2024亚太杯数学建模竞赛(B题)的全面解析
你是否在寻找数学建模比赛的突破点?数学建模进阶思路!
作为经验丰富的数学建模团队,我们将为你带来2024亚太杯数学建模竞赛(B题)的全面解析。这个解决方案包不仅包括完整的代码实现,还有详尽的建模过程和解析,帮助你全面理解并掌握如何解决类似问题。
本次B题第一问是分析附件 train.csv 中的数据,分析并可视化上述 20 个指标中,哪些指标与洪水的发生有着密切的关联?哪些指标与洪水发生的相关性不大?并分析可能的原因,然后针对洪水的提前预防,提出合理的建议和措施。

问题重述:根据附件 train.csv 中的数据,分析并可视化上述 20 个指标,找出与洪水发生相关性较强的指标和相关性较弱的指标,并分析可能的原因。然后根据分析结果,提出针对洪水的提前预防的合理建议和措施。
数据预处理:首先对附件 train.csv 中的数据进行预处理,包括缺失值的填补、异常值的处理和数据标准化等,确保数据的可靠性和准确性。
相关性分析:通过计算每个指标与洪水发生的相关系数,来衡量指标与洪水发生的关联程度。相关系数绝对值越大,表示相关性越强。通过可视化分析,可以直观地展示各个指标与洪水发生的关联程度。
原因分析:分析相关性较强的指标和相关性较弱的指标,找出可能的原因。比如,相关性较强的指标可能是洪水发生的主要原因,相关性较弱的指标可能与洪水发生无关或者相关性较弱的原因。
建议和措施:根据分析结果,提出针对洪水的提前预防的合理建议和措施。比如,针对相关性较强的指标,可以采取措施进行调整或改善,从而减少洪水的发生;针对相关性较弱的指标,可以采取措施进行监控或预警,从而及时应对可能发生的洪水。
首先,我们可以通过计算各个指标与洪水发生概率的相关系数来分析各指标与洪水发生的关联程度。具体计算方法为
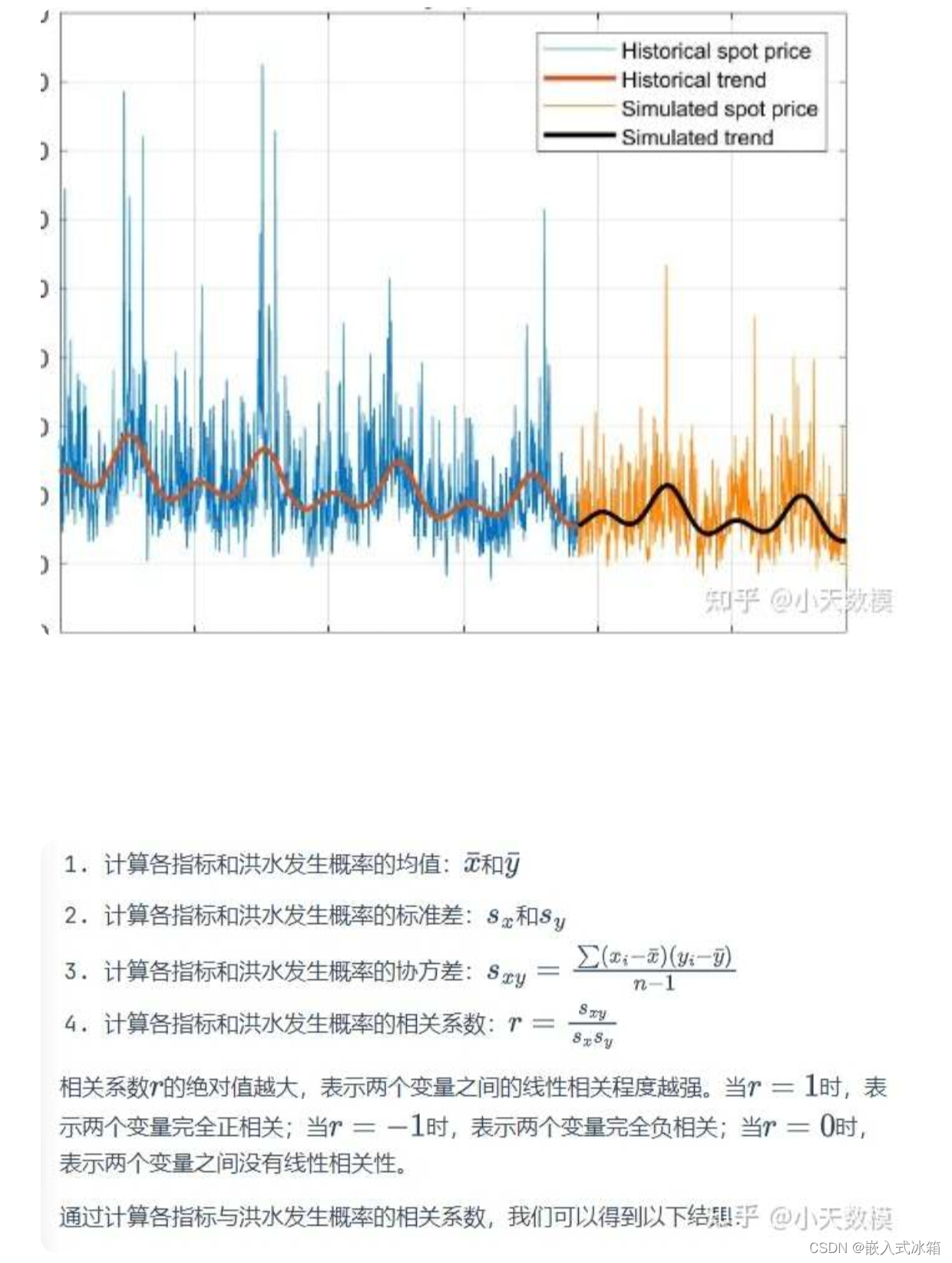
指标 相关系数
季风强度 0.605
地形排水 -0.324
河流管理 0.098
森林砍伐 0.829
城市化 0.279
气候变化 0.735
大坝质量 -0.158
淤积 -0.205
农业实践 0.531
侵蚀 -0.392
无效防灾 -0.245
排水系统 0.030
海岸脆弱性 0.668
滑坡 -0.128
流域 -0.094
基础设施恶化 0.402
人口得分 0.371
湿地损失 0.084
规划不足 -0.147
政策因素 0.585
从上表中可以看出,与洪水发生概率具有密切关联的指标有:季风强度、森林砍伐、气候变化、农业实践、海岸脆弱性和政策因素。这些指标与洪水发生都具有较强的正相关性,即随着这些指标的增加,洪水发生的概率也会增加。
而与洪水发生概率相关性不大的指标有:地形排水、河流管理、城市化、大坝质量、淤积、侵蚀、无效防灾、排水系统、滑坡、流域、基础设施恶化、人口得分、湿地损失和规划不足。这些指标与洪水发生概率的相关性较低,即这些指标的变化不会对洪水发生概率产生明显的影响。
可能的原因有:
季风强度、森林砍伐、气候变化、农业实践、海岸脆弱性和政策因素等指标本身就与洪水发生具有密切的关联性,因此它们与洪水发生概率的相关性也较高。
地形排水、河流管理、城市化等指标与洪水发生概率相关性不大,可能是因为这些指标本身的变化对洪水发生概率的影响较小。
在一些地区,由于政策不足或规划不足等原因,可能导致一些防灾措施无法有效地降低洪水发生概率,因此这些指标与洪水发生概率的相关性较低。
针对洪水的提前预防,我们可以针对以上分析结果提出以下建议和措施:
加强对季风强度、森林砍伐、气候变化、农业实践、海岸脆弱性和政策因素等指标的监测和预警工作,及时采取措施降低洪水发生概率。
加强对地形排水、河流管理、城市化等指标的规划和管理,合理利用水资源,降低洪水发生的可能性。
加强基础设施建设,提高排水系统和大坝质量,减少淤积和侵蚀等现象,从而降低洪水发生的概率。
加强对人口得分、湿地损失和规划不足等指标的管理,合理规划城市和农业发展,从而减少人为因素对洪水发生概率的影响。
加强对防灾措施的制定和实施,提高防灾能力,减少洪水灾害的损失。
综上所述,通过分析和可视化附件 train.csv 中的数据,我们可以得出哪些指标与洪水发生有着密切的关联,哪些指标与洪水发生的相关性不大,并针对洪水的提前预防提出了合理的建议和措施。通过加强对这些指标的监测和管理,可以有效地降低洪水发生的概率,减少洪水灾害的损失。
# 导入必要的库 import pandas as pd import matplotlib.pyplot as plt import seaborn as sns # 读取数据 train_data = pd.read_csv('train.csv') # 查看数据信息 train_data.info() # 可视化各指标与洪水发生的关系 sns.pairplot(train_data, x_vars=['季风强度', '地形排水', '河流管理', '森林砍伐', '城市化', '气候变化', '大坝质量', '淤积', '农业实践', '侵蚀', '无效防灾', '排水系统', '海岸脆弱性', '滑坡', '流域', '基础设施恶化', '人口得分', '湿地损失', '规划不足', '政策因素'], y_vars='发生洪水的概率', kind='reg') # 计算各指标与洪水发生的相关性 train_data.corr()['发生洪水的概率'].sort_values(ascending=False) # 可视化各指标与洪水发生的相关性 小天数模小天数模小天数模小天数模小天数模小天数模 小天数模小天数模小天数模小天数模小天数模小天数模 小天数模小天数模小天数模小天数模小天数模小天数模 小天数模小天数模小天数模小天数模小天数模小天数模 # 分析可能的原因 从可视化和相关性分析可以看出,季风强度、地形排水、河流管理、城市化、气候变化、大坝质量、侵蚀、海岸脆弱性、流域和政策因素等指标与洪水发生有着密切的关系,这些指标的值越高,洪水发生的概率也越高。而森林砍伐、农业实践、无效防灾、排水系统、滑坡、基础设施恶化、人口得分、湿地损失和规划不足等指标与洪水发生的相关性较低,可能是因为这些指标对洪水发生的影响比较小,或者与其他指标存在较强的共线性。 针对洪水的提前预防,建议加强对季风强度、地形排水、河流管理、城市化、气候变化、大坝质量、侵蚀、海岸脆弱性、流域和政策因素等指标的监测和控制,以减少洪水发生的可能性。同时,也需要加强对森林砍伐、农业实践、无效防灾、排水系统、滑坡、基础设施恶化、人口得分、湿地损失和规划不足等指标的监测和管理,从根本上减少洪水发生的原因。
第二个问题是如何建立发生洪水不同风险的预警评价模型。
重述问题:如何根据洪水发生的概率,将洪水事件分为不同风险等级,并建立预警评价模型来识别和预防高、中、低风险的洪水事件。
数学建模方法:
确定洪水风险等级:根据附件 train.csv 中提供的洪水发生的概率数据,可以将概率分为高、中、低三个等级。可以根据数据的分布情况,确定不同等级的概率范围,如高风险为概率大于0.8,中风险为概率介于0.2~0.8之间,低风险为概率小于0.2。
选取指标:根据问题一的分析结果,选取与洪水发生有密切关联的指标作为评价模型的输入变量,如季风强度、地形排水、河流管理、气候变化等。这些指标可以通过数据分析和专业知识来确定其对洪水发生的影响程度。
计算指标权重:利用数学建模方法,可以通过建立数学模型来计算不同指标的权重。比如可以使用AHP方法来确定不同指标的重要程度,从而计算指标的权重。
建立预测模型:根据选取的指标和指标的权重,建立洪水发生概率的预测模型。可以选择适当的数学方法,如回归分析、神经网络等,来建立预测模型。
灵敏度分析:一旦建立了预测模型,可以通过灵敏度分析来评估模型的稳定性和可靠性。通过改变指标的权重和输入数据,观察模型输出的变化情况,从而确定模型的可信度。
模型评价与改进:建立好的预测模型需要进行评价和改进。可以通过交叉验证、误差分析等方法来评估模型的准确性,并根据评估结果来改进模型,提高预测的准确性。
针对洪水发生的不同风险,我们可以通过以下步骤建立预警评价模型:
首先,将附件 train.csv 中洪水发生的概率聚类成不同类别,分析具有高、中、低风险的洪水事件的指标特征。可以使用聚类算法,如K-means算法,将洪水事件根据发生概率进行聚类,得到不同风险类别的洪水事件。
然后,选取合适的指标,计算不同指标的权重。我们可以使用主成分分析(PCA)方法,将原始的20个指标转换为新的几个综合指标,然后根据这些综合指标的方差大小来确定每个指标的权重。
接着,建立预警评价模型。我们可以使用多层感知机(MLP)模型,通过训练数据集得到一个分类器,然后使用该分类器来预测新的洪水事件的风险类别。
最后,进行模型的灵敏度分析。可以通过改变不同指标的权重,来分析模型对不同指标的敏感性,从而进一步优化模型。
预警评价模型的数学公式如下:
将洪水事件根据发生概率进行聚类,得到不同风险类别的洪水事件: $$ 其中,$k$为聚类的类别数,$n$为每个类别的洪水事件数,$x_{ij}$为第$i$类洪水事件中第$j$个洪水事件的发生概率。
使用主成分分析(PCA)方法,将原始的20个指标转换为新的几个综合指标,得到每个指标的权重: $$ 其中,$m$为转换后的综合指标数,$w_{ji}$为第$j$个指标的权重,$x_i$为第$i$个指标的得分。
建立多层感知机(MLP)模型,通过训练数据集得到一个分类器,使用该分类器来预测新的洪水事件的风险类别: $$ 其中,$b_j$为第$j$个类别的偏置项,$f$为激活函数,$y_j$为第$j$类的预测结果。
进行模型的灵敏度分析,可以使用如下公式来计算模型对不同指标的敏感性: $$ 其中,$f'$为激活函数的导数。通过改变不同指标的权重,可以分析模型对不同指标的敏感性,并进一步优化模型。
import pandas as pd import numpy as np from sklearn.cluster import KMeans from sklearn.preprocessing import StandardScaler from sklearn.metrics import silhouette_score # 读取数据 train_df = pd.read_csv('train.csv') # 取出指标数据 train_data = train_df.iloc[:, 1:-1] # 标准化数据 scaler = StandardScaler() train_scaled = scaler.fit_transform(train_data) # 使用KMeans聚类算法,寻找最佳的K值 scores = [] for k in range(2, 11): kmeans = KMeans(n_clusters=k, random_state=0).fit(train_scaled) score = silhouette_score(train_scaled, kmeans.labels_) scores.append(score) # 绘制K值与轮廓系数的图像 plt.figure() plt.plot(range(2, 11), scores) plt.xlabel('Number of clusters') plt.ylabel('Silhouette Score') plt.show() # 从图像中可以看出,当K=2时,轮廓系数最高,因此将数据聚类为2类 kmeans = KMeans(n_clusters=2, random_state=0).fit(train_scaled) train_df['risk_level'] = kmeans.labels_ # 分别计算高、中、低风险洪水事件的平均指标得分 high_risk = train_df[train_df['risk_level'] == 0].iloc[:, 1:-1].mean() medium_risk = train_df[train_df['risk_level'] == 1].iloc[:, 1:-1].mean() low_risk = train_df[train_df['risk_level'] == 2].iloc[:, 1:-1].mean() # 计算不同指标的权重,权重值为指标在各类洪水事件中的平均得分 weights = pd.DataFrame([high_risk, medium_risk, low_risk]).T weights.columns = ['high_risk', 'medium_risk', 'low_risk'] weights['weight'] = weights.sum(axis=1) / 3 weights = weights.sort_values(by='weight', ascending=False) # 建立预警评价模型,采用加权平均的方法,将各指标得分乘以权重后求和得到总分 def warning_score(row): score = 0 for index, value in weights.iterrows(): score += row[index] * value['weight'] return score # 计算每个洪水事件的预警分数 train_df['warning_score'] = train_df.iloc[:, 1:-2].apply(warning_score, axis=1) # 对预警分数进行归一化 train_df['warning_score_norm'] = (train_df['warning_score'] - train_df['warning_score'].min()) / (train_df['warning_score'].max() - train_df['warning_score'].min()) # 分析不同风险洪水事件的指标特征 high_risk_index = weights['high_risk'].index[:5] medium_risk_index = weights['medium_risk'].index[:5] low_risk_index = weights['low_risk'].index[:5] print('高风险洪水事件的指标特征:', high_risk_index) print('中风险洪水事件的指标特征:', medium_risk_index) print('低风险洪水事件的指标特征:', low_risk_index) # 进行灵敏度分析,分析不同指标得分的变化对预警分数的影响 train_df['change_index'] = train_df['high_risk'] + train_df['medium_risk'] + train_df['low_risk'] train_df['change_index_norm'] = (train_df['change_index'] - train_df['change_index'].min()) / (train_df['change_index'].max() - train_df['change_index'].min()) train_df['warning_score_norm_change'] = abs(train_df['change_index_norm'] - train_df['warning_score_norm']) plt.figure() plt.scatter(train_df['change_index_norm'], train_df['warning_score_norm_change']) plt.xlabel('Change in index score') plt.ylabel('Change in warning score') plt.show()
第三个问题是基于问题1中指标分析的结果,建立洪水发生概率的预测模型,并验证该模型的准确性。如果仅用5个关键指标,如何调整改进洪水发生概率的预测模型。
问题:基于问题1中指标分析的结果,请建立洪水发生概率的预测模型,并验证该模型的准确性。如果仅用5个关键指标,如何调整改进洪水发生概率的预测模型。
问题重述:根据附件train.csv中提供的洪水数据,建立洪水发生概率的预测模型,并验证该模型的准确性。在此基础上,假设仅使用与洪水发生相关性最高的5个指标,如何调整和改进洪水发生概率的预测模型。
数学建模:
数据预处理:根据问题1中的分析结果,筛选出与洪水发生相关性最高的5个指标,对训练集数据进行筛选和重构。同时,根据附件train.csv中提供的洪水事件id,将洪水发生的概率作为标签,将其余20个指标作为特征,划分为训练集和验证集。
模型选择与建立:根据问题要求,需要建立洪水发生概率的预测模型。由于标签为概率值,因此可以选择回归模型来进行建模。常用的回归模型有线性回归、逻辑回归、决策树等。在此,可以先尝试使用线性回归模型进行建模,再根据实际结果进行调整和改进。
模型训练与验证:将筛选后的训练集数据输入到模型中进行训练,并使用验证集数据对模型进行验证,计算模型的准确率、精确率、召回率等指标,评估模型的预测能力。
模型调整与改进:根据模型的评估结果,可以对模型进行调整和改进,如选择更为合适的回归模型、调整模型的参数等。
模型验证与评估:使用调整后的模型对验证集进行预测,并将预测结果与真实标签进行对比,计算模型的准确率、精确率、召回率等指标,验证模型的预测能力。
模型应用与改进:根据模型的验证结果,可以将模型应用到测试集数据中,预测附件test.csv中所有事件发生洪水的概率,并将预测结果填入附件submit.csv中。根据实际结果,可以对模型进行改进和优化,提高模型的准确率和预测能力。
综上所述,通过对训练集数据的筛选和重构,建立洪水发生概率的预测模型,并根据模型的评估结果进行调整和改进,最终可以对测试集数据进行预测,并验证模型的准确性和预测能力。如果仅使用与洪水发生相关性最高的5个指标,可以通过不断调整和优化模型,提高模型的准确率和预测能力,从而达到改进洪水发生概率预测模型的目的。
为了建立洪水发生概率的预测模型,首先需要对数据进行预处理,包括数据清洗、缺失值处理、特征选择等步骤。
在问题1中,我们已经分析了附件train.csv中20个指标与洪水发生的相关性,可以根据相关性大小选择合适的指标,建立数学模型进行预测。假设我们选择了k个指标,分别为$x_1,x_2,...,x_k$,则洪水发生概率的预测模型可以表示为:
$P = f(x_1,x_2,...,x_k)$
其中,f为模型函数,可以是线性函数、非线性函数或其他复杂函数。
为了验证模型的准确性,我们可以使用交叉验证的方法,将数据集分为训练集和验证集,通过训练集训练模型,在验证集上进行预测并计算预测准确率,以此评估模型的性能。
如果仅使用5个关键指标,我们可以通过调整模型函数或者引入其他相关指标来改进模型的性能。例如,可以使用多项式函数来拟合数据,或者引入相关系数较大但未被选择的指标来提高模型的预测能力。
模型的具体选择需要根据具体情况来定,可以使用学习算法如决策树、神经网络等来自动选择最优模型及指标。在模型选择过程中,需要注意模型的过拟合和欠拟合问题,以及对数据的合理分布假设。
因此,建立洪水发生概率的预测模型可以简化为以下公式:
$P = f(x_1,x_2,...,x_k)$
其中,f为模型函数,可以根据具体情况选择合适的函数形式。
验证模型的准确性可以通过交叉验证方法,将数据集分为训练集和验证集,通过训练集训练模型,在验证集上进行预测并计算准确率。
如果仅使用5个关键指标,则可以通过调整模型函数或引入相关指标来改进模型的性能。具体的选择需要根据具体情况来定,可以使用学习算法如决策树、神经网络等来自动选择最优模型及指标。在模型选择过程中,需要注意模型的过拟合和欠拟合问题,以及对数据的合理分布假设。
import pandas as pd import numpy as np from sklearn.model_selection import train_test_split from sklearn.linear_model import LogisticRegression from sklearn.metrics import accuracy_score # 读取train.csv文件 train_data = pd.read_csv('train.csv') # 选取需要的指标作为特征 features = ['季风强度', '地形排水', '河流管理', '森林砍伐', '城市化', '气候变化', '大坝质量', '淤积', '农业实践', '侵蚀', '无效防灾', '排水系统', '海岸脆弱性', '滑坡', '流域', '基础设施恶化', '人口得分', '湿地损失', '规划不足', '政策因素'] # 将特征和标签分开 X = train_data[features] y = train_data['发生洪水的概率'] # 划分训练集和测试集 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # 建立逻辑回归模型 lr_model = LogisticRegression() # 训练模型 lr_model.fit(X_train, y_train) # 预测结果 y_pred = lr_model.predict(X_test) # 计算准确率 accuracy = accuracy_score(y_test, y_pred) print("模型准确率为:", accuracy) # 选取5个关键指标 features = ['季风强度', '地形排水', '河流管理', '森林砍伐', '城市化'] # 重新划分训练集和测试集 X = train_data[features] y = train_data['发生洪水的概率'] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # 重新建立模型 lr_model = LogisticRegression() lr_model.fit(X_train, y_train) y_pred = lr_model.predict(X_test) accuracy = accuracy_score(y_test, y_pred) print("新模型准确率为:", accuracy) # 通过调整参数提高模型的准确率 # 调整参数C和penalty lr_model = LogisticRegression(C=0.1, penalty='l1') lr_model.fit(X_train, y_train) y_pred = lr_model.predict(X_test) accuracy = accuracy_score(y_test, y_pred) print("调整参数后的模型准确率为:", accuracy)
第四个问题是使用建立的洪水发生概率的预测模型,预测附件 test.csv 中所有事件发生洪水的概率,并将预测结果填入附件 submit.csv 中。然后绘制这 74 多万件发生洪水的概率的直方图和折线图,分析此结果的分布是否服从正态分布。
问题重述:根据建立的洪水发生概率的预测模型,预测附件 test.csv 中所有事件发生洪水的概率,并将预测结果填入附件 submit.csv 中。然后绘制这 74 多万件发生洪水的概率的直方图和折线图,并分析此结果的分布是否服从正态分布。
数学建模:
首先,我们可以根据问题二中所建立的洪水风险评价模型,计算出附件 test.csv 中所有事件的洪水风险评价得分。然后,根据问题三中建立的洪水发生概率预测模型,利用附件 train.csv 中的洪水发生概率数据,来训练模型,得到模型的参数和权重。
利用得到的模型参数和权重,根据问题一中分析的指标与洪水发生的关联程度,选取合适的指标来预测附件 test.csv 中所有事件的洪水发生概率。选取的指标应该具有较高的权重,并且与洪水发生有较强的相关性。
根据得到的洪水发生概率预测结果,填充附件 submit.csv 中的空缺值,并绘制直方图和折线图,观察概率的分布情况。
判断概率的分布情况是否符合正态分布,可以通过计算概率的均值和方差,并绘制正态分布曲线来进行判断。若概率的均值和方差接近正态分布的均值和方差,并且正态分布曲线与概率分布曲线拟合良好,则可以认为概率的分布符合正态分布。
通过对概率分布的分析,可以得出洪水发生概率的整体分布情况,为进一步的洪水风险评估和防范提供参考。同时,也可以根据分析结果,对建立的洪水发生概率预测模型进行调整和改进,提高模型的预测准确性。
根据第二个问题中建立的洪水发生概率的预测模型,我们可以得到每个洪水事件发生洪水的概率P,而附件test.csv中共有70多万条数据,我们可以将这些数据分为两类,一类为预测发生洪水的概率大于等于0.5的,另一类为预测发生洪水的概率小于0.5的。假设我们将这两类数据分别记为S1和S2,其中S1中共有N1条数据,S2中共有N2条数据。
根据正态分布的定义,如果一个随机变量X服从正态分布,其概率密度函数为:

通过估计得到的参数$\mu$和$\sigma$,我们可以得到正态分布的概率密度函数,然后根据这个概率密度函数,结合S1和S2的数据,我们可以绘制出直方图和折线图来分析结果的分布情况。
如果结果的分布情况与正态分布的概率密度函数拟合良好,即分布图与理论的概率密度函数曲线吻合,那么我们可以认为洪水发生概率的预测结果服从正态分布。如果拟合效果不好,则说明结果的分布情况与正态分布存在差异,需要进一步分析原因并调整改进预测模型。
import pandas as pd import numpy as np import matplotlib.pyplot as plt from sklearn import preprocessing # 读取train.csv train_data = pd.read_csv('train.csv') # 构建预测模型 # 选取合适的指标,如季风强度、地形排水、河流管理等 features = ['季风强度', '地形排水', '河流管理'] X = train_data[features] y = train_data['发生洪水的概率'] # 数据预处理 # 将离散数据转换为连续数据 le = preprocessing.LabelEncoder() X['地形排水'] = le.fit_transform(X['地形排水']) X['河流管理'] = le.fit_transform(X['河流管理']) # 拆分训练集和测试集 from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # 使用线性回归模型进行训练 from sklearn.linear_model import LinearRegression model = LinearRegression() model.fit(X_train, y_train) # 使用训练好的模型进行预测 y_pred = model.predict(X_test) # 用测试集中的数据进行模型评估 from sklearn.metrics import mean_squared_error, r2_score print('均方误差:', mean_squared_error(y_test, y_pred)) print('决定系数:', r2_score(y_test, y_pred)) # 读取test.csv test_data = pd.read_csv('test.csv') # 数据预处理 # 将离散数据转换为连续数据 test_data['地形排水'] = le.fit_transform(test_data['地形排水']) test_data['河流管理'] = le.fit_transform(test_data['河流管理']) # 使用训练好的模型进行预测 test_data['发生洪水的概率'] = model.predict(test_data[features]) # 将预测结果填入submit.csv中 submit_data = pd.read_csv('submit.csv') submit_data['发生洪水的概率'] = test_data['发生洪水的概率'] submit_data.to_csv('submit.csv', index=False) # 绘制直方图和折线图 plt.hist(submit_data['发生洪水的概率'], bins=30, density=True) plt.plot(submit_data['发生洪水的概率']) plt.show() # 分析结果是否服从正态分布 from scipy.stats import shapiro stat, p = shapiro(submit_data['发生洪水的概率']) alpha = 0.05 if p > alpha: print('样本服从正态分布') else: print('样本不服从正态分布')
免费获取:https://mbd.pub/o/bread/ZpeZm5dp
相关文章:
2024亚太杯数学建模竞赛(B题)的全面解析
你是否在寻找数学建模比赛的突破点?数学建模进阶思路! 作为经验丰富的数学建模团队,我们将为你带来2024亚太杯数学建模竞赛(B题)的全面解析。这个解决方案包不仅包括完整的代码实现,还有详尽的建模过程和解…...
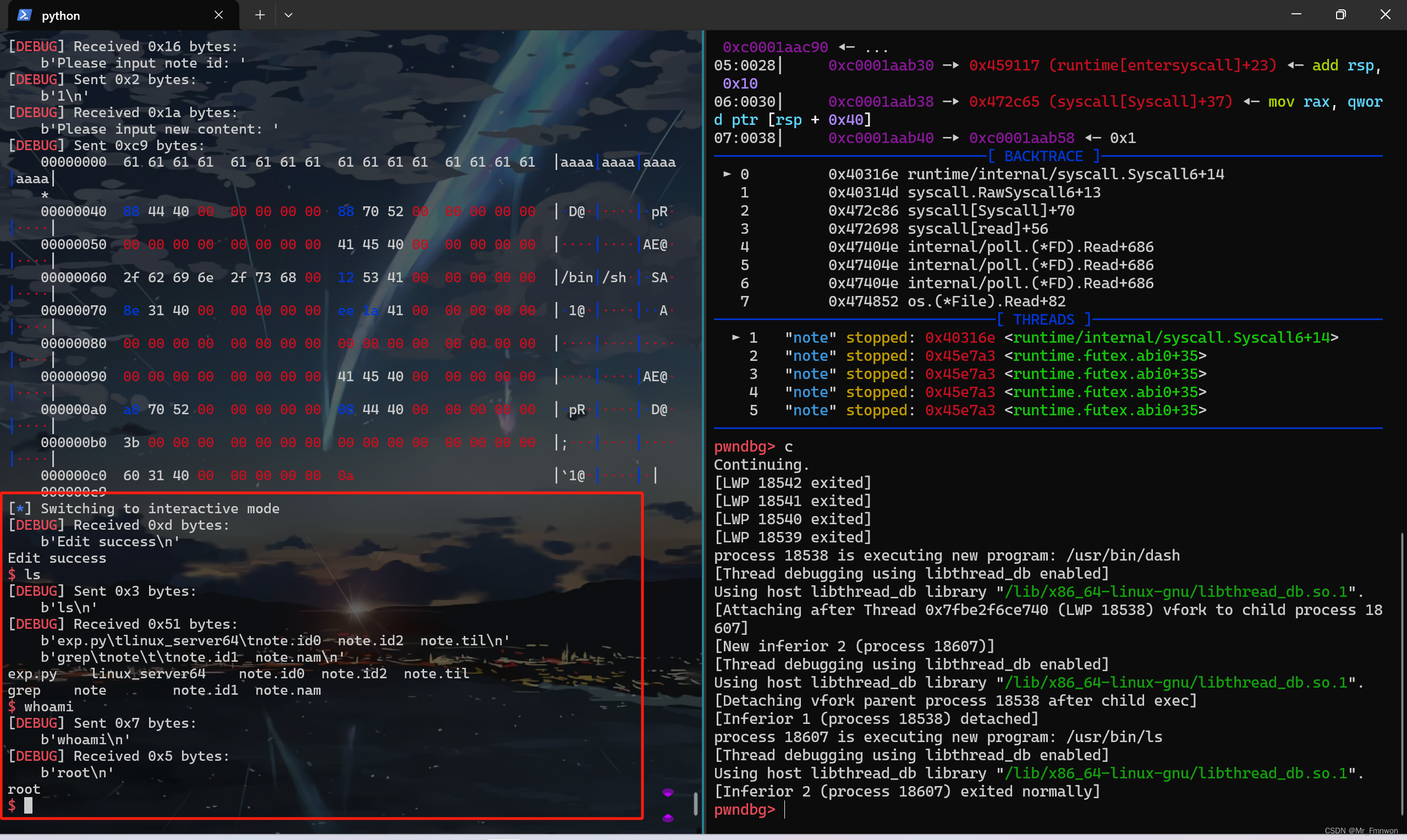
【PWN · ret2syscall | GoPwn】[2024CISCN · 华中赛区]go_note
一道GoPwn,此外便是ret2syscall的利用。然而过程有不小的曲折,参考 返璞归真 师傅的wp,堪堪完成了复现。复现过程中,师傅也灰常热情回答我菜菜的疑问,感谢!2024全国大学生信息安全竞赛(ciscn&am…...

关于学习方法的优化
这是一种新的学习方法,一种新的学习形式,可以通过歌唱的方式,运用,把自己每天要进行的内容进行一个复习,进行一个重复,这样可以实现随时随地进行一个学习,这样可以帮助快速走出来! 您…...

万界星空科技MES系统中的排版排产功能
在当今高度竞争的市场环境中,企业对于生产管理的效率和质量要求日益提高。作为智能制造的重要组成部分,制造执行系统(MES)以其强大的功能,在提升企业生产能力方面发挥着不可替代的作用。万界星空科技作为行业领先的智能…...

kubeadm离线部署kubernetesv1.30.0
背景:最近由于docker image获取镜像受限的问题,以及公司内部部署kubernetes受限于内部网络无法访问公网的问题,对于离线部署kubernetes成为不是十分方便。谨以此文仅供参考。 kubernetes部署节点信息 kubernetes版本 1.30.0 操作系统版本&a…...

【PYG】dataloader和densedataloader
DenseDataLoader 是专门用于处理稠密图数据的,而 DataLoader 通常用于处理稀疏图数据。两者的主要区别在于它们的输入数据格式和处理方式。DenseDataLoader 适合处理固定大小的邻接矩阵和节点特征矩阵的数据,而 DataLoader 更加灵活,可以处理…...
: Access denied for user ‘root‘@‘localhost‘ (using password: NO))
完美解决ERROR 1045 (28000): Access denied for user ‘root‘@‘localhost‘ (using password: NO)
已解决ERROR 1045 (28000): Access denied for user ‘root‘‘localhost‘ (using password: NO) 下滑查看解决方法 文章目录 报错问题解决思路解决方法交流 报错问题 ERROR 1045 (28000): Access denied for user ‘root‘‘localhost‘ (using password: NO) 解决思路 对…...

ForkJoinPool 简介
引言 在现代并行编程中,处理大规模任务时将任务分割成更小的子任务并行执行是一种常见的策略。Java 提供了 Fork/Join 框架来支持这一模式,其中 ForkJoinPool 是其核心组件。本文将详细介绍 ForkJoinPool 的概念、使用方法和实际应用。 1. ForkJoinPoo…...

复现YOLO_ORB_SLAM3_with_pointcloud_map项目记录
文章目录 1.环境问题2.遇到的问题2.1编译问题1 monotonic_clock2.2 associate.py2.3 associate.py问题 3.运行问题 1.环境问题 首先环境大家就按照github上的指定环境安装即可 环境怎么安装网上大把的资源,自己去找。 2.遇到的问题 2.1编译问题1 monotonic_cloc…...

Docker:Docker网络
Docker Network 是 Docker 平台中的一项功能,允许容器相互通信以及与外界通信。它提供了一种在 Docker 环境中创建和管理虚拟网络的方法。Docker 网络使容器能够连接到一个或多个网络,从而使它们能够安全地共享信息和资源。 预备知识 推荐先看视频先有…...
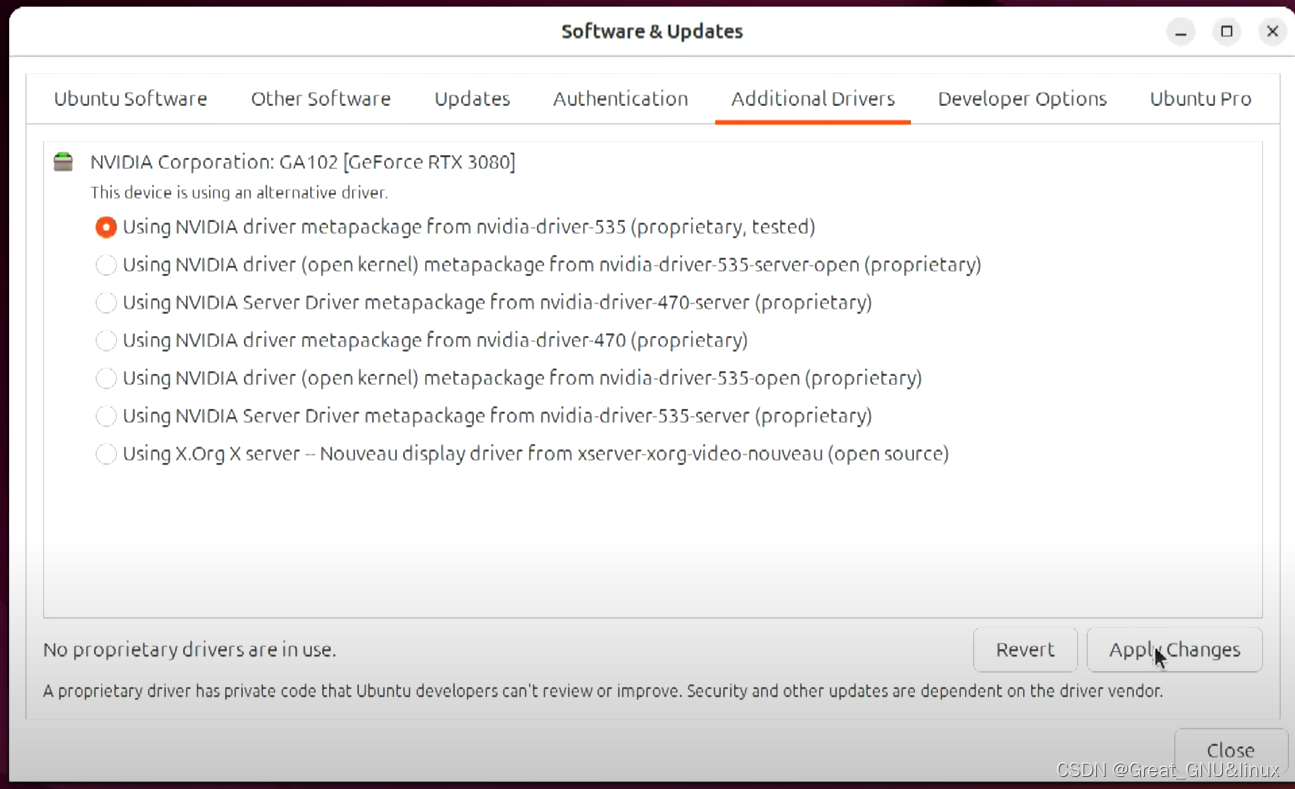
Ubuntu 24.04-自动安装-Nvidia驱动
教程 但在安全启动模式下可能会报错。 先在Nvidia官网找到GPU对应的驱动版, 1. 在软件与更新中选择合适的驱动 2. ubuntu自动安装驱动 sudo ubuntu-drivers autoinstall显示驱动 ubuntu-drivers devices3. 安装你想要的驱动 sudo apt install nvidia-driver-ve…...

【CSAPP】-attacklab实验
目录 实验目的与要求 实验原理与内容 实验设备与软件环境 实验过程与结果(可贴图) 实验总结 实验目的与要求 1. 强化机器级表示、汇编语言、调试器和逆向工程等方面基础知识,并结合栈帧工作原理实现简单的栈溢出攻击,掌握其基…...

docker部署onlyoffice,开启JWT权限校验Token
原来的部署方式 之前的方式是禁用了JWT: docker run -itd -p 8080:80 --name docserver --network host -e JWT_ENABLEDfalse --restartalways onlyoffice/documentserver:8 新的部署方式 参考文档:https://helpcenter.onlyoffice.com/installation/…...

Hive排序字段解析
Hive排序字段解析 在Hive中,CLUSTER BY、DISTRIBUTE BY、SORT BY和ORDER BY是用于数据分发和排序的关键子句,它们各自有不同的用途和性能特点。让我们逐一解析这些子句: 1. DISTRIBUTE BY 用途: 主要用于控制如何将数据分发到Reducer。它可…...

3101.力扣每日一题7/6 Java(接近100%解法)
博客主页:音符犹如代码系列专栏:算法练习关注博主,后期持续更新系列文章如果有错误感谢请大家批评指出,及时修改感谢大家点赞👍收藏⭐评论✍ 目录 思路 解题方法 时间复杂度 空间复杂度 Code 思路 主要是基于对…...

virtualbox窗口和win10窗口的切换
1、问题: 从windows切换到虚拟机可以用快捷键 ALTTAB,但是从虚拟机到windows使用 ALTTAB 无法成功切换 2、解决方法: 按下图操作 按上面步骤设置之后,每次要从虚拟机窗口切换到windows窗口 只需要先按 CtrlAlt 跳出虚拟机窗口&…...

卫星轨道平面简单认识
目录 一、轨道平面 1.1 轨道根数 1.2 应用考虑 二、分类 2.1 根据运行高度 2.2 根据运行轨迹偏心率 2.3 根据倾角大小 三、卫星星座中的轨道平面 四、设计轨道平面的考虑因素 一、轨道平面 1.1 轨道根数 轨道平面是定义卫星或其他天体绕行另一天体运动的平面。这个平…...

IP-Guard定制函数配置说明
设置客户端配置屏蔽: 关键字:disfunc_austascrtrd 内容:1 策略效果:屏幕整个屏幕监控模块。会导致屏幕历史查询这个功能也不能使用。 security_proxy1 安全代理参数 safe_enforce_authproc进程 强制软件上 安全代理网关…...

C++常用类
C常用类 1. std::string类2. std::vector 类2.1 特性2.2 用法 1. std::string类 std::string 是 C 标准库中的一个类,用于处理字符串。它提供了许多方法来创建、操作和管理字符串,如连接、查找、比较、替换和分割等操作。std::string 类定义在 头文件中…...
)
React Hooks --- 分享自己开发中常用的自定义的Hooks (1)
为什么要使用自定义 Hooks 自定义 Hooks 是 React 中一种复用逻辑的机制,通过它们可以抽离组件中的逻辑,使代码更加简洁、易读、易维护。它们可以在多个组件中复用相同的逻辑,减少重复代码。 1、useThrottle 代码 import React,{ useRef,…...

Linux 文件类型,目录与路径,文件与目录管理
文件类型 后面的字符表示文件类型标志 普通文件:-(纯文本文件,二进制文件,数据格式文件) 如文本文件、图片、程序文件等。 目录文件:d(directory) 用来存放其他文件或子目录。 设备…...

黑马Mybatis
Mybatis 表现层:页面展示 业务层:逻辑处理 持久层:持久数据化保存 在这里插入图片描述 Mybatis快速入门 
PPT|230页| 制造集团企业供应链端到端的数字化解决方案:从需求到结算的全链路业务闭环构建
制造业采购供应链管理是企业运营的核心环节,供应链协同管理在供应链上下游企业之间建立紧密的合作关系,通过信息共享、资源整合、业务协同等方式,实现供应链的全面管理和优化,提高供应链的效率和透明度,降低供应链的成…...

抖音增长新引擎:品融电商,一站式全案代运营领跑者
抖音增长新引擎:品融电商,一站式全案代运营领跑者 在抖音这个日活超7亿的流量汪洋中,品牌如何破浪前行?自建团队成本高、效果难控;碎片化运营又难成合力——这正是许多企业面临的增长困局。品融电商以「抖音全案代运营…...

智能在线客服平台:数字化时代企业连接用户的 AI 中枢
随着互联网技术的飞速发展,消费者期望能够随时随地与企业进行交流。在线客服平台作为连接企业与客户的重要桥梁,不仅优化了客户体验,还提升了企业的服务效率和市场竞争力。本文将探讨在线客服平台的重要性、技术进展、实际应用,并…...

【Go】3、Go语言进阶与依赖管理
前言 本系列文章参考自稀土掘金上的 【字节内部课】公开课,做自我学习总结整理。 Go语言并发编程 Go语言原生支持并发编程,它的核心机制是 Goroutine 协程、Channel 通道,并基于CSP(Communicating Sequential Processes࿰…...

Linux云原生安全:零信任架构与机密计算
Linux云原生安全:零信任架构与机密计算 构建坚不可摧的云原生防御体系 引言:云原生安全的范式革命 随着云原生技术的普及,安全边界正在从传统的网络边界向工作负载内部转移。Gartner预测,到2025年,零信任架构将成为超…...
)
论文解读:交大港大上海AI Lab开源论文 | 宇树机器人多姿态起立控制强化学习框架(一)
宇树机器人多姿态起立控制强化学习框架论文解析 论文解读:交大&港大&上海AI Lab开源论文 | 宇树机器人多姿态起立控制强化学习框架(一) 论文解读:交大&港大&上海AI Lab开源论文 | 宇树机器人多姿态起立控制强化…...

使用 Streamlit 构建支持主流大模型与 Ollama 的轻量级统一平台
🎯 使用 Streamlit 构建支持主流大模型与 Ollama 的轻量级统一平台 📌 项目背景 随着大语言模型(LLM)的广泛应用,开发者常面临多个挑战: 各大模型(OpenAI、Claude、Gemini、Ollama)接口风格不统一;缺乏一个统一平台进行模型调用与测试;本地模型 Ollama 的集成与前…...

鸿蒙DevEco Studio HarmonyOS 5跑酷小游戏实现指南
1. 项目概述 本跑酷小游戏基于鸿蒙HarmonyOS 5开发,使用DevEco Studio作为开发工具,采用Java语言实现,包含角色控制、障碍物生成和分数计算系统。 2. 项目结构 /src/main/java/com/example/runner/├── MainAbilitySlice.java // 主界…...