Elasticsearch:Retrievers 介绍 - Python Jupyter notebook

在今天的文章里,我是继上一篇文章 “Elasticsearch:介绍 retrievers - 搜索一切事物” 来使用一个可以在本地设置的 Elasticsearch 集群来展示 Retrievers 的使用。在本篇文章中,你将学到如下的内容:
- 从 Kaggle 下载 IMDB 数据集
- 创建两个推理服务
- 部署 ELSER
- 部署 e5-small
- 创建摄取管道
- 创建映射
- 摄取 IMDB 数据,在摄取过程中创建嵌入
- 缩小查询负载模型
- 运行示例检索器
安装
Elasticsearch 及 Kibana
如果你还没有安装好自己的 Elasticsearch 及 Kibana,请参考如下的链接来进行安装:
- 如何在 Linux,MacOS 及 Windows 上进行安装 Elasticsearch
- Kibana:如何在 Linux,MacOS 及 Windows上安装 Elastic 栈中的 Kibana
在安装的时候,我们选择 Elastic Stack 8.x 来进行安装。在首次启动 Elasticsearch 的时候,我们可以看到如下的输出:
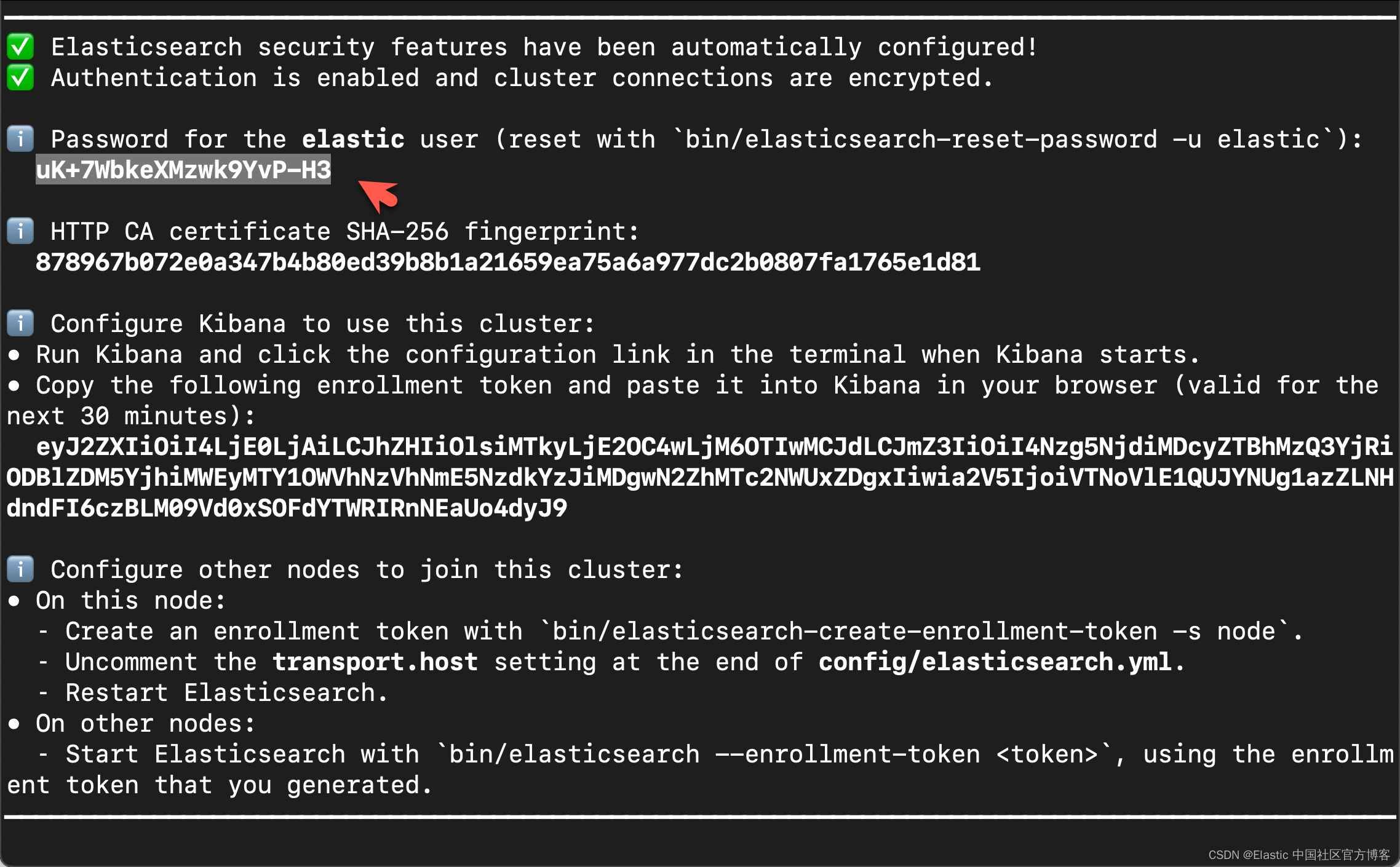
在上面,我们可以看到 elastic 超级用户的密码。我们记下它,并将在下面的代码中进行使用。
我们还可以在安装 Elasticsearch 目录中找到 Elasticsearch 的访问证书:
$ pwd
/Users/liuxg/elastic/elasticsearch-8.14.1/config/certs
$ ls
http.p12 http_ca.crt transport.p12在上面,http_ca.crt 是我们需要用来访问 Elasticsearch 的证书。
我们首先克隆已经写好的代码:
git clone https://github.com/liu-xiao-guo/elasticsearch-labs我们然后进入到该项目的根目录下:
$ pwd
/Users/liuxg/python/elasticsearch-labs/supporting-blog-content/introducing-retrievers
$ ls
retrievers_intro_notebook.ipynb如上所示,retrievers_intro_notebook.ipynb 就是我们今天想要工作的 notebook。
我们通过如下的命令来拷贝所需要的证书:
$ pwd
/Users/liuxg/python/elasticsearch-labs/supporting-blog-content/introducing-retrievers
$ cp ~/elastic/elasticsearch-8.14.1/config/certs/http_ca.crt .
$ ls
http_ca.crt retrievers_intro_notebook.ipynb安装所需要的 python 依赖包
pip3 install -qqq pandas elasticsearch python-dotenv我们可以使用如下的方法来查看 elasticsearch 的版本:
$ pip3 list | grep elasticsearch
elasticsearch 8.14.0创建环境变量
为了能够使得下面的应用顺利执行,在项目当前的目录下运行如下的命令:
export ES_ENDPOINT="localhost"
export ES_USER="elastic"
export ES_PASSWORD="uK+7WbkeXMzwk9YvP-H3"你需要根据自己的 Elasticsearch 设置进行相应的修改。
下载数据集
我们去到地址 IMDB movies dataset | Kaggle 下载数据集并解压缩。
$ pwd
/Users/liuxg/python/elasticsearch-labs/supporting-blog-content/introducing-retrievers
$ ls
archive (13).zip http_ca.crt retrievers_intro_notebook.ipynb
$ unzip archive\ \(13\).zip
Archive: archive (13).zipinflating: imdb_movies.csv
$ mkdir -p content
$ mv imdb_movies.csv content/$ tree -L 2
.
├── archive\ (13).zip
├── content
│ └── imdb_movies.csv
├── http_ca.crt
└── retrievers_intro_notebook.ipynb
如上所示,我们吧 imdb_movies.csv 文件置于当前工作目录下的 content 目录下。
代码展示
我们在当前项目的根目录下打入如下的命令:
设置
import os
import zipfile
import pandas as pd
from elasticsearch import Elasticsearch, helpers
from elasticsearch.exceptions import ConnectionTimeout
from elastic_transport import ConnectionError
from time import sleep
import time
import logging# Get the logger for 'elastic_transport.node_pool'
logger = logging.getLogger("elastic_transport.node_pool")# Set its level to ERROR
logger.setLevel(logging.ERROR)# Suppress warnings from the elastic_transport module
logging.getLogger("elastic_transport").setLevel(logging.ERROR)连接到 Elasticsearch
from dotenv import load_dotenvload_dotenv()ES_USER = os.getenv("ES_USER")
ES_PASSWORD = os.getenv("ES_PASSWORD")
ES_ENDPOINT = os.getenv("ES_ENDPOINT")
COHERE_API_KEY = os.getenv("COHERE_API_KEY")url = f"https://{ES_USER}:{ES_PASSWORD}@{ES_ENDPOINT}:9200"
print(url)es = Elasticsearch(url, ca_certs = "./http_ca.crt", verify_certs = True)
print(es.info())
如上所示,我们的客户端连接到 Elasticsearch 是成功的。
部署 ELSER 及 E5
下面的两个代码块将部署嵌入模型并自动扩展 ML 容量。
部署及启动 ELSER
from elasticsearch.exceptions import BadRequestErrortry:resp = es.options(request_timeout=5).inference.put_model(task_type="sparse_embedding",inference_id="my-elser-model",body={"service": "elser","service_settings": {"num_allocations": 64, "num_threads": 1},},)
except ConnectionTimeout:pass
except BadRequestError as e:print(e)如果你之前已经部署过 ELSER,你可能会得到一个 resource already exists 这样的错误。你可以使用如下的命令来删除之前的 inference_id。
DELETE /_inference/my-elser-model在运行完上面的命令后,需要经过一定的时间下载 ELSER 模型。这个依赖于你的网络速度。我们可以在 Kibana 中进行查看:

部署及启动 es-small
try:resp = es.inference.put_model(task_type="text_embedding",inference_id="my-e5-model",body={"service": "elasticsearch","service_settings": {"num_allocations": 8,"num_threads": 1,"model_id": ".multilingual-e5-small",},},)
except ConnectionTimeout:pass
except BadRequestError as e:print(e)在运行完上面的代码后,我们可以在 Kibana 界面中:

点击上面的 "Add trained model" 来安装 .multilingual-e5-small 模型。

我们到最后能看到这个:

整个下载及部署需要很长的时间,需要你耐心等待!
提示:如果你的机器是在 x86 架构的机器上运行的话,那么你在上面可以选择 .multilingual-e5-small_linux-x86_64 作为其 model_id。
检查模型部署状态
这将循环检查,直到 ELSER 和 e5 都已完全部署。如果你在上面已经等了足够久的话,那么下面的代码讲很快地执行。
如果需要分配额外容量来运行模型,这可能需要几分钟
from time import sleep
from elasticsearch.exceptions import ConnectionTimeoutdef wait_for_models_to_start(es, models):model_status_map = {model: False for model in models}while not all(model_status_map.values()):try:model_status = es.ml.get_trained_models_stats()except ConnectionTimeout:print("A connection timeout error occurred.")continuefor x in model_status["trained_model_stats"]:model_id = x["model_id"]# Skip this model if it's not in our list or it has already startedif model_id not in models or model_status_map[model_id]:continueif "deployment_stats" in x:if ("nodes" in x["deployment_stats"]and len(x["deployment_stats"]["nodes"]) > 0):if (x["deployment_stats"]["nodes"][0]["routing_state"]["routing_state"]== "started"):print(f"{model_id} model deployed and started")model_status_map[model_id] = Trueif not all(model_status_map.values()):sleep(0.5)models = [".elser_model_2", ".multilingual-e5-small"]
wait_for_models_to_start(es, models).elser_model_2 model deployed and started
.multilingual-e5-small model deployed and started创建索引模板并链接到摄取管道
template_body = {"index_patterns": ["imdb_movies*"],"template": {"settings": {"index": {"default_pipeline": "elser_e5_embed"}},"mappings": {"properties": {"budget_x": {"type": "double"},"country": {"type": "keyword"},"crew": {"type": "text"},"date_x": {"type": "date", "format": "MM/dd/yyyy||MM/dd/yyyy[ ]"},"genre": {"type": "keyword"},"names": {"type": "text"},"names_sparse": {"type": "sparse_vector"},"names_dense": {"type": "dense_vector"},"orig_lang": {"type": "keyword"},"orig_title": {"type": "text"},"overview": {"type": "text"},"overview_sparse": {"type": "sparse_vector"},"overview_dense": {"type": "dense_vector"},"revenue": {"type": "double"},"score": {"type": "double"},"status": {"type": "keyword"},}},},
}# Create the template
es.indices.put_index_template(name="imdb_movies", body=template_body)创建采集管道
# Define the pipeline configuration
pipeline_body = {"processors": [{"inference": {"model_id": ".multilingual-e5-small","description": "embed names with e5 to names_dense nested field","input_output": [{"input_field": "names", "output_field": "names_dense"}],}},{"inference": {"model_id": ".multilingual-e5-small","description": "embed overview with e5 to names_dense nested field","input_output": [{"input_field": "overview", "output_field": "overview_dense"}],}},{"inference": {"model_id": ".elser_model_2","description": "embed overview with .elser_model_2 to overview_sparse nested field","input_output": [{"input_field": "overview", "output_field": "overview_sparse"}],}},{"inference": {"model_id": ".elser_model_2","description": "embed names with .elser_model_2 to names_sparse nested field","input_output": [{"input_field": "names", "output_field": "names_sparse"}],}},],"on_failure": [{"append": {"field": "_source._ingest.inference_errors","value": [{"message": "{{ _ingest.on_failure_message }}","pipeline": "{{_ingest.pipeline}}","timestamp": "{{{ _ingest.timestamp }}}",}],}}],
}# Create the pipeline
es.ingest.put_pipeline(id="elser_e5_embed", body=pipeline_body)提取文档
这将
- 进行一些预处理
- 批量提取 10,178 条 IMDB 记录
- 使用 ELSER 模型为 overview 和 name 字段生成稀疏向量嵌入
- 使用 ELSER 模型为 overview 和 name 字段生成密集向量嵌入
使用上述分配设置通常需要一定的时间才能完成。这个依赖于你自己电脑的配置。
# Load CSV data into a pandas DataFrame
df = pd.read_csv("./content/imdb_movies.csv")# Replace all NaN values in DataFrame with None
df = df.where(pd.notnull(df), None)# Convert DataFrame into a list of dictionaries
# Each dictionary represents a document to be indexed
documents = df.to_dict(orient="records")# Define a function to generate actions for bulk API
def generate_bulk_actions(documents):for doc in documents:yield {"_index": "imdb_movies","_source": doc,}# Use the bulk helper to insert documents, 200 at a time
start_time = time.time()
helpers.bulk(es, generate_bulk_actions(documents), chunk_size=200)
end_time = time.time()print(f"The function took {end_time - start_time} seconds to run")我们可以在 Kibana 中进行查看:




我们需要等一定的时间来完成上面的摄取工作。值得注意的是:在上面的代码中我把 chunk_size 设置为 20。这个是为了避免 "Connection timeout" 错误。如果我们把这个值设置很大,那么摄取的时间可能过长,那么就会发生 "Connection timeout" 这样的错误。我们在批量处理时,选择比较少的文档来完成摄取工作。有关如何设置这个 timeout 的时间,我们可以参考文章 “在 Elasticsearch 中扩展 ML 推理管道:如何避免问题并解决瓶颈”。
针对我的电脑,它花费了如下的时间来完成 10,178 个文档的摄取:
The function took 1292.8102316856384 seconds to run这个将近20分钟。
缩小 ELSER 和 e5 模型
我们不需要大量的模型分配来进行测试查询,因此我们将每个模型分配缩小到 1 个
for model_id in [".elser_model_2","my-e5-model"]:result = es.perform_request("POST",f"/_ml/trained_models/{model_id}/deployment/_update",headers={"content-type": "application/json", "accept": "application/json"},body={"number_of_allocations": 1},)Retriever 测试
我们将使用搜索输入 clueless slackers 在数据集中的 overview 字段(文本或嵌入)中搜索电影
请随意将下面的 movie_search 变量更改为其他内容
movie_search = "clueless slackers"Standard - 搜索所有文本! - bm25
response = es.search(index="imdb_movies",body={"query": {"match": {"overview": movie_search}},"size": 3,"fields": ["names", "overview"],"_source": False,},
)for hit in response["hits"]["hits"]:print(f"{hit['fields']['names'][0]}\n- {hit['fields']['overview'][0]}\n") 
kNN-搜索所有密集向量!
response = es.search(index="imdb_movies",body={"retriever": {"knn": {"field": "overview_dense","query_vector_builder": {"text_embedding": {"model_id": "my-e5-model","model_text": movie_search,}},"k": 5,"num_candidates": 5,}},"size": 3,"fields": ["names", "overview"],"_source": False,},
)for hit in response["hits"]["hits"]:print(f"{hit['fields']['names'][0]}\n- {hit['fields']['overview'][0]}\n") 
text_expansion - 搜索所有稀疏向量! - elser
response = es.search(index="imdb_movies",body={"retriever": {"standard": {"query": {"text_expansion": {"overview_sparse": {"model_id": ".elser_model_2","model_text": movie_search,}}}}},"size": 3,"fields": ["names", "overview"],"_source": False,},
)for hit in response["hits"]["hits"]:print(f"{hit['fields']['names'][0]}\n- {hit['fields']['overview'][0]}\n") 
rrf — 将所有事物结合起来!
response = es.search(index="imdb_movies",body={"retriever": {"rrf": {"retrievers": [{"standard": {"query": {"term": {"overview": movie_search}}}},{"knn": {"field": "overview_dense","query_vector_builder": {"text_embedding": {"model_id": "my-e5-model","model_text": movie_search,}},"k": 5,"num_candidates": 5,}},{"standard": {"query": {"text_expansion": {"overview_sparse": {"model_id": ".elser_model_2","model_text": movie_search,}}}}},],"window_size": 5,"rank_constant": 1,}},"size": 3,"fields": ["names", "overview"],"_source": False,},
)for hit in response["hits"]["hits"]:print(f"{hit['fields']['names'][0]}\n- {hit['fields']['overview'][0]}\n") 
所有的源码可以在地址 elasticsearch-labs/supporting-blog-content/introducing-retrievers/retrievers_intro_notebook.ipynb at main · liu-xiao-guo/elasticsearch-labs · GitHub
下载。
相关文章:
Elasticsearch:Retrievers 介绍 - Python Jupyter notebook
在今天的文章里,我是继上一篇文章 “Elasticsearch:介绍 retrievers - 搜索一切事物” 来使用一个可以在本地设置的 Elasticsearch 集群来展示 Retrievers 的使用。在本篇文章中,你将学到如下的内容: 从 Kaggle 下载 IMDB 数据集…...

5 webSocket
webSockets 简介 什么是 websocket webSockets 是一种先进的技术;它可以在用户的浏览器和服务器之间打开交互式通信会话;使用此 API,您可以向服务器发送消息并接收事件驱动的响应,而无需通过轮询服务器的方式以获得响应 websocket 是一种网络通信协议,是HTML5开始提供的一种在单…...

PD芯片诱骗取电电压给后端小家电用电:LDR6328
在智能家居浪潮的推动下,小家电作为日常生活中不可或缺的一部分,其供电方式的创新与优化正逐步成为行业关注的焦点。随着快充技术的普及,特别是Power Delivery(PD)协议的广泛应用,一种新型供电模式——利用…...

深入解析Linux文件权限管理:掌握`chmod`和`chown`命令
深入解析Linux文件权限管理:掌握chmod和chown命令 深入解析Linux文件权限管理:掌握chmod和chown命令 大纲:摘要:内容: 1. 引言2. 理解文件权限3. 使用chmod命令4. 使用chown命令5. 综合应用6. 常见问题与解决方案7. 结…...

3.Implementing Controllers
Implementing Controllers 控制器提供了对应用程序行为的访问,这些行为通常通过一个服务接口来定义。控制器解释用户输入,并将其转换为由视图展示给用户的模型。Spring 以非常抽象的方式实现了控制器,使得你能够创建各种各样的控制器。 Spr…...

如何分清楚常见的 Git 分支管理策略Git Flow、GitHub Flow 和 GitLab Flow
Git Flow、GitHub Flow 和 GitLab Flow 是几种常见的 Git 分支管理策略,它们帮助开发团队更高效地管理代码库和协同开发。 Git Flow Git Flow 是一种功能强大的分支管理模型,由 Vincent Driessen 提出,适用于发布周期较长、需要严格管理发布…...

Java垃圾收集器选择与优化策略
1.垃圾收集算法有哪些,可以聊一下吗? 如何确定一个对象是垃圾? 要想进行垃圾回收,得先知道什么样的对象是垃圾。 1.1 引用计数法 对于某个对象而言,只要应用程序中持有该对象的引用,就说明该对象不是垃圾。如果一个对象没有任何指针对其引用,它就是垃圾。 弊端:如果…...

django命令
Django 的命令行工具 django-admin(或 manage.py 中的 manage 函数)提供了一系列的命令,用于执行各种管理任务。 1. check: 检查项目的 full 路径,确保没有错误配置。 2. compilemessages: 编译 .po 文件中的翻译,生…...

23种设计模式之命令模式
命令模式 1、定义 命令模式:将一个请求封装为一个对象,从而可用不同的请求对客户进行参数化,对请求排队或者记录请求日志,以及支持可撤销的操作 2、命令模式结构 Command(抽象命令类):一般是…...
)
esp8266模块(1)
1WiFi的两种模式 1AP模式:ESP8266模块充当一个无线接入点,类似于一个路由器。(如手机开热点) 2Station模式(sta):ESP8266模块作为客户端连接到一个现有的WiFi网络。(如路由器&#…...

LDR6020:重塑iPad一体式有线键盘体验的创新力量
在移动办公与娱乐日益融合的时代,iPad凭借其强大的性能和便携性,成为了众多用户不可或缺的生产力工具。然而,为了进一步提升iPad的使用体验,一款高效、便捷的键盘成为了不可或缺的配件。今天,我们要介绍的,…...
几何 9 立方贝塞尔线段)
ArcGIS Pro SDK (九)几何 9 立方贝塞尔线段
ArcGIS Pro SDK (九)几何 9 立方贝塞尔线段 文章目录 ArcGIS Pro SDK (九)几何 9 立方贝塞尔线段1 构建立方贝塞尔线段 - 从坐标2 构建立方贝塞尔线段 - 从地图点3 构造立方贝塞尔线段 - 从映射点的枚举4 立方贝塞尔线段生成器属性…...

c语言之 *指针与 **指针
*n 一级指针: &nn*n自身地址指向地址指向地址值 **s 二级指针: &ss*s**s自身地址一级指针地址一级指针指向地址一级指针指向地址值 CHILD *walk, *next, *tmp_child, **scan;next walk->next scan &walk->next; while (*scan) { …...

navicat 导入 sql 遇到的问题
错误1 [Err] 1064 - You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near SET FOREIGN_KEY_CHECKS 0;DROP TABLE IF EXISTS tmp_tables; CREATE TABLE at line 1 [Err] &…...

压缩pdf大小的方法 指定大小软件且清晰
在数字化时代,pdf文件因其良好的兼容性和稳定性,已成为文档分享的主流格式。然而,高版本的pdf文件往往体积较大,传输和存储都相对困难。本文将为您详细介绍几种简单有效的方法,帮助您减小pdf文件的大小,让您…...
PHP上门按摩专业版防东郊到家系统源码小程序
💆♀️【尊享级体验】上门按摩专业版,告别东郊到家,解锁全新放松秘籍!🏠✨ 🔥【开篇安利,告别传统束缚】🔥 亲们,是不是厌倦了忙碌生活中的疲惫感?想要享…...

从微软发iPhone,聊聊企业设备管理
今天讲个上周的旧闻,微软给员工免费发iPhone。其实上周就有很多朋友私信问我,在知乎上邀请我回答相关话题,今天就抽点时间和大家一起聊聊这事。我不想讨论太多新闻本身,而是更想聊聊事件的主要原因——微软企业设备管理࿰…...
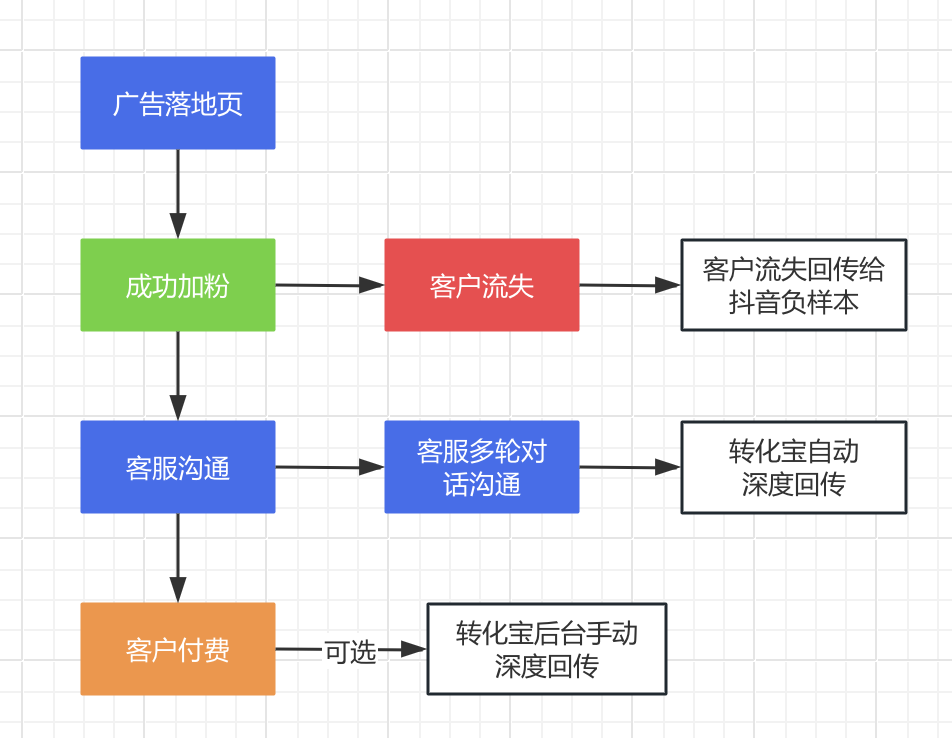
抖音/腾讯/百度ocpm深度回传如何操作?广告投放双出价的投放技巧?
要实现抖音、腾讯和百度的OCPM(Optimized Cost Per Mille)深度回传,可以通过借助第三方平台,例如(转化宝)实现广告数据精准回传,如此之外,在广告投放过程中还需要注重这些方面。 转化…...
的深入探索与使用)
DPKG(Debian / Ubuntu包管理工具)的深入探索与使用
DPKG(Debian / Ubuntu包管理工具)的深入探索与使用 在Linux世界中,特别是基于Debian及其衍生系统(如Ubuntu)的环境中,dpkg是管理Debian软件包(.deb文件)的核心工具。它不仅用于安装…...

Godot学习笔记2——GDScript变量与函数
Godot使用的编程语言是GDS,语法上与python有些类似。 一、代码编写界面 在新建的Godot项目中,点击“创建根节点”中的“其他节点”,选择“Node”。 点击场景界面右上角的绿色加号,路径处重新命名,模板选择“Empty”&…...

Zustand 状态管理库:极简而强大的解决方案
Zustand 是一个轻量级、快速和可扩展的状态管理库,特别适合 React 应用。它以简洁的 API 和高效的性能解决了 Redux 等状态管理方案中的繁琐问题。 核心优势对比 基本使用指南 1. 创建 Store // store.js import create from zustandconst useStore create((set)…...

uni-app学习笔记二十二---使用vite.config.js全局导入常用依赖
在前面的练习中,每个页面需要使用ref,onShow等生命周期钩子函数时都需要像下面这样导入 import {onMounted, ref} from "vue" 如果不想每个页面都导入,需要使用node.js命令npm安装unplugin-auto-import npm install unplugin-au…...

《Playwright:微软的自动化测试工具详解》
Playwright 简介:声明内容来自网络,将内容拼接整理出来的文档 Playwright 是微软开发的自动化测试工具,支持 Chrome、Firefox、Safari 等主流浏览器,提供多语言 API(Python、JavaScript、Java、.NET)。它的特点包括&a…...

关于iview组件中使用 table , 绑定序号分页后序号从1开始的解决方案
问题描述:iview使用table 中type: "index",分页之后 ,索引还是从1开始,试过绑定后台返回数据的id, 这种方法可行,就是后台返回数据的每个页面id都不完全是按照从1开始的升序,因此百度了下,找到了…...

苍穹外卖--缓存菜品
1.问题说明 用户端小程序展示的菜品数据都是通过查询数据库获得,如果用户端访问量比较大,数据库访问压力随之增大 2.实现思路 通过Redis来缓存菜品数据,减少数据库查询操作。 缓存逻辑分析: ①每个分类下的菜品保持一份缓存数据…...

听写流程自动化实践,轻量级教育辅助
随着智能教育工具的发展,越来越多的传统学习方式正在被数字化、自动化所优化。听写作为语文、英语等学科中重要的基础训练形式,也迎来了更高效的解决方案。 这是一款轻量但功能强大的听写辅助工具。它是基于本地词库与可选在线语音引擎构建,…...

VM虚拟机网络配置(ubuntu24桥接模式):配置静态IP
编辑-虚拟网络编辑器-更改设置 选择桥接模式,然后找到相应的网卡(可以查看自己本机的网络连接) windows连接的网络点击查看属性 编辑虚拟机设置更改网络配置,选择刚才配置的桥接模式 静态ip设置: 我用的ubuntu24桌…...

CRMEB 中 PHP 短信扩展开发:涵盖一号通、阿里云、腾讯云、创蓝
目前已有一号通短信、阿里云短信、腾讯云短信扩展 扩展入口文件 文件目录 crmeb\services\sms\Sms.php 默认驱动类型为:一号通 namespace crmeb\services\sms;use crmeb\basic\BaseManager; use crmeb\services\AccessTokenServeService; use crmeb\services\sms\…...
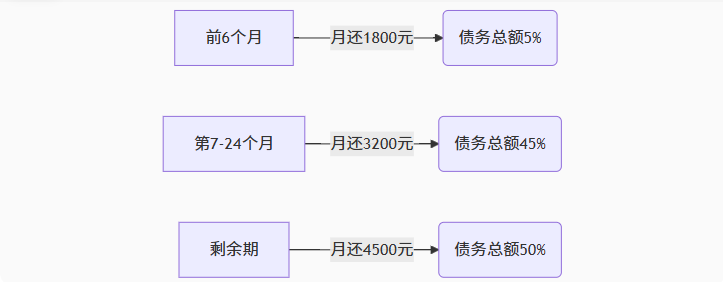
【无标题】湖北理元理律师事务所:债务优化中的生活保障与法律平衡之道
文/法律实务观察组 在债务重组领域,专业机构的核心价值不仅在于减轻债务数字,更在于帮助债务人在履行义务的同时维持基本生活尊严。湖北理元理律师事务所的服务实践表明,合法债务优化需同步实现三重平衡: 法律刚性(债…...

虚幻基础:角色旋转
能帮到你的话,就给个赞吧 😘 文章目录 移动组件使用控制器所需旋转:组件 使用 控制器旋转将旋转朝向运动:组件 使用 移动方向旋转 控制器旋转和移动旋转 缺点移动旋转:必须移动才能旋转,不移动不旋转控制器…...