【JS逆向课件:第十六课:Scrapy基础2】
ImagePipeLines的请求传参
-
环境安装:pip install Pillow
-
USER_AGENT = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.109 Safari/537.36' -
需求:将图片的名称和详情页中图片的数据进行爬取,持久化存储。
-
分析:
- 深度爬取:请求传参
- 多页的数据爬取:手动请求的发送
-
爬虫文件:
-
import scrapyfrom ..items import DeepimgproItem class ImgSpider(scrapy.Spider):name = 'img'# allowed_domains = ['www.xxx.com']start_urls = ['https://pic.netbian.com/4kmeinv/']#通用的url模板url_model = 'https://pic.netbian.com/4kmeinv/index_%d.html'page_num = 2def parse(self, response):#解析出了图片的名称和详情页的urlli_list = response.xpath('//*[@id="main"]/div[3]/ul/li')for li in li_list:title = li.xpath('./a/b/text()').extract_first() + '.jpg'detail_url = 'https://pic.netbian.com'+li.xpath('./a/@href').extract_first()item = DeepimgproItem()item['title'] = title#需要对详情页的url发起请求,在详情页中获取图片的下载链接yield scrapy.Request(url=detail_url,callback=self.detail_parse,meta={'item':item})if self.page_num <= 5:new_url = format(self.url_model%self.page_num)self.page_num += 1yield scrapy.Request(url=new_url,callback=self.parse)#解析详情页的数据def detail_parse(self,response):meta = response.metaitem = meta['item']img_src = 'https://pic.netbian.com'+response.xpath('//*[@id="img"]/img/@src').extract_first()item['img_src'] = img_srcyield item -
管道:
-
# Define your item pipelines here # # Don't forget to add your pipeline to the ITEM_PIPELINES setting # See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html# useful for handling different item types with a single interface import scrapy from itemadapter import ItemAdapterfrom scrapy.pipelines.images import ImagesPipeline class DeepimgproPipeline(ImagesPipeline):# def process_item(self, item, spider):# return itemdef get_media_requests(self, item, info):img_src = item['img_src']#请求传参,将item中的图片名称传递给file_path方法#meta会将自身传递给file_pathprint(item['title'],'保存下载成功!')yield scrapy.Request(url=img_src,meta={'title':item['title']})def file_path(self, request, response=None, info=None, *, item=None):#返回图片的名称#接收请求传参过来的数据title = request.meta['title']return titledef item_completed(self, results, item, info):return item
-
如何提高scrapy的爬取效率
增加并发:默认scrapy开启的并发线程为32个,可以适当进行增加。在settings配置文件中修改CONCURRENT_REQUESTS = 100值为100,并发设置成了为100。降低日志级别:在运行scrapy时,会有大量日志信息的输出,为了减少CPU的使用率。可以设置log输出信息为WORNING或者ERROR即可。在配置文件中编写:LOG_LEVEL = ‘ERROR’post请求发送
-
问题:在之前代码中,我们从来没有手动的对start_urls列表中存储的起始url进行过请求的发送,但是起始url的确是进行了请求的发送,那这是如何实现的呢?
-
解答:其实是因为爬虫文件中的爬虫类继承到了Spider父类中的start_requests(self)这个方法,该方法就可以对start_urls列表中的url发起请求:
-
def start_requests(self):for u in self.start_urls:yield scrapy.Request(url=u,callback=self.parse) -
【注意】该方法默认的实现,是对起始的url发起get请求,如果想发起post请求,则需要子类重写该方法。
- yield scrapy.Request():发起get请求
- yield scrapy.FormRequest():发起post请求
-
import scrapy class FanyiSpider(scrapy.Spider):name = 'fanyi'# allowed_domains = ['www.xxx.com']start_urls = ['https://fanyi.baidu.com/sug']#父类中的方法:该方法是用来给起始的url列表中的每一个url发请求def start_requests(self):data = {'kw':'dog'}for url in self.start_urls:#formdata是用来指定请求参数yield scrapy.FormRequest(url=url,callback=self.parse,formdata=data)def parse(self, response):result = response.json()print(result)
-
scrapy的核心组件
- 从中可以大致了解scrapy框架的一个运行机制
- 引擎(Scrapy)用来处理整个系统的数据流处理, 触发事务(框架核心)
- 调度器(Scheduler)用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址
- 下载器(Downloader)用于下载网页内容, 并将网页内容返回给蜘蛛(Scrapy下载器是建立在twisted这个高效的异步模型上的)
- 爬虫(Spiders)爬虫是主要干活的, 用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面
- 项目管道(Pipeline)负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。
中间件
-
scrapy的中间件有两个:
- 爬虫中间件
- 下载中间件
- 中间件的作用是什么?
- 观测中间件在五大核心组件的什么位置,根据位置了解中间件的作用
- 下载中间件位于引擎和下载器之间
- 引擎会给下载器传递请求对象,下载器会给引擎返回响应对象。
- 作用:可以拦截到scrapy框架中所有的请求和响应。
- 拦截请求干什么?
- 修改请求的ip,修改请求的头信息,设置请求的cookie
- 拦截响应干什么?
- 可以修改响应数据
- 拦截请求干什么?
- 观测中间件在五大核心组件的什么位置,根据位置了解中间件的作用
-
中间件重要方法:
-
# Define here the models for your spider middleware # # See documentation in: # https://docs.scrapy.org/en/latest/topics/spider-middleware.htmlfrom scrapy import signals# useful for handling different item types with a single interface from itemadapter import is_item, ItemAdapter from scrapy.http import HtmlResponseclass MiddleproDownloaderMiddleware:#拦截处理所有的请求对象#参数:request就是拦截到的请求对象,spider爬虫文件中爬虫类实例化的对象#spider参数的作用可以实现爬虫类和中间类的数据交互def process_request(self, request, spider):return None#拦截处理所有的响应对象#参数:response就是拦截到的响应对象,request就是被拦截到响应对象对应的唯一的一个请求对象def process_response(self, request, response, spider):#篡改了拦截到的响应数据:返回一个自定义的新的响应对象response = HtmlResponse(request=request,body='123',url=request.url,encoding='utf-8')return response#拦截和处理发生异常的请求对象#参数:reqeust就是拦截到的发生异常的请求对象def process_exception(self, request, exception, spider):pass#控制日志数据的(忽略)def spider_opened(self, spider):spider.logger.info('Spider opened: %s' % spider.name)
开发代理中间件
-
request.meta[‘proxy’] = proxy
-
# Define here the models for your spider middleware # # See documentation in: # https://docs.scrapy.org/en/latest/topics/spider-middleware.htmlfrom scrapy import signals# useful for handling different item types with a single interface from itemadapter import is_item, ItemAdapter from scrapy import Requestclass MiddleproDownloaderMiddleware:#类方法:作用是返回一个下载器对象(忽略)@classmethoddef from_crawler(cls, crawler):# This method is used by Scrapy to create your spiders.s = cls()crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)return s#拦截处理所有的请求对象#参数:request就是拦截到的请求对象,spider爬虫文件中爬虫类实例化的对象#spider参数的作用可以实现爬虫类和中间类的数据交互def process_request(self, request, spider):#是的所有的请求都是用代理,则代理操作可以写在该方法中request.meta['proxy'] = 'http://ip:port'#弊端:会使得整体的请求效率变低print(request.url+':请求对象拦截成功!')return None#拦截处理所有的响应对象#参数:response就是拦截到的响应对象,request就是被拦截到响应对象对应的唯一的一个请求对象def process_response(self, request, response, spider):print(request.url+':响应对象拦截成功!')return response#拦截和处理发生异常的请求对象#参数:reqeust就是拦截到的发生异常的请求对象#方法存在的意义:将发生异常的请求拦截到,然后对其进行修正def process_exception(self, request, exception, spider):print(request.url+':发生异常的请求对象被拦截到!')#修正操作#只有发生了异常的请求才使用代理机制,则可以写在该方法中request.meta['proxy'] = 'https://ip:port'return request #对请求对象进行重新发送#控制日志数据的(忽略)def spider_opened(self, spider):spider.logger.info('Spider opened: %s' % spider.name)
开发UA中间件
-
request.headers[‘User-Agent’] = ua
-
def process_request(self, request, spider):request.headers['User-Agent'] = '从列表中随机选择的一个UA值'print(request.url+':请求对象拦截成功!')return None
开发Cookie中间件
-
request.cookies = cookies
-
def process_request(self, request, spider):request.headers['cookie'] = 'xxx'#request.cookies = 'xxx'print(request.url+':请求对象拦截成功!')return None
CrawlSpider
-
实现网站的全站数据爬取
- 就是将网站中所有页码对应的页面数据进行爬取。
-
crawlspider其实就是scrapy封装好的一个爬虫类,通过该类提供的相关的方法和属性就可以实现全新高效形式的全站数据爬取。
-
使用流程:
-
新建一个scrapy项目
-
cd 项目
-
创建爬虫文件(*):
-
scrapy genspider -t crawl spiderName www.xxx.com
-
爬虫文件中发生的变化有哪些?
- 当前爬虫类的父类为CrawlSpider
- 爬虫类中多了一个类变量叫做rules
- LinkExtractor:链接提取器
- 可以根据allow参数表示的正则在当前页面中提取符合正则要求的链接
- Rule:规则解析器
- 可以接收链接提取器提取到的链接,并且对每一个链接进行请求发送
- 可以根据callback指定的回调函数对每一次请求到的数据进行数据解析
- LinkExtractor:链接提取器
- 思考:如何将一个网站中所有的链接都提取到呢?
- 只需要在链接提取器的allow后面赋值一个空正则表达式即可
- 目前在scrapy中有几种发送请求的方式?
- start_urls列表可以发送请求
- scrapy.Request()
- scrapy.FormRequest()
- Rule规则解析器
-
-
-
注意:
- 链接提取器和规则解析器是一一对应的(一对一的关系)
- 建议在使用crawlSpider实现深度爬取的时候,需要配合手动请求发送的方式进行搭配!
-
USER_AGENT = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36' -
爬取不同页码下的标题数据
-
import scrapy from time import sleep from scrapy.linkextractors import LinkExtractor from scrapy.spiders import CrawlSpider, Rule #LinkExtractor链接提取器:可以根据指定的规则进行链接的提取 #Rule规则解析器:可以根据指定规则对请求到的数据进行数据解析 class SunSpider(CrawlSpider):name = 'sun'# allowed_domains = ['www.xxx.com']start_urls = ['https://wz.sun0769.com/political/index/politicsNewest?id=1&page=1']#link就表示创建出来的一个链接提取器#allow参数后面要跟一个正则表达式,就可以作为链接提取的规则#link首先会去start_urls表示的页面中进行链接的提取link = LinkExtractor(allow=r'id=1&page=(\d+)')rules = (#创建了一个规则解析器#链接提取器提取到的链接会发送给Rule这个规则解析器#规则解析器接收到链接后,会对链接进行请求发送,并且根据callback指定的函数进行数据解析Rule(link, callback='parse_item', follow=True),)#解析方法的调用次数取决于link提取到的链接的个数def parse_item(self, response):li_list = response.xpath('/html/body/div[2]/div[3]/ul[2]/li')for li in li_list:title = li.xpath('./span[3]/a/text()').extract_first()print(title)
-
-
爬取页码对应页面的标题数据和详情页中的详细内容数据(深度爬取)
-
import scrapy from time import sleep from scrapy.linkextractors import LinkExtractor from scrapy.spiders import CrawlSpider, Rule from crawlPro.items import CrawlproItem #LinkExtractor链接提取器:可以根据指定的规则进行链接的提取 #Rule规则解析器:可以根据指定规则对请求到的数据进行数据解析 class SunSpider(CrawlSpider):name = 'sun'# allowed_domains = ['https://wz.sun0769.com']start_urls = ['https://wz.sun0769.com/political/index/politicsNewest?id=1&page=1']#链接提取器和规则解析器一定是一对一关系#提取页码链接link = LinkExtractor(allow=r'id=1&page=\d+')rules = (#解析页面对应页面中的标题数据Rule(link, callback='parse_item', follow=False),)#解析方法的调用次数取决于link提取到的链接的个数def parse_item(self, response):li_list = response.xpath('/html/body/div[2]/div[3]/ul[2]/li')for li in li_list:title = li.xpath('./span[3]/a/text()').extract_first()detail_url = 'https://wz.sun0769.com' + li.xpath('./span[3]/a/@href').extract_first()item = CrawlproItem()item['title'] = titleyield scrapy.Request(url=detail_url, callback=self.parse_detail,meta={'item':item})def parse_detail(self,response):item = response.meta['item']detail_content = response.xpath('/html/body/div[3]/div[2]/div[2]/div[2]//text()').extract()item['content'] = detail_contentyield item
-
分布式
-
分布式在日常开发中并不常用,只是一个噱头!
-
概念:
- 可以使用多台电脑搭建一个分布式机群,使得多台对电脑可以对同一个网站的数据进行联合且分布的数据爬取。
-
声明:
- 原生的scrapy框架并无法实现分布式操作!why?
- 多台电脑之间无法共享同一个调度器
- 多台电脑之间无法共享同一个管道
- 原生的scrapy框架并无法实现分布式操作!why?
-
如何是的scrapy可以实现分布式呢?
- 借助于一个组件:scrapy-redis
- scrapy-redis的作用是什么?
- 可以给原生的scrapy框架提供可被共享的调度器和管道!
- 环境安装:pip install scrapy-redis
- 注意:scrapy-redis该组件只可以将爬取到的数据存储到redis数据库
-
编码流程(重点):
-
1.创建项目
-
2.cd 项目
-
3.创建基于crawlSpider的爬虫文件
- 3.1 修改爬虫文件
- 导包:from scrapy_redis.spiders import RedisCrawlSpider
- 修改当前爬虫类的父类为 RedisCrawlSpider
- 将start_urls替换成redis_key的操作
- redis_key变量的赋值为字符串,该字符串表示调度器队列的名称
- 进行常规的请求操作和数据解析
- 3.1 修改爬虫文件
-
4.settings配置文件的修改
-
常规内容修改(robots和ua等),先不指定日志等级
-
指定可以被共享的管道类
-
ITEM_PIPELINES = {'scrapy_redis.pipelines.RedisPipeline': 400 }
-
-
指定可以被共享的调度器
-
# 使用scrapy-redis组件的去重队列 DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter" # 使用scrapy-redis组件自己的调度器 SCHEDULER = "scrapy_redis.scheduler.Scheduler" # 是否允许暂停 SCHEDULER_PERSIST = True
-
-
指定数据库
-
REDIS_HOST = '127.0.0.1' REDIS_PORT = 6379
-
-
-
5.修改redis数据库的配置文件(redis.windows.conf)
-
在配置文件中改行代码是没有没注释的:
-
bind 127.0.0.1 #将上述代码注释即可(解除本机绑定,实现外部设备访问本机数据库如果配置文件中还存在:protected-mode = true,将true修改为false, 修改为false后表示redis数据库关闭了保护模式,表示其他设备可以远程访问且修改你数据库中的数据
-
-
-
6.启动redis数据库的服务端和客户端
-
7.运行项目,发现程序暂定一直在等待,等待爬取任务
-
8.需要向可以被共享的调度器的队列(redis_key的值)中放入一个起始的url
-
-
爬虫应用场景分类
-
通用爬虫
-
聚焦爬虫
-
功能爬虫
-
分布式爬虫
-
增量式:
- 用来监测网站数据更新的情况(爬取网站最新更新出来的数据)。
- 只是一种程序设计的思路,使用什么技术都是可以实现的。
- 核心:
- 去重。
- 使用一个记录表来实现数据的去重:
- 记录表:存储爬取过的数据的记录
- 如何构建和设计一个记录表:
- 记录表需要具备的特性:
- 去重
- 需要持久保存的
- 方案1:使用Python的set集合充当记录表?
- 不可以的!因为set集合无法实现持久化存储
- 方案2:使用redis的set集合充当记录表?
- 可以的,因为redis的set既可以实现去重又可以进行数据的持久化存储。
- 记录表需要具备的特性:
- 使用一个记录表来实现数据的去重:
- 去重。
-
import scrapy import redis from ..items import Zlsdemo2ProItem class JianliSpider(scrapy.Spider):name = 'jianli'# allowed_domains = ['www.xxx.com']start_urls = ['https://sc.chinaz.com/jianli/free.html']conn = redis.Redis(host='127.0.0.1',port=6379)def parse(self, response):div_list = response.xpath('//*[@id="container"]/div')for div in div_list:title = div.xpath('./p/a/text()').extract_first()#充当数据指纹detail_url = 'https:'+div.xpath('./p/a/@href').extract_first()ex = self.conn.sadd('data_id',detail_url)item = Zlsdemo2ProItem()item['title'] = titleif ex == 1:print('有最新数据的更新,正在采集......')yield scrapy.Request(url=detail_url,callback=self.parse_detail,meta={'item':item})else:print('暂无数据更新!')def parse_detail(self,response):item = response.meta['item']download_url = response.xpath('//*[@id="down"]/div[2]/ul/li[1]/a/@href').extract_first()item['download_url'] = download_urlyield item
-
相关文章:

【JS逆向课件:第十六课:Scrapy基础2】
ImagePipeLines的请求传参 环境安装:pip install Pillow USER_AGENT Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.109 Safari/537.36需求:将图片的名称和详情页中图片的数据进行爬取&a…...

使用 PowerShell 自动化图像识别与鼠标操作
目录 前言功能概述代码实现1. 引入必要的程序集2. 定义读取文件行的函数3. 定义加载图片的函数4. 定义查找小图像在大图像中的位置的函数5. 定义截取全屏的函数6. 定义模拟鼠标点击的函数7. 定义主函数 配置文件示例运行脚本结语全部代码提示打包exe 下载地址 前言 在日常工作…...

组队学习——支持向量机
本次学习支持向量机部分数据如下所示 IDmasswidthheightcolor_scorefruit_namekind 其中ID:1-59是对应训练集和验证集的数据,60-67是对应测试集的数据,其中水果类别一共有四类包括apple、lemon、orange、mandarin。要求根据1-59的数据集的自…...

【数据中心】数据中心的IP封堵防护:构建网络防火墙的基石
数据中心的IP封堵防护:构建网络防火墙的基石 引言一、理解IP封堵二、IP封堵的功能模块及其核心技术三、实施IP封堵的关键策略四、结论 引言 在当今高度互联的世界里,数据中心成为信息流动和存储的神经中枢,承载着企业和组织的大量关键业务。…...
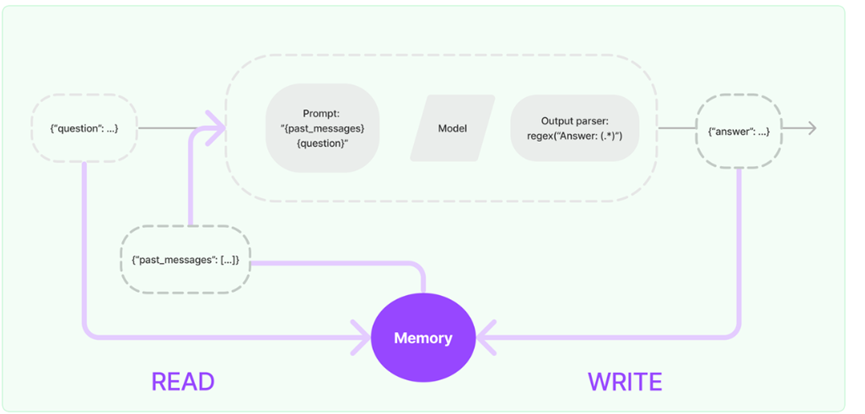
LangChain的使用详解
一、 概念介绍 1.1 Langchain 是什么? 官方定义是:LangChain是一个强大的框架,旨在帮助开发人员使用语言模型构建端到端的应用程序,它提供了一套工具、组件和接口,可简化创建由大型语言模型 (LLM) 和聊天模型提供…...
Modbus转BACnet/IP网关快速对接Modbus协议设备与BA系统
摘要 在智能建筑和工业自动化领域,Modbus和BACnet/IP协议的集成应用越来越普遍。BA(Building Automation,楼宇自动化)系统作为现代建筑的核心,需要高效地处理来自不同协议的设备数据,负责监控和管理建筑内…...

万字长文之分库分表里无分库分表键如何查询【后端面试题 | 中间件 | 数据库 | MySQL | 分库分表 | 其他查询】
在很多业务里,分库分表键都是根据主要查询筛选出来的,那么不怎么重要的查询怎么解决呢? 比如电商场景下,订单都是按照买家ID来分库分表的,那么商家该怎么查找订单呢?或是买家找客服,客服要找到对…...

如何查看jvm资源占用情况
如何设置jar的内存 java -XX:MetaspaceSize256M -XX:MaxMetaspaceSize256M -XX:AlwaysPreTouch -XX:ReservedCodeCacheSize128m -XX:InitialCodeCacheSize128m -Xss512k -Xmx2g -Xms2g -XX:UseG1GC -XX:G1HeapRegionSize4M -jar your-application.jar以上配置为堆内存4G jar项…...

科研绘图系列:R语言TCGA分组饼图(multiple pie charts)
介绍 在诸如癌症基因组图谱(TCGA)等群体研究项目中,为了有效地表征和比较不同群体的属性分布,科研人员广泛采用饼图作为数据可视化的工具。饼图通过将一个完整的圆形划分为若干个扇形区域,每个扇形区域的面积大小直接对应其代表的属性在整体中的占比。这种图形化的展示方…...

ReadAgent,一款具有要点记忆的人工智能阅读代理
人工智能咨询培训老师叶梓 转载标明出处 现有的大模型(LLMs)在处理长文本时受限于固定的最大上下文长度,并且当输入文本越来越长时,性能往往会下降,即使在没有超出明确上下文窗口的情况下,LLMs 的性能也会随…...

构建智能:利用Gradle项目属性控制构建行为
构建智能:利用Gradle项目属性控制构建行为 Gradle作为一款强大的构建工具,提供了丰富的项目属性管理功能。通过项目属性,开发者可以灵活地控制构建行为,实现条件编译、动态配置和多环境构建等高级功能。本文将详细解释如何在Grad…...

如何通过smtp设置使ONLYOFFICE协作空间服务器可以发送注册邀请邮件
什么是ONLYOFFICE协作空间 ONLYOFFICE协作空间,是Ascensio System SIA公司出品的,基于Web的,开源的,跨平台的,在线文档编辑和协作的解决方案。在线Office包含了最基本的办公三件套:文档编辑器、幻灯片编辑…...

SQL labs靶场-SQL注入入门
靶场及环境配置参考 一,工具准备。 推荐下载火狐浏览器,并下载harkbar插件(v2)版本。hackbar使用教程在此不做过多描述。 补充:url栏内部信息会进行url编码。 二,SQL注入-less1。 1,判断传参…...

HarmonyOS应用开发者高级认证,Next版本发布后最新题库 - 单选题序号4
基础认证题库请移步:HarmonyOS应用开发者基础认证题库 注:有读者反馈,题库的代码块比较多,打开文章时会卡死。所以笔者将题库拆分,单选题20个为一组,多选题10个为一组,题库目录如下,…...

使用LSTM完成时间序列预测
c 在本教程中,我们将介绍一个简单的示例,旨在帮助初学者入门时间序列预测和 PyTorch 的使用。通过这个示例,你可以学习如何使用 LSTMCell 单元来处理时间序列数据。 我们将使用两个 LSTMCell 单元来学习从不同相位开始的正弦波信号。模型在…...

《数据结构:顺序实现二叉树》
文章目录 一、树1、树的结构与概念2、树相关术语 二、二叉树1、概念与结构2、满二叉树3、完全二叉树 三、顺序二叉树存储结构四、实现顺序结构二叉树1、堆的概念与结构2、堆的实现3、堆的排序 一、树 1、树的结构与概念 树是一种非线性的数据结构,它是由nÿ…...

【HarmonyOS】HarmonyOS NEXT学习日记:六、渲染控制、样式结构重用
【HarmonyOS】HarmonyOS NEXT学习日记:六、渲染控制、样式&结构重用 渲染控制包含了条件渲染和循环渲染,所谓条件渲染,即更具状态不同,选择性的渲染不同的组件。 而循环渲染则是用于列表之内的、多个重复元素组成的结构中。 …...

【防火墙】防火墙NAT、智能选路综合实验
实验拓扑 实验要求 7,办公区设备可以通过电信链路和移动链路上网(多对多的NAT,并且需要保留一个公网IP不能用来转换) 8,分公司设备可以通过总公司的移动链路和电信链路访问到Dmz区的http服务器 9,多出口环境基于带宽比例进行选路…...

VUE之---slot插槽
什么是插槽 slot 【插槽】, 是 Vue 的内容分发机制, 组件内部的模板引擎使用slot 元素作为承载分发内容的出口。slot 是子组件的一个模板标签元素, 而这一个标签元素是否显示, 以及怎么显示是由父组件决定的。 VUE中slot【插槽】…...

linux、windows、macos,命令终端清屏
文章目录 LinuxWindowsmacOS 在Linux、Windows和macOS的命令终端中,清屏的命令或方法各不相同。以下是针对这三种系统的清屏方法: Linux clear命令:这是最常用的清空终端屏幕的命令之一。在终端中输入clear命令后,屏幕上的所有内容…...

【Axure高保真原型】引导弹窗
今天和大家中分享引导弹窗的原型模板,载入页面后,会显示引导弹窗,适用于引导用户使用页面,点击完成后,会显示下一个引导弹窗,直至最后一个引导弹窗完成后进入首页。具体效果可以点击下方视频观看或打开下方…...

相机Camera日志实例分析之二:相机Camx【专业模式开启直方图拍照】单帧流程日志详解
【关注我,后续持续新增专题博文,谢谢!!!】 上一篇我们讲了: 这一篇我们开始讲: 目录 一、场景操作步骤 二、日志基础关键字分级如下 三、场景日志如下: 一、场景操作步骤 操作步…...

C# SqlSugar:依赖注入与仓储模式实践
C# SqlSugar:依赖注入与仓储模式实践 在 C# 的应用开发中,数据库操作是必不可少的环节。为了让数据访问层更加简洁、高效且易于维护,许多开发者会选择成熟的 ORM(对象关系映射)框架,SqlSugar 就是其中备受…...

今日科技热点速览
🔥 今日科技热点速览 🎮 任天堂Switch 2 正式发售 任天堂新一代游戏主机 Switch 2 今日正式上线发售,主打更强图形性能与沉浸式体验,支持多模态交互,受到全球玩家热捧 。 🤖 人工智能持续突破 DeepSeek-R1&…...

爬虫基础学习day2
# 爬虫设计领域 工商:企查查、天眼查短视频:抖音、快手、西瓜 ---> 飞瓜电商:京东、淘宝、聚美优品、亚马逊 ---> 分析店铺经营决策标题、排名航空:抓取所有航空公司价格 ---> 去哪儿自媒体:采集自媒体数据进…...

Spring Cloud Gateway 中自定义验证码接口返回 404 的排查与解决
Spring Cloud Gateway 中自定义验证码接口返回 404 的排查与解决 问题背景 在一个基于 Spring Cloud Gateway WebFlux 构建的微服务项目中,新增了一个本地验证码接口 /code,使用函数式路由(RouterFunction)和 Hutool 的 Circle…...

基于PHP的连锁酒店管理系统
有需要请加文章底部Q哦 可远程调试 基于PHP的连锁酒店管理系统 一 介绍 连锁酒店管理系统基于原生PHP开发,数据库mysql,前端bootstrap。系统角色分为用户和管理员。 技术栈 phpmysqlbootstrapphpstudyvscode 二 功能 用户 1 注册/登录/注销 2 个人中…...
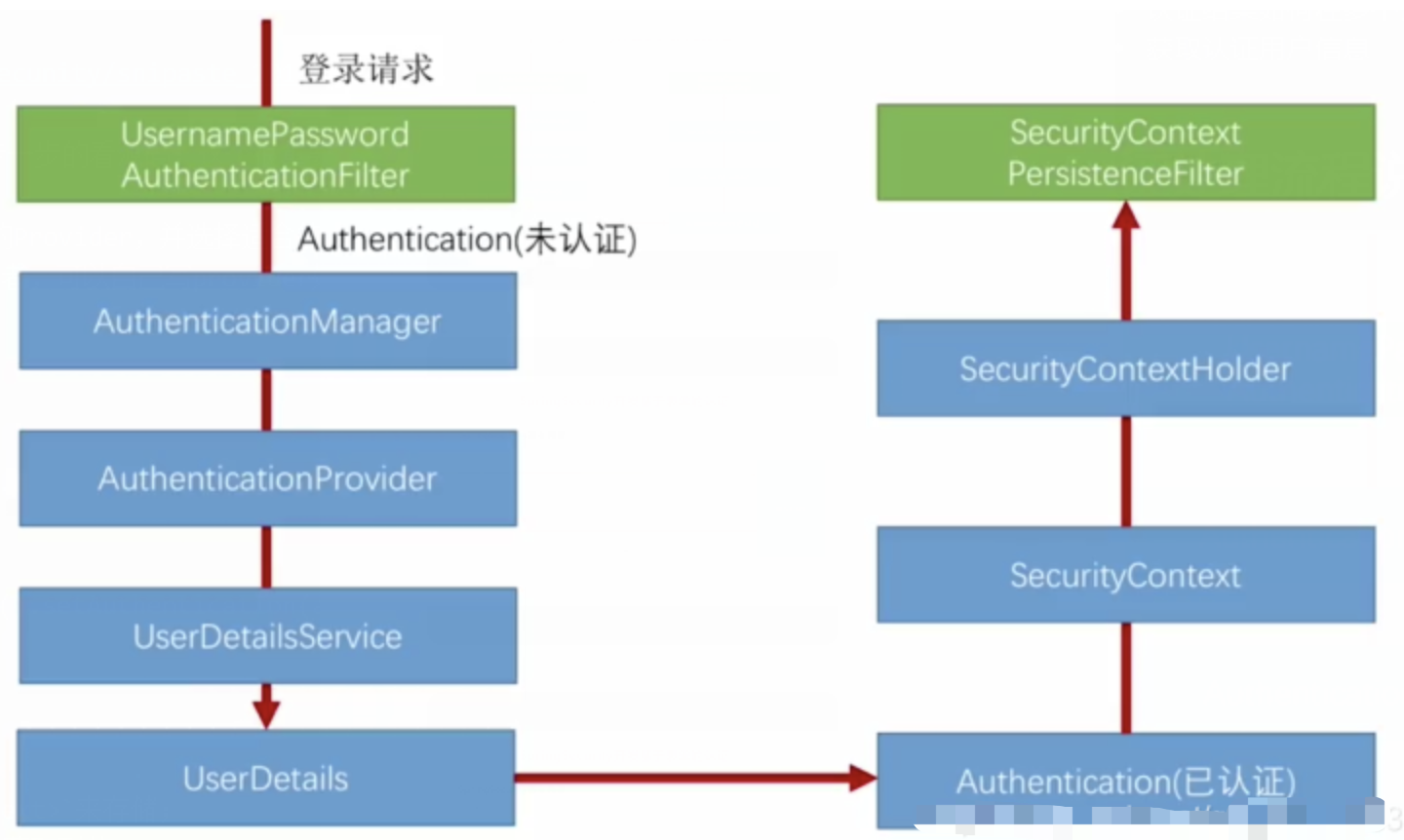
spring Security对RBAC及其ABAC的支持使用
RBAC (基于角色的访问控制) RBAC (Role-Based Access Control) 是 Spring Security 中最常用的权限模型,它将权限分配给角色,再将角色分配给用户。 RBAC 核心实现 1. 数据库设计 users roles permissions ------- ------…...

在golang中如何将已安装的依赖降级处理,比如:将 go-ansible/v2@v2.2.0 更换为 go-ansible/@v1.1.7
在 Go 项目中降级 go-ansible 从 v2.2.0 到 v1.1.7 具体步骤: 第一步: 修改 go.mod 文件 // 原 v2 版本声明 require github.com/apenella/go-ansible/v2 v2.2.0 替换为: // 改为 v…...
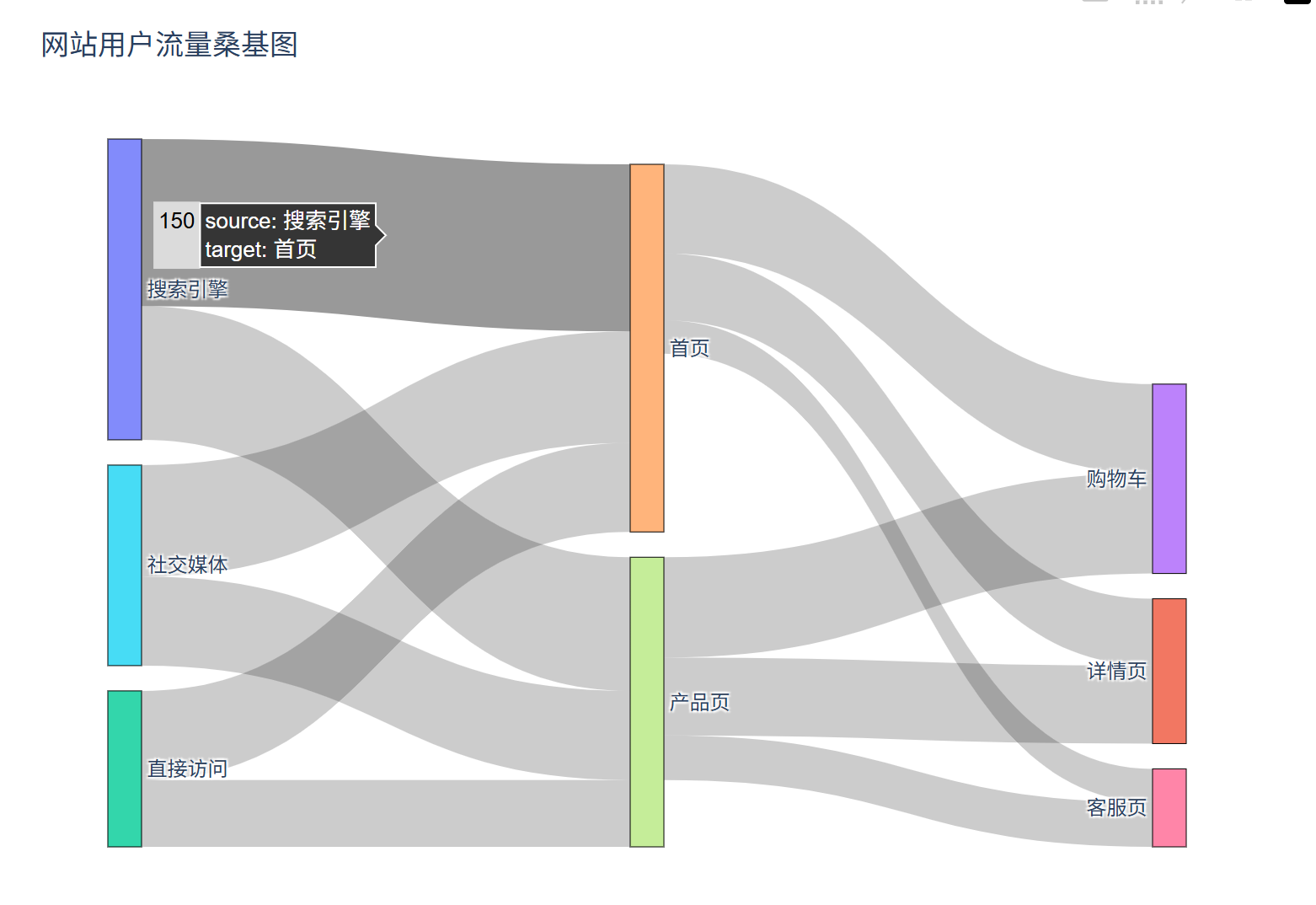
相关类相关的可视化图像总结
目录 一、散点图 二、气泡图 三、相关图 四、热力图 五、二维密度图 六、多模态二维密度图 七、雷达图 八、桑基图 九、总结 一、散点图 特点 通过点的位置展示两个连续变量之间的关系,可直观判断线性相关、非线性相关或无相关关系,点的分布密…...