ELK 企业实战7
ELK+kafka+filebeat企业内部日志分析系统
1、组件介绍
1、Elasticsearch:
是一个基于Lucene的搜索服务器。提供搜集、分析、存储数据三大功能。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。
2、Logstash:
主要是用来日志的搜集、分析、过滤日志的工具。用于管理日志和事件的工具,你可以用它去收集日志、转换日志、解析日志并将他们作为数据提供给其它模块调用,例如搜索、存储等。
3、Kibana:
是一个优秀的前端日志展示框架,它可以非常详细的将日志转化为各种图表,为用户提供强大的数据可视化支持,它能够搜索、展示存储在 Elasticsearch 中索引数据。使用它可以很方便的用图表、表格、地图展示和分析数据。
4、Kafka:
数据缓冲队列。作为消息队列解耦合处理过程,同时提高了可扩展性。具有峰值处理能力,使用消息队列能够使关键组件顶住突发的访问压力,而不会因为突发的超负荷的请求而完全崩溃。
- 1.发布和订阅记录流,类似于消息队列或企业消息传递系统。
- 2.以容错持久的方式存储记录流。
- 3.处理记录发生的流。
5、Filebeat:
隶属于Beats,轻量级数据收集引擎。基于原先 Logstash-fowarder 的源码改造出来。换句话说:Filebeat就是新版的 Logstash-fowarder,也会是 ELK Stack 在 Agent 的第一选择,目前Beats包含四种工具:
- 1.Packetbeat(搜集网络流量数据)
- 2.Metricbeat(搜集系统、进程和文件系统级别的 CPU 和内存使用情况等数据。通过从操作系统和服务收集指标,帮助您监控服务器及其托管的服务。)
- 3.Filebeat(搜集文件数据)
- 4.Winlogbeat(搜集 Windows 事件日志数据)
2、环境介绍
注:以下为环境所需所有服务器,配置为测试环境配置。
| 安装软件 | 主机名 | IP地址 | 系统版本 | 配置 |
|---|---|---|---|---|
| Elasticsearch/Logstash/kibana | Elk | 10.3.145.14 | centos7.5.1804 | 2核4G |
| Elasticsearch | Es1 | 10.3.145.56 | centos7.5.1804 | 2核3G |
| Elasticsearch | Es2 | 10.3.145.57 | centos7.5.1804 | 2核3G |
| zookeeper/kafka | Kafka1 | 10.3.145.41 | centos7.5.1804 | 1核2G |
| zookeeper/kafka | Kafka2 | 10.3.145.42 | centos7.5.1804 | 1核2G |
| zookeeper/kafka | Kafka3 | 10.3.145.43 | centos7.5.1804 | 1核2G |
| Filebeat |
3、版本说明
Elasticsearch: 7.13.2
Logstash: 7.13.2
Kibana: 7.13.2
Kafka: 2.11-1
Filebeat: 7.13.2
相应的版本最好下载对应的插件
4、搭建架构
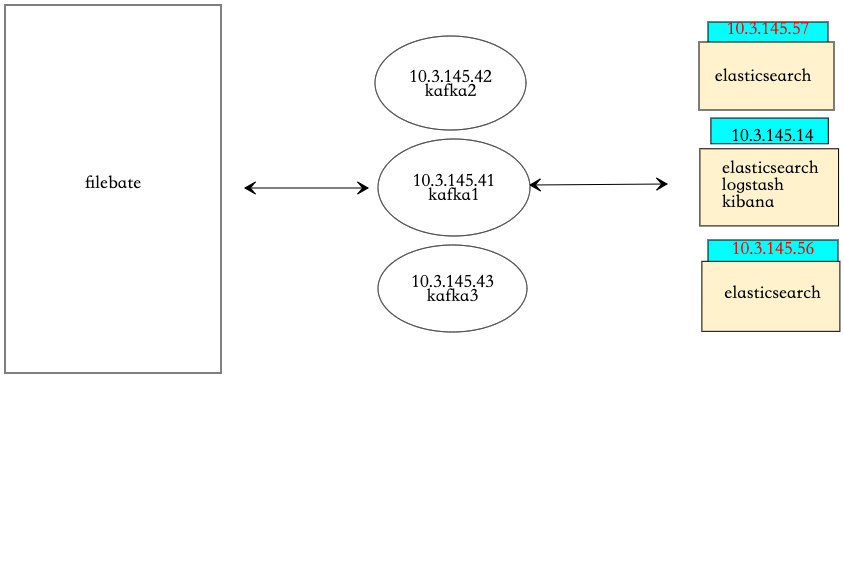
1、日志数据由filebate进行收集,定义日志位置,定义kafka集群,定义要传给kafka的那个topic
2、kafka接受到数据后,端口为9092,等待消费
3、logstash消费kafka中的数据,对数据进行搜集、分析,根据输入条件,过滤条件,输出条件处理后,将数据传输给es集群
4、es集群接受数据后,搜集、分析、存储
5、kibana提供可视化服务,将es中的数据展示。
相关地址:
官网地址:https://www.elastic.co
官网搭建:https://www.elastic.co/guide/index.html
5、实施部署
1、 Elasticsearch集群部署
- 服务器
| 安装软件 | 主机名 | IP地址 | 系统版本 | 配置 |
|---|---|---|---|---|
| Elasticsearch | Elk | 10.3.145.14 | centos7.5.1804 | 2核4G |
| Elasticsearch | Es1 | 10.3.145.56 | centos7.5.1804 | 2核3G |
| Elasticsearch | Es2 | 10.3.145.57 | centos7.5.1804 | 2核3G |
- 软件版本:elasticsearch-7.13.2.tar.gz
- 示例节点:10.3.145.14
1、安装配置jdk
可以自行安装,es安装包中自带了jdk
2、安装配置ES
(1)创建运行ES的普通用户
[root@elk ~]# useradd es
[root@elk ~]# echo "******" | passwd --stdin "es"
(2)安装配置ES
[root@elk ~]# tar zxvf /usr/local/package/elasticsearch-7.13.2-linux-x86_64.tar.gz -C /usr/local/
[root@elk ~]# mv /usr/local/elasticsearch-7.13.2 /usr/local/es
[root@elk ~]# vim /usr/local/es/config/elasticsearch.yml
cluster.name: bjbpe01-elk
cluster.initial_master_nodes: ["192.168.1.101","192.168.1.102","192.168.1.103"] # 单节点模式这里的地址只填写本机地址
node.name: elk01
node.master: true
node.data: true
path.data: /data/elasticsearch/data
path.logs: /data/elasticsearch/logs
bootstrap.memory_lock: false
bootstrap.system_call_filter: false
network.host: 0.0.0.0
http.port: 9200
transport.tcp.port: 9300
# 单节点模式下,将discovery开头的行注释
discovery.seed_hosts: ["192.168.1.102","192.168.1.103"]
discovery.zen.minimum_master_nodes: 2
discovery.zen.ping_timeout: 150s
discovery.zen.fd.ping_retries: 10
client.transport.ping_timeout: 60s
http.cors.enabled: true
http.cors.allow-origin: "*"# 由于我们的笔记本性能有限,如果要使用单节点多实例的话,添加在原有配置中添加
node.max_local_storage_nodes: 这个配置限制了单节点上可以开启的ES存储实例的个数
配置项含义:
cluster.name 集群名称,各节点配成相同的集群名称。
cluster.initial_master_nodes 集群ip,默认为空,如果为空则加入现有集群,第一次需配置
node.name 节点名称,各节点配置不同。
node.master 指示某个节点是否符合成为主节点的条件。
node.data 指示节点是否为数据节点。数据节点包含并管理索引的一部分。
path.data 数据存储目录。
path.logs 日志存储目录。
bootstrap.memory_lock 内存锁定,是否禁用交换,测试环境建议改为false。
bootstrap.system_call_filter 系统调用过滤器。
network.host 绑定节点IP。
http.port rest api端口。
discovery.seed_hosts 提供其他 Elasticsearch 服务节点的单点广播发现功能,这里填写除了本机的其他ip
discovery.zen.minimum_master_nodes 集群中可工作的具有Master节点资格的最小数量,官方的推荐值是(N/2)+1,其中N是具有master资格的节点的数量。
discovery.zen.ping_timeout 节点在发现过程中的等待时间。
discovery.zen.fd.ping_retries 节点发现重试次数。
http.cors.enabled 是否允许跨源 REST 请求,用于允许head插件访问ES。
http.cors.allow-origin 允许的源地址。
(3)设置JVM堆大小 #7.0默认为4G
[root@elk ~]# sed -i 's/## -Xms4g/-Xms4g/' /usr/local/es/config/jvm.options
[root@elk ~]# sed -i 's/## -Xmx4g/-Xmx4g/' /usr/local/es/config/jvm.options
注意:
确保堆内存最小值(Xms)与最大值(Xmx)的大小相同,防止程序在运行时改变堆内存大小。
如果系统内存足够大,将堆内存最大和最小值设置为31G,因为有一个32G性能瓶颈问题。
堆内存大小不要超过系统内存的50%
(4)创建ES数据及日志存储目录
[root@elk ~]# mkdir -p /data/elasticsearch/data (/data/elasticsearch)
[root@elk ~]# mkdir -p /data/elasticsearch/logs (/log/elasticsearch)
(5)修改安装目录及存储目录权限
[root@elk ~]# chown -R es.es /data/elasticsearch
[root@elk ~]# chown -R es.es /usr/local/es
3、系统优化
(1)增加最大文件打开数
永久生效方法:
[root@elk ~]# echo "* soft nofile 65536" >> /etc/security/limits.conf
(2)增加最大进程数
[root@elk ~]# echo "* soft nproc 65536" >> /etc/security/limits.conf
* soft nofile 65536
* hard nofile 131072
* soft nproc 4096
* hard nproc 4096
更多的参数调整可以直接用这个
(3)增加最大内存映射数
[root@elk ~]# echo "vm.max_map_count=262144" >> /etc/sysctl.conf
[root@elk ~]# sysctl -p
启动如果报下列错误
memory locking requested for elasticsearch process but memory is not locked
elasticsearch.yml文件
bootstrap.memory_lock : false
/etc/sysctl.conf文件
vm.swappiness=0错误:
max file descriptors [4096] for elasticsearch process is too low, increase to at least [65536]意思是elasticsearch用户拥有的客串建文件描述的权限太低,知道需要65536个解决:切换到root用户下面,[root@elk ~]# vim /etc/security/limits.conf在最后添加
* hard nofile 65536
* hard nproc 65536
重新启动elasticsearch,还是无效?
必须重新登录启动elasticsearch的账户才可以,例如我的账户名是elasticsearch,退出重新登录。
另外*也可以换为启动elasticsearch的账户也可以,* 代表所有,其实比较不合适启动还会遇到另外一个问题,就是
max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
意思是:elasticsearch用户拥有的内存权限太小了,至少需要262114。这个比较简单,也不需要重启,直接执行
sysctl -w vm.max_map_count=262144
就可以了4、启动ES
[root@elk ~]# su - es -c "cd /usr/local/es && nohup bin/elasticsearch &"
测试:浏览器访问http://10.3.145.14:9200
5.安装配置head监控插件 (只在第一台es部署)
- 服务器
| 安装软件 | 主机名 | IP地址 | 系统版本 | 配置 |
|---|---|---|---|---|
| Elasticsearch-head-master | Elk | 10.3.145.14 | centos7.5.1804 | 2核4G |
(1)安装node
[root@elk ~]# wget https://npm.taobao.org/mirrors/node/latest-v10.x/node-v10.0.0-linux-x64.tar.gz
[root@elk ~]# tar -zxf node-v10.0.0-linux-x64.tar.gz –C /usr/local
[root@elk ~]# echo "
NODE_HOME=/usr/local/node-v10.0.0-linux-x64
PATH=\$NODE_HOME/bin:\$PATH
export NODE_HOME PATH
" >>/etc/profile
[root@elk ~]# source /etc/profile
[root@elk ~]# node --version #检查node版本号
(2)下载head插件
[root@elk ~]# wget https://github.com/mobz/elasticsearch-head/archive/master.zip[root@elk ~]# unzip -d /usr/local elasticsearch-head-master.zip
(3)安装grunt
[root@elk ~]# cd /usr/local/elasticsearch-head-master
[root@elk elasticsearch-head-master]# npm install -g grunt-cli
[root@elk elasticsearch-head-master]# grunt -version #检查grunt版本号
(4)修改head源码
[root@elk ~]# vi /usr/local/elasticsearch-head-master/Gruntfile.js +99
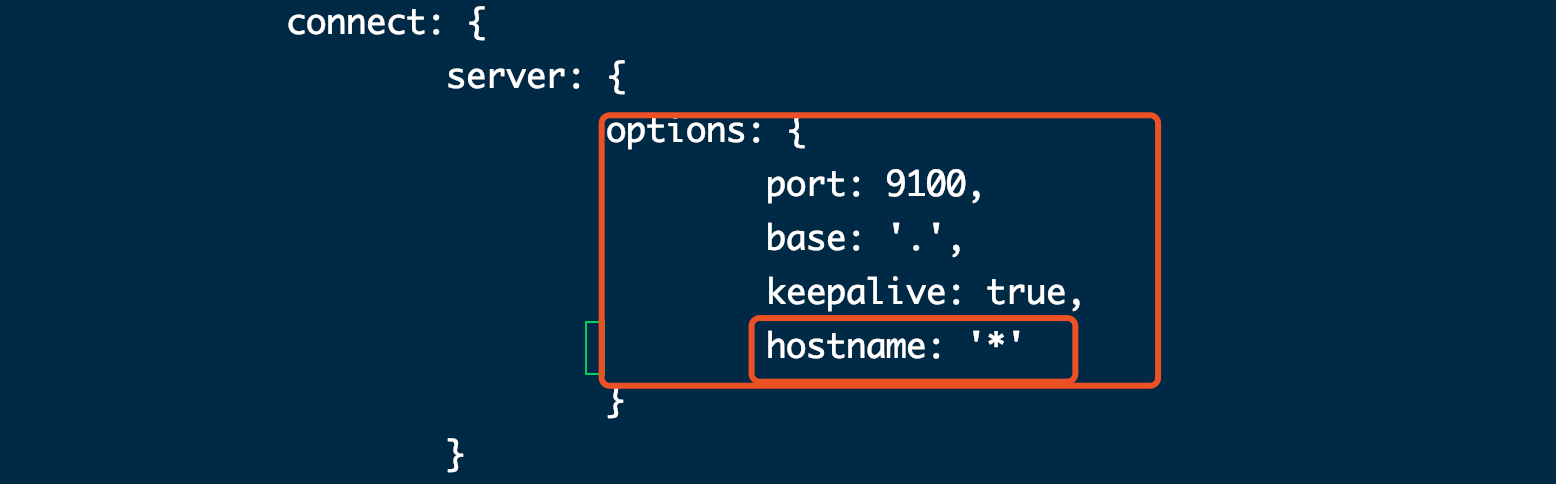
添加hostname,注意在上一行末尾添加逗号,hostname 不需要添加逗号
[root@elk ~]# vim /usr/local/elasticsearch-head-master/_site/app.js +4388

原本是http://localhost:9200 ,如果head和ES不在同一个节点,注意修改成ES的IP地址
(5)下载head必要的文件
[root@elk ~]# wget https://github.com/Medium/phantomjs/releases/download/v2.1.1/phantomjs-2.1.1-linux-x86_64.tar.bz2
[root@elk ~]# yum -y install bzip2
[root@elk ~]# mkdir /tmp/phantomjs
[root@elk ~]# mv phantomjs-2.1.1-linux-x86_64.tar.bz2 /tmp/phantomjs/
[root@elk ~]# chmod 777 /tmp/phantomjs -R
(6)运行head
[root@elk ~]# cd /usr/local/elasticsearch-head-master/
[root@elk elasticsearch-head-master]# npm install
[root@elk elasticsearch-head-master]# nohup grunt server &
[root@elk elasticsearch-head-master]# ss -tnlpnpm install 执行错误解析:
npm ERR! code ELIFECYCLE
npm ERR! errno 1
npm ERR! phantomjs-prebuilt@2.1.16 install: `node install.js`
npm ERR! Exit status 1
npm ERR!
npm ERR! Failed at the phantomjs-prebuilt@2.1.16 install script.
npm ERR! This is probably not a problem with npm. There is likely additional logging output above.npm ERR! A complete log of this run can be found in:
npm ERR! /root/.npm/_logs/2021-04-21T09_49_34_207Z-debug.log解决:
[root@elk elasticsearch-head-master]# npm install phantomjs-prebuilt@2.1.16 --ignore-scripts # 具体的版本按照上述报错修改
(7)测试
访问http://10.3.145.14:9100
2、 Kibana部署
- 服务器
| 安装软件 | 主机名 | IP地址 | 系统版本 | 配置 |
|---|---|---|---|---|
| Kibana | Elk | 10.3.145.14 | centos7.5.1804 | 2核4G |
| 软件版本:nginx-1.14.2、kibana-7.13.2-linux-x86_64.tar.gz |
1. 安装配置Kibana
(1)安装
[root@elk ~]# tar zxf kibana-7.13.2-linux-x86_64.tar.gz -C /usr/local/
(2)配置
[root@elk ~]# echo '
server.port: 5601
server.host: "10.3.145.14"
elasticsearch.hosts: ["http://10.3.145.14:9200"]
kibana.index: ".kibana"
i18n.locale: "zh-CN"
'>>/usr/local/kibana-7.13.2-linux-x86_64/config/kibana.yml
配置项含义:
server.port kibana服务端口,默认5601
server.host kibana主机IP地址,默认localhost
elasticsearch.url 用来做查询的ES节点的URL,默认http://localhost:9200
kibana.index kibana在Elasticsearch中使用索引来存储保存的searches, visualizations和dashboards,默认.kibana
(3)启动
[root@elk ~]# cd /usr/local/kibana-7.13.2-linux-x86_64/
[root@elk ~]# nohup ./bin/kibana --allow-root &
2. 安装配置Nginx反向代理
(1)配置YUM源:
[root@elk ~]# rpm -ivh <http://nginx.org/packages/centos/7/noarch/RPMS/nginx-release-centos-7-0.el7.ngx.noarch.rpm>
(2)安装:
[root@elk ~]# yum install -y nginx httpd-tools
注意:httpd-tools用于生成nginx认证访问的用户密码文件
(3)配置反向代理
[root@elk ~]# cat /etc/nginx/nginx.conf
user nginx;
worker_processes 4;
error_log /var/log/nginx/error.log;
pid /var/run/nginx.pid;
worker_rlimit_nofile 65535;events {worker_connections 65535;use epoll;
}http {include mime.types;default_type application/octet-stream;log_format main '$remote_addr - $remote_user [$time_local] "$request" ''$status $body_bytes_sent "$http_referer" ''"$http_user_agent" "$http_x_forwarded_for"';access_log /var/log/nginx/access.log main;server_names_hash_bucket_size 128;autoindex on;sendfile on;tcp_nopush on;tcp_nodelay on;keepalive_timeout 120;fastcgi_connect_timeout 300;fastcgi_send_timeout 300;fastcgi_read_timeout 300;fastcgi_buffer_size 64k;fastcgi_buffers 4 64k;fastcgi_busy_buffers_size 128k;fastcgi_temp_file_write_size 128k;#gzip模块设置gzip on; #开启gzip压缩输出gzip_min_length 1k; #最小压缩文件大小gzip_buffers 4 16k; #压缩缓冲区gzip_http_version 1.0; #压缩版本(默认1.1,前端如果是squid2.5请使用1.0)gzip_comp_level 2; #压缩等级gzip_types text/plain application/x-javascript text/css application/xml; #压缩类型,默认就已经包含textml,所以下面就不用再写了,写上去也不会有问题,但是会有一个warn。gzip_vary on;#开启限制IP连接数的时候需要使用#limit_zone crawler $binary_remote_addr 10m;#tips:#upstream bakend{#定义负载均衡设备的Ip及设备状态}{# ip_hash;# server 127.0.0.1:9090 down;# server 127.0.0.1:8080 weight=2;# server 127.0.0.1:6060;# server 127.0.0.1:7070 backup;#}#在需要使用负载均衡的server中增加 proxy_pass http://bakend/;server {listen 80;server_name 172.16.244.28;#charset koi8-r;# access_log /var/log/nginx/host.access.log main;access_log off;location / { auth_basic "Kibana"; #可以是string或off,任意string表示开启认证,off表示关闭认证。auth_basic_user_file /etc/nginx/passwd.db; #指定存储用户名和密码的认证文件。proxy_pass http://172.16.244.28:5601;proxy_set_header Host $host:5601; proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header Via "nginx"; }location /status { stub_status on; #开启网站监控状态 access_log /var/log/nginx/kibana_status.log; #监控日志 auth_basic "NginxStatus"; } location /head/{auth_basic "head";auth_basic_user_file /etc/nginx/passwd.db;proxy_pass http://172.16.244.25:9100/;proxy_set_header Host $host:9100;proxy_set_header X-Real-IP $remote_addr;proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;proxy_set_header Via "nginx";} # redirect server error pages to the static page /50x.htmlerror_page 500 502 503 504 /50x.html;location = /50x.html {root html;}}
}
(4)配置授权用户和密码
[root@elk ~]# htpasswd -cm /etc/nginx/passwd.db kibana
(5)启动nginx
[root@elk ~]# systemctl start nginx
浏览器访问http://10.3.145.14 刚开始没有任何数据,会提示你创建新的索引。
3、 Kafka部署
- 服务器
| 安装软件 | 主机名 | IP地址 | 系统版本 | 配置 |
|---|---|---|---|---|
| zookeeper/kafka | Kafka1 | 10.3.145.41 | centos7.5.1804 | 1核2G |
| zookeeper/kafka | Kafka2 | 10.3.145.42 | centos7.5.1804 | 1核2G |
| zookeeper/kafka | Kafka3 | 10.3.145.43 | centos7.5.1804 | 1核2G |
- 软件版本:jdk-8u121-linux-x64.tar.gz、kafka_2.11-2.0.0.tgz
- 示例节点:10.3.145.41
1.安装配置jdk8
(1)Kafka、Zookeeper(简称:ZK)运行依赖jdk8
[root@kafka1 ~]# tar zxvf /usr/local/package/jdk-8u121-linux-x64.tar.gz -C /usr/local/
[root@kafka1 ~]# echo '
JAVA_HOME=/usr/local/jdk1.8.0_121
PATH=$JAVA_HOME/bin:$PATH
export JAVA_HOME PATH
' >>/etc/profile
[root@kafka1 ~]# source /etc/profile
2.安装配置ZK
Kafka运行依赖ZK,Kafka官网提供的tar包中,已经包含了ZK,这里不再额下载ZK程序。
(1)安装
[root@kafka1 ~]# tar zxvf /usr/local/package/kafka_2.11-2.0.0.tgz -C /usr/local/
(2)配置
[root@kafka1 ~]# echo '
dataDir=/opt/data/zookeeper/data
dataLogDir=/opt/data/zookeeper/logs
clientPort=2181
tickTime=2000
initLimit=20
syncLimit=10
server.1=10.3.145.41:2888:3888 //kafka集群IP:Port .1为id 3处要对应
server.2=10.3.145.42:2888:3888
server.3=10.3.145.43:2888:3888
'> /usr/local/kafka_2.11-2.0.0/config/zookeeper.properties
配置项含义:
dataDir ZK数据存放目录。
dataLogDir ZK日志存放目录。
clientPort 客户端连接ZK服务的端口。
tickTime ZK服务器之间或客户端与服务器之间维持心跳的时间间隔。
initLimit 允许follower(相对于Leaderer言的“客户端”)连接并同步到Leader的初始化连接时间,以tickTime为单位。当初始化连接时间超过该值,则表示连接失败。
syncLimit Leader与Follower之间发送消息时,请求和应答时间长度。如果follower在设置时间内不能与leader通信,那么此follower将会被丢弃。
server.1=172.16.244.31:2888:3888 2888是follower与leader交换信息的端口,3888是当leader挂了时用来执行选举时服务器相互通信的端口。
创建data、log目录
[root@kafka1 ~]# mkdir -p /opt/data/zookeeper/{data,logs}
创建myid文件
[root@kafka1 ~]# echo 1 > /opt/data/zookeeper/data/myid
3.配置Kafka
(1)配置
[root@kafka1 ~]# echo '
broker.id=1
listeners=PLAINTEXT://10.3.145.41:9092
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=/opt/data/kafka/logs
num.partitions=6
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=2
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
log.retention.hours=168
log.segment.bytes=536870912
log.retention.check.interval.ms=300000
zookeeper.connect=10.3.145.41:2181,10.3.145.42:2181,10.3.145.43:2181
zookeeper.connection.timeout.ms=6000
group.initial.rebalance.delay.ms=0
' >/usr/local/kafka_2.11-2.0.0/config/server.properties
配置项含义:
broker.id 每个server需要单独配置broker id,如果不配置系统会自动配置。
listeners 监听地址,格式PLAINTEXT://IP:端口。
num.network.threads 接收和发送网络信息的线程数。
num.io.threads 服务器用于处理请求的线程数,其中可能包括磁盘I/O。
socket.send.buffer.bytes 套接字服务器使用的发送缓冲区(SO_SNDBUF)
socket.receive.buffer.bytes 套接字服务器使用的接收缓冲区(SO_RCVBUF)
socket.request.max.bytes 套接字服务器将接受的请求的最大大小(防止OOM)
log.dirs 日志文件目录。
num.partitions partition数量。
num.recovery.threads.per.data.dir 在启动时恢复日志、关闭时刷盘日志每个数据目录的线程的数量,默认1。
offsets.topic.replication.factor 偏移量话题的复制因子(设置更高保证可用),为了保证有效的复制,偏移话题的复制因子是可配置的,在偏移话题的第一次请求的时候可用的broker的数量至少为复制因子的大小,否则要么话题创建失败,要么复制因子取可用broker的数量和配置复制因子的最小值。
log.retention.hours 日志文件删除之前保留的时间(单位小时),默认168
log.segment.bytes 单个日志文件的大小,默认1073741824
log.retention.check.interval.ms 检查日志段以查看是否可以根据保留策略删除它们的时间间隔。
zookeeper.connect ZK主机地址,如果zookeeper是集群则以逗号隔开。
zookeeper.connection.timeout.ms 连接到Zookeeper的超时时间。
创建log目录
[root@kafka1 ~]# mkdir -p /opt/data/kafka/logs
4、其他kafka节点配置
只需把配置好的安装包直接分发到其他节点,然后修改ZK的myid,Kafka的broker.id和listeners就可以了。
5、启动、验证ZK集群
(1)启动
在三个节点依次执行:
[root@kafka1 ~]# cd /usr/local/kafka_2.11-2.0.0/
[root@kafka1 ~]# nohup bin/zookeeper-server-start.sh config/zookeeper.properties &
(2)验证
查看ZK配置
下载nmap
[root@kafka1 ~]# yum install nmap
[root@kafka1 ~]# echo conf | nc 127.0.0.1 2181
clientPort=2181
dataDir=/opt/data/zookeeper/data/version-2
dataLogDir=/opt/data/zookeeper/logs/version-2
tickTime=2000
maxClientCnxns=60
minSessionTimeout=4000
maxSessionTimeout=40000
serverId=1
initLimit=20
syncLimit=10
electionAlg=3
electionPort=3888
quorumPort=2888
peerType=0
查看ZK状态
[root@kafka1 ~]# echo stat |nc 127.0.0.1 2181
Zookeeper version: 3.4.13-2d71af4dbe22557fda74f9a9b4309b15a7487f03, built on 06/29/2018 00:39 GMT
Clients:/127.0.0.1:51876[0](queued=0,recved=1,sent=0)Latency min/avg/max: 0/0/0
Received: 2
Sent: 1
Connections: 1
Outstanding: 0
Zxid: 0x0
Mode: follower
Node count: 4
查看端口
[root@kafka1 ~]# lsof -i:2181
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
java 15002 root 98u IPv4 43385 0t0 TCP *:eforward (LISTEN)
6、启动、验证Kafka
(1)启动
在三个节点依次执行:
[root@kafka1 ~]# cd /usr/local/kafka_2.11-2.0.0/
[root@kafka1 ~]# nohup bin/kafka-server-start.sh config/server.properties &
(2)验证
在10.3.145.41上创建topic
[root@kafka1 ~]# bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic testtopic
Created topic "testtopic".
查询10.3.145.41上的topic
[root@kafka1 ~]# bin/kafka-topics.sh --zookeeper 10.3.145.41:2181 --list
testtopic
查询10.3.145.42上的topic
[root@kafka1 ~]# bin/kafka-topics.sh --zookeeper 10.3.145.42:2181 --list
testtopic
查询10.3.145.43上的topic
[root@kafka1 ~]# bin/kafka-topics.sh --zookeeper 10.3.145.43:2181 --list
testtopic
模拟消息生产和消费
发送消息到10.3.145.41
[root@kafka1 ~]# bin/kafka-console-producer.sh --broker-list 10.3.145.41:9092 --topic testtopic
>Hello World!
从10.3.145.42接受消息
[root@kafka1 ~]# bin/kafka-console-consumer.sh --bootstrap-server 10.3.145.41:9092 --topic testtopic --from-beginning
Hello World!
7、监控 Kafka Manager
Kafka-manager 是 Yahoo 公司开源的集群管理工具。
可以在 Github 上下载安装:https://github.com/yahoo/kafka-manager
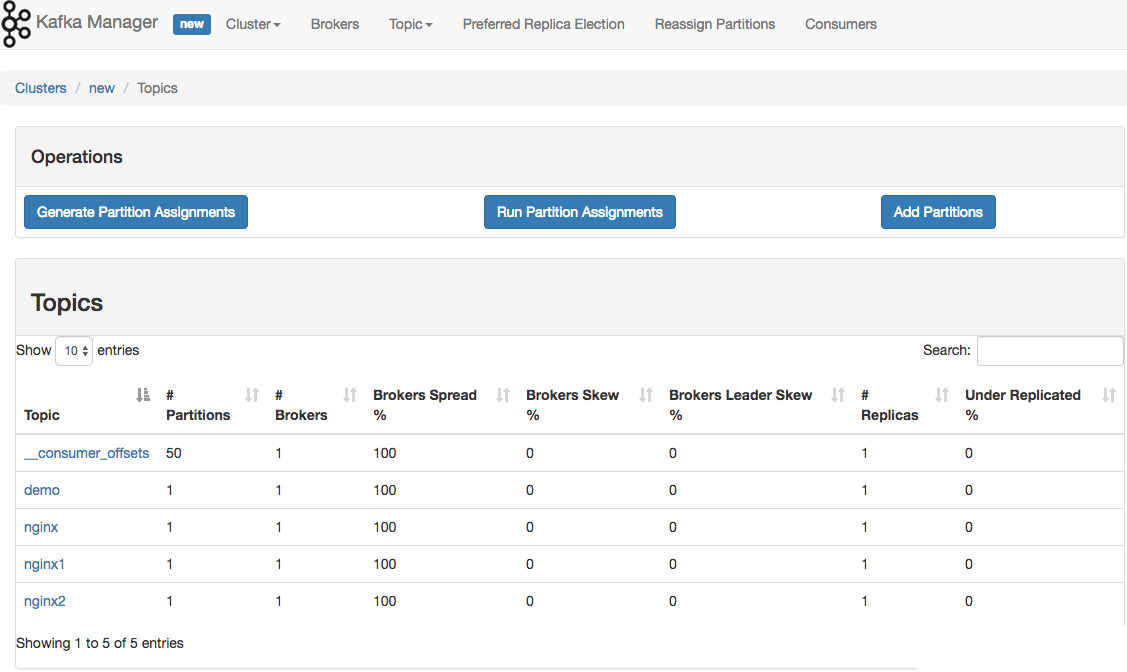
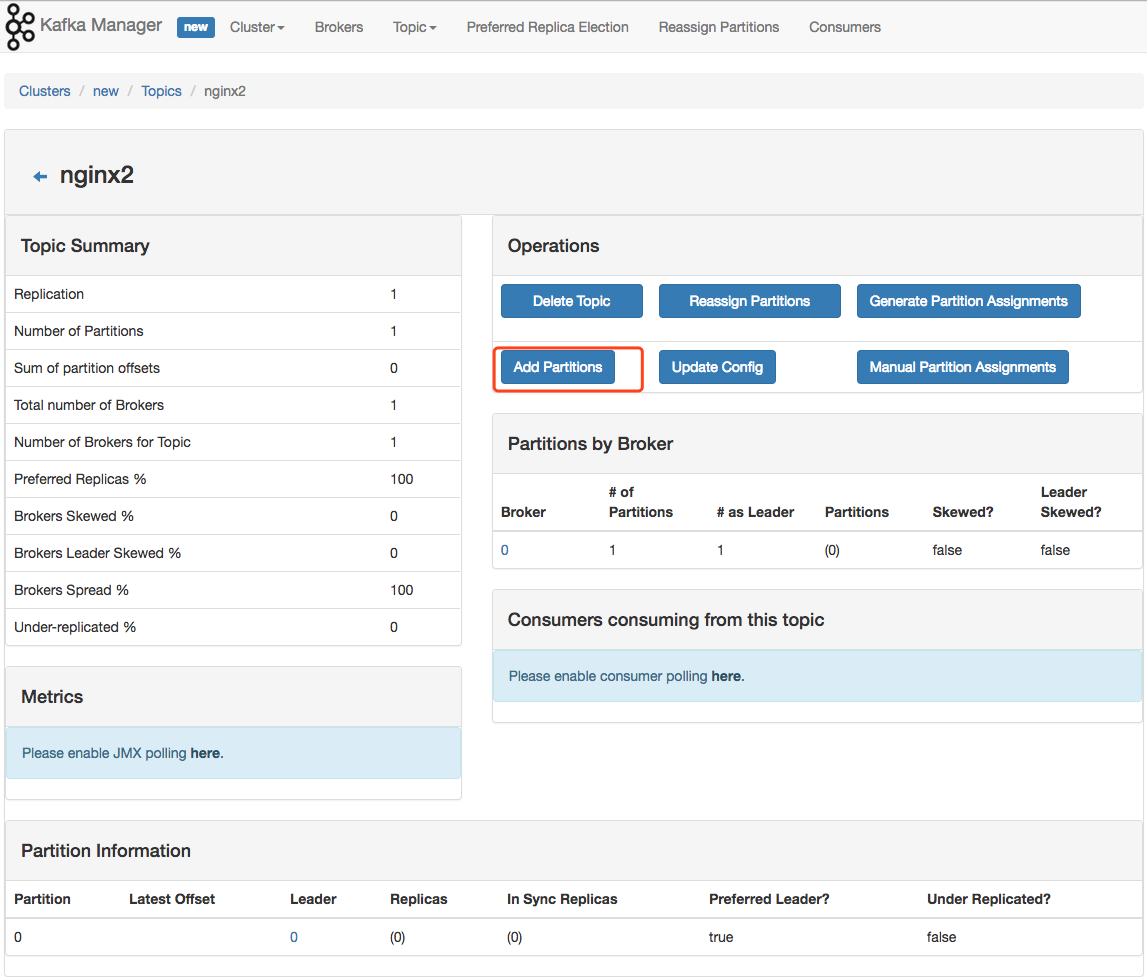
如果遇到 Kafka 消费不及时的话,可以通过到具体 cluster 页面上,增加 partition。Kafka 通过 partition 分区来提高并发消费速度
4、 Logstash部署
- 服务器
| 安装软件 | 主机名 | IP地址 | 系统版本 | 配置 |
|---|---|---|---|---|
| Logstash | Elk | 10.3.145.14 | centos7.5.1804 | 2核4G |
- 软件版本:logstash-7.13.2.tar.gz
1.安装配置Logstash
Logstash运行同样依赖jdk,本次为节省资源,故将Logstash安装在了10.3.145.14节点。
(1)安装
[root@elk ~]# tar zxf /usr/local/package/logstash-7.13.2.tar.gz -C /usr/local/
(2)测试文件
标准输入=>标准输出
1、启动logstash
2、logstash启动后,直接进行数据输入
3、logstash处理后,直接进行返回
input {stdin {}
}
output {stdout {codec => rubydebug}
}
标准输入=>标准输出及es集群
1、启动logstash
2、启动后直接在终端输入数据
3、数据会由logstash处理后返回并存储到es集群中
input {stdin {}
}
output {stdout {codec => rubydebug}elasticsearch {hosts => ["10.3.145.14","10.3.145.56","10.3.145.57"]index => 'logstash-debug-%{+YYYY-MM-dd}'}
}
端口输入=>字段匹配=>标准输出及es集群
1、由tcp 的8888端口将日志发送到logstash
2、数据被grok进行正则匹配处理
3、处理后,数据将被打印到终端并存储到es
input {tcp {port => 8888}
}
filter {grok {match => {"message" => "%{DATA:key} %{NUMBER:value:int}"} }
}
output {stdout {codec => rubydebug}elasticsearch {hosts => ["10.3.145.14","10.3.145.56","10.3.145.57"]index => 'logstash-debug-%{+YYYY-MM-dd}'}
}
# yum install -y nc
# free -m |awk 'NF==2{print $1,$3}' |nc logstash_ip 8888
文件输入=>字段匹配及修改时间格式修改=>es集群
1、直接将本地的日志数据拉去到logstash当中
2、将日志进行处理后存储到es
input {file {type => "nginx-log"path => "/var/log/nginx/error.log"start_position => "beginning" # 此参数表示在第一次读取日志时从头读取# sincedb_path => "自定义位置" # 此参数记录了读取日志的位置,默认在 data/plugins/inputs/file/.sincedb*}
}
filter {grok {match => { "message" => '%{DATESTAMP:date} [%{WORD:level}] %{DATA:msg} client: %{IPV4:cip},%{DATA}"%{DATA:url}"%{DATA}"%{IPV4:host}"'} } date {match => [ "timestamp" , "dd/MMM/YYYY:HH:mm:ss Z" ] }
}output {if [type] == "nginx-log" {elasticsearch {hosts => ["192.168.249.139:9200","192.168.249.149:9200","192.168.249.159:9200"]index => 'logstash-audit_log-%{+YYYY-MM-dd}'}}}
filebeat => 字段匹配 => 标准输出及es
input {beats {port => 5000}
}
filter {grok {match => {"message" => "%{IPV4:cip}"} }
}
output {elasticsearch {hosts => ["192.168.249.139:9200","192.168.249.149:9200","192.168.249.159:9200"]index => 'test-%{+YYYY-MM-dd}'}stdout { codec => rubydebug }
}
(3)配置
创建目录,我们将所有input、filter、output配置文件全部放到该目录中。
[root@elk ~]# mkdir -p /usr/local/logstash-7.13.2/etc/conf.d
[root@elk ~]# vim /usr/local/logstash-7.13.2/etc/conf.d/input.conf
input {
kafka {type => "audit_log"codec => "json"topics => "nginx"decorate_events => truebootstrap_servers => "10.3.145.41:9092, 10.3.145.42:9092, 10.3.145.43:9092"}
}[root@elk ~]# vim /usr/local/logstash-7.13.2/etc/conf.d/filter.conf
filter {json { # 如果日志原格式是json的,需要用json插件处理source => "message"target => "nginx" # 组名}
}[root@elk ~]# vim /usr/local/logstash-7.13.2/etc/conf.d/output.conf
output {if [type] == "audit_log" {elasticsearch {hosts => ["10.3.145.14","10.3.145.56","10.3.145.57"]index => 'logstash-audit_log-%{+YYYY-MM-dd}'}}}
(3)启动
[root@elk ~]# cd /usr/local/logstash-7.13.2
[root@elk ~]# nohup bin/logstash -f etc/conf.d/ --config.reload.automatic &
5、Filebeat 部署
为什么用 Filebeat ,而不用原来的 Logstash 呢?
原因很简单,资源消耗比较大。
由于 Logstash 是跑在 JVM 上面,资源消耗比较大,后来作者用 GO 写了一个功能较少但是资源消耗也小的轻量级的 Agent 叫 Logstash-forwarder。
后来作者加入 elastic.co 公司, Logstash-forwarder 的开发工作给公司内部 GO 团队来搞,最后命名为 Filebeat。
Filebeat 需要部署在每台应用服务器上,可以通过 Salt 来推送并安装配置。
- 服务器
| 安装软件 | 主机名 | IP地址 | 系统版本 | 配置 |
|---|---|---|---|---|
| filebeat | Kafka3 | 10.3.145.43 | centos7.5.1804 | 1核2G |
- 软件版本 filebeat-7.13.2-x86_64.rpm
(1)下载
[root@kafka3 ~]# curl -L -O https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.13.2-x86_64.rpm
(2)解压
[root@kafka3 ~]# yum install -y filebeat-7.13.2-x86_64.rpm
(3)修改配置
修改 Filebeat 配置,支持收集本地目录日志,并输出日志到 Kafka 集群中
[root@kafka3 ~]# vim filebeat.yml
filebeat.inputs:
- type: logenabled: truepaths:- /var/log/nginx/access.log
output.logstash:hosts: ["10.3.145.14:5000"]output.kafka: hosts: ["10.3.145.41:9092","10.3.145.42:9092","10.3.145.43:9092"]topic: 'nginx'# 注意,如果需要重新读取,请删除/data/registry目录
Filebeat 6.0 之后一些配置参数变动比较大,比如 document_type 就不支持,需要用 fields 来代替等等。
(4)启动
[root@kafka3 ~]# ./filebeat -e -c filebeat.yml
(5)配置nginx
因为日志格式的切割需要json格式,kibana中会报错 error decoding json,所以在这里我们将nginx的日志格式修改为json格式。[root@kafka3 ~]# vim /etc/nginx/nginx.conf
# log_format main '$remote_addr - $remote_user [$time_local] "$request" '
# '$status $body_bytes_sent "$http_referer" '
# '"$http_user_agent" "$http_x_forwarded_for"';log_format main '{"user_ip":"$http_x_real_ip","lan_ip":"$remote_addr","log_time":"$time_iso8601","user_req":"$request","http_code":"$status","body_bytes_sents":"$body_bytes_sent","req_time":"$request_time","user_ua":"$http_user_agent"}';access_log /var/log/nginx/access.log main;
.logstash:
hosts: [“10.3.145.14:5000”]
output.kafka:
hosts: [“10.3.145.41:9092”,“10.3.145.42:9092”,“10.3.145.43:9092”]
topic: ‘nginx’
注意,如果需要重新读取,请删除/data/registry目录
Filebeat 6.0 之后一些配置参数变动比较大,比如 document_type 就不支持,需要用 fields 来代替等等。##### (4)启动```shell
[root@kafka3 ~]# ./filebeat -e -c filebeat.yml
(5)配置nginx
因为日志格式的切割需要json格式,kibana中会报错 error decoding json,所以在这里我们将nginx的日志格式修改为json格式。[root@kafka3 ~]# vim /etc/nginx/nginx.conf
# log_format main '$remote_addr - $remote_user [$time_local] "$request" '
# '$status $body_bytes_sent "$http_referer" '
# '"$http_user_agent" "$http_x_forwarded_for"';log_format main '{"user_ip":"$http_x_real_ip","lan_ip":"$remote_addr","log_time":"$time_iso8601","user_req":"$request","http_code":"$status","body_bytes_sents":"$body_bytes_sent","req_time":"$request_time","user_ua":"$http_user_agent"}';access_log /var/log/nginx/access.log main;[外链图片转存中…(img-cx6jVENl-1719491920553)]
相关文章:
ELK 企业实战7
ELKkafkafilebeat企业内部日志分析系统 1、组件介绍 1、Elasticsearch: 是一个基于Lucene的搜索服务器。提供搜集、分析、存储数据三大功能。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java开发的ÿ…...
linux 下neo4j的安装
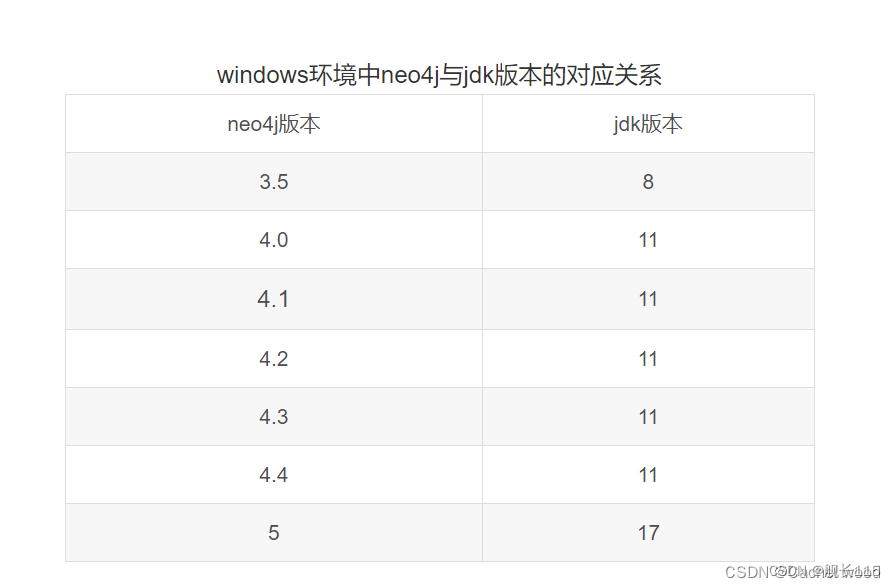
一、neo4j简介 Neo4j 是一个高性能的 NoSQL 图形数据库,它将结构化数据存储在网络(从数学角度叫做图)上而不是表中。Neo4j 也可以被看作是一个高性能的图引擎,该引擎具有成熟数据库的所有特性。 neo4j与jdk版本对应 neo4j的版本需要与jdk版本相适配,否则容易出现安装失…...

Flink ProcessFunction不同流异同及应用场景
ProcessFunction系列对比概览 函数类别关键特性应用场景示例ProcessFunction基础类,处理单个事件,支持事件时间、水位线、状态管理、定时器。单独处理每个事件,执行复杂逻辑,如基于事件内容动态响应。KeyedProcessFunction基于键…...

Matplotlib 文本
可以使用 xlabel、ylabel、text向图中添加文本 mu, sigma 100, 15 x mu sigma * np.random.randn(10000)# the histogram of the data n, bins, patches plt.hist(x, 50, densityTrue, facecolorg, alpha0.75)plt.xlabel(Smarts) plt.ylabel(Probability) plt.title(Histo…...

信创产业政策,信创测试方面
信创产业的政策支持主要体现在多个方面,这些政策旨在推动产业的快速发展,加强自主创新能力,保障国家信息安全,以及促进产业结构的优化升级。 首先,政府通过财政支持、税收优惠等方式,加大对信创产业的资金…...

微信云数据库迁移到unicloud云数据库
背景 早期只有一个微信小程序,后来了解到uniapp的跨端解决方案,开始从小程序代码迁移到uniapp。对于后端采用的微信云开发方案,迁移的时候主要要解决从openid的用户体系转移到unicloud提供的uni-id体系(使用uid)。 方案 利用微信云数据库的…...

快速上手文心一言指令
“文心一言”指的是百度公司开发的自然语言处理与生成技术,它类似于ChatGPT,是一种基于大规模语言模型的AI对话系统,能够理解和生成自然语言文本,进行问答、创作等多种任务。由于“文心一言”是一个复杂的系统,其内部指…...
零基础STM32单片机编程入门(五)FreeRTOS实时操作系统详解及实战含源码视频
文章目录 一.概要二.什么是实时操作系统三.FreeRTOS的特性四.FreeRTOS的任务详解1.任务函数定义2.任务的创建3.任务的调度原理 五.CubeMX配置一个FreeRTOS例程1.硬件准备2.创建工程3.调试FreeRTOS任务调度 六.CubeMX工程源代码下载七.讲解视频链接地址八.小结 一.概要 FreeRTO…...
leetCode.96. 不同的二叉搜索树
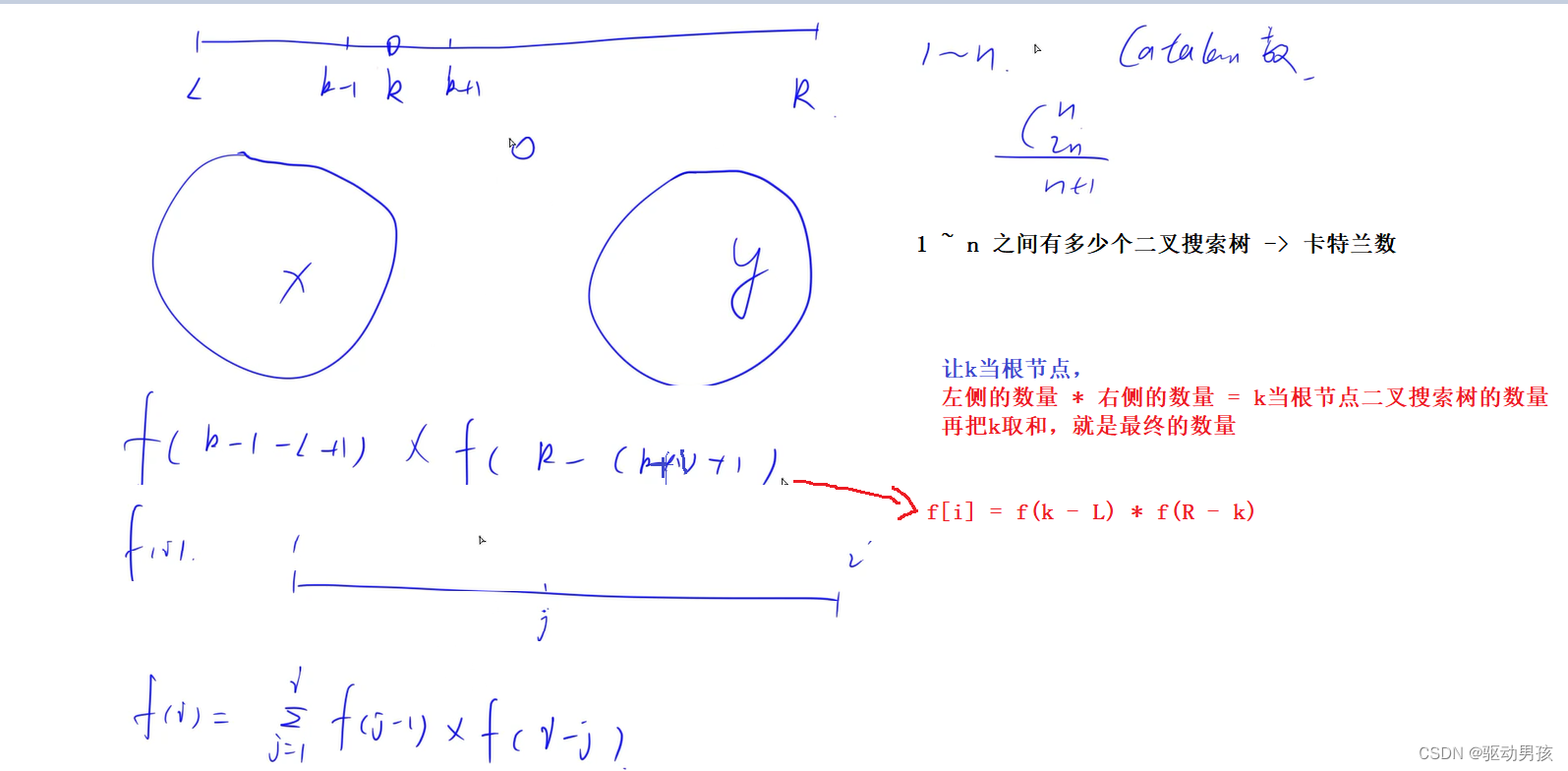
leetCode.96. 不同的二叉搜索树 题目思路 代码 // 方法一:直接用卡特兰数就行 // 方法二:递归方法 class Solution { public:int numTrees(int n) {// 这里把 i当成整个结点,j当成左子树最左侧结点,并一次当根节点尝试// f[ i ] f[ j - 1…...

PyAutoGUI 使用详解
文章目录 简介PyAutoGUI 的原理安装 PyAutoGUI基本使用示例鼠标控制键盘控制截屏图像识别消息框 高级功能防止误操作多屏幕支持鼠标平滑移动 结论 简介 PyAutoGUI 是一个用于自动化控制鼠标和键盘的 Python 库。它可以帮助开发者编写脚本,以模拟用户在计算机上的操…...

MySQL——备份
为什么要备份? 保证重要的数据不丢失 方便数据转移 MySQL数据库备份方式: 1. 直接拷贝物理文件 2. 在可视化工具中手动导出 —— 在想要导出的表或者库中,右键选择备份或导出 3. 使用命令行导出 mysqldump ——cmd打开命令行 —…...

科东软件精彩亮相华南工博会,展现未来工业前沿技术
近日,华南国际工业博览会在深圳成功举办。科东软件携众多前沿技术、解决方案及最新应用案例精彩亮相,为参展观众带来了一场工业智能的科技盛宴。 鸿道操作系统(Intewell) 科东软件重点展示了鸿道操作系统(Intewell&…...
详解flink sql, calcite logical转flink logical
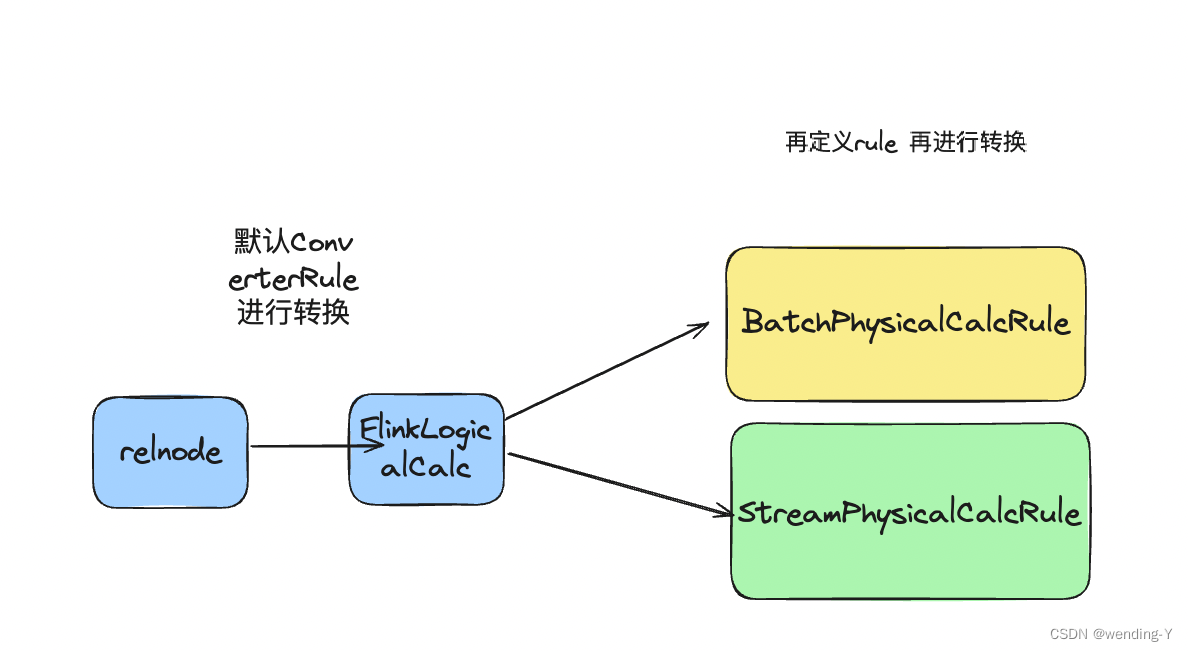
文章目录 背景示例FlinkLogicalCalcConverterBatchPhysicalCalcRuleStreamPhysicalCalcRule其它算子FlinkLogicalAggregateFlinkLogicalCorrelateFlinkLogicalDataStreamTableScanFlinkLogicalDistributionFlinkLogicalExpandFlinkLogicalIntermediateTableScanFlinkLogicalInt…...

PostgreSQL的系统视图pg_statio_all_indexes
PostgreSQL的系统视图pg_statio_all_indexes 在 PostgreSQL 数据库中,pg_statio_all_indexes 视图提供了有关所有索引的 I/O 活动的统计信息。这些统计信息对于了解索引的使用情况和性能调优非常有帮助。 pg_statio_all_indexes 视图的结构 以下是 pg_statio_all…...

【C++ Primer Plus学习记录】函数和C-风格字符串
将字符串作为参数时意味着传递的是地址,但可以使用const来禁止对字符串参数进行修改。 假设要将字符串作为参数传递给函数,则表示字符串的方式有三种: (1)char数组 (2)用引号括起来的字符串常…...
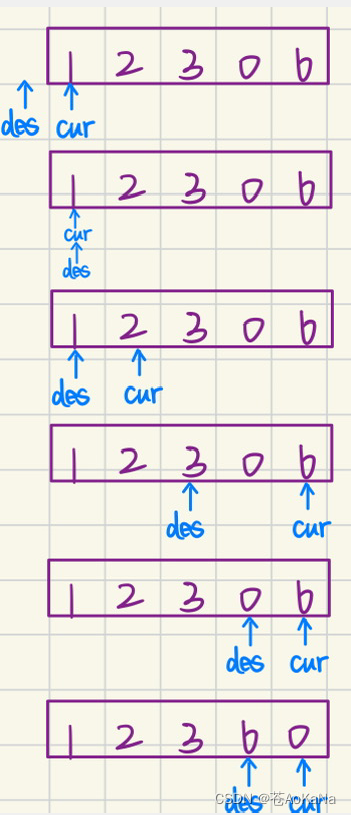
力扣双指针算法题目:移动零
1.题目 . - 力扣(LeetCode) 2.思路解析 这个题目的思路和“使用递归排序快速排序解决数组的排序问题”相同 class solution { public:void QuickSort(vector<int>& nums, int left, int right){if (left > right) return;int key left…...
)
day60---面试专题(微服务面试题-参考回答)
微服务面试题 **面试官:**Spring Cloud 5大组件有哪些? 候选人: 早期我们一般认为的Spring Cloud五大组件是 Eureka : 注册中心Ribbon : 负载均衡Feign : 远程调用Hystrix : 服务熔断Zuul/Gateway : 网关 随着SpringCloudAlibba在国内兴起 , …...

laravel+phpoffice+easyexcel实现导入
资源包下载地址 https://download.csdn.net/download/QiZong__BK/89503486 easy-excel下载: "dcat/easy-excel": "^1.0", 命令行: composer require dcat/easy-excel 前端代码 <!doctype html> <html lang"en&…...

Spring Boot集成多数据源的最佳实践
Spring Boot集成多数据源的最佳实践 大家好,我是免费搭建查券返利机器人省钱赚佣金就用微赚淘客系统3.0的小编,也是冬天不穿秋裤,天冷也要风度的程序猿! 为什么需要多数据源? 在实际的应用开发中,有时候…...

Java项目:基于SSM框架实现的班主任助理管理系统【ssm+B/S架构+源码+数据库+开题报告+毕业论文】
一、项目简介 本项目是一套基于SSM框架实现的班主任助理管理系统 包含:项目源码、数据库脚本等,该项目附带全部源码可作为毕设使用。 项目都经过严格调试,eclipse或者idea 确保可以运行! 该系统功能完善、界面美观、操作简单、功…...
)
uniapp 对接腾讯云IM群组成员管理(增删改查)
UniApp 实战:腾讯云IM群组成员管理(增删改查) 一、前言 在社交类App开发中,群组成员管理是核心功能之一。本文将基于UniApp框架,结合腾讯云IM SDK,详细讲解如何实现群组成员的增删改查全流程。 权限校验…...

CVPR 2025 MIMO: 支持视觉指代和像素grounding 的医学视觉语言模型
CVPR 2025 | MIMO:支持视觉指代和像素对齐的医学视觉语言模型 论文信息 标题:MIMO: A medical vision language model with visual referring multimodal input and pixel grounding multimodal output作者:Yanyuan Chen, Dexuan Xu, Yu Hu…...

Linux-07 ubuntu 的 chrome 启动不了
文章目录 问题原因解决步骤一、卸载旧版chrome二、重新安装chorme三、启动不了,报错如下四、启动不了,解决如下 总结 问题原因 在应用中可以看到chrome,但是打不开(说明:原来的ubuntu系统出问题了,这个是备用的硬盘&a…...

vue3+vite项目中使用.env文件环境变量方法
vue3vite项目中使用.env文件环境变量方法 .env文件作用命名规则常用的配置项示例使用方法注意事项在vite.config.js文件中读取环境变量方法 .env文件作用 .env 文件用于定义环境变量,这些变量可以在项目中通过 import.meta.env 进行访问。Vite 会自动加载这些环境变…...

Java面试专项一-准备篇
一、企业简历筛选规则 一般企业的简历筛选流程:首先由HR先筛选一部分简历后,在将简历给到对应的项目负责人后再进行下一步的操作。 HR如何筛选简历 例如:Boss直聘(招聘方平台) 直接按照条件进行筛选 例如:…...

dify打造数据可视化图表
一、概述 在日常工作和学习中,我们经常需要和数据打交道。无论是分析报告、项目展示,还是简单的数据洞察,一个清晰直观的图表,往往能胜过千言万语。 一款能让数据可视化变得超级简单的 MCP Server,由蚂蚁集团 AntV 团队…...

七、数据库的完整性
七、数据库的完整性 主要内容 7.1 数据库的完整性概述 7.2 实体完整性 7.3 参照完整性 7.4 用户定义的完整性 7.5 触发器 7.6 SQL Server中数据库完整性的实现 7.7 小结 7.1 数据库的完整性概述 数据库完整性的含义 正确性 指数据的合法性 有效性 指数据是否属于所定…...

使用LangGraph和LangSmith构建多智能体人工智能系统
现在,通过组合几个较小的子智能体来创建一个强大的人工智能智能体正成为一种趋势。但这也带来了一些挑战,比如减少幻觉、管理对话流程、在测试期间留意智能体的工作方式、允许人工介入以及评估其性能。你需要进行大量的反复试验。 在这篇博客〔原作者&a…...

Razor编程中@Html的方法使用大全
文章目录 1. 基础HTML辅助方法1.1 Html.ActionLink()1.2 Html.RouteLink()1.3 Html.Display() / Html.DisplayFor()1.4 Html.Editor() / Html.EditorFor()1.5 Html.Label() / Html.LabelFor()1.6 Html.TextBox() / Html.TextBoxFor() 2. 表单相关辅助方法2.1 Html.BeginForm() …...

【Android】Android 开发 ADB 常用指令
查看当前连接的设备 adb devices 连接设备 adb connect 设备IP 断开已连接的设备 adb disconnect 设备IP 安装应用 adb install 安装包的路径 卸载应用 adb uninstall 应用包名 查看已安装的应用包名 adb shell pm list packages 查看已安装的第三方应用包名 adb shell pm list…...