算法工程师第十四天(找树左下角的值 路径总和 从中序与后序遍历序列构造二叉树 )
参考文献 代码随想录
一、找树左下角的值
给定一个二叉树的 根节点 root,请找出该二叉树的 最底层 最左边 节点的值。
假设二叉树中至少有一个节点。
示例 1:
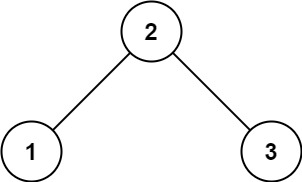
输入: root = [2,1,3] 输出: 1
示例 2:
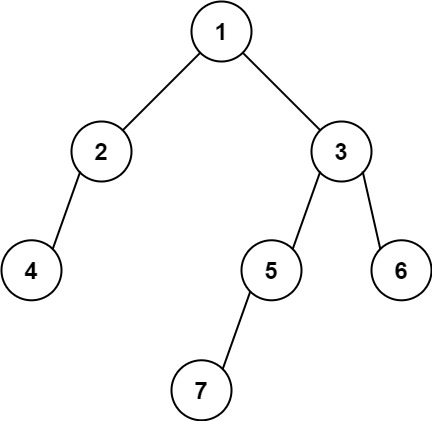
输入: [1,2,3,4,null,5,6,null,null,7] 输出: 7
层次遍历:收集每一层的结果,然后取最后一层的第一个值
# Definition for a binary tree node. # class TreeNode(object): # def __init__(self, val=0, left=None, right=None): # self.val = val # self.left = left # self.right = right class Solution(object):def findBottomLeftValue(self, root):""":type root: TreeNode:rtype: int"""# 层次遍历from collections import dequequeen = deque() # 使用队列存储数据ans = deque() # 存放每层的结果if root:queen.append(root)while queen:count = len(queen) # 记录每层的个数tmp = [] # 暂时存放每一层的结果while count: # 出队列node = queen.popleft()# 收集结果tmp.append(node.val)# 收集每层的结果,左边和右边同时收集,为什么能呢,因为count是记录着每一层的节点数,这样才能控制要收集左右孩子多少个if node.left:queen.append(node.left) # 判断左边是右值,如果有,则进入队列if node.right:queen.append(node.right)count -= 1# 把每一层的结果放入最后的结果集中ans.append(tmp)return ans[len(ans) - 1][0]
前序遍历:求所以路径
# Definition for a binary tree node. # class TreeNode(object): # def __init__(self, val=0, left=None, right=None): # self.val = val # self.left = left # self.right = right class Solution(object):def findBottomLeftValue(self, root):""":type root: TreeNode:rtype: int"""# 层次遍历from collections import dequetmp = [] # 使用队列存储数据ans = [0 for _ in range(10001)] # 存放每层的结果,为什么要初始化呢,因为我们存储的是每一条路基,而我们只需要输出最长路径并且是最左边的,ans[i]代表的是路径长度为i的路径ans[i]if not root:return 0def dfs(cur):if not cur: # 说明当前节点为零return 0# 中tmp.append(cur.val) # 收集每条路的节点if not cur.left and not cur.right: # 说明到了叶子节点if not ans[len(tmp)]: # 因为这个遍历的顺序是中左右,所以先收集的结果是左边的,为了防止长度相等的路,所以一旦有值,就不重新赋值了,这样就收集了长度相等的最左边的ans[len(tmp)] = tmp[:]return # 左 tmp = [1, 2]if cur.left: # 判断左边是否有左孩子,如果有,那么就一直到低,碰到叶子节点就回收dfs(cur.left) # 结束收集左边的节点,如果遇到了那么本次的循环就终止掉,然后到上一层循环,因为这个递归是一个套娃的左右就像 f(f(f(f(x)))),无限的套进去,最里面的函数终止了,说明就不往下走了,那么就开始执行每次的函数,第一次函数是执行2,然在到1,tmp.pop() # 回溯 然后回退一个,if cur.right: # 判断回退的这个节点是否有有孩子,如果有那就往右边找,如果没有,那么将会进入到有没有左孩子dfs(cur.right,)tmp.pop()dfs(root)for i in range(10000, -1, -1):if ans[i]:return ans[i][-1]
递归:
# Definition for a binary tree node. # class TreeNode(object): # def __init__(self, val=0, left=None, right=None): # self.val = val # self.left = left # self.right = right class Solution(object):def findBottomLeftValue(self, root):""":type root: TreeNode:rtype: int"""""" 问题分析:首先是最底层,然后是左节点,然后判断是否到底最底层呢,就是你比较每次的深度大小,然后只收集最大的叶子点的值"""self.maxD = float("-inf") # 存放的是每次最大深度的结果 self.resul = None # 存放的是最后的结果# deepth = 0 # 记录每次的叶子长度if not root:return 0self.dfs(root, 0)return self.resuldef dfs(self, cur, deepth):# 没有返回if not cur.left and not cur.right: # 对比深度,大的话,就跟新result值if deepth > self.maxD:self.maxD = deepthself.resul = cur.valreturn # 左if cur.left:self.dfs(cur.left, deepth + 1)if cur.right:self.dfs(cur.right, deepth + 1)
二、路径总和
给你二叉树的根节点 root 和一个表示目标和的整数 targetSum 。判断该树中是否存在 根节点到叶子节点 的路径,这条路径上所有节点值相加等于目标和 targetSum 。如果存在,返回 true ;否则,返回 false 。
叶子节点 是指没有子节点的节点。
示例 1:
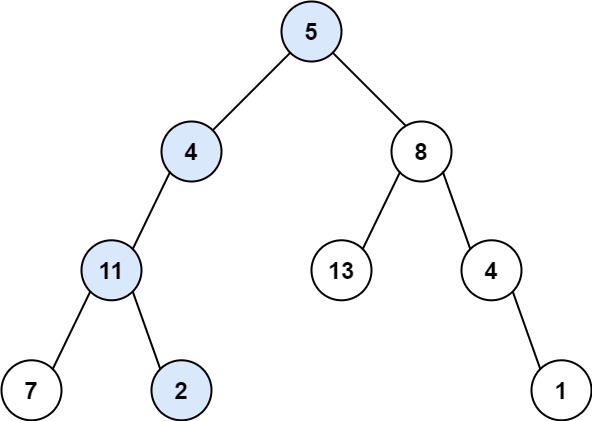
输入:root = [5,4,8,11,null,13,4,7,2,null,null,null,1], targetSum = 22 输出:true 解释:等于目标和的根节点到叶节点路径如上图所示。
递归:
# Definition for a binary tree node. # class TreeNode(object): # def __init__(self, val=0, left=None, right=None): # self.val = val # self.left = left # self.right = right class Solution(object):def hasPathSum(self, root, targetSum):""":type root: TreeNode:type targetSum: int:rtype: bool"""self.tmp = []self.r = []if not root:return Falseself.dfs(root)if targetSum in self.r:return Truereturn Falsedef dfs(self, root):if not root:return 0self.tmp.append(root.val)if not root.left and not root.right:self.r.append(sum(self.tmp))if root.left:self.dfs(root.left)self.tmp.pop()if root.right:self.dfs(root.right)self.tmp.pop()
递归简化版:
# Definition for a binary tree node. # class TreeNode(object): # def __init__(self, val=0, left=None, right=None): # self.val = val # self.left = left # self.right = right class Solution(object):def hasPathSum(self, root, targetSum):""":type root: TreeNode:type targetSum: int:rtype: bool"""self.f = Falseself.r = targetSumif not root:return Falseself.dfs(root, root.val)return self.fdef dfs(self, root, tmp):if not root:return 0if not root.left and not root.right:if tmp == self.r:self.f = Trueif root.left:self.dfs(root.left, tmp + root.left.val) # tmp + root.left.val回溯,因为递归解释回溯if root.right:self.dfs(root.right, tmp + root.right.val)
三、路径总和 II
给你二叉树的根节点 root 和一个整数目标和 targetSum ,找出所有 从根节点到叶子节点 路径总和等于给定目标和的路径。
叶子节点 是指没有子节点的节点。
示例 1:
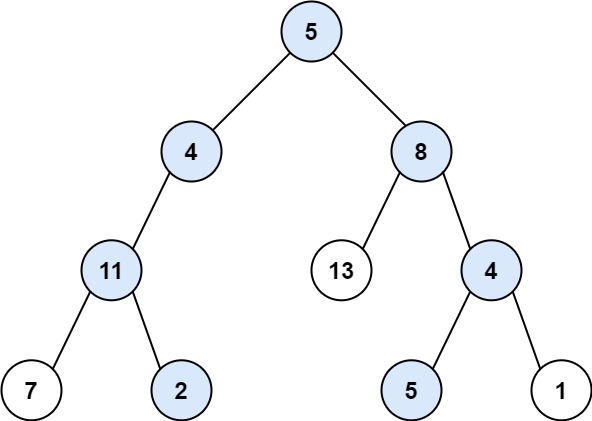
输入:root = [5,4,8,11,null,13,4,7,2,null,null,5,1], targetSum = 22 输出:[[5,4,11,2],[5,8,4,5]]
示例 2:
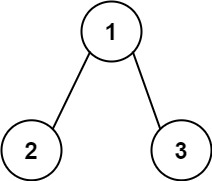
输入:root = [1,2,3], targetSum = 5 输出:[]
示例 3:
输入:root = [1,2], targetSum = 0 输出:[]
问题分析:前序遍历,一个统计和,一个统计节点
# Definition for a binary tree node. # class TreeNode(object): # def __init__(self, val=0, left=None, right=None): # self.val = val # self.left = left # self.right = right class Solution(object):def pathSum(self, root, targetSum):""":type root: TreeNode:type targetSum: int:rtype: List[List[int]]"""# Definition for a binary tree node. # class TreeNode(object): # def __init__(self, val=0, left=None, right=None): # self.val = val # self.left = left # self.right = rightself.tmp = []self.r = targetSumif not root:return []self.dfs(root, root.val, [int(root.val)])return self.tmpdef dfs(self, root, tmp, tl):if not root:return 0if not root.left and not root.right:if tmp == self.r:self.tmp.append(tl)if root.left:self.dfs(root.left, tmp + root.left.val, tl + [root.left.val]) # tmp + root.left.val回溯,因为递归解释回溯if root.right:self.dfs(root.right, tmp + root.right.val, tl + [root.right.val])
四、从中序与后序遍历序列构造二叉树
给定两个整数数组 inorder 和 postorder ,其中 inorder 是二叉树的中序遍历, postorder 是同一棵树的后序遍历,请你构造并返回这颗 二叉树 。
示例 1:
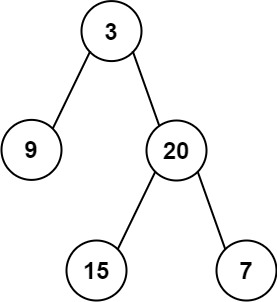
输入:inorder = [9,3,15,20,7], postorder = [9,15,7,20,3] 输出:[3,9,20,null,null,15,7]
示例 2:
输入:inorder = [-1], postorder = [-1] 输出:[-1]
提示:
1 <= inorder.length <= 3000postorder.length == inorder.length-3000 <= inorder[i], postorder[i] <= 3000inorder和postorder都由 不同 的值组成postorder中每一个值都在inorder中inorder保证是树的中序遍历postorder保证是树的后序遍历
class Solution:def buildTree(self, inorder: List[int], postorder: List[int]) -> TreeNode:# 第一步: 特殊情况讨论: 树为空. (递归终止条件)if not postorder:return None# 第二步: 后序遍历的最后一个就是当前的中间节点.root_val = postorder[-1]root = TreeNode(root_val)# 第三步: 找切割点.separator_idx = inorder.index(root_val)# 第四步: 切割inorder数组. 得到inorder数组的左,右半边.inorder_left = inorder[:separator_idx]inorder_right = inorder[separator_idx + 1:]# 第五步: 切割postorder数组. 得到postorder数组的左,右半边.# ⭐️ 重点1: 中序数组大小一定跟后序数组大小是相同的.postorder_left = postorder[:len(inorder_left)]postorder_right = postorder[len(inorder_left): len(postorder) - 1]# 第六步: 递归root.left = self.buildTree(inorder_left, postorder_left)root.right = self.buildTree(inorder_right, postorder_right)# 第七步: 返回答案return root
相关文章:
算法工程师第十四天(找树左下角的值 路径总和 从中序与后序遍历序列构造二叉树 )
参考文献 代码随想录 一、找树左下角的值 给定一个二叉树的 根节点 root,请找出该二叉树的 最底层 最左边 节点的值。 假设二叉树中至少有一个节点。 示例 1: 输入: root [2,1,3] 输出: 1示例 2: 输入: [1,2,3,4,null,5,6,null,null,7] 输出: 7 层次遍历&#…...

memcached 高性能内存对象缓存
memcached 高性能内存对象缓存 memcache是一款开源的高性能分布式内存对象缓存系统,常用于做大型动态web服务器的中间件缓存。 mamcached做web服务的中间缓存示意图 当web服务器接收到请求需要处理动态页面元素时,通常要去数据库调用数据,但…...

C语言 分割链表
题目来源: 代码部分,参考官方题解的写法: // 思路: 就是把原始链表,拆分为2部分,最后再拼接一下。struct ListNode* partition(struct ListNode* head, int x) {struct ListNode* small malloc(sizeof(struct ListNode));struct ListNode*…...
spring ioc的原理
1、控制反转(IOC):对象的创建控制权由程序自身转移到外部(容器) 2、依赖注入(DI):所谓依赖注入,就是由IOC容器在运行期间,动态地将某种依赖关系注入到对象之中。 Spring 中的 IoC 的实现原理就是工厂模式加反射机制。 参考资料…...

npm安装依赖包报错,npm ERR! code ENOTFOUND
一、报错现象: npm WARN registry Unexpected warning for https://registry.npmjs.org/: Miscellaneous Warning ETIMEDOUT: request to https://registry.npmjs.org/vue failed, reason: connect ETIMEDOUT 104.16.23.35:443 npm WARN registry Using stale data…...

【iOS】——内存对齐
内存对齐是什么 内存对齐指的是数据在内存中的布局方式,它确保每个数据类型的起始地址能够满足该类型对齐的要求。这是因为现代处理器在访问内存时,如果数据的起始地址能够对齐到一定的边界,那么访问速度会更快。这种对齐通常是基于数据类型…...

网络安全-网络安全及其防护措施10
46.软件定义网络(SDN) 软件定义网络(SDN)的概念和特点 软件定义网络(SDN)是一种新兴的网络架构,通过将网络的控制平面(Control Plane)和数据转发平面(Data …...

Pytorch基础应用
1.数据加载 1.1 读取文本文件 方法一:使用 open() 函数和 read() 方法 # 打开文件并读取全部内容 file_path example.txt # 替换为你的文件路径 with open(file_path, r) as file:content file.read()print(content)方法二:逐行读取文件内容 # 逐…...
Axure 教程 | 设置文本框背景透明
在AXURE软件中,部件样式可以编辑,但有时却无法满足所有个性化原型的需求。例如文本框部件,可以设置是否隐藏边框,但即使隐藏边框之后,文本框还会有白色的背景。 当界面需要一个无背景色的输入框时,对于完…...

【BUG】已解决:NOAUTH Authentication required
已解决:NOAUTH Authentication required 欢迎来到英杰社区https://bbs.csdn.net/topics/617804998 欢迎来到我的主页,我是博主英杰,211科班出身,就职于医疗科技公司,热衷分享知识,武汉城市开发者社区主理人…...

全国产服务器主板:搭载飞腾FT2000+/64处理器的高性能加固服务器
近期很多朋友咨询全国产化的服务器主板。搭载的是飞腾FT-2000/64的全国产化服务器主板。他的主要特点是:①丰富的PCIe、千兆以太网、SATA接口,可用作数据处理、存储、通信服务器;②板载独立显示芯片,对外HDMI/VGA/L…...
OPC UA边缘计算耦合器BL205工业通信的最佳解决方案
OPC UA耦合器BL205是钡铼技术基于下一代工业互联网技术推出的分布式、可插拔、结构紧凑、可编程的IO系统,可直接接入SCADA、MES、MOM、ERP等IT系统,无缝链接OT与IT层,是工业互联网、工业4.0、智能制造、数字化转型解决方案中IO系统最佳方案。…...

【已解决】Django连接MySQL启动报错Did you install mysqlclient?
在终端执行python manage.py makemigrations报错问题汇总 错误1:已安装mysqlclient,提示Did you install mysqlclient? 当你看到这样的错误信息,表明Django尝试加载MySQLdb模块但未找到,因为MySQLdb已被mysqlclient替代。 【解…...

ubuntu gcc g++版本切换
要将 GCC 和 G 的版本从 12.4 降低到 9,你可以按照以下步骤操作: 安装 GCC 和 G 9: sudo apt update sudo apt install gcc-9 g-9 使用 update-alternatives 设置优先级: sudo update-alternatives --install /usr/bin/gcc gcc…...

如何发一篇顶会论文? 涉及3D高斯,slam,自动驾驶,三维点云等等
SLAM&3DGS 1)SLAM/3DGS/三维点云/医疗图像/扩散模型/结构光/Transformer/CNN/Mamba/位姿估计 顶会论文指导 2)基于环境信息的定位,重建与场景理解 3)轻量级高保真Gaussian Splatting 4)基于大模型与GS的 6D pose e…...

Java面试八股之什么是Redis的缓存更新
什么是Redis的缓存更新 Redis的缓存更新是指当缓存中的数据发生变化时,需要将这些变化同步到缓存中以保持数据的一致性。缓存更新的目的是确保缓存中的数据始终是最新的,以便用户可以获取到最新的数据。 常见的缓存更新策略包括: 直接覆盖…...

新华三H3CNE网络工程师认证—VLAN使用场景与原理
通过华三的技术原理与VLAN配置来学习,首先介绍VLAN,然后介绍VLAN的基本原理,最后介绍VLAN的基本配置。 一、传统以太网问题 在传统网络中,交换机的数量足够多就会出现问题,广播域变得很大,分割广播域需要…...

Linux-开机自动挂载(文件系统、交换空间)
准备磁盘 添加三块磁盘(两块SATA,一块NVMe) 查看设备: [rootlocalhost jian]# ll /dev/sd* [rootlocalhost jian]# ll /dev/nvme0n2 扩:查看当前主机上的所有块设备,通过如下指令实现: [root…...

[003-02-10].第10节:Docker环境下搭建Redis主从复制架构
我的博客大纲 我的后端学习大纲 我的Redis学习大纲 1.cluster(集群)模式-docker版 哈希槽分区进行亿级数据存储 1.1.面试题:1~2亿条数据需要缓存,请问如何设计这个存储案例 1.回答:单机单台100%不可能,肯…...

uni-app学习HBuilderX学习-微信开发者工具配置
HBuilderX官网:简介 - HBuilderX 文档 (dcloud.net.cn)https://hx.dcloud.net.cn/ uni-app官网: uni-app官网 (dcloud.net.cn)https://uniapp.dcloud.net.cn/quickstart-hx.htmlHBuilder下载安装:打开官网 uni-app项目的微信开发者工具配置…...

【Oracle APEX开发小技巧12】
有如下需求: 有一个问题反馈页面,要实现在apex页面展示能直观看到反馈时间超过7天未处理的数据,方便管理员及时处理反馈。 我的方法:直接将逻辑写在SQL中,这样可以直接在页面展示 完整代码: SELECTSF.FE…...

R语言AI模型部署方案:精准离线运行详解
R语言AI模型部署方案:精准离线运行详解 一、项目概述 本文将构建一个完整的R语言AI部署解决方案,实现鸢尾花分类模型的训练、保存、离线部署和预测功能。核心特点: 100%离线运行能力自包含环境依赖生产级错误处理跨平台兼容性模型版本管理# 文件结构说明 Iris_AI_Deployme…...

Redis相关知识总结(缓存雪崩,缓存穿透,缓存击穿,Redis实现分布式锁,如何保持数据库和缓存一致)
文章目录 1.什么是Redis?2.为什么要使用redis作为mysql的缓存?3.什么是缓存雪崩、缓存穿透、缓存击穿?3.1缓存雪崩3.1.1 大量缓存同时过期3.1.2 Redis宕机 3.2 缓存击穿3.3 缓存穿透3.4 总结 4. 数据库和缓存如何保持一致性5. Redis实现分布式…...

iPhone密码忘记了办?iPhoneUnlocker,iPhone解锁工具Aiseesoft iPhone Unlocker 高级注册版分享
平时用 iPhone 的时候,难免会碰到解锁的麻烦事。比如密码忘了、人脸识别 / 指纹识别突然不灵,或者买了二手 iPhone 却被原来的 iCloud 账号锁住,这时候就需要靠谱的解锁工具来帮忙了。Aiseesoft iPhone Unlocker 就是专门解决这些问题的软件&…...

2024年赣州旅游投资集团社会招聘笔试真
2024年赣州旅游投资集团社会招聘笔试真 题 ( 满 分 1 0 0 分 时 间 1 2 0 分 钟 ) 一、单选题(每题只有一个正确答案,答错、不答或多答均不得分) 1.纪要的特点不包括()。 A.概括重点 B.指导传达 C. 客观纪实 D.有言必录 【答案】: D 2.1864年,()预言了电磁波的存在,并指出…...

什么是库存周转?如何用进销存系统提高库存周转率?
你可能听说过这样一句话: “利润不是赚出来的,是管出来的。” 尤其是在制造业、批发零售、电商这类“货堆成山”的行业,很多企业看着销售不错,账上却没钱、利润也不见了,一翻库存才发现: 一堆卖不动的旧货…...

python执行测试用例,allure报乱码且未成功生成报告
allure执行测试用例时显示乱码:‘allure’ �����ڲ����ⲿ���Ҳ���ǿ�&am…...

【Java学习笔记】BigInteger 和 BigDecimal 类
BigInteger 和 BigDecimal 类 二者共有的常见方法 方法功能add加subtract减multiply乘divide除 注意点:传参类型必须是类对象 一、BigInteger 1. 作用:适合保存比较大的整型数 2. 使用说明 创建BigInteger对象 传入字符串 3. 代码示例 import j…...

Java + Spring Boot + Mybatis 实现批量插入
在 Java 中使用 Spring Boot 和 MyBatis 实现批量插入可以通过以下步骤完成。这里提供两种常用方法:使用 MyBatis 的 <foreach> 标签和批处理模式(ExecutorType.BATCH)。 方法一:使用 XML 的 <foreach> 标签ÿ…...

VM虚拟机网络配置(ubuntu24桥接模式):配置静态IP
编辑-虚拟网络编辑器-更改设置 选择桥接模式,然后找到相应的网卡(可以查看自己本机的网络连接) windows连接的网络点击查看属性 编辑虚拟机设置更改网络配置,选择刚才配置的桥接模式 静态ip设置: 我用的ubuntu24桌…...