基于 PyTorch 的模型瘦身三部曲:量化、剪枝和蒸馏,让模型更短小精悍!
基于 PyTorch 的模型量化、剪枝和蒸馏
- 1. 模型量化
- 1.1 原理介绍
- 1.2 PyTorch 实现
- 2. 模型剪枝
- 2.1 原理介绍
- 2.2 PyTorch 实现
- 3. 模型蒸馏
- 3.1 原理介绍
- 3.2 PyTorch 实现
- 参考文献
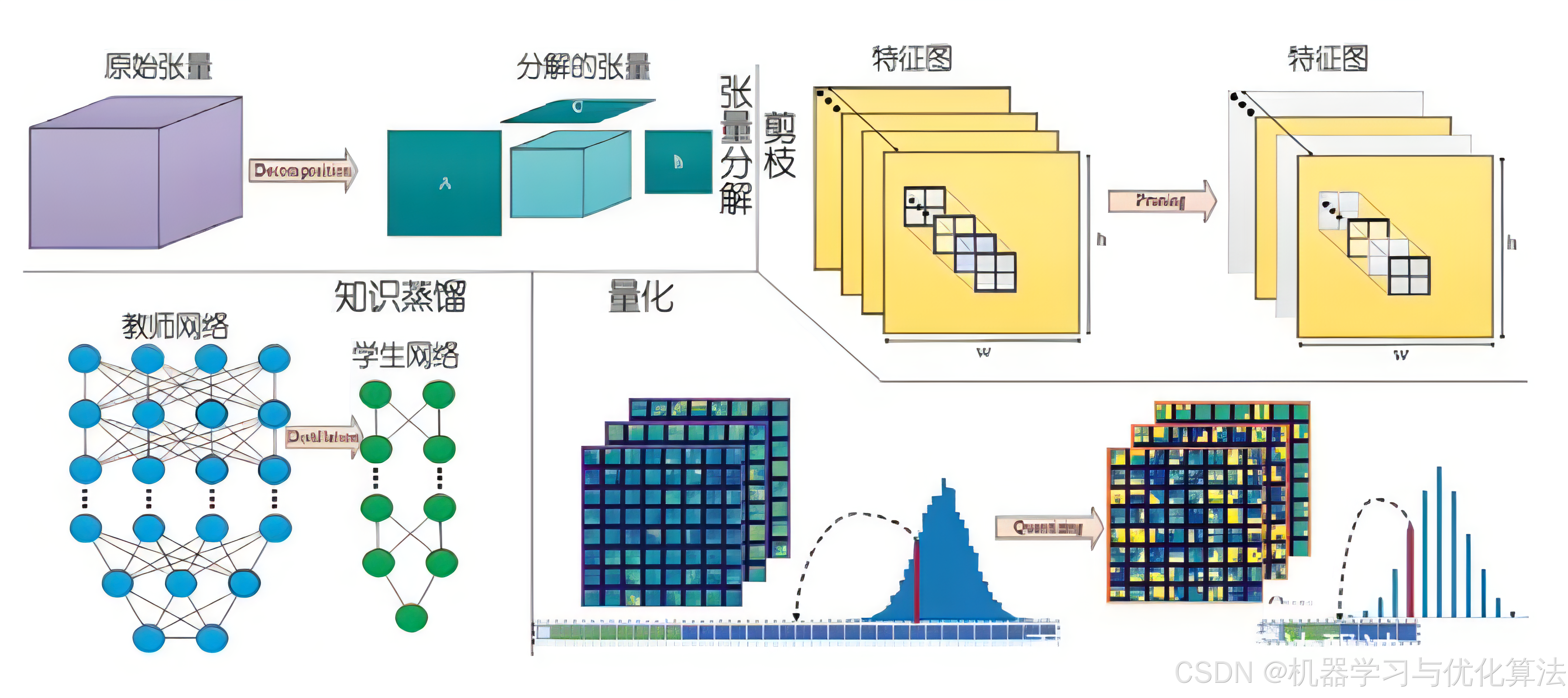
1. 模型量化
1.1 原理介绍
模型量化是将模型参数从高精度(通常是 float32)转换为低精度(如 int8 或更低)的过程。这种技术可以显著减少模型大小、降低计算复杂度,并加快推理速度,同时尽可能保持模型的性能。

量化的主要方法包括:
-
动态量化:
- 在推理时动态地将权重从 float32 量化为 int8。
- 激活值在计算过程中保持为浮点数。
- 适用于 RNN 和变换器等模型。
-
静态量化:
- 在推理之前,预先将权重从 float32 量化为 int8。
- 在推理过程中,激活值也被量化。
- 需要校准数据来确定激活值的量化参数。
-
量化感知训练(QAT):
- 在训练过程中模拟量化操作。
- 允许模型适应量化带来的精度损失。
- 通常能够获得比后量化更高的精度。
1.2 PyTorch 实现
import torch# 1. 动态量化
model_fp32 = MyModel()
model_int8 = torch.quantization.quantize_dynamic(model_fp32, # 原始模型{torch.nn.Linear, torch.nn.LSTM}, # 要量化的层类型dtype=torch.qint8 # 量化后的数据类型
)# 2. 静态量化
model_fp32 = MyModel()
model_fp32.eval() # 设置为评估模式# 设置量化配置
model_fp32.qconfig = torch.quantization.get_default_qconfig('fbgemm')
model_fp32_prepared = torch.quantization.prepare(model_fp32)# 使用校准数据进行校准
with torch.no_grad():for batch in calibration_data:model_fp32_prepared(batch)# 转换模型
model_int8 = torch.quantization.convert(model_fp32_prepared)# 3. 量化感知训练
model_fp32 = MyModel()
model_fp32.train() # 设置为训练模式# 设置量化感知训练配置
model_fp32.qconfig = torch.quantization.get_default_qat_qconfig('fbgemm')
model_fp32_prepared = torch.quantization.prepare_qat(model_fp32)# 训练循环
for epoch in range(num_epochs):for batch in train_data:output = model_fp32_prepared(batch)loss = criterion(output, target)loss.backward()optimizer.step()# 转换模型
model_int8 = torch.quantization.convert(model_fp32_prepared)
2. 模型剪枝
2.1 原理介绍
模型剪枝是一种通过移除模型中不重要的权重或神经元来减少模型复杂度的技术。剪枝可以减少模型大小、降低计算复杂度,并可能改善模型的泛化能力。

主要的剪枝方法包括:
-
权重剪枝:
- 移除绝对值小于某个阈值的单个权重。
- 可以大幅减少模型参数数量,但可能导致非结构化稀疏性。
-
结构化剪枝:
- 移除整个卷积核、神经元或通道。
- 产生更加规则的稀疏结构,有利于硬件加速。
-
重要性剪枝:
- 基于权重或激活值的重要性评分来决定剪枝对象。
- 常用的重要性度量包括权重幅度、激活值、梯度等。
2.2 PyTorch 实现
import torch
import torch.nn.utils.prune as prunemodel = MyModel()# 1. 权重剪枝
prune.l1_unstructured(model.conv1, name='weight', amount=0.3)# 2. 结构化剪枝
prune.ln_structured(model.conv1, name='weight', amount=0.5, n=2, dim=0)# 3. 全局剪枝
parameters_to_prune = ((model.conv1, 'weight'),(model.conv2, 'weight'),(model.fc1, 'weight'),
)
prune.global_unstructured(parameters_to_prune,pruning_method=prune.L1Unstructured,amount=0.2
)# 4. 移除剪枝
for module in model.modules():if isinstance(module, torch.nn.Conv2d):prune.remove(module, 'weight')
3. 模型蒸馏
3.1 原理介绍
模型蒸馏是一种将复杂模型(教师模型)的知识转移到简单模型(学生模型)的技术。这种方法可以在保持性能的同时,大幅减少模型的复杂度和计算需求。

主要的蒸馏方法包括:
-
响应蒸馏:
- 学生模型学习教师模型的最终输出(软标签)。
- 软标签包含了教师模型对不同类别的置信度信息。
-
特征蒸馏:
- 学生模型学习教师模型的中间层特征。
- 可以传递更丰富的知识,但需要设计合适的映射函数。
-
关系蒸馏:
- 学习样本之间的关系,如相似度或排序。
- 有助于保持教师模型学到的数据结构。
3.2 PyTorch 实现
import torch
import torch.nn as nn
import torch.nn.functional as Fclass DistillationLoss(nn.Module):def __init__(self, alpha=0.5, temperature=2.0):super().__init__()self.alpha = alphaself.T = temperaturedef forward(self, student_outputs, teacher_outputs, labels):# 硬标签损失hard_loss = F.cross_entropy(student_outputs, labels)# 软标签损失soft_loss = F.kl_div(F.log_softmax(student_outputs / self.T, dim=1),F.softmax(teacher_outputs / self.T, dim=1),reduction='batchmean') * (self.T * self.T)# 总损失loss = (1 - self.alpha) * hard_loss + self.alpha * soft_lossreturn loss# 训练循环
teacher_model = TeacherModel().eval()
student_model = StudentModel().train()
distillation_loss = DistillationLoss(alpha=0.5, temperature=2.0)for epoch in range(num_epochs):for batch, labels in train_loader:optimizer.zero_grad()with torch.no_grad():teacher_outputs = teacher_model(batch)student_outputs = student_model(batch)loss = distillation_loss(student_outputs, teacher_outputs, labels)loss.backward()optimizer.step()
通过这些技术的组合使用,可以显著减小模型大小、提高推理速度,同时尽可能保持模型性能。在实际应用中,可能需要根据具体任务和硬件限制来选择和调整这些方法。
参考文献
[1]Jacob, B., Kligys, S., Chen, B., Zhu, M., Tang, M., Howard, A., Adam, H., & Kalenichenko, D. (2018). Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (pp. 2704-2713).[2]Krishnamoorthi, R. (2018). Quantizing deep convolutional networks for efficient inference: A whitepaper. arXiv preprint arXiv:1806.08342.[3]Han, S., Pool, J., Tran, J., & Dally, W. (2015). Learning both Weights and Connections for Efficient Neural Network. In Advances in Neural Information Processing Systems (NeurIPS) (pp. 1135-1143).[4]Li, H., Kadav, A., Durdanovic, I., Samet, H., & Graf, H. P. (2016). Pruning Filters for Efficient ConvNets. arXiv preprint arXiv:1608.08710.[5]Hinton, G., Vinyals, O., & Dean, J. (2015). Distilling the Knowledge in a Neural Network. arXiv preprint arXiv:1503.02531.[6]Romero, A., Ballas, N., Kahou, S. E., Chassang, A., Gatta, C., & Bengio, Y. (2014). FitNets: Hints for Thin Deep Nets. arXiv preprint arXiv:1412.6550.
创作不易,烦请各位观众老爷给个三连,小编在这里跪谢了!

相关文章:
基于 PyTorch 的模型瘦身三部曲:量化、剪枝和蒸馏,让模型更短小精悍!
基于 PyTorch 的模型量化、剪枝和蒸馏 1. 模型量化1.1 原理介绍1.2 PyTorch 实现 2. 模型剪枝2.1 原理介绍2.2 PyTorch 实现 3. 模型蒸馏3.1 原理介绍3.2 PyTorch 实现 参考文献 1. 模型量化 1.1 原理介绍 模型量化是将模型参数从高精度(通常是 float32࿰…...

二、原型模式
文章目录 1 基本介绍2 实现方式深浅拷贝目标2.1 使用 Object 的 clone() 方法2.1.1 代码2.1.2 特性2.1.3 实现深拷贝 2.2 在 clone() 方法中使用序列化2.2.1 代码 2.2.2 特性 3 实现的要点4 Spring 中的原型模式5 原型模式的类图及角色5.1 类图5.1.1 不限制语言5.1.2 在 Java 中…...

【目标检测】Anaconda+PyTorch(GPU)+PyCharm(Yolo5)配置
前言 本文主要介绍在windows系统上的Anaconda、PyTorch、PyCharm、Yolov5关键步骤安装,为使用yolo所需的环境配置完善。同时也算是记录下我的配置流程,为以后用到的时候能笔记查阅。 Anaconda 软件安装 Anaconda官网:https://www.anaconda…...

Django实战项目之进销存数据分析报表——第二天:项目创建和 PyCharm 配置
在上一篇博客中,我们讨论了如何搭建一个全栈 Web 应用的开发环境,包括 Python 环境的创建、Django 和 MySQL 的安装以及前端技术栈的选择。现在,让我们继续深入,学习如何在 PyCharm 中创建一个新的 Django 项目并进行配置。 一…...

静态路由实验
1.实验拓扑图 二、实验要求 1.R6为ISP,接口IP地址均为公有地址,该设备只能配置IP地址,之后不能再对其进行任何配置; 2.R1-R5为局域网,私有IP地址192.168.1.0/24,请合理分配; 3.R1、R2、R4&…...

VSCode STM32嵌入式开发插件记录
要卸载之前搭建的VSCode嵌入式开发环境了,记录一下用的插件。 1.Cortex-Debug https://github.com/Marus/cortex-debug 2.Embedded IDE https://github.com/github0null/eide 3.Keil uVision Assistant https://github.com/jacksonjim/keil-assistant/ 4.RTO…...

linux cpu 占用超100% 分析。
感谢: https://www.cnblogs.com/wolfstark/p/16450131.html 总结: 查看进程中各个线程占用百分比 top -H -p <pid> 某线程100%了 说明 任务处理不过来 会卡 但是永远不可能超100% 系统监视器里面看到的是 所有线程占用的 总和会超100%。 所以最好的情况是&…...

自然学习法和科学学习法
一、自然学习法 自然学习法:什么事自然学习法,特意让kimi来回答了一下。所谓的自然学习法说的俗一点就是野路子学习方法。这种学习方法的特点是“慢”“没有系统性”,学完之后感觉都会了,但是又感觉什么都不会。 二、科学学习法 …...
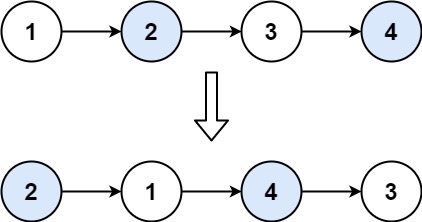
力扣第二十四题——两两交换链表中的节点
内容介绍 给你一个链表,两两交换其中相邻的节点,并返回交换后链表的头节点。你必须在不修改节点内部的值的情况下完成本题(即,只能进行节点交换)。 示例 1: 输入:head [1,2,3,4] 输出ÿ…...

C语言柔性数组详解
目录 1.柔性数组 2.柔性数组的特点 3.柔性数组的使用 4.柔性数组的优势 1.柔性数组 C99 中,结构体中的最后一个元素允许是未知大小的数组,这就叫做『柔性数组』成员。 例如: struct S {char c;int n;int arr[];//柔性数组 }; struct …...
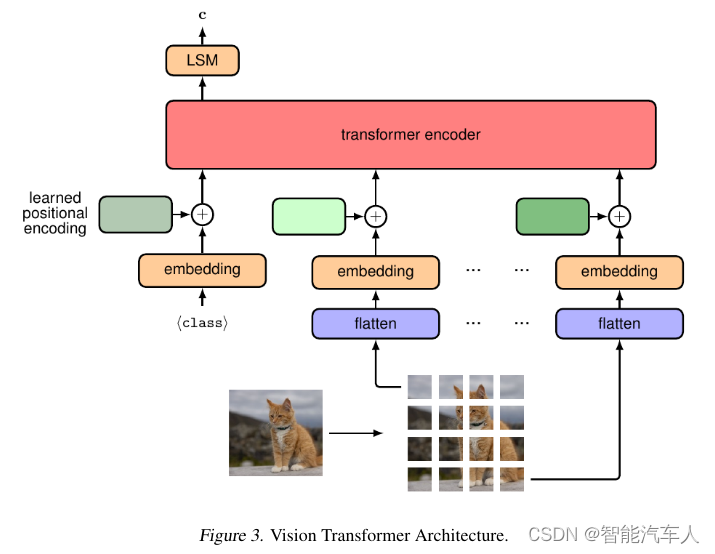
自动驾驶---视觉Transformer的应用
1 背景 在过去的几年,随着自动驾驶技术的不断发展,神经网络逐渐进入人们的视野。Transformer的应用也越来越广泛,逐步走向自动驾驶技术的前沿。笔者也在博客《人工智能---什么是Transformer?》中大概介绍了Transformer的一些内容:…...

预训练语言模型实践笔记
Roberta output_hidden_statesTrue和last_hidden_states和pooler_output 在使用像BERT或RoBERTa这样的transformer模型时,output_hidden_states和last_hidden_state是两个不同的概念。 output_hidden_states: 这是一个布尔值,决定了模型是否应该返回所…...

Perl 哈希
Perl 哈希 Perl 哈希是一种强大的数据结构,用于存储键值对集合。它是 Perl 语言的核心特性之一,广泛应用于各种编程任务中。本文将详细介绍 Perl 哈希的概念、用法和最佳实践。 什么是 Perl 哈希? Perl 哈希是一种关联数组,其中…...

Linux之Mysql索引和优化
一、MySQL 索引 索引作为一种数据结构,其用途是用于提升数据的检索效率。 1、索引分类 - 普通索引(INDEX):索引列值可重复 - 唯一索引(UNIQUE):索引列值必须唯一,可以为NULL - 主键索引(PRIMARY KEY):索引列值必须唯一,不能为NULL,一个表只能有一个主键索引 - 全…...

springboot业务逻辑写在controller层吗
Spring Boot中的业务逻辑不应该直接写在Controller层。 在Spring Boot项目中,通常将业务逻辑分为几个层次,包括Controller层、Service层、Mapper层和Entity层。 1.其中,Controller层主要负责处理HTTP请求,通过注…...

Ubuntu 24.04 LTS 桌面安装MT4或MT5 (MetaTrader)教程
运行脚本即可在 Ubuntu 24.04 LTS Noble Linux 上轻松安装 MetaTrader 5 或 4 应用程序,使用 WineHQ 进行外汇交易。 MetaTrader 4 (MT4) 或 MetaTrader 5 是用于交易外汇对和商品的流行平台。它支持各种外汇经纪商、内置价格分析工具以及通过专家顾问 (EA) 进行自…...

Go基础编程 - 12 -流程控制
流程控制 1. 条件语句1.1. if...else 语句1.2. switch 语句1.3. select 语句1.3.1. select 语句的通信表达式1.3.2. select 的基特性1.3.3. select 的实现原理1.3.4. 经典用法1.3.4.1 超时控制1.3.4.2 多任务并发控制1.3.4.3 监听多通道消息1.3.4.4 default 实现非堵塞读写 2. …...

汽车信息安全--TLS,OpenSSL
目录 TLS相关知识 加密技术 对称加密 非对称加密 数字签名和CA 信任链 根身份证和自签名 双方TLS认证 加密和解密的性能 TLS相关知识 加密技术 TLS依赖两种加密技术 1. 对称加密(symmetric encryption) 2. 非对称加密(asymmetri…...
与左模糊匹配(LIKE LEFT))
深入探索 SQL 中的 LIKE 右模糊匹配(LIKE RIGHT)与左模糊匹配(LIKE LEFT)
引言 在数据库操作中,LIKE 子句是执行模糊搜索的强大工具,用于匹配列中的数据与指定的模式。本文将详细介绍 LIKE 子句中的两种常用模式:右模糊匹配(LIKE RIGHT)和左模糊匹配(LIKE LEFT)&#…...

mybatis 多数据源 TDataSource required a single bean, but 2 were found
情况说明: 项目中本来就有一个数据源了,运行的好好的后来又合并了另一个项目,另一个项目也配置了数据源。 于是出现了如下错误: mybatis 多数据源 TDataSource required a single bean, but 2 were found 解决方法:…...

业务系统对接大模型的基础方案:架构设计与关键步骤
业务系统对接大模型:架构设计与关键步骤 在当今数字化转型的浪潮中,大语言模型(LLM)已成为企业提升业务效率和创新能力的关键技术之一。将大模型集成到业务系统中,不仅可以优化用户体验,还能为业务决策提供…...

反向工程与模型迁移:打造未来商品详情API的可持续创新体系
在电商行业蓬勃发展的当下,商品详情API作为连接电商平台与开发者、商家及用户的关键纽带,其重要性日益凸显。传统商品详情API主要聚焦于商品基本信息(如名称、价格、库存等)的获取与展示,已难以满足市场对个性化、智能…...

JVM垃圾回收机制全解析
Java虚拟机(JVM)中的垃圾收集器(Garbage Collector,简称GC)是用于自动管理内存的机制。它负责识别和清除不再被程序使用的对象,从而释放内存空间,避免内存泄漏和内存溢出等问题。垃圾收集器在Ja…...

江苏艾立泰跨国资源接力:废料变黄金的绿色供应链革命
在华东塑料包装行业面临限塑令深度调整的背景下,江苏艾立泰以一场跨国资源接力的创新实践,重新定义了绿色供应链的边界。 跨国回收网络:废料变黄金的全球棋局 艾立泰在欧洲、东南亚建立再生塑料回收点,将海外废弃包装箱通过标准…...

OkHttp 中实现断点续传 demo
在 OkHttp 中实现断点续传主要通过以下步骤完成,核心是利用 HTTP 协议的 Range 请求头指定下载范围: 实现原理 Range 请求头:向服务器请求文件的特定字节范围(如 Range: bytes1024-) 本地文件记录:保存已…...

EtherNet/IP转DeviceNet协议网关详解
一,设备主要功能 疆鸿智能JH-DVN-EIP本产品是自主研发的一款EtherNet/IP从站功能的通讯网关。该产品主要功能是连接DeviceNet总线和EtherNet/IP网络,本网关连接到EtherNet/IP总线中做为从站使用,连接到DeviceNet总线中做为从站使用。 在自动…...

QT: `long long` 类型转换为 `QString` 2025.6.5
在 Qt 中,将 long long 类型转换为 QString 可以通过以下两种常用方法实现: 方法 1:使用 QString::number() 直接调用 QString 的静态方法 number(),将数值转换为字符串: long long value 1234567890123456789LL; …...

Spring AI与Spring Modulith核心技术解析
Spring AI核心架构解析 Spring AI(https://spring.io/projects/spring-ai)作为Spring生态中的AI集成框架,其核心设计理念是通过模块化架构降低AI应用的开发复杂度。与Python生态中的LangChain/LlamaIndex等工具类似,但特别为多语…...

以光量子为例,详解量子获取方式
光量子技术获取量子比特可在室温下进行。该方式有望通过与名为硅光子学(silicon photonics)的光波导(optical waveguide)芯片制造技术和光纤等光通信技术相结合来实现量子计算机。量子力学中,光既是波又是粒子。光子本…...

视频行为标注工具BehaviLabel(源码+使用介绍+Windows.Exe版本)
前言: 最近在做行为检测相关的模型,用的是时空图卷积网络(STGCN),但原有kinetic-400数据集数据质量较低,需要进行细粒度的标注,同时粗略搜了下已有开源工具基本都集中于图像分割这块,…...