【AI绘画教程】Stable Diffusion 1.5 vs 2
在本文中,我们将总结稳定扩散 1 与稳定扩散 2 辩论中的所有要点。我们将在第一部分中查看这些差异存在的实际原因,但如果您想直接了解实际差异,您可以跳下否定提示部分。让我们开始吧!

Stable Diffusion 2.1 发布与1.5相比,2.1旨在解决2.0的许多相对缺点。本文的内容与理解 Stable Diffusion 1 与 2 仍然相关,但读者应确保额外阅读附加的 Stable Diffusion 2.1 部分以了解全貌。
OpenCLIP
Stable Diffusion 2 所做的最重要的转变是替换了文本编码器。Stable Diffusion 1 使用 OpenAI 的 CLIP,这是一个开源模型,可以学习标题描述图像的程度。虽然模型本身是开源的,但训练 CLIP 的数据集很重要,它不是公开的。
Stable Diffusion 2 改用 OpenCLIP,这是 CLIP 的开源版本,它是使用已知数据集训练的——LAION-5B 的一个美学子集,可以过滤掉 NSFW 图像。Stability AI表示,OpenCLIP“大大提高了生成图像的质量”,事实上,在指标上优于未发布的CLIP版本。
为什么这很重要
撇开这些模型的相对性能不谈,从 CLIP 到 OpenCLIP 的转变是 Stable Diffusion 1 和 Stable Diffusion 2 之间许多差异的根源。
特别是,许多 Stable Diffusion 2 的用户声称它不能像 Stable Diffusion 1 那样代表名人或艺术风格,尽管 Stable Diffusion 2 的训练数据没有被故意过滤以删除艺术家。这种差异源于这样一个事实,即CLIP的训练数据比LAION数据集有更多的名人和艺术家。由于CLIP的数据集不向公众开放,因此无法仅使用LAION数据集恢复相同的功能。换言之,Stable Diffusion 1 的许多规范提示方法对于 Stable Diffusion 2 来说几乎已经过时了。
这意味着什么
这种向完全开源、开放数据模型的改变标志着 Stable Diffusion 故事的重要转变。对 Stable Diffusion 2 进行微调并构建人们希望看到的功能将落在开源社区的肩上,但这实际上是 Stable Diffusion ab initio 的意图——一个由社区驱动的、完全开放的项目。虽然一些用户目前可能对 Stable Diffusion 2 的相对性能感到失望,但 StabilityAI 团队已经花费了超过 100 万 A100 小时来构建一个坚实的基础。
此外,虽然创建者没有明确提及,但这种从使用 CLIP 的转变可能会为项目贡献者提供一些保护,防止潜在的责任问题,考虑到即将到来的知识产权诉讼浪潮,这很重要。
考虑到这个背景,现在是时候讨论 Stable Diffusion 1 和 2 之间的实际区别了。
Negative Prompts
我们首先检查负面提示,与 SD 1 相比,它似乎对 Stable Diffusion(SD) 2 的强劲性能更重要,如下所示:

现在让我们更详细地看一下负面提示。
Simple Prompt
首先,我们将提示“无边池”提供给 Stable Diffusion 1.5 和 Stable Diffusion 2,没有负面提示。显示了每个模型的三张图像,其中每列对应于不同的随机种子。

prompt: "infinity pool"
size: 512x512
guidance scale: 12
steps: 50
sampler: DDIM
正如我们所看到的,Stable Diffusion 1.5 总体上似乎比 Stable Diffusion 2 表现更好。在SD 2中,最左边的图像有一个贴片,与图像不匹配,而最右边的图像几乎是不连贯的。
现在,我们以相同的方式从相同的起始噪声生成图像,这次使用负提示。我们添加了否定提示“丑陋、平铺、画得不好的手、画得不好的脚、画得不好的脸、出框、突变、突变、额外的四肢、额外的腿、额外的手臂、毁容、变形、斗鸡眼、身体出框、模糊、糟糕的艺术、糟糕的解剖学、模糊、文本、水印、颗粒状”(ugly, tiling, poorly drawn hands, poorly drawn feet, poorly drawn face, out of frame, mutation, mutated, extra limbs, extra legs, extra arms, disfigured, deformed, cross-eye, body out of frame, blurry, bad art, bad anatomy, blurred, text, watermark, grainy),这是 Emad Mostaque 使用的否定提示。
添加否定提示后,SD 1.5 通常表现更好,尽管中间图像的标题对齐方式可能较差。对于 SD 2,改进更为剧烈,尽管整体性能仍然不如 SD 1.5

prompt: "infinity pool"
size: 512x512
guidance scale: 12
steps: 50
sampler: DDIM
negative prompt: "ugly, tiling, poorly drawn hands, poorly drawn feet, poorly drawn face, out of frame, mutation, mutated, extra limbs, extra legs, extra arms, disfigured, deformed, cross-eye, body out of frame, blurry, bad art, bad anatomy, blurred, text, watermark, grainy"
我们直接比较有和没有负面提示的 SD 2 性能。检查揭示了否定提示对可持续发展 2 至关重要这一命题的支持。

下面我们可以看到 SD 1.5 和 2 生成的最终图像的比较,无论有没有否定提示,从同一个随机种子开始。

Complicated Prompt
我们运行与上面相同的实验,这次使用更复杂(积极)的提示。这一次,我们使用的不是“无边泳池”,而是“无边泳池,背景是热带森林,分辨率高,细节,8 k,数码单反相机,良好的照明,光线追踪,逼真”(infinity pool with a tropical forest in the background, high resolution, detail, 8 k, dslr, good lighting, ray tracing, realistic)。虽然我们可以省略“背景中有热带森林”部分,以隔离纯粹的美学添加,但我们包括它是为了更好地探索更复杂提示的语义拟合度。
同样,我们在没有负面提示的情况下显示结果。图像看起来不再逼真,标题对齐可以说更好。SD 1.5 的水质地也要好得多。

prompt: "infinity pool with a tropical forest in the background, high resolution, detail, 8 k, dslr, good lighting, ray tracing, realistic"
size: 512x512
guidance scale: 12
steps: 50
sampler: DDIM
一旦我们添加了与上一个示例相同的否定提示,我们就会看到一些有趣的结果。特别是,否定提示似乎实际上可能会对 SD 1 产生不利影响,但对 SD 2 有普遍帮助。SD 2 中的每张图像在否定提示下都更好,而 SD 1 的标题对齐方式似乎普遍下降。有趣的是,添加否定提示似乎将生成的图像推向了照片级真实感。

prompt: "infinity pool with a tropical forest in the background, high resolution, detail, 8 k, dslr, good lighting, ray tracing, realistic"
size: 512x512
guidance scale: 12
steps: 50
sampler: DDIM
negative prompt: "ugly, tiling, poorly drawn hands, poorly drawn feet, poorly drawn face, out of frame, mutation, mutated, extra limbs, extra legs, extra arms, disfigured, deformed, cross-eye, body out of frame, blurry, bad art, bad anatomy, blurred, text, watermark, grainy"
我们再次直接比较从各种随机种子生成的图像,有和没有 SD 2 的负面提示。

最后,我们再次显示 SD 1.5/SD2 与带/不带负提示矩阵的比较:

Textual Inversion(文本反转)
除了普通的否定提示,Stable Diffusion 还支持文本反转。文本反转是一种方法,其中可以使用少量参考图像来生成表示图像的新“单词”。一旦学会了“单词”,就可以像往常一样在提示中使用,使我们能够生成忠实地映射到参考图像的图像。在下面的示例中,一个小图形的 4 个图像被反转为“S_*”。然后像往常一样在各种提示中使用这个“词”,将参考图像与其他语义概念忠实地结合在一起:

在下面的示例中,我们使用 Stable Diffusion 2.0 从基本提示“美味的汉堡包”创建了几张图像。然后,此提示将使用正提示或文本反转标记和/或负提示或文本反转标记进行扩充。例如,第二行最右边的图像使用引用 Midjourney 的文本倒置标记和正常的否定提示“丑陋、无聊、糟糕的解剖学”来增强基本提示。

正如我们所看到的,文本反转的使用显着提高了 Stable Diffusion 2.0 的性能。
名人
鉴于 LAION 包含的名人图像比 CLIP 的训练数据少,因此知道许多 SD 2 用户观察到生成名人图像的能力比 SD 1.5 更差也就不足为奇了。
下面我们展示了从 3 个随机种子(列)生成的图像,有和没有 SD 1.5 和 SD 2 的负面提示。提示是“基努·里维斯”,此图像的全分辨率版本也可用。

prompt: "keanu reeves"
size: 512x512
guidance scale: 7
steps: 50
seed: 119
sampler: DDIM
negative prompt: "ugly, tiling, poorly drawn hands, poorly drawn feet, poorly drawn face, out of frame, mutation, mutated, extra limbs, extra legs, extra arms, disfigured, deformed, cross-eye, body out of frame, blurry, bad art, bad anatomy, blurred, text, watermark, grainy"
总体而言,SD 2 在此特定提示方面的性能可与 SD 1.5 相媲美。话虽如此,Stable Diffusion 2 描绘名人的能力在与语义概念相结合时似乎会崩溃。我们在下面对两个这样的提示进行比较,其中图像中的每一列再次对应于给定的随机种子。这一次,我们在每种情况下都使用否定提示。

prompt: "a white marble bust of Robert Downey Jr. in a museum, cinematic lighting, hyperdetailed, 8 k realistic, global illumination, radiant light, frostbite 3 engine, cryengine, trending on artstation, digital art, fantasy background"
size: 512x512
guidance scale: 12
steps: 50
seed: 120-122
sampler: DPM-Solver++
negative prompt: "ugly, tiling, out of frame, deformed, blurry, bad art, blurred, watermark, grainy"

prompt: "a studio photograph of Robert Downey Jr., cinematic lighting, hyperdetailed, 8 k realistic, global illumination, radiant light, frostbite 3 engine, cryengine, trending on artstation, digital art"
size: 512x512
guidance scale: 7
steps: 50
seed: 119-121
sampler: DPM-Solver++
negative prompt: "ugly, tiling, poorly drawn hands, poorly drawn feet, poorly drawn face, out of frame, mutation, mutated, extra limbs, extra legs, extra arms, disfigured, deformed, cross-eye, body out of frame, blurry, bad art, bad anatomy, blurred, text, watermark, grainy"
正如我们所看到的,Stable Diffusion 1.5 在这方面往往优于 Stable Diffusion 2(它甚至一度似乎描绘了史蒂夫·卡雷尔而不是小罗伯特·唐尼)。虽然这种差异是意料之中的,但考虑到基努·里维斯的例子的结果,其程度可能比预期的要大。
艺术图像
如 OpenCLIP 部分所述,除了包含的名人图像比 CLIP 训练数据少之外,LAION 数据集还包含更少的艺术图像。这意味着生成程式化图像变得更加困难,并且“以_____风格_____”的规范方法不再像在 Stable Diffusion 1 中那样起作用。下面我们比较了 Stable Diffusion 1.5 和 Stable Diffusion 2 的 4 个随机种子的图像,我们尝试以 Greg Rutkowski 的风格生成图像。

prompt: "A monster fighting a hero by greg rutkowski, romanticism, cinematic lighting, hyperdetailed, 8 k realistic, global illumination, radiant light, trending on artstation, digital art"
size: 512x512
guidance scale: 9
steps: 50
seed: 119-122
sampler: DPM-Solver++
negative prompt: "ugly, tiling, poorly drawn hands, poorly drawn feet, poorly drawn face, out of frame, mutation, mutated, extra limbs, extra legs, extra arms, disfigured, deformed, cross-eye, body out of frame, blurry, bad art, bad anatomy, blurred, text, watermark, grainy"
结果是激烈的 - Stable Diffusion 1.5 再次成为 Stable Diffusion 2 的明显赢家(开箱即用)。虽然使用其他未明确引用艺术家的描述符来增强提示,但仍然可以使用 SD 2 生成风格化图像,但性能仍然不如 SD 1.5,如下所示:

另一方面,一些用户发现 SD 2 在生成逼真的图像方面具有很强的能力:

文本连贯性
与 Stable Diffusion 1 相比,Stable Diffusion 2 可能具有开箱即用的优势,其中一个地方是文本连贯性。大多数文本到图像模型在表示文本方面都很差。这完全不足为奇——虽然我们人类很容易解析文本,但我们必须记住,单词是极其复杂的语言系统的一部分,根据特殊规则排列以传达含义。此外,这些单词本身以明显近乎随机的方式由字母组成;而且,更进一步,这些字母的实际视觉表现可能会有很大差异(例如,比较 Jokerman 和 Consolas 字体)。这些考虑因素(以及其他因素)为这些模型无法正确传达文本提供了一些解释,尤其是在简单单词之外。
话虽如此,Stable Diffusion 2 在传达文本方面似乎比 Stable Diffusion 1 略好一些。下面我们提供几张图片进行比较:

正如我们所看到的,这两种情况的结果都不是很好,负面提示似乎在这方面影响不大。虽然很难对这些模型生成文本的效果提出客观的衡量标准,但可以说普通人会认为 Stable Diffusion 2 稍微好一点。
其他型号
除了从 CLIP 到 OpenCLIP 的转变之外,Stable Diffusion 2 还发布了一些其他强大的功能,我们在下面总结了这些功能。
深度模型
深度模型与SD 2一起发布。此模型采用 2D 图像并返回该图像的预测深度图。然后,除了文本之外,这些信息还可用于条件图像生成,从而允许用户生成忠实于参考图像几何形状的新图像。

下面我们可以看到一连串这样的图像,它们都保留了相同的基本几何结构。

升级模型
Stable Diffusion 2 还发布了一个升级模型,可以将图像放大到原始边长的 4 倍。这意味着放大图像的面积是原始图像的 16 倍!
下面我们可以看到放大我们之前生成的图像之一的结果:

如果我们放大每张图像中兔子的眼睛,差异会立即显现出来,并且非常令人印象深刻。

修复模型
Stable Diffusion 2 还附带了更新的修复模型,可让您修改图像的子部分,使补丁在美学上符合
768 x 768 Model
最后,Stable Diffusion 2 现在支持 768 x 768 图像 - 是 Stable Diffusion 1 的 512 x 512 图像面积的两倍多。
Stable Diffusion 2.1
Stable Diffusion 2.1 是在 Stable Diffusion 2.0 发布后不久发布的。SD 2.1 旨在解决 2.0 相对于 1.5 的许多相对缺点。让我们来看看 2.1 是如何做到这一点的。
NSFW过滤器
相对于 2.0,2.1 的最大变化是修改了 NSFW 滤波器。回想一下,2.0 是在 LAION 数据集的一个子集上训练的,该子集使用 NSFW 过滤器过滤了不适当的内容,这反过来又导致描绘人类的能力相对降低。
Stable Diffusion 2.1 也使用这样的过滤器进行训练,尽管过滤器本身被修改为限制较少。特别是,过滤器抛出的误报更少,这大大增加了能够通过过滤器并训练模型的图像数量。训练数据的增加导致了描绘人物的能力的提高。我们再次展示了小罗伯特·唐尼(Robert Downey Jr.)使用相同设置创建的几张图像,除了用于生成它们的模型版本,这次包括Stable Diffusion 2.1。

prompt: "a studio photograph of Robert Downey Jr., cinematic lighting, hyperdetailed, 8 k realistic, global illumination, radiant light, frostbite 3 engine, cryengine, trending on artstation, digital art"
size: 512x512
guidance scale: 7
steps: 50
seed: 119
sampler: DPM-Solver++
negative prompt: "ugly, tiling, poorly drawn hands, poorly drawn feet, poorly drawn face, out of frame, mutation, mutated, extra limbs, extra legs, extra arms, disfigured, deformed, cross-eye, body out of frame, blurry, bad art, bad anatomy, blurred, text, watermark, grainy"
正如我们所看到的,Stable Diffusion 2.1 比 Stable Diffusion 2 有了显着的改进,能够实际描绘小罗伯特·唐尼。 此外,SD 2.1 的皮肤纹理甚至比 SD 1.5 更好。
艺术风格
不幸的是,SD 2.1 描绘特定艺术家风格的能力显然仍然达不到 SD 1.5。下面我们再次看到使用相同设置创建的图像,除了用于创建它们的模型。这些图像旨在捕捉格雷格·鲁特科夫斯基(Greg Rutkowski)的风格。

prompt: "A monster fighting a hero by greg rutkowski, romanticism, cinematic lighting, hyperdetailed, 8 k realistic, global illumination, radiant light, trending on artstation, digital art"
size: 512x512
guidance scale: 9
steps: 50
seed: 158
sampler: DPM-Solver++
negative prompt: "ugly, tiling, poorly drawn hands, poorly drawn feet, poorly drawn face, out of frame, mutation, mutated, extra limbs, extra legs, extra arms, disfigured, deformed, cross-eye, body out of frame, blurry, bad art, bad anatomy, blurred, text, watermark, grainy"
正如我们所看到的,Stable Diffusion 1.5 在这方面仍然占据着至高无上的地位。
常规图像
我们重复上一节中关于普通提示与“增强”提示的实验,再次仅更改模型版本。

"Original" prompt: "a cute rabbit"
"Augmented" prompt: "a cute rabbit, cinematic lighting, hyperdetailed, 8 k realistic, global illumination, radiant light, frostbite 3 engine, cryengine, trending on artstation, digital art, fantasy background"
size: 512x512
guidance scale: 9
steps: 50
seed: 119
sampler: DPM-Solver++
negative prompt: "ugly, tiling, out of frame, deformed, blurry, bad art, blurred, watermark, grainy"
正如我们所看到的,2.1 的“原始”纹理比 2.0 有所改进。2.1 的“增强”图像比 2.0 的更具风格化,但总体上非常相似。
结论
虽然这些实验肯定不是严格或详尽的,但它们提供了一些关于 SD 1 和 SD 2 的相对性能的见解。
相关文章:
【AI绘画教程】Stable Diffusion 1.5 vs 2
在本文中,我们将总结稳定扩散 1 与稳定扩散 2 辩论中的所有要点。我们将在第一部分中查看这些差异存在的实际原因,但如果您想直接了解实际差异,您可以跳下否定提示部分。让我们开始吧! Stable Diffusion 2.1 发布与1.5相比&#x…...

纯前端小游戏,4096小游戏,有音效,Html5,可学习使用
// 游戏开始运行create: function(){this.fieldArray [];this.fieldGroup this.add.group();this.score 0;//4096 增加得分this.bestScore localStorage.getItem(gameOptions.localStorageName) null ? 0 : localStorage.getItem(gameOptions.localStorageName);for(var …...

ROS、pix4、gazebo、qgc仿真ubuntu20.04
一、ubuntu、ros安装教程比较多,此文章不做详细讲解。该文章基于ubuntu20.04系统。 pix4参考地址:https://docs.px4.io/main/zh/index.html 二、安装pix4 1. git clone https://github.com/PX4/PX4-Autopilot.git --recursive 2. bash ./PX4-Autopilot…...

qt 国际化语言,英文和中文切换
1、把需要翻译转换的内用用tr()包含,比如: label->setText("hello word"); 2、在 .pro 文件中添加 TRANSLATIONS lang_en.ts \ lang_zn.ts 3、利用lupdate 工具提取…...

机器学习入门【经典的CIFAR10分类】
模型 神经网络采用下图 我使用之后发现迭代多了之后一直最高是正确率65%左右,然后我自己添加了一些Relu激活函数和正则化,现在正确率可以有80%左右。 模型代码 import torch from torch import nnclass YmModel(nn.Module):def __init__(self):super(…...

01 安装
安装和卸载中,用户全部切换为root,一旦安装,普通用户也能使用 初期不进行用户管理,全部用root进行,使用mysql语句 1. 卸载内置环境 检查是否有mariadb存在,存在走a部分卸载 ps axj | grep mysql ps ajx |…...

AI 模型本地推理 - YYPOLOE - Python - Windows - GPU - 吸烟检测(目标检测)- 有配套资源直接上手实现
Python 运行 - GPU 推理 - windows 环境准备python 代码 环境准备 FastDeploy预编译库下载 conda config --add channels conda-forge && conda install cudatoolkit11.2 cudnn8.2 pip install fastdeploy_gpu_python-0.0.0-cp38-cp38-win_amd64.whlpython 代码 impo…...

全国媒体邀约,主流媒体到场出席采访报道
传媒如春雨,润物细无声,大家好,我是51媒体网胡老师。 全国媒体邀约,确保主流媒体到场出席采访报道,可以带来一系列的好处,这些好处不仅能够增强活动的可见度,还能对品牌或组织的长期形象产生积…...

计算机视觉8 图像增广
图像增广(image augmentation)是通过对训练图像进行一系列随机改变,从而产生相似但又不同的训练样本的技术。 图像增广有以下两个主要作用: 扩大训练数据集的规模;随机改变训练样本可以降低模型对某些属性的依赖&#…...
Transformer中的自注意力是怎么实现的?
在Transformer模型中,自注意力(Self-Attention)是核心组件,用于捕捉输入序列中不同位置之间的关系。自注意力机制通过计算每个标记与其他所有标记之间的注意力权重,然后根据这些权重对输入序列进行加权求和,…...
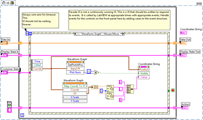
LabVIEW鼠标悬停在波形图上的曲线来自动显示相应点的坐标
步骤 创建事件结构: 打开LabVIEW,创建一个新的VI。 在前面板上添加一个Waveform Graph控件。 在后面板上添加一个While Loop和一个事件结构(Event Structure)。 配置事件结构,选择Waveform Graph作为事件源…...

操作系统发展简史(Unix/Linux 篇 + DOS/Windows 篇)+ Mac 与 Microsoft 之风云争霸
操作系统发展简史(Unix/Linux 篇) 说到操作系统,大家都不会陌生。我们天天都在接触操作系统 —— 用台式机或笔记本电脑,使用的是 windows 和 macOS 系统;用手机、平板电脑,则是 android(安卓&…...

钡铼分布式 IO 系统 OPC UA边缘计算耦合器BL205
深圳钡铼技术推出的BL205耦合器支持OPC UA Server功能,以服务器形式对外提供数据。符合IEC 62541工业自动化统一架构通讯标准,数据可以选择加密(X.509证书)、身份验证方式传送。 安全策略支持basic128rsa15、basic256、basic256s…...

实现了一个心理测试的小程序,微信小程序学习使用问题总结
1. 如何在跳转页面中传递参数 ,在 onLoad 方法中通过 options 接收 2. radio 如何获取选中的值? bindchange 方法 参数e, e.detail.value 。 如果想要获取其他属性,使用data-xx 指定,然后 e.target.dataset.xx 获取。 3. 不刷…...

vue是如何进行监听数据变化的?vue2和vue3分别是什么?vue3为什么要更换?
Vue如何进行监听数据变化的? Vue.js 通过其响应式系统来监听数据变化。这个系统允许你声明式地将数据和 DOM 绑定,一旦数据发生变化,相关的 DOM 将自动更新。Vue 使用以下机制来实现数据的监听和响应: 响应式数据:在 …...

数据结构day3
一、思维导图 二、 #include "seqlist.h"#include<myhead.h> int main(int argc, const char *argv[]) {//创建一个顺序表SeqListPtr L list_create();if(NULL L){return -1;}//调用添加函数list_add(L,123);list_add(L,435);list_add(L,856);list_add(L,65…...

免费的数字孪生平台助力产业创新,让新质生产力概念有据可依
关于新质生产力的概念,在如今传统企业现代化发展中被反复提及。 那到底什么是新质生产力?它与哪些行业存在联系,我们又该使用什么工具来加快新质生产力的发展呢?今天我将介绍一款为发展新质生产力而量身定做的数字孪生工具。 新…...

mtsys2 编译 qemu 记录
参考链接 下载 MSYS2 MSYS2 MSYS2 换源 进入目录\msys64\etc\pacman.d, 在文件mirrorlist.msys的前面插入 Server http://mirrors.ustc.edu.cn/msys2/msys/$arch在文件mirrorlist.mingw32的前面插入 Server http://mirrors.ustc.edu.cn/msys2/mingw/i686在…...

【Python数据分析】数据分析三剑客:NumPy、SciPy、Matplotlib中常用操作汇总
文章目录 NumPy常见操作汇总SciPy常见操作汇总Matplotlib常见操作汇总官方文档链接NumPy常见操作汇总 在Python的NumPy库中,有许多常用的知识点,这里列出了一些核心功能和常见操作: 类别函数或特性描述基础操作np.array创建数组np.shape获取数组形状np.dtype查看数组数据类…...

STM32智能家居电力管理系统教程
目录 引言环境准备智能家居电力管理系统基础代码实现:实现智能家居电力管理系统 4.1 数据采集模块 4.2 数据处理与控制模块 4.3 通信与网络系统实现 4.4 用户界面与数据可视化应用场景:电力管理与优化问题解决方案与优化收尾与总结 1. 引言 智能家居电…...
4.0内存数据滞留Bug分析与临时解决方案)
串口调试助手(CM野人版)4.0内存数据滞留Bug分析与临时解决方案
1. 串口调试助手(CM野人版)4.0内存数据滞留Bug详解 最近在嵌入式开发圈里,不少同行都在讨论CM野人版串口调试助手4.0的一个奇怪现象。我自己在做STM32项目时也遇到了同样的问题:明明已经修改了程序代码,重新烧录后串口输出的却还是旧数据。刚…...

手把手教你用Simulink实现逆变器dq解耦控制:含FFT分析模块搭建教程
从零构建逆变器dq解耦控制模型:Simulink实战与FFT分析全解析 在电力电子领域,逆变器的控制技术一直是工程师们关注的焦点。特别是对于新能源发电、电机驱动等应用场景,如何实现精准的电流控制直接关系到系统性能和效率。dq解耦控制作为一种经…...

从NASA Earthdata获取ASTER L2地表温度数据的完整实战指南
1. 从零开始:NASA Earthdata账号注册与准备 第一次接触遥感数据下载的朋友可能会觉得有点懵,但别担心,我刚开始也是这样。NASA Earthdata这个平台其实对科研人员非常友好,只是需要掌握几个关键步骤。先说账号注册,这就…...

SolidWorks2021 Toolbox标准件库实战:从零配置到高效拖放的完整指南
SolidWorks 2021 Toolbox标准件库全流程实战:从基础配置到企业级应用 第一次打开SolidWorks的设计库时,很多工程师都会被Toolbox中琳琅满目的标准件震撼到——从GB螺栓到ANSI轴承,几乎囊括了机械设计中的所有标准件。但真正要用好这个"百…...

windows操作系统上的Java版更新
如何安装 JDK 17 1. 下载 JDK 17 访问 Oracle JDK 17 下载页面 或使用开源的 Adoptium (Eclipse Temurin)。 选择与您操作系统匹配的安装包(Windows x64 MSI 或压缩包)。 2. 安装并配置环境变量 以 Windows 为例: 运行安装程序ÿ…...

CLIP-GmP-ViT-L-14环境部署:Ubuntu+Python3+Gradio一站式配置指南
CLIP-GmP-ViT-L-14环境部署:UbuntuPython3Gradio一站式配置指南 1. 项目介绍 CLIP-GmP-ViT-L-14是一个经过几何参数化(GmP)微调的CLIP模型,在ImageNet和ObjectNet数据集上能达到约90%的准确率。这个强大的视觉-语言模型可以帮助你实现: 计…...

TikTok风控核心:X-Gorgon协议算法逆向与变种RC4的魔改细节揭秘
TikTok风控体系深度解析:X-Gorgon协议与魔改RC4算法实战 在移动互联网安全攻防领域,应用层协议逆向工程始终是技术对抗的前沿阵地。本文将深入剖析TikTok风控体系中的核心组件X-Gorgon协议,重点解密其基于RC4算法的深度定制化改造方案。不同于…...

Linux OOM Killer实战解析:从日志分析到问题定位
1. 当你的Linux服务器突然“发疯”:OOM Killer登场 不知道你有没有遇到过这种情况:服务器上跑得好好的一个服务,突然就没了,查日志发现进程被系统“杀”了,留下一脸懵的你。或者,你的嵌入式设备在长时间运行…...

Qwen2-VL-2B-Instruct入门教程:3步完成开源多模态模型GPU部署
Qwen2-VL-2B-Instruct入门教程:3步完成开源多模态模型GPU部署 想试试最近挺火的开源多模态模型,但被复杂的部署环境劝退?看着别人用AI模型分析图片、生成描述,自己却卡在第一步?别担心,今天咱们就来手把手…...
【独家原创】基于(蜜獾算法)HBA-Transformer单变量时序预测(单输入单输出) Matlab代码
✅作者简介:热爱科研的Matlab仿真开发者,擅长数据处理、建模仿真、程序设计、完整代码获取、论文复现及科研仿真。🍎 往期回顾关注个人主页:Matlab科研工作室🍊个人信条:格物致知,完整Matlab代码及仿真咨询…...