深入浅出WebRTC—LossBasedBweV2
WebRTC 同时使用基于丢包的带宽估计算法和基于延迟的带宽估计算法那,能够实现更加全面和准确的带宽评估和控制。基于丢包的带宽估计算法主要依据网络中的丢包情况来动态调整带宽估计,以适应网络状况的变化。本文主要讲解最新 LossBasedBweV2 的实现。
1. 静态结构
LossBasedBweV2 的静态结构比较简单,如下图所示。LossBasedBweV2 被包含在 SendSideBandwidthEstimation 之中,GoogCcNetworkController 不直接与 LossBasedBweV2 打交道,而是通过 SendSideBandwidthEstimation 获取最终带宽估计值。LossBasedBweV2 静态结构虽然简单,但其内部实现一点都不简单,做好心理准备。
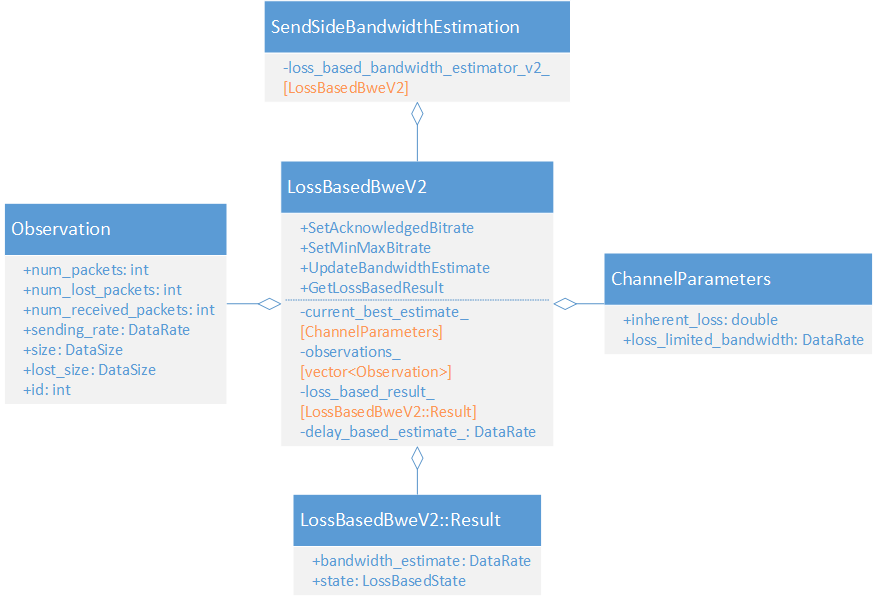
2. 重要属性
1)current_best_estimate_
从候选估计值中选择的当前最佳估计值,包含带宽估计值和链路固有丢包率。
struct ChannelParameters {// 链路固有丢包率(非带宽受限导致的丢包率)double inherent_loss = 0.0;// 丢包限制下的带宽DataRate loss_limited_bandwidth = DataRate::MinusInfinity();
};2)observations_
历史观测值集合。一个 Observation 代表一个观测值:发送码率和丢包率,估计算法中会用到。
struct Observation {bool IsInitialized() const { return id != -1; }// 报文总数int num_packets = 0;// 丢包数量int num_lost_packets = 0;// 接收数量int num_received_packets = 0;// 根据观察时间计算DataRate sending_rate = DataRate::MinusInfinity();// 报文总大小DataSize size = DataSize::Zero();// 丢包总大小DataSize lost_size = DataSize::Zero();int id = -1;
};3)loss_based_result_
基于丢包的带宽估计值和状态。
struct Result {// 估算的带宽DataRate bandwidth_estimate = DataRate::Zero();// 如果处于kIncreasing状态,则需要做带宽探测LossBasedState state = LossBasedState::kDelayBasedEstimate;
};enum class LossBasedState {// 使用丢包估计带宽,正在增加码率kIncreasing = 0,// 使用丢包估计带宽,正在使用padding增加带宽(探测)kIncreaseUsingPadding = 1,// 使用丢包估计带宽,由于丢包增大,正在降低码率kDecreasing = 2,// 使用延迟估计带宽kDelayBasedEstimate = 3
};3. 重要方法
1)SetAcknowledgedBitrate
设置 ACK 码率,ACK 码率在很多地方都会被用到,比如计算基于丢包带宽估计值的上限和下限,生成候选者带宽,
2)SetMinMaxBitrate
设置基于丢包带宽估计的上限值和下限值。
3)UpdateBandwidthEstimate
SendSideBandwidthEstimation 调用此接口,传入 TransportFeedback、延迟估计带宽和 ALR 状态等参数。
4)GetLossBasedResult
获取基于丢包带宽估计结果。
4. 源码分析
4.1. UpdateBandwidthEstimate
UpdateBandwidthEstimate 是丢包估计的主函数,代码非常多,其主体流程如下图所示:
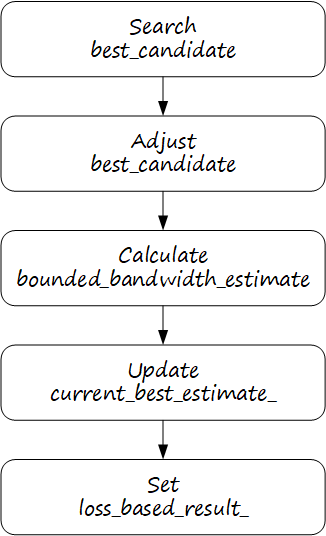
4.1.1. 搜索最佳候选者
搜索最佳候选者的逻辑如下图所示,解释如下:
1)基于 TransportFeedback 构建观测值,每一组观测值设置了最小观测时长。如果产生了新的观测值,则进人新一轮的带宽估计。
2)使用一定算法生成一系列候选者(candidate),只需确定候选者带宽即可。
3)基于观测数据,使用牛顿方法计算候选者的最优固有丢包率。
4)基于观测数据,对每个候选者计算目标函数值,取目标函数值最大者为最佳候选者。
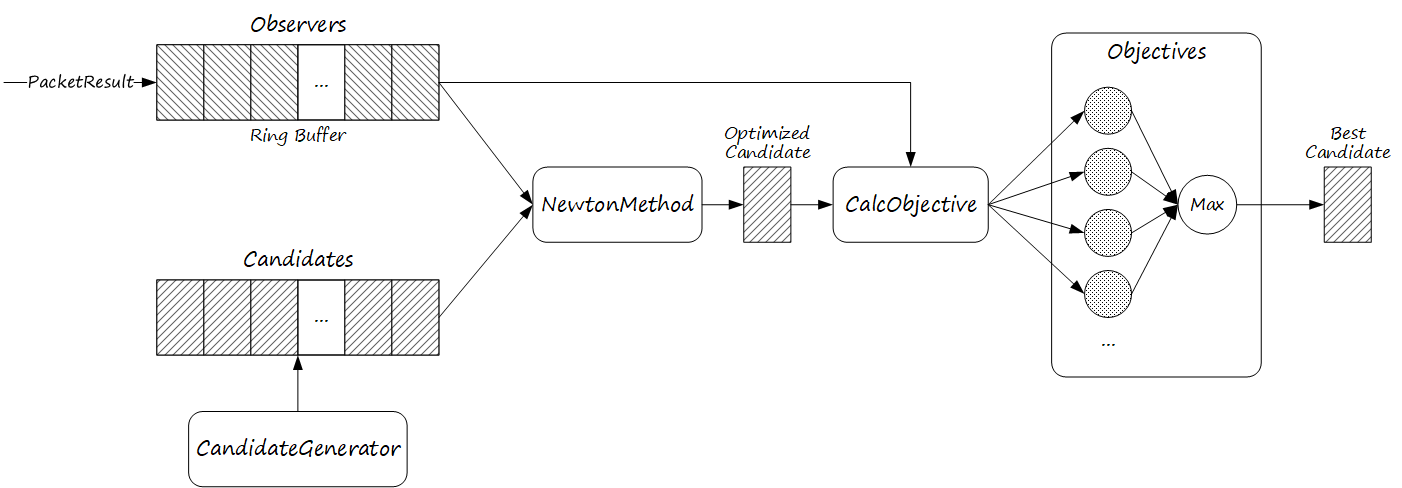
// 尝试将新的观测数据加入到历史数据中,如果没有产生新的observation则返回
if (!PushBackObservation(packet_results)) {return;
}// 初始化最佳带宽估计,如果没有有效的丢包限制带宽估计,则使用基于延迟的估计
if (!IsValid(current_best_estimate_.loss_limited_bandwidth)) {if (!IsValid(delay_based_estimate)) {return;}current_best_estimate_.loss_limited_bandwidth = delay_based_estimate;loss_based_result_ = {.bandwidth_estimate = delay_based_estimate,.state = LossBasedState::kDelayBasedEstimate};
}ChannelParameters best_candidate = current_best_estimate_;
double objective_max = std::numeric_limits<double>::lowest();// 生成并遍历所有candidate,找到最优candidate
for (ChannelParameters candidate : GetCandidates(in_alr)) {// 使用牛顿法搜索最优固有丢包率NewtonsMethodUpdate(candidate);// 基于带宽和固有丢包率计算收益值const double candidate_objective = GetObjective(candidate);// 找到收益值最大的Candidateif (candidate_objective > objective_max) {objective_max = candidate_objective;best_candidate = candidate;}
}4.1.2. 调整丢包限制带宽
通过算法计算得到的最佳候选者还不可靠,需要进行调整。 在丢包限制状态下,如果带宽增加过快则限制带宽增长,并使用爬坡因子来调整带宽估计。增加带宽过快可能会再次引发丢包。
// best_candidate 的估计带宽与其固有丢包率是匹配的,如果 best_candidate 的估计带宽大于
// 上一次的估计带宽,但真实丢包率大于 best_candidate 的固有丢包率,那么有理由认为
// best_candidate 的估计带宽是不可靠的。
if (GetAverageReportedLossRatio() > best_candidate.inherent_loss &&config_->not_increase_if_inherent_loss_less_than_average_loss &¤t_best_estimate_.loss_limited_bandwidth <best_candidate.loss_limited_bandwidth) {best_candidate.loss_limited_bandwidth =current_best_estimate_.loss_limited_bandwidth;
}// 下面这一坨都是在调整best_candidate.loss_limited_bandwidth
if (IsInLossLimitedState()) {if (recovering_after_loss_timestamp_.IsFinite() &&recovering_after_loss_timestamp_ + config_->delayed_increase_window >last_send_time_most_recent_observation_ &&best_candidate.loss_limited_bandwidth > bandwidth_limit_in_current_window_) {best_candidate.loss_limited_bandwidth = bandwidth_limit_in_current_window_;}bool increasing_when_loss_limited = IsEstimateIncreasingWhenLossLimited(/*old_estimate=*/current_best_estimate_.loss_limited_bandwidth,/*new_estimate=*/best_candidate.loss_limited_bandwidth);// Bound the best candidate by the acked bitrate.if (increasing_when_loss_limited && IsValid(acknowledged_bitrate_)) {// 爬坡因子double rampup_factor = config_->bandwidth_rampup_upper_bound_factor;// 使用更保守的爬坡因子if (IsValid(last_hold_info_.rate) &&acknowledged_bitrate_ <config_->bandwidth_rampup_hold_threshold * last_hold_info_.rate) {rampup_factor = config_->bandwidth_rampup_upper_bound_factor_in_hold;}// 保证带宽估计值不会低于当前的最佳估计值。// 同时,限制在不超过新计算的候选值和基于 ACK 码率计算的增长上限之间的较小值。best_candidate.loss_limited_bandwidth =std::max(current_best_estimate_.loss_limited_bandwidth,std::min(best_candidate.loss_limited_bandwidth,rampup_factor * (*acknowledged_bitrate_)));// 为了避免估计值长时间停滞导致算法无法切换到kIncreasing,这里将带宽估计增加1kbps。if (loss_based_result_.state == LossBasedState::kDecreasing &&best_candidate.loss_limited_bandwidth ==current_best_estimate_.loss_limited_bandwidth) {best_candidate.loss_limited_bandwidth =current_best_estimate_.loss_limited_bandwidth +DataRate::BitsPerSec(1);}}
}
4.1.3. 计算有界带宽估计
取丢包估计带宽和延迟估计带宽的较小者,并将估计值限制在合理范围,获得 bounded_bandwidth_estimate。
// 施加了范围限制的带宽估计值
DataRate bounded_bandwidth_estimate = DataRate::PlusInfinity();if (IsValid(delay_based_estimate_)) {// 取丢包估计带宽和延迟估计带宽中的较小者bounded_bandwidth_estimate =std::max(GetInstantLowerBound(),std::min({best_candidate.loss_limited_bandwidth,GetInstantUpperBound(), delay_based_estimate_}));
} else {// 没有延迟估计值,则使用丢包估计值bounded_bandwidth_estimate = std::max(GetInstantLowerBound(), std::min(best_candidate.loss_limited_bandwidth, GetInstantUpperBound()));
}4.1.4. 更新当前最佳估计
根据配置和估计结果更新当前最佳估计值。
if (config_->bound_best_candidate && bounded_bandwidth_estimate < best_candidate.loss_limited_bandwidth) {// 如果配置了对 best_candidate 进行约束,则限制 // best_candidate.loss_limited_bandwidth 不能大于 bounded_bandwidth_estimatecurrent_best_estimate_.loss_limited_bandwidth = bounded_bandwidth_estimate;current_best_estimate_.inherent_loss = 0;
} else {// 没有配置就等于筛选出来的最优值current_best_estimate_ = best_candidate;
}4.1.5. 设置带宽估计结果
获取 bounded_bandwidth_estimate 后,接下来需要更新 loss_based_result.state,并设置估计带宽。以下代码逻辑异常复杂,条件一大堆,是 LossBasedBweV2 最难理解的部分。
// 当前是在 kDecreasing 状态,此次丢包估计带宽低于延迟估计带宽,不允许估计带宽
// 立即上升到可能引起丢包的水平。
if (loss_based_result_.state == LossBasedState::kDecreasing && last_hold_info_.timestamp > last_send_time_most_recent_observation_ && bounded_bandwidth_estimate < delay_based_estimate_) {loss_based_result_.bandwidth_estimate =std::min(last_hold_info_.rate, bounded_bandwidth_estimate);return; // 直接返回,状态保持LossBasedState::kDecreasing
}// 带宽增加
if (IsEstimateIncreasingWhenLossLimited(/*old_estimate=*/loss_based_result_.bandwidth_estimate,/*new_estimate=*/bounded_bandwidth_estimate) &&CanKeepIncreasingState(bounded_bandwidth_estimate) &&bounded_bandwidth_estimate < delay_based_estimate_ &&bounded_bandwidth_estimate < max_bitrate_) {if (config_->padding_duration > TimeDelta::Zero() &&bounded_bandwidth_estimate > last_padding_info_.padding_rate) {// 开启一个新的填充周期last_padding_info_.padding_rate = bounded_bandwidth_estimate;last_padding_info_.padding_timestamp =last_send_time_most_recent_observation_;}loss_based_result_.state = config_->padding_duration > TimeDelta::Zero()? LossBasedState::kIncreaseUsingPadding: LossBasedState::kIncreasing;
}
// 带宽减少
else if (bounded_bandwidth_estimate < delay_based_estimate_ &&bounded_bandwidth_estimate < max_bitrate_) {if (loss_based_result_.state != LossBasedState::kDecreasing &&config_->hold_duration_factor > 0) {last_hold_info_ = {.timestamp = last_send_time_most_recent_observation_ +last_hold_info_.duration,.duration =std::min(kMaxHoldDuration, last_hold_info_.duration *config_->hold_duration_factor),.rate = bounded_bandwidth_estimate};}last_padding_info_ = PaddingInfo();loss_based_result_.state = LossBasedState::kDecreasing;
} else {// 如果以上条件都不满足,表明基于延迟的估计应该被采纳,// 或者当前状态需要重置以避免带宽被错误地限制在低水平。last_hold_info_ = {.timestamp = Timestamp::MinusInfinity(),.duration = kInitHoldDuration,.rate = DataRate::PlusInfinity()};last_padding_info_ = PaddingInfo();loss_based_result_.state = LossBasedState::kDelayBasedEstimate;
}// 更新丢包限制的评估带宽
loss_based_result_.bandwidth_estimate = bounded_bandwidth_estimate;4.2. 相关算法
基于丢包带宽估计的核心问题可以表述为:带宽和固有丢包率是链路的两个属性,现在我们有一组观测值,每个观测值记录了码率和丢包率,如何通过这些观测值反推链路的带宽和固有丢包率?
WebRTC 假定链路丢包符合二项分布,先生成一组候选者(candidate),根据经验设置候选者的带宽,然后用牛顿方法在观测值上搜索候选者的最优固有丢包率,最后用候选者带宽和固有丢包率计算一个收益函数,取收益函数最大的候选者作为最佳估计。
4.2.1. 搜集观测值
Observation 基于 TransportFeedback 生成,收集足够时长报文成为一个观测值。
bool LossBasedBweV2::PushBackObservation(rtc::ArrayView<const PacketResult> packet_results) {if (packet_results.empty()) {return false;}// 获取报文数组的统计信息PacketResultsSummary packet_results_summary =GetPacketResultsSummary(packet_results);// 累加报文数量partial_observation_.num_packets += packet_results_summary.num_packets;// 累加丢包数量partial_observation_.num_lost_packets +=packet_results_summary.num_lost_packets;// 累加报文大小partial_observation_.size += packet_results_summary.total_size;// 累加丢包大小partial_observation_.lost_size += packet_results_summary.lost_size;// This is the first packet report we have received.if (!IsValid(last_send_time_most_recent_observation_)) {last_send_time_most_recent_observation_ =packet_results_summary.first_send_time;}// 报文组中最晚发包时间const Timestamp last_send_time = packet_results_summary.last_send_time;// 距离上一组 last_send_time 时间差const TimeDelta observation_duration =last_send_time - last_send_time_most_recent_observation_;// 两组报文时间差要达到阈值才能创建一个完整的 observationif (observation_duration <= TimeDelta::Zero() ||observation_duration < config_->observation_duration_lower_bound) {return false;}// 更新last_send_time_most_recent_observation_ = last_send_time;// 创建 oberservationObservation observation;observation.num_packets = partial_observation_.num_packets;observation.num_lost_packets = partial_observation_.num_lost_packets;observation.num_received_packets =observation.num_packets - observation.num_lost_packets;observation.sending_rate =GetSendingRate(partial_observation_.size / observation_duration);observation.lost_size = partial_observation_.lost_size;observation.size = partial_observation_.size;observation.id = num_observations_++;// 保存 observationobservations_[observation.id % config_->observation_window_size] =observation;// 重置 partialpartial_observation_ = PartialObservation();CalculateInstantUpperBound();return true;
}4.2.2. 生成候选者
搜索最佳后选择之前,需要生成一系列候选者。由于是有限集合搜索,候选者带宽的选取要考虑上界、下界以及分布的合理性,以形成一个有效的搜索空间,获得准确的搜索结果。
std::vector<LossBasedBweV2::ChannelParameters> LossBasedBweV2::GetCandidates(bool in_alr) const {// 当前的最佳带宽估计中提取信息ChannelParameters best_estimate = current_best_estimate_;// 用于存储即将生成的候选带宽std::vector<DataRate> bandwidths;// 基于当前最佳估计带宽和生成因子生成一系列候选带宽值: 1.02, 1.0, 0.95// 新的带宽在当前最佳估计带宽左右的概率比较高(带宽不会瞬变)for (double candidate_factor : config_->candidate_factors) {bandwidths.push_back(candidate_factor *best_estimate.loss_limited_bandwidth);}// ACK码率是链路容量的一个真实测量值,添加一个基于ACK码率但进行了回退因子调整的候选带宽if (acknowledged_bitrate_.has_value() &&config_->append_acknowledged_rate_candidate) {if (!(config_->not_use_acked_rate_in_alr && in_alr) ||(config_->padding_duration > TimeDelta::Zero() &&last_padding_info_.padding_timestamp + config_->padding_duration >=last_send_time_most_recent_observation_)) {bandwidths.push_back(*acknowledged_bitrate_ *config_->bandwidth_backoff_lower_bound_factor);}}// 满足以下条件,延迟估计带宽也作为带宽候选者之一// 1)延迟估计带宽有效// 2)配置允许// 3)延迟估计带宽高于当前最佳估计丢包限制带宽if (IsValid(delay_based_estimate_) &&config_->append_delay_based_estimate_candidate) {if (delay_based_estimate_ > best_estimate.loss_limited_bandwidth) {bandwidths.push_back(delay_based_estimate_);}}// 满足以下条件,当前带宽上界也作为带宽候选者之一// 1)处于ALR状态// 2)配置允许时// 3)最佳估计丢包限制带宽大于当前带宽上界if (in_alr && config_->append_upper_bound_candidate_in_alr &&best_estimate.loss_limited_bandwidth > GetInstantUpperBound()) {bandwidths.push_back(GetInstantUpperBound());}// 计算一个候选带宽的上界,用于限制生成的候选带宽值不超过这个上界。const DataRate candidate_bandwidth_upper_bound =GetCandidateBandwidthUpperBound();std::vector<ChannelParameters> candidates;candidates.resize(bandwidths.size());for (size_t i = 0; i < bandwidths.size(); ++i) {ChannelParameters candidate = best_estimate;// 丢包限制带宽设置为当前最佳估计的丢包限制带宽与候选带宽值、上界之间的最小值candidate.loss_limited_bandwidth =std::min(bandwidths[i], std::max(best_estimate.loss_limited_bandwidth,candidate_bandwidth_upper_bound));// 使用最佳估计的丢包率candidate.inherent_loss = GetFeasibleInherentLoss(candidate);candidates[i] = candidate;}return candidates;
}4.2.3. 牛顿方法
牛顿方法要解决的问题是,在候选者的估计带宽下,基于当前观测值,求最大似然概率下的固有丢包率。可以这么理解,已知当前链路的带宽,测得一组观测值,观测值描述了收发数据和丢包情况,现在需要计算一个最优的固定丢包率,使得当前观测值出现的联合概率最大。
观测数据可以简化描述为:在一段时间内统计,丢失了 n 个报文,接收到 m 个报文。假设链路的固有丢包率为p,由于观测结果属于二项分布,其概率密度函数可以表示为:
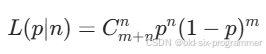
现在测得一组观测数据,要求链路固有丢包率的最大似然概率。我们可以将 k 次观测数据的似然函数相乘,得到联合似然函数,因为每次实验是独立的:
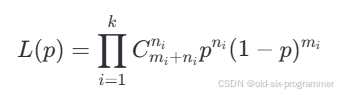
直接最大化上述似然函数可能比较复杂,可以先对似然函数取自然对数,转换为对数似然函数,方便计算:
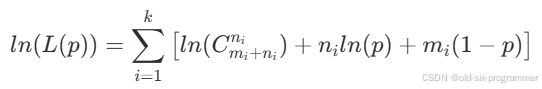
由于 不依赖于
,在求导时会消失,因此在最大化对数似然函数时可以忽略这一项。对
关于
求导,并令导数等于0,可以找到
的最大似然估计值
。
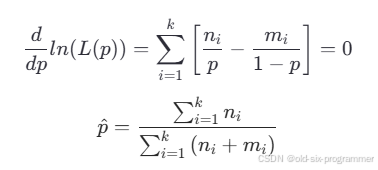
理论上,代入观测数据就可以求得最优固有丢包率。但这里不能这么计算,原因有两个:
1)这里的丢包率并不是固有丢包率 inherent_loss,而是丢包概率 loss_probability,loss_probability 除 inherent_loss 之外,还包括发送速率超出链路带宽导致的丢包。
2)即使计算得到 loss_probability 的最大似然估计值,仍然不能直接求得 inherent_loss 的最大似然估计值,因为 inherent_loss 与 loss_probability 之间并不是简单的线性关系,如下所示。
double GetLossProbability(double inherent_loss, DataRate loss_limited_bandwidth,DataRate sending_rate) {if (inherent_loss < 0.0 || inherent_loss > 1.0) {inherent_loss = std::min(std::max(inherent_loss, 0.0), 1.0);}double loss_probability = inherent_loss;// 如果发送速率大于丢包限制带宽,真实丢包率会更高if (IsValid(sending_rate) && IsValid(loss_limited_bandwidth) && (sending_rate > loss_limited_bandwidth)) {loss_probability += (1 - inherent_loss) *(sending_rate - loss_limited_bandwidth) / sending_rate;}// 限制范围[1.0e-6, 1.0 - 1.0e-6]return std::min(std::max(loss_probability, 1.0e-6), 1.0 - 1.0e-6);
}既然如此,WebRTC 就通过计算似然函数的一阶导数和二阶导数,然后使用牛顿方法来搜索 inherent_loss 的最优值。代码如下所示,标准的牛顿方法。
void LossBasedBweV2::NewtonsMethodUpdate(ChannelParameters& channel_parameters) const {// 没有可用的观测值if (num_observations_ <= 0) {return;}// 指定带宽下,根据观测值,求得最大似然丢包率for (int i = 0; i < config_->newton_iterations; ++i) {// 计算一阶导数和二阶导数const Derivatives derivatives = GetDerivatives(channel_parameters);// 基于一阶导数和二阶导数进行迭代搜索,newton_step_size = 0.75channel_parameters.inherent_loss -=config_->newton_step_size * derivatives.first / derivatives.second;// 固有丢包率的界限约束channel_parameters.inherent_loss = GetFeasibleInherentLoss(channel_parameters);}
}一阶导数和二阶导数的计算如下所示,不过这里有两个需要注意的点:
1)这里计算的并不是 inherent_loss 而是 loss_probability 的最大似然函数的导数,由于 loss_probability 是 inherent_loss 的函数,根据链式法则,使用 loss_probability 的导数来计算 inherent_loss 的最优值是有效的。
2)这里的一阶导数和二阶导数是多个观测值计算的累加值,由于多个观测值之间是独立同分布的,所以,这也是没问题的。
LossBasedBweV2::Derivatives LossBasedBweV2::GetDerivatives(const ChannelParameters& channel_parameters) const {Derivatives derivatives;for (const Observation& observation : observations_) {// 无效的观测值if (!observation.IsInitialized()) {continue;}// 计算在给定通道参数下的丢包概率,如果发送速率超过丢包限制带宽,// 则很可能会产生链路拥塞,从而导致真实丢包率高于链路固有丢包率double loss_probability = GetLossProbability(channel_parameters.inherent_loss,channel_parameters.loss_limited_bandwidth, observation.sending_rate);// 施加一个时间权重,距当前时间越近,数据越“新鲜”,权重越高double temporal_weight =temporal_weights_[(num_observations_ - 1) - observation.id];// 基于丢失和接收到的数据量分别计算一阶导数和二阶导数的累加项if (config_->use_byte_loss_rate) {// derivatives.first += w*((lost/p) - (total-lost)/(1-p))derivatives.first +=temporal_weight *((ToKiloBytes(observation.lost_size) / loss_probability) -(ToKiloBytes(observation.size - observation.lost_size) /(1.0 - loss_probability)));// derivatives.second -= w*((lost/p^2) + (total-lost)/(1-p)^2)derivatives.second -=temporal_weight *((ToKiloBytes(observation.lost_size) /std::pow(loss_probability, 2)) +(ToKiloBytes(observation.size - observation.lost_size) /std::pow(1.0 - loss_probability, 2)));// 基于丢失和接收到的数据包数量分别计算一阶导数和二阶导数的累加项} else {derivatives.first +=temporal_weight *((observation.num_lost_packets / loss_probability) -(observation.num_received_packets / (1.0 - loss_probability)));derivatives.second -=temporal_weight *((observation.num_lost_packets / std::pow(loss_probability, 2)) +(observation.num_received_packets /std::pow(1.0 - loss_probability, 2)));}}// 理论上,二阶导数应为负(表示带宽估计函数的凸性),// 若出现非预期的正值,进行校正,以避免数学异常或不合理的进一步计算。if (derivatives.second >= 0.0) {derivatives.second = -1.0e-6;}return derivatives;
}4.2.4. 目标函数
经牛顿方法搜索后的固有丢包率,加上链路带宽,带入目标函数进行计算,目标值越大则结果越可信。
目标函数分为两部分,第一部分是似然概率,代表了模型对观测数据的解释能力,其中 是时间权重因子,数据越“新鲜”权重越高。
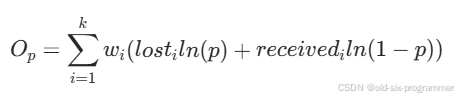
目标函数的第二部分是高带宽偏置,鼓励算法探索更高带宽的潜在收益,其他项相同的前提下,带宽越高越受青睐。其中 是时间权重因子,数据越“新鲜”权重越高。
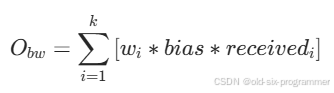
double LossBasedBweV2::GetObjective(const ChannelParameters& channel_parameters) const {double objective = 0.0;// 计算高带宽偏置,鼓励探索更高带宽const double high_bandwidth_bias =GetHighBandwidthBias(channel_parameters.loss_limited_bandwidth);for (const Observation& observation : observations_) {if (!observation.IsInitialized()) {continue;}// 考虑发送码率高于限制码率情况导致的拥塞丢包double loss_probability = GetLossProbability(channel_parameters.inherent_loss,channel_parameters.loss_limited_bandwidth, observation.sending_rate);// 应用一个时间权重给每个观测,新近的观测通常会有更大的影响double temporal_weight =temporal_weights_[(num_observations_ - 1) - observation.id];if (config_->use_byte_loss_rate) {// 固有丢包率收益objective +=temporal_weight *((ToKiloBytes(observation.lost_size) * std::log(loss_probability)) +(ToKiloBytes(observation.size - observation.lost_size) *std::log(1.0 - loss_probability)));// 带宽收益objective +=temporal_weight * high_bandwidth_bias * ToKiloBytes(observation.size);} else {objective +=temporal_weight *((observation.num_lost_packets * std::log(loss_probability)) +(observation.num_received_packets *std::log(1.0 - loss_probability)));objective +=temporal_weight * high_bandwidth_bias * observation.num_packets;}}return objective;
}5. 总结
与带宽一样,固有丢包率(inherent loss)也是网路链路的一个属性,而且是动态变化的。当观察到丢包的时候,我们如何判断这是由于链路固有丢包率导致的丢包还是由于网络拥塞导致的丢包?除非我们知道链路的固有丢包率和带宽,但显然这是无法办到的。WebRTC 为解决这个问题打开了一扇窗,其思路是建立网络丢包的二项式分布模型,通过搜集足够多的观测值,构造目标函数,使用牛顿方法去搜索链路带宽和固有丢包率的最佳组合。然后对这个最佳组合进行必要的校正与调整。不过,从 WebRTC 的实现来看,调整算法太过复杂,有理由相信通过算法得到的估计值可靠性不是非常高,如何优化和简化这一部分的实现逻辑是一个挑战。
相关文章:
深入浅出WebRTC—LossBasedBweV2
WebRTC 同时使用基于丢包的带宽估计算法和基于延迟的带宽估计算法那,能够实现更加全面和准确的带宽评估和控制。基于丢包的带宽估计算法主要依据网络中的丢包情况来动态调整带宽估计,以适应网络状况的变化。本文主要讲解最新 LossBasedBweV2 的实现。 1…...

就业难?誉天Linux云计算架构师涨薪班,不涨薪退学费
2024年,我国高校毕业生人数约为1179 万人,再创历史新高。根据智联招聘今年发布的《大学生就业力调研报告》,可以看到:应届生慢就业、自由职业的比重分别从去年的18.9%、13.2%增长到今年的19.1%、13.7%。 这里我们可以看出…...

从零开始!Jupyter Notebook的安装教程
目录 一、准备工作二、安装Jupyter Notebook方法一:使用pip安装方法二:使用Anaconda安装 三、配置和使用四、常见问题及解决办法如何解决Jupyter Notebook安装过程中遇到的依赖项无法同步的问题?Jupyter Notebook的配置文件在哪里,…...

FastAPI(七十)实战开发《在线课程学习系统》接口开发--留言功能开发
源码见:"fastapi_study_road-learning_system_online_courses: fastapi框架实战之--在线课程学习系统" 在之前的文章:FastAPI(六十九)实战开发《在线课程学习系统》接口开发--修改密码,这次分享留言功能开发 我们梳理…...

04-数据库MySQL
一、项目要求 二、项目过程介绍 1、新建数据库 2、新建表 3、处理表 1.修改student 表中年龄(sage)字段属性,数据类型由int 改变为smallint 2.为Course表中Cno 课程号字段设置索引,并查看索引 3.为SC表建立按学号(sno)和课程号(cno)组合的升序的主键索引…...

神经网络理论(机器学习)
motivation 如果逻辑回归的特征有很多,会造出现一些列问题,比如: 线性假设的限制: 逻辑回归是基于线性假设的分类模型,即认为特征与输出之间的关系是线性的。如果特征非常多或者特征与输出之间的关系是非线性的&#…...

JNI回调用中不同线程的env无法找到正确的kotlin的class
不同线程都需要通过 JavaVM 获取到的 JNIEnv 指针, 如果有两个线程有两个 env。 其中一个是jni接口自己传过来的,可以正常使用,正常获取kotlin中的class。但是通过 JavaVM 新获取的env 无法找到kotlin的class 1. 确保线程已附加到 JVM 确保…...

免费HTML模板网站汇总
PS:基本上都是可以免费下载使用的,而且有一些是说明了可以用于商用和个人的。部分网站可能需要科学上网才能访问,如无法访问可留言或私信。 1、https://www.tooplate.com/free-templates 2、https://htmlrev.com/ 3、https://html5up.net/ 4、…...

大屏数据看板一般是用什么技术实现的?
我们看到过很多企业都会使用数据看板,那么大屏看板的真正意义是什么呢?难道只是为了好看?答案当然不仅仅是。 大屏看板不仅可以提升公司形象,还可以提升企业的管理层次。对于客户,体现公司实力和品牌形象,…...

在 Kubernetes 中设置 Pod 优先级及其调度策略详解
个人名片 🎓作者简介:java领域优质创作者 🌐个人主页:码农阿豪 📞工作室:新空间代码工作室(提供各种软件服务) 💌个人邮箱:[2435024119qq.com] 📱…...

Spring框架、02SpringAOP
SpringAOP 日志功能 基本方法 分析代码问题 目前代码存在两个问题 代码耦合性高:业务代码和日志代码耦合在了一起 代码复用性低:日志代码在每个方法都要书写一遍 问题解决方案 使用动态代理,将公共代码抽取出来 JDK动态代理 使用JDK动…...

基于python的网络爬虫爬取天气数据及可视化分析
要创建一个基于Python的网络爬虫来爬取天气数据并进行可视化分析,我们可以采用以下几个步骤来实现: 1. 选择数据源 首先,需要确定一个可靠的天气数据源。常用的有OpenWeatherMap、Weather API、Weatherstack等。这些API通常需要注册并获取一个API密钥(API Key)来使用。 …...

【WPF开发】上位机开发-串口收发
一、引言 在现代工业控制、嵌入式系统等领域,串口通信作为一种常见的通信方式,被广泛应用于各种场景。C#作为一门强大的编程语言,结合Windows Presentation Foundation(WPF)框架,可以轻松实现串口通信功能…...

ubuntu开启 远程登录 允许root远程登录
如果没有22端口服务 sudo apt update sudo apt install openssh-server sudo ufw allow.ssh sudo passwd root 修改配置文件 sudo vim /etc/ssh/sshd_config Port 22 修改为 Port 22 #PermitRootLogin prohibit-password 修改为 PermitRootLogin yes service ssh restart …...

《昇思25天学习打卡营第23天|RNN实现情感分类》
使用RNN进行情感分类:基于IMDB数据集的LSTM应用 引言 情感分析是自然语言处理(NLP)中的一个重要应用,广泛用于电影评论、社交媒体等文本数据的情感分类任务。本文将介绍如何使用递归神经网络(RNN)实现情感…...
机械设计基础B(学习笔记)
绪论 机构:是一些具备各自特点的和具有确定的相对运动的基本组合的统称。 组成机构的各个相对运动部分称为构件。构件作为运动单元,它可以是单一的整体,也可以是由几个最基本的事物(通常称为零件)组成的刚性结构。 构件…...

MybatisPlusException: Error: Method queryTotal execution error of sql 的报错解决
项目场景: 相关背景: 开发环境 开发系统时 系统页面加载正常 ,发布运行环境后运行一段时间,前端页面 突然出现 报错信息, 报错信息如下: MybatisPlusException: Error: Method queryTotal execution erro…...

人工智能领域的顶尖影响力人物(部分代表)
人工智能(AI)是模拟人类智能过程的计算机系统或机器的理论和开发。它致力于创建能够执行需要人类智能的任务的机器,如视觉感知、语音识别、决策制定和翻译之间的语言。AI领域包括机器学习、深度学习、自然语言处理等子领域,并涉及…...

Python:jsonl文件转json文件,并做字段处理
在使用LLaMA-Factory对shenzhi-wang/Llama3-8B-Chinese-Chat(https://huggingface.co/shenzhi-wang/Llama3-8B-Chinese-Chat/tree/main)进行微调时,希望使用COIG-CQIA的小红书数据集(https://huggingface.co/datasets/m-a-p/COIG-…...

安全产品在防御勒索病毒中的作用
在数字时代,网络安全威胁日益严峻,其中勒索病毒尤为猖獗,它通过加密受害者的数据并要求赎金换取解密密钥,给个人和企业带来了巨大的经济损失。然而,关于安全产品是否真正有效的问题一直存在争议。本文将通过一个模拟实…...

19c补丁后oracle属主变化,导致不能识别磁盘组
补丁后服务器重启,数据库再次无法启动 ORA01017: invalid username/password; logon denied Oracle 19c 在打上 19.23 或以上补丁版本后,存在与用户组权限相关的问题。具体表现为,Oracle 实例的运行用户(oracle)和集…...

CentOS下的分布式内存计算Spark环境部署
一、Spark 核心架构与应用场景 1.1 分布式计算引擎的核心优势 Spark 是基于内存的分布式计算框架,相比 MapReduce 具有以下核心优势: 内存计算:数据可常驻内存,迭代计算性能提升 10-100 倍(文档段落:3-79…...

[ICLR 2022]How Much Can CLIP Benefit Vision-and-Language Tasks?
论文网址:pdf 英文是纯手打的!论文原文的summarizing and paraphrasing。可能会出现难以避免的拼写错误和语法错误,若有发现欢迎评论指正!文章偏向于笔记,谨慎食用 目录 1. 心得 2. 论文逐段精读 2.1. Abstract 2…...

IoT/HCIP实验-3/LiteOS操作系统内核实验(任务、内存、信号量、CMSIS..)
文章目录 概述HelloWorld 工程C/C配置编译器主配置Makefile脚本烧录器主配置运行结果程序调用栈 任务管理实验实验结果osal 系统适配层osal_task_create 其他实验实验源码内存管理实验互斥锁实验信号量实验 CMISIS接口实验还是得JlINKCMSIS 简介LiteOS->CMSIS任务间消息交互…...

大学生职业发展与就业创业指导教学评价
这里是引用 作为软工2203/2204班的学生,我们非常感谢您在《大学生职业发展与就业创业指导》课程中的悉心教导。这门课程对我们即将面临实习和就业的工科学生来说至关重要,而您认真负责的教学态度,让课程的每一部分都充满了实用价值。 尤其让我…...

Vue 模板语句的数据来源
🧩 Vue 模板语句的数据来源:全方位解析 Vue 模板(<template> 部分)中的表达式、指令绑定(如 v-bind, v-on)和插值({{ }})都在一个特定的作用域内求值。这个作用域由当前 组件…...
DAY 45 超大力王爱学Python
来自超大力王的友情提示:在用tensordoard的时候一定一定要用绝对位置,例如:tensorboard --logdir"D:\代码\archive (1)\runs\cifar10_mlp_experiment_2" 不然读取不了数据 知识点回顾: tensorboard的发展历史和原理tens…...

CSS 工具对比:UnoCSS vs Tailwind CSS,谁是你的菜?
在现代前端开发中,Utility-First (功能优先) CSS 框架已经成为主流。其中,Tailwind CSS 无疑是市场的领导者和标杆。然而,一个名为 UnoCSS 的新星正以其惊人的性能和极致的灵活性迅速崛起。 这篇文章将深入探讨这两款工具的核心理念、技术差…...

无需布线的革命:电力载波技术赋能楼宇自控系统-亚川科技
无需布线的革命:电力载波技术赋能楼宇自控系统 在楼宇自动化领域,传统控制系统依赖复杂的专用通信线路,不仅施工成本高昂,后期维护和扩展也极为不便。电力载波技术(PLC)的突破性应用,彻底改变了…...
Springboot 高校报修与互助平台小程序
一、前言 随着我国经济迅速发展,人们对手机的需求越来越大,各种手机软件也都在被广泛应用,但是对于手机进行数据信息管理,对于手机的各种软件也是备受用户的喜爱,高校报修与互助平台小程序被用户普遍使用,为…...