昇思25天学习打卡营第18天 | 基于MindSpore的GPT2文本摘要
昇思25天学习打卡营第18天 | 基于MindSpore的GPT2文本摘要
文章目录
- 昇思25天学习打卡营第18天 | 基于MindSpore的GPT2文本摘要
- 数据集
- 创建数据集
- 数据预处理
- Tokenizer
- 模型构建
- 构建GPT2ForSummarization模型
- 动态学习率
- 模型训练
- 模型推理
- 总结
- 打卡
数据集
实验使用nlpcc2017摘要数据,内容为新闻正文及其摘要,总计50000个样本。
创建数据集
from mindnlp.utils import http_get# download dataset
url = 'https://download.mindspore.cn/toolkits/mindnlp/dataset/text_generation/nlpcc2017/train_with_summ.txt'
path = http_get(url, './')from mindspore.dataset import TextFileDataset# load dataset
dataset = TextFileDataset(str(path), shuffle=False)
dataset.get_dataset_size()
数据预处理
原始数据:
article: [CLS] article_context [SEP]
summary: [CLS] summary_context [SEP]
处理后的数据:
[CLS] article_context [SEP] summary_context [SEP]
import json
import numpy as np# preprocess dataset
def process_dataset(dataset, tokenizer, batch_size=6, max_seq_len=1024, shuffle=False):def read_map(text):data = json.loads(text.tobytes())return np.array(data['article']), np.array(data['summarization'])def merge_and_pad(article, summary):# tokenization# pad to max_seq_length, only truncate the articletokenized = tokenizer(text=article, text_pair=summary,padding='max_length', truncation='only_first', max_length=max_seq_len)return tokenized['input_ids'], tokenized['input_ids']dataset = dataset.map(read_map, 'text', ['article', 'summary'])# change column names to input_ids and labels for the following trainingdataset = dataset.map(merge_and_pad, ['article', 'summary'], ['input_ids', 'labels'])dataset = dataset.batch(batch_size)if shuffle:dataset = dataset.shuffle(batch_size)return dataset
Tokenizer
由于GPT2无中文tokenizer,使用BertTokenizer替代。
from mindnlp.transformers import BertTokenizer# We use BertTokenizer for tokenizing chinese context.
tokenizer = BertTokenizer.from_pretrained('bert-base-chinese')
len(tokenizer)train_dataset = process_dataset(train_dataset, tokenizer, batch_size=4)
模型构建
构建GPT2ForSummarization模型
from mindspore import ops
from mindnlp.transformers import GPT2LMHeadModelclass GPT2ForSummarization(GPT2LMHeadModel):def construct(self,input_ids = None,attention_mask = None,labels = None,):outputs = super().construct(input_ids=input_ids, attention_mask=attention_mask)shift_logits = outputs.logits[..., :-1, :]shift_labels = labels[..., 1:]# Flatten the tokensloss = ops.cross_entropy(shift_logits.view(-1, shift_logits.shape[-1]), shift_labels.view(-1), ignore_index=tokenizer.pad_token_id)return loss
动态学习率
from mindspore import ops
from mindspore.nn.learning_rate_schedule import LearningRateScheduleclass LinearWithWarmUp(LearningRateSchedule):"""Warmup-decay learning rate."""def __init__(self, learning_rate, num_warmup_steps, num_training_steps):super().__init__()self.learning_rate = learning_rateself.num_warmup_steps = num_warmup_stepsself.num_training_steps = num_training_stepsdef construct(self, global_step):if global_step < self.num_warmup_steps:return global_step / float(max(1, self.num_warmup_steps)) * self.learning_ratereturn ops.maximum(0.0, (self.num_training_steps - global_step) / (max(1, self.num_training_steps - self.num_warmup_steps))) * self.learning_rate
模型训练
num_epochs = 1
warmup_steps = 2000
learning_rate = 1.5e-4num_training_steps = num_epochs * train_dataset.get_dataset_size()from mindspore import nn
from mindnlp.transformers import GPT2Config, GPT2LMHeadModelconfig = GPT2Config(vocab_size=len(tokenizer))
model = GPT2ForSummarization(config)lr_scheduler = LinearWithWarmUp(learning_rate=learning_rate, num_warmup_steps=warmup_steps, num_training_steps=num_training_steps)
optimizer = nn.AdamWeightDecay(model.trainable_params(), learning_rate=lr_scheduler)from mindnlp._legacy.engine import Trainer
from mindnlp._legacy.engine.callbacks import CheckpointCallbackckpoint_cb = CheckpointCallback(save_path='checkpoint', ckpt_name='gpt2_summarization',epochs=1, keep_checkpoint_max=2)trainer = Trainer(network=model, train_dataset=train_dataset,epochs=1, optimizer=optimizer, callbacks=ckpoint_cb)
trainer.set_amp(level='O1') # 开启混合精度trainer.run(tgt_columns="labels")
模型推理
def process_test_dataset(dataset, tokenizer, batch_size=1, max_seq_len=1024, max_summary_len=100):def read_map(text):data = json.loads(text.tobytes())return np.array(data['article']), np.array(data['summarization'])def pad(article):tokenized = tokenizer(text=article, truncation=True, max_length=max_seq_len-max_summary_len)return tokenized['input_ids']dataset = dataset.map(read_map, 'text', ['article', 'summary'])dataset = dataset.map(pad, 'article', ['input_ids'])dataset = dataset.batch(batch_size)return datasettest_dataset = process_test_dataset(test_dataset, tokenizer, batch_size=1)
model = GPT2LMHeadModel.from_pretrained('./checkpoint/gpt2_summarization_epoch_0.ckpt', config=config)model.set_train(False)
model.config.eos_token_id = model.config.sep_token_id
i = 0
for (input_ids, raw_summary) in test_dataset.create_tuple_iterator():output_ids = model.generate(input_ids, max_new_tokens=50, num_beams=5, no_repeat_ngram_size=2)output_text = tokenizer.decode(output_ids[0].tolist())print(output_text)i += 1if i == 1:break
总结
这一节介绍了在MindSpore中使用GPT2LMHeadModel实现文本摘要的实验。实验使用nlpcc2017摘要数据,并使用BertTokenizer进行中文分词,此外还使用了动态学习率来调整模型收敛速度。
打卡

相关文章:
昇思25天学习打卡营第18天 | 基于MindSpore的GPT2文本摘要
昇思25天学习打卡营第18天 | 基于MindSpore的GPT2文本摘要 文章目录 昇思25天学习打卡营第18天 | 基于MindSpore的GPT2文本摘要数据集创建数据集数据预处理Tokenizer 模型构建构建GPT2ForSummarization模型动态学习率 模型训练模型推理总结打卡 数据集 实验使用nlpcc2017摘要数…...

科研绘图系列:R语言circos图(circos plot)
介绍 Circos图是一种数据可视化工具,它以圆形布局展示数据,通常用于显示数据之间的关系和模式。这种图表特别适合于展示分层数据或网络关系。Circos图的一些关键特点包括: 圆形布局:数据被组织在一个或多个同心圆中,每个圆可以代表不同的数据维度或层次。扇区:每个圆被划…...

追踪Conda包的踪迹:深入探索依赖关系与管理
追踪Conda包的踪迹:深入探索依赖关系与管理 Conda作为Python和其他科学计算语言的包管理器,不仅提供了安装、更新和卸载包的功能,还有一个强大的包跟踪功能,帮助用户理解包之间的依赖关系和管理环境。本文将详细解释如何在Conda中…...

苹果电脑pdf合并软件 苹果电脑合并pdf 苹果电脑pdf怎么合并
在数字化办公日益普及的今天,pdf文件因其跨平台兼容性强、格式稳定等特点,已经成为工作、学习和生活中不可或缺的文件格式。然而,我们常常面临一个问题:如何将多个pdf文件合并为一个?这不仅有助于文件的整理和管理&…...
)
axios(ajax请求库)
json-server(搭建http服务) json-server用来快速搭建模拟的REST API的工具包 使用json-server 下载:npm install -g json-server创建数据库json文件:db.json开启服务:json-srver --watch db.json axios的基本使用 <!doctype html>…...

Ideal窗口中左右侧栏消失了
不知道大家在工作过程中有没有遇到过此类问题,不论是Maven项目还是Gradle项目,突然发现Ideal窗口右侧图标丢失了,同事今天突然说大象图标不见了,不知道怎样刷新gradle。 不要慌张,下面提供一些解决思路: 1…...

麦芒30全新绽放,中国电信勾勒出AI手机的新方向
高通总裁兼CEO克里斯蒂亚诺阿蒙曾在媒体采访时表示:2024年将成为全球AI手机元年,生成式AI正在“非常快”的进入手机。 把大模型装进手机,由此成了智能终端演进的新方向。三星、华为、OPPO、小米等品牌动作频频,纷纷抢滩AI手机市场…...

数据结构之初始二叉树(3)
找往期文章包括但不限于本期文章中不懂的知识点: 个人主页:我要学编程(ಥ_ಥ)-CSDN博客 所属专栏:数据结构(Java版) 二叉树的基本操作 通过上篇文章的学习,我们简单的了解了二叉树的相关操作。接下来就是有…...

egret 白鹭的编译太慢了 自己写了一个
用的swc 他会检测git的改变 const simpleGit require(simple-git); const fs require(fs); const path require(path); // 初始化 simple-git const swc require(swc/core); const baseDir D:\\project; const gameDir game\\module\\abcdefg; const gitDir D:\\projec…...

<数据集>pcb板缺陷检测数据集<目标检测>
数据集格式:VOCYOLO格式 图片数量:693张 标注数量(xml文件个数):693 标注数量(txt文件个数):693 标注类别数:6 标注类别名称:[missing_hole, mouse_bite, open_circuit, short, spurious_copper, spur…...

实验四:图像的锐化处理
目录 一、实验目的 二、实验原理 1. 拉普拉斯算子 2. Sobel算子 3. 模板大小对滤波的影响 三、实验内容 四、源程序和结果 (1) 主程序(matlab) (2) 函数GrayscaleFilter (3) 函数MatrixAbs 五、结果分析 1. 拉普拉斯滤波 2. Sobel滤波 3. 不同大小模板的滤波…...

【Linux】权限的管理和Linux上的一些工具
文章目录 权限管理chgrpchownumaskfile指令sudo指令 目录权限粘滞位Linux中的工具1.软件包管理器yum2.rzsz Linux开发工具vim 总结 权限管理 chgrp 功能:修改文件或目录的所属组 格式:chgrp [参数] 用户组名 文件名 常用选项:-R 递归修改文…...
)
ES6 字符串的新增方法(二十)
1. String.prototype.startsWith(searchString, position) 特性:判断字符串是否以指定的子字符串开始。 用法:检查字符串的开始部分。 const str "Hello World"; console.log(str.startsWith("Hello")); // 输出:true…...

如何将MP3或WAV文件解码成PCM文件
文章目录 概要整体架构流程技术细节 概要 本文介绍使用 FFmpeg,将MP3或WAV文件解码成PCM文件的方法。 整体架构流程 首先,使用的 FFmpeg 库要支持 MP3/WAV 解码功能,即编译的时候要加上(编译 FFmpeg 库可以参考:Win…...

OpenAI 推出 GPT-4o mini,一种更小、更便宜的人工智能模型
OpenAI 最近推出了新型人工智能模型 GPT-4o mini,以其较小体积和低成本受到关注。这款模型在文本和视觉推理任务上性能优越,且比现有小型模型更快、更经济。GPT-4o mini 已向开发者和消费者发布,企业用户将在下周获得访问权限。 喜好儿网 在…...
源码分析(服务端))
Nacos 服务发现(订阅)源码分析(服务端)
前言: 前文我们分析了 Nacos 服务发现(订阅)的流程,从 Nacos Client 端的源码分析了服务发现的过程,服务发现最终还是要调用 Nacos Server 端来获取服务信息,缓存到客户端本地,并且会定时向 Na…...

DICOM CT\MR片子免费在线查看工具;python pydicom包加载查看;mayavi 3d查看
DICOM CT\MR片子免费在线查看工具 参考: https://zhuanlan.zhihu.com/p/668804209 dicom格式: DICOM(Digital Imaging and Communications in Medicine)是医学数字成像和通信的标准。它定义了医学图像(如CT、MRI、X…...

VSCode远程连接Ubuntu/Linux
文章目录 前言SSH(Secure Shell)简介主要功能工作原理常见的 SSH 客户端和服务器 Ubuntu安装sshvscode远程插件安装远程插件开始远程连接 打开文件夹新建终端 总结 前言 在现代开发环境中,远程工作和跨平台开发变得越来越普遍。Visual Studi…...

【Nginx80端口被占用】80端口被System占用如何解决【已解决】
【Nginx80端口被占用】80端口被System占用如何解决【已解决】 01 问题背景 Nginx 版本 1.19及以上80端口被System占用,无法kill tcp6 0 0 :::111 :::* LISTEN 1/systemd tcp6 0 0 :::80 :::* LISTEN 1/systemd 执行以下代码无效&…...

云计算的发展历程与边缘计算
云计算的发展历程 初期发展(1960s-1990s) 概念萌芽:云计算的概念可以追溯到1960年代,当时约翰麦卡锡(John McCarthy)提出了“计算将来可能成为一种公共设施”的想法。这个概念类似于现代的云计算…...

DeepSeek 赋能智慧能源:微电网优化调度的智能革新路径
目录 一、智慧能源微电网优化调度概述1.1 智慧能源微电网概念1.2 优化调度的重要性1.3 目前面临的挑战 二、DeepSeek 技术探秘2.1 DeepSeek 技术原理2.2 DeepSeek 独特优势2.3 DeepSeek 在 AI 领域地位 三、DeepSeek 在微电网优化调度中的应用剖析3.1 数据处理与分析3.2 预测与…...

智慧工地云平台源码,基于微服务架构+Java+Spring Cloud +UniApp +MySql
智慧工地管理云平台系统,智慧工地全套源码,java版智慧工地源码,支持PC端、大屏端、移动端。 智慧工地聚焦建筑行业的市场需求,提供“平台网络终端”的整体解决方案,提供劳务管理、视频管理、智能监测、绿色施工、安全管…...

大型活动交通拥堵治理的视觉算法应用
大型活动下智慧交通的视觉分析应用 一、背景与挑战 大型活动(如演唱会、马拉松赛事、高考中考等)期间,城市交通面临瞬时人流车流激增、传统摄像头模糊、交通拥堵识别滞后等问题。以演唱会为例,暖城商圈曾因观众集中离场导致周边…...

五年级数学知识边界总结思考-下册
目录 一、背景二、过程1.观察物体小学五年级下册“观察物体”知识点详解:由来、作用与意义**一、知识点核心内容****二、知识点的由来:从生活实践到数学抽象****三、知识的作用:解决实际问题的工具****四、学习的意义:培养核心素养…...

Module Federation 和 Native Federation 的比较
前言 Module Federation 是 Webpack 5 引入的微前端架构方案,允许不同独立构建的应用在运行时动态共享模块。 Native Federation 是 Angular 官方基于 Module Federation 理念实现的专为 Angular 优化的微前端方案。 概念解析 Module Federation (模块联邦) Modul…...

爬虫基础学习day2
# 爬虫设计领域 工商:企查查、天眼查短视频:抖音、快手、西瓜 ---> 飞瓜电商:京东、淘宝、聚美优品、亚马逊 ---> 分析店铺经营决策标题、排名航空:抓取所有航空公司价格 ---> 去哪儿自媒体:采集自媒体数据进…...

回溯算法学习
一、电话号码的字母组合 import java.util.ArrayList; import java.util.List;import javax.management.loading.PrivateClassLoader;public class letterCombinations {private static final String[] KEYPAD {"", //0"", //1"abc", //2"…...
恶补电源:1.电桥
一、元器件的选择 搜索并选择电桥,再multisim中选择FWB,就有各种型号的电桥: 电桥是用来干嘛的呢? 它是一个由四个二极管搭成的“桥梁”形状的电路,用来把交流电(AC)变成直流电(DC)。…...

第八部分:阶段项目 6:构建 React 前端应用
现在,是时候将你学到的 React 基础知识付诸实践,构建一个简单的前端应用来模拟与后端 API 的交互了。在这个阶段,你可以先使用模拟数据,或者如果你的后端 API(阶段项目 5)已经搭建好,可以直接连…...
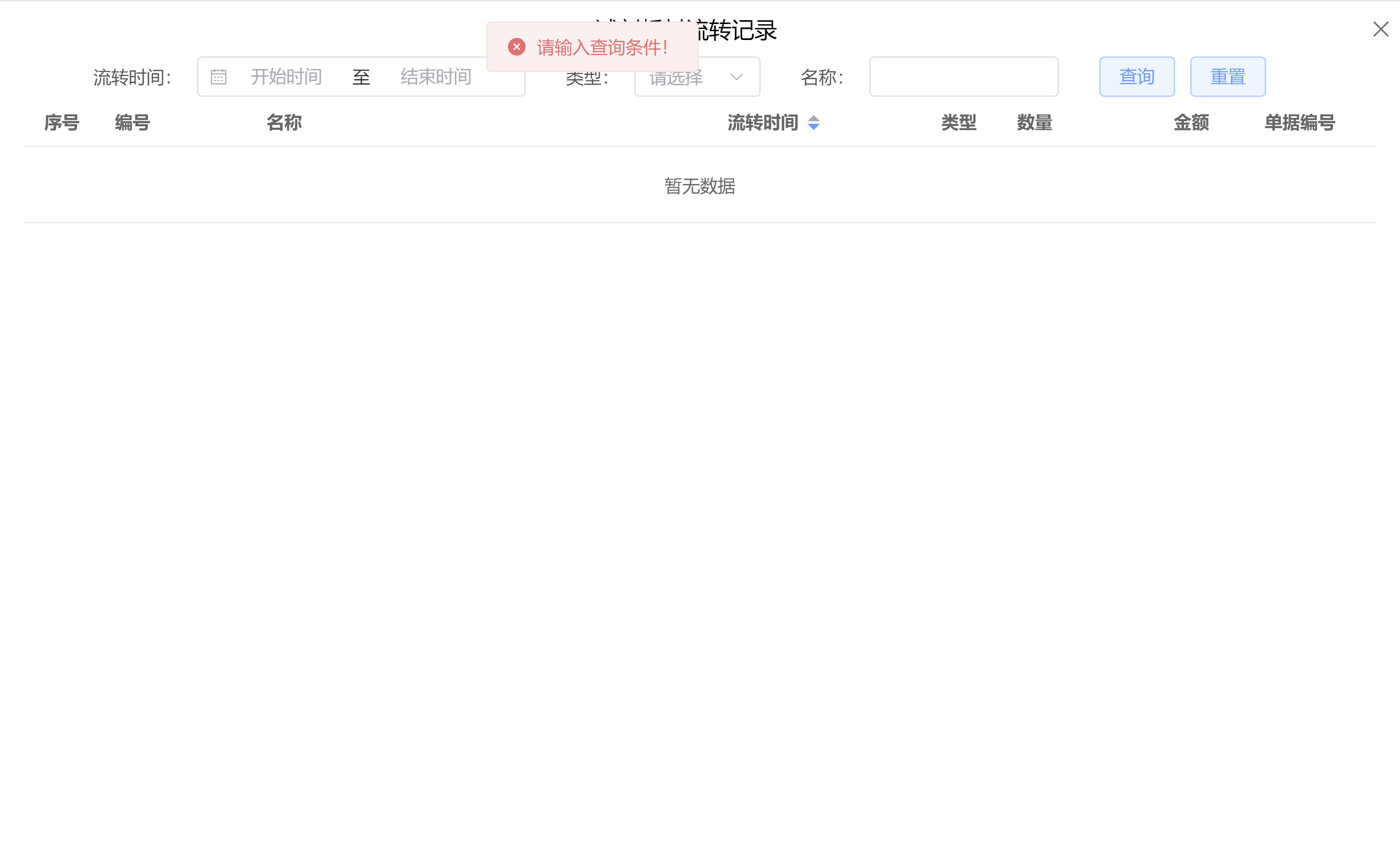
Java后端检查空条件查询
通过抛出运行异常:throw new RuntimeException("请输入查询条件!");BranchWarehouseServiceImpl.java // 查询试剂交易(入库/出库)记录Overridepublic List<BranchWarehouseTransactions> queryForReagent(Branch…...