。常用的特征提取方法基于卷积神经网络(CNN)。
- 卷积层能够自动学习图像中的局部特征,通过不同大小的卷积核来捕捉不同尺度的信息。例如,较小的卷积核可以提取细节特征,如边缘和纹理;较大的卷积核则能获取更宏观的特征,如物体的形状。
- 池化层用于降低特征图的分辨率,减少计算量并实现一定的平移不变性。但过度的池化可能会导致信息丢失,因此一些先进的方法采用了空洞卷积来在不降低分辨率的情况下扩大感受野。
🍍上采样和下采样
- 下采样通过卷积和池化操作降低图像的分辨率,提取抽象的语义信息,但会丢失空间细节。
- 上采样则相反,用于恢复图像的分辨率,将低分辨率的特征图映射回原始图像大小。常见的上采样方法包括双线性插值、反卷积等。
- 例如,在卫星图像分割中,下采样用于获取大范围的地理特征,而上采样则能精确描绘小区域的细节。
🍍注意力机制
- 注意力机制使模型能够聚焦于图像中的重要区域,从而提高分割的准确性。
- 空间注意力机制可以根据像素之间的空间关系来分配权重,突出重要的空间位置。
- 通道注意力机制则关注不同特征通道的重要性,为更有价值的通道赋予更高的权重。
- 比如在场景复杂的图像中,注意力机制能够让模型优先关注主要物体,而不是被背景干扰。
🍍多尺度融合
- 由于图像中的物体大小不一,单一尺度的特征可能无法很好地进行分割。
- 多尺度融合方法将不同层次和尺度的特征进行组合。
- 例如,通过金字塔池化模块获取不同尺度的特征图,并进行融合,从而能够同时分割大物体和小物体。
🍍损失函数
- 损失函数用于衡量模型预测结果与真实标签之间的差异,引导模型的训练。
- 常见的损失函数有交叉熵损失、Dice 损失等。
- 交叉熵损失常用于二分类和多分类问题,但对于类别不平衡的图像分割任务,Dice 损失可能更有效,它更关注前景区域的分割准确性。
- 例如,在医学图像中,病变区域通常较小,使用 Dice 损失可以更好地优化分割模型。
🍉分割方法
🍈基于阈值的分割方法
基于阈值的分割方法是一种简单而直接的图像分割技术,其核心思想是通过设定一个或多个阈值,将图像中的像素分为不同的类别或区域。
🍍基本原理
该方法基于像素的灰度值、颜色值或其他特征值与设定阈值的比较来进行分类。如果像素的值大于阈值,则将其分配到一个类别;如果小于阈值,则分配到另一个类别。当使用多个阈值时,可以实现更复杂的多类别分割。
🍍阈值的选择
全局阈值:为整个图像设定一个固定的阈值。选择全局阈值的方法包括手动选择、基于图像的灰度直方图分析(如选择直方图双峰之间的谷底作为阈值)等。
- 例如,对于具有明显双峰灰度直方图的图像,可直观地确定阈值。
局部阈值:根据像素的局部邻域信息来确定每个像素的阈值。这对于光照不均匀或对比度变化较大的图像更有效。
- 比如在一张部分区域明亮、部分区域昏暗的图像中,局部阈值能更好地适应不同区域的特征。
🍍优点
- 计算简单,效率高,尤其对于简单的图像能快速实现分割。
- 不需要复杂的先验知识和模型训练。
🍍缺点
- 对噪声较为敏感,噪声可能导致像素值的异常,从而影响阈值的选择和分割结果。
- 对于复杂的图像,可能难以找到一个合适的全局阈值,导致分割不准确。
🍍应用场景
- 目标和背景灰度差异明显的图像,如文档图像中的文字和背景分离。
- 简单的工业检测图像,例如检测产品表面的缺陷。
🍍改进方法
为了克服基于阈值分割方法的一些局限性,发展出了一些改进的方法,如自适应阈值法、多阈值结合形态学操作等。
🍈基于边缘检测的分割方法
基于边缘检测的分割方法旨在通过识别图像中像素值的显著变化来确定物体的边界,从而实现图像分割。
🍍基本原理
图像中的边缘通常对应着物体的轮廓、纹理的变化或者不同区域的交界。边缘检测算法通过计算像素及其邻域像素之间的差异来确定边缘的位置。这种差异可以通过梯度、导数等数学运算来衡量。
🍍常见的边缘检测算子
- Sobel 算子:对水平和垂直方向分别进行卷积运算,得到相应方向的边缘强度。
- Prewitt 算子:与 Sobel 算子类似,用于检测边缘。
- Roberts 算子:计算对角方向上的梯度。
- Canny 算子:被认为是一种较为优秀的边缘检测算法,具有较好的信噪比和定位精度。它包括高斯滤波平滑图像、计算梯度幅值和方向、非极大值抑制以及双阈值检测和边缘连接等步骤。
🍍优点
- 能够有效地捕捉物体的轮廓信息,为图像分割提供重要的线索。
- 计算相对简单,效率较高。
🍍缺点
- 对噪声敏感,噪声可能会导致虚假边缘的出现。
- 检测到的边缘可能不连续,需要后续的处理来连接边缘。
- 只能检测到灰度值的变化,对于颜色或纹理复杂的区域可能效果不佳。
🍍应用场景
- 工业检测中对物体外形的提取。
- 医学图像中器官边界的确定。
🍍改进和扩展
为了改善边缘检测的效果,常常会采取以下措施:
- 先对图像进行平滑去噪处理,再进行边缘检测。
- 结合其他分割方法,如区域生长,以利用边缘信息和区域信息来提高分割的准确性。
🍈基于区域的分割方法
基于区域的分割方法是一种通过将具有相似特征的像素组合成区域来实现图像分割的技术。
🍍基本原理
从初始的像素或小区域开始,根据预先定义的相似性准则,逐步合并或分裂这些区域,直到满足特定的终止条件。相似性可以基于像素的灰度值、颜色、纹理、形状等特征来衡量。
🍍常见的基于区域的分割方法
区域生长法:选择一个或多个种子点作为起始,然后将邻域中与种子点具有相似特征的像素合并到当前区域,不断重复这个过程,直到没有可合并的像素为止。
- 例如,在一张肺部 CT 图像中,选择一个位于肺部组织内的像素作为种子点,基于灰度值相似性逐渐生长出整个肺部区域。
区域分裂合并法:首先将图像视为一个整体区域,然后根据某种不相似性准则将其分裂为较小的子区域,接着对相邻的子区域进行合并,直到满足终止条件。
- 比如对于一幅包含多个物体的图像,先将其大致分裂为几个区域,再根据区域之间的相似性判断是否合并。
🍍相似性准则
- 灰度值:比较像素之间的灰度差异。
- 颜色:基于颜色空间(如 RGB、HSV 等)的距离。
- 纹理:分析像素的纹理特征,如粗糙度、方向性等。
🍍优点
- 对噪声的敏感度相对较低,能够得到较为完整和连续的区域。
- 通常能够产生有意义的区域,符合人类对图像的直观理解。
🍍缺点
- 计算复杂度较高,特别是对于大规模图像和复杂的相似性准则。
- 初始种子点的选择或区域的初始划分对最终结果有较大影响。
- 相似性准则的定义和选择可能具有一定的主观性。
🍍应用场景
- 卫星图像中不同地理区域的划分。
- 医学图像中对病变组织的提取。
🍍改进和发展
为了提高基于区域分割方法的性能,出现了一些改进措施,如结合多尺度分析、使用自适应的相似性准则、引入先验知识等。
🍈基于聚类的分割方法
基于聚类的分割方法将图像中的像素看作数据点,根据它们之间的相似性将像素分组为不同的簇,每个簇对应一个分割区域。
常见的聚类算法包括 K-Means 、层次聚类等。
🍍以 K-Means 为例,其工作步骤如下:
- 随机选择 K 个像素作为初始聚类中心。
- 计算每个像素到 K 个中心的距离,将像素分配到距离最近的中心所属的簇。
- 重新计算每个簇的中心。
- 重复步骤 2 和 3 ,直到聚类中心不再变化或达到设定的迭代次数。
🍍优点
- 能够自动确定分割的类别数量。
- 对于数据分布有一定的适应性。
🍍缺点
- 对初始聚类中心敏感,不同的初始选择可能导致不同的结果。
- 难以处理复杂的形状和空间关系。
🍍应用场景
- 例如对自然场景图像中的不同颜色区域进行分割。
🍈基于图的分割方法
基于图的分割方法将图像构建为一个图,其中像素是节点,像素之间的关系是边,边的权重表示像素之间的相似性。
常见的算法如 Graph Cut (图割)。
其基本思想是将图像分割问题转化为一个能量最小化问题。通过定义一个能量函数,包括区域项和边界项,区域项鼓励像素在区域内具有相似性,边界项鼓励边界在低能量处切割。
🍍优点
- 能够处理复杂的结构和全局关系。
- 可以结合先验知识和约束条件。
🍍缺点
- 计算复杂度高,尤其是对于大规模图像。
- 参数设置较为复杂。
🍍应用场景
在医学图像分割中,处理具有复杂结构的器官。
🍈基于深度学习的分割方法
基于深度学习的分割方法利用深度卷积神经网络(CNN)自动学习图像的特征,并进行像素级的分类预测。
常见的模型如 FCN (全卷积网络)、U-Net 等。
这些模型通过大量的有标注数据进行训练,学习到不同类别像素的特征模式。
🍍优点
- 分割精度高,能够处理复杂的场景和多类别分割任务。
- 具有强大的泛化能力,可以应用于各种类型的图像。
🍍缺点
- 需要大量的标注数据和强大的计算资源进行训练。
- 模型解释性较差。
🍍应用场景
自动驾驶中的道路和车辆分割、医学图像中的肿瘤和器官分割等。
🍉示例
🍈以下是一个使用 Python 和 TensorFlow 实现简单的全卷积网络(FCN)进行自然图像分割的示例。
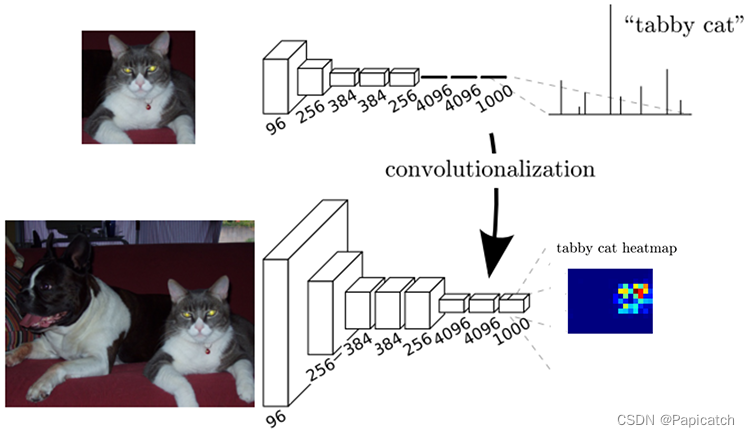
import tensorflow as tf
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, Conv2D, MaxPooling2D, UpSampling2D, concatenatedef fcn_model(input_shape=(224, 224, 3), num_classes=2):# 输入层inputs = Input(shape=input_shape)# 编码器:卷积和池化层conv1 = Conv2D(64, (3, 3), activation='relu', padding='same')(inputs)conv1 = Conv2D(64, (3, 3), activation='relu', padding='same')(conv1)pool1 = MaxPooling2D((2, 2), strides=(2, 2))(conv1)conv2 = Conv2D(128, (3, 3), activation='relu', padding='same')(pool1)conv2 = Conv2D(128, (3, 3), activation='relu', padding='same')(conv2)pool2 = MaxPooling2D((2, 2), strides=(2, 2))(conv2)conv3 = Conv2D(256, (3, 3), activation='relu', padding='same')(pool2)conv3 = Conv2D(256, (3, 3), activation='relu', padding='same')(conv3)conv3 = Conv2D(256, (3, 3), activation='relu', padding='same')(conv3)pool3 = MaxPooling2D((2, 2), strides=(2, 2))(conv3)conv4 = Conv2D(512, (3, 3), activation='relu', padding='same')(pool3)conv4 = Conv2D(512, (3, 3), activation='relu', padding='same')(conv4)conv4 = Conv2D(512, (3, 3), activation='relu', padding='same')(conv4)pool4 = MaxPooling2D((2, 2), strides=(2, 2))(conv4)conv5 = Conv2D(512, (3, 3), activation='relu', padding='same')(pool4)conv5 = Conv2D(512, (3, 3), activation='relu', padding='same')(conv5)conv5 = Conv2D(512, (3, 3), activation='relu', padding='same')(conv5)# 解码器:上采样和特征融合up6 = concatenate([UpSampling2D((2, 2))(conv5), conv4], axis=-1)conv6 = Conv2D(256, (3, 3), activation='relu', padding='same')(up6)conv6 = Conv2D(256, (3, 3), activation='relu', padding='same')(conv6)up7 = concatenate([UpSampling2D((2, 2))(conv6), conv3], axis=-1)conv7 = Conv2D(128, (3, 3), activation='relu', padding='same')(up7)conv7 = Conv2D(128, (3, 3), activation='relu', padding='same')(conv7)up8 = concatenate([UpSampling2D((2, 2))(conv7), conv2], axis=-1)conv8 = Conv2D(64, (3, 3), activation='relu', padding='same')(up8)conv8 = Conv2D(64, (3, 3), activation='relu', padding='same')(conv8)# 输出层outputs = Conv2D(num_classes, (1, 1), activation='softmax')(conv8)model = Model(inputs=inputs, outputs=outputs)return model# 示例用法
model = fcn_model()
model.summary()以下是对关键部分的解析:
- 编码器部分:通过一系列的卷积和池化层逐渐降低特征图的分辨率,提取图像的高级特征。
Conv2D层用于进行卷积操作,提取特征。MaxPooling2D层用于降低特征图的大小,减少计算量。
- 解码器部分:通过上采样和特征融合来恢复图像的分辨率,并进行像素级的分类预测。
UpSampling2D层用于对特征图进行上采样。concatenate用于融合不同层次的特征。
- 输出层:使用
Conv2D层和softmax激活函数进行像素级的分类,得到每个像素属于不同类别的概率。
🍈以下是一个使用 Python 和 TensorFlow 实现简单的 U-Net 模型进行医学图像分割的示例

import tensorflow as tf
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, Conv2D, MaxPooling2D, UpSampling2D, concatenatedef unet_model(input_shape=(256, 256, 1), num_classes=2):# 输入层inputs = Input(shape=input_shape)# 收缩路径(编码器)conv1 = Conv2D(64, (3, 3), activation='relu', padding='same')(inputs)conv1 = Conv2D(64, (3, 3), activation='relu', padding='same')(conv1)pool1 = MaxPooling2D((2, 2))(conv1)conv2 = Conv2D(128, (3, 3), activation='relu', padding='same')(pool1)conv2 = Conv2D(128, (3, 3), activation='relu', padding='same')(conv2)pool2 = MaxPooling2D((2, 2))(conv2)conv3 = Conv2D(256, (3, 3), activation='relu', padding='same')(pool2)conv3 = Conv2D(256, (3, 3), activation='relu', padding='same')(conv3)pool3 = MaxPooling2D((2, 2))(conv3)conv4 = Conv2D(512, (3, 3), activation='relu', padding='same')(pool3)conv4 = Conv2D(512, (3, 3), activation='relu', padding='same')(conv4)drop4 = tf.keras.layers.Dropout(0.5)(conv4) # 添加 dropout 防止过拟合pool4 = MaxPooling2D((2, 2))(drop4)conv5 = Conv2D(1024, (3, 3), activation='relu', padding='same')(pool4)conv5 = Conv2D(1024, (3, 3), activation='relu', padding='same')(conv5)drop5 = tf.keras.layers.Dropout(0.5)(conv5) # 添加 dropout 防止过拟合# 扩展路径(解码器)up6 = concatenate([UpSampling2D((2, 2))(drop5), conv4], axis=3)conv6 = Conv2D(512, (3, 3), activation='relu', padding='same')(up6)conv6 = Conv2D(512, (3, 3), activation='relu', padding='same')(conv6)up7 = concatenate([UpSampling2D((2, 2))(conv6), conv3], axis=3)conv7 = Conv2D(256, (3, 3), activation='relu', padding='same')(up7)conv7 = Conv2D(256, (3, 3), activation='relu', padding='same')(conv7)up8 = concatenate([UpSampling2D((2, 2))(conv7), conv2], axis=3)conv8 = Conv2D(128, (3, 3), activation='relu', padding='same')(up8)conv8 = Conv2D(128, (3, 3), activation='relu', padding='same')(conv8)up9 = concatenate([UpSampling2D((2, 2))(conv8), conv1], axis=3)conv9 = Conv2D(64, (3, 3), activation='relu', padding='same')(up9)conv9 = Conv2D(64, (3, 3), activation='relu', padding='same')(conv9)# 输出层outputs = Conv2D(num_classes, (1, 1), activation='softmax')(conv9)model = Model(inputs=inputs, outputs=outputs)return model# 示例用法
model = unet_model()
model.summary()以下是对关键部分的分析:
- 收缩路径(编码器)
- 通过一系列的卷积和最大池化操作逐渐降低特征图的分辨率,提取图像的高层抽象特征。每经过一次卷积操作,特征通道数增加,以获取更丰富的特征表示。
Dropout层用于随机地将神经元的输出设置为 0,以防止模型过拟合。
- 扩展路径(解码器)
- 通过上采样操作逐渐恢复特征图的分辨率,并与来自收缩路径的对应特征图进行拼接(concatenate),融合高层和低层的特征信息。
- 随后经过卷积操作进一步处理特征,以得到更准确的分割预测。
- 输出层
- 最终使用一个
Conv2D层和softmax激活函数进行像素级的分类,输出每个像素属于不同类别的概率。
- 最终使用一个
🍉总结
图像语义分割是计算机视觉领域中的关键任务,旨在为图像中的每个像素赋予特定的类别标签,以实现对图像内容的精细理解和划分。
其具有广泛的应用,涵盖了自动驾驶、医学图像分析、卫星图像解译等众多领域。在技术层面,它融合了多种方法和技术,如基于阈值、边缘检测、区域、聚类、图以及深度学习的分割方法。
基于阈值的方法简单直接,但对复杂图像效果有限;边缘检测能捕捉物体轮廓,但易受噪声影响且可能存在边缘不连续;区域方法对噪声敏感度低,但计算复杂且受初始条件影响;聚类方法自动确定类别数量,但对初始选择敏感;图方法处理复杂结构出色,但计算和参数设置复杂;深度学习方法,尤其是如 FCN、U-Net 等模型,分割精度高、泛化能力强,但依赖大量标注数据和强大计算资源。
未来,图像语义分割有望在技术创新、性能提升、多模态数据融合以及更广泛的应用场景拓展等方面取得进一步的发展,为解决各种实际问题提供更强大的支持。

相关文章:
人工智能--图像语义分割
个人主页:欢迎来到 Papicatch的博客 课设专栏 :学生成绩管理系统 专业知识专栏:专业知识 文章目录 🍉引言 🍉介绍 🍈工作原理 🍍数据准备 🍍特征提取 🍍像素分…...

fl studio20和21用哪一个好?FL-Chan from FL Studio欣赏
最近接到很多小伙伴的私信,都在问我平时会使用哪些音乐软件,能不能给一些参考。其实每个人的使用习惯不一样,需求也不一样。以DAW为例,有些人就是喜欢FL Studio,有些人吹爆Studio One,还有些人习惯使用Cuba…...

OpenCV直方图计算函数calcHist的使用
操作系统:ubuntu22.04OpenCV版本:OpenCV4.9IDE:Visual Studio Code编程语言:C11 功能描述 图像的直方图是一种统计表示方法,用于展示图像中不同像素强度(通常是灰度值或色彩强度)出现的频率分布。具体来说…...
09 docker 安装tomcat 详解
目录 一、安装tomcat 1. tomcat镜像的获取 2. docker创建容器实列 3. 访问测试 404错误 4. 解决方案 5. 使用免修改版容器镜像 5.1. 运行实列的创建 5.2. 出现问题及解决: 6. 验证 OK 一、安装tomcat 1. tomcat镜像的获取 docker search tomcat #docker …...

44.实现管理HOOK点的链表对象
上一个内容:43.实现HOOK接管寄存器数据 以 43.实现HOOK接管寄存器数据 它的代码为基础进行修改 首先创建一个类 这里创建的名为HOOKPOINT.h HOOKPOINT.cpp文件里面的内容 #include "pch.h" #include "HOOKPOINT.h"HOOKPOINT::HOOKPOINT() {…...

Unity小知识
1.当我们把摄像机的内容渲染到RenderTexture上而不是屏幕上时,那么相机的Aspect默认会设置成和RenderTexture的分辨率一样.不过最终如果把RenderTexture作为贴图贴到模型上去的时候还是会被UV拉伸和缩小的。 2.要想自定义UnityPackage的内容,只要找到UnityProject/L…...

【Jupyter Notebook与Git完美融合】在Notebook中驾驭版本控制的艺术
标题:【Jupyter Notebook与Git完美融合】在Notebook中驾驭版本控制的艺术 Jupyter Notebook是一个流行的开源Web应用程序,允许用户创建和共享包含实时代码、方程、可视化和解释性文本的文档。而Git是一个广泛使用的分布式版本控制系统,用于跟…...
Python开发者必看:内存优化的实战技巧
更多Python学习内容:ipengtao.com Python是一种高级编程语言,以其易读性和强大的功能而广受欢迎。然而,由于其动态类型和自动内存管理,Python在处理大量数据或高性能计算时,内存使用效率可能不如一些低级语言。本文将介…...

Golang | Leetcode Golang题解之第214题最短回文串
题目: 题解: func shortestPalindrome(s string) string {n : len(s)fail : make([]int, n)for i : 0; i < n; i {fail[i] -1}for i : 1; i < n; i {j : fail[i - 1]for j ! -1 && s[j 1] ! s[i] {j fail[j]}if s[j 1] s[i] {fail[i…...

【ajax实战08】分页功能
本文章目标:点击上/下一页按钮,实现对应页面的变化 实现基本步骤: 一:保存并设置文章总条数 设置一个全局变量,将服务器返回的数据返回给全局变量 二:点击下一页,做临界值判断,并…...

基于Hadoop平台的电信客服数据的处理与分析②项目分析与设计---需求分析-项目场景引入
任务描述 需求分析是软件生命周期中一个非常重要的过程,它决定着整个软件项目的质量,也是整个软件开发的成败所在。本环节任务是完成软件需求规格说明书。 知识点 :软件需求规格说明书的编写 重 点 :软件需求规格说明书内容的…...

debug-mmlab
mmyolo bug1: MMYOLO for yolov5 instance segmentation on balloon dataset getting this error "ValueError: Key img_path is not in available keys. solution: pip install albumentations1.3.1 reference...

年轻人为什么那么爱喝奶茶?
作者 | 艾泊宇 为什么年轻人那么爱喝奶茶?答案很简单:对他们来说,奶茶之于年轻人,正如白酒之于中年人。 奶茶不仅仅是一种饮料,它已经演化成一种文化现象,代表着温暖和爱的象征,甚至在某种程度上…...

手写数组去重
方法1-判断相邻元素 function _deleteRepeat(arr){if(!Array.isArray(arr)){throw new Error(参数必须是数组)}let res[];// 使用slice创建arr的副本,并排序let sortArrarr.slice().sort((a,b)>a-b);for(let i0;i<sortArr.length;i){if(isortArr.length-1||s…...

Firewalld 防火墙
1. 概述 在 RHEL7 系统中,firewalld 防火墙取代了传统的 iptables 防火墙。iptables 的防火墙策略是通过内核层面的 netfilter 网络过滤器来处理的,而 firewalld 则是通过内核层面的 nftables 包过滤框架来处理。firewalld 提供了更为丰富的功能和动态更…...

Hive查询优化 - 面试工作不走弯路
引言:Hive作为一种基于Hadoop的数据仓库工具,广泛应用于大数据分析。然而,由于其依赖于MapReduce框架,查询的性能可能会受到影响。为了确保Hive查询能够高效运行,掌握查询优化技巧至关重要。在日常工作中,高…...

【VUE3】uniapp + vite中 uni.scss 使用 /deep/ 不生效(踩坑记录三)
vite 中使用 /deep/ 进行样式穿透报错 原因:vite 中不支持,换成 ::v-deep 或:deep即可...
容器部署rabbitmq集群迁移
1、场景: 因业务需要,要求把rabbitmq-A集群上的数据迁移到rabbitmq-B集群上,rabbitmq的数据包括元数据(RabbitMQ用户、vhost、队列、交换和绑定)和消息数据,而消息数据存储在单独的消息存储库中。 2、迁移要…...

DP:背包问题----0/1背包问题
文章目录 💗背包问题💛背包问题的变体🧡0/1 背包问题的数学定义💚解决背包问题的方法💙例子 💗解决背包问题的一般步骤?💗例题💗总结 ❤️❤️❤️❤️❤️博客主页&…...

React antd umi 监听当前页面离开,在菜单栏提示操作
需求是我这里有个页面,离开当前页面之后,需要在菜单栏显示个提示,也就是Tour const [unblock, setUnblock] useState<() > void>(() > () > {});const [next, setNext] useState();useEffect(() > {const unblockHandler…...

【SpringBoot】100、SpringBoot中使用自定义注解+AOP实现参数自动解密
在实际项目中,用户注册、登录、修改密码等操作,都涉及到参数传输安全问题。所以我们需要在前端对账户、密码等敏感信息加密传输,在后端接收到数据后能自动解密。 1、引入依赖 <dependency><groupId>org.springframework.boot</groupId><artifactId...

Psychopy音频的使用
Psychopy音频的使用 本文主要解决以下问题: 指定音频引擎与设备;播放音频文件 本文所使用的环境: Python3.10 numpy2.2.6 psychopy2025.1.1 psychtoolbox3.0.19.14 一、音频配置 Psychopy文档链接为Sound - for audio playback — Psy…...

涂鸦T5AI手搓语音、emoji、otto机器人从入门到实战
“🤖手搓TuyaAI语音指令 😍秒变表情包大师,让萌系Otto机器人🔥玩出智能新花样!开整!” 🤖 Otto机器人 → 直接点明主体 手搓TuyaAI语音 → 强调 自主编程/自定义 语音控制(TuyaAI…...

UR 协作机器人「三剑客」:精密轻量担当(UR7e)、全能协作主力(UR12e)、重型任务专家(UR15)
UR协作机器人正以其卓越性能在现代制造业自动化中扮演重要角色。UR7e、UR12e和UR15通过创新技术和精准设计满足了不同行业的多样化需求。其中,UR15以其速度、精度及人工智能准备能力成为自动化领域的重要突破。UR7e和UR12e则在负载规格和市场定位上不断优化…...

CMake控制VS2022项目文件分组
我们可以通过 CMake 控制源文件的组织结构,使它们在 VS 解决方案资源管理器中以“组”(Filter)的形式进行分类展示。 🎯 目标 通过 CMake 脚本将 .cpp、.h 等源文件分组显示在 Visual Studio 2022 的解决方案资源管理器中。 ✅ 支持的方法汇总(共4种) 方法描述是否推荐…...

有限自动机到正规文法转换器v1.0
1 项目简介 这是一个功能强大的有限自动机(Finite Automaton, FA)到正规文法(Regular Grammar)转换器,它配备了一个直观且完整的图形用户界面,使用户能够轻松地进行操作和观察。该程序基于编译原理中的经典…...

React---day11
14.4 react-redux第三方库 提供connect、thunk之类的函数 以获取一个banner数据为例子 store: 我们在使用异步的时候理应是要使用中间件的,但是configureStore 已经自动集成了 redux-thunk,注意action里面要返回函数 import { configureS…...

安宝特案例丨Vuzix AR智能眼镜集成专业软件,助力卢森堡医院药房转型,赢得辉瑞创新奖
在Vuzix M400 AR智能眼镜的助力下,卢森堡罗伯特舒曼医院(the Robert Schuman Hospitals, HRS)凭借在无菌制剂生产流程中引入增强现实技术(AR)创新项目,荣获了2024年6月7日由卢森堡医院药剂师协会࿰…...

虚拟电厂发展三大趋势:市场化、技术主导、车网互联
市场化:从政策驱动到多元盈利 政策全面赋能 2025年4月,国家发改委、能源局发布《关于加快推进虚拟电厂发展的指导意见》,首次明确虚拟电厂为“独立市场主体”,提出硬性目标:2027年全国调节能力≥2000万千瓦࿰…...

【JVM】Java虚拟机(二)——垃圾回收
目录 一、如何判断对象可以回收 (一)引用计数法 (二)可达性分析算法 二、垃圾回收算法 (一)标记清除 (二)标记整理 (三)复制 (四ÿ…...