【Python学习笔记】:Python爬取音频
【Python学习笔记】:Python爬取音频
背景前摇(省流可以不看):
人工智能公司实习,好奇技术老师训练语音模型的过程,遂请教,得知训练数据集来源于爬取某网页的音频。
很久以前看B站@同济子豪兄的《两天搞定图像识别毕业设计》系列,见识到了(祖传代码)爬虫爬取大量图片制作训练数据集的能力,然后我就想到,我之前学的BeautifulSoup和Scrapy都是爬网页文本的,我还从来没有写代码成功且专门爬过视频和图片的经验,那正好学一下,以后没准也可以拿来做自己的数据集,这次就先搞定音频的爬取吧。
原理讲解这部分,我认为下面这个视频无懈可击——言简意赅,简明扼要,时长感人,堪称吾辈楷模!!
【python】几分钟教你如何用python爬取音频数据:
https://www.bilibili.com/video/BV1mL4y1N7eV/?spm_id_from=333.1007.top_right_bar_window_custom_collection.content.click&vd_source=cdfd0a0810bcc0bcdbcf373dafdf6a82
传送门












网址后缀只有mp3

————————————————————————————————
原理明白了,下面进入实操细节:我承认我选这个教程的很大原因,是被“突破网站反爬”几个字吸引了。
突破网站反爬-制作简易的音乐播放器【Python】:https://www.bilibili.com/list/watchlater?oid=1556173520&bvid=BV1e1421b73k&spm_id_from=333.1007.top_right_bar_window_view_later.content.click
传送门
老师这个清晰的板书风格,爱了。


意外收获找个歌曲的宝藏网站一枚:歌曲宝,能在线听也能下载
(说真的,感觉有这网站在都不用劳动爬虫大驾,笑死)
https://www.gequbao.com/
传送门————————————————————————————————
思路梳理:




————————————————————————————————
第一部分,单首歌曲采集:
F12/右键——检查,选择”网络“模块,然后点击页面上的刷新按钮,让网页数据重新加载出来。

右边示范的这个链接还是歌曲本身:

下面这个play_url就是我们需要的歌曲播放链接了:
 这个有点难点到,先点play_url下面的数据内容,然后再选Headers。
这个有点难点到,先点play_url下面的数据内容,然后再选Headers。

然后就可以看到数据的标头了——可以得知请求网站,请求方法和请求参数等等都可看到。

数据包地址Request URL: https://www.gequbao.com/api/play_url?id=402856&json=1

————————————————————————————————
思路分析清楚后,就该到代码实践步骤了:


主要使用的是请求标头里面的参数,比如这个User-Agent:
user-agent: Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36
插入代码后要注意写成字典形式:

# 模拟浏览器
headers = {#User-Agent 用户代理,表示浏览器基本身份信息'User-Agent' :'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36'
}

# 请求网址
url = 'https://www.gequbao.com/api/play_url?id=402856&json=1'


————————————————————————————————
经过以上步骤,可以成功获取一个格式类似json的结果:

#导入数据请求模块
import requests'''发送请求'''
# 模拟浏览器
headers = {#User-Agent 用户代理,表示浏览器基本身份信息'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36'
}
# 请求网址
url = 'https://www.gequbao.com/api/play_url?id=402856&json=1'
# 发送请求
response = requests.get(url=url, headers=headers)'''获取数据'''
#获取响应json数据——字典数据
json_data = response.json()
print(json_data)
输出:
{'code': 1, 'data': {'url': 'https://sy-sycdn.kuwo.cn/edde772eaab20af3f141ec9f2561df44/66912c2a/resource/n2/70/55/756351052.mp3?bitrate$128&from=vip'}, 'msg': '操作成功'}
通过键值对取值的方式,一层一层获得歌曲的播放链接:

'''获取数据'''
#获取响应json数据——字典数据
json_data = response.json()
'''解析数据'''
#提取歌曲链接(键值对取值)
play_url = json_data['data']['url']
print(json_data)
print(play_url)
 ————————————————————————————————
————————————————————————————————
下一步是保存数据,现在我们拿到的只是一个链接地址,要想保存到本地,要向这个链接发出请求获取音频内容。
写入数据这部分要用到os这个包,并且写之前要判断是否存在目标路径,如果没有的话会报错。

UP老师为了直观省事(毕竟这个程序很简单)直接指定文件夹的名字并且把存在与否的逻辑判断放在了最开头,但我见的更多的写法是和文件操作放在一起写,比如执行读写操作之前判断一下有无此目录,如果没有的话再建立。

#导入数据请求模块
import requests
#导入文件操作模块
import os'''自动创建保存音频的文件夹'''
file = 'music'
#判断文件夹是否存在
if not os.path.exists(file):#创建文件夹os.mkdir(file)'''发送请求'''
# 模拟浏览器
headers = {#User-Agent 用户代理,表示浏览器基本身份信息music'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36'
}
# 请求网址
url = 'https://www.gequbao.com/api/play_url?id=402856&json=1'
# 发送请求
response = requests.get(url=url, headers=headers)'''获取数据'''
#获取响应json数据——字典数据
json_data = response.json()
'''解析数据'''
#提取歌曲链接(键值对取值)
play_url = json_data['data']['url']
print('json_data = ',json_data)
print('play_url = ',play_url)
'''保存数据'''
#对于音频链接发送请求,获取音频内容
music_content = requests.get(url = play_url, headers = headers).content
#数据保存
with open('music\\晴天.mp3', mode = 'wb') as f:#写入数据f.write(music_content)执行完这一步以后,打开本地文件夹可以看到《晴天》这首歌已经顺利存到本地了,并且点击可以电脑上播放:


到这里单首歌曲的采集就结束了,可以说是给了我很大信心,但我还不够满意,因为要做人工智能音频数据集的话需要大量爬取音频数据,之前问过做分布式Python的技术老师用的是Scrapy,但我一下子没找到用Scrapy或者其他框架大规模深度爬取数据的好例子,先把手上这个学完吧。
截至第一步的完整代码内容:
#导入数据请求模块
import requests
#导入文件操作模块
import os'''自动创建保存音频的文件夹'''
file = 'music'
#判断文件夹是否存在
if not os.path.exists(file):#创建文件夹os.mkdir(file)'''发送请求'''
# 模拟浏览器
headers = {#User-Agent 用户代理,表示浏览器基本身份信息music'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36'
}
# 请求网址
url = 'https://www.gequbao.com/api/play_url?id=402856&json=1'
# 发送请求
response = requests.get(url=url, headers=headers)'''获取数据'''
#获取响应json数据——字典数据
json_data = response.json()
'''解析数据'''
#提取歌曲链接(键值对取值)
play_url = json_data['data']['url']
print('json_data = ',json_data)
print('play_url = ',play_url)
'''保存数据'''
#对于音频链接发送请求,获取音频内容
music_content = requests.get(url = play_url, headers = headers).content
#数据保存
with open('music\\晴天.mp3', mode = 'wb') as f:#写入数据f.write(music_content)————————————————————————————————
第二部分:搜索下载:
老师讲到这部分已经有点批量采集的意思了,要分析链接的变化规律,要说这个我可就不困了。
选择另一首歌曲《稻香》,如法炮制,播放歌曲,刷新检查界面的Network下属Media栏,一样的办法找到url。(如果发现没有歌曲的链接出现的话,应该是没有播放歌曲)


正好老师的视频也在讲这个播放一下出链接的解决办法,甚至还让不出来就拉进度条,哈哈:

再故技重施找链接:

通过对比,发现不同的歌曲主要是id不同。只要能把所有的歌曲ID都拿到,那就可以采集全部的歌曲。(好耶!音频训练数据集不是梦?!)
————————————————————————————————

那么关键的id该怎么找呢?老师告诉我们,和浏览器上方网址导航栏里面是一样的:

而导航栏这个链接,是搜索出的集合页面“下载”按钮点进来的:

在搜索页面搜一下单首歌曲的id:


发现这一页歌名,作者,id都有:

那么要抓取的请求网址自然也是这个页面的Request URL了:

Request URL: https://www.gequbao.com/s/%E5%91%A8%E6%9D%B0%E4%BC%A6


————————————————————————————————
老师的总结:三种获取内容的方式



前面我们根据链接直接下载歌曲文件的时候,就用的content方法,直接获取歌曲的二进制文件并保存。


最开始获取歌曲链接的时候就是返回的json格式:
json_data = {'code': 1, 'data': {'url': 'https://sy-sycdn.kuwo.cn/6dafd418ad3ba5d48a41948554b060df/669147fa/resource/n2/70/55/756351052.mp3?bitrate$128&from=vip'}, 'msg': '操作成功'
(另外提一句,我实习做内容安全方向的AI训练数据标注师的时候,每天审核的文本训练集就是json文件,所有数据都有整齐划一的格式,主题、回答什么的排得清清楚楚,甚至还是放在VSCode里打开删改。然后根据技术老师的答疑这些训练数据很多也是爬虫得到的,所以response.json()在文本数据集制作应该会很常用,但如果是训练语音模型、图像识别模型的话,应该response.content会更吃香。)
————————————————————————————————
具体选择用哪种方法呢?要根据获取的目标网页内容决定:
1.这种网页前端,HTML的格式就用获取文本response.text

2.这种花括号包起来的用response.json()

3.二进制音频/视频/图片/文件链接,用response.content

保存代码不是固定的,要看保存成什么样子。
————————————————————————————————




切到元素分栏,鼠标选择找到CSS标签:


看一下查到的84条row标签,发现首尾几条代表的并不是我们想要的歌曲,所以要对返回的列表做切片。
————————————————————————————————
找到a标签并且提取歌名文字内容以后,发现歌名的后面还跟着很多空格:

使用**strip()**方法,去掉歌名左右两边的空格。
 ————————————————————————————————
————————————————————————————————
提取歌曲id要注意,id并不是文字内容,而是标签里面的属性,要用 attr(属性名称) 来获取。

这块是有一点绕,一会是文字一会是属性的,对HTML比较熟的看起来要容易一些,或者对着老师的教程多看几遍,自己多尝试,不懂的问问Kimi。


歌手也如法炮制——找到标签,提取文本信息:

将之前请求网址的格式更换为通用匹配id的形式:

保存的格式也换成歌名和歌手通用的形式:

————————————————————————————————
批量采集的思路捋一捋:先通过单首歌曲的链接和浏览器网址对比,发现每首歌曲有id作为唯一辨识符,那么只要知道所有id,就可以爬取所有歌曲。
(我想如果对网页很熟了,知道要找歌曲id来下载,应该可以直接进行批量爬取,不需要再拿单首歌曲测试)
于是就去搜索页面这种有大量id的网页,通过检查HTML代码的方法,找到了要薅羊毛的这个大集合目标网址的HTML代码,然后写爬虫获取网页源代码,通过CSS解析出当中隐藏的一大堆歌名、id等信息,最后再拿这一大堆id组合成完整歌曲链接,去爬想要的一大堆歌曲并且保存到本地。
————————————————————————————————
不知道为什么,我下着下着就报了一个bug,看原网页这也不是当前目录的最后一首歌(而且似乎也不是按顺序下载的)。


仔细看老师的下载列表,跟我一样也是到这首歌就停了。

询问了一下Kimi,我感觉可能是有的歌曲解析失败无法提供播放链接造成的,之前在这个网站试着搜了一些想听的歌,结果有好几首无法播放,说《解析失败》。

加上Kimi提供的这段代码以后,确实程序容错性变高了,下载到本地的歌曲明显多了,也不会因为中间出问题而中断。

而且我们还能看到,出bug的是这首《霍元甲》:

这首歌到网站里面点开发现是能正常播放的,那就不是音源找不到的问题,我们把错误给Kimi看一下——原来是歌曲名太刁钻了。


按照Kimi的提示改一下:

但我试过以后还是报这个刁钻古怪的问题……看网页源代码也看不出bug

那看来是不得不使用Kimi建议的另一个方法——清理一下文件名了:

这次奏效了!成功把《霍元甲》这首歌爬下来了,而且爬取效果比我想得要好,甚至电影题目都还在!!


这段代码成功顺利跑完了爬取流程,再没有报错!起立欢呼!!

#导入数据请求模块
import requests
#导入文件操作模块
import os
#导入数据解析模块
import parsel
import re
def clean_filename(filename):# 替换文件名中的特殊字符为下划线return re.sub(r'[<>:"/\\|?*\r\n]', '_', filename)'''自动创建保存音频的文件夹'''
file = 'music'
#判断文件夹是否存在
if not os.path.exists(file):#创建文件夹os.mkdir(file)'''发送请求'''
# 模拟浏览器
headers = {#User-Agent 用户代理,表示浏览器基本身份信息music'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36'
}
#搜索网址
link = 'https://www.gequbao.com/s/%E5%91%A8%E6%9D%B0%E4%BC%A6'
# 发送请求
link_response = requests.get(url=link, headers=headers)
#获取响应文本数据
html = link_response.text
'''解析数据'''
#把html字符串数据转换为可解析对象
selector = parsel.Selector(html)
#第一次提取,提取所有歌曲信息所在div标签类名row
rows = selector.css('.row')[2:-1]
#for循环遍历,提取列表里面元素
for row in rows:'''提取每一条歌曲具体信息'''#提取歌名SongName = clean_filename(row.css('a.text-primary::text').get().strip())#提取idSongId = row.css('a.text-primary::attr(href)').get().split('/')[-1]#提取歌手singer = row.css('.text-success::text').get().strip()print(SongName, SongId, singer)# 请求网址url = f'https://www.gequbao.com/api/play_url?id={SongId}&json=1'# 发送请求response = requests.get(url=url, headers=headers)# 检查响应状态码if response.status_code == 200:try: '''获取数据'''# 尝试获取响应json数据json_data = response.json()print('json_data = ', json_data)except ValueError:# 如果解析JSON失败,打印原始响应文本print('Failed to parse JSON from response text:')print(response.text)else:print('Failed to retrieve data, status code:', response.status_code)'''解析数据'''#提取歌曲链接(键值对取值)play_url = json_data['data']['url']print('json_data = ',json_data)print('play_url = ',play_url)'''保存数据'''#对于音频链接发送请求,获取音频内容music_content = requests.get(url = play_url, headers = headers).content#数据保存# 使用原始字符串来避免转义字符问题with open(f'music\\{SongName}-{singer}.mp3', mode='wb') as f:#写入数据f.write(music_content)————————————————————————————————————————————
接下来就进入第三部分:搜索歌曲
老师使用了一个比较陌生的新库prettytable,这会打印出很整齐的表格:
(操作过程比较零碎,要多看慢慢跟)
这个prettytable我在命令行里装了好几回,明明都requirements satisfied了,一跑还是报没有这个module,在jupyter里面单独又装了一次,这回正常了。


(老师给的建议是最好把这块代码重构写成函数,不然很麻烦。)
能实现输入汉字找到对应歌曲的原因我猜测应该是和这个网页链接有关,能匹配上歌曲的搜索界面网页关键词,然后获取这个网页的HTML代码,有了歌曲id就能指哪打哪:
这次我们就可以随心所欲输入关键字和目标序号,随心所欲下载自己喜欢的歌曲啦:

搜索部分完整代码:
#导入数据请求模块
import requests
#导入文件操作模块
import os
#导入数据解析模块
import parsel
#导入制表模块
from prettytable import PrettyTable
import re
def clean_filename(filename):# 替换文件名中的特殊字符为下划线return re.sub(r'[<>:"/\\|?*\r\n]', '_', filename)'''自动创建保存音频的文件夹'''
file = 'music'
#判断文件夹是否存在
if not os.path.exists(file):#创建文件夹os.mkdir(file)'''发送请求'''
# 模拟浏览器
headers = {#User-Agent 用户代理,表示浏览器基本身份信息music'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36'
}
#输入搜索内容
key = input('请输入搜索内容:')
#搜索网址
link = f'https://www.gequbao.com/s/{key}'
# 发送请求
link_response = requests.get(url=link, headers=headers)
#获取响应文本数据
html = link_response.text
'''解析数据'''
#把html字符串数据转换为可解析对象
selector = parsel.Selector(html)
#第一次提取,提取所有歌曲信息所在div标签类名row
rows = selector.css('.row')[2:-1]#实例化对象
tb = PrettyTable()
#添加字段名
tb.field_names = ['序号', '歌名', '歌手']
#自定义变量
page = 0
#创建空列表
info_list = []#for循环遍历,提取列表里面元素
for row in rows:'''提取每一条歌曲具体信息'''#提取歌名SongName = clean_filename(row.css('a.text-primary::text').get().strip())#提取idSongId = row.css('a.text-primary::attr(href)').get().split('/')[-1]#提取歌手singer = row.css('.text-success::text').get().strip()#print(SongName, SongId, singer)#添加数据存在字典中dit = {'歌名':SongName,'歌手':singer,'ID':SongId,}#给info_list添加元素info_list.append(dit)#添加内容tb.add_row([page, SongName, singer])page += 1print(tb)
num = input('请输入你要下载的歌曲序号:')
#获取歌曲ID
music_id = info_list[int(num)]['ID']# 请求网址
url = f'https://www.gequbao.com/api/play_url?id={music_id}&json=1'
# 发送请求
response = requests.get(url=url, headers=headers)# 检查响应状态码
if response.status_code == 200:try: '''获取数据'''# 尝试获取响应json数据json_data = response.json()print('json_data = ', json_data)except ValueError:# 如果解析JSON失败,打印原始响应文本print('Failed to parse JSON from response text:')print(response.text)
else:print('Failed to retrieve data, status code:', response.status_code)'''解析数据'''
#提取歌曲链接(键值对取值)
play_url = json_data['data']['url']
print('json_data = ',json_data)
print('play_url = ',play_url)
'''保存数据'''
#对于音频链接发送请求,获取音频内容
music_content = requests.get(url = play_url, headers = headers).content
#数据保存
# 使用原始字符串来避免转义字符问题
with open(f'music\\{info_list[int(num)]["歌名"]}-{info_list[int(num)]["歌手"]}.mp3', mode='wb') as f:#写入数据f.write(music_content)
效果如图所示:

————————————————————————————————————————————
然后我想试着爬取一个某知名的有声书网站,但发现很难搜到搜索界面的Request URL。


为了解决这个问题我也查了一些教程:
Python爬虫实战案例之爬取喜马拉雅音频数据详解:https://www.jb51.net/article/201564.htm
传送门
在观看老师的操作,和我自己的操作结果对比发现,现在的网址跟以前有些不一样了。

老师的视频是23年上传的,看下面截图,他找到的播放链接和上面歌曲宝一样,只有id不同。

但等我真正自己(今天是2024年7月15日)去找的时候,发现现在链接大不一样了:

Request URL: https://a.xmcdn.com/download/1.0.0/group30/M02/3F/2A/wKgJXlmBkw2zg0LjAKntzSZLubI803-aacv2-48K.m4a?sign=132430e114a56804799c6cc645b6d251&buy_key=www2_e039a2bf-161311236×tamp=1721007591951000&token=8248&duration=1377
现在的链接看起来要复杂的多,变化也更多,不仅仅是一个简单的id替换就能搞定的。
然后问了一下Kimi,发现可能用到了动态生成:

目前我还只知道怎么爬简单的换id的网址,这种动态的问题对我来说有点太复杂了,不过可以作为以后一个进阶的学习方向。
本次我跟着视频教程写的代码也会发到CSDN资源库上,有需要的读者可以下载:

————————————————————————————————————————————
一些搜索过程中遇到的其他好帖子也发在这里一起分享出来:
解析Python爬虫常见异常及处理方法:https://zhuanlan.zhihu.com/p/650309507
添加链接描述

Python常见问题-如何爬取动态网页内容:https://www.bilibili.com/video/BV1of4y15736/?spm_id_from=333.337.search-card.all.click&vd_source=cdfd0a0810bcc0bcdbcf373dafdf6a82
添加链接描述
这个视频主要教授的是动态网页的爬取,和之前找的Media栏目不同,这次主要找的是JS和Fetch/XHR目录下的内容。
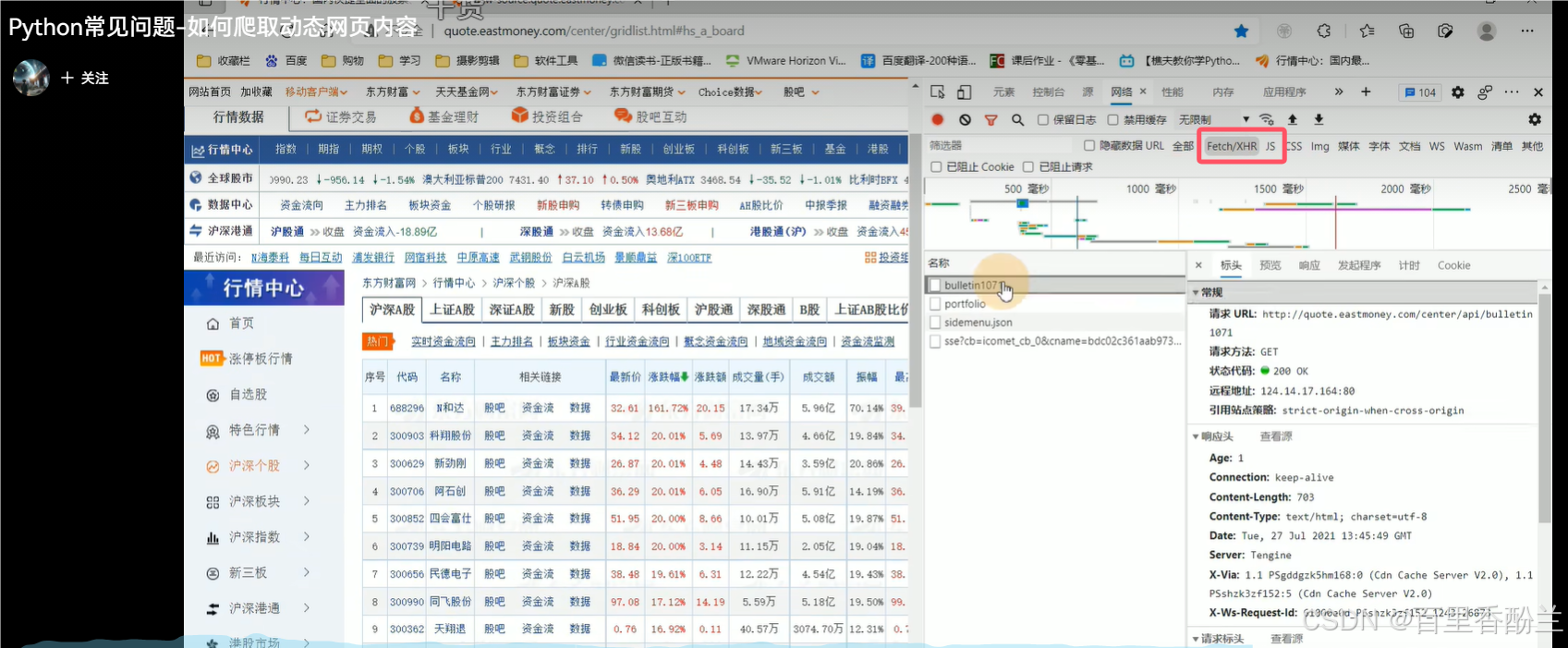
有个弹幕说的好:找数据在那个包里不难 难的是找出数据包链接的规律从而一次爬多页的数据
相关文章:
【Python学习笔记】:Python爬取音频
【Python学习笔记】:Python爬取音频 背景前摇(省流可以不看): 人工智能公司实习,好奇技术老师训练语音模型的过程,遂请教,得知训练数据集来源于爬取某网页的音频。 很久以前看B站同济子豪兄的《…...
4 C 语言控制流与循环结构的深入解读
目录 1 复杂表达式的计算过程 2 if-else语句 2.1 基本结构及示例 2.2 if-else if 多分支 2.3 嵌套 if-else 2.4 悬空的 else 2.5 注意事项 2.5.1 if 后面不要加分号 2.5.2 省略 else 2.5.3 省略 {} 2.5.4 注意点 3 while 循环 3.1 一般形式 3.2 流程特点 3.3 注…...

vue排序
onEnd 函数示例,它假设 drag.value 是一个包含多个对象(每个对象至少包含 orderNum 和 label 属性)的数组,且您希望在拖动结束后更新所有元素的 orderNum 以反映新的顺序: function onEnd(e) { // 首先,确…...

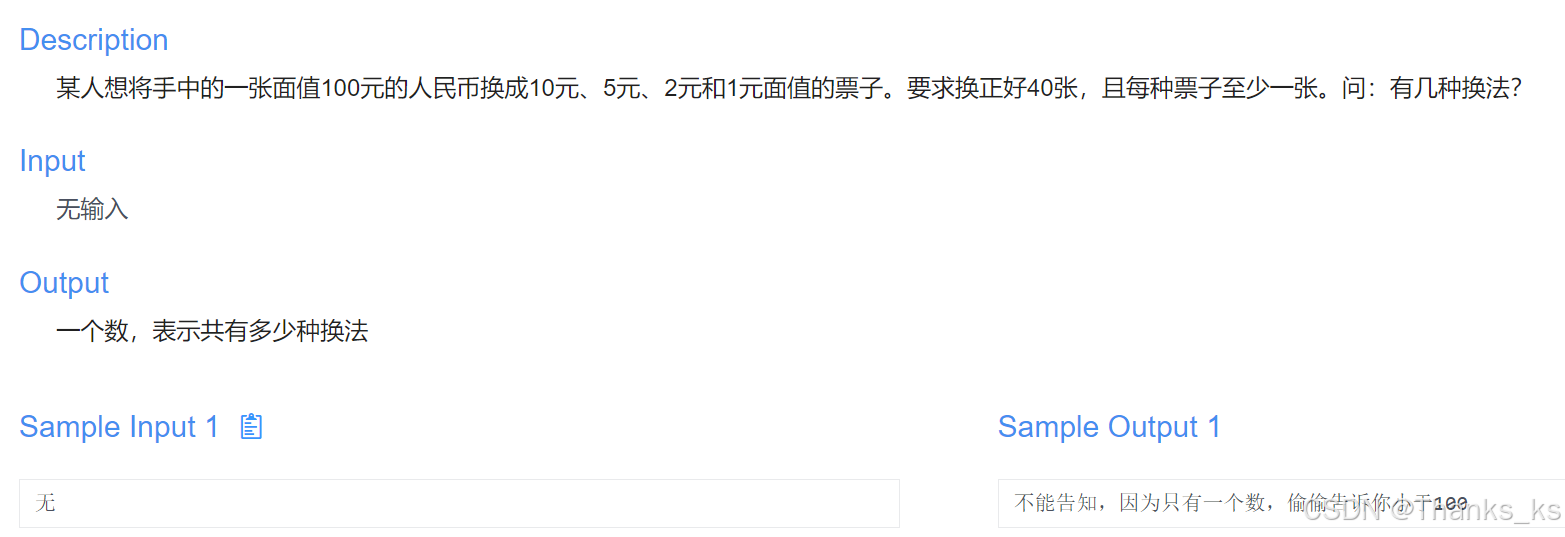
agv叉车slam定位精度测试标准化流程
相对定位精度 条件:1.5m/s最高速度;基于普通直行任务 数据采集(3个不同位置的直行任务,每个任务直行约10m,每个10次) 测量每次走过的实际距离,与每次根据定位结果算得的相对距离,两…...
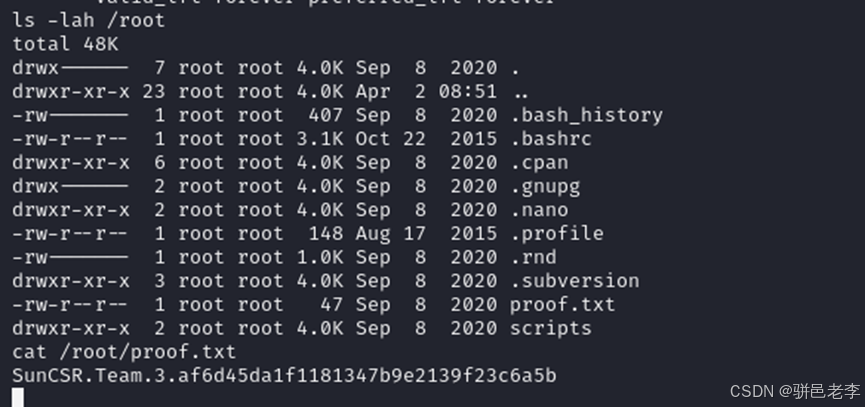
实战打靶集锦-31-monitoring
文章目录 1. 主机发现2. 端口扫描3. 服务枚举4. 服务探查4.1 ssh服务4.2 smtp服务4.3 http/https服务 5. 系统提权5.1 枚举系统信息5.2 枚举passwd文件5.3 枚举定时任务5.4 linpeas提权 6. 获取flag 靶机地址:https://download.vulnhub.com/monitoring/Monitoring.o…...
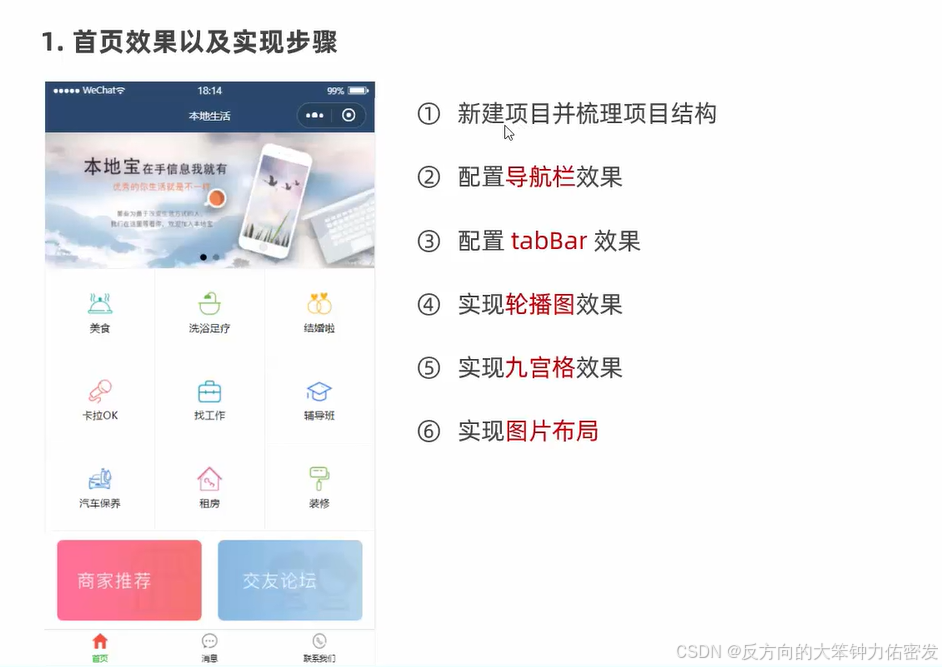
小程序-模板与配置
一、WXML模板语法 1.数据绑定 2.事件绑定 什么是事件 小程序中常用的事件 事件对象的属性列表 target和currentTarget的区别 bindtap的语法格式 在事件处理函数中为data中的数据赋值 3.事件传参与数据同步 事件传参 (以下为错误示例) 以上两者的…...

交叉编译aarch64的Qt5.12.2,附带Mysql插件编译
一、配置交叉编译工具链 1、交叉编译工具链目录 /opt/zlg/m3568-sdk-v1.0.0-ga/gcc-buildroot-9.3.0-2020.03-x86_64_aarch64-rockchip-linux-gnu/bin/aarch64-rockchip-linux-gnu-g /opt/zlg/m3568-sdk-v1.0.0-ga/gcc-buildroot-9.3.0-2020.03-x86_64_aarch64-rockchip-linu…...

好用的Ubuntu下的工具合集[持续增加]
1. 终端工具 UBUNTU下有哪些好用的终端软件? - 知乎 (zhihu.com) sudo apt install terminator...

Xcode 16 beta3 真机调试找不到 Apple Watch 的尝试解决
很多小伙伴们想用 Xcode 在 Apple Watch 真机上调试运行 App 时却发现:在 Xcode 设备管理器中压根找不到对应的 Apple Watch 设备。 大家是否已将 Apple Watch 和 Mac 都重启一万多遍了,还是束手无策。 Apple Watch not showing in XCodeApple Watch wo…...
Three.JS 使用RGBELoader和CubeTextureLoader 添加环境贴图
导入RGBELoader模块: import { RGBELoader } from "three/examples/jsm/loaders/RGBELoader.js"; 使用 addRGBEMappingk(environment, background,url) {rgbeLoader new RGBELoader();rgbeLoader.loadAsync(url).then((texture) > {//贴图模式 经纬…...

k8s logstash多管道配置
背景 采用的是标准的ELKfilebeat架构 ES版本:7.17.15 logstash版本:7.17.15 filebeat版本: 7.17.15 helm版本:7.17.3,官方地址:elastic/helm-charts 说一下为什么会想到使用多管道的原因 我们刚开始…...

【CMU博士论文】结构化推理增强大语言模型(Part 0)
问题 :语言生成和推理领域的快速发展得益于围绕大型语言模型的用户友好库的普及。这些解决方案通常依赖于Seq2Seq范式,将所有问题视为文本到文本的转换。尽管这种方法方便,但在实际部署中存在局限性:处理复杂问题时的脆弱性、缺乏…...

Odoo创建一个自定义UI视图
Odoo能够为给定的模型生成默认视图。在实践中,默认视图对于业务应用程序来说是绝对不可接受的。相反,我们至少应该以合乎逻辑的方式组织各个字段。 视图在带有Actions操作和Menus菜单的 XML 文件中定义。它们是模型的 ir.ui.view 实例。 列表视图 列表视…...
Day16_集合与迭代器
Day16-集合 Day16 集合与迭代器1.1 集合的概念 集合继承图1.2 Collection接口1、添加元素2、删除元素3、查询与获取元素不过当我们实际使用都是使用的他的子类Arraylist!!! 1.3 API演示1、演示添加2、演示删除3、演示查询与获取元素 2 Iterat…...
html2canvas + jspdf 纯前端HTML导出PDF的实现与问题
前言 这几天接到一个需求,富文本编辑器的内容不仅要展示出来,还要实现展示的内容导出pdf文件。一开始导出pdf的功能是由后端来做的,然后发现对于宽度太大的图片,导出的pdf文件里部分图片内容被遮盖了,但在前端是正常显…...

【JVM】JVM调优练习-随笔
JVM实战笔记-随笔 前言字节码如何查看字节码文件jclasslibJavapArthasArthurs监控面板Arthus查看字节码信息 内存调优内存溢出的常见场景解决内存溢出发现问题Top命令VisualVMArthas使用案例 Prometheus Grafana案例 堆内存情况对比内存泄漏的原因:代码中的内存泄漏并发请求问…...

如何解决 CentOS 7 官方 yum 仓库无法使用
一、背景介绍 编译基于 CentOS 7.6.1810 镜像的 Dockerfile 过程中,执行 yum install 指令时,遇到了错误:Could not resolve host: mirrorlist.centos.org; Unknown error。 二、原因分析 官方停止维护 CentOS 7。该系统内置的 yum.repo 所使用的域名 mirrorlist.centos.o…...

分布式唯一id的7种方案
背景 为什么需要使用分布式唯一id? 如果我们的系统是单体的,数据库是单库,那无所谓,怎么搞都行。 但是如果系统是多系统,如果id是和业务相关,由各个系统生成的情况下,那每个主机生成的主键id就…...

嵌入式物联网在医疗行业中的应用——案例分析
作者主页: 知孤云出岫 目录 嵌入式物联网在医疗行业中的应用——案例分析引言1. 智能病房监控1.1 实时患者监控系统 2. 智能医疗设备管理2.1 设备使用跟踪与维护 3. 智能药物管理3.1 药物分配与跟踪 4. 智能远程医疗4.1 远程患者监控与诊断 总结 嵌入式物联网在医疗行业中的应…...

C语言 底层逻辑详细阐述指针(一)万字讲解 #指针是什么? #指针和指针类型 #指针的解引用 #野指针 #指针的运算 #指针和数组 #二级指针 #指针数组
文章目录 前言 序1:什么是内存? 序2:地址是怎么产生的? 一、指针是什么 1、指针变量的创建及其意义: 2、指针变量的大小 二、指针的解引用 三、指针类型存在的意义 四、野指针 1、什么是野指针 2、野指针的成因 a、指…...

[2025CVPR]DeepVideo-R1:基于难度感知回归GRPO的视频强化微调框架详解
突破视频大语言模型推理瓶颈,在多个视频基准上实现SOTA性能 一、核心问题与创新亮点 1.1 GRPO在视频任务中的两大挑战 安全措施依赖问题 GRPO使用min和clip函数限制策略更新幅度,导致: 梯度抑制:当新旧策略差异过大时梯度消失收敛困难:策略无法充分优化# 传统GRPO的梯…...

HTML 语义化
目录 HTML 语义化HTML5 新特性HTML 语义化的好处语义化标签的使用场景最佳实践 HTML 语义化 HTML5 新特性 标准答案: 语义化标签: <header>:页头<nav>:导航<main>:主要内容<article>&#x…...

调用支付宝接口响应40004 SYSTEM_ERROR问题排查
在对接支付宝API的时候,遇到了一些问题,记录一下排查过程。 Body:{"datadigital_fincloud_generalsaas_face_certify_initialize_response":{"msg":"Business Failed","code":"40004","sub_msg…...

边缘计算医疗风险自查APP开发方案
核心目标:在便携设备(智能手表/家用检测仪)部署轻量化疾病预测模型,实现低延迟、隐私安全的实时健康风险评估。 一、技术架构设计 #mermaid-svg-iuNaeeLK2YoFKfao {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg…...
中的KV缓存压缩与动态稀疏注意力机制设计)
大语言模型(LLM)中的KV缓存压缩与动态稀疏注意力机制设计
随着大语言模型(LLM)参数规模的增长,推理阶段的内存占用和计算复杂度成为核心挑战。传统注意力机制的计算复杂度随序列长度呈二次方增长,而KV缓存的内存消耗可能高达数十GB(例如Llama2-7B处理100K token时需50GB内存&a…...

微软PowerBI考试 PL300-在 Power BI 中清理、转换和加载数据
微软PowerBI考试 PL300-在 Power BI 中清理、转换和加载数据 Power Query 具有大量专门帮助您清理和准备数据以供分析的功能。 您将了解如何简化复杂模型、更改数据类型、重命名对象和透视数据。 您还将了解如何分析列,以便知晓哪些列包含有价值的数据,…...

CSS设置元素的宽度根据其内容自动调整
width: fit-content 是 CSS 中的一个属性值,用于设置元素的宽度根据其内容自动调整,确保宽度刚好容纳内容而不会超出。 效果对比 默认情况(width: auto): 块级元素(如 <div>)会占满父容器…...

C++使用 new 来创建动态数组
问题: 不能使用变量定义数组大小 原因: 这是因为数组在内存中是连续存储的,编译器需要在编译阶段就确定数组的大小,以便正确地分配内存空间。如果允许使用变量来定义数组的大小,那么编译器就无法在编译时确定数组的大…...

视频行为标注工具BehaviLabel(源码+使用介绍+Windows.Exe版本)
前言: 最近在做行为检测相关的模型,用的是时空图卷积网络(STGCN),但原有kinetic-400数据集数据质量较低,需要进行细粒度的标注,同时粗略搜了下已有开源工具基本都集中于图像分割这块,…...

招商蛇口 | 执笔CID,启幕低密生活新境
作为中国城市生长的力量,招商蛇口以“美好生活承载者”为使命,深耕全球111座城市,以央企担当匠造时代理想人居。从深圳湾的开拓基因到西安高新CID的战略落子,招商蛇口始终与城市发展同频共振,以建筑诠释对土地与生活的…...