机器学习 | 阿里云安全恶意程序检测
目录
- 一、数据探索
- 1.1 数据说明
- 1.2 训练集数据探索
- 1.2.1 数据特征类型
- 1.2.2 数据分布
- 1.2.3 缺失值
- 1.2.4 异常值
- 1.2.5 标签分布探索
- 1.3 测试集探索
- 1.3.1 数据信息
- 1.3.2 缺失值
- 1.3.3 数据分布
- 1.3.4 异常值
- 1.4 数据集联合分析
- 1.4.1 file_id 分析
- 1.4.2 API 分析
- 二、特征工程与基线模型
- 2.1 特征工程基础部分
- 2.2 基线模型
- 2.2.1 数据读取
- 2.2.2 特征工程
- 2.2.3 基线构建
- 2.3.4 特征重要性分析
- 2.3.5 模型测试
- 三、高阶数据探索
- 3.1 数据读取
- 3.2 多变量交叉探索
- 四、特征工程进阶与方案优化
- 4.1 特征工程基础部分
- (1)导入工具包,读取数据
- (2)内存管理
- (3)基础特征工程建造
- (4)特征获取
- 4.2 特征工程进阶部分
- (1)每个 API 调用线程 tid 的次数
- (2)每个 API 调用不同线程 tid 的次数
- (3)特征获取
- 4.3 基于 LightGBM 的模型验证
- (1)获取标签
- (2)训练集与测试集的构建(将之前提取的特征与新生成的特征进行合并)
- (3)评估指标构建
- (4)模型采用 5 折交叉验证方式
- 4.4 模型结果分析
- 4.5 模型测试
Hi,大家好,我是半亩花海。 阿里云作为国内最大的云服务提供商,每天都面临着网络上海量的恶意攻击。恶意软件是一种被设计用来对目标计算机造成破坏或者占用目标计算机资源的软件,传统的恶意软件包括蠕虫、木马等。本项目来源于“阿里云天池”的“学习赛”的赛题,针对恶意软件检测的现实场景而提出,应用机器学习相关模型实现阿里云安全恶意程序的检测,在一定程度上提高泛化能力,
提升对恶意样本的识别率。数据集来自:阿里云安全恶意程序检测_数据集-阿里云天池 (aliyun.com)。
一、数据探索
1.1 数据说明
本项目提供的数据来自经过沙箱程序模拟运行后的 API 指令序列,全为 Windows 二进制可执行程序,经过脱敏处理;样本数据均来自互联网,其中恶意文件的类型有感染型病毒、木马程序、挖矿程序、DDoS木马、勒索病毒等,数据总计 6 亿条。
(1)训练数据调用记录近 9000 万次,文件 1 万多个(以文件编号汇总),字段描述如表所示:
| 字段 | 类型 | 解释 |
|---|---|---|
| field_id | bigint | 文件编号 |
| label | bigint | 文件标签 |
| api | string | 文件调用的 API 名称 |
| tid | bigint | 调用 API 的线程编号 |
| index | string | 线程中 API 调用的顺序编号 |
其中,文件标签有 8 种:0-正常 / 1-勒索病毒 / 2-挖矿程序 / 3-DDoS 木马 / 4-蠕虫病毒 / 5-感染型病毒 / 6-后门程序 / 7-木马程序。
注意:
① 一个文件调用的 API 数量有可能很多,对于一个 tid 中调用超过 5000 个 API 的文件,我们进行了截断,按照顺序保留了每个 tid 前 5000 个 API 的记录。
② 不同线程 tid 之间没有顺序关系,同一个 tid 中的 index 由小到大代表调用的先后顺序关系。
③ index 是单个文件在沙箱执行时的全局顺序,由于沙箱执行时间有精度限制,因此在同一个index 上会出现同线程或者不同线程都在多次执行 API 的情况,其可以保证与 tid 内部的顺序相同,但不保证连续。
(2)测试数据调用记录近 8000 万次,文件 1 万多个。除了没有 label 字段,数据格式与
训练数据一致。
1.2 训练集数据探索
1.2.1 数据特征类型
# 导入相关应用包
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt# 忽略警告信息
import warnings
warnings.filterwarnings("ignore")%matplotlib inline# 读取数据
path = './security_data/'
train = pd.read_csv(path + 'security_train.csv') # 训练集
test = pd.read_csv(path + 'security_test.csv') # 测试集
用 DataFrame.info() 函数查看训练集的大小、数据类型等信息。
train.info()

从运行结果可以看出:
- 数据中有 4 个 int64 类型(file_id, label, tid, index)的数据和 1 个 object 类型的数据(api)
- 整个数据集的大小为 3.3 GB
- 数据一共有 89806693 条记录
用 DataFrame.head() 函数查看训练集的头几行数据。
train.head()

用 DataFrame.describe() 函数查看训练集的统计信息。

1.2.2 数据分布
使用箱线图查看单个变量的分布情况。下面以训练集为例,取前10000条数据绘制“tid”变量的箱线图,代码和运行结果如下:
sns.boxplot(x=train.iloc[:10000]["tid"])

用 nunique() 函数查看训练集中变量取值的分布。
train.nunique()

由运行结果可知,file_id 的含有的信息如下:
- 13887 个不同的值
- 8 种不同的 labe
- 295 个不同的 API
- 2782 个不同的 tid
- 5001 个不同的 index
1.2.3 缺失值
查看训练集数据的缺失情况。
train.isnull().sum()

从运行结果看,数据不存在缺失的情况。
1.2.4 异常值
分析训练集“index”特征:
train['index'].describe()

“index”特征的最小值为 0,最大值为 5000,刚好是 5001 个值,看不出异常值。
分析训练集的“tid”特征:
train['tid'].describe()

“tid”特征的最小值为 100,最大值为 20896,因为这个字段表示的是线程,所以我们目前也没办法判断是否有异常值。
1.2.5 标签分布探索
统计标签取值的分布情况。
“label”对应的含义如下表所示:
| 值 | 分类 |
|---|---|
| 0 | 正常 |
| 1 | 勒索病毒 |
| 2 | 挖矿程序 |
| 3 | DDoS 木马 |
| 4 | 蠕虫病毒 |
| 5 | 感染型病毒 |
| 6 | 后门程序 |
| 7 | 木马程序 |
train['label'].value_counts()

由标签分布可以发现:训练集中一共有 16375107 个正常文件(label=0);2254561 个勒索病毒(label=1);9693969 个挖矿程序(label=2);8117585 个DDoS木马(label=3);663815 个虫病毒(label=4);33033543 个感染型病毒(label=5);4586578 个后门程序(label=6);15081535 个木马程序(label=7)。
为了直观化,我们可以通过条型图看数据的大小,同时用饼图看数据的比例,代码和结果如下:
plt.figure(figsize=(12, 4), dpi=150)
train['label'].value_counts().sort_index().plot(kind = 'bar')

plt.figure(figsize=(4, 4), dpi=150)
train['label'].value_counts().sort_index().plot(kind = 'pie')

1.3 测试集探索
1.3.1 数据信息
用 DataFrame.head() 函数查看测试集的头几行数据。
test.head()

用 DataFrame.info() 函数查看测试集的大小、数据类型等信息。
test.info()

从运行结果可以看出:
- 数据中有 3 个 int64 类型(file_id, tid, index)的数据和 1 个 object 类型的数据(api)
- 整个数据集的大小为 2.4 GB
- 数据一共有 79288375 条记录
1.3.2 缺失值
查看测试集数据的缺失情况。
test.isnull().sum()

可知,数据不存在缺失的情况。
1.3.3 数据分布
查看测试集中变量取值的分布。
sns.boxplot(x=test.iloc[:10000]["tid"])

test.nunique()

由运行结果可知,file_id 的含有的信息如下:
- 12955 个不同的值
- 298 个不同的 API
- 2047 个不同的 tid
- 5001 个不同的 index
1.3.4 异常值
查看测试集的“index”特征:
test['index'].describe()

由结果可知,“index”特征的最小值为 0,最大值为 5000,刚好是 5001 个值,看不出任何异常的情况。
查看测试集的“tid”特征:
test['tid'].describe()

由结果可知,“tid”特征的最小值为 100,最大值为 9196,因为这个字段表示的是线程,所以目前也没办法判断是否有异常值。
1.4 数据集联合分析
1.4.1 file_id 分析
对比分析 “fleid” 变量在训练集和测试集中分布的重合情况:
train_fileids = train['file_id'].unique()
test_fileids = test['file_id'].unique()
len(set(train_fileids) - set(test_fileids))
运行结果表明,有 932 个训练文件是测试文件中没有的。
len(set(test_fileids) - set(train_fileids))
运行结果表明,测试文件中有的文件在训练文件中都有。
我们发现训练数据集和测试数据集的 file_id 存在交叉,也就是说 file_id 在训练集和测试集不是完全无交集的,这个时候不能直接合并,需要进行其他的处理来区分训练集和测试集。
1.4.2 API 分析
对比分析 “API” 变量在训练集和测试集中分布的重合情况:
train_apis = train['api'].unique()
test_apis = test['api'].unique()
set(test_apis) - set(train_apis)
运行结果表明,测试集中有 6 个 API 未出现在训练集中,分别是 reateDirectoryExW,InternetGetConnectedStateExA,MessageBoxTimeoutW, NtCreateUserProcess, NtDeleteFile,TaskDialog。
set(train_apis) - set(test_apis)
运行结果表明,训练集中有 3 个 API 未出现在测试集中,分别是 EncryptMessage,RtlCompressBuffer 和 WSASendTo。
二、特征工程与基线模型
2.1 特征工程基础部分
import numpy as np
import pandas as pd
from tqdm import tqdm class _Data_Preprocess:def __init__(self):self.int8_max = np.iinfo(np.int8).maxself.int8_min = np.iinfo(np.int8).minself.int16_max = np.iinfo(np.int16).maxself.int16_min = np.iinfo(np.int16).minself.int32_max = np.iinfo(np.int32).maxself.int32_min = np.iinfo(np.int32).minself.int64_max = np.iinfo(np.int64).maxself.int64_min = np.iinfo(np.int64).minself.float16_max = np.finfo(np.float16).maxself.float16_min = np.finfo(np.float16).minself.float32_max = np.finfo(np.float32).maxself.float32_min = np.finfo(np.float32).minself.float64_max = np.finfo(np.float64).maxself.float64_min = np.finfo(np.float64).mindef _get_type(self, min_val, max_val, types):if types == 'int':if max_val <= self.int8_max and min_val >= self.int8_min:return np.int8elif max_val <= self.int16_max <= max_val and min_val >= self.int16_min:return np.int16elif max_val <= self.int32_max and min_val >= self.int32_min:return np.int32return Noneelif types == 'float':if max_val <= self.float16_max and min_val >= self.float16_min:return np.float16if max_val <= self.float32_max and min_val >= self.float32_min:return np.float32if max_val <= self.float64_max and min_val >= self.float64_min:return np.float64return Nonedef _memory_process(self, df):init_memory = df.memory_usage().sum() / 1024 ** 2 / 1024print('Original data occupies {} GB memory.'.format(init_memory))df_cols = df.columnsfor col in tqdm_notebook(df_cols):try:if 'float' in str(df[col].dtypes):max_val = df[col].max()min_val = df[col].min()trans_types = self._get_type(min_val, max_val, 'float')if trans_types is not None:df[col] = df[col].astype(trans_types)elif 'int' in str(df[col].dtypes):max_val = df[col].max()min_val = df[col].min()trans_types = self._get_type(min_val, max_val, 'int')if trans_types is not None:df[col] = df[col].astype(trans_types)except:print(' Can not do any process for column, {}.'.format(col)) afterprocess_memory = df.memory_usage().sum() / 1024 ** 2 / 1024print('After processing, the data occupies {} GB memory.'.format(afterprocess_memory))return df
2.2 基线模型
2.2.1 数据读取
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as pltimport lightgbm as lgb
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import OneHotEncoderimport warnings
warnings.filterwarnings('ignore')
%matplotlib inline
path = './security_data/'
train = pd.read_csv(path + 'security_train.csv')
test = pd.read_csv(path + 'security_test.csv')
train.head()

2.2.2 特征工程
(1)利用 count() 函数和 nunique() 函数生成特征:反映样本调用 api,tid,index 的频率信息。
def simple_sts_features(df):simple_fea = pd.DataFrame()simple_fea['file_id'] = df['file_id'].unique()simple_fea = simple_fea.sort_values('file_id')df_grp = df.groupby('file_id')simple_fea['file_id_api_count'] = df_grp['api'].count().valuessimple_fea['file_id_api_nunique'] = df_grp['api'].nunique().valuessimple_fea['file_id_tid_count'] = df_grp['tid'].count().valuessimple_fea['file_id_tid_nunique'] = df_grp['tid'].nunique().valuessimple_fea['file_id_index_count'] = df_grp['index'].count().valuessimple_fea['file_id_index_nunique'] = df_grp['index'].nunique().valuesreturn simple_fea
(2)利用 mean() 函数、min() 函数、std() 函数、max() 函数生成特征:tid,index 可认为是数值特征,可提取对应的统计特征。
def simple_numerical_sts_features(df):simple_numerical_fea = pd.DataFrame()simple_numerical_fea['file_id'] = df['file_id'].unique()simple_numerical_fea = simple_numerical_fea.sort_values('file_id')df_grp = df.groupby('file_id')simple_numerical_fea['file_id_tid_mean'] = df_grp['tid'].mean().valuessimple_numerical_fea['file_id_tid_min'] = df_grp['tid'].min().valuessimple_numerical_fea['file_id_tid_std'] = df_grp['tid'].std().valuessimple_numerical_fea['file_id_tid_max'] = df_grp['tid'].max().valuessimple_numerical_fea['file_id_index_mean'] = df_grp['index'].mean().valuessimple_numerical_fea['file_id_index_min'] = df_grp['index'].min().valuessimple_numerical_fea['file_id_index_std'] = df_grp['index'].std().valuessimple_numerical_fea['file_id_index_max'] = df_grp['index'].max().valuesreturn simple_numerical_fea
(3)利用定义的特征生成函数,并生成训练集和测试集的统计特征。
反映样本调用 api,tid,index 的频率信息的统计特征。
%%time
simple_train_fea1 = simple_sts_features(train)
CPU times: total: 37 s
Wall time: 37.1 s
%%time
simple_test_fea1 = simple_sts_features(test)
CPU times: total: 32.5 s
Wall time: 32.6 s
反映 tid,index 等数值特征的统计特征。
%%time
simple_train_fea2 = simple_numerical_sts_features(train)
CPU times: total: 6.14 s
Wall time: 6.15 s
%%time
simple_test_fea2 = simple_numerical_sts_features(test)
CPU times: total: 5.38 s
Wall time: 5.42 s
2.2.3 基线构建
获取标签:
train_label = train[['file_id','label']].drop_duplicates(subset = ['file_id','label'], keep = 'first')
test_submit = test[['file_id']].drop_duplicates(subset = ['file_id'], keep = 'first')
训练集和测试集的构建:
### 训练集&测试集构建
train_data = train_label.merge(simple_train_fea1, on ='file_id', how='left')
train_data = train_data.merge(simple_train_fea2, on ='file_id', how='left')test_submit = test_submit.merge(simple_test_fea1, on ='file_id', how='left')
test_submit = test_submit.merge(simple_test_fea2, on ='file_id', how='left')
因为本赛题给出的指标和传统的指标略有不同,所以需要自己写评估指标,这样方便对比线下与线上的差距,以判断是否过拟合、是否出现线上线下不一致的问题等。
关于 LGB 的自定义评估指标的书写,可以参考 LightGBM 的文档。以下为赛题的模型评估函数:
def lgb_logloss(preds,data):labels_ = data.get_label() classes_ = np.unique(labels_) preds_prob = []for i in range(len(classes_)):preds_prob.append(preds[i*len(labels_):(i+1) * len(labels_)] )preds_prob_ = np.vstack(preds_prob) loss = []for i in range(preds_prob_.shape[1]): # 样本个数sum_ = 0for j in range(preds_prob_.shape[0]): #类别个数pred = preds_prob_[j,i] # 第i个样本预测为第j类的概率if j == labels_[i]:sum_ += np.log(pred)else:sum_ += np.log(1 - pred)loss.append(sum_) return 'loss is: ',-1 * (np.sum(loss) / preds_prob_.shape[1]),False
线下验证。因为数据与时间的相关性并不是非常大,所以此处我们用传统的 5 折交叉验证来构建线下验证集。
### 模型验证
train_features = [col for col in train_data.columns if col not in ['label','file_id']]
train_label = 'label'
使用 5 折交叉验证,采用 LightGBM 模型,代码和运行结果如下:
%%time
from sklearn.model_selection import StratifiedKFold,KFold
params = {'task':'train', 'num_leaves': 255,'objective': 'multiclass','num_class': 8,'min_data_in_leaf': 50,'learning_rate': 0.05,'feature_fraction': 0.85,'bagging_fraction': 0.85,'bagging_freq': 5, 'max_bin': 128,'random_state': 100, 'verbose': 50,'early_stopping_rounds': 100} folds = KFold(n_splits=5, shuffle=True, random_state=15)
oof = np.zeros(len(train))predict_res = 0
models = []
for fold_, (trn_idx, val_idx) in enumerate(folds.split(train_data)):print("fold n°{}".format(fold_))trn_data = lgb.Dataset(train_data.iloc[trn_idx][train_features], label=train_data.iloc[trn_idx][train_label].values)val_data = lgb.Dataset(train_data.iloc[val_idx][train_features], label=train_data.iloc[val_idx][train_label].values) clf = lgb.train(params, trn_data, num_boost_round=2000,valid_sets=[trn_data,val_data], feval=lgb_logloss) models.append(clf)

2.3.4 特征重要性分析
通过特征重要性分析,可以看到在当前指标显示的成绩下,影响因子最高的特征因素,从而更好地理解题目,同时在此基础上进行特征工程的延伸。相应的代码和可视化结果如下:
feature_importance = pd.DataFrame()
feature_importance['fea_name'] = train_features
feature_importance['fea_imp'] = clf.feature_importance()
feature_importance = feature_importance.sort_values('fea_imp',ascending = False)plt.figure(figsize=[20, 10,])
sns.barplot(x = feature_importance['fea_name'], y = feature_importance['fea_imp'])
#sns.barplot(x = "fea_name",y = "fea_imp", data = feature_importance)

由运行结果可以看出:
- (1)API 的调用次数和 API 的调用类别数是最重要的两个特征,即不同的病毒常常会调用不同的 API,而且由于有些病毒需要复制自身的原因,因此调用 API 的次数会明显比其他不同类别的病毒多。
- (2)第三到第五强的都是线程统计特征,这也较为容易理解,因为木马等病毒经常需要通过线程监听一些内容,所以在线程等使用上会表现的略有不同。
2.3.5 模型测试
至此,通过前期的数据探索分析和基础的特征工程,我们已经得到了一个可以线上提交的基线模型。此处我们采用 LightGBM 进行 5 折交叉验证,也就是用上面训练的 5 个 LightGBM 分别对测试集进行预测,然后将所有预测结果的均值作为最终结果。其预测结果并不能 100% 超过单折全量数据的 LightGBM,但是大多数还是不错的,建议将此作为 Baseline 方法的候选方法。
pred_res = 0
fold = 5
for model in models:pred_res += model.predict(test_submit[train_features]) * 1.0 / foldtest_submit['prob0'] = 0
test_submit['prob1'] = 0
test_submit['prob2'] = 0
test_submit['prob3'] = 0
test_submit['prob4'] = 0
test_submit['prob5'] = 0
test_submit['prob6'] = 0
test_submit['prob7'] = 0test_submit[['prob0','prob1','prob2','prob3','prob4','prob5','prob6','prob7']] = pred_res
test_submit[['file_id','prob0','prob1','prob2','prob3','prob4','prob5','prob6','prob7']].to_csv('baseline.csv',index = None)
三、高阶数据探索
3.1 数据读取
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline### 数据读取
path = './security_data/'
train = pd.read_csv(path + 'security_train.csv')
test = pd.read_csv(path + 'security_test.csv')
3.2 多变量交叉探索
(1)通过统计特征 file_id_cnt,分析 变量 file_id 和 api 之间的关系。
train_analysis = train[['file_id','label']].drop_duplicates(subset = ['file_id','label'], keep = 'last')dic_ = train['file_id'].value_counts().to_dict()
train_analysis['file_id_cnt'] = train_analysis['file_id'].map(dic_).values
train_analysis['file_id_cnt'].value_counts()

可以看到,文件调用 API 次数出现最多的是 5001 次。
sns.distplot(train_analysis['file_id_cnt'])

print('There are {} data are below 10000'.format(np.sum(train_analysis['file_id_cnt'] <= 1e / train_analysis.shape[0]))
There are 0.8012529704039749 data are below 10000
我们也发现,API 调用次数的 80% 都集中在 10000 次以下。
(2)为了便于分析变量 file_id_cnt 与 label 的关系,将数据按 file_id_cnt 变量(即 API 调用次数)取值划分为 16 个区间。
### file_id_cnt & label 分析
def file_id_cnt_cut(x):if x< 15000:return x // 1e3else:return 15 train_analysis['file_id_cnt_cut'] = train_analysis['file_id_cnt'].map(file_id_cnt_cut).values
然后随机选取 4 个区间进行查看,代码及运行结果如下所示。
plt.figure(figsize=[16,20])
plt.subplot(321)
train_analysis[train_analysis['file_id_cnt_cut'] == 0]['label'].value_counts().sort_index().plot(kind = 'bar')
plt.title('file_id_cnt_cut = 0')
plt.xlabel('label')
plt.ylabel('label_number')plt.subplot(322)
train_analysis[train_analysis['file_id_cnt_cut'] == 1]['label'].value_counts().sort_index().plot(kind = 'bar')
plt.title('file_id_cnt_cut = 1')
plt.xlabel('label')
plt.ylabel('label_number')plt.subplot(323)
train_analysis[train_analysis['file_id_cnt_cut'] == 14]['label'].value_counts().sort_index().plot(kind = 'bar')
plt.title('file_id_cnt_cut = 14')
plt.xlabel('label')
plt.ylabel('label_number')plt.subplot(324)
train_analysis[train_analysis['file_id_cnt_cut'] == 15]['label'].value_counts().sort_index().plot(kind = 'bar')
plt.title('file_id_cnt_cut = 15')
plt.xlabel('label')
plt.ylabel('label_number')plt.subplot(313)
train_analysis['label'].value_counts().sort_index().plot(kind = 'bar')
plt.title('All Data')
plt.xlabel('label')
plt.ylabel('label_number')



从图中可以看到:当 API 调用次数越多时,该 API 是第五类病毒(感染型病毒)的可能性就越大。
用分簇散点图查看 label 下file_id_cnt的分布,由于绘制分簇散点图比较耗时,因此我们采用 1000 个样本点。
plt.figure(figsize=[16, 10])
sns.swarmplot(x = train_analysis.iloc[:1000]['label'], y = train_analysis.iloc[:1000]['file_id_cnt'])

从图中得到以下结论:从频次上看,第 5 类病毒调用 API 的次数最多:从调用峰值上看第 2 类和 7 类病毒有时能调用 150000 次的 API。
(3)首先通过文件调用 API 的类别数 file_id_api_nunique,分析变量 file_id 和 API 的关系。
dic_ = train.groupby('file_id')['api'].nunique().to_dict()
train_analysis['file_id_api_nunique'] = train_analysis['file_id'].map(dic_).values sns.distplot(train_analysis['file_id_api_nunique'])

train_analysis['file_id_api_nunique'].describe()

文件调用 API 的类别数绝大部分都在 100 以内,最少的是 1 个,最多的是 170 个。
然后分析变量 file_id_api_nunique 和 label 的关系。
train_analysis.loc[train_analysis.file_id_api_nunique >=100]['label'].value_counts().sort_index().plot(kind = 'bar')
plt.title('File with api nunique >= 100')
plt.xlabel('label')
plt.ylabel('label_number')

从图中可以发现,第 5 类病毒调用不同 API 的次数是最多的。在上面的分析中,我们也发现第 5 类病毒调用 API 的次数最多,调用不同 API 的次数多也是可以理解的。
plt.figure(figsize=[16, 10])
sns.boxplot(x = train_analysis['label'], y = train_analysis['file_id_api_nunique'])

从图中得到以下结论:第 3 类病毒调用不同 API 的次数相对较多,第 2 类病毒调用不同 API 的次数最少:第 4,6,7 类病毒的离群点较少,第 1 类病毒的离群点最多,第 3 类病毒的离群点主要在下方;第 0 类和第 5 类的离群点则集中在上方。
(4)首先,通过 file_id_index_nunique 和 file_id_index_max 两个统计特征,分析变量 file_id 和 index 之间的关系。有个奇怪的现象,我们发现调用 API 顺序编号的两个边缘(0 和 5001)的样本数是最多的,因此可以单独看一下这两个点的 label 分布。
dic_ = train.groupby('file_id')['index'].nunique().to_dict()
train_analysis['file_id_index_nunique'] = train_analysis['file_id'].map(dic_).valuestrain_analysis['file_id_index_nunique'].describe()

sns.distplot(train_analysis['file_id_index_nunique'])

dic_ = train.groupby('file_id')['index'].max().to_dict()
train_analysis['file_id_index_max'] = train_analysis['file_id'].map(dic_).values sns.distplot(train_analysis['file_id_index_max'])

从图中可以看出,文件调用 index 有两个极端:一个是在 1 附近,另一个是在 5000 附近。
然后分析变量 file_id_index_nunique 和 file_id_index_max 与 label 的关系。
plt.figure(figsize=[16,8])
plt.subplot(121)
train_analysis.loc[train_analysis.file_id_index_nunique == 1]['label'].value_counts().sort_index().plot(kind = 'bar')
plt.title('File with index nunique = 1')
plt.xlabel('label')
plt.ylabel('label_number') plt.subplot(122)
train_analysis.loc[train_analysis.file_id_index_nunique == 5001]['label'].value_counts().sort_index().plot(kind = 'bar')
plt.title('File with index nunique = 5001')
plt.xlabel('label')
plt.ylabel('label_number')

从图中可以发现,在文件顺序编号只有一个时,文件的标签只会是 0(正常)、2(挖矿程序)或 5(感染型病毒),而不会是其他病毒,而且最大概率可能是 5;对于顺序次数大于 5000 个的文件,其和上面调用 API 次数很大时类似。
还可以通过绘制小提琴图、分类散点图分析,代码和结果如下:
plt.figure(figsize=[16,10])
sns.violinplot(x =train_analysis['label'], y = train_analysis['file_id_api_nunique'])

plt.figure(figsize=[16,10])
sns.violinplot(x =train_analysis['label'], y = train_analysis['file_id_index_max'])

plt.figure(figsize=[16,10])
sns.stripplot(x =train_analysis['label'], y = train_analysis['file_id_index_max'])

从图中得到的结论:第 3 类病毒调用不同 index 次数的平均值最大;第 2 类病毒调用不同 index 次数的平均值最小;第 5,6,7 类病毒调用不同 index 次数的平均值相似。
(5)首先通过 file_id_tid_nunique和 file_id_tid_max 两个统计特征,分析变量 file_id 和 tid 之间的关系。
dic_ = train.groupby('file_id')['tid'].nunique().to_dict()
train_analysis['file_id_tid_nunique'] = train_analysis['file_id'].map(dic_).values train_analysis['file_id_tid_nunique'].describe()

sns.distplot(train_analysis['file_id_tid_nunique'])

dic_ = train.groupby('file_id')['tid'].max().to_dict()
train_analysis['file_id_tid_max'] = train_analysis['file_id'].map(dic_).values train_analysis['file_id_tid_max'].describe()

sns.distplot(train_analysis['file_id_tid_max'])

然后分析变量 file_id_tid_nunique 和 file_id_tid_max 与 label 的关系。
plt.figure(figsize=[16,8])
plt.subplot(121)
train_analysis.loc[train_analysis.file_id_tid_nunique < 5]['label'].value_counts().sort_index().plot(kind = 'bar')
plt.title('File with tid nunique < 5')
plt.xlabel('label')
plt.ylabel('label_number') plt.subplot(122)
train_analysis.loc[train_analysis.file_id_tid_nunique >= 20]['label'].value_counts().sort_index().plot(kind = 'bar')
plt.title('File with tid nunique >= 20')
plt.xlabel('label')
plt.ylabel('label_number')

其中,0:正常文件;1:勒索病毒;2:挖矿程序;3:DDoS 木马;4:蠕虫病毒;5:感染型病毒;6:后门程序;7:木马程序。
还可以通过箱线图和小提琴图进一步分析。
plt.figure(figsize=[12,8])
sns.boxplot(x =train_analysis['label'], y = train_analysis['file_id_tid_nunique'])

plt.figure(figsize=[12,8])
sns.violinplot(x =train_analysis['label'], y = train_analysis['file_id_tid_nunique'])

分析 file_id 和 tid 的 max 特征,我们将 tid 最大值大于 3000 的数据和整体比较,发现分布差异并不是非常大。
plt.figure(figsize=[16,8])
plt.subplot(121)
train_analysis.loc[train_analysis.file_id_tid_max >= 3000]['label'].value_counts().sort_index().plot(kind = 'bar')
plt.title('File with tid max >= 3000')
plt.xlabel('label')
plt.ylabel('label_number') plt.subplot(122)
train_analysis['label'].value_counts().sort_index().plot(kind = 'bar')
plt.title('All Data')
plt.xlabel('label')
plt.ylabel('label_number')

从图中得出的结论:所有文件调用的线程都相对较少;第 7 类病毒调用的线程数的范围最大;第 0 类,3 类和 4 类调用的不同线程数类似。
(6)分析变量 API 与 label 的关系,代码及运行结果如下:
train['api_label'] = train['api'] + '_' + train['label'].astype(str)
dic_ = train['api_label'].value_counts().to_dict()df_api_label = pd.DataFrame.from_dict(dic_,orient = 'index').reset_index()
df_api_label.columns = ['api_label', 'api_label_count']df_api_label['label'] = df_api_label['api_label'].apply(lambda x:int(x.split('_')[-1]))labels = df_api_label['label'].unique()
for label in range(8):print('*' * 50, label,'*' * 50)print(df_api_label.loc[df_api_label.label == label].sort_values('api_label_count').iloc[-5:][['api_label','api_label_count']])print('*' * 103)


从结果可以得到以下结论:LdrGetProcedureAddress,所有病毒和正常文件都是调用比较多的;第 5 类病毒:Thread32Next 调用得较多;第 6 类和 7 类病毒:NtDelayExecution 调用得较多;第 2 类和 7 类病毒:Process32NextW 调用得较多。
四、特征工程进阶与方案优化
在快速 Baseline 的基础上,通过对多变量的交叉分析,可以增加新的 pivot 特征,迭代优化一般新的模型。
4.1 特征工程基础部分
(1)导入工具包,读取数据
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as pltimport lightgbm as lgb
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import OneHotEncoderfrom tqdm import tqdm_notebookimport warnings
warnings.filterwarnings('ignore')
%matplotlib inline### 数据读取
path = './security_data/'
train = pd.read_csv(path + 'security_train.csv')
test = pd.read_csv(path + 'security_test.csv')
(2)内存管理
# 内存管理
import numpy as np
import pandas as pd
from tqdm import tqdm class _Data_Preprocess:def __init__(self):self.int8_max = np.iinfo(np.int8).maxself.int8_min = np.iinfo(np.int8).minself.int16_max = np.iinfo(np.int16).maxself.int16_min = np.iinfo(np.int16).minself.int32_max = np.iinfo(np.int32).maxself.int32_min = np.iinfo(np.int32).minself.int64_max = np.iinfo(np.int64).maxself.int64_min = np.iinfo(np.int64).minself.float16_max = np.finfo(np.float16).maxself.float16_min = np.finfo(np.float16).minself.float32_max = np.finfo(np.float32).maxself.float32_min = np.finfo(np.float32).minself.float64_max = np.finfo(np.float64).maxself.float64_min = np.finfo(np.float64).mindef _get_type(self, min_val, max_val, types):if types == 'int':if max_val <= self.int8_max and min_val >= self.int8_min:return np.int8elif max_val <= self.int16_max <= max_val and min_val >= self.int16_min:return np.int16elif max_val <= self.int32_max and min_val >= self.int32_min:return np.int32return Noneelif types == 'float':if max_val <= self.float16_max and min_val >= self.float16_min:return np.float16if max_val <= self.float32_max and min_val >= self.float32_min:return np.float32if max_val <= self.float64_max and min_val >= self.float64_min:return np.float64return Nonedef _memory_process(self, df):init_memory = df.memory_usage().sum() / 1024 ** 2 / 1024print('Original data occupies {} GB memory.'.format(init_memory))df_cols = df.columnsfor col in tqdm_notebook(df_cols):try:if 'float' in str(df[col].dtypes):max_val = df[col].max()min_val = df[col].min()trans_types = self._get_type(min_val, max_val, 'float')if trans_types is not None:df[col] = df[col].astype(trans_types)elif 'int' in str(df[col].dtypes):max_val = df[col].max()min_val = df[col].min()trans_types = self._get_type(min_val, max_val, 'int')if trans_types is not None:df[col] = df[col].astype(trans_types)except:print(' Can not do any process for column, {}.'.format(col)) afterprocess_memory = df.memory_usage().sum() / 1024 ** 2 / 1024print('After processing, the data occupies {} GB memory.'.format(afterprocess_memory))return dfmemory_process = _Data_Preprocess()
(3)基础特征工程建造
def simple_sts_features(df):simple_fea = pd.DataFrame()simple_fea['file_id'] = df['file_id'].unique()simple_fea = simple_fea.sort_values('file_id')df_grp = df.groupby('file_id')simple_fea['file_id_api_count'] = df_grp['api'].count().valuessimple_fea['file_id_api_nunique'] = df_grp['api'].nunique().valuessimple_fea['file_id_tid_count'] = df_grp['tid'].count().valuessimple_fea['file_id_tid_nunique'] = df_grp['tid'].nunique().valuessimple_fea['file_id_index_count'] = df_grp['index'].count().valuessimple_fea['file_id_index_nunique'] = df_grp['index'].nunique().valuesreturn simple_feadef simple_numerical_sts_features(df):simple_numerical_fea = pd.DataFrame()simple_numerical_fea['file_id'] = df['file_id'].unique()simple_numerical_fea = simple_numerical_fea.sort_values('file_id')df_grp = df.groupby('file_id')simple_numerical_fea['file_id_tid_mean'] = df_grp['tid'].mean().valuessimple_numerical_fea['file_id_tid_min'] = df_grp['tid'].min().valuessimple_numerical_fea['file_id_tid_std'] = df_grp['tid'].std().valuessimple_numerical_fea['file_id_tid_max'] = df_grp['tid'].max().valuessimple_numerical_fea['file_id_index_mean'] = df_grp['index'].mean().valuessimple_numerical_fea['file_id_index_min'] = df_grp['index'].min().valuessimple_numerical_fea['file_id_index_std'] = df_grp['index'].std().valuessimple_numerical_fea['file_id_index_max'] = df_grp['index'].max().valuesreturn simple_numerical_fea
(4)特征获取
%%time
simple_train_fea1 = simple_sts_features(train)
CPU times: total: 37.2 s
Wall time: 37.4 s
%%time
simple_test_fea1 = simple_sts_features(test)
CPU times: total: 31.4 s
Wall time: 31.5 s
%%time
simple_train_fea2 = simple_numerical_sts_features(train)
CPU times: total: 5.95 s
Wall time: 6.02 s
%%time
simple_test_fea2 = simple_numerical_sts_features(test)
CPU times: total: 5.28 s
Wall time: 5.32 s
4.2 特征工程进阶部分
(1)每个 API 调用线程 tid 的次数
def api_pivot_count_features(df):tmp = df.groupby(['file_id','api'])['tid'].count().to_frame('api_tid_count').reset_index()tmp_pivot = pd.pivot_table(data = tmp, index = 'file_id', columns='api', values='api_tid_count', fill_value=0)tmp_pivot.columns = [tmp_pivot.columns.names[0] + '_pivot_'+ str(col) for col in tmp_pivot.columns]tmp_pivot.reset_index(inplace = True)tmp_pivot = memory_process._memory_process(tmp_pivot)return tmp_pivot
(2)每个 API 调用不同线程 tid 的次数
def api_pivot_nunique_features(df):tmp = df.groupby(['file_id','api'])['tid'].nunique().to_frame('api_tid_nunique').reset_index()tmp_pivot = pd.pivot_table(data = tmp, index = 'file_id', columns='api', values='api_tid_nunique', fill_value=0)tmp_pivot.columns = [tmp_pivot.columns.names[0] + '_pivot_'+ str(col) for col in tmp_pivot.columns]tmp_pivot.reset_index(inplace = True)tmp_pivot = memory_process._memory_process(tmp_pivot)return tmp_pivot
(3)特征获取
%%time
simple_train_fea3 = api_pivot_count_features(train)

%%time
simple_test_fea3 = api_pivot_count_features(test)

%%time
simple_train_fea4 = api_pivot_count_features(train)

%%time
simple_test_fea4 = api_pivot_count_features(test)

4.3 基于 LightGBM 的模型验证
(1)获取标签
train_label = train[['file_id','label']].drop_duplicates(subset = ['file_id','label'], keep = 'first')
test_submit = test[['file_id']].drop_duplicates(subset = ['file_id'], keep = 'first')
(2)训练集与测试集的构建(将之前提取的特征与新生成的特征进行合并)
train_data = train_label.merge(simple_train_fea1, on ='file_id', how='left')
train_data = train_data.merge(simple_train_fea2, on ='file_id', how='left')
train_data = train_data.merge(simple_train_fea3, on ='file_id', how='left')
train_data = train_data.merge(simple_train_fea4, on ='file_id', how='left')test_submit = test_submit.merge(simple_test_fea1, on ='file_id', how='left')
test_submit = test_submit.merge(simple_test_fea2, on ='file_id', how='left')
test_submit = test_submit.merge(simple_test_fea3, on ='file_id', how='left')
test_submit = test_submit.merge(simple_test_fea4, on ='file_id', how='left')
(3)评估指标构建
分数采用 logloss 计算公式,如下:
logloss = 1 N ∑ j N ∑ i M [ y i j log ( P i j ) + ( 1 − y i j ) log ( 1 − P i j ) ] \text { logloss }=\frac{1}{N} \sum_j^N \sum_i^M\left[y_{i j} \log \left(P_{i j}\right)+\left(1-y_{i j}\right) \log \left(1-P_{i j}\right)\right] logloss =N1j∑Ni∑M[yijlog(Pij)+(1−yij)log(1−Pij)]
其中,M 代表分类数,N 代表测试集样本数, y i j {y}_{ij} yij 为代表第 i 个样本是否为类别 j(1为是,0为否), P i j {P}_{ij} Pij 代表选手提交的第 i 个样本被预测为类别 j 的概率,最终公布的 logloss 保留小数点后 6 位。
需特别注意,log 对于小于 1 的数是非常敏感的。比如 log0.1 和 log0.000001 的单个样本的误差为 10 左右,而 1og0.99 和 1og0.95 的单个误差为 0.1 左右。
logloss 和 AUC 的区别:AUC 只在乎把正样本排到前面的能力,logloss 更加注重评估的准确性。如果给预测值乘以一个倍数,则 AUC 不会变,但是 logloss 会变。
### 评估指标构建
def lgb_logloss(preds,data):labels_ = data.get_label() classes_ = np.unique(labels_) preds_prob = []for i in range(len(classes_)):preds_prob.append(preds[i*len(labels_):(i+1) * len(labels_)] )preds_prob_ = np.vstack(preds_prob) loss = []for i in range(preds_prob_.shape[1]): sum_ = 0for j in range(preds_prob_.shape[0]): pred = preds_prob_[j,i] if j == labels_[i]:sum_ += np.log(pred)else:sum_ += np.log(1 - pred)loss.append(sum_) return 'loss is: ',-1 * (np.sum(loss) / preds_prob_.shape[1]),False
(4)模型采用 5 折交叉验证方式
train_features = [col for col in train_data.columns if col not in ['label','file_id']]
train_label = 'label'%%time
from sklearn.model_selection import StratifiedKFold,KFold
params = {'task':'train', 'num_leaves': 255,'objective': 'multiclass','num_class': 8,'min_data_in_leaf': 50,'learning_rate': 0.05,'feature_fraction': 0.85,'bagging_fraction': 0.85,'bagging_freq': 5, 'max_bin':128,'random_state':100,'verbose': 50,'early_stopping_rounds': 100} folds = KFold(n_splits=5, shuffle=True, random_state=15)
oof = np.zeros(len(train))predict_res = 0
models = []
for fold_, (trn_idx, val_idx) in enumerate(folds.split(train_data)):print("fold n°{}".format(fold_))trn_data = lgb.Dataset(train_data.iloc[trn_idx][train_features], label=train_data.iloc[trn_idx][train_label].values)val_data = lgb.Dataset(train_data.iloc[val_idx][train_features], label=train_data.iloc[val_idx][train_label].values) clf = lgb.train(params, trn_data, num_boost_round=2000,valid_sets=[trn_data,val_data], feval=lgb_logloss) models.append(clf)

4.4 模型结果分析
特征相关性分析: 计算特征之间的相关性系数,并用热力图可视化显示。
这里采样 10000个 样本,观察其中 20 个特征的线性相关性。
plt.figure(figsize=[10,8])
sns.heatmap(train_data.iloc[:10000, 1:21].corr())

通过查看特征变量与 label 的相关性,我们也可以再次验证之前数据探索 EDA 部分的结论,每个文件调用 API 的次数与病毒类型是强相关的。
特征重要性分析的代码和结果如下:
### 特征重要性分析
feature_importance = pd.DataFrame()
feature_importance['fea_name'] = train_features
feature_importance['fea_imp'] = clf.feature_importance()
feature_importance = feature_importance.sort_values('fea_imp',ascending = False)feature_importance.sort_values('fea_imp', ascending = False)

我们把 LightGBM 的特征重要性进行排序并输出,同样也可以再次验证之前 EDA 部分的结论,每个文件调用 API 的次数与病毒类型是强相关的。
plt.figure(figsize=[20, 10,])
plt.figure(figsize=[20, 10,])
sns.barplot(x = feature_importance.iloc[:10]['fea_name'], y = feature_importance.iloc[:10]['fea_imp'])

plt.figure(figsize=[20, 10,])
sns.barplot(x = feature_importance['fea_name'], y = feature_importance['fea_imp'])

对特征的重要性分析也再一次验证了我们的想法:
API 的调用次数及 API 的调用类别数是最重要的两个特征,也就是说不同的病毒常常会调用不同的 API,而且因为有些病毒需要复制自身的原因,调用 API 的次数会非常多:第三到第五强的都是线程统计特征,这也较为容易理解,因为木马等病毒经常需要通过线程监听一些内容,所以在线程数量的使用上也会表现的略不相同。
树模型绘制。我们把 LightGBM 的树模型依次输出,并结合绘制的树模型进行业务的理解。
ax = lgb.plot_tree(clf, tree_index=1, figsize=(20, 8), show_info=['split_gain'])
plt.show()

4.5 模型测试
此处,我们采用 LightGBM 模型进行 5 折交叉验证,取预测均值作为最终结果。
LightGBM 模型进行 5 折交叉验证的预测并不能 100% 超过单折全量数据的 LightGBM,但是在大多数时候取得的效果还是不错的,建议将此作为 Baseline 方法的候选。
pred_res = 0
flod = 5
for model in models:pred_res += model.predict(test_submit[train_features]) * 1.0 / flodtest_submit['prob0'] = 0
test_submit['prob1'] = 0
test_submit['prob2'] = 0
test_submit['prob3'] = 0
test_submit['prob4'] = 0
test_submit['prob5'] = 0
test_submit['prob6'] = 0
test_submit['prob7'] = 0test_submit[['prob0','prob1','prob2','prob3','prob4','prob5','prob6','prob7']] = pred_res
test_submit[['file_id','prob0','prob1','prob2','prob3','prob4','prob5','prob6','prob7']].to_csv('baseline2.csv',index = None)

最后这里有点小报错,但我一直不能很好地解决,尝试多次,暂罢,大家可以多多交流学习!
相关文章:
机器学习 | 阿里云安全恶意程序检测
目录 一、数据探索1.1 数据说明1.2 训练集数据探索1.2.1 数据特征类型1.2.2 数据分布1.2.3 缺失值1.2.4 异常值1.2.5 标签分布探索 1.3 测试集探索1.3.1 数据信息1.3.2 缺失值1.3.3 数据分布1.3.4 异常值 1.4 数据集联合分析1.4.1 file_id 分析1.4.2 API 分析 二、特征工程与基…...

python打包exe文件-实现记录
1、使用pyinstaller库 安装库: pip install pyinstaller打包命令标注主入库程序: pyinstaller -F.\程序入口文件.py 出现了一个问题就是我在打包运行之后会出现有一些插件没有被打包。 解决问题: 通过添加--hidden-importcomtypes.strea…...

基本的DQL语句-单表查询
一、DQL语言 DQL(Data Query Language 数据查询语言)。用途是查询数据库数据,如SELECT语句。是SQL语句 中最核心、最重要的语句,也是使用频率最高的语句。其中,可以根据表的结构和关系分为单表查询和多 表联查。 注意:所有的查询…...

Vue3 对比 Vue2
相关信息简介2020年9月18日,Vue.js发布3.0版本,代号:One Piece(海贼王) 2 年多开发, 100位贡献者, 2600次提交, 600次 PR、30个RFC Vue3 支持 vue2 的大多数特性 可以更好的支持 Typescript,提供了完整的…...

2024中国大学生算法设计超级联赛(1)
🚀欢迎来到本文🚀 🍉个人简介:陈童学哦,彩笔ACMer一枚。 🏀所属专栏:杭电多校集训 本文用于记录回顾总结解题思路便于加深理解。 📢📢📢传送门 A - 循环位移解…...

offer题目51:数组中的逆序对
题目描述:在数组中的两个数字,如果前面一个数字大于后面的数字,则这两个数字组成一个逆序对。输入一个数组,求出这个数组中的逆序对的总数。例如,在数组{7,5,6,4}中,一共存在5个逆序对,分别是(7…...

45、PHP 实现滑动窗口的最大值
题目: PHP 实现滑动窗口的最大值 描述: 给定一个数组和滑动窗口的大小,找出所有滑动窗口里数值的最大值。 例如: 如果输入数组{2,3,4,2,6,2,5,1}及滑动窗口的大小3, 那么一共存在6个滑动窗口, 他们的最大值…...

【计算机视觉】siamfc论文复现实现目标追踪
什么是目标跟踪 使用视频序列第一帧的图像(包括bounding box的位置),来找出目标出现在后序帧位置的一种方法。 什么是孪生网络结构 孪生网络结构其思想是将一个训练样本(已知类别)和一个测试样本(未知类别)输入到两个CNN(这两个CNN往往是权值共享的)中࿰…...

数学建模学习(111):改进遗传算法(引入模拟退火、轮盘赌和网格搜索)求解JSP问题
文章目录 一、车间调度问题1.1目前处理方法1.2简单案例 二、基于改进遗传算法求解车间调度2.1车间调度背景介绍2.2遗传算法介绍2.2.1基本流程2.2.2遗传算法的基本操作和公式2.2.3遗传算法的优势2.2.4遗传算法的不足 2.3讲解本文思路及代码2.4算法执行结果: 三、本文…...

Golang | Leetcode Golang题解之第241题为运算表达式设计优先级
题目: 题解: const addition, subtraction, multiplication -1, -2, -3func diffWaysToCompute(expression string) []int {ops : []int{}for i, n : 0, len(expression); i < n; {if unicode.IsDigit(rune(expression[i])) {x : 0for ; i < n &…...

Unity客户端接入原生Google支付
Unity客户端接入原生Google支付 1. Google后台配置2. 开始接入Java部分C#部分Lua部分 3. 导出工程打包测试参考踩坑注意 1. Google后台配置 找到内部测试(这个测试轨道过审最快),打包上传,这个包不需要接入支付,如果已…...

Spring Cloud之五大组件
Spring Cloud 是一系列框架的有序集合,为开发者提供了快速构建分布式系统的工具。这些组件可以帮助开发者做服务发现,配置管理,负载均衡,断路器,智能路由,微代理,控制总线等。以下是 Spring Cl…...
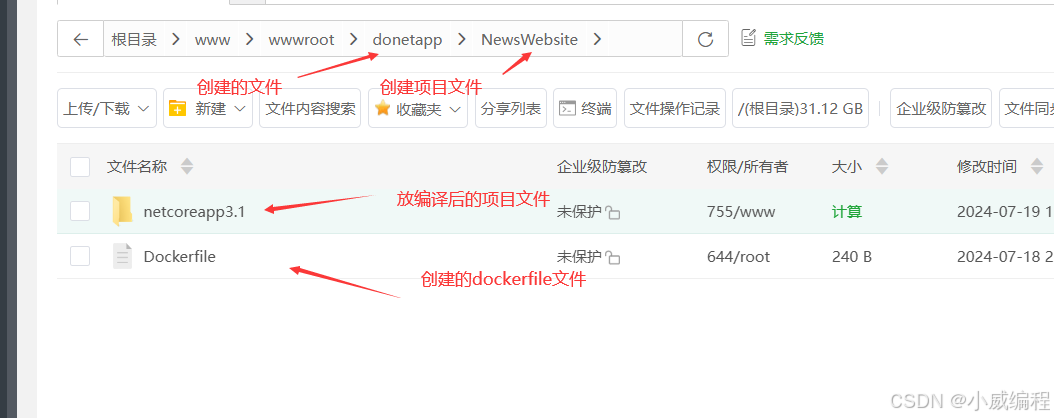
在 CentOS 7 上安装 Docker 并安装和部署 .NET Core 3.1
1. 安装 Docker 步骤 1.1:更新包索引并安装依赖包 先安装yum的扩展,yum-utils提供了一些额外的工具,这些工具可以执行比基本yum命令更复杂的任务 sudo yum install -y yum-utils sudo yum update -y #更新系统上已安装的所有软件包到最新…...

redis的学习(一):下载安装启动连接
简介 redis的下载,安装,启动,连接使用 nosql nosql,即非关系型数据库,和传统的关系型数据库的对比: sqlnosql数据结构结构化非结构化数据关联关联的非关联的查询方式sql查询非sql查询事务特性acidbase存…...

前端设计模式面试题汇总
面试题 1. 简述对网站重构的理解? 参考回答: 网站重构:在不改变外部行为的前提下,简化结构、添加可读性,而在网站前端保持一致的行为。也就是说是在不改变UI的情况下,对网站进行优化, 在扩展的…...
安装python3.12.2环境)
linux(CentOS、Ubuntu)安装python3.12.2环境
1.下载官网Python安装包 wget https://www.python.org/ftp/python/3.12.2/Python-3.12.2.tar.xz 1.1解压 tar -xf Python-3.12.2.tar.xz 解压完后切换到Python-3.12.2文件夹(这里根据自己解压的文件夹路径) cd /usr/packages/Python-3.12.2/ 1.2升级软件包管理器 CentOS系…...

CSS 中border-radius 属性
border-radius 属性在 CSS 中用于创建圆角边框。它可以接受一到四个值,这些值可以是长度值(如像素 px、em 等)或百分比(%)。当提供四个值时,它们分别对应于边框的左上角、右上角、右下角和左下角的圆角半径…...

【大数据专题】数据仓库
1. 简述数据仓库架构 ? 数据仓库的核心功能从源系统抽取数据,通过清洗、转换、标准化,将数据加载到BI平台,进而满足业 务用户的数据分析和决策支持。 数据仓库架构包含三个部分:数据架构、应用程序架构、底层设施 1&…...

go关于string与[]byte再学深一点
目标:充分理解string与[]bytes零拷贝转换的实现 先回顾下string与[]byte的基本知识 1. string与[]byte的数据结构 reflect包中关于字符串的数据结构 // StringHeader is the runtime representation of a string.type StringHeader struct {Data uintptrLen int} …...
元对象系统 | 7.4、属性系统:深度解析与应用)
Qt 实战(7)元对象系统 | 7.4、属性系统:深度解析与应用
文章目录 一、属性系统:深度解析与应用1、定义属性2、属性系统的作用3、属性系统工作原理(1)Q_PROPERTY宏(2)moc 的作用(3)属性在元对象中的注册 4、获取与设置属性4.1、QObject::property()与Q…...

KubeSphere 容器平台高可用:环境搭建与可视化操作指南
Linux_k8s篇 欢迎来到Linux的世界,看笔记好好学多敲多打,每个人都是大神! 题目:KubeSphere 容器平台高可用:环境搭建与可视化操作指南 版本号: 1.0,0 作者: 老王要学习 日期: 2025.06.05 适用环境: Ubuntu22 文档说…...

PPT|230页| 制造集团企业供应链端到端的数字化解决方案:从需求到结算的全链路业务闭环构建
制造业采购供应链管理是企业运营的核心环节,供应链协同管理在供应链上下游企业之间建立紧密的合作关系,通过信息共享、资源整合、业务协同等方式,实现供应链的全面管理和优化,提高供应链的效率和透明度,降低供应链的成…...

无法与IP建立连接,未能下载VSCode服务器
如题,在远程连接服务器的时候突然遇到了这个提示。 查阅了一圈,发现是VSCode版本自动更新惹的祸!!! 在VSCode的帮助->关于这里发现前几天VSCode自动更新了,我的版本号变成了1.100.3 才导致了远程连接出…...

工程地质软件市场:发展现状、趋势与策略建议
一、引言 在工程建设领域,准确把握地质条件是确保项目顺利推进和安全运营的关键。工程地质软件作为处理、分析、模拟和展示工程地质数据的重要工具,正发挥着日益重要的作用。它凭借强大的数据处理能力、三维建模功能、空间分析工具和可视化展示手段&…...

[Java恶补day16] 238.除自身以外数组的乘积
给你一个整数数组 nums,返回 数组 answer ,其中 answer[i] 等于 nums 中除 nums[i] 之外其余各元素的乘积 。 题目数据 保证 数组 nums之中任意元素的全部前缀元素和后缀的乘积都在 32 位 整数范围内。 请 不要使用除法,且在 O(n) 时间复杂度…...

USB Over IP专用硬件的5个特点
USB over IP技术通过将USB协议数据封装在标准TCP/IP网络数据包中,从根本上改变了USB连接。这允许客户端通过局域网或广域网远程访问和控制物理连接到服务器的USB设备(如专用硬件设备),从而消除了直接物理连接的需要。USB over IP的…...

【从零学习JVM|第三篇】类的生命周期(高频面试题)
前言: 在Java编程中,类的生命周期是指类从被加载到内存中开始,到被卸载出内存为止的整个过程。了解类的生命周期对于理解Java程序的运行机制以及性能优化非常重要。本文会深入探寻类的生命周期,让读者对此有深刻印象。 目录 …...
)
C++课设:简易日历程序(支持传统节假日 + 二十四节气 + 个人纪念日管理)
名人说:路漫漫其修远兮,吾将上下而求索。—— 屈原《离骚》 创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊) 专栏介绍:《编程项目实战》 目录 一、为什么要开发一个日历程序?1. 深入理解时间算法2. 练习面向对象设计3. 学习数据结构应用二、核心算法深度解析…...
django blank 与 null的区别
1.blank blank控制表单验证时是否允许字段为空 2.null null控制数据库层面是否为空 但是,要注意以下几点: Django的表单验证与null无关:null参数控制的是数据库层面字段是否可以为NULL,而blank参数控制的是Django表单验证时字…...

SQL Server 触发器调用存储过程实现发送 HTTP 请求
文章目录 需求分析解决第 1 步:前置条件,启用 OLE 自动化方式 1:使用 SQL 实现启用 OLE 自动化方式 2:Sql Server 2005启动OLE自动化方式 3:Sql Server 2008启动OLE自动化第 2 步:创建存储过程第 3 步:创建触发器扩展 - 如何调试?第 1 步:登录 SQL Server 2008第 2 步…...