【Langchain大语言模型开发教程】基于文档问答
🔗 LangChain for LLM Application Development - DeepLearning.AI
Embedding: https://huggingface.co/BAAI/bge-large-en-v1.5/tree/main
学习目标
1、Embedding and Vector Store
2、RetrievalQA
引包、加载环境变量
import osfrom dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv()) # read local .env filefrom langchain.indexes import VectorstoreIndexCreator
from langchain.chains import RetrievalQA
from langchain_openai import ChatOpenAI
from langchain.document_loaders import CSVLoader
from langchain.vectorstores import DocArrayInMemorySearch
from langchain_huggingface import HuggingFaceEmbeddings
from IPython.display import display, Markdown加载一下我们的文件
file = 'OutdoorClothingCatalog_1000.csv'
loader = CSVLoader(file_path=file, encoding='utf-8')
docs = loader.load()Embedding and vector Store
大语言模型一次只能处理几千个单词,如果我们有一个非常大的文档的话,大语言模型不能一次全部处理,怎么办?

这时候就需要用到embeding和 vector store,先来看看embeding

embeding将一段文本转化成数字,用一组数字来表示这段文本。这组数字捕捉了这段文本表示的内容,内容相似的文本,将会有相似的向量值。我们可以在向量空间中比较文本片段来查看他们之间的相似性。
我们使用智源实验室推出的BGE Embedding模型;
model_name = "bge-large-en-v1.5"
embeddings = HuggingFaceEmbeddings(model_name=model_name)有了embedding模型后,我们还需要一个向量数据库, 创建向量数据库,首先需要将文档进行切片分割操作,把文档切分成一个个块(chunks),然后对每个块做embedding,最后再把由embedding生成的所有向量存储在向量数据库中;

我们使用DocArrayInMemorySearch作为向量数据库,DocArrayInMemorySearch是由Docarray提供的文档索引,它将会整个文档以向量的形式存储在内存中;
db = DocArrayInMemorySearch.from_documents(docs, embeddings)
当我们完成了向量数据库构建后,在用户提问时,用户的问题通过Embedding操作生成一组向量,接下来将该向量与向量数据库中的所有向量进行比较,找出前n个最相似的向量并将其转换成对应的文本信息。我们有这样一个问题,现在我们通过向量数据库来查找和该问题相似度最高的内容;
query = "Please suggest a shirt with sunblocking"docs = db.similarity_search(query)我们这里查看一下检索到的第一条数据 ,确实是跟防嗮有关的;
最后,我们将这些与用户问题最相似的文本信息输入到LLM,并由LLM生成最终的回复;
# 创建一个检索器
retriever = db.as_retriever()# 初始化LLM
llm = ChatOpenAI(api_key=os.environ.get('ZHIPUAI_API_KEY'),base_url=os.environ.get('ZHIPUAI_API_URL'),model="glm-4",temperature=0.98)刚刚我们输入了一个问题并在向量数据库中检索到了一些相关信息,接下来我们将这些信息和问题一起输入到大语言模型中,使用markdown的格式展示一下效果;
docs_str = "".join([docs[i].page_content for i in range(len(docs))])response = llm.invoke(f"{docs_str} Question: Please list all your shirts with sun protection in a table in markdown and summarize each one.")display(Markdown(response.content))这是智谱GLM4帮我们整理之后的答案,并且帮我们整理好了;

RetrievalQA
当然,如果你觉得这很麻烦,我们可以创建一个RetrievalQA链,这样调用也是可以的;
qa_stuff = RetrievalQA.from_chain_type(llm=llm, chain_type="stuff", retriever=retriever, verbose=True
)query = "Please list all your shirts with sun protection in a table in markdown and summarize each one."response = qa_stuff.invoke(query)该chain包含三个主要的参数,其中llm参数是我们的智谱GLM4, retriever参数设置设置为前面我们由DocArrayInMemorySearch创建的retriever,最后一个重要的参数为chain_type,该参数包含了四个可选值:stuff,map_reduce,refine,map_rerank,接下来我们简单了解一下这些选择的区别;

这种最简单粗暴,会把所有的 document 一次全部传给 llm 模型进行总结。如果document很多话,可能会报超出最大 token 限制的错。

这个方式会先将每个 document 通过llm 进行总结,最后将所有 document 总结出的结果再进行一次总结。

这种方式会先总结第一个 document,然后在将第一个 document 总结出的内容和第二个document 一起发给 llm 模型再进行总结,以此类推。这种方式的好处就是在总结后一个 document 的时候,会带着前一个的 document 进行总结,给需要总结的 document 添加了上下文,增加了总结内容的连贯性。

这种方式会通过llm对每个文档进行一次总结,然后得到一个分数,最后选择一个分数最高的总结作为最终回复。
相关文章:
【Langchain大语言模型开发教程】基于文档问答
🔗 LangChain for LLM Application Development - DeepLearning.AI Embedding: https://huggingface.co/BAAI/bge-large-en-v1.5/tree/main 学习目标 1、Embedding and Vector Store 2、RetrievalQA 引包、加载环境变量 import osfrom dotenv import…...

大厂面试-基本功
大厂面试第4季 服务可用性多少个9是什么意思遍历集合add或remove操作bughashcode冲突案例BigdecimalList去重复IDEA Debugger测试框架ThreaLocal父子线程数据同步 InheritableThreadLocal完美解决线程数据同步方案 TransmittableThreadLocal 服务可用性多少个9是什么意思 遍历集…...

RV1103使用rtsp和opencv推流视频到网页端
参考: Luckfox-Pico/Luckfox-Pico-RV1103/Luckfox-Pico-pinout/CSI-Camera Luckfox-Pico/RKMPI-example Luckfox-Pico/RKMPI-example 下载源码 其中源码位置:https://github.com/luckfox-eng29/luckfox_pico_rtsp_opencv 使用git clone由于项目比较大&am…...

与Bug较量:Codigger之软件项目体检Software Project HealthCheck来帮忙
在软件工程师的世界里,与 Java 小程序中的 Bug 作战是一场永不停歇的战役。每一个隐藏在代码深处的 Bug 都像是一个狡猾的敌人,时刻准备着给我们的项目带来麻烦。 最近,我就陷入了这样一场与 Java 小程序 Bug 的激烈较量中。这个小程序原本应…...

Git --- Branch Diverged
Git --- Branch Diverged Branch Diverged是如何形成的如何解决RebaseMerge Branch Diverged是如何形成的 尝试提交并将更改推送到 master 分支时,是否看到这条烦人的消息 原因是: 直到更改 B 之前,我的分支和“origin/master”完全相同。从…...

go标准库---net/http服务端
1、http简单使用 go的http标准库非常强大,调用了两个函数就能够实现一个简单的http服务: func HandleFunc(pattern string, handler func(ResponseWriter, *Request)) func ListenAndServe(addr string, handler Handler) error handleFunc注册一个路…...

Linux文件和目录常用命令
1.操作命令 查看目录内容 ls 切换目录 cd 创建和删除操作 touch rm mkdir 拷贝和移动文件 cp mv 查看文件内容 cat more grep 其他 echo 重定向 > 和 >> 管道 | 1.1 终端实用技巧 1>自动补全 在敲出 文件/目录/命令 的前几个字母之后,按下…...

【C++刷题】优选算法——链表
链表常用技巧和操作总结 常用技巧 画图 引入虚拟头节点 不要吝啬空间,大胆定义变量 快慢双指针常用操作 创建一个新节点 尾插 头插 两数相加 ListNode* addTwoNumbers(ListNode* l1, ListNode* l2) {int carry 0;ListNode* newHead new ListNode, *cur newHea…...

Flex和Bison
Flex和Bison是Linux和Unix环境下两个非常强大的工具,分别用于生成词法分析器和语法分析器。它们在编译器设计、文本处理等领域有着广泛的应用。下面我将详细介绍Flex和Bison的基本概念、功能、用法以及它们之间的关系。 一、Flex 1. 基本概念 Flex(其…...

Matlab-FPGA 小数转换为定点二进制小数脚本和转coe文件格式脚本
Matlab-FPGA 小数转换为定点二进制小数脚本: % 更新于2023年6月17日,修改旋转因子文件,不修改fpga %首先明确我们的二维FFT的数组维数,此为1024*8的二维矩阵,1024行,8列 column 1024; row 8; nk[]; Ncolumn*row; fo…...

逆向案例二十三——请求头参数加密,某区块链交易逆向
网址:aHR0cHM6Ly93d3cub2tsaW5rLmNvbS96aC1oYW5zL2J0Yy90eC1saXN0L3BhZ2UvNAo 抓包分析,发现请求头有X-Apikey参数加密,其他表单和返回内容没有加密。 直接搜索关键字,X-Apikey,找到疑似加密位置,注意这里…...

CSS 导航栏:设计、定制与优化
CSS 导航栏:设计、定制与优化 CSS(层叠样式表)是网页设计中不可或缺的一部分,它允许开发者通过定义样式来控制网页的布局和外观。在网页设计中,导航栏是一个关键元素,它帮助用户浏览网站并找到他们感兴趣的…...

JS 如何处理链接被用户点击中键的操作
今天在开发中遇到一个问题,在使用类似Bootstrap中的Tabs组件时,当在tab导航链接点击中键时会打开一个新的窗口访问链接,于是我尝试在别的普通链接上点击中键时也会如此,我猜测这是浏览器的默认行为。 由于我开发的是一个浏览器在…...
)
Android 11 使用HAL层的ffmpeg库(1)
1.frameworks/av/media目录下面的修改 From edd6f1374c1f15783d9920ebda22ea915e503775 Mon Sep 17 00:00:00 2001 From: GW00219471 <zhumingxingnoboauto.com> Date: Wed, 17 Jan 2024 15:16:10 0800 Subject: [PATCH] ?UTF-8?q?[V35CUX-4542]:E7A7BBE6A48Dcux20E8…...

友力科技数据中心搬迁方案
将当前运行机房中的所有设备、应用系统安全搬迁至新数据中心机房,实现平滑切换、平稳过渡,最大限度地降低搬迁工作对业务的影响。 为了确保企事业单位能够顺利完成数据中心机房搬迁工作,我们根据实际经验提供了4个基本原则,希望能…...

GitHub敏感信息扫描工具
目录 功能设计 技术实现 程序使用 文件配置 下载地址 功能设计 GitPrey是根据企业关键词进行项目检索以及相应敏感文件和敏感文件内容扫描的工具,其设计思路如下: 根据关键词在GitHub中进行全局代码内容和路径的搜索(in:file,path),将项目结果做项目信息去重整理得到…...

Linux云计算 |【第一阶段】ENGINEER-DAY4
主要内容: 配置Linux网络参数、配置静态主机名、查看/修改/激活/禁用网络连接、指定DNS、虚拟网络连接、虚拟机克隆、SSH客户端、SCP远程复制、SSH无密码验证(SERVICE-DAY5)、虚拟网络类型 一、网络参数配置 修改网卡配置文件主要是需要配置…...

C++与VLC制作独属于你的动态壁纸背景
文章目录 前言效果展示为什么要做他如何实现他实现步骤获取桌面句柄代码获取桌面句柄libvlc_media_player_set_hwnd函数 动态壁纸代码 总结 前言 在当今的数字世界中,个性化和自定义化的体验越来越受到人们的欢迎。动态壁纸是其中一种很受欢迎的方式,它…...

平凯星辰黄东旭出席 2024 全球数字经济大会 · 开放原子开源数据库生态论坛
7 月 5 日,以“开源生态筑基础,数字经济铸未来”为主题的 2024 全球数字经济大会——开放原子开源数据库生态论坛在北京成功举办。平凯星辰(北京)科技有限公司联合创始人黄东旭发表了题为《TiDB 助力金融行业关键业务系统实践》的…...

Mac OS 下安装 NVM,1秒教会你
1.下载 curl -o- https://raw.githubusercontent.com/nvm-sh/nvm/v0.39.7/install.sh | bash或者wget -qO- https://raw.githubusercontent.com/nvm-sh/nvm/v0.39.7/install.sh | bash 2.安装成功后执行 nvm 提示 command not found 首先查看 ~/.bash_profile 文件是否存在&…...

定时器任务——若依源码分析
分析util包下面的工具类schedule utils: ScheduleUtils 是若依中用于与 Quartz 框架交互的工具类,封装了定时任务的 创建、更新、暂停、删除等核心逻辑。 createScheduleJob createScheduleJob 用于将任务注册到 Quartz,先构建任务的 JobD…...

Qt Http Server模块功能及架构
Qt Http Server 是 Qt 6.0 中引入的一个新模块,它提供了一个轻量级的 HTTP 服务器实现,主要用于构建基于 HTTP 的应用程序和服务。 功能介绍: 主要功能 HTTP服务器功能: 支持 HTTP/1.1 协议 简单的请求/响应处理模型 支持 GET…...

c#开发AI模型对话
AI模型 前面已经介绍了一般AI模型本地部署,直接调用现成的模型数据。这里主要讲述讲接口集成到我们自己的程序中使用方式。 微软提供了ML.NET来开发和使用AI模型,但是目前国内可能使用不多,至少实践例子很少看见。开发训练模型就不介绍了&am…...

C++_哈希表
本篇文章是对C学习的哈希表部分的学习分享 相信一定会对你有所帮助~ 那咱们废话不多说,直接开始吧! 一、基础概念 1. 哈希核心思想: 哈希函数的作用:通过此函数建立一个Key与存储位置之间的映射关系。理想目标:实现…...
与文本切分器(Splitter)详解《二》)
LangChain 中的文档加载器(Loader)与文本切分器(Splitter)详解《二》
🧠 LangChain 中 TextSplitter 的使用详解:从基础到进阶(附代码) 一、前言 在处理大规模文本数据时,特别是在构建知识库或进行大模型训练与推理时,文本切分(Text Splitting) 是一个…...

Appium下载安装配置保姆教程(图文详解)
目录 一、Appium软件介绍 1.特点 2.工作原理 3.应用场景 二、环境准备 安装 Node.js 安装 Appium 安装 JDK 安装 Android SDK 安装Python及依赖包 三、安装教程 1.Node.js安装 1.1.下载Node 1.2.安装程序 1.3.配置npm仓储和缓存 1.4. 配置环境 1.5.测试Node.j…...

【QT】qtdesigner中将控件提升为自定义控件后,css设置样式不生效(已解决,图文详情)
目录 0.背景 1.解决思路 2.详细代码 0.背景 实际项目中遇到的问题,描述如下: 我在qtdesigner用界面拖了一个QTableView控件,object name为【tableView_electrode】,然后【提升为】了自定义的类【Steer_Electrode_Table】&…...
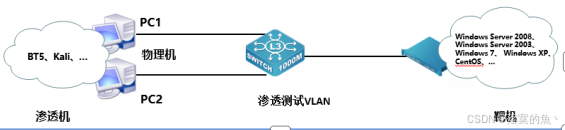
2025年上海市“星光计划”第十一届职业院校技能大赛 网络安全赛项技能操作模块样题
2025年上海市“星光计划”第十一届职业院校技能大赛 网络安全赛项技能操作模块样题 (二)模块 A:安全事件响应、网络安全数据取证、应用安全、系统安全任务一:漏洞扫描与利用:任务二:Windows 操作系统渗透测试 :任务三&…...
SeaweedFS S3 Spring Boot Starter
SeaweedFS S3 Spring Boot Starter 源码特性环境要求快速开始1. 添加依赖2. 配置文件3. 使用方式方式一:注入服务类方式二:使用工具类 API 文档SeaweedFsS3Service 主要方法SeaweedFsS3Util 工具类方法 配置参数运行测试构建项目注意事项集成应用更多项目…...

0x-2-Oracle Linux 9上安装JDK配置环境变量
一、JDK选择和使用 安装完Oracle Linux9.6,同时使用rpm包安装Oracle 23 ai free后, 将面临sqlcl程序无法使用和java无法使用,需要相应进行变量配置问题。 1、java 环境运行不存在,Oracle 23ai free安装后默认安装JDK 11 /opt/…...