Hadoop3:HDFS-通过配置黑白名单对集群进行扩缩容,并实现数据均衡(实用)
一、集群情况介绍
我的本地虚拟机,一共有三个节点,hadoop102、hadoop103、hadoop104
二、白名单
创建白名单文件whitelist,通过白名单的配置,只允许集群包含102和103两台机器可以存储数据,104无法存储数据。
需求

1、创建白名单
这个位置是任意选择的,因为,hadoop配置文件都在这里,所以我就放这个下面了。
cd /opt/module/hadoop-3.1.3/etc/hadoop
vim whitelist

2、HDFS关联白名单
在hdfs-site.xml配置文件中增加dfs.hosts配置参数
<!-- 白名单 -->
<property><name>dfs.hosts</name><value>/opt/module/hadoop-3.1.3/etc/hadoop/whitelist</value>
</property>
3、分发配置文件
xsync whitelist hdfs-site.xml
4、重启集群
第一次配置白明单,需要重启集群。
myhadoop stop
myhadoop start
5、查看页面
发现只有102和103节点


6、查看进程状态
发现104正常启动的

7、从104上传文件
cd /opt/module/hadoop-3.1.3/
hadoop fs -put NOTICE.txt /
可以正常上传

查看页面
只有102和103有数据块,并且副本数依然是3个。


8、重新配置104到白名单

分发文件
xsync whitelist
刷新节点,无需重启
hdfs dfsadmin -refreshNodes

查看页面
节点添加成功,且104也自动增加一份副本数据。


9、结论
通过上述实验,我们证明了,104被排除出集群了,可以上传文件,只是104的客户端功能。
但是,104无法存储数据块了。
实现了预期效果。
且,再次修改白名单,无需重启集群。
三、动态扩容
集群运行状态下,进行服务器节点的增加扩容。
新节点的初始化配置
添加新节点到集群
1、添加新节点到白名单文件
cd /opt/module/hadoop-3.1.3/etc/hadoop
vim whitelist
xsync whitelist

2、单点启动新节点的Hadoop
hdfs --daemon start datanode
yarn --daemon start nodemanager

3、刷新集群白名单配置
hdfs dfsadmin -refreshNodes

4、新节点测试
上传一个文件到集群
hadoop fs -put wc.jar /

发现,无需重启集群,我们就给集群新增了一个节点,并能正常使用。
5、集群数据均衡
一般,我们新增一个节点之后,这个节点是没有数据的。
所以,我们需要进行一次数据均衡操作,这样,才能让新增的节点分担集群压力。
cd /opt/module/hadoop-3.1.3/
sbin/start-balancer.sh -threshold 10
sbin/stop-balancer.sh
命令解释
sbin/start-balancer.sh -threshold 10
对于参数10,代表的是集群中各个节点的磁盘空间利用率相差不超过10%,可根据实际情况进行调整。
sbin/stop-balancer.sh
停止均衡操作
注意:由于HDFS需要启动单独的Rebalance Server来执行Rebalance操作
所以尽量不要在NameNode上执行start-balancer.sh,而是找一台比较空闲的机器。
四、黑名单配置实现退役服务器
1、说明
黑名单:表示在黑名单的主机IP地址不可以,用来存储数据。
企业中:配置黑名单,用来退役服务器。
通过定义可以知道,黑名单的IP必定在白名单中。否则,没意义。
2、配置黑名单
cd /opt/module/hadoop-3.1.3/etc/hadoop
vim blacklist

3、HDFS关联黑名单
在hdfs-site.xml配置文件中增加dfs.hosts配置参数
<!-- 白名单 -->
<property><name>dfs.hosts</name><value>/opt/module/hadoop-3.1.3/etc/hadoop/blacklist</value>
</property>
4、分发配置
xsync blacklist hdfs-site.xml
5、刷新集群配置
hdfs dfsadmin -refreshNodes
6、查看网页
正在退役105服务器
因为105有数据,所以,需要一段时间

数据同步完成后的状态

wc.jar的副本多了一个103,说明,105的副本拷贝到103上了。

6、停止105的Hadoop服务
hdfs --daemon stop datanode
yarn --daemon stop nodemanager
需要到10分钟30秒后,才会从页面清除节点信息。

7、数据均衡
一般,退役一个节点,也要进行一次数据均衡
sbin/start-balancer.sh -threshold 10
相关文章:
Hadoop3:HDFS-通过配置黑白名单对集群进行扩缩容,并实现数据均衡(实用)
一、集群情况介绍 我的本地虚拟机,一共有三个节点,hadoop102、hadoop103、hadoop104 二、白名单 创建白名单文件whitelist,通过白名单的配置,只允许集群包含102和103两台机器可以存储数据,104无法存储数据。 需求 …...

TensorFlow系列:第五讲:移动端部署模型
项目地址:https://github.com/LionJackson/imageClassification Flutter项目地址:https://github.com/LionJackson/flutter_image 一. 模型转换 编写tflite模型工具类: import osimport PIL import tensorflow as tf import keras import …...

深度学习DeepLearning二元分类 学习笔记
文章目录 类别区分变量与概念逻辑回归Sigmoid函数公式决策边逻辑损失函数和代价函数逻辑回归的梯度下降泛化过拟合的解决方案正则化 类别区分 变量与概念 决策边置信度阈值threshold过拟合欠拟合正则化高偏差lambda(λ) 线性回归受个别极端值影响&…...

Eureka 介绍与使用
Eureka 是一个开源的服务发现框架,它主要用于在分布式系统中管理和发现服务实例。它由 Netflix 开发并开源,是 Netflix OSS 中的一部分。 使用 Eureka 可以方便地将新的服务实例注册到 Eureka 服务器,并且让其他服务通过 Eureka 服务器来发现…...

Java异常体系、UncaughtExceptionHandler、Spring MVC统一异常处理、Spring Boot统一异常处理
概述 所有异常都是继承自java.lang.Throwable类,Throwable有两个直接子类,Error和Exception。 Error用来表示程序底层或硬件有关的错误,这种错误和程序本身无关,如常见的NoClassDefFoundError。这种异常和程序本身无关࿰…...

bash终端快捷键
快捷键作用ShiftCtrlC复制ShiftCtrlV粘贴CtrlAltT新建终端ShiftPgUp/PgDn终端上下翻页滚动CtrlC终止命令CtrlD关闭终端CtrlA光标移动到最开始为止CtrlE光标移动到最末尾CtrlK删除此处到末尾的所有内容CtrlU删除此处至开始的所有内容CtrlD删除当前字符CtrlH删除当前字符的前一个…...

【Visual Studio】Visual Studio报错合集及解决办法
目录 Visual Studio报错:error LNK2001 Visual Studio报错:error C2061 Visual Studio报错:error C1075 Visual Studio报错:error C4430 Visual Studio报错error C3867 概述 持续更细Visual Studio报错及解决方法 Visual Studio报错:error LNK2001 问题 : error LNK2001…...

【微信小程序知识点】转发功能的实现
转发功能,主要帮助用户更流畅地与好友分享内容与服务。 想实现转发功能,有两种方式: 1.页面js文件必须声明onShareAppMessage事件监听函数,并自定义转发内容。只有定义了此事件处理函数,右上角菜单才会显示“转发”按…...

用python识别二维码(python实例二十三)
目录 1.认识Python 2.环境与工具 2.1 python环境 2.2 Visual Studio Code编译 3.识别二维码 3.1 代码构思 3.2 代码实例 3.3 运行结果 4.总结 1.认识Python Python 是一个高层次的结合了解释性、编译性、互动性和面向对象的脚本语言。 Python 的设计具有很强的可读性&…...
电脑文件夹怎么设置密码?让你的文件更安全!
在日常使用电脑的过程中,我们常常会有一些需要保护的个人文件或资料。为了防止这些文件被他人未经授权访问,对重要文件夹设置密码是一种有效的保护措施,可是电脑文件夹怎么设置密码呢?本文将介绍2种简单有效的方法帮助您为电脑文件…...

paddla模型转gguf
在使用ollama配置本地模型时,只支持gguf格式的模型,所以我们首先需要把自己的模型转化为bin格式,本文为paddle,onnx,pytorch格式的模型提供说明,safetensors格式比较简单请参考官方文档,或其它教…...

Memcached vs Redis——Java项目缓存选择
在Java项目开发中,缓存系统作为提升性能、优化资源利用的关键技术之一,扮演着至关重要的角色。Memcached和Redis作为两种流行的缓存解决方案,各有其独特的优势和应用场景。本文旨在通过分析项目大小、用户访问量、业务复杂度以及服务器部署情…...

大模型最新黑书:基于GPT-3、ChatGPT、GPT-4等Transformer架构的自然语言处理 PDF
今天给大家推荐一本丹尼斯罗斯曼(Denis Rothman)编写的关于大语言模型(LLM)权威教程<<大模型应用解决方案> 基于GPT-3、ChatGPT、GPT-4等Transformer架构的自然语言处理>!Google工程总监Antonio Gulli作序,这含金量不…...

【电子数据取证】电子数据司法鉴定
文章关键词:电子数据取证、司法鉴定服务、司法鉴定流程 一、定义 什么是司法鉴定? 在诉讼活动中鉴定人运用科学技术或者专业知识对诉讼涉及的专门性问题进行鉴别和判断并提供鉴定意见的活动。 电子数据司法鉴定 那么电子数据司法鉴定,就…...

使用 OpenCV 的 inRange 函数进行颜色分割
使用 OpenCV 的 inRange 函数进行颜色分割 在图像处理领域,颜色分割是一个常见的任务,常用于识别和提取图像中的特定颜色区域。OpenCV 提供了一个非常方便的函数 inRange 来实现这一功能。在这篇博客中,我们将详细介绍 inRange 函数的用法&a…...
OpenAI终止对中国提供API服务,对国内AI市场产生重大冲击?
6月25日,OpenAI突然宣布终止向包括中国在内的国家地区提供API服务,本月9日这一政策已经正式生效了! 有人说,这个事件给中国AI行业带来很大冲击!是这样吗?在展开讨论前,我们先来看看什么是API服务…...

JavaDS —— 栈 Stack 和 队列 Queue
栈的概念 栈是一种先进后出的线性表,只允许在固定的一端进行插入和删除操作。 进行插入和删除操作的一端被称为栈顶,另一端被称为栈底 栈的插入操作叫做进栈/压栈/入栈 栈的删除操作叫做出栈 现实生活中栈的例子: 栈的模拟实现 下面是Jav…...

C++进阶:继承和多态
文章目录 ❤️继承🩷继承与友元🧡继承和静态成员💛菱形继承及菱形虚拟继承💚继承和组合 ❤️多态🩷什么是多态?🧡多态的定义以及实现💛虚函数💚虚函数的重写💙…...
(冒泡、快排、堆排、选择排序))
【八大排序】java版(上)(冒泡、快排、堆排、选择排序)
文章目录 一、冒泡排序(重点)思路代码 二、快排(面试重点)思路代码 三、堆排序(面试重点)思路代码 四、选择排序思路代码 一、冒泡排序(重点) 思路 前后两两数据进行比较,小的数据往前走,大的数据往后走,每一轮结束之后,最大的数…...

.Net Core 微服务之Consul(二)-集群搭建
引言: 集合上一期.Net Core 微服务之Consul(一)(.Net Core 微服务之Consul(一)-CSDN博客) 。 目录 一、 Consul集群搭建 1. 高可用 1.1 高可用性概念 1.2 高可用集群的基本原理 1.3 高可用集群的架构设计 1.3.1 主从复制架构 1.3.2 共享存储架构 1.3.3 负载均衡…...

测试微信模版消息推送
进入“开发接口管理”--“公众平台测试账号”,无需申请公众账号、可在测试账号中体验并测试微信公众平台所有高级接口。 获取access_token: 自定义模版消息: 关注测试号:扫二维码关注测试号。 发送模版消息: import requests da…...

调用支付宝接口响应40004 SYSTEM_ERROR问题排查
在对接支付宝API的时候,遇到了一些问题,记录一下排查过程。 Body:{"datadigital_fincloud_generalsaas_face_certify_initialize_response":{"msg":"Business Failed","code":"40004","sub_msg…...

Spark 之 入门讲解详细版(1)
1、简介 1.1 Spark简介 Spark是加州大学伯克利分校AMP实验室(Algorithms, Machines, and People Lab)开发通用内存并行计算框架。Spark在2013年6月进入Apache成为孵化项目,8个月后成为Apache顶级项目,速度之快足见过人之处&…...

DeepSeek 赋能智慧能源:微电网优化调度的智能革新路径
目录 一、智慧能源微电网优化调度概述1.1 智慧能源微电网概念1.2 优化调度的重要性1.3 目前面临的挑战 二、DeepSeek 技术探秘2.1 DeepSeek 技术原理2.2 DeepSeek 独特优势2.3 DeepSeek 在 AI 领域地位 三、DeepSeek 在微电网优化调度中的应用剖析3.1 数据处理与分析3.2 预测与…...

边缘计算医疗风险自查APP开发方案
核心目标:在便携设备(智能手表/家用检测仪)部署轻量化疾病预测模型,实现低延迟、隐私安全的实时健康风险评估。 一、技术架构设计 #mermaid-svg-iuNaeeLK2YoFKfao {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg…...

学校招生小程序源码介绍
基于ThinkPHPFastAdminUniApp开发的学校招生小程序源码,专为学校招生场景量身打造,功能实用且操作便捷。 从技术架构来看,ThinkPHP提供稳定可靠的后台服务,FastAdmin加速开发流程,UniApp则保障小程序在多端有良好的兼…...

零基础设计模式——行为型模式 - 责任链模式
第四部分:行为型模式 - 责任链模式 (Chain of Responsibility Pattern) 欢迎来到行为型模式的学习!行为型模式关注对象之间的职责分配、算法封装和对象间的交互。我们将学习的第一个行为型模式是责任链模式。 核心思想:使多个对象都有机会处…...

DeepSeek 技术赋能无人农场协同作业:用 AI 重构农田管理 “神经网”
目录 一、引言二、DeepSeek 技术大揭秘2.1 核心架构解析2.2 关键技术剖析 三、智能农业无人农场协同作业现状3.1 发展现状概述3.2 协同作业模式介绍 四、DeepSeek 的 “农场奇妙游”4.1 数据处理与分析4.2 作物生长监测与预测4.3 病虫害防治4.4 农机协同作业调度 五、实际案例大…...

day36-多路IO复用
一、基本概念 (服务器多客户端模型) 定义:单线程或单进程同时监测若干个文件描述符是否可以执行IO操作的能力 作用:应用程序通常需要处理来自多条事件流中的事件,比如我现在用的电脑,需要同时处理键盘鼠标…...
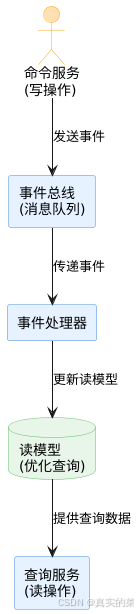
消息队列系统设计与实践全解析
文章目录 🚀 消息队列系统设计与实践全解析🔍 一、消息队列选型1.1 业务场景匹配矩阵1.2 吞吐量/延迟/可靠性权衡💡 权衡决策框架 1.3 运维复杂度评估🔧 运维成本降低策略 🏗️ 二、典型架构设计2.1 分布式事务最终一致…...