【Karapathy大神build-nanogpt】Take Away Notes
B站翻译LINK
Personal Note
Andrej rebuild gpt2 in pytorch.
Take Away Points
- Before entereing serious training, he use Shakespear’s work as a small debugging datset to see if a model can overfit. Overfitging is a should thing.
- If we use TF32 or BF32, (by default is FP32 in pytorch it takes more memory), gpu can do hundred times faster. Becuase the core is computing really fast, most time (more than 40%) it is waiting for the memory allocation/transfer… Every computation is done in a manner like breaking down to 4x4 matrix multiplication.
- when time a gpu programing, remember torch.cuda.synchronize()
- watch gpu: watch -n 0.1 nvidia-smi
- torch.set_float32_matmul_precision(‘high’) easily activate tf32 mode
- default is highest -> float 32
- High-> if avaible tensorflow32 (depends on GPU)
- simply use torch.set_float32_matmul_precision(‘high’) theoraticlaly should make us have 8x speed. However we only achieve 3x. Becuse we are still memory bound, moving data around still cost a lot.
- This can only be used in Amphere:
use torch.autocast(device_type=device,dtype=torch.bfloat16) to wrap the forward process. In this wrap, some CUDA ops can autocast to BF16, many other stays in float32. Matrix Multiplication will be BF16. - One debug technique: import code; code.interact(local=locals())
- torch.compile! Model = torch.compile(model)
- Flash Attention. Flash Attention2. Online softmax.
Use F.scale_dot_product_attention(q,k,v,is_causal=True) instead - Look for ugly numbers, make it to beautiful numbers. Any ugly numbers->increase it to have as much as 2 (Although flops will increase, time will decrease)
- ALL ABOVE CHANGES MAKE PRAGRAM TRAINING 10x FASTER!!
- Linear_warmup + cosine learning rate with minimum learning rate, see GPT3 paper for more details
- First stage of the training, the model is not differing each tokens, they are just learning which tokens can show up which are not and driving them probability to zero. It is the reason that why in the early training stage, a small batchsize will be OK, as the gradients will not behave different if you use full batchsize.
- parameters that should be weight decayed and should not be. WD: all weight tensors + embeddings (p.dim()>=2), NWD: all biaes, layernorms (p.dim()<2)
- AdamW’s use_fused configuration (accelarate training process)
- Model size up, lr down, batchsize up.
- Grad accumulation: Remember to normalize: loss /= grad_accum_steps
- when evaluation, use torch.Generator to create object used in torch.multinomial(xx,xx,generator=.), so that the generating process do not impact the global random number generator used for training.
- However, torch.compile must be banned, so that you can sample in the training process.
CODES FOR DDP (SAMPLE)
# torchrun --stand_alone --nproc_per_node=<num_gpu_per_node> <your_training_script.py> <script_arguments>
# Above only applies for single node training.# SETTINGS FOR EACH DIFFERENT RANK
ddp = int(os.environ.get('RANK',-1))!=-1
if ddp:assert torch.cuda.is_available()init_process_group(backend='nccl')ddp_rank = int(os.environ['RANK']) # It is a global rank, for each process it has a unique ddp_rankddp_local_rank = int(os.environ['LOCAL_RANK']) # It is a local rank in the local machine (node)ddp_world_size = int(os.environ['WORLD_SIZE']) # How many gpus (processes) in totaldevice = f'cuda:{ddp_local_rank}'torch.cuda.set_device(device)master_process = ddp_rank == 0
else:ddp_rank = 0ddp_local_rank = 0ddp_world_size = 1master_process = Truedevice = "cpu"if torhc.cuda.is_available():device = "cuda"elif hasattr(torch.backends,"mps") and torch.bakends.mps.is_available():device = "mps"print(f"using device:{device}")# IF YOU USE GRAD ACCUMULATION
total_batch_size = 524288 # batch size measured in token numbers
B = 16 # micro batch for each process
T = 1024 # sequence length
assert total_batch%(B * T * ddp_world_size) == 0
grad_accum_steps = total_batch_size // (B * T * ddp_world_size)# SET DATALOADER
Dataloader = DataLoader(*args, ddp_world_size, ddp_rank) # MUST! make each process deal with different part of datset# CREATE MODEL
model = createmodel()
model.to(device)
model = torch.compile(model)
if ddp:model = DDP(model,device_ids=[ddp_local_rank]) # this must be ddp_local_rank not ddp_rank
raw_model = model.module if ddp else model# FIX SEED
seed = 'YOUR LUCKY NUMBER'
torch.mannual_seed(seed)
if torch.cuda.is_available():torch.cuda.manual_seed(seed)# TRAIN
for step in range(max_steps):t0 = time.time() model.train()optimizer.zero_grad()loss_accum = 0.0for micro_step in range(grad_accum_steps):x,y = Dataloader.next_batch()x,y = x.to(device),y.to(device)with torch.autocast(device_type=device,dtype=torch.bfloat16):logits, loss = model(x,y)loss = loss / grad_accum_stepsloss_accum += loss.detach()if ddp:model.require_backward_grad_sync = (micro_step == grad_accum_steps - 1) # The ddp sync if applied to every micro step will be wasting time. So only the last backward in one accum cycle should be synchronized. See ddp.no_sync() contextmanager for official advice. Or use it in this way shown here.loss.backward() if ddp:torch.distributed.all_reduce(loss_accum,op=torch.distributed.ReduceOp.AVG)
norm = torch.nn.utils.clip_grad_norm_(model.parameters(),1.0)if step%100 == 0:# start evaluationmodel.eval()with torch.no_grad():# SOME EVALUATION CODE
if ddp:destroy_process_group()
相关文章:

【Karapathy大神build-nanogpt】Take Away Notes
B站翻译LINK Personal Note Andrej rebuild gpt2 in pytorch. Take Away Points Before entereing serious training, he use Shakespear’s work as a small debugging datset to see if a model can overfit. Overfitging is a should thing.If we use TF32 or BF32, (by…...

MySQL学习记录 —— 이십이 MySQL服务器日志
文章目录 1、日志介绍2、一般、慢查询日志1、一般查询日志2、慢查询日志FILE格式TABLE格式 3、错误日志4、二进制日志5、日志维护 1、日志介绍 中继服务器的数据来源于集群中的主服务。每次做一些操作时,把操作保存到重做日志,这样崩溃时就可以从重做日志…...
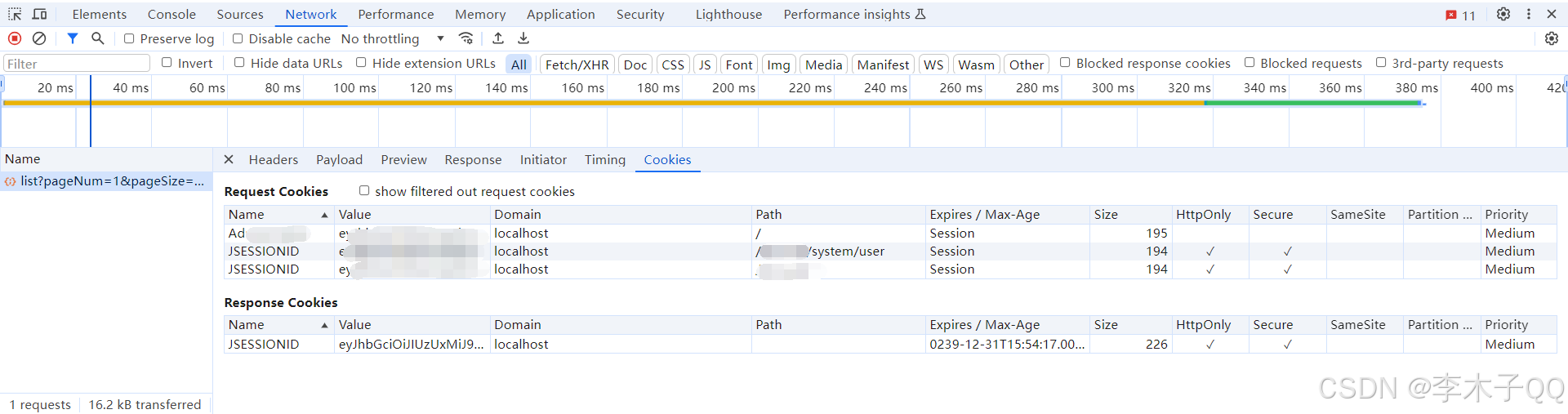
HTTPS请求头缺少HttpOnly和Secure属性解决方案
问题描述: 建立Filter拦截器类 package com.ruoyi.framework.security.filter;import com.ruoyi.common.core.domain.model.LoginUser; import com.ruoyi.common.utils.SecurityUtils; import com.ruoyi.common.utils.StringUtils; import com.ruoyi.framework.…...

react基础样式控制
行内样式 <div style{{width:500px, height:300px,background:#ccc,margin:200px auto}}>文本</div> class类名 注意:在react中使用class类名必须使用className 在外部src下新建index.css文件写入你的样式 .fontcolor{color:red } 在用到的页面引入…...
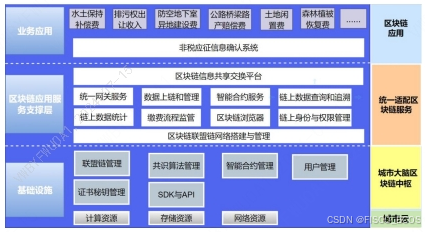
【区块链 + 智慧政务】涉税行政事业性收费“e 链通”项目 | FISCO BCOS应用案例
国内很多城市目前划转至税务部门征收的非税收入项目已达 17 项,其征管方式为行政主管部门核定后交由税务 部门征收。涉税行政事业性收费受限于传统的管理模式,缴费人、业务主管部门、税务部门、财政部门四方处于 相对孤立的状态,信息的传递靠…...

Socket、WebSocket 和 MQTT 的区别
Socket 协议 定义:操作系统提供的网络通信接口,抽象了TCP/IP协议,支持TCP和UDP。特点: 通用性:不限于Web应用,适用于各种网络通信。协议级别:直接使用TCP/UDP,需要手动管理连接和数…...
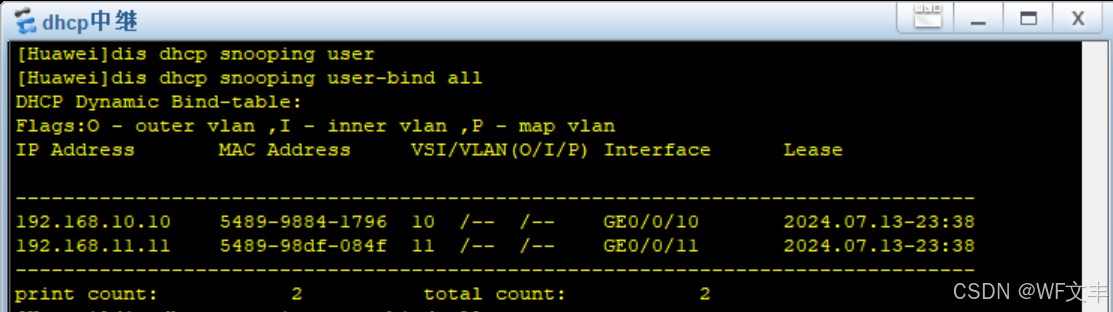
企业网络实验(vmware虚拟机充当DHCP服务器)所有IP全部保留,只为已知mac分配固定IP
文章目录 需求实验修改dhcp虚拟机配置文件测试PC获取IP查看user-bind 需求 (vmware虚拟机充当DHCP服务器)所有IP全部保留,只为已知mac分配固定IP 实验 前期配置: https://blog.csdn.net/xzzteach/article/details/140406092 后续配置均在以上配置的前…...
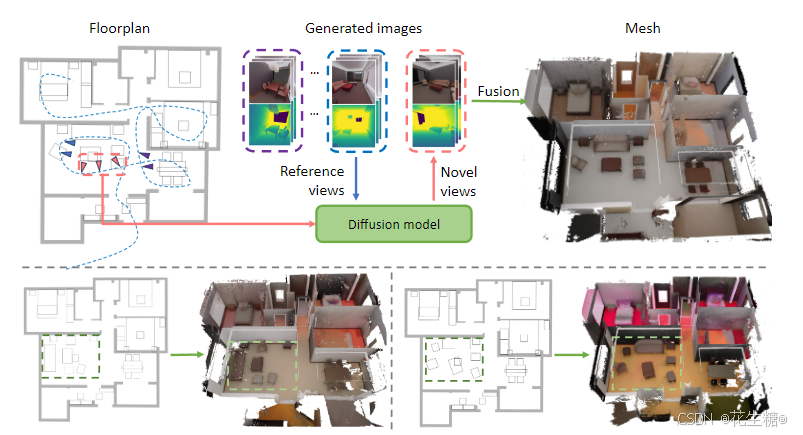
HouseCrafter:平面草稿至3D室内场景的革新之旅
在室内设计、房地产展示和影视布景设计等领域,将平面草稿图快速转换为立体的3D场景一直是一个迫切的需求。HouseCrafter,一个创新的AI室内设计方案,正致力于解决这一挑战。本文将探索HouseCrafter如何将这一过程自动化并提升至新的高度。 一、定位:AI室内设计的革新者 Ho…...
C#统一委托Func与Action
C#在System命名空间下提供两个委托Action和Func,这两个委托最多提供16个参数,基本上可以满足所有自定义事件所需的委托类型。几乎所有的 事件 都可以使用这两个内置的委托Action和Func进行处理。 Action委托: Action定义提供0~16个参数&…...

MongoDB 基本查询语句
基本查询 查询所有文档: db.collection.find()示例: db.users.find()按条件查询文档: db.collection.find({ key: value })示例: db.users.find({ age: 25 })查询并格式化输出: db.collection.find().pretty()示例&…...
28_EfficientNetV2网络详解
V1:https://blog.csdn.net/qq_51605551/article/details/140487051?spm1001.2014.3001.5502 1.1 简介 EfficientNetV2是Google研究人员Mingxing Tan和Quoc V. Le等人在2021年提出的一种深度学习模型,它是EfficientNet系列的最新迭代,旨在提…...

PyCharm查看文件或代码变更记录
背景: Mac笔记本上有一个截图的定时任务在运行,本地Python使用的是PyCharm IDE,负责的同事休假,然后定时任务运行的结果不符合预期,一下子不知道问题出现在哪里。 定位思路: 1、先确认网络、账号等基本的…...

Java开发手册中-避免Random实例被多线程使用、多线程下Random与ThreadLoacalRandom性能对比
场景 Java中使用JMH(Java Microbenchmark Harness 微基准测试框架)进行性能测试和优化: Java中使用JMH(Java Microbenchmark Harness 微基准测试框架)进行性能测试和优化_java热点函数-CSDN博客 参考以上性能测试工具的使用。 Java开发手册中有这样一条…...
【Arduino IDE】安装及开发环境、ESP32库
一、Arduino IDE下载 二、Arduino IDE安装 三、ESP32库 四、Arduino-ESP32库配置 五、新建ESP32-S3N15R8工程文件 乐鑫官网 Arduino官方下载地址 Arduino官方社区 Arduino中文社区 一、Arduino IDE下载 ESP-IDF、MicroPython和Arduino是三种不同的开发框架,各自适…...
【C++开源】GuiLite:超轻量UI框架-入门
开发环境说明 使用visual Studio 2022进行开发 下载源码 从如下的网址进行源码和示例代码的下载: GitHub源码网址为:idea4good/GuiLite示例代码路径为:idea4good/GuiLiteExample使用方法 GuiLite是一个仅有头文件的一个库,使用的时候直接include到自己的UIcode.cpp文件…...
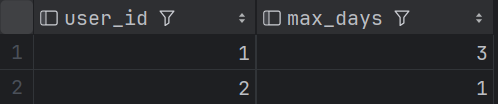
SQL面试题练习 —— 查询每个用户最大连续登录天数
目录 1 题目2 建表语句3 题解 1 题目 查询每个用户最大连续登录天数 样例数据如下 login_log: 2 建表语句 --建表语句 create table if not exists login_log (user_id int comment 用户id,login_time date comment 登录时间 ); --数据插入 INSERT overwrit…...
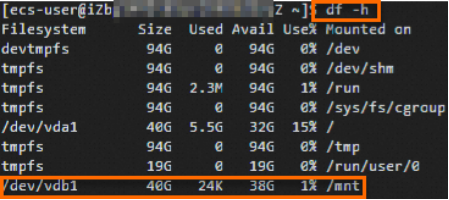
服务器系统盘存储不够,添加数据盘并挂载(阿里云)
目录 1.获取数据盘设备名称 2.为数据盘创建分区 3.为分区创建文件系统 4.配置开机自动挂载分区 阿里云数据盘挂载说明链接:在Linux系统中初始化小于等于2 TiB的数据盘_云服务器 ECS(ECS)-阿里云帮助中心 1.获取数据盘设备名称 sudo fdisk -lu 运行结果如下所示…...
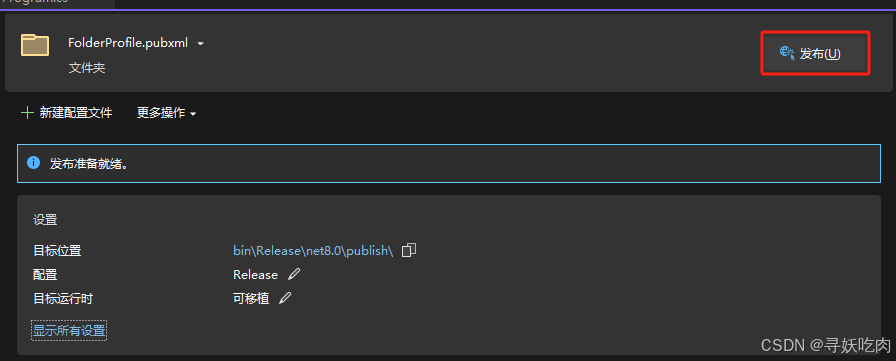
Visual Studio2022中使用.Net 8 在 Windows 下使用 Worker Service 创建守护进程
Visual Studio2022中使用.Net 8 在 Windows 下创建 Worker Service 1 什么是 .NET Core Worker Service1.1 确认Visual Studio中安装了 ASP.NET和Web开发2 创建 WorkerService项目2.1 新建一个WorkerService项目2.2 项目结构说明3 将应用转换成 Windows 服务3.1 安装Microsoft.…...

HTML5应用的安全防护策略与实践
随着HTML5及其相关技术(如CSS3和JavaScript)的普及,Web应用变得越来越强大和复杂,同时也成为黑客攻击的目标。本文将探讨HTML5应用面临的常见安全威胁,以及如何通过最佳实践和代码示例来增强应用的安全性。 HTML5安全…...

堆叠和集群
堆叠和集群 堆叠/集群:把多条/两台设备通过线缆进行连接,逻辑上组成一台设备,作为应该整体来管 理和转发流量 堆叠和集群的区别 1. 何时设备支持对贴,框式设备支持集群 2. 堆叠可以支持多台,框式只能支持两台 堆…...

WeReader:微信读书专业笔记助手,轻松打造个人知识库
WeReader:微信读书专业笔记助手,轻松打造个人知识库 【免费下载链接】wereader 一个浏览器扩展:主要用于微信读书做笔记,对常使用 Markdown 做笔记的读者比较有帮助。 项目地址: https://gitcode.com/gh_mirrors/wer/wereader …...

小白友好!Ostrakon-VL-8B Docker部署教程:一键启动餐饮零售AI视觉助手
小白友好!Ostrakon-VL-8B Docker部署教程:一键启动餐饮零售AI视觉助手 你是不是一直想试试那些厉害的AI视觉模型,看看它们能不能帮你分析店铺照片、检查厨房卫生,或者数数货架上有多少商品?但每次看到复杂的安装步骤、…...
)
零基础入门前端JavaScript 基础语法详解(可用于备赛蓝桥杯Web应用开发)
一、注释注释是代码中不被执行的部分,用于说明代码功能。单行注释:// 这是单行注释多行注释:/* 这是多行注释 */二、变量声明JavaScript 中有三种变量声明方式,区别如下:关键字作用域变量提升重复声明重新赋值var函数作…...

嵌入式系统集成DeepSeek-OCR-2:资源受限环境优化
嵌入式系统集成DeepSeek-OCR-2:资源受限环境优化 1. 为什么嵌入式场景需要特别对待DeepSeek-OCR-2 在工业现场、智能终端和边缘设备上部署OCR能力,和在数据中心跑模型完全是两回事。我第一次把DeepSeek-OCR-2直接扔进一台ARM Cortex-A53的工控机时&…...

TM1640驱动避坑指南:解决STM32通信中的三大常见问题
TM1640驱动避坑指南:解决STM32通信中的三大常见问题 当你在STM32项目中使用TM1640驱动LED显示屏时,是否遇到过数据发送后屏幕毫无反应、显示内容杂乱无章,或者亮度调节完全失效的情况?这些问题往往让开发者陷入长时间的调试困境。…...

OpenClaw二手数据抓取:Qwen3-32B监控多个平台价格变动
OpenClaw二手数据抓取:Qwen3-32B监控多个平台价格变动 1. 为什么需要自动化价格监控 作为一个经常在二手平台淘货的玩家,我发现自己总是错过最佳购买时机。要么是刚买完就降价,要么是犹豫太久被其他人抢走。手动刷新比价不仅效率低下&#…...

别再只会用平均滤波了!ADC信号处理实战:从Arduino到STM32,这几种滤波算法你得会
ADC信号处理实战指南:从基础滤波到高阶算法的嵌入式实现 在嵌入式开发领域,ADC信号处理是每个工程师都无法回避的核心技能。无论是工业控制中的传感器数据采集,还是消费电子产品的用户交互设计,干净可靠的信号都是系统稳定运行的基…...

【STM32实战】三模联动智能药盒:从传感器融合到云平台交互
1. 三模联动智能药盒的设计初衷 家里老人经常忘记吃药,或者药品存放不当导致变质?这种场景可能很多人都遇到过。传统的药盒功能单一,无法满足现代家庭对药品管理的需求。这正是我们设计这款三模联动智能药盒的初衷——用STM32为核心ÿ…...

HY-Motion 1.0动作风格迁移:从古典舞到现代舞
HY-Motion 1.0动作风格迁移:从古典舞到现代舞 当古典舞的优雅韵律遇上现代舞的自由奔放,AI能创造出怎样的艺术融合? 1. 开场:当传统遇见现代的艺术蜕变 想象一下,一位古典舞者正在表演优美的"飞天"舞姿&…...

嵌入式C语言断言机制:从原理到工程化实践
1. C语言断言机制的工程化应用解析断言(Assertion)是嵌入式系统开发中一种被严重低估却极具价值的调试辅助机制。在资源受限、可靠性要求严苛的嵌入式环境中,合理运用断言不仅能显著提升代码质量与可维护性,更能构建起从开发调试到…...