ES中的数据类型学习之Aggregate metric(聚合计算)
Aggregate metric field type | Elasticsearch Guide [7.17] | Elastic

对于object类型的字段来说,可以存子字段为 min/max/sum/value_count
PUT my-index {"mappings": {"properties": {"my-agg-metric-field": { -- 字段名"type": "aggregate_metric_double", --字段类型"metrics": [ "min", "max", "sum", "value_count" ], --那些聚合操作"default_metric": "max" -- 默认显示的聚合字段 用来query的}}} }
Parameters for aggregate_metric_double fields
metrics(Required, array of strings) Array of metric sub-fields to store. Each value corresponds to a metric aggregation. Valid values are min, max, sum, and value_count. You must specify at least one value.
--只能是min/max/sum/value_count
default_metric(Required, string) Default metric sub-field to use for queries, scripts, and aggregations that don’t use a sub-field. Must be a value from the
metricsarray.-- 必须是metrics里的
time_series_metric[preview] This functionality is in technical preview and may be changed or removed in a future release. Elastic will work to fix any issues, but features in technical preview are not subject to the support SLA of official GA features. (Optional, string)
For internal use by Elastic only.
--还没开放。
Uses
We designed
aggregate_metric_doublefields for use with the following aggregations:
- A min aggregation returns the minimum value of all
minsub-fields.- A max aggregation returns the maximum value of all
maxsub-fields.- A sum aggregation returns the sum of the values of all
sumsub-fields.- A value_count aggregation returns the sum of the values of all
value_countsub-fields.- A avg aggregation. There is no
avgsub-field; the result of theavgaggregation is computed using thesumandvalue_countmetrics. To run anavgaggregation, the field must contain bothsumandvalue_countmetric sub-field.-- 这里的sum和value_count都是 sum,但是value_count的用处是来计算avg
Running any other aggregation on an
aggregate_metric_doublefield will fail with an "unsupported aggregation" error.Finally, an
aggregate_metric_doublefield supports the following queries for which it behaves as adoubleby delegating its behavior to itsdefault_metricsub-field:
- exists
- range
- term
- terms
-- 目前type=
aggregate_metric_double 只持支持min/max/sum/value_count,其他类型会报错,目前也只支持下面4种查询
实战开始。
PUT stats-index
{
"mappings": {
"properties": {
"agg_metric": {
"type": "aggregate_metric_double",
"metrics": [ "min", "max", "sum", "value_count" ],
"default_metric": "max"
}
}
}
}PUT stats-index/_doc/1
{
"agg_metric": {
"min": -302.50,
"max": 702.30,
"sum": 200.0,
"value_count": 25
}
}PUT stats-index/_doc/2
{
"agg_metric": {
"min": -93.00,
"max": 1702.30,
"sum": 300.00,
"value_count": 25
}
}
查询数据
POST stats-index/_search?size=0
{
"aggs": {
"metric_min": { "min": { "field": "agg_metric" } },
"metric_max": { "max": { "field": "agg_metric" } },
"metric_value_count": { "value_count": { "field": "agg_metric" } },
"metric_sum": { "sum": { "field": "agg_metric" } },
"metric_avg": { "avg": { "field": "agg_metric" } }
}
}-- 说下这个查询
-- size=0 意思是不看基础数据,只看聚合后的结果数据
-- aggs 是类似 term must 代表现在查的聚合数据
-- metric_min 代表聚合后的字段名,
--min 代表是哪个聚合方式min/max。。。
--"field": "agg_metric" 代表的是对哪个字段进行聚合可能有agg_metric1,agg_metric2

查询基础数据
GET stats-index/_search
{
"query": {
"term": {
"agg_metric": {
"value": 1702.30
}
}
}
}
注意这里查询的是 max的值 也就是上文提到的default_metric
相关文章:

ES中的数据类型学习之Aggregate metric(聚合计算)
Aggregate metric field type | Elasticsearch Guide [7.17] | Elastic 对于object类型的字段来说,可以存子字段为 min/max/sum/value_count PUT my-index {"mappings": {"properties": {"my-agg-metric-field": { -- 字段名"ty…...

看准JS逆向案例:webpack逆向解析
🔍 逆向思路与步骤 抓包分析与参数定位 首先,我们通过抓包工具对看准网的请求进行分析。 发现请求中包含加密的参数b和kiv。 为了分析这些加密参数,我们需要进一步定位JS加密代码的位置。 扣取JS加密代码 定位到JS代码中的加密实现后&a…...

【C语言】 利用栈完成十进制转二进制(分文件编译,堆区申请空间malloc)
利用栈先进后出的特性,在函数内部,进行除二取余的操作,把每次的余数存入栈内,最后输出刚好就是逆序输出,为二进制数 学习过程中,对存储栈进行堆区的内存申请时候,并不是很熟练,一开始…...

如何解决ChromeDriver 126找不到chromedriver.exe问题
引言 在使用Selenium和ChromeDriver进行网页自动化时,ChromeDriver与Chrome浏览器版本不匹配的问题时有发生。最近,许多开发者在使用ChromeDriver 126时遇到了无法找到chromedriver.exe文件的错误。本文将介绍该问题的原因,并提供详细的解决…...

Anaconda下安装配置Jupyter
Anaconda下安装配置Jupyter 1、安装 conda activate my_env #激活虚拟环境 pip install jupyter #安装 jupyter notebook --generate-config #生成配置文件提示配置文件的位置: Writing default config to: /root/.jupyter/jupyter_notebook_config.py检查版本&am…...

蓝队黑名单IP解封提取脚本
应用场景:公司给蓝队人员一个解封IP列表,假如某个IP满足属于某某C段,则对该IP进行解封。该脚本则是进行批量筛选出符合条件的白名单IP 实操如下:公司给了一个已经封禁了的黑名单IP列表如下(black) 公司要求…...

共享充电桩语音ic方案,展现它的“说话”的能力
随着电动汽车的普及,充电设施的便捷性、智能化需求日益凸显,共享充电桩语音IC应运而生,成为连接人与机器、实现智能交互的桥梁。本文将为大家介绍共享充电桩语音ic的概述、应用词条以及优势,希望能够帮助您。 一、NV170D语音ic概述…...

ARM 单片机裸机任务调度框架
前言: 在没有使用操作系统的情况下,一个合理的裸机任务调度方式,可以更好的提供数据的处理,和用户体验,有多种任务调度的方式。 方案 1: 从上到下的任务调度方式,C语言程序的代码是在main函数…...
)
.Net 8 控制台程序部署(Linux篇)
在无流量Linux环境下部署.NET8开发的控制台程序 写在前面准备远程访问安装环境程序部署1.下载并导入2.解压并配置3.发布程序4.创建Systemd服务单元文件5.启用并启动服务 写在结尾 写在前面 好久没更新文章了,今天给大家带来的是在在无流量的Linux工控机上部署.Net8…...
)
LeetCode:x的平方根(C语言)
1、问题概述:给你一个非负整数 x,计算并返回 x 的 算术平方根 ,返回类型得是一个整数,小数舍弃 2、示例 示例 1: 输入:x 4 输出:2 示例 2: 输入:x 8 输出:…...

深入浅出WebRTC—DelayBasedBwe
WebRTC 中的带宽估计是其拥塞控制机制的核心组成部分,基于延迟的带宽估计是其中的一种策略,它主要基于延迟变化推断出可用的网络带宽。 1. 总体架构 1.1. 静态结构 1)DelayBasedBwe 受 GoogCcNetworkController 控制,接收其输入…...

JAVA开发工具IDEA如何连接操作数据库
一、下载驱动 下载地址:【免费】mysql-connector-j-8.2.0.jar资源-CSDN文库 二、导入驱动 鼠标右击下载到IDEA中的jar包,选择Add as Library选项 如图就导入成功 三、加载驱动 Class.forName("com.mysql.cj.jdbc.Driver"); 四、驱动管理…...

简化AI模型:PyTorch量化技术在边缘计算中的应用
引言 在资源受限的设备上部署深度学习模型时,模型量化技术可以显著提高模型的部署效率。通过将模型的权重和激活从32位浮点数转换为更低位数的值,量化可以减少模型的大小,加快推理速度,同时降低能耗。 模型量化概述 定义与优势…...

拥抱AI时代:解锁Prompt技术的无限潜力与深远影响
拥抱AI时代:解锁Prompt技术的无限潜力与深远影响 引言 在人工智能的浩瀚星空中,自然语言处理(NLP)无疑是最耀眼的星辰之一。随着技术的不断演进,NLP已经从最初的简单问答系统发展成为能够生成复杂文本、理解人类情感与…...

第123天:内网安全-域防火墙入站出站规则不出网隧道上线组策略对象同步
目录 案例一: 单机-防火墙-限制端口\协议出入站 案例二:不出网的解决思路 入站连接 隧道技术 案例三:域控-防火墙-组策略对象同步 案例四:域控-防火墙-组策略不出网上线 msf cs 案例一: 单机-防火墙-限制端口\…...

博客建站4 - ssh远程连接服务器
1. 什么是SSH?2. 下载shh客户端3. 配置ssh密钥4. 连接服务器5. 常见问题 5.1. IT IS POSSIBLE THAT SOMEONE IS DOING SOMETHING NASTY! 1. 什么是SSH? SSH(Secure Shell)是一种加密的网络协议,用于在不安全的网络中安全地远程登录到其他…...
)
MySQL--索引(3)
1.索引创建注意点 选择合适的字段 1.不为 NULL 的字段 索引字段的数据应该尽量不为 NULL,因为对于数据为 NULL 的字段,数据库较难优化。如果字段频繁被查询,但又避免不了为 NULL,建议使用 0,1,true,false 这样语义较为清晰的短值或…...

sql_exporter通过sql收集业务数据并通过prometheus+grafana展示
下载并解压安装sql_exporter wget https://github.com/free/sql_exporter/releases/download/0.5/sql_exporter-0.5.linux-amd64.tar.gz #解压 tar xvf sql_exporter-0.5.linux-amd64.tar.gz -C /usr/local/修改主配置文件 cd /usr/local/ mv sql_exporter-0.5.linux-amd64 s…...

pytorch 笔记:torch.optim.Adam
torch.optim.Adam 是一个实现 Adam 优化算法的类。Adam 是一个常用的梯度下降优化方法,特别适合处理大规模数据集和参数的深度学习模型 torch.optim.Adam(params, lr0.001, betas(0.9, 0.999), eps1e-08, weight_decay0, amsgradFalse, *, foreachNone, maximizeFa…...

开源AI智能名片小程序:深度剖析体验优化策略,激活小程序生命力的运营之道
摘要:在移动互联网的浪潮中,微信小程序凭借其无需下载、即用即走的特性,迅速成为企业连接用户、拓展市场的重要桥梁。开源AI智能名片小程序,作为这一领域的创新尝试,旨在通过融合人工智能技术与传统商务名片的概念&…...

大数据学习栈记——Neo4j的安装与使用
本文介绍图数据库Neofj的安装与使用,操作系统:Ubuntu24.04,Neofj版本:2025.04.0。 Apt安装 Neofj可以进行官网安装:Neo4j Deployment Center - Graph Database & Analytics 我这里安装是添加软件源的方法 最新版…...

OpenPrompt 和直接对提示词的嵌入向量进行训练有什么区别
OpenPrompt 和直接对提示词的嵌入向量进行训练有什么区别 直接训练提示词嵌入向量的核心区别 您提到的代码: prompt_embedding = initial_embedding.clone().requires_grad_(True) optimizer = torch.optim.Adam([prompt_embedding...

uniapp中使用aixos 报错
问题: 在uniapp中使用aixos,运行后报如下错误: AxiosError: There is no suitable adapter to dispatch the request since : - adapter xhr is not supported by the environment - adapter http is not available in the build 解决方案&…...

ArcGIS Pro制作水平横向图例+多级标注
今天介绍下载ArcGIS Pro中如何设置水平横向图例。 之前我们介绍了ArcGIS的横向图例制作:ArcGIS横向、多列图例、顺序重排、符号居中、批量更改图例符号等等(ArcGIS出图图例8大技巧),那这次我们看看ArcGIS Pro如何更加快捷的操作。…...

网络编程(UDP编程)
思维导图 UDP基础编程(单播) 1.流程图 服务器:短信的接收方 创建套接字 (socket)-----------------------------------------》有手机指定网络信息-----------------------------------------------》有号码绑定套接字 (bind)--------------…...

GC1808高性能24位立体声音频ADC芯片解析
1. 芯片概述 GC1808是一款24位立体声音频模数转换器(ADC),支持8kHz~96kHz采样率,集成Δ-Σ调制器、数字抗混叠滤波器和高通滤波器,适用于高保真音频采集场景。 2. 核心特性 高精度:24位分辨率,…...

10-Oracle 23 ai Vector Search 概述和参数
一、Oracle AI Vector Search 概述 企业和个人都在尝试各种AI,使用客户端或是内部自己搭建集成大模型的终端,加速与大型语言模型(LLM)的结合,同时使用检索增强生成(Retrieval Augmented Generation &#…...

Python基于历史模拟方法实现投资组合风险管理的VaR与ES模型项目实战
说明:这是一个机器学习实战项目(附带数据代码文档),如需数据代码文档可以直接到文章最后关注获取。 1.项目背景 在金融市场日益复杂和波动加剧的背景下,风险管理成为金融机构和个人投资者关注的核心议题之一。VaR&…...

面向无人机海岸带生态系统监测的语义分割基准数据集
描述:海岸带生态系统的监测是维护生态平衡和可持续发展的重要任务。语义分割技术在遥感影像中的应用为海岸带生态系统的精准监测提供了有效手段。然而,目前该领域仍面临一个挑战,即缺乏公开的专门面向海岸带生态系统的语义分割基准数据集。受…...
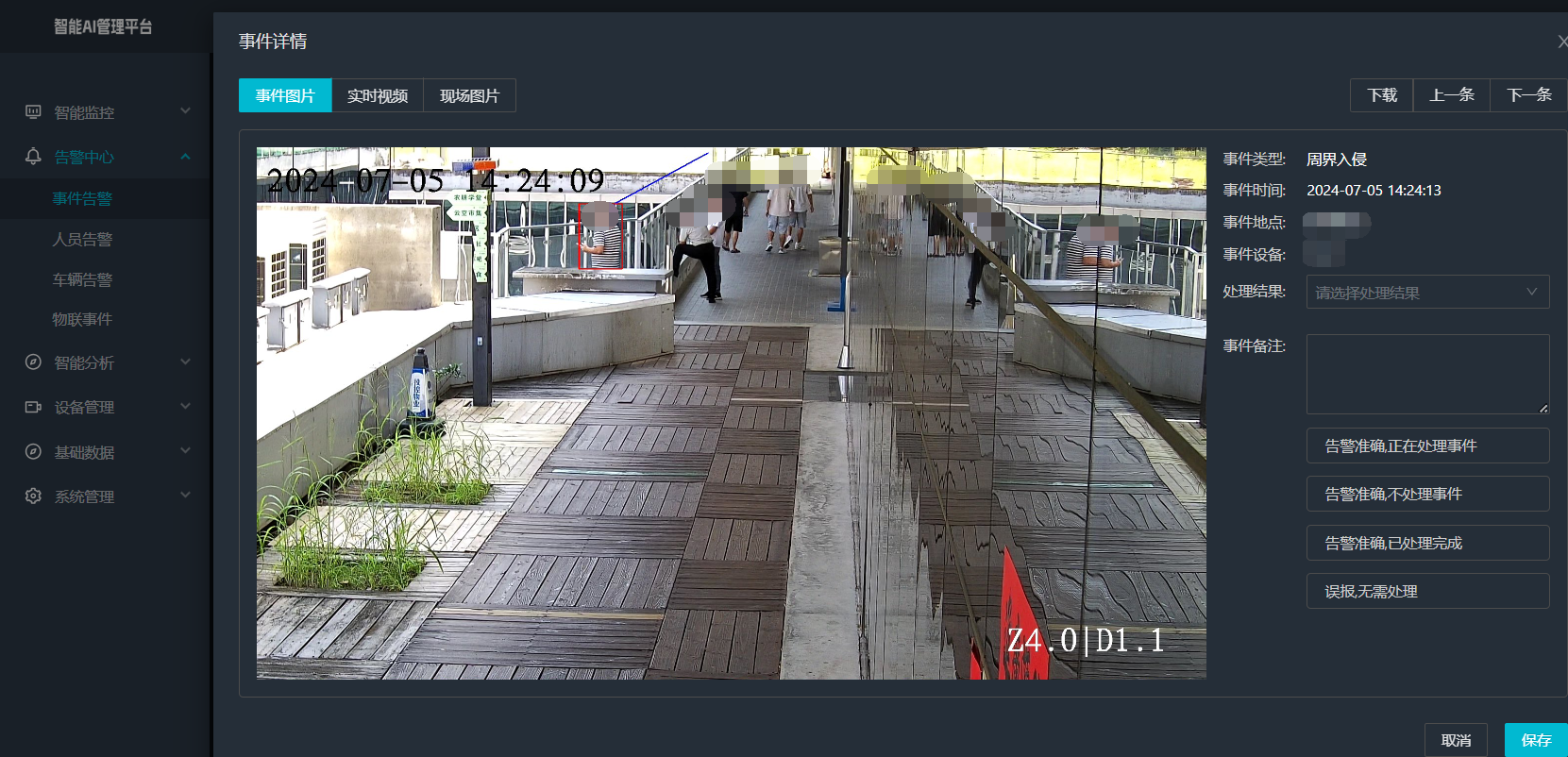
打手机检测算法AI智能分析网关V4守护公共/工业/医疗等多场景安全应用
一、方案背景 在现代生产与生活场景中,如工厂高危作业区、医院手术室、公共场景等,人员违规打手机的行为潜藏着巨大风险。传统依靠人工巡查的监管方式,存在效率低、覆盖面不足、判断主观性强等问题,难以满足对人员打手机行为精…...