26.7 Django单表操作
1. 模型管理器
1.1 Manager管理器
Django ORM中, 每个Django模型(Model)至少有一个管理器, 默认的管理器名称为objects.
objects是一个非常重要的管理器(Manager)实例, 它提供了与数据库进行交互的接口.通过管理器, 可以执行数据库查询, 保存对象到数据库等操作.objects管理器的主要作用:
- 创建和保存对象: 虽然直接通过模型类也可以创建和保存对象, 但objects管理器也提供了如create()这样的方法来一次性创建并保存对象.
- 查询数据库: 通过objects管理器, 可以使用Django提供的查询集(QuerySet)API来构建和执行复杂的数据库查询.
- 删除对象: 使用objects.delete()方法可以删除查询集中的所有对象, 或者使用.delete()方法在单个对象上调用以删除该对象.
- 自定义管理器: 虽然每个模型都有一个默认的objects管理器, 但也可以定义自己的管理器来执行特定的数据库操作.通过ORM模型管理器提供的API(objects的方法), 开发者可以像操作对象一样来操作数据库中的数据, 而不需要编写大量的SQL语句.
1.2 测试环境搭建
1.2.1 测试模型
修改models文件, 创建一个User模型用于测试:
# index的models.py
from django.db import models# 用户模型
class User(models.Model):# id字段(自动增加)# 用户名name = models.CharField(max_length=32)# 年龄age = models.IntegerField()# 注册时间(实例被保存到数据库时自动设置为当前的日期和时间)register_time = models.DateTimeField(auto_now_add=True)
DateTimeField是一个非常常用的字段类型, 用于存储日期和时间.
当设置auto_now_add=True时, Django会自动在对象首次被保存到数据库时设置这个字段的值为当前的日期和时间.Django确实会默认使用UTC时间来存储时间戳, 但这主要取决于Django项目的时区设置.
Django通过在settings.py文件的TIME_ZONE设置来指定项目的时区.如果TIME_ZONE设置为'UTC', 那么auto_now_add=True将会以UTC时间来保存日期和时间.
如果TIME_ZONE设置为其他时区(例如: 'Asia/Shanghai'), Django在内部仍然会使用UTC来存储时间戳,
但在模板渲染, 表单处理或管理界面等地方, Django会根据TIME_ZONE的设置自动进行时区转换, 以便显示给用户的是他们所在时区的时间.
执行数据迁移命令:
# 生成迁移记录
PS D:\MyDjango> python manage.py makemigrations
Migrations for 'index':index\migrations\0001_initial.py- Create model User# 执行迁移
PS D:\MyDjango> python manage.py migrate
Operations to perform:Apply all migrations: admin, auth, contenttypes, index, sessions
Running migrations:Applying contenttypes.0001_initial... OKApplying auth.0001_initial... OKApplying admin.0001_initial... OKApplying admin.0002_logentry_remove_auto_add... OKApplying admin.0003_logentry_add_action_flag_choices... OKApplying contenttypes.0002_remove_content_type_name... OKApplying auth.0002_alter_permission_name_max_length... OKApplying auth.0003_alter_user_email_max_length... OKApplying auth.0004_alter_user_username_opts... OKApplying auth.0005_alter_user_last_login_null... OKApplying auth.0006_require_contenttypes_0002... OKApplying auth.0007_alter_validators_add_error_messages... OKApplying auth.0008_alter_user_username_max_length... OKApplying auth.0009_alter_user_last_name_max_length... OKApplying auth.0010_alter_group_name_max_length... OKApplying auth.0011_update_proxy_permissions... OKApplying auth.0012_alter_user_first_name_max_length... OKApplying index.0001_initial... OKApplying sessions.0001_initial... OK
PS D:\MyDjango> 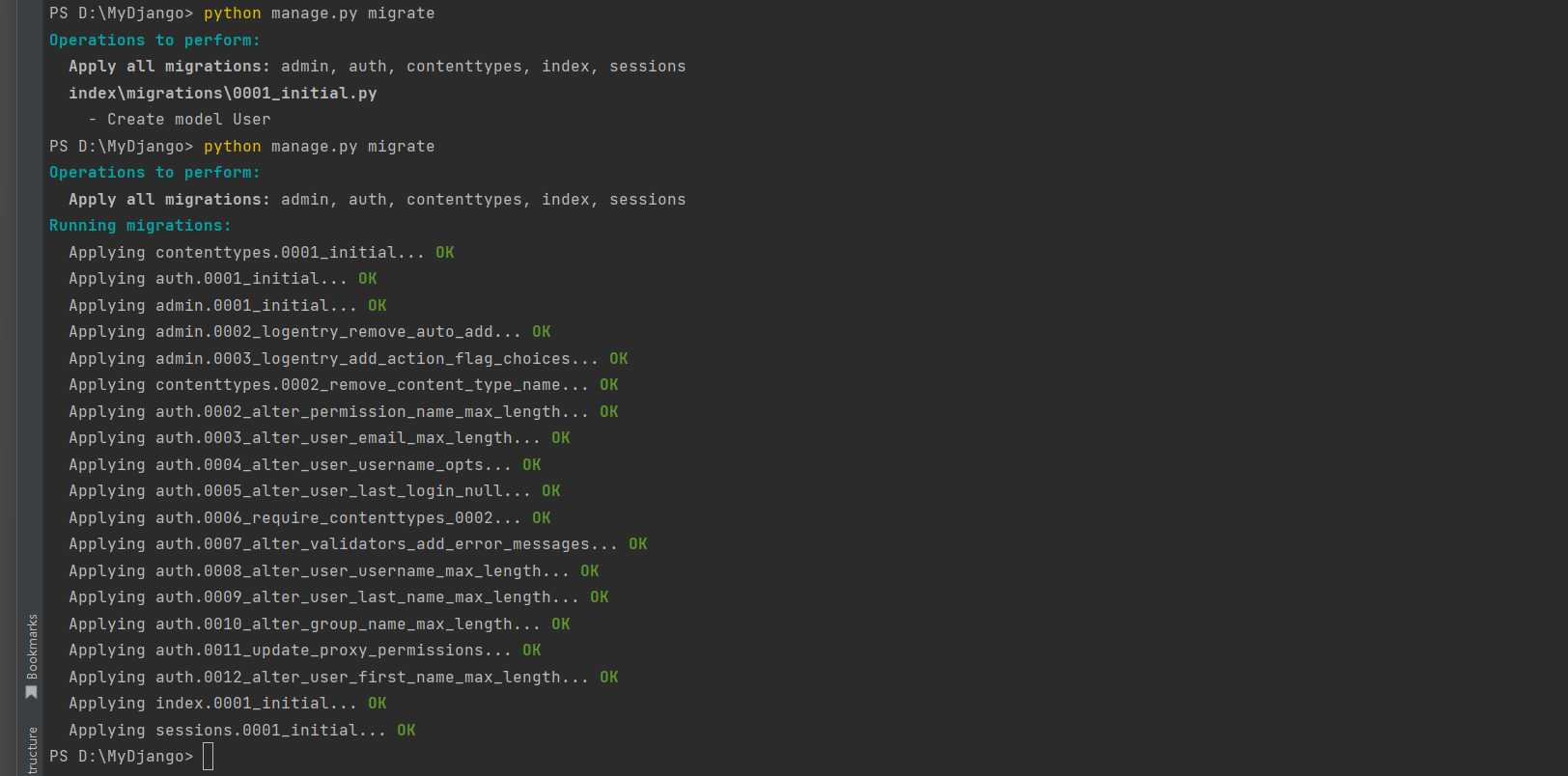
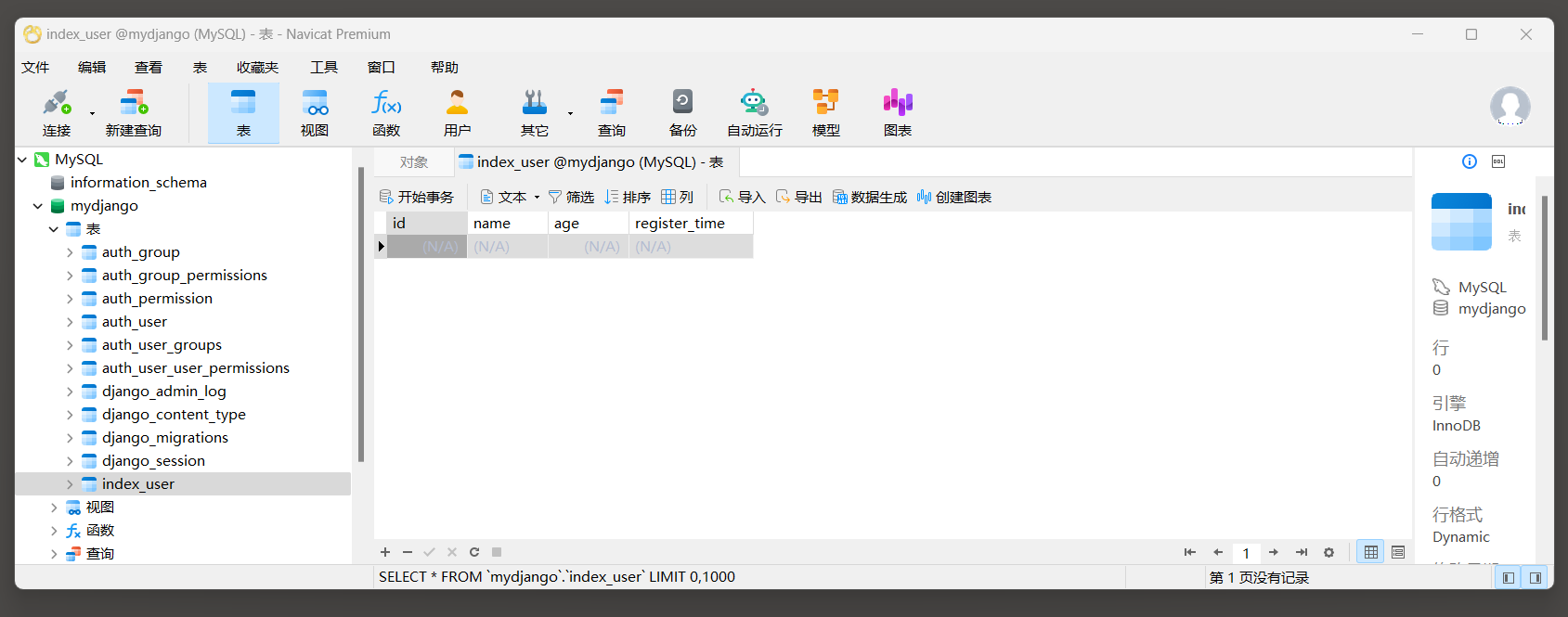
使用Navicat工具查看创建的表格.
1.2.2 ORM日志
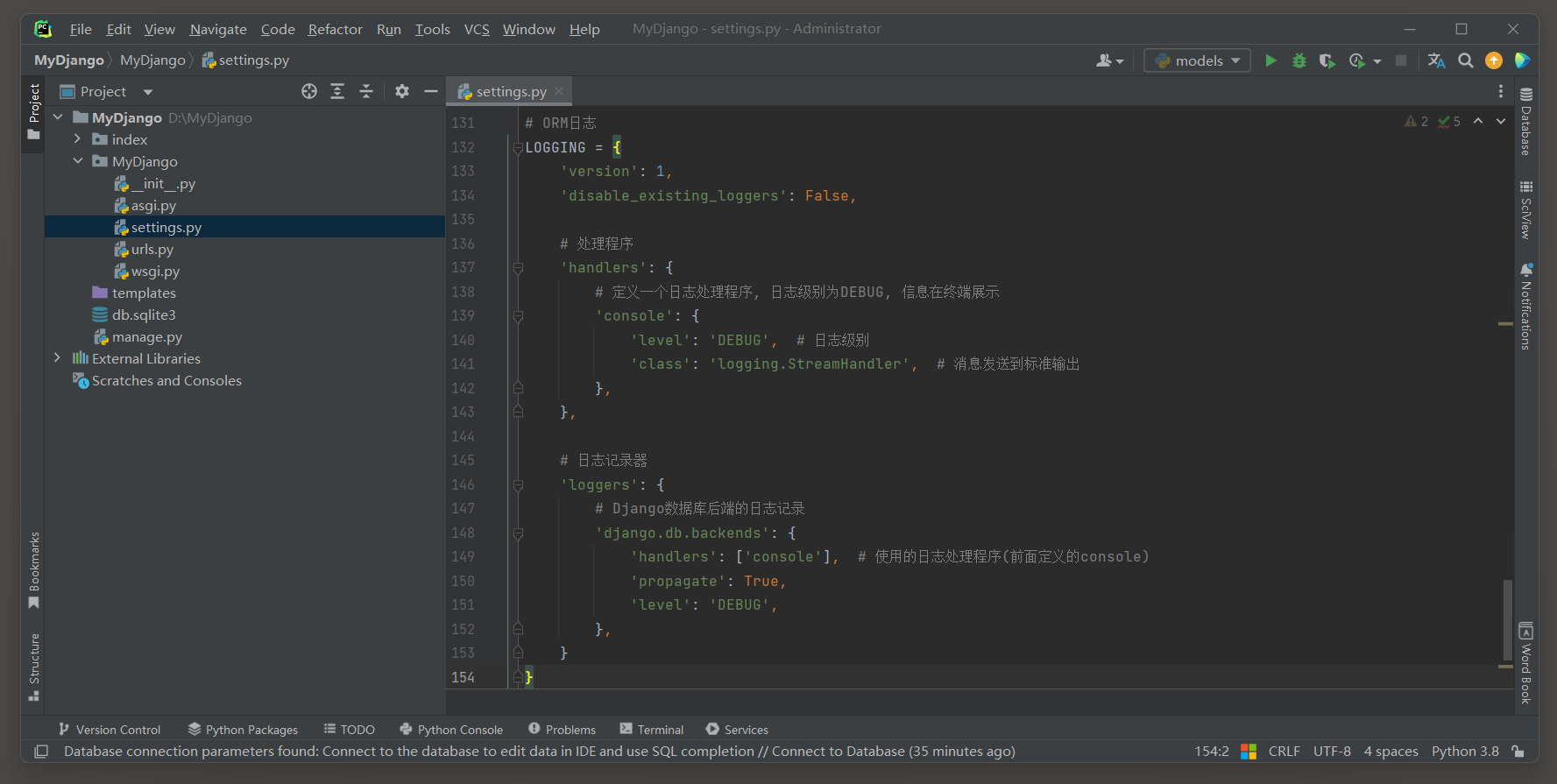
如果想要查看API转换的SQL语句, 记得在settings.py配置文件中添加ORM日志.
# ORM日志
LOGGING = {'version': 1,'disable_existing_loggers': False,# 处理程序'handlers': {# 定义一个日志处理程序, 日志级别为DEBUG, 信息在终端展示'console': {'level': 'DEBUG', # 日志级别'class': 'logging.StreamHandler', # 消息发送到标准输出},},# 日志记录器'loggers': {# Django数据库后端的日志记录'django.db.backends': {'handlers': ['console'], # 使用的日志处理程序(前面定义的console)'propagate': True,'level': 'DEBUG',},}
}
1.2.3 测试文件
每个Django应用(app)通常会有一个tests.py文件, 这个文件用于存放该应用的测试代码.
下面的代码片段主要用于在脚本或命令行环境中直接运行Django的代码.
(这种做法通常用于脚本或临时测试, 而不是标准的Django测试用例.)
# index的test.py(不要执行)
import osif __name__ == "__main__":# 设置 DJANGO_SETTINGS_MODULE 环境变量os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'MyDjango.settings') # !!!需要修改为自己的配置文件# 导入Django, 以便可以调用setup()import django# 初始化Django项目django.setup()# 现在可以安全地导入Django模型和其他组件from index import models# 在这里, 可以编写代码来测试或操作Django模型# 例如, 创建一个新的模型实例instance = models.User.objects.create(field1='value1', field2='value2')print(instance)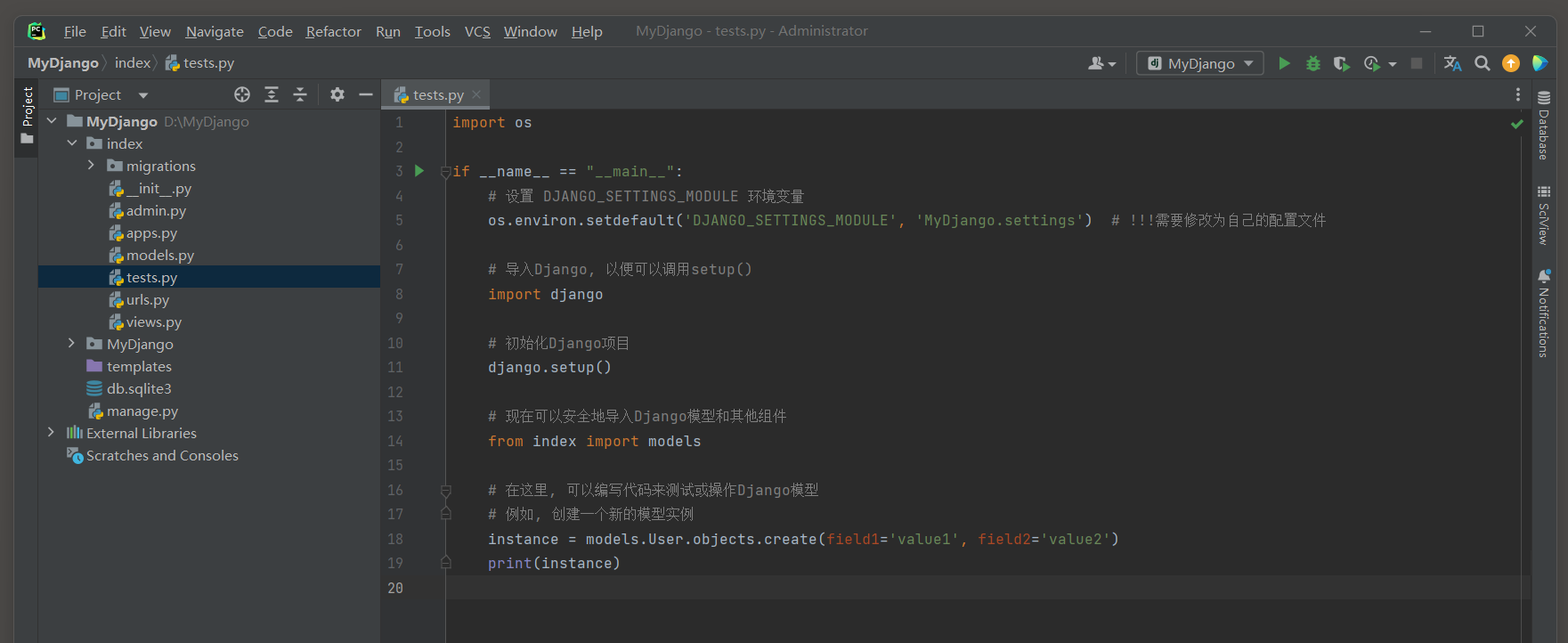
1.3 pk主键字段
在Django框架中, id和pk(Primary Key)通常用于指代数据库表中的主键字段, 但在实际使用上它们之间有着微妙的区别和联系.id通常是Django自动为模型(Model)添加的一个主键字段, 除非你在模型中显式定义了其他字段作为主键.
Django在创建模型时, 默认会添加一个名为id的AutoField字段作为主键, 如果没有指定其他主键字段的话.
当查询或引用某个模型实例时, 可以直接使用id来访问其主键值.pk是primary key的缩写, 用于指代模型实例的主键.
在Django的模型实例上, pk是一个属性, 它总是指向该实例的主键值, 无论主键字段的名称是什么.
如果模型的主键字段名为id(这是最常见的情况), 那么pk和id在大多数情况下可以互换使用.
但是, 如果模型显式定义了一个不同的主键字段(比如user_id), 那么pk仍然会指向这个主键字段的值,
而id则不会存在(除非你同时也定义了一个名为id的字段).
1.4 查看SQL语句
QuerySet对象有一个query属性: 用于查看ORM生成的SQL语句.
这个属性主要面向Django内部开发者和高级用户, 了解它可以更深入地理解Django如何与数据库交互.注意事项:
在使用query属性时, 需要先调用其他操作方法, 否则会引发异常.
query属性仅用于调试目的, 不应在生产环境中使用.
假设我们有一个User模型, 如下所示:
# 测试文件代码(现在看一眼, 不要去运行)
import osif __name__ == "__main__":os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'MyDjango.settings') # !!!需要修改为自己的配置文件import djangodjango.setup()from index.models import Usersql = User.objects.all().queryprint(sql)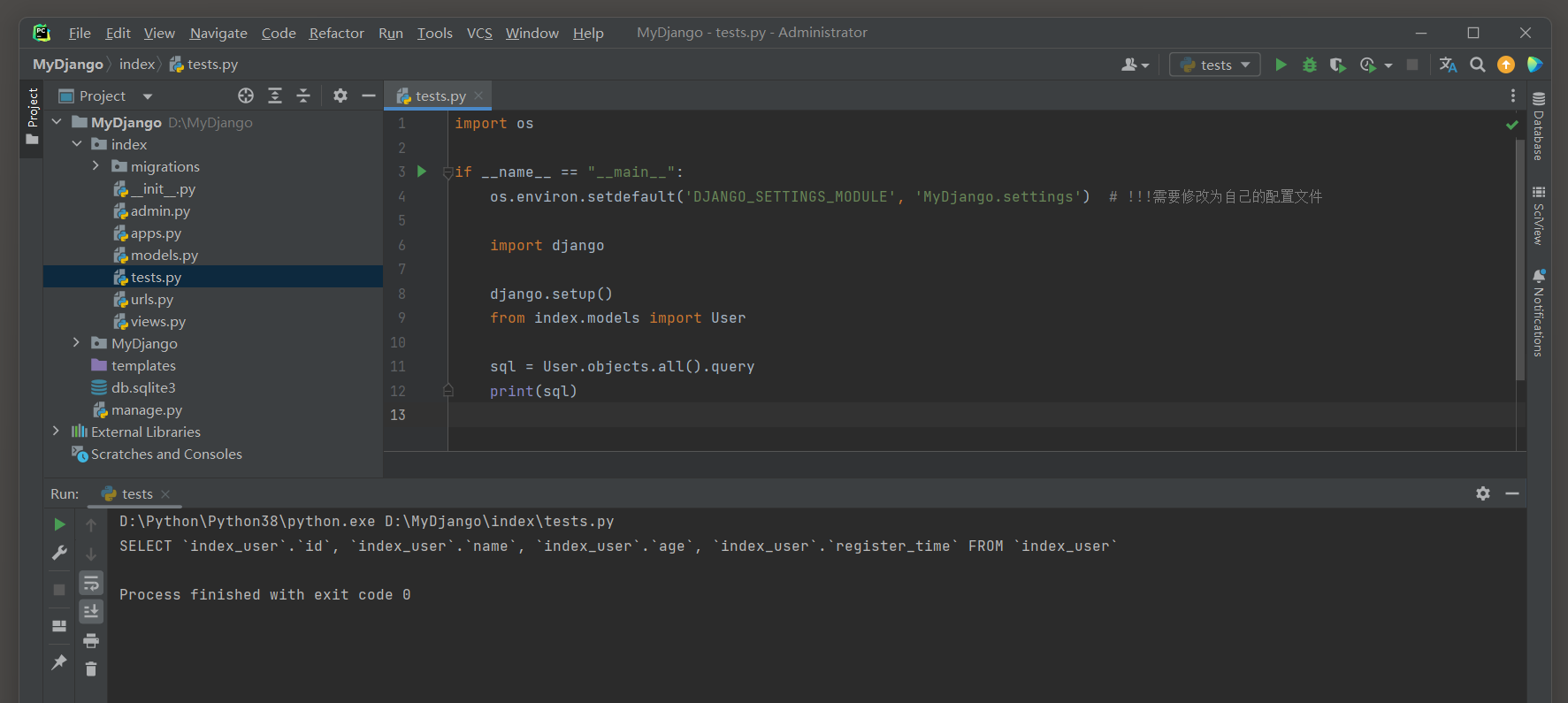
User.objects.all().query是一个Django查询, 用于获取User模型的所有对象.
这里涉及到以下几个部分:
- User: 这是一个Django模型类, 表示数据库中的一个表.
- objects: 这是Django模型类的一个管理器(Manager), 用于对数据库进行操作.
- all(): 这是一个方法, 用于获取模型类对应的表中的所有记录.
- query: 这是一个属性, 用于查看生成的SQL查询语句.
2. 新增记录
2.1 create()方法
create()方法是模型管理器(通常是objects)的一个便捷方法, 它可以一次性设置模型字段的值并保存新创建的实例到数据库中.
create()方法会返回一个保存后的数据对象, 这意味着可以通过'对象.field'访问这个实例的任何字段.
# index的test.py
import osif __name__ == "__main__":# 设置 DJANGO_SETTINGS_MODULE 环境变量os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'MyDjango.settings') # !!!需要修改为自己的配置文件# 导入Django, 以便可以调用setup()import django# 初始化Django项目django.setup()# 现在可以安全地导入Django模型和其他组件from index import models# 创建用户信息new_user = models.User.objects.create(name='kid', age=18)print(new_user, type(new_user)) # User object (2) <class 'index.models.User'>print(new_user.id) # 访问idprint(new_user.pk) # 访问主键print(new_user.name) # 访问name字段的值print(new_user.age) # 访问age字段的值print(new_user.register_time) # 访问register_time字段的值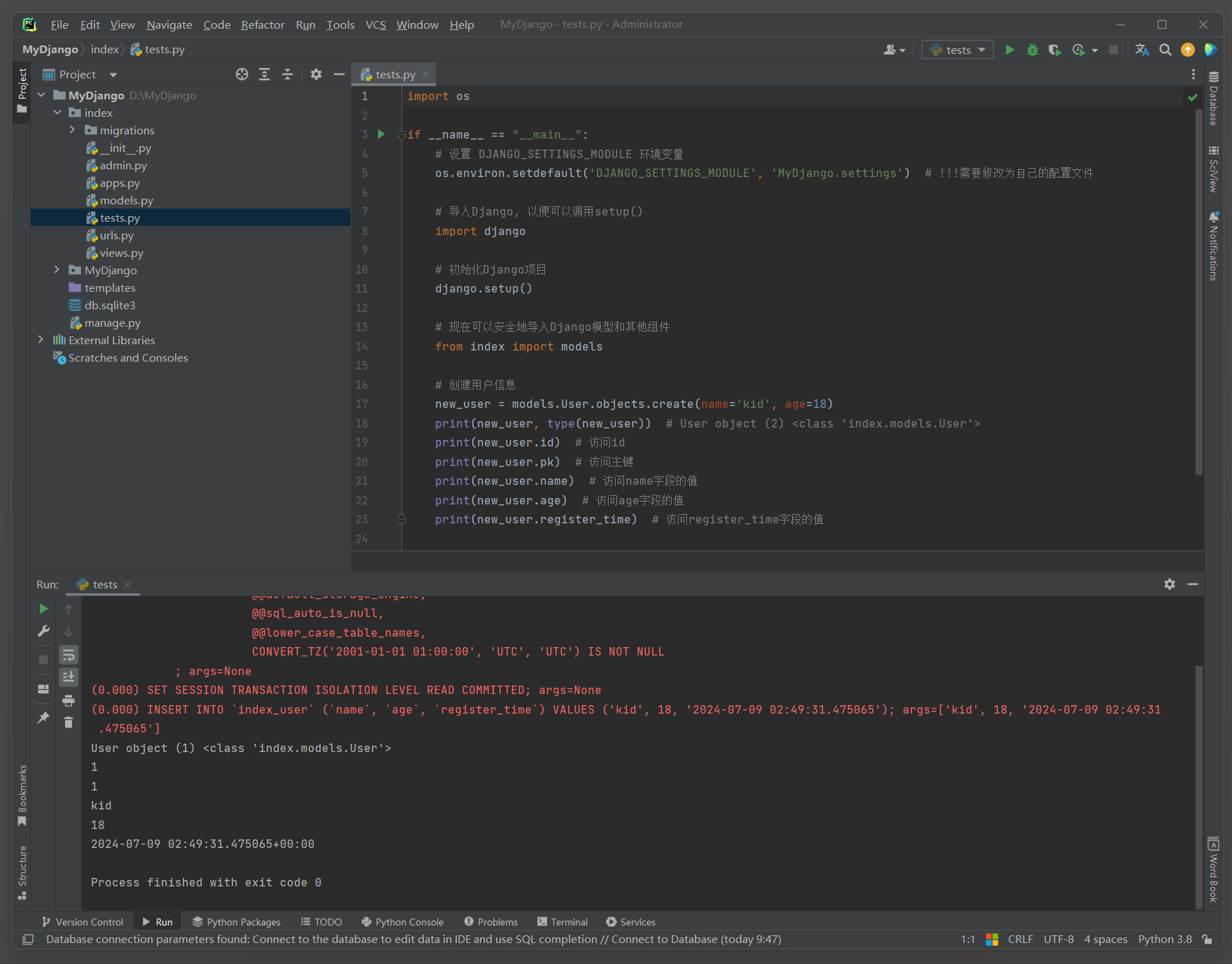
# ORM日志:
(0.015)
INSERT INTO `index_user` (`name`, `age`, `register_time`)
VALUES ('kid', 18, '2024-07-09 02:28:30.707461');
args=['kid', 18, '2024-07-09 02:28:30.707461']
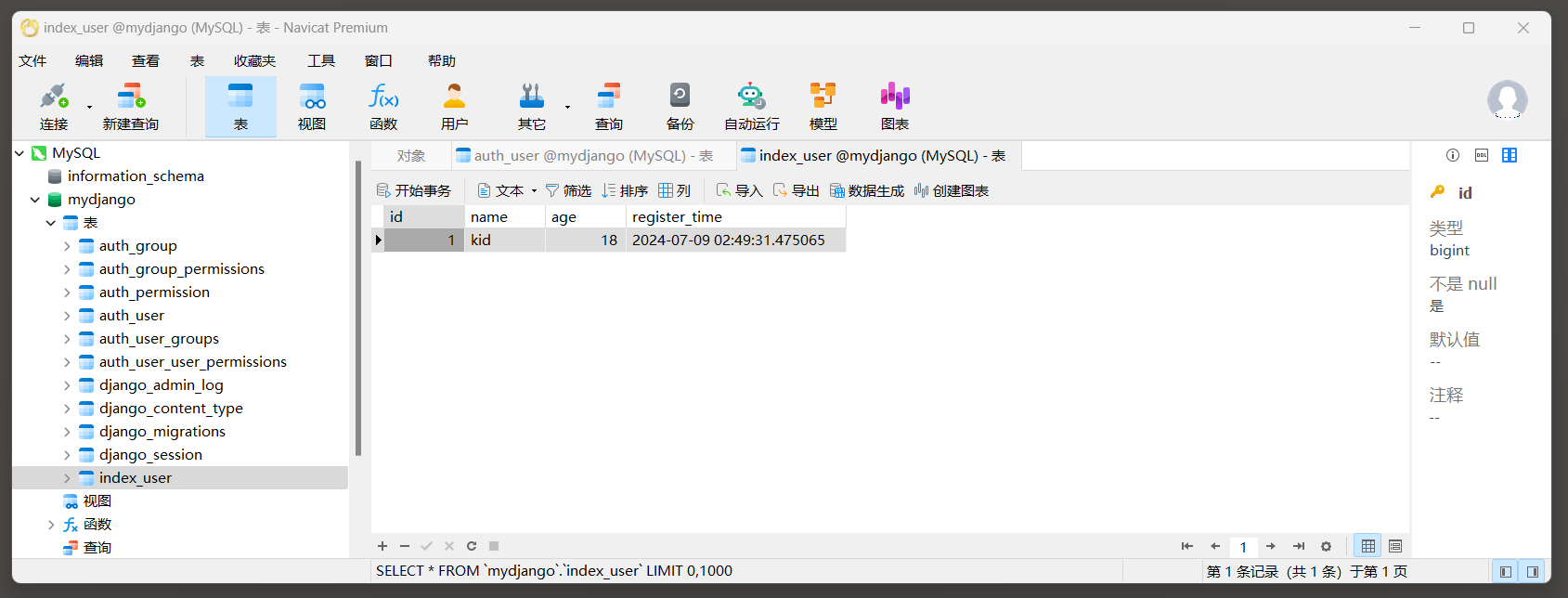
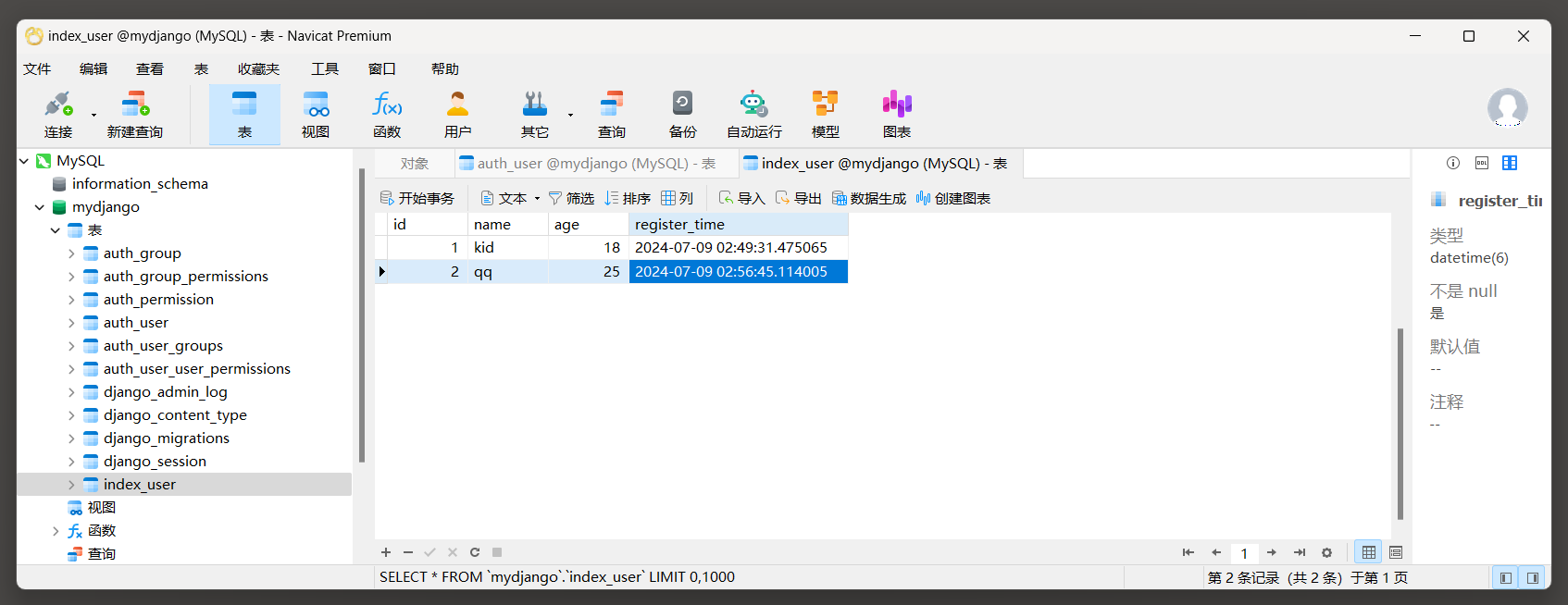
使用Navicat工具查看index_user表数据.
2.2 save()方法
如果需要在将数据保存到数据库之前执行一些自定义操作,
比如设置额外的字段值或基于其他字段的值进行计算, 可以首先创建一个模型(Model)的实例.
随后, 可以对这个实例进行修改, 以满足需求.
最后, 通过调用该实例的save()方法, 将修改后的数据保存到数据库中.
save()方法通常没有返回值.
# index的test.py
import osif __name__ == "__main__":# 设置 DJANGO_SETTINGS_MODULE 环境变量os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'MyDjango.settings') # !!!需要修改为自己的配置文件# 导入Django, 以便可以调用setup()import django# 初始化Django项目django.setup()# 现在可以安全地导入Django模型和其他组件from index import models# 先创建一个User实例, 但不保存到数据库new_user = models.User(name='qq')print(new_user, type(new_user))# 在这里, 可以进行任何必要的自定义操作# 例如, 基于其他字段的值设置age字段new_user.age = 25 # 假设这是基于某些逻辑计算得出的# 现在, 将实例保存到数据库res = new_user.save()print(res)
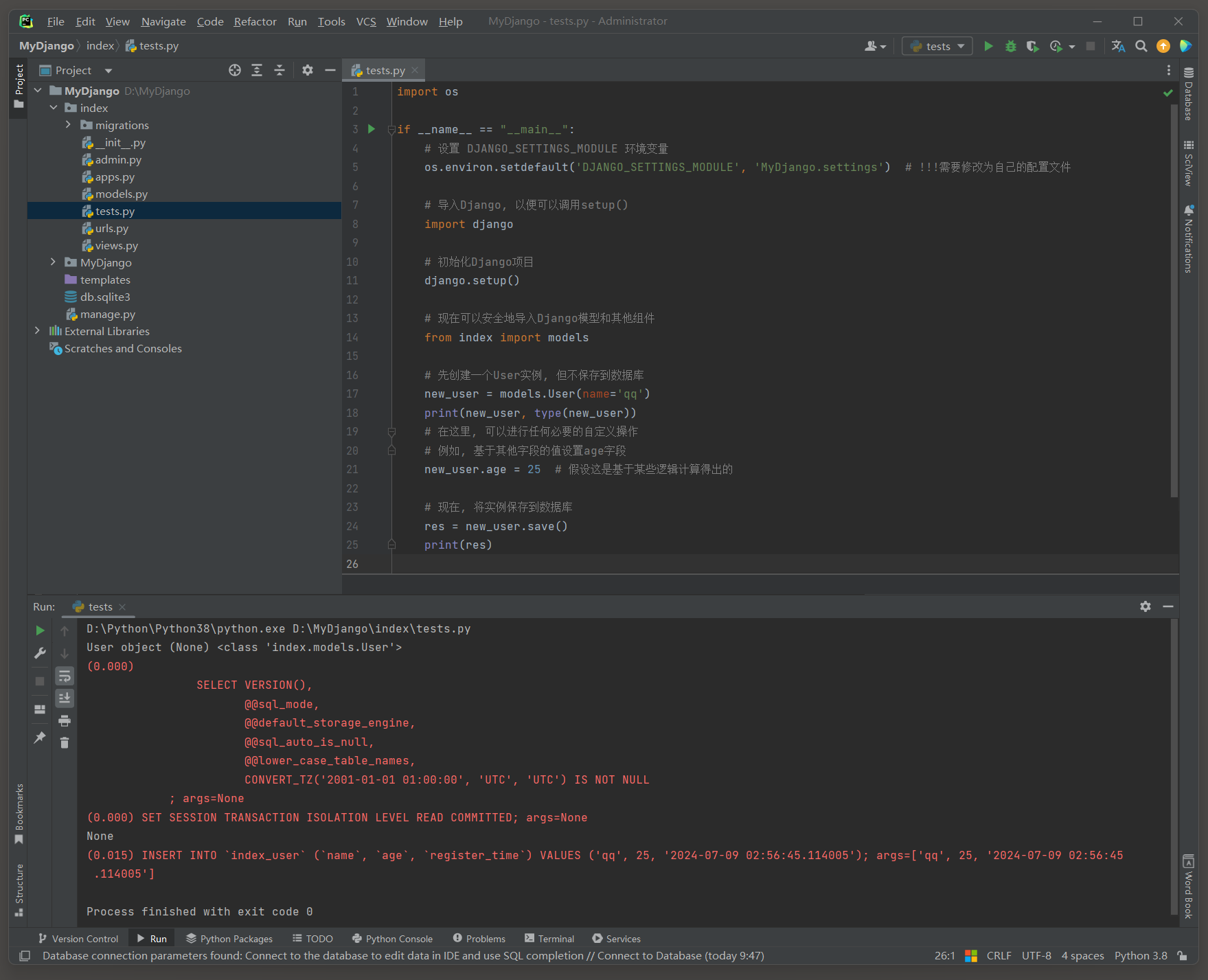
# ORM日志:
(0.015)
INSERT INTO `index_user` (`name`, `age`, `register_time`)
VALUES ('qq', 25, '2024-07-09 02:56:45.114005');
args=['qq', 25, '2024-07-09 02:56:45.114005']
执行脚本之后, 使用Navicat工具查看index_user表格的数据.
2.3 bulk_create()方法
对于需要批量创建大量记录的场景, 可以使用Django的批量创建bulk_create()方法.
调用create()时, Django都会执行一个单独的数据库查询来插入新记录.
而bulk_create()则将所有待插入的记录组合成一个单一的数据库查询, 这显著减少了与数据库的交互次数, 从而提高了效率.
bulk_create()方法中, 不能直接为创建的对象设置主键值(自增的ID字段).
这是因为bulk_create()旨在高效地批量插入数据到数据库中,
是通过构建一个SQL语句来一次性插入多个记录, 而不会为每个记录单独发送SQL语句.
如果允许用户指定主键值可能会破坏批量插入的性能优势, 特别是当主键是自增类型时.
bulk_create()方法返回一个包含所有新创建对象的列表, 但这些对象通常是传入bulk_create()方法的原始对象的副本.
这些对象不包含由数据库自动生成的id字段值, 默认值不其他参数自动生成的值不受影响.
如果尝试访问这些新创建对象的ID, 会遇到None. 实际应用中, 如果不需要立即访问这些自动生成的字段值, 那么bulk_create()是一个非常好的选择, 因为它可以显著提高大量数据插入的性能.如果需要这些值, 可能需要重新考虑的数据处理策略.
# index的test.py
import osif __name__ == "__main__":# 设置 DJANGO_SETTINGS_MODULE 环境变量os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'MyDjango.settings') # !!!需要修改为自己的配置文件# 导入Django, 以便可以调用setup()import django# 初始化Django项目django.setup()# 现在可以安全地导入Django模型和其他组件from index.models import User# 准备模型实例列表Users = [User(name="aa", age=19),User(name="bb", age=19),User(name="cc", age=19),]# 批量创建并保存到数据库created_users = User.objects.bulk_create(Users) # created_users是Users列表的副本print(created_users, type(created_users))# 打印用户信息for user in created_users:print(user.name, user.age, user.id)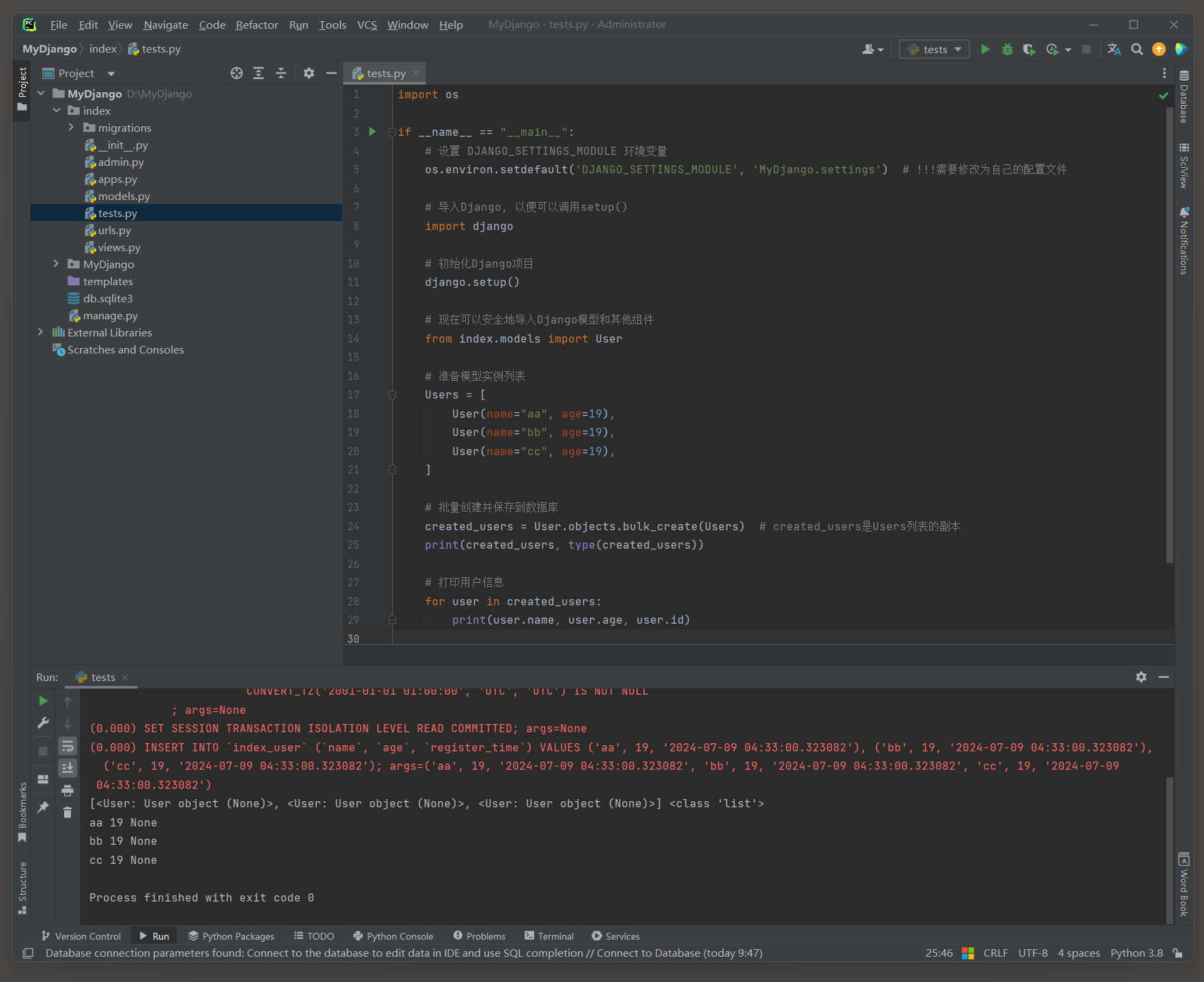
# ORM日志:
(0.000)
INSERT INTO `index_user`
(`name`, `age`, `register_time`)
VALUES
('aa', 19, '2024-07-09 04:33:00.323082'),
('bb', 19, '2024-07-09 04:33:00.323082'),
('cc', 19, '2024-07-09 04:33:00.323082');
args=(
'aa', 19, '2024-07-09 04:33:00.323082',
'bb', 19, '2024-07-09 04:33:00.323082',
'cc', 19, '2024-07-09 04:33:00.323082'
)
2.4 区别概述
new_user = models.User.objects.create(name='qq', ...)
自动保存: 此方法会立即将新创建的用户对象保存到数据库中.
返回值: 它返回新创建并保存到数据库中的用户对象实例. 这个实例包含了由数据库自动生成的字段值(如自增ID).new_user = models.User(name='qq')
不自动保存: 此方法仅创建一个用户对象的实例(未分配ID), 但它不会立即将这个实例保存到数据库中.
手动保存: 为了将对象保存到数据库中, 需要手动调用该实例的save()方法.
save()方法的返回值: 当调用save()方法时, 它会将对象保存到数据库中. 没有返回值.created_users = User.objects.bulk_create(Users)
批量保存: 此方法接受一个对象列表(例子中Users包含多个User实例), 并将它们一次性插入到数据库中.
这是一个高效的批量插入操作, 比单独调用每个对象的save()方法要快得多.
返回值: bulk_create()返回一个包含所有传入对象的列表(副本). 这些对象没有从数据库中检索更新后的值(id字段).
3. 模型的字符串表现形式
在Django中, 当使用models.User.objects.create()方法创建一个新的用户实例并保存到数据库中时, 得到的是一个User对象的实例.
这个实例代表了数据库中新创建的行(或记录). 当打印这个对象时(如print(new_user)),
Django默认的行为是显示这个对象的类型(这里是User)和它的数据库ID(在这个例子中是1), 这就是为什么看到输出是: User object (1).这个输出并不是特别有用, 尤其是当想要查看或调试这个对象的详细信息时.
为了更清晰地看到对象的属性, 在Django模型中, 可以通过定义__str__方法来指定打印对象时应该显示什么.
__str__方法是Python中的一个特殊方法, 用于定义对象的字符串表示形式. 它对用户友好, 通常用于打印输出或转换为字符串的操作.注意: 修改__str__方法不需要数据迁移, 因为它不改变数据库的结构或内容. 它只是改变了对象在Python代码中的表示方式.
例如, 如果想要在打印时显示用户名, 可以这样做:
# index的models.py
from django.db import models# 用户模型
class User(models.Model):# id字段(自动增加)# 用户名name = models.CharField(max_length=32)# 年龄age = models.IntegerField()# 注册时间(实例被保存到数据库时自动设置为当前的日期和时间)register_time = models.DateTimeField(auto_now_add=True)# 打印对象时展示的信息, 显示对象的name属性.def __str__(self): return self.name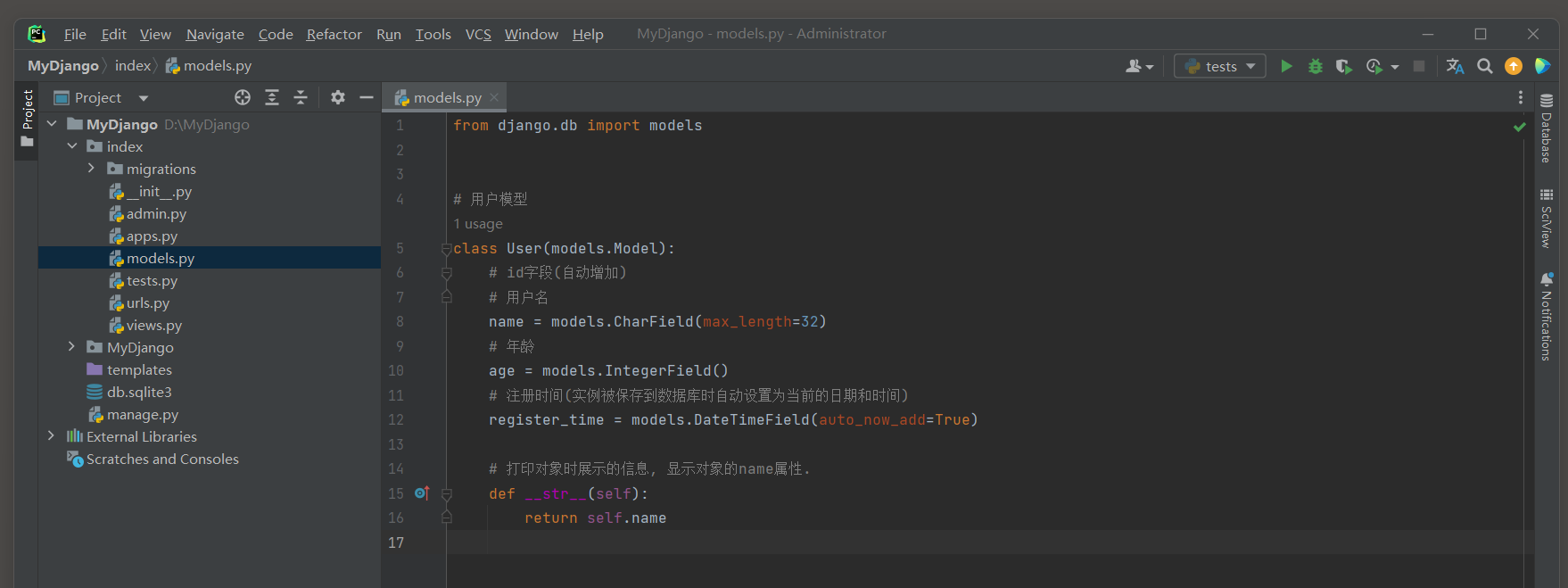
在测试的时候, 打印用户对象则会展示其字符串的表现形式.
# index的test.py
import osif __name__ == "__main__":# 设置 DJANGO_SETTINGS_MODULE 环境变量os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'MyDjango.settings') # !!!需要修改为自己的配置文件# 导入Django, 以便可以调用setup()import django# 初始化Django项目django.setup()# 现在可以安全地导入Django模型和其他组件from index import models# 查询name字段为kid的记录new_user = models.User.objects.filter(name='kid')print(new_user) # <QuerySet [<User: kid>]>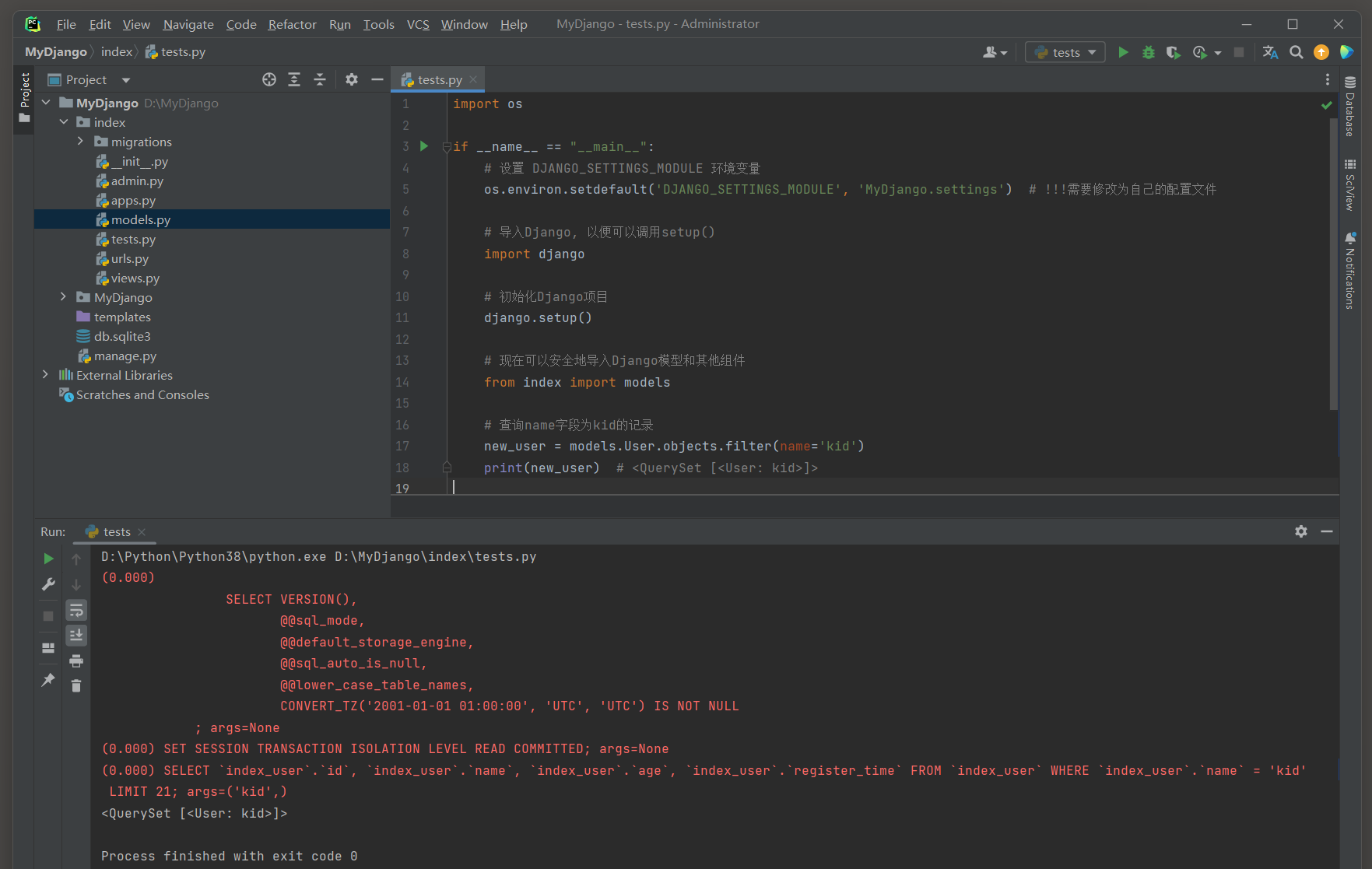
(0.000) SELECT `index_user`.`id`, `index_user`.`name`, `index_user`.`age`, `index_user`.`register_time`
FROM `index_user`
WHERE `index_user`.`name` = 'kid'
LIMIT 21; args=('kid',)
# 注意 LIMIT 21是默认值, 这个参数是可能控制的.
现在, 当打印new_user时, 它将显示'kid'而不是User object (1).
也可以使用Python的字符串格式化功能来打印对象的多个属性:
return f"User: {new_user.name}, Age: {new_user.age}"
这样更清晰地看到模型对象的详细信息.
4. 查询记录
4.1 查询方法
objects管理器提供了许多方法来执行数据库查询和相关的操作.
这些方法使得Django ORM能够以一种非常Pythonic的方式来操作数据库, 以下是一些常用的查询方法:
* 1. all()或get_queryset: 返回查询集中所有的对象. (all()方法只干了一件事, 那就是是调用get_queryset方法...)
* 2. filter(kwargs): 返回一个新的查询集, 它包含满足给定查找参数的对象.
* 3. exclude(kwargs): 返回一个新的查询集, 它包含不满足给定查找参数的对象.
* 4. get(kwargs): 返回与所给查找参数相匹配的对象, 如果找到多个匹配项, 则抛出MultipleObjectsReturned异常,如果没有找到任何匹配项, 则抛出DoesNotExist异常.
* 5. order_by(*fields): 根据提供的字段对查询集进行排序.
* 6. reverse(): 将查询集中的对象顺序反转.
* 7. values(*fields, expressions): 返回一个包含字典的查询集, 每个字典表示一个对象, 字典的键由指定的字段名组成.
* 7. values_list(*fields, flat=False): 与values()类似, 但返回的是元组而不是字典.如果flat=True, 并且只有一个字段被指定, 则返回的将是单个值的列表.
* 7. distinct(*fields): 返回查询集中不同(去重)的对象集合.如果指定了*fields, 则仅在这些字段上进行去重.
* 8. count(): 返回查询集中的对象数量.
* 9. first()和last(): 分别返回查询集中的第一个和最后一个对象.
* 10. exists(): 如果查询集包含数据, 则返回True, 否则返回False.
4.2 QuerySet查询集
Django ORM中的QuerySet对象是一种特殊的'不可变'集合, 用于表示数据库查询的结果, 并具备一系列独特而强大的特性.
QuerySet的特性及说明:
* 1. 惰性执行: 当通过Django ORM的API执行数据库查询时, 并不会立即执行查询操作.相反, 会返回一个QuerySet对象, 该对象包含了执行查询所需的所有信息(包括构建一个查询的SQL语句), 但实际的数据库查询会被延迟.查询的执行被延迟到QuerySet被迭代(如通过for循环遍历), 或者调用一些触发查询的方法时(如count(), exists(), list()等).
* 2. 缓存: Django会对每个QuerySet的查询结果进行缓存.这意味着, 如果对同一个QuerySet进行多次求值(例如, 在多次迭代或调用触发查询的方法时),Django会返回之前缓存的结果, 而不是重新执行数据库查询.需要注意的是, 缓存是针对同一个QuerySet实例的.如果对QuerySet进行修改(如添加过滤条件或排序), 则会生成一个新的QuerySet实例, 并可能执行新的查询.
* 3. 可迭代性: QuerySet是可迭代的, 这意味着可以使用Python的for循环来遍历它, 获取其中的元素(即数据库中的记录).
* 4. 支持切片: QuerySet支持Python的切片语法, 允许限制查询结果集的大小(类似于SQL中的LIMIT和OFFSET).这对于分页显示数据非常有用.
* 5. 链式调用: QuerySet的API设计支持链式调用, 允许通过在一系列方法调用中构建复杂的查询.例如, 可以连续使用.filter(), .exclude(), .order_by()等方法来逐步构建查询条件.
4.3 获取所有对象
all()方法: 用于从数据库中检索模型的所有对象. 返回一个QuerySet对象, 该对象包含了模型表中所有记录的查询集.
# index的test.py
import osif __name__ == "__main__":# 设置 DJANGO_SETTINGS_MODULE 环境变量os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'MyDjango.settings') # !!!需要修改为自己的配置文件# 导入Django, 以便可以调用setup()import django# 初始化Django项目django.setup()# 现在可以安全地导入Django模型和其他组件from index.models import User# 获取所有用户的查询集Users = User.objects.all() # 直到这里不执行查询操作print(Users) # 打印QuerySet对象时执行SQL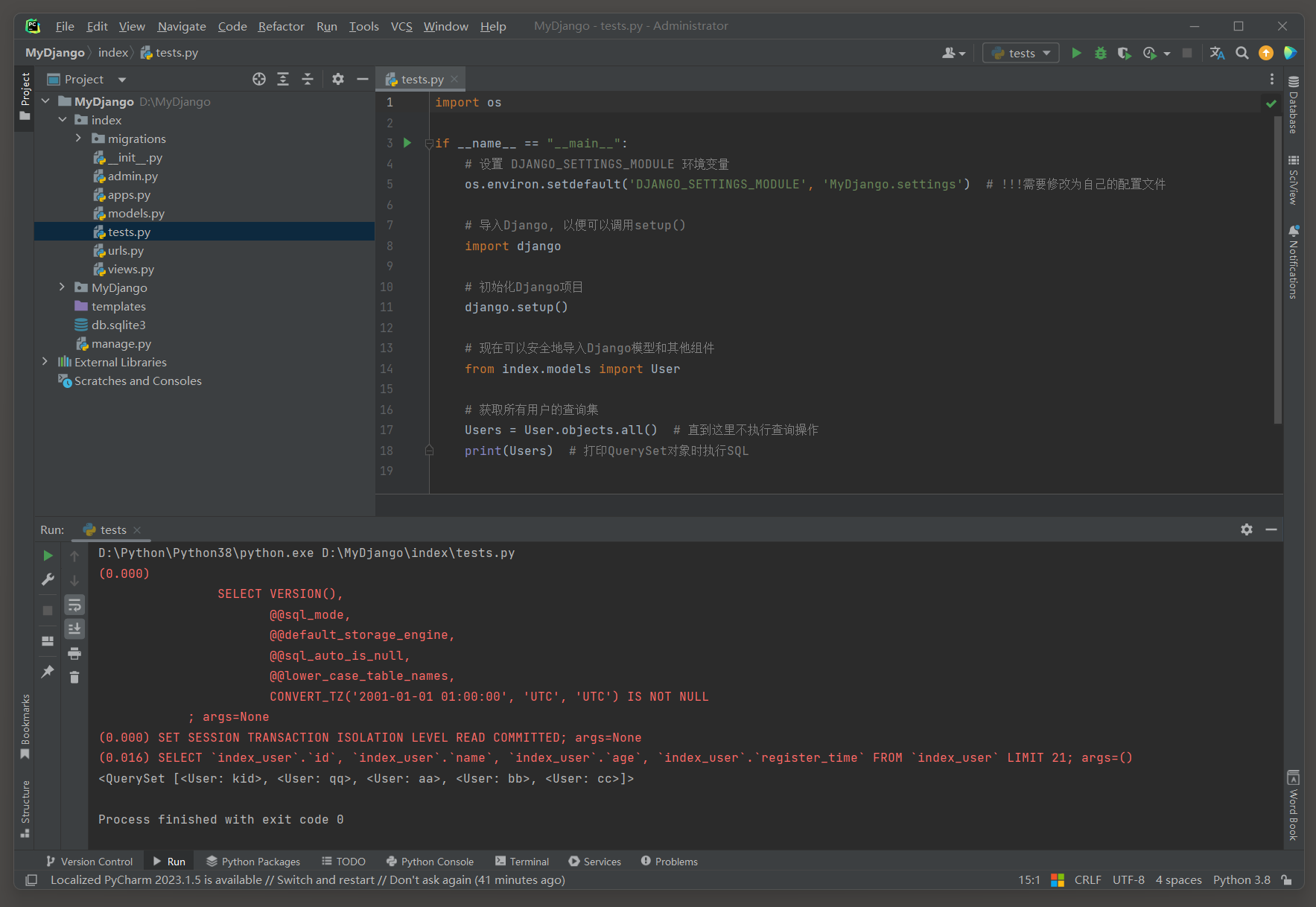
# ORM日志:
(0.016)
SELECT `index_user`.`id`, `index_user`.`name`, `index_user`.`age`, `index_user`.`register_time`
FROM `index_user`
LIMIT 21; # 后续会说明LIMIT 21
args=()
在这个例子中, User.objects.all()返回一个包含所有用户对象的查询集.
然后, 可以打印或遍历这个查询集, 并对每个用户对象执行操作, 比如打印用户的名字.
4.4 特性说明
4.4.1 惰性加载
Django的ORM是惰性的, 意味着它会在需要时才真正执行数据库查询.
这种机制是为了优化性能, 避免不必要的数据库访问.
QuerySet评估(Evaluation)是一个重要的概念, 它指的是QuerySet对象与数据库进行交互, 并实际执行查询操作的过程.评估触发: 有几种情况会触发QuerySet的评估, 包括但不限于:
* 1. 遍历QuerySet(如使用for循环).
* 2. 对QuerySet进行切片操作, 并且使用了步长(step)参数.
* 3. 对QuerySet调用len()函数(注意, 这会触发查询并将所有结果加载到内存中, 因此在使用时应谨慎).
* 4. 在布尔上下文中使用QuerySet(如if语句), 但通常建议使用exists()方法代替, 因为它更高效且不会触发QuerySet的完全评估.
上例中执行: Users = User.objects.all()时, 这行代码本身并不直接触发数据库的查询而是返回一个查询集(QuerySet).
这个查询集是一个特殊的Python对象, 它表示了数据库中的一个查询, 但在这个查询实际执行并返回数据之前, 它不会与数据库进行交互.当将for user in Users:这行代码注释掉时, 由于Users = User.objects.all()之后的代码块没有执行任何会触发查询的操作
(比如迭代, 切片, 列表化等), Django的ORM日志就不会显示任何数据库查询的信息.
# index的test.py
import osif __name__ == "__main__":# 设置 DJANGO_SETTINGS_MODULE 环境变量os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'MyDjango.settings') # !!!需要修改为自己的配置文件# 导入Django, 以便可以调用setup()import django# 初始化Django项目django.setup()# 现在可以安全地导入Django模型和其他组件from index.models import User# 获取所有用户的查询集Users = User.objects.all() # 直到这里不执行查询操作
4.4.2 索引访问
使用索引来访问QuerySet中的单个对象, 注意: QuerySet不支持负数索引, 否则会显示AssertionError错误.
但这种方式并不推荐用于遍历, 因为它可能会导致查询被多次触发,特别是在遍历整个QuerySet时.
对QuerySet使用索引时, Django ORM会将其转换为SQL查询中的LIMIT和OFFSET子句.
# index的test.py
import osif __name__ == "__main__":# 设置 DJANGO_SETTINGS_MODULE 环境变量os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'MyDjango.settings') # !!!需要修改为自己的配置文件# 导入Django, 以便可以调用setup()import django# 初始化Django项目django.setup()# 现在可以安全地导入Django模型和其他组件from index.models import User# 获取所有用户的查询集Users = User.objects.all() # 直到这里不执行查询操作# 通过索引获取对象for i in range(5):print(Users[i])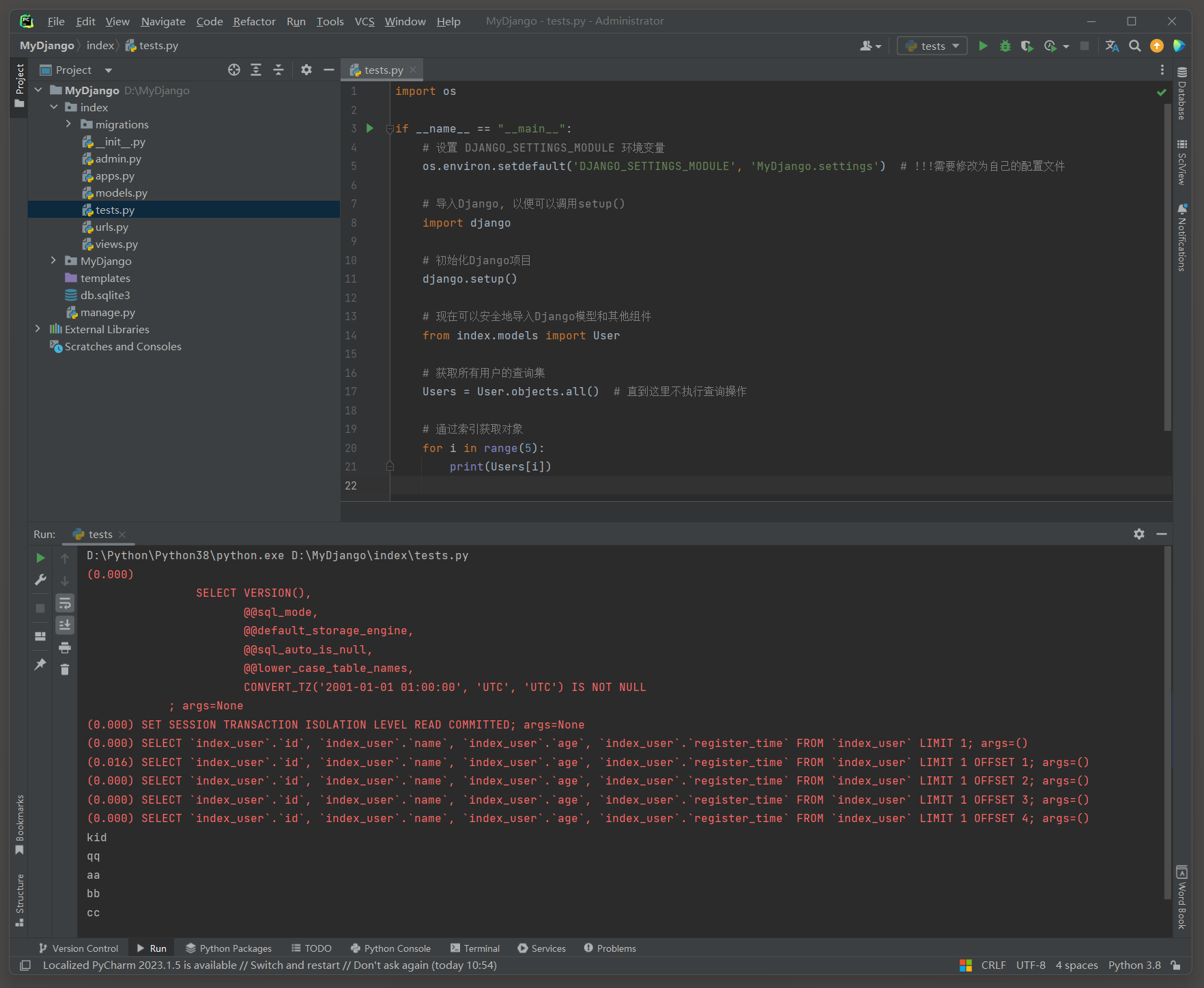
# ORM日志(简化一下字段为*):
(0.000) SELECT * FROM `index_user` LIMIT 1; args=()
(0.000) SELECT * FROM `index_user` LIMIT 1 OFFSET 1; args=()
(0.000) SELECT * FROM `index_user` LIMIT 1 OFFSET 2; args=()
(0.000) SELECT * FROM `index_user` LIMIT 1 OFFSET 3; args=()
(0.000) SELECT * FROM `index_user` LIMIT 1 OFFSET 4; args=()
当处理大量数据时, 为了避免一次性将所有数据加载到内存中, 可以使用QuerySet的iterator()方法.
这个方法会返回一个生成器, 允许一次只从数据库中获取一个对象, 从而降低内存消耗.调用iterator()时, Django会执行一个数据库查询来获取数据的游标(cursor),
然后iterator()方法会逐个从这个游标中读取数据, 直到所有数据都被遍历完毕.
游标是数据库管理系统(DBMS)提供的一种机制, 允许按顺序遍历查询结果集中的数据, 而不需要一次性将整个结果集加载到内存中.
每次获取下一个对象时, Django会检查是否已经加载了下一个对象到内存中.
如果没有, 它会通过游标从数据库中检索下一个对象并将其加载到内存中.
这个过程会一直持续到结果集中的所有对象都被遍历完毕.注意事项:
- 使用iterator()后, 将无法再次遍历相同的QuerySet, 因为它会消耗掉生成器中的元素.
- 虽然iterator()减少了内存使用, 但它可能会稍微降低性能, 因为每次迭代都需要与数据库进行交互(尽管这种交互通常是通过高效的游标操作来完成的).如果查询结果集非常大, 而又需要遍历整个结果集, 那么使用iterator()可能会比一次性加载整个结果集到内存中需要更长的时间.然而, 在内存受限的情况下, iterator()是一个非常有用的工具.
4.4.3 切片操作
在Django的ORM中, 可以像Python列表一样使用切片来限制QuerySet返回的查询结果集的大小.
对QuerySet使用切片时, Django ORM会将其转换为SQL查询中的LIMIT和OFFSET子句.
例如, MyModel.objects.all()[:2]会生成一个SQL查询, 该查询仅返回表中的前10条记录.
这里是一个使用切片来限制QuerySet返回结果的例子:
# index的test.py
import osif __name__ == "__main__":# 设置 DJANGO_SETTINGS_MODULE 环境变量os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'MyDjango.settings') # !!!需要修改为自己的配置文件# 导入Django, 以便可以调用setup()import django# 初始化Django项目django.setup()# 现在可以安全地导入Django模型和其他组件from index.models import User# 获取User表中的前2条记录queryset = User.objects.all()[:2]# 现在queryset包含了MyModel表中的前2条记录for user in queryset:print(user)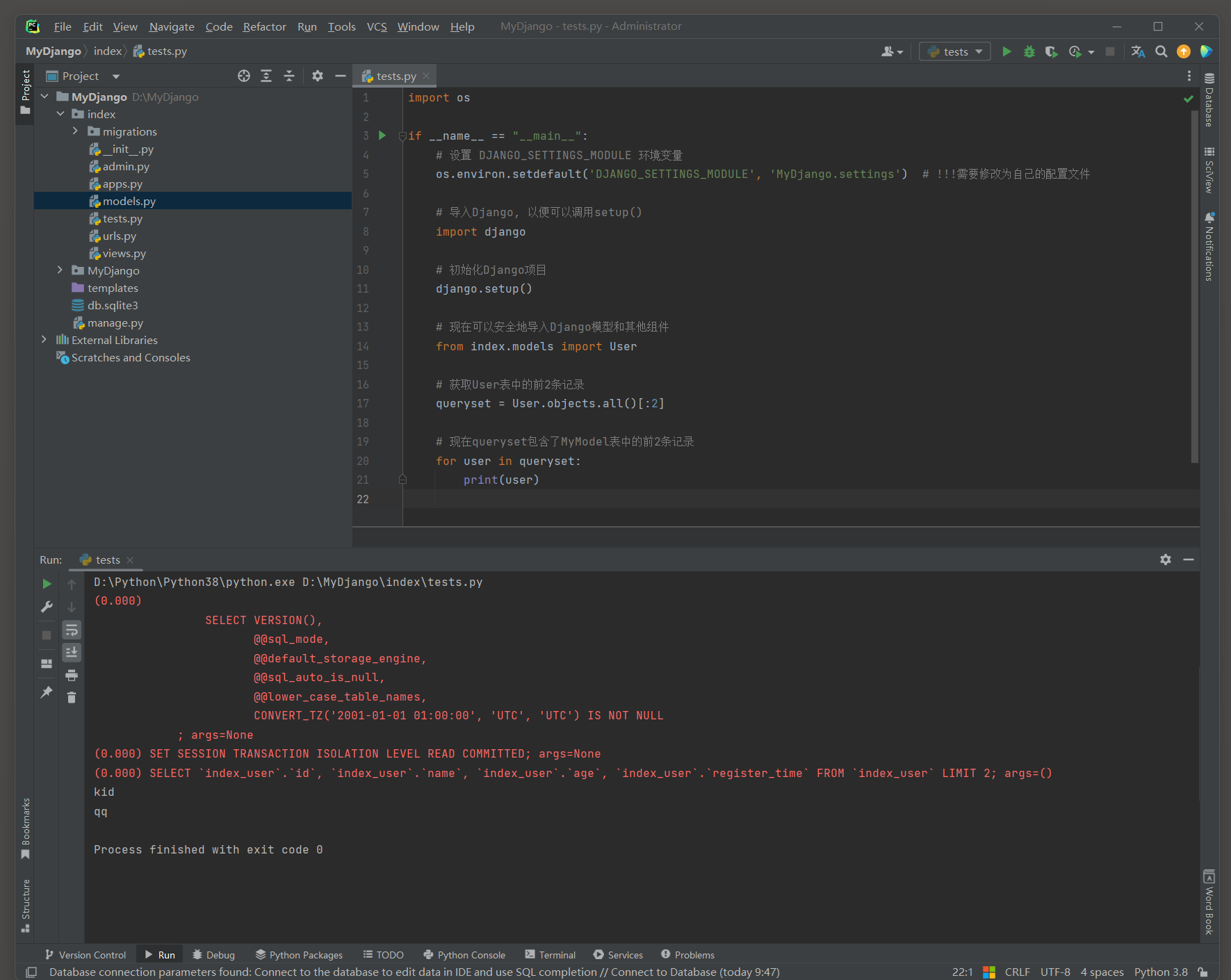
切片同样可以指定起始点, 比如获取第3条到第5条记录(注意Python切片是左闭右开的).
# index的test.py
import osif __name__ == "__main__":# 设置 DJANGO_SETTINGS_MODULE 环境变量os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'MyDjango.settings') # !!!需要修改为自己的配置文件# 导入Django, 以便可以调用setup()import django# 初始化Django项目django.setup()# 现在可以安全地导入Django模型和其他组件from index.models import User# 获取User表中的前2条记录queryset = User.objects.all()[2:6]# 现在queryset包含了MyModel表中的前2条记录for user in queryset:print(user)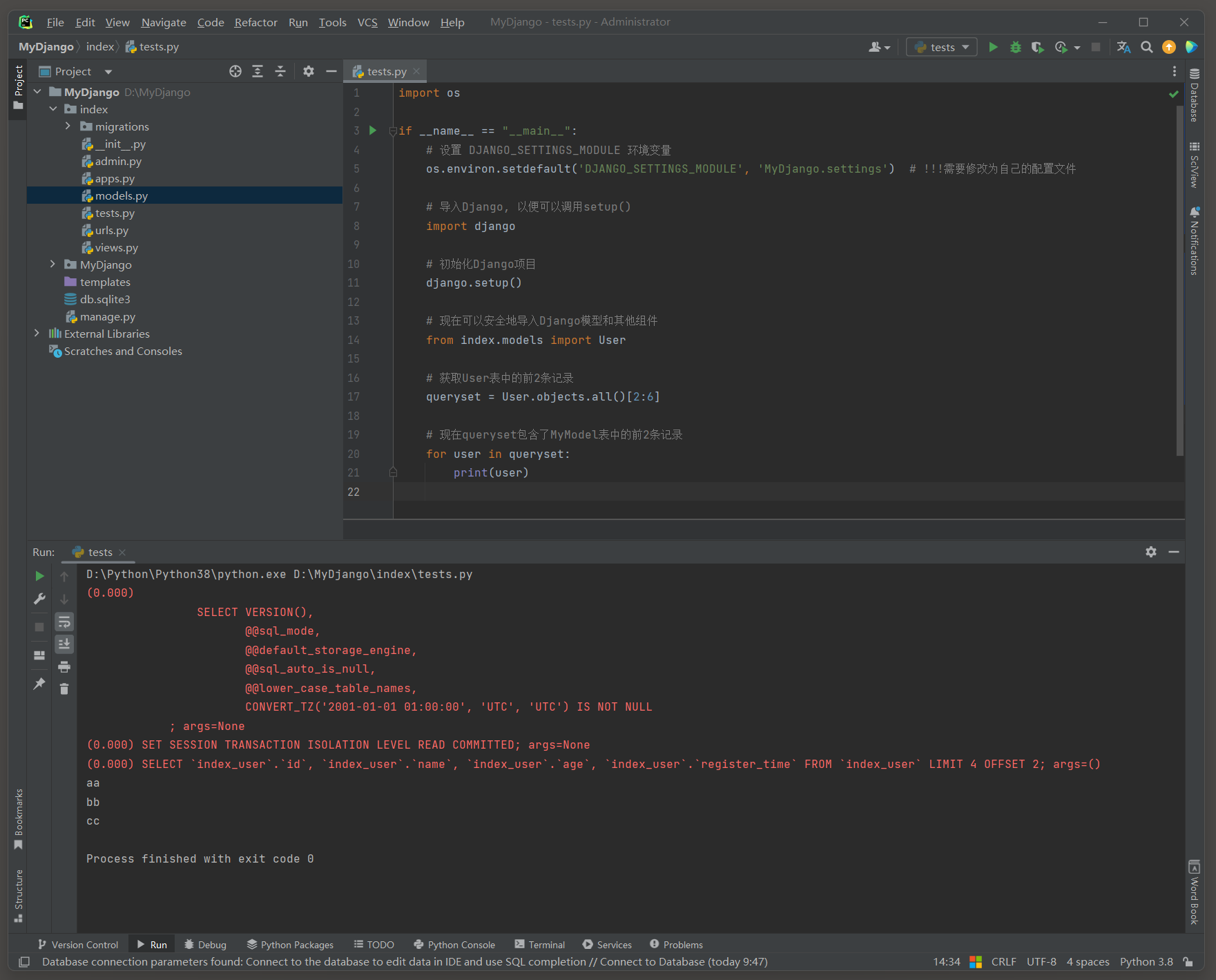
# ORM日志:
(0.000)
SELECT `index_user`.`id`, `index_user`.`name`, `index_user`.`age`, `index_user`.`register_time`
FROM `index_user`
LIMIT 4 OFFSET 2;
args=()
没有设置切片的时候, 默认情况下LIMIT的值为21, 如下图所示.
ORM日志(字段简化为*): SELECT * FROM `index_user` LIMIT 21;
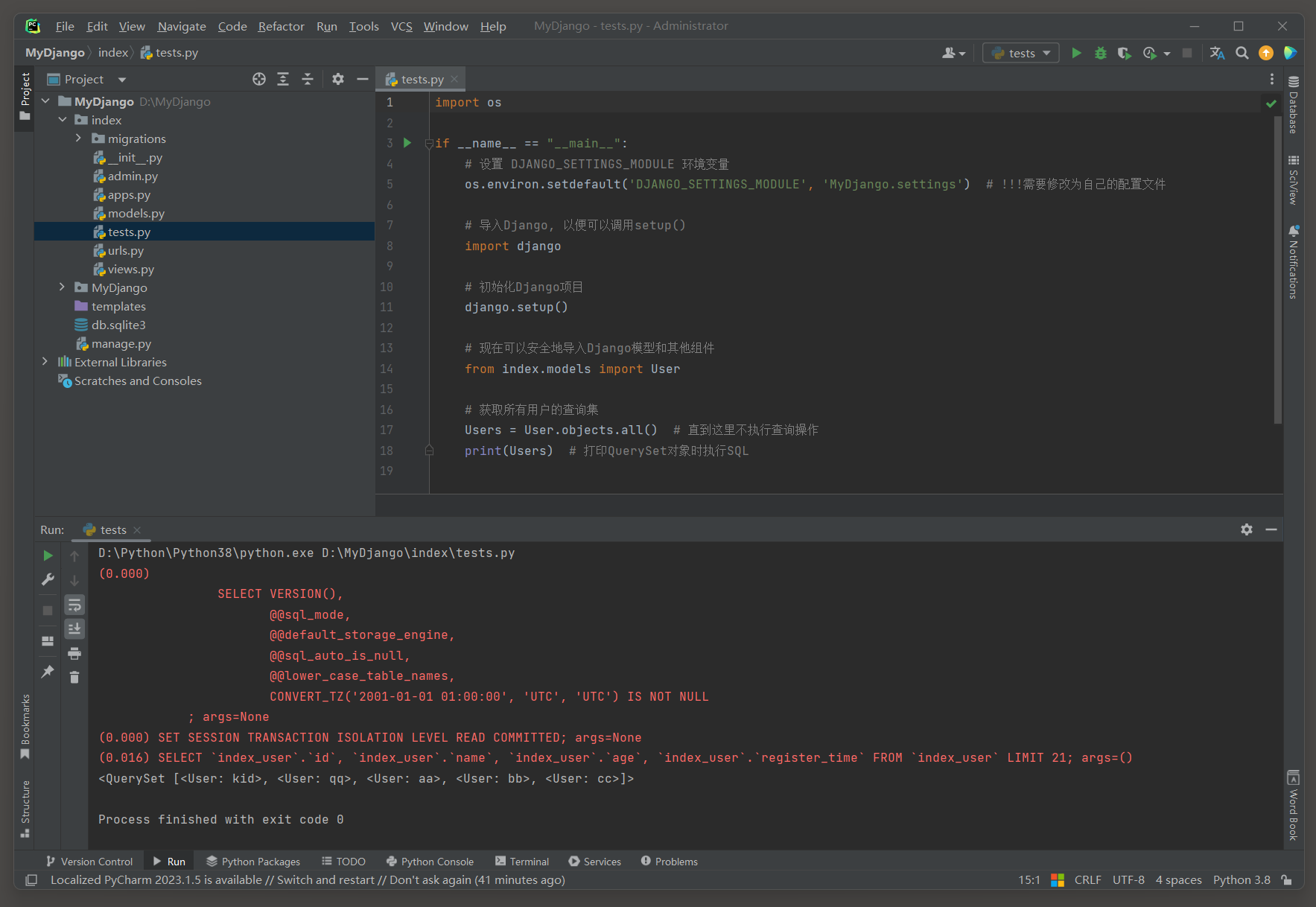
如果QuerySet对象的数据超过了21条数据, 直接打印这个它,
第21条记录会显示"...(remaining elements truncated, 剩余元素被截断)...".
这意味着原本应该展示更多内容的地方, 由于某种原因(如空间限制, 性能考虑, 用户设置等), 只展示了部分内容, 而剩余的部分被省略了.
<QuerySet [<User: User object (1)>, <User: User object (2)>, <User: User object (3)>, <User: User object (4)>,
<User: User object (5)>, <User: User object (6)>, <User: User object (7)>, <User: User object (8)>,
<User: User object (9)>, <User: User object (10)>, <User: User object (11)>, <User: User object (12)>,
<User: User object (13)>, <User: User object (14)>, <User: User object (15)>, <User: User object (16)>,
<User: User object (17)>, <User: User object (18)>, <User: User object (19)>, <User: User object (20)>,
'...(remaining elements truncated)...']>
如果需要获取全部的数据, 可以通过遍历QuerySet对象开解决.
4.4.4 遍历对象
QuerySet是可迭代的, 这意味着可以使用Python的迭代机制(如for循环)来遍历它.
QuerySet最常见的遍历方式就是使用for循环.
在循环开始前执行一个查询来获取结果集中的所有对象, 并将这些对象一次性加载到内存中.
然后, for循环会逐个遍历这些已经加载到内存中的对象.直接使用for循环遍历一个QuerySet时, Django会在循环开始之前执行一个查询来获取所有的对象.
这意味着无论QuerySet有多大, 都只会执行一次查询来获取所有的结果, 但这可能会导致大量的数据被加载到内存中.
# index的test.py
import osif __name__ == "__main__":# 设置 DJANGO_SETTINGS_MODULE 环境变量os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'MyDjango.settings') # !!!需要修改为自己的配置文件# 导入Django, 以便可以调用setup()import django# 初始化Django项目django.setup()# 现在可以安全地导入Django模型和其他组件from index.models import User# 获取所有用户的查询集Users = User.objects.all() # 直到这里不执行查询操作# 打印查询集中的每个用户对象for user in Users: # 遍历对象的时候执行SQLprint(user)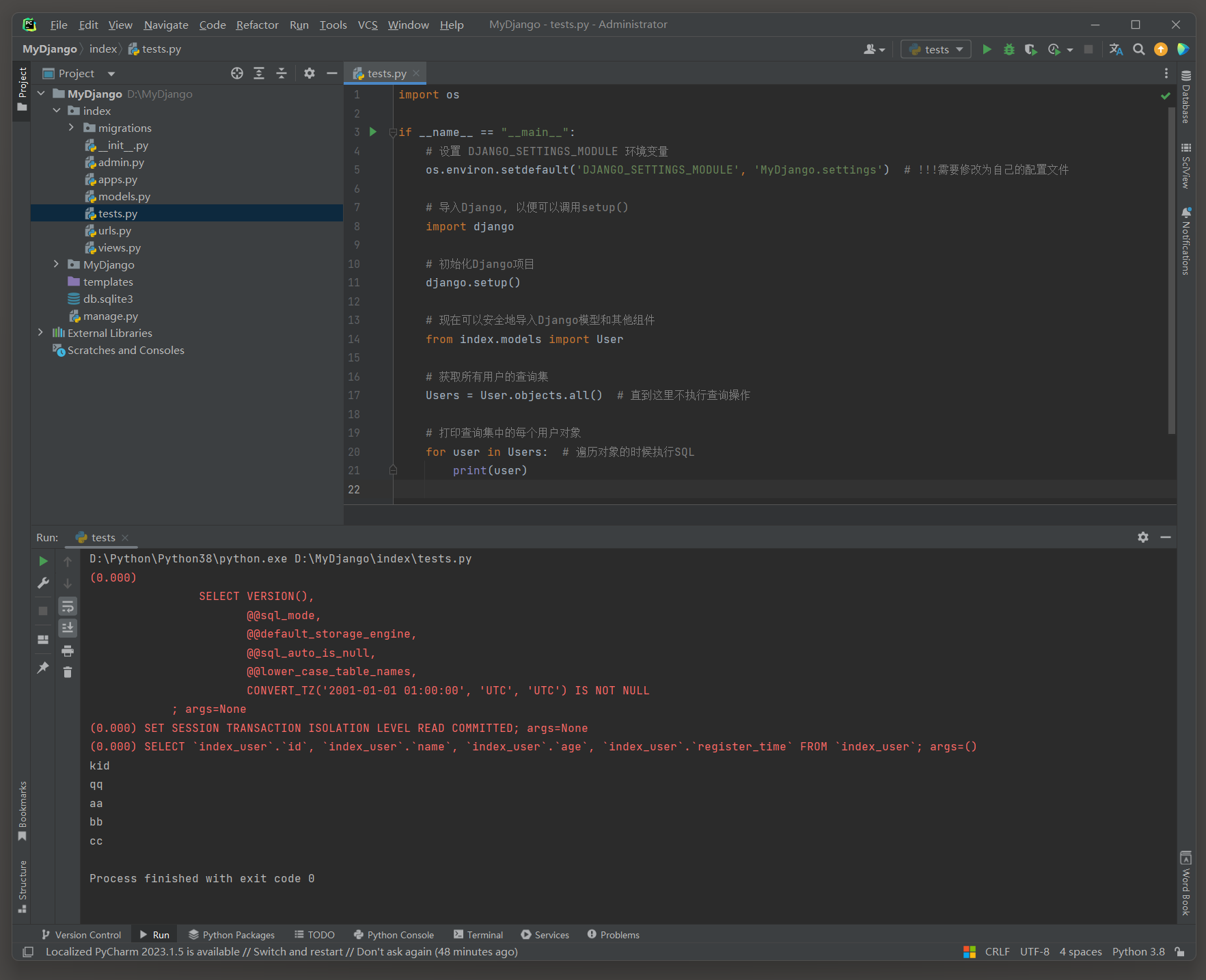
# ORM日志:
(0.000)
SELECT `index_user`.`id`, `index_user`.`name`, `index_user`.`age`, `index_user`.`register_time`
FROM `index_user`; # User.objects.all()语句是有LIMIT 21 限制的, 然后遍历的时候, 语句又重构了没了LIMIT 21 限制.
args=()
当处理大量数据时, 为了避免一次性将所有数据加载到内存中, 可以使用QuerySet的iterator()方法.
这个方法会返回一个生成器, 允许一次只从数据库中获取一个对象, 从而降低内存消耗.调用iterator()时, Django会执行一个数据库查询来获取数据的游标(cursor),
然后iterator()方法会逐个从这个游标中读取数据, 直到所有数据都被遍历完毕.
游标是数据库管理系统(DBMS)提供的一种机制, 允许按顺序遍历查询结果集中的数据, 而不需要一次性将整个结果集加载到内存中.
每次获取下一个对象时, Django会检查是否已经加载了下一个对象到内存中.
如果没有, 它会通过游标从数据库中检索下一个对象并将其加载到内存中.
这个过程会一直持续到结果集中的所有对象都被遍历完毕.注意事项:
- 使用iterator()后, 将无法再次遍历相同的QuerySet, 因为它会消耗掉生成器中的元素.
- 虽然iterator()减少了内存使用, 但它可能会稍微降低性能, 因为每次迭代都需要与数据库进行交互(尽管这种交互通常是通过高效的游标操作来完成的).如果查询结果集非常大, 而又需要遍历整个结果集, 那么使用iterator()可能会比一次性加载整个结果集到内存中需要更长的时间.然而, 在内存受限的情况下, iterator()是一个非常有用的工具.
# index的test.py
import osif __name__ == "__main__":# 设置 DJANGO_SETTINGS_MODULE 环境变量os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'MyDjango.settings') # !!!需要修改为自己的配置文件# 导入Django, 以便可以调用setup()import django# 初始化Django项目django.setup()# 现在可以安全地导入Django模型和其他组件from index.models import User# 获取所有用户的查询集Users = User.objects.iterator() # 直到这里不执行查询操作# 遍历对象for user in Users:print(user)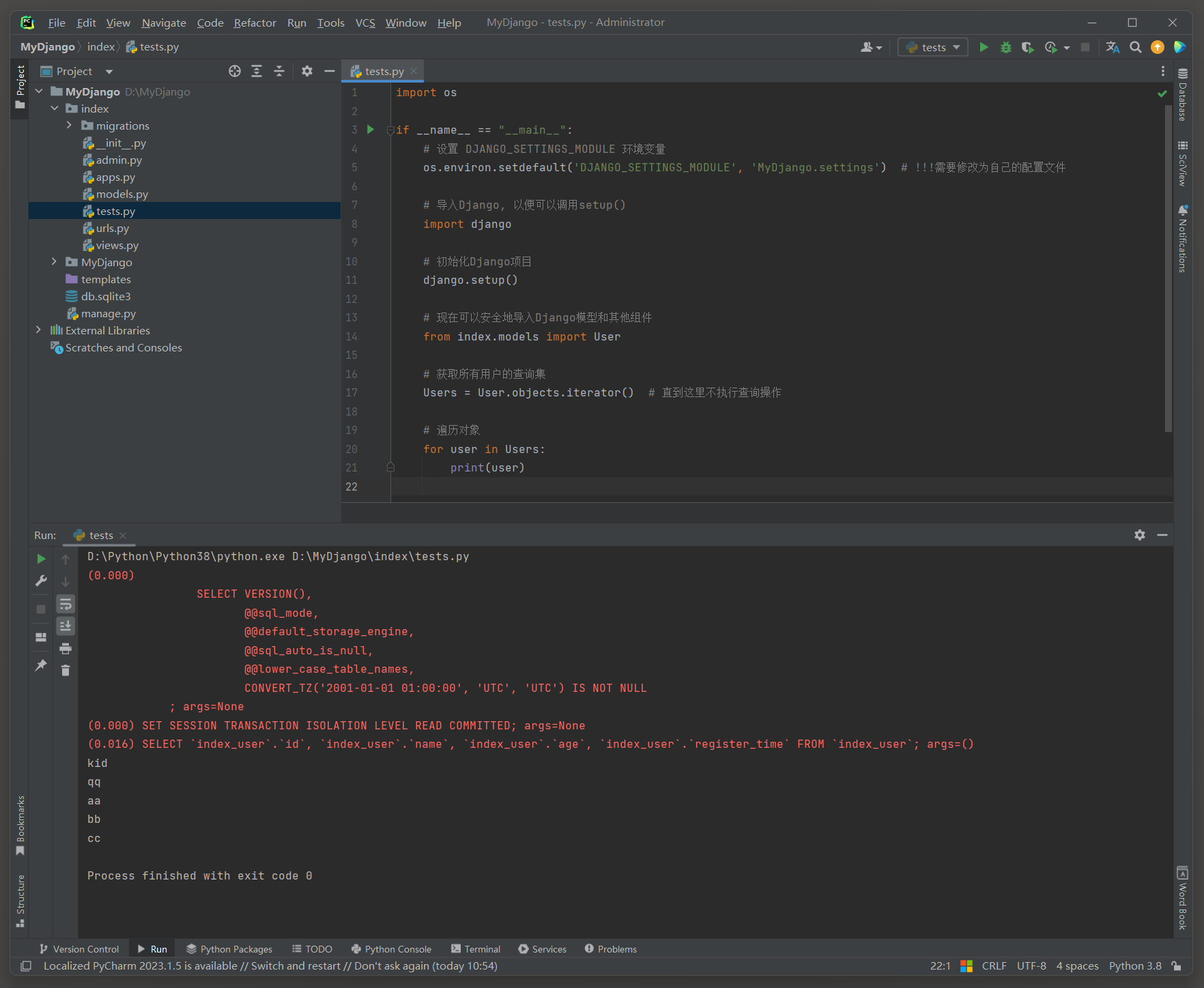
(0.016)
SELECT `index_user`.`id`, `index_user`.`name`, `index_user`.`age`, `index_user`.`register_time`
FROM `index_user`;
args=()
总结: 在大多数情况下, 如果不确定数据集的大小, 或者数据集可能很大, 那么使用iterator()是一个更安全的选择.
但是, 如果知道数据集很小, 或者你需要对结果集进行多次迭代, 并且希望避免多次查询数据库, 那么直接遍历QuerySet可能更合适.
4.5 过滤查询
filter()方法: 用于根据给定的条件过滤查询集, 返回一个新的查询集, 这个查询集包含了满足条件的所有对象.
filter()方法总是返回一个查询集, 即使没有任何对象满足条件也是如此(这时返回的查询集将是空的).与all()方法不同, filter()方法接受一个或多个关键字参数, 这些参数指定了过滤条件.
传递多个参数来应用多个过滤条件时这些条件作为AND逻辑连接起来.与all()方法一样, filter()方法也是惰性的, 即它不会立即执行数据库查询, 而是返回一个可以链式调用的查询集对象.
数据库查询只会在需要查询集中的数据时执行.
# index的test.py
import osif __name__ == "__main__":# 设置 DJANGO_SETTINGS_MODULE 环境变量os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'MyDjango.settings') # !!!需要修改为自己的配置文件# 导入Django, 以便可以调用setup()import django# 初始化Django项目django.setup()# 现在可以安全地导入Django模型和其他组件from index.models import User# 单个过滤条件: 获取用户年龄为19的记录Users = User.objects.filter(age=19)# 遍历并打印用户姓名for user in Users:print(user.name)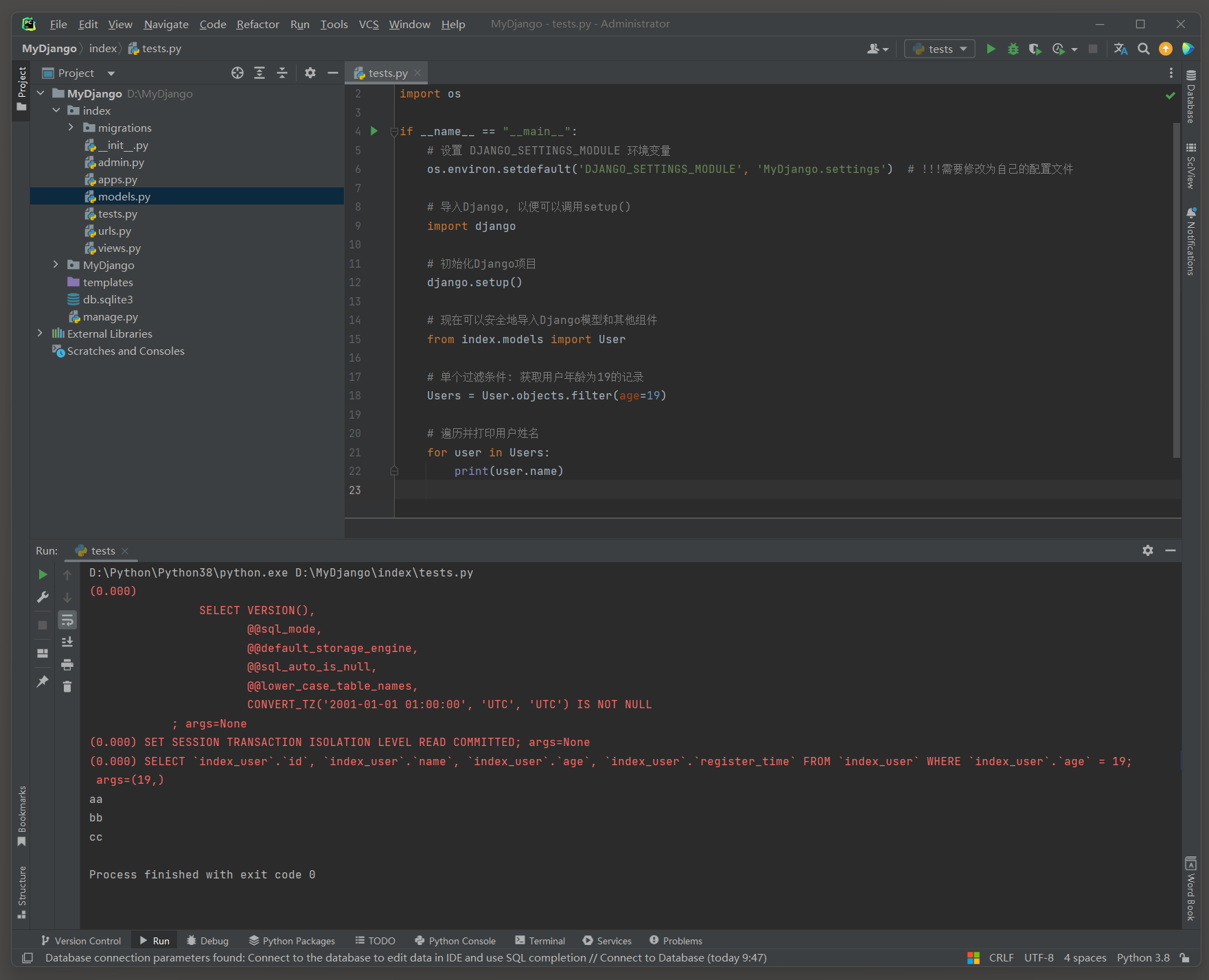
# ORM日志:
(0.000)
SELECT `index_user`.`id`, `index_user`.`name`, `index_user`.`age`, `index_user`.`register_time`
FROM `index_user`
WHERE `index_user`.`age` = 19; a
rgs=(19,)
过滤条件可以基于模型的任何字段, 并且可以使用Django提供的字段查找(如: __year, __gt(大于), __lt(小于)等)来进一步细化查询.
# index的test.py
import osif __name__ == "__main__":# 设置 DJANGO_SETTINGS_MODULE 环境变量os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'MyDjango.settings') # !!!需要修改为自己的配置文件# 导入Django, 以便可以调用setup()import django# 初始化Django项目django.setup()# 现在可以安全地导入Django模型和其他组件from index.models import User# 多个过滤条件: 获取用户年龄为19且id>4的记录Users = User.objects.filter(age=19, id__gt=4)# 遍历并打印用户姓名for user in Users:print(user.name)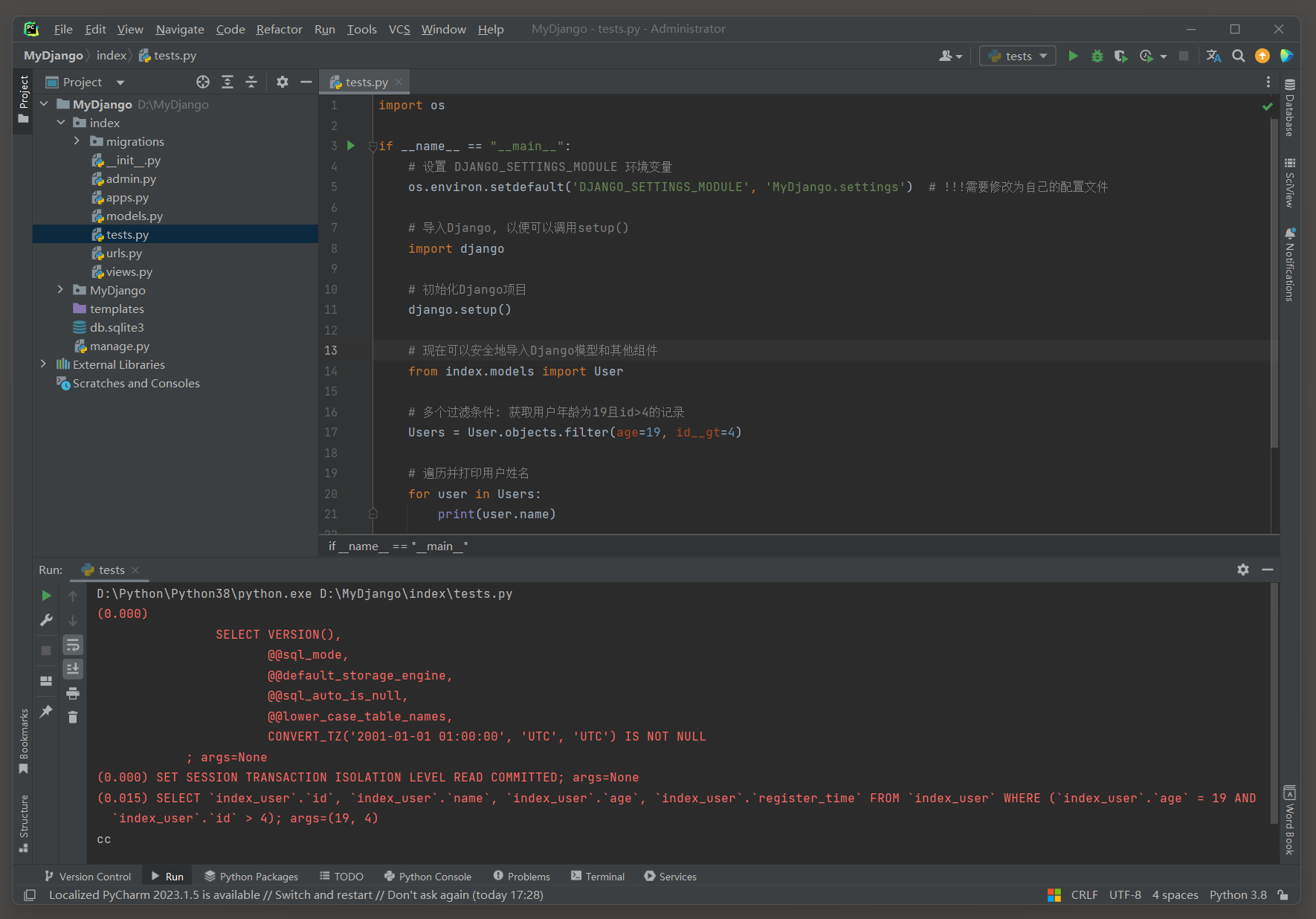
# ORM日志:
(0.000)
SELECT `index_user`.`id`, `index_user`.`name`, `index_user`.`age`, `index_user`.`register_time`
FROM `index_user`
WHERE (`index_user`.`age` = 19 AND `index_user`.`id` > 4);
args=(19, 4)
4.6 排除条件
exclude()方法: 用于从查询集中排除满足给定条件的对象.
传递多个参数来应用多个排除条件时这些条件作为AND逻辑连接起来.这个方法与filter()方法相反, filter()是筛选出满足条件的对象, 而exclude()则是过滤掉满足条件的对象.
# index的test.py (单条件)
import osif __name__ == "__main__":# 设置 DJANGO_SETTINGS_MODULE 环境变量os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'MyDjango.settings') # !!!需要修改为自己的配置文件# 导入Django, 以便可以调用setup()import django# 初始化Django项目django.setup()# 现在可以安全地导入Django模型和其他组件from index.models import User# 获取所有年龄不等于19的用户信息Users = User.objects.exclude(age=19)# 打印查询集中的每个用户对象for user in Users: # 遍历对象的时候才执行查询print(user.name)
# ORM日志:
(0.000)
SELECT `index_user`.`id`, `index_user`.`name`, `index_user`.`age`, `index_user`.`register_time`
FROM `index_user`
WHERE NOT (`index_user`.`age` = 19);
args=(19,)
# index的test.py (多条件)
import osif __name__ == "__main__":# 设置 DJANGO_SETTINGS_MODULE 环境变量os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'MyDjango.settings') # !!!需要修改为自己的配置文件# 导入Django, 以便可以调用setup()import django# 初始化Django项目django.setup()# 现在可以安全地导入Django模型和其他组件from index.models import User# 获取所有年龄不等于18, 名字不是'kid'的用户信息Users = User.objects.exclude(age=18, name='kid')# 打印查询集中的每个用户对象for user in Users: # 遍历对象的时候才执行查询print(user.name)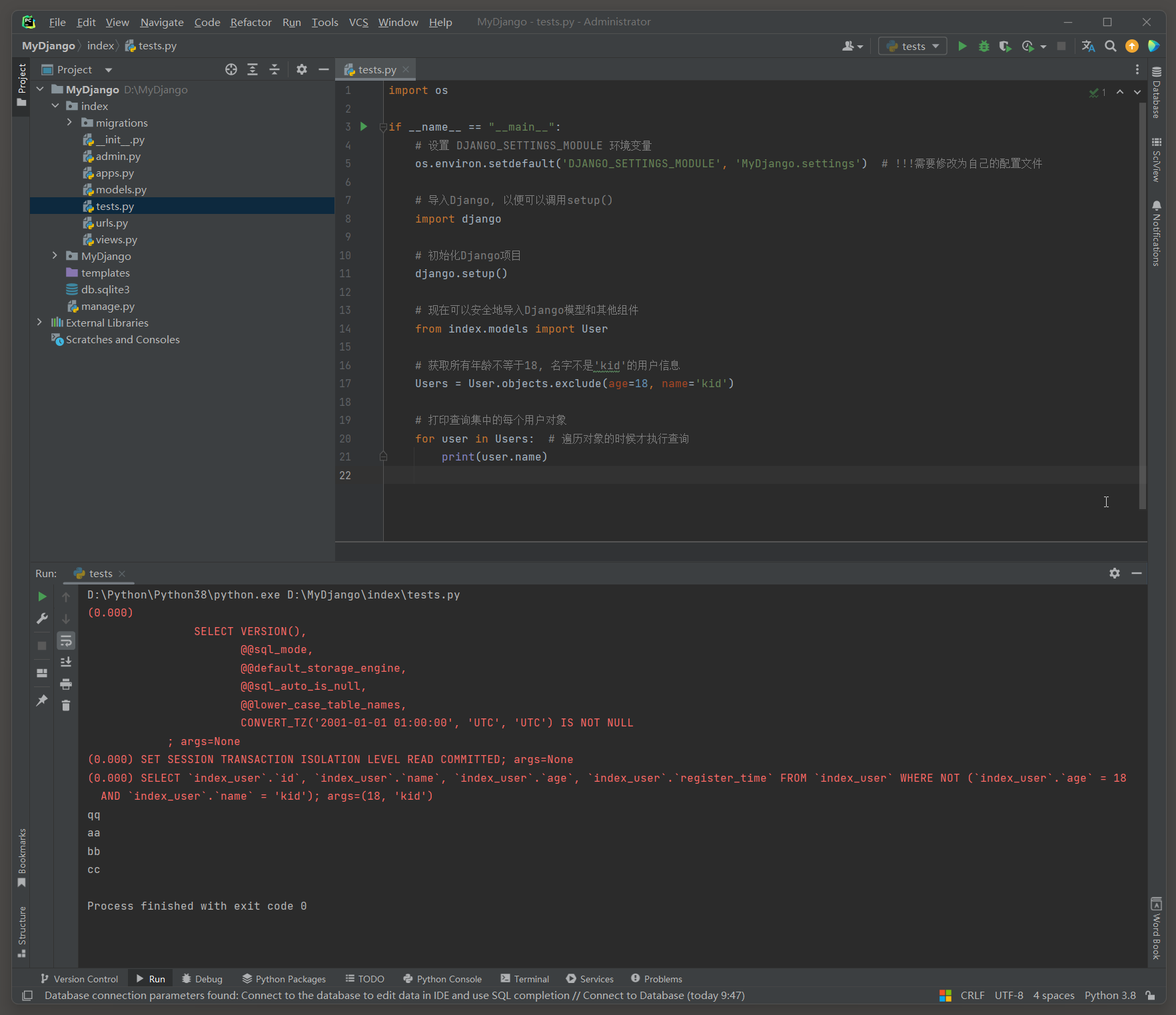
# ORM日志:
(0.000)
SELECT `index_user`.`id`, `index_user`.`name`, `index_user`.`age`, `index_user`.`register_time`
FROM `index_user`
WHERE NOT (`index_user`.`age` = 18 AND `index_user`.`name` = 'kid');
args=(18, 'kid')
4.7 获取单条记录
get()方法: 用于从数据库中检索并返回一个满足特定条件的记录对象.
注意事项:
get()方法接收一个或多个关键字参数, 这些参数定义了要检索的对象的查询条件.
如果数据库中存在一个且仅有一个对象满足这些条件, 那么该对象将被检索并返回.
如果查询匹配多个对象或没有对象, get()方法将引发异常.详细说明:
- 如果找到多个匹配的对象, get()方法将引发MultipleObjectsReturned(返回了多个对象)异常.
- 如果没有找到任何匹配的对象, get()方法将引发DoesNotExist(不存在)异常.
这些异常都是Django ORM定义的, 允许优雅地处理查询结果不符合预期的情况.建议(不推荐使用get方法):
如果不确定查询是否会返回多个结果, 或者希望查询返回可能存在的多个对象, 那么使用filter()方法可能更合适.
filter()方法返回一个查询集, 它可以包含零个, 一个或多个对象, 而不会引发异常.
# index的test.py
import osif __name__ == "__main__":# 设置 DJANGO_SETTINGS_MODULE 环境变量os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'MyDjango.settings') # !!!需要修改为自己的配置文件# 导入Django, 以便可以调用setup()import django# 初始化Django项目django.setup()# 现在可以安全地导入Django模型和其他组件from index.models import User# 获取名字是'kid'的用户记录user = User.objects.get(name='kid')# 直接拿到对象print(user.name) # 打印name字段信息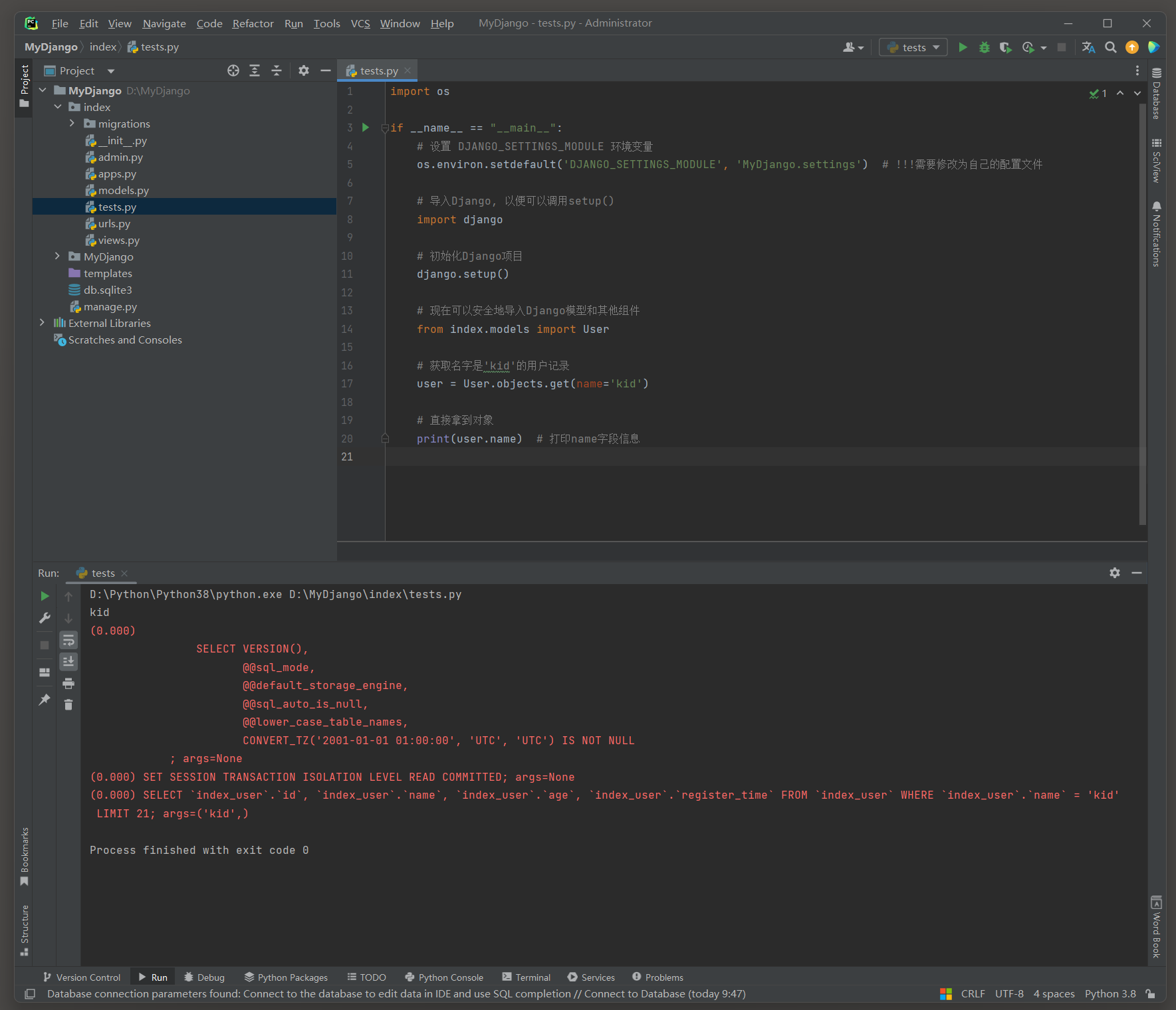
# ORM日志:
(0.000)
SELECT `index_user`.`id`, `index_user`.`name`, `index_user`.`age`, `index_user`.`register_time`
FROM `index_user`
WHERE `index_user`.`name` = 'kid'
LIMIT 21; args=('kid',)
MultipleObjectsReturned异常测试, 如果有多个记录会抛出异常.
# index的test.py
import osif __name__ == "__main__":# 设置 DJANGO_SETTINGS_MODULE 环境变量os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'MyDjango.settings') # !!!需要修改为自己的配置文件# 导入Django, 以便可以调用setup()import django# 初始化Django项目django.setup()# 现在可以安全地导入Django模型和其他组件from index.models import User# 获取年龄为19的用户记录Users = User.objects.get(age=19)print(Users)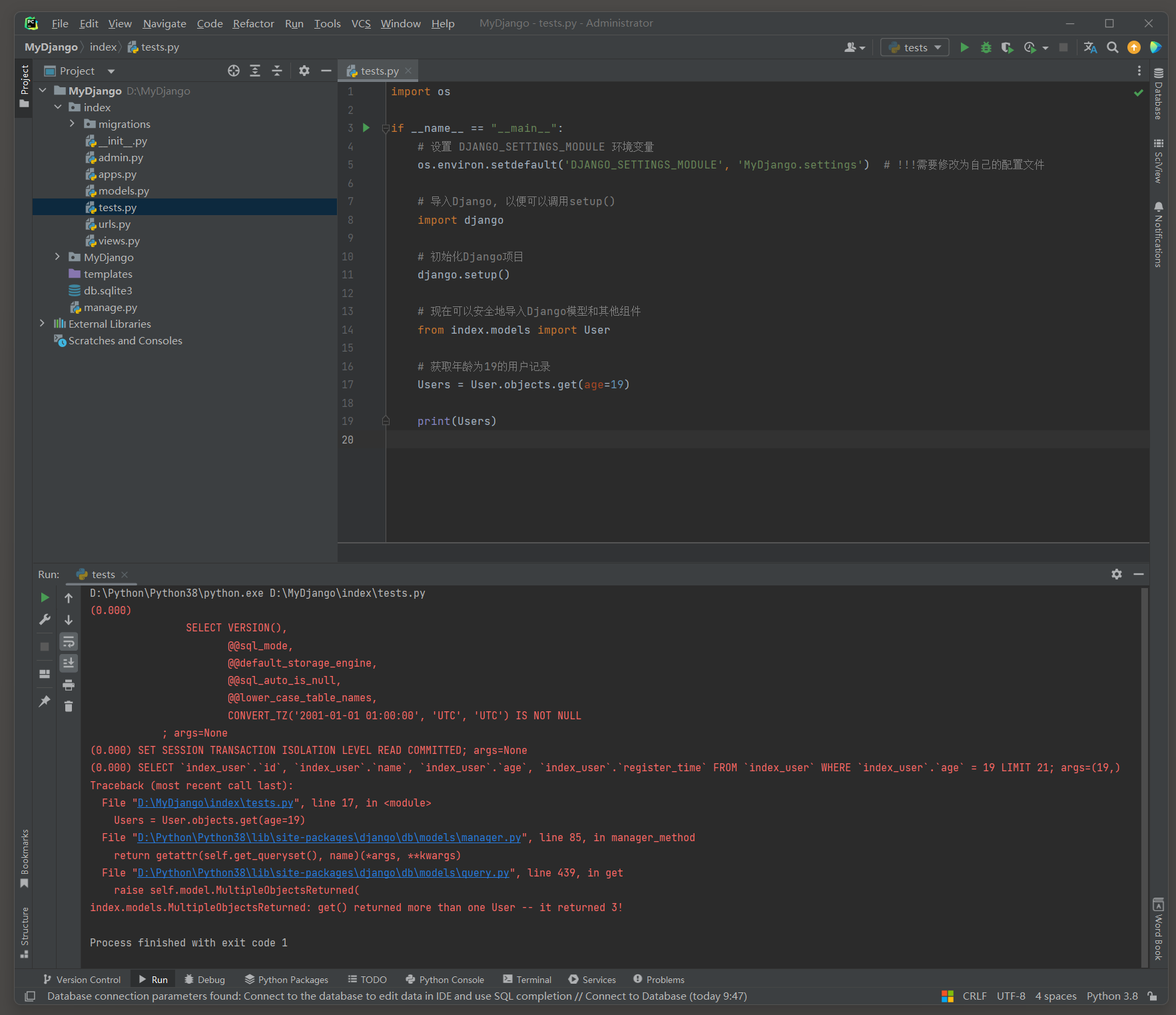
# ORM日志
(0.000)
SELECT `index_user`.`id`, `index_user`.`name`, `index_user`.`age`, `index_user`.`register_time`
FROM `index_user`
WHERE `index_user`.`age` = 19
LIMIT 21;
args=(19,)
错误提示信息: index.models.MultipleObjectsReturned: get() returned more than one User -- it returned 3!
DoesNotExist异常测试, 如果没有获取到记录会抛出异常.
# index的test.py
import osif __name__ == "__main__":os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'MyDjango.settings') # !!!需要修改为自己的配置文件import djangodjango.setup()from index.models import User# 获取年龄为199的用户记录Users = User.objects.get(age=199)print(Users)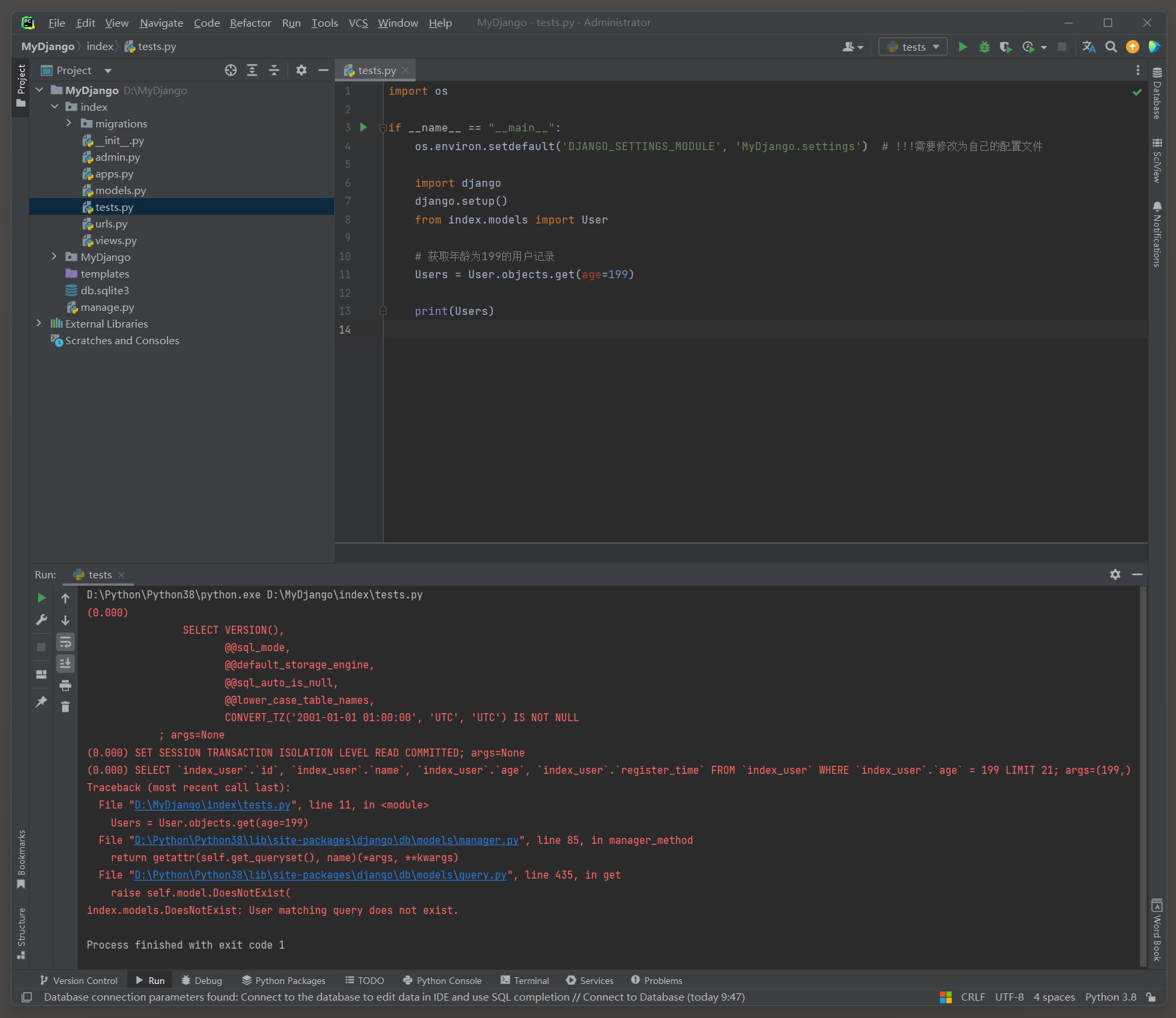
# ORM日志:
(0.000)
SELECT `index_user`.`id`, `index_user`.`name`, `index_user`.`age`, `index_user`.`register_time`
FROM `index_user`
WHERE `index_user`.`age` = 199
LIMIT 21;
args=(199,)
错误提示信息: index.models.DoesNotExist: User matching query does not exist.
4.8 查询集排序
order_by()方法: 用于对查询集中的对象进行排序.
可以指定一个或多个字段名, 以及排序的方向(升序或降序), 以此来决定查询结果中对象的顺序.
当指定多个字段进行排序时, 这些字段将按照你提供的顺序被依次考虑.
只有在前一个字段的值相同的情况下, 才会根据下一个字段的值来进行排序.每个字段都可能带有前缀以指示降序排序, 这些前缀参数决定了查询集中对象的排序方式, 排序前缀如下:
* 1. 默认情况下, 字段名前面的负号(-)表示降序排序.
* 2. 如果没有前缀或前缀为正号(+)表示升序排序.注意, 正号通常是可选的, 因为升序是默认的.注意事项:
- User.objects.order_by('xx')和User.objects.all().order_by('')这两种情况在逻辑上是等效的, 它们都会生成相同的SQL查询.在实践中, 直接使用User.objects.order_by('xx')更为简洁, 且没有性能上的损失.
- order_by()方法返回的是一个新的查询集, 它包含了根据指定字段排序后的对象, 原始查询集不会被修改(如果有的话).在大多数情况下, 直接对模型管理器如: User.objects调用order_by()时, 并没有一个显式的'原始查询集'变量).
- 应该避免在大型数据集上进行复杂的排序操作, 因为这可能会对数据库性能产生不利影响.
- 如果可能的话, 考虑在数据库级别上优化查询或使用索引来加速排序操作.
- 没有提供参数时, Django生成的SQL查询将不包含ORDER BY子句, 因此数据库将返回其默认的, 不可预测的结果顺序.这意味着数据库将按照它自己的默认方式返回查询结果, 这通常是基于表在磁盘上的物理存储顺序,但这个顺序对于开发者来说是不可预测的, 因为它可能会随着数据的插入, 更新, 删除等操作而发生变化.
没有提供参数时, Django生成的SQL查询将不包含ORDER BY子句.
# index的test.py
import osif __name__ == "__main__":os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'MyDjango.settings') # !!!需要修改为自己的配置文件import djangodjango.setup()from index.models import User# 获取所有数据Users = User.objects.order_by()print(Users)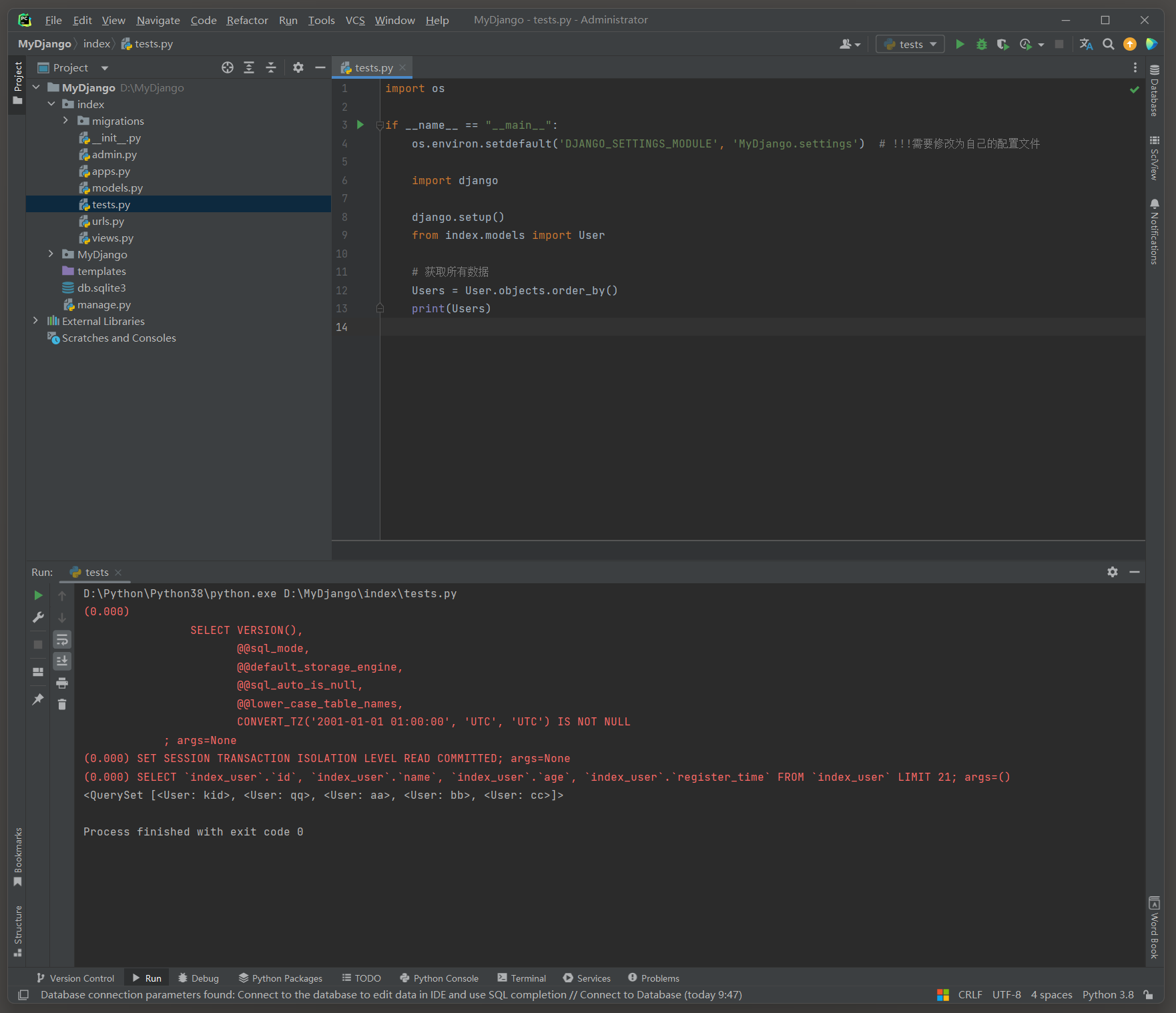
# ORM日志
(0.000)
SELECT `index_user`.`id`, `index_user`.`name`, `index_user`.`age`, `index_user`.`register_time`
FROM `index_user`
LIMIT 21; args=()
查询所有数据先按age字段升序, 在按age字段降序.
# index的test.py
import osif __name__ == "__main__":os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'MyDjango.settings') # !!!需要修改为自己的配置文件import djangodjango.setup()from index.models import User# 获取所有数据按年龄升序排列Users = User.objects.order_by('age')for user in Users:print(user.age)print('---------------')# 获取所有数据按年龄降序排列Users = User.objects.order_by('-age') # 或 Users = Users.order_by('-age')for user in Users:print(user.age)
# ORM日志:
(0.000)
SELECT `index_user`.`id`, `index_user`.`name`, `index_user`.`age`, `index_user`.`register_time`
FROM `index_user`
ORDER BY `index_user`.`age` ASC;
args=()(0.000)
SELECT `index_user`.`id`, `index_user`.`name`, `index_user`.`age`, `index_user`.`register_time`
FROM `index_user`
ORDER BY `index_user`.`age` DESC;
args=()
User.objects.order_by('xx')和User.objects.all().order_by('')这两种情况在逻辑上是等效的.
# index的test.py
import osif __name__ == "__main__":os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'MyDjango.settings') # !!!需要修改为自己的配置文件import djangodjango.setup()from index.models import User# 获取所有数据Users = User.objects.all() # 第一次构造语句# 按年龄升序Users = Users.order_by('age') # 第二次构造语句for user in Users: # 执行查询语句print(user.age)print('---------------')# 获取所有数据按年龄升序Users = User.objects.order_by('age')for user in Users:print(user.age)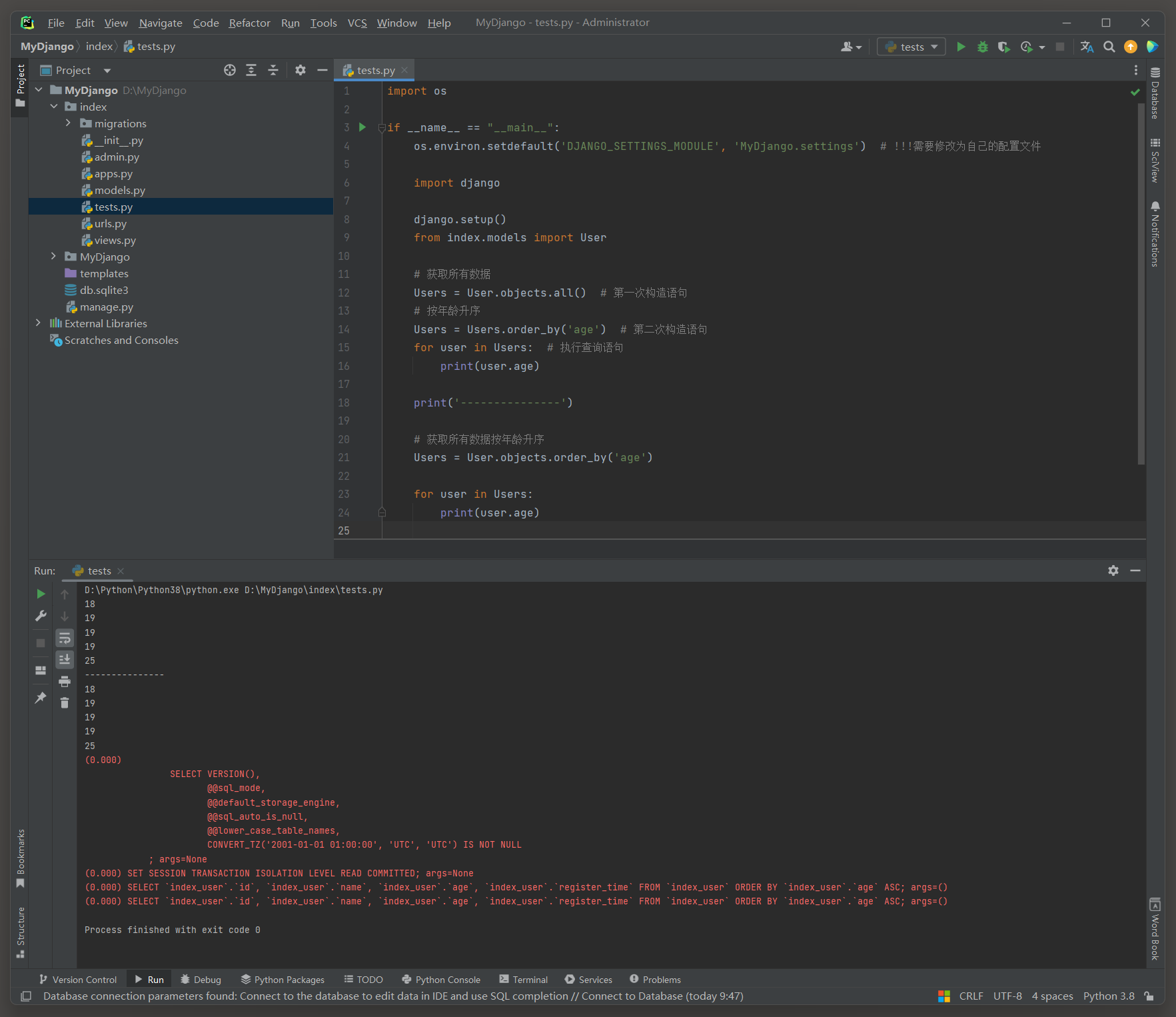
# ORM日志:
(0.000)
SELECT `index_user`.`id`, `index_user`.`name`, `index_user`.`age`, `index_user`.`register_time`
FROM `index_user`
ORDER BY `index_user`.`age` ASC;
args=()(0.000)
SELECT `index_user`.`id`, `index_user`.`name`, `index_user`.`age`, `index_user`.`register_time`
FROM `index_user`
ORDER BY `index_user`.`age` ASC;
args=()
4.9 链式调用
在Django ORM中, 查询集的链式调用是一个强大的特性, 它允许开发者通过连续调用多个方法, 在一个查询集对象上逐步构建出复杂的查询逻辑.当对一个模型的objects管理器调用方法(如all(), order_by()等)时, 会获得一个查询集对象.
这个对象代表了数据库查询的初始状态, 此时并没有立即执行数据库查询, 只是构建了一个查询的'蓝图'或'规范'.开发者可以逐步向这个'蓝图'中添加筛选条件, 排序字段等, 从而构建出满足特定需求的查询规范.
新增的调用方法会返回一个新的QuerySet对象, 它包含了原始QuerySet的所有条件以及新添加的条件.注意: QuerySet是不可变的, 这意味着当对一个QuerySet链式调用方法时, 而不是修改原始的QuerySet对象.
链式调用可以写成一句或多句, 这主要取决于编码风格和可读性需求.
链式调用允许以流畅的方式将多个方法调用串联起来, 每个方法调用都返回一个新的查询集, 该查询集包含了对前一个查询集进行修改后的结果.
写成一句通常是为了提高代码的可读性和简洁性. 例如:
# index的test.py
import osif __name__ == "__main__":os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'MyDjango.settings') # !!!需要修改为自己的配置文件import djangodjango.setup()from index.models import User# 获取age为19的用户, 并按name字段升序Users = User.objects.filter(age=19).order_by('name')for user in Users:print(user.name)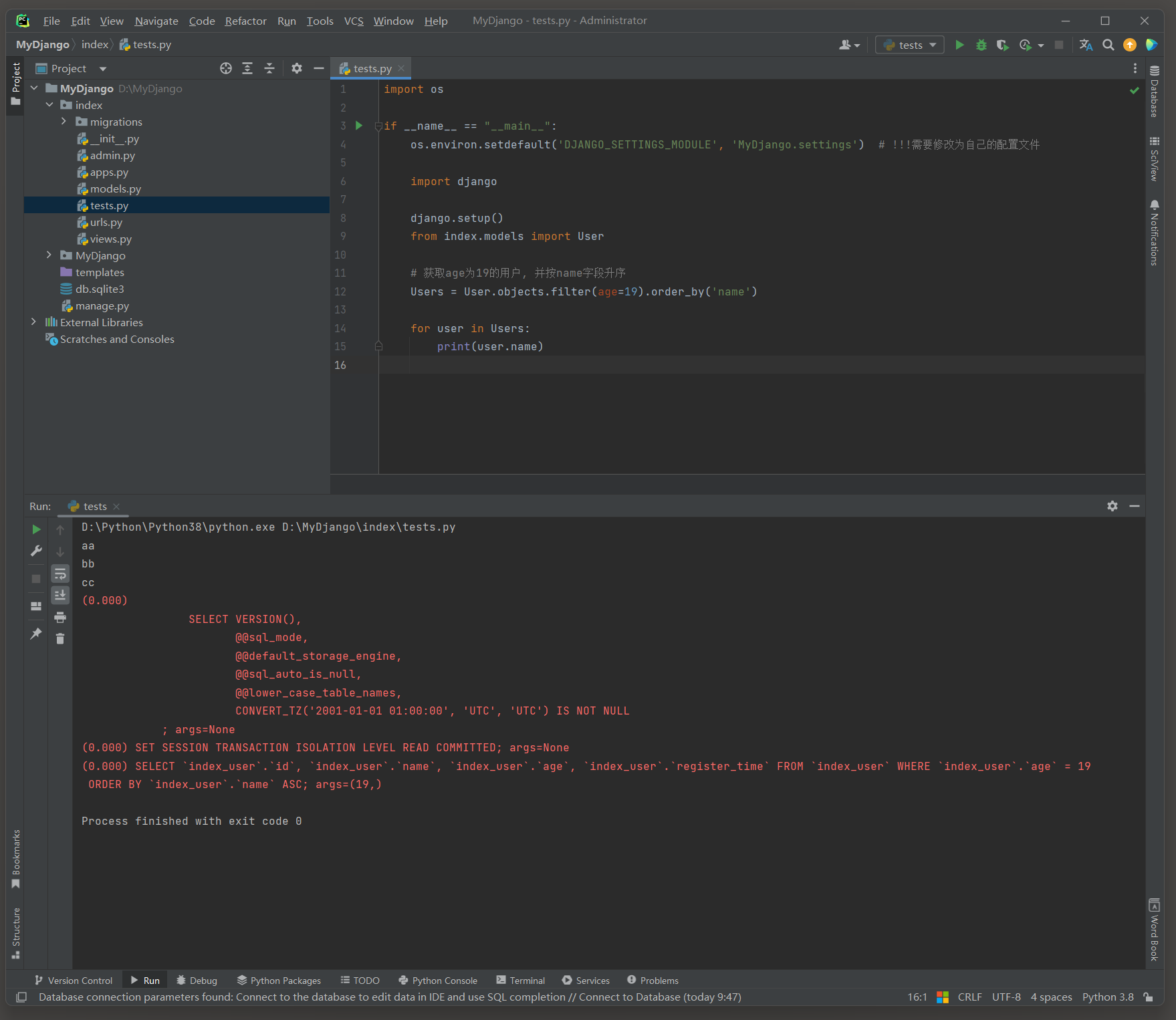
# ORM日志
(0.000)
SELECT `index_user`.`id`, `index_user`.`name`, `index_user`.`age`, `index_user`.`register_time`
FROM `index_user`
WHERE `index_user`.`age` = 19
ORDER BY `index_user`.`name` ASC;
args=(19,)
可以基于之前的查询集对象在后面链接上其他方法, 以构建更复杂的查询条件.
因此可以根据需要在任何时候向查询集中添加额外的过滤, 排序或其他操作.
# index的test.py
import osif __name__ == "__main__":os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'MyDjango.settings') # !!!需要修改为自己的配置文件import djangodjango.setup()from index.models import User# 获取age为19的用户user_age_19 = User.objects.filter(age=19) # 第一次构建语句print(user_age_19)# 某种情况下, 需要添加新的查询条件, 如需要过滤姓名user_name_aa = user_age_19.filter(name='aa') # 在前面的语句中添加过滤名字的功能print(user_name_aa)
# ORM日志:
(0.000)
SELECT `index_user`.`id`, `index_user`.`name`, `index_user`.`age`, `index_user`.`register_time`
FROM `index_user`
WHERE `index_user`.`age` = 19
LIMIT 21;
args=(19,)(0.000)
SELECT `index_user`.`id`, `index_user`.`name`, `index_user`.`age`, `index_user`.`register_time`
FROM `index_user`
WHERE (`index_user`.`age` = 19 AND `index_user`.`name` = 'aa')
LIMIT 21;
args=(19, 'aa')
QuerySet在Django中是不可变的(immutable), 这意味着当你对一个QuerySet进行链式调用方法时,
实际上是在创建并返回一个新的QuerySet对象, 而不是修改原始的QuerySet对象.
# index的test.py
import osif __name__ == "__main__":os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'MyDjango.settings') # 设置为你的Django项目设置文件import djangodjango.setup()from index.models import User# 第一次构建QuerySet,获取所有用户all_users = User.objects.all()print("原始QuerySet:", all_users)# 获取age为19的用户user_age_19 = all_users.filter(age=19) # 链式调用filter方法, 返回一个新的QuerySetprint("age为19的用户QuerySet:", user_age_19) # 这也是一个新的QuerySet对象# 展示不可变性: 原始QuerySet没有改变print("原始QuerySet:", all_users)# 进一步操作, 如排序sorted_user_age_19 = user_age_19.order_by('name') # 再次链式调用, 返回另一个新的QuerySetprint("按name排序的age为19的用户QuerySet:", sorted_user_age_19)# 展示user_age_19也没有改变print("age为19的用户QuerySet:", user_age_19)
# ORM日志:
(0.000)
SELECT `index_user`.`id`, `index_user`.`name`, `index_user`.`age`, `index_user`.`register_time`
FROM `index_user`
LIMIT 21;
args=()(0.000)
SELECT `index_user`.`id`, `index_user`.`name`, `index_user`.`age`, `index_user`.`register_time`
FROM `index_user` WHERE `index_user`.`age` = 19
LIMIT 21;
args=(19,)(0.000)
SELECT `index_user`.`id`, `index_user`.`name`, `index_user`.`age`, `index_user`.`register_time`
FROM `index_user`
LIMIT 21;
args=()(0.016)
SELECT `index_user`.`id`, `index_user`.`name`, `index_user`.`age`, `index_user`.`register_time`
FROM `index_user`
WHERE `index_user`.`age` = 19
ORDER BY `index_user`.`name` ASC
LIMIT 21;
args=(19,)(0.000)
SELECT `index_user`.`id`, `index_user`.`name`, `index_user`.`age`, `index_user`.`register_time`
FROM `index_user`
WHERE `index_user`.`age` = 19
LIMIT 21;
args=(19,)
4.10 反转有序查询集
reverse()方法: 用于反转查询集中对象的顺序.
注意: 这个方法必须与order_by()方法一起使用, 确保在反转之前查询集已经根据某个或某些字段进行了排序, 否则没有效果.
# index的test.py
import osif __name__ == "__main__":os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'MyDjango.settings') # !!!需要修改为自己的配置文件import djangodjango.setup()from index.models import User# 错误实例Users = User.objects.reverse()print(Users)# 倒序Users = User.objects.order_by('id').reverse()print(Users)
# ORM日志:
(0.000)
SELECT `index_user`.`id`, `index_user`.`name`, `index_user`.`age`, `index_user`.`register_time`
FROM `index_user`
LIMIT 21;
args=()(0.000)
SELECT `index_user`.`id`, `index_user`.`name`, `index_user`.`age`, `index_user`.`register_time`
FROM `index_user`
ORDER BY `index_user`.`id` DESC
LIMIT 21;
args=()
4.11 字典格式查询集
values(*fields, expressions)方法: 返回一个包含字典的查询集.
每个字典代表数据库中的一个对象(通常是模型的一个实例), 字典的键是传递给values()方法的字段名, 而字典的值则是对应字段的值.
# index的test.py
import osif __name__ == "__main__":os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'MyDjango.settings') # !!!需要修改为自己的配置文件import djangodjango.setup()from index.models import User# 获取所有用户信息Users = User.objects.values('pk', 'name', 'age')print(Users)
# ORM日志
(0.000)
SELECT `index_user`.`id`, `index_user`.`name`, `index_user`.`age`
FROM `index_user`
LIMIT 21;
args=()
4.12 元组格式查询集
values_list(*fields, flat=False)方法: 与values()类似, 但它返回的是元组的列表, 而不是字典的列表.
元组的每个元素对应于传递给values_list()方法的字段名.
如果flat设置为True, 并且只传递了一个字段名给values_list(), 那么返回的将是一个单一值的列表, 而不是元组的列表.
这在只需要模型的一个字段值时特别有用.
# index的test.py
import osif __name__ == "__main__":os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'MyDjango.settings') # !!!需要修改为自己的配置文件import djangodjango.setup()from index.models import User# 获取所有用户信息Users = User.objects.values_list('pk', 'name', 'age')print(Users)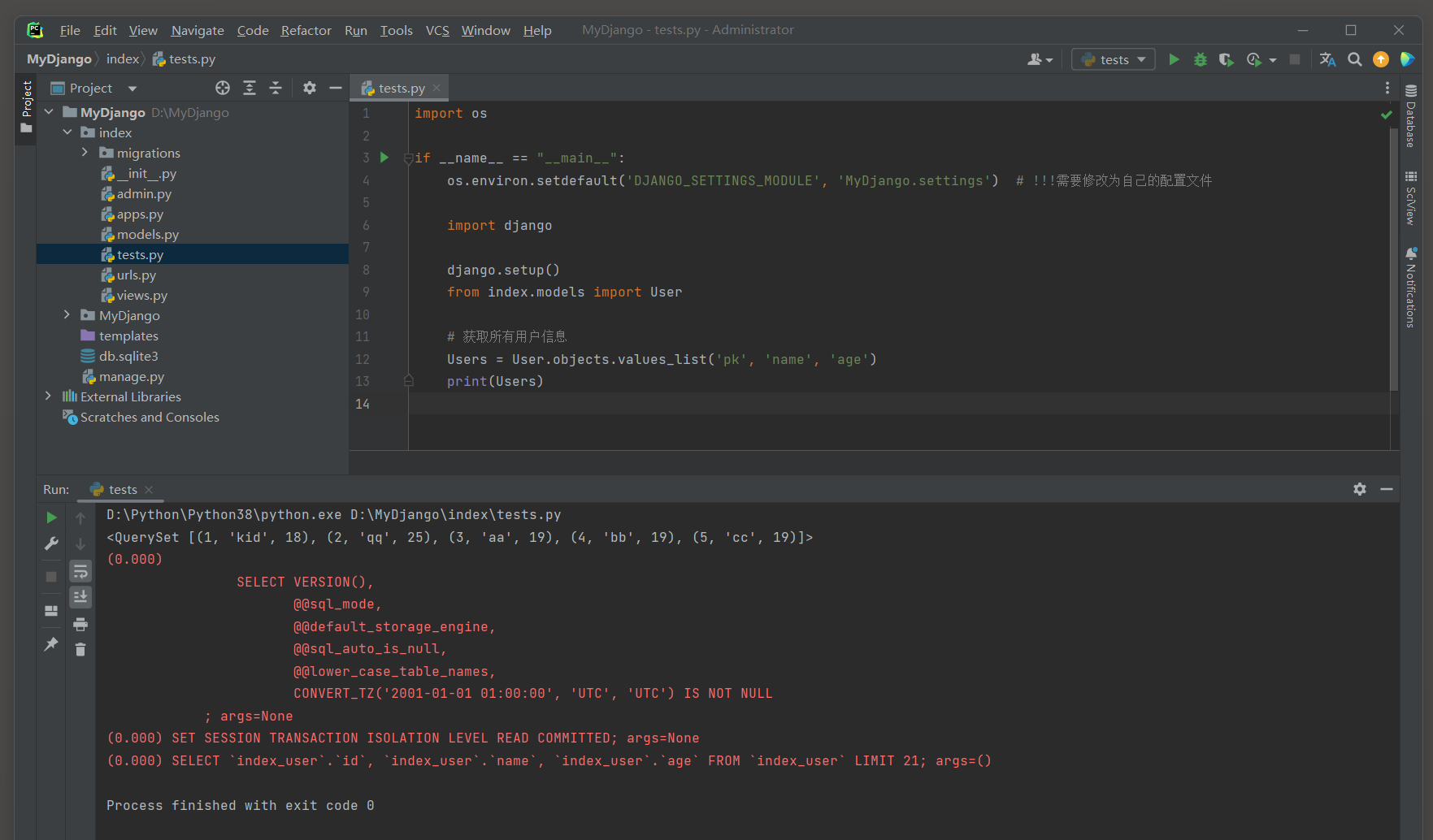
# ORM日志:
(0.000)
SELECT `index_user`.`id`, `index_user`.`name`, `index_user`.`age`
FROM `index_user`
LIMIT 21;
args=()
如果设置flat=True并只传递一个字段, 则返回一个包含所有字段值的列表.
# index的test.py
import osif __name__ == "__main__":os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'MyDjango.settings') # !!!需要修改为自己的配置文件import djangodjango.setup()from index.models import User# 获取所有用户信息Users = User.objects.values_list('name', flat=True)print(Users)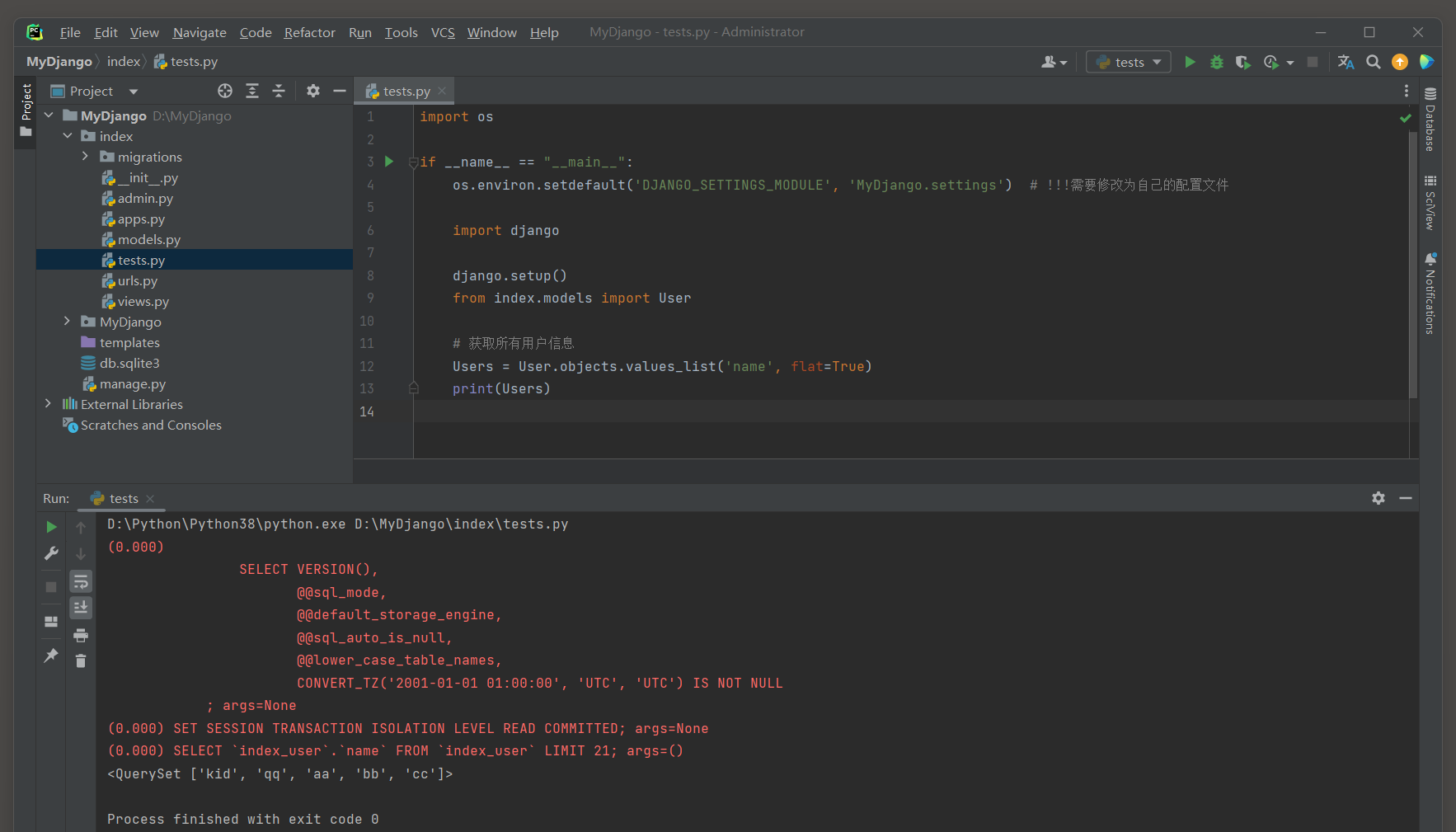
# ORM日志:
(0.000)
SELECT `index_user`.`name`
FROM `index_user`
LIMIT 21;
args=()
4.13 去重查询
distinct(*fields): 返回查询集中不同(去重)的对象集合.
如果指定了*fields, 则仅在这些字段上进行去重.distinct()方法默认作用于所有查询的字段上, 以去除完全相同的记录.
但是, Django ORM并不直接支持在指定字段上进行去重, 因为数据库层面的DISTINCT操作通常是针对整行记录而言的.
不过, 可以通过一些技巧(如使用values()或values_list()与distinct()结合)来模拟在特定字段上的去重效果.注意: 所有键(包括id)唯一才去重, 并且id几乎不会重复, 索引写查询语句一定排除id字段, 否则无效果.
# index的test.py
import osif __name__ == "__main__":os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'MyDjango.settings') # !!!需要修改为自己的配置文件import djangodjango.setup()from index.models import User# 需要先插入两条相同的数据:# User.objects.create(name='zxc', age=18)# User.objects.create(name='zxc', age=18)# 获取数据Users = User.objects.distinct()for user in Users:print(user.name, user.age)# 针对某些字段进行去重Users = User.objects.values('name', 'age').distinct()print(Users)for user in Users:print(user)
# ORM日志:
(0.000)
SELECT DISTINCT `index_user`.`id`, `index_user`.`name`, `index_user`.`age`, `index_user`.`register_time`
FROM `index_user`
LIMIT 21;
args=()(0.000)
SELECT DISTINCT `index_user`.`name`, `index_user`.`age`
FROM `index_user`
LIMIT 21;
args=()
4.14 获取首尾对象
first()方法: 返回查询集中的第一个对象(按id升序获取第一条记录).
last()方法: 返回查询集中的最后一个对象(按id降序获取第一条记录).注意事项:
- 使用first()和last()时, 确保查询集已经通过order_by()方法进行了排序, 因为'第一个'和'最后一个'的定义依赖于排序的顺序.
- 如果查询集是空的(即没有找到任何匹配的对象), first()和last()都会返回None.
- 在处理大量数据时, first()和last()方法比检索整个查询集并手动选择第一个或最后一个元素要高效得多,因为它们允许数据库在内部进行优化, 只返回需要的一个对象.
# index的test.py
import osif __name__ == "__main__":os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'MyDjango.settings') # !!!需要修改为自己的配置文件import djangodjango.setup()from index.models import User# ORDER BY `index_user`.`id` ASC LIMIT 1;user = User.objects.first()print(user.id)# ORDER BY `index_user`.`id` DESC LIMIT 1;user = User.objects.last()print(user.id)
# ORM日志:
(0.000)
SELECT `index_user`.`id`, `index_user`.`name`, `index_user`.`age`, `index_user`.`register_time`
FROM `index_user`
ORDER BY `index_user`.`id` ASC
LIMIT 1;
args=()(0.000)
SELECT `index_user`.`id`, `index_user`.`name`, `index_user`.`age`, `index_user`.`register_time`
FROM `index_user`
ORDER BY `index_user`.`id` DESC
LIMIT 1;
args=()
4.15 查询集统计
count()方法: 用于返回查询集中对象的数量.注意: 频繁使用count()方法可能会对性能产生影响, 特别是当处理大量数据时.
在这种情况下, 考虑是否有其他方法来优化你的查询或逻辑, 比如使用缓存来存储计算结果等.
# index的test.py
import osif __name__ == "__main__":os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'MyDjango.settings') # !!!需要修改为自己的配置文件import djangodjango.setup()from index.models import User# 获取数据条目数num = User.objects.count()print(num) # 7
# ORM日志:
(0.015)
SELECT COUNT(*) AS `__count` FROM `index_user`;
args=()
4.16 存在性检查
exists()方法: 返回一个布尔值(True 或 False), 用于检查查询集中是否存在至少一个对象.
exists()方法是处理大型数据集时检查查询集是否为空的推荐方法, 因为它可以显著提高性能.
它直接对数据库执行一个EXISTS SQL查询, 这通常比检索整个查询集然后检查其长度要快得多.
if queryset: 会导致Django执行查询并加载整个查询集到内存中(如果查询集还没有被加载的话), 即使只是想要检查查询集是否为空.
这可能会消耗大量的内存和处理时间, 特别是在处理大量数据时. (最慢, 数据越少越慢)
执行的SQL语句为: SELECT * FROM `index_user`;
# index的test.py
import osif __name__ == "__main__":os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'MyDjango.settings') # !!!需要修改为自己的配置文件import djangodjango.setup()from index.models import Userqueryset = User.objects.all()if queryset:print(1)
# ORM日志:
(0.000)
SELECT `index_user`.`id`, `index_user`.`name`, `index_user`.`age`, `index_user`.`register_time`
FROM `index_user`;
args=() # 没有LIMIT
queryset.count()方法: 会返回查询集中的对象数量, 但它也会执行一个查询来计算这个数量. (稍快)
执行的SQL语句为: SELECT COUNT(*) AS `__count` FROM `index_user`;
# index的test.py
import osif __name__ == "__main__":os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'MyDjango.settings') # !!!需要修改为自己的配置文件import djangodjango.setup()from index.models import Userqueryset = User.objects.all()if queryset.count():print(1)
# ORM日志:
(0.000) SELECT COUNT(*) AS `__count` FROM `index_user`; args=()
exists()方法: 只需要检查是否存在至少一个对象, 而不需要计算确切的数量, (最快)
执行的SQL语句为: SELECT 1 AS `a` FROM `index_user` LIMIT 1; 代码的意思是: 如果index_user表是空的(即不包含任何行), 那么由于LIMIT 1的存在, 查询将不会返回任何行.
因为即使尝试检索, 也没有符合条件的行可以返回.
如果index_user表包含至少一行数据, 那么查询将返回一行, 这一行的a列值为1.
这是因为查询指定了SELECT 1 AS a, 即无论表中有什么数据, 都会返回一个值为1的a列, 并且由于LIMIT 1, 它只返回这一行.
# index的test.py
import osif __name__ == "__main__":os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'MyDjango.settings') # !!!需要修改为自己的配置文件import djangodjango.setup()from index.models import Userqueryset = User.objects.all()if queryset.exists():print(1)
# ORM日志:
(0.000) SELECT (1) AS `a` FROM `index_user` LIMIT 1; args=()
4.17 查询缓存
Django ORM中的QuerySet缓存机制是一个重要的特性, 用于减少不必要的数据库查询, 提高应用性能.
缓存机制: Django会为已经评估过的QuerySet提供缓存机制.
一旦QuerySet被完整评估并返回结果, 这些结果就会被缓存起来.
如果后续再次对该QuerySet进行评估(且查询条件没有变化), Django就会直接返回缓存中的结果, 而无需再次与数据库交互.Django的QuerySet缓存机制是在QuerySet被评估(即触发数据库查询)后起作用的, 而不是在'普通评估'(如过滤, 排序等操作)阶段.
这些'普通评估'操作只是构建了查询的条件, 而真正的查询和缓存发生在这些条件被用来从数据库中检索数据时.触发完整评估的方法:
- 迭代QuerySet, 迭代QuerySet会触发完整评估(即执行数据库查询并缓存结果).使用iterator()会绕过Django的QuerySet缓存机制, 因为每次调用next()时都会从数据库中检索下一个数据项.
- 转换为列表: 使用Python内置的list()函数将QuerySet对象转换为列表.这个操作会触发QuerySet的完整评估, 因为列表需要包含QuerySet中所有的数据项.
- 检查QuerySet是否为真: 在布尔上下文中使用QuerySet(如使用bool()函数或在if语句中)也会触发完整评估.Django会检查QuerySet中是否有数据项存在, 以决定是否返回True或False.
- 序列化QuerySet: 当需要将QuerySet对象序列化为JSON或其他格式时, 也会触发完整评估.因为序列化过程需要遍历QuerySet中的所有数据项, 并将其转换为指定的格式.
- 其他方法: 还有一些其他方法可能会触发QuerySet的完整评估, 如: len()获取QuerySet的长度.如果只对QuerySet进行了部分迭代或切片, 而没有进行完整迭代, 通常不会触发缓存.
因为Django无法确定是否需要缓存整个QuerySet的结果.
当QuerySet被完整迭代时, Django会执行查询并将结果存储在QuerySet的_result_cache属性中.
这意味着, 之后对相同QuerySet的任何迭代都将直接从缓存中读取数据, 而不需要再次查询数据库.
# index的test.py
import osif __name__ == "__main__":os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'MyDjango.settings') # !!!需要修改为自己的配置文件import djangodjango.setup()from index.models import Userqueryset = User.objects.all()for user in queryset: # 首次迭代, 触发数据库查询并缓存结果print(user)for user in queryset: # 第二次迭代, 使用缓存中的数据print(user)print(queryset._result_cache) # 查看缓存
注意:
执行queryset = User.objects.all()之后,
直接打印queryset, 执行的的SQL是: SELECT * FROM `index_user` LIMIT 21; 做了性能优化, 没有缓存.
使用for遍历queryset, 执行的的SQL是: SELECT * FROM `index_user`; 获取所有数据, 可以缓存.
# ORM日志:
(0.000)
SELECT `index_user`.`id`, `index_user`.`name`, `index_user`.`age`, `index_user`.`register_time`
FROM `index_user`;
args=()
如果只对QuerySet进行了部分迭代或切片, 而没有进行完整迭代, 通常不会触发缓存(一般只有完整的).
# index的test.py
import osif __name__ == "__main__":os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'MyDjango.settings') # !!!需要修改为自己的配置文件import djangodjango.setup()from index.models import Userqueryset = User.objects.all()# 我们只对QuerySet进行了部分迭代for user in queryset[:2]: # 这里切片了QuerySet, 只迭代了前2个对象print(user)# 再次尝试迭, Django会再次执行一个查询for user in queryset[:2]:print(user)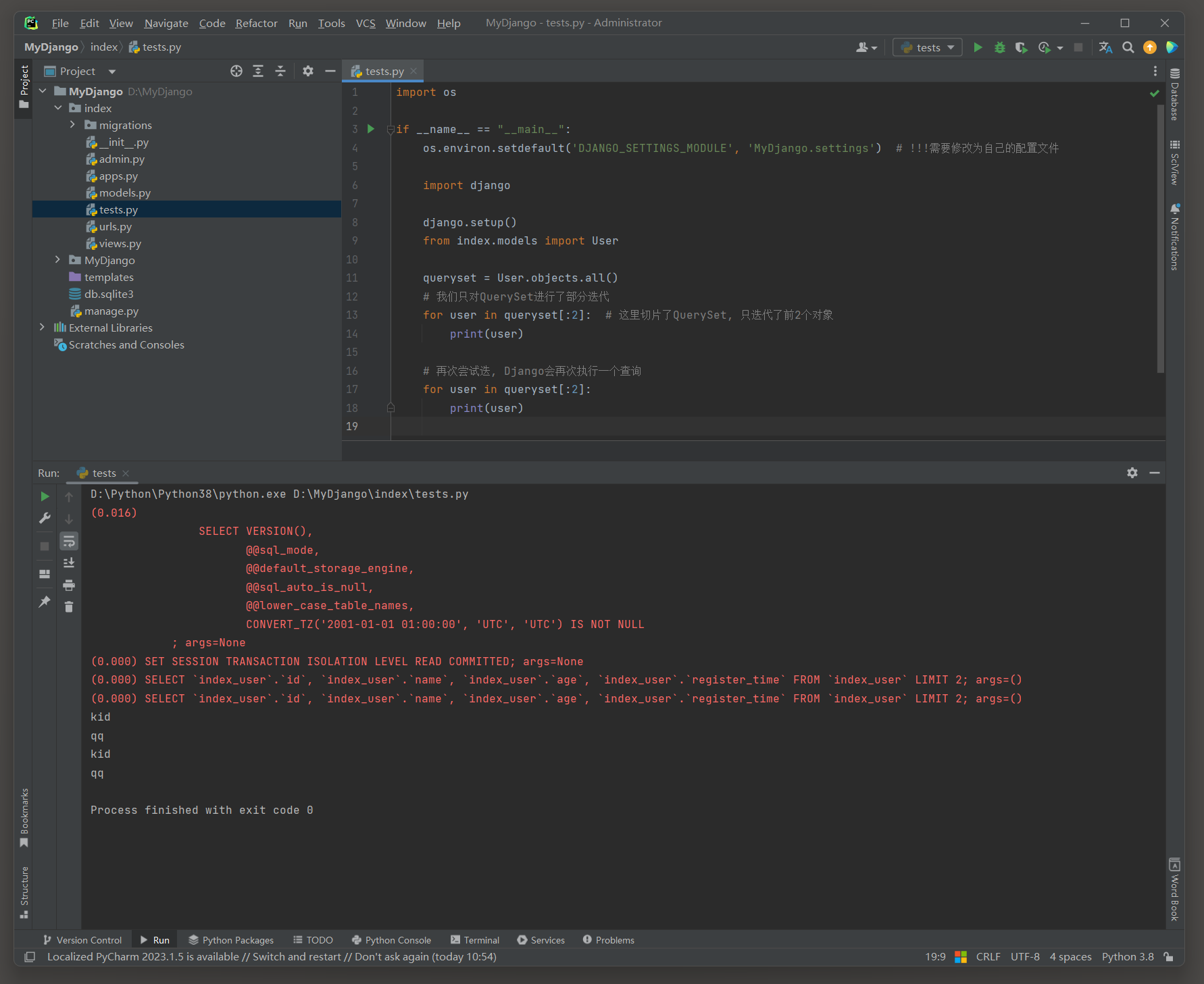
# ORM日志:
(0.000)
SELECT `index_user`.`id`, `index_user`.`name`, `index_user`.`age`, `index_user`.`register_time`
FROM `index_user`
LIMIT 2;
args=()(0.000)
SELECT `index_user`.`id`, `index_user`.`name`, `index_user`.`age`, `index_user`.`register_time`
FROM `index_user`
LIMIT 2;
args=()
可以用Python内置的list()函数将QuerySet对象转换为列表, 这个操作会触发QuerySet的完整评估.
# index的test.py
import osif __name__ == "__main__":os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'MyDjango.settings') # !!!需要修改为自己的配置文件import djangodjango.setup()from index.models import Userqueryset = User.objects.all()print(list(queryset)) # 评估QuerySet, 执行数据库查询, 并将结果缓存print(list(queryset)) # 再次评估相同的QuerySet, 但这次直接从缓存中返回结果, 不执行数据库查询print(queryset) # 从缓存中读取print(queryset._result_cache)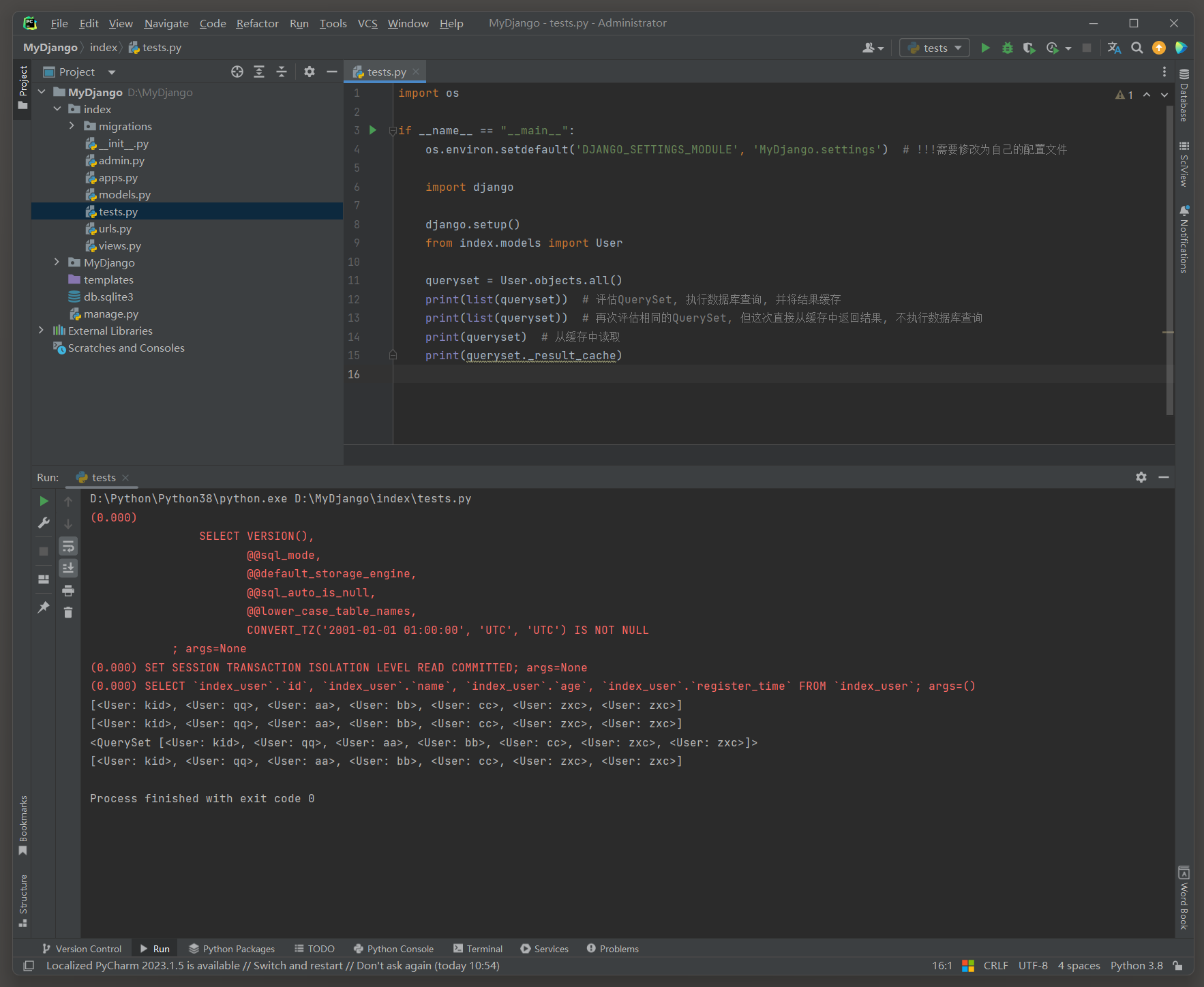
# ORM 日志
(0.000)
SELECT `index_user`.`id`, `index_user`.`name`, `index_user`.`age`, `index_user`.`register_time`
FROM `index_user`
WHERE `index_user`.`age` = 19;
args=(19,)
在布尔上下文中使用QuerySet, 如: if queryset执行的SQL语句是: SELECT * FROM `table`; 获取所有数据, 会触发完整评估.
# index的test.py
import osif __name__ == "__main__":os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'MyDjango.settings') # !!!需要修改为自己的配置文件import djangodjango.setup()from index.models import Userqueryset = User.objects.all()# 触发完整评估if queryset:print(1)if queryset.count():print(1)if queryset.exists():print(1)
# ORM日志:
(0.000)
SELECT `index_user`.`id`, `index_user`.`name`, `index_user`.`age`, `index_user`.`register_time`
FROM `index_user`;
args=()
queryset.count()和queryset.exists() 在Django中确实不会触发对QuerySet的完整评估, 即它们不会检索QuerySet中的所有数据项.
这两个方法都用于检查QuerySet是否包含数据, 但它们以不同的方式执行此操作, 并且都旨在优化性能.
4.18 原始查询
尽管Django ORM提供了丰富的 API 来执行大多数数据库操作, 但在某些情况下, 可能需要编写自定义的SQL查询.
raw()方法允许执行原始SQL查询并返回一个RawQuerySet.
# index的test.py
import osif __name__ == "__main__":os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'MyDjango.settings') # !!!需要修改为自己的配置文件import djangodjango.setup()from index.models import Usersql = "SELECT * FROM index_user WHERE name = %s"# 使用params参数来传递查询参数, 这样Django会正确地处理它们以防止SQL注入raw_queryset = User.objects.raw(sql, ['kid'])for user in raw_queryset:print(user.id, user.name)
# ORM日志:
(0.000) SELECT * FROM index_user WHERE name = 'kid'; args('kid', )
5. 字段查找操作符
在Django的ORM中, 构造一个查询条件, 比如: id > 4, 这样的条件不能直接作为位置参数传递给filter()方法.
在方法调用时像filter(id > 4)这样写, Python解释器会将id > 4视为一个布尔值表达式,
会将表达式的值(True或False)传递给filter(), 这显然不是想要的结果.
5.1 查找操作符介绍
Django提供了一系列的字段查找操作符, 用于在filter(), exclude(), annotate(), order_by()等查询方法中构建复杂的查询条件.
以下是一些常用的Django ORM字段查找操作符及其简介:
* 1. __exact: 精确匹配.这是默认的查找方式, 如果没有指定查找类型, 则使用__exact. 例如, filter(name__exact="John")等同于filter(name="John").
* 2. __iexact: 不区分大小写的精确匹配.例如, filter(name__iexact="john")会匹配John, john, JOHN等.
* 3. __contains: 包含.对于文本字段, 匹配字段中包含的字符串. 例如, filter(name__contains="ohn")会匹配John, Jonathan等.
* 4. __icontains: 不区分大小写的包含.例如, filter(name__icontains="ohn")会匹配John, john, jOhn等.
* 5. __gt, __gte, __lt, __lte: 分别表示大于, 大于等于, 小于, 小于等于. 这些操作符通常用于数值或日期字段, 例如, filter(age__gt=18)会匹配所有年龄大于18的记录.
* 6. __in: 如果指定的字段在序列中, 则返回True; 否则返回False.例如, filter(id__in=[1, 2, 3])会匹配ID为1, 2或3的记录.
* 7. __startswith, __istartswith: 以指定值开始. __istartswith是不区分大小写的版本.例如, filter(name__startswith="J")会匹配所有名字以J开头的记录.
* 8. __endswith, __iendswith: 以指定值结束. __iendswith是不区分大小写的版本.
* 9. __isnull: 判断字段是否为NULL.例如, filter(birthday__isnull=True)会匹配所有没有生日(即birthday字段为NULL)的记录.
* 9. __range: 指定一个范围, 以筛选出位于这个范围内的记录. 通常用于数值或日期字段.例如, filter(age__range=(20, 30))会匹配年龄在18到30岁之间的记录(包括20和30).
* 10. __year, __month, __day, __week_day, __hour, __minute, __second: 这些操作符用于日期和时间字段,分别提取并匹配年, 月, 日, 星期几, 小时, 分钟, 秒.
* 11. __regex, __iregex: 正则表达式匹配. __iregex是不区分大小写的版本.例如, filter(name__regex=r'^J')会匹配所有名字以J开头的记录.请注意, 上述操作符中的__前缀是Django ORM用于区分字段名和查找类型的约定.
此外, Django还提供了更多的高级查找功能, 如Q对象(用于构建复杂查询逻辑, 如OR查询)和F表达式(用于数据库级别的字段值比较和计算).
5.2 测试环境
定义一个Person的模型用于测试, 表中包含id, name, age, birthday字段.
# index的models.py
from django.db import models class Person(models.Model): name = models.CharField(max_length=100) age = models.IntegerField() birthday = models.DateTimeField(null=True, blank=True) def __str__(self): return self.name
# 执行数据迁移
PS D:\MyDjango> python manage.py makemigrationsMigrations for 'index':index\migrations\0002_person.py- Create model Person
...PS D:\MyDjango> python manage.py makemigrations
...
在Django中, 当USE_TZ=True时, 所有DateTimeField都应该接收时区感知的datetime对象, 这些对象包含时区信息.
如果你不提供时区信息, Django会尝试使用默认的时区(TIME_ZONE设置在settings.py中)来转换这个naive datetime对象,
但这可能会导致不期望的行为(例: RuntimeWarning), 特别是当数据库服务器和Django应用的时区设置不一致时.
创建一些示例数据:
# index的test.py
import osif __name__ == "__main__":os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'MyDjango.settings') # !!!需要修改为自己的配置文件import djangodjango.setup()from index.models import Personfrom datetime import datetimefrom django.utils import timezone# 使用 timezone.make_aware 来创建一个时区感知的 datetime 对象# 假设应用时区与默认时区相同(这通常是通过 TIME_ZONE 设置的_aware_datetime1 = timezone.make_aware(datetime(1995, 10, 10, 14, 30, 45), timezone.get_default_timezone())aware_datetime2 = timezone.make_aware(datetime(1990, 5, 5, 16, 11, 45), timezone.get_default_timezone())aware_datetime3 = timezone.make_aware(datetime(1985, 2, 10, 20, 30, 45), timezone.get_default_timezone())# 创建一些示例数据Person.objects.create(name="John Doe", age=25, birthday=aware_datetime1)Person.objects.create(name="john smith", age=30, birthday=aware_datetime2)Person.objects.create(name="Jane Doe", age=22, birthday=None)Person.objects.create(name="Jonathan Davis", age=35, birthday=aware_datetime3)
# ORM日志:
(0.000)
INSERT INTO `index_person` (`name`, `age`, `birthday`)
VALUES ('John Doe', 25, '1995-10-10 14:30:45');
args=['John Doe', 25, '1995-10-10 14:30:45'](0.000)
INSERT INTO `index_person` (`name`, `age`, `birthday`)
VALUES ('john smith', 30, '1990-05-05 16:11:45');
args=['john smith', 30, '1990-05-05 16:11:45'](0.000)
INSERT INTO `index_person` (`name`, `age`, `birthday`)
VALUES ('Jane Doe', 22, NULL);
args=['Jane Doe', 22, None](0.000)
INSERT INTO `index_person` (`name`, `age`, `birthday`)
VALUES ('Jonathan Davis', 35, '1985-02-10 20:30:45');
args=['Jonathan Davis', 35, '1985-02-10 20:30:45']
5.3 精准匹配
__exact: 精确匹配.
这是默认的查找方式, 如果没有指定查找类型, 则使用__exact.
例如, filter(name__exact="John")等同于filter(name="John").__iexact: 不区分大小写的精确匹配(使用了LIKE模糊查询).
例如, filter(name__iexact="john")会匹配John, john, JOHN等.
# index的test.py
import osif __name__ == "__main__":os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'MyDjango.settings') # !!!需要修改为自己的配置文件import djangodjango.setup()from index.models import Person# 精准匹配print(Person.objects.filter(name__exact="John Doe"))# 精确匹配(不区分大小写)print(Person.objects.filter(name__iexact="john doe"))
# ORM日志:
(0.000)
SELECT `index_person`.`id`, `index_person`.`name`, `index_person`.`age`, `index_person`.`birthday`
FROM `index_person`
WHERE `index_person`.`name` = 'John Doe'
LIMIT 21;
args=('John Doe',)(0.000)
SELECT `index_person`.`id`, `index_person`.`name`, `index_person`.`age`, `index_person`.`birthday`
FROM `index_person`
WHERE `index_person`.`name` LIKE 'john doe'
LIMIT 21;
args=('john doe',)
5.4 模糊查询
__contains: 包含. (使用了%%通配符)
对于文本字段, 匹配字段中包含的字符串.
例如, filter(name__contains="ohn")会匹配John, Jonathan等.__icontains: 不区分大小写的包含. (%like%)
例如, filter(name__icontains="ohn")会匹配John, john, jOhn等.
# index的test.py
import osif __name__ == "__main__":os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'MyDjango.settings') # !!!需要修改为自己的配置文件import djangodjango.setup()from index.models import Person# 模糊查询, 包含指定字符(区分大小写)print(Person.objects.filter(name__contains="Doe"))# 模糊查询, 包含指定字符(不区分大小写)print(Person.objects.filter(name__icontains="doe"))
# ORM日志:
(0.000)
SELECT `index_person`.`id`, `index_person`.`name`, `index_person`.`age`, `index_person`.`birthday`
FROM `index_person`
WHERE `index_person`.`name` LIKE BINARY '%Doe%'
LIMIT 21;
args=('%Doe%',)(0.000)
SELECT `index_person`.`id`, `index_person`.`name`, `index_person`.`age`, `index_person`.`birthday`
FROM `index_person`
WHERE `index_person`.`name` LIKE '%doe%'
LIMIT 21;
args=('%doe%',)
5.5 比较操作
__gt, __gte, __lt, __lte: 分别表示大于, 大于等于, 小于, 小于等于. 这些操作符通常用于数值或日期字段,
例如, filter(age__gt=18)会匹配所有年龄大于18的记录.
# index的test.py
import osif __name__ == "__main__":os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'MyDjango.settings') # !!!需要修改为自己的配置文件import djangodjango.setup()from index.models import Person# 比较操作符print(Person.objects.filter(age__gt=25)) # 大于25岁的print(Person.objects.filter(age__lt=25)) # 小于25岁的
# ORM日志:
(0.000)
SELECT `index_person`.`id`, `index_person`.`name`, `index_person`.`age`, `index_person`.`birthday`
FROM `index_person`
WHERE `index_person`.`age` > 25
LIMIT 21;
args=(25,)(0.000)
SELECT `index_person`.`id`, `index_person`.`name`, `index_person`.`age`, `index_person`.`birthday`
FROM `index_person`
WHERE `index_person`.`age` < 25
LIMIT 21;
args=(25,)
5.6 成员运算
__in: 如果指定的字段在序列中, 则返回True; 否则返回False.
例如, filter(id__in=[1, 2, 3])会匹配ID为1, 2或3的记录.
# index的test.py
import osif __name__ == "__main__":os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'MyDjango.settings') # !!!需要修改为自己的配置文件import djangodjango.setup()from index.models import Person# in操作print(Person.objects.filter(age__in=[25, 30])) # 查询25岁与30岁的用户信息
# ORM日志:
(0.000)
SELECT `index_person`.`id`, `index_person`.`name`, `index_person`.`age`, `index_person`.`birthday`
FROM `index_person`
WHERE `index_person`.`age` IN (25, 30)
LIMIT 21;
args=(25, 30)
5.7 边界匹配
__startswith, __istartswith(不区分大小写): 以指定值开始.
__endswith, __iendswith(不区分大小写): 以指定值结束.
例如, filter(name__startswith="J")会匹配所有名字以J开头的记录.
# index的test.py
import osif __name__ == "__main__":os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'MyDjango.settings') # !!!需要修改为自己的配置文件import djangodjango.setup()from index.models import Person# 以指定字符开头print(Person.objects.filter(name__startswith="J")) # name以J开头# 以指定字符开头(不区分大小写)print(Person.objects.filter(name__istartswith="e")) # name以e开头# 以指定字符结尾print(Person.objects.filter(name__iendswith="Doe")) # name以Doe结尾# 以指定字符结尾(不区分大小写)print(Person.objects.filter(name__iendswith="doe")) # name以doe结尾
# ORM日志:
(0.000)
SELECT `index_person`.`id`, `index_person`.`name`, `index_person`.`age`, `index_person`.`birthday`
FROM `index_person`
WHERE `index_person`.`name` LIKE BINARY 'J%'
LIMIT 21;
args=('J%',)(0.000)
SELECT `index_person`.`id`, `index_person`.`name`, `index_person`.`age`, `index_person`.`birthday`
FROM `index_person`
WHERE `index_person`.`name` LIKE 'e%'
LIMIT 21;
args=('e%',)(0.000)
SELECT `index_person`.`id`, `index_person`.`name`, `index_person`.`age`, `index_person`.`birthday`
FROM `index_person`
WHERE `index_person`.`name` LIKE '%Doe'
LIMIT 21;
args=('%Doe',)(0.000)
SELECT `index_person`.`id`, `index_person`.`name`, `index_person`.`age`, `index_person`.`birthday`
FROM `index_person`
WHERE `index_person`.`name` LIKE '%doe'
LIMIT 21;
args=('%doe',)
5.8 空值判断
__isnull: 判断字段是否为NULL.
例如, filter(birthday__isnull=True)会匹配所有没有生日(即birthday字段为NULL)的记录.
# index的test.py
import osif __name__ == "__main__":os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'MyDjango.settings') # !!!需要修改为自己的配置文件import djangodjango.setup()from index.models import Person# 判断是否为NULLprint(Person.objects.filter(birthday__isnull=True))
# ORM日志:
(0.000)
SELECT `index_person`.`id`, `index_person`.`name`, `index_person`.`age`, `index_person`.`birthday`
FROM `index_person`
WHERE `index_person`.`birthday` IS NULL
LIMIT 21;
args=()
5.9 范围匹配
__range: 指定一个范围, 以筛选出位于这个范围内的记录. 通常用于数值或日期字段.
例如, filter(age__range=(20, 30))会匹配年龄在20到30岁之间的记录(包括20和30).
# index的test.py
import osif __name__ == "__main__":os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'MyDjango.settings') # !!!需要修改为自己的配置文件import djangodjango.setup()from index.models import Person# 指定范围print(Person.objects.filter(age__range=(20, 30)))
# ORM日志:
(0.000)
SELECT `index_person`.`id`, `index_person`.`name`, `index_person`.`age`, `index_person`.`birthday`
FROM `index_person`
WHERE `index_person`.`age` BETWEEN 20 AND 30
LIMIT 21;
args=(20, 30)
5.10 日期匹配
__year: 匹配年份部分.
__month: 匹配月份部分.
__day: 匹配日份部分.
__week_day: 用于匹配星期几(通常是从0或1开始的索引, 表示星期一到星期日).
# index的test.py
import osif __name__ == "__main__":os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'MyDjango.settings') # !!!需要修改为自己的配置文件import djangodjango.setup()from index.models import Person# 年月日匹配print(Person.objects.filter(birthday__year=1995))print(Person.objects.filter(birthday__month=10))print(Person.objects.filter(birthday__day=10))# 星期几匹配print(Person.objects.filter(birthday__week_day=3))
# ORM日志
(0.000) SELECT `index_person`.`id`, `index_person`.`name`, `index_person`.`age`, `index_person`.`birthday`
FROM `index_person`
WHERE `index_person`.`birthday` BETWEEN '1995-01-01 00:00:00' AND '1995-12-31 23:59:59.999999'
LIMIT 21;
args=('1995-01-01 00:00:00', '1995-12-31 23:59:59.999999')(0.000)
SELECT `index_person`.`id`, `index_person`.`name`, `index_person`.`age`, `index_person`.`birthday`
FROM `index_person`
WHERE EXTRACT(MONTH FROM `index_person`.`birthday`) = 10
LIMIT 21;
args=(10,)(0.000)
SELECT `index_person`.`id`, `index_person`.`name`, `index_person`.`age`, `index_person`.`birthday`
FROM `index_person`
WHERE EXTRACT(DAY FROM `index_person`.`birthday`) = 10
LIMIT 21;
args=(10,)(0.000) SELECT `index_person`.`id`, `index_person`.`name`, `index_person`.`age`, `index_person`.`birthday`
FROM `index_person`
WHERE DAYOFWEEK(`index_person`.`birthday`) = 3
LIMIT 21;
args=(3,)
EXTRACT是一个SQL函数, 用于从日期或时间值中提取特定的部分)如年, 月, 日, 小时等).
- EXTRACT(MONTH FROM `index_person`.`birthday`): 这个函数调用从birthday字段中提取月份部分.
- EXTRACT(DAY FROM `index_person`.`birthday`): 这个函数调用从birthday字段中提取日期部分.
DAYOFWEEK()函数用于获取一个日期是周几.
5.11 时间匹配
__hour: 匹配小时部分.
__minute: 匹配分钟部分.
__second: 匹配取秒部分.
# index的test.py
import osif __name__ == "__main__":os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'MyDjango.settings') # !!!需要修改为自己的配置文件import djangodjango.setup()from index.models import Person# 时分秒匹配print(Person.objects.filter(birthday__hour=14))print(Person.objects.filter(birthday__minute=30))print(Person.objects.filter(birthday__second=45))
# ORM日志:
(0.000)
SELECT `index_person`.`id`, `index_person`.`name`, `index_person`.`age`, `index_person`.`birthday`
FROM `index_person`
WHERE EXTRACT(HOUR FROM `index_person`.`birthday`) = 14
LIMIT 21;
args=(14,)(0.000)
SELECT `index_person`.`id`, `index_person`.`name`, `index_person`.`age`, `index_person`.`birthday`
FROM `index_person`
WHERE EXTRACT(MINUTE FROM `index_person`.`birthday`) = 30
LIMIT 21;
args=(30,)(0.000)
SELECT `index_person`.`id`, `index_person`.`name`, `index_person`.`age`, `index_person`.`birthday`
FROM `index_person`
WHERE EXTRACT(SECOND FROM `index_person`.`birthday`) = 45
LIMIT 21;
args=(45,)
EXTRACT(HOUR FROM `index_person`.`birthday`): 这个函数调用从birthday字段中提取小时部分.
EXTRACT(MINUTE FROM `index_person`.`birthday`): 这个函数调用从birthday字段中提取分钟部分.
EXTRACT(SECOND FROM `index_person`.`birthday`): 这个函数调用从birthday字段中提取秒部分.
5.12 正则匹配
__regex, __iregex(不区分大小): 正则表达式匹配.
例如, filter(name__regex=r'^J')会匹配所有名字以J开头的记录.
# index的test.py
import osif __name__ == "__main__":os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'MyDjango.settings') # !!!需要修改为自己的配置文件import djangodjango.setup()from index.models import Person# 正则匹配print(Person.objects.filter(name__regex=r'^J'))# 正则匹配(不区分大小写)print(Person.objects.filter(name__iregex=r'^j'))
(0.000)
SELECT `index_person`.`id`, `index_person`.`name`, `index_person`.`age`, `index_person`.`birthday`
FROM `index_person`
WHERE REGEXP_LIKE(`index_person`.`name`, '^J', 'c') # 使用了修饰符'i', 表示区分大小写
LIMIT 21;
args=('^J',)(0.016)
SELECT `index_person`.`id`, `index_person`.`name`, `index_person`.`age`, `index_person`.`birthday`
FROM `index_person`
WHERE REGEXP_LIKE(`index_person`.`name`, '^j', 'i') # 使用了修饰符'i', 表示不区分大小写
LIMIT 21;
args=('^j',)
6. 修改表纪录
Django ORM提供了多种修改数据库表记录的方式, 主要包括更新记录, 批量更新记录等方式.
更新记录通常涉及以下几个步骤:
* 1. 查询记录: 首先, 使用filter()等方法查询出需要更新的记录集(QuerySet).
* 2.1 保存更改: 如果使用对象属性修改方式, 则需要调用对象的save()方法来保存更改;
* 2.2 修改属性: 然后, 可以通过遍历QuerySet中的对象并修改其属性, 或者直接使用update()方法(对于QuerySet)来更新字段值.
6.1 修改记录并保存
save()方法: 它是Django模型(Model)实例的一个方法, 用于将模型的更改保存到数据库中.
当修改了模型实例的某个字段后, 调用该实例的save()方法会将这些更改提交到数据库, 并触发相关的模型信号(如:pre_save和post_save).
返回值: save()方法没有返回值(在Python中, 这通常意味着返回None).
# index的test.py
import osif __name__ == "__main__":os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'MyDjango.settings') # !!!需要修改为自己的配置文件import djangodjango.setup()from index.models import User# 使用对象属性修改方式user = User.objects.get(id=1)user.name = '张三'res = user.save() # 没有返回值print(res)
# ORM日志:
(0.000)
SELECT `index_user`.`id`, `index_user`.`name`, `index_user`.`age`, `index_user`.`register_time`
FROM `index_user`
WHERE `index_user`.`id` = 1
LIMIT 21;
args=(1,)(0.016)
UPDATE `index_user`
SET `name` = '张三', `age` = 18, `register_time` = '2024-07-09 02:49:31.475065'
WHERE `index_user`.`id` = 1;
args=('张三', 18, '2024-07-09 02:49:31.475065', 1)
批量修改: 通过循环遍历模型的查询集并为每个模型字段设置新的字段然后调用save()方法.
# index的test.py
import osif __name__ == "__main__":os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'MyDjango.settings') # !!!需要修改为自己的配置文件import djangodjango.setup()from index.models import User# 获取多个对象Users = User.objects.filter(age=19)for user in Users:user.age = 20user.save()
# ORM日志:
(0.000)
SELECT `index_user`.`id`, `index_user`.`name`, `index_user`.`age`, `index_user`.`register_time`
FROM `index_user`
WHERE `index_user`.`age` = 19;
args=(19,)(0.016)
UPDATE `index_user`
SET `name` = 'aa', `age` = 20, `register_time` = '2024-07-09 04:33:00.323082'
WHERE `index_user`.`id` = 3;
args=('aa', 20, '2024-07-09 04:33:00.323082', 3)(0.000)
UPDATE `index_user` SET `name` = 'bb', `age` = 20, `register_time` = '2024-07-09 04:33:00.323082'
WHERE `index_user`.`id` = 4;
args=('bb', 20, '2024-07-09 04:33:00.323082', 4)(0.000)
UPDATE `index_user` SET `name` = 'cc', `age` = 20, `register_time` = '2024-07-09 04:33:00.323082'
WHERE `index_user`.`id` = 5;
args=('cc', 20, '2024-07-09 04:33:00.323082', 5)
对于大量的数据更新, 这种方法会非常低效, 因为它会产生大量的数据库调用.
这种情况, Django ORM中推荐的批量更新是使用update()方法.
6.2 批量更新
update()方法: 它是Django查询集(QuerySet)的一个方法, 用于批量更新满足特定条件的记录.
与save()方法不同, update()直接在数据库层面执行更新操作, 不需要先加载记录到内存中.
返回值: update()方法返回一个整数, 表示受影响的记录数(即被更新的记录数).
# index的test.py
import osif __name__ == "__main__":os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'MyDjango.settings') # !!!需要修改为自己的配置文件import djangodjango.setup()from index.models import User# 使用update()方法res = User.objects.filter(age=20).update(age=21)print(res)这种方式比遍历QuerySet中的每个对象并调用save()方法更高效, 因为它减少了数据库交互的次数.

# ORM日志:
(0.000) UPDATE `index_user` SET `age` = 21 WHERE `index_user`.`age` = 20; args=(21, 20)
7. 删除表纪录
在Django ORM中, 删除表中的记录可以通过模型的delete()方法来完成.
这个方法既可以应用于单个模型实例, 也可以应用于一个查询集(QuerySet).返回值: delete()方的返回值是一个元组, 其中包含两个整数值:
第一个元素是一个整数, 表示被直接删除的记录总数(即调用.delete()方法的查询集中所包含的记录数).
第二个元素是一个字典, 其键是的字符串表示, 值是该模型删除的记录数.
如果每次删除记录则显示为: (0, {}).注意事项:
- 在使用delete()方法时, Django会发出pre_delete和post_delete信号, 如果需要在删除操作前后执行一些自定义逻辑, 可以监听这些信号.
- 删除操作是不可逆的, 因此在执行之前请确保这是真正想要的操作.
7.1 删除单条记录
删除单条记录: 需要先获取到想要删除的模型实例, 一旦有了这个实例, 就可以调用它的delete()方法来删除它.
# index的test.py
import osif __name__ == "__main__":os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'MyDjango.settings') # !!!需要修改为自己的配置文件import djangodjango.setup()from index.models import User# 删除ID为1的User实例user = User.objects.filter(id=1)res = user.delete()print(res)
# ORM日志:
(0.000) DELETE FROM `index_user` WHERE `index_user`.`id` = 1; args=(1,)
7.2 删除多条记录
删除查询集中的多个记录: 先获取查询集(QuerySet), 在调用它的delete()方法删除查询集中所有的记录.
# index的test.py
import osif __name__ == "__main__":os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'MyDjango.settings') # !!!需要修改为自己的配置文件import djangodjango.setup()from index.models import User# 删除age为21的User实例res = User.objects.filter(age=21).delete()print(res)
# ORM日志:
(0.016) DELETE FROM `index_user` WHERE `index_user`.`age` = 21; args=(21,)
8. 原始SQL
Raw SQL, 即原始SQL, 指的是直接在应用程序或数据库管理系统中执行的SQL(Structured Query Language, 结构化查询语言)语句.
Raw SQL的使用允许开发者绕过ORM(对象关系映射)框架或其他数据库抽象层, 直接对数据库执行具体的SQL语句.在Django中, 虽然ORM(对象关系映射)是推荐的方式来与数据库交互, 但在某些情况下, 可能需要直接使用原始SQL语句来执行数据库操作.
这可以通过Django的cursor对象来实现.
在Django框架中, django.db.connection是一个代表当前数据库连接的对象.
这个对象提供了与数据库交互的能力, 包括执行SQL查询, 管理事务等.
使用connection.cursor()方法可以获取一个数据库游标(cursor)对象, 这个游标对象允许执行SQL语句并获取结果.
手写的sql语句可以不在末尾加上;号, 使用的数据库模块会自动加上.
如果加上了;号, 在ORM日志中会看到执行的SQL语句会有两个分号;;.
8.1 新增记录
使用原始SQL插入一条记录到User表中:
# index的test.py
import osif __name__ == "__main__":os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'MyDjango.settings') # !!!需要修改为自己的配置文件import djangodjango.setup()from django.db import connectionimport timewith connection.cursor() as cursor:sql = "INSERT INTO index_user (name, age, register_time) VALUES (%s, %s, %s);"formatted_time = time.strftime("%Y-%m-%d %H:%M:%S")val = ('Python', 18, formatted_time)# 返回新增的记录数res = cursor.execute(sql, val)print(res)with connection.cursor() as cursor: 这行代码利用了Python的上下文管理器(context manager)特性,
这是一种常用的模式, 用于确保资源(如文件句柄, 数据库连接等)在使用后能够被正确释放或关闭.

# ORM日志
(0.000)
INSERT INTO index_user (name, age, register_time)
VALUES ('Python', 18, '2024-07-12 16:55:28');; # 两个分号;;
args=('Python', 18, '2024-07-12 16:55:28')
8.2 查询记录
使用原始SQL查询User表中的数据:
# index的test.py
import osif __name__ == "__main__":os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'MyDjango.settings') # !!!需要修改为自己的配置文件import djangodjango.setup()from django.db import connectionwith connection.cursor() as cursor:sql = "SELECT * FROM index_user WHERE id = %s;"cursor.execute(sql, (8,))# 返回记录row = cursor.fetchone()if row:print(f'id: {row[0]}, name: {row[1]}, register_time:{row[3]}')
# ORM日志
(0.000) SELECT * FROM index_user WHERE id = 8;; args=(8,)
8.3 修改记录
使用原始SQL修改User表中的一条记录:
# index的test.py
import osif __name__ == "__main__":os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'MyDjango.settings') # !!!需要修改为自己的配置文件import djangodjango.setup()from django.db import connectionwith connection.cursor() as cursor:sql = "UPDATE index_user SET name = %s WHERE id = %s"val = ('Linux', 8)# 返回修改的记录数res = cursor.execute(sql, val)print(res)
# ORM日志:
(0.015) UPDATE index_user SET name = 'Linux' WHERE id = 8; args=('Linux', 8)
8.4 删除记录
使用原始SQL删除User表中的一条记录:
import osif __name__ == "__main__":os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'MyDjango.settings') # !!!需要修改为自己的配置文件import djangodjango.setup()from django.db import connectionwith connection.cursor() as cursor:sql = "DELETE FROM index_user WHERE id = %s;"val = (8,)# 返回删除的记录数res = cursor.execute(sql, val)print(res)
# ORM日志:
(0.000) DELETE FROM index_user WHERE id = 8;; args=(8,)
9. Q查询
Q查询提供了在查询中构建复杂逻辑条件的能力.
默认情况下, Django ORM的查询是逻辑与(AND)连接的, 而Q查询允许使用逻辑或(OR), 逻辑非(NOT)等条件来构建更复杂的查询.
导入方式: from django.db.models import Q
Q对象之间可以使用: |(OR), &(AND), ~(NOT)操作符来组合使用.
9.1 测试环境
定义一个图书表模型示例, 使用它来举例说明Q查询.
# index的models.py
from django.db import modelsclass Book(models.Model):# 书名title = models.CharField(max_length=25)# 作者author = models.CharField(max_length=25)# 价格price = models.DecimalField(max_digits=10, decimal_places=2)def __str__(self):return self.title
生成迁移文件并执行数据迁移:
PS D:\MyDjango>python manage.py makemigrations
...
PS D:\MyDjango>python manage.py migrate
...
写入一些测试数据:
# index的models.py
import osif __name__ == "__main__":os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'MyDjango.settings') # !!!需要修改为自己的配置文件import djangodjango.setup()from index.models import Book# 插入测试数据Book.objects.create(title='Python', author='aa', price=52.0)Book.objects.create(title='Linux', author='bb', price=45.0)Book.objects.create(title='MySQL', author='cc', price=40.0)9.2 默认多条件查询关系

过滤方法中可以提供多个参数作为查询条件, 这个条件之间是AND关系.
例如, 查询书名为'Python', 作者是'aa'的书籍记录.
# index的models.py
import osif __name__ == "__main__":os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'MyDjango.settings') # !!!需要修改为自己的配置文件import djangodjango.setup()from index.models import Book# 查询书名为'Python', 作者是'aa'的书籍记录.query_set = Book.objects.filter(title='Python', author='aa')print(query_set)# ORM日志:
(0.000)
SELECT `index_book`.`id`, `index_book`.`title`, `index_book`.`author`, `index_book`.`price`
FROM `index_book`
WHERE (`index_book`.`author` = 'aa' AND `index_book`.`title` = 'Python')
LIMIT 21;
args=('aa', 'Python')
查看ORM日志, 可以得出结论: 默认情况下, Django ORM的查询是逻辑与(AND)连接的.
9.3 Q对象使用逻辑或
Q查询允许使用逻辑或(OR)条件来构建更复杂的查询.
# index的models.py
import osif __name__ == "__main__":os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'MyDjango.settings') # !!!需要修改为自己的配置文件import djangodjango.setup()from index.models import Bookfrom django.db.models import Q# 查询书名为'Python' 或者 作者是'aa'的书籍记录.query_set = Book.objects.filter(Q(title='Python') | Q(author='aa'))print(query_set)
# ORM日志:
(0.000)
SELECT `index_book`.`id`, `index_book`.`title`, `index_book`.`author`, `index_book`.`price`
FROM `index_book`
WHERE (`index_book`.`title` = 'Python' OR `index_book`.`author` = 'aa')
LIMIT 21;
args=('Python', 'aa')
在这个例子中, Q(title='Python') 和 Q(author='aa') 分别构建了两个查询条件, 然后通过 |(逻辑或)操作符将它们组合起来.
这样, Django ORM 就会返回所有满足任一条件的Book实例.
9.4 Q查询使用逻辑非
Q查询允许使用逻辑非(NOT)条件来构建更复杂的查询.
# index的models.py
import osif __name__ == "__main__":os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'MyDjango.settings') # !!!需要修改为自己的配置文件import djangodjango.setup()from index.models import Bookfrom django.db.models import Q# 查询书名不为'Python'的书籍记录.query_set = Book.objects.filter(~ Q(title='Python'))print(query_set)
# ORM日志:
(0.000)
SELECT `index_book`.`id`, `index_book`.`title`, `index_book`.`author`, `index_book`.`price`
FROM `index_book`
WHERE (NOT (`index_book`.`title` = 'Python') AND NOT (`index_book`.`author` = 'aa'))
LIMIT 21;
args=('Python', 'aa')
9.5 逻辑关系混用
Q查询允许混合使用逻辑操作符(如&, |, ~)来构建复杂的查询条件.
# index的models.py
import osif __name__ == "__main__":os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'MyDjango.settings') # !!!需要修改为自己的配置文件import djangodjango.setup()from index.models import Bookfrom django.db.models import Q# 查询书名不为'Python' 或者 作者不是'aa'的书籍记录.query_set = Book.objects.filter(~ Q(title='Python') | ~Q(author='aa'))print(query_set)# 查询书名不为'Python' 而且 作者不是'aa'的书籍记录.query_set = Book.objects.filter(~ Q(title='Python') & ~Q(author='aa'))print(query_set)
(0.000)
SELECT `index_book`.`id`, `index_book`.`title`, `index_book`.`author`, `index_book`.`price`
FROM `index_book`
WHERE NOT (`index_book`.`title` = 'Python')
LIMIT 21;
args=('Python',)(0.000)
SELECT `index_book`.`id`, `index_book`.`title`, `index_book`.`author`, `index_book`.`price`
FROM `index_book`
WHERE (NOT (`index_book`.`title` = 'Python') OR NOT (`index_book`.`author` = 'aa'))
LIMIT 21;
args=('Python', 'aa')
10. F 查询
F查询用于在更新操作中引用字段的当前值.
导入方式: from django.db.models import F
这在需要根据字段的当前值来更新它时非常有用.
比如, 想将一个字段的值增加或减少一定的量, 而不是直接设置为一个固定的值.
10.1 基本使用
Django支持多种操作符与F()表达式一起使用, 包括但不限于加法(+), 减法(-), 乘法(*), 除法(/), 模除(%), 幂运算(**)...
示例: 为Book模型的price字段的价格增加10%.
# index的models.py
import osif __name__ == "__main__":os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'MyDjango.settings') # !!!需要修改为自己的配置文件import djangodjango.setup()from index.models import Bookfrom django.db.models import Fprice_tup = Book.objects.values_list('price', flat=True)print(price_tup)# 为price字段的价格增加10%res = Book.objects.all().update(price=F('price') * 1.1)# 返回修改的记录数print(res)price_tup = Book.objects.values_list('price', flat=True)print(price_tup)
F对象允许在查询中动态地引用字段的值.
这意味着可以在查询中直接使用字段名(通过F对象封装)来引用该字段在数据库中的当前值.
# ORM日志:
(0.000) SELECT `index_book`.`price` FROM `index_book` LIMIT 21; args=()
(0.000) UPDATE `index_book` SET `price` = (`index_book`.`price` * 1.1e0); args=(1.1,) # 引用字段的值进行计算
(0.000) SELECT `index_book`.`price` FROM `index_book` LIMIT 21; args=()
在这个例子中, F('price')引用了Book模型中每个实例的price字段的当前值, 并将其乘以1.1来更新该字段.
Book.objects.all().update(price=F('price') * 1.1)可以省略all()方法,
直接写为: Book.objects.update(price=F('price') * 1.1)
这行代码的效率和效果与原始代码完全相同, 但更加简洁.
这是Django ORM设计的一个便利之处, 允许开发者以更直观和高效的方式与数据库交互.
10.2 搭配查找操作符
F()查询表达式可以与Django ORM中的查找操作符(如: __lt、__lte、__gt、__gte 等)结合使用.
注意: 这些查找操作符通常用于filter(), exclude()等方法中来过滤查询集, 而不是直接用于update()方法中的赋值表达式.
示例: 为价格大于50的书籍打9折.
# index的models.py
import osif __name__ == "__main__":os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'MyDjango.settings') # !!!需要修改为自己的配置文件import djangodjango.setup()from index.models import Bookfrom django.db.models import Fprice_tup = Book.objects.values_list('price', flat=True)print(price_tup)# 为价格大于50的书籍打9折Book.objects.filter(price__gt=50).update(price=F('price') * 0.9)price_tup = Book.objects.values_list('price', flat=True)print(price_tup)
# ORM日志:
(0.000) SELECT `index_book`.`price` FROM `index_book` LIMIT 21; args=()
(0.000) UPDATE `index_book` SET `price` = (`index_book`.`price` * 0.9e0) WHERE `index_book`.`price` > 50;
args=(0.9, Decimal('50'))
(0.016) SELECT `index_book`.`price` FROM `index_book` LIMIT 21; args=()
10.3 字段表达式
字段表达式允许在查询时构建复杂的字段值, 这些值可以基于模型字段的当前值, 常量值, 函数调用等.
在Django ORM中, Concat函数和Value函数是用于数据库查询时构造复杂字段表达式的工具.Concat函数: 用于将多个字段值或常量值连接(拼接)成一个字符串. 这在需要将多个字段的值合并为一个单一字段的查询结果时非常有用.
Concat函数可以接受多个参数, 这些参数可以是字段的引用(使用F()表达式), 也可以是常量值(使用Value()函数).
导入方式: from django.db.models.functions import ConcatValue函数: 用于在查询中插入一个常量值. 这个值可以是任何类型, 但在与Concat函数一起使用时, 它通常是一个字符串.
Value函数使得在数据库查询中直接包含静态值成为可能.
导入方式: from django.db.models import Value
示例: 为所有的书籍名称添加一个后缀, (例如, 格式为'书名-v1'), 可以这样做:
# index的models.py
import osif __name__ == "__main__":os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'MyDjango.settings') # !!!需要修改为自己的配置文件import djangodjango.setup()from index.models import Bookfrom django.db.models import F, Valuefrom django.db.models.functions import Concattitle_tup = Book.objects.values_list('title', flat=True)print(title_tup)# 使用Concat为书名标题添加-v1后缀books = Book.objects.update(title=Concat(F('title'), Value('-v1')))title_tup = Book.objects.values_list('title', flat=True)print(title_tup)在这个例子中, Concat函数将title字段, 一个常量值'-v1'连接起来.

# ORM日志:
(0.000) SELECT `index_book`.`title` FROM `index_book` LIMIT 21; args=()
(0.016) UPDATE `index_book` SET `title` = CONCAT_WS('', `index_book`.`title`, '-v1'); args=('-v1',)
(0.000) SELECT `index_book`.`title` FROM `index_book` LIMIT 21; args=()
10.4 字符替换
Replace函数: 是一个数据库函数封装, 用于在查询集(QuerySet)的更新或注释(annotation)操作中执行字符串替换.
Replace函数通常接受三个参数: 原始字符串, 要查找的子字符串, 以及用于替换的子字符.
导入方式: from django.db.models.functions import Replace
# index的models.py
import osif __name__ == "__main__":os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'MyDjango.settings') # !!!需要修改为自己的配置文件import djangodjango.setup()from index.models import Bookfrom django.db.models import F, Value, Funcfrom django.db.models.functions import Replace# 使用Replace函数移除-v1后缀Book.objects.update(title=Replace(F('title'), Value('-v1'), Value('')))title_tup = Book.objects.values_list('title', flat=True)print(title_tup)
# ORM日志:
(0.000) UPDATE `index_book` SET `title` = REPLACE(`index_book`.`title`, '-v1', ''); args=('-v1', '')
(0.000) SELECT `index_book`.`title` FROM `index_book` LIMIT 21; args=()
值得一提的是从Django 2.2开始, Django ORM引入了对更多数据库函数的支持.
相关文章:
26.7 Django单表操作
1. 模型管理器 1.1 Manager管理器 Django ORM中, 每个Django模型(Model)至少有一个管理器, 默认的管理器名称为objects. objects是一个非常重要的管理器(Manager)实例, 它提供了与数据库进行交互的接口.通过管理器, 可以执行数据库查询, 保存对象到数据库等操作.objects管理器…...

Android --- Kotlin学习之路:自己写一个SDK给别的APP用(暴漏一个接口,提供学生的身高数据)
今天又来肝kotlin了,主题是:用kt写一个SDK给其他人用,这个小技能在项目中会经常用到,应该有很多小伙伴还不会用,不会的请往下看—⬇ 在项目里面新建一个module 选择Android library,然后点击finish就行了 …...

租用海外服务器需要考虑哪些因素
当企业选择租用海外服务器时需要考虑到哪些因素呢? 对于海外服务器的租用我们需要考虑到机房的位置以及服务器的稳定性如何,所以企业可以选择离目标用户群体比较近一点的机房,以此来降低服务器的延迟度并且能够提高用户的访问速度。 对于机房…...

php将png转为jpg,可设置压缩率
/** * 将PNG文件转换为JPG文件 * param $pngFilePath string PNG文件路径 * param $jpgFilePath string JPG文件路径 * param $quality int JPG质量,0-100,值越低,压缩率越高 * return void * throws Exception */ function convertPngToJpg($pngFilePath, $jpgFile…...

华为HCIP Datacom H12-821 卷37
1.多选题 下面关于Network- Summary-LSA 描述正确的是 A、Network- Summary-LSA中的Metric被设置成从该ABR到达目的网段的开销值 B、Network- Sumary-LSA中的Net mask 被设置成目的网段的网络掩码 C、Network- Summary-LSA 是由ASBR产生的 D、Network- Summary-LSA 中的Li…...
某某会员小程序后端性能优化
背景 某某会员小程序后台提供开放平台能力,为三方油站提供会员积分、优惠劵等api。当用户在油站加油,油站收银会调用我们系统为用户发放积分、优惠劵等。用户反馈慢,三方调用发放积分接口性能极低,耗时30s; 接口情况…...

Docker:基础概念、架构与网络模式详解
1.Docker的基本概念 1.1.什么是docker Docker是一个用于开发,交付和运行应用程序的开放平台.docker使您能够将应用程序域基础框架分开,以便你可以快速开发交付软件.使用docker,你可以管理你的基础架构以管理应用程序相同的方式.通过利用docker用于交付,测试和部署代码的方法,你…...

全国大学生数据建模比赛c题——基于蔬菜类商品的自动定价与补货决策的研究分析
基于蔬菜类商品的自动定价与补货决策的研究分析 摘要 商超蔬菜不易保存,其质量会随着销售时间的增加而变差,影响商超收益,因此,基于各蔬菜品类的历史销售数据,制定合理的销售策略和补货决策对商超的营收十分关键。本文…...

【漏洞复现】飞企互联-FE企业运营管理平台 uploadAttachmentServlet—文件上传漏洞
声明:本文档或演示材料仅用于教育和教学目的。如果任何个人或组织利用本文档中的信息进行非法活动,将与本文档的作者或发布者无关。 一、漏洞描述 企互联-FE企业运营管理平台是一个利用云计算、人工智能、大数据、物联网和移动互联网等现代技术构建的云…...

基于深度学习的语言生成
基于深度学习的语言生成(NLG, Natural Language Generation)是一种利用深度学习模型生成自然语言文本的技术。它在智能写作、自动摘要、对话系统、机器翻译等领域有广泛应用。以下是对这一领域的系统介绍: 1. 任务和目标 语言生成的主要任务…...

Kafka Rebalance详解
作者:耀灵 1.rebalance概览 rebalance中文含义为再平衡。它本质上是一组协议,规定了一个 consumer group 是如何达成一致来分配订阅 topic 的所有分区的。比方说Consumer Group A 有3个consumer 实例,它要消费一个拥有6个分区的topic&#…...

在 Markdown 编辑器中插入 空格 Space 和 空行 Enter
1. 空格 Space  2.空行 Enter <br/>...

js逆向-webpack-python
网站(base64):aHR0cHM6Ly93d3cuY29pbmdsYXNzLmNvbS96aA 案例响应解密爬取(webpack) 1、找到目标url 2、进行入口定位(此案例使用 ‘decrypt(’ 关键字搜索 ) 3、找到位置进行分析 --t 为 dat…...

Python精神病算法和自我认知异类数学模型
🎯要点 🎯空间不确定性和动态相互作用自我认知异类模型 | 🎯精神病神经元算法推理 | 🎯集体信念催化个人行动力数学模型 | 🎯物种基因进化关系网络算法 | 🎯电路噪声低功耗容错解码算法 📜和-…...

npm install 报错:PhantomJS not found on PATH
npm install 报错:PhantomJS not found on PATH 整体报错内容 npm ERR! code 1 npm ERR! path G:\work-learn\open-coding\bruno\node_modules\phantomjs-prebuilt npm ERR! command failed npm ERR! command C:\Windows\system32\cmd.exe /d /s /c node install.…...

【C++进阶学习】第六弹——set和map——体会用C++来构建二叉搜索树
set和map基础:【C进阶学习】第五弹——二叉搜索树——二叉树进阶及set和map的铺垫-CSDN博客 前言: 在上篇的学习中,我们已经学习了如何使用C语言来实现二叉搜索树,在C中,我们是有现成的封装好的类模板来实现二叉搜索树…...

sqlmap确定目标/实操
安装kali,kali自带sqlmap,在window系统中跟linux系统操作有区别 sqlmap是一款自动化SQL工具,打开kali终端,输入sqlmap,出现以下界面,就说明sqlmap可用。 sqlmap确定目标 一、sqlmap直连数据库 1、直连数据库…...

Java笔试|面试 —— 对多态性的理解
谈谈对多态性的理解: 一个事物的多种形态(编译和运行时状态不一致性) 实现机制:通过继承、重写和向上转型(Object obj new 子类())来实现。 1.广义上的理解 子类对象的多态性,方法的重写&am…...
从RL的专业角度解惑 instruct GPT的目标函数
作为早期chatGPT背后的核心技术,instruct GPT一直被业界奉为里程碑式的著作。但是这篇论文关于RL的部分确写的非常模糊,几乎一笔带过。当我们去仔细审查它的目标函数的时候,心中不免有诸多困惑。特别是作者提到用PPO来做强化学习,…...

location匹配的优先级和重定向
nginx的重定向(rewrite) location 匹配 location匹配的就是后面的uri /wordpress 192.168.233.10/wordpress location匹配的分类和优先级 1.精确匹配 location / 对字符串进行完全匹配,必须完全符合 2.正则匹配 ^-前缀级别ÿ…...

PHP和Node.js哪个更爽?
先说结论,rust完胜。 php:laravel,swoole,webman,最开始在苏宁的时候写了几年php,当时觉得php真的是世界上最好的语言,因为当初活在舒适圈里,不愿意跳出来,就好比当初活在…...

【Redis技术进阶之路】「原理分析系列开篇」分析客户端和服务端网络诵信交互实现(服务端执行命令请求的过程 - 初始化服务器)
服务端执行命令请求的过程 【专栏简介】【技术大纲】【专栏目标】【目标人群】1. Redis爱好者与社区成员2. 后端开发和系统架构师3. 计算机专业的本科生及研究生 初始化服务器1. 初始化服务器状态结构初始化RedisServer变量 2. 加载相关系统配置和用户配置参数定制化配置参数案…...

376. Wiggle Subsequence
376. Wiggle Subsequence 代码 class Solution { public:int wiggleMaxLength(vector<int>& nums) {int n nums.size();int res 1;int prediff 0;int curdiff 0;for(int i 0;i < n-1;i){curdiff nums[i1] - nums[i];if( (prediff > 0 && curdif…...

ETLCloud可能遇到的问题有哪些?常见坑位解析
数据集成平台ETLCloud,主要用于支持数据的抽取(Extract)、转换(Transform)和加载(Load)过程。提供了一个简洁直观的界面,以便用户可以在不同的数据源之间轻松地进行数据迁移和转换。…...

VTK如何让部分单位不可见
最近遇到一个需求,需要让一个vtkDataSet中的部分单元不可见,查阅了一些资料大概有以下几种方式 1.通过颜色映射表来进行,是最正规的做法 vtkNew<vtkLookupTable> lut; //值为0不显示,主要是最后一个参数,透明度…...
详解:相对定位 绝对定位 固定定位)
css的定位(position)详解:相对定位 绝对定位 固定定位
在 CSS 中,元素的定位通过 position 属性控制,共有 5 种定位模式:static(静态定位)、relative(相对定位)、absolute(绝对定位)、fixed(固定定位)和…...

基于Java+MySQL实现(GUI)客户管理系统
客户资料管理系统的设计与实现 第一章 需求分析 1.1 需求总体介绍 本项目为了方便维护客户信息为了方便维护客户信息,对客户进行统一管理,可以把所有客户信息录入系统,进行维护和统计功能。可通过文件的方式保存相关录入数据,对…...

土建施工员考试:建筑施工技术重点知识有哪些?
《管理实务》是土建施工员考试中侧重实操应用与管理能力的科目,核心考查施工组织、质量安全、进度成本等现场管理要点。以下是结合考试大纲与高频考点整理的重点内容,附学习方向和应试技巧: 一、施工组织与进度管理 核心目标: 规…...

边缘计算网关提升水产养殖尾水处理的远程运维效率
一、项目背景 随着水产养殖行业的快速发展,养殖尾水的处理成为了一个亟待解决的环保问题。传统的尾水处理方式不仅效率低下,而且难以实现精准监控和管理。为了提升尾水处理的效果和效率,同时降低人力成本,某大型水产养殖企业决定…...

LTR-381RGB-01RGB+环境光检测应用场景及客户类型主要有哪些?
RGB环境光检测 功能,在应用场景及客户类型: 1. 可应用的儿童玩具类型 (1) 智能互动玩具 功能:通过检测环境光或物体颜色触发互动(如颜色识别积木、光感音乐盒)。 客户参考: LEGO(乐高&#x…...