【论文阅读笔记】Hierarchical Neural Coding for Controllable CAD Model Generation
摘要
作者提出了一种CAD的创新生成模型,该模型将CAD模型的高级设计概念表示为从全局部件排列到局部曲线几何的三层神经代码的层级树,并且通过指定目标设计的代码树来控制CAD模型的生成或完成。具体而言,一种带有“掩码跳过连接”的向量量化变分自编码器(VAE)的新变体在三个层次上提取设计变化作为神经码本。两阶段的级联自回归Transformer学习从不完整的CAD模型生成代码树,然后根据预期设计完成CAD模型。广泛的实验表明,在无条件生成等传统任务上表现出优越性能,同时在条件生成任务中实现了新颖的交互能力。
【code】
1 引言
大多数现代CAD设计工具采用“草图和拉伸”风格的工作流程,以这种方式创建的CAD模型具有自然的树结构,支持局部编辑。树叶处的曲线可以调整并重新生成拉伸以更新最终形状。对于设计师来说,重要的是编辑要保留“设计意图”。而设计意图定义也有不同:
-
Otey等人将设计意图定义为“在修改时CAD模型的预期行为”
-
Martin描述为“对象之间的关系,使得对一个对象的更改可以自动传播到其他对象”。
虽然“草图和拉伸”允许局部更改,但它不提供在编辑模型时给出预期行为所需的关系。一个能理解设计意图的计算系统将彻底改变CAD的实践。这种系统可以帮助设计师在:
-
根据高级设计概念生成多样化的CAD模型;
-
在约束某些模型属性的情况下修改现有的CAD模型;
-
交互式地自动完成设计(如下图)。
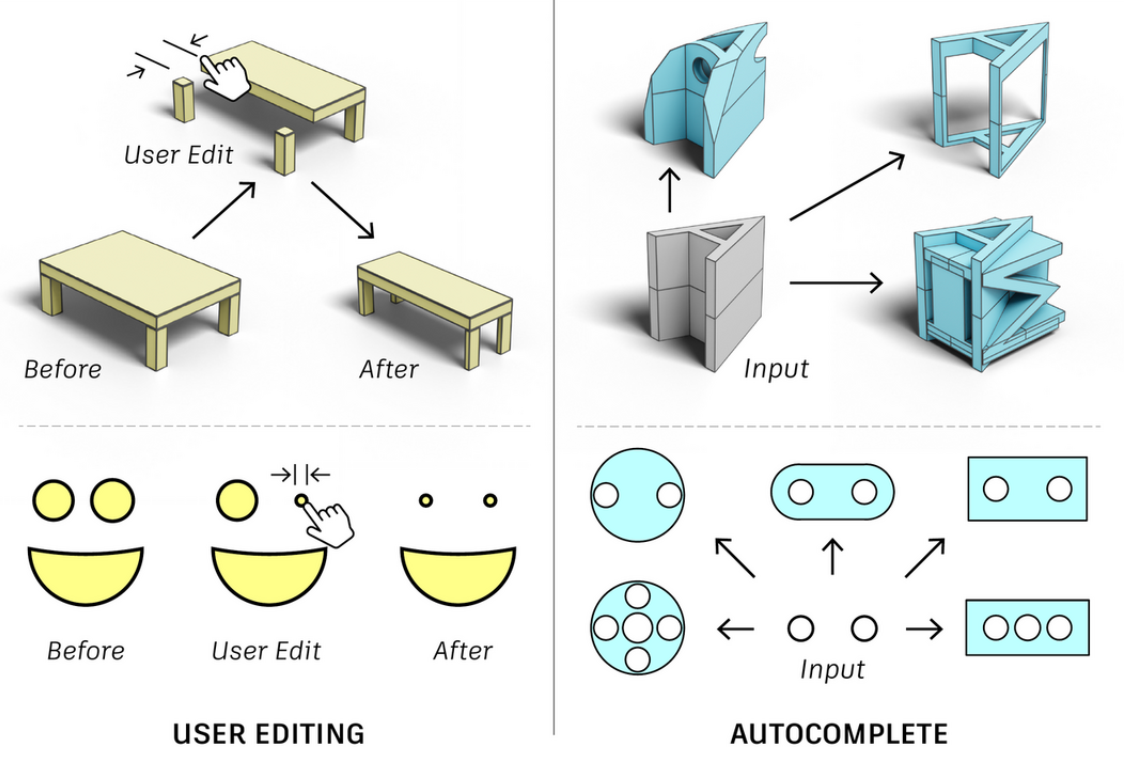
但目前还没有这样的系统,当前行业标准通过手动指定参数和方程,以定义轮廓的位置和尺寸,以及用于对齐几何的约束,这种称为参数化CAD的过程需要专业技能,并且在意外编辑时很容易出错。下图展示了编辑约束不良的CAD模型的几何形状时原始设计意图被破坏的示例。

现有的工作并未利用CAD设计的层次性来提供有效的设计控制。作者提出了一种新颖的生成网络,将CAD模型的设计意图捕获为从局部几何特征到全局部件排列的三层神经代码树,并根据编码树或不完整的CAD模型指定的设计意图控制CAD模型的生成或完成。CAD模型以建模操作的序列形式生成,然后转换为工业标准的边界表示(B-Rep)格式,以便在CAD软件中进行编辑。
具体来说,作者提出了一种带有“掩码跳过连接”的矢量量化VAE变体,从大规模草图和拉伸CAD数据集(DeepCAD数据集)中学习设计变化形成三个神经码本。掩码跳过连接简单但有效,可以提取高度抽象的码本,使代码与生成的几何形状之间的关系变得直观。然后,两阶段级联自回归Transformer学习生成:
-
给定不完整CAD模型的三层代码树
-
给定编码树和不完整数据的完整CAD模型
设计师还可以直接提供编码树以生成模型。
与其他生成baseline的定性和定量评估表明,在随机生成任务中,该系统生成了更逼真和复杂的模型。在用户控制的条件生成任务中,系统展示了灵活和优越的几何控制,这得益于层次编码树表示,优于当前最先进的基于深度学习的生成模型(例如SkexGen,DeepCAD)。总之,我们的贡献包括:
- 编码层次设计概念的神经代码树表示,支持高质量和复杂模型的生成、设计意图感知的用户编辑和设计自动完成。
- 带有掩码跳过连接的新型向量量化变分自编码器,用于增强代码簿学习。
- 在CAD模型生成方面相对于之前的最先进方法的性能提升。
2 相关工作
-
构造性实体几何(CSG)
3D形状由参数化基元通过布尔运算组成的CSG树表达。这种轻量级表示通过程序合成和无监督学习重建CAD形状。但参数化CAD仍主导机械设计,并且广泛使用草图和拉伸建模操作。
-
直接CAD生成
最近一些工作专注于在没有任何CAD建模序列监督的情况下直接生成CAD模型。作者更专注于以草图和拉伸序列形式进行的参数化CAD的可控生成。
-
草图和拉伸CAD生成
最近大规模参数化CAD数据集的可用性使基于学习的方法能够利用CAD建模序列历史和草图约束生成工程草图和实体模型。生成的序列可以用实体建模内核解析,以获得包含2D工程草图或3D CAD形状的可编辑参数化CAD文件。此外,生成可以受目标B-rep、草图、图像、体素网格或点云的影响。但这种控制是全局级别的,而作者旨在支持设计保持编辑和自动完成等应用程序的全局和局部级别的层次控制。
-
用户控制的CAD生成
提供用户对生成过程的控制,同时保持设计意图,是生成模型在实际CAD软件中采用的关键。尽管以前的方法可以基于高级指导生成多样化的形状,但使用户能够控制生成过程更具挑战性。Sketch2CAD和Free2CAD专注于设计过程的局部控制,并且需要大量的输入。最近的一些工作还利用文本提示和用户指定的指导。SkexGen允许用户通过解耦全局控制CAD形状的拓扑和几何来探索设计变化。然而,其方法仅有助于从零开始创建新设计,无法轻易修改以提供用户期望的智能编辑CAD模型或自动完成下一步操作的交互体验。与现有工作不同,作者的方法利用CAD模型内部存在的自然层次结构,提供对生成过程的全局和局部控制。
3 层次CAD属性
草图和拉伸的CAD模型具有自然的层次结构,如下图所示。
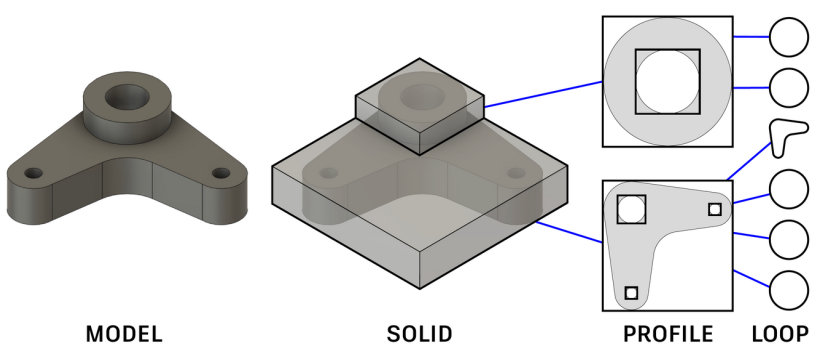
其中一个环定义了一条封闭的曲线路径,一个轮廓在草图平面内由一个外环和一些内环限定了一个封闭区域,而一个实体则表示一组拉伸的轮廓组合成整个模型。我们的目标是实现在生成CAD模型时的局部和全局控制,即用户可以编辑任何一个实体,并期望其余部分自动进行合理的更新。为了实现这一目标,我们在神经网络的潜在空间中捕捉这种层次结构。在层次结构的较高层上,网络学习较低层次几何实体的相对位置,即构成模型的轮廓和拉伸的边界框。具体来说,我们将CAD模型视为一个实心(S)—轮廓(P)—环(L)树:
-
环(L) :在树的叶子上,我们有环。每个环由一组线和弧或一个圆组成。环(L)的属性定义为一系列由特殊 <SEP> \text{<SEP>} <SEP> token分隔的x-y坐标:
L = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , <SEP> , ( x 3 , y 3 ) , … } . L = \{(x_1, y_1), (x_2, y_2), \text{<SEP>}, (x_3, y_3), \ldots\}. L={(x1,y1),(x2,y2),<SEP>,(x3,y3),…}.线由两个点(起点和终点)的xy坐标表示;弧由三个点表示,包括起点、中点和终点;圆由曲线上四个均匀分布的点表示。使用这种表示法,可以通过点的数量识别曲线类型。我们对环中的曲线进行排序,使得初始曲线是起点坐标最小的曲线,下一条是与其逆时针方向相连的曲线。
-
轮廓(P):轮廓位于叶子层之上。由于环的几何结构在叶子层捕捉,轮廓节点的属性定义为草图平面内环的二维边界框参数系列:
P = { ( x i , y i , w i , h i ) } i = 1 N i loop . P = \{(x_i, y_i, w_i, h_i)\}_{i=1}^{N^{\text{loop}}_i}. P={(xi,yi,wi,hi)}i=1Niloop.
其中 i i i是轮廓内 N i loop N^{\text{loop}}_i Niloop个环的索引。 ( x i , y i ) (x_i, y_i) (xi,yi)是边界框的左下角, ( w i , h i ) (w_i, h_i) (wi,hi)是宽度和高度。我们通过对所有二维边界框的左下角进行升序排序来确定轮廓 P P P中边界框参数的顺序。
-
实体(S):在轮廓层之上,我们有通过拉伸一个或多个轮廓形成的三维实体模型。实体节点的属性捕获拉伸轮廓的排列,使用一系列三维边界框参数:
S = { ( x j , y j , z j , w j , h j , d j ) } j = 1 N j profile . S = \{(x_j, y_j, z_j, w_j, h_j, d_j)\}_{j=1}^{N^{\text{profile}}_j}. S={(xj,yj,zj,wj,hj,dj)}j=1Njprofile.
其中 j j j是模型中 N j profile N^{\text{profile}}_j Njprofile个拉伸轮廓的索引。 ( x j , y j , z j ) (x_j, y_j, z_j) (xj,yj,zj)是边界框的左下角, ( w j , h j , d j ) (w_j, h_j, d_j) (wj,hj,dj)是其尺寸。同样, S S S中的参数按所有拉伸的三维边界框的左下角进行升序排序。
4 三层码本学习
给定一个以S-P-L树格式表示的草图和拉伸CAD模型数据集,一种新的向量量化VAE(VQ-VAE)变体学习它们的潜在模式,作为三个离散的码本,这些码本将CAD模型编码为一棵神经码树,用于下游应用。
遵循SkexGen,我们用于学习码本的架构基础是一个VQ-VAE,由一个Transformer编码器 E E E和解码器 D D D组成,如下图所示。
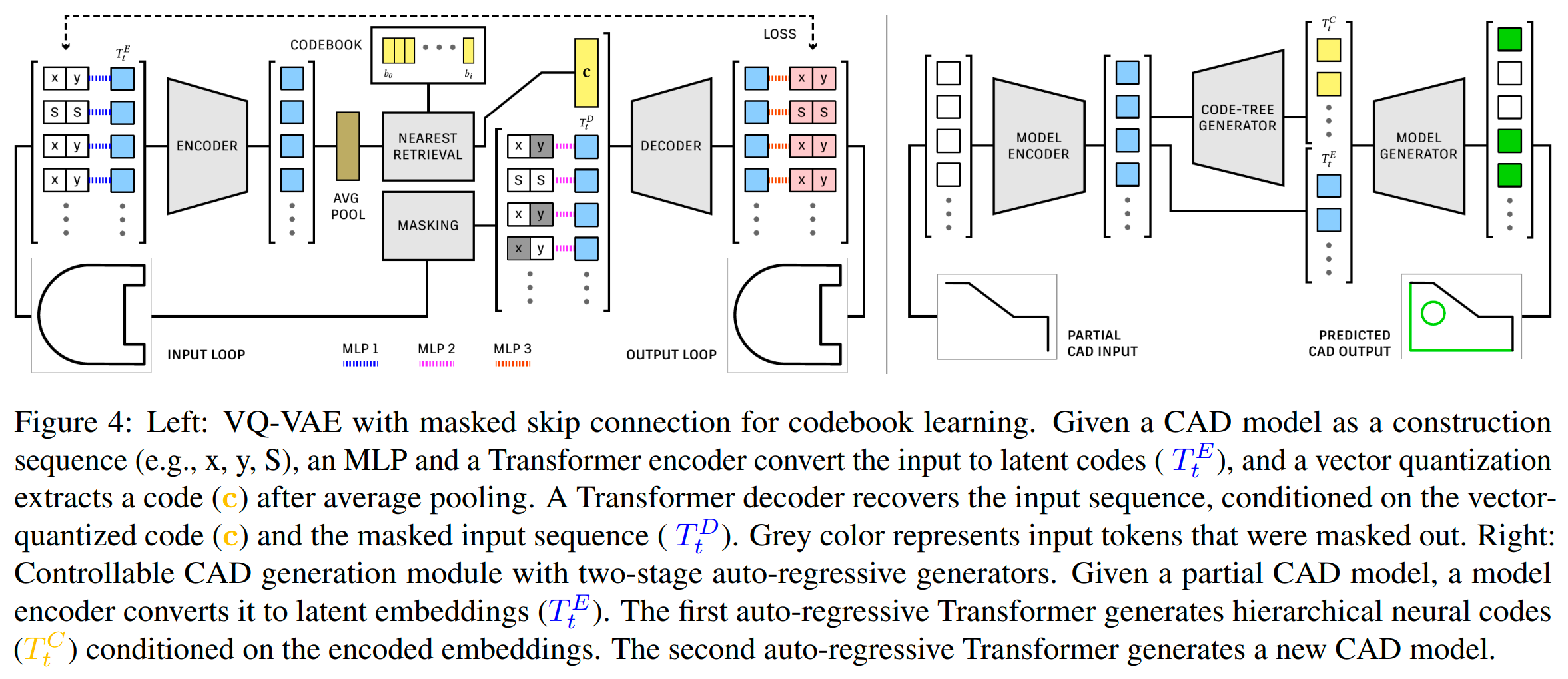
我们独立学习L、P和S的码本。与SkexGen和之前的掩码学习工作不同,我们在从编码器输入到解码器输入的跳过连接上应用掩码。直观来说,一个标准的VQ-VAE(即没有跳过连接)被训练用来恢复实例特定的输入细节,这对于正在学习实例无关设计模式的量化码来说是一个挑战。一个天真的跳过连接允许解码器通过直接复制输入来作弊。掩码跳过连接迫使解码器从未掩码元素中关联部分细节和填补缺失部分,其中关系由编码在码中的设计模式引导。
-
编码器: 考虑一个 L L L(方程1),包含一系列的x-y坐标和特殊的 <SEP> \text{<SEP>} <SEP> token。我们使用65维的独热向量来表示一个token,其中一个坐标被量化为6位(即64维), <SEP> \text{<SEP>} <SEP>需要一个额外的维度。设 T t E T^E_t TtE表示Transformer编码器的第 t t t个token的256维嵌入。嵌入初始化为:
T t E ← { MLP ( W emb x t ∥ W emb y t ) + γ t (for x-y) , MLP ( W emb < SEP > ∥ W emb < SEP > ) + γ t . T_t^E\leftarrow\begin{cases}\text{MLP}(W_\text{emb}x_t\parallel W_\text{emb}y_t)+\gamma_t\quad\text{(for x-y)},\\\text{MLP} (W_\text{emb}<\text{SEP}>\parallel W_\text{emb}<\text{SEP}>)+ \gamma_t.\end{cases} TtE←{MLP(Wembxt∥Wembyt)+γt(for x-y),MLP(Wemb<SEP>∥Wemb<SEP>)+γt.
W emb W_\text{emb} Wemb是一个 65 × 32 65\times 32 65×32的token嵌入矩阵。 ∥ \parallel ∥是拼接运算符。 MLP \text{MLP} MLP是一个两层的多层感知器。 γ t \gamma_t γt是一个可学习的256维位置嵌入。第二种情况是对于 <SEP> \text{<SEP>} <SEP>,其值重复两次。对于P和S,我们处理每个二维或三维边界框参数的方式与 x t , y t x_t, y_t xt,yt坐标相同,但没有 <SEP> \text{<SEP>} <SEP> token。
-
向量量化: 编码器 E E E的输出,序列长度为 T T T,首先进行平均池化,形成 E ‾ ( T E ) \overline{E}(T^E) E(TE)。然后应用标准的向量量化程序来获得一个256维的码本向量 c c c。更具体地说,我们比较码本向量 b \mathbf{b} b和编码的 E ‾ ( T E ) \overline{E}(T^E) E(TE)之间的欧几里得距离,并执行最近邻查找。
c ← b k , where k = a r g m i n i ∣ ∣ E ‾ ( T E ) − b i ∣ ∣ 2 . \mathbf{c}\leftarrow\mathbf{b}_k,\quad\text{where}\quad k=\mathrm{argmin}_i\left|\left|\overline{E}(T^E)-\mathbf{b}_i\right|\right|^2. c←bk,wherek=argmini E(TE)−bi 2. -
带掩码跳过连接的解码器: 解码器接收量化码 c c c和掩码的x-y坐标和 <SEP> \text{<SEP>} <SEP> token序列,并预测被掩码的token。例如,在一个环节点的情况下,任何 x t , y t x_t, y_t xt,yt和 <SEP> \text{<SEP>} <SEP> token都可以被掩码(具体来说,每个模型随机掩码30%到70%的token)。设 T t D T^D_t TtD表示为解码器输入的第 t t t个token的嵌入。每个token的嵌入方式与编码器嵌入方程完全相同,只是被掩码的token的嵌入被一个可学习的共享32维掩码token嵌入 m m m取代。来自编码器的256维码本向量 c c c与 { T t D } \{T^D_t\} {TtD}拼接在一起并传递给解码器 D D D,解码器有四个自注意力层。这里的思想是迫使编码器学习有用的潜在特征,可以帮助解码器预测被掩码的token。最后,在解码器后对每个token嵌入(除了码本向量)应用一个MLP,以生成(2 × 65)维的logits,即一对在65类标签上的概率值,分别用于预测xy坐标或 <SEP> \text{<SEP>} <SEP> token。
-
损失函数: 训练损失由三项组成:
∑ t E M D ( D ( c , { T t D } ) , 1 T t ) + ∣ ∣ s g [ E ‾ ( T E ) ] − c ∣ ∣ 2 2 + β ∣ ∣ E ‾ ( T E ) − s g [ c ] ∣ ∣ 2 2 . \begin{aligned}&\sum_{t}\mathrm{EMD}\Big(D(\mathbf{c},\{T_{t}^{D}\}) , \mathbb{1}_{T_{t}}\Big)+\\&\left|\left|sg[\overline{E}(T^{E})]-\mathbf{c}\right|\right|_{2}^{2}+\beta\left|\left|\overline{E}(T^{E})-sg[\mathbf{c}]\right|\right|_{2}^{2}.\end{aligned} t∑EMD(D(c,{TtD}),1Tt)+ sg[E(TE)]−c 22+β E(TE)−sg[c] 22.
第一项是解码器输出概率和相应数据属性的独热编码 1 T t \mathbb{1}_{T_t} 1Tt之间的平方EMD损失。损失仅应用于被掩码的token。我们使用的EMD损失函数,该函数假设有序的类标签,并对接近真实值的预测进行较少的惩罚。这比交叉熵损失更好,因为x-y坐标携带距离关系,使得损失可以集中在远离真实值的预测上。注意,我们对环数据属性中的 <SEP> \text{<SEP>} <SEP> token处理不同,应用标准的交叉熵损失,因为这不是一个有序类标签。
第二和第三项是VQ-VAE中使用的码本和承诺损失。 s g sg sg表示停止梯度操作,在前向传播中是恒等函数,但在后向传播中阻止梯度。 β \beta β缩放承诺损失,设为 0.25 0.25 0.25。我们使用衰减率为 0.99 0.99 0.99的指数移动平均更新。
5 可控CAD生成
环、轮廓和实体码本使我们能够将CAD模型的设计概念表达为层次化的神经代码,从而实现多样化和高质量的生成、新颖的用户控制以指定设计意图,以及自动完成不完整的CAD模型。具体来说,给定一个不完整的CAD模型作为草图和拉伸构建序列:
- 模型编码器将输入序列转换为潜在嵌入;
- 自回归Transformer根据嵌入的输入序列生成代码树;
- 第二个自回归Transformer根据嵌入的输入序列和代码树生成完整的CAD模型。
-
模型编码器: 模型编码器的主体是标准的Transformer编码器模块,具有6个自注意力层。我们借用了SkexGen中使用的格式,并将模型表示为一个token序列,每个token是一个独热向量,唯一确定一个曲线类型、量化曲线参数和量化拉伸参数。编码器将独热向量转换为一系列256维的潜在嵌入 { T t E } \{T^E_t\} {TtE}。
-
编码树生成器: G code G_\text{code} Gcode是一个自回归解码器,它生成代码的层次结构 { T t C } \{T^C_t\} {TtC}。每个实体、轮廓或环从相应的码本中分配一个代码,条件是编码的嵌入 { T t E } \{T^E_t\} {TtE}。类似于层次属性表示,层次代码表示为一系列特征向量,指示代码或分隔token。具体来说,一个特征是一个独热向量,其大小是三个码本中代码的总数加上一个分隔符。例如,考虑上图示例中的代码树,包含一个实体、两个轮廓和两个或四个环。这个树的特征表示为 [ S , <SEP> , P , L , L , <SEP> , P , L , L , L , L ] [S, \text{<SEP>}, P, L, L, \text{<SEP>}, P, L, L, L, L] [S,<SEP>,P,L,L,<SEP>,P,L,L,L,L]。这里我们执行神经代码树的深度优先遍历,边界命令 <SEP> \text{<SEP>} <SEP>用于指示轮廓和环代码的新分组。
G code G_\text{code} Gcode有6个自注意力(SA)层与6个交叉注意力(CA)层交替。第一个SA层是在查询token { T t C ˉ } \{T^{\bar{C}}_t\} {TtCˉ}上,每个查询token由位置编码 γ t \gamma_t γt初始化并自回归估计。每个CA层的输入是 { T t E } \{T^E_t\} {TtE}。每个SA或CA层都有8个头的注意力,随后是一个Add-Norm层。一个查询token { T t c ˉ } \{T^{\bar{c}}_t\} {Ttcˉ}将有一个生成的代码索引,该索引转换为一个代码 { T t C } \{T^C_t\} {TtC}。分隔符被一个可学习的嵌入取代。
T t C ← { Codebook ( T t C ~ ) + γ t (for code), W emb < SEP> + γ t (for<SEP>). T_t^C\leftarrow\begin{cases}\text{Codebook}(T_t^{\tilde{C}})+ \gamma_t&\text{(for code),}\\W_\text{emb}<\text{SEP>}&+\gamma_t&\text{(for<SEP>).}\end{cases} TtC←{Codebook(TtC~)+γtWemb<SEP>(for code),+γt(for<SEP>).
Codebook表示从代码索引到代码的映射。我们使用标准的交叉熵损失训练 G code G_\text{code} Gcode。注意,对于无条件生成,我们删除部分CAD模型编码器,并仅使用查询token { T t C ˉ } \{T^{\bar{C}}_t\} {TtCˉ}训练SA层,没有交叉注意力层和 { T t E } \{T^E_t\} {TtE}。
-
模型生成器: 模型生成器是第二个自回归解码器 G cad G_\text{cad} Gcad,生成一个草图和拉伸的CAD模型。 G cad G_\text{cad} Gcad与SkexGen解码器相同,不同的是部分CAD模型嵌入 { T t E } \{T^E_t\} {TtE}和层次神经代码 { T t C } \{T^C_t\} {TtC}通过交叉注意力层控制生成,而SkexGen仅允许全局代码的指定。架构规格与第一个解码器相同。查询token ( T t out T^\text{out}_t Ttout)包含生成的CAD命令序列作为独热向量,我们使用相同的标准交叉熵损失。
6 实验
本节展示了无条件和有条件生成的结果,证明了以下几点:
- 相较于当前最先进的技术,生成的质量更高、种类更多、复杂性更强;
- 通过层次化神经代码实现可控生成;
- 两个重要应用,用户编辑和自动补全。
6.1 实验设置
-
数据集: 使用大规模DeepCAD数据集,包含178,238个草图及拉伸模型,按90%训练、5%验证、5%测试划分。去除重复模型和属性,并限制训练模型的复杂度(最多5个实体、20个环/轮廓、60条曲线/环、200个命令/序列),最终训练集包含102,114个实体、60,584个轮廓、150,158个环和124,451个草图和拉伸序列用于CAD模型训练。对于CAD工程图,我们遵循SkexGen并从DeepCAD中提取草图。在移除重复后,共有99,650个草图用于训练。
-
实施细节: 在Nvidia RTX A6000 GPU上训练,批次大小256。码本模块和生成模块分别训练250和350轮。采用改进的Transformer主干,输入嵌入维度256,前馈维度512,Dropout率0.1,各含6层、每层8头注意力。码本学习网络有4层。使用AdamW优化器,学习率0.001,线性预热2000步。测试时采用核采样,对输入曲线坐标添加随机噪声减少过拟合,针对码本坍塌问题采取重新初始化策略。最优代码本大小约为轮廓和实体3,500,环2,500,压缩比约60x、17x和29x。
6.2 指标
五个已建立的指标定量评估随机生成
-
点云指标:基于模型表面采样的2000点比较生成和真实数据的点云集,评估多样性与质量。
- 覆盖率(COV):至少匹配一个生成样本的真实模型百分比,反映生成形状的多样性。
- 最小匹配距离(MMD):平均最小匹配距离,衡量两组之间的接近程度。
- Jensen-Shannon散度(JSD):两个概率分布间的相似性,计算占用相同空间位置的频率。
-
token指标:衡量唯一性。数值字段量化为6位。
- 新颖性(Novel):未出现在训练集中的生成CAD序列比例。
- 唯一性(Unique):在生成集中仅出现一次的数据比例。
6.3 无条件生成
对比DeepCAD与SkexGen,所有方法生成10,000个CAD模型,与测试集随机选取的2,500个真实模型比较。
-
**定量评估:**如下表所示,我们的方法在所有三个点云评估指标上超越baseline,展现显著的质量和多样性提升。在Unique指标上,我们的方法与SkexGen相当,远超DeepCAD。Novel指标上略逊于SkexGen,但明显优于DeepCAD;此差距源于较小且多样性不足的训练集,且仅包含少量复杂形状所致。SkexGen因无法生成非常复杂的模型而受此影响较小。

-
定性评估: 下图显示我们的方法能生成结构良好、几何形状复杂、部件布局精细的CAD模型,与真实世界实例相似。

-
人工评估: 通过亚马逊众包平台进行人类感知质量评估,针对具有三个或更多拉伸的模型。在与真实模型并列展示的情况下,我们的方法在“真实感”评分上表现突出,分布对称,表明生成模型难以被区分。比较之下,DeepCAD和SkexGen的分布偏向“较不真实”,表明易被识别为简单或不规范的模型。我们的方法中有49.2%的生成模型被认定为比训练数据更“真实”,SkexGen为46.9%,DeepCAD为38.7%。

6.4 可控生成
我们在两种“编辑”和一种“自动补全”应用场景中展示了可控生成。
-
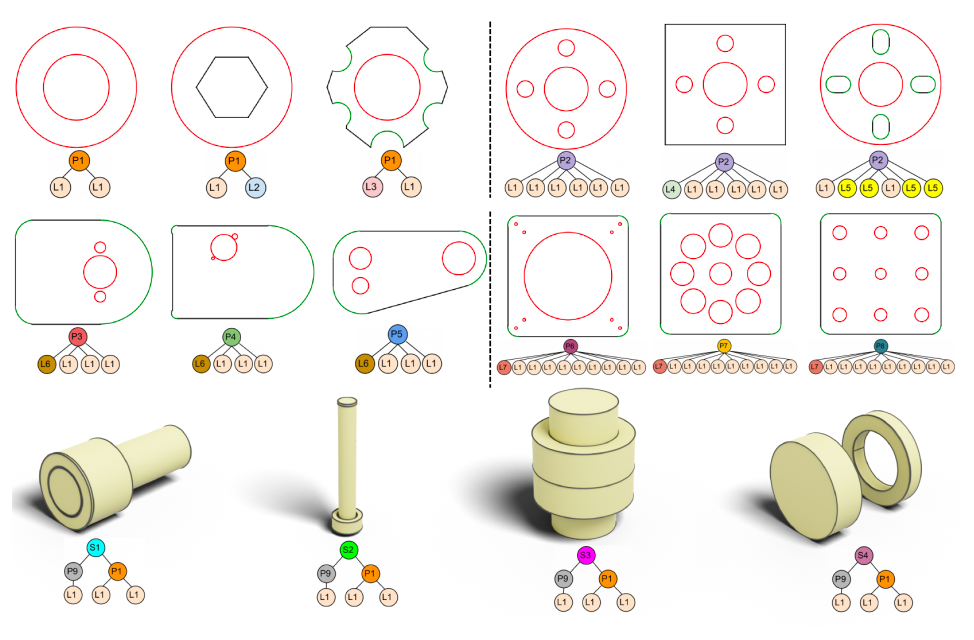
代码树编辑: 用户可编辑不同层次的代码节点,实现局部到全局的CAD层次修改,这是以往方法所不具备的。编辑结果多样化且控制精确,如下图所示。
-
保持设计的编辑: 在固定代码树的基础上,用户可迭代地调整模型参数以细化设计,同时保持当前设计不变。如下图所示,局部尺寸调整后,相关部分会自动调整以适应更改。

-
从用户输入的自动补全: 根据用户提供的部分轮廓或环,预测可能的代码集以完成CAD模型。图9和图10展示了从部分轮廓和拉伸轮廓开始的自动补全结果,每行展示不同生成代码的结果。相比最近邻搜索baseline,我们的方法在多样性和精确匹配用户输入方面表现更优,如图11所示。
7 总结
作者引入了一种新颖的可控CAD生成模型。方法的关键是三层神经编码,它在建模层次结构的不同层次上捕获设计模式和意图。本文在包含用户反馈的智能生成设计方向上又迈出了重要一步。广泛的评估显示,生成质量有了显著提升,并展示了作者的分层神经编码在意图感知编辑和自动补全等应用中的巨大潜力。其主要创新点和限制如下:
创新点:
- 分层神经编码:提出了一种三层次的神经编码方法,将CAD模型的高级设计概念表示为从全局部件布局到局部曲线几何的树状结构。
- 设计意图的捕捉与控制:通过指定目标设计来生成或完成CAD模型,使用代码树来控制生成过程。
- 新型变分自编码器(VAE):提出了一种新型的向量量化VAE变体,具有“掩蔽跳跃连接”,用于从大规模草图和挤出CAD数据集中提取设计变化作为神经代码本。
- 两阶段级联自回归变换器:用于从不完整的CAD模型生成代码树,然后根据预期设计完成CAD模型。
限制:
- 有效性问题:当前系统在生成具有自相交边或实体的CAD模型时可能存在有效性问题,因为损失函数没有明确地惩罚无效的几何形状。未来的工作是增加一个损失函数,利用领域知识明确对 CAD 模型的无效性进行惩罚。
- 恢复失败的能力:系统在面对失败情况时,缺乏从错误中恢复的能力,这主要是因为缺乏“无效CAD模型数据集”来训练这种恢复机制。
- 模型格式限制:该方法使用的是草图和拉伸CAD格式,这可能排除了其他流行的建模操作,如旋转、镜像和扫掠等。
相关文章:
【论文阅读笔记】Hierarchical Neural Coding for Controllable CAD Model Generation
摘要 作者提出了一种CAD的创新生成模型,该模型将CAD模型的高级设计概念表示为从全局部件排列到局部曲线几何的三层神经代码的层级树,并且通过指定目标设计的代码树来控制CAD模型的生成或完成。具体而言,一种带有“掩码跳过连接”的向量量化变…...

Unity扩展SVN命令
可以直接在unity里右键文件提交和查看提交记录 顶部菜单栏上回退和更新整个unity工程 SvnForUnity.CS 记得要放在Editor文件夹下 using System.Collections; using System.Collections.Generic; using System.Diagnostics; using System.IO; using UnityEditor; using Unity…...
「实战应用」如何用DHTMLX将上下文菜单集成到JavaScript甘特图中(三)
DHTMLX Gantt是用于跨浏览器和跨平台应用程序的功能齐全的Gantt图表。可满足项目管理应用程序的所有需求,是最完善的甘特图图表库。 DHTMLX Gantt是一个高度可定制的工具,可以与项目管理应用程序所需的其他功能相补充。在本文中您将学习如何使用自定义上…...

微服务保护
1、什么是微服务保护 微服务保护是指在微服务架构中采取的一系列措施,以确保各个服务的稳定性、可靠性和安全性。微服务是一种将应用程序作为一套小服务开发的方法,每个服务运行在其独立的进程中,并通常围绕特定的业务能力进行构建。微服务保…...

Python语言的优势所在
Python语言具有多个显著的优势,这些优势使得它在软件开发、数据分析、机器学习、Web开发等众多领域广受欢迎。以下是Python语言的一些主要优势: 简单易学:Python的语法清晰简洁,接近自然语言,易于理解和编写。对于初学…...

npm install时报错 reason: certificate has expired
在VS code中导入新项目,执行npm install时报错: npm warn old lockfile Could not fetch metadata for antv/g3.4.10 FetchError: request to https://registry.npm.taobao.org/antv%2fg failed, reason: certificate has expirednpm warn old lockfile …...
价格战再起:OpenAI 发布更便宜、更智能的 GPT-4o Mini 模型|TodayAI
OpenAI 今日推出了一款名为 GPT-4o Mini 的新模型,这款模型较轻便且成本更低,旨在为开发者提供一个经济实惠的选择。与完整版模型相比,GPT-4o mini 在成本效益方面表现卓越,价格仅为每百万输入 tokens 15 美分和每百万输出 tokens…...

从0开始对时间序列模型ACF和PACF的理解(以股价预测为例子)
目录 ACF模型选择问题ACF处理问题 PACF(偏自相关系数)模型选择 ACF 先了解一下概念,我不喜欢用公式套话讲。 ACF(自相关函数):就是看看当前的股票价格和之前的股票价格之间有没有关系。比如说,…...
基础知识全解析)
MybatisPlus(MP)基础知识全解析
MyBatis-Plus(简称MP)是一个基于Java的持久层框架,它在MyBatis的基础上提供了许多实用的功能增强,使得开发者可以更加便捷地进行数据库操作。本文将介绍MyBatis-Plus的基础知识,包括其特性、核心组件以及如何使用它进行…...
前端组件化实践:Vue自定义加载Loading组件的设计与实现
摘要 随着前端技术的飞速发展,组件化开发已成为提高开发效率、降低维护成本的重要方法。本文介绍了前端Vue自定义加载Loading组件的设计思路与实现过程,该组件通过设置gif动画实现加载效果,可广泛应用于页面请求加载场景。通过该组件的实践&…...

LLaMA 背景
什么是LLaMA? 模型介绍:LLaMA是Meta开发的语言模型,旨在推动开放科学和人工智能的实践。 参数范围:这些模型的参数数量从7B到65B不等,覆盖了不同规模的需求。 训练数据:LLaMA模型是在数万亿个公开数据集的…...

硅谷裸机云多IP服务器怎么样?
硅谷裸机云多IP服务器是一种在硅谷地区提供的、具有多个IP地址的裸机云服务器。这种服务器结合了裸机服务器的高性能和云服务器的灵活性,同时提供了多个IP地址,为用户的各种需求提供了支持。以下是关于硅谷裸机云多IP服务器的一些详细信息,ra…...

Python+Django+MySQL的新闻发布管理系统【附源码,运行简单】
PythonDjangoMySQL的新闻发布管理系统【附源码,运行简单】 总览 1、《新闻发布管理系统》1.1 方案设计说明书设计目标工具列表 2、详细设计2.1 登录2.2 程序主页面2.3 新闻新增界面2.4 文章编辑界面2.5 新闻详情页2.7 其他功能贴图 3、下载 总览 自己做的项目&…...

实战项目:仿muduo库实现并发服务器
目录 项目初始与项目演示HTTP服务器基础认识Reactor模式基础认识单Reactor单线程模式认识单Reactor多线程模式认识多Reactor多线程模式认识 目标定位总体大模块划分server模块的管理思想Buffer子模块Socket子模块Channel子模块Connection子模块Acceptor子模块TimerQueue子模块P…...

提高Java程序效率:ImmutableList、Stream API 和 JSON序列化实战指南
常用列表构建方法: 1.ImmutableList.of() : 静态方法、不可变的列表 可以接受任意数量的参数,并将它们作为元素添加到新创建的列表中,但是一旦创建,集合的内容就不能被改变。在多线程环境中非常有用,因为…...

[CP_AUTOSAR]_分层软件架构_接口之通信模块交互介绍
目录 1、协议数据单元(PDU)传输2、通信模块的案例2.1、SDU、 PCI & PDU2.2、通信模块构成2.3、从数据传输的角度看Communication2.4、Communication中的接口 在前面 《关于接口的一些说明》 以及 《Memory软件模块接口说明》 中,简要介绍了CP_AUTOSAR分层…...

C语言 ——— 浮点数类型 在 内存中 的 存储模式
目录 浮点数存储规则 单\双精度浮点数 存储 S、M、E 的布局 有效数字M 和 指数位E 的特殊规定 浮点数在内存中是否存储的S、M、E 浮点数存储规则 根据国际标准IEEE754(电气和电子工程协会)规定:任意一个 浮点数F的二进制 都可以表示成…...

socket 收发TCP/UDP
一、c 个人测试记录,有问题还请指出,谢谢 参考:C开发基础之网络编程WinSock库使用详解TCP/UDP Socket开发_c udp使用什么库-CSDN博客 代码中Logger测试见文章: c中spdlog的使用/python中logger的使用-CSDN博客 1、main.cpp 收…...

Nest.js 实战 (三):使用 Swagger 优雅地生成 API 文档
什么是 Swagger ? Swagger 是一组围绕 OpenAPI 规范构建的开源工具,可以帮助您设计、构建、记录和使用 REST API。主要的 Swagger 工具 包括: Swagger Editor:基于浏览器的编辑器,您可以在其中编写 OpenAPI 定义Swagger UI&…...

spark shell
1.进行shell命令行 spark-shell 2.创建RDD 2.1 读取文件创建RDD 2.1.1读取linux文件系统的文件创建RDD --需要保证每一个worker中都有该文件 val data1 sc.textFile("file:/opt/file/word.txt") 2.1.2读取hdfs文件系统上的文件创建RDD val data2sc.textFile("…...
。】2022-5-15)
【根据当天日期输出明天的日期(需对闰年做判定)。】2022-5-15
缘由根据当天日期输出明天的日期(需对闰年做判定)。日期类型结构体如下: struct data{ int year; int month; int day;};-编程语言-CSDN问答 struct mdata{ int year; int month; int day; }mdata; int 天数(int year, int month) {switch (month){case 1: case 3:…...

Cursor实现用excel数据填充word模版的方法
cursor主页:https://www.cursor.com/ 任务目标:把excel格式的数据里的单元格,按照某一个固定模版填充到word中 文章目录 注意事项逐步生成程序1. 确定格式2. 调试程序 注意事项 直接给一个excel文件和最终呈现的word文件的示例,…...

RocketMQ延迟消息机制
两种延迟消息 RocketMQ中提供了两种延迟消息机制 指定固定的延迟级别 通过在Message中设定一个MessageDelayLevel参数,对应18个预设的延迟级别指定时间点的延迟级别 通过在Message中设定一个DeliverTimeMS指定一个Long类型表示的具体时间点。到了时间点后…...

循环冗余码校验CRC码 算法步骤+详细实例计算
通信过程:(白话解释) 我们将原始待发送的消息称为 M M M,依据发送接收消息双方约定的生成多项式 G ( x ) G(x) G(x)(意思就是 G ( x ) G(x) G(x) 是已知的)࿰…...

Cilium动手实验室: 精通之旅---20.Isovalent Enterprise for Cilium: Zero Trust Visibility
Cilium动手实验室: 精通之旅---20.Isovalent Enterprise for Cilium: Zero Trust Visibility 1. 实验室环境1.1 实验室环境1.2 小测试 2. The Endor System2.1 部署应用2.2 检查现有策略 3. Cilium 策略实体3.1 创建 allow-all 网络策略3.2 在 Hubble CLI 中验证网络策略源3.3 …...

深入理解JavaScript设计模式之单例模式
目录 什么是单例模式为什么需要单例模式常见应用场景包括 单例模式实现透明单例模式实现不透明单例模式用代理实现单例模式javaScript中的单例模式使用命名空间使用闭包封装私有变量 惰性单例通用的惰性单例 结语 什么是单例模式 单例模式(Singleton Pattern&#…...

基础测试工具使用经验
背景 vtune,perf, nsight system等基础测试工具,都是用过的,但是没有记录,都逐渐忘了。所以写这篇博客总结记录一下,只要以后发现新的用法,就记得来编辑补充一下 perf 比较基础的用法: 先改这…...

Java多线程实现之Callable接口深度解析
Java多线程实现之Callable接口深度解析 一、Callable接口概述1.1 接口定义1.2 与Runnable接口的对比1.3 Future接口与FutureTask类 二、Callable接口的基本使用方法2.1 传统方式实现Callable接口2.2 使用Lambda表达式简化Callable实现2.3 使用FutureTask类执行Callable任务 三、…...

Qt Http Server模块功能及架构
Qt Http Server 是 Qt 6.0 中引入的一个新模块,它提供了一个轻量级的 HTTP 服务器实现,主要用于构建基于 HTTP 的应用程序和服务。 功能介绍: 主要功能 HTTP服务器功能: 支持 HTTP/1.1 协议 简单的请求/响应处理模型 支持 GET…...

JDK 17 新特性
#JDK 17 新特性 /**************** 文本块 *****************/ python/scala中早就支持,不稀奇 String json “”" { “name”: “Java”, “version”: 17 } “”"; /**************** Switch 语句 -> 表达式 *****************/ 挺好的ÿ…...