【课程总结】Day13(上):使用YOLO进行目标检测
前言
在上一章《【课程总结】Day11(下):YOLO的入门使用》的学习中,我们通过YOLO实现了对图片的分类任务。本章的学习内容,将以目标检测为切入口,了解目标检测流程,包括:数据标准、模型训练以及模型预测。
图片分类vs目标检测
通过查看YOLO网站的task目录,我们可以看到:在计算机视觉领域中,常见的任务包括目标检测(detect)、语义分割(segment)、图像分类(classify)、人体姿态估计(pose)、以及有向边界框(Oriented Bounding Box,OBB)等。
- 图像分类(classify)
- 定义:图片分类是指根据图像的内容将其分为不同的类别或标签。
- 输入:
- 输入是一张图像,通常是固定大小的RGB图像。
- 输出:
- 输出是图像所属的类别或标签,通常以概率分布的形式(例如:[0.2, 0.5, 0.1, 0.2])表示每个类别的概率。
- 模型会输出每个类别的概率值,最终选择概率最高的类别作为预测结果。
- 目标检测(detect)
- 定义:目标检测是指在图像中检测和定位物体的任务,同时识别物体的类别。
- 输入:
- 输入是一张图像,同样是RGB图像。
- 输出:
- 输出是图像中检测到的所有物体的边界框和类别信息。
- 通常是一个包含物体位置、类别和置信度的列表。
目标检测的问题

通过上图可以看到,目标检测会遇到以下问题:
- 图片中包含多个动物,并不能简单的分类这张图是长颈鹿还是斑马;
- 图片中的动物所在的位置也是大小不同,位置不同;
- …
传统算法的解决思路
在利用深度学习做物体检测之前,传统算法对于目标检测通常分为3个阶段:区域选取、特征提取和体征分类。
- 区域选取:首先选取图像中可能出现物体的位置,由于物体位置、大小都不固定,因此传统算法通常使用滑动窗口(Sliding Windows)算法,但这种算法会存在大量的冗余框,并且计算复杂度高。

- 特征提取:在得到物体位置后,通常使用人工精心设计的提取器进行特征提取,如SIFT和HOG等。由于提取器包含的参数较少,并且人工设计的鲁棒性较低,因此特征提取的质量并不高。

- 特征分类:最后,对上一步得到的特征进行分类,通常使用如SVM、AdaBoost的分类器。
深度学习的解决思路
Anchor-based(基于锚框)
定义:Anchor-based 方法通过在图像上生成一组预定义的锚框(Anchor Boxes),然后利用这些锚框进行目标检测。
流程:
- 生成锚框:在图像上生成一组不同尺寸和长宽比的锚框。
- 特征提取:通过卷积神经网络提取图像特征(套种图片中的物体)。
- 预测:对每个锚框预测偏移量和目标类别信息。
- 筛选:通过非极大值抑制(NMS)等方法筛选出最终的检测结果。
核心思想:
- 死框+修正量
20×20的锚框

40×40的锚框

80×80的锚框

优点:
- 相对容易实现和训练。
- 可以处理多尺度目标和不同长宽比的目标。
缺点:
- 需要预定义大量的锚框,增加了计算复杂度和训练难度。
- 对于不规则形状的目标可能不够灵活。
Anchor-free(无锚框)
定义:Anchor-free 方法不依赖于预定义的锚框,而是直接预测目标的位置和类别信息。
流程:
- 中心点检测:首先,在图像上“撒豆子”(也称为“CenterNet”),即在图像的每个位置(像素)处预测目标中心点的存在概率。这些中心点通常表示可能存在目标的位置。
- 边界框预测:对于每个被预测为目标中心点的位置,模型会进一步预测目标的边界框(向上下左右生长,套住要预测的问题)。
- 后处理:通过后处理算法(如非极大值抑制)来筛选和优化检测结果,以获得最终的目标检测结果。
核心思想:
- 中心点 + 四个方向的生长

优点:
- 更加灵活,可以适应各种目标形状和尺度。
- 减少了预定义锚框带来的计算复杂度。
缺点:
- 相对 Anchor-based 方法,Anchor-free 方法可能需要更多的训练数据和更复杂的网络结构。
- 在处理小目标或密集目标时可能性能略逊于 Anchor-based 方法。
目前,目标检测基本使用anchor-free的方法。
目标检测的两种策略
目标检测具体的开展策略有两种:
| 方式 | 过程 | 代表 |
|---|---|---|
| 方式1 | 1. 先对输入图像进行切片。 2. 对每一片进行特征提取。 3. 对提取的特征进行分类和回归。 | MTCNN |
| 方式2 | 1. 先对输入图像进行特征提取。 2. 对提取的特征进行切片。 3. 对每一片进行分类和回归。 | YOLO |
两个例子
获取视频头内容进行目标检测
from ultralytics import YOLO
import cv2# 加载YOLO模型
model = YOLO("yolov8n.pt")cap = cv2.VideoCapture(0)while cap.isOpened():# 读取视频帧ret, frame = cap.read()if not ret:break# 使用YOLO模型检测物体results = model(frame)# 绘制预测结果img = results[0].plot()# 显示检测结果cv2.imshow("frame", img)if cv2.waitKey(1) == ord("q"):break# 释放资源
cap.release()
cv2.destroyAllWindows()
运行以上代码,YOLO可以将摄像头中的视频按帧逐帧检测物体。
读取图片进行目标检测
import cv2
from ultralytics import YOLO
import os# 设置环境变量,解决OMP: Error #15: Initializing libiomp5.dylib, but found libiomp5.dylib already initialized的问题
os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE"# 加载模型
model = YOLO("yolov8n.pt") # 使用预训练模型权重# 读取图片
image = cv2.imread("animal.png")# 预测
results = model(image)result = results[0]
img = result.plot()from matplotlib import pyplot as plt# 对对象进行可视化,从RGB转换为BGR
plt.imshow(X=img[:, :, ::-1])运行结果:

通过查看result的内容,可以得到:
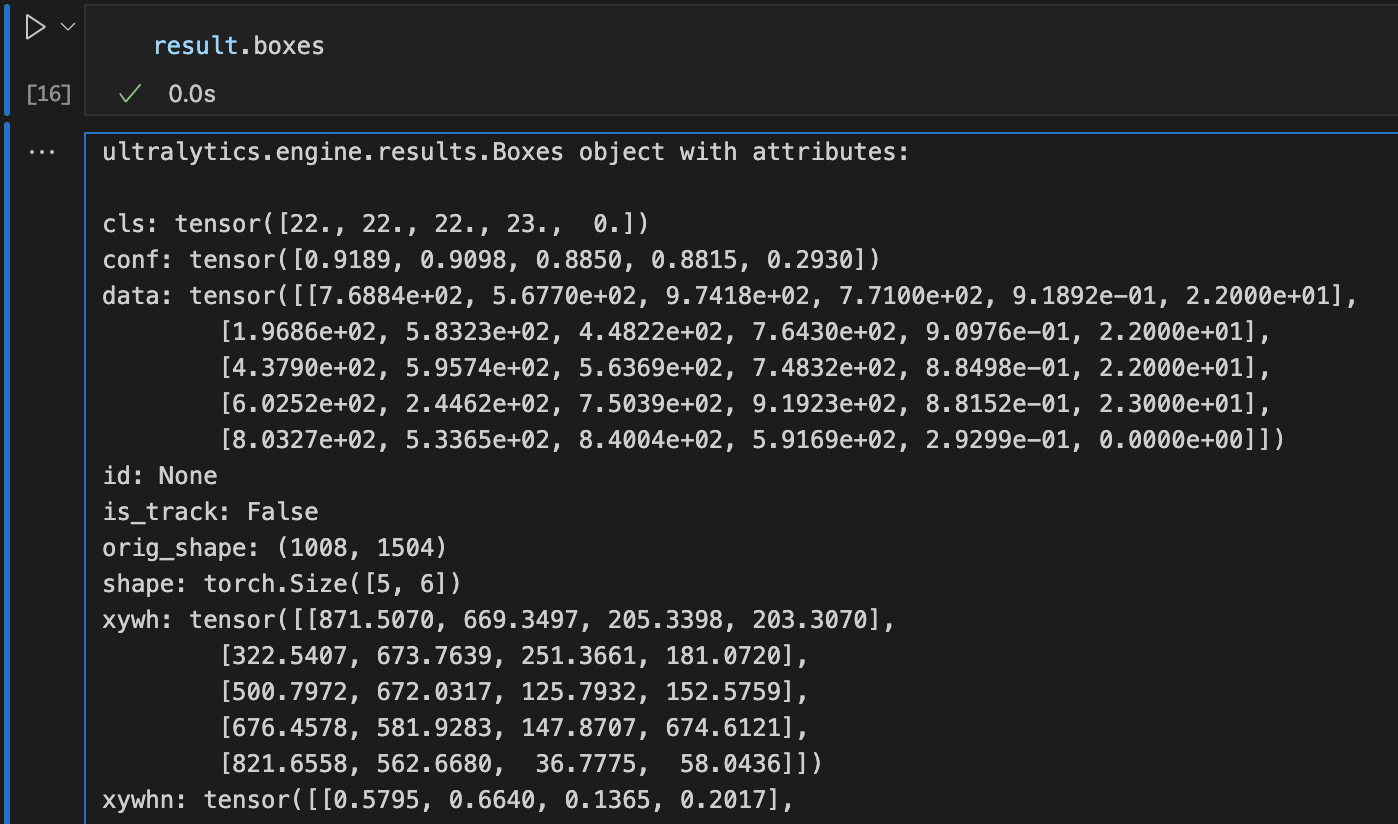
cls: 表示检测到的物体类别,是一个包含类别标识号的张量。
例如:上例分别为类别22、22、22、23和0。这意味着模型在图像中检测到了不同类别的物体。
conf: 表示置信度,即模型对检测结果的信心程度,是一个包含置信度值的张量。
例如:上例分别为[0.9189, 0.9098, 0.8850, 0.8815, 0.2930]表示模型对每个检测结果的置信度,置信度值越高,表示模型对该检测结果的信心程度越高。
data: 包含了检测结果的详细数据,如边界框坐标、置信度、类别等信息。
例如:第一行数据[7.6884e+02, 5.6770e+02, 9.7418e+02, 7.7100e+02, 9.1892e-01, 22]表示一个边界框的左上角和右下角坐标、置信度和类别。
shape: 结果张量的形状。
例如:[5, 6]表示这个张量是一个二维张量,上图中一共预测了5个目标检测结果。
xywh: 表示边界框的中心坐标、宽度和高度。
例如:[[871.5070, 669.3497, 205.3398, 203.3070], [322.5407, 673.7639, 251.3661, 181.0720], …]表示了每个检测结果的边界框信息。
xyxy: 表示边界框的左上角和右下角坐标。
例如:[[768.8371, 567.6962, 974.1769, 771.0032], [196.8576, 583.2280, 448.2238, 764.2999], …]表示了每个检测结果的边界框的左上角和右下角坐标。
自定义模型训练
以上的目标检测都是基于预先训练好的模型,如果想自主实现一个模型的训练以及目标检测,具体流程如下:
数据准备
为了更加接近实战,我计划在天池及飞桨社区找一份数据集进行目标检测的模型训练。
数据集地址:https://aistudio.baidu.com/datasetdetail/91732
数据集简述:
一个理想的智能零售结算系统应当能够精准地识别每一个商品,并且能够返回完整地购物清单及顾客应付的实际商品总价格。这是一份智能零售柜识别的图片数据集,非常适用于进行目标检测。

数据分析
由于该数据集采用VOC格式,其内容形式与YOLOv8的格式不同,所以我们需要做相关的处理。
VOC数据集目录格式:
我有一个VOC的目标检测数据集,其目录结构为:VOC
|-Annotations|-ori_000_XYGOC20200313162026456_1.xml|-ori_000_XYGOC20200313162953549_1.xml|-ori_001_11_0.xml|-ori_001_4_0.xml|-ori_001_6_0.xml|-ori_t1_TEST20191101164758498_1.xml|-ori_t1_TEST20191101164829232_1.xml|-...
|-JPEGImages|-ori_000_XYGOC20200313162026456_1.jpg|-ori_000_XYGOC20200313162953549_1.jpg|-ori_001_11_0.jpg|-ori_001_4_0.jpg|-ori_001_6_0.jpg|-ori_t1_TEST20191101164758498_1.jpg|-ori_t1_TEST20191101164829232_1.jpg|-...
|-labels.txt
|-test_list.txt
|-train_list.txt
|-val_list.txt
# labels.txt的内容格式为如下:
3+2-2
3jia2
aerbeisi
anmuxi
aoliao
asamu
baicha
baishikele
...# train_list.txt内容格式如下:
JPEGImages/ori_XYGOC2021042115092870201IK-4_0.jpg Annotations/ori_XYGOC2021042115092870201IK-4_0.xml
JPEGImages/ori_XYGOC2021010413165585501IK-3_0.jpg Annotations/ori_XYGOC2021010413165585501IK-3_0.xml
YOLOv8数据集的目录结构
|-images|-train|-ori_000_XYGOC20200313162026456_1.jpg...|-val|-ori_t1_TEST20191101164758498_1.jpg...
|-lables|-train|-ori_000_XYGOC20200313162026456_1.txt|-val|-ori_t1_TEST20191101164829232_1.txt
数据转换
1. 创建Dataset根目录
import os# 创建Dataset根目录,同时按照YOLO的格式分别创建train和val目录
def create_directories(base_dir):dirs = [os.path.join(base_dir, "images/train"),os.path.join(base_dir, "images/val"),os.path.join(base_dir, "labels/train"),os.path.join(base_dir, "labels/val")]for dir in dirs:os.makedirs(dir, exist_ok=True)
2. 读取classes类别
def read_classes(classes_file):"""从类别文件中读取类别名称,并返回类别名称与索引的映射字典。参数:- classes_file (str): 类别文件路径返回:- classes (dict): 类别名称与索引的映射字典"""classes = {}with open(classes_file, "r") as f:lines = f.readlines()for index, line in enumerate(lines):class_name = line.strip()classes[index] = class_namereturn classes3. 读取xml文件并转换为yolo格式
def parse_xml(xml_path, classes_dict):"""解析XML文件,获取图像的宽度、高度以及对象的类别和边界框坐标。参数:- xml_path (str): XML文件路径返回:- width (int): 图像宽度- height (int): 图像高度- objects (list): 包含对象信息的列表,每个对象信息包括类别和边界框坐标"""tree = ET.parse(xml_path)root = tree.getroot()size = root.find("size")width = int(size.find("width").text)height = int(size.find("height").text)objects = []for obj in root.findall("object"):name = obj.find("name").textlabel_index = get_label_index(name, classes_dict)bndbox = obj.find("bndbox")xmin = int(bndbox.find("xmin").text)ymin = int(bndbox.find("ymin").text)xmax = int(bndbox.find("xmax").text)ymax = int(bndbox.find("ymax").text)objects.append({"label_index": label_index, "xmin": xmin, "ymin": ymin, "xmax": xmax, "ymax": ymax})return width, height, objectsdef convert_to_yolo_format(width, height, obj):"""将对象信息转换为适合YOLO格式的坐标。参数:- width (int): 图像宽度- height (int): 图像高度- obj (dict): 包含对象信息的字典,包括类别和边界框坐标"""x_center = (obj["xmin"] + obj["xmax"]) / 2 / widthy_center = (obj["ymin"] + obj["ymax"]) / 2 / heightw = (obj["xmax"] - obj["xmin"]) / widthh = (obj["ymax"] - obj["ymin"]) / heightreturn x_center, y_center, w, h4. 将xml文件转换为txt文件
def write_txt_file(file_path, content):"""创建或写入内容到.txt文件参数:- file_path (str): 目标.txt文件路径- content (str): 写入文件的内容"""try:if not os.path.exists(file_path):open(file_path, 'w').close() # 创建空的目标文件with open(file_path, "a") as f:f.write(content)print(f"成功写入文件 {file_path}")except Exception as e:print(f"写入文件时发生异常: {e}")def process_VOC_data(root_dir, train_list_file, images_dst, labels_dst, classes_dict):"""从VOC数据集中读取训练列表文件,解析xml文件并将图像复制到目标目录中,并将类别和bbox信息写入标签文件中。参数:- root_dir (str): VOC数据集的根目录- train_list_file (str): 训练列表文件路径- image_folder (str): 图像文件夹的相对路径- images_dst (str): 图像目标目录- labels_dst (str): 标签目标目录"""with open(train_list_file, "r") as f:lines = f.readlines()# 逐行读取列表文件for line in lines:line = line.strip()image_path, xml_path = line.split(" ")# 获取xml文件绝对路径xml_path = os.path.join(root_dir, xml_path)# 获取image文件绝对路径image_path = os.path.join(root_dir, image_path)width, height, objects = parse_xml(xml_path, classes_dict)copy_image(image_path, images_dst)for obj in objects:label_name = os.path.splitext(os.path.basename(image_path))[0] + ".txt"label_dst = os.path.join(labels_dst, label_name)yolo_format = convert_to_yolo_format(width, height, obj)content = f"{obj['label_index']} {yolo_format[0]} {yolo_format[1]} {yolo_format[2]} {yolo_format[3]}\n"write_txt_file(label_dst, content)5. 保存.txt文件到新目录下,同时拷贝图像
def copy_image(image_path, images_dst):"""将图像从原路径复制到目标路径。参数:- image_path (str): 原图像路径- images_dst (str): 目标图像路径"""image_name = os.path.basename(image_path)image_dst = os.path.join(images_dst, image_name)if not os.path.exists(image_path):print(f"原图像路径 '{image_path}' 未找到文件")returnif os.path.exists(image_dst):print(f"目标路径 '{image_dst}' 中已存在同名图像文件")returntry:shutil.copy(image_path, image_dst)print(f"成功复制图像 {image_name} 到目标目录")except Exception as e:print(f"拷贝图像时发生异常: {e}")
完整代码如下:
import xml.etree.ElementTree as ET
import shutil
import os# 创建Dataset根目录,同时按照YOLO的格式分别创建train和val目录
def create_directories(base_dir):dirs = [os.path.join(base_dir, "images/train"),os.path.join(base_dir, "images/val"),os.path.join(base_dir, "labels/train"),os.path.join(base_dir, "labels/val")]for dir in dirs:os.makedirs(dir, exist_ok=True)def get_label_index(name, classes_dict):"""根据类别名称从类别字典中获取对应的序号。参数:- name (str): 类别名称- classes_dict (dict): 包含类别名称和对应序号的字典返回:- label_index (int): 类别名称对应的序号,如果不存在则返回-1"""label_index = -1for key, value in classes_dict.items():if value == name:label_index = keybreakreturn label_indexdef parse_xml(xml_path, classes_dict):"""解析XML文件,获取图像的宽度、高度以及对象的类别和边界框坐标。参数:- xml_path (str): XML文件路径返回:- width (int): 图像宽度- height (int): 图像高度- objects (list): 包含对象信息的列表,每个对象信息包括类别和边界框坐标"""tree = ET.parse(xml_path)root = tree.getroot()size = root.find("size")width = int(size.find("width").text)height = int(size.find("height").text)objects = []for obj in root.findall("object"):name = obj.find("name").textlabel_index = get_label_index(name, classes_dict)bndbox = obj.find("bndbox")xmin = int(bndbox.find("xmin").text)ymin = int(bndbox.find("ymin").text)xmax = int(bndbox.find("xmax").text)ymax = int(bndbox.find("ymax").text)objects.append({"label_index": label_index, "xmin": xmin, "ymin": ymin, "xmax": xmax, "ymax": ymax})return width, height, objectsdef convert_to_yolo_format(width, height, obj):"""将对象信息转换为适合YOLO格式的坐标。参数:- width (int): 图像宽度- height (int): 图像高度- obj (dict): 包含对象信息的字典,包括类别和边界框坐标"""x_center = (obj["xmin"] + obj["xmax"]) / 2 / widthy_center = (obj["ymin"] + obj["ymax"]) / 2 / heightw = (obj["xmax"] - obj["xmin"]) / widthh = (obj["ymax"] - obj["ymin"]) / heightreturn x_center, y_center, w, hdef copy_image(image_path, images_dst):"""将图像从原路径复制到目标路径。参数:- image_path (str): 原图像路径- images_dst (str): 目标图像路径"""image_name = os.path.basename(image_path)image_dst = os.path.join(images_dst, image_name)if not os.path.exists(image_path):print(f"原图像路径 '{image_path}' 未找到文件")returnif os.path.exists(image_dst):print(f"目标路径 '{image_dst}' 中已存在同名图像文件")returntry:shutil.copy(image_path, image_dst)print(f"成功复制图像 {image_name} 到目标目录")except Exception as e:print(f"拷贝图像时发生异常: {e}")def write_txt_file(file_path, content):"""创建或写入内容到.txt文件参数:- file_path (str): 目标.txt文件路径- content (str): 写入文件的内容"""try:if not os.path.exists(file_path):open(file_path, 'w').close() # 创建空的目标文件with open(file_path, "a") as f:f.write(content)print(f"成功写入文件 {file_path}")except Exception as e:print(f"写入文件时发生异常: {e}")def process_VOC_data(root_dir, train_list_file, images_dst, labels_dst, classes_dict):"""从VOC数据集中读取训练列表文件,解析xml文件并将图像复制到目标目录中,并将类别和bbox信息写入标签文件中。参数:- root_dir (str): VOC数据集的根目录- train_list_file (str): 训练列表文件路径- image_folder (str): 图像文件夹的相对路径- images_dst (str): 图像目标目录- labels_dst (str): 标签目标目录"""with open(train_list_file, "r") as f:lines = f.readlines()# 逐行读取列表文件for line in lines:line = line.strip()image_path, xml_path = line.split(" ")# 获取xml文件绝对路径xml_path = os.path.join(root_dir, xml_path)# 获取image文件绝对路径image_path = os.path.join(root_dir, image_path)width, height, objects = parse_xml(xml_path, classes_dict)copy_image(image_path, images_dst)for obj in objects:label_name = os.path.splitext(os.path.basename(image_path))[0] + ".txt"label_dst = os.path.join(labels_dst, label_name)yolo_format = convert_to_yolo_format(width, height, obj)content = f"{obj['label_index']} {yolo_format[0]} {yolo_format[1]} {yolo_format[2]} {yolo_format[3]}\n"write_txt_file(label_dst, content)def read_classes(classes_file):"""从类别文件中读取类别名称,并返回类别名称与索引的映射字典。参数:- classes_file (str): 类别文件路径返回:- classes (dict): 类别名称与索引的映射字典"""classes = {}with open(classes_file, "r") as f:lines = f.readlines()for index, line in enumerate(lines):class_name = line.strip()classes[index] = class_namereturn classesdef generate_coco8_yaml_content(dataset_root, train_images, val_images, classes):"""生成类似COCO8数据集配置文件的内容参数:- dataset_root (str): 数据集根目录路径- train_images (str): 训练图像相对于根目录的路径- val_images (str): 验证图像相对于根目录的路径- classes (dict): 类别名称与索引的映射字典返回:- content (str): COCO8数据集配置文件内容"""content = f"path: ../datasets/{dataset_root} # dataset root dir\n"content += f"train: {train_images} # train images (relative to 'path') 4 images\n"content += f"val: {val_images} # val images (relative to 'path') 4 images\n"content += "test: # test images (optional)\n\n"content += "# Classes\n"content += "names:\n"for index, class_name in classes.items():content += f" {index}: {class_name}\n"return contentdef write_yaml_file(file_path, content):"""创建或写入内容到.yaml文件参数:- file_path (str): 目标.yaml文件路径- content (str): 写入文件的内容"""try:if not os.path.exists(file_path):open(file_path, 'w').close() # 创建空的目标文件with open(file_path, "w") as f:f.write(content)print(f"成功写入文件 {file_path}")except Exception as e:print(f"写入文件时发生异常: {e}")if __name__ == "__main__":# VOC数据集根目录root_dir = "VOC"train_list_file = os.path.join(root_dir, "train_list.txt")test_list_file = os.path.join(root_dir, "val_list.txt")classes_file = "VOC/labels.txt"# 设置转换后YOLO的图像和标签目录dataset_root = "cabinet"train_images = "images/train"train_labels = "labels/train"val_images = "images/val"val_labels = "labels/val"yaml_file_name = "cabinet.yaml"images_dst_train = os.path.join(dataset_root, train_images)labels_dst_train = os.path.join(dataset_root, train_labels)images_dst_test = os.path.join(dataset_root, val_images)labels_dst_test = os.path.join(dataset_root, val_labels)yaml_file = os.path.join(dataset_root, yaml_file_name)# 创建YOLO数据集目录create_directories(dataset_root)# 读取类别文件classes = read_classes(classes_file)# 转换训练数据集process_VOC_data(root_dir, train_list_file, images_dst_train, labels_dst_train, classes)# 转换测试数据集process_VOC_data(root_dir, test_list_file, images_dst_test, labels_dst_test, classes)# 生成COCO8.yaml文件content = generate_coco8_yaml_content(dataset_root, train_images, val_images, classes)write_yaml_file(yaml_file, content)
以上转换后的数据,我也打包上传到网盘,可直接使用。
网盘地址:https://pan.baidu.com/s/1DyoK7r_74OzrRdoogrtTKw?pwd=q4ww
模型训练
第一步:拷贝数据到YOLO的datasets目录下
第二步:拷贝cabinet.yaml文件到YOLO的cfg\datasets目录下
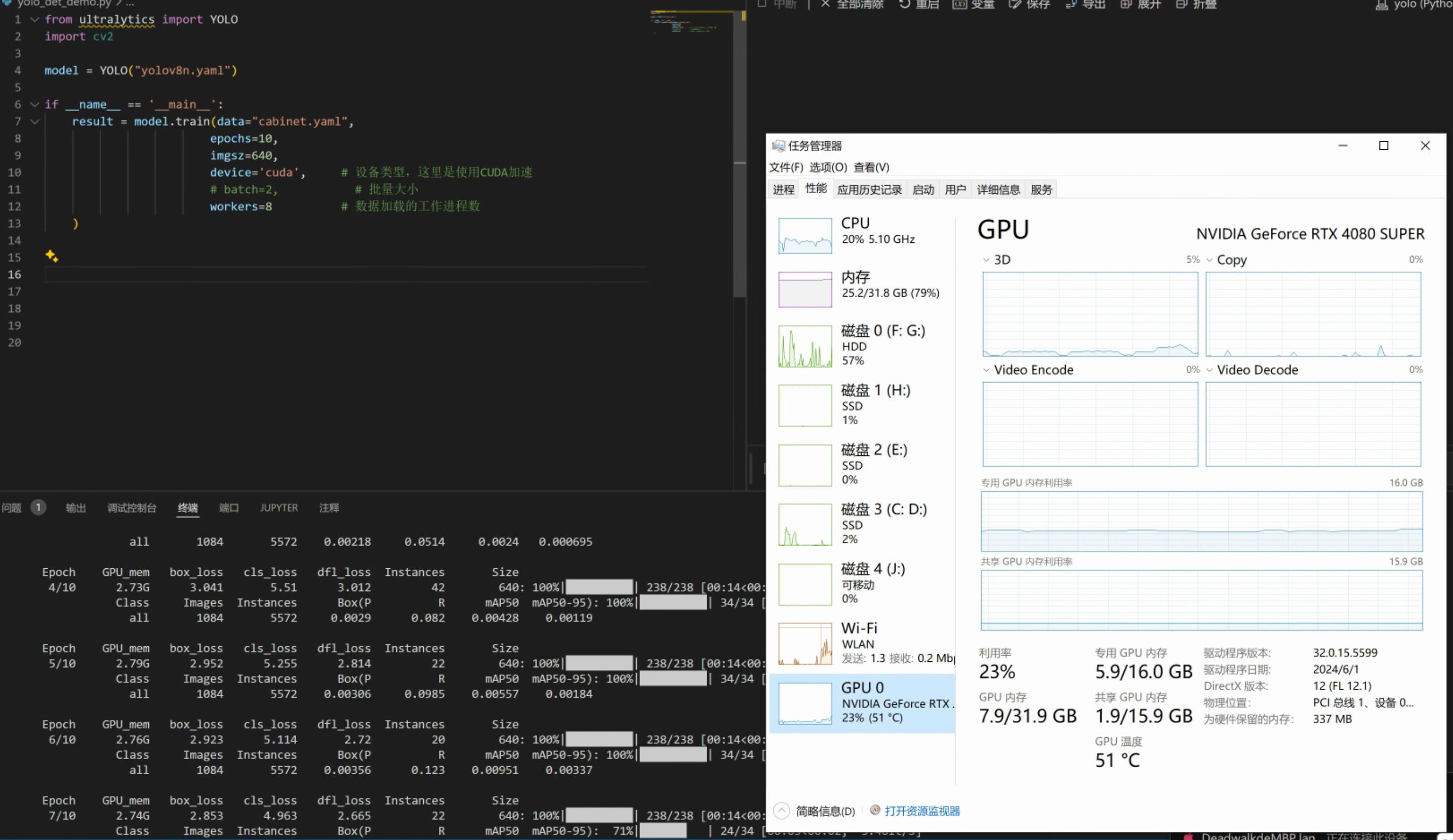
第三步:使用命令行训练模型
from ultralytics import YOLO
import cv2model = YOLO("yolov8n.yaml")if __name__ == '__main__':result = model.train(data="cabinet.yaml", epochs=10, imgsz=640,device='cuda', # 设备类型,这里是使用CUDA加速# batch=2, # 批量大小workers=8 # 数据加载的工作进程数)
训练时显存占用情况
训练结果:
训练完毕后,在run\train*目录下生成对应的训练结果
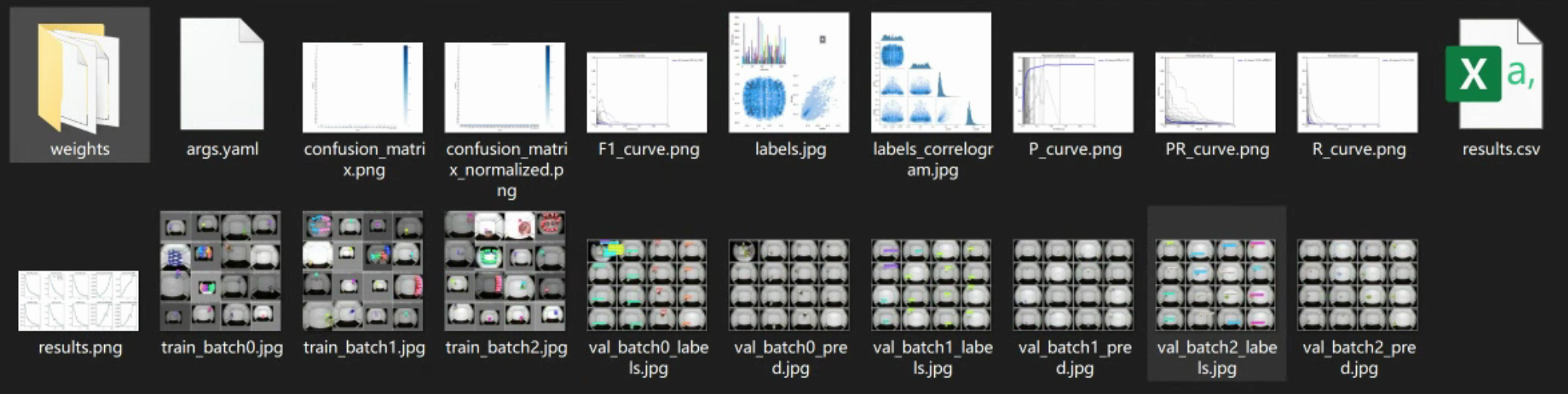
查看其中的验证集显示内容,看起来结果是正常的

由于时间原因,本次就没有开发相关的前端页面来进行模型加载和图片识别,但是可以想象:如果模型加载后同时开启智能柜的摄像头,那么就可以实时对售卖柜内的商品进行目标检测。
附录
labelimg进行数据标注
简介
LabelImg是一个用于图像标注的开源工具,它可以帮助用户快速而准确地为图像创建标注框,并生成相应的标注文件。
使用步骤
安装并打开labelimg
第一步:在conda创建新环境labelimg,指令如下:
conda create -n labelimg python=3.9
第二步:激活lalelimg环境,指令如下:
conda activate labelimg
第三步:在此环境下安装labelimg,指令可如下:
pip install labelimg
第四步:命令行下打开
labelimg

内容小结
- 目标检测理论
- 在计算机视觉领域中,常见的任务包括目标检测(detect)、图像分类(classify)
- 目标检测输入是一张图像,输出是图像中检测到的所有物体的边界框和类别信息
- 目标检测在深度学习下有了新的发展,有
Anchor-based(基于锚框)和Anchor-free(无锚框)两种解决思路 - Anchor-based的核心思想是:
死框+修正量,Anchor-free的核心思想是:中心点 + 四个方向的生长 - 相对 Anchor-based 方法,Anchor-free 方法可能需要更多的训练数据和更复杂的网络结构。
- 目标检测使用
- 使用YOLO进行目标检测后,结果保存在results中,results中有
cls(物体类别)、conf(表示置信度)、data(详细数据,如边界框坐标等) - 如果要自定义数据集训练,可以按照coco8的目录结构和yaml文件准备数据
- 训练数据集可以通过labelimg来进行标注,使用前需要建立独立的虚拟环境
- 如果从网上下载的训练集是VOC格式,需要对其进行转换后训练®
- 使用YOLO进行目标检测后,结果保存在results中,results中有
参考资料
CSDN:目标检测(Object Detection)
博客园:目标检测及锚框、IoU
目标检测数据集汇总
相关文章:
【课程总结】Day13(上):使用YOLO进行目标检测
前言 在上一章《【课程总结】Day11(下):YOLO的入门使用》的学习中,我们通过YOLO实现了对图片的分类任务。本章的学习内容,将以目标检测为切入口,了解目标检测流程,包括:数据标准、模…...

老年生活照护实训室:探索现代养老服务的奥秘
在老龄化社会加速发展的今天,如何为老年人提供优质、贴心的生活照护服务,成为了社会关注的焦点。老年生活照护实训室作为培养专业养老服务人才的重要场所,正逐渐揭开现代养老服务的神秘面纱,为我们展现出一幅充满关爱与智慧的画卷…...

python-字典
为什么需要字典 字典的定义 字典数据的获取 字典的嵌套 嵌套字典的内容获取 字典的注意事项: 字典的常用操作 新增元素 更新元素 删除元素 清空字典 汇总 字典的特点...

使用java stream对集合中的对象按指定字段进行分组并统计
一、概述 有这样一个需求,在一个list集合中的对象有相同的name,我需要把相同name的对象进行汇总计算。使用java stream来实现这个需求,这里做一个记录,希望对有需求的同学提供帮助 一、根据指定字段进行分组 一、先准备好给前端要…...

03.C1W2.Sentiment Analysis with Naïve Bayes
目录 Probability and Bayes’ RuleIntroductionProbabilitiesProbability of the intersection Bayes’ RuleConditional ProbabilitiesBayes’ RuleQuiz: Bayes’ Rule Applied Nave Bayes IntroductionNave Bayes for Sentiment Analysis P ( w i ∣ c l a s s ) P(w_i|clas…...

一个强大的分布式锁框架——Lock4j
一、简介 Lock4j是一个分布式锁组件,它提供了多种不同的支持以满足不同性能和环境的需求,基于Spring AOP的声明式和编程式分布式锁,支持RedisTemplate、Redisson、Zookeeper。 二、特性 • 简单易用,功能强大,扩展性…...
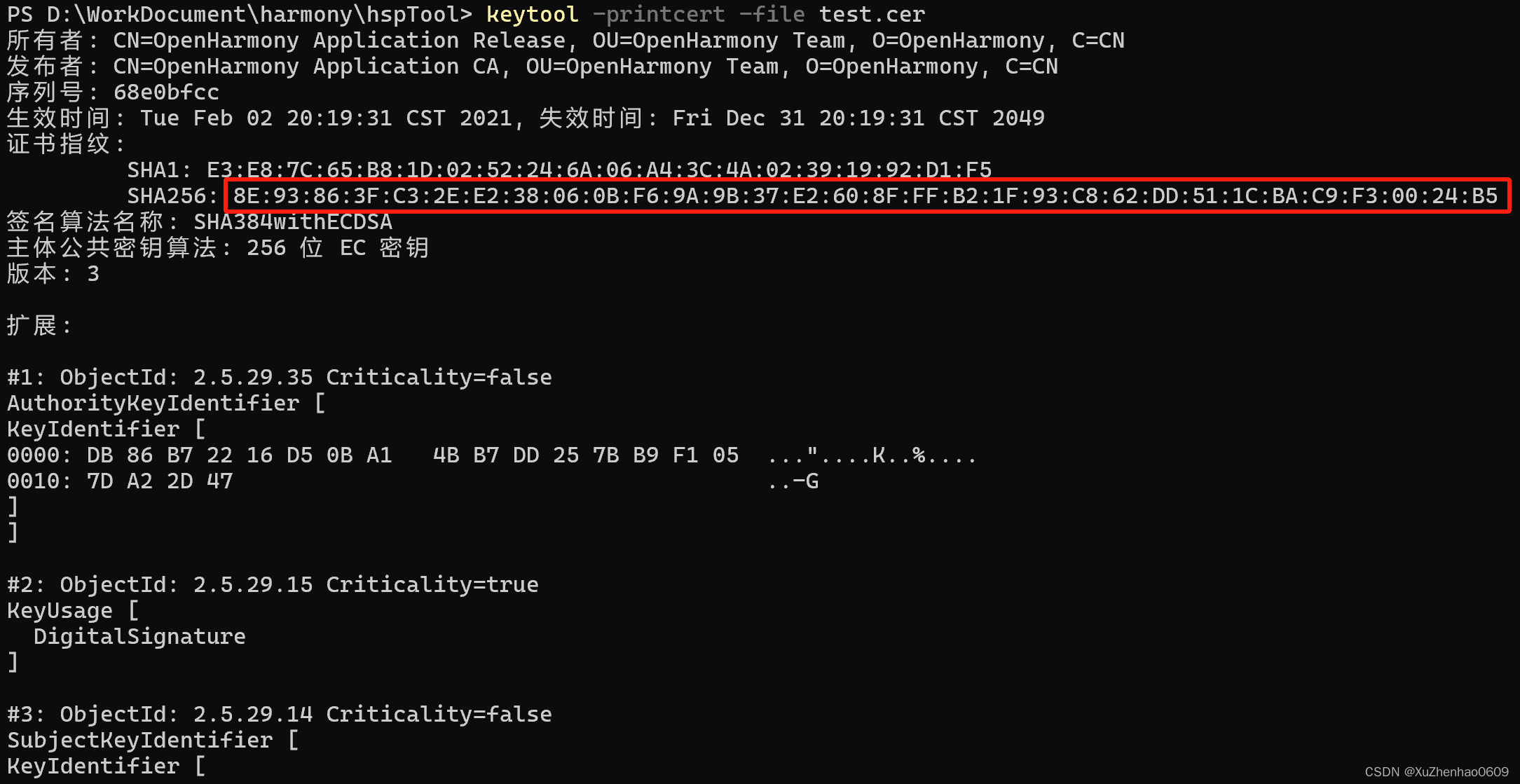
HarmonyOS - 通过.p7b文件获取fingerprint
1、查询工程所对应的 .p7b 文件 通常新工程运行按照需要通过 DevEco Studio 的 Project Structure 勾选 Automatically generate signature 自动生成签名文件,自动生成的 .p7b 文件通常默认在系统用户目录下. 如:C:/Users/zhangsan/.ohos/config/default…...

vue3实现echarts——小demo
版本: 效果: 代码: <template><div class"middle-box"><div class"box-title">检验排名TOP10</div><div class"box-echart" id"chart1" :loading"loading1"&…...
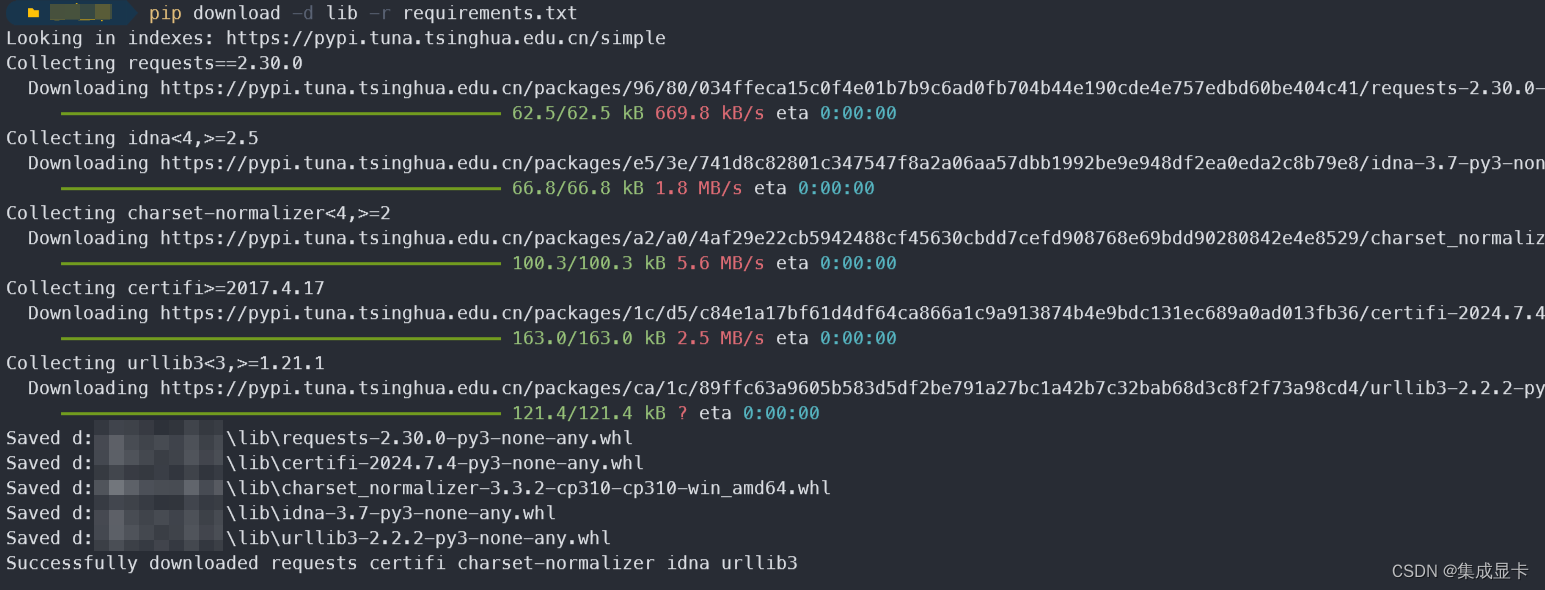
Python 项目依赖离线管理 pip + requirements.txt
背景 项目研发环境不支持联网,无法通过常规 pip install 来安装依赖,此时需要在联网设备下载依赖,然后拷贝到离线设备进行本地安装。 两台设备的操作系统、Python 版本尽可能一致。 离线安装依赖 # 在联网设备上安装项目所需的依赖 # -d …...
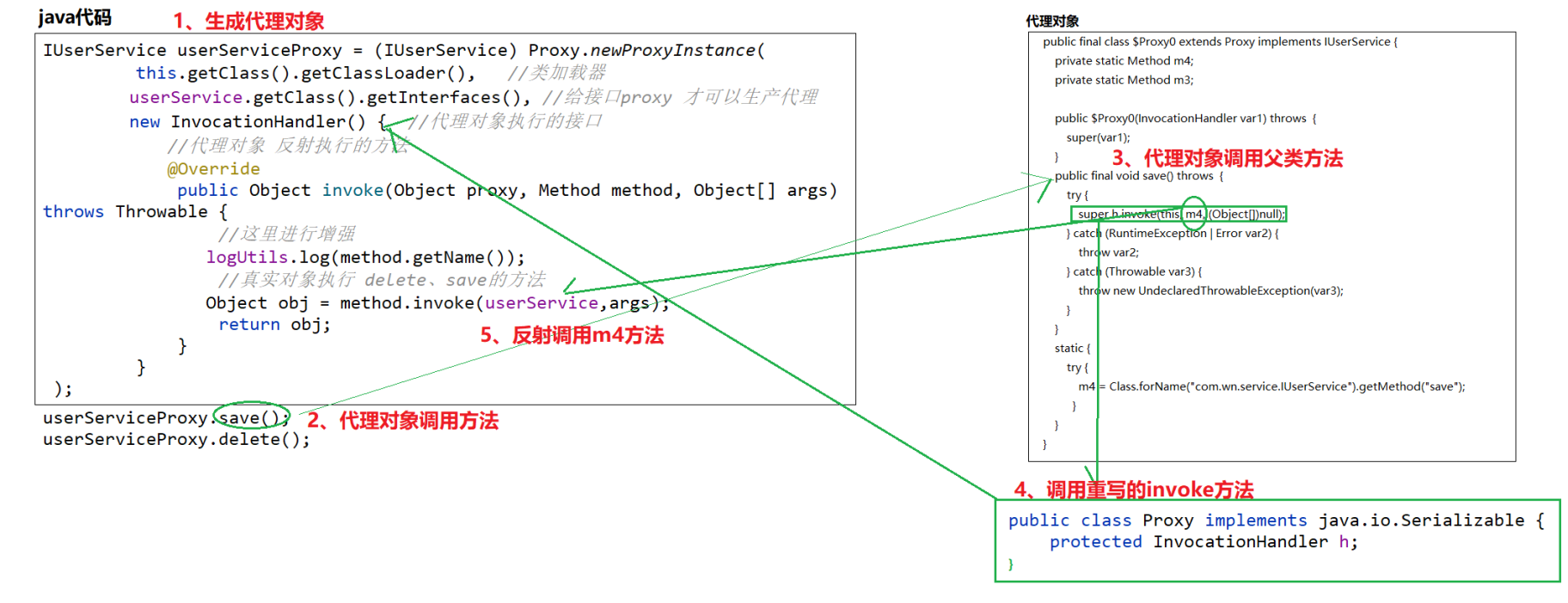
jdk动态代理代码实现
1、jdk动态代理代码实现 1、接口 public interface IUserService {void save();void delete();}2、接口实现 Service public class UserServiceImpl implements IUserService {Overridepublic void save() {System.out.println("UserServiceImpl.save");}Override…...

mybatis的xml如何使用java枚举
mybatis的xml如何使用java枚举 使用方式 ${com.haier.baseManage.enums.LoganUploadTaskTypeEnumLOG_TYPE.type} 例子 <?xml version"1.0" encoding"UTF-8"?> <!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" &quo…...

SQL Server中设置端口号
在SQL Server中设置端口号可以通过SQL Server配置管理器进行。以下是具体步骤: 使用SQL Server 配置管理器设置端口 打开SQL Server配置管理器: 在Windows开始菜单中搜索“SQL Server 配置管理器”,然后打开它。 配置SQL Server网络配置&…...
)
CSS Border(边框)
CSS Border(边框) 引言 在网页设计中,边框是增强元素视觉效果和页面布局的重要工具。CSS 提供了丰富的边框样式属性,允许开发者自定义边框的宽度、颜色、样式等。本文将详细介绍 CSS 边框的相关属性,包括基本用法和高级技巧,帮助…...

【鸿蒙学习笔记】@Prop装饰器:父子单向同步
官方文档:Prop装饰器:父子单向同步 [Q&A] Prop装饰器作用 Prop装饰的变量可以和父组件建立单向的同步关系。Prop装饰的变量是可变的,但是变化不会同步回其父组件。 [Q&A] Prop装饰器特点 1・Prop装饰器不能在Entry装饰的…...
-状态模式)
设计模式(实战项目)-状态模式
需求背景:存在状态流转的预约单 一.数据库设计 CREATE TABLE appointment (id bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT 主键id,appoint_type int(11) NOT NULL COMMENT 预约类型(0:线下查房...),appoint_user_id bigint(20) NOT NULL COMMENT 预约人…...

【python】OpenCV—Color Map
文章目录 cv2.applyColorMapcv2.putText小试牛刀自定义颜色 参考学习来自 OpenCV基础(21)使用 OpenCV 中的applyColorMap实现伪着色 cv2.applyColorMap cv2.applyColorMap() 是 OpenCV 中的一个函数,用于将灰度图像或单通道图像应用一个颜色…...

MySQL:表的内连接和外连接、索引
文章目录 1.内连接2.外连接2.1 左外连接2.2 右外连接 3.综合练习4.索引4.1见一见索引4.2 硬件理解4.3 MySQL 与磁盘交互基本单位(软件理解)4.4 (MySQL选择的数据结构)索引的理解4.5 聚簇索引 VS 非聚簇索引 5.索引操作5.1 创建索引5.2 查询索引5.3 删除索引 1.内连接 内连接实…...
Chrome备份数据
Chrome备份数据 1、 导出谷歌浏览器里的历史记录 参考:https://blog.csdn.net/qq_32824605/article/details/127504219 在资源管理器中找到History文件,文件路径: C:\Users\你的电脑用户名\AppData\Local\Google\Chrome\User Data\Default …...
visual studio远程调试
场景一(被远程调试的电脑) 确定系统位数 我这里是x64的 找到msvsmon.exe msvsmon.exe目录位置解释: “F:\App\VisualStudio\an\Common7\IDE\”是visual studio所在位置、 “Remote Debugger\”是固定位置、 “x64”是系统位数。 拼起来就是…...

if __name__ == “__main__“
在Python中,if __name__ "__main__": 这行代码非常常见,它用于判断当前运行的脚本是否是主程序。这里的 __name__ 是一个特殊变量,当Python文件被直接运行时,__name__ 被自动设置为字符串 "__main__"。但是&…...

3分钟实现本地图片秒搜:ImageSearch从入门到精通
3分钟实现本地图片秒搜:ImageSearch从入门到精通 【免费下载链接】ImageSearch 基于.NET8的本地硬盘千万级图库以图搜图案例Demo和图片exif信息移除小工具分享 项目地址: https://gitcode.com/gh_mirrors/im/ImageSearch 副标题:献给摄影爱好者与…...

资源加速通道:百度网盘高效下载解决方案与实践指南
资源加速通道:百度网盘高效下载解决方案与实践指南 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 在数字化协作日益频繁的今天,云存储服务已成为信息传…...

解锁3大核心优势:GHelper华硕ROG笔记本优化工具完全指南
解锁3大核心优势:GHelper华硕ROG笔记本优化工具完全指南 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops. Control tool for ROG Zephyrus G14, G15, G16, M16, Flow X13, Flow X16, TUF, Strix, Scar and other models 项目地…...

O3DE引擎全面解析:从基础到高级的开源3D创作平台完全指南
O3DE引擎全面解析:从基础到高级的开源3D创作平台完全指南 【免费下载链接】o3de Open 3D Engine (O3DE) is an Apache 2.0-licensed multi-platform 3D engine that enables developers and content creators to build AAA games, cinema-quality 3D worlds, and hi…...

ProcessHacker进程活动时间线:可视化展示进程的生命周期
ProcessHacker进程活动时间线:可视化展示进程的生命周期 【免费下载链接】systeminformer A free, powerful, multi-purpose tool that helps you monitor system resources, debug software and detect malware. Brought to you by Winsider Seminars & Soluti…...

G6与React集成终极指南:构建现代化图可视化应用
G6与React集成终极指南:构建现代化图可视化应用 【免费下载链接】G6 ♾ A Graph Visualization Framework in JavaScript 项目地址: https://gitcode.com/gh_mirrors/g6/G6 G6 是一款功能强大的 JavaScript 图可视化框架,而 React 则是当下最流行…...

Ostrakon-VL-8B惊艳效果:复杂光照下多品牌饮料瓶自动计数与定位热力图
Ostrakon-VL-8B惊艳效果:复杂光照下多品牌饮料瓶自动计数与定位热力图 1. 引言:当AI走进零售货架 想象一下这个场景:一家大型连锁超市的饮料区,货架上密密麻麻摆满了各种品牌的饮料瓶。有可乐、雪碧、矿泉水、果汁,包…...

3.1-mapper映射文件:结果映射机制
将数据库查询结果集转换为 Java 对象的核心技术 一、 核心知识点概述 MyBatis 的结果映射机制,本质是将 SQL 查询返回的数据库结果集(ResultSet),按照指定规则封装为 Java 对象(实体类、包装类等)或集合的过…...

ArcGIS栅格计算NDVI:从整数陷阱到浮点精度的实战解析
1. 为什么你的NDVI结果只有-1、0、1?揭秘“整数陷阱” 如果你用过ArcGIS的栅格计算器来算NDVI,十有八九踩过这个坑:满怀期待地输入了(NIR - R) / (NIR R)这个经典公式,结果出来的栅格图层,在符号化后一看,…...

基于Python的代驾管理系统毕设源码
博主介绍:✌ 专注于Java,python,✌关注✌私信我✌具体的问题,我会尽力帮助你。一、研究目的本研究旨在开发一套基于Python的代驾管理系统,以满足现代城市交通中代驾服务的需求。具体研究目的如下: 首先,通过构建一套完…...