昇思MindSpore学习笔记6-01LLM原理和实践--FCN图像语义分割
摘要:
记录MindSpore AI框架使用FCN全卷积网络理解图像进行图像语议分割的过程、步骤和方法。包括环境准备、下载数据集、数据集加载和预处理、构建网络、训练准备、模型训练、模型评估、模型推理等。
一、概念
1.语义分割
图像语义分割
semantic segmentation
图像处理
机器视觉
图像理解
AI领域重要分支
应用
人脸识别
物体检测
医学影像
卫星图像分析
自动驾驶感知
目的
图像每个像素点分类
输出与输入大小相同的图像
输出图像的每个像素对应了输入图像每个像素的类别
图像领域语义
图像的内容
对图片意思的理解
实例

2.FCN全卷积网络
Fully Convolutional Networks
图像语义分割框架
2015年UC Berkeley提出
端到端(end to end)像素级(pixel level)预测全卷积网络

全卷积神经网络主要使用三种技术:
1.卷积化Convolutional
VGG-16
FCN的backbone
输入224*224RGB图像
固定大小的输入
丢弃了空间坐标
产生非空间输出
输出1000个预测值
卷积层
输出二维矩阵
生成输入图片映射的heatmap

2.上采样Upsample
卷积过程
卷积操作
池化操作
特征图尺寸变小
上采样操作
得到原图大小的稠密图像预测
双线性插值参数
初始化上采样逆卷积参数
反向传播学习非线性上采样

3.跳跃结构Skip Layer
将深层的全局信息与浅层的局部信息相结合
底层stride 32的预测FCN-32s 2倍上采样
融合(相加) pool4层stride 16的预测FCN-16s 2倍上采样
融合(相加) pool3层stride 8的预测FCN-8s

特点:
(1)不含全连接层(fc)的全卷积(fully conv)网络,可适应任意尺寸输入。
(2)增大数据尺寸的反卷积(deconv)层,能够输出精细的结果。
(3)结合不同深度层结果的跳级(skip)结构,同时确保鲁棒性和精确性。
二、环境准备
%%capture captured_output
# 实验环境已经预装了mindspore==2.2.14,如需更换mindspore版本,可更改下面mindspore的版本号
!pip uninstall mindspore -y
!pip install -i https://pypi.mirrors.ustc.edu.cn/simple mindspore==2.2.14
# 查看当前 mindspore 版本
!pip show mindspore输出:
Name: mindspore
Version: 2.2.14
Summary: MindSpore is a new open source deep learning training/inference framework that could be used for mobile, edge and cloud scenarios.
Home-page: https://www.mindspore.cn
Author: The MindSpore Authors
Author-email: contact@mindspore.cn
License: Apache 2.0
Location: /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages
Requires: asttokens, astunparse, numpy, packaging, pillow, protobuf, psutil, scipy
Required-by: 三、数据处理
1.下载数据集
from download import download
url = "https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/notebook/datasets/dataset_fcn8s.tar"
download(url, "./dataset", kind="tar", replace=True)输出:
Creating data folder...
Downloading data from https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/notebook/datasets/dataset_fcn8s.tar (537.2 MB)file_sizes: 100%|█████████████████████████████| 563M/563M [00:03<00:00, 160MB/s]
Extracting tar file...
Successfully downloaded / unzipped to ./dataset
'./dataset'2.数据预处理
PASCAL VOC 2012数据集图像分辨率不一致
标准化处理
3.数据加载
混合PASCAL VOC 2012数据集、SDB数据集
import numpy as np
import cv2
import mindspore.dataset as ds
class SegDataset:def __init__(self,image_mean,image_std,data_file='',batch_size=32,crop_size=512,max_scale=2.0,min_scale=0.5,ignore_label=255,num_classes=21,num_readers=2,num_parallel_calls=4):
self.data_file = data_fileself.batch_size = batch_sizeself.crop_size = crop_sizeself.image_mean = np.array(image_mean, dtype=np.float32)self.image_std = np.array(image_std, dtype=np.float32)self.max_scale = max_scaleself.min_scale = min_scaleself.ignore_label = ignore_labelself.num_classes = num_classesself.num_readers = num_readersself.num_parallel_calls = num_parallel_callsmax_scale > min_scale
def preprocess_dataset(self, image, label):image_out = cv2.imdecode(np.frombuffer(image, dtype=np.uint8), cv2.IMREAD_COLOR)label_out = cv2.imdecode(np.frombuffer(label, dtype=np.uint8), cv2.IMREAD_GRAYSCALE)sc = np.random.uniform(self.min_scale, self.max_scale)new_h, new_w = int(sc * image_out.shape[0]), int(sc * image_out.shape[1])image_out = cv2.resize(image_out, (new_w, new_h), interpolation=cv2.INTER_CUBIC)label_out = cv2.resize(label_out, (new_w, new_h), interpolation=cv2.INTER_NEAREST)
image_out = (image_out - self.image_mean) / self.image_stdout_h, out_w = max(new_h, self.crop_size), max(new_w, self.crop_size)pad_h, pad_w = out_h - new_h, out_w - new_wif pad_h > 0 or pad_w > 0:image_out = cv2.copyMakeBorder(image_out, 0, pad_h, 0, pad_w, cv2.BORDER_CONSTANT, value=0)label_out = cv2.copyMakeBorder(label_out, 0, pad_h, 0, pad_w, cv2.BORDER_CONSTANT, value=self.ignore_label)offset_h = np.random.randint(0, out_h - self.crop_size + 1)offset_w = np.random.randint(0, out_w - self.crop_size + 1)image_out = image_out[offset_h: offset_h + self.crop_size, offset_w: offset_w + self.crop_size, :]label_out = label_out[offset_h: offset_h + self.crop_size, offset_w: offset_w+self.crop_size]if np.random.uniform(0.0, 1.0) > 0.5:image_out = image_out[:, ::-1, :]label_out = label_out[:, ::-1]image_out = image_out.transpose((2, 0, 1))image_out = image_out.copy()label_out = label_out.copy()label_out = label_out.astype("int32")return image_out, label_out
def get_dataset(self):ds.config.set_numa_enable(True)dataset = ds.MindDataset(self.data_file, columns_list=["data", "label"],shuffle=True, num_parallel_workers=self.num_readers)transforms_list = self.preprocess_datasetdataset = dataset.map(operations=transforms_list, input_columns=["data", "label"],output_columns=["data", "label"],num_parallel_workers=self.num_parallel_calls)dataset = dataset.shuffle(buffer_size=self.batch_size * 10)dataset = dataset.batch(self.batch_size, drop_remainder=True)return dataset
# 定义创建数据集的参数
IMAGE_MEAN = [103.53, 116.28, 123.675]
IMAGE_STD = [57.375, 57.120, 58.395]
DATA_FILE = "dataset/dataset_fcn8s/mindname.mindrecord"
# 定义模型训练参数
train_batch_size = 4
crop_size = 512
min_scale = 0.5
max_scale = 2.0
ignore_label = 255
num_classes = 21
# 实例化Dataset
dataset = SegDataset(image_mean=IMAGE_MEAN,image_std=IMAGE_STD,data_file=DATA_FILE,batch_size=train_batch_size,crop_size=crop_size,max_scale=max_scale,min_scale=min_scale,ignore_label=ignore_label,num_classes=num_classes,num_readers=2,num_parallel_calls=4)
dataset = dataset.get_dataset()4.训练集可视化
import numpy as np
import matplotlib.pyplot as plt
plt.figure(figsize=(16, 8))
# 对训练集中的数据进行展示
for i in range(1, 9):plt.subplot(2, 4, i)show_data = next(dataset.create_dict_iterator())show_images = show_data["data"].asnumpy()show_images = np.clip(show_images, 0, 1)
# 将图片转换HWC格式后进行展示plt.imshow(show_images[0].transpose(1, 2, 0))plt.axis("off")plt.subplots_adjust(wspace=0.05, hspace=0)
plt.show()输出:

四、网络构建
FCN网络流程
输入图像image
pool1池化
尺寸变为原始尺寸的1/2
pool2池化
尺寸变为原始尺寸的1/4
pool3池化
尺寸变为原始尺寸的1/8
pool4池化
尺寸变为原始尺寸的1/16
pool5池化
尺寸变为原始尺寸的1/32
conv6-7卷积
输出尺寸原图的1/32
FCN-32s
反卷积扩大到原始尺寸
FCN-16s
融合
conv7反卷积尺寸扩大两倍至原图的1/16
pool4特征图
反卷积扩大到原始尺寸
FCN-8s
融合
conv7反卷积尺寸扩大4倍
pool4特征图反卷积扩大2倍
pool3特征图
反卷积扩大到原始尺寸

构建FCN-8s网络代码:
import mindspore.nn as nn
class FCN8s(nn.Cell):def __init__(self, n_class):super().__init__()self.n_class = n_classself.conv1 = nn.SequentialCell(nn.Conv2d(in_channels=3, out_channels=64,kernel_size=3, weight_init='xavier_uniform'),nn.BatchNorm2d(64),nn.ReLU(),nn.Conv2d(in_channels=64, out_channels=64,kernel_size=3, weight_init='xavier_uniform'),nn.BatchNorm2d(64),nn.ReLU())self.pool1 = nn.MaxPool2d(kernel_size=2, stride=2)self.conv2 = nn.SequentialCell(nn.Conv2d(in_channels=64, out_channels=128,kernel_size=3, weight_init='xavier_uniform'),nn.BatchNorm2d(128),nn.ReLU(),nn.Conv2d(in_channels=128, out_channels=128,kernel_size=3, weight_init='xavier_uniform'),nn.BatchNorm2d(128),nn.ReLU())self.pool2 = nn.MaxPool2d(kernel_size=2, stride=2)self.conv3 = nn.SequentialCell(nn.Conv2d(in_channels=128, out_channels=256,kernel_size=3, weight_init='xavier_uniform'),nn.BatchNorm2d(256),nn.ReLU(),nn.Conv2d(in_channels=256, out_channels=256,kernel_size=3, weight_init='xavier_uniform'),nn.BatchNorm2d(256),nn.ReLU(),nn.Conv2d(in_channels=256, out_channels=256,kernel_size=3, weight_init='xavier_uniform'),nn.BatchNorm2d(256),nn.ReLU())self.pool3 = nn.MaxPool2d(kernel_size=2, stride=2)self.conv4 = nn.SequentialCell(nn.Conv2d(in_channels=256, out_channels=512,kernel_size=3, weight_init='xavier_uniform'),nn.BatchNorm2d(512),nn.ReLU(),nn.Conv2d(in_channels=512, out_channels=512,kernel_size=3, weight_init='xavier_uniform'),nn.BatchNorm2d(512),nn.ReLU(),nn.Conv2d(in_channels=512, out_channels=512,kernel_size=3, weight_init='xavier_uniform'),nn.BatchNorm2d(512),nn.ReLU())self.pool4 = nn.MaxPool2d(kernel_size=2, stride=2)self.conv5 = nn.SequentialCell(nn.Conv2d(in_channels=512, out_channels=512,kernel_size=3, weight_init='xavier_uniform'),nn.BatchNorm2d(512),nn.ReLU(),nn.Conv2d(in_channels=512, out_channels=512,kernel_size=3, weight_init='xavier_uniform'),nn.BatchNorm2d(512),nn.ReLU(),nn.Conv2d(in_channels=512, out_channels=512,kernel_size=3, weight_init='xavier_uniform'),nn.BatchNorm2d(512),nn.ReLU())self.pool5 = nn.MaxPool2d(kernel_size=2, stride=2)self.conv6 = nn.SequentialCell(nn.Conv2d(in_channels=512, out_channels=4096,kernel_size=7, weight_init='xavier_uniform'),nn.BatchNorm2d(4096),nn.ReLU(),)self.conv7 = nn.SequentialCell(nn.Conv2d(in_channels=4096, out_channels=4096,kernel_size=1, weight_init='xavier_uniform'),nn.BatchNorm2d(4096),nn.ReLU(),)self.score_fr = nn.Conv2d(in_channels=4096, out_channels=self.n_class,kernel_size=1, weight_init='xavier_uniform')self.upscore2 = nn.Conv2dTranspose(in_channels=self.n_class, out_channels=self.n_class,kernel_size=4, stride=2, weight_init='xavier_uniform')self.score_pool4 = nn.Conv2d(in_channels=512, out_channels=self.n_class,kernel_size=1, weight_init='xavier_uniform')self.upscore_pool4 = nn.Conv2dTranspose(in_channels=self.n_class, out_channels=self.n_class,kernel_size=4, stride=2, weight_init='xavier_uniform')self.score_pool3 = nn.Conv2d(in_channels=256, out_channels=self.n_class,kernel_size=1, weight_init='xavier_uniform')self.upscore8 = nn.Conv2dTranspose(in_channels=self.n_class, out_channels=self.n_class,kernel_size=16, stride=8, weight_init='xavier_uniform')
def construct(self, x):x1 = self.conv1(x)p1 = self.pool1(x1)x2 = self.conv2(p1)p2 = self.pool2(x2)x3 = self.conv3(p2)p3 = self.pool3(x3)x4 = self.conv4(p3)p4 = self.pool4(x4)x5 = self.conv5(p4)p5 = self.pool5(x5)x6 = self.conv6(p5)x7 = self.conv7(x6)sf = self.score_fr(x7)u2 = self.upscore2(sf)s4 = self.score_pool4(p4)f4 = s4 + u2u4 = self.upscore_pool4(f4)s3 = self.score_pool3(p3)f3 = s3 + u4out = self.upscore8(f3)return out五、训练准备
1.导入VGG-16部分预训练权重
from download import download
from mindspore import load_checkpoint, load_param_into_net
url = "https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/notebook/datasets/fcn8s_vgg16_pretrain.ckpt"
download(url, "fcn8s_vgg16_pretrain.ckpt", replace=True)
def load_vgg16():ckpt_vgg16 = "fcn8s_vgg16_pretrain.ckpt"param_vgg = load_checkpoint(ckpt_vgg16)load_param_into_net(net, param_vgg)输出:
Downloading data from https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/notebook/datasets/fcn8s_vgg16_pretrain.ckpt (513.2 MB)file_sizes: 100%|█████████████████████████████| 538M/538M [00:03<00:00, 179MB/s]
Successfully downloaded file to fcn8s_vgg16_pretrain.ckpt2.损失函数
交叉熵损失函数
mindspore.nn.CrossEntropyLoss()
计算FCN网络输出与mask之间的交叉熵损失
3.自定义评价指标 Metrics
用于评估模型效果
设共有 K+1个类
从 到
其中包含一个空类或背景
表示本属于i类但被预测为j类的像素数量
表示真正的数量
则分别被解释为假正和假负
Pixel Accuracy
PA像素精度
标记正确的像素占总像素的比例。
Mean Pixel Accuracy
MPA均像素精度
计算每个类内正确分类像素数的比例
求所有类的平均
Mean Intersection over Union
MloU均交并比
语义分割的标准度量
计算两个集合的交集和并集之比
交集为真实值(ground truth)
并集为预测值(predicted segmentation)
两者之比:正真数 (intersection) /(真正+假负+假正(并集))
在每个类上计算loU
平均
Frequency Weighted Intersection over Union
FWIoU频权交井比
根据每个类出现的频率设置权重
import numpy as np
import mindspore as ms
import mindspore.nn as nn
import mindspore.train as train
class PixelAccuracy(train.Metric):def __init__(self, num_class=21):super(PixelAccuracy, self).__init__()self.num_class = num_class
def _generate_matrix(self, gt_image, pre_image):mask = (gt_image >= 0) & (gt_image < self.num_class)label = self.num_class * gt_image[mask].astype('int') + pre_image[mask]count = np.bincount(label, minlength=self.num_class**2)confusion_matrix = count.reshape(self.num_class, self.num_class)return confusion_matrix
def clear(self):self.confusion_matrix = np.zeros((self.num_class,) * 2)
def update(self, *inputs):y_pred = inputs[0].asnumpy().argmax(axis=1)y = inputs[1].asnumpy().reshape(4, 512, 512)self.confusion_matrix += self._generate_matrix(y, y_pred)
def eval(self):pixel_accuracy = np.diag(self.confusion_matrix).sum() / self.confusion_matrix.sum()return pixel_accuracy
class PixelAccuracyClass(train.Metric):def __init__(self, num_class=21):super(PixelAccuracyClass, self).__init__()self.num_class = num_class
def _generate_matrix(self, gt_image, pre_image):mask = (gt_image >= 0) & (gt_image < self.num_class)label = self.num_class * gt_image[mask].astype('int') + pre_image[mask]count = np.bincount(label, minlength=self.num_class**2)confusion_matrix = count.reshape(self.num_class, self.num_class)return confusion_matrix
def update(self, *inputs):y_pred = inputs[0].asnumpy().argmax(axis=1)y = inputs[1].asnumpy().reshape(4, 512, 512)self.confusion_matrix += self._generate_matrix(y, y_pred)
def clear(self):self.confusion_matrix = np.zeros((self.num_class,) * 2)
def eval(self):mean_pixel_accuracy = np.diag(self.confusion_matrix) / self.confusion_matrix.sum(axis=1)mean_pixel_accuracy = np.nanmean(mean_pixel_accuracy)return mean_pixel_accuracy
class MeanIntersectionOverUnion(train.Metric):def __init__(self, num_class=21):super(MeanIntersectionOverUnion, self).__init__()self.num_class = num_class
def _generate_matrix(self, gt_image, pre_image):mask = (gt_image >= 0) & (gt_image < self.num_class)label = self.num_class * gt_image[mask].astype('int') + pre_image[mask]count = np.bincount(label, minlength=self.num_class**2)confusion_matrix = count.reshape(self.num_class, self.num_class)return confusion_matrix
def update(self, *inputs):y_pred = inputs[0].asnumpy().argmax(axis=1)y = inputs[1].asnumpy().reshape(4, 512, 512)self.confusion_matrix += self._generate_matrix(y, y_pred)
def clear(self):self.confusion_matrix = np.zeros((self.num_class,) * 2)
def eval(self):mean_iou = np.diag(self.confusion_matrix) / (np.sum(self.confusion_matrix, axis=1) + np.sum(self.confusion_matrix, axis=0) -np.diag(self.confusion_matrix))mean_iou = np.nanmean(mean_iou)return mean_iou
class FrequencyWeightedIntersectionOverUnion(train.Metric):def __init__(self, num_class=21):super(FrequencyWeightedIntersectionOverUnion, self).__init__()self.num_class = num_class
def _generate_matrix(self, gt_image, pre_image):mask = (gt_image >= 0) & (gt_image < self.num_class)label = self.num_class * gt_image[mask].astype('int') + pre_image[mask]count = np.bincount(label, minlength=self.num_class**2)confusion_matrix = count.reshape(self.num_class, self.num_class)return confusion_matrix
def update(self, *inputs):y_pred = inputs[0].asnumpy().argmax(axis=1)y = inputs[1].asnumpy().reshape(4, 512, 512)self.confusion_matrix += self._generate_matrix(y, y_pred)
def clear(self):self.confusion_matrix = np.zeros((self.num_class,) * 2)
def eval(self):freq = np.sum(self.confusion_matrix, axis=1) / np.sum(self.confusion_matrix)iu = np.diag(self.confusion_matrix) / (np.sum(self.confusion_matrix, axis=1) + np.sum(self.confusion_matrix, axis=0) -np.diag(self.confusion_matrix))
frequency_weighted_iou = (freq[freq > 0] * iu[freq > 0]).sum()return frequency_weighted_iou六、模型训练
导入VGG-16预训练参数
实例化损失函数、优化器
Model接口编译网络
训练FCN-8s网络
import mindspore
from mindspore import Tensor
import mindspore.nn as nn
from mindspore.train import ModelCheckpoint, CheckpointConfig, LossMonitor, TimeMonitor, Model
device_target = "Ascend"
mindspore.set_context(mode=mindspore.PYNATIVE_MODE, device_target=device_target)
train_batch_size = 4
num_classes = 21
# 初始化模型结构
net = FCN8s(n_class=21)
# 导入vgg16预训练参数
load_vgg16()
# 计算学习率
min_lr = 0.0005
base_lr = 0.05
train_epochs = 1
iters_per_epoch = dataset.get_dataset_size()
total_step = iters_per_epoch * train_epochs
lr_scheduler = mindspore.nn.cosine_decay_lr(min_lr,base_lr,total_step,iters_per_epoch,decay_epoch=2)
lr = Tensor(lr_scheduler[-1])
# 定义损失函数
loss = nn.CrossEntropyLoss(ignore_index=255)
# 定义优化器
optimizer = nn.Momentum(params=net.trainable_params(), learning_rate=lr, momentum=0.9, weight_decay=0.0001)
# 定义loss_scale
scale_factor = 4
scale_window = 3000
loss_scale_manager = ms.amp.DynamicLossScaleManager(scale_factor, scale_window)
# 初始化模型
if device_target == "Ascend":model = Model(net, loss_fn=loss, optimizer=optimizer, loss_scale_manager=loss_scale_manager, metrics={"pixel accuracy": PixelAccuracy(), "mean pixel accuracy": PixelAccuracyClass(), "mean IoU": MeanIntersectionOverUnion(), "frequency weighted IoU": FrequencyWeightedIntersectionOverUnion()})
else:model = Model(net, loss_fn=loss, optimizer=optimizer, metrics={"pixel accuracy": PixelAccuracy(), "mean pixel accuracy": PixelAccuracyClass(), "mean IoU": MeanIntersectionOverUnion(), "frequency weighted IoU": FrequencyWeightedIntersectionOverUnion()})
# 设置ckpt文件保存的参数
time_callback = TimeMonitor(data_size=iters_per_epoch)
loss_callback = LossMonitor()
callbacks = [time_callback, loss_callback]
save_steps = 330
keep_checkpoint_max = 5
config_ckpt = CheckpointConfig(save_checkpoint_steps=10,keep_checkpoint_max=keep_checkpoint_max)
ckpt_callback = ModelCheckpoint(prefix="FCN8s",directory="./ckpt",config=config_ckpt)
callbacks.append(ckpt_callback)
model.train(train_epochs, dataset, callbacks=callbacks)输出:
epoch: 1 step: 1, loss is 3.0504844
epoch: 1 step: 2, loss is 3.017057
epoch: 1 step: 3, loss is 2.9523003
epoch: 1 step: 4, loss is 2.9488814
epoch: 1 step: 5, loss is 2.666231
epoch: 1 step: 6, loss is 2.7145326
epoch: 1 step: 7, loss is 1.796408
epoch: 1 step: 8, loss is 1.5167583
epoch: 1 step: 9, loss is 1.6862022
epoch: 1 step: 10, loss is 2.4622822
......
epoch: 1 step: 1141, loss is 1.70966
epoch: 1 step: 1142, loss is 1.434751
epoch: 1 step: 1143, loss is 2.406475
Train epoch time: 762889.258 ms, per step time: 667.445 ms七、模型评估
IMAGE_MEAN = [103.53, 116.28, 123.675]
IMAGE_STD = [57.375, 57.120, 58.395]
DATA_FILE = "dataset/dataset_fcn8s/mindname.mindrecord"
# 下载已训练好的权重文件
url = "https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/notebook/datasets/FCN8s.ckpt"
download(url, "FCN8s.ckpt", replace=True)
net = FCN8s(n_class=num_classes)
ckpt_file = "FCN8s.ckpt"
param_dict = load_checkpoint(ckpt_file)
load_param_into_net(net, param_dict)
if device_target == "Ascend":model = Model(net, loss_fn=loss, optimizer=optimizer, loss_scale_manager=loss_scale_manager, metrics={"pixel accuracy": PixelAccuracy(), "mean pixel accuracy": PixelAccuracyClass(), "mean IoU": MeanIntersectionOverUnion(), "frequency weighted IoU": FrequencyWeightedIntersectionOverUnion()})
else:model = Model(net, loss_fn=loss, optimizer=optimizer, metrics={"pixel accuracy": PixelAccuracy(), "mean pixel accuracy": PixelAccuracyClass(), "mean IoU": MeanIntersectionOverUnion(), "frequency weighted IoU": FrequencyWeightedIntersectionOverUnion()})
# 实例化Dataset
dataset = SegDataset(image_mean=IMAGE_MEAN,image_std=IMAGE_STD,data_file=DATA_FILE,batch_size=train_batch_size,crop_size=crop_size,max_scale=max_scale,min_scale=min_scale,ignore_label=ignore_label,num_classes=num_classes,num_readers=2,num_parallel_calls=4)
dataset_eval = dataset.get_dataset()
model.eval(dataset_eval)输出:
Downloading data from https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/notebook/datasets/FCN8s.ckpt (1.00 GB)file_sizes: 100%|██████████████████████████| 1.08G/1.08G [00:10<00:00, 99.7MB/s]
Successfully downloaded file to FCN8s.ckpt
/
{'pixel accuracy': 0.9734831394168291,'mean pixel accuracy': 0.9423324801371116,'mean IoU': 0.8961453779807752,'frequency weighted IoU': 0.9488883312345654}八、模型推理
使用训练的网络对模型推理结果进行展示。
import cv2
import matplotlib.pyplot as plt
net = FCN8s(n_class=num_classes)
# 设置超参
ckpt_file = "FCN8s.ckpt"
param_dict = load_checkpoint(ckpt_file)
load_param_into_net(net, param_dict)
eval_batch_size = 4
img_lst = []
mask_lst = []
res_lst = []
# 推理效果展示(上方为输入图片,下方为推理效果图片)
plt.figure(figsize=(8, 5))
show_data = next(dataset_eval.create_dict_iterator())
show_images = show_data["data"].asnumpy()
mask_images = show_data["label"].reshape([4, 512, 512])
show_images = np.clip(show_images, 0, 1)
for i in range(eval_batch_size):img_lst.append(show_images[i])mask_lst.append(mask_images[i])
res = net(show_data["data"]).asnumpy().argmax(axis=1)
for i in range(eval_batch_size):plt.subplot(2, 4, i + 1)plt.imshow(img_lst[i].transpose(1, 2, 0))plt.axis("off")plt.subplots_adjust(wspace=0.05, hspace=0.02)plt.subplot(2, 4, i + 5)plt.imshow(res[i])plt.axis("off")plt.subplots_adjust(wspace=0.05, hspace=0.02)
plt.show()输出:

九、总结
FCN
使用全卷积层
通过学习让图片实现端到端分割。
优点:
输入接受任意大小的图像
高效,避免了由于使用像素块而带来的重复存储和计算卷积的问题。
待改进之处:
结果不够精细。比较模糊和平滑,边界处细节不敏感。
像素分类,没有考虑像素之间的关系(如不连续性和相似性)
忽略空间规整(spatial regularization)步骤,缺乏空间一致性。
相关文章:
昇思MindSpore学习笔记6-01LLM原理和实践--FCN图像语义分割
摘要: 记录MindSpore AI框架使用FCN全卷积网络理解图像进行图像语议分割的过程、步骤和方法。包括环境准备、下载数据集、数据集加载和预处理、构建网络、训练准备、模型训练、模型评估、模型推理等。 一、概念 1.语义分割 图像语义分割 semantic segmentation …...
】解码源码)
【FFMPEG基础(一)】解码源码
学习分享 main函数decodetorgb32.h 文件decodetorgb32 .cpp文件 main函数 #include <QApplication> #include "decodetorgb32.h" int main(int argc, char *argv[]) {QApplication a(argc, argv);DecodeToRGB32 toRGB32;int restoRGB32.openVideo("../fi…...

第二证券股市资讯:深夜!突然暴涨75%!
一则重磅收买引发医药圈轰动。 北京时间7月8日晚间,美股开盘后,美国生物制药公司Morphic股价一度暴升超75%。音讯面上,生物医药巨子礼来公司官宣,将以57美元/股的价格现金收买Morphic,较上星期五的收盘价溢价79%&…...

flutter 使用wechat_assets_picker的权限检测
https://pub.dev/packages/wechat_assets_picker AssetPicker.pickAssets之前进行权限检查 pickImages() async {try {if (PermissionState.authorized ! await AssetPicker.permissionCheck()) {PermissionUtil.showAllPermissions(Permission.storage, 1);return;}final Lis…...
)
Mojo入门案例教程(上手篇)
以下是 Mojo 编程语言入门案例教程,内容包括 Mojo 的基本概念、变量、控制结构、函数等方面: Mojo 的基本概念 1.什么是 Mojo?:Mojo 是一种函数式编程语言,用于开发小型应用程序、脚本和工具。 2.Mojo 的特点&#x…...

如何在window执行mkfile
1、Windows cmd中出现错误:“‘make‘ 不是内部或外部命令,也不是可运行的程序或批处理文件。”的解决方法_windows_是板栗啊-GitCode 开源社区 2、安装cmder,再通过包管理工具下载make...

Nginx 是一个非常流行的 Web 服务器和反向代理服务器
Nginx 是一个非常流行的 Web 服务器和反向代理服务器,以其高性能、稳定性、丰富的功能集和低资源消耗而闻名。下面是一个简化的 Nginx 使用教程,包括基本的安装、配置和一些常见用途。 安装 Nginx 在 Ubuntu/Debian 上安装: sudo apt upda…...

mysql怎么调整缓冲区大小
MySQL中调整缓冲区大小是数据库性能优化的重要一环。缓冲区大小直接影响了数据库的读写性能和响应速度。以下是一些常见的MySQL缓冲区及其调整方法: 一、InnoDB缓冲池(InnoDB Buffer Pool) InnoDB缓冲池是InnoDB存储引擎用来缓存表数据和索…...
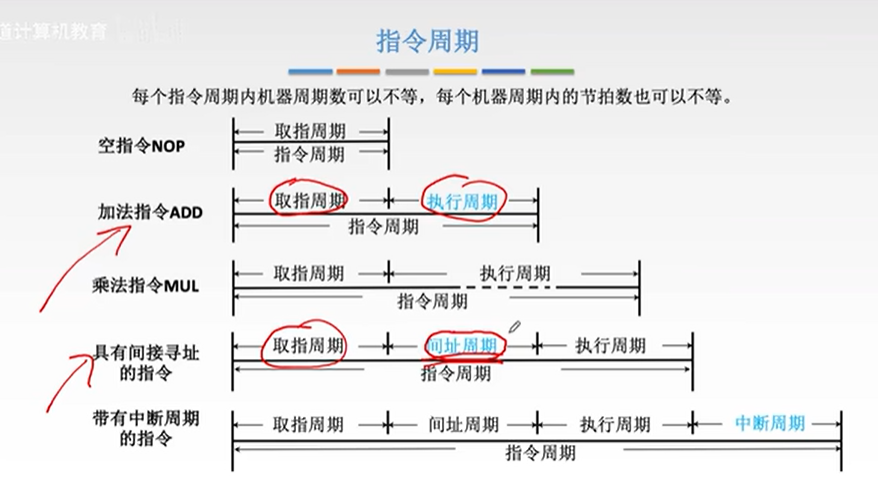
计算机组成原理学习笔记(一)
计算机组成原理 [类型:: [[计算机基础课程]] ] [来源:: [[B站]] ] [主讲人:: [[咸鱼学长]] ] [评价:: ] [知识点:: [[系统软件]] & [[应用软件]] ] [简单解释:: 管理计算机系统的软件; 按照任务需要编写的程序 ] [问题:: ] [知识点:: [[机器字长]] ] [简单…...

Vue3 对跳转 同一路由传入不同参数的页面分别进行缓存
1:使用场景 从列表页跳转至不同的详情页面,对这些详情页面分别进行缓存 2:核心代码 2.1: 配置路由文件 在路由文件里对需要进行缓存的路由对象添加meta 属性 // 需要缓存的详情页面路由 { name: detail, path: /myRouter/detail…...

LinearLayout的测量流程
在日常开发中我们常常使用LinearLayout作为布局Group,本文从其源码实现出发分析测量流程。大家可以带着问题进入下面的分析流程,看看是否能找到答案。 垂直测量 View的测量入口方法是onmeasure方法。LinearLayout的onMeasure方法根据其方向而做不同的处…...

数据无忧:Ubuntu 系统迁移备份全指南
唠唠闲话 最近电脑出现了一些故障,送修期间,不得不在实验室的台式机上重装系统,配环境的过程花费了不少时间。为避免未来处理类似事情时耗费时间,特此整理一些备份策略。 先做以下准备: U盘启动盘,参考 …...

中国IDC圈探访北京•光子1号金融算力中心
今天,“AI”、“大模型”是最炙手可热的话题,全球有海量人群在工作生活中使用大模型,大模型产品涉及多模态,应用范围已涵盖电商、传媒、金融、短视频、制造等众多行业。 而回看2003年的互联网记忆, “上网”“在线”是…...

[Unity入门01] Unity基本操作
参考的傅老师的教程学了一下Unity的基础操作: [傅老師/Unity教學] Unity3D基礎入門 [華梵大學] 遊戲引擎應用基礎(Unity版本) Class#01 移动:鼠标中键旋转:鼠标右键放大:鼠标滚轮飞行模式:右键WASDQEFocus模式&…...

vivado DELAY_VALUE_XPHY、DIFF_TERM
延迟_值_XPHY PORT对象上的DELAY_VALUE_XPHY属性指定要添加的延迟量 Versal XPHY逻辑接口的输入或输出路径。在的早期阶段 opt_design在重新生成高级I/O向导IP时 DELAY_VALUE_XPHY值将从PORT复制到的XPHY实例上 输入或输出路径。Vivado设计套件中存在DRCs,以确保 DE…...

C++语言相关的常见面试题目(三)
1. List底层实现原理 省流: list底层实现了一个双向循环链表。 每个元素(或节点)包含三个部分:数据域(_M_Storage)、前驱指针(_M_prev)、后继指针(_M_next)。 数据域:存储实际数据。 前驱指针:指向链表中…...

代码随想录-Day53
739. 每日温度 给定一个整数数组 temperatures ,表示每天的温度,返回一个数组 answer ,其中 answer[i] 是指对于第 i 天,下一个更高温度出现在几天后。如果气温在这之后都不会升高,请在该位置用 0 来代替。 示例 1: …...

Android 如何通过代码实时设置EditTextView光标
背景:换肤框架下,QA进行深色浅色切换说输入框光标颜色没有改变,转UI结果UI说需要修改!!!!! 本来有方法可以设置,但是 设置后未生效。重新进入该页面才生效!&a…...

202488读书笔记|《365日创意文案》——无聊的 到底是这世间, 还是自己?懂得忘却的人才能前进
202488读书笔记|《365日创意文案》——无聊的 到底是这世间, 还是自己?懂得忘却的人才能前进 1月2月3月4月5月6月7月8月9月10月11月12月 《365日创意文案》WRITES PUBLISHING,一些日常,是烟火,也是幸福的印记。 当下也…...

iperf3: error - unable to connect to server: No route to host
1.确认iperf3版本是否统一。 2.确认防火墙是否关闭。 关闭防火墙 : systemctl stop firewalld 查看防火墙状态: systemctl status firewalld 3.重新建起链接...

HTML 语义化
目录 HTML 语义化HTML5 新特性HTML 语义化的好处语义化标签的使用场景最佳实践 HTML 语义化 HTML5 新特性 标准答案: 语义化标签: <header>:页头<nav>:导航<main>:主要内容<article>&#x…...

零门槛NAS搭建:WinNAS如何让普通电脑秒变私有云?
一、核心优势:专为Windows用户设计的极简NAS WinNAS由深圳耘想存储科技开发,是一款收费低廉但功能全面的Windows NAS工具,主打“无学习成本部署” 。与其他NAS软件相比,其优势在于: 无需硬件改造:将任意W…...

PPT|230页| 制造集团企业供应链端到端的数字化解决方案:从需求到结算的全链路业务闭环构建
制造业采购供应链管理是企业运营的核心环节,供应链协同管理在供应链上下游企业之间建立紧密的合作关系,通过信息共享、资源整合、业务协同等方式,实现供应链的全面管理和优化,提高供应链的效率和透明度,降低供应链的成…...

React Native在HarmonyOS 5.0阅读类应用开发中的实践
一、技术选型背景 随着HarmonyOS 5.0对Web兼容层的增强,React Native作为跨平台框架可通过重新编译ArkTS组件实现85%以上的代码复用率。阅读类应用具有UI复杂度低、数据流清晰的特点。 二、核心实现方案 1. 环境配置 (1)使用React Native…...

如何在看板中有效管理突发紧急任务
在看板中有效管理突发紧急任务需要:设立专门的紧急任务通道、重新调整任务优先级、保持适度的WIP(Work-in-Progress)弹性、优化任务处理流程、提高团队应对突发情况的敏捷性。其中,设立专门的紧急任务通道尤为重要,这能…...

ETLCloud可能遇到的问题有哪些?常见坑位解析
数据集成平台ETLCloud,主要用于支持数据的抽取(Extract)、转换(Transform)和加载(Load)过程。提供了一个简洁直观的界面,以便用户可以在不同的数据源之间轻松地进行数据迁移和转换。…...

Spring Boot+Neo4j知识图谱实战:3步搭建智能关系网络!
一、引言 在数据驱动的背景下,知识图谱凭借其高效的信息组织能力,正逐步成为各行业应用的关键技术。本文聚焦 Spring Boot与Neo4j图数据库的技术结合,探讨知识图谱开发的实现细节,帮助读者掌握该技术栈在实际项目中的落地方法。 …...

return this;返回的是谁
一个审批系统的示例来演示责任链模式的实现。假设公司需要处理不同金额的采购申请,不同级别的经理有不同的审批权限: // 抽象处理者:审批者 abstract class Approver {protected Approver successor; // 下一个处理者// 设置下一个处理者pub…...

CVE-2020-17519源码分析与漏洞复现(Flink 任意文件读取)
漏洞概览 漏洞名称:Apache Flink REST API 任意文件读取漏洞CVE编号:CVE-2020-17519CVSS评分:7.5影响版本:Apache Flink 1.11.0、1.11.1、1.11.2修复版本:≥ 1.11.3 或 ≥ 1.12.0漏洞类型:路径遍历&#x…...

系统掌握PyTorch:图解张量、Autograd、DataLoader、nn.Module与实战模型
本文较长,建议点赞收藏,以免遗失。更多AI大模型应用开发学习视频及资料,尽在聚客AI学院。 本文通过代码驱动的方式,系统讲解PyTorch核心概念和实战技巧,涵盖张量操作、自动微分、数据加载、模型构建和训练全流程&#…...