基于YOLOv10+YOLOP+PYQT的可视化系统,实现多类别目标检测+可行驶区域分割+车道线分割【附代码】
文章目录
- 前言
- 视频效果
- 必要环境
- 一、代码结构
- 1、 训练参数解析
- 2、 核心代码解析
- 1.初始化Detector类
- 2. @torch.no_grad()
- 3. 复制输入图像并初始化计数器
- 4. 调用YOLOv10模型进行目标检测
- 5. 提取检测结果信息
- 6. 遍历检测结果并在图像上绘制边界框和标签
- 7. 准备输入图像以适应End-to-end模型
- 8. 使用YOLOP模型进行推理
- 9. 处理可行驶区域分割结果
- 10. 处理车道线分割结果
- 二、效果展示
- 三、完整代码获取
- 总结
前言
在往期博客中,我们详细介绍了如何搭建YOLOv10和YOLOP的环境。本期将结合这两个算法,实现多类别目标检测、可行驶区域分割和车道线分割等多种任务,并将其部署到PYQT界面中进行展示。
视频效果
b站链接:基于YOLOv10+YOLOP+PYQT的可视化系统,实现多类别目标检测+可行驶区域分割+车道线分割多种任务
必要环境
- 配置yolov10环境 可参考往期博客
地址:搭建YOLOv10环境 训练+推理+模型评估
- 配置yolop环境 可参考往期博客
地址:YOLOP 训练+测试+模型评估
一、代码结构
1、 训练参数解析
首先,我们利用 argparse 模块来设置命令行参数,以便灵活配置模型的权重路径、使用设备(cpu、gpu)等信息
# 解析命令行参数
parser.add_argument('--v10weights', default=r"yolov10s.pt", type=str, help='weights path')
parser.add_argument('--weights', default=r"weights/End-to-end.pth", type=str, help='weights path')
parser.add_argument('--device', default='0', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--imgsz', type=int, default=640, help='image size')
parser.add_argument('--merge_nms', default=False, action='store_true', help='merge class')
parser.add_argument('--conf_thre', type=float, default=0.3, help='conf_thre')
parser.add_argument('--iou_thre', type=float, default=0.2, help='iou_thre')
parser.add_argument('--augment', action='store_true', help='augmented inference')
opt = parser.parse_args()
关键参数详解:
-
–v10weights: 指定YOLOv10模型的权重文件路径。
-
–weights: 指定YOLOP模型的权重文件路径,这个模型包含了车道线分割和可行驶区域分割的任务
-
–device: 指定运行模型的设备,可以是单个GPU(如 0),或者是CPU(cpu)
-
–imgsz: 指定输入图像的尺寸,输入图像会被调整为这个尺寸,以适应模型的输入要求
-
–conf_thre: 设置初始置信度阈值,只有置信度高于这个阈值的检测框才会被保留
-
–iou_thre: 设置初始IOU阈值,在NMS过程中,只有IOU低于这个阈值的检测框才会被保留
2、 核心代码解析
此部分包含车道线分割、可行驶区域分割和目标检测等关键部分的代码
1.初始化Detector类
这段代码定义了一个名为Detector的类,该类初始化了两个模型:一个是用于End-to-end检测的YOLOP模型,另一个是用于目标检测的YOLOv10模型。通过加载权重文件、设置设备、调整图像大小以及配置模型参数,实现了对这两个模型的初始化和准备工作
class Detector:def __init__(self, v10weights, cfg, device, model_path=r'./best_dist_model.pt', imgsz=640, conf=0.5, iou=0.0625, merge_nms=False):self.device = deviceself.model = get_net(cfg)checkpoint = torch.load(model_path, map_location=device)self.model.load_state_dict(checkpoint['state_dict'])self.model = self.model.to(device)img_w = torch.zeros((1, 3, imgsz, imgsz), device=device)_ = self.model(img_w)self.model.eval()self.stride = int(self.model.stride.max())self.imgsz = check_img_size(imgsz, s=self.stride)self.merge_nms = merge_nmsself.model_v10 = YOLOv10(v10weights)self.names = self.model_v10.names
2. @torch.no_grad()
这是一个装饰器,用于禁用梯度计算,可以减少内存消耗并加快推理速度,通常在推理时使用
@torch.no_grad()
def __call__(self, image: np.ndarray, conf, iou):
3. 复制输入图像并初始化计数器
复制输入图像以便在结果图像上进行操作,并初始化一个默认字典来记录每个类别的检测次数
img_vis = image.copy()
class_counts = defaultdict(int)
4. 调用YOLOv10模型进行目标检测
使用YOLOv10模型在输入图像上进行目标检测,返回检测结果
results = self.model_v10(image, verbose=True, conf=conf, iou=iou, device=self.device)
5. 提取检测结果信息
提取检测结果中的类别、置信度和边界框坐标
bboxes_cls = results[0].boxes.cls
bboxes_conf = results[0].boxes.conf
bboxes_xyxy = results[0].boxes.xyxy.cpu().numpy().astype('uint32')
6. 遍历检测结果并在图像上绘制边界框和标签
遍历所有检测到的目标,在图像上绘制边界框和标签,并记录每个类别的检测次数
for idx in range(len(bboxes_cls)):box_cls = int(bboxes_cls[idx])bbox_xyxy = bboxes_xyxy[idx]bbox_label = self.names[box_cls]class_counts[bbox_label] += 1box_conf = f"{bboxes_conf[idx]:.2f}"xmax, ymax, xmin, ymin = bbox_xyxy[2], bbox_xyxy[3], bbox_xyxy[0], bbox_xyxy[1]img_vis = cv2.rectangle(img_vis, (xmin, ymin), (xmax, ymax), get_color(box_cls + 2), 3)cv2.putText(img_vis, f'{str(bbox_label)}/{str(box_conf)}', (xmin, ymin - 10),cv2.FONT_HERSHEY_SIMPLEX, 1.0, get_color(box_cls + 2), 3)
7. 准备输入图像以适应End-to-end模型
对输入图像进行调整和预处理,以适应End-to-end模型的输入要求
img, ratio, pad = letterbox_for_img(image, new_shape=self.imgsz, auto=True)
pad_w, pad_h = pad
pad_w = int(pad_w)
pad_h = int(pad_h)
ratio = ratio[1]
img = np.ascontiguousarray(img)
img = transform(img).to(self.device)
im = img.float()
if im.ndimension() == 3:im = im.unsqueeze(0)
8. 使用YOLOP模型进行推理
在预处理后的图像上运行End-to-end模型,输出检测结果、车道线分割结果和可行驶区域分割结果
det_out, da_seg_out, ll_seg_out = self.model(im)
9. 处理可行驶区域分割结果
这段代码将对可行驶区域的分割结果进行后处理,首先从模型输出中裁剪出实际的分割结果,通过双线性插值恢复到原始图像尺寸,然后提取每个像素的类别索引,最终生成可行驶区域的分割掩码
_, _, height, width = im.shape
da_predict = da_seg_out[:, :, pad_h:(height - pad_h), pad_w:(width - pad_w)]
da_seg_mask = torch.nn.functional.interpolate(da_predict, scale_factor=int(1 / ratio), mode='bilinear')
_, da_seg_mask = torch.max(da_seg_mask, 1)
da_seg_mask = da_seg_mask.int().squeeze().cpu().numpy()
10. 处理车道线分割结果
这段代码将对车道线分割结果进行后处理,和处理可行驶区域分割结果同理,首先从模型输出中裁剪出实际的分割结果,并通过双线性插值恢复到原始图像尺寸,然后提取每个像素的类别索引,生成最终的分割掩码
ll_predict = ll_seg_out[:, :, pad_h:(height - pad_h), pad_w:(width - pad_w)]
ll_seg_mask = torch.nn.functional.interpolate(ll_predict, scale_factor=int(1 / ratio), mode='bilinear')
_, ll_seg_mask = torch.max(ll_seg_mask, 1)
ll_seg_mask = ll_seg_mask.int().squeeze().cpu().numpy()
二、效果展示


三、完整代码获取
链接:基于YOLOv10+YOLOP+PYQT的可视化系统,实现多类别目标检测+可行驶区域分割+车道线分割
总结
本期博客就到这里啦,喜欢的小伙伴们可以点点关注,感谢!
最近经常在b站上更新一些有关目标检测的视频,大家感兴趣可以来看看 https://b23.tv/1upjbcG
学习交流群:995760755
相关文章:
基于YOLOv10+YOLOP+PYQT的可视化系统,实现多类别目标检测+可行驶区域分割+车道线分割【附代码】
文章目录 前言视频效果必要环境一、代码结构1、 训练参数解析2、 核心代码解析1.初始化Detector类2. torch.no_grad()3. 复制输入图像并初始化计数器4. 调用YOLOv10模型进行目标检测5. 提取检测结果信息6. 遍历检测结果并在图像上绘制边界框和标签7. 准备输入图像以适应End-to-…...

计算机网络之令牌总线
上文内容:什么是以太网 1.令牌总线工作原理 在总线的基础上,通过在网络结点之间有序地传递令牌来分配各结点对共享型总线的访问权利,形成闭合的逻辑环路。 完全采用半双工的操作方式,只有获得令牌的结点才能发送信息ÿ…...

策略模式的应用
前言 系统有一个需求就是采购员审批注册供应商的信息时,会生成一个供应商的账号,此时需要发送供应商的账号信息(账号、密码)到注册填写的邮箱中,通知供应商账号信息,当时很快就写好了一个工具类࿰…...

如何使用uer做多分类任务
如何使用uer做多分类任务 语料集下载 找到这里点击即可 里面是这有json文件的 因此我们对此要做一些处理,将其转为tsv格式 # -*- coding: utf-8 -*- import json import csv import chardet# 检测文件编码 def detect_encoding(file_path):with open(file_path,…...

【HICE】转发服务器实验
1.在本地主机上操作 2.在客户端操作设置主机的IP地址为dns 3.测试,客户机是否能ping通...

MATLAB-分类CPO-RF-Adaboost冠豪猪优化器(CPO)优化RF随机森林结合Adaboost分类预测(二分类及多分类)
MATLAB-分类CPO-RF-Adaboost冠豪猪优化器(CPO)优化RF随机森林结合Adaboost分类预测(二分类及多分类) 分类CPO-RF-Adaboost冠豪猪优化器(CPO)优化RF随机森林结合Adaboost分类预测(二分类及多分类…...
绝区贰--及时优化降低 LLM 成本和延迟
前言 大型语言模型 (LLM) 为各行各业带来了变革性功能,让用户能够利用尖端的自然语言处理技术处理各种应用。然而,这些强大的 AI 系统的便利性是有代价的 — 确实如此。随着 LLM 变得越来越普及,其计算成本和延迟可能会迅速增加,…...

JDBC【封装工具类、SQL注入问题】
day54 JDBC 封装工具类01 创建配置文件 DBConfig.properties driverNamecom.mysql.cj.jdbc.Driver urljdbc:mysql://localhost:3306/qnz01?characterEncodingutf8&serverTimezoneUTC usernameroot passwordroot新建配置文件,不用写后缀名 创建工具类 将变…...
Windows打开redis以及Springboot整合redis
目录 前言Windows系统打开redisSpringboot整合redis依赖实体类yml配置文件config配置各个数据存储类型分别说明记录string数据写入redis,并查询通过命令行查询 list插入数据到redis中从redis中读取命令读取数据 hash向redis中逐个添加map键值对获取key对应的map中所…...

MySQL使用LIKE索引是否失效的验证
1、简单的示例展示 在MySQL中,LIKE查询可以通过一些方法来使得LIKE查询能够使用索引。以下是一些可以使用的方法: 使用前导通配符(%),但确保它紧跟着一个固定的字符。 避免使用后置通配符(%)&…...
封装日历uniapp,只显示年月不显示日
默认展示最新日期 子组件 <template><view class"date-picker"><picker mode"date" fields"month" change"onDateChange" :value"selectedDate"><view class"picker">{{ selectedDate…...
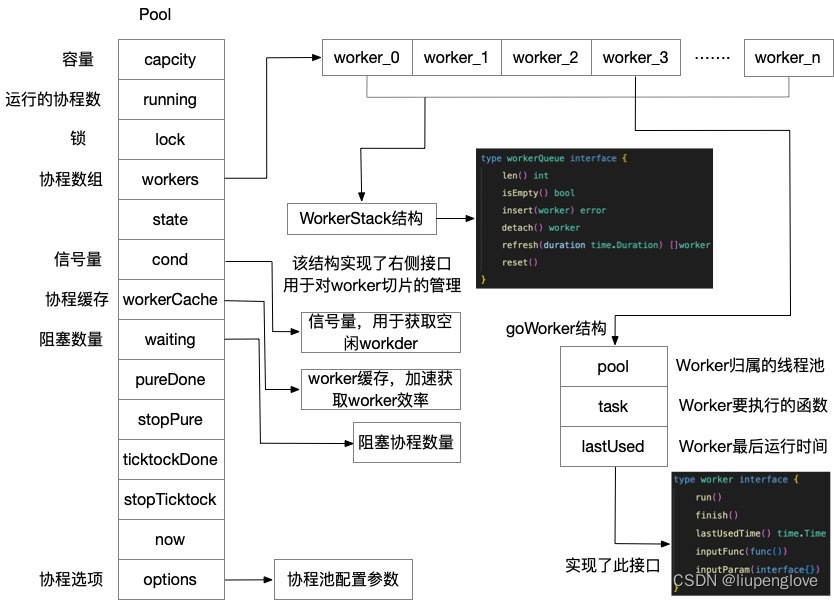
golang线程池ants-实现架构
1、总体架构 ants协程池,在使用上有多种方式(使用方式参考这篇文章:golang线程池ants-四种使用方法),但是在实现的核心就一个,如下架构图: 总的来说,就是三个数据结构: Pool、WorkerStack、goW…...
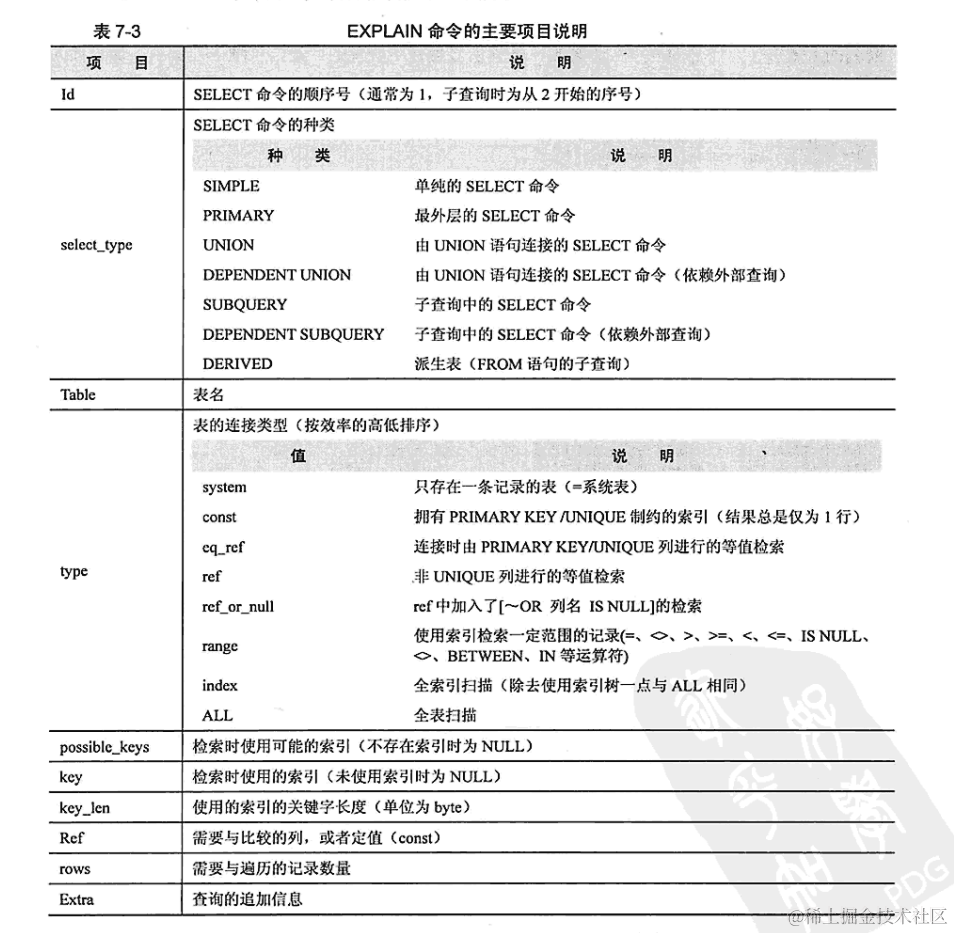
Mysql面试合集
概念 是一个开源的关系型数据库。 数据库事务及其特性 事务:是一系列的数据库操作,是数据库应用的基本逻辑单位。 事务特性: (1)原子性:即不可分割性,事务要么全部被执行,要么就…...
: 构建变体与自定义任务)
Android Gradle 开发与应用 (五): 构建变体与自定义任务
目录 1. 概述 2. 构建变体 2.1 构建变体的概念 2.2 构建类型 2.3 产品风味 2.4 构建变体的使用 3. 自定义任务 3.1 自定义任务的概念 3.2 创建自定义任务 3.3 配置任务依赖 3.4 任务类型 3.5 动态任务 3.6 自定义任务执行顺序 4. 案例 4.1 多渠道打包 4.2 自动…...

Django学习第六天
启动项目命令 python manage.py runserver 取消模态框功能 js实现列表数据删除 第二种实现思路 使用jquery修改模态框标题 编辑页面拿到数据库数据显示默认数据功能实现 想要去数据库中获取数据时:对象/字典 三种不同的数据类型 使用Ajax传入数据实现表单编辑&…...

docker部署mycat,连接上面一篇的一主二从mysql
一、docker下载mycat镜像 查看安装结果 这个名称太长,在安装容器时不方便操作,设置标签为mycat docker tag longhronshens/mycat-docker mycat 二、安装容器 先安装一个,主要目的是获得配置文件 docker run -it -d --name mycat -p 8066:…...

VUE2拖拽组件:vue-draggable-resizable-gorkys
vue-draggable-resizable-gorkys组件基于vue-draggable-resizable进行二次开发, 用于可调整大小和可拖动元素的组件并支持冲突检测、元素吸附、元素对齐、辅助线 安装: npm install --save vue-draggable-resizable-gorkys 全局引用: import Vue from vue import vdr fro…...

容器:stack
以下是关于stack容器的一些总结: stack容器比较简单,主要包括: 1、构造函数:stack [staName] 2、添加、删除元素: push() 、pop() 3、获取栈顶元素:top() 4、获取栈的大小:size() 5、判断栈是否为空&#x…...
跨平台Ribbon UI组件QtitanRibbon全新发布v6.7.0——支持Qt 6.6.3
没有Microsoft在其办公解决方案中提供的界面,就无法想象现代应用程序,这个概念称为Ribbon UI,目前它是使应用程序与时俱进的主要属性。QtitanRibbon是一款遵循Microsoft Ribbon UI Paradigm for Qt技术的Ribbon UI组件,QtitanRibb…...
 深入探索Python-Pandas库的核心数据结构:DataFrame全面解析)
(6) 深入探索Python-Pandas库的核心数据结构:DataFrame全面解析
目录 前言1. DataFrame 简介2. DataFrame的特点3. DataFrame的创建3.1 使用字典创建DataFrame3.2 使用列表的列表(或元组)创建DataFrame3.3 使用NumPy数组创建DataFrame3.4 使用Series构成的字典创建DataFrame3.5 使用字典构成的字典创建DataFrame 4. 从…...

MPNet:旋转机械轻量化故障诊断模型详解python代码复现
目录 一、问题背景与挑战 二、MPNet核心架构 2.1 多分支特征融合模块(MBFM) 2.2 残差注意力金字塔模块(RAPM) 2.2.1 空间金字塔注意力(SPA) 2.2.2 金字塔残差块(PRBlock) 2.3 分类器设计 三、关键技术突破 3.1 多尺度特征融合 3.2 轻量化设计策略 3.3 抗噪声…...

Cesium1.95中高性能加载1500个点
一、基本方式: 图标使用.png比.svg性能要好 <template><div id"cesiumContainer"></div><div class"toolbar"><button id"resetButton">重新生成点</button><span id"countDisplay&qu…...

将对透视变换后的图像使用Otsu进行阈值化,来分离黑色和白色像素。这句话中的Otsu是什么意思?
Otsu 是一种自动阈值化方法,用于将图像分割为前景和背景。它通过最小化图像的类内方差或等价地最大化类间方差来选择最佳阈值。这种方法特别适用于图像的二值化处理,能够自动确定一个阈值,将图像中的像素分为黑色和白色两类。 Otsu 方法的原…...

土地利用/土地覆盖遥感解译与基于CLUE模型未来变化情景预测;从基础到高级,涵盖ArcGIS数据处理、ENVI遥感解译与CLUE模型情景模拟等
🔍 土地利用/土地覆盖数据是生态、环境和气象等诸多领域模型的关键输入参数。通过遥感影像解译技术,可以精准获取历史或当前任何一个区域的土地利用/土地覆盖情况。这些数据不仅能够用于评估区域生态环境的变化趋势,还能有效评价重大生态工程…...

UR 协作机器人「三剑客」:精密轻量担当(UR7e)、全能协作主力(UR12e)、重型任务专家(UR15)
UR协作机器人正以其卓越性能在现代制造业自动化中扮演重要角色。UR7e、UR12e和UR15通过创新技术和精准设计满足了不同行业的多样化需求。其中,UR15以其速度、精度及人工智能准备能力成为自动化领域的重要突破。UR7e和UR12e则在负载规格和市场定位上不断优化…...

laravel8+vue3.0+element-plus搭建方法
创建 laravel8 项目 composer create-project --prefer-dist laravel/laravel laravel8 8.* 安装 laravel/ui composer require laravel/ui 修改 package.json 文件 "devDependencies": {"vue/compiler-sfc": "^3.0.7","axios": …...

10-Oracle 23 ai Vector Search 概述和参数
一、Oracle AI Vector Search 概述 企业和个人都在尝试各种AI,使用客户端或是内部自己搭建集成大模型的终端,加速与大型语言模型(LLM)的结合,同时使用检索增强生成(Retrieval Augmented Generation &#…...

WebRTC从入门到实践 - 零基础教程
WebRTC从入门到实践 - 零基础教程 目录 WebRTC简介 基础概念 工作原理 开发环境搭建 基础实践 三个实战案例 常见问题解答 1. WebRTC简介 1.1 什么是WebRTC? WebRTC(Web Real-Time Communication)是一个支持网页浏览器进行实时语音…...
ubuntu22.04有线网络无法连接,图标也没了
今天突然无法有线网络无法连接任何设备,并且图标都没了 错误案例 往上一顿搜索,试了很多博客都不行,比如 Ubuntu22.04右上角网络图标消失 最后解决的办法 下载网卡驱动,重新安装 操作步骤 查看自己网卡的型号 lspci | gre…...

前端高频面试题2:浏览器/计算机网络
本专栏相关链接 前端高频面试题1:HTML/CSS 前端高频面试题2:浏览器/计算机网络 前端高频面试题3:JavaScript 1.什么是强缓存、协商缓存? 强缓存: 当浏览器请求资源时,首先检查本地缓存是否命中。如果命…...