强化学习-6 DDPG、PPO、SAC算法
文章目录
- 1 DPG方法
- 2 DDPG算法
- 3 DDPG算法的优缺点
- 4 TD3算法
- 4.1 双Q网络
- 4.2 延迟更新
- 4.3 噪声正则
- 5 附1
- 5.1 Ornstein-Uhlenbeck (OU) 噪声
- 5.1.1 定义
- 5.1.2 特性
- 5.1.3 直观理解
- 5.1.4 数学性质
- 5.1.5 代码示例
- 5.1.6 总结
- 6 重要性采样
- 7 PPO算法
- 8 附2
- 8.1 重要性采样方差计算
- 8.1.1 公式解释
- 8.1.2 方差定义
- 8.1.3 公式验证
- 8.1.4 结论
- 8.2 目标函数 式12.5 解释
- 8.2.1 公式解释
- 8.2.2 直观解释
- 8.2.3 总结
- 9 最大熵强化学习
- 10 Soft Q-Learning
- 11 SAC
- 12 自动调节温度因子
1 DPG方法
想适配连续动作空间,我们干脆就将选择动作的过程变成一个直接从状态映射到具体动作的函数 μ θ ( s ) \mu_\theta (s) μθ(s),其中 θ \theta θ 表示模型的参数,这样一来就把求解 Q Q Q 函数、贪心选择动作这两个过程合并成了一个函数,也就是我们常说的 Actor \text{Actor} Actor 。注意,这里的 μ θ ( s ) \mu_\theta (s) μθ(s) 输出的是一个动作值,而不是像 Actor-Critic \text{Actor-Critic} Actor-Critic 章节中提到的概率分布 π θ ( a ∣ s ) \pi_{\theta}(a|s) πθ(a∣s)。
| DQN \text{DQN} DQN | DPG \text{DPG} DPG | |
|---|---|---|
| 适用范围 | 不能用于连续动作空间 | 连续动作空间 |
| 算法特点 | DQN \text{DQN} DQN 算法中动作是通过贪心策略或者说 argmax \text{argmax} argmax 的方式来从 Q Q Q 函数间接得到 | 把求解 Q Q Q 函数、贪心选择动作这两个过程合并成了一个函数 |
| ε − greedy \varepsilon-\text{greedy} ε−greedy | Actor \text{Actor} Actor |
2 DDPG算法
| 技巧 | 目的 |
|---|---|
| 目标网络 | |
| 经验回放 | |
| 引入噪声 | 增加策略的探索性 |
强化学习算法的基础核心问题
| 主题 | 目的 | 方法 |
|---|---|---|
| 如何提高对值函数的估计 | 保证其准确性,即尽量无偏且低方差 | 1. 用深度神经网络替代简单的 Q Q Q 表 2. 结合蒙特卡洛和时序差分的 TD ( λ ) \text{TD}(\lambda) TD(λ) 3. 引入目标网络以及广义优势估计 |
| 如何提高探索以及平衡探索-利用的问题 | 例如 DQN \text{DQN} DQN 和 DDPG \text{DDPG} DDPG 算法都会利用各种技巧来提高探索 | 1. 经验回放 2. ε − greedy \varepsilon-\text{greedy} ε−greedy 策略 3. 噪声网络 |
引入噪声最简单的方式就是在输出的值上加上一个随机数,这个随机数可以是正态分布的(即高斯噪声),也可以是均匀分布的,只要能够保证这个随机数的值不要过大就行。
| OU \text{OU} OU 噪声 | 高斯噪声 | |
|---|---|---|
| 具有回归特性的随机过程。 | 独立 | |
| 探索性 | 持续的、自相关的特性。更加平滑、更加稳定。有助于探索更广泛的动作空间,并且更容易找到更好的策略。 | |
| 控制幅度 | 可以通过调整其参数来控制噪声的幅度。可以通过调整 OU \text{OU} OU 噪声的方差来控制噪声的大小,从而平衡探索性和利用性。较大的方差会增加探索性,而较小的方差会增加利用性。 | |
| 稳定性 | 回归特性使得噪声在训练过程中具有一定的稳定性。相比于纯粹的随机噪声, OU \text{OU} OU 噪声可以更好地保持动作的连续性,避免剧烈的抖动,从而使得训练过程更加平滑和稳定。 | |
| 可控性 | 具有回归特性,它在训练过程中逐渐回归到均值,因此可以控制策略的探索性逐渐减小。这种可控性使得在训练的早期增加探索性,然后逐渐减小探索性,有助于更有效地进行训练。 |
3 DDPG算法的优缺点
| 优点 | 原因 |
|---|---|
| 适用于连续动作空间 | 采用了确定性策略来选择动作。不需要进行动作采样,更容易优化和学习。缓解了在连续动作空间中的高方差问题。 |
| 高效的梯度优化 | 使用策略梯度方法进行优化。同时,通过 Actor-Critic 结构,算法可以利用值函数来辅助策略的优化,提高算法的收敛速度和稳定性。 |
| 经验回放和目标网络 | 经验回放机制可以减少样本之间的相关性,提高样本的有效利用率,并且增加训练的稳定性。 目标网络可以稳定训练过程,避免值函数估计和目标值之间的相关性问题,从而提高算法的稳定性和收敛性。 |
| 缺点 | 原因 |
|---|---|
| 只适用于连续动作空间 | |
| 高度依赖超参数 | 1. DQN的算法参数例如学习率、批量大小、目标网络的更新频率等 2. OU 噪声的参数 |
| 高度敏感的初始条件 | 初始策略和值函数的参数设置可能会影响算法的收敛性和性能,需要仔细选择和调整。 |
| 容易陷入局部最优 | 由于采用了确定性策略,可能会导致算法陷入局部最优。需要采取一些措施,如加入噪声策略或使用其他的探索方法。 |
4 TD3算法
英文全称为 twin delayed DDPG \text{twin delayed DDPG} twin delayed DDPG,中文全称为双延迟确定性策略梯度算法。相对于 DDPG \text{DDPG} DDPG 算法, TD3 \text{TD3} TD3 算法的改进主要做了三点重要的改进,一是双 Q Q Q 网络,体现在名字中的 twin \text{twin} twin,二是 延迟更新,体现在名字中的 delayed \text{delayed} delayed,三是 躁声正则( noise regularisation \text{noise regularisation} noise regularisation )。
4.1 双Q网络
跟 Double DQN \text{Double DQN} Double DQN 的原理本质上是一样的,这样做的好处是可以减少 Q Q Q 值的过估计,从而提高算法的稳定性和收敛性。
4.2 延迟更新
可以在训练中让 Actor \text{Actor} Actor 的更新频率低于 Critic \text{Critic} Critic 的更新频率,这样一来 Actor \text{Actor} Actor 的更新就会比较稳定,不会受到 Critic \text{Critic} Critic 的影响,从而提高算法的稳定性和收敛性。
4.3 噪声正则
给 Critic \text{Critic} Critic 引入一个噪声提高其抗干扰性,这样一来就可以在一定程度上提高 Critic \text{Critic} Critic 的稳定性,从而进一步提高算法的稳定性和收敛性。注意,这里的噪声是在 Critic \text{Critic} Critic 网络上引入的,而不是在输出动作上引入的,因此它跟 DDPG \text{DDPG} DDPG 算法中的噪声是不一样的。具体来说,我们可以在计算 TD \text{TD} TD 误差的时候,给目标值 y y y 加上一个噪声,并且为了让噪声不至于过大,还增加了一个裁剪( clip \text{clip} clip ),如式 (11.5) \text{(11.5)} (11.5) 所示。
y = r + γ Q θ ′ ( s ′ , π ϕ ′ ( s ′ ) + ϵ ) ϵ ∼ clip ( N ( 0 , σ ) , − c , c ) (11.5) \tag{11.5} y=r+\gamma Q_{\theta^{\prime}}\left(s^{\prime}, \pi_{\phi^{\prime}}\left(s^{\prime}\right)+\epsilon\right) \epsilon \sim \operatorname{clip}(N(0, \sigma),-c, c) y=r+γQθ′(s′,πϕ′(s′)+ϵ)ϵ∼clip(N(0,σ),−c,c)(11.5)
\qquad 其中 N ( 0 , σ ) N(0, \sigma) N(0,σ) 表示均值为 0 \text{0} 0,方差为 σ \sigma σ 的高斯噪声, ϵ \epsilon ϵ 表示噪声, clip \operatorname{clip} clip 表示裁剪函数,即将噪声裁剪到 [ − c , c ] [-c, c] [−c,c] 的范围内, c c c 是一个超参数,用于控制噪声的大小。可以看到,这里噪声更像是一种正则化的方式,使得值函数更新更加平滑。
5 附1
5.1 Ornstein-Uhlenbeck (OU) 噪声
Ornstein-Uhlenbeck (OU) 噪声是一种具有回归特性的随机过程,常用于模拟具有均值回归特性的噪声过程。在强化学习和金融数学中,OU 噪声常用于描述具有回归特性的动态变化。以下是对 OU 噪声的详细解释和理解。
5.1.1 定义
Ornstein-Uhlenbeck 噪声是一个连续时间的马尔科夫过程,其微分方程形式为:
d X t = θ ( μ − X t ) d t + σ d W t dX_t = \theta (\mu - X_t) dt + \sigma dW_t dXt=θ(μ−Xt)dt+σdWt
其中:
- X t X_t Xt 是在时间 t t t 的 OU 过程的值。即当前的噪声值,这个 t t t 也是强化学习中的时步( time step \text{time step} time step )。
- θ \theta θ 是均值回归速度,决定了该过程回归到均值 μ \mu μ 的速度。
- μ \mu μ 是长期均值。表示噪声在长时间尺度上的平均值。
- σ \sigma σ 是噪声的强度,表示随机高斯噪声的标准差,决定了随机扰动的大小。
- W t W_t Wt 是标准布朗运动(或维纳过程)。是一个随机项,表示随机高斯噪声的微小变化。
5.1.2 特性
-
均值回归:
- OU 过程具有均值回归特性,这意味着它会倾向于回归到其长期均值 μ \mu μ。当 X t X_t Xt 偏离均值时,回归项 θ ( μ − X t ) \theta (\mu - X_t) θ(μ−Xt) 会推动它回到均值。
- 如果 X t > μ X_t > \mu Xt>μ,回归项为负,将 X t X_t Xt 拉回均值。
- 如果 X t < μ X_t < \mu Xt<μ,回归项为正,将 X t X_t Xt 推回均值。
-
随机扰动:
- OU 过程包括一个随机扰动项 σ d W t \sigma dW_t σdWt,这个项引入了噪声,使得过程具有随机性。
- σ \sigma σ 越大,随机扰动越显著。
5.1.3 直观理解
可以将 OU 噪声过程想象成一个受阻尼的随机过程。以下是一些直观的类比:
- 弹簧模型:想象一个弹簧的质量块,质量块的位置 X t X_t Xt 在长期均值 μ \mu μ 附近振荡。弹簧力(类似于回归项 θ ( μ − X t ) \theta (\mu - X_t) θ(μ−Xt))将质量块拉回均值位置,同时随机的震动(类似于 σ d W t \sigma dW_t σdWt)不断扰动质量块的位置。
- 金融资产价格:OU 过程可以用来模拟资产价格的变化,假设价格有一个长期均值,价格会围绕这个均值波动并具有回归特性。
5.1.4 数学性质
-
平稳分布:
- OU 过程在长期情况下具有平稳分布,其均值为 μ \mu μ,方差为 σ 2 2 θ \frac{\sigma^2}{2\theta} 2θσ2。
-
自相关函数:
- OU 过程的自相关函数为:
ρ ( τ ) = e − θ τ \rho(\tau) = e^{-\theta \tau} ρ(τ)=e−θτ - 自相关函数随着时间差 τ \tau τ 指数衰减,衰减速度由 θ \theta θ 决定。
- OU 过程的自相关函数为:
5.1.5 代码示例
以下是如何在 Python 中生成 OU 噪声过程的示例代码:
import numpy as np
import matplotlib.pyplot as pltdef generate_ou_process(T, dt, mu=0.0, theta=0.15, sigma=0.2, x0=None):"""Generate an Ornstein-Uhlenbeck process.Parameters:T (float): Total time.dt (float): Time step.mu (float): Long-term mean.theta (float): Speed of mean reversion.sigma (float): Volatility parameter.x0 (float): Initial value of the process (optional).Returns:np.ndarray: Generated OU process."""n_steps = int(T / dt)x = np.zeros(n_steps)if x0 is not None:x[0] = x0else:x[0] = mufor t in range(1, n_steps):dx = theta * (mu - x[t-1]) * dt + sigma * np.sqrt(dt) * np.random.normal()x[t] = x[t-1] + dxreturn x#Parameters
T = 10.0 # Total time
dt = 0.01 # Time step
mu = 0.0 # Long-term mean
theta = 0.15 # Speed of mean reversion
sigma = 0.2 # Volatility parameter
x0 = 1.0 # Initial value#Generate OU process
ou_process = generate_ou_process(T, dt, mu, theta, sigma, x0)#Plot the result
time = np.arange(0, T, dt)
plt.plot(time, ou_process)
plt.xlabel('Time')
plt.ylabel('X(t)')
plt.title('Ornstein-Uhlenbeck Process')
plt.show()
5.1.6 总结
Ornstein-Uhlenbeck 噪声是一种具有均值回归特性的随机过程,其主要特性包括回归到长期均值和随机扰动。通过调节其参数,可以模拟不同类型的具有均值回归特性的动态变化。在强化学习中,OU 噪声常用于添加到动作选择中,以平衡探索和利用。
\qquad PPO \text{PPO} PPO 算法是一类典型的 Actor-Critic \text{Actor-Critic} Actor-Critic 算法,既适用于连续动作空间,也适用于离散动作空间。
\qquad PPO \text{PPO} PPO 算法的主要思想是通过在策略梯度的优化过程中引入一个重要性权重来限制策略更新的幅度,从而提高算法的稳定性和收敛性。 PPO \text{PPO} PPO 算法的优点在于简单、易于实现、易于调参,应用十分广泛,正可谓 “遇事不决 PPO \text{PPO} PPO ”。
6 重要性采样
p ( x ) p(x) p(x)难采样, q ( x ) q(x) q(x)容易采样,通过q采样来替代p采样。
\qquad 重要性采样( importance sampling \text{importance sampling} importance sampling )。重要性采样是一种估计随机变量的期望或者概率分布的统计方法。它的原理也很简单,假设有一个函数 f ( x ) f(x) f(x) ,需要从分布 p ( x ) p(x) p(x) 中采样来计算其期望值,但是在某些情况下我们可能很难从 p ( x ) p(x) p(x) 中采样,这个时候我们可以从另一个比较容易采样的分布 q ( x ) q(x) q(x) 中采样,来间接地达到从 p ( x ) p(x) p(x) 中采样的效果。这个过程的数学表达式如式 (12.1) \text{(12.1)} (12.1) 所示。
E p ( x ) [ f ( x ) ] = ∫ a b f ( x ) p ( x ) q ( x ) q ( x ) d x = E q ( x ) [ f ( x ) p ( x ) q ( x ) ] (12.1) \tag{12.1} E_{p(x)}[f(x)]=\int_{a}^{b} f(x) \frac{p(x)}{q(x)} q(x) d x=E_{q(x)}\left[f(x) \frac{p(x)}{q(x)}\right] Ep(x)[f(x)]=∫abf(x)q(x)p(x)q(x)dx=Eq(x)[f(x)q(x)p(x)](12.1)
\qquad 对于离散分布的情况,可以表达为式 (12.2) \text{(12.2)} (12.2) 。
E p ( x ) [ f ( x ) ] = 1 N ∑ f ( x i ) p ( x i ) q ( x i ) (12.2) \tag{12.2} \begin{aligned} E_{p(x)}[f(x)]=\frac{1}{N} \sum f\left(x_{i}\right) \frac{p\left(x_{i}\right)}{q\left(x_{i}\right)} \end{aligned} Ep(x)[f(x)]=N1∑f(xi)q(xi)p(xi)(12.2)
\qquad 这样一来原问题就变成了只需要从 q ( x ) q(x) q(x) 中采样,然后计算两个分布之间的比例 p ( x ) q ( x ) \frac{p(x)}{q(x)} q(x)p(x) 即可,这个比例称之为重要性权重。换句话说,每次从 q ( x ) q(x) q(x) 中采样的时候,都需要乘上对应的重要性权重来修正采样的偏差,即两个分布之间的差异。当然这里可能会有一个问题,就是当 p ( x ) p(x) p(x) 不为 0 \text{0} 0 的时候, q ( x ) q(x) q(x) 也不能为 0 \text{0} 0,但是他们可以同时为 0 \text{0} 0 ,这样 p ( x ) q ( x ) \frac{p(x)}{q(x)} q(x)p(x) 依然有定义,具体的原理由于并不是很重要,因此就不展开讲解了。
\qquad 通常来讲,我们把这个 p ( x ) p(x) p(x) 叫做目标分布, q ( x ) q(x) q(x) 叫做提议分布( Proposal Distribution \text{Proposal Distribution} Proposal Distribution ), 那么重要性采样对于提议分布有什么要求呢? 其实理论上 q ( x ) q(x) q(x) 可以是任何比较好采样的分布,比如高斯分布等等,但在实际训练的过程中,聪明的读者也不难想到我们还是希望 q ( x ) q(x) q(x) 尽可能 p ( x ) p(x) p(x),即重要性权重尽可能接近于 1 \text{1} 1 。我们可以从方差的角度来具体展开讲讲为什么需要重要性权重尽可能等于 1 1 1 ,回忆一下方差公式,如式 (12.3) \text{(12.3)} (12.3) 所示。
V a r x ∼ p [ f ( x ) ] = E x ∼ p [ f ( x ) 2 ] − ( E x ∼ p [ f ( x ) ] ) 2 (12.3) \tag{12.3} Var_{x \sim p}[f(x)]=E_{x \sim p}\left[f(x)^{2}\right]-\left(E_{x \sim p}[f(x)]\right)^{2} Varx∼p[f(x)]=Ex∼p[f(x)2]−(Ex∼p[f(x)])2(12.3)
\qquad 结合重要性采样公式,我们可以得到式 (12.4) \text{(12.4)} (12.4) 。
V a r x ∼ q [ f ( x ) p ( x ) q ( x ) ] = E x ∼ q [ ( f ( x ) p ( x ) q ( x ) ) 2 ] − ( E x ∼ q [ f ( x ) p ( x ) q ( x ) ] ) 2 = E x ∼ p [ f ( x ) 2 p ( x ) q ( x ) ] − ( E x ∼ p [ f ( x ) ] ) 2 (12.4) \tag{12.4} \begin{aligned} Var_{x \sim q}\left[f(x) \frac{p(x)}{q(x)}\right]=E_{x \sim q}\left[\left(f(x) \frac{p(x)}{q(x)}\right)^{2}\right]-\left(E_{x \sim q}\left[f(x) \frac{p(x)}{q(x)}\right]\right)^{2} \\ = E_{x \sim p}\left[f(x)^{2} \frac{p(x)}{q(x)}\right]-\left(E_{x \sim p}[f(x)]\right)^{2} \end{aligned} Varx∼q[f(x)q(x)p(x)]=Ex∼q[(f(x)q(x)p(x))2]−(Ex∼q[f(x)q(x)p(x)])2=Ex∼p[f(x)2q(x)p(x)]−(Ex∼p[f(x)])2(12.4)
\qquad 不难看出,当 q ( x ) q(x) q(x) 越接近 p ( x ) p(x) p(x) 的时候,方差就越小,也就是说重要性权重越接近于 1 1 1 的时候,反之越大。
\qquad 其实重要性采样也是蒙特卡洛估计的一部分,只不过它是一种比较特殊的蒙特卡洛估计,允许我们在复杂问题中利用已知的简单分布进行采样,从而避免了直接采样困难分布的问题,同时通过适当的权重调整,可以使得蒙特卡洛估计更接近真实结果。
7 PPO算法
\qquad 重要性采样本质上是一种在某些情况下更优的蒙特卡洛估计,再结合前面 Actor-Critic \text{Actor-Critic} Actor-Critic 章节中我们讲到策略梯度算法的高方差主要来源于 Actor \text{Actor} Actor 的策略梯度采样估计。 PPO \text{PPO} PPO 算法的核心思想就是通过重要性采样来优化原来的策略梯度估计,其目标函数表示如式 (12.5) \text{(12.5)} (12.5) 所示。
J T R P O ( θ ) = E [ r ( θ ) A ^ θ old ( s , a ) ] r ( θ ) = π θ ( a ∣ s ) π θ old ( a ∣ s ) (12.5) \tag{12.5} \begin{gathered} J^{\mathrm{TRPO}}(\theta)=\mathbb{E}\left[r(\theta) \hat{A}_{\theta_{\text {old }}}(s, a)\right] \\ r(\theta)=\frac{\pi_\theta(a \mid s)}{\pi_{\theta_{\text {old }}}(a \mid s)} \end{gathered} JTRPO(θ)=E[r(θ)A^θold (s,a)]r(θ)=πθold (a∣s)πθ(a∣s)(12.5)
\qquad 这个损失就是置信区间的部分,一般称作 TRPO \text{TRPO} TRPO 损失。这里旧策略分布 π θ old ( a ∣ s ) \pi_{\theta_{\text {old }}}(a \mid s) πθold (a∣s) 就是重要性权重部分的目标分布 p ( x ) p(x) p(x) ,目标分布是很难采样的,所以在计算重要性权重的时候这部分通常用上一次与环境交互采样中的概率分布来近似。相应地, π θ ( a ∣ s ) \pi_\theta(a \mid s) πθ(a∣s) 则是提议分布,即通过当前网络输出的 probs 形成的类别分布 Catagorical \text{Catagorical} Catagorical 分布(离散动作)或者 Gaussian \text{Gaussian} Gaussian 分布(连续动作)。
\qquad 读者们可能对这个写法感到陌生,似乎少了 Actor-Critic \text{Actor-Critic} Actor-Critic 算法中的 logit_p,但其实这个公式等价于式 (12.6) \text{(12.6)} (12.6) 。
J T R P O ( θ ) = E ( s t , a t ) ∼ π θ ′ [ p θ ( a t ∣ s t ) p θ ′ ( a t ∣ s t ) A θ ′ ( s t , a t ) ∇ log p θ ( a t n ∣ s t n ) ] (12.6) \tag{12.6} J^{\mathrm{TRPO}}(\theta)=E_{\left(s_t, a_t\right) \sim \pi_{\theta^{\prime}}}\left[\frac{p_\theta\left(a_t \mid s_t\right)}{p_{\theta^{\prime}}\left(a_t \mid s_t\right)} A^{\theta^{\prime}}\left(s_t, a_t\right) \nabla \log p_\theta\left(a_t^n \mid s_t^n\right)\right] JTRPO(θ)=E(st,at)∼πθ′[pθ′(at∣st)pθ(at∣st)Aθ′(st,at)∇logpθ(atn∣stn)](12.6)
\qquad 换句话说,本质上 PPO \text{PPO} PPO 算法就是在 Actor-Critic \text{Actor-Critic} Actor-Critic 算法的基础上增加了重要性采样的约束而已,从而确保每次的策略梯度估计都不会过分偏离当前的策略,也就是减少了策略梯度估计的方差,从而提高算法的稳定性和收敛性。
\qquad 前面我们提到过,重要性权重最好尽可能地等于 1 \text{1} 1 ,而在训练过程中这个权重它是不会自动地约束到 1 1 1 附近的,因此我们需要在损失函数中加入一个约束项或者说正则项,保证重要性权重不会偏离 1 \text{1} 1 太远。具体的约束方法有很多种,比如 KL \text{KL} KL 散度、 JS \text{JS} JS 散度等等,但通常我们会使用两种约束方法,一种是 clip \text{clip} clip 约束 ,另一种是 KL \text{KL} KL 散度。 clip \text{clip} clip 约束定义如式 (12.7) \text{(12.7)} (12.7) 所示。
J clip ( θ ) = E ^ t [ min ( r t ( θ ) A ^ t , clip ( r t ( θ ) , 1 − ϵ , 1 + ϵ ) A ^ t ) ] (12.7) \tag{12.7} J_{\text {clip }}(\theta)=\hat{\mathbb{E}}_{t}\left[\min \left(r_{t}(\theta) \hat{A}_{t}, \operatorname{clip}\left(r_{t}(\theta), 1-\epsilon, 1+\epsilon\right) \hat{A}_{t}\right)\right] Jclip (θ)=E^t[min(rt(θ)A^t,clip(rt(θ),1−ϵ,1+ϵ)A^t)](12.7)
\qquad 其中 ϵ \epsilon ϵ 是一个较小的超参,一般取 0.1 \text{0.1} 0.1 左右。这个 clip \text{clip} clip 约束的意思就是始终将重要性权重 r ( θ ) r(\theta) r(θ) 裁剪在 1 1 1 的邻域范围内,实现起来非常简单。
\qquad 另一种 KL \text{KL} KL 约束定义如式 (12.8) \text{(12.8)} (12.8) 所示。
J K L ( θ ) = E ^ t [ π θ ( a t ∣ s t ) π θ old ( a t ∣ s t ) A ^ t − β K L [ π θ old ( ⋅ ∣ s t ) , π θ ( ⋅ ∣ s t ) ] ] (12.8) \tag{12.8} J^{KL}(\theta)=\hat{\mathbb{E}}_t\left[\frac{\pi_\theta\left(a_t \mid s_t\right)}{\pi_{\theta_{\text {old }}}\left(a_t \mid s_t\right)} \hat{A}_t-\beta \mathrm{KL}\left[\pi_{\theta_{\text {old }}}\left(\cdot \mid s_t\right), \pi_\theta\left(\cdot \mid s_t\right)\right]\right] JKL(θ)=E^t[πθold (at∣st)πθ(at∣st)A^t−βKL[πθold (⋅∣st),πθ(⋅∣st)]](12.8)
\qquad KL \text{KL} KL 约束一般也叫 KL-penalty \text{KL-penalty} KL-penalty,它的意思是在 TRPO \text{TRPO} TRPO 损失的基础上,加上一个 KL \text{KL} KL 散度的惩罚项,这个惩罚项的系数 β \beta β 一般取 0.01 0.01 0.01 左右。这个惩罚项的作用也是保证每次更新的策略分布都不会偏离上一次的策略分布太远,从而保证重要性权重不会偏离 1 1 1 太远。在实践中,我们一般用 clip \text{clip} clip 约束,因为它更简单,计算成本较低,而且效果也更好。
\qquad 到这里,我们就基本讲完了 PPO \text{PPO} PPO 算法的核心内容,其实在熟练掌握 Actor-Critic \text{Actor-Critic} Actor-Critic 算法的基础上,去学习这一类的其他算法是不难的,读者只需要注意每个算法在 Actor-Critic \text{Actor-Critic} Actor-Critic 框架上做了哪些改进,取得了什么效果即可。
8 附2
8.1 重要性采样方差计算
这个公式描述了在重要性采样(Importance Sampling)中的方差计算过程。首先,让我们逐步分解这个公式,以确保每一步都正确。
8.1.1 公式解释
这个公式描述了权重调整后采样的方差计算方法。公式如下:
Var x ∼ q [ f ( x ) p ( x ) q ( x ) ] = E x ∼ q [ ( f ( x ) p ( x ) q ( x ) ) 2 ] − ( E x ∼ q [ f ( x ) p ( x ) q ( x ) ] ) 2 \text{Var}_{x \sim q} \left[ f(x) \frac{p(x)}{q(x)} \right] = \mathbb{E}_{x \sim q} \left[ \left( f(x) \frac{p(x)}{q(x)} \right)^2 \right] - \left( \mathbb{E}_{x \sim q} \left[ f(x) \frac{p(x)}{q(x)} \right] \right)^2 Varx∼q[f(x)q(x)p(x)]=Ex∼q[(f(x)q(x)p(x))2]−(Ex∼q[f(x)q(x)p(x)])2
8.1.2 方差定义
方差的定义是期望的平方与平方的期望之差,即:
Var [ X ] = E [ X 2 ] − ( E [ X ] ) 2 \text{Var}[X] = \mathbb{E}[X^2] - (\mathbb{E}[X])^2 Var[X]=E[X2]−(E[X])2
在这里,随机变量 X X X是 f ( x ) p ( x ) q ( x ) f(x) \frac{p(x)}{q(x)} f(x)q(x)p(x),且其分布是由 q ( x ) q(x) q(x) 定义的。因此,我们有:
Var x ∼ q [ f ( x ) p ( x ) q ( x ) ] = E x ∼ q [ ( f ( x ) p ( x ) q ( x ) ) 2 ] − ( E x ∼ q [ f ( x ) p ( x ) q ( x ) ] ) 2 \text{Var}_{x \sim q} \left[ f(x) \frac{p(x)}{q(x)} \right] = \mathbb{E}_{x \sim q} \left[ \left( f(x) \frac{p(x)}{q(x)} \right)^2 \right] - \left( \mathbb{E}_{x \sim q} \left[ f(x) \frac{p(x)}{q(x)} \right] \right)^2 Varx∼q[f(x)q(x)p(x)]=Ex∼q[(f(x)q(x)p(x))2]−(Ex∼q[f(x)q(x)p(x)])2
8.1.3 公式验证
- 计算期望的平方:
( E x ∼ q [ f ( x ) p ( x ) q ( x ) ] ) 2 \left( \mathbb{E}_{x \sim q} \left[ f(x) \frac{p(x)}{q(x)} \right] \right)^2 (Ex∼q[f(x)q(x)p(x)])2
- 计算平方的期望:
E x ∼ q [ ( f ( x ) p ( x ) q ( x ) ) 2 ] \mathbb{E}_{x \sim q} \left[ \left( f(x) \frac{p(x)}{q(x)} \right)^2 \right] Ex∼q[(f(x)q(x)p(x))2]
这一步中,首先需要计算:
( f ( x ) p ( x ) q ( x ) ) 2 = f ( x ) 2 ( p ( x ) q ( x ) ) 2 \left( f(x) \frac{p(x)}{q(x)} \right)^2 = f(x)^2 \left( \frac{p(x)}{q(x)} \right)^2 (f(x)q(x)p(x))2=f(x)2(q(x)p(x))2
然后取其在 q ( x ) q(x) q(x) 分布下的期望:
E x ∼ q [ f ( x ) 2 ( p ( x ) q ( x ) ) 2 ] \mathbb{E}_{x \sim q} \left[ f(x)^2 \left( \frac{p(x)}{q(x)} \right)^2 \right] Ex∼q[f(x)2(q(x)p(x))2]
- 方差公式:
将上述两步结合,我们得到方差的计算公式:
Var x ∼ q [ f ( x ) p ( x ) q ( x ) ] = E x ∼ q [ f ( x ) 2 ( p ( x ) q ( x ) ) 2 ] − ( E x ∼ q [ f ( x ) p ( x ) q ( x ) ] ) 2 \text{Var}_{x \sim q} \left[ f(x) \frac{p(x)}{q(x)} \right] = \mathbb{E}_{x \sim q} \left[ f(x)^2 \left( \frac{p(x)}{q(x)} \right)^2 \right] - \left( \mathbb{E}_{x \sim q} \left[ f(x) \frac{p(x)}{q(x)} \right] \right)^2 Varx∼q[f(x)q(x)p(x)]=Ex∼q[f(x)2(q(x)p(x))2]−(Ex∼q[f(x)q(x)p(x)])2
8.1.4 结论
这个公式是正确的,没有错误。它精确地描述了在重要性采样中加权采样值的方差计算方法。这个过程对于理解和应用重要性采样技术非常重要,尤其是在涉及到蒙特卡洛方法和其他采样技术时。
8.2 目标函数 式12.5 解释
这个公式与强化学习中的策略优化方法——信赖域策略优化(Trust Region Policy Optimization, TRPO)相关。TRPO是一种用于保证策略更新稳定性和提高收敛速度的优化算法。公式中的每一部分都有特定的含义,下面我们逐一解释。
8.2.1 公式解释
8.2.1.1 目标函数 J TRPO ( θ ) J^{\text{TRPO}}(\theta) JTRPO(θ)
J TRPO ( θ ) = E [ r ( θ ) A ^ θ old ( s , a ) ] J^{\text{TRPO}}(\theta) = \mathbb{E} \left[ r(\theta) \hat{A}_{\theta_{\text{old}}}(s, a) \right] JTRPO(θ)=E[r(θ)A^θold(s,a)]
-
目标函数 J TRPO ( θ ) J^{\text{TRPO}}(\theta) JTRPO(θ): TRPO 的目标是通过优化策略参数 θ \theta θ 来最大化这个期望值。这个期望值是对策略在给定状态 s s s 下采取动作 a a a 所获得的优势函数的加权平均。
-
期望值 E [ ⋅ ] \mathbb{E}[\cdot] E[⋅]: 表示在所有状态 s s s 和动作 a a a 上进行期望。期望是根据当前策略 π θ \pi_{\theta} πθ 进行采样的。
-
优势函数 A ^ θ old ( s , a ) \hat{A}_{\theta_{\text{old}}}(s, a) A^θold(s,a): 这是旧策略 θ old \theta_{\text{old}} θold 下的优势函数。优势函数表示在特定状态 s s s 下选择动作 a a a 相对于平均水平(基于旧策略)所带来的额外奖励。
8.2.1.2 比率函数 r ( θ ) r(\theta) r(θ)
r ( θ ) = π θ ( a ∣ s ) π θ old ( a ∣ s ) r(\theta) = \frac{\pi_{\theta}(a \mid s)}{\pi_{\theta_{\text{old}}}(a \mid s)} r(θ)=πθold(a∣s)πθ(a∣s)
- 比率函数 r ( θ ) r(\theta) r(θ): 这个比率函数表示新策略 π θ \pi_{\theta} πθ与旧策略 π θ old \pi_{\theta_{\text{old}}} πθold在相同状态 s s s和动作 a a a下的概率比值。
- π θ ( a ∣ s ) \pi_{\theta}(a \mid s) πθ(a∣s) : 新策略在状态 : 新策略在状态 :新策略在状态s 下选择动作 下选择动作 下选择动作a 的概率。 − 的概率。 - 的概率。−\pi_{\theta_{\text{old}}}(a \mid s)$ : 旧策略在状态 : 旧策略在状态 :旧策略在状态s 下选择动作 下选择动作 下选择动作a$的概率。
这个比率用来调整优势函数,使得策略更新时考虑到新旧策略的变化。
8.2.2 直观解释
-
策略更新的目标: TRPO的目标是找到一个新的策略 π θ \pi_{\theta} πθ,使得在策略更新过程中保持策略的稳定性和收敛性。通过最大化目标函数 J TRPO ( θ ) J^{\text{TRPO}}(\theta) JTRPO(θ),TRPO确保策略更新是在一个受信赖的范围内进行的。
-
优势函数: 优势函数 A ^ θ old ( s , a ) \hat{A}_{\theta_{\text{old}}}(s, a) A^θold(s,a)表示在给定状态 s s s下选择动作 a a a比起选择其他动作的好坏程度。TRPO使用这个函数来衡量当前策略相对于旧策略的性能提升。
-
概率比率: 比率函数 r ( θ ) r(\theta) r(θ)调整优势函数的影响,使得新的策略不会偏离旧的策略太远,从而保证策略更新的稳定性。这个调整有助于避免策略在更新过程中出现剧烈变化,确保每次更新都在信赖域内。
8.2.3 总结
TRPO 的核心思想是通过最大化目标函数 J TRPO ( θ ) J^{\text{TRPO}}(\theta) JTRPO(θ),在策略更新时考虑新旧策略的变化,确保更新的稳定性。比率函数 r ( θ ) r(\theta) r(θ)和优势函数 A ^ θ old ( s , a ) \hat{A}_{\theta_{\text{old}}}(s, a) A^θold(s,a)的结合,使得新的策略在获得更高奖励的同时,保持与旧策略的相似性,从而实现稳定和高效的策略优化。
Soft Actor-Critic \text{Soft Actor-Critic} Soft Actor-Critic 算法,简写为 SAC \text{SAC} SAC 。 SAC \text{SAC} SAC 算法是一种基于最大熵强化学习的策略梯度算法,它的目标是最大化策略的熵,从而使得策略更加鲁棒。 SAC \text{SAC} SAC 算法的核心思想是,通过最大化策略的熵,使得策略更加鲁棒,经过超参改良后的 SAC \text{SAC} SAC 算法在稳定性方面是可以与 PPO \text{PPO} PPO 算法华山论剑的。
9 最大熵强化学习
确定性策略和随机性策略,确定性策略是指在给定相同状态下,总是选择相同的动作。
随机性策略则是在给定状态下可以选择多种可能的动作。
| 优势 | 劣势 | 代表算法 | |
|---|---|---|---|
| 确定性策略 | 稳定性且可重复性。可控性好,容易达到最优解。 | 缺乏探索性。容易陷入局部最优解。 | DQN、DDPG |
| 随机性策略 | 更加灵活。能够在一定程度探索未知状态和动作。有助于避免陷入局部最优解。 | 不稳定。可重复性差。可能策略收敛慢,影响效率和性能。 | A2C、PPO |
10 Soft Q-Learning
11 SAC
12 自动调节温度因子
相关文章:

强化学习-6 DDPG、PPO、SAC算法
文章目录 1 DPG方法2 DDPG算法3 DDPG算法的优缺点4 TD3算法4.1 双Q网络4.2 延迟更新4.3 噪声正则 5 附15.1 Ornstein-Uhlenbeck (OU) 噪声5.1.1 定义5.1.2 特性5.1.3 直观理解5.1.4 数学性质5.1.5 代码示例5.1.6 总结 6 重要性采样7 PPO算法8 附28.1 重要性采样方差计算8.1.1 公…...

vue3实现多表头列表el-table,拖拽,鼠标滑轮滚动条优化
需求背景解决效果index.vue 需求背景 需要实现多表头列表的用户体验优化 解决效果 index.vue <!--/** * author: liuk * date: 2024-07-03 * describe:**** 多表头列表 */--> <template><el-table ref"tableRef" height"calc(100% - 80px)&qu…...

Micron近期发布了32Gb DDR5 DRAM
Micron Technology近期发布了一项内存技术的重大突破——一款32Gb DDR5 DRAM芯片,这项创新不仅将存储容量翻倍,还显著提升了针对人工智能(AI)、机器学习(ML)、高性能计算(HPC)以及数…...

SQL Server时间转换
第一种:format --转化成年月日 select format( GETDATE(),yyyy-MM-dd) --转化年月日,时分秒,这里的HH指24小时的,hh是12小时的 select format( GETDATE(),yyyy-MM-dd HH:mm:ss) --转化成时分秒的,这里就不一样的&…...

kubernetes集群部署:node节点部署和CRI-O运行时安装(三)
关于CRI-O Kubernetes最初使用Docker作为默认的容器运行时。然而,随着Kubernetes的发展和OCI标准的确立,社区开始寻找更专门化的解决方案,以减少复杂性和提高性能。CRI-O的主要目标是提供一个轻量级的容器运行时,它可以直接运行O…...

03:Spring MVC
文章目录 一:Spring MVC简介1:说说自己对于Spring MVC的了解?1.1:流程说明: 一:Spring MVC简介 Spring MVC就是一个MVC框架,Spring MVC annotation式的开发比Struts2方便,可以直接代…...

玩转springboot之springboot注册servlet
springboot注册servlet 有时候在springboot中依然需要注册servlet,filter,listener,就以servlet为例来进行说明,另外两个也都类似 使用WebServlet注解 在servlet3.0之后,servlet注册支持注解注册,而不需要在…...

推荐好玩的工具之OhMyPosh使用
解除禁止脚本 Set-ExecutionPolicy RemoteSigned 下载Oh My Posh winget install oh-my-posh 或者 Install-Module oh-my-posh -Scope AllUsers 下载Git提示 Install-Module posh-git -Scope CurrentUser 或者 Install-Module posh-git -Scope AllUser 下载命令提示 Install-Mo…...
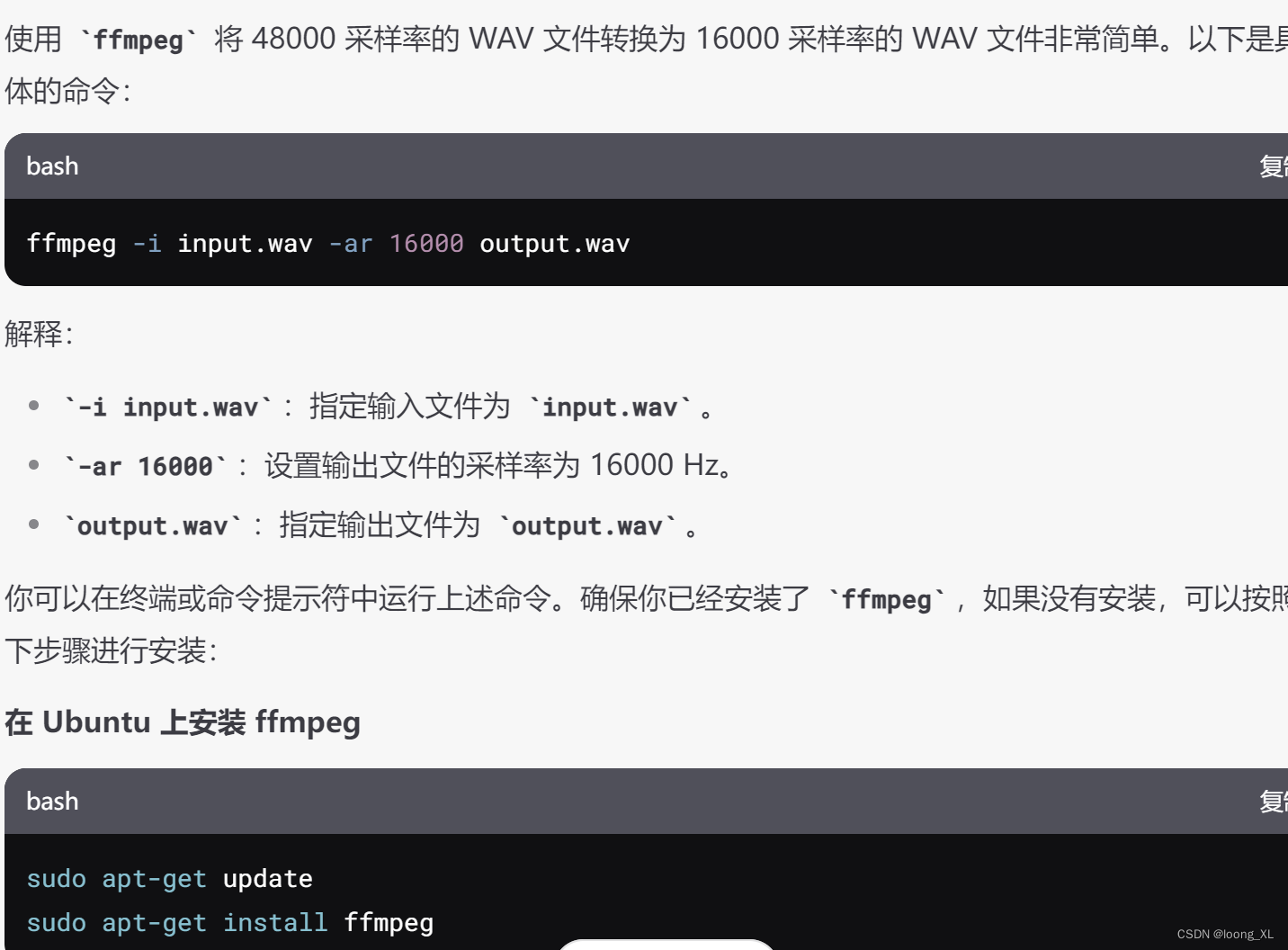
pydub、ffmpeg 音频文件声道选择转换、采样率更改
快速查看音频通道数和每个通道能力判断具体哪个通道说话;一般能量大的那个算是说话 import wave from pydub import AudioSegment import numpy as npdef read_wav_file(file_path):with wave.open(file_path, rb) as wav_file:params wav_file.getparams()num_cha…...

0803实操-Windows Server系统管理
Windows Server系统管理 系统管理与基础配置 查看系统信息、更改计算机名称 网络配置 启用网络发现 Windows启用网络发现是指在网络设置中启用一个功能,该功能允许您的计算机在网络上识别和访问其他设备和计算机。具体来说,启用网络发现后ÿ…...

使用Java构建物联网应用的最佳实践
使用Java构建物联网应用的最佳实践 大家好,我是免费搭建查券返利机器人省钱赚佣金就用微赚淘客系统3.0的小编,也是冬天不穿秋裤,天冷也要风度的程序猿! 随着物联网(IoT)技术的快速发展,越来越…...
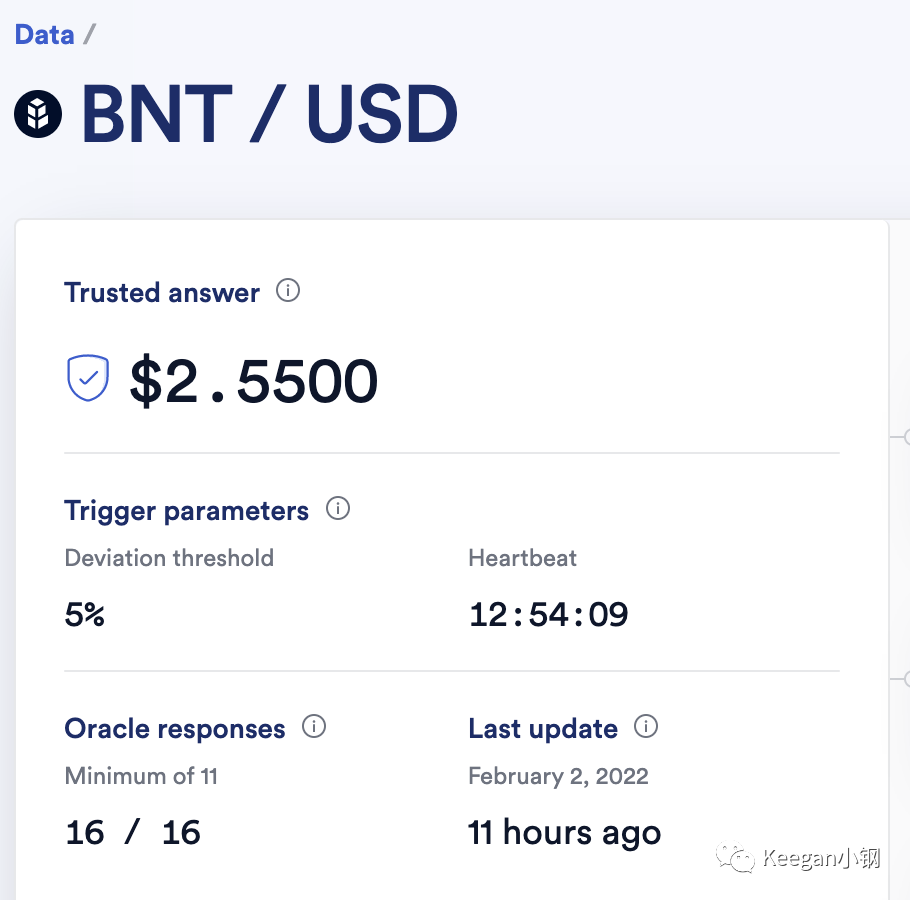
价格预言机的使用总结(一):Chainlink篇
文章首发于公众号:Keegan小钢 前言 价格预言机已经成为了 DeFi 中不可获取的基础设施,很多 DeFi 应用都需要从价格预言机来获取稳定可信的价格数据,包括借贷协议 Compound、AAVE、Liquity ,也包括衍生品交易所 dYdX、PERP 等等。…...
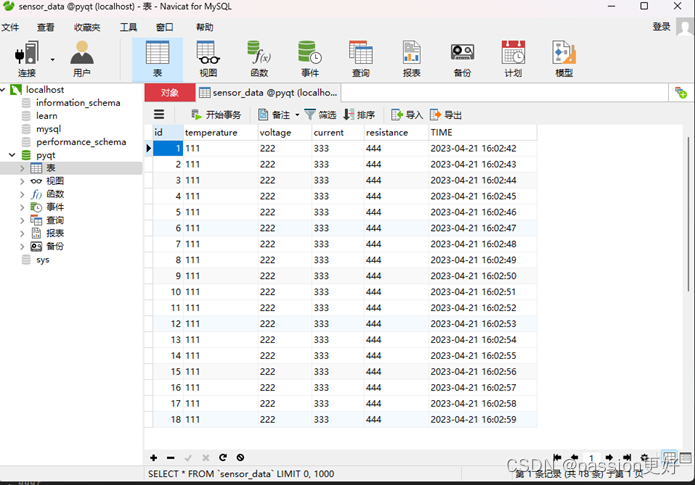
【Pyhton】读取寄存器数据到MySQL数据库
目录 步骤 modsim32软件配置 Navicat for MySQL 代码实现 步骤 安装必要的库:确保安装了pymodbus和pymysql。 配置Modbus连接:设置Modbus从站的IP地址、端口(对于TCP)或串行通信参数(对于RTU)。 连接M…...

jmeter-beanshell学习3-beanshell获取请求报文和响应报文
前后两个报文,后面报文要用前面报文的响应结果,这个简单,正则表达式或者json提取器,都能实现。但是如果后面报文要用前面请求报文的内容,感觉有点难。最早时候把随机数写在自定义变量,前后两个接口都用这个…...

【C++】B树及其实现
写目录 一、B树的基本概念1.引入2.B树的概念 二、B树的实现1.B树的定义2.B树的查找3.B树的插入操作4.B树的删除5.B树的遍历6.B树的高度7.整体代码 三、B树和B*树1.B树2.B*树3.总结 一、B树的基本概念 1.引入 我们已经学习过二叉排序树、AVL树和红黑树三种树形查找结构&#x…...

C++(Qt)-GIS开发-QGraphicsView显示瓦片地图简单示例
C(Qt)-GIS开发-QGraphicsView显示瓦片地图简单示例 文章目录 C(Qt)-GIS开发-QGraphicsView显示瓦片地图简单示例1、概述2、实现效果3、主要代码4、源码地址 更多精彩内容👉个人内容分类汇总 👈👉GIS开发 👈 1、概述 支持多线程加…...

CTFShow的RE题(三)
数学不及格 strtol 函数 long strtol(char str, char **endptr, int base); 将字符串转换为长整型 就是解这个方程组了 主要就是 v4, v9的关系, 3v9-(v10v11v12)62d10d4673 v4 v12 v11 v10 0x13A31412F8C 得到 3*v9v419D024E75FF(1773860189695) 重点&…...
WordPress主题开发进群付费主题v1.1.2 多种引流方式
全新前端UI界面,多种前端交互特效让页面不再单调,进群页面群成员数,群成员头像名称,每次刷新页面随机更新不重复,最下面评论和点赞也是如此随机刷新不重复 进群页面简介,群聊名称,群内展示&…...
SAP中的 UPDATA TASK 和 BACKGROUND TASK
前言: 记录这篇文章起因是调查生产订单报工问题引申出来的一个问题,后来再次调查后了解了其中缘由,大概记录以下,如有不对,欢迎指正。问题原贴如下: SAP CO11N BAPI_PRODORDCONF_CREATE_TT连续报工异步更…...
UDP协议:独特之处及其在网络通信中的应用
在网络通信领域,UDP(用户数据报协议,User Datagram Protocol)是一种广泛使用的传输层协议。与TCP(传输控制协议,Transmission Control Protocol)相比,UDP具有其独特的特点和适用场景…...

燃油车虎视眈眈,电车涨价的图谋必将落空,油价上涨的利好将消失
近期以来多家电车企业涨价,美国电车涨价尤为明显,最高涨幅2万元,而国产电车涨价3000-1.4万元不等,凸显出电车似乎突然间对市场乐观起来,导致他们信心十足的在于3月份以来的油价上涨,但是这种涨价将迅速导致…...

嵌入式AI边缘计算原型:STM32与云端PyTorch模型协同工作流设计
嵌入式AI边缘计算原型:STM32与云端PyTorch模型协同工作流设计 1. 场景需求与痛点分析 在智能家居、工业监测等物联网场景中,我们常常遇到这样的矛盾:边缘设备需要实时响应,但计算能力有限;云端算力强大,但…...
)
嵌入式开发实战:用状态机+事件驱动框架搞定串口通信(附完整代码)
嵌入式开发实战:状态机与事件驱动框架在串口通信中的高效应用 串口通信作为嵌入式系统中最基础也最常用的外设接口之一,其稳定性和效率直接影响着整个系统的性能表现。传统的轮询式串口处理方式不仅占用大量CPU资源,还难以应对复杂通信协议和…...

SDMatte在电商场景落地:商品主图自动去背景+透明PNG生成完整工作流
SDMatte在电商场景落地:商品主图自动去背景透明PNG生成完整工作流 1. 电商场景中的图像处理痛点 在电商运营中,商品主图的质量直接影响转化率。传统处理方式面临三大难题: 人工成本高:专业设计师处理一张图平均耗时15-30分钟边…...
工程入门:从零到一掌握高效对话技巧)
S2-Pro提示词(Prompt)工程入门:从零到一掌握高效对话技巧
S2-Pro提示词(Prompt)工程入门:从零到一掌握高效对话技巧 1. 为什么需要学习提示词工程 你可能已经发现,同样的AI模型,在不同人手里表现天差地别。有人能让它写出专业报告,有人却只能得到敷衍的回复。这中…...

2026年多模态AI前瞻:Qwen3-VL-2B开源生态发展潜力分析
2026年多模态AI前瞻:Qwen3-VL-2B开源生态发展潜力分析 1. 项目概述与核心价值 Qwen3-VL-2B-Instruct作为新一代开源视觉语言模型,代表了多模态AI技术的重要发展方向。这个模型不仅能够理解文本,更重要的是具备了"看"的能力——它…...

SecGPT-14B部署教程:模型热更新机制设计,不中断服务切换安全知识版本
SecGPT-14B部署教程:模型热更新机制设计,不中断服务切换安全知识版本 1. SecGPT-14B简介 SecGPT是由云起无垠推出的开源大语言模型,专门针对网络安全领域设计。这个模型融合了自然语言理解、代码生成和安全知识推理等核心能力,能…...

ViGEmBus如何解决Windows游戏控制器兼容性难题?
ViGEmBus如何解决Windows游戏控制器兼容性难题? 【免费下载链接】ViGEmBus Windows kernel-mode driver emulating well-known USB game controllers. 项目地址: https://gitcode.com/gh_mirrors/vi/ViGEmBus ViGEmBus是一款专业的Windows内核模式驱动程序&a…...

帆软报表嵌入避坑指南:5步解决重定向死循环与XSS防护矛盾
帆软报表深度嵌入实战:安全与功能平衡的5步架构方案 当企业级报表系统需要嵌入现有业务平台时,iframe方案往往成为首选,但随之而来的安全策略冲突让不少开发团队陷入两难——单点登录要求与XSS防护似乎水火不容。我曾为某省级政务平台实施帆软…...

STM32温湿度监控系统设计与实现
## 1. 工业生产线温湿度监控系统设计### 1.1 系统架构设计 基于STM32F103C8T6微控制器的工业级温湿度监控系统采用三层架构: - **感知层**:3个DHT22数字温湿度传感器 - **控制层**:STM32F103C8T6最小系统板 - **云平台层**:ESP826…...