实习日志1之大模型相关知识概览
一、RAB
1、介绍(提供检索和生成)
RAG,全称为Retrieval-Augmented Generation,中文可以翻译为"检索增强生成",也有人说是召回增强生成。这是一种结合了检索和生成两种机器学习方法的新型框架,主要用于自然语言处理(NLP)任务,如问答系统、对话系统等。
| 模型类型 | 优点 | 缺点 |
| 生成模型(如GPT) | 可以生成新的、连贯的文本 | 无法精确地检索出特定的知识片段 |
| 检索模型(如BERT) | 可以精确地检索出特定的知识片段 | 无法生成新的、连贯的文本 |
RAG框架的出现,是为了结合这两种模型的优点,提供更准确、更具有连贯性的响应。RAG框架的工作方式是,首先使用检索模型从大量的文本数据中检索出相关的文本片段,然后将这些文本片段作为上下文,输入到生成模型中,生成响应。这样,生成的响应既可以包含特定的知识片段,也可以具有连贯的语句结构。
例如,在问答系统中,用户可能会提出一些需要特定知识片段才能回答的问题,此时,如果只使用生成模型或检索模型,可能无法给出准确的回答。但是,如果使用RAG框架,就可以结合检索模型的精确检索能力和生成模型的连贯生成能力,给出更准确、更满意的答案。
利用RAGFlow,让你轻松实现 RAG
RAGFlow 是一个基于深度文档理解的开源 RAG(检索增强生成)引擎,开源没有几天,目前已经6K 的 star 了,一句话概括他的特点就是质量进,质量出。它为任何规模的企业提供了简化的 RAG 工作流程,结合了 LLM(大型语言模型)以提供真实的问答功能,并由来自各种复杂格式数据的有根据的引用提供支持。Docker 部署,方便快捷,傻瓜式操作,让你的数据处理更智能和可解释。下面是它的架构图:

- 项目主要特色:
- 基于深度文档理解的知识提取,能在数据量巨大的环境中找出关键信息。
- 提供了模板化的数据分块技术,使数据处理更智能和可解释。
- 提供引用可视化,降低误读可能性,方便人工干预数据提取和生成过程。
- 与各种数据源的兼容性强,支持 Word、幻灯片、excel、txt、图片、扫描文档、结构化数据、网页等格式的数据。
- 提供了流程自动化和方便的 RAG 工作流程,易于进行配置和调整,并支持多种排序模型,且 API 设计直观,便于与商业环境进行集成。
如果你希望在业务中实现从文档中自动提取知识,然后基于这些知识进行问题回答的使用场景,这个工具值得一试。
地址:https://github.com/infiniflow/ragflow,
可以直接访问> https://demo.ragflow.io/knowledge。下面就是我体验的 demo,操作非常简单,内置了一些免费可用的embedding模型和对话模型。
项目存储库:https://github.com/infiniflow/ragflow
项目网站:RAGFlow | RAGFlow
在线演示:RAGFlow
2、RAG架构
2.1 RAG实现过程
RAG在问答系统中的一个典型应用主要包括三个步骤:
Indexing(索引):将文档分割成chunk,编码成向量,并存储在向量数据库中。
Retrieval(检索):根据语义相似度检索与问题最相关的前k个chunk。
Generation(生成):将原始问题和检索到的chunk一起输入到LLM中,生成最终答案。

2.2 RAG在线检索架构

3、RAG流程
完整的RAG应用流程主要包含两个阶段:
- 数据准备阶段:数据提取——>文本分割——>向量化(embedding)——>数据入库
- 应用阶段:用户提问——>数据检索(召回)——>注入Prompt——>LLM生成答案
数据准备阶段:
数据准备一般是一个离线的过程,主要是将私域数据向量化后构建索引并存入数据库的过程。主要包括:数据提取、文本分割、向量化、数据入库等环节。
- 数据提取
- 数据加载:包括多格式数据加载、不同数据源获取等,根据数据自身情况,将数据处理为同一个范式。
- 数据处理:包括数据过滤、压缩、格式化等。
- 元数据获取:提取数据中关键信息,例如文件名、Title、时间等 。
- 文本分割:
- 句分割:以”句”的粒度进行切分,保留一个句子的完整语义。常见切分符包括:句号、感叹号、问号、换行符等。
- 固定长度分割:根据embedding模型的token长度限制,将文本分割为固定长度(例如256/512个tokens),这种切分方式会损失很多语义信息,一般通过在头尾增加一定冗余量来缓解。
- 向量化(embedding):
向量化是一个将文本数据转化为向量矩阵的过程,该过程会直接影响到后续检索的效果。目前常见的embedding模型如表中所示,这些embedding模型基本能满足大部分需求,但对于特殊场景(例如涉及一些罕见专有词或字等)或者想进一步优化效果,则可以选择开源Embedding模型微调或直接训练适合自己场景的Embedding模型。
- 数据入库:
数据向量化后构建索引,并写入数据库的过程可以概述为数据入库过程,适用于RAG场景的数据库包括:FAISS、Chromadb、ES、milvus等。一般可以根据业务场景、硬件、性能需求等多因素综合考虑,选择合适的数据库。
应用阶段:
在应用阶段,我们根据用户的提问,通过高效的检索方法,召回与提问最相关的知识,并融入Prompt;大模型参考当前提问和相关知识,生成相应的答案。关键环节包括:数据检索、注入Prompt等。
- 数据检索
常见的数据检索方法包括:相似性检索、全文检索等,根据检索效果,一般可以选择多种检索方式融合,提升召回率。
-
- 相似性检索:即计算查询向量与所有存储向量的相似性得分,返回得分高的记录。常见的相似性计算方法包括:余弦相似性、欧氏距离、曼哈顿距离等。
- 全文检索:全文检索是一种比较经典的检索方式,在数据存入时,通过关键词构建倒排索引;在检索时,通过关键词进行全文检索,找到对应的记录。
- 注入Prompt
Prompt作为大模型的直接输入,是影响模型输出准确率的关键因素之一。在RAG场景中,Prompt一般包括任务描述、背景知识(检索得到)、任务指令(一般是用户提问)等,根据任务场景和大模型性能,也可以在Prompt中适当加入其他指令优化大模型的输出。一个简单知识问答场景的Prompt如下所示:
【任务描述】
假如你是一个专业的客服机器人,请参考【背景知识】,回
【背景知识】
{content} // 数据检索得到的相关文本 【问题】 石头扫地机器人P10的续航时间是多久?
Prompt的设计只有方法、没有语法,比较依赖于个人经验,在实际应用过程中,往往需要根据大模型的实际输出进行针对性的Prompt调优。
4、RAG存在的问题
知识的局限性:模型自身的知识完全源于它的训练数据,而现有的主流大模型(ChatGPT、文心一言、通义千问…)的训练集基本都是构建于网络公开的数据,对于一些实时性的、非公开的或离线的数据是无法获取到的,这部分知识也就无从具备。
幻觉问题:所有的AI模型的底层原理都是基于数学概率,其模型输出实质上是一系列数值运算,大模型也不例外,所以它有时候会一本正经地胡说八道,尤其是在大模型自身不具备某一方面的知识或不擅长的场景。而这种幻觉问题的区分是比较困难的,因为它要求使用者自身具备相应领域的知识。
数据安全性:对于企业来说,数据安全至关重要,没有企业愿意承担数据泄露的风险,将自身的私域数据上传第三方平台进行训练。这也导致完全依赖通用大模型自身能力的应用方案不得不在数据安全和效果方面进行取舍。
5、Graph RGA
RAG是将文档切成一小块,就是chunk,然后将所有的块存到一个数据库里,当用户提问时,就将问题和文档块里面的信息进行相似度比较,把相似度较高的文档块返回给大模型,让大模型根据这些文档块的内容整合起来回答这个问题,如果是比较具体的问题能够文档中找到相关答案。但是如果是文档中没有具体答案的或者是综合性的问题,大模型就没有办法很好的回答出来。传统的RAG是根据语义的相关性去找一个个单独的片段,所以对于一些宏观视角全局性的问题就回答不了。而Graph RAG可以解决。
Graph RAG首先根据一个个散落在各个块的信息先提取出关键信息,然后将他们关联起来,这个过程就是建立一个知识图谱,这个建立知识图谱的过程也是由一个大模型完成的。这就是Graph RAG最重要的一个思想,首先,提前用一个大模型整理输入文档中的数据和关系成一个知识图谱;其次,它还将这些信息做了一个分层聚类。
缺点:成本高,很多时候需要人工整理,更新麻烦
二、LLaMA-Factory
目前的思路,一是RAG(retrieval augmented generation),在模型的输入prompt中加入尽可能多的“目标领域”的相关知识,引导模型在生成时尽量靠拢目标领域,运用prompt中给予的目标知识;二是有监督微调,用适量的专业领域的数据(或混通用语料)让模型更能生成目标场景的内容。
什么是LLaMA-Factory
当我们想要微调大模型的时候,一个粗略的实验过程无外乎以下几个环节:
准备好硬件(GPU)、数据;通过各方面的资讯选中你想要微调的基座模型
准备好代码:输入数据 + 模型 -> 在GPU上反复训练
训练结束以后,得到训练过程中的checkpoint + 一些log信息
根据log信息选一些比较有希望的checkpoint在自己的测试集上推理,获得相应的结果
分析结果,获得下一轮实验(数据、训练方案的迭代)思路
而LLaMA-Factory就是一个很好的负责step 2的工具(当然它能做到的远不止step2,我们后面也会提),你可以理解为,他是一份写好的代码,你只需要把你准备好的数据、硬件、模型,以传参的方式传入,运行代码,模型就开始训练了。等训练结束以后,你把训练好的模型、测试集、硬件又作为参数传入,它就会帮你推理。
LLaMA-Factory的优点
LLaMA-Factory非常适合实验阶段使用,因为:
支持很多种开源大语言模型:
实验阶段我们肯定有好几个觉得靠谱的模型,它们往往有自己的标准输入模板(尤其是代码补全这类任务,涉及较多的special token),你想试试的模型LLaMA-Factory基本都支持,通过template参数可以很方便地指定prompt的模板
支持非常多种训练方法:
全量调参 vs Lora vs … 或预训练模型 vs 有监督fine-tuning,以及DPO PPO的对齐方案。
你想试试的基本也都有,也是通过指定训练模式参数即可
Log:
训练过程中记录的内容比较全,除了同步能够输出loss曲线图以外,还自带bleu等评测指标
测试环节也很方便:
支持merge model(比如微调后的adapter合并到原模型以便作为一个模型导出推理);
支持各种时下比较流行的量化加速方案;
支持vllm等高并发要求的推理框架;
需要的话还可以快速搭建一个Gradio UI用于demo展示或可视化分析
三、dify(语言模型平台)
1、简介
Dify AI是一款强大的LLMOps(Language Model Operations)平台,专为用户提供便捷的人工智能应用程序开发体验。 该平台支持GPT系列模型和其他模型,适用于各种团队,无论是用于内部还是外部的AI应用程序开发。
它结合了后端即服务和LLMOps的概念,使开发人员能够快速构建生产级生成AI应用程序。即使是非技术人员也可以参与人工智能应用的定义和数据操作。
通过集成构建LLM应用程序所需的关键技术栈,包括对数百个模型的支持、直观的Prompt编排接口、高质量的RAG引擎和灵活的Agent框架,同时提供一组易于使用的接口和api, Dify为开发人员节省了大量重新发明轮子的时间,使他们能够专注于创新和业务需求。
访问链接:Dify.AI · 生成式 AI 应用创新引擎
2、架构图

3、七个特点
Dify Orchestration Studio
可视化编排生成式 AI 应用的专业工作站 All in One Place
RAG Pipeline
安全构建私有数据与大型语言模型之间的数据通道,包括各种基于全文索引或向量数据库嵌入的 RAG 能力,允许直接上传 PDF、TXT 等各种文本格式
Prompt IDE
为提示词工程师精心设计,友好易用的提示词开发工具,支持无缝切换多种大型语言模型。和团队一起在 Dify 协作,通过可视化的 Prompt 和应用编排工具开发 AI 应用。 支持无缝切换多种大型语言模型。
Enterprise LLMOps
开发者可以观测推理过程、记录日志、标注数据、训练并微调模型。监控和优化模型推理,记录日志,标注数据和微调模型。
BaaS Solution
基于后端及服务理念的 API 设计,大幅简化生成式 AI 应用研发流程。通过全面的后端API将人工智能集成到任何产品中。
LLM Agent DSL
大型语言模型作为智能内核,低代码构建面向特定业务领域的半自主 Agent。
Plugins Toolbo
既可自行封装 API 为插件,也可集成第三方插件,将API打包成工具,为LLM提供扩展功能。
4、为什么选择 Dify
官方给的解释:
Dify 具有模型中立性,相较 LangChain 等硬编码开发库 Dify 是一个完整的、工程化的技术栈,而相较于 OpenAI 的 Assistants API 你可以完全将服务部署在本地。
你可以把像LangChain这样的库想象成带有锤子、钉子等工具的工具箱。相比之下,Dify提供了一个更适合生产的、完整的解决方案——可以把Dify看作是一个具有精细工程设计和软件测试的脚手架系统。
重要的是,Dify是开源的,由专业的全职团队和社区共同创建。您可以基于任何模型自部署类似于assistant API和gpt的功能,以灵活的安全性保持对数据的完全控制,所有这些都在易于使用的界面上。
创业公司——快速将你的人工智能想法变成现实,加速成功和失败。在现实世界中,几十个团队已经通过Dify建立了mvp,以获得资金或赢得客户订单。
将llm整合到现有业务中-通过引入llm来增强当前应用程序的功能。访问Dify的RESTful api,将提示从业务逻辑中解耦。使用Dify的管理界面来跟踪数据、成本和使用情况,同时不断提高性能。
企业LLM基础设施——一些银行和互联网公司正在部署Dify作为内部LLM网关,加速GenAI技术的采用,同时实现集中治理。
探索LLM功能-即使作为技术爱好者,您也可以通过Dify轻松练习提示工程和代理技术。甚至在GPTs出现之前,就有超过6万名开发者在Dify上开发了他们的第一款应用。
特定领域的聊天机器人和 AI 助理
通过可视化的提示词编排和数据集嵌入,零代码即可快速构建对话机器人或 AI 助理,并可持续优化对话策略,革新人机交互体验。
私有化部署-再造企业效能
LLMs 再造企业效能
高可靠性、合规、数据安全,通过 Dify 的私有化部署解决方案,将 LLMs 深度嵌入到企业的内部系统和业务流程中,实现对流程和工具的智能升级,实现千人千面的客户体验。
四、Function Calling(函数调用)
1、 背景与概念
ChatGPT 的 Function Calling 机制允许模型调用外部函数获取信息或执行操作。这种机制不仅增强了模型的功能,使其能够处理更复杂的任务,还大大扩展了 AI 在实际应用中的能力范围。不再局限于静态知识库的回答,ChatGPT 通过 Function Calling 可以动态获取最新信息,执行特定操作,极大提高了实用性和灵活性。
2、主要组件
Function Calling 机制主要由以下几个关键组件构成:
函数定义:预先定义可调用的函数,包括名称、参数类型和返回值类型等。
函数调用请求:用户或系统发出的调用请求,包含函数名称及所需参数。
函数执行器:实际执行函数的组件,可能是外部的 API 或本地逻辑处理器。
结果返回:函数执行完毕后,返回结果给 ChatGPT,继续对话。
3、 Function Calling 机制详细解析
一个应用如何与OpenAI的API进行交互,通过发送函数定义,接收参数,调用函数,再将结果与其他信息结合生成最终的回答,并返回给用户。下面是每一步的详细说明:
一个应用如何与 OpenAI 的 API 进行交互?以下是详细的步骤说明:
最终回答通过应用服务返回给用户。
传入函数定义:应用服务将函数定义传递给 OpenAI。
返回调用参数:OpenAI 返回调用函数所需的参数。
调用函数:应用服务使用这些参数调用相应的函数。
传入结果:函数调用结果被传递回 OpenAI。
组合回答:OpenAI 将函数结果与其他相关信息结合,生成完整的回答。
返回答案:
4. 安全与控制
为了确保安全性和控制,函数调用机制通常包括以下措施:
权限控制:仅允许调用经过安全审查的函数。
输入验证:验证输入参数的合法性,防止恶意输入。
错误处理:处理函数调用过程中可能出现的错误,如网络错误、参数错误等。
5. 示例应用
这种机制在许多应用场景中非常有用,例如:
信息查询:调用外部 API 获取天气、新闻、股票价格等实时信息。
操作执行:调用函数执行系统操作,如发送邮件、创建日历事件等。
数据处理:调用数据处理函数,如数据分析、图表生成等。
六、Langchain (大语言模型应用开发框架)
LangChain 提供了一系列的工具和接口,让开发者可以轻松地构建和部署基于 LLM 的应用 。LangChain 围绕将不同组件 “链接” 在一起的核心概念构建,简化了与 GPT-3.5、GPT-4 等 LLM 合作的过程,使得我们可以轻松创建定制的高级用例。
LangChain 已经成为大模型应用开发的最主流框架(之一)。目前, LangChain 支持 Python 和 TypeScript 两种语言。
Langchain官网:Introduction | 🦜️🔗 LangChain
1、为什么需要 LangChian
想一想,虽然我们有了乐高积木,但如果没有说明书或者构建工具,那么要搭建出一个复杂的模型将是非常困难的。同样地,即使我们有了强大 的 LLM,比如 GPT-4,它们也需要 “说明书” 和 “工具” 来更好地服务于现实世界的需求。GPT-4 有无与伦比的能力去处理语言,但是它还是需要额外的组件和连接才能完全发挥潜力,比如访问最新的数据、与外部 API 互动、处理用户的上下文信息等。LangChain 就是这样一套 “说明书” 和 “工具”,让 GPT-4 能够更好地融入到我们的应用中去。
模型接口的统一
现在的大模型除了大家熟知的 ChatGPT,还有 Meta 开源的 LLaMA,清华大学的 GLM 等,这些模型的使用方法包括 api 和推理方式都相差甚远,如果你想从使用 ChatGPT 切换到调用 LLaMA,需要花费不少的精力去开发前置的模型使用模块,会有大量重复繁琐的工作。而 LangChain 对好多常见的 API 和大模型做了封装,可以直接拿来就用,节省了大量的时间。
向量数据 embedding
像 ChatGPT 这样的语言模型,数据只更新到 2021 年,如何让大模型回答和学习到之后的知识就是一个很重要的问题。而且 ChatGPT 的 API 是有提示词和返回内容的限制的,3.5 是 4k,4 则是 8k,而我们往往需要从自己的数据、自己的文档中获取特定的信息,这可能是一本书、一个 PDF 文件、一个带有专有信息的数据库。这些信息的 token 数量会远高于 4k 的阈值,直接使用大模型是无法获取到相应的知识的,因为超过阈值的信息就被截断了。
LangChain 提供了对向量数据库的支持,能够把超长的 txt、pdf 等通过大模型转换为 embedding 的形式,存到向量数据库中,然后利用数据库进行检索。这样就可以支持更多长度的输入,解放了 LLM 的优势。
2、Langchain 组件

Langchain 主要提供了 6 大类组件帮助我们更好的使用大语言模型。
模型是任何 LLM 应用中最核心的一点,LangChain 可以让我们方便的接入各种各样的语言模型,并且提供了许多接口,主要有三个组件组成,包括模型(Models),提示词(Prompts)和解析器(Output parsers)。
1)Models
LangChain 中提供了多种不同的语言模型,按功能划分,主要有两种。
语言模型(LLMs):我们通常说的语言模型,给定输入的一个文本,会返回一个相应的文本。常见的语言模型有 GPT3.5,chatglm,GPT4All 等。
from langchain.llms import OpenAI
llm = OpenAI(openai_api_key="...")聊天模型(Chat model):可以看做是封装好的拥有对话能力的 LLM,这些模型允许你使用对话的形式和其进行交互,能够支持将聊天信息作为输入,并返回聊天信息。这些聊天信息都是封装好的结构体,而非一个简单的文本字符串。常见的聊天模型有 GPT4、Llama 和 Llama2,以及微软云 Azure 相关的 GPT 模型。
from langchain.chat_models import ChatOpenAI
chat = ChatOpenAI(openai_api_key="...")2) Prompts
提示词是模型的输入,通过编写提示词可以和模型进行交互。LangChain 中提供了许多模板和函数用于模块化构建提示词,这些模板可以提供更灵活的方法去生成提示词,具有更好的复用性。根据调用的模型方式不同,提示词模板主要分为普通模板以及聊天提示词模板。
提示模板(PromptTemplate)
提示模板是一种生成提示的方式,包含一个带有可替换内容的模板,从用户那获取一组参数并生成提示
提示模板用来生成 LLMs 的提示,最简单的使用场景,比如 “我希望你扮演一个代码专家的角色,告诉我这个方法的原理 {code}”。
类似于 python 中用字典的方式格式化字符串,但在 langchain 中都被封装成了对象
一个简单的调用样例如下所示:
from langchain import PromptTemplatetemplate = """\
You are a naming consultant for new companies.
What is a good name for a company that makes {product}?
"""prompt = PromptTemplate.from_template(template)
prompt.format(product="colorful socks")输出结果
# 实际输出
You are a naming consultant for new companies.
What is a good name for a company that makes colorful socks?
聊天提示模板(ChatPromptTemplate)
聊天模型接收聊天消息作为输入,这些聊天消息通常称为 Message,和原始的提示模板不一样的是,这些消息都会和一个角色进行关联。
在使用聊天模型时,建议使用聊天提示词模板,这样可以充分发挥聊天模型的潜力。
一个简单的使用示例如下:
from langchain.prompts import (ChatPromptTemplate,PromptTemplate,SystemMessagePromptTemplate,AIMessagePromptTemplate,HumanMessagePromptTemplate,
)
from langchain.schema import (AIMessage,HumanMessage,SystemMessage
)template="You are a helpful assistant that translates {input_language} to {output_language}."
system_message_prompt = SystemMessagePromptTemplate.from_template(template)
human_template="{text}"
human_message_prompt = HumanMessagePromptTemplate.from_template(human_template)
chat_prompt = ChatPromptTemplate.from_messages([system_message_prompt, human_message_prompt])# get a chat completion from the formatted messages
chat_prompt.format_prompt(input_language="English",output_language="French", text="I love programming.").to_messages()输出结果
[SystemMessage(content='You are a helpful assistant that translatesEnglish to French.', additional_kwargs={}),HumanMessage(content='I love programming.', additional_kwargs={})]Output parsers
语言模型输出的是普通的字符串,有的时候我们可能想得到结构化的表示,比如 JSON 或者 CSV,一个有效的方法就是使用输出解析器。
输出解析器是帮助构建语言模型输出的类,主要实现了两个功能:
获取格式指令,是一个文本字符串需要指明语言模型的输出应该如何被格式化
解析,一种接受字符串并将其解析成固定结构的方法,可以自定义解析字符串的方式
一个简单的使用示例如下:
from langchain.prompts import PromptTemplate, ChatPromptTemplate, HumanMessagePromptTemplate
from langchain.llms import OpenAI
from langchain.chat_models import ChatOpenAIfrom langchain.output_parsers import PydanticOutputParser
from pydantic import BaseModel, Field, validator
from typing import Listmodel_name = 'text-davinci-003'
temperature = 0.0
model = OpenAI(model_name=model_name, temperature=temperature)
# Define your desired data structure.
class Joke(BaseModel):setup: str = Field(description="question to set up a joke")punchline: str = Field(description="answer to resolve the joke")# You can add custom validation logic easily with Pydantic.@validator('setup')def question_ends_with_question_mark(cls, field):if field[-1] != '?':raise ValueError("Badly formed question!")return field# Set up a parser + inject instructions into the prompt template.
parser = PydanticOutputParser(pydantic_object=Joke)
prompt = PromptTemplate(template="Answer the user query.\n{format_instructions}\n{query}\n",input_variables=["query"],partial_variables={"format_instructions": parser.get_format_instructions()}
)
# And a query intended to prompt a language model to populate the data structure.
joke_query = "Tell me a joke."
_input = prompt.format_prompt(query=joke_query)
output = model(_input.to_string())
parser.parse(output)输出结果:
Joke(setup='Why did the chicken cross the road?', punchline='To get to the other side!')
3) Data Connection(index)
有的时候,我们希望语言模型可以从自己的数据中进行查询,而不是仅依靠自己本身输出一个结果。数据连接器的组件就允许你使用内置的方法去读取、修改,存储和查询自己的数据,主要有下面几个组件组成。
文档加载器(Document loaders):连接不同的数据源,加载文档。
文档转换器(Document transformers):定义了常见的一些对文档加工的操作,比如切分文档,丢弃无用的数据
文本向量模型(Text embedding models):将非结构化的文本数据转换成一个固定维度的浮点数向量
向量数据库(Vector stores):存储和检索你的向量数据
检索器(Retrievers):用于检索你的数据
4)Chains
只使用一个 LLM 去开发应用,比如聊天机器人是很简单的,但更多的时候,我们需要用到许多 LLM 去共同完成一个任务,这样原来的模式就不足以支撑这种复杂的应用。
为此 LangChain 提出了 Chain 这个概念,也就是一个所有组件的序列,能够把一个个独立的 LLM 链接成一个组件,从而可以完成更复杂的任务。举个例子,我们可以创建一个 chain,用于接收用户的输入,然后使用提示词模板将其格式化,最后将格式化的结果输出到一个 LLM。通过这种链式的组合,就可以构成更多更复杂的 chain。
在 LangChain 中有许多实现好的 chain,以最基础的 LLMChain 为例,它主要实现的就是接收一个提示词模板,然后对用户输入进行格式化,然后输入到一个 LLM,最终返回 LLM 的输出。
from langchain.llms import OpenAI
from langchain.prompts import PromptTemplatellm = OpenAI(temperature=0.9)
prompt = PromptTemplate(input_variables=["product"],template="What is a good name for a company that makes {product}?",
)from langchain.chains import LLMChain
chain = LLMChain(llm=llm, prompt=prompt)# Run the chain only specifying the input variable.
print(chain.run("colorful socks"))LLMChain 不仅支持 llm,同样也支持 chat llm,下面是一个调用示例:
from langchain.chat_models import ChatOpenAI
from langchain.prompts.chat import (ChatPromptTemplate,HumanMessagePromptTemplate,
)human_message_prompt = HumanMessagePromptTemplate(prompt=PromptTemplate(template="What is a good name for a company that makes {product}?",input_variables=["product"],))
chat_prompt_template = ChatPromptTemplate.from_messages([human_message_prompt])
chat = ChatOpenAI(temperature=0.9)
chain = LLMChain(llm=chat, prompt=chat_prompt_template)
print(chain.run("colorful socks"))5) Memory
大多数的 LLM 应用程序都会有一个会话接口,允许我们和 LLM 进行多轮的对话,并有一定的上下文记忆能力。但实际上,模型本身是不会记忆任何上下文的,只能依靠用户本身的输入去产生输出。而实现这个记忆功能,就需要额外的模块去保存我们和模型对话的上下文信息,然后在下一次请求时,把所有的历史信息都输入给模型,让模型输出最终结果。
而在 LangChain 中,提供这个功能的模块就称为 Memory,用于存储用户和模型交互的历史信息。在 LangChain 中根据功能和返回值的不同,会有多种不同的 Memory 类型,主要可以分为以下几个类别:
对话缓冲区内存(ConversationBufferMemory),最基础的内存模块,用于存储历史的信息
对话缓冲器窗口内存(ConversationBufferWindowMemory),只保存最后的 K 轮对话的信息,因此这种内存空间使用会相对较少
对话摘要内存(ConversationSummaryMemory),这种模式会对历史的所有信息进行抽取,生成摘要信息,然后将摘要信息作为历史信息进行保存。
对话摘要缓存内存(ConversationSummaryBufferMemory),这个和上面的作用基本一致,但是有最大 token 数的限制,达到这个最大 token 数的时候就会进行合并历史信息生成摘要
值得注意的是,对话摘要内存的设计出发点就是语言模型能支持的上下文长度是有限的(一般是 2048),超过了这个长度的数据天然的就被截断了。这个类会根据对话的轮次进行合并,默认值是 2,也就是每 2 轮就开启一次调用 LLM 去合并历史信息。
from langchain.memory import ConversationBufferMemory
memory = ConversationBufferMemory(memory_key="chat_history")
memory.chat_memory.add_user_message("hi!")
memory.chat_memory.add_ai_message("whats up?")参考官方的教程,Memory 同时支持 LLM 和 Chat model。
from langchain.llms import OpenAI
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
from langchain.memory import ConversationBufferMemory# llm
llm = OpenAI(temperature=0)
# Notice that "chat_history" is present in the prompt template
template = """You are a nice chatbot having a conversation with a human.Previous conversation:
{chat_history}New human question: {question}
Response:"""
prompt = PromptTemplate.from_template(template)
# Notice that we need to align the `memory_key`
memory = ConversationBufferMemory(memory_key="chat_history")
conversation = LLMChain(llm=llm,prompt=prompt,verbose=True,memory=memory
)
conversation({"question": "hi"})from langchain.chat_models import ChatOpenAI
from langchain.prompts import (ChatPromptTemplate,MessagesPlaceholder,SystemMessagePromptTemplate,HumanMessagePromptTemplate,
)
from langchain.chains import LLMChain
from langchain.memory import ConversationBufferMemoryllm = ChatOpenAI()
prompt = ChatPromptTemplate(messages=[SystemMessagePromptTemplate.from_template("You are a nice chatbot having a conversation with a human."),# The `variable_name` here is what must align with memoryMessagesPlaceholder(variable_name="chat_history"),HumanMessagePromptTemplate.from_template("{question}")]
)
# Notice that we `return_messages=True` to fit into the MessagesPlaceholder
# Notice that `"chat_history"` aligns with the MessagesPlaceholder name.
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)
conversation = LLMChain(llm=llm,prompt=prompt,verbose=True,memory=memory
)
conversation({"question": "hi"})6) Agents
代理的核心思想就是使用 LLM 去选择对用户的输入,应该使用哪个特定的工具去进行操作。这里的工具可以是另外的一个 LLM,也可以是一个函数或者一个 chain。在代理模块中,有三个核心的概念。
1、代理(Agent),依托于强力的语言模型和提示词,代理是用来决定下一步要做什么,其核心也是构建一个优秀的提示词。这个提示词大致有下面几个作用:
角色定义,给代理设定一个符合自己的身份
上下文信息,提供给他更多的信息来要求他可以执行什么任务
丰富的提示策略,增加代理的推理能力
2、工具(Tools),代理会选择不同的工具去执行不同的任务。工具主要给代理提供调用自己的方法,并且会描述自己如何被使用。工具的这两点都十分重要,如果你没有提供可以调用工具的方法,那么代理就永远完不成自己的任务;同时如果没有正确的描述工具,代理就不知道如何去使用工具。
3、工具包(Toolkits),LangChain 提供了工具包的使用,在一个工具包里通常包含 3-5 个工具。
Agent 技术是目前大语言模型研究的一个前沿和热点方向,但是目前受限于大模型的实际效果,仅 GPT 4.0 可以有效的开展 Agent 相关的研究。我们相信在未来,随着大模型性能的优化和迭代,Agent 技术应该能有更好的发展和前景。
Callbacks
回调,字面解释是让系统回过来调用我们指定好的函数。在 LangChain 中就提供了一个这样的回调系统,允许你进行日志的打印、监控,以及流式传输等其他任务。通过直接在 API 中提供的回调参数,就可以简单的实现回调的功能。LangChain 内置了许多可以实现回调功能的对象,我们通常称为 handlers,用于定义在不同事件触发的时候可以实现的功能。
不管使用 Chains、Models、Tools、Agents,去调用 handlers,均通过是使用 callbacks 参数,这个参数可以在两个不同的地方进行使用:
构造函数中,但它的作用域只能是该对象。比如下面这个 LLMChain 的构造函数可以进行回调,但这个回调函数对于链接到它的 LLM 模型是不生效的。
LLMChain(callbacks=[handler], tags=['a-tag'])在 run()/apply() 方法中调用,只有当前这一次请求才会相应这个回调函数,但是当前请求包含的子请求都会调用这个回调。比如,使用了一个 chain 去触发这个请求,连接到它的 LLM 模型也会调用这个回调。
chain.run(input, callbacks=[handler])3、 LangChain 的优势
和 LangChain 类似的 LLM 应用开发框架:
OpenAI 的 GPT-3.5/4 API
Hugging Face 的 Transformers(多模态机器学习模型,支持上千预训练模型)
Google 的 T5(NLP 框架)等
LangChain 的优势:
能力更强,更新 by days
代码设计优雅,模块化程度高,Chain、Agent、Memory 模块的抽象程度高,便于结合应用
集成工具完善,从数据预处理、LLM 模型、向量化到图数据库等
支持常用 LLM 和大量商业化 NLP 模型
商业化:Azure OpenAI、OpenAI
开源:Hugging Face、GPT4All
有大量的 LLM 用例供参考
4、基于 LangChain 的应用
从上文中,我们了解了 LangChain 的基本概念,以及主要的组件,利用这些能帮助我们快速上手构建 app。LangChain 能够在很多使用场景中进行应用,包括但不限于:
个人助手和聊天机器人;能够记住和你的每一次互动,并进行个性化的交互
基于文档的问答系统;在特定文档上回答问题,可以减少大模型的幻觉问题
表格数据查询;提供了对结构化数据的查询功能,如 CSV,PDF,SQL,DataFrame 等
API 交互;可以对接不同语言模型的API,并产生交互和调用
信息提取;从文本中提取结构化的信息,并输出
文档总结;利用 LLM 和 embedding 对长文档进行压缩和总结
七、LlamaIndex(检索数据)
LlamaIndex 是一个基于 LLM(大语言模型)的应用程序数据框架,适用于受益于上下文增强的场景。
这类 LLM 系统被称为 RAG(检索增强生成)系统。
LlamaIndex 提供了必要的抽象层,以便更容易地摄取、结构化和访问私有或特定领域的数据,从而安全可靠地将这些数据注入 LLM 中,以实现更准确的文本生成。
它支持 Python(本文档)和 TypeScript。
为什么选择上下文增强?
LLM 为人类与数据之间提供自然语言接口。广泛可用的模型预先训练在大量公开数据上,如维基百科、邮件列表、教科书、源代码等。
然而,尽管 LLM 接受了大量的数据训练,但它们并未针对您的数据进行训练,而这些数据可能是私有的,或者与您试图解决的问题密切相关。它们可能隐藏在 API 中、存放在 SQL 数据库中,或者困在 PDF 和幻灯片中。
您可能会选择使用您的数据对 LLM 进行微调,但:
- 训练 LLM 成本高昂;
- 由于训练成本高,难以用最新信息更新 LLM;
- 观察性不足。当您向 LLM 提问时,无法明确得知 LLM 如何得出答案。
作为替代方案,可以采用名为检索增强生成(RAG)的上下文增强模式,以获得与您的特定数据相关的更准确文本生成。RAG 包括以下高级步骤:
- 首先从您的数据源检索信息;
- 将这些信息添加到问题中作为上下文;
- 请求 LLM 根据丰富后的提示回答问题。
通过这种方式,RAG 克服了微调方法的三个弱点:
- 不涉及训练,因此成本低廉;
- 数据仅在请求时抓取,始终保持最新;
- LlamaIndex 可以显示检索到的文档,从而更具可信度。
🦙 为何选择 LlamaIndex 进行上下文增强?
首先,LlamaIndex 并不限制您如何使用 LLM。您仍然可以将其用作自动补全、聊天机器人、半自主代理等(参见左侧的使用案例)。它只是让 LLM 更贴近您的需求。
LlamaIndex 提供以下工具,帮助您快速构建生产级 RAG 系统:
- 数据连接器:从原生来源和格式摄取现有数据,如 APIs、PDF、SQL 等;
- 数据索引:将您的数据结构化为易于 LLM 消耗且性能优异的中间表示形式;
- 引擎:提供对您数据的自然语言访问,例如:
- 查询引擎:强大的检索界面,用于知识增强输出;
- 聊天引擎:对话式接口,用于与数据进行多消息、“来回”交互;
- 数据代理:由工具(从简单辅助函数到 API 集成等)增强的 LLM 动力知识工作者;
- 应用集成:将 LlamaIndex 与您的生态系统其余部分(如 LangChain、Flask、Docker、ChatGPT 或任何其他工具)紧密关联。
LlamaIndex的功能
LlamaIndex 有用性的核心是其有助于构建 LLM 应用程序的功能和工具。在这里,我们详细讨论它们:
数据连接器
LlamaIndex 提供数据连接器,可以提取您现有的数据源和格式。无论是 API、PDF、文档还是 SQL 数据库,LlamaIndex 都可以与它们无缝集成,为您的 LLM 准备数据。
数据结构
使用 LLM 的主要挑战之一是以易于使用的方式构建数据。LlamaIndex 提供了在索引或图表中构建数据的工具。
高级检索/查询界面
LlamaIndex 不仅仅是摄取和构建数据。它还为您的数据提供高级检索或查询界面。只需输入任何 LLM 输入提示,LlamaIndex 将返回检索到的上下文和知识增强输出。
与其他框架集成
LlamaIndex 允许与您的外部应用程序框架轻松集成。您可以将它与 LangChain、Flask、Docker、ChatGPT 以及您的项目可能需要的任何其他工具一起使用。
高级和低级 API
无论您的熟练程度如何,LlamaIndex 都能满足您的需求。初学者用户会喜欢高级 API,它允许使用 LlamaIndex 以仅五行代码来摄取和查询他们的数据。另一方面,高级用户可以根据需要利用较低级别的 API 自定义和扩展任何模块(数据连接器、索引、检索器、查询引擎、重新排名模块)。
相关文章:
实习日志1之大模型相关知识概览
一、RAB 1、介绍(提供检索和生成) RAG,全称为Retrieval-Augmented Generation,中文可以翻译为"检索增强生成",也有人说是召回增强生成。这是一种结合了检索和生成两种机器学习方法的新型框架,主…...
)
华为嵌入式面试题及参考答案(持续更新)
目录 详细讲TCP/IP协议的层数 材料硬度由什么决定? SD3.0接口电压标准 晶振市场失效率 RS232-C的硬件接口组成 详细讲眼图的功能 局域网传输介质有哪几类? 详细讲OSI模型 NMOS与PMOS的区别 I2C和SPI的区别 Static在C语言中的用法 堆栈和队列的区别 数组的时间复…...

Java二十三种设计模式-装饰器模式(7/23)
装饰器模式:动态扩展功能的灵活之选 引言 装饰器模式(Decorator Pattern)是一种结构型设计模式,用于在不修改对象自身的基础上,通过添加额外的职责来扩展对象的功能。 基础知识,java设计模式总体来说设计…...

正则表达式与文本处理
目录 一、正则表达式 1、正则表达式定义 1.1正则表达式的概念及作用 1.2、正则表达式的工具 1.3、正则表达式的组成 2、基础正则表达式 3、扩展正则表达式 4、元字符操作 4.1、查找特定字符 4.2、利用中括号“[]”来查找集合字符 4.3、查找行首“^”与行尾字符“$”…...

Python | Leetcode Python题解之第283题移动零
题目: 题解: class Solution:def moveZeroes(self, nums: List[int]) -> None:n len(nums)left right 0while right < n:if nums[right] ! 0:nums[left], nums[right] nums[right], nums[left]left 1right 1...

微信小程序面试题汇总
面试题 1. 请简述微信小程序主要目录和文件的作用? 参考回答: 微信小程序主要目录和文件的作用:(1)project.config.json:项目配置文件,用的最多的就是配置是否开启https校验 (2&am…...

学习日志:JVM垃圾回收
文章目录 前言一、堆空间的基本结构二、内存分配和回收原则对象优先在 Eden 区分配大对象直接进入老年代长期存活的对象将进入老年代主要进行 gc 的区域空间分配担保 三、死亡对象判断方法引用计数法可达性分析算法引用类型总结1.强引用(StrongReference…...
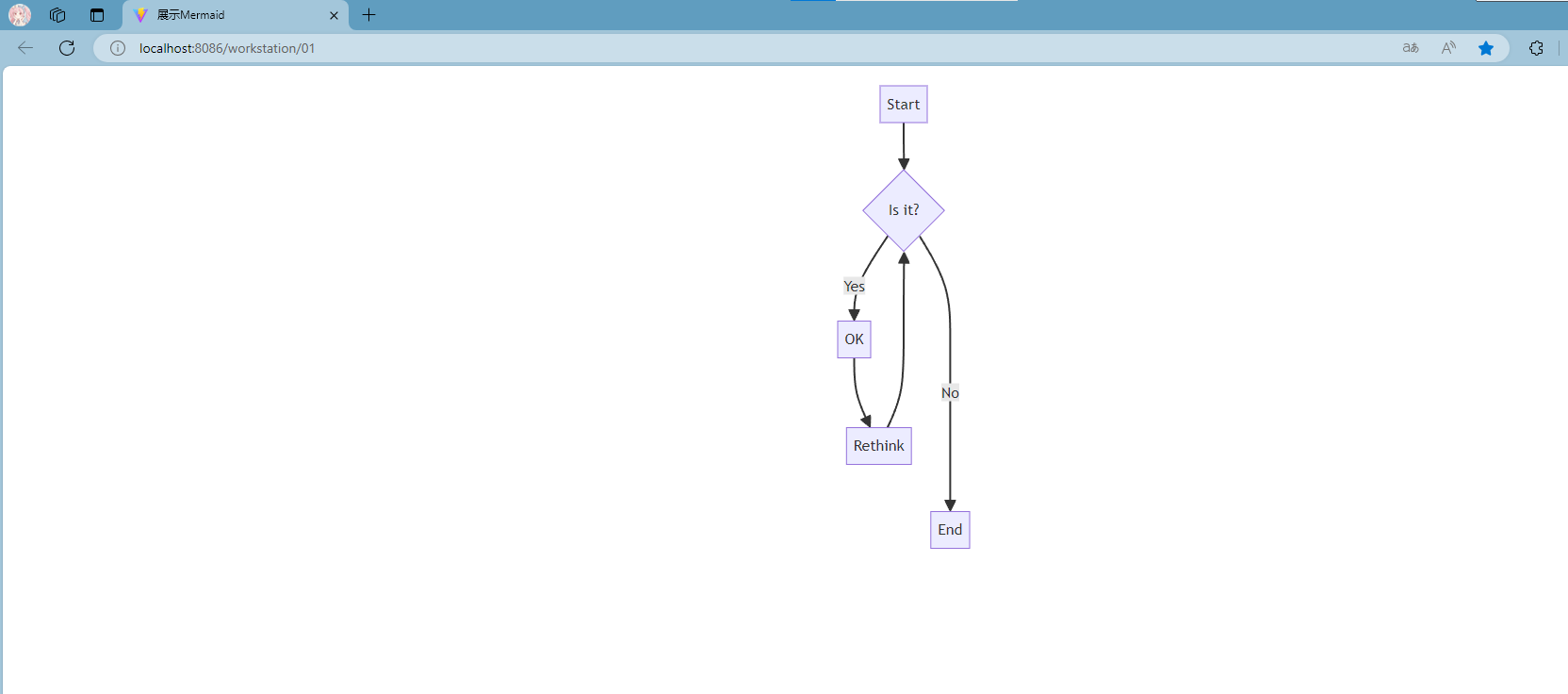
Vue前端页面嵌入mermaid图表--流程图
一、安装Mermaid 首先,你需要在你的项目中安装Mermaid。可以通过npm或yarn来安装: npm install mermaid --save # 或者 yarn add mermaid结果如图: 二、Vue 方法一:使用pre标签 使用ref属性可以帮助你在Vue组件中访问DOM元素 …...

【web]-反序列化-easy ? not easy
打开后看到源码 <?php error_reporting(0); highlight_file(__FILE__);class A{public $class;public $para;public $check;public function __construct(){$this->class "B";$this->para "ctfer";echo new $this->class ($this->para…...

python 内置函数、math模块
一、内置函数 内置函数是 Python 解释器内置的一组函数,它们可以直接在 Python 程序中使用,无需额外导入模块。这些内置函数提供了基本的操作和功能,涵盖了广泛的用途,从数学运算到数据结构操作等等。 import mathprint(type(10)…...

Ubuntu Docker 安装
Ubuntu Docker 安装 1. 引言 Docker 是一个开源的应用容器引擎,它允许开发者打包他们的应用以及依赖包到一个可移植的容器中,然后发布到任何流行的 Linux 机器上,也可以实现虚拟化。容器是完全使用沙箱机制,相互之间不会有任何接口。 2. 系统要求 在安装 Docker 之前,…...

vue接入google map自定义marker教程
需求背景 由于客户需求,原来系统接入的高德地图,他们不接受,需要换成google地图。然后就各种百度,各种Google,却不能实现。----无语,就连google地图官方的api也是一坨S-H-I。所以才出现这篇文章。 google地…...

Spring Boot集成Redis与Lua脚本:构建高效的分布式多规则限流系统
文章目录 Redis多规则限流和防重复提交记录访问次数解决临界值访问问题实现多规则限流先确定最终需要的效果编写注解(RateLimiter,RateRule)拦截注解 RateLimiter 编写lua脚本UUID时间戳编写 AOP 拦截 总结 Redis多规则限流和防重复提交 市面…...

四、单线程多路IO复用+多线程业务工作池
文章目录 一、前言1 编译方法 二、单线程多路IO复用多线程业务工作池结构三、重写Client_Context类四、编写Server类 一、前言 我们以及讲完单线程多路IO复用 以及任务调度与执行的C线程池,接下来我们就给他结合起来。 由于项目变大,尝试解耦项目&#…...

单元测试--Junit
Junit是Java的单元测试框架提供了一些注解方便我们进行单元测试 1. 常用注解 常用注解: TestBeforeAll,AfterAllBeforeEach,AfterEach 使用这些注解需要先引入依赖: <dependency><groupId>org.junit.jupiter<…...

达梦数据库系列—30. DTS迁移Mysql到DM
目录 1.MySQL 源端信息 2.DM 目的端信息 3.迁移评估 4.数据库迁移 4.1源端 MySQL 准备 4.2目的端达梦准备 初始化参数设置 兼容性参数设置 创建迁移用户和表空间 4.3迁移步骤 创建迁移 配置迁移对象及策略 开始迁移 对象补迁 5.数据校验 统计 MySQL 端对象及数…...

随记0000——从0、1 到 C语言
C语言的发展历程是计算机科学史上的一个重要里程碑。 下面是从最早的机器语言到汇编语言,再到高级语言如 C 语言的简化演进过程: 1. 机器语言 定义与特点 机器语言是最底层的编程语言,由一系列二进制代码组成。直接被CPU执行,…...

C++ | Leetcode C++题解之第264题丑数II
题目: 题解: class Solution { public:int nthUglyNumber(int n) {vector<int> dp(n 1);dp[1] 1;int p2 1, p3 1, p5 1;for (int i 2; i < n; i) {int num2 dp[p2] * 2, num3 dp[p3] * 3, num5 dp[p5] * 5;dp[i] min(min(num2, num3…...

前端系列-8 集中式状态管理工具pinia
集中式状态管理工具—pinia vue3中使用pinia作为集中式状态管理工具,替代vue2中的vuex。 pinia文档可参考: https://pinia.web3doc.top/introduction.html 1.项目集成pinia 安装pinia依赖: npm install pinia在main.ts中引入pinia import { createApp } from vu…...

pytest使用
主要技术内容 1.pytest设计 接口测试 框架设想 common—公共的东西封装 1.request请求 2.Session 3.断言 4.Log 5.全局变量 6.shell命令 ❖ config---配置文件及读取 ❖ Log— ❖ payload—请求参数—*.yaml及读取 ❖ testcases—conftest.py; testcase1.py…….可…...

1号店应用商店与Obtainium:电商应用更新的终极对决
1号店应用商店与Obtainium:电商应用更新的终极对决 【免费下载链接】Obtainium Get Android App Updates Directly From the Source. 项目地址: https://gitcode.com/GitHub_Trending/ob/Obtainium 在移动应用日新月异的今天,及时获取应用更新成为…...

工业数据智能:从数据堆积到系统认知的深层跃迁
在制造业的数字化转型浪潮中,工业数据智能早已超越了“采集-展示-分析”的初级阶段。过去,企业热衷于部署大屏、连接传感器、搭建数据中台,以为数据量的积累就是智能化的起点。然而现实往往令人失望——中控室里跳动的曲线,未必能…...

Chord高清视频理解案例:1080P视频边界框定位精度实测报告
Chord高清视频理解案例:1080P视频边界框定位精度实测报告 1. 引言:当AI学会“看”视频 想象一下,你有一段30秒的短视频,里面有一只猫从沙发跳到茶几上。现在,你需要知道: 这只猫在视频的哪几秒出现了&am…...

Phi-3-vision-128k-instruct惊艳表现:乐谱图片→MIDI生成+演奏风格分析
Phi-3-vision-128k-instruct惊艳表现:乐谱图片→MIDI生成演奏风格分析 1. 模型简介 Phi-3-Vision-128K-Instruct是当前最先进的轻量级开放多模态模型,专注于高质量的文本和视觉数据处理能力。这个模型属于Phi-3系列,特别之处在于它支持长达…...

15瓦至1000瓦完整量产版开关电源方案:含图纸、BOM、变压器及磁芯图纸,可直接生产
15瓦到1000瓦完整量产版开关电源方案,有图纸,bom,变压器和各种磁芯图纸,可以直接生产最近在搞开关电源量产方案的朋友有福了,这套从15W到1000W全覆盖的设计方案绝对能让你少掉几根头发。先说重点:整套方案已…...

基于CW32F030的DIY电压电流表:从PCB设计到3D打印外壳的全流程实战
基于CW32F030的DIY电压电流表:从PCB设计到3D打印外壳的全流程实战 最近有不少朋友问我,想自己动手做一个实用的测量工具,比如一个能同时测电压和电流的小表,该怎么从零开始。正好,我之前用国产的CW32F030单片机&#x…...

从ElementPlus警告看前端数据清洗:el-pagination的total传值避坑指南
从ElementPlus分页器警告谈前端数据清洗的工程实践 最近在项目中使用ElementPlus的el-pagination组件时,不少开发者都遇到了一个看似简单却值得深思的问题——控制台突然弹出警告提示,指出分页器的某些用法已被废弃。经过排查,发现问题往往出…...
)
Unity游戏安全实战:如何用Zygisk-IL2CppDumper动态分析你的游戏代码(附防御方案)
Unity游戏安全实战:动态分析与防御的艺术 在移动游戏开发领域,安全防护与破解攻防始终是一场没有硝烟的战争。作为Unity开发者,我们既需要了解前沿的逆向分析技术来评估自身产品的安全强度,又需要掌握有效的防御手段来保护来之不易…...

Windows 11系统优化工具:让你的电脑重获新生
Windows 11系统优化工具:让你的电脑重获新生 【免费下载链接】Win11Debloat 一个简单的PowerShell脚本,用于从Windows中移除预装的无用软件,禁用遥测,从Windows搜索中移除Bing,以及执行各种其他更改以简化和改善你的Wi…...

仁王3的宏 和 浪人崛起 战神3模拟器设置 the dark rites of akham
the dark rites of akham: 卡关点: 地下室的box里面有刀. 警局垃圾箱里面有面包. 警局的玩硬币之后拿到硬币,之后去精神医院门口报纸机器拿报纸. 罐头打开之后放雨伞上. 互动大地图:https://www.gamersky.com/tools/map/rw3/ 用来找武士益发, 忍者益发. 仁王3里面99武器适合狂按…...