SQL执行流程、SQL执行计划、SQL优化
select查询语句
select查询语句中join连接是如何工作的?

1、INNER JOIN
返回两个表中的匹配行。
2、LEFT JOIN
返回左表中的所有记录以及右表中的匹配记录。
3、RIGHT JOIN
返回右表中的所有记录以及左表中的匹配记录。
4、FULL OUTER JOIN
返回左侧或右侧表中有匹配的所有记录。
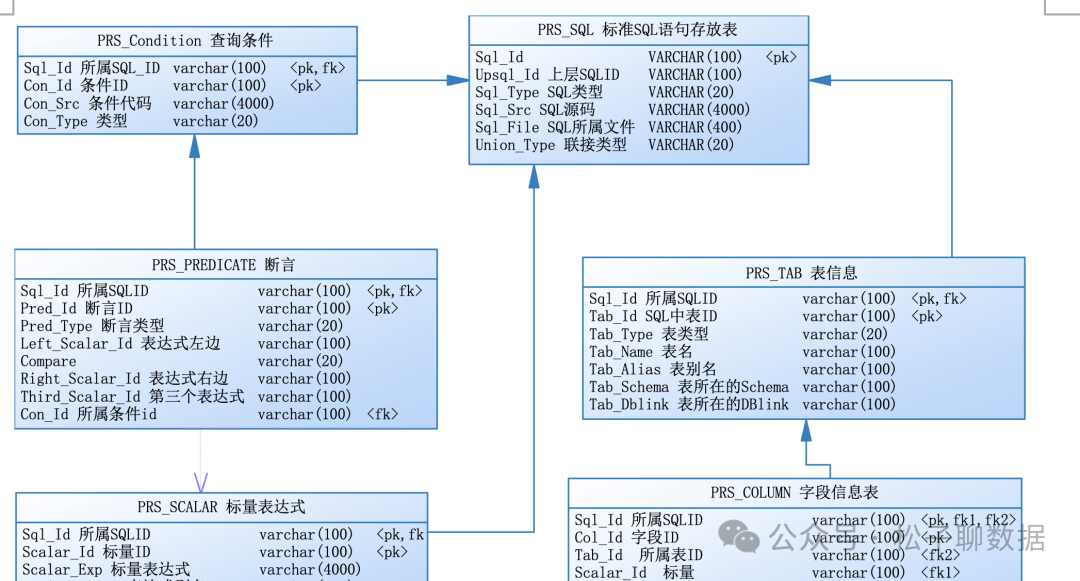
select查询语句执行顺序
SQL查询语句的执行顺序以及JOIN的使用。作为一种声明式编程语言,SQL的执行顺序和我们编写的语句顺序并不完全相同。
理解SQL的执行顺序,有助于使用者更好地优化查询语句,提高查询效率。此外,SQL中的JOIN语句是非常重要和常用的,用于关联多个表进行查询。
SQL是一种声明式的编程语言。这意味着使用者在编写SQL查询语句时,只需要指定想要的结果,而不需要关心具体的实现步骤。数据库系统会根据最优的执行计划来执行使用者的查询。

- SELECT DISTINCT Table1., Table2.
- FROM
- Table1 JOIN Table2 ON matching_condition
- WHERE constraint_expression
- GROUP BY [columns]
- HAVING constraint_expression
- ORDER BY [columns] LIMIT count
-
-
-
- select distinct s.id
- from T t join S s on t.id=s.id
- where t.name="zhouxx"
- group by t.mobile
- having count(*)>2
- order by s.create_time
- limit 5;


- 按照的顺序:
-
- 1. FROM & JOIN: 集合的交并补,即上面的join连接操作
- FROM子句:确定数据来源,包括JOIN的表 ON子句:执行JOIN条件。 JOIN子句:如果有的话,根据JOIN类型(如INNER、LEFT)连接表:
- Left 左表为基础表,右表对应数据不存在则为Null,形成新的虚拟表
- RIGHT 右表为基础表,左表对应数据不存在则为Null,形成新的虚拟表
-
- 首先根据FROM后边的前两个表做一个笛卡尔积生成虚拟表table1,对应步骤1中的from
- 然后根据ON语句的条件对table1进行筛选生成table2,对应步骤1中的on
- 然后根据连接关键字Left、Right、Outer等,对table2进行补充形成table3,对应步骤1中的join
- 如果超过两张表就重复1-3最终形成虚拟表table4
-
- 2. WHERE: 过滤记录
- 对上一步得到的中间结果集进行过滤。
-
- 通过where语句进行筛选,形成虚拟表table5,对应步骤2
- 条件是订单的创建时间(create_time)在'2023-01-01'到'2023-12-31'之间。
- 这一步删除了不在指定时间范围内的订单数据。
-
- 3. GROUP BY: 根据指定的列分组记录
- 就对table5分组形成 虚拟表table6,对应步骤3
- 将上一步的结果集按照用户所在地区(region)进行分组。
- 这一步将相同地区的用户订单信息聚合在一起。
-
- 4. HAVING: 过滤分组GROUP BY
- 对分组后的结果集进一步过滤。
- 条件是每个地区的总订单金额大于1000000。
- 这一步删除了消费总额不满足条件的地区。
-
- 5. SELECT: 选取特定的列
- DISTINCT子句:去除重复数据。
- 函数:对列做特殊运算
- 选择结果集中需要保留的列,包括地区(region)和总金额(total_amount)。
- 其中总金额是通过SUM(o.amount)计算得到的。
-
- 6. ORDER BY: 最后对结果进行排序
- 执行order by子句,此时返回的一个游标,对应步骤6
- 按照总金额(total_amount)对结果集进行倒序排序。
- 这一步将消费总额高的地区排在前面。
-
- 7. LIMIT:
- LIMIT/OFFSET子句(或者是TOP,或者是FETCH):最后的结果截取。
- 限制结果集的数量为10。
- 这一步返回消费总额最高的前10个地区。
-
- ============================================================
- 一 、select语句关键字的定义顺序:
- select distinct <select_list>
- from <left_table>
- <join_type> join
- on <join_condition>
- where <where_condition>
- group by <group_by_list>
- having <having_condition>
- order by <order_by_condition>
- limit <limit_number>
- 二 、 select语句关键字的执行顺序:
- (7) select
- (8) distinct <select_list>
- (1) from <left_table>
- (3) <join_type> join <right_table>
- (2) on <join_condition>
- (4) where <where_condition>
- (5) group by <group_by_list>
- (6) having <having_condition>
- (9) order by <order_by_condition>
- (10) limit <limit_number>
- 第一步 执行 from 知道先从<left_table>这个表开始的
- 第二步 执行 on 过滤 根据 <join_condition> 这里的条件过滤掉不符合内容的数据
- 第三步 执行 join 添加外部行
- -------- inner join 找两张表共同的部分
- --------- left join 以左表为准,找出左表所有的信息,包括右表没有的
- --------- right join 以右表为准,找出左表所有的信息,包括左表没有的
- --------- #注意:mysql不支持全外连接 full JOIN 可以用union
- 第四步 执行 where 条件 where后加需要满足的条件,然后就会得到满足条件的数据
- 第五步 执行 group by 分组 当我们得到满足where条件后的数据时候,group by 可以对其进行分组操作
- 第六步 执行 having 过滤 having 和 group by 通常配合使用,可以对 满足where条件内容进行过滤
- 第七步 执行 select 打印操作 当以上内容都满足之后,才会执行得到select列表
- 第八步 执行 distinct 去重 得到select列表之后,如果指定有 distinct ,执行select后会执行 distinct去重操作
- 第九步 执行 order by 排序 以上得到select列表 也经过去重 基本上就已经得到想要的所有内容了 然后就会执行 order by 排序asc desc
- 第十步 执行 limit 限制打印行数,我们可以用limit 来打印出我们想要显示多少行。
select语句疑惑问题
分析完mysql的执行顺序,很明显别名不可以在join on中使用,因为join on在select之前就执行了,但是我又产生了新的疑问:
- select在group by之后执行,为什么group by中可以使用别名?
- 用on筛选和用where筛选有什么区别?
- order by在select之后,为什么order by可以用select中未选择的列呢?
问题1:select在group by之后执行,为什么group by中可以使用别名?
mysql官网也没有给出具体原因

但目前可以确定的是:select肯定在group by之前执行了一次,可以理解成在原有顺序的基础上的预加载,也就是说对于mysql,每一次运行代码,实际上执行了至少两次select。
问题2:用on筛选和用where筛选有什么区别?
on和where的最大区别在于,如果在on应用逻辑表达式那么在第三步join中还可以把移除的行再次添加回来,而where的移除的最终的;
问题3:order by在select之后,为什么order by可以用select中未选择的列呢?
没找到答案,希望大佬可以解惑。
SQL解析器构思元数据并产出影响与血缘分析

通过该解释器将ETL的SQL 全部解析
ETL名称:in 、out、表、字段、条件 的结构。最后将这些结构连起来就是一个血缘图。下图是完整SQL元数据结构部分模型
其主要的内容可以简单理解为,将SQL语句解析为语法分析树,然后通过Toke序列转化为语法分析树,最终抽象语法树被传递给错误检查和语义分析阶段进行处理。
-
SQL语句:用户或应用程序提交一个或多个SQL语句给数据库执行。
-
SQL语句解析:数据库接收到SQL语句后,会对其进行词法和语法分析。词法分析将SQL语句分解成一个个Token(如关键字、标识符、运算符等),语法分析则根据SQL语法规则验证这些Token序列是否构成一个有效的SQL语句
-
生成语法树:如果SQL语句通过了词法和语法检查,解析器会根据语句的结构生成一棵语法树。语法树以树形结构表示SQL语句各个语法单元之间的关系,叶子节点对应SQL语句中的原子元素如表名、列名、值等,非叶节点则对应各种SQL子句如SELECT、FROM、WHERE等
-
语义分析:语法树生成后还需进行语义检查,如检查表和列是否存在,列之间的数据类型是否匹配等
MySQL架构

Server层负责建立连接、分析和执行SQL
- 连接器、查询缓存、解析器、预处理器、优化器、执行器
- 内置函数:日期、事件、数学、加密函数
- 跨存储引擎的功能:存储过程、触发器、视图
存储引擎负责数据的存储和提取
- InnoDB(5.5版本开始默认引擎)
- MyISAM
- Memory
我们常说的索引数据结构,就是由存储引擎层实现的,不同的存储引擎支持的索引类型也不相同,比如 InnoDB 支持索引类型是 B+树 ,且是默认使用,也就是说在数据表中创建的主键索引和二级索引默认使用的是 B+ 树索引。
连接器
- 建立连接(TCP三次握手、四次挥手)
- 管理连接
- 校验用户身份
如果一个用户已经建立了连接,即使管理员中途修改了该用户的权限,也不会影响已经存在连接的权限。修改完成后,只有再新建的连接才会使用新的权限设置。
查询缓存
如果 SQL 是查询语句(select 语句),MySQL 就会先去查询缓存( Query Cache )里查找缓存数据,看看之前有没有执行过这一条命令,这个查询缓存是以 key-value 形式保存在内存中的,key 为 SQL 查询语句,value 为 SQL 语句查询的结果。
如果查询的语句命中查询缓存,那么就会直接返回 value 给客户端。如果查询的语句没有命中查询缓存中,那么就要往下继续执行,等执行完后,查询的结果就会被存入查询缓存中。
MySQL 8.0 版本直接将查询缓存删掉了,也就是说 MySQL 8.0 开始,执行一条 SQL 查询语句,不会再走到查询缓存这个阶段了。对于 MySQL 8.0 之前的版本,如果想关闭查询缓存,我们可以通过将参数 query_cache_type 设置成 DEMAND。
解析SQL
解析器
-
词法分析,构建出 SQL 语法树
-
语法分析,判断 SQL 语句是否满足 MySQL 语法(关键字拼写错误)
执行SQL
预处理器
- 检查 SQL 查询语句中的表或者字段是否存在(不存在报错);
- 将
select *中的*符号,扩展为表上的所有列;
优化器
优化器主要负责将 SQL 查询语句的执行方案确定下来,比如在表里面有多个索引的时候,优化器会基于查询成本的考虑,来决定选择使用哪个索引。
主键索引
- 属于聚簇索引,索引和数据一块储存
- InnoDB只有主键索引才能是聚簇索引
所谓的聚簇索引,就是一个节点就是整个的一行数据。我们平常见到的二叉树数据结构像这样
- struct TreeNode {
- int val;
- TreeNode *left;
- TreeNode *right;
- TreeNode() : val(0), left(nullptr), right(nullptr) {}
- TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
- TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
- };
数据结构中只有左右指针和当前节点的值,可以根据节点的值建立二叉搜索树。代入到聚簇索引的定义中,根据主键建立B+树,就像二叉搜索树左孩子val小于自己,右孩子大于自己。数据结构储存更多的东西,把表中一行的所有内容都作为成员变量存起来。找到了主键的节点,也就找到了这一行的所有数据。
非聚簇索引则是使用索引项建立B+树,例如根据年龄、名字等,节点里面则储存着对应行的主键。比如我要查询年龄大于21岁的人,并且年龄这一列拥有索引(显然应该是非聚簇的,因为年龄可能重复)。抽象地,我们认为把年龄进行了排序,我们仅能看到一群年龄从小到大,而不知道这些人是谁。我们把大于21岁人拉过来,挨个撕开他们的面纱,也就是他们的主键,才知道是谁。非聚簇索引只储存主键,如果要查询那一行的其他信息,则要根据主键再进行查询,也就是用上面的那个聚簇索引,找到了主键就找到了那一行的所有值。这称为回表查询。
非聚簇索引不一定进行回表查询。覆盖索引即需要查询的字段正好是索引的字段,那么直接根据该索引,就可以查到数据了, 而无需回表查询。
用户准备使用 SQL 查询用户名,而用户名字段正好建立了索引。那么这个索引的 key 本身就是 name,查到对应的 name 直接返回就行了,无需回表查询。(是不是很神奇?这不废话吗
二级索引
二级索引又称为辅助索引,是因为二级索引的叶子节点存储的数据是主键。也就是说,通过二级索引,可以定位主键的位置。二级索引都是非聚簇索引。
- 唯一索引(Unique Key)
- 普通索引(Index)
- 前缀索引(Prefix)
回到优化器,举一个例子:
select id from product where id > 1 and name like 'i%';
product 表有主键索引(id)和普通索引(name)。这条查询语句的结果既可以使用主键索引,也可以使用普通索引,但是执行的效率会不同。这时,就需要优化器来决定使用哪个索引了。
很显然这条查询语句是覆盖索引,直接在二级索引就能查找到结果(因为二级索引的 B+ 树的叶子节点的数据存储的是主键值),就没必要在主键索引查找了,因为查询主键索引的 B+ 树的成本会比查询二级索引的 B+ 的成本大,优化器基于查询成本的考虑,会选择查询代价小的普通索引。
执行器
在执行的过程中,执行器和存储引擎交互,交互是以记录为单位的。
- 主键索引查询
select * from product where id = 1;
存储引擎通过主键索引的 B+ 树结构定位到 id = 1的第一条记录,如果记录是不存在的,就会向执行器上报记录找不到的错误,然后查询结束。如果记录是存在的,就会将记录返回给执行器;
执行器从存储引擎读到记录后,接着判断记录是否符合查询条件(其他查询条件,这一步只是满足了主键的条件),如果符合则发送给客户端,如果不符合则跳过该记录。
- 全表扫描
存储引擎把一条记录取出后就将其返回给执行器(Server层),执行器继续判断条件,不符合查询条件即跳过该记录,否则发送到客户端;
Server 层每从存储引擎读到一条记录就会发送给客户端,之所以客户端显示的时候是直接显示所有记录的,是因为客户端是等查询语句查询完成后,才会显示出所有的记录
- 索引下推
MySQL 5.6 推出的查询优化策略。索引下推能够减少二级索引在查询时的回表操作,提高查询的效率,因为它将 Server 层部分负责的事情,交给存储引擎层去处理了。
select * from t_user where age > 20 and reward = 100000;
联合索引当遇到范围查询 (>、<) 就会停止匹配,也就是 age 字段能用到联合索引,但是 reward 字段则无法利用到索引。
那么,不使用索引下推(MySQL 5.6 之前的版本)时,执行器与存储引擎的执行流程是这样的:
- Server 层首先调用存储引擎的接口定位到满足查询条件的第一条二级索引记录,也就是定位到 age > 20 的第一条记录;
- 存储引擎根据二级索引的 B+ 树快速定位到这条记录后,获取主键值,然后进行回表操作,将完整的记录返回给 Server 层;
- Server 层在判断该记录的 reward 是否等于 100000,如果成立则将其发送给客户端;否则跳过该记录;
- 接着,继续向存储引擎索要下一条记录,存储引擎在二级索引定位到记录后,获取主键值,然后回表操作,将完整的记录返回给 Server 层;
- 如此往复,直到存储引擎把表中的所有记录读完。
可以看到,没有索引下推的时候,每查询到一条二级索引记录,都要进行回表操作,然后将记录返回给 Server,接着 Server 再判断该记录的 reward 是否等于 100000。
而使用索引下推后,判断记录的 reward 是否等于 100000 的工作交给了存储引擎层,过程如下 :
- Server 层首先调用存储引擎的接口定位到满足查询条件的第一条二级索引记录,也就是定位到 age > 20 的第一条记录;
- 存储引擎定位到二级索引后,先不执行回表操作,而是先判断一下该索引中包含的列(reward列)的条件(reward 是否等于 100000)是否成立。如果条件不成立,则直接跳过该二级索引。如果成立,则执行回表操作,将完成记录返回给 Server 层。
- Server 层在判断其他的查询条件(本次查询没有其他条件)是否成立,如果成立则将其发送给客户端;否则跳过该记录,然后向存储引擎索要下一条记录。
- 如此往复,直到存储引擎把表中的所有记录读完。
可以看到,使用了索引下推后,虽然 reward 列无法使用到联合索引,但是因为它包含在联合索引(age,reward)里,所以直接在存储引擎过滤出满足 reward = 100000 的记录后,才去执行回表操作获取整个记录。相比于没有使用索引下推,节省了很多回表操作。
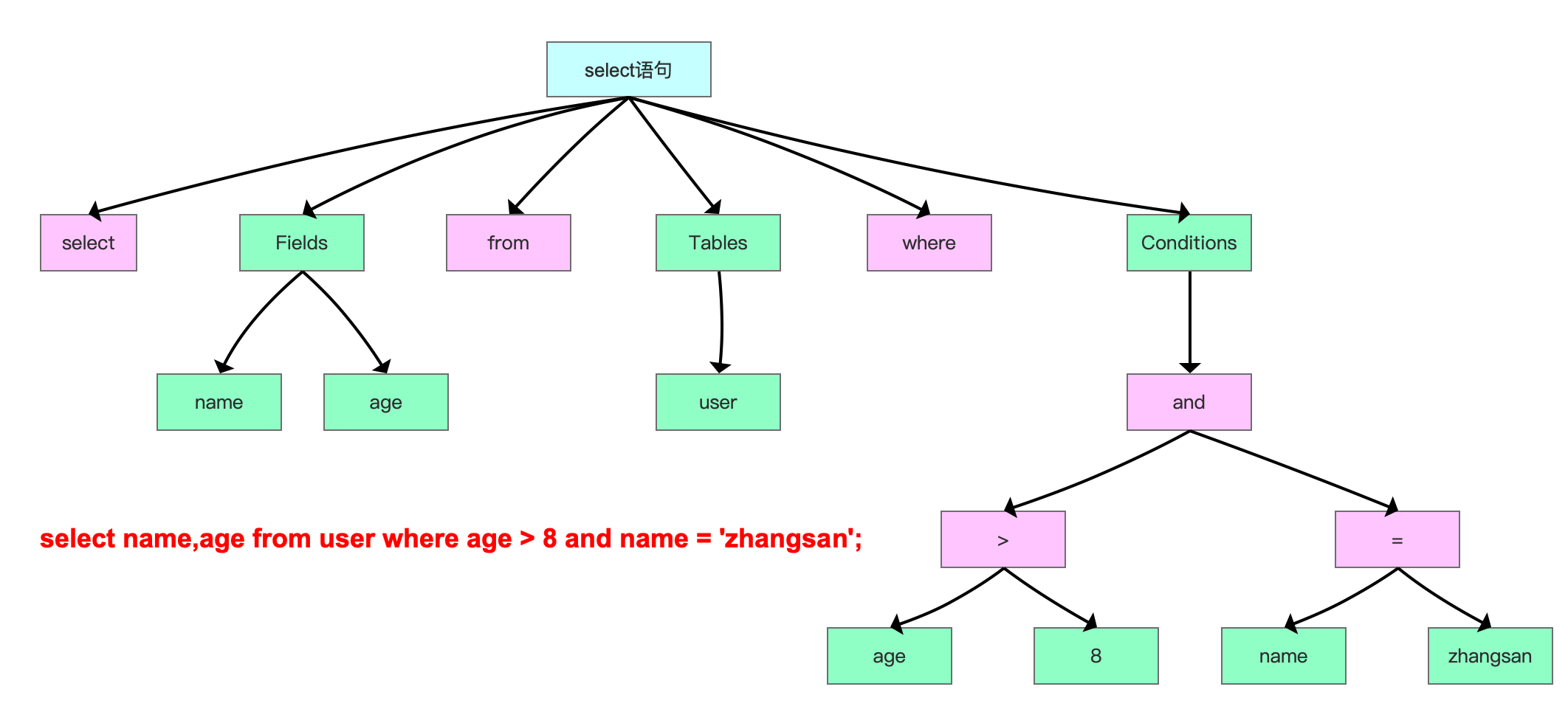
MySQL执行sql语句的流程

贴一个全的图:添删改查语句执行过程
1.1:连接器(Connection Manager)
MySQL 的执行流程始于连接器。当客户端请求与 MySQL 建立连接时,连接器负责处理这些连接请求。它验证客户端的身份和权限,然后分配一个线程来处理该连接。MySQL 每个连接线程会创建一个会话(session),在这个会话中,客户端可以发送 SQL 语句进行增删改查等操作。
连接器的主要职责就是:
- ①负责与客户端的通信,是半双工模式,这就意味着某一固定时刻只能由客户端向服务器请求或者服务器向客户端发送数据,而不能同时进行,其中mysql在与客户端连接TC/IP的
- ②验证请求用户的账户和密码是否正确,如果账户和密码错误,会报错:Access denied for user 'root'@'localhost' (using password: YES)
- ③如果用户的账户和密码验证通过,会在mysql自带的权限表中查询当前用户的权限:
相关文章:
SQL执行流程、SQL执行计划、SQL优化
select查询语句 select查询语句中join连接是如何工作的? 1、INNER JOIN 返回两个表中的匹配行。 2、LEFT JOIN 返回左表中的所有记录以及右表中的匹配记录。 3、RIGHT JOIN 返回右表中的所有记录以及左表中的匹配记录。 4、FULL OUTER JOIN 返回左侧或右侧表中有匹…...

【前端】JavaScript入门及实战41-45
文章目录 41 嵌套的for循环42 for循环嵌套练习(1)43 for循环嵌套练习(2)44 break和continue45 质数练习补充 41 嵌套的for循环 <!DOCTYPE html> <html> <head> <title></title> <meta charset "utf-8"> <script type"…...
更加深入Mysql-04-MySQL 多表查询与事务的操作
文章目录 多表查询内连接隐式内连接显示内连接 外连接左外连接右外连接 子查询 事务事务隔离级别 多表查询 有时我们不仅需要一个表的数据,数据可能关联到俩个表或者三个表,这时我们就要进行夺标查询了。 数据准备: 创建一个部门表并且插入…...

基于最新版的flutter pointycastle: ^3.9.1的AES加密
基于最新版的flutter pointycastle: ^3.9.1的AES加密 自己添加pointycastle: ^3.9.1库config.dartaes_encrypt.dart 自己添加pointycastle: ^3.9.1库 config.dart import dart:convert; import dart:typed_data;class Config {static String password 成都推理计算科技; // …...

K8S内存资源配置
在 Kubernetes (k8s) 中,资源请求和限制用于管理容器的 CPU 和内存资源。配置 CPU 和内存资源时,使用特定的单位来表示资源的数量。 CPU 资源配置 CPU 单位:Kubernetes 中的 CPU 资源以 “核” (cores) 为单位。1 CPU 核心等于 1 vCPU/Core…...

【多任务YOLO】 A-YOLOM: You Only Look at Once for Real-Time and Generic Multi-Task
You Only Look at Once for Real-Time and Generic Multi-Task 论文链接:http://arxiv.org/abs/2310.01641 代码链接:https://github.com/JiayuanWang-JW/YOLOv8-multi-task 一、摘要 高精度、轻量级和实时响应性是实现自动驾驶的三个基本要求。本研究…...

数学建模--灰色关联分析法
目录 简介 基本原理 应用场景 优缺点 优点: 缺点: 延伸 灰色关联分析法在水质评价中的具体应用案例是什么? 如何克服灰色关联分析法在主观性强时的数据处理和改进方法? 灰色关联分析法与其他系统分析方法(如A…...
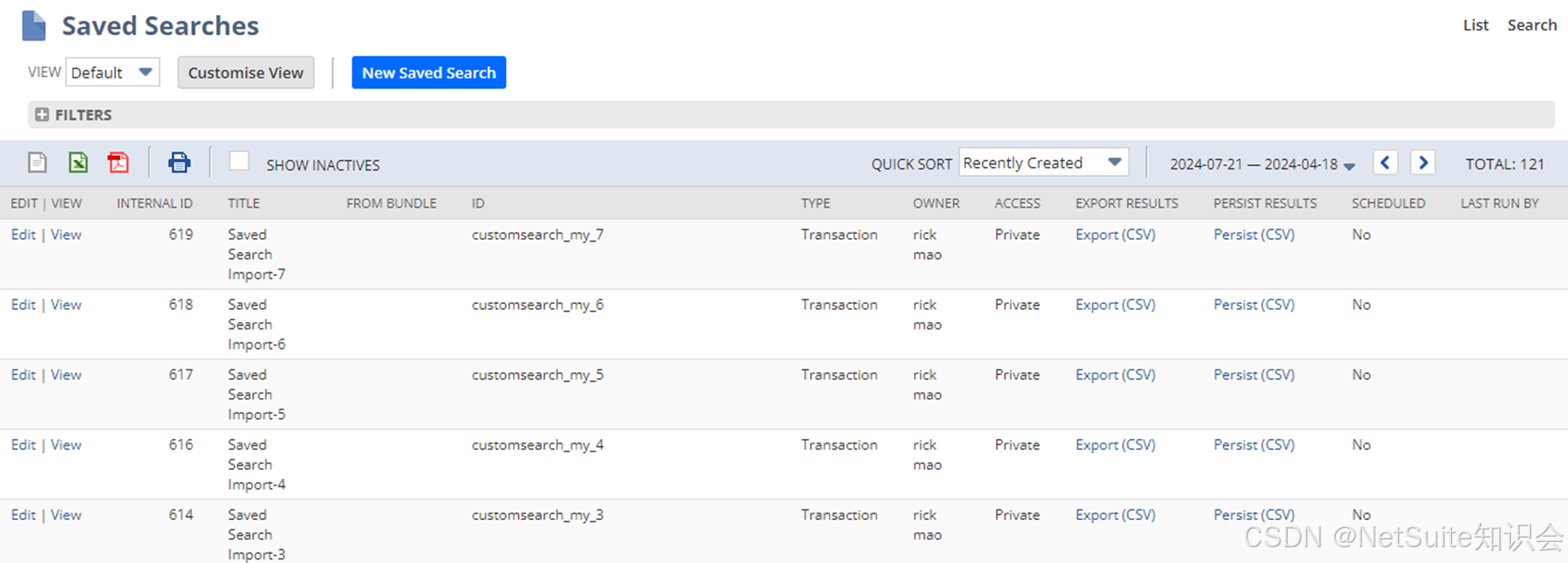
NetSuite Saved Search迁移工具
我们需要在系统间迁移Saved Search,但是采用Copy To Account或者Bundle时,会有一些Translation不能迁移,或者很多莫名其妙的Dependency,导致迁移失败。因此,我们想另辟蹊径,借助代码完成Saved Search的迁移…...
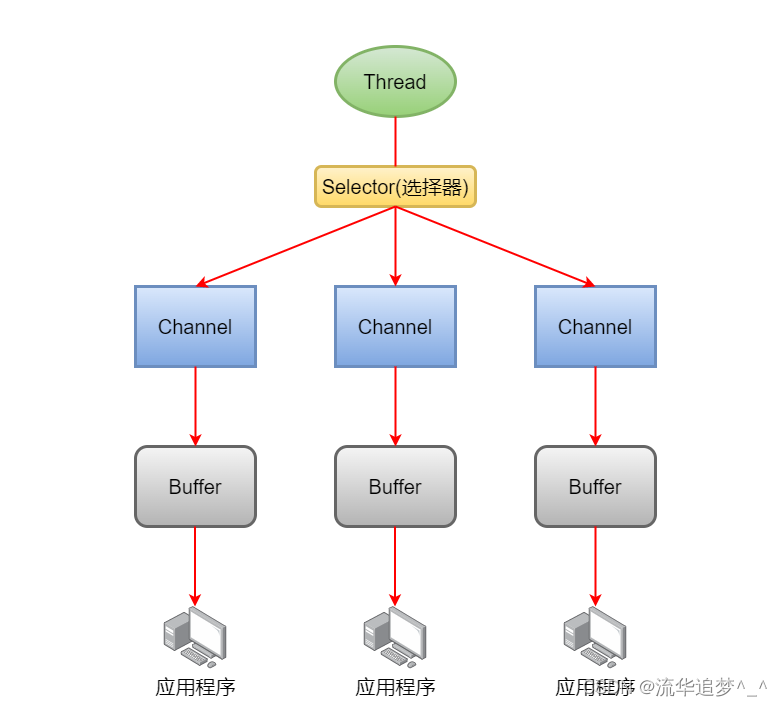
Java IO模型深入解析:BIO、NIO与AIO
Java IO模型深入解析:BIO、NIO与AIO 一. 前言 在Java编程中,IO(Input/Output)操作是不可或缺的一部分,它涉及到文件读写、网络通信等方面。Java提供了多种类和API来支持这些操作。本文将从IO的基础知识讲起ÿ…...
《从C/C++到Java入门指南》- 9.字符和字符串
字符和字符串 字符类型 Java 中一个字符保存一个Unicode字符,所以一个中文和一个英文字母都占用两个字节。 // 计算1 .. 100 public class Hello {public static void main(String[] args) {char a A;char b 中;System.out.println(a);System.out.println(b)…...
Adobe国际认证详解-视频剪辑
在数字化时代,视频剪辑已成为创意表达和视觉传播的重要手段。随着技术的不断进步,熟练掌握视频剪辑技能的专业人才需求日益增长。在这个背景下,Adobe国际认证应运而生,成为全球创意设计领域的重要标杆。 Adobe国际认证是由Adobe公…...

昇思25天学习打卡营第19天|MindNLP ChatGLM-6B StreamChat
文章目录 昇思MindSpore应用实践ChatGML-6B简介基于MindNLP的ChatGLM-6B StreamChat Reference 昇思MindSpore应用实践 本系列文章主要用于记录昇思25天学习打卡营的学习心得。 ChatGML-6B简介 ChatGLM-6B 是由清华大学和智谱AI联合研发的产品,是一个开源的、支持…...

.NET在游戏开发中有哪些成功的案例?
简述 在游戏开发的多彩世界中,技术的选择往往决定了作品的成败。.NET技术,以其跨平台的性能和强大的开发生态,逐渐成为游戏开发者的新宠。本文将带您探索那些利用.NET技术打造出的著名游戏案例,领略.NET在游戏开发中的卓越表现。 …...

搜维尔科技:我们用xsens完成了一系列高难度的运动项目并且捕获动作
我们用xsens完成了一系列高难度的运动项目并且捕获动作 搜维尔科技:我们用xsens完成了一系列高难度的运动项目并且捕获动作...

深入探讨:Node.js、Vue、SSH服务与SSH免密登录
在这篇博客中,我们将深入探讨如何在项目中使用Node.js和Vue,并配置SSH服务以及实现SSH免密登录。我们会一步步地进行讲解,并提供代码示例,确保你能轻松上手。 一、Node.js 与 Vue 的结合 1.1 Node.js 简介 Node.js 是一个基于 …...
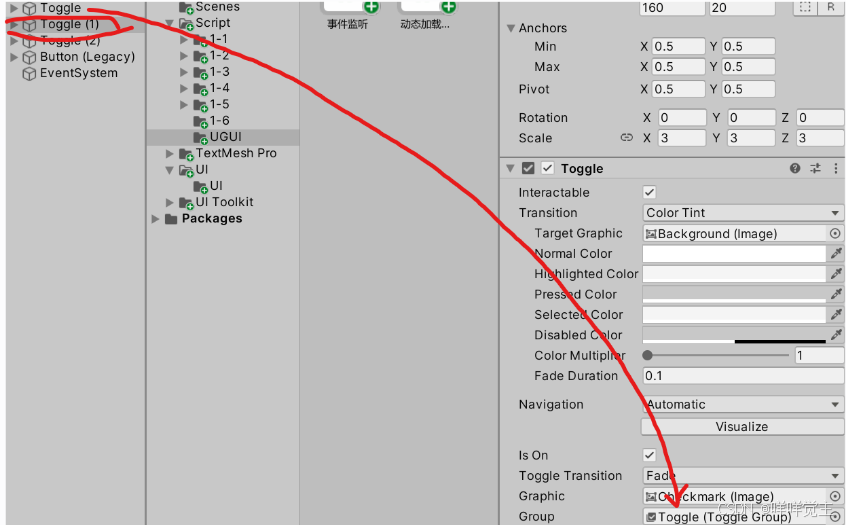
Unity UGUI 之 Toggle
本文仅作学习笔记与交流,不作任何商业用途本文包括但不限于unity官方手册,唐老狮,麦扣教程知识,引用会标记,如有不足还请斧正 1.什么是Toggle? Unity - Manual: Toggle 带复选框的开关,可…...

Git报错:error: fsmonitor--daemon failed to start处理方法
问题描述 git用了很久了,但是后面突然发现执行命令时,后面都会出现这个报错,虽然该报错好像不会影响正常的命令逻辑,但是还是感觉有天烦人,就去找了找资料。 $ git status error: fsmonitor--daemon failed to start…...
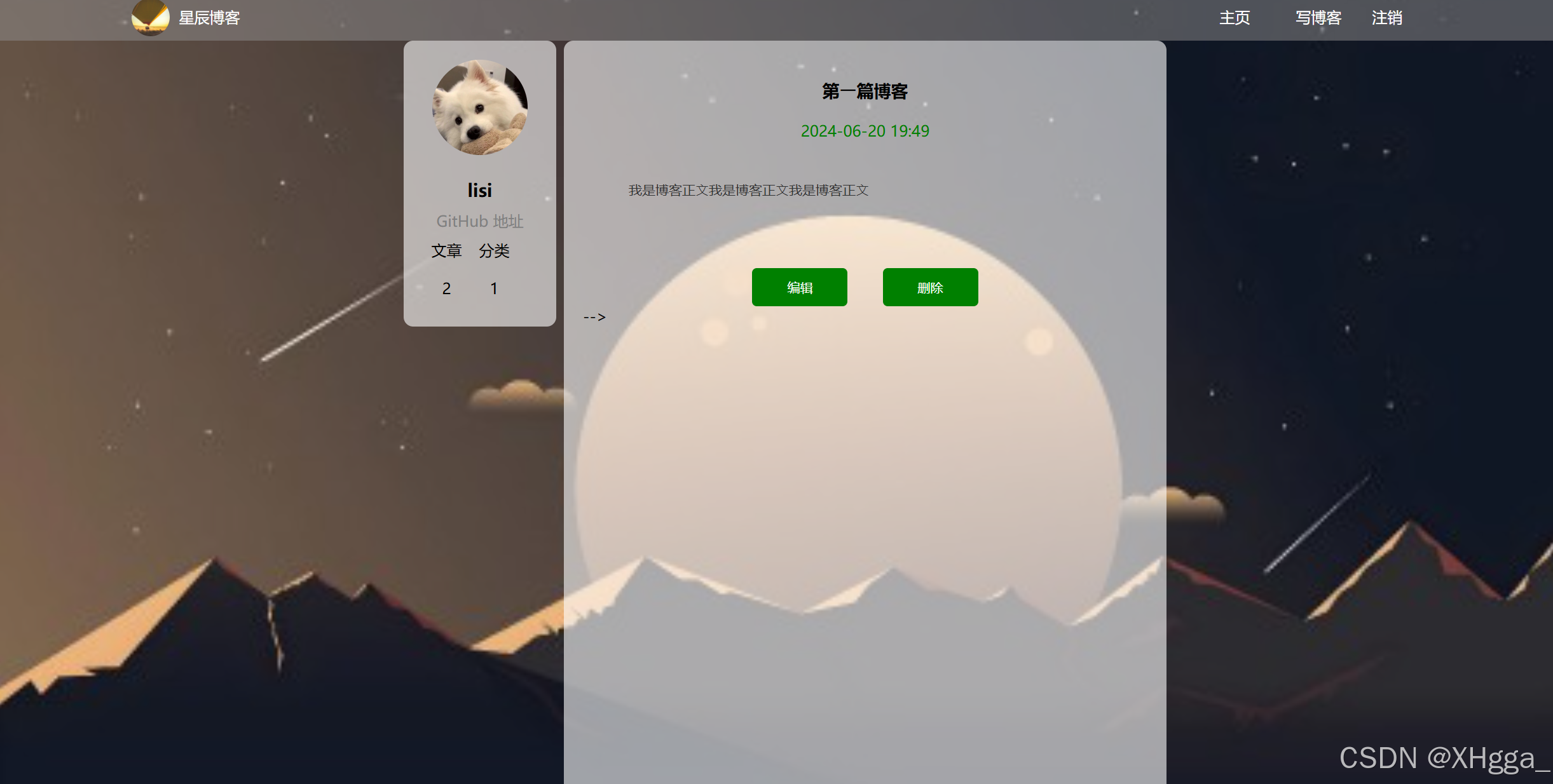
【项目】星辰博客介绍
目录 一、项目背景 二、项目功能 1. 登录功能: 2. 列表页面: 3. 详情页面: 4. 写博客: 三、技术实现 四、功能页面展示 1. 用户登录 2. 博客列表页 3. 博客编辑更新页 4.博客发表页 5. 博客详情页 五.系统亮点 1.强…...

从0开始的STM32HAL库学习6
外部时钟源选择 配置环境 选择TIM2 配置红色框图中的各种配置 时钟源选择外部时钟 2 1. 预分频器 Prescaler ,下面填0,不分频 2. 计数模式 CounterModer ,计数模式选择为向上计数 3. 自动重装寄存器 CouterPeriod ,自动重…...

Elasticsearch ILM 热节点迁移至冷节点 IO 打满、影响读写解决方案探讨
1、实战问题 ILM(索引生命周期管理) 遇到热数据迁移至冷节点时造成 IO 打满影响读写的情况。 现在采取的方案是调整索引生命周期策略,定时的将Cold phase 开启/关闭。低峰开启,高峰关闭。 就是不知道这里面会有啥坑。 热节点&…...
详解)
后进先出(LIFO)详解
LIFO 是 Last In, First Out 的缩写,中文译为后进先出。这是一种数据结构的工作原则,类似于一摞盘子或一叠书本: 最后放进去的元素最先出来 -想象往筒状容器里放盘子: (1)你放进的最后一个盘子(…...

挑战杯推荐项目
“人工智能”创意赛 - 智能艺术创作助手:借助大模型技术,开发能根据用户输入的主题、风格等要求,生成绘画、音乐、文学作品等多种形式艺术创作灵感或初稿的应用,帮助艺术家和创意爱好者激发创意、提高创作效率。 - 个性化梦境…...
:にする)
日语学习-日语知识点小记-构建基础-JLPT-N4阶段(33):にする
日语学习-日语知识点小记-构建基础-JLPT-N4阶段(33):にする 1、前言(1)情况说明(2)工程师的信仰2、知识点(1) にする1,接续:名词+にする2,接续:疑问词+にする3,(A)は(B)にする。(2)復習:(1)复习句子(2)ために & ように(3)そう(4)にする3、…...

JavaScript 中的 ES|QL:利用 Apache Arrow 工具
作者:来自 Elastic Jeffrey Rengifo 学习如何将 ES|QL 与 JavaScript 的 Apache Arrow 客户端工具一起使用。 想获得 Elastic 认证吗?了解下一期 Elasticsearch Engineer 培训的时间吧! Elasticsearch 拥有众多新功能,助你为自己…...

基于Uniapp开发HarmonyOS 5.0旅游应用技术实践
一、技术选型背景 1.跨平台优势 Uniapp采用Vue.js框架,支持"一次开发,多端部署",可同步生成HarmonyOS、iOS、Android等多平台应用。 2.鸿蒙特性融合 HarmonyOS 5.0的分布式能力与原子化服务,为旅游应用带来…...

[ICLR 2022]How Much Can CLIP Benefit Vision-and-Language Tasks?
论文网址:pdf 英文是纯手打的!论文原文的summarizing and paraphrasing。可能会出现难以避免的拼写错误和语法错误,若有发现欢迎评论指正!文章偏向于笔记,谨慎食用 目录 1. 心得 2. 论文逐段精读 2.1. Abstract 2…...

Java-41 深入浅出 Spring - 声明式事务的支持 事务配置 XML模式 XML+注解模式
点一下关注吧!!!非常感谢!!持续更新!!! 🚀 AI篇持续更新中!(长期更新) 目前2025年06月05日更新到: AI炼丹日志-28 - Aud…...
)
.Net Framework 4/C# 关键字(非常用,持续更新...)
一、is 关键字 is 关键字用于检查对象是否于给定类型兼容,如果兼容将返回 true,如果不兼容则返回 false,在进行类型转换前,可以先使用 is 关键字判断对象是否与指定类型兼容,如果兼容才进行转换,这样的转换是安全的。 例如有:首先创建一个字符串对象,然后将字符串对象隐…...

CVE-2020-17519源码分析与漏洞复现(Flink 任意文件读取)
漏洞概览 漏洞名称:Apache Flink REST API 任意文件读取漏洞CVE编号:CVE-2020-17519CVSS评分:7.5影响版本:Apache Flink 1.11.0、1.11.1、1.11.2修复版本:≥ 1.11.3 或 ≥ 1.12.0漏洞类型:路径遍历&#x…...

AGain DB和倍数增益的关系
我在设置一款索尼CMOS芯片时,Again增益0db变化为6DB,画面的变化只有2倍DN的增益,比如10变为20。 这与dB和线性增益的关系以及传感器处理流程有关。以下是具体原因分析: 1. dB与线性增益的换算关系 6dB对应的理论线性增益应为&…...