【数据降维-第2篇】核主成分分析(KPCA)快速理解,及MATLAB实现
一篇介绍了PCA算法的快速理解和应用,本章讲一下KPCA。
KPCA方法与PCA方法一样,是有着扎实的理论基础的,相关理论在论文上以及网络上可以找到大量的材料,所以这篇文章还是聚焦在方法的快速理解以及应用上,此外还会对同学们可能比较关注的参数设置方式进行说明,从而达到快速上手应用的目的。
一、KPCA的基本概念
核主成分分析(Kernel Principal Component Analysis, KPCA)方法是PCA方法的改进,从名字上也可以很容易看出,不同之处就在于“核”。使用核函数的目的:用以构造复杂的非线性分类器。
核方法(Kernel Methods)是一种在机器学习领域广泛使用的非参数统计学习方法。它可以用于分类、回归、聚类等任务,并被广泛应用于计算机视觉、自然语言处理、生物信息学等领域。比如“核”在SVM方法中也是核心概念之一。
核方法的核心思想是通过映射将输入空间中的数据点转换到一个特征空间中,从而使得在特征空间中的数据点能够更容易地被处理和分析。而这种映射通常是通过核函数(Kernel Function)来实现的。
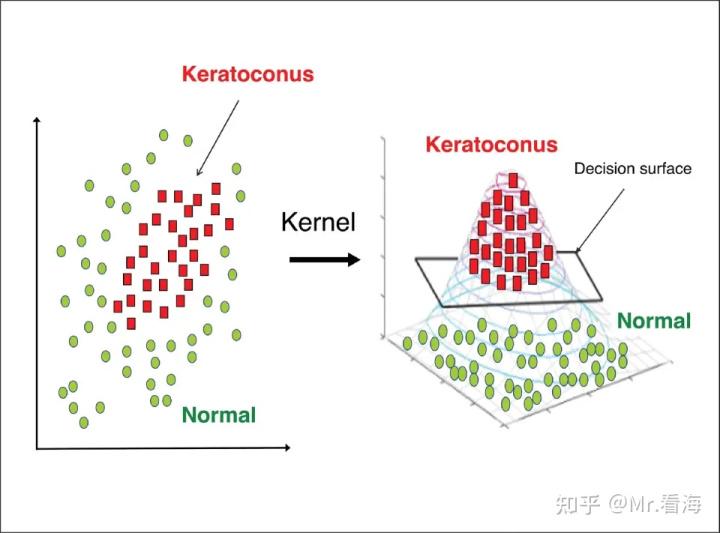
低纬到高纬转换示意图,来源:https://entokey.com/artificial-intelligence-in-keratoconus/
需要注意的是,核函数本身并不会显式地定义高维特征空间,而是通过核技巧来实现数据从低维空间到高维特征空间的映射。这种方法可以大大降低计算复杂度,同时可以处理非线性问题,因为它可以将原始数据映射到一个非线性特征空间中,从而使得在特征空间中的数据点更容易被线性分类器或回归器处理。
下边我来举两个例子(与之前PCA的文章一致),说明一下KPCA常见的应用场合和使用方法,以及与KPCA方法的一些不同之处。
二、为什么要数据降维
数据降维是指将高维度的数据映射到低维度的空间中,同时保留数据中的重要信息。这种降维的操作可以帮助我们更好地理解和处理数据,并且可以降低计算的复杂度,提高机器学习算法的效率和准确率。
举个例子,假设我们有一个人口统计数据集,其中包含了10000个人的各种信息,如年龄、性别、职业、收入等。这些信息可以表示为10000行x10列的矩阵,即每个人的信息用一个10维向量表示。然而,在进行机器学习分析时,这些维度可能是冗余的,而且会带来很高的计算成本。因此,我们可以考虑对这些数据进行降维操作,将其映射到一个更低维度的空间中,比如3维或2维。在这个新的低维空间中,我们仍然可以保留数据中的重要信息,比如不同职业之间的差异、年龄与收入之间的相关性等,但是计算复杂度会大大降低,更适合于机器学习算法的处理。
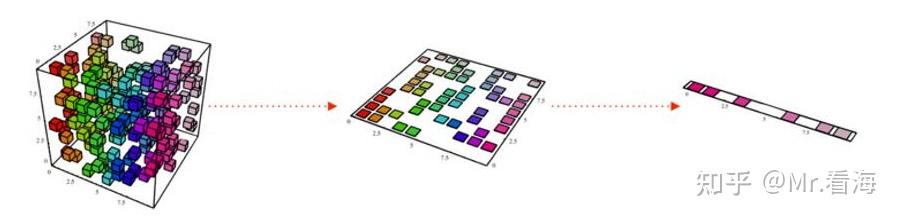
来源:https://blog.csdn.net/danwenxuan/article/details/76647940,演示的是3维降到1维,上述人口的例子是从10维往下降
数据降维有很多用处,以下是其中一些常见的用途:
1.数据可视化:在高维数据中,人类的视觉系统难以直观地理解数据的特征和关系。通过将数据降维到二维或三维空间,我们可以更容易地对数据进行可视化和探索。
2.去除冗余特征:在一些应用中,数据集可能存在大量冗余特征,这些特征对于建模没有帮助,甚至会影响模型性能。通过数据降维,我们可以去除冗余特征,提高建模效率和性能。
3.加速算法:在一些算法中,如聚类和分类,高维数据会导致计算复杂度的急剧增加。通过数据降维,我们可以将高维数据降到低维,从而加速算法的运行。
4.降低存储和计算成本:随着数据集的不断增大,存储和计算成本也会急剧增加。通过数据降维,我们可以将数据的维度降到更低,从而减少存储和计算成本。
三、为什么用KPCA
KPCA是PCA的一种扩展形式,它可以有效地应对非线性数据,并且具有以下几个优点:
1.更好的数据可分性
KPCA在将数据映射到高维空间后,能够更好地区分不同类别的数据,提高了数据的可分性。举例来说,如果数据集是一个螺旋形状,那么使用 PCA 很难将这个数据集分离成两个类别,因为 PCA 只能处理线性数据结构。但是,如果使用 KPCA,可以将数据映射到高维空间中,使得数据在新的空间中变得线性可分,从而更容易进行分类。
2.善于处理非线性数据
与PCA只能处理线性数据不同,KPCA可以处理非线性数据。KPCA使用核函数,将原始数据映射到一个高维的特征空间上,该空间具有更强的表达能力,能够处理非线性关系。在这个高维特征空间中,我们可以使用PCA来提取主成分,再将它们映射回原始空间。这样就可以在原始空间中实现非线性变换,从而更好地处理非线性数据。对于许多实际问题有很好的应用前景,例如图像处理和模式识别。
3.更加灵活的使用方式
KPCA的核函数还可以通过调整参数来进一步调整模型的复杂度和鲁棒性。因此,相对于PCA,KPCA具有更多的灵活性和可调性,可以更好地适应不同的数据场景和需求。
四、KPCA中的几个重要参数
1.核函数(Kernel Function)
核函数用于将原始数据映射到一个高维空间中,从而能够更好地区分数据。常见的核函数包括线性核(linear)、多项式核(poly)、高斯核(gaussian)等,径向基核(RBF)是高斯核的另一种表达形式,本质上是相同的。不同的核函数可以对数据进行不同类型的变换,从而影响降维效果。
2.核函数参数(Kernel Function Parameter)
核函数通常包含一个或多个参数,例如高斯核就有一个标准差参数。这些参数影响了核函数变换的程度,可以通过交叉验证等方法来确定最佳参数值。
2.1 高斯核函数中的gamma(γ)参数:高斯核函数定义为 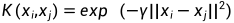 ,其中,γ是高斯核函数的一个超参数。它控制了数据点在高维空间中的分布情况。当γ越大时,高斯核函数会使得数据点在高维空间中的分布更加集中,因此,降维后的数据将更容易区分。常见的取值范围为
,其中,γ是高斯核函数的一个超参数。它控制了数据点在高维空间中的分布情况。当γ越大时,高斯核函数会使得数据点在高维空间中的分布更加集中,因此,降维后的数据将更容易区分。常见的取值范围为 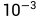 到
到 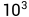 。
。
2.2 多项式核函数中的r和d参数:多项式核函数定义为 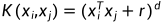 ,其中,r是常数项,d是多项式的阶数,这两个参数控制了多项式核函数的形状。
,其中,r是常数项,d是多项式的阶数,这两个参数控制了多项式核函数的形状。
r是平移参数,它的作用是将多项式核函数平移一定的距离,使得更多的数据被映射到高维空间。
d的取值范围为1到10之间的整数。如果d取值过大,会导致过拟合的问题,如果取值过小,则可能会欠拟合数据。
3.降维后的维度(Number of Components)
该参数是需要同学们自己指定的,在实际使用中通常需要结合实际应用场景进行设置。如果不知道该怎样设置,可以结合各个成分的贡献度进行筛选。贡献度越高,表示该主成分对数据的解释能力越强,因此在选择主成分时可以根据其贡献度进行排序,选择贡献度较高的主成分作为保留的特征。
比如上边人口统计的例子中,经kpca融合后得到的特征就会按照贡献度从大到小排序,我们可以取总贡献度之和达到85%或者90%(自定)的前几个特征作为降维后的特征数据,而这个特征数量就是降维后的维度。
下边我们举例说明一下。
五、案例:降维、聚类与分类
举一个PCA中介绍过的例子。
这里介绍一下鸢尾花数据集,鸢尾花在机器学习里是常客之一。数据集由具有150个实例组成,其特征数据包括四个:萼片长、萼片宽、花瓣长、花瓣宽。数据集中一共包括三种鸢尾花,分别叫做Setosa、Versicolor、Virginica,就像下图:

也就是说这组数据的维度是150*4,数据是有标签的。(有标签是指每个实例我们都知道它对应的类别)
此时我们进行KPCA降维,可以得到每个主成分解释方差占总方差的百分比,这个数值可以用以表示每个主成分中包含的信息量,从计算结果上来看,第1个主成分和第2个主成分的百分比之和已经超过95%,前三个主成分百分比之和更是超过了99%。此时我们就可以按照贡献率来筛选降维后的维度了,比如设置总贡献度能达到99%以上,那么就把降维维度设置为2即可。

我们可以绘制一下数据降到二维和三维时,降维数据的分布情况:
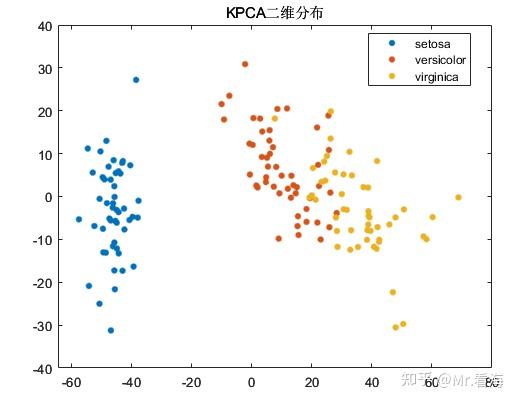

尽管PCA算法的初衷是降维而非聚类,不过由于KPCA降维后的数据常常会用做机器学习的输入数据,在数据降维的同时查看降维后数据的分布情况,对于模式识别/分类任务的中间状态确定还是十分有益的,再直白些说,这些图片放在论文里丰富一下内容也是极好的。
在这种应用场景下,数据降维的最主要目的其实还是解决数据特征过于庞大的问题,这个例子中特征只有4个,所以还不太明显。很多时候我们面对的是几十上百乃至更多的特征维度,这些特征中包含着大量冗余信息,使得计算任务变得非常繁重,调参的难度和会大大增加。此时加入一步数据降维就是十分有必要的了。
六、MATLAB的KPCA降维快速实现
KPCA算法在MATLAB中还没有官方函数,不过已经有前辈造出了轮子。大家可以在下边链接下载和使用:
MATLAB-Kernel-PCA
对于不熟悉MATLAB编程,或者希望更简洁的方法实现KPCA降维,并同时绘制出相关图片的同学,则可以考虑使用本专栏封装的函数,它可以实现:
1.输入数据的行列方向纠正。是的,MATLAB的pca函数对特征矩阵的输入方向是有要求的,如果搞不清,程序可以帮你自动纠正。
options.autoDir='on';%是否进行自动纠错,'on'为是,否则为否。开启自动纠错后会智能调整数据的行列方向。2.指定输出的维度。也就是降维之后的维度,当然这个数不能大于输入数据的特征维度。
options.NumDimensions=3;%降维后的数据维度3.数据归一化。你可以选择在PCA之前,对特征数据进行归一化,这也只需要设置一个参数。
options.AutoScale=false;%输入数据是否进行标准化,false (默认) | true 4.绘制特征分布图和成分百分比图。在降维维度为2或者3时,可以绘制特征分布图,当然你也可以选择设置不画图,图个清静。
figflag='on';%是否画图,'on'为画图,'off'为不画,只有NumDimensions为2或者3时起作用,3以上无法画图5.相关超参数设置。
options.gamma=2;%超参数gamma的数值,默认为2,只对gaussian核有效options.r=1;%超参数r的数值,默认为1,只对polynomial核有效options.d=2;%超参数d的数值,默认为2,只对polynomial核有效设置好这些配置参数后,只需要调用下边这行代码:
[kpcaVal,explained]=khKPCA(data,options,species,figflag);%kpcaVal为降维后的数据矩阵,explained为各成分贡献度就可以绘制出这样两张图:
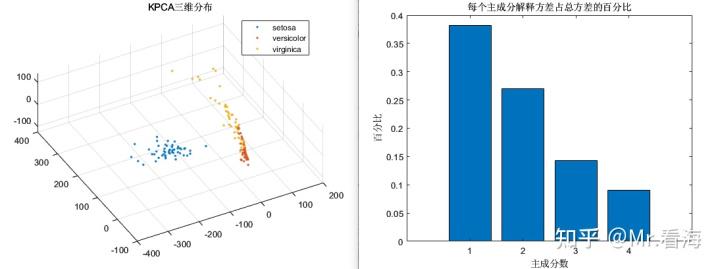
绘制三维分布图
如果要绘制二维图,把options.NumDimensions设置成2就好了。绘制出来是这样:

绘制二维分布图
不过上述是知道标签值species的情况,如果不知道标签值,设置species=[]就行了,此时画出来的分布图是单一颜色的。
上述代码秉承了本专栏一向的易用属性,功能全部集中在khPCA函数里了,这个函数更详细的介绍如下:
[kpcaVal,explained] = khKPCA(data,options,species,figflag);
% 执行KPCA操作,并实现画图
% 依赖函数:KernelPca.m,原始代码见:https://github.com/kitayama1234/MATLAB-Kernel-PCA
% 输入:
% data:拟进行降维的数据,data维度为m*n,其中m为特征值种类数,n为每个特征值数据长度
% options:一些与kpca降维有关的设置,使用结构体方式赋值,比如 options.autoDir = 'on',具体包括:
% -autoDir:是否进行自动纠错,'on'为是,否则为否。开启自动纠错后会智能调整数据的行列方向。
% -NumDimensions:降维后的数据维度,默认为2,注意NumDimensions不能大于data原本维度
% -kernel: kernel类型选择('linear', 'gaussian', or 'polynomial'),默认为linear
% -gamma:超参数gamma的数值,默认为2
% -r:超参数r的数值,默认为1
% -d:超参数d的数值,默认为2
% -AutoScale:是否进行标准化,True或False,默认为False
%
% species:分组变量,可以是数组、数值向量、字符数组、字符串数组等,但是需要注意此变量维度需要与Fea的组数一致。该变量可以不赋值,调用时对应位置写为[]即可
% 例如species可以是[1,1,1,2,2,2,3,3,3]这样的数组,代表了Fea前3行数据为第1组,4-6行数据为第2组,7-9行数据为第三组。
% 关于此species变量更多信息,可以查看下述链接中的"Grouping variable":
% https://ww2.mathworks.cn/help/stats/gscatter.html?s_tid=doc_ta#d124e492252
%
% figflag:是否画图,'on'为画图,'off'为不画,只有NumDimensions为2或者3时起作用,3以上无法画图
% 输出:
% pcaVal:主成分分数,即经过pca分析计算得到的主元,每一列是一个主元
% explained:每个主成分解释方差占总方差的百分比,以列向量形式返回。需要上边这个函数文件以及测试代码的同学,可以在下边链接获取:
核主成分分析(KPCA)降维|工具箱
附录
linear核函数 :
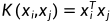
gaussian核函数 :
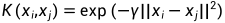
polynomial核函数 :
相关文章:
【数据降维-第2篇】核主成分分析(KPCA)快速理解,及MATLAB实现
一篇介绍了PCA算法的快速理解和应用,本章讲一下KPCA。KPCA方法与PCA方法一样,是有着扎实的理论基础的,相关理论在论文上以及网络上可以找到大量的材料,所以这篇文章还是聚焦在方法的快速理解以及应用上,此外还会对同学…...
Python+ChatGPT实战之进行游戏运营数据分析
文章目录一、数据二、目标三、解决方案1. DAU2. 用户等级分布3. 付费率4. 收入情况5. 付费用户的ARPU最近ChatGPT蛮火的,今天试着让ta写了一篇数据分析实战案例,大家来评价一下!一、数据 您的团队已经为您提供了一些游戏数据,包括…...

Java每日一练(20230313)
目录 1. 字符串统计 ★ 2. 单词反转 ★★ 3. 俄罗斯套娃信封问题 ★★★ 🌟 每日一练刷题专栏 C/C 每日一练 专栏 Python 每日一练 专栏 Java 每日一练 专栏 1. 字符串统计 编写一个程序,对于输入的一段英语文本,可以统计&#…...

国内ChatGPT日趋成熟后,可以优先解决的几个日常小问题
现在ChatGPT的发展可谓如日中天,国内很多大的公司例如百度、京东等也开始拥抱新技术,推出自己的应用场景,但可以想象到的是,他们必定利用这个新技术在巩固自己的现有应用场景,比如某些客服,你都不用想&…...

业内人士真心话,软件测试是没有前途的,我慌了......
我在测试行业爬模滚打7年,从点点点的功能测试到现在成为高级测试,工资也翻了几倍。个人觉得,测试的前景并不差,只要自己肯努力。 我刚出来的时候是在鹅厂做外包的功能测试,天天点点点,很悠闲,点…...
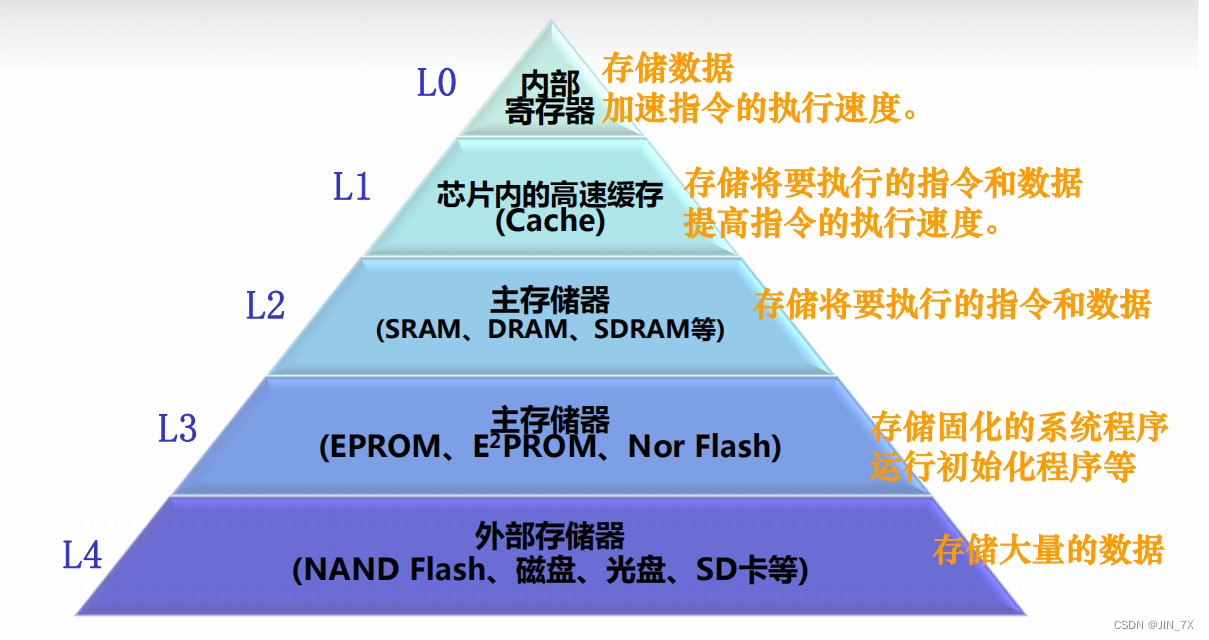
哈佛与冯诺依曼结构
1. 下图是典型的冯诺依曼结构 2. CPU分为三部分:ALU运算单元,CU控制单元,寄存器组。 3. 分析51单片机为何能使用汇编进行编程 51指令集(Instruction Set)是单片机CPU能够执行的所有指令的集合。在编写51单片机程序时&a…...

传输安全HTTPS
为什么要有 HTTPS 为什么要有 HTTPS?简单的回答是:“因为 HTTP 不安全”。HTTP 怎么不安全呢? 通信的消息会被窃取,无法保证机密性(保密性):由于 HTTP 是 “明文” 传输,整个通信过…...

Docker--(六)--Docker资源限制
前言系统压力测试Cpu资源限制Mem资源限制IO 资源限制【扩展】 1.前言 在使用 Docker 运行容器时,一台主机上可能会运行几百个容器,这些容器虽然互相隔离,但是底层却使用着相同的 CPU、内存和磁盘资源。如果不对容器使用的资源进行限制&#x…...

消息队列总结及案例
文章目录python内置队列先进先出的队列Queue分布式队列rabbitmqrocketmqredis list 队列python内置队列 标准库queue提供Queue队列、LifoQueue栈、PriorityQueue优先级队列用于单机的生产者、消费者缓冲队列; 生产者,生产消息的进程或线程;…...

通过WiFi连接adb调试
通过WiFi连接adb调试 解决 cannot connect to 192.168.1.136:5555: 由于目标计算机积极拒绝,无法连接。 (10061) 解决办法1 (Windows下cmd环境执行) 1.连接USB数据线,打开USB调试 使用windows的“运行”命令行方式:&a…...
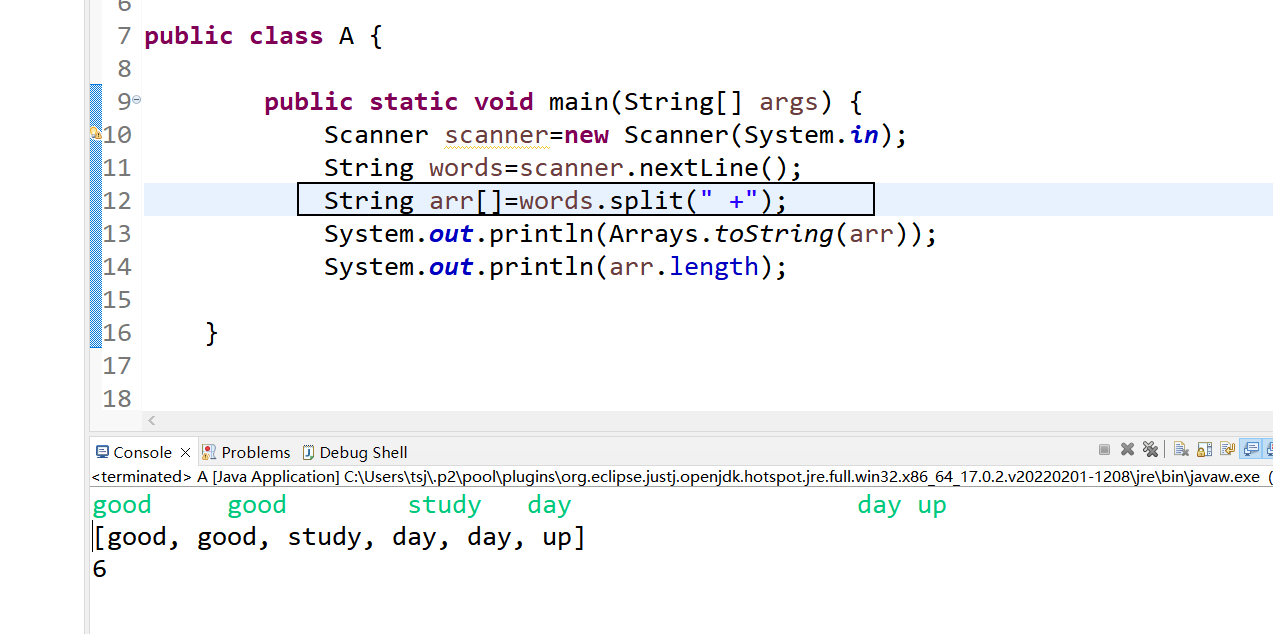
【蓝桥杯-筑基篇】常用API 运用(1)
🍓系列专栏:蓝桥杯 🍉个人主页:个人主页 目录 🍍1.输入身份证,判断性别🍍 🍍2.输入英语句子,统计单词个数🍍 🥝3.加密解密🥝 🌎4.相邻重复子串…...

想要成为高级网络工程师,只需要具备这几点
首先,成为高级网络工程师的目的,就是为了搞钱。高级网络工程师肯定是不缺钱的,但成为高级网络工程师你一定要具备以下几点:第一 心态作为一个高级网工,首先你必须情绪要稳定,在碰到重大故障的时候不慌&…...

c++ 每日十问3-处理数据
1.为什么 C有多种整型? 解析: C语言中包含多种整数类型,主要包括 short、int、long 和 long long 这4种,每一种还分别包含有符号类型和无符号类型(unsigned)。此外,char 类型也可以看作一种小整数类型。C语言中这些整数类型的主要区别在于存…...

【MySQL】实验一 数据定义
目录 1. 表定义:创建工程项目表 2. 表定义:创建供应商表 3. 表定义:创建供应情况表 4. 表定义:创建零件表 5. 表定义:创建student表 6. 表定义:创建course表 7. 表定义:创建sc表 8.…...
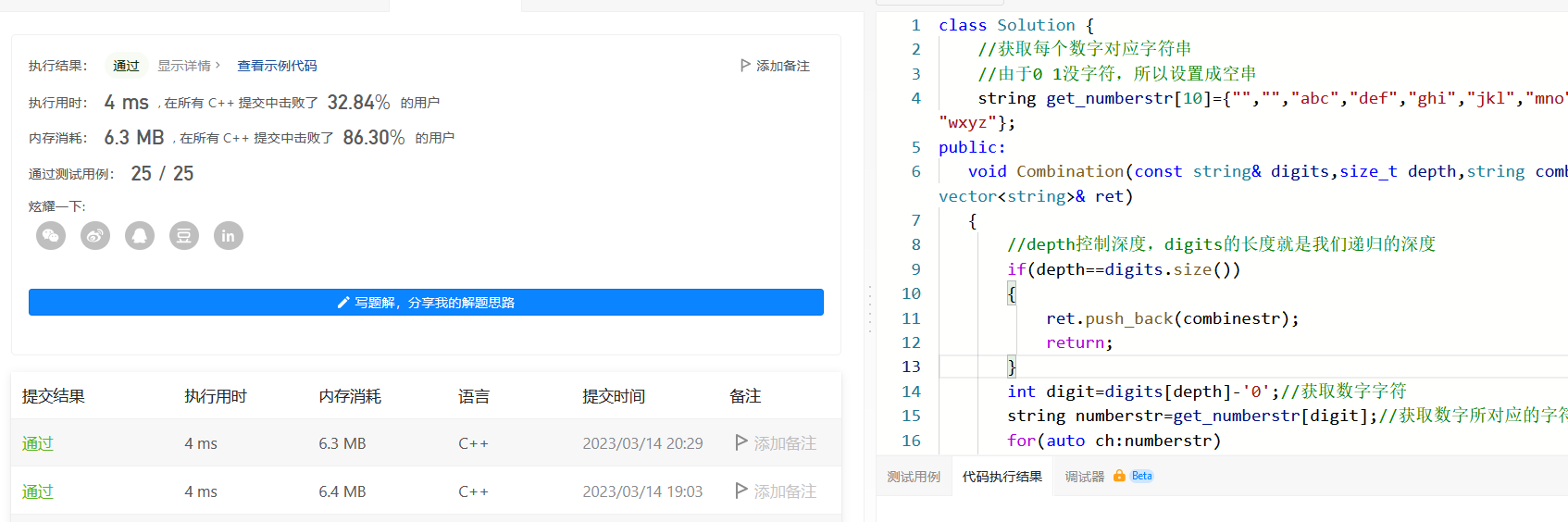
17.电话号码的字母组合(深度递归遍历解决经典老题)
前文C深度递归遍历解决"电话号码的字母组合问题",本题考察的比较全面,考察到vector的使用,深度遍历以及递归的熟练度,希望能对铁子们有所帮助一,题目链接:https://leetcode.cn/problems/letter-c…...

Python 基础教程【1】:Python介绍、变量和数据类型、输入输出、运算符
本文已收录于专栏🌻《Python 基础》文章目录1、Python 介绍2、变量和数据类型2.1 注释的使用2.2 变量以及数据类型2.2.1 什么是变量?2.2.2 怎么给变量起名?2.2.3 变量的类型🎨 整数 int🎨 浮点数(小数&…...

【RPC】Apache Thrift系列详解 - 概述与入门
文章目录前言正文Thrift的技术栈Thrift的特性(一) 开发速度快(二) 接口维护简单(三) 学习成本低(四) 多语言/跨语言支持(五) 稳定/广泛使用Thrift的数据类型Thrift的协议Thrift的传输层Thrift的服务端类型Thrift入门示例(一) 编写Thrift IDL文件(二) 新建Maven工程总结前言 Th…...
class03:MVVM模型与响应式原理
目录一、MVVM模型二、内在1. 深入响应式原理2. Object.entries3. 底层搭建一、MVVM模型 MVVM,即Model 、View、ViewModel。 Model > data数据 view > 视图(vue模板) ViewModel > vm > vue 返回的实例 > 控制中心, 负责监听…...
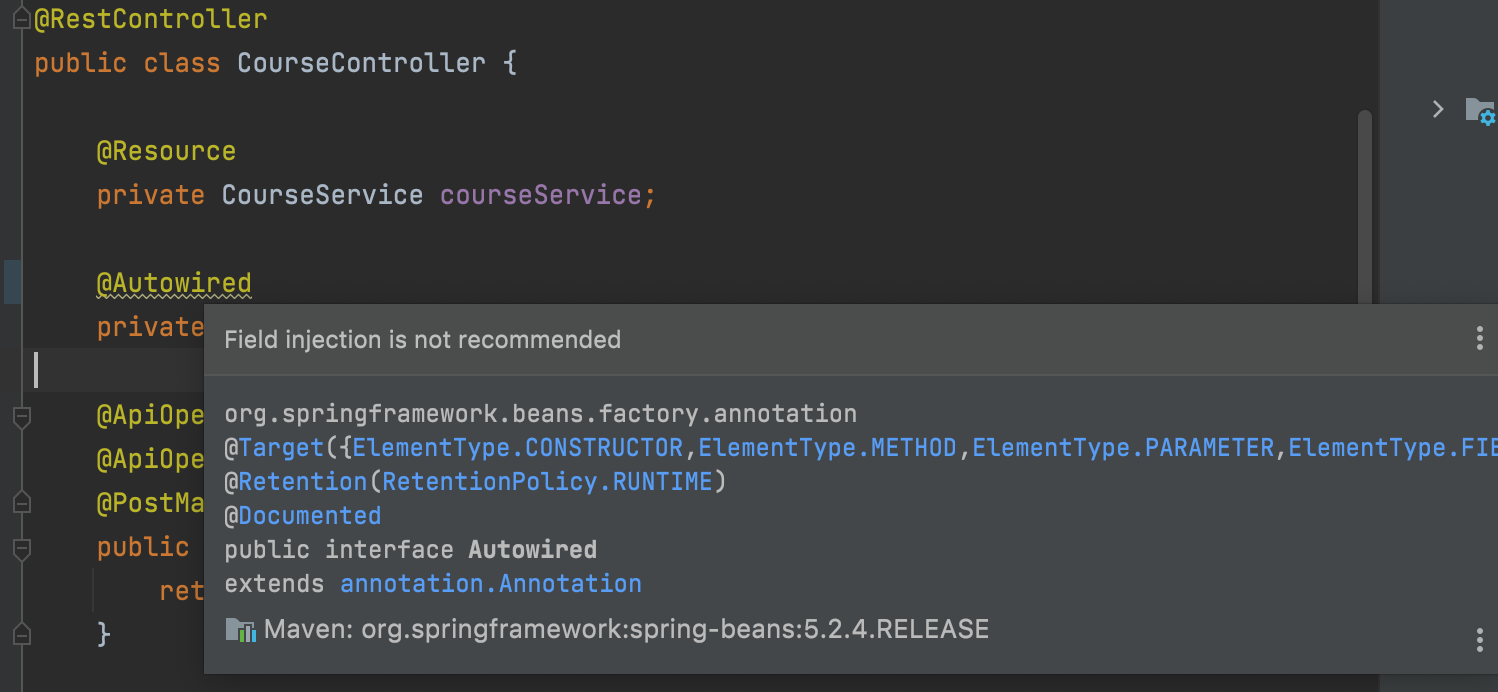
[Spring学习]08 @Resource和@Autowired注解的区别
目录前言一、Resource和Autowired注解的身世1、Resource注解2、Autowired注解3、常见的三种依赖注入方式及区别1. Filed注入2. Setter注入3. Constructor注入4. 三种依赖注入方式的区别二、Resource和Autowired注解的区别三、Resource和Autowired注解的推荐用法前言 当我们在属…...
前端开发神器VS Code安装教程
✅作者简介:CSDN一位小博主,正在学习前端 📃个人主页:白月光777的CSDN博客 💬个人格言:但行好事,莫问前程 安装VS CodeVS Code简介VS Code安装VS Code汉化结束语💡💡&…...

深度学习从心电信号中解码呼吸频率:原理、实现与临床价值
1. 项目概述:从心电信号中“听”到呼吸声呼吸频率,这个我们每分钟都在进行却很少被精确量化的生命体征,在临床医学中扮演着至关重要的角色。它不仅是评估呼吸系统功能的直接指标,更是反映全身代谢、循环乃至神经系统状态的“窗口”…...

告别虚拟机卡顿:在Windows 11的WSL2里搞定Lichee Nano交叉编译环境
告别虚拟机卡顿:在Windows 11的WSL2里搞定Lichee Nano交叉编译环境 对于嵌入式开发者来说,配置开发环境往往是个令人头疼的问题。传统虚拟机方案虽然能提供完整的Linux体验,但资源占用高、启动慢、与宿主系统交互不便等问题一直困扰着开发者。…...

2026年一键生成论文工具对比实测:5款神器从选题到格式全流程护航
写论文的焦虑,是每个科研人和学生都心照不宣的“隐形压力”。选题无从下手,文献检索耗时费力,逻辑框架反复推翻,格式排版让人抓狂,查重降重更是像在和系统玩“猫鼠游戏”。2026年的AI工具早已不是过去那种“打字机”&a…...

深度解析HS2-HF Patch:从技术框架到创作工具链的完整升级方案
深度解析HS2-HF Patch:从技术框架到创作工具链的完整升级方案 【免费下载链接】HS2-HF_Patch Automatically translate, uncensor and update HoneySelect2! 项目地址: https://gitcode.com/gh_mirrors/hs/HS2-HF_Patch 你是否曾因Honey Select 2的原版体验受…...

抖音内容批量下载实战:从零开始构建个人视频资料库
抖音内容批量下载实战:从零开始构建个人视频资料库 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback support.…...

事故数据四年连降,为何山西煤矿的命还是悬在一根绳上?
说实话,写到山西煤矿这四个字,我心里就咯噔一下。2026年5月22日19时29分,山西长治市沁源县山西通洲集团留神峪煤业有限公司井下发生瓦斯爆炸事故,截至到写稿,事故已造成90人遇难。看的心里堵得慌。我特意去翻了翻这些年…...
如何实现那些酷炫的UI与特效)
从《原神》到独立游戏:聊聊URP相机Stack(Overlay)如何实现那些酷炫的UI与特效
从《原神》到独立游戏:URP相机堆叠技术如何重塑游戏视觉表现当你在《原神》中打开地图界面时,是否注意到背景世界依然保持着动态光影效果?当角色受伤时,那层红色渐隐特效为何能如此自然地覆盖在3D场景之上?这些看似简单…...

Hearthstone-Script终极指南:如何用开源炉石脚本实现智能自动对战
Hearthstone-Script终极指南:如何用开源炉石脚本实现智能自动对战 【免费下载链接】Hearthstone-Script Hearthstone script(炉石传说脚本) 项目地址: https://gitcode.com/gh_mirrors/he/Hearthstone-Script 还在为炉石传说繁琐的日常…...

Hotkey Detective:3步快速定位Windows快捷键冲突的终极指南
Hotkey Detective:3步快速定位Windows快捷键冲突的终极指南 【免费下载链接】hotkey-detective A small program for investigating stolen key combinations under Windows 7 and later. 项目地址: https://gitcode.com/gh_mirrors/ho/hotkey-detective 你是…...

Wand-Enhancer终极指南:三步免费解锁WeMod专业版所有功能
Wand-Enhancer终极指南:三步免费解锁WeMod专业版所有功能 【免费下载链接】Wand-Enhancer Advanced UX and interoperability extension for Wand (WeMod) app 项目地址: https://gitcode.com/gh_mirrors/we/Wand-Enhancer 还在为WeMod免费版的限制而烦恼吗&…...