【Python数据增强】图像数据集扩充
前言:该脚本用于图像数据增强,特别是目标检测任务中的图像和标签数据增强。通过应用一系列数据增强技术(如旋转、平移、裁剪、加噪声、改变亮度、cutout、翻转等),生成多样化的图像数据集,以提高目标检测模型的鲁棒性和准确性。
效果:img存的原始图像168张图片,img2扩充的数量为5040张图片


目录
1.环境准备
2.显示图片函数
3.数据增强类
3.1类初始化
3.2数据增强方法
3.3 数据增强主方法
4.XML解析工具类
4.1 解析XML
4.2 保存图片
4.3 保存XML
5. 主函数
完整程序
1.环境准备
这段代码导入了脚本所需的库,用于图像处理(cv2、numpy)、随机操作(random)、文件操作(os)、XML解析(etree)等。
# -*- coding=utf-8 -*-
import time
import random
import copy
import cv2
import os
import math
import numpy as np
from skimage.util import random_noise
from lxml import etree, objectify
import xml.etree.ElementTree as ET
import argparse
2.显示图片函数
该函数用于显示图片,并在图片上绘制边界框(bounding box)。
def show_pic(img, bboxes=None):'''输入:img: 图像arraybboxes: 图像的所有bounding box list, 格式为[[x_min, y_min, x_max, y_max]....]'''for i in range(len(bboxes)):bbox = bboxes[i]x_min = bbox[0]y_min = bbox[1]x_max = bbox[2]y_max = bbox[3]cv2.rectangle(img, (int(x_min), int(y_min)), (int(x_max), int(y_max)), (0, 255, 0), 3)cv2.namedWindow('pic', 0)cv2.moveWindow('pic', 0, 0)cv2.resizeWindow('pic', 1200, 800)cv2.imshow('pic', img)cv2.waitKey(0)cv2.destroyAllWindows()
3.数据增强类
3.1类初始化
该类初始化函数设置了数据增强的各种参数和是否启用某种增强方式的标志。
class DataAugmentForObjectDetection():def __init__(self, rotation_rate=0.5, max_rotation_angle=5,crop_rate=0.5, shift_rate=0.5, change_light_rate=0.5,add_noise_rate=0.5, flip_rate=0.5,cutout_rate=0.5, cut_out_length=50, cut_out_holes=1, cut_out_threshold=0.5,is_addNoise=True, is_changeLight=True, is_cutout=True, is_rotate_img_bbox=True,is_crop_img_bboxes=True, is_shift_pic_bboxes=True, is_filp_pic_bboxes=True):self.rotation_rate = rotation_rateself.max_rotation_angle = max_rotation_angleself.crop_rate = crop_rateself.shift_rate = shift_rateself.change_light_rate = change_light_rateself.add_noise_rate = add_noise_rateself.flip_rate = flip_rateself.cutout_rate = cutout_rateself.cut_out_length = cut_out_lengthself.cut_out_holes = cut_out_holesself.cut_out_threshold = cut_out_thresholdself.is_addNoise = is_addNoiseself.is_changeLight = is_changeLightself.is_cutout = is_cutoutself.is_rotate_img_bbox = is_rotate_img_bboxself.is_crop_img_bboxes = is_crop_img_bboxesself.is_shift_pic_bboxes = is_shift_pic_bboxesself.is_filp_pic_bboxes = is_filp_pic_bboxes
3.2数据增强方法
加噪声。为图像添加高斯噪声。
def _addNoise(self, img):return random_noise(img, mode='gaussian', clip=True) * 255
改变亮度。随机改变图像亮度。
def _changeLight(self, img):alpha = random.uniform(0.35, 1)blank = np.zeros(img.shape, img.dtype)return cv2.addWeighted(img, alpha, blank, 1 - alpha, 0)
cutout。随机在图像中遮挡某些部分(cutout),避免遮挡太多目标。
def _cutout(self, img, bboxes, length=100, n_holes=1, threshold=0.5):def cal_iou(boxA, boxB):xA = max(boxA[0], boxB[0])yA = max(boxA[1], boxB[1])xB = min(boxA[2], boxB[2])yB = min(boxA[3], boxB[3])if xB <= xA or yB <= yA:return 0.0interArea = (xB - xA + 1) * (yB - yA + 1)boxAArea = (boxA[2] - boxA[0] + 1) * (boxA[3] - boxA[1] + 1)boxBArea = (boxB[2] - boxB[0] + 1) * (boxB[3] - boxB[1] + 1)iou = interArea / float(boxBArea)return iouif img.ndim == 3:h, w, c = img.shapeelse:_, h, w, c = img.shapemask = np.ones((h, w, c), np.float32)for n in range(n_holes):chongdie = Truewhile chongdie:y = np.random.randint(h)x = np.random.randint(w)y1 = np.clip(y - length // 2, 0, h)y2 = np.clip(y + length // 2, 0, h)x1 = np.clip(x - length // 2, 0, w)x2 = np.clip(x + length // 2, 0, w)chongdie = Falsefor box in bboxes:if cal_iou([x1, y1, x2, y2], box) > threshold:chongdie = Truebreakmask[y1: y2, x1: x2, :] = 0.img = img * maskreturn img
旋转。旋转图像和对应的边界框。
def _rotate_img_bbox(self, img, bboxes, angle=5, scale=1.):w, h = img.shape[1], img.shape[0]rangle = np.deg2rad(angle)nw = (abs(np.sin(rangle) * h) + abs(np.cos(rangle) * w)) * scalenh = (abs(np.cos(rangle) * h) + abs(np.sin(rangle) * w)) * scalerot_mat = cv2.getRotationMatrix2D((nw * 0.5, nh * 0.5), angle, scale)rot_move = np.dot(rot_mat, np.array([(nw - w) * 0.5, (nh - h) * 0.5, 0]))rot_mat[0, 2] += rot_move[0]rot_mat[1, 2] += rot_move[1]rot_img = cv2.warpAffine(img, rot_mat, (int(math.ceil(nw)), int(math.ceil(nh))), flags=cv2.INTER_LANCZOS4)rot_bboxes = []for bbox in bboxes:points = np.array([[bbox[0], bbox[1]], [bbox[2], bbox[1]], [bbox[2], bbox[3]], [bbox[0], bbox[3]]])new_points = cv2.transform(points[None, :, :], rot_mat)[0]rx, ry, rw, rh = cv2.boundingRect(new_points)corrected_bbox = [max(0, rx), max(0, ry), min(nw, rx + rw), min(nh, ry + rh)]corrected_bbox = [int(val) for val in corrected_bbox]rot_bboxes.append(corrected_bbox)return rot_img, rot_bboxes
裁剪。随机裁剪图像,同时裁剪对应的边界框。
def _crop_img_bboxes(self, img, bboxes):w = img.shape[1]h = img.shape[0]x_min = wx_max = 0y_min = hy_max = 0for bbox in bboxes:x_min = min(x_min, bbox[0])y_min = min(y_min, bbox[1])x_max = max(x_max, bbox[2])y_max = max(y_max, bbox[3])d_to_left = x_mind_to_right = w - x_maxd_to_top = y_mind_to_bottom = h - y_maxcrop_x_min = int(x_min - random.uniform(0, d_to_left))crop_y_min = int(y_min - random.uniform(0, d_to_top))crop_x_max = int(x_max + random.uniform(0, d_to_right))crop_y_max = int(y_max + random.uniform(0, d_to_bottom))crop_x_min = max(0, crop_x_min)crop_y_min = max(0, crop_y_min)crop_x_max = min(w, crop_x_max)crop_y_max = min(h, crop_y_max)crop_img = img[crop_y_min:crop_y_max, crop_x_min:crop_x_max]crop_bboxes = list()for bbox in bboxes:crop_bboxes.append([bbox[0] - crop_x_min, bbox[1] - crop_y_min, bbox[2] - crop_x_min, bbox[3] - crop_y_min])return crop_img, crop_bboxes
平移。随机平移图像和对应的边界框。
def _shift_pic_bboxes(self, img, bboxes):h, w = img.shape[:2]x = random.uniform(-w * 0.2, w * 0.2)y = random.uniform(-h * 0.2, h * 0.2)M = np.float32([[1, 0, x], [0, 1, y]])shift_img = cv2.warpAffine(img, M, (w, h))shift_bboxes = []for bbox in bboxes:new_bbox = [bbox[0] + x, bbox[1] + y, bbox[2] + x, bbox[3] + y]corrected_bbox = [max(0, new_bbox[0]), max(0, new_bbox[1]), min(w, new_bbox[2]), min(h, new_bbox[3])]corrected_bbox = [int(val) for val in corrected_bbox]shift_bboxes.append(corrected_bbox)return shift_img, shift_bboxes
翻转。随机翻转图像和对应的边界框。
def _filp_pic_bboxes(self, img, bboxes):flipCode = random.choice([-1, 0, 1])flip_img = cv2.flip(img, flipCode)h, w, _ = img.shapeflip_bboxes = []for bbox in bboxes:x_min, y_min, x_max, y_max = bboxif flipCode == 0:new_bbox = [x_min, h - y_max, x_max, h - y_min]elif flipCode == 1:new_bbox = [w - x_max, y_min, w - x_min, y_max]else:new_bbox = [w - x_max, h - y_max, w - x_min, h - y_min]flip_bboxes.append(new_bbox)return flip_img, flip_bboxes
3.3 数据增强主方法
综合应用各种数据增强方法,对输入图像和边界框进行增强。
def dataAugment(self, img, bboxes):change_num = 0while change_num < 1:if self.is_rotate_img_bbox:if random.random() > self.rotation_rate:change_num += 1angle = random.uniform(-self.max_rotation_angle, self.max_rotation_angle)scale = random.uniform(0.7, 0.8)img, bboxes = self._rotate_img_bbox(img, bboxes, angle, scale)if self.is_shift_pic_bboxes:if random.random() < self.shift_rate:change_num += 1img, bboxes = self._shift_pic_bboxes(img, bboxes)if self.is_changeLight:if random.random() > self.change_light_rate:change_num += 1img = self._changeLight(img)if self.is_addNoise:if random.random() < self.add_noise_rate:change_num += 1img = self._addNoise(img)if self.is_cutout:if random.random() < self.cutout_rate:change_num += 1img = self._cutout(img, bboxes, length=self.cut_out_length, n_holes=self.cut_out_holes,threshold=self.cut_out_threshold)if self.is_filp_pic_bboxes:if random.random() < self.flip_rate:change_num += 1img, bboxes = self._filp_pic_bboxes(img, bboxes)return img, bboxes
4.XML解析工具类
4.1 解析XML
从XML文件中提取边界框信息。
class ToolHelper():def parse_xml(self, path):tree = ET.parse(path)root = tree.getroot()objs = root.findall('object')coords = list()for ix, obj in enumerate(objs):name = obj.find('name').textbox = obj.find('bndbox')x_min = int(box[0].text)y_min = int(box[1].text)x_max = int(box[2].text)y_max = int(box[3].text)coords.append([x_min, y_min, x_max, y_max, name])return coords
4.2 保存图片
保存增强后的图片。
def save_img(self, file_name, save_folder, img):cv2.imwrite(os.path.join(save_folder, file_name), img)
4.3 保存XML
保存增强后的XML文件。
def save_xml(self, file_name, save_folder, img_info, height, width, channel, bboxs_info):folder_name, img_name = img_infoE = objectify.ElementMaker(annotate=False)anno_tree = E.annotation(E.folder(folder_name),E.filename(img_name),E.path(os.path.join(folder_name, img_name)),E.source(E.database('Unknown'),),E.size(E.width(width),E.height(height),E.depth(channel)),E.segmented(0),)labels, bboxs = bboxs_infofor label, box in zip(labels, bboxs):anno_tree.append(E.object(E.name(label),E.pose('Unspecified'),E.truncated('0'),E.difficult('0'),E.bndbox(E.xmin(box[0]),E.ymin(box[1]),E.xmax(box[2]),E.ymax(box[3]))))etree.ElementTree(anno_tree).write(os.path.join(save_folder, file_name), pretty_print=True)
5. 主函数
首先新建几个文件夹,修改主函数里相应的文件路径,即可。

- img 用于存放自己手里已有的数据集图片
- img2 用于存放增强后的数据集图片
- xml 用于存放自己手里已有的数据集图片对应的标签(这里必须是VOC格式)
- xml2 用于存放增强后的数据集图片对应的标签
- txt 用于存放将xml2中的voc格式的标签转换成txt格式(yolov识别txt格式的标签)

修改每个图片的增强次数即可决定增强图片的数量。

主函数:
- 解析命令行参数,获取图片和XML文件路径。
- 创建保存路径文件夹(如果不存在)。
- 遍历源图片路径,读取图片和对应的XML文件。
- 应用数据增强,保存增强后的图片和XML文件。
if __name__ == '__main__':need_aug_num = 30 # 每张图片需要增强的次数is_endwidth_dot = True # 文件是否以.jpg或者png结尾dataAug = DataAugmentForObjectDetection() # 数据增强工具类toolhelper = ToolHelper() # 工具# 获取相关参数parser = argparse.ArgumentParser()parser.add_argument('--source_img_path', type=str, default='D:/lenovo/Archie/shujukuochongv1.0/img')parser.add_argument('--source_xml_path', type=str, default='D:/lenovo/Archie/shujukuochongv1.0/xml')parser.add_argument('--save_img_path', type=str, default='D:/lenovo/Archie/shujukuochongv1.0/img2')parser.add_argument('--save_xml_path', type=str, default='D:/lenovo/Archie/shujukuochongv1.0/xml2')args = parser.parse_args()source_img_path = args.source_img_path # 图片原始位置source_xml_path = args.source_xml_path # xml的原始位置save_img_path = args.save_img_path # 图片增强结果保存文件save_xml_path = args.save_xml_path # xml增强结果保存文件if not os.path.exists(save_img_path):os.mkdir(save_img_path)if not os.path.exists(save_xml_path):os.mkdir(save_xml_path)for parent, _, files in os.walk(source_img_path):files.sort()for file in files:cnt = 0pic_path = os.path.join(parent, file)xml_path = os.path.join(source_xml_path, file[:-4] + '.xml')values = toolhelper.parse_xml(xml_path)coords = [v[:4] for v in values]labels = [v[-1] for v in values]if is_endwidth_dot:dot_index = file.rfind('.')_file_prefix = file[:dot_index]_file_suffix = file[dot_index:]img = cv2.imread(pic_path)while cnt < need_aug_num:auged_img, auged_bboxes = dataAug.dataAugment(img, coords)auged_bboxes_int = np.array(auged_bboxes).astype(np.int32)height, width, channel = auged_img.shapeimg_name = '{}_{}{}'.format(_file_prefix, cnt + 1, _file_suffix)tool
完整程序
该脚本用于对图像数据进行各种数据增强操作,并保存增强后的图像和标签数据。通过这些增强操作,可以生成大量多样化的训练数据,提升目标检测模型的鲁棒性和准确性。
# -*- coding=utf-8 -*-import time
import random
import copy
import cv2
import os
import math
import numpy as np
from skimage.util import random_noise
from lxml import etree, objectify
import xml.etree.ElementTree as ET
import argparse# 显示图片
def show_pic(img, bboxes=None):'''输入:img:图像arraybboxes:图像的所有boudning box list, 格式为[[x_min, y_min, x_max, y_max]....]names:每个box对应的名称'''for i in range(len(bboxes)):bbox = bboxes[i]x_min = bbox[0]y_min = bbox[1]x_max = bbox[2]y_max = bbox[3]cv2.rectangle(img, (int(x_min), int(y_min)), (int(x_max), int(y_max)), (0, 255, 0), 3)cv2.namedWindow('pic', 0) # 1表示原图cv2.moveWindow('pic', 0, 0)cv2.resizeWindow('pic', 1200, 800) # 可视化的图片大小cv2.imshow('pic', img)cv2.waitKey(0)cv2.destroyAllWindows()# 图像均为cv2读取
class DataAugmentForObjectDetection():def __init__(self, rotation_rate=0.5, max_rotation_angle=5,crop_rate=0.5, shift_rate=0.5, change_light_rate=0.5,add_noise_rate=0.5, flip_rate=0.5,cutout_rate=0.5, cut_out_length=50, cut_out_holes=1, cut_out_threshold=0.5,is_addNoise=True, is_changeLight=True, is_cutout=True, is_rotate_img_bbox=True,is_crop_img_bboxes=True, is_shift_pic_bboxes=True, is_filp_pic_bboxes=True):# 配置各个操作的属性self.rotation_rate = rotation_rateself.max_rotation_angle = max_rotation_angleself.crop_rate = crop_rateself.shift_rate = shift_rateself.change_light_rate = change_light_rateself.add_noise_rate = add_noise_rateself.flip_rate = flip_rateself.cutout_rate = cutout_rateself.cut_out_length = cut_out_lengthself.cut_out_holes = cut_out_holesself.cut_out_threshold = cut_out_threshold# 是否使用某种增强方式self.is_addNoise = is_addNoiseself.is_changeLight = is_changeLightself.is_cutout = is_cutoutself.is_rotate_img_bbox = is_rotate_img_bboxself.is_crop_img_bboxes = is_crop_img_bboxesself.is_shift_pic_bboxes = is_shift_pic_bboxesself.is_filp_pic_bboxes = is_filp_pic_bboxes# ----1.加噪声---- #def _addNoise(self, img):'''输入:img:图像array输出:加噪声后的图像array,由于输出的像素是在[0,1]之间,所以得乘以255'''# return cv2.GaussianBlur(img, (11, 11), 0)return random_noise(img, mode='gaussian', clip=True) * 255# ---2.调整亮度--- #def _changeLight(self, img):alpha = random.uniform(0.35, 1)blank = np.zeros(img.shape, img.dtype)return cv2.addWeighted(img, alpha, blank, 1 - alpha, 0)# ---3.cutout--- #def _cutout(self, img, bboxes, length=100, n_holes=1, threshold=0.5):'''原版本:https://github.com/uoguelph-mlrg/Cutout/blob/master/util/cutout.pyRandomly mask out one or more patches from an image.Args:img : a 3D numpy array,(h,w,c)bboxes : 框的坐标n_holes (int): Number of patches to cut out of each image.length (int): The length (in pixels) of each square patch.'''def cal_iou(boxA, boxB):'''boxA, boxB为两个框,返回iouboxB为bouding box'''# determine the (x, y)-coordinates of the intersection rectanglexA = max(boxA[0], boxB[0])yA = max(boxA[1], boxB[1])xB = min(boxA[2], boxB[2])yB = min(boxA[3], boxB[3])if xB <= xA or yB <= yA:return 0.0# compute the area of intersection rectangleinterArea = (xB - xA + 1) * (yB - yA + 1)# compute the area of both the prediction and ground-truth# rectanglesboxAArea = (boxA[2] - boxA[0] + 1) * (boxA[3] - boxA[1] + 1)boxBArea = (boxB[2] - boxB[0] + 1) * (boxB[3] - boxB[1] + 1)iou = interArea / float(boxBArea)return iou# 得到h和wif img.ndim == 3:h, w, c = img.shapeelse:_, h, w, c = img.shapemask = np.ones((h, w, c), np.float32)for n in range(n_holes):chongdie = True # 看切割的区域是否与box重叠太多while chongdie:y = np.random.randint(h)x = np.random.randint(w)y1 = np.clip(y - length // 2, 0,h) # numpy.clip(a, a_min, a_max, out=None), clip这个函数将将数组中的元素限制在a_min, a_max之间,大于a_max的就使得它等于 a_max,小于a_min,的就使得它等于a_miny2 = np.clip(y + length // 2, 0, h)x1 = np.clip(x - length // 2, 0, w)x2 = np.clip(x + length // 2, 0, w)chongdie = Falsefor box in bboxes:if cal_iou([x1, y1, x2, y2], box) > threshold:chongdie = Truebreakmask[y1: y2, x1: x2, :] = 0.img = img * maskreturn img# ---4.旋转--- #def _rotate_img_bbox(self, img, bboxes, angle=5, scale=1.):w, h = img.shape[1], img.shape[0]rangle = np.deg2rad(angle) # angle in radiansnw = (abs(np.sin(rangle) * h) + abs(np.cos(rangle) * w)) * scalenh = (abs(np.cos(rangle) * h) + abs(np.sin(rangle) * w)) * scalerot_mat = cv2.getRotationMatrix2D((nw * 0.5, nh * 0.5), angle, scale)rot_move = np.dot(rot_mat, np.array([(nw - w) * 0.5, (nh - h) * 0.5, 0]))rot_mat[0, 2] += rot_move[0]rot_mat[1, 2] += rot_move[1]rot_img = cv2.warpAffine(img, rot_mat, (int(math.ceil(nw)), int(math.ceil(nh))), flags=cv2.INTER_LANCZOS4)rot_bboxes = []for bbox in bboxes:points = np.array([[bbox[0], bbox[1]], [bbox[2], bbox[1]], [bbox[2], bbox[3]], [bbox[0], bbox[3]]])new_points = cv2.transform(points[None, :, :], rot_mat)[0]rx, ry, rw, rh = cv2.boundingRect(new_points)corrected_bbox = [max(0, rx), max(0, ry), min(nw, rx + rw), min(nh, ry + rh)]corrected_bbox = [int(val) for val in corrected_bbox] # Convert to int and correct order if necessaryrot_bboxes.append(corrected_bbox)return rot_img, rot_bboxes# ---5.裁剪--- #def _crop_img_bboxes(self, img, bboxes):'''裁剪后的图片要包含所有的框输入:img:图像arraybboxes:该图像包含的所有boundingboxs,一个list,每个元素为[x_min, y_min, x_max, y_max],要确保是数值输出:crop_img:裁剪后的图像arraycrop_bboxes:裁剪后的bounding box的坐标list'''# 裁剪图像w = img.shape[1]h = img.shape[0]x_min = w # 裁剪后的包含所有目标框的最小的框x_max = 0y_min = hy_max = 0for bbox in bboxes:x_min = min(x_min, bbox[0])y_min = min(y_min, bbox[1])x_max = max(x_max, bbox[2])y_max = max(y_max, bbox[3])d_to_left = x_min # 包含所有目标框的最小框到左边的距离d_to_right = w - x_max # 包含所有目标框的最小框到右边的距离d_to_top = y_min # 包含所有目标框的最小框到顶端的距离d_to_bottom = h - y_max # 包含所有目标框的最小框到底部的距离# 随机扩展这个最小框crop_x_min = int(x_min - random.uniform(0, d_to_left))crop_y_min = int(y_min - random.uniform(0, d_to_top))crop_x_max = int(x_max + random.uniform(0, d_to_right))crop_y_max = int(y_max + random.uniform(0, d_to_bottom))# 随机扩展这个最小框 , 防止别裁的太小# crop_x_min = int(x_min - random.uniform(d_to_left//2, d_to_left))# crop_y_min = int(y_min - random.uniform(d_to_top//2, d_to_top))# crop_x_max = int(x_max + random.uniform(d_to_right//2, d_to_right))# crop_y_max = int(y_max + random.uniform(d_to_bottom//2, d_to_bottom))# 确保不要越界crop_x_min = max(0, crop_x_min)crop_y_min = max(0, crop_y_min)crop_x_max = min(w, crop_x_max)crop_y_max = min(h, crop_y_max)crop_img = img[crop_y_min:crop_y_max, crop_x_min:crop_x_max]# 裁剪boundingbox# 裁剪后的boundingbox坐标计算crop_bboxes = list()for bbox in bboxes:crop_bboxes.append([bbox[0] - crop_x_min, bbox[1] - crop_y_min, bbox[2] - crop_x_min, bbox[3] - crop_y_min])return crop_img, crop_bboxes# ---6.平移--- #def _shift_pic_bboxes(self, img, bboxes):h, w = img.shape[:2]x = random.uniform(-w * 0.2, w * 0.2)y = random.uniform(-h * 0.2, h * 0.2)M = np.float32([[1, 0, x], [0, 1, y]])shift_img = cv2.warpAffine(img, M, (w, h))shift_bboxes = []for bbox in bboxes:new_bbox = [bbox[0] + x, bbox[1] + y, bbox[2] + x, bbox[3] + y]corrected_bbox = [max(0, new_bbox[0]), max(0, new_bbox[1]), min(w, new_bbox[2]), min(h, new_bbox[3])]corrected_bbox = [int(val) for val in corrected_bbox] # Convert to int and correct order if necessaryshift_bboxes.append(corrected_bbox)return shift_img, shift_bboxes# ---7.镜像--- #def _filp_pic_bboxes(self, img, bboxes):# Randomly decide the flip methodflipCode = random.choice([-1, 0, 1]) # -1: both; 0: vertical; 1: horizontalflip_img = cv2.flip(img, flipCode) # Apply the fliph, w, _ = img.shapeflip_bboxes = []for bbox in bboxes:x_min, y_min, x_max, y_max = bboxif flipCode == 0: # Vertical flipnew_bbox = [x_min, h - y_max, x_max, h - y_min]elif flipCode == 1: # Horizontal flipnew_bbox = [w - x_max, y_min, w - x_min, y_max]else: # Both flipsnew_bbox = [w - x_max, h - y_max, w - x_min, h - y_min]flip_bboxes.append(new_bbox)return flip_img, flip_bboxes# 图像增强方法def dataAugment(self, img, bboxes):'''图像增强输入:img:图像arraybboxes:该图像的所有框坐标输出:img:增强后的图像bboxes:增强后图片对应的box'''change_num = 0 # 改变的次数# print('------')while change_num < 1: # 默认至少有一种数据增强生效if self.is_rotate_img_bbox:if random.random() > self.rotation_rate: # 旋转change_num += 1angle = random.uniform(-self.max_rotation_angle, self.max_rotation_angle)scale = random.uniform(0.7, 0.8)img, bboxes = self._rotate_img_bbox(img, bboxes, angle, scale)if self.is_shift_pic_bboxes:if random.random() < self.shift_rate: # 平移change_num += 1img, bboxes = self._shift_pic_bboxes(img, bboxes)if self.is_changeLight:if random.random() > self.change_light_rate: # 改变亮度change_num += 1img = self._changeLight(img)if self.is_addNoise:if random.random() < self.add_noise_rate: # 加噪声change_num += 1img = self._addNoise(img)if self.is_cutout:if random.random() < self.cutout_rate: # cutoutchange_num += 1img = self._cutout(img, bboxes, length=self.cut_out_length, n_holes=self.cut_out_holes,threshold=self.cut_out_threshold)if self.is_filp_pic_bboxes:if random.random() < self.flip_rate: # 翻转change_num += 1img, bboxes = self._filp_pic_bboxes(img, bboxes)return img, bboxes# xml解析工具
class ToolHelper():# 从xml文件中提取bounding box信息, 格式为[[x_min, y_min, x_max, y_max, name]]def parse_xml(self, path):'''输入:xml_path: xml的文件路径输出:从xml文件中提取bounding box信息, 格式为[[x_min, y_min, x_max, y_max, name]]'''tree = ET.parse(path)root = tree.getroot()objs = root.findall('object')coords = list()for ix, obj in enumerate(objs):name = obj.find('name').textbox = obj.find('bndbox')x_min = int(box[0].text)y_min = int(box[1].text)x_max = int(box[2].text)y_max = int(box[3].text)coords.append([x_min, y_min, x_max, y_max, name])return coords# 保存图片结果def save_img(self, file_name, save_folder, img):cv2.imwrite(os.path.join(save_folder, file_name), img)# 保持xml结果def save_xml(self, file_name, save_folder, img_info, height, width, channel, bboxs_info):''':param file_name:文件名:param save_folder:#保存的xml文件的结果:param height:图片的信息:param width:图片的宽度:param channel:通道:return:'''folder_name, img_name = img_info # 得到图片的信息E = objectify.ElementMaker(annotate=False)anno_tree = E.annotation(E.folder(folder_name),E.filename(img_name),E.path(os.path.join(folder_name, img_name)),E.source(E.database('Unknown'),),E.size(E.width(width),E.height(height),E.depth(channel)),E.segmented(0),)labels, bboxs = bboxs_info # 得到边框和标签信息for label, box in zip(labels, bboxs):anno_tree.append(E.object(E.name(label),E.pose('Unspecified'),E.truncated('0'),E.difficult('0'),E.bndbox(E.xmin(box[0]),E.ymin(box[1]),E.xmax(box[2]),E.ymax(box[3]))))etree.ElementTree(anno_tree).write(os.path.join(save_folder, file_name), pretty_print=True)if __name__ == '__main__':need_aug_num = 30 # 每张图片需要增强的次数is_endwidth_dot = True # 文件是否以.jpg或者png结尾dataAug = DataAugmentForObjectDetection() # 数据增强工具类toolhelper = ToolHelper() # 工具# 获取相关参数parser = argparse.ArgumentParser()parser.add_argument('--source_img_path', type=str, default='D:/lenovo/Archie/shujukuochongv1.0/img')parser.add_argument('--source_xml_path', type=str, default='D:/lenovo/Archie/shujukuochongv1.0/xml')parser.add_argument('--save_img_path', type=str, default='D:/lenovo/Archie/shujukuochongv1.0/img2')parser.add_argument('--save_xml_path', type=str, default='D:/lenovo/Archie/shujukuochongv1.0/xml2')args = parser.parse_args()source_img_path = args.source_img_path # 图片原始位置source_xml_path = args.source_xml_path # xml的原始位置save_img_path = args.save_img_path # 图片增强结果保存文件save_xml_path = args.save_xml_path # xml增强结果保存文件# 如果保存文件夹不存在就创建if not os.path.exists(save_img_path):os.mkdir(save_img_path)if not os.path.exists(save_xml_path):os.mkdir(save_xml_path)for parent, _, files in os.walk(source_img_path):files.sort()for file in files:cnt = 0pic_path = os.path.join(parent, file)xml_path = os.path.join(source_xml_path, file[:-4] + '.xml')values = toolhelper.parse_xml(xml_path) # 解析得到box信息,格式为[[x_min,y_min,x_max,y_max,name]]coords = [v[:4] for v in values] # 得到框labels = [v[-1] for v in values] # 对象的标签# 如果图片是有后缀的if is_endwidth_dot:# 找到文件的最后名字dot_index = file.rfind('.')_file_prefix = file[:dot_index] # 文件名的前缀_file_suffix = file[dot_index:] # 文件名的后缀img = cv2.imread(pic_path)# show_pic(img, coords) # 显示原图while cnt < need_aug_num: # 继续增强auged_img, auged_bboxes = dataAug.dataAugment(img, coords)auged_bboxes_int = np.array(auged_bboxes).astype(np.int32)height, width, channel = auged_img.shape # 得到图片的属性img_name = '{}_{}{}'.format(_file_prefix, cnt + 1, _file_suffix) # 图片保存的信息toolhelper.save_img(img_name, save_img_path,auged_img) # 保存增强图片toolhelper.save_xml('{}_{}.xml'.format(_file_prefix, cnt + 1),save_xml_path, (save_img_path, img_name), height, width, channel,(labels, auged_bboxes_int)) # 保存xml文件# show_pic(auged_img, auged_bboxes) # 强化后的图print(img_name)cnt += 1 # 继续增强下一张相关文章:
【Python数据增强】图像数据集扩充
前言:该脚本用于图像数据增强,特别是目标检测任务中的图像和标签数据增强。通过应用一系列数据增强技术(如旋转、平移、裁剪、加噪声、改变亮度、cutout、翻转等),生成多样化的图像数据集,以提高目标检测模…...

实时同步:使用 Canal 和 Kafka 解决 MySQL 与缓存的数据一致性问题
目录 1. 准备工作 2. 将需要缓存的数据存储 Redis 3. 监听 canal 存储在 Kafka Topic 中数据 1. 准备工作 1. 开启并配置MySQL的 BinLog(MySQL 8.0 默认开启) 修改配置:C:\ProgramData\MySQL\MySQL Server 8.0\my.ini log-bin"HELO…...

WINUI——Microsoft.UI.Xaml.Markup.XamlParseException:“无法找到与此错误代码关联的文本。
开发环境 VS2022 .net core6 问题现象 在Canvas内的子控件要绑定Canvas的兄弟控件的一个属性,在运行时出现了下述报错。 可能原因 在 WinUI(特别是用于 UWP 或 Windows App SDK 的版本)中,如果你尝试在 XAML 中将 Canvas 内的…...

C语言 | Leetcode C语言题解之第283题移动零
题目: 题解: void swap(int *a, int *b) {int t *a;*a *b, *b t; }void moveZeroes(int *nums, int numsSize) {int left 0, right 0;while (right < numsSize) {if (nums[right]) {swap(nums left, nums right);left;}right;} }...

WPF项目实战视频《二》(主要为prism框架)
14.prism框架知识(1) 使用在多个平台的MVVM框架 新建WPF项目prismDemo 项目中:工具-NuGet包管理:安装Prism.DryIoc框架 在git中能看Prism的结构和源代码:git链接地址 例如:Prism/src/Wpf/Prism.DryIoc.Wpf…...

【微信小程序实战教程】之微信小程序 WXS 语法详解
WXS语法 WXS是微信小程序的一套脚本语言,其特性包括:模块、变量、注释、运算符、语句、数据类型、基础类库等。在本章我们主要介绍WXS语言的特性与基本用法,以及 WXS 与 JavaScript 之间的不同之处。 1 WXS介绍 在微信小程序中,…...

Android中Service学习记录
目录 一 概述二 生命周期2.1 启动服务startService()2.2 绑定服务bindService()2.3 先启动后绑定2.4 先绑定后启动 三 使用3.1 本地服务(启动式)3.2 可通信的服务(绑定式)3.3 前台服务3.4 IntentService 总结参考 一 概述 Servic…...

Elasticsearch:Java ECS 日志记录 - log4j2
ECS 记录器是你最喜欢的日志库的格式化程序/编码器插件。它们可让你轻松将日志格式化为与 ECS 兼容的 JSON。ECS 兼容的 JSON 日志记录可以帮我们简化很多分析,可视化及解析的工作。在今天的文章里,我来详述如何在 Java 应用里生成 ECS 相兼容的日志。 …...
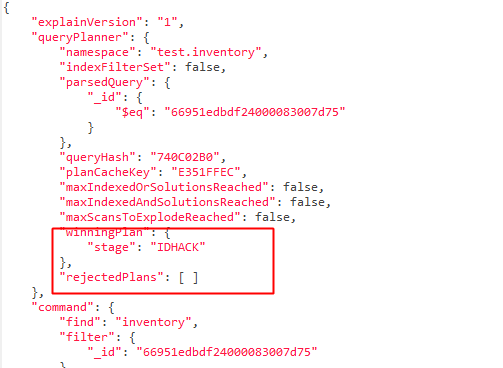
MongoDB自学笔记(四)
一、前文回顾 上一篇文章中我们学习了MongoDB中的更新方法,也学了一部分操作符。今天我们将学习最后一个操作“删除”。 二、删除 原始数据如下: 1、deleteOne 语法:db.collection.deleteOne(< query >,< options >) 具体参…...

时序分解 | Matlab基于CEEMDAN-CPO-VMD的CEEMDAN结合冠豪猪优化算法(CPO)优化VMD二次分解
时序分解 | Matlab基于CEEMDAN-CPO-VMD的CEEMDAN结合冠豪猪优化算法(CPO)优化VMD二次分解 目录 时序分解 | Matlab基于CEEMDAN-CPO-VMD的CEEMDAN结合冠豪猪优化算法(CPO)优化VMD二次分解效果一览基本介绍程序设计参考资料 效果一览…...

新版海螺影视主题模板M3.1全解密版本多功能苹果CMSv10后台自适应主题
苹果CMS2022新版海螺影视主题M3.1版本,这个主题我挺喜欢的,之前也有朋友给我提供过原版主题,一直想要破解但是后来找了几个SG11解密的大哥都表示解密需要大几百大洋,所以一直被搁置了。这个版本是完全解密的,无需SG11加…...

汽车免拆诊断案例 | 2014 款上汽名爵 GT 车发动机无法起动
故障现象 一辆2014款上汽名爵GT车,搭载15S4G发动机,累计行驶里程约为18.4万km。该车因左前部发生碰撞事故进厂维修,更换损坏的部件后起动发动机,起动机运转有力,但无着机迹象。用故障检测仪检测,发现无法与…...

vue3前端开发-小兔鲜项目-登录功能的业务接口调用
vue3前端开发-小兔鲜项目-登录功能的业务接口调用!这次,正式调用远程服务器的登录接口了。大家要必须使用测试账号密码,才能验证我们的代码。 测试账号密码是:账号(xiaotuxian001);密码是(1234…...

【Linux】vim编辑器使用详解
目录 一、vim编辑器简介二、 vim编辑器使用指南1.基本操作1.进入与退出2.模式切换 2.命令模式1.移动光标2.选择文本(可视模式)3.删除文字4.复制粘贴5.替换6.撤销7.注释8.多文件窗口切换 3.底行模式1.列出每行的行号2.跳转到某行3.查找字符4.保存文件5.在…...

手机怎么设置不同的ip地址
在数字化日益深入的今天,智能手机已成为我们生活、工作和学习中不可或缺的设备。然而,随着网络应用的广泛和深入,我们有时需要为手机设置不同的IP地址来满足特定需求。比如,避免网络限制、提高网络安全、或者进行网络测试等。本文…...

SpringBoot读取配置的6种方式
在SpringBoot应用开发中,配置文件是不可或缺的一部分。它们帮助我们管理应用的运行时参数,使得应用的部署和维护变得更加灵活。SpringBoot提供了多种方式来读取配置文件,每种方式都有其适用场景和优缺点。本文将介绍六种常用的SpringBoot读取…...

1.1 openCv -- 介绍
OpenCV(开放源代码计算机视觉库:http://opencv.org)是一个开源库,包含了数百种计算机视觉算法。本文件描述了所谓的OpenCV 2.x API,这是一个本质上基于C++的API,与基于C的OpenCV 1.x API(C API已被弃用,并且自从OpenCV 2.4版本起不再使用“C”编译器进行测试)相对。 …...

探索PostgreSQL的GUI工具:提升数据库管理效率
在当今快速发展的技术世界中,数据库管理是任何软件开发项目的核心部分。PostgreSQL,作为一款功能强大的开源关系型数据库管理系统,因其稳定性、可靠性和高度的可扩展性而广受开发者和数据库管理员的青睐。然而,尽管PostgreSQL自带…...

【从零开始实现stm32无刷电机FOC】【实践】【5/7 stm32 adc外设的高级用法】
目录 采样时刻触发采样同步采样 点击查看本文开源的完整FOC工程 本节介绍的adc外设高级用法用于电机电流控制。 从前面几节可知,电机力矩来自于转子的q轴受磁力,而磁场强度与电流成正比,也就是说电机力矩与q轴电流成正相关,控制了…...

springcloud接入seata管理分布式事务
下载安装包 链接: seata 配置seata-server 文件上传Linux解压 压缩包我放在/usr/local/seata中 tar -zxvf seata-server-2.0.0.tar.gz修改配置文件 设置nacos为注册和配置中心 进入文件夹 cd /usr/local/seata/seata/conf修改application.yml文件 ...... ...... cons…...

使用van-uploader 的UI组件,结合vue2如何实现图片上传组件的封装
以下是基于 vant-ui(适配 Vue2 版本 )实现截图中照片上传预览、删除功能,并封装成可复用组件的完整代码,包含样式和逻辑实现,可直接在 Vue2 项目中使用: 1. 封装的图片上传组件 ImageUploader.vue <te…...

ETLCloud可能遇到的问题有哪些?常见坑位解析
数据集成平台ETLCloud,主要用于支持数据的抽取(Extract)、转换(Transform)和加载(Load)过程。提供了一个简洁直观的界面,以便用户可以在不同的数据源之间轻松地进行数据迁移和转换。…...

Spring AI 入门:Java 开发者的生成式 AI 实践之路
一、Spring AI 简介 在人工智能技术快速迭代的今天,Spring AI 作为 Spring 生态系统的新生力量,正在成为 Java 开发者拥抱生成式 AI 的最佳选择。该框架通过模块化设计实现了与主流 AI 服务(如 OpenAI、Anthropic)的无缝对接&…...

爬虫基础学习day2
# 爬虫设计领域 工商:企查查、天眼查短视频:抖音、快手、西瓜 ---> 飞瓜电商:京东、淘宝、聚美优品、亚马逊 ---> 分析店铺经营决策标题、排名航空:抓取所有航空公司价格 ---> 去哪儿自媒体:采集自媒体数据进…...

全面解析各类VPN技术:GRE、IPsec、L2TP、SSL与MPLS VPN对比
目录 引言 VPN技术概述 GRE VPN 3.1 GRE封装结构 3.2 GRE的应用场景 GRE over IPsec 4.1 GRE over IPsec封装结构 4.2 为什么使用GRE over IPsec? IPsec VPN 5.1 IPsec传输模式(Transport Mode) 5.2 IPsec隧道模式(Tunne…...

MySQL账号权限管理指南:安全创建账户与精细授权技巧
在MySQL数据库管理中,合理创建用户账号并分配精确权限是保障数据安全的核心环节。直接使用root账号进行所有操作不仅危险且难以审计操作行为。今天我们来全面解析MySQL账号创建与权限分配的专业方法。 一、为何需要创建独立账号? 最小权限原则…...

Java毕业设计:WML信息查询与后端信息发布系统开发
JAVAWML信息查询与后端信息发布系统实现 一、系统概述 本系统基于Java和WML(无线标记语言)技术开发,实现了移动设备上的信息查询与后端信息发布功能。系统采用B/S架构,服务器端使用Java Servlet处理请求,数据库采用MySQL存储信息࿰…...

Bean 作用域有哪些?如何答出技术深度?
导语: Spring 面试绕不开 Bean 的作用域问题,这是面试官考察候选人对 Spring 框架理解深度的常见方式。本文将围绕“Spring 中的 Bean 作用域”展开,结合典型面试题及实战场景,帮你厘清重点,打破模板式回答,…...

Kubernetes 网络模型深度解析:Pod IP 与 Service 的负载均衡机制,Service到底是什么?
Pod IP 的本质与特性 Pod IP 的定位 纯端点地址:Pod IP 是分配给 Pod 网络命名空间的真实 IP 地址(如 10.244.1.2)无特殊名称:在 Kubernetes 中,它通常被称为 “Pod IP” 或 “容器 IP”生命周期:与 Pod …...

pycharm 设置环境出错
pycharm 设置环境出错 pycharm 新建项目,设置虚拟环境,出错 pycharm 出错 Cannot open Local Failed to start [powershell.exe, -NoExit, -ExecutionPolicy, Bypass, -File, C:\Program Files\JetBrains\PyCharm 2024.1.3\plugins\terminal\shell-int…...