多任务高斯过程数学原理和Pytorch实现示例
高斯过程其在回归任务中的应用我们都很熟悉了,但是我们一般介绍的都是针对单个任务的,也就是单个输出。本文我们将讨论扩展到多任务gp,强调它们的好处和实际实现。
本文将介绍如何通过共区域化的内在模型(ICM)和共区域化的线性模型(LMC),使用高斯过程对多个相关输出进行建模。
多任务高斯过程
高斯过程是回归和分类任务中的一个强大工具,提供了一种非参数方式来定义函数的分布。当处理多个相关输出时,多任务高斯过程可以模拟这些任务之间的依赖关系,从而带来更好的泛化和预测效果。
数学上,高斯过程被定义为一组随机变量,其中任何有限数量的变量都具有联合高斯分布。对于一组输入点 X,相应的输出值 f(X) 是联合高斯分布的:
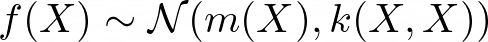
其中 m(X) 是均值函数,k(X, X) 是协方差矩阵。
在多任务环境中,目标是建模函数 f: X → R^T,这样我们就有 T 个输出或任务,f_t(X) 对于 t = 1, …, T。这意味着均值函数是 m: X → R^T,核函数是 k: X × X → R^{T × T}。
我们如何模拟这些任务之间的相关性?
独立多任务高斯过程
一个简单的独立多输出高斯过程模型将每个任务独立建模,不考虑任务之间的任何相关性。在这种情况下,每个任务都有自己的高斯过程,具有自己的均值和协方差函数。数学上可以表达为:
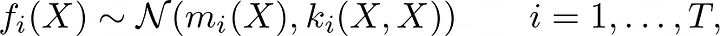
这使得协方差矩阵 k(x, x) 是块对角形的,即 diag(k_1(x, x), …, k_T(x, x))。
这种方法没有利用任务之间的共享信息,可能导致性能不佳,尤其是当某些任务的数据有限时。
Intrinsic model of coregionalization(ICM)
ICM(共区域化的内在模型)方法通过引入核心区域化矩阵 (B) 来推广独立多输出高斯过程,该矩阵模型化任务之间的相关性。ICM方法中的协方差函数定义如下:
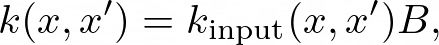
其中 k_input是在输入空间上定义的协方差函数(例如,平方指数核),而 B ∈ R^{T × T} 是捕捉任务特定协方差的核心区域化矩阵。矩阵 (B) 通常参数化为 (B = W W^T),其中W ∈ R^{T × r*}* ,且 ® 是核心区域化矩阵的秩。这确保了核函数是半正定的。
ICM方法可以学习任务之间的共享结构。任务之间的皮尔逊相关系数可以表示为:
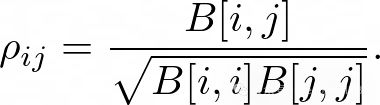
Linear model of coregionalization (LMC)
另一种常见的方法是LMC(线性核心区域化模型)模型,它通过允许更多种类的输入核来扩展ICM。在LMC模型中,协方差函数定义为:
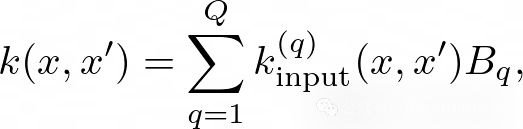
其中 (Q) 是基核的数量,k_input^q 是基核,而 (B_q) 是每个基核的核心区域化矩阵。通过结合多个基核,这个模型可以捕捉任务之间更复杂的相关性。
我们可以通过设置 (Q=1) 来恢复ICM模型。或者说ICM是Q=1的LMC模型
噪声建模
在多任务高斯过程中,我们需要考虑一个多输出似然函数,该函数为每个任务模型化噪声。
标准的似然函数通常是多维高斯似然,可以表示为:

其中 (y) 是观测输出,(f(x)) 是潜在函数,Sigma是噪声协方差矩阵。
这里的灵活性在于噪声协方差矩阵的选择,它可以是对角线Σ=diag(σ12,…,σT2)(每个任务独立噪声)或完整(任务间相关噪声)。
后者通常表示为 Σ=LLT,其中 L∈RT×r,且 r是噪声协方差矩阵的秩。这允许捕捉不同任务的噪声项之间的相关性。
最终包含噪声的协方巧矩阵则由以下给出:
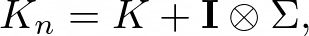
其中 (K) 是没有噪声的协方差矩阵,(I) 是单位矩阵,⊗表示克罗内克乘积,以便将噪声项添加到协方差矩阵的对角块中。
PyTorch实现
我们上面介绍了多任务的高斯过程的数学原理,下面开使用’ GPyTorch '与ICM内核实现多任务GP的示例。
首先需要安装所需的软件包,包括’ Torch ', ’ GPyTorch ', ’ matplotlib ‘和’ seaborn ', ’ numpy '。
%pip install torch gpytorch matplotlib seaborn numpy pandasimport torchimport gpytorchfrom matplotlib import pyplot as pltimport numpy as npimport seaborn as snsimport pandas as pd
然后,定义多任务GP模型。使用ICM内核(秩r=1)来捕获任务之间的相关性。
我们为两个任务(正弦和移位正弦)生成合成的噪声训练数据,以便有相关的输出。
噪声协方差矩阵为
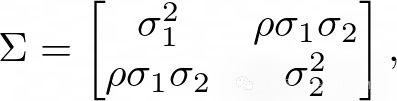
其中σ²1 = σ²2 = 0.1²,ρ = 0.3。
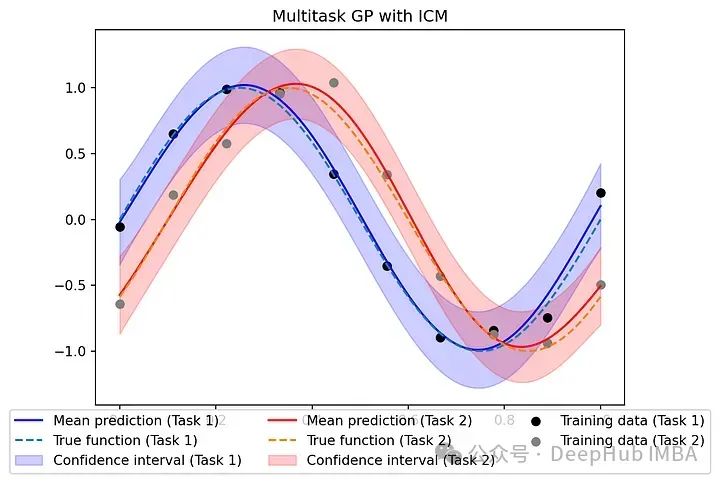
最后,我们通过绘制每个任务的平均预测和置信区间来训练模型并评估其性能。
# Define the kernel with coregionalizationclass MultitaskGPModel(gpytorch.models.ExactGP):def __init__(self, train_x, train_y, likelihood, num_tasks):super(MultitaskGPModel, self).__init__(train_x, train_y, likelihood)self.mean_module = gpytorch.means.MultitaskMean(gpytorch.means.ConstantMean(), num_tasks=num_tasks)self.covar_module = gpytorch.kernels.MultitaskKernel(gpytorch.kernels.RBFKernel(), num_tasks=num_tasks, rank=1)def forward(self, x):mean_x = self.mean_module(x)covar_x = self.covar_module(x)return gpytorch.distributions.MultitaskMultivariateNormal(mean_x, covar_x)# Training dataf1 = lambda x: torch.sin(x * (2 * torch.pi))f2 = lambda x: torch.sin((x - 0.1) * (2 * torch.pi))train_x = torch.linspace(0, 1, 10)train_y = torch.stack([f1(train_x),f2(train_x)]).T# Define the noise covariance matrix with correlation = 0.3sigma2 = 0.1**2Sigma = torch.tensor([[sigma2, 0.3 * sigma2], [0.3 * sigma2, sigma2]])# Add noise to the training datatrain_y += torch.tensor(np.random.multivariate_normal(mean=[0,0], cov=Sigma, size=len(train_x)))# Model and likelihoodnum_tasks = 2likelihood = gpytorch.likelihoods.MultitaskGaussianLikelihood(num_tasks=num_tasks, rank=1)model = MultitaskGPModel(train_x, train_y, likelihood, num_tasks)# Training the modelmodel.train()likelihood.train()optimizer = torch.optim.Adam(model.parameters(), lr=0.1)mll = gpytorch.mlls.ExactMarginalLogLikelihood(likelihood, model)scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=50, gamma=0.5)num_iter = 500for i in range(num_iter):optimizer.zero_grad()output = model(train_x)loss = -mll(output, train_y)loss.backward()optimizer.step()scheduler.step()# Evaluationmodel.eval()likelihood.eval()test_x = torch.linspace(0, 1, 100)with torch.no_grad(), gpytorch.settings.fast_pred_var():pred_multi = likelihood(model(test_x))# Plot predictionsfig, ax = plt.subplots()colors = ['blue', 'red']for i in range(num_tasks):ax.plot(test_x, pred_multi.mean[:, i], label=f'Mean prediction (Task {i+1})', color=colors[i])ax.plot(test_x, [f1(test_x), f2(test_x)][i], linestyle='--', label=f'True function (Task {i+1})')lower = pred_multi.confidence_region()[0][:, i].detach().numpy()upper = pred_multi.confidence_region()[1][:, i].detach().numpy()ax.fill_between(test_x,lower,upper,alpha=0.2,label=f'Confidence interval (Task {i+1})',color=colors[i])ax.scatter(train_x, train_y[:, 0], color='black', label=f'Training data (Task 1)')ax.scatter(train_x, train_y[:, 1], color='gray', label=f'Training data (Task 2)')ax.set_title('Multitask GP with ICM')ax.legend(loc='lower center', bbox_to_anchor=(0.5, -0.2),ncol=3, fancybox=True)
在使用
GPyTorch
时,通过使用
MultitaskMean
、
MultitaskKernel
和
MultitaskGaussianLikelihood
类,ICM模型的实现非常简单。这些类可以处理多任务结构、噪声和核心区域化矩阵,允许我们专注于模型定义和训练。
训练的循环也与标准高斯过程类似,以负边际对数似然作为损失函数,并使用优化器来更新模型参数。
在训练过程中添加了一个调度器来降低学习率,这可以帮助稳定优化过程。
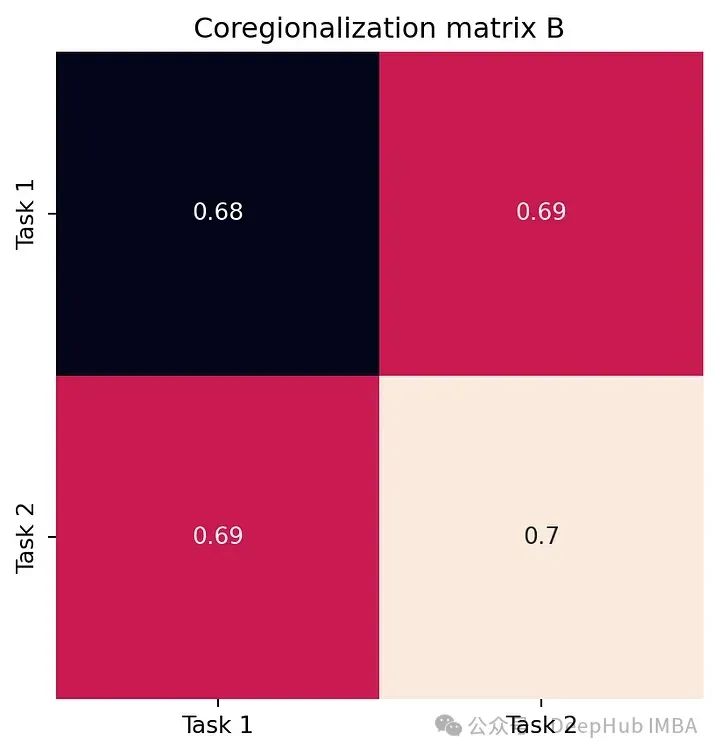
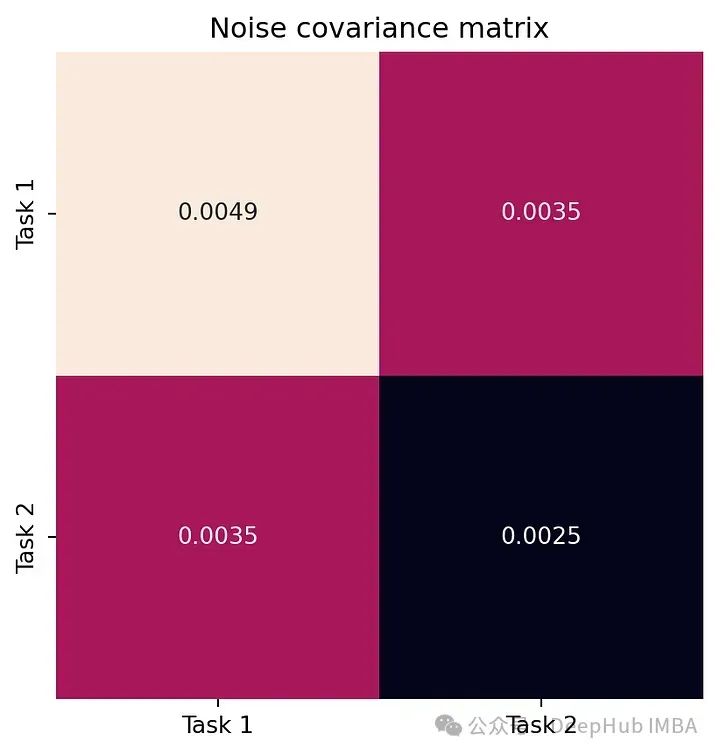
W = model.covar_module.task_covar_module.covar_factorB = W @ W.Tfig, ax = plt.subplots()sns.heatmap(B.detach().numpy(), annot=True, ax=ax, cbar=False, square=True)ax.set_xticklabels(['Task 1', 'Task 2'])ax.set_yticklabels(['Task 1', 'Task 2'])ax.set_title('Coregionalization matrix B')fig.show()L = model.likelihood.task_noise_covar_factor.detach().numpy()Sigma = L @ L.Tfig, ax = plt.subplots()sns.heatmap(Sigma, annot=True, ax=ax, cbar=False, square=True)ax.set_xticklabels(['Task 1', 'Task 2'])ax.set_yticklabels(['Task 1', 'Task 2'])ax.set_title('Noise covariance matrix')fig.show()
下面的图展示了模型学习的核心区域化矩阵 B 以及噪声协方差矩阵 Σ。
这张图捕捉了任务之间的相关性。如我们所见,B 的非对角线元素是正的。
这个图代表每个任务的噪声水平。注意到模型已经正确学习了噪声相关性。
比较
为了突出使用ICM方法对相关输出建模的优势,我们可以将其与独立处理每个任务、忽略任务之间任何潜在相关性的模型进行比较。
为每个任务定义一个单独的GP,训练它们,并在测试数据上评估它们的性能。
class IndependentGPModel(gpytorch.models.ExactGP):def __init__(self, train_x, train_y, likelihood):super(IndependentGPModel, self).__init__(train_x, train_y, likelihood)self.mean_module = gpytorch.means.ConstantMean()self.covar_module = gpytorch.kernels.ScaleKernel(gpytorch.kernels.RBFKernel())def forward(self, x):mean_x = self.mean_module(x)covar_x = self.covar_module(x)return gpytorch.distributions.MultivariateNormal(mean_x, covar_x)# Create models and likelihoods for each tasklikelihoods = [gpytorch.likelihoods.GaussianLikelihood() for _ in range(num_tasks)]models = [IndependentGPModel(train_x, train_y[:, i], likelihoods[i]) for i in range(num_tasks)]# Training the independent modelsfor i, (model, likelihood) in enumerate(zip(models, likelihoods)):model.train()likelihood.train()optimizer = torch.optim.Adam(model.parameters(), lr=0.1)mll = gpytorch.mlls.ExactMarginalLogLikelihood(likelihood, model)scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=50, gamma=0.5)for _ in range(num_iter):optimizer.zero_grad()output = model(train_x)loss = -mll(output, train_y[:, i])loss.backward()optimizer.step()scheduler.step()# Evaluationfor model, likelihood in zip(models, likelihoods):model.eval()likelihood.eval()with torch.no_grad(), gpytorch.settings.fast_pred_var():pred_inde = [likelihood(model(test_x)) for model, likelihood in zip(models, likelihoods)]# Plot predictionsfig, ax = plt.subplots()for i in range(num_tasks):ax.plot(test_x, pred_inde[i].mean, label=f'Mean prediction (Task {i+1})', color=colors[i])ax.plot(test_x, [f1(test_x), f2(test_x)][i], linestyle='--', label=f'True function (Task {i+1})')lower = pred_inde[i].confidence_region()[0]upper = pred_inde[i].confidence_region()[1]ax.fill_between(test_x,lower,upper,alpha=0.2,label=f'Confidence interval (Task {i+1})',color=colors[i])ax.scatter(train_x, train_y[:, 0], color='black', label='Training data (Task 1)')ax.scatter(train_x, train_y[:, 1], color='gray', label='Training data (Task 2)')ax.set_title('Independent GPs')ax.legend(loc='lower center', bbox_to_anchor=(0.5, -0.2),ncol=3, fancybox=True)
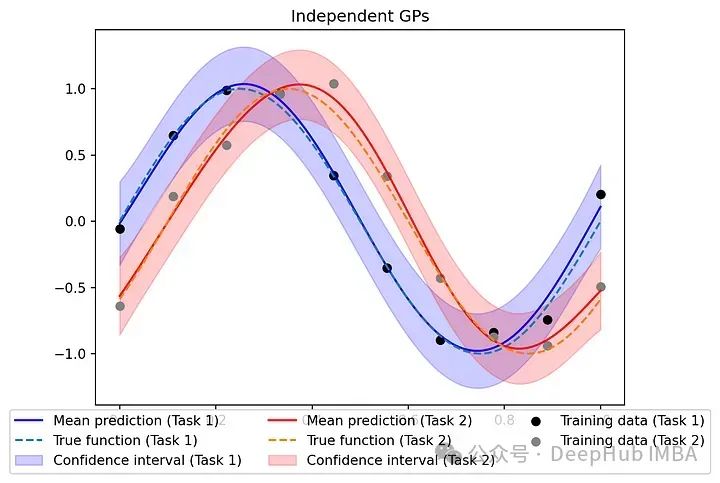
在性能方面,比较多任务GP与ICM和独立GP在测试数据上预测的均方误差(MSE)。
mean_multi = pred_multi.mean.numpy()mean_inde = np.stack([pred.mean.numpy() for pred in pred_inde]).Ttest_y = torch.stack([f1(test_x), f2(test_x)]).T.numpy()MSE_multi = np.mean((mean_multi - test_y) ** 2)MSE_inde = np.mean((mean_inde - test_y) ** 2)df = pd.DataFrame({'Model': ['ICM', 'Independent'],'MSE': [MSE_multi, MSE_inde]})df

可以看到由于共区域化矩阵学习到的共享结构,ICM在MSE方面略优于独立gp。当处理更复杂的任务或有限的数据时,这种改进可能更为显著。
在独立GP的场景中,每个GP从一个较小的10个点的数据集中学习,这可能会导致过拟合或次优泛化。具有ICM的多任务GP使用所有20个点来学习指数核参数的平方。这种共享信息有助于改进对这两个任务的预测。
https://avoid.overfit.cn/post/f804e93bd5dd4c4ab9ede5bf1bc9b6c8
作者:Andrea Ruglioni
相关文章:
多任务高斯过程数学原理和Pytorch实现示例
高斯过程其在回归任务中的应用我们都很熟悉了,但是我们一般介绍的都是针对单个任务的,也就是单个输出。本文我们将讨论扩展到多任务gp,强调它们的好处和实际实现。 本文将介绍如何通过共区域化的内在模型(ICM)和共区域化的线性模型(LMC)&…...

【PPT把当前页输出为图片】及【PPT导出图片模糊】的解决方法(sci论文图片清晰度)
【PPT把当前页输出为图片】及【PPT导出图片模糊】的解决方法 内容一:ppt把当前页输出为图片:内容二:ppt导出图片模糊的解决方法:方法:步骤1:打开注册表编辑器步骤2:修改注册表: 该文…...
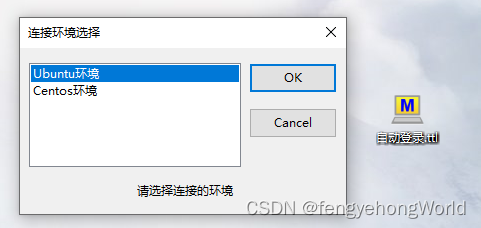
TeraTerm 使用技巧
参考资料 自分がよく使うTeratermマクロによる自動ログインのやり方をまとめてみたよTera Term マクロでログインを自動化してみたTera Term のススメ 目录 简介一. 常用基础设置1.1 语言变更1.2 log设置 二. 小技巧2.1 指定host别名2.2 新开窗口2.3 设置粘贴多行命令时的行间…...

意得润色打折啦
新注册使用可以减15%,ABSJU202,直接使用哦ㅤ 此外,如果老板经费充足,预算高,完全可以试试他家的投稿套餐,科学深度编辑,从期刊选择,到投稿协助,投稿信都帮你写好…...

微软研发致胜策略 06:学无止境
这是一本老书,作者 Steve Maguire 在微软工作期间写了这本书,英文版于 1994 年发布。我们看到的标题是中译版名字,英文版的名字是《Debugging the Development Process》,这本书详细阐述了软件开发过程中的常见问题及其解决方案&a…...

学习大数据DAY21 Linux基本指令2
目录 思维导图 搜索查看查找类 find 从指定目录查找文件 head 与 tail 查看行 cat 查看内容 more 查看大内容 grep 过滤查找 history 查看已经执行过的历史命令 wc 统计文件 du 查看空间 管道符号 | 配合命令使用 上机练习 4 解压安装类 zip unzip 压缩解压 tar …...
 - Handler)
【18】Android 线程间通信(三) - Handler
概述 接下来我们会从native层来分析一下,Handler做了什么,以及之前提到过的应用层的两个native的调用链。 nativeWake 最早接触这个方法还记得是什么时候吗?MessageQueue#enqueueMessage中,在这个方法的末尾,我们看…...

静态路由技术
一、路由的概念 路由是指指导IP报文发送的路径信息。 二、路由表的结构 1、Destination/Mask:IP报文的接收方的IP地址及其子网掩码; 2、proto:协议(Static:静态路由协议,Direct:表示直连路由) 3、pref:优先级(数值和优先级成反比) 4、cost:路由开销(从源到目的…...

SpringBoot缓存注解使用
背景 除了 RedisTemplate 外, 自Spring3.1开始,Spring自带了对缓存的支持。我们可以直接使用Spring缓存技术将某些数据放入本机的缓存中;Spring缓存技术也可以搭配其他缓存中间件(如Redis等)进行使用,将某些数据写入到缓存中间件…...

@RequestBody接收到的参数中如何限制List的长度?
在Spring MVC中,你可以使用Valid注解和自定义的验证注解来限制List的长度,防止DOS攻击。具体步骤如下: 创建自定义注解:首先,创建一个自定义注解来验证List的长度。 import javax.validation.Constraint; import jav…...

Linux C语言 54-目录操作
Linux C语言 54-目录操作 本节关键字:Linux、C语言、目录操作、遍历目录 相关C库函数:opendir、readdir、closedir 遍历目录 #include <stdio.h> #include <stdlib.h> #include <unistd.h> #include <dirent.h> #include <…...

Java实战中如何使用多线程(线程池)及其为什么使用?
这个话题在入行之前就想过很多次,很多8古文或者你搜索的结果都是告诉你什么提高高并发或者是一些很高大上的话,既没有案例也没有什么公式去证明,但是面试中总是被问到,也没有实战经历,所以面试时一问到多线程的东西就无…...

kafka集群搭建-使用zookeeper
1.环境准备: 使用如下3台主机搭建zookeeper集群,由于默认的9092客户端连接端口不在本次使用的云服务器开放端口范围内,故端口改为了8093。 172.2.1.69:8093 172.2.1.70:8093 172.2.1.71:8093 2.下载地址 去官网下载,或者使用如…...

【python】Numpy运行报错分析:IndexError与形状不匹配问题
✨✨ 欢迎大家来到景天科技苑✨✨ 🎈🎈 养成好习惯,先赞后看哦~🎈🎈 🏆 作者简介:景天科技苑 🏆《头衔》:大厂架构师,华为云开发者社区专家博主,…...

你有多自律就有多自由
当你失去对时间的控制权,生活也就失去了平衡。 真正对自己有要求的人,都是高度自律的人。 追求自己想要的生活,任何时候开始都不会晚,关键在于你能够坚持下去,以高度自律的精神,日复一日、年复一年的坚持下…...
 文字讲解+视频讲解)
Codeforces Round 959 (Div. 1 + Div. 2 ABCDEFG 题) 文字讲解+视频讲解
Problem A. Diverse Game Statement 给定 n m n\times m nm 的矩形 a a a, a a a 中的每一个数均在 1 ∼ n m 1\sim nm 1∼nm 之间且互不相同。求出 n m n\times m nm 的矩形 b b b, b b b 中的每一个数均在 1 ∼ n m 1\sim nm 1∼nm 之间且互…...

WSL2 Centos7 Docker服务启动失败怎么办?
wsl 安装的CentOS7镜像,安装了Docker之后,发现用systemctl start docker 无法将docker启动起来。 解决办法 1、编辑文件 vim /usr/lib/systemd/system/docker.service将13行注释掉,然后在下面新增14行的内容。然后保存退出。 2、再次验证 可以发现,我们已经可以正常通过s…...

分布式锁-redisson锁重试和WatchDog机制
抢锁过程中,获得当前线程,通过tryAcquire进行抢锁,该抢锁逻辑和之前逻辑相同。 1、先判断当前这把锁是否存在,如果不存在,插入一把锁,返回null 2、判断当前这把锁是否是属于当前线程,如果是&a…...

ESP8266模块(2)
实例1 查看附近的WiFi 步骤1:进入AT指令模式 使用USB转串口适配器将ESP8266模块连接到电脑。打开串口终端软件,并设置正确的串口和波特率(通常为115200)。输入以下命令并按回车确认: AT如果模块响应OK,…...

Docker安装笔记
1. Mac安装Docker 1.1 Docker安装包下载 1.1.1 阿里云 对于10.10.3以下的用户 推荐使用 对于10.10.3以上的用户 推荐使用 1.1.2 官网下载 系统和芯片选择适合自己的安装包 1.2 镜像加速 【推荐】阿里镜像 登陆后,左侧菜单选中镜像加速器就可以看到你的专属地…...

UDP(Echoserver)
网络命令 Ping 命令 检测网络是否连通 使用方法: ping -c 次数 网址ping -c 3 www.baidu.comnetstat 命令 netstat 是一个用来查看网络状态的重要工具. 语法:netstat [选项] 功能:查看网络状态 常用选项: n 拒绝显示别名&#…...

零基础设计模式——行为型模式 - 责任链模式
第四部分:行为型模式 - 责任链模式 (Chain of Responsibility Pattern) 欢迎来到行为型模式的学习!行为型模式关注对象之间的职责分配、算法封装和对象间的交互。我们将学习的第一个行为型模式是责任链模式。 核心思想:使多个对象都有机会处…...

Caliper 配置文件解析:config.yaml
Caliper 是一个区块链性能基准测试工具,用于评估不同区块链平台的性能。下面我将详细解释你提供的 fisco-bcos.json 文件结构,并说明它与 config.yaml 文件的关系。 fisco-bcos.json 文件解析 这个文件是针对 FISCO-BCOS 区块链网络的 Caliper 配置文件,主要包含以下几个部…...

Java 二维码
Java 二维码 **技术:**谷歌 ZXing 实现 首先添加依赖 <!-- 二维码依赖 --><dependency><groupId>com.google.zxing</groupId><artifactId>core</artifactId><version>3.5.1</version></dependency><de…...
相比,优缺点是什么?适用于哪些场景?)
Redis的发布订阅模式与专业的 MQ(如 Kafka, RabbitMQ)相比,优缺点是什么?适用于哪些场景?
Redis 的发布订阅(Pub/Sub)模式与专业的 MQ(Message Queue)如 Kafka、RabbitMQ 进行比较,核心的权衡点在于:简单与速度 vs. 可靠与功能。 下面我们详细展开对比。 Redis Pub/Sub 的核心特点 它是一个发后…...

Aspose.PDF 限制绕过方案:Java 字节码技术实战分享(仅供学习)
Aspose.PDF 限制绕过方案:Java 字节码技术实战分享(仅供学习) 一、Aspose.PDF 简介二、说明(⚠️仅供学习与研究使用)三、技术流程总览四、准备工作1. 下载 Jar 包2. Maven 项目依赖配置 五、字节码修改实现代码&#…...

Netty从入门到进阶(二)
二、Netty入门 1. 概述 1.1 Netty是什么 Netty is an asynchronous event-driven network application framework for rapid development of maintainable high performance protocol servers & clients. Netty是一个异步的、基于事件驱动的网络应用框架,用于…...

作为测试我们应该关注redis哪些方面
1、功能测试 数据结构操作:验证字符串、列表、哈希、集合和有序的基本操作是否正确 持久化:测试aof和aof持久化机制,确保数据在开启后正确恢复。 事务:检查事务的原子性和回滚机制。 发布订阅:确保消息正确传递。 2、性…...
)
华为OD最新机试真题-数组组成的最小数字-OD统一考试(B卷)
题目描述 给定一个整型数组,请从该数组中选择3个元素 组成最小数字并输出 (如果数组长度小于3,则选择数组中所有元素来组成最小数字)。 输入描述 行用半角逗号分割的字符串记录的整型数组,0<数组长度<= 100,0<整数的取值范围<= 10000。 输出描述 由3个元素组成…...

ArcGIS Pro+ArcGIS给你的地图加上北回归线!
今天来看ArcGIS Pro和ArcGIS中如何给制作的中国地图或者其他大范围地图加上北回归线。 我们将在ArcGIS Pro和ArcGIS中一同介绍。 1 ArcGIS Pro中设置北回归线 1、在ArcGIS Pro中初步设置好经纬格网等,设置经线、纬线都以10间隔显示。 2、需要插入背会归线…...