Linux--线程(概念篇)
目录
1.背景知识
再谈地址空间:
关于页表(32bit机器上)
2.线程的概念和Linux中线程的实现
概念部分:
代码部分:
问题:
3.关于线程的有点与缺点
4.进程VS线程
1.背景知识
再谈地址空间:
我们都知道系统和磁盘文件进行IO的基本单位是内存块4KB--8个扇区。我们以4GB大小的物理内存为例,物理内存被分为一个一个的页框,一个页框的大小也就是4KB,那么我们也就清楚了,磁盘加载到物理内存,操作系统会从磁盘中读取该页面并将其加载到物理内存中的一个页框/页帧中。
当我们谈及操作系统对内存的管理工作,基本单位也是4KB!
现在有一个问题:在父子进程进行共享内存的全局变量int只占四个字节,我对他写入时要发生写时拷贝,写时拷贝的本质就让操作系统重新申请内存,那么拷贝的时候是拷贝四个字节还是4kb呢?
对于全局变量
int的写入操作,通常不会触发写时拷贝。全局变量是在进程的地址空间中分配的,每个进程都有自己的全局变量副本(除非它们通过某种形式的共享内存机制显式地共享)。当你修改一个全局int变量时,你只是在当前进程的地址空间中修改了该变量的4个字节。如果全局变量是通过某种形式的共享内存在不同的进程之间共享的,并且你在这些进程之一中修改了该变量,这时一般会触发写时拷贝,写时拷贝也不会仅仅拷贝4个字节;相反,它会拷贝包含该变量的整个页框(即4KB)。如果操作系统在每次修改共享内存中的变量时都只拷贝变量的实际大小,那么这将大大增加管理的复杂性,并可能导致内存碎片化。通过以页面为单位进行拷贝,操作系统可以简化内存管理,减少内存碎片,并提高内存访问的效率。
那么操作系统是如何对物理内存做管理的呢?
首先物理内存是被划分为一个一个的页框的,若物理内存的大小为4GB,那么页框的数量就有1048576个,那么操作系统就要知道这些页框的使用状态,那么操作系统是如何管理这些页框的呢? 操作系统由对应的结构体struct page ,其中int flag变量就是管理页框是否被占有,是否有脏页,是否被锁定的,还会包含mode(权限),等等。 struct page memory[1048576]把内存管理起来,用下标转化为每一个页框的起始地址。
关于页表(32bit机器上)
我们都知道虚拟地址是32个比特位组成的,一共有2^32个。
虚拟地址是如何转化为物理地址的呢?
我们都知道虚拟地址转化为物理地址都是要通过页表映射,关键就在于页表。页表并不是简单的一一映射,他是有多级结构的,以32bit机器为例:
在32位系统中,虚拟地址的32个比特位通常按照以下方式划分(以多级页表为例):
页目录索引:高位的比特位用于索引页目录。页目录是一个包含多个页表项的数组,每个页表项指向一个页表。页目录索引的位数决定了页目录中页表项的数量,进而影响页目录的大小。
页表索引:紧接着页目录索引之后的比特位用于索引页表。页表也是一个包含多个页表项的数组,每个页表项包含物理页帧的起始地址和其他信息(如访问权限)。页表索引的位数决定了页表中页表项的数量,进而影响页表的大小。
页内偏移:最低位的比特位用于在物理页帧内定位数据。页内偏移的位数决定了页帧的大小,通常是固定的(如4KB)。
具体划分示例
以常见的32位系统为例,虚拟地址的32个比特位可能被划分为10-10-12的形式:
- 高10位:作为页目录索引,可以索引到最多1024(2^10)个页表。
- 中间10位:作为页表索引,每个页表可以包含最多1024(2^10)个页表项。
- 低12位:作为页内偏移,用于在4KB(2^12字节)的页帧内定位数据。一个页帧的大小刚好是4KB,也就是说,页内偏移量可以定位到每一个字节。
- 那么我们也就知道了,前20位的作用就是定位到页框号,本质就是搜索页框,后12那就是用来定位页框内的如何一个字节。这个方案就叫二级页表。这大大的节省了空间(1024个页表*2KB=2MB+4kb页目录,这是在拉满的情况下),在这种方式下,只要知道取的数据是什么类型,就知道要取几个字节,就能获取数据了。
CPU想要通过页表获取物理地址,首先就是要找到页表,那么页表在哪里呢?
CR3:控制寄存器3,也被称为PDBR(页目录基址寄存器),用于存储页目录表的物理地址。通过改变CR3寄存器的值,可以实现不同虚拟地址空间之间的切换。
MMU接收到CPU发出的虚拟地址后,会根据当前CR3寄存器中存储的页目录表物理地址,以及虚拟地址的结构(如页目录索引、页表索引、页内偏移等),在页目录表和页表中查找对应的物理地址。最后,从CPU中出来的直接就是虚拟地址。




2.线程的概念和Linux中线程的实现
概念部分:
线程:在进程内部运行,是cpu调度的基本单位。
初步理解:在下面,一个一个的tesk_struct就是一个一个的执行流,地址空间的正文代码也会被分为4部分,让每一个执行流去执行,这一个一个的执行流就是Linux中的线程,这是我们对线程的初步理解,一个进程中可以并发多个线程,每条线程并行执行不同的任务。
在学习进程的时候我们得出结论:进程=内核数据结构+进程的代码和数据。
现在我们从内核观点给出进程的定义:进程是承担分配系统资源的基本实体!
对比以前对进程的理解区别在于:内部只有一个执行流的进程。
OS关于线程的设计
在windows系统下,线程是真实存在的,有自己的控制结构体与调度算法;
从内核的角度来看,Linux并没有线程这个概念。Linux的线程通常被当作一种特殊的进程(是进程模拟的)来实现。每个线程都拥有自己独立的task_struct内核数据结构对象,但在进程内部,多个线程共享进程的地址空间和其他资源。
对于CPU来说,调度一个task_struct<=进程,因为task_struct可能只是一个进程的一个执行流。那么CPU要不要区分task_struct是进程还是线程?
当然不必区分,对于CPU来说都叫做执行流,所以之前与进程有关的知识,在Linux下仍然适用,因为线程就是一个特殊的进程。(CPU看到的执行流<=进程。因此我们称Linux中的执行流:轻量级进程!!!)
代码部分:
先见一见:
引入函数pthread_create,,用于在程序中创建一个新的线程
参数说明:
- thread:指向
pthread_t类型的指针,用于存储新创建的线程的标识符。成功调用后,这个标识符可以用来引用该线程。- attr:指向
pthread_attr_t类型的指针,用于设置线程的属性,如线程栈的大小、调度策略等。如果传递NULL,则使用默认属性。- start_routine:线程将要执行的函数的指针。这个函数应该接受一个
void*类型的参数,并返回一个void*类型的值。这个函数是线程开始执行时调用的函数。- arg:传递给
start_routine函数的参数。这个参数的类型是void*,这意味着你可以传递任何类型的指针。主线程和新创建的线程会并行执行,直到新线程完成其任务。
eg:两个执行流同时跑死循环
在进行线程的编译时,要引入第三方库:pthread:它提供了一套创建和管理线程的API。这些API使得在多种UNIX系统上编写多线程程序成为可能,同时也增强了程序的可移植性。
编译时要带-lpthread链接pthread库
test1:test.ccg++ -o $@ $^ -std=c++11 -lpthread .PHONY:clean clean:rm -rf test1代码:
#include <iostream> #include <unistd.h>//新进程 void *threadStart(void *args) {while (true){sleep(1);std::cout << "new thread running..." <<std::endl;} }int main() {pthread_t tid1;pthread_create(&tid1, nullptr, threadStart, (void *)"thread-new");//主线程while(true){sleep(1);std::cout << "main thread running..." <<std::endl;}return 0; }同时执行两个死循环,这就是一个多线程的代码。
这时候你查询系统中的进程时,发现只有一个进程
更改代码后,让它们打出各自的pid,果然都一样:
原因是:这两个线程属于一个进程内部。
但也是可以通过命令看到有几个线程的:ps -aL,我们可以看到LWP(Lightweight Process)轻量级进程,OS进行调度的时候看的就是LWP,而不是PID,LWP才是标识一个 执行流的概念,LWP和PID相等的执行流,我们称之为主线程(特殊情况:多进程,单进程调度时看OS根据PID来区分,这不矛盾,因为在这两种情况下PID==LWP)
每个线程都有自己要执行的代码,每行代码都有自己的地址,在逻辑上只要每个线程拿到自己代码所对应的那部分页表,就能找到自己执行代码的地址了,就能执行代码了。
问题:
1.已经有多进程了,为什么要有多线程呢?
创建: 首先进程创建的成本是非常高的(进程是系统资源分配的基本单位,每个进程都拥有独立的地址空间、内存、文件描述符等资源。)而创建线程:1.创建PCB 2.将进程已有的资源获取就好了。
运行:线程调度成本低
删除一个线程的成本也是低的
2. 线程这么好,为什么要有进程呢?
由于线程共享进程的内存空间,因此一个线程中的错误可能会影响到进程中的其他线程。例如,如果一个线程发生段错误(如访问了非法地址),则可能导致整个进程崩溃,进而影响到该进程内的所有线程。相比之下,进程间的独立性使得一个进程的崩溃不会影响到其他进程。(健壮性降低,当然还有其它方面,进程和线程都有自己的不可取代性)。
3.线程调度的成本为什么低?
CPU为了加速访存会存在一个cache的硬件,它会遵循局部性原理,将执行代码的前几行和后几行全都加载到cache当中,这一部分我们称为进程执行的热数据。当CPU执行到某行代码的时候,如果这部分缓存命中了,则直接从cache中读取,如果没命中,再从内存中缓存,重新置换到cache当中。
这意味着,如果是A,B进程间要进行切换,除了pcb,地址空间,页表要切,A和B要执行的任务肯定是不一样的,进程Acache缓存的热数据,进程B用不上,这意味着进程B要重新cache,这就慢了。但线程进行切换的时候,由于线程共享进程的地址空间和资源,因此缓存中的内容仍然有效,无需进行替换。这减少了缓存失效的次数和缓存加载的时间,从而降低了调度的成本。(主要矛盾)







3.关于线程的有点与缺点
优点:
- 创建一个新线程的代价要比创建一个新进程小得多
- 与进程之间的切换相比,线程之间的切换需要操作系统做的工作要少很多
- 线程占用的资源要比进程少很多
- 能充分利用多处理器的可并行数量
- 在等待慢速I/O操作结束的同时,程序可执行其他的计算任务
- 计算密集型应用,为了能在多处理器系统上运行,将计算分解到多个线程中实现
- I/O密集型应用,为了提高性能,将I/O操作重叠。线程可以同时等待不同的I/O操作。
缺点:
- 性能损失
一个很少被外部事件阻塞的计算密集型线程往往无法与共它线程共享同一个处理器。如果计算密集型线程的数量比可用的处理器多,那么可能会有较大的性能损失,这里的性能损失指的是增加了额外的同步和调度开销,而可用的资源不变。
- 健壮性降低
编写多线程需要更全面更深入的考虑,在一个多线程程序里,因时间分配上的细微偏差或者因共享了不该共享的变量而造成不良影响的可能性是很大的,换句话说线程之间是缺乏保护的。
eg:我们写了一段代码, 我们发现创建出3个线程,加上一个主线程,只要有一个线程出问题了,其它的线程就都受影响终止了(一个线程出问题,OS就是识别到整个进程出问题,OS就会给进程发信号,每个线程都要处理)。
#include <iostream> #include <unistd.h> #include <ctime>// 新线程void *threadStart(void *args) {while (true){int x = rand() % 5;std::cout << "new thread running..." << ", pid: " << getpid()<<":"<< x <<std::endl;sleep(1);if(x == 0){int *p = nullptr;*p = 100; // 野指针}} }int main() {srand(time(nullptr));pthread_t tid1;pthread_create(&tid1, nullptr, threadStart, (void *)"thread-new");pthread_t tid2;pthread_create(&tid2, nullptr, threadStart, (void *)"thread-new");pthread_t tid3;pthread_create(&tid3, nullptr, threadStart, (void *)"thread-new");// 主线程while(true){sleep(1);std::cout << "main thread running..." <<",pid"<<getpid()<<std::endl;}return 0; }
- 缺乏访问控制
进程是访问控制的基本粒度,在一个线程中调用某些OS函数会对整个进程造成影响。
eg:我们发现只要主线程更改了全局变量gvall的值,其它线程都是会受影响的,因为线程大部分的资源都是共享的
#include <iostream> #include <unistd.h> #include <ctime>int gval = 100;// 新线程 void *threadStart(void *args) {while (true){sleep(1);std::cout << "new thread running..." << ", pid: " << getpid()<< ", gval: " << gval << ", &gval: " << &gval << std::endl;} }int main() {srand(time(nullptr));pthread_t tid1;pthread_create(&tid1, nullptr, threadStart, (void *)"thread-new");pthread_t tid2;pthread_create(&tid2, nullptr, threadStart, (void *)"thread-new");pthread_t tid3;pthread_create(&tid3, nullptr, threadStart, (void *)"thread-new");// 主线程while (true){std::cout << "main thread running..." << ", pid: " << getpid()<< ", gval: " << gval << ", &gval: " << &gval << std::endl;gval++; // 修改!sleep(1);}return 0; }
- 编程难度提高
编写与调试一个多线程程序比单线程程序困难得多


4.进程VS线程
进程的多个线程共享 同一地址空间,因此Text Segment、Data Segment都是共享的,如果定义一个函数,在各线程 中都可以调用,如果定义一个全局变量,在各线程中都可以访问到,除此之外,各线程还共享以下进程资源和环境:
- 文件描述符表
- 每种信号的处理方式(SIG_ IGN、SIG_ DFL或者自定义的信号处理函数)
- 当前工作目录
- 用户id和组id
进程和线程的关系如下图:
进程是资源分配的基本单位
线程是调度的基本单位
线程共享进程数据,但也拥有自己的一部分数据:
- 线程ID
- 一组寄存器(与硬件上下文数据有关--线程是在动态运行的
- 栈(线程在运行的时候,本质是在运行一个函数,会形成各种临时变量,临时变量会被每个线程保存在自己的栈区)
- errno
- 信号屏蔽字
- 调度优先级
相关文章:

Linux--线程(概念篇)
目录 1.背景知识 再谈地址空间: 关于页表(32bit机器上) 2.线程的概念和Linux中线程的实现 概念部分: 代码部分: 问题: 3.关于线程的有点与缺点 4.进程VS线程 1.背景知识 再谈地址空间:…...

Mojo: 轻量级Perl框架的魔力
在Perl的丰富生态系统中,Mojolicious(简称Mojo)是一个轻量级的实时Web框架,以其极简的API和强大的功能而受到开发者的喜爱。Mojo不仅适用于构建高性能的Web应用,还可以用来编写简单的脚本和命令行工具。本文将带你探索…...

Python 游戏服务器架构优化
优化 Python 游戏服务器的架构涉及多个方面,包括性能、可伸缩性、并发处理和网络通信。下面是一些优化建议: 1、问题背景 在设计 Python 游戏服务器时,如何实现服务器的横向扩展,以利用多核处理器的资源,并确保服务器…...

13 学习总结:指针 · 其一
目录 一、内存和地址 (一)内存 (二)内存单元 (三)地址 (四)拓展:CPU与内存的联系 二、指针变量和地址 (一)创建变量的本质 (二…...

golang 项目打包部署环境变量设置
最近将 golang 项目打包部署在不同环境,总结一下自己的心得体会,供大家参考。 1、首先要明确自己目标服务器的系统类型(例如 windows 或者Linux) ,如果是Linux 还需要注意目标服务器的CPU架构(amd或者arm) 目标服务器的CPU架构可执行命令&…...

【Linux进程】进程优先级 Linux 2.6内核进程的调度
目录 前言 1. 进程优先级 2. 并发 3. Linux kernel 2.6 内核调度队列与调度原理 总结 前言 进程是资源分配的基本单位, 在OS中存在这很多的进程, 那么就必然存在着资源竞争的问题, 操作系统是如何进行资源分配的? 对于多个进程同时运行, 操作系统又是如何调度达到并发呢?…...

Linux中的粘滞位及mysql日期函数
只要用户具有目录的写权限, 用户就可以删除目录中的文件, 而不论这个用户是否有这个文件的写 权限. 为了解决这个不科学的问题, Linux引入了粘滞位的概念. 粘滞位 当一个目录被设置为"粘滞位"(用chmod t),则该目录下的文件只能由 一、超级管理员删除 二、该目录…...

BP神经网络的实践经验
目录 一、BP神经网络基础知识 1.BP神经网络 2.隐含层选取 3.激活函数 4.正向传递 5.反向传播 6.不拟合与过拟合 二、BP神经网络设计流程 1.数据处理 2.网络搭建 3.网络运行过程 三、BP神经网络优缺点与改进方案 1.BP神经网络的优缺点 2.改进方案 一、BP神经网络基…...

PCL 点云FPFH特征描述子
点云FPFH特征描述子 一、概述1.1 FPFH概念1.2 基本原理1.3 PFH和FPFH的区别二、代码实现三、结果示例一、概述 1.1 FPFH概念 快速点特征直方图(FPFH)描述子:计算 PFH 特征的效率其实是十分低的,这样的算法复杂度无法实现实时或接近实时的应用。因此,这篇文章将介绍 PFH 的简…...

基于golang的文章信息抓取
基于golang的文章信息抓取 学习golang爬虫,实现广度爬取,抓取特定的网页地址:测试站点新笔趣阁(https://www.xsbiquge.com/) 主要学习golang的goroutine和channel之间的协作,无限爬取站点小说的地址仅限书目…...

【手撕数据结构】卸甲时/空间复杂度
目录 前言时间复杂度概念⼤O的渐进表⽰法小试牛刀 空间复杂度 前言 要想知道什么是空/时间复杂度,就得知道什么是数据结构。 这得分两层来理解。我们生活中处处存在数据,什么抖音热点上的国际大事,什么懂的都懂的雍正卸甲等等一系列我们用户看得到的&a…...

消防认证-防火窗
一、消防认证 消防认证是指消防产品符合国家相关技术要求和标准,且通过了国家认证认可监督管理委员会审批,获得消防认证资质的认证机构颁发的证书,消防产品具有完好的防火功能,是住房和城乡建设领域验收的重要指标。 二、认证依据…...

C++进阶-二叉树进阶(二叉搜索树)
1. 二叉搜索树 1.1 二叉搜索树概念 二叉搜索树又称二叉排序树,它或者是一棵空树,或者是具有以下性质的二叉树: 1.若它的左子树不为空,则左子树上所有节点的值都小于根节点的值2.若它的右子树不为空,则右子树上所有节点的值都大于…...

【Unity小知识】UnityEngine.UI程序集丢失的问题
问题表现 先来说一下问题的表现,今天在开发的时候工程突然出现了报错,编辑器提示UnityEngine.UI缺少程序集引用。 问题分析与解决(一) 既然是程序集缺失,我们首先查看一下工程项目是否引用了程序集。在项目引用中查找一…...

CentOS 离线安装部署 MySQL 8详细教程
1、简介 MySQL是一个流行的开源关系型数据库管理系统(RDBMS),它基于SQL(Structured Query Language,结构化查询语言)进行操作。MySQL最初由瑞典的MySQL AB公司开发,后来被Sun Microsystems公司…...

云计算【第一阶段(28)】DNS域名解析服务
一、DNS解析的定义与作用 1.1、DNS解析的定义 DNS解析(Domain Name System Resolution)是互联网服务中的一个核心环节,它负责将用户容易记住的域名转换成网络设备能够识别和使用的IP地址。一般来讲域名比 IP 地址更加的有含义、也更容易记住…...

pygame 音乐粒子特效
代码 import pygame import numpy as np import pymunk from pymunk import Vec2d import random import librosa import pydub# 初始化pygame pygame.init()# 创建屏幕 screen pygame.display.set_mode((1920*2-10, 1080*2-10)) clock pygame.time.Clock()# 加载音乐文件 a…...

Leetcode 295.数据流的中位数
295.数据流的中位数 问题描述 中位数是有序整数列表中的中间值。如果列表的大小是偶数,则没有中间值,中位数是两个中间值的平均值。 例如 arr [2,3,4] 的中位数是 3 。例如 arr [2,3] 的中位数是 (2 3) / 2 2.5 。 实现 MedianFinder 类: Media…...

A59 STM32_HAL库函数 之 TIM扩展驱动 -- A -- 所有函数的介绍及使用
A59 STM32_HAL库函数 之 TIM扩展驱动 -- A -- 所有函数的介绍及使用 1 该驱动函数预览1.1 HAL_TIMEx_HallSensor_Init1.2 HAL_TIMEx_HallSensor_DeInit1.3 HAL_TIMEx_HallSensor_MspInit1.4 HAL_TIMEx_HallSensor_MspDeInit1.5 HAL_TIMEx_HallSensor_Start1.6 HAL_TIMEx_HallSe…...
【Unity】UGUI的基本介绍
Unity的UGUI(Unity User Interface)是Unity引擎内自带的UI系统,官方称之为UnityUI,是目前Unity商业游戏开发中使用最广泛的UI系统开发解决方案。以下是关于Unity的UGUI的详细介绍: 一、UGUI的特点 灵活性:…...

使用docker在3台服务器上搭建基于redis 6.x的一主两从三台均是哨兵模式
一、环境及版本说明 如果服务器已经安装了docker,则忽略此步骤,如果没有安装,则可以按照一下方式安装: 1. 在线安装(有互联网环境): 请看我这篇文章 传送阵>> 点我查看 2. 离线安装(内网环境):请看我这篇文章 传送阵>> 点我查看 说明:假设每台服务器已…...

Android Wi-Fi 连接失败日志分析
1. Android wifi 关键日志总结 (1) Wi-Fi 断开 (CTRL-EVENT-DISCONNECTED reason3) 日志相关部分: 06-05 10:48:40.987 943 943 I wpa_supplicant: wlan0: CTRL-EVENT-DISCONNECTED bssid44:9b:c1:57:a8:90 reason3 locally_generated1解析: CTR…...

Debian系统简介
目录 Debian系统介绍 Debian版本介绍 Debian软件源介绍 软件包管理工具dpkg dpkg核心指令详解 安装软件包 卸载软件包 查询软件包状态 验证软件包完整性 手动处理依赖关系 dpkg vs apt Debian系统介绍 Debian 和 Ubuntu 都是基于 Debian内核 的 Linux 发行版ÿ…...

多模态大语言模型arxiv论文略读(108)
CROME: Cross-Modal Adapters for Efficient Multimodal LLM ➡️ 论文标题:CROME: Cross-Modal Adapters for Efficient Multimodal LLM ➡️ 论文作者:Sayna Ebrahimi, Sercan O. Arik, Tejas Nama, Tomas Pfister ➡️ 研究机构: Google Cloud AI Re…...

以光量子为例,详解量子获取方式
光量子技术获取量子比特可在室温下进行。该方式有望通过与名为硅光子学(silicon photonics)的光波导(optical waveguide)芯片制造技术和光纤等光通信技术相结合来实现量子计算机。量子力学中,光既是波又是粒子。光子本…...

R 语言科研绘图第 55 期 --- 网络图-聚类
在发表科研论文的过程中,科研绘图是必不可少的,一张好看的图形会是文章很大的加分项。 为了便于使用,本系列文章介绍的所有绘图都已收录到了 sciRplot 项目中,获取方式: R 语言科研绘图模板 --- sciRplothttps://mp.…...

苹果AI眼镜:从“工具”到“社交姿态”的范式革命——重新定义AI交互入口的未来机会
在2025年的AI硬件浪潮中,苹果AI眼镜(Apple Glasses)正在引发一场关于“人机交互形态”的深度思考。它并非简单地替代AirPods或Apple Watch,而是开辟了一个全新的、日常可接受的AI入口。其核心价值不在于功能的堆叠,而在于如何通过形态设计打破社交壁垒,成为用户“全天佩戴…...

认识CMake并使用CMake构建自己的第一个项目
1.CMake的作用和优势 跨平台支持:CMake支持多种操作系统和编译器,使用同一份构建配置可以在不同的环境中使用 简化配置:通过CMakeLists.txt文件,用户可以定义项目结构、依赖项、编译选项等,无需手动编写复杂的构建脚本…...
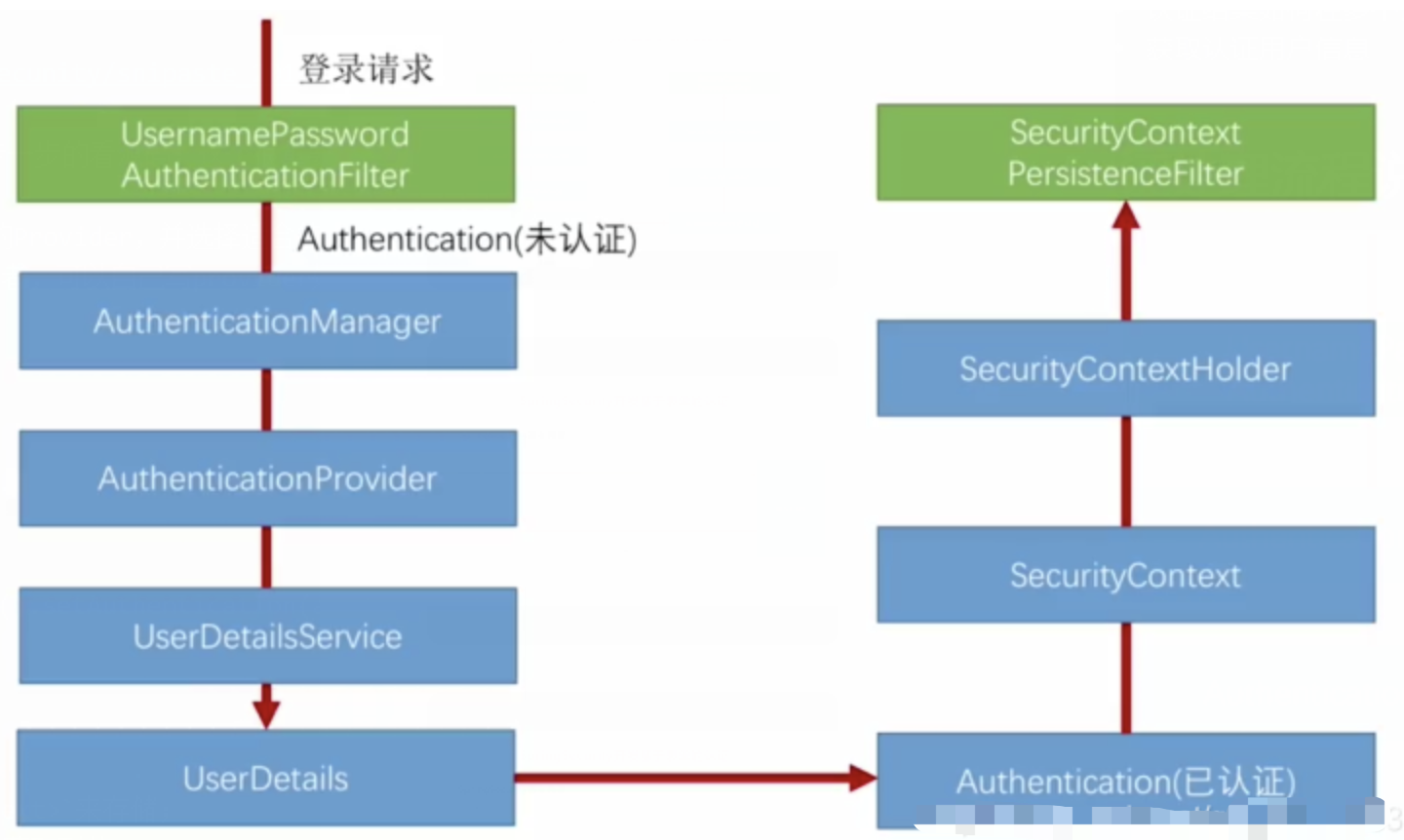
spring Security对RBAC及其ABAC的支持使用
RBAC (基于角色的访问控制) RBAC (Role-Based Access Control) 是 Spring Security 中最常用的权限模型,它将权限分配给角色,再将角色分配给用户。 RBAC 核心实现 1. 数据库设计 users roles permissions ------- ------…...

python打卡第47天
昨天代码中注意力热图的部分顺移至今天 知识点回顾: 热力图 作业:对比不同卷积层热图可视化的结果 def visualize_attention_map(model, test_loader, device, class_names, num_samples3):"""可视化模型的注意力热力图,展示模…...