python爬虫学习(三十三天)---多线程上篇
hello,小伙伴们!我是喔的嘛呀。今天我们来学习多线程方面的知识。
目录
一、了解多线程
(1)大概描述
(2)多线程爬虫的优势
(3)多线程爬虫的实现方式
(4)多线程爬虫的注意事项
二、Python中的多线程实现
1. 基本概念
2. 线程创建与启动
示例代码:
3. 线程同步与互斥
示例代码:使用锁(Lock)
4. 线程池
示例代码:使用线程池
5. 总结
三、 线程安全和数据共享
线程安全
示例代码:使用锁确保线程安全
数据共享
示例代码:线程间共享数据
一、了解多线程
(1)大概描述
多线程爬虫是一种使用多个线程同时执行网页爬取任务的爬虫技术。在传统的单线程爬虫中,爬虫会按照顺序逐个访问URL并下载网页内容,这种方式在处理大量URL或网络延迟较高时效率较低。而多线程爬虫则通过创建多个线程,每个线程独立地访问和下载网页,从而显著提高爬取效率。
(2)多线程爬虫的优势
- 提高爬取效率:多线程可以并行处理多个任务,使得爬虫能够同时访问和下载多个网页,从而显著缩短整体爬取时间。
- 充分利用资源:多线程能够充分利用计算机的多核处理器资源,使得爬虫在处理大规模爬取任务时更加高效。
- 减少网络延迟影响:由于网络延迟的存在,单线程爬虫在访问每个URL时都需要等待网络响应。而多线程爬虫可以同时处理多个URL,从而减少等待时间,降低网络延迟对爬取效率的影响。
- 实现复杂的爬取策略:多线程爬虫可以方便地实现复杂的爬取策略,如分布式爬取、优先级调度等。通过合理分配线程资源,可以实现对不同网页的优先爬取或并行爬取。
(3)多线程爬虫的实现方式
在Python中,可以使用threading模块来实现多线程爬虫。通常的做法是创建一个线程池,然后向线程池中提交任务(即访问和下载网页的任务)。线程池中的线程会并行执行这些任务,并返回结果。为了避免线程间的竞争和冲突,需要使用线程安全的队列(如queue.Queue)来管理待爬取的URL和已爬取的数据。
(4)多线程爬虫的注意事项
- 线程安全:多线程编程时需要注意线程安全,避免多个线程同时访问和修改共享资源导致的数据混乱和错误。可以通过使用锁(如
threading.Lock)或其他同步机制来保证线程安全。 - 资源消耗:多线程会消耗更多的系统资源(如CPU、内存等),因此需要合理控制线程数量,避免过度消耗资源导致系统崩溃或性能下降。
- 网络爬虫法规:在编写多线程爬虫时需要遵守相关法律法规和网站的使用协议,不得进行恶意爬取、数据滥用等行为。
- 异常处理:多线程爬虫在执行过程中可能会遇到各种异常情况(如网络错误、页面结构变化等),需要编写健壮的异常处理代码来确保程序的稳定性和可靠性。
二、Python中的多线程实现
在Python中,多线程的实现主要依赖于threading模块。下面将详细介绍Python中多线程的实现,并附带示例代码。
1. 基本概念
在Python中,线程是程序执行的最小单元。多线程允许在单个程序中并发地执行多个线程。由于Python的全局解释器锁(GIL),多线程在CPU密集型任务上的并行执行效果并不明显,但在I/O密集型任务(如网络请求)中,多线程可以显著提高性能。
2. 线程创建与启动
在Python中,可以通过继承threading.Thread类并重写run方法来创建一个线程,然后调用start方法启动线程。
示例代码:
import threading
import time def worker(name): """线程执行的函数""" print(f"线程 {name} 开始工作") time.sleep(2) # 模拟耗时操作 print(f"线程 {name} 工作完成") # 继承 threading.Thread 类
class MyThread(threading.Thread): def __init__(self, name): super().__init__() # 调用父类构造函数 self.name = name def run(self): """线程运行的函数""" worker(self.name) # 调用上面定义的函数 # 创建并启动线程
threads = []
for i in range(5): t = MyThread(f"Thread-{i}") t.start() # 启动线程 threads.append(t) # 等待所有线程完成
for t in threads: t.join() print("所有线程已完成")
3. 线程同步与互斥
由于多线程并发执行,可能会存在对共享资源的竞争访问问题。Python提供了多种同步机制来解决这个问题,如锁(Lock)、条件变量(Condition)、信号量(Semaphore)等。
示例代码:使用锁(Lock)
import threading class Counter: def __init__(self): self.lock = threading.Lock() self.value = 0 def increment(self): with self.lock: # 使用 with 语句自动管理锁的获取和释放 self.value += 1 # 创建多个线程,每个线程都调用 Counter 的 increment 方法
threads = []
counter = Counter()
for i in range(1000): t = threading.Thread(target=counter.increment) t.start() threads.append(t) # 等待所有线程完成
for t in threads: t.join() print(f"最终计数值:{counter.value}") # 应该输出 1000
4. 线程池
为了避免创建过多线程导致的系统资源耗尽问题,可以使用线程池来限制同时运行的线程数量。Python的concurrent.futures模块提供了ThreadPoolExecutor类来实现线程池。
示例代码:使用线程池
import concurrent.futures
import time def worker(n): print(f"开始工作:{n}") time.sleep(2) # 模拟耗时操作 return f"结果:{n}" # 创建一个线程池,最大线程数为 5
with concurrent.futures.ThreadPoolExecutor(max_workers=5) as executor: # 提交多个任务到线程池执行 futures = [executor.submit(worker, i) for i in range(10)] # 等待所有任务完成,并获取结果 for future in concurrent.futures.as_completed(futures): try: result = future.result() print(result) except Exception as e: print(f"生成了一个异常:{e}") print("所有任务已完成")
5. 总结
Python中的多线程实现主要依赖于threading模块,通过继承threading.Thread类并重写run方法可以创建自定义的线程。同时,Python也提供了多种同步机制来解决多线程并发执行时可能存在的共享资源竞争访问问题。为了避免创建过多线程导致的系统资源耗尽问题,可以使用线程池来限制同时运行的线程数量。
三、 线程安全和数据共享
线程安全和数据共享是在多线程编程中必须考虑的两个重要概念。线程安全指的是在多线程环境下,代码的执行结果总是符合预期,不会因为线程间的并发执行而导致数据不一致或其他不可预期的结果。数据共享则是指多个线程访问和操作同一块内存区域的数据。
在Python中,由于全局解释器锁(GIL)的存在,CPU密集型任务在多线程中并不会真正并行执行,但对于I/O密集型任务或外部资源的访问(如文件、网络请求等),多线程仍然可以提高程序的效率。然而,即使在这些情况下,我们也需要确保线程安全和数据共享的正确性。
线程安全
线程安全通常通过以下几种方式实现:
- 避免共享状态:尽量让线程只操作自己的局部变量,避免共享状态。
- 使用线程同步机制:如锁(Lock)、条件变量(Condition)、信号量(Semaphore)等。
- 使用线程安全的数据结构:Python标准库中的
queue模块提供了线程安全的队列实现。
示例代码:使用锁确保线程安全
import threading class SharedCounter: def __init__(self): self.lock = threading.Lock() self.value = 0 def increment(self): with self.lock: self.value += 1 def decrement(self): with self.lock: self.value -= 1 def get_value(self): # 这里没有修改值,所以不需要加锁 return self.value # 创建多个线程对SharedCounter进行操作
def worker(counter, action, n): for _ in range(n): if action == 'inc': counter.increment() elif action == 'dec': counter.decrement() threads = []
counter = SharedCounter() # 创建增加线程
for _ in range(10): t = threading.Thread(target=worker, args=(counter, 'inc', 1000)) threads.append(t) t.start() # 创建减少线程(为了演示,这里只创建一个)
t = threading.Thread(target=worker, args=(counter, 'dec', 500))
threads.append(t)
t.start() # 等待所有线程完成
for t in threads: t.join() # 输出最终值,应该接近5000(10个线程各增加1000次,1个线程减少500次)
print(counter.get_value())
数据共享
在Python中,由于所有对象都是通过引用传递的,因此数据共享是隐式的。但是,当多个线程需要访问和修改同一块数据时,就需要考虑线程同步和数据一致性的问题。
示例代码:线程间共享数据
import threading # 共享的数据
shared_data = {'count': 0}
lock = threading.Lock() def increment_data(): global shared_data for _ in range(100000): with lock: shared_data['count'] += 1 def decrement_data(): global shared_data for _ in range(50000): with lock: shared_data['count'] -= 1 # 创建线程
t1 = threading.Thread(target=increment_data)
t2 = threading.Thread(target=decrement_data) # 启动线程
t1.start()
t2.start() # 等待线程完成
t1.join()
t2.join() # 输出最终结果,由于有线程竞争和同步,结果可能不是精确的50000
print(shared_data['count'])
在这个例子中,我们使用了全局变量shared_data来模拟共享数据,并使用锁来确保在修改shared_data时的线程安全。需要注意的是,即使使用了锁,由于线程调度的不确定性,最终的结果可能不是精确的50000,但它应该是一个接近这个值的数。
好了,今天我们先学习多进程爬虫的三个知识点,明天我们将会学习后三个。再见啦,兄弟姐妹们。
相关文章:
---多线程上篇)
python爬虫学习(三十三天)---多线程上篇
hello,小伙伴们!我是喔的嘛呀。今天我们来学习多线程方面的知识。 目录 一、了解多线程 (1)大概描述 (2)多线程爬虫的优势 (3)多线程爬虫的实现方式 (4)…...
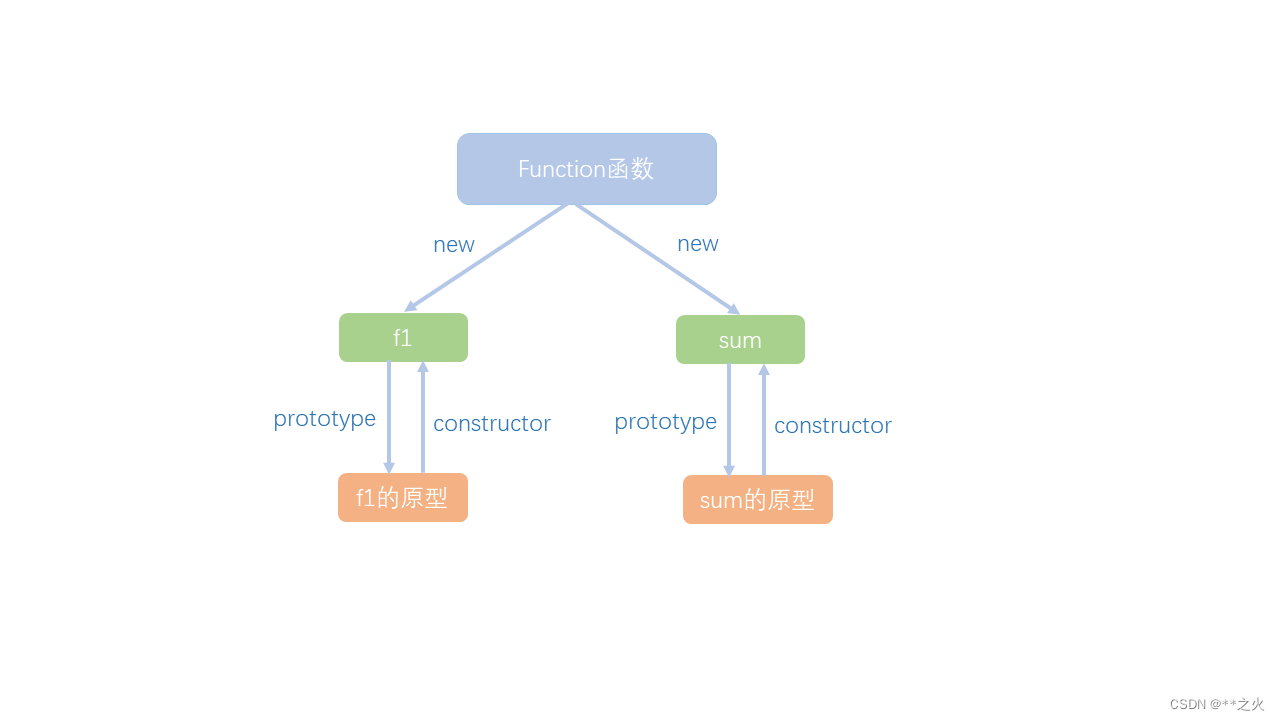
JavaScript 原型链那些事
在讲原型之前我们先来了解一下函数。 在JS中,函数的本质就是对象,它与其他对象不同的是,创建它的构造函数与创建其他对象的构造函数不一样。那产生函数对象的构造函数是什么呢?是一个叫做Function的特殊函数,通过newFu…...

nginx的知识面试易考点
Nginx概念 Nginx 是一个高性能的 HTTP 和反向代理服务。其特点是占有内存少,并发能力强,事实上nginx的并发能力在同类型的网页服务器中表现较好。 Nginx 专为性能优化而开发,性能是其最重要的考量指标,实现上非常注重效率&#…...

每日Attention学习9——Efficient Channel Attention
模块出处 [CVPR 20] [link] [code] ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks 模块名称 Efficient Channel Attention (ECA) 模块作用 通道注意力 模块结构 模块代码 import torch import torch.nn as nn import torch.nn.functional …...

Java语言程序设计——篇三(1)
选择结构 概述选择单分支if语句例题讲解 双分支if-else语句例题讲解 条件运算符多分支的if-else语句例题讲解 嵌套的if语句例题讲解 switch语句结构例题讲解代码演示运行结果 概述 Java中的控制结构,包括: 1、选择结构( if、if-else、switch ) 2、循环结…...

基于SpringBoot实现轻量级的动态定时任务调度
在使用SpringBoot框架进行开发时,一般都是通过Scheduled注解进行定时任务的开发: Component public class TestTask {Scheduled(cron"0/5 * * * * ? ") //每5秒执行一次public void execute(){SimpleDateFormat df new SimpleDateFormat(…...

夸克升级“超级搜索框” 推出AI搜索为中心的一站式AI服务
大模型时代,生成式AI如何革新搜索产品?阿里智能信息事业群旗下夸克“举手答题”。7月10日,夸克升级“超级搜索框”,推出以AI搜索为中心的一站式AI服务,为用户提供从检索、创作、总结,到编辑、存储、分享的一…...
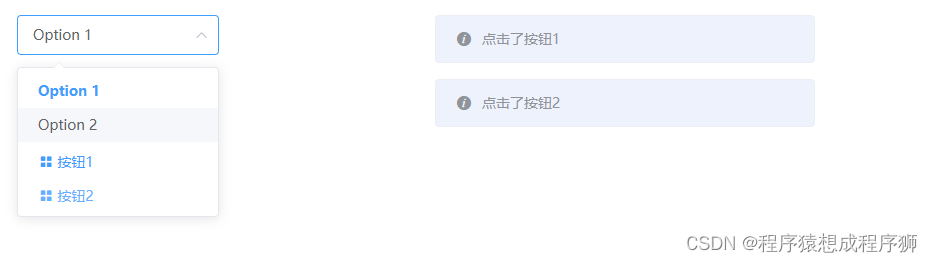
element-ui el-select选择器组件下拉框增加自定义按钮
element-ui el-select选择器组件下拉框增加自定义按钮 先看效果 原理:在el-select下添加禁用的el-option,将其value绑定为undefined,然后覆盖el-option禁用状态下的默认样式即可 示例代码如下: <template><div class…...

Python基于you-get下载网页上的视频
1.python 下载地址 下载 : https://www.python.org/downloads/ 2. 配置环境变量 配置 python_home 地址 配置 python_scripts 地址 在path 中加入对应配置 3. 验证 C:\Users>python --version Python 3.12.4C:\Users>wheel version wheel 0.43.04. 下载 c…...

大模型/NLP/算法面试题总结3——BERT和T5的区别?
1、BERT和T5的区别? BERT和T5是两种著名的自然语言处理(NLP)模型,它们在架构、训练方法和应用场景上有一些显著的区别。以下是对这两种模型的详细比较: 架构 BERT(Bidirectional Encoder Representation…...

vue3项目打包的时候,怎么区别测试环境,和本地环境
在Vue 3项目中区别测试环境和本地环境,并标记接口的方法可以通过环境变量来实现。 首先,你可以在你的项目根目录下创建一个.env文件,并定义你的环境变量。比如,你可以创建.env.local作为本地环境的配置文件,.env.test…...

小特性 大用途 —— YashanDB JDBC驱动的这些特性你都get了吗?
在现代数据库应用场景中,系统的高可用性和负载均衡是确保服务稳定性的基石。YashanDB JDBC驱动通过其创新的多IP配置特性,为用户带来了简洁而强大的解决方案,以实现数据库连接的高可用性和负载均衡,满足企业级应用的高要求。 01 …...

全网最全的软件测试面试八股文
前面看到了一些面试题,总感觉会用得到,但是看一遍又记不住,所以我把面试题都整合在一起,都是来自各路大佬的分享,为了方便以后自己需要的时候刷一刷,不用再到处找题,今天把自己整理的这些面试题…...

VMware虚拟机配置桥接网络
转载:虚拟机桥接网络配置 一、VMware三种网络连接方式 VMware提供了三种网络连接方式,VMnet0, VMnet1, Vmnet8,分别代表桥接,Host-only及NAT模式。在VMware的编辑-虚拟网络编辑器可看到对应三种连接方式的设置(如下图…...

华为机考真题 -- 攀登者1
题目描述: 攀登者喜欢寻找各种地图,并且尝试攀登到最高的山峰。地图表示为一维数组,数组的索引代表水平位置,数组的元素代表相对海拔高度。其中数组元素0代表地面。 一个山脉可能有多座山峰(山峰定义:高度大于相邻位置的高度,或在地图边界且高度大于相邻的高度)。登山者…...

深入理解Python密码学:使用PyCrypto库进行加密和解密
深入理解Python密码学:使用PyCrypto库进行加密和解密 引言 在现代计算领域,信息安全逐渐成为焦点话题。密码学,作为信息保护的关键技术之一,允许我们加密(保密)和解密(解密)数据。P…...

MMSegmentation笔记
如何训练自制数据集? 首先需要在 mmsegmentation/mmseg/datasets 目录下创建一个自制数据集的配置文件,以我的苹果叶片病害分割数据集为例,创建了mmsegmentation/mmseg/datasets/appleleafseg.py 可以看到,这个配置文件主要定义…...

Python基础语法:变量和数据类型详解(整数、浮点数、字符串、布尔值)①
文章目录 变量和数据类型详解(整数、浮点数、字符串、布尔值)一、变量二、数据类型1. 整数(int)2. 浮点数(float)3. 字符串(str)4. 布尔值(bool) 三、类型转换…...

【C++航海王:追寻罗杰的编程之路】关联式容器的底层结构——红黑树
目录 1 -> 红黑树 1.1 -> 红黑树的概念 1.2 -> 红黑树的性质 1.3 -> 红黑树节点的定义 1.4 -> 红黑树的结构 1.5 -> 红黑树的插入操作 1.6 -> 红黑树的验证 1.8 -> 红黑树与AVL树的比较 2 -> 红黑树模拟实现STL中的map与set 2.1 -> 红…...

MySQL DDL
数据库 1 创建数据库 CREATE DATABASE 数据库名 CREATE DATABASE IF NOT EXISTS 数据库名;(判断是否存在) CREATE DATABASE 数据库名 CHARACTER SET 字符 2 查看数据库 SHOW DATABASES; 查看某个数据库的信息 SHOW CAEATE DATABASE 数据库名 3 修改数据库 …...

智能手机相机光谱特性测量与多光谱成像技术
1. 智能手机相机光谱特性测量基础智能手机相机的光谱灵敏度函数(Spectral Sensitivity Function, SSF)和透射率函数是计算摄影领域的核心参数,它们决定了设备对光信号的响应特性。准确获取这些参数对色彩还原、光谱重建和白平衡校准等任务至关重要。1.1 光谱灵敏度函…...

[智能体-69]:重新认知MCP:协议不生产智能,只是AI全域交互的标准化基石
MCP只是提供了大模型、编排调度、外部工具能够进行结构化交流的标准,而整个系统的智能主要依赖编排调度,与外部软件系统的交互取决于外部工具,包括外部语音交互、视觉交互、数字化交互。当下MCP(Model Context Protocol࿰…...

户外实用|艾迪欧 R6000 测评 —— 户外 / 自驾 / 露营的通讯好搭档
户外出行,通讯工具的核心是稳定、清晰、耐用、续航久、功能全。艾迪欧 R6000 作为一款兼顾专业与户外的 DMR 对讲机,全频段覆盖、双模通讯、自定义功能、长续航,完美适配自驾、露营、登山、越野等户外场景,是户外爱好者的靠谱通讯…...

Taotoken平台快速获取APIKey并开始你的第一个Python调用示例
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken平台快速获取APIKey并开始你的第一个Python调用示例 1. 准备工作:注册与登录 要开始使用Taotoken,…...

SMUDebugTool终极指南:如何深度掌控AMD Ryzen处理器的隐藏性能
SMUDebugTool终极指南:如何深度掌控AMD Ryzen处理器的隐藏性能 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: ht…...
--脚本介绍)
二十六.签名与脚本(1)--脚本介绍
1.区块链脚本介绍在之前的章节中,我们了解了签名与验证相关,但是btc的交易数据,签名和验证,不是单纯的,还有脚本深度参与其中。我们从开始来:bool SendMoney(CScript scriptPubKey, int64 nValue, CWalletT…...

【python】ImportError: DLL load failed while importing QtWidgets: 找不到指定的程序。重新安装后搞定
文章目录前言一、PyQt6引用后报错二、使用步骤总结前言 想做个好看的界面,引用了PyQt6,却产生了新问题。 pip install pyqt6-tools,优先做这个动作进行修复。 一、PyQt6引用后报错 python里引用: from PyQt6.QtWidgets import…...

XXPermissions:Android权限管理框架的架构设计与最佳实践
XXPermissions:Android权限管理框架的架构设计与最佳实践 【免费下载链接】XXPermissions Android Permissions Framework, Adapt to Android 16 项目地址: https://gitcode.com/GitHub_Trending/xx/XXPermissions 在Android应用开发中,权限管理一…...

智能体任务分配算法:从启发式到深度强化学习的演进与实践
1. 项目概述:从“谁来做”到“如何做得更好”的智能进化在机器人集群、无人机编队或是自动化仓储系统中,我们常常面临一个看似简单实则复杂的问题:眼前有一堆任务,手头有一群可用的智能体(机器人、无人机、服务器等&am…...

具身智能的发展对人类社会的影响有哪些?
具身智能对人类社会影响一、经济产业层面产业重构:催生机器人、智能制造、自动驾驶新产业,重塑生产链条效率跃升:替代重复繁重劳作,工厂、农业、物流产能大幅提升就业结构变化:低端体力岗位缩减,运维、研发…...