【pytorch】手写数字识别
https://blog.csdn.net/qq_45588019/article/details/120935828 基本均参考该博客
《深度学习原理Pytorch实战》
初步处理
导包
import torch
import numpy as np
from matplotlib import pyplot as plt
from torch.utils.data import DataLoader
from torchvision import transforms
from torchvision import datasets
import torch.nn.functional as F
定义超参数
learning_rate = 0.01
momentum = 0.5 # 动量
EPOCH = 10 #训练总的循环周期
batch_size = 64 # 一个批次的大小,64张图片
加载MNIST数据集
#加载MNIST数据,如果没有下载过,系统就会在当前路径下新建/data子目录
train_dataset = datasets.MNIST(root='./data', train=True, transform=transform,download=True) # 本地没有就加上download=True
test_dataset = datasets.MNIST(root='./data', train=False, transform=transform,download=True) # train=True训练集,=False测试集# 训练集的加载器,自动将数据切分成批,顺序随机打乱
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
加载器(dataloader)主要负责在程序中对数据集的使用。例如,我们在训练神经网络的过程中需要逐批加载训练数据,加载器就会自动帮我们逐批输出数据。使用加载器比直接使用张量手动加载数据更好,因为当数据集超大的时候,我们无法将所有数据全部装载到内存中,必须从硬盘上加载数据,而加载器可以让这一过程自动化。
采样器(sampler)为加载器提供了一个每一批抽取数据集中样本的方法。我们可以按照顺序将数据集中的数据逐个抽取到加载器中,也可以完全随机地抽取,甚至可以依某种概率分布抽取。
总之,数据集、加载器和采样器可以让数据的处理过程更加便捷和标准。
打印查看加载的数据
fig = plt.figure()
for i in range(12):plt.subplot(3, 4, i+1)plt.tight_layout()plt.imshow(train_dataset.train_data[i], cmap='gray', interpolation='none')plt.title("Labels: {}".format(train_dataset.train_labels[i]))plt.xticks([])plt.yticks([])
plt.show()

构建网络
构造ConvNet类,它是对nn.Module类的继承,即nn.Module是父类,ConvNet为子类。nn.Module中包含了绝大部分关于神经网络的通用计算,如初始化、前传等,用户可以重写nn.Module中的部分函数以实现定制化,如init()构造函数和forward()函数。
其次,复写init()和forward()这两个函数。init()为构造函数,每当类ConvNet被具体化一个实例的时候就会被调用。forward()函数则是在正向运行神经网络时被自动调用,它负责数据的向前传递过程,同时构造计算图。
class ConvNet(torch.nn.Module):def __init__(self):super(ConvNet, self).__init__()self.conv1 = torch.nn.Sequential(#定义一个卷积层,输入通道为1,输出通道为10,窗口大小为5torch.nn.Conv2d(1, 10, kernel_size=5),torch.nn.ReLU(),torch.nn.MaxPool2d(kernel_size=2),)self.conv2 = torch.nn.Sequential(torch.nn.Conv2d(10, 20, kernel_size=5),torch.nn.ReLU(),torch.nn.MaxPool2d(kernel_size=2),)self.fc = torch.nn.Sequential(torch.nn.Linear(320, 50),torch.nn.Linear(50, 10),)def forward(self, x):batch_size = x.size(0)x = self.conv1(x) # 一层卷积层,一层池化层,一层激活层(图是先卷积后激活再池化,差别不大)x = self.conv2(x) # 再来一次x = x.view(batch_size, -1) # flatten 变成全连接网络需要的输入 (batch, 20,4,4) ==> (batch,320), -1 此处自动算出的是320x = self.fc(x)return x # 最后输出的是维度为10的,也就是(对应数学符号的0~9)卷积层

torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding)
in_channels:输入通道
out_channels:输出通道
kernel_size:卷积核大小
stride:步长
padding:填充
池化层

torch.nn.MaxPool2d(input, kernel_size, stride, padding)
激活函数
torch.nn.ReLU()
CNN模型

比如输入一个手写数字“5”的图像,它的维度为(batch,1,28,28)即单通道高宽分别为28像素。
1、首先通过一个卷积核为5×5的卷积层,其通道数从1变为10,高宽分别为24像素;
2、然后通过一个卷积核为2×2的最大池化层,通道数不变,高宽变为一半,即维度变成(batch,10,12,12);
3、然后再通过一个卷积核为5×5的卷积层,其通道数从10变为20,高宽分别为8像素;
4、再通过一个卷积核为2×2的最大池化层,通道数不变,高宽变为一半,即维度变成(batch,20,4,4);
5、之后将其view展平,使其维度变为320(2044)之后进入全连接层,用线性函数将其输出为10类,即“0-9”10个数字。
class ConvNet(torch.nn.Module):def __init__(self):super(ConvNet, self).__init__()self.conv1 = torch.nn.Sequential(torch.nn.Conv2d(1, 10, kernel_size=5),torch.nn.ReLU(),torch.nn.MaxPool2d(kernel_size=2),)self.conv2 = torch.nn.Sequential(torch.nn.Conv2d(10, 20, kernel_size=5),torch.nn.ReLU(),torch.nn.MaxPool2d(kernel_size=2),)#全连接层self.fc = torch.nn.Sequential(torch.nn.Linear(320, 50),torch.nn.Linear(50, 10),)def forward(self, x):batch_size = x.size(0)x = self.conv1(x) # 一层卷积层,一层池化层,一层激活层(图是先卷积后激活再池化,差别不大)x = self.conv2(x) # 再来一次x = x.view(batch_size, -1) # flatten 变成全连接网络需要的输入 (batch, 20,4,4) ==> (batch,320), -1 此处自动算出的是320x = self.fc(x)return x # 最后输出的是维度为10的,也就是(对应数学符号的0~9)model = ConvNet()可以在全连接层之前加上
#以默认0.5的概率对这一层进行dropout操作,防止过拟合
x=F.dropout (x,training=self.training)
神经网络在训练中具有强大的拟合数据的能力,因此常常会出现过拟合的情形,这会使得神经网络局限在见过的样本中。dropout正是一种防止过拟合的技术。简单来说,dropout就是指在深度网络的训练过程中,根据一定的概率随机将其中的一些神经元暂时丢弃。这样在每个批的训练中,我们都是在训练不同的神经网络,最后在测试的时候再使用全部的神经元,以此增强模型的泛化能力。

为了防止过拟合,dropout操作可以在训练阶段将一部分神经元随机关闭,而在校验和测试的时候再打开。
可以使用net.eval(),相当于把dropout关闭
训练和测试
损失函数和优化器
criterion = torch.nn.CrossEntropyLoss() # 交叉熵损失
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate, momentum=momentum) # lr学习率,momentum冲量
enumerate起到构造一个枚举器的作用。在对train_loader做循环迭代时,enumerate会自动输出一个数字指示循环次数,并记录在batch_idx中,它就等于0,1,2,… train_loader每迭代一次,就会输出一对数据inputs和target,分别对应一个批中的手写数字图像及对应的标签。
def train(epoch):running_loss = 0.0 # 这整个epoch的loss清零running_total = 0running_correct = 0for batch_idx, data in enumerate(train_loader, 0):inputs, target = dataoptimizer.zero_grad() #清空梯度# forward + backward + updateoutputs = model(inputs) #神经网络完成一次前馈的计算过程,得到预测输出outputloss = criterion(outputs, target) #将output与标签target比较,计算误差loss.backward() #反向传播optimizer.step() #随机梯度下降# 把运行中的loss累加起来,为了下面300次一除running_loss += loss.item()# 把运行中的准确率acc算出来_, predicted = torch.max(outputs.data, dim=1)running_total += inputs.shape[0]running_correct += (predicted == target).sum().item()if batch_idx % 300 == 299: # 不想要每一次都出loss,浪费时间,选择每300次出一个平均损失,和准确率print('[%d, %5d]: loss: %.3f , acc: %.2f %%'% (epoch + 1, batch_idx + 1, running_loss / 300, 100 * running_correct / running_total))running_loss = 0.0 # 这小批300的loss清零running_total = 0running_correct = 0 # 这小批300的acc清零测试
def test():correct = 0total = 0with torch.no_grad(): # 测试集不用算梯度for data in test_loader:images, labels = dataoutputs = model(images)_, predicted = torch.max(outputs.data, dim=1) # dim = 1 列是第0个维度,行是第1个维度,沿着行(第1个维度)去找1.最大值和2.最大值的下标total += labels.size(0) # 张量之间的运算correct += (predicted == labels).sum().item()acc = correct / totalprint('[%d / %d]: Accuracy on test set: %.1f %% ' % (epoch+1, EPOCH, 100 * acc)) # 求测试的准确率,正确数/总数return acc总的代码
import torch
import numpy as np
from matplotlib import pyplot as plt
from torch.utils.data import DataLoader
from torchvision import transforms
from torchvision import datasets
import torch.nn.functional as F"""
卷积运算 使用mnist数据集,和10-4,11类似的,只是这里:1.输出训练轮的acc 2.模型上使用torch.nn.Sequential
"""
# Super parameter ------------------------------------------------------------------------------------
batch_size = 64
learning_rate = 0.01
momentum = 0.5
EPOCH = 10# Prepare dataset ------------------------------------------------------------------------------------
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))])
# softmax归一化指数函数(https://blog.csdn.net/lz_peter/article/details/84574716),其中0.1307是mean均值和0.3081是std标准差train_dataset = datasets.MNIST(root='./data', train=True, transform=transform,download=True) # 本地没有就加上download=True
test_dataset = datasets.MNIST(root='./data', train=False, transform=transform,download=True) # train=True训练集,=False测试集
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)fig = plt.figure()
for i in range(12):plt.subplot(3, 4, i+1)plt.tight_layout()plt.imshow(train_dataset.train_data[i], cmap='gray', interpolation='none')plt.title("Labels: {}".format(train_dataset.train_labels[i]))plt.xticks([])plt.yticks([])
plt.show()# 训练集乱序,测试集有序
# Design model using class ------------------------------------------------------------------------------
class ConvNet(torch.nn.Module):def __init__(self):super(ConvNet, self).__init__()self.conv1 = torch.nn.Sequential(torch.nn.Conv2d(1, 10, kernel_size=5),torch.nn.ReLU(),torch.nn.MaxPool2d(kernel_size=2),)self.conv2 = torch.nn.Sequential(torch.nn.Conv2d(10, 20, kernel_size=5),torch.nn.ReLU(),torch.nn.MaxPool2d(kernel_size=2),)self.fc = torch.nn.Sequential(torch.nn.Linear(320, 50),torch.nn.Linear(50, 10),)def forward(self, x):batch_size = x.size(0)x = self.conv1(x) # 一层卷积层,一层池化层,一层激活层(图是先卷积后激活再池化,差别不大)x = self.conv2(x) # 再来一次x = x.view(batch_size, -1) # flatten 变成全连接网络需要的输入 (batch, 20,4,4) ==> (batch,320), -1 此处自动算出的是320x = self.fc(x)return x # 最后输出的是维度为10的,也就是(对应数学符号的0~9)model = ConvNet()# Construct loss and optimizer ------------------------------------------------------------------------------
criterion = torch.nn.CrossEntropyLoss() # 交叉熵损失
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate, momentum=momentum) # lr学习率,momentum冲量# Train and Test CLASS --------------------------------------------------------------------------------------
# 把单独的一轮一环封装在函数类里
def train(epoch):print("training ",epoch)running_loss = 0.0 # 这整个epoch的loss清零running_total = 0running_correct = 0for batch_idx, data in enumerate(train_loader, 0):inputs, target = dataoptimizer.zero_grad()# forward + backward + updateoutputs = model(inputs)loss = criterion(outputs, target)loss.backward()optimizer.step()# 把运行中的loss累加起来,为了下面300次一除running_loss += loss.item()# 把运行中的准确率acc算出来_, predicted = torch.max(outputs.data, dim=1)running_total += inputs.shape[0]running_correct += (predicted == target).sum().item()if batch_idx % 300 == 299: # 不想要每一次都出loss,浪费时间,选择每300次出一个平均损失,和准确率print('[%d, %5d]: loss: %.3f , acc: %.2f %%'% (epoch + 1, batch_idx + 1, running_loss / 300, 100 * running_correct / running_total))running_loss = 0.0 # 这小批300的loss清零running_total = 0running_correct = 0 # 这小批300的acc清零# torch.save(model.state_dict(), './model_Mnist.pth')# torch.save(optimizer.state_dict(), './optimizer_Mnist.pth')def test():correct = 0total = 0with torch.no_grad(): # 测试集不用算梯度for data in test_loader:images, labels = dataoutputs = model(images)_, predicted = torch.max(outputs.data, dim=1) # dim = 1 列是第0个维度,行是第1个维度,沿着行(第1个维度)去找1.最大值和2.最大值的下标total += labels.size(0) # 张量之间的比较运算correct += (predicted == labels).sum().item()acc = correct / totalprint('[%d / %d]: Accuracy on test set: %.1f %% ' % (epoch+1, EPOCH, 100 * acc)) # 求测试的准确率,正确数/总数return acc# Start train and Test --------------------------------------------------------------------------------------
if __name__ == '__main__':acc_list_test = []for epoch in range(EPOCH):train(epoch)# if epoch % 10 == 9: #每训练10轮 测试1次acc_test = test()acc_list_test.append(acc_test)plt.plot(acc_list_test)plt.xlabel('Epoch')plt.ylabel('Accuracy On TestSet')plt.show()

相关文章:
【pytorch】手写数字识别
https://blog.csdn.net/qq_45588019/article/details/120935828 基本均参考该博客 《深度学习原理Pytorch实战》 初步处理 导包 import torch import numpy as np from matplotlib import pyplot as plt from torch.utils.data import DataLoader from torchvision import tr…...

SpringBoot3.3.0升级方案
本文介绍了由SpringBoot2升级到SpringBoot3.3.0升级方案,新版本的升级可以解决旧版本存在的部分漏洞问题。 一、jdk17下载安装 1、下载 官网下载地址 Java Archive Downloads - Java SE 17 Jdk17下载后,可不设置系统变量java_home,仅在id…...

用 Kotlin 编写四则运算计算器:从零开始的简单教程
人不走空 🌈个人主页:人不走空 💖系列专栏:算法专题 ⏰诗词歌赋:斯是陋室,惟吾德馨 目录 🌈个人主页:人不走空 💖系列专栏:算法专题 ⏰诗词歌…...

java算法day13
java算法day13 104 二叉树的最大深度111 二叉树的最小深度226 翻转二叉树101 对称二叉树100 相同的树 104 二叉树的最大深度 我最开始想到的是用层序遍历。处理每一层然后计数。思路非常的清楚。 迭代法: /*** Definition for a binary tree node.* public class…...

方便快捷传文件—搭建rsync文件传输服务器
比如我们有一个服务器,想把各个机器的文件都通过脚本传给这台机,用sftp或者直接rsync就必须输密码,肯定不行,做等效性免密又麻烦,怎么办呢,这么办! 在服务端 yum -y install rsync #编辑&…...

python调用qt编写的dll
报错:FileNotFoundError: Could not find module F:\pythonProject\MINGW\sgp4Lib.dll (or one of its dependencies). Try using the full path with constructor syntax. 只有两种情况: 1.路径不对 2.库的依赖不全 1、如果是使用了qt库的࿰…...
SCI一区级 | Matlab实现NGO-CNN-LSTM-Mutilhead-Attention多变量时间序列预测
SCI一区级 | Matlab实现NGO-CNN-LSTM-Mutilhead-Attention多变量时间序列预测 目录 SCI一区级 | Matlab实现NGO-CNN-LSTM-Mutilhead-Attention多变量时间序列预测预测效果基本介绍程序设计参考资料 预测效果 基本介绍 1.Matlab实现NGO-CNN-LSTM-Mutilhead-Attention北方苍鹰算…...

【Redis】初识 Redis
文章目录 1 什么是 Redis2 Redis 的特点2.1 速度快2.2 可编程性2.3 可拓展性2.4 持久化2.5 主从复制2.5 高可用和分布式2.6 客户端语言多 3 Redis 使用场景3.1 实时数据存储3.2 缓存和 Session 存储3.3 消息队列 4 Redis 重大版本5 CentOS7 安装 Redis5 1 什么是 Redis Redis …...

【PTA天梯赛】L1-003 个位数统计(15分)
作者:指针不指南吗 专栏:算法刷题 🐾或许会很慢,但是不可以停下来🐾 文章目录 题目题解总结 题目 题目链接 题解 使用string把长度达1000位的数字存起来开一个代表个位数的数组 a[11]倒序计算最后一位,…...

c语言位操作符相关题目之交换两个数的值
文章目录 一、题目二、方法11,思路2,代码实现 三、方法21,思路2,代码实现 四、方法31,思路2,代码实现 总结 提示:以下是本篇文章正文内容,下面案例可供参考 一、题目 实现两个变量的…...

智能家居装修怎么布线?智能家居网络与开关插座布置
打造全屋智能家居。计划的智能家居方案以米家系列为主,智能家居联网方案以无线为主。装修前为了装备智能家居做了很多准备工作,本文深圳侨杰智能分享一个智能家居装修和布线方面的心得与实战知识。希望能对大家的装修有所帮助。 1.关于网络 如果房子比…...

GD32MCU最小系统构成条件
大家是否有这个疑惑:大学课程学习51的时候,老师告诉我们51的最小系统构成?那么进入32位单片机时代,gd32最小系统构成又是怎么样的呢? 1.供电电路 需要确保供电的电压电流稳定,以东方红开发版为例ÿ…...

C语言——循环结构:while、do...while、for
while循环 基本结构 C语言中的while循环是一种基本的循环控制结构,它允许程序重复执行一段代码块,直到指定的条件不再满足为止。while循环的语法结构如下: while (condition) { // 循环体 // 在这里编写要重复执行的代码 } condition …...

C#实现最短路径算法
创建点集 double r 200 * 500;double width 1920;double height 1080;int col (int)(r / width);int row (int)(r / height);List<(double, double)> list1 new List<(double, double)>();for (int i 0; i < row; i){var y i * height;if (y < r){va…...

Python函数 之 匿名函数
1.概念 匿名函数: 使用 lambda 关键字 定义的表达式,称为匿名函数. 2.语法 lambda 参数, 参数: 一行代码 # 只能实现简单的功能,只能写一行代码 # 匿名函数 一般不直接调用,作为函数的参数使用的 3.代码 4.练习 # 1, 定义匿名函数, 参数…...

深入解析 Mybatis 中 Mapper 接口的实现原理
《深入解析 Mybatis 中 Mapper 接口的实现原理》 在使用 Mybatis 进行数据库操作时,Mapper 接口扮演着重要的角色。它提供了一种简洁、类型安全的方式来与数据库进行交互。那么,Mybatis 是如何实现 Mapper 接口的呢? 一、Mybatis 简介 Myb…...

微信小程序获取用户头像
微信为了安全更改了许多API接口,属实烦人。这次带来的是微信小程序基础库3.5.0还能使用的获取用户头像方法 按键式 <view><view><button open-type"chooseAvatar" bindchooseavatar"onGetUserImage">获取用户头像</butto…...

uniapp小程序连接蓝牙设备
uniapp小程序连接蓝牙设备 一、初始化蓝牙模块二、开始搜索三、连接蓝牙四、监听特征值变化五、调用示例utils.js文件 一、初始化蓝牙模块 这一步是必须的,在开发项目过程中,初始化蓝牙模块之后,紧接着就要开启一些监听的api,供后…...

AI大模型推理过程与优化技术深度剖析
在人工智能的浩瀚星空中,AI大模型以其卓越的性能和广泛的应用前景,成为了推动技术进步的璀璨明星。本文旨在深入探讨AI大模型的推理过程及其背后的优化技术,为理解这一复杂而精妙的技术体系提供一个清晰的视角。 一、AI大模型的推理过程揭秘 …...

Dubbo 核心概念介绍
Dubbo 是一款阿里巴巴开源的高性能 RPC(远程过程调用)框架,广泛应用于微服务架构中。它主要解决服务治理、负载均衡、故障转移等分布式系统问题。本文将介绍 Dubbo 的核心概念,包括服务提供者(Provider)、服…...

Java 8 Stream API 入门到实践详解
一、告别 for 循环! 传统痛点: Java 8 之前,集合操作离不开冗长的 for 循环和匿名类。例如,过滤列表中的偶数: List<Integer> list Arrays.asList(1, 2, 3, 4, 5); List<Integer> evens new ArrayList…...

vue3 字体颜色设置的多种方式
在Vue 3中设置字体颜色可以通过多种方式实现,这取决于你是想在组件内部直接设置,还是在CSS/SCSS/LESS等样式文件中定义。以下是几种常见的方法: 1. 内联样式 你可以直接在模板中使用style绑定来设置字体颜色。 <template><div :s…...

Unsafe Fileupload篇补充-木马的详细教程与木马分享(中国蚁剑方式)
在之前的皮卡丘靶场第九期Unsafe Fileupload篇中我们学习了木马的原理并且学了一个简单的木马文件 本期内容是为了更好的为大家解释木马(服务器方面的)的原理,连接,以及各种木马及连接工具的分享 文件木马:https://w…...

Java + Spring Boot + Mybatis 实现批量插入
在 Java 中使用 Spring Boot 和 MyBatis 实现批量插入可以通过以下步骤完成。这里提供两种常用方法:使用 MyBatis 的 <foreach> 标签和批处理模式(ExecutorType.BATCH)。 方法一:使用 XML 的 <foreach> 标签ÿ…...

车载诊断架构 --- ZEVonUDS(J1979-3)简介第一篇
我是穿拖鞋的汉子,魔都中坚持长期主义的汽车电子工程师。 老规矩,分享一段喜欢的文字,避免自己成为高知识低文化的工程师: 做到欲望极简,了解自己的真实欲望,不受外在潮流的影响,不盲从,不跟风。把自己的精力全部用在自己。一是去掉多余,凡事找规律,基础是诚信;二是…...

《Offer来了:Java面试核心知识点精讲》大纲
文章目录 一、《Offer来了:Java面试核心知识点精讲》的典型大纲框架Java基础并发编程JVM原理数据库与缓存分布式架构系统设计二、《Offer来了:Java面试核心知识点精讲(原理篇)》技术文章大纲核心主题:Java基础原理与面试高频考点Java虚拟机(JVM)原理Java并发编程原理Jav…...

医疗AI模型可解释性编程研究:基于SHAP、LIME与Anchor
1 医疗树模型与可解释人工智能基础 医疗领域的人工智能应用正迅速从理论研究转向临床实践,在这一过程中,模型可解释性已成为确保AI系统被医疗专业人员接受和信任的关键因素。基于树模型的集成算法(如RandomForest、XGBoost、LightGBM)因其卓越的预测性能和相对良好的解释性…...

ABB馈线保护 REJ601 BD446NN1XG
配电网基本量程数字继电器 REJ601是一种专用馈线保护继电器,用于保护一次和二次配电网络中的公用事业和工业电力系统。该继电器在一个单元中提供了保护和监控功能的优化组合,具有同类产品中最佳的性能和可用性。 REJ601是一种专用馈线保护继电器…...

CMake系统学习笔记
CMake系统学习笔记 基础操作 最基本的案例 // code #include <iostream>int main() {std::cout << "hello world " << std::endl;return 0; }// CMakeLists.txt cmake_minimum_required(VERSION 3.0)# 定义当前工程名称 project(demo)add_execu…...
[electron]预脚本不显示内联script
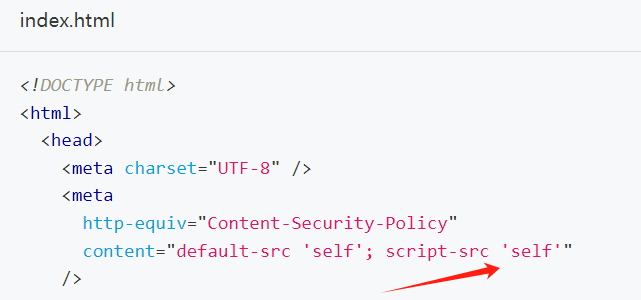
script-src self 是 Content Security Policy (CSP) 中的一个指令,它的作用是限制加载和执行 JavaScript 脚本的来源。 具体来说: self 表示 当前源。也就是说,只有来自当前网站或者当前页面所在域名的 JavaScript 脚本才被允许执行。"…...