图形化深度学习开发平台PaddleStudio(代码开源)
目录
- 一、PaddleStudio概述
- 二、环境准备
- 2.1 安装PaddlePaddle
- 2.2 安装依赖库
- 三、基本使用介绍
- 3.1 启动
- 3.2 快速体验
- 3.2.1 下载示例项目
- 3.2.2 训练
- 3.2.3 评估
- 3.2.4 测试
- 3.2.5 静态图导出
- 四、数据集格式
- 4.1 图像分类
- 4.2 目标检测
- 4.3 语义分割
- 4.4 实例分割
- 五、趣味项目实战(动作捕捉游戏操控装置)
- 5.1 任务概述
- 5.2 数据集准备
- 5.3 算法研发
- 5.3.1 数据集导入
- 5.3.2 训练
- 5.3.3 推理
- 5.3.4 静态图导出
- 5.4 Paddle Inference部署
- 5.4.1 PaddleInference概述
- 5.4.2 PaddleInference单张图片推理
- 5.5 集成测试
- 六、其它
- 6.1 联系和反馈
- 6.2 贡献代码
- 6.3 教学书籍
- 6.4 线上GPU平台
PaddleStudio开源网址:https://github.com/PuhuaCloud/PaddleStudio
一、PaddleStudio概述
本项目源自于PaddleX的Restful项目,依托国产深度学习框架PaddlePaddle打造的图形化深度学习开发平台,旨在让非AI开发者以最便捷的方式完成AI模型研发。目前平台功能涵盖图像分类、目标检测、实例分割、语义分割等常规CV训练任务,未来将逐步打通数据标注、算法训练和部署三大流程,真正的让用户可以感受到“无代码”化的便捷。
由于PaddleX项目官方已停止更新,本项目将PaddleX的GUI部分独立出来并且进行了重组,由飞桨社区开发者共同维护,遵循Apache License 2.0开源协议,欢迎各位小伙伴前来体验和参与,多多提出您的宝贵意见。
二、环境准备
2.1 安装PaddlePaddle
PaddleStudio依赖PaddlePaddle框架执行训练,因此首先要安装PaddlePaddle。
参照PaddlePaddle官网进行安装,安装时需要注意CUDA版本的一致性。例如,对于已经安装CUDA11.6的Windows操作系统,可以使用下面的命令安装PaddlePaddle2.4:
python -m pip install paddlepaddle-gpu==2.4.1.post116 -f https://www.paddlepaddle.org.cn/whl/windows/mkl/avx/stable.html
安装完成后可以使用python命令进入python解释器,输入下面的命令:
import paddle
paddle.utils.run_check()
如果出现PaddlePaddle is installed successfully!,说明您已成功安装PaddlePaddle。
2.2 安装依赖库
首先下载PaddleStudio项目:
git clone https://github.com/PuhuaCloud/PaddleStudio.git
然后进入项目根目录并安装相关依赖库:
cd PaddleStudio
pip install -r requirements.txt -i https://mirror.baidu.com/pypi/simple
到这里,PaddleStudio所需要的环境就已经全部准备好了。下面介绍如何启动并使用PaddleStudio。
三、基本使用介绍
3.1 启动
进入PaddleStudio项目根目录后使用下面的命令进行启动:
python app.py
正常情况下输出如下:
2023-01-31 16:38:25,616 app.py[line:1045] INFO:PaddleStudio服务启动成功后,您可以在浏览器打开网址 192.168.8.113:5000 进行界面操作* Serving Flask app 'app' (lazy loading)* Environment: productionWARNING: This is a development server. Do not use it in a production deployment.Use a production WSGI server instead.* Debug mode: on
2023-01-31 16:38:25,664 _internal.py[line:224] INFO: * Running on all addresses (0.0.0.0)WARNING: This is a development server. Do not use it in a production deployment. * Running on http://127.0.0.1:5000* Running on http://192.168.8.113:5000 (Press CTRL+C to quit)
2023-01-31 16:38:25,667 _internal.py[line:224] INFO: * Restarting with stat
2023-01-31 16:38:26,305 app.py[line:1045] INFO:PaddleStudio服务启动成功后,您可以在浏览器打开网址 192.168.8.113:5000 进行界面操作
2023-01-31 16:38:26,323 _internal.py[line:224] WARNING: * Debugger is active!
2023-01-31 16:38:26,331 _internal.py[line:224] INFO: * Debugger PIN: 339-955-950
2023-01-31 16:38:30,447 _internal.py[line:224] INFO:192.168.8.113 - - [31/Jan/2023 16:38:30] "GET / HTTP/1.1" 200 -
2023-01-31 16:38:30,756 _internal.py[line:224] INFO:192.168.8.113 - - [31/Jan/2023 16:38:30] "GET /project HTTP/1.1" 200 -
2023-01-31 16:38:30,764 _internal.py[line:224] INFO:192.168.8.113 - - [31/Jan/2023 16:38:30] "GET /favicon.ico HTTP/1.1" 200 -
成功启动后系统会默认给出PaddleStudio的访问路径,如下例所示:
http://192.168.8.113:5000
此时可以通过浏览器访问该网址打开PaddleStudio平台首页,如下图所示:

需要注意,首次打开时会在当前服务器的PaddleStudio根目录下创建一个名为workspace的文件夹作为工作区,用来存放数据集和模型训练的相关信息。
下面针对常见的图像分类任务讲解如何快速使用PaddleStudio。
3.2 快速体验
3.2.1 下载示例项目
PaddleStudio提供了每种任务对应的示例项目,方便用户快速了解每种任务的完整操作流程。下面以图像分类项目为例进行讲解。
首先,单击中间提示框“暂无项目,点击下载示例项目”,出现下图所示界面:

接下来勾选“下载图像分类示例项目”并单击“开始下载”按钮进行下载,如下图所示:

下载结束后单击“关闭窗口”按钮,在主界面上会出现对应的项目信息,是一个果蔬图像分类任务,如下图所示:

我们可以打开工作区文件夹PaddleStudio/workspace,其中有一个projects文件夹,该文件夹存放了所有项目信息。刚下载的项目其项目号为P0001,因此,对应工作区文件夹路径为PaddleStudio/workspace/projects/P0001。与此同时,在PaddleStudio/workspace/datasets存放着刚下载的数据集,位于D0001子文件夹下面,其内容如下图所示:

其中bocai、changqiezi、hongxiancai、huluobo、xihongshi、xilanhua这几个文件夹下面各自存放着不同品种的果蔬图片。labels.txt存放着对应的类别标签。train_list.txt、val_list.txt和test_list.txt分别存放着训练集、验证集、测试集的图片路径列表,形式如下所示:
./bocai/142.jpg 0
./bocai/149.jpg 0
./changqiezi/57.jpg 1
./changqiezi/191.jpg 1
每行表示一个样本图片,分成前后两部分,中间用空格分隔,前半部分为图片相对路径,后半部分为对应的类别数字标签。
可以看到,为了尽可能方便PaddlePaddle用户,PaddleStudio沿用了PaddleClas套件的数据集格式基本规则,对于图像分类任务,只需要按照上述格式进行数据集组织即可。
3.2.2 训练
单击下载的项目,然后单击项目窗口打开任务配置属性窗口,如下图所示:

在该任务所列属性参数中列出了训练所需的重要配置参数,例如模型、骨干网络、迭代轮数等,用户可以根据自己数据集的实际情况进行调整,调整完成后单击“启动训练”按钮开始训练,此时项目的任务状态会显示“训练中”,如下图所示:

可以继续单击主界面上的项目查看训练日志,如下图所示:

训练完成后可以单击“评估和导出模型”按钮,进入“模型评估&导出”模块,如下图所示:

3.2.3 评估
在“模型评估&导出”界面上,单击启动评估按钮,可以快速进行模型精度验证,结果如下图所示:

可以看到,当前训练的模型Top1分类准确率Acc1=0.6,Topk分类准确率Acck=1.0。如果想要进一步提高精度,可以在模型训练过程中修改迭代轮数属性,增加训练迭代次数,也可以选用更重量级的分类模型。
3.2.4 测试
训练好模型以后,PaddleStudio还提供了在线预测功能。单击“模型测试”按钮,然后进入“模型测试”界面,选择一张图片并单击预测按钮,效果如下图所示:

针对上述图像分类任务,预测结果会给出预测类别和对应的置信度。
3.2.5 静态图导出
前面训练好的模型是PaddlePaddle的动态图模型,为了方便部署应用,需要将动态图模型转换成静态图模型,PaddleStudio提供了现成的转换办法。
在下图所示界面上单击“导出”按钮:

导出完成后会有相应的提示信息并且会给出导出后的静态图模型路径,如下图所示:

到这里,一个相对完整的图像分类算法模型就已经研发完毕了。后面可以结合PaddlePaddle的原生部署工具PaddleInference来完成最终的算法部署任务。
本小节内容主要讲解了如何使用PaddleStudio进行图像分类算法开发,如果想要自行开发类似的图像分类、目标检测、语义分割、实例分割等算法模型,可以参照PaddleStudio官网说明并结合相应的示例工程进行开发。从整个使用体验上来看,只要按照PaddleStudio的各个任务准备好对应的数据集,就可以直接使用图形化操作界面“傻瓜式”完成整个算法训练任务。
下面讲解如何按照PaddleStudio的方式组织相应任务的数据集。
四、数据集格式
4.1 图像分类
数据集组织格式如下图所示:

- 类别文件夹命名:每个子文件夹名为需要分类的类名,子文件夹名称可以使英文字符和数字,不可包含:空格、中文或特殊字符;
- 图片格式:支持png,jpg,jpeg,bmp格式;
4.2 目标检测
数据集组织格式如下图所示:

- 文件夹命名:图片文件夹需要命名为”JPEGImages”,标签文件夹需要命名为”Annotations”;
- 图片格式:支持png,jpg,jpeg,bmp格式;标签文件格式为.xml;
4.3 语义分割
数据集组织格式如下图所示:

- 文件夹命名:图片文件名需要为”JPEGImages”,标签文件夹命名需要为”Annotations”;
- 图片格式:支持png,jpg,jpeg,bmp格式;
- 标注掩码图:Annotations中存放的标注掩码图片需要与JPEGImages中的原始图片像素严格保持一一对应,格式只可为png。每个像素值需标注为[0,255]区间,从0开始依序递增,其中255表示模型中需忽略的像素,0为背景类;
- 可选文件label.txt:可以提供一份命名为”labels.txt”的包含所有标注名的清单;
4.4 实例分割
数据集组织格式如下图所示:

- 文件夹命名:图片文件名需要为”JPEGImages”,标签文件名需要为”annotations.json”;
- 图片格式:支持png,jpg,jpeg,bmp格式;标签文件格式为.json;
五、趣味项目实战(动作捕捉游戏操控装置)
5.1 任务概述
下面我们给出一个全流程的趣味实战项目,利用PaddleStudio研发一款游戏动捕装置,通过摄像头实时识别手势动作,操控“超级玛丽”小游戏。
实现思路:定义四种不同的手势,分别对应左移、右移、停止、跳跃,通过摄像头实时捕获手部图片,然后利用深度学习模型进行实时手部图像分类,根据分类结果模拟键盘按键操作,进而操控游戏。需要注意的是,考虑到实现简单以及实时性,本项目采用逐帧图像识别方案,而不是基于逐段视频识别的方案。
具体实现效果如下所示:
动作识别游戏动作捕捉
如果看不了上述视频那么也可以访问哔哩哔哩上的 视频进行查看。
本趣味实战项目完整数据和代码下载链接如下(包含所有训练数据、训练结果、静态图模型和超级玛丽游戏模拟器):
链接:https://pan.baidu.com/s/1ZPSW_spmN_G6ZAk154-VBg?pwd=sfyw
提取码:sfyw
5.2 数据集准备
下载的代码资料包中提供了数据采集的脚本get_samples.py,代码如下:
import os
import cv2
import timeif __name__ == '__main__':# 手势名称gestname = "stop"# 创建图像文件存储目录data_root = 'gestdata'if not os.path.exists(data_root):os.makedirs(data_root)img_folder = os.path.join(data_root,gestname)if not os.path.exists(img_folder):os.makedirs(img_folder)pic_index = len(os.listdir(img_folder))# 识别框位置x0 = 300y0 = 150height = 300width = 300# 打开摄像头并设置采集分辨率cap = cv2.VideoCapture(0)cap.set(cv2.CAP_PROP_FRAME_WIDTH, 640)cap.set(cv2.CAP_PROP_FRAME_HEIGHT, 480)# 保存图片开关saveimg = False# 循环采集while (True):ret, frame = cap.read()if ret == True:frame = cv2.flip(frame, 1)roi = frame[y0:y0+height, x0:x0+width]cv2.rectangle(frame, (x0, y0), (x0+width, y0+height), (0, 255, 0), 1)if saveimg:savepath = os.path.join(img_folder, str(pic_index)+'.jpg')print(savepath)cv2.imwrite(savepath, roi)pic_index = pic_index + 1time.sleep(0.3)# 相关操作提示cv2.putText(frame, 'push key s to save samples', (10, 35),cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0, 255, 0), 2, 1)cv2.putText(frame, 'push key q to stop saving', (10, 55),cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0, 255, 0), 2, 1)cv2.putText(frame, 'push key Esc to equit', (10, 75),cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0, 255, 0), 2, 1)# 显示摄像头内容 cv2.imshow('Original', frame)key = cv2.waitKey(5) & 0xff# Esc键退出if key == 27:print('正常退出')cap.release()cv2.destroyAllWindows()elif key == ord('s'):saveimg = Trueelif key == ord('q'):saveimg = False
上述代码会自动在当前项目目录下创建一个名为gestdata的文件夹用来收集手部动作图片。其中,初始时定义的gestname变量表明当前要采集的动作类型,例如gestdata=‘stop’,相应的图像数据会保存在gestdata/stop文件夹下面。如果要采集其他动作图片,那么可以修改这个变量名称,依次修改为stop、jump、left、right等,对应动作含义是停止、跳跃、向左走、向右走。
运行后效果如下图所示:

采集的时候,将手部放在绿色框内,然后按s键开始采集,程序会裁剪出绿色框内的图片进行保存。每秒大概采集3张图片,每张图片大小为300x300像素。在采集的过程中可以稍微改变一点手部动作,或者也可以在采集时适当的移动摄像头和手部,切换不同的背景,这样就可以尽可能采集到不同的图片。按q键可以停止采集,按Esc键退出程序。
完成一轮采集后改变gestname名称,重新开始下一种动作采集。每种动作采集500张左右图片即可。
最后采集的所有数据都位于名为gestdata的文件夹下面,该文件夹下的每个子文件夹都存放着对应手势动作的图片,如下图所示:

到这里,项目所需要的数据集就准备完毕了。
5.3 算法研发
本节内容我们将使用前面介绍的PaddleStudio来完成深度学习算法研发。使用前首先请按照第二章内容完成环境准备,然后使用命令python app.py启动PaddleStudio。
5.3.1 数据集导入
首先单击顶部菜单栏“数据集管理”—>“新建数据集”,然后填入相关数据集描述信息,在数据集类型上选择图像分类(本趣味实战项目采用图像分类方法实现),如下图所示:

创建成功后如下图所示,在数据集管理界面上多出现了一个状态为“未导入”的空数据集,如下图所示:

接下来我们就需要将前面采集好的数据集导入到这个新创建的数据集中,并且完成数据切分(分为训练集、验证集、测试集)和校验。
单击创建的数据集,弹出导入数据集界面,输入对应的数据集地址即可,如下图所示:

然后单击导入按钮进行导入。稍等几秒钟时间,然后刷新页面,可以看到数据集已经完成了导入和校验,如下图所示效果:

接下来,我们对数据集进行切分,单击该数据集,按照下图所示进行切分:

整个训练集、验证集、测试集的比例加起来保证100%即可。最后单击“切分”按钮完成数据集切分,效果如下图所示:

到这里,一个符合PaddleStudio要求的图像分类数据集就完全准备好了。
5.3.2 训练
接下来,我们单击菜单栏“项目管理”—>“创建项目”按钮,在弹出的新建项目界面上,输入项目名称,在项目类型上选择图像分类,在数据集上选择刚才创建并导入成功的手势识别数据集,这里需要注意的是,如果想要使用的数据集状态不是“已校验&已切分”,那么这里在选择数据集的时候对应的数据集名称是不会显示的。最后输入项目描述即可。

最后,单击创建按钮完成项目创建。
PaddleStudio是以“项目—任务”这样两个级别进行使用的,一个项目下面可以挂载多个任务,每个任务对应一种环境配置及训练结果。在项目主界面上单击刚才创建的项目进入任务界面,然后单击“新建任务”按钮,打开任务配置界面,如下图所示:

默认首选分类模型为MobileNetV2,这是一个轻量级的图像分类模型,适合对推理速度要求比较高的场景,本项目就采用这个模型来实现。需要注意的是,对于数据增强策略的几个选项,默认开启了随机水平翻转、随机垂直翻转和随机旋转的增强,由于这个手势识别数据集对于方向是敏感的,所以这几个增强策略需要关闭,如下图所示:

修改完成后,单击“创建并启动训练”按钮,进行训练。效果如下所示:

单击该任务,可以查看具体的训练进度及训练信息,如下图所示:

等待训练完成即可。
5.3.3 推理
训练完成后,可以使用训练好的动态图模型进行测试。单击“评估和导出模型”按钮,然后再单击“模型测试”按钮进入模型测试界面。选择一张图片,然后单击预测,效果如下图所示:

可以看到,对于向左的手势,预测结果是left,置信度是1.0,由此可见训练的模型是有效的。
5.3.4 静态图导出
为了方便后面部署,可以使用PaddleStudio的静态图导出功能,生成静态图模型文件。单击“导出”按钮即可完成,效果如下图所示:

用户可以根据对应的导出路径去获取最终的静态图模型,其内容如下:
inference_model├─.success├─model.pdiparams├─model.pdiparams.info├─model.pdmodel├─model.yml├─pipeline.yml
各文件说明如下:
- .success:PaddleStudio生成的导出成功标志文件,实际部署时不需要;- model.pdiparams:模型参数文件;- model.pdiparams.info:模型参数信息文件,实际部署时不需要;- model.pdmodel:模型结构文件;- model.yml:模型配置文件,实际部署时不需要;- model.yml:PaddleStudio流程文件,实际部署时不需要;
上述几个文件,真正需要的就是model.pdiparams和model.pdmodel这两个文件。除了这两个文件以外,我们需要额外注意model.yml文件,该文件记录了模型的相关预处理和后处理信息,内容如下所示:
Model: MobileNetV2
Transforms:
- ResizeByShort:interp: LINEARmax_size: -1short_size: 256
- CenterCrop:crop_size: 224
- Normalize:is_scale: truemax_val:- 255.0- 255.0- 255.0mean:- 0.485- 0.456- 0.406min_val:- 0- 0- 0std:- 0.229- 0.224- 0.225
_Attributes:best_accuracy: !!python/object/apply:numpy.core.multiarray.scalar- !!python/object/apply:numpy.dtypeargs:- f4- false- truestate: !!python/tuple- 3- <- null- null- null- -1- -1- 0- !!binary |AACAPw==best_model_epoch: 5eval_metrics:acc1: 1.0fixed_input_shape:- -1- 3- -1- -1labels:- jump- left- right- stopmodel_type: classifiernum_classes: 4
_init_params:num_classes: 4
completed_epochs: 0
status: Infer
version: 2.1.0
在进行后面的模型部署任务时,需要结合这个配置文件指明的相关前后处理操作进行实现。
到这里,通过PaddleStudio完成了算法研发,得到了我们想要的手势识别模型,整个这个训练部分没有写一行代码,只需要使用图形界面进行操作即可。接下来就开始进行部署。
5.4 Paddle Inference部署
5.4.1 PaddleInference概述
Paddle Inference是飞桨PaddlePaddle的原生推理库,提供服务器端的高性能推理能力。由于Paddle Inference直接面向飞桨的训练算子,因此它支持飞桨训练出的所有模型的推理。Paddle Inference功能特性丰富,性能优异,针对不同平台不同的应用场景进行了深度的适配优化,做到高吞吐、低时延,保证了飞桨模型在服务器端即训即用,快速部署。
值得注意的是,飞桨提供了众多部署工具,例如PaddleLite、PaddleServing、FastDeploy、PaddleJS等,在众多的部署工具中Paddle Inference是最本源的部署工具。从某种意义上来说,可以将Paddle Inference看作是PaddlePaddle的静态图推理引擎,与PaddlePaddle训练出来的模型完全适配,并且Python版本的PaddleInference自动集成在了PaddlePaddle中,如果想使用Python语言调用Paddle Inference接口,那么只需要按照2.1节的内容安装好PaddlePaddle以后就可以直接使用Paddle Inference了。当然,如果想使用C++等语言调用PaddleInference,可以参照Paddle Inference官网教程下载相应的C++预测库进行配置和使用。
5.4.2 PaddleInference单张图片推理
Paddle Inference官网提供了很多预测示例,参照这些示例就可以顺利的编写对应的模型预测代码。本项目参照官网的Resnet50图像分类案例,编写了对应的手势识别推理脚本infer.py,其内容如下:
import numpy as np
import cv2from paddle.inference import Config
from paddle.inference import create_predictorfrom img_preprocess import preprocessdef init_predictor():'''配置预测器'''config = Config('inference_model/model.pdmodel', 'inference_model/model.pdiparams')config.enable_use_gpu(500, 0)config.enable_memory_optim() predictor = create_predictor(config)return predictordef run(predictor, img):'''单张图像预测'''input_names = predictor.get_input_names()for i, name in enumerate(input_names):input_tensor = predictor.get_input_handle(name)input_tensor.reshape(img[i].shape)input_tensor.copy_from_cpu(img[i].copy())predictor.run()results = []output_names = predictor.get_output_names()for i, name in enumerate(output_names):output_tensor = predictor.get_output_handle(name)output_data = output_tensor.copy_to_cpu()results.append(output_data)return resultsif __name__ == '__main__':# 创建预测器model = init_predictor()# 读取图像img = cv2.imread('gestdata/stop/0.jpg')# 图像预处理img = preprocess(img)# 执行预测result = run(model, [img])label = np.argmax(result[0][0])score = result[0][0][label]print("class index: ", label ," score: ",score)
上述脚本读取图片gestdata/stop/0.jpg然后调用静态图模型完成推理,在使用时需要将前面导出的静态图模型文件夹inference_model拷贝到当前项目根目录下。另外,该脚本中用到了一些官方为我们编写好的预处理代码,位于img_preprocess.py,其完整内容如下:
import cv2
import numpy as npdef resize_short(img, target_size):""" resize_short """percent = float(target_size) / min(img.shape[0], img.shape[1])resized_width = int(round(img.shape[1] * percent))resized_height = int(round(img.shape[0] * percent))resized = cv2.resize(img, (resized_width, resized_height))return resizeddef crop_image(img, target_size, center):""" crop_image """height, width = img.shape[:2]size = target_sizeif center == True:w_start = (width - size) / 2h_start = (height - size) / 2else:w_start = np.random.randint(0, width - size + 1)h_start = np.random.randint(0, height - size + 1)w_end = w_start + sizeh_end = h_start + sizeimg = img[int(h_start):int(h_end), int(w_start):int(w_end), :]return imgdef preprocess(img):mean = [0.485, 0.456, 0.406]std = [0.229, 0.224, 0.225]img = resize_short(img, 256)img = crop_image(img, 224, True)# bgr-> rgb && hwc->chwimg = img[:, :, ::-1].astype('float32').transpose((2, 0, 1)) / 255img_mean = np.array(mean).reshape((3, 1, 1))img_std = np.array(std).reshape((3, 1, 1))img -= img_meanimg /= img_stdreturn img[np.newaxis, :]
该预处理脚本需要结合我们模型的model.yaml配置文件相关参数进行修改。
预测结果如下图所示:

class index: 3 score: 0.999998
到这里,我们就完成了整个模型的研发和部署,下面我们将模型预测部分集成到最终的游戏控制逻辑脚本playgame.py中去。
5.5 集成测试
新建游戏逻辑控制脚本playgame.py,完整代码如下:
import numpy as np
import cv2
import win32api
import win32con
from img_preprocess import preprocess
from infer import init_predictor,rundef keybd_event(VK_CODE):'''按下按键'''VK_CODE = int(VK_CODE)#按键按下win32api.keybd_event(VK_CODE, 0, 0, 0)if __name__ == '__main__':# 定义手势识别框位置x0 = 300y0 = 150height = 300width = 300# 打开摄像头并设置采集分辨率cap = cv2.VideoCapture(0)cap.set(cv2.CAP_PROP_FRAME_WIDTH, 640)cap.set(cv2.CAP_PROP_FRAME_HEIGHT, 480)# 加载神经网络model = init_predictor()# 逐帧处理gesture = 'stop'pre_gesture = 'stop'while(True):ret, frame = cap.read()if ret == True:frame = cv2.flip(frame, 1)roi = frame[y0:y0+height, x0:x0+width]cv2.rectangle(frame, (x0, y0), (x0+width, y0+height), (0, 255, 0), 1)# 预处理roi = preprocess(roi)# 执行预测result = run(model, [roi])label = np.argmax(result[0][0])score = result[0][0][label]print(label,score)# 解析手势thr = 0.9if label==0 and score>thr:gesture = 'jump'elif label==1 and score>thr:gesture = 'left'elif label==2 and score>thr:gesture = 'right'else:gesture = 'stop'#显示摄像头内容和处理后手势的图像内容cv2.imshow('Original',frame)if gesture=='left':win32api.keybd_event(68, 0, win32con.KEYEVENTF_KEYUP, 0)keybd_event(65) #键盘按下左 pre_gesture = gesture elif gesture=='right':win32api.keybd_event(65, 0, win32con.KEYEVENTF_KEYUP, 0)keybd_event(68) #键盘按下右 pre_gesture = gesture elif gesture=='jump':keybd_event(87)# X键if pre_gesture=='left':keybd_event(65)elif pre_gesture=='right':keybd_event(68) else:win32api.keybd_event(65, 0, win32con.KEYEVENTF_KEYUP, 0)win32api.keybd_event(68, 0, win32con.KEYEVENTF_KEYUP, 0)win32api.keybd_event(87, 0, win32con.KEYEVENTF_KEYUP, 0)key = cv2.waitKey(5) & 0xff#Esc键退出if key == 27:cap.release()cv2.destroyAllWindows()break
脚本启动后,打开游戏模拟器,依次单击“文件”-“打开”按钮,选择游戏文件Super_Mario_Bros.nes,然后就可以打开超级玛丽游戏。这里我们选择单人游戏, 直接按回车就可以进入游戏界面,然后将手部放在摄像头监控画面的绿色框中,按照前面定义的动作摆手势,程序会自动检测手势并模拟按键。
该模拟器默认使用WAD键,W表示跳跃,A表示向左,D表示向右。如果发现键盘按键不对,可以单击顶部菜单栏“选项”-“控制器”按钮,进入按键配置界面,重新进行配置即可,如下图所示:

最终效果如下图所示:

六、其它
6.1 联系和反馈
PaddleStudio目前处在快速更新迭代中,相关功能模块也在不断丰富和完善。如果在使用过程中遇到问题或者有相关好的建议,可以在PaddleStudio官网上提issue,或者也可以加入飞桨PaddleX的qq群提意见,群号:957286141。
为了更准确快速的定位所出现的异常问题,可以在使用过程中将遇到的问题通过截图形式给出,尤其是PaddleStudio后台的报错信息,建议截取出关键的Python异常代码报错提示。
6.2 贡献代码
如果对PaddleStudio项目感兴趣,欢迎加入我们,跟我们一起开发,一起打造国产的深度学习Matlab,让全国乃至全世界的用户都用上你开发的产品。
6.3 教学书籍
如果对PaddlePaddle感兴趣,想要系统学习深度学习技术或者想要系统学习PaddlePaddle框架,可以选择官方推荐的教学书籍《深度学习与图像处理PaddlePaddle》,由清华大学出版社出版,钱彬和朱会杰著(预计2023年8月出版)。除了本篇博客涉及到的PaddleStudio内容以外,书中还会详细讲解图像分类、目标检测、语义分割、OCR识别、GAN图像变换等算法原理,并结合真实的项目实战案例使用PaddlePaddle全流程讲解算法研发和部署。
6.4 线上GPU平台
如果用户身边暂时没有GPU机器,那么可以使用免费的GPU云平台完成开发,例如AI Studio、Kaggle、Google Colaboratory等。考虑到平台的稳定性以及额外的增值服务优势,也可以使用一些付费云平台,这里推荐使用普华云,整体价格较低,并且可以提供一对一的个性化服务需求,另外,平台上有现成的PaddleStudio镜像可以直接使用,不需要再安装相关环境或依赖库。
相关文章:
图形化深度学习开发平台PaddleStudio(代码开源)
目录一、PaddleStudio概述二、环境准备2.1 安装PaddlePaddle2.2 安装依赖库三、基本使用介绍3.1 启动3.2 快速体验3.2.1 下载示例项目3.2.2 训练3.2.3 评估3.2.4 测试3.2.5 静态图导出四、数据集格式4.1 图像分类4.2 目标检测4.3 语义分割4.4 实例分割五、趣味项目实战…...

【力扣-LeetCode】1138. 字母板上的路径-C++题解
1138. 字母板上的路径难度中等98收藏分享切换为英文接收动态反馈我们从一块字母板上的位置 (0, 0) 出发,该坐标对应的字符为 board[0][0]。在本题里,字母板为board ["abcde", "fghij", "klmno", "pqrst", &quo…...

基于Java+SpringBoot+Vue前后端分离酒店管理系统设计与实现
博主介绍:✌全网粉丝3W,全栈开发工程师,从事多年软件开发,在大厂呆过。持有软件中级、六级等证书。可提供微服务项目搭建、毕业项目实战、项目定制✌ 博主作品:《微服务实战》专栏是本人的实战经验总结,《S…...

【软考系统架构设计师】2022下综合知识历年真题
【软考系统架构设计师】2022下综合知识历年真题 【2022下架构真题第01题:绿色】 01.云计算服务体系结构如下图所示,图中①、②、③分别与SaaS、PaaS、Iaas相对应,图中①、②、③应为( ) A.应用层、基础设施层、平台层 B.应用层、平台层、基础…...
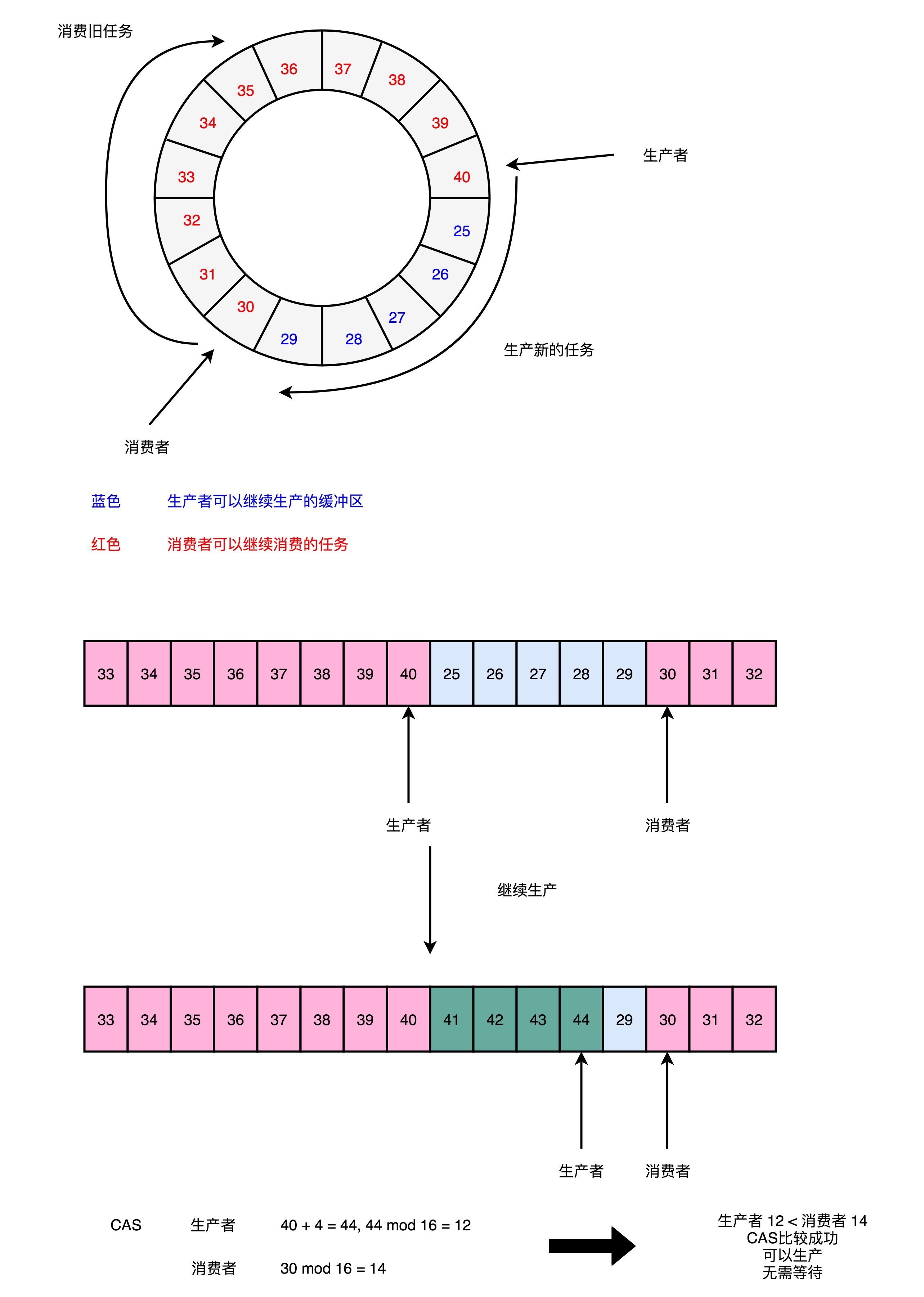
【计组】理解Disruptor--《计算机组成原理》(十五)
Disruptor 的开发语言,并不是很多人心目中最容易做到性能极限的 C/C,而是性能受限于 JVM 的 Java。其实只要通晓硬件层面的原理,即使是像 Java 这样的高级语言,也能够把 CPU 的性能发挥到极限。 一、Padding Cache Lineÿ…...
Windows11 安装Apache24全过程
Windows11 安装Apache24全过程 一、准备工作 1、apache-httpd-2.4.55-win64-VS17.zip - 蓝奏云 2、Visual Studio Code-x64-1.45.1.exe - 蓝奏云 二、实际操作 1、将下载好的zip文件解压放到指定好的文件夹。我的是D:\App\PHP下 个人习惯把版本号带上。方便检测错误。 2…...
)
1302机器翻译(队列)
目录 题目描述 提示 解题思路 代码部分 题目描述 小晨的电脑上安装了一个机器翻译软件,他经常用这个软件来翻译英语文章。 这个翻译软件的原理很简单,它只是从头到尾,依次将每个英文单词用对应的中文含义来替换。对于每个英文单词&#…...

AcWing、第 90 场周赛:4806. 首字母大写、4807. 找数字、4808. 构造字符串(C++)
目录 4806. 首字母大写 题目描述: 实现代码: 4807. 找数字 题目描述: 实现代码: 回溯(超时): 原理思路: 贪心: 原理思路: 4808. 构造字符串 问题…...

跟同事杠上了,Apache Beanutils为什么被禁止使用?
收录于热门专栏Java基础教程系列(进阶篇) 在实际的项目开发中,对象间赋值普遍存在,随着双十一、秒杀等电商过程愈加复杂,数据量也在不断攀升,效率问题,浮出水面。 问:如果是你来写…...

Golang 模糊测试的使用
一 背景 在 Go 1.18 中,Go 语言新增模糊测试(Fuzzing)。Fuzzing,又叫fuzz testing,中文叫做模糊测试或随机测试。其本质上是一种自动化测试技术,更具体一点,它是一种基于随机输入的自动化测试技术,常被用于发现处理用户输入的代码中存在的bug和问题。模糊测试和常规的功能…...

RSA公钥加密机制跨语言应用实战
在公钥密码学中(也称为非对称密码学),加密机制依赖于两个密钥:公钥和私钥。公钥用于加密消息,而只有私钥的所有者才能解密消息。实际应用中通常需要对公钥和私钥进行序列化,然后分发密钥实现在不同场景、不同语言环境中使用。本文…...

P7面试送命题
面试总结,对标市场P7。什么叫送命题,一道题回答不上来面试直接挂的题目。JVM 运行时数据区域内存回收机制GC root有哪些volatile原理synchronize原理JDK 集合家族介绍HashMap原理ConcurrentHashMap原理Thread生命周期ThreadPoolExecutor生命周期、实例化…...
零信任-微软零信任介绍(2)
微软零信任是什么? Microsoft Zero Trust 是一种安全架构,旨在在没有信任任何设备、用户或网络的情况下保护网络。这种架构使用多重验证和分段技术,以确保每个请求和资源的安全性。 零信任不假定任何内部用户或设备是安全的ÿ…...

C++中对象调用成员函数this指针的作用
C中对象调用成员函数this指针的作用 Sales_data total;//定义对象 total.isbn();//调用对象中的成员函数isbn成员函数isbn()通过一个名为this的额外隐式参数来访问调用它的对象total。当我们调用一个成员函数时,用请求该函数的对象地址初始化this。 例如࿰…...

JavaScript------数组
目录 一、简介 1、什么是数组? 2、创建数组 3、数组的数据类型 4、向数组中添加元素 5、读取数组中的元素 6、实例属性:length 二、遍历数组 方式一:for循环 方式二:for...of 三、数组方法(常用)…...

迷宫《1》
一天蒜头君掉进了一个迷宫里面,蒜头君想逃出去,可怜的蒜头君连迷宫是否有能逃出去的路都不知道。看在蒜头君这么可怜的份上,就请聪明的你告诉蒜头君是否有可以逃出去的路。输入格式第一行输入两个整数 �n 和 �m&#x…...

剑指 Offer 20. 表示数值的字符串
剑指 Offer 20. 表示数值的字符串 请实现一个函数用来判断字符串是否表示数值(包括整数和小数)。 数值(按顺序)可以分成以下几个部分: 若干空格 一个 小数 或者 整数 (可选)一个 ‘e’ 或 ‘…...

阻抗匹配之反射波形测量
稍微接触过高速信号的朋友,一定对阻抗匹配和信号反射都有所了解,甚至可以按照公式,把反射波形一路推导出来。但是,纸上得来终绝浅,绝知此事要躬行。 今天,我们就来实测一下信号反射波形,测试环…...
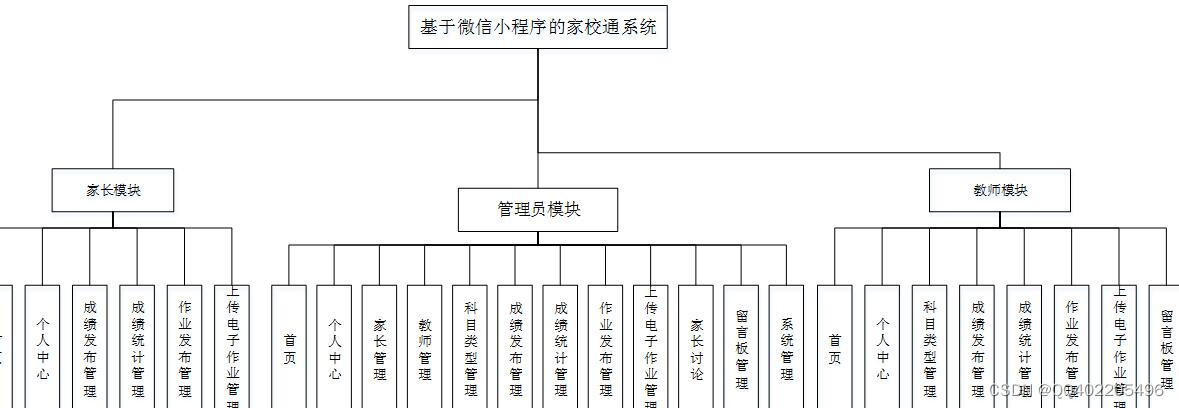
微信小程序 java家校通Springboot中小学家校联系电子作业系统
小程序前端框架:uniapp 小程序运行软件:微信开发者 后端技术:javaSsm(SpringSpringMVCMyBatis)vue.js 后端开发环境:idea/eclipse 数据库:mysql 通过对各种资料的收集,了解到“校讯通”是联系社会的窗口,是实现家校联系工作和学校…...

Fluent Python 笔记 第 8 章 对象引用、可变性和垃圾回收
本章先以一个比喻说明 Python 的变量:变量是标注,而不是盒子。如果你不知道引用式变量是什么,可以像这样对别人解释别名。 然后,本章讨论对象标识、值和别名等概念。随后,本章会揭露元组的一个神奇特性:元…...

KubeSphere 容器平台高可用:环境搭建与可视化操作指南
Linux_k8s篇 欢迎来到Linux的世界,看笔记好好学多敲多打,每个人都是大神! 题目:KubeSphere 容器平台高可用:环境搭建与可视化操作指南 版本号: 1.0,0 作者: 老王要学习 日期: 2025.06.05 适用环境: Ubuntu22 文档说…...

JavaScript 中的 ES|QL:利用 Apache Arrow 工具
作者:来自 Elastic Jeffrey Rengifo 学习如何将 ES|QL 与 JavaScript 的 Apache Arrow 客户端工具一起使用。 想获得 Elastic 认证吗?了解下一期 Elasticsearch Engineer 培训的时间吧! Elasticsearch 拥有众多新功能,助你为自己…...

FastAPI 教程:从入门到实践
FastAPI 是一个现代、快速(高性能)的 Web 框架,用于构建 API,支持 Python 3.6。它基于标准 Python 类型提示,易于学习且功能强大。以下是一个完整的 FastAPI 入门教程,涵盖从环境搭建到创建并运行一个简单的…...

前端开发面试题总结-JavaScript篇(一)
文章目录 JavaScript高频问答一、作用域与闭包1.什么是闭包(Closure)?闭包有什么应用场景和潜在问题?2.解释 JavaScript 的作用域链(Scope Chain) 二、原型与继承3.原型链是什么?如何实现继承&a…...

如何理解 IP 数据报中的 TTL?
目录 前言理解 前言 面试灵魂一问:说说对 IP 数据报中 TTL 的理解?我们都知道,IP 数据报由首部和数据两部分组成,首部又分为两部分:固定部分和可变部分,共占 20 字节,而即将讨论的 TTL 就位于首…...

【碎碎念】宝可梦 Mesh GO : 基于MESH网络的口袋妖怪 宝可梦GO游戏自组网系统
目录 游戏说明《宝可梦 Mesh GO》 —— 局域宝可梦探索Pokmon GO 类游戏核心理念应用场景Mesh 特性 宝可梦玩法融合设计游戏构想要素1. 地图探索(基于物理空间 广播范围)2. 野生宝可梦生成与广播3. 对战系统4. 道具与通信5. 延伸玩法 安全性设计 技术选…...

听写流程自动化实践,轻量级教育辅助
随着智能教育工具的发展,越来越多的传统学习方式正在被数字化、自动化所优化。听写作为语文、英语等学科中重要的基础训练形式,也迎来了更高效的解决方案。 这是一款轻量但功能强大的听写辅助工具。它是基于本地词库与可选在线语音引擎构建,…...

GitFlow 工作模式(详解)
今天再学项目的过程中遇到使用gitflow模式管理代码,因此进行学习并且发布关于gitflow的一些思考 Git与GitFlow模式 我们在写代码的时候通常会进行网上保存,无论是github还是gittee,都是一种基于git去保存代码的形式,这样保存代码…...

莫兰迪高级灰总结计划简约商务通用PPT模版
莫兰迪高级灰总结计划简约商务通用PPT模版,莫兰迪调色板清新简约工作汇报PPT模版,莫兰迪时尚风极简设计PPT模版,大学生毕业论文答辩PPT模版,莫兰迪配色总结计划简约商务通用PPT模版,莫兰迪商务汇报PPT模版,…...

Go语言多线程问题
打印零与奇偶数(leetcode 1116) 方法1:使用互斥锁和条件变量 package mainimport ("fmt""sync" )type ZeroEvenOdd struct {n intzeroMutex sync.MutexevenMutex sync.MutexoddMutex sync.Mutexcurrent int…...