从零开始实现大语言模型(三):Token Embedding与位置编码
1. 前言
Embedding是深度学习领域一种常用的类别特征数值化方法。在自然语言处理领域,Embedding用于将对自然语言文本做tokenization后得到的tokens映射成实数域上的向量。
本文介绍Embedding的基本原理,将训练大语言模型文本数据对应的tokens转换成Embedding向量,介绍并实现OpenAI的GPT系列大语言模型中将tokens在文本数据中的位置编码成Embedding向量的方法。
2. Embedding
Embedding是指将类别特征(categorical feature)映射到连续向量空间中,即使用实数域上的向量表示类别特征。其中,向量的长度是超参数,必须人为设定。向量中每一个元素的值,均是模型的参数,必须从训练数据中学习获得,即通过大量数据训练,模型自动获得每一个类别特征该被表示成一个怎样的向量。
Deep Learning is all about “Embedding Everything”.
Embedding的核心思想是将离散对象映射到连续的向量空间中,其主要目的是将非数值类型的数据转换成神经网络可以处理的格式。
Embedding向量维度的设定并没有精确的理论可以指导,设定的原则是:Embedding向量表示的对象包含的信息越多,则Embedding向量维度应该越高;训练数据集越大,Embedding向量维度可以设置得更高。在大语言模型出现前,深度学习自然语言处理领域,一般Embedding向量的维度是8维(对于小型数据集)到1024维(对于超大型数据集)。更高维度得Embedding向量可以捕获特征对象之间更精细的关系,但是需要更多数据去学习,否则模型非常容易过拟合。GPT-2 small版本使用的Embedding向量维度是768,GPT-3 175B版本使用的Embedding向量维度是12288。
在自然语言处理领域,可以将一个单词或token映射成一个Embedding向量,也可以一个句子、一个文本段落或一整篇文档映射成一个向量。对句子或一段文本做Embedding是检索增强生成(RAG, retrieval-augmented generation)领域最常用的技术方法,RAG是目前缓解大语言模型幻觉现象最有效的技术方法之一。
将一个单词或token映射成一个Embedding向量,只需要构造一个token ID到向量的映射表。将一个句子、一个文本段落或一整篇文档映射成一个向量,往往需要使用一个神经网络模型。模型的输入是一段文本的tokens对应的token ID,输出是一个向量。
以前比较流行的学习一个单词对应的Embedding向量的方法是Word2Vec。Word2Vec的主要思想是具有相同上下文的单词一般有相似的含义,因此可以构造一个给定单词的上下文预测任务来学习单词对应的Embedding向量。如下图所示,如果将单词对应的Embedding向量维度设置为2,可以发现具有相似属性的单词对应的Embedding向量在向量空间中的距离更近,反之则更远。

在大语言模型中不会使用Word2Vec等算法训练生成的Embedding向量,而是直接使用torch.nn.Embedding随机初始化各个tokens对应的Embedding向量,并在训练阶段更新这些Embedding向量中各个元素的值。将各个tokens对应的Embedding向量作为大语言模型的参数,可以确保学到的Embedding向量更加适合当前任务。
在自然语言处理项目实践中,如果训练数据集足够大,一般会使用上述随机初始化并训练Embedding向量的方法,如果训练数据集不够大,则更推荐使用在大数据集上预训练生成的Embedding向量,或者可以直接将预训练模型作为特征提取器,在其后接一个面向下游任务的输出层,只训练输出层参数。
3. 将Tokens转换成Embedding向量
对训练大语言模型的自然语言文本做tokenization,可以将文本转换成一系列tokens。通过词汇表(vocabulary)可以将tokens转换成token IDs。torch.nn.Embedding层可以将token ID映射成Embedding向量。
假设词汇表中共包含6个不同的tokens,每个token对应的Embedding向量维度设置为3。可以使用如下代码随机初始化各个tokens对应的Embedding向量:
import torchtorch.manual_seed(123)input_ids = torch.tensor([5, 1, 3, 2])
vocabulary_size = 6
embedding_dim = 3token_embedding_layer = torch.nn.Embedding(vocabulary_size, embedding_dim)
print(token_embedding_layer.weight)
执行上面代码,打印结果如下:
Parameter containing:
tensor([[ 0.3374, -0.1778, -0.1690],[ 0.9178, 1.5810, 1.3010],[ 1.2753, -0.2010, -0.1606],[-0.4015, 0.9666, -1.1481],[-1.1589, 0.3255, -0.6315],[-2.8400, -0.7849, -1.4096]], requires_grad=True)
Embedding层的权重(weight)矩阵是一个二维的张量,矩阵的行数为6,列数为3,每一行是一个3维向量。词汇表中共6个不同的tokens,第1个token对应的Embedding向量即为权重矩阵的第1行,第2个token对应的Embedding向量即为权重矩阵的第2行。依次类推,第6个token对应的Embedding向量为权重矩阵第6行的向量。权重矩阵是随机初始化的,会在模型训练期间使用随机梯度下降算法更新。
假设输入文本对应的token ID列表为[5, 1, 3, 2],可以使用如下代码,将文本对应的token IDs全部转换成Embedding向量:
input_ids = torch.tensor([5, 1, 3, 2])
token_embeddings = token_embedding_layer(input_ids)
print(token_embeddings)
执行上面代码,打印结果如下:
tensor([[-2.8400, -0.7849, -1.4096],[ 0.9178, 1.5810, 1.3010],[-0.4015, 0.9666, -1.1481],[ 1.2753, -0.2010, -0.1606]], grad_fn=<EmbeddingBackward0>)
将文本对应的4个token IDs输入Embedding层,输出一个4行3列的张量矩阵。可以观察到矩阵的第1行即为Embedding层权重矩阵第6行对应的向量,第2行即为Embedding层权重矩阵第2行对应的向量,第3行即为Embedding层权重矩阵第4行对应的向量,第4行即为Embedding层权重矩阵第3行对应的向量。
如下图所示,输入的token ID列表为[5, 1, 3, 2],输出的张量矩阵分别由Embedding层权重矩阵的第6、2、4、3行的向量构成。由此可见,Embedding层本质上是初始化了一个token ID到Embedding向量的映射,将token ID列表输入Embedding层,会依次索引不同token ID对应的Embedding向量,返回一个Embedding向量矩阵。

4. 位置编码(Positional Encoding)
Embedding层构造了词汇表中全部token IDs到Embedding向量的映射,输入文本数据对应的token ID列表,Embedding层输出相应Embedding向量。Embedding向量与token ID是一一对应关系,token ID列表中不同位置的相同token ID对应的Embedding向量相同,即Embedding层输出的Embedding向量不包含token的位置信息。

大语言模型使用自注意力机制(self-attention)处理自然语言文本,其神经网络不具备循环结构。自注意力机制无法捕捉输入文本中的token序列位置信息,将两个含义不同的文本序列“你爸妈对我的看法”和“我爸妈对你的看法”输入自注意力层,生成的用于预测下一个字的输出向量会完全相同。
后续文章将详细介绍自注意力机制理论原理,提前了解自注意力机制无法捕捉输入文本中的token序列位置信息的原因,可以参见本人写的博客文章BERT与ERNIE - 4. Self-Attention层无法捕捉句子中词序信息原因。
在输入文本对应token的Embedding向量中添加token位置信息的方法有两种:相对位置编码(relative positional embeddings)和绝对位置编码(absolute positional embeddings)。
如下图所示,绝对位置编码直接将输入文本token的绝对位置编码成Embedding向量。假设大语言模型支持的最大输入token数量为 k k k,则总共包含 k k k个不同的待学习的位置Embedding向量。将token对应的Embedding向量与token所在位置对应的Embedding向量相加,生成最终输入大语言模型的Embedding向量。
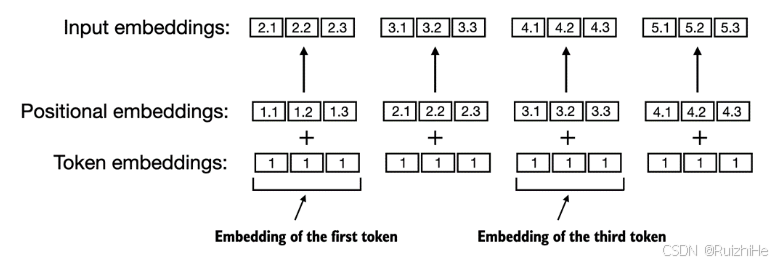
相对位置编码并不将输入token的绝对位置编码成Embedding向量,而是将不同token之间的相对位置编码成Embedding向量。假设设定的最大输入token数量为 k k k,则总共包含 2 k − 1 2k-1 2k−1个不同的待学习的相对位置Embedding向量。
2 k − 1 2k-1 2k−1个不同的带学习的位置Embedding向量分别为: e − k + 1 , e − k + 2 , ⋯ , e − 1 , e 0 , e 1 , ⋯ , e i , ⋯ , e k − 2 , e k − 1 e_{-k+1}, e_{-k+2}, \cdots, e_{-1}, e_0, e_1, \cdots, e_i, \cdots, e_{k-2}, e_{k-1} e−k+1,e−k+2,⋯,e−1,e0,e1,⋯,ei,⋯,ek−2,ek−1,其中 i i i表示与当前token的相对距离为多少个token。
除了上述两种将token位置编码成Embedding向量的位置编码方法,还有许多其他类型的位置编码方法。不管那种位置编码方法,都是为了使大语言模型具备理解token之间顺序及位置关系的能力。OpenAI的GPT系列大语言模型使用的是上述绝对位置编码方法。
假设大语言模型支持的最大输入token数量为8,则可以使用如下代码随机初始化各个位置对应的Embedding向量,并生成输入文本对应的token ID列表中各个token位置对应的Embedding向量:
context_len = 8position_embedding_layer = torch.nn.Embedding(context_len, embedding_dim)
position_embeddings = position_embedding_layer(torch.arange(input_ids.shape[0]))
print(position_embeddings)
执行上面代码,打印结果如下:
tensor([[-2.1338, 1.0524, -0.3885],[-0.9343, -0.4991, -1.0867],[ 0.9624, 0.2492, -0.9133],[-0.4204, 1.3111, -0.2199]], grad_fn=<EmbeddingBackward0>)
将输入文本对应的token_embeddings与position_embeddings相加,即可生成最终输入大语言模型的Embedding向量:
input_embeddings = token_embeddings + position_embeddings
print(input_embeddings)
执行上面代码,打印结果如下:
tensor([[-4.9737, 0.2675, -1.7981],[-0.0166, 1.0818, 0.2144],[ 0.5609, 1.2158, -2.0615],[ 0.8549, 1.1101, -0.3805]], grad_fn=<AddBackward0>)
5. 结束语
对自然语言文本数据做tokenization,可以将文本分割成一连串tokens,并通过词汇表映射成token ID列表。使用Embedding层将token IDs及其位置转换成相同维度的Embedding向量,token对应的Embedding向量与其位置对应的Embedding向量相加,最终生成输入大语言模型的Embedding向量。
接下来,我们该去了解注意力机制了!
相关文章:
从零开始实现大语言模型(三):Token Embedding与位置编码
1. 前言 Embedding是深度学习领域一种常用的类别特征数值化方法。在自然语言处理领域,Embedding用于将对自然语言文本做tokenization后得到的tokens映射成实数域上的向量。 本文介绍Embedding的基本原理,将训练大语言模型文本数据对应的tokens转换成Em…...
视频怎么压缩变小?最佳视频压缩器
即使在云存储和廉价硬盘空间时代,大视频文件使用起来仍然不方便。无论是存储、发送到电子邮件帐户还是刻录到 DVD,拥有最好的免费压缩软件可以确保您快速缩小文件大小,而不必担心视频质量下降。继续阅读以探索一些顶级最佳 免费视频压缩器选项…...

LLM - 绝对与相对位置编码 与 RoPE 旋转位置编码 源码
欢迎关注我的CSDN:https://spike.blog.csdn.net/ 本文地址:https://spike.blog.csdn.net/article/details/140281680 免责声明:本文来源于个人知识与公开资料,仅用于学术交流,欢迎讨论,不支持转载。 Transformer 是基于 MHSA (多头自注意力),然而,MHSA 对于位置是不敏感…...

B3917 [语言月赛 202401] 小跳蛙
OK 挠~ stop here~ 好啊,现在呢,把手头的事情先放一放啊,我们来做道练习 OK? 好啊来: 小跳蛙 题目描述 有 𝑛−1 只小跳蛙在池塘中,依次被编号为 1,2,⋯ ,𝑛−1。池塘里有 &am…...

Bash ——shell
Bash作为用户与操作系统之间的接口,让用户通过命令行输入各种指令来控制和操作计算机系统。 shell的两种解释: 1.linux命令解释器 Terminal 终端 ——》shell命令 ——》 Linux kernel (内核) Linux内核的作用: 1.…...

PyTorch复现PointNet——模型训练+可视化测试显示
因为项目涉及到3D点云项目,故学习下PointNet这个用来处理点云的神经网络 论文的话,大致都看了下,网络结构有了一定的了解,本博文主要为了下载调试PointNet网络源码,训练和测试调通而已。 我是在Anaconda下创建一个新的…...

分享五款软件,成为高效生活的好助手
给大家分享一些优秀的软件工具,是一件让人很愉悦的事情,今天继续带来5款优质软件。 1.图片放大——Bigjpg Bigjpg是一款图片放大软件,采用先进的AI算法,能够在不损失图片质量的前提下,将低分辨率图片放大至所需尺寸。无论…...

代码随想录算法训练营DAY58|101.孤岛的总面积、102.沉没孤岛、103. 水流问题、104.建造最大岛屿
忙。。。写了好久。。。。慢慢补吧。 101.孤岛的总面积 先把周边的岛屿变成水dfs def dfs(x, y, graph, s):if x<0 or x>len(graph) or y<0 or y>len(graph[0]) or graph[x][y]0:return sgraph[x][y]0s1s dfs(x1, y, graph, s)s dfs(x-1, y, graph, s)s dfs(…...

韦尔股份:深蹲起跳?
利润大增7倍,是反转信号还是回光返照? 今天我们聊聊光学半导体龙头——韦尔股份。 上周末,韦尔股份发布半年业绩预告,预计上半年净利润13至14亿,同比增幅高达 754%至 819%。 然而,回首 2023 年它的净利仅 …...

docs | 使用 sphinx 转化rst文件为html文档
1. 效果图 book 风格。 优点: 极简风格右边有标题导航左侧是文件导航,可隐藏 2. 使用方式 reST 格式,比markdown格式更复杂。 推荐使用 book 风格。 文档构建工具是 sphinx,是一个python包。 $ pip3 list | grep -i Sphinx …...
【ChatGPT 消费者偏好】第二弹:ChatGPT在日常生活中的使用—推文分享—2024-07-10
今天的推文主题还是【ChatGPT & 消费者偏好】 第一篇:哪些动机因素和技术特征的组合能够导致ChatGPT用户中高和低的持续使用意图。第二篇:用户对ChatGPT的互动性、性能期望、努力期望以及社会影响如何影响他们继续使用这些大型语言模型的意向&#x…...

Webpack配置及工作流程
Webpack是一个现代JavaScript应用程序的静态模块打包器(module bundler)。当Webpack处理应用程序时,它会在内部构建一个依赖图(dependency graph),该图会映射项目所需的每个模块,并生成一个或多…...

华为ensp实现防火墙的区域管理与用户认证
实验环境 基于该总公司内网,实现图片所在要求 后文配置请以本图为准 接口配置与网卡配置 1、创建vlan 2、防火墙g0/0/0与云页面登录 登录admin,密码Admin123,自行更改新密码 更改g0/0/0口ip,敲下命令service-manage all permit 网卡配置…...

深入解析 Laravel 策略路由:提高应用安全性与灵活性的利器
引言 Laravel 是一个功能强大的 PHP Web 应用框架,以其优雅和简洁的语法而受到开发者的喜爱。在 Laravel 中,路由是应用中非常重要的一部分,它负责将用户的请求映射到相应的控制器方法上。Laravel 提供了多种路由方式,其中策略路…...

Java | Leetcode Java题解之第228题汇总区间
题目: 题解: class Solution {public List<String> summaryRanges(int[] nums) {List<String> ans new ArrayList<>();for (int i 0, j, n nums.length; i < n; i j 1) {j i;while (j 1 < n && nums[j 1] num…...

使用Simulink基于模型设计(三):建模并验证系统
可以对系统结构中的每个组件进行建模,以表示该组件的物理行为或功能行为。通过使用测试数据对组件进行仿真,以验证它们的基本行为。 打开系统布局 对各个组件进行建模时,需要从大局上把握整个系统布局。首先加载布局模型。这里以simulink自…...

基于go 1.19的站点模板爬虫
好像就三步: 1 建立http连接 2 解析html内容 3 递归遍历 创建一个基于 Go 1.19 的网站模板爬虫主要涉及几个步骤,包括设置 HTTP 客户端来获取网页内容、解析 HTML 来提取所需的数据,以及处理可能的并发和错误。下面我会给出一个简单的例子来说明如何…...

0基础学会在亚马逊云科技AWS上搭建生成式AI云原生Serverless问答QA机器人(含代码和步骤)
小李哥今天带大家继续学习在国际主流云计算平台亚马逊云科技AWS上开发生成式AI软件应用方案。上一篇文章我们为大家介绍了,如何在亚马逊云科技上利用Amazon SageMaker搭建、部署和测试开源模型Llama 7B。下面我将会带大家探索如何搭建高扩展性、高可用的完全托管云原…...

[PaddlePaddle飞桨] PaddleOCR图像小模型部署
PaddleOCR的GitHub项目地址 推荐环境: PaddlePaddle > 2.1.2 Python > 3.7 CUDA > 10.1 CUDNN > 7.6pip下载指令: python -m pip install paddlepaddle-gpu2.5.1 -i https://pypi.tuna.tsinghua.edu.cn/simple pip install paddleocr2.7…...

C语言 | Leetcode C语言题解之第227题基本计算题II
题目: 题解: int calculate(char* s) {int n strlen(s);int stk[n], top 0;char preSign ;int num 0;for (int i 0; i < n; i) {if (isdigit(s[i])) {num num * 10 (int)(s[i] - 0);}if (!isdigit(s[i]) && s[i] ! || i n - 1) {s…...

应用升级/灾备测试时使用guarantee 闪回点迅速回退
1.场景 应用要升级,当升级失败时,数据库回退到升级前. 要测试系统,测试完成后,数据库要回退到测试前。 相对于RMAN恢复需要很长时间, 数据库闪回只需要几分钟。 2.技术实现 数据库设置 2个db_recovery参数 创建guarantee闪回点,不需要开启数据库闪回。…...

前端倒计时误差!
提示:记录工作中遇到的需求及解决办法 文章目录 前言一、误差从何而来?二、五大解决方案1. 动态校准法(基础版)2. Web Worker 计时3. 服务器时间同步4. Performance API 高精度计时5. 页面可见性API优化三、生产环境最佳实践四、终极解决方案架构前言 前几天听说公司某个项…...

8k长序列建模,蛋白质语言模型Prot42仅利用目标蛋白序列即可生成高亲和力结合剂
蛋白质结合剂(如抗体、抑制肽)在疾病诊断、成像分析及靶向药物递送等关键场景中发挥着不可替代的作用。传统上,高特异性蛋白质结合剂的开发高度依赖噬菌体展示、定向进化等实验技术,但这类方法普遍面临资源消耗巨大、研发周期冗长…...

ServerTrust 并非唯一
NSURLAuthenticationMethodServerTrust 只是 authenticationMethod 的冰山一角 要理解 NSURLAuthenticationMethodServerTrust, 首先要明白它只是 authenticationMethod 的选项之一, 并非唯一 1 先厘清概念 点说明authenticationMethodURLAuthenticationChallenge.protectionS…...

从零实现STL哈希容器:unordered_map/unordered_set封装详解
本篇文章是对C学习的STL哈希容器自主实现部分的学习分享 希望也能为你带来些帮助~ 那咱们废话不多说,直接开始吧! 一、源码结构分析 1. SGISTL30实现剖析 // hash_set核心结构 template <class Value, class HashFcn, ...> class hash_set {ty…...

高防服务器能够抵御哪些网络攻击呢?
高防服务器作为一种有着高度防御能力的服务器,可以帮助网站应对分布式拒绝服务攻击,有效识别和清理一些恶意的网络流量,为用户提供安全且稳定的网络环境,那么,高防服务器一般都可以抵御哪些网络攻击呢?下面…...

CVE-2020-17519源码分析与漏洞复现(Flink 任意文件读取)
漏洞概览 漏洞名称:Apache Flink REST API 任意文件读取漏洞CVE编号:CVE-2020-17519CVSS评分:7.5影响版本:Apache Flink 1.11.0、1.11.1、1.11.2修复版本:≥ 1.11.3 或 ≥ 1.12.0漏洞类型:路径遍历&#x…...
的使用)
Go 并发编程基础:通道(Channel)的使用
在 Go 中,Channel 是 Goroutine 之间通信的核心机制。它提供了一个线程安全的通信方式,用于在多个 Goroutine 之间传递数据,从而实现高效的并发编程。 本章将介绍 Channel 的基本概念、用法、缓冲、关闭机制以及 select 的使用。 一、Channel…...

uniapp 字符包含的相关方法
在uniapp中,如果你想检查一个字符串是否包含另一个子字符串,你可以使用JavaScript中的includes()方法或者indexOf()方法。这两种方法都可以达到目的,但它们在处理方式和返回值上有所不同。 使用includes()方法 includes()方法用于判断一个字…...

毫米波雷达基础理论(3D+4D)
3D、4D毫米波雷达基础知识及厂商选型 PreView : https://mp.weixin.qq.com/s/bQkju4r6med7I3TBGJI_bQ 1. FMCW毫米波雷达基础知识 主要参考博文: 一文入门汽车毫米波雷达基本原理 :https://mp.weixin.qq.com/s/_EN7A5lKcz2Eh8dLnjE19w 毫米波雷达基础…...