昇思25天学习打卡营第16天|基于MindSpore通过GPT实现情感分类
文章目录
- 昇思MindSpore应用实践
- 1、基于MindSpore通过GPT实现情感分类
- GPT 模型(Generative Pre-Training)简介
- imdb影评数据集情感分类
- 2、Tokenizer导入预训练好的GPT
- 3、基于预训练的GPT微调实现情感分类
- Reference
昇思MindSpore应用实践
本系列文章主要用于记录昇思25天学习打卡营的学习心得。
1、基于MindSpore通过GPT实现情感分类
GPT 模型(Generative Pre-Training)简介
GPT-1模型是一种基于神经网络的自回归(AR)语言模型。该模型使用了“Transformer”的编解码架构,一种新型的序列到序列(Seq2Seq)模型,能够在处理长序列数据时避免传统的循环神经网络(Recurrent Neural Network,RNN)中存在的梯度消失问题。
Transformer架构中的关键组件包括多头自注意力机制和残差连接等,GPT使用了Transformer的解码器部分。

预训练技术:GPT-1使用了一种称为“生成式预训练”(Generative Pre-Training,GPT)的技术。
预训练分为两个阶段:预训练和微调(fine-tuning)。
在预训练阶段,GPT-1使用了大量的无标注文本数据集,例如维基百科和网页文本等。通过最大化预训练数据集上的log-likelihood来训练模型参数。
在微调阶段,GPT-1将预训练模型的参数用于特定的自然语言处理任务,如文本分类和问答系统等。
多层模型:GPT-1模型由多个堆叠的Transformer编码器组成,每个编码器包含多个注意力头和前向神经网络。这使得模型可以从多个抽象层次对文本进行建模,从而更好地捕捉文本的语义信息。
通过使用上述预训练任务,研究团队成功地训练出了一个大规模的语言模型GPT。该模型在多项语言理解任务上取得了显著的成果,包括阅读理解、情感分类和自然语言推理等任务。
imdb影评数据集情感分类
import osimport mindspore
from mindspore.dataset import text, GeneratorDataset, transforms
from mindspore import nnfrom mindnlp.dataset import load_datasetfrom mindnlp._legacy.engine import Trainer, Evaluator
from mindnlp._legacy.engine.callbacks import CheckpointCallback, BestModelCallback
from mindnlp._legacy.metrics import Accuracyimdb_ds = load_dataset('imdb', split=['train', 'test'])
imdb_train = imdb_ds['train']
imdb_test = imdb_ds['test']imdb_train.get_dataset_size()import numpy as npdef process_dataset(dataset, tokenizer, max_seq_len=512, batch_size=4, shuffle=False):is_ascend = mindspore.get_context('device_target') == 'Ascend'def tokenize(text):if is_ascend:tokenized = tokenizer(text, padding='max_length', truncation=True, max_length=max_seq_len)else:tokenized = tokenizer(text, truncation=True, max_length=max_seq_len)return tokenized['input_ids'], tokenized['attention_mask']if shuffle:dataset = dataset.shuffle(batch_size)# map datasetdataset = dataset.map(operations=[tokenize], input_columns="text", output_columns=['input_ids', 'attention_mask'])dataset = dataset.map(operations=transforms.TypeCast(mindspore.int32), input_columns="label", output_columns="labels")# batch datasetif is_ascend:dataset = dataset.batch(batch_size)else:dataset = dataset.padded_batch(batch_size, pad_info={'input_ids': (None, tokenizer.pad_token_id),'attention_mask': (None, 0)})return dataset
2、Tokenizer导入预训练好的GPT
from mindnlp.transformers import GPTTokenizer
# tokenizer
gpt_tokenizer = GPTTokenizer.from_pretrained('openai-gpt')# add sepcial token: <PAD>
special_tokens_dict = {"bos_token": "<bos>","eos_token": "<eos>","pad_token": "<pad>",
}
num_added_toks = gpt_tokenizer.add_special_tokens(special_tokens_dict)# split train dataset into train and valid datasets,训练集和验证集分割
imdb_train, imdb_val = imdb_train.split([0.7, 0.3])dataset_train = process_dataset(imdb_train, gpt_tokenizer, shuffle=True)
dataset_val = process_dataset(imdb_val, gpt_tokenizer)
dataset_test = process_dataset(imdb_test, gpt_tokenizer)next(dataset_train.create_tuple_iterator())[Tensor(shape=[4, 512], dtype=Int64, value=[[11295, 246, 244 ... 40480, 40480, 40480],[ 616, 509, 246 ... 40480, 40480, 40480],[ 616, 4894, 498 ... 40480, 40480, 40480],[ 589, 500, 589 ... 40480, 40480, 40480]]),Tensor(shape=[4, 512], dtype=Int64, value=[[1, 1, 1 ... 0, 0, 0],[1, 1, 1 ... 0, 0, 0],[1, 1, 1 ... 0, 0, 0],[1, 1, 1 ... 0, 0, 0]]),Tensor(shape=[4], dtype=Int32, value= [0, 0, 0, 1])]
3、基于预训练的GPT微调实现情感分类
from mindnlp.transformers import GPTForSequenceClassification
from mindspore.experimental.optim import Adam# set bert config and define parameters for training
model = GPTForSequenceClassification.from_pretrained('openai-gpt', num_labels=2)
model.config.pad_token_id = gpt_tokenizer.pad_token_id
model.resize_token_embeddings(model.config.vocab_size + 3)optimizer = nn.Adam(model.trainable_params(), learning_rate=2e-5)metric = Accuracy()# define callbacks to save checkpoints
ckpoint_cb = CheckpointCallback(save_path='checkpoint', ckpt_name='gpt_imdb_finetune', epochs=1, keep_checkpoint_max=2)
best_model_cb = BestModelCallback(save_path='checkpoint', ckpt_name='gpt_imdb_finetune_best', auto_load=True)trainer = Trainer(network=model, train_dataset=dataset_train,eval_dataset=dataset_train, metrics=metric,epochs=1, optimizer=optimizer, callbacks=[ckpoint_cb, best_model_cb],jit=False)trainer.run(tgt_columns="labels")

Reference
[1] 北方的郎-从GPT-1到GPT-4,GPT系列模型详解
[2] 昇思大模型平台
[3] 昇思官方文档-基于MindSpore通过GPT实现情感分类
相关文章:
昇思25天学习打卡营第16天|基于MindSpore通过GPT实现情感分类
文章目录 昇思MindSpore应用实践1、基于MindSpore通过GPT实现情感分类GPT 模型(Generative Pre-Training)简介imdb影评数据集情感分类 2、Tokenizer导入预训练好的GPT3、基于预训练的GPT微调实现情感分类 Reference 昇思MindSpore应用实践 本系列文章主…...

服务器借助笔记本热点WIFI上网
一、同一局域网环境 1、当前环境,已有交换机组网环境,服务器已配置IP信息。 设备ip服务器125.10.100.12交换机125.10.100.0/24笔记本125.10.100.39 2、拓扑图 #mermaid-svg-D4moqMym9i0eeRBm {font-family:"trebuchet ms",verdana,arial,sa…...

开发实战中Git的常用操作
Git基础操作 1.初始化仓库 git init解释:在当前目录中初始化一个新的Git仓库。 2.克隆远程仓库 git clone <repository-url>解释:从远程仓库克隆一个完整的Git仓库到本地。 3.检查当前状态 git status解释:查看当前工作目录的状态…...

python调用chrome浏览器自动化如何选择元素
功能描述:在对话框输入文字,并发送。 注意: # 定位到多行文本输入框并输入内容。在selenium 4版本中,元素定位需要填写父元素和子元素名。 textarea driver.find_element(By.CSS_SELECTOR,textarea.el-textarea__inner) from …...

深入理解JS中的排序
在JavaScript开发中,排序是一项基础而重要的操作。本文将探讨JavaScript中几种常见的排序算法,包括它们的原理、实现方式以及适用场景。 1、冒泡排序 1.1、原理 通过比较相邻两个数的大小,交换位置排序:如果后一个数比前一个数小,则交换两个数的位置,重复这个过程,直…...

Kafka之存储设计
文章目录 1. 分区和副本的存储结构1. 分区和副本的分布2. 存储目录结构3. 文件描述 2. 相关配置3. 数据文件类型4. 数据定位原理LogSegment 类UnifiedLog 类 5. 副本数据同步HW水位线LEO末端偏移量HW更新原理 6. 数据清除 1. 分区和副本的存储结构 在一个多 broker 的 Kafka 集…...

Python面试整理-Python中的函数定义和调用
在Python中,函数是一种封装代码的方式,使得代码模块化和复用性更强。定义和调用函数是Python编程中的基本技能。以下是关于如何在Python中定义和调用函数的详细介绍: 函数定义 函数在Python中使用def关键字进行定义。函数体开始前,通常有一个可选的文档字符串(docstring)…...

HTTP协议、Wireshark抓包工具、json解析、天气爬虫
HTTP超文本传输协议 HTTP(Hyper Text Transfer Protocol): 全称超文本传输协议,是用于从万维网(WWW:World Wide Web )服务器传输超文本到本地浏览器的传送协议。 HTTP 协议的重要特点: 一发一收…...

electron项目中实现视频下载保存到本地
第一种方式:用户自定义选择下载地址位置 渲染进程 // 渲染进程// 引入 import { ipcRenderer } from "electron";// 列表行数据下载视频操作,diffVideoUrl 是视频请求地址 handleDownloadClick(row) {if (!row.diffVideoUrl) {this.$message…...

基于chrome插件的企业应用
一、chrome插件技术介绍 1、chrome插件组件介绍 名称 职责 访问权限 DOM访问情况 popup 弹窗页面。即打开形式是通过点击在浏览器右上方的icon,一个弹窗的形式。 注: 展示维度 browser_action:所有页面 page_action:指定页面 可访问绝大部分api 不可以 bac…...

unittest框架和pytest框架区别及示例
unittest框架和pytest框架区别及示例 类型unittest框架pytest框架unittest框架示例pytest框架示例安装python内置的一个单元测试框架,标准库,不需要安装第三方单元测试库,需要安装使用时直接引用 import unittest安装命令:pip3 install pyte…...

IDEA性能优化方法解决卡顿
文章目录 前言一、可以采取以下措施:二、VM Options的参数解释1. 内存设置2. 性能调优3. GC(垃圾回收)调优4. 调试和诊断5. 其它设置6.设置 VM Options 的步骤: 总结 前言 我们在使用 IntelliJ IDEA的时候有时候会觉得卡顿&#x…...

Mysql集合转多行
mysql 集合转多行 SELECT substring_index(substring_index(t1.group_ids, ,, n), ,, -1) AS group_id FROM (select 908,909 as group_ids ) t1, (SELECT rownum : rownum 1 AS n FROM ( SELECT rownum : 0 ) r, orders ) t2 WHERE n < ( LENGTH( t1.group_ids ) - LENGT…...

MFC:只允许产生一个应用程序实例的具体实现
在MFC(Microsoft Foundation Class)应用程序中,如果你想限制只允许产生一个应用程序实例,通常会使用互斥体(Mutex)来实现。这可以确保如果用户尝试启动第二个实例时,它会被阻止或将焦点返回到已…...

深入理解TCP/IP协议中的三次握手
👍 个人网站:【洛秋资源小站】 深入理解TCP/IP协议中的三次握手 在计算机网络中,TCP/IP协议是通信的基石。理解TCP/IP协议中的三次握手是掌握网络通信的关键步骤之一。本文将详细解释TCP/IP协议中的三次握手过程,探讨其工作原理&…...

【React】事件绑定、React组件、useState、基础样式
React 教程 目录 事件绑定 1.1. 基础实现 1.2. 使用事件参数 1.3. 传递自定义参数 1.4. 同时传递事件对象和自定义参数 React 组件 2.1. 组件是什么 2.2. 组件基础使用 useState:状态管理 3.1. 基础使用 3.2. 状态的修改规则 3.3. 修改对象状态 基础样式 4.1. 行…...

x264、x265、libaom 编码对比实验
介绍 x264 是一个开源的高性能 H.264/MPEG-4 AVC 编码器,它以其优秀的压缩比和广泛的适用性而闻名。x265 是一种用于将视频流编码成 H.265/MPEG-H HEVC 压缩格式的免费软件库和应用程序,以其下一代压缩能力和卓越的质量而闻名 。作为 x264 的继任者,x265 支持 HEVC 的 Main、…...

c++网络编程实战——开发基于ftp协议的文件传输模块(二) 配置ftp服务与手动执行ftp命令
配置FTP服务 一.前言 博主的环境是阿里云服务器,操作系统版本为 ubuntu20.04,一下所有操作都基于以上环境下进行的操作,同时为了简化操作我将开放同一个云服务器的不同端口,让它同时充当服务端和客户端,大家如果想测试效果更好且…...

Sphinx 安装相关指令解释
安装指令 pip3 install sphinx-autobuildpip3 install sphinx_rtd_themepip3 install sphinx_markdown_tablepip3 install sphinx_markdown_tables pip3 install sphinx-autobuild 功能:安装 sphinx-autobuild 包。作用:sphinx-autobuild 是一个工具&am…...

npm下载包-更改默认缓存目录
npm(Node Package Manager)的缓存目录是npm用于存储已下载包的本地位置,以便在后续安装相同包时能够快速复用,从而节省时间和带宽。npm缓存目录的具体位置会根据操作系统的不同而有所差异。 Windows系统 在Windows系统中&#x…...

day52 ResNet18 CBAM
在深度学习的旅程中,我们不断探索如何提升模型的性能。今天,我将分享我在 ResNet18 模型中插入 CBAM(Convolutional Block Attention Module)模块,并采用分阶段微调策略的实践过程。通过这个过程,我不仅提升…...

JavaScript 中的 ES|QL:利用 Apache Arrow 工具
作者:来自 Elastic Jeffrey Rengifo 学习如何将 ES|QL 与 JavaScript 的 Apache Arrow 客户端工具一起使用。 想获得 Elastic 认证吗?了解下一期 Elasticsearch Engineer 培训的时间吧! Elasticsearch 拥有众多新功能,助你为自己…...

服务器硬防的应用场景都有哪些?
服务器硬防是指一种通过硬件设备层面的安全措施来防御服务器系统受到网络攻击的方式,避免服务器受到各种恶意攻击和网络威胁,那么,服务器硬防通常都会应用在哪些场景当中呢? 硬防服务器中一般会配备入侵检测系统和预防系统&#x…...

智能分布式爬虫的数据处理流水线优化:基于深度强化学习的数据质量控制
在数字化浪潮席卷全球的今天,数据已成为企业和研究机构的核心资产。智能分布式爬虫作为高效的数据采集工具,在大规模数据获取中发挥着关键作用。然而,传统的数据处理流水线在面对复杂多变的网络环境和海量异构数据时,常出现数据质…...

高效线程安全的单例模式:Python 中的懒加载与自定义初始化参数
高效线程安全的单例模式:Python 中的懒加载与自定义初始化参数 在软件开发中,单例模式(Singleton Pattern)是一种常见的设计模式,确保一个类仅有一个实例,并提供一个全局访问点。在多线程环境下,实现单例模式时需要注意线程安全问题,以防止多个线程同时创建实例,导致…...

解读《网络安全法》最新修订,把握网络安全新趋势
《网络安全法》自2017年施行以来,在维护网络空间安全方面发挥了重要作用。但随着网络环境的日益复杂,网络攻击、数据泄露等事件频发,现行法律已难以完全适应新的风险挑战。 2025年3月28日,国家网信办会同相关部门起草了《网络安全…...

pikachu靶场通关笔记19 SQL注入02-字符型注入(GET)
目录 一、SQL注入 二、字符型SQL注入 三、字符型注入与数字型注入 四、源码分析 五、渗透实战 1、渗透准备 2、SQL注入探测 (1)输入单引号 (2)万能注入语句 3、获取回显列orderby 4、获取数据库名database 5、获取表名…...
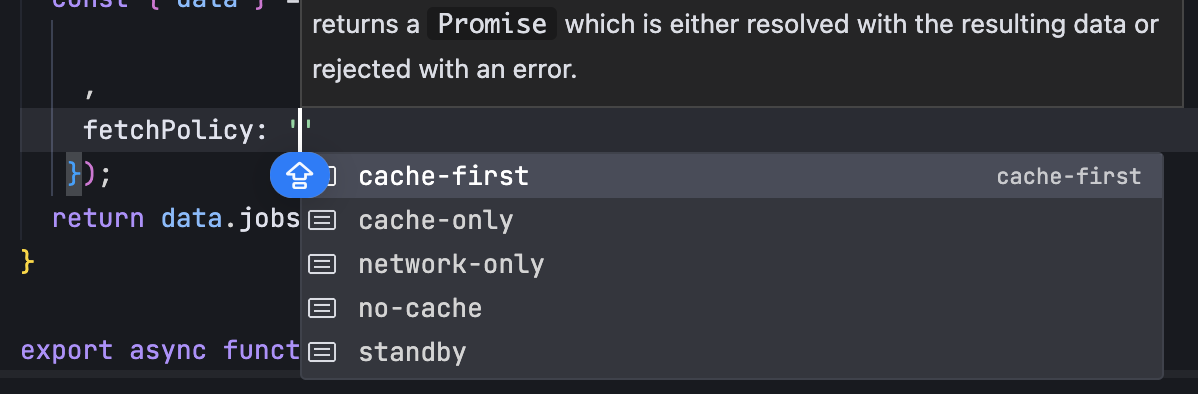
GraphQL 实战篇:Apollo Client 配置与缓存
GraphQL 实战篇:Apollo Client 配置与缓存 上一篇:GraphQL 入门篇:基础查询语法 依旧和上一篇的笔记一样,主实操,没啥过多的细节讲解,代码具体在: https://github.com/GoldenaArcher/graphql…...
0609)
书籍“之“字形打印矩阵(8)0609
题目 给定一个矩阵matrix,按照"之"字形的方式打印这个矩阵,例如: 1 2 3 4 5 6 7 8 9 10 11 12 ”之“字形打印的结果为:1,…...
)
41道Django高频题整理(附答案背诵版)
解释一下 Django 和 Tornado 的关系? Django和Tornado都是Python的web框架,但它们的设计哲学和应用场景有所不同。 Django是一个高级的Python Web框架,鼓励快速开发和干净、实用的设计。它遵循MVC设计,并强调代码复用。Django有…...