数据结构--二叉树详解
一,概念
1,结点的度:一个结点含有子树的个数称为该结点的度
2, 树的度:一棵树中,所有结点度的最大值称为树的度;
3,叶子结点或终端结点:度为0的结点称为叶结点;
4,双亲结点或父结点:若一个结点含有子结点,则这个结点称为其子结点的父结点,
5,孩子结点或子结点:一个结点含有的子树的根结点称为该结点的子结点;
6,根结点:一棵树中,没有双亲结点的结点;
7,树的高度或深度:树中结点的最大层次;
二,二叉树的分类
1,满二叉树
每层的结点数都达到最大值,则这棵二叉树就是满二叉树。满二叉树是一种特殊的完全二叉树
2,完全二叉树
从上到下,从左到右一次排列
三,二叉树的基本性
1,若规定根节点的层数为1,则一颗非空二叉树的第i层上最多有2^i-1个节点
2, 如规定根结点的二叉树的深度为为1,则深度为k的二叉树的最大节点数是2^-1
3,对任意一颗二叉树,如果其叶节点的个数为n0,度为2的非叶节点个数为n2,则有n0=n2+1
4,具有n个节点的完全二叉树的深度为log2(n+1)上取整
5,对于具有n个节点的完全二叉树,如果按照从上至下从左至右所有节点从0开始编号,如果父节点的下标为i,则孩子节点为2i+1,2i+2。但是如果2i+1>=n,左无左孩子,若2i+2>=n,否则没有右孩子
6,知道孩子的下标,父节点的下标为(i-1)/2,如果i=0,则无则无双亲节点
7, 二叉树存储分为顺序存储,和链式储存,链式储存是通过一个一个节点的引用起来的。
以链式储存为例:
例如:
public class BinaryTree {public TreeNode root;static class TreeNode{public char val;public TreeNode left;public TreeNode right;public TreeNode(char val) {this.val = val;}}
}
四,二叉树的遍历
分类:
二叉树的遍历分为大体四种:前序遍历,中序遍历,后序遍历,层序遍历。前三种遍历的方式又可以写为递归的形式和非递归的形式
前序遍历:
二叉树中的每一棵树都要符合先遍历根,然后遍历左树,最后是右树(根左右)
递归:
如果根为空,直接return。先打印根,然后打印左树,最后是右树
public void preOrder(TreeNode root){if (root==null){return;}System.out.print(root.val+" ");preOrder(root.left);preOrder(root.right);
}
非递归:
法一:
借助栈。先将根放到栈中,然后弹出,记录下来(赋值给cur),并打印。然后先将cur的右根放到栈中,再放cur的左根。在再弹出栈顶元素也就是左根,重复上述步骤(记录下来,并打印,将其右左树再放到栈中)
注意:
1,一定是先放右树,再放左树
2,将左右树放到栈中时要分别判断左右树是否为空,如果为空则不进栈
public void preOrder2(TreeNode root){Stack<TreeNode> stack=new Stack<>();stack.push(root);TreeNode cur=stack.pop();stack.push(cur.right);stack.push(cur.left);System.out.print(cur.val+" ");while (!stack.isEmpty()){cur=stack.pop();if (cur.right!=null){stack.push(cur.right);}if (cur.left!=null) {stack.push(cur.left);}System.out.print(cur.val+" ");}
}
法二:
借助栈。将root赋值给cur,进入两次循环,内循环是找到cur最左边的树并把过程中经过的每一个节点放到栈中,直到找到null。因为这里是前序遍历,所以每找到一个节点就要打印出来。当找到null时,走出循环。这时弹出栈顶元素,cur等于栈顶元素的右树(通过前面步骤,已知栈顶元素的左树为空)。然后cur开始外循环。由于内循环的条件是cur!=null,所以当右树为空时,不进入内循环,直接再次弹出栈顶元素。如果不为空是,则进入内循环,寻找它的左树……
public void preOrder3(TreeNode root){Stack<TreeNode> stack=new Stack<>();TreeNode cur=root;while (cur!=null||!stack.isEmpty()){while (cur!=null){stack.push(cur);System.out.print(cur.val+" ");cur=cur.left;}TreeNode old=stack.pop();cur=old.right;}System.out.println();
}
中序遍历:
二叉树中的每一棵树都要符合先遍历左树,然后遍历根,最后是右树(左根右)
递归:
public void midOrder(TreeNode root){if (root==null){return;}midOrder(root.left);System.out.print(root.val+" ");midOrder(root.right);
非递归:
与前序遍历非递归的法二原理相似,只是根打印的位置不相同,所以在走内循环时不打印节点,走完后,在打印,这样保证先打印的是左树。
public void midOrder2(TreeNode root){Stack<TreeNode>stack=new Stack<>();TreeNode cur=root;while (cur!=null||!stack.isEmpty()){while (cur!=null){stack.push(cur);cur=cur.left;}TreeNode old=stack.pop();System.out.print(old.val+" ");cur=old.right;}System.out.println();
}
后序遍历:
二叉树中的每一棵树都要符合先遍历左树,然后遍历右树,最后是根(左右根)
递归:
public void postOrder(TreeNode root){if (root==null){return;}postOrder(root.left);postOrder(root.right);System.out.print(root.val+" ");
}
非递归:
与中序遍历非递归思路相似,只是根打印的位置不相同,所以在走内循环,及走完内循环后均不打印,完成内循环后,直接判断栈顶元素右树是否为空,如果为空,就可以弹出栈顶元素,并且打印。但是如果不为空,就要先走右树(因为后序遍历的顺序是左右根,已知没有左树,所以要先打印右树)。
注意:要把每次遍历完的节点储存一下。因为每次内循环走完左树为空时,到判断栈顶元素A右树时(在右树不为空的情况下),这时会开始遍历右树,当遍历完右树后,又会回到这个起点(判断该栈顶元素A是否有右树),这时就会进入死循环,所以这里的判断条件进行丰富,即栈顶元素既有右树且之前没有遍历过【注意栈顶元素A,只是举了一个例子,方便理解!】
public void postOrder2(TreeNode root){Stack<TreeNode>stack=new Stack<>();TreeNode cur=root;TreeNode prev=null;while (cur!=null||!stack.isEmpty()){while (cur!=null){stack.push(cur);cur=cur.left;}TreeNode old=stack.peek();if (old.right==null||prev==old.right){stack.pop();System.out.print(old.val+" ");prev=old;}else {cur=old.right;}}System.out.println();
}
层序遍历:
一层一层的进行遍历
这里我们用到了队列,先把根放进去,弹出时,记录下来(赋值到ret中)并打印,然后根据ret,将ret的左树和右树也放到队列里面,重复上述步骤(弹出,记录下来,并打印,将其左右树再放到队列中),循环上述步骤,直到队列为空,则遍历完成。需要注意的是:将左右树放到队列中时要分别判断左右树是否为空,如果为空则不进队列,只有不为空时,才能放入。
法一:
public void levelOrder(TreeNode root){Queue<TreeNode> queue=new LinkedList<>();if (root==null){return;}queue.offer(root);while (!queue.isEmpty()){TreeNode ret=queue.peek();if (ret.left!=null){queue.offer(ret.left);}if (ret.right!=null){queue.offer(ret.right);}System.out.print(queue.poll().val+" ");}System.out.println();
}
法二:
这种方法是将每一层的节点放到一个链表中,然后将每一层的的链表放到一个“大的链表”中。先将根放到队列中,计算这一层的大小size,则决定着这一层的的链表的大小。然后循环size次,从而将这一层的每个元素均放到该层链表中。然后将这一层的每个元素的左右树再放到队列中,重复上述步骤,直到链表为空。
public List<List<Character>> levelOrder2(TreeNode root){List<List<Character>> ret=new LinkedList<>();if (root==null){return ret;}Queue<TreeNode> queue=new LinkedList<>();queue.offer(root);while (!queue.isEmpty()){int size= queue.size();List<Character> list=new LinkedList<>();while (size>0){TreeNode node=queue.peek();if (node.left!=null){queue.offer(node.left);}if (node.right!=null) {queue.offer(node.right);}list.add(queue.poll().val);size--;}ret.add(list);}return ret;}
五,求二叉树的简单性质
1,一棵树的节点个数
法一:
我们遍历二叉树时,遍历了每个节点,所以只需要将遍历中打印的步骤改为count++,就可以得到节点的个数
public static int sizeNode;
public void size2(TreeNode root) {if (root==null){return ;}sizeNode++;size2(root.left);size2(root.right);
}
法二:
一棵树的节点个数=这棵树的左子树的节点个数+右子树的节点个数+1.(这个1是根节点)
public int size(TreeNode root){if (root==null){return 0;}return 1+size(root.left)+size(root.right);
}
2,求叶子节点的个数
法一:
叶子结点的性质是左子树和右子树均为null,所以当遇到这样的节点时,返回1。整颗树的叶子结点个数=左子树叶子节点的个数+右子树叶子结点个数
public int getLeafNodeCount(TreeNode root){if (root==null){return 0;}if (root.left==null&&root.right==null){return 1;}return getLeafNodeCount(root.left)+getLeafNodeCount(root.right);
}
法二:
也可以遍历二叉树,找到左子树和右子树均为null的节点,count++.
public static int sizeLeafNode;
public void getLeafNodeCount2(TreeNode root){if (root==null){return ;}if (root.left==null&&root.right==null){sizeLeafNode++;}getLeafNodeCount2(root.left);getLeafNodeCount2(root.right);}
3,获取k层节点的个数
我们每递归一层时,让参数k-1,这样当k==1时,就是k层的节点,我们只需要返回1,整颗树的k层结点个数=左子树的k层节点的个数+右子树的k层结点个数
public int getKLevelNodeCount(TreeNode root,int k){if (root==null ){return 0;}if (k==1){return 1;}return getKLevelNodeCount(root.left,k-1)+getKLevelNodeCount(root.right,k-1);
}
4,树的高度
树的高度=左子树高度和右子树高度的最大值+1
public int getHeight(TreeNode root){if (root==null){return 0;}int leftHeight=getHeight(root.left);int rightHeight=getHeight(root.right);return Math.max(leftHeight,rightHeight)+1;
}
5,找到某个节点
如果找到该节点,返回该节点的根。左子树递归完后,如果找到了,直接返回,如果没有找到,再右子树递归,这样可以提高效率
public TreeNode find(TreeNode root,char val){if (root==null){return null;}if (root.val==val){return root;}TreeNode ret=find(root.left,val);if (ret!=null){return ret;}ret=find(root.right,val);if (ret!=null){return ret;}else {return null;}
}
六,简单应用
1,检查两棵树是否相同
如果两棵树均为空,则相同。因为我们需要用递归来实现,所以写的时候我们用if语句(两棵树一定不相同的条件)来快速排除
排除条件
(1)如果一棵树为空,一棵树不为空,直接返回false
(2)如果对应节点的值不一样,直接返回false
当两棵树对应的左树与右树均相同,则两棵树相同
public boolean isSameTree(TreeNode p,TreeNode q){if (p==null&&q==null){return true;}if (p==null&&q!=null||p!=null&&q==null){return false;}if (p.val!= q.val){return false;}return isSameTree(p.left,q.left)&&isSameTree(p.right,q.right);}
2,第二棵树是否是第一棵树的子树
我们先找到第一棵树是否有节点与第二棵树的根结点一致,如果有相同的节点,调用方法一,看两棵树是否相同。我们分别从左树和右树中寻找,只要有一边找到了,就说明第二棵树是第一棵树的子树
public boolean isSubTree(TreeNode root,TreeNode subRoot){if (root==null&&subRoot!=null){return false;}if (root.val== subRoot.val){return isSameTree(root,subRoot);}return isSubTree(root.left,subRoot)||isSubTree(root.right,subRoot);
}
3,翻转二叉树

当根为空,或者根的左右树均为空,则直接返回根。如果不是,交换左右树
private void swap(TreeNode root){TreeNode tmp=root.left;root.left=root.right;root.right=tmp;
}
public TreeNode reverseTree(TreeNode root){if (root==null||root.left==null&&root.right==null){return root;}swap(root);reverseTree(root.left);reverseTree(root.right);return root;
}
4,判断一棵二叉树是否是平衡二叉树
即:所有节点的高度差小于等于一
法一:
算左右树的高度,如果差的绝对值小于1,且左树和右树每一棵子树的左右树的高度差的绝对值小于1,则是平衡二叉树
public boolean isBalanced(TreeNode root){if (root==null){return true;}int leftHeight=getHeight(root.left);int rightHeight=getHeight(root.right);return Math.abs(leftHeight-rightHeight)<=1&&isBalanced(root.left)&&isBalanced(root.right);
}
法二(优化):
重写计算书的高度的方法,如果树的左右树的高度差小于1,则返回该树的高度,如果高度差大于1,返回-1,最后看树的高度是否大于0,如果大于0,则说明每一棵树的左右子树的高度差均小于1,如果小于0,则说明有树的左右子树的高度差均大于1,则不是平衡二叉树
public int getHeight2(TreeNode root){if (root==null){return 0;}int left=getHeight2(root.left);if (left<0){return -1;}int right=getHeight2(root.right);if (right<0){return -1;}if (Math.abs(left-right)<=1){return Math.max(left,right)+1;}else {return -1;}
}
public boolean isBalanced2(TreeNode root){if (root==null){return true;}return getHeight2(root)>0;}
5,对称二叉树
如果根为空或者根的左树右树均为空,则是对称二叉树。
(1)如果跟的左树,右树一个为空一个不为空,则不是对称二叉树
(2)如果根的左树和右树的值不一样,则不是对称二叉树
然后判断左右,这两棵树是否镜面对称,我们再写一个子方法。
(1)如果这两棵树的左右树均为空,则是对称二叉树
(2)如果一棵树的左树,与一棵树的右树,一颗为空,一颗不为空,则不是对称二叉树
(3)如果一棵树的右树,与一棵树的左树,一颗为空,一颗不为空,则不是对称二叉树
(4)如果一棵树的左树,与另一棵树的右树的值不相同,或者一棵树的右树,与一棵树的左树的值不相同,则不是对称二叉树
private boolean isSymmetricChild(TreeNode p,TreeNode q){if (p.left==null&&p.right==null&&q.left==null&&q.right==null){return true;}if (p.left!=null&&q.right==null||p.left==null&&q.right!=null||p.right!=null&&q.left==null||p.right==null&&q.left!=null){return false;}if (p.left.val!=q.right.val||p.right.val!=q.left.val){return false;}return isSymmetricChild(p.left,q.right)&&isSymmetricChild(p.right,q.left);
}public boolean isSymmetric(TreeNode root){if (root==null||root.left==null&&root.right==null){return true;}if (root.left==null&&root.right!=null||root.left!=null&&root.right==null){return false;}if (root.left.val!=root.right.val){return false;}return isSymmetricChild(root.left,root.right);
}
相关文章:
数据结构--二叉树详解
一,概念 1,结点的度:一个结点含有子树的个数称为该结点的度 2, 树的度:一棵树中,所有结点度的最大值称为树的度; 3,叶子结点或终端结点:度为0的结点称为叶结点&#x…...

最短路径 | 743. 网络延迟时间之 Dijkstra 算法和 Floyd 算法
目录 1 基于 Dijkstra 算法1.1 代码说明1.2 完整代码 2 基于 Floyd 算法2.1 代码说明2.2 完整代码 前言:我在做「399. 除法求值」时,看到了基于 Floyd 算法的解决方案,突然想起来自己还没有做过最短路径相关的题。因此找来了「743. 网络…...

LLM模型与实践之基于 MindSpore 实现 BERT 对话情绪识别
安装环境 # 该案例在 mindnlp 0.3.1 版本完成适配,如果发现案例跑不通,可以指定mindnlp版本,执行!pip install mindnlp0.3.1 !pip install mindnlp 模型简介 BERT是一种由Google于2018年发布的新型语言模型,它是基于Transforme…...

单例模式学习cpp
现在我们要求定义一个表示总统的类型。presented可以从该类型继承出French present和American present的等类型。这些派生类型都只能产生一个实例 为了设计一个表示总统的类型,并从该类型派生出只能产生一个实例的具体总统(如法国总统和美国总统&#x…...

第5讲:Sysmac Studio中的硬件拓扑
Sysmac Studio软件概述 一、创建项目 在打开的软件中选择新建工程 然后在工程属性中输入工程名称,作者,类型选择“标准工程”即可。 在选择设备处,类型选择“控制器”。 在版本处,可以在NJ控制器的硬件右侧标签处找到这样一个版本号。 我们今天用到的是1.40,所以在软…...

使用GoAccess进行Web日志可视化
运行网站的挑战之一是了解您的 Web 服务器正在做什么。虽然各种监控应用程序可以在您的服务器以高负载或页面响应缓慢运行时提醒您,但要完全了解正在发生的事情,唯一的方法是查看 Web 日志。阅读日志数据页面并了解正在发生的事情可能需要花费大量时间。…...

GD 32 流水灯
前言: 通过后面的学习掌握了一些逻辑架构的知识,通过复习的方式将学到的裸机任务架构的知识运用起来,同时巩固前面学到的知识,GPIO的配置等。 开发板上LED引脚使用示意图 注:此次LED灯的点亮凡是是高电平点亮ÿ…...

数据结构之栈详解
1. 栈的概念以及结构 栈:一种特殊的线性表,其只允许在固定的一端进行插入和删除元素操作。进行数据插入和删除操作的一端称为栈顶,另一端称为栈底。栈中的数据元素遵守后进先出LIFO(Last In First Out)的原则。 压栈…...
算法:BFS解决 FloodFill 算法
目录 FloodFill 算法 题目一:图像渲染 题目二:岛屿数量 题目三:岛屿的最大面积 题目四:被围绕的区域 FloodFill 算法 在递归搜索回溯中已经说到过 FloodFill 算法了,但是那里是用 dfs 解决的,这里会使…...

Python 中文双引号 “”
Python 中文双引号 “” 1. SyntaxError: invalid character in identifier2. CorrectionReferences 1. SyntaxError: invalid character in identifier print(Albert Einstein once said, “A person who never made a mistake never tried anything new.”) print(Albert Ei…...
)
以太网(Ethernet)
目录 1. What is Internet?1.1. What is Ethernet?2. TCP/IP3. Physical Layer(PHY)4. Data Link Layer4.1. MAC Sublayer5. Network Layer5.1. IP5.2. ARP6. Transport Layer6.1. UDP6.2. TCP7. Application LayerFPGA实现以太网(一)——以太网简介 网络与路由交换 菜鸟FP…...
 doesn‘t match this client (39); killing...)
Scrcpy adb server version (41) doesn‘t match this client (39); killing...
通过Snap 在Ubuntu上安装 scrcpy之后,启动会导致无法同时 scrcpy和adb logcat 过滤日志 目前最新的安装的platforms-tools下面的adb 版本最新都是 adb 41版本 解决办法: 在这里链接里面 下载 adb 1.0.39 版本,替换 /home/host/Android/Sdk/…...

微服务实战系列之玩转Docker(四)
前言 幸福,就是继续追寻已经拥有的东西。 ——圣奥古斯丁 什么算已经拥有的?比如爱你的人在等你,比如每日热腾腾的三餐,比如身边可爱的同事,又比如此刻的你,看见了这篇博文(😁&#…...

微信小程序-自定义组件生命周期
一.created 组件实例创建完毕调用。定义在lifetimes对象里。 不能在方法里面更改data对象里面的值,但是可以定义属性值。 lifetimes:{//不能给data设置值created(){this.testaaconsole.log("created") }}二. attached 模板解析完成挂载到页面。 可以更…...

2024年7月23日(samba DNS)
回顾 1、关闭防火墙,关闭selinux systemctl stop firewalld systemctl disable firewalld setenforce 0 2、修改静态IP地址 vim /etc/sysconfig/network-scripts/ifcfg-ens33 #修改uuid的目的是为了保证网络的唯一性 3、重启网络服务 systemctl restart netwo…...

Hyperledger顶级项目特点和介绍
Hyperledger的顶级项目 Hyperledger是Linux基金会主持的开源区块链项目,其目的是推动跨行业的区块链技术的开发和应用。以下是Hyperledger的顶级项目: 1. Hyperledger Fabric 描述:Hyperledger Fabric是一个可扩展的企业级区块链平台&…...

操作系统——笔记(1)
操作系统是管理计算机硬件资源,控制其他程序运行并为用户提供交互操作界面的系统软件的集合,控制和管理着整个计算机系统的硬件和软件资源,是最基本的系统软件。 常见的操作系统:ios、windows、Linux。 计算机系统的结构层次&am…...
isEmpty() 和 isBlank()的区别
isEmpty() 和 isBlank()的区别 平时自己开发的时候没有注意到这个地方,直到实习的时候代码审查的时候发现其用法上两者的不同. isEmpty() public static boolean isEmpty(String str) {return str null || str.length() 0; }isBlank() public static boolean isBlank(Strin…...

scrapy生成爬虫数据为excel
scrapy生成爬虫数据为excel 使用openpyxl(推荐)安装openpyxl库建一个新的Item Pipeline类在settings.py中启用ExcelPipeline说明 使用scrapy-xlsx首先,安装scrapy-xlsx:然后在Scrapy爬虫中使用管道:说明 要使用Scrapy生…...

vscode debug C++无法输入问题
研究了半天vscode debug c无法输入的问题,原来vscode的文档里面已经记录了。issue都是2020年提的了,还没解决。。。 不过人家也确实给了一个解法:用外部的terminal。 不过怎么看都还不是很方便,所以还是推荐直接使用CodeLLDB插件来…...

CTF show Web 红包题第六弹
提示 1.不是SQL注入 2.需要找关键源码 思路 进入页面发现是一个登录框,很难让人不联想到SQL注入,但提示都说了不是SQL注入,所以就不往这方面想了 先查看一下网页源码,发现一段JavaScript代码,有一个关键类ctfs…...

Golang 面试经典题:map 的 key 可以是什么类型?哪些不可以?
Golang 面试经典题:map 的 key 可以是什么类型?哪些不可以? 在 Golang 的面试中,map 类型的使用是一个常见的考点,其中对 key 类型的合法性 是一道常被提及的基础却很容易被忽视的问题。本文将带你深入理解 Golang 中…...
` 方法)
深入浅出:JavaScript 中的 `window.crypto.getRandomValues()` 方法
深入浅出:JavaScript 中的 window.crypto.getRandomValues() 方法 在现代 Web 开发中,随机数的生成看似简单,却隐藏着许多玄机。无论是生成密码、加密密钥,还是创建安全令牌,随机数的质量直接关系到系统的安全性。Jav…...

【解密LSTM、GRU如何解决传统RNN梯度消失问题】
解密LSTM与GRU:如何让RNN变得更聪明? 在深度学习的世界里,循环神经网络(RNN)以其卓越的序列数据处理能力广泛应用于自然语言处理、时间序列预测等领域。然而,传统RNN存在的一个严重问题——梯度消失&#…...

《用户共鸣指数(E)驱动品牌大模型种草:如何抢占大模型搜索结果情感高地》
在注意力分散、内容高度同质化的时代,情感连接已成为品牌破圈的关键通道。我们在服务大量品牌客户的过程中发现,消费者对内容的“有感”程度,正日益成为影响品牌传播效率与转化率的核心变量。在生成式AI驱动的内容生成与推荐环境中࿰…...

多模态商品数据接口:融合图像、语音与文字的下一代商品详情体验
一、多模态商品数据接口的技术架构 (一)多模态数据融合引擎 跨模态语义对齐 通过Transformer架构实现图像、语音、文字的语义关联。例如,当用户上传一张“蓝色连衣裙”的图片时,接口可自动提取图像中的颜色(RGB值&…...

智能分布式爬虫的数据处理流水线优化:基于深度强化学习的数据质量控制
在数字化浪潮席卷全球的今天,数据已成为企业和研究机构的核心资产。智能分布式爬虫作为高效的数据采集工具,在大规模数据获取中发挥着关键作用。然而,传统的数据处理流水线在面对复杂多变的网络环境和海量异构数据时,常出现数据质…...

安宝特方案丨船舶智造的“AR+AI+作业标准化管理解决方案”(装配)
船舶制造装配管理现状:装配工作依赖人工经验,装配工人凭借长期实践积累的操作技巧完成零部件组装。企业通常制定了装配作业指导书,但在实际执行中,工人对指导书的理解和遵循程度参差不齐。 船舶装配过程中的挑战与需求 挑战 (1…...

R 语言科研绘图第 55 期 --- 网络图-聚类
在发表科研论文的过程中,科研绘图是必不可少的,一张好看的图形会是文章很大的加分项。 为了便于使用,本系列文章介绍的所有绘图都已收录到了 sciRplot 项目中,获取方式: R 语言科研绘图模板 --- sciRplothttps://mp.…...
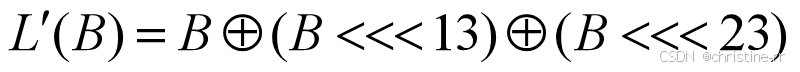
密码学基础——SM4算法
博客主页:christine-rr-CSDN博客 专栏主页:密码学 📌 【今日更新】📌 对称密码算法——SM4 目录 一、国密SM系列算法概述 二、SM4算法 2.1算法背景 2.2算法特点 2.3 基本部件 2.3.1 S盒 2.3.2 非线性变换 编辑…...