昇思25天学习打卡营第3天|基础知识-数据集Dataset
目录
环境
环境
导包
数据集加载
数据集迭代
数据集常用操作
shuffle
map
batch
自定义数据集
可随机访问数据集
可迭代数据集
生成器
MindSpore提供基于Pipeline的数据引擎,通过数据集(Dataset)和数据变换(Transforms)实现高效的数据预处理。
其中Dataset是Pipeline的起始,用于加载原始数据。
mindspore.dataset提供了内置的文本、图像、音频等数据集加载接口,并提供了自定义数据集加载接口。
环境
环境
%%capture captured_output
# 实验环境已经预装了mindspore==2.2.14,如需更换mindspore版本,可更改下面mindspore的版本号
!pip uninstall mindspore -y
!pip install -i https://pypi.mirrors.ustc.edu.cn/simple mindspore==2.2.14导包
import numpy as np
from mindspore.dataset import vision
from mindspore.dataset import MnistDataset, GeneratorDataset
import matplotlib.pyplot as plt数据集加载
以Mnist数据集作为样例,使用mindspore.dataset进行加载。
mindspore.dataset提供的接口仅支持解压后的数据文件,使用download库下载数据集并解压。
Mnist数据集,是一个广泛应用于机器学习领域的手写数字图像数据集。所有图像都是28×28的灰度图像,每张图像包含一个手写数字(0-9)。
# Download data from open datasets
from download import downloadurl = "https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/" \"notebook/datasets/MNIST_Data.zip"
path = download(url, "./", kind="zip", replace=True)压缩文件删除后,直接加载,可以看到其数据类型为MnistDataset。
train_dataset = MnistDataset("MNIST_Data/train", shuffle=False)
print(type(train_dataset))# <class 'mindspore.dataset.engine.datasets_vision.MnistDataset'>数据集迭代
数据集加载后,一般以迭代方式获取数据,然后送入神经网络中进行训练。
可以用create_tuple_iterator或create_dict_iterator接口创建数据迭代器,迭代访问数据。
访问的数据类型默认为Tensor;若设置output_numpy=True,访问的数据类型为Numpy。
下面定义一个可视化函数,迭代9张图片进行展示。
def visualize(dataset):# 使用plt.figure(figsize=(4, 4))初始化一个图形figure = plt.figure(figsize=(4, 4))cols, rows = 3, 3# 用于调整子图之间的水平和垂直间距plt.subplots_adjust(wspace=0.5, hspace=0.5)# 使用enumerate(dataset.create_tuple_iterator())遍历数据集,每次迭代返回一个索引(idx)、图像(image)和标签(label)# figure.add_subplot(rows, cols, idx + 1)用于在图形中添加子图,但注意索引是从1开始的,因为Matplotlib的子图索引是基于1的。# plt.title(int(label))设置子图的标题为标签的整数值。# plt.axis("off")关闭子图的坐标轴。# plt.imshow(image.asnumpy().squeeze(), cmap="gray")显示图像。这里image.asnumpy().squeeze()假设image是一个可以转换为NumPy数组的对象,并且squeeze()用于移除单维度条目。for idx, (image, label) in enumerate(dataset.create_tuple_iterator()):figure.add_subplot(rows, cols, idx + 1)plt.title(int(label))plt.axis("off")plt.imshow(image.asnumpy().squeeze(), cmap="gray")# 确保只绘制前9个图像if idx == cols * rows - 1:breakplt.show()visualize(train_dataset)
数据集常用操作
Pipeline的设计理念使得数据集的常用操作采用dataset = dataset.operation()的异步执行方式,执行操作返回新的Dataset,此时不执行具体操作,而是在Pipeline中加入节点,最终进行迭代时,并行执行整个Pipeline。
几种常见的数据集操作如下:
shuffle
数据集随机shuffle可以消除数据排列造成的分布不均问题。

mindspore.dataset提供的数据集在加载时可配置shuffle=True,或使用如下操作:
train_dataset = train_dataset.shuffle(buffer_size=64)visualize(train_dataset)
map
map操作是数据预处理的关键操作,可以针对数据集指定列(column)添加数据变换(Transforms),将数据变换应用于该列数据的每个元素,并返回包含变换后元素的新数据集。
image, label = next(train_dataset.create_tuple_iterator())
print(image.shape, image.dtype)# (28, 28, 1) UInt8对Mnist数据集做数据缩放处理,将图像统一除以255,数据类型由uint8转为了float32。
train_dataset = train_dataset.map(vision.Rescale(1.0 / 255.0, 0), input_columns='image')对比map前后的数据,看数据类型变化。
image, label = next(train_dataset.create_tuple_iterator())
print(image.shape, image.dtype)# (28, 28, 1) Float32batch
将数据集打包为固定大小的batch是在有限硬件资源下使用梯度下降进行模型优化的折中方法,可以保证梯度下降的随机性和优化计算量。

一般我们会设置一个固定的batch size,将连续的数据分为若干批(batch)
train_dataset = train_dataset.batch(batch_size=32)batch后的数据增加一维,大小为batch_size
image, label = next(train_dataset.create_tuple_iterator())
print(image.shape, image.dtype)# (32, 28, 28, 1) Float32自定义数据集
mindspore.dataset模块提供了一些常用的公开数据集和标准格式数据集的加载API。
对于MindSpore暂不支持直接加载的数据集,可以构造自定义数据加载类或自定义数据集生成函数的方式来生成数据集,然后通过GeneratorDataset接口实现自定义方式的数据集加载。
GeneratorDataset支持通过可随机访问数据集对象、可迭代数据集对象和生成器(generator)构造自定义数据集。
可随机访问数据集
可随机访问数据集是实现了__getitem__和__len__方法的数据集,表示可以通过索引/键直接访问对应位置的数据样本。
例如,当使用dataset[idx]访问这样的数据集时,可以读取dataset内容中第idx个样本或标签。
# Random-accessible object as input source
class RandomAccessDataset:def __init__(self):self._data = np.ones((5, 2))self._label = np.zeros((5, 1))def __getitem__(self, index):return self._data[index], self._label[index]def __len__(self):return len(self._data)loader = RandomAccessDataset()
dataset = GeneratorDataset(source=loader, column_names=["data", "label"])for data in dataset:print(data)# [Tensor(shape=[2], dtype=Float64, value= [ 1.00000000e+00, 1.00000000e+00]),
# Tensor(shape=[1], dtype=Float64, value= [ 0.00000000e+00])]
# [Tensor(shape=[2], dtype=Float64, value= [ 1.00000000e+00, 1.00000000e+00]),
# Tensor(shape=[1], dtype=Float64, value= [ 0.00000000e+00])]
# [Tensor(shape=[2], dtype=Float64, value= [ 1.00000000e+00, 1.00000000e+00]),
# Tensor(shape=[1], dtype=Float64, value= [ 0.00000000e+00])]
# [Tensor(shape=[2], dtype=Float64, value= [ 1.00000000e+00, 1.00000000e+00]),
# Tensor(shape=[1], dtype=Float64, value= [ 0.00000000e+00])]
# [Tensor(shape=[2], dtype=Float64, value= [ 1.00000000e+00, 1.00000000e+00]), #Tensor(shape=[1], dtype=Float64, value= [ 0.00000000e+00])]# list, tuple are also supported.
loader = [np.array(0), np.array(1), np.array(2)]
dataset = GeneratorDataset(source=loader, column_names=["data"])for data in dataset:print(data)# [Tensor(shape=[], dtype=Int64, value= 0)]
# [Tensor(shape=[], dtype=Int64, value= 1)]
# [Tensor(shape=[], dtype=Int64, value= 2)]
可迭代数据集
可迭代的数据集是实现了__iter__和__next__方法的数据集,表示可以通过迭代的方式逐步获取数据样本。这种类型的数据集特别适用于随机访问成本太高或者不可行的情况。
例如,当使用iter(dataset)的形式访问数据集时,可以读取从数据库、远程服务器返回的数据流。
下面构造一个简单迭代器,并将其加载至GeneratorDataset。
# Iterator as input source
class IterableDataset():def __init__(self, start, end):'''init the class object to hold the data'''self.start = startself.end = enddef __next__(self):'''iter one data and return'''return next(self.data)def __iter__(self):'''reset the iter'''self.data = iter(range(self.start, self.end))return selfloader = IterableDataset(1, 5)
dataset = GeneratorDataset(source=loader, column_names=["data"])for d in dataset:print(d)# [Tensor(shape=[], dtype=Int64, value= 1)]
# [Tensor(shape=[], dtype=Int64, value= 2)]
# [Tensor(shape=[], dtype=Int64, value= 3)]
# [Tensor(shape=[], dtype=Int64, value= 4)]生成器
生成器也属于可迭代的数据集类型,其直接依赖Python的生成器类型generator返回数据,直至生成器抛出StopIteration异常。
下面构造一个生成器,并将其加载至GeneratorDataset。
# Generator
def my_generator(start, end):for i in range(start, end):yield i# since a generator instance can be only iterated once, we need to wrap it by lambda to generate multiple instances
dataset = GeneratorDataset(source=lambda: my_generator(3, 6), column_names=["data"])for d in dataset:print(d)# [Tensor(shape=[], dtype=Int64, value= 3)]
# [Tensor(shape=[], dtype=Int64, value= 4)]
# [Tensor(shape=[], dtype=Int64, value= 5)]学习打卡第三天

相关文章:
昇思25天学习打卡营第3天|基础知识-数据集Dataset
目录 环境 环境 导包 数据集加载 数据集迭代 数据集常用操作 shuffle map batch 自定义数据集 可随机访问数据集 可迭代数据集 生成器 MindSpore提供基于Pipeline的数据引擎,通过数据集(Dataset)和数据变换(Transfor…...

C++11新特性——智能指针——参考bibi《 原子之音》的视频以及ChatGpt
智能指针 一、内存泄露1.1 内存泄露常见原因1.2 如何避免内存泄露 二、实例Demo2.1 文件结构2.2 Dog.h2.3 Dog.cpp2.3 mian.cpp 三、独占式智能指针:unique _ptr3.1 创建方式3.1.1 ⭐从原始(裸)指针转换:3.1.2 ⭐⭐使用 new 关键字直接创建:3.1.3 ⭐⭐⭐…...
“微软蓝屏”全球宕机,敲响基础软件自主可控警钟
上周五,“微软蓝屏”“感谢微软 喜提假期”等词条冲上热搜,全球百万打工人受此影响,共同见证这一历史性事件。据微软方面发布消息称,旗下Microsoft 365系列服务出现访问中断。随后在全球范围内,包括企业、政府、个人在…...

【Linux C | 网络编程】进程间传递文件描述符socketpair、sendmsg、recvmsg详解
我们的目的是,实现进程间传递文件描述符,是指 A进程打开文件fileA,获得文件描述符为fdA,现在 A进程要通过某种方法,传递fdA,使得另一个进程B,获得一个新的文件描述符fdB,这个fdB在进程B中的作用…...
Page Cache回收功能的实现)
高并发内存池(六)Page Cache回收功能的实现
当Page Cache接收了一个来自Central Cache的Span,根据Span的起始页的_pageId来对前一页所对应的Span进行查找,并判断该Span,是否处于使用状态,从而看是否可以合并,如果可以合并继续向前寻找。 当该Span前的空闲Span查…...

浅析JWT原理及牛客出现过的相关面试题
原文链接:https://kixuan.github.io/posts/f568/ 对jwt总是一知半解,而且项目打算写个关于JWT登录的点,所以总结关于JWT的知识及网上面试考察过的点 参考资料: Cookie、Session、Token、JWT_通俗地讲就是验证当前用户的身份,证明-…...

Spring AI (五) Message 消息
5.Message 消息 在Spring AI提供的接口中,每条信息的角色总共分为三类: SystemMessage:系统限制信息,这种信息在对话中的权重很大,AI会优先依据SystemMessage里的内容进行回复; UserMessage:用…...

【windows Docker desktop】在git bash中报错 docker: command not found 解决办法
【windows Docker desktop】在git bash中报错 docker: command not found 解决办法 1. 首先检查在windows中环境变量是否设置成功2. 检查docker在git bash中环境变量是否配置3. 重新加载终端配置4. 最后在校验一下是否配置成功 1. 首先检查在windows中环境变量是否设置成功 启…...

02.FreeRTOS的移植
文章目录 FreeRTOS移植到STM32F103ZET6上的详细步骤1. 移植前的准备工作2. 添加FreeRTOS文件3. 修改SYSTEM文件4. 修改中断相关文件5. 修改FreeRTOSConfig.h文件6. 可选步骤 FreeRTOS移植到STM32F103ZET6上的详细步骤 1. 移植前的准备工作 **基础工程:**内存管理部…...

【个人笔记】一个例子理解工厂模式
工厂模式优点:创建时类名过长或者参数过多或者创建很麻烦等情况时用,可以减少重复代码,简化对象的创建过程,避免暴露创建逻辑,也适用于需要统一管理所有创建对象的情况,比如线程池的工厂类Executors 简单工…...

【C语言】数组栈的实现
栈的概念及结构 栈:一种特殊的线性表,其只允许在固定的一端进行插入和删除元素操作。进行数据插入和删除操作的一端 称为栈顶,另一端称为栈底。栈中的数据元素遵守后进先出LIFO(Last In First Out)的原则。 压栈&#…...

kafka 各种选举过程
一、kafka 消费者组协调器 如何选举 Kafka 中的消费者组协调器(Group Coordinator)是通过以下步骤选举的: 分区映射: Kafka 使用一个特殊的内部主题 __consumer_offsets 来存储消费者组的元数据。该主题有多个分区,每…...

树与二叉树【数据结构】
前言 之前我们已经学习过了各种线性的数据结构,顺序表、链表、栈、队列,现在我们一起来了解一下一种非线性的结构----树 1.树的结构和概念 1.1树的概念 树是一种非线性的数据结构,它是由n(n>0)个有限结点组成一…...

简单几步,把浏览器书签转换成导航网页
废话不多说直奔主题上干货 Step 1 下载浏览器书签 1,电脑浏览器点击下载Pintree Pintree 是一个开源项目,旨在将浏览器书签导出成导航网站。通过简单的几步操作,就可以将你的书签转换成一个美观且易用的导航页面。 2. 安装 Pintree B…...

Mac安装Hoomebrew与升级Python版本
参考 mac 安装HomeBrew(100%成功)_mac安装homebrew-CSDN博客 /bin/zsh -c "$(curl -fsSL https://gitee.com/cunkai/HomebrewCN/raw/master/Homebrew.sh)" 安装了Python 3.x版本,你可以使用以下命令来设置默认的Python版本: # 首先找到新安…...

代码审计:Bluecms v1.6
代码审计:Bluecms v1.6 漏洞列表如下(附Exp): 未完待续… 1、include/common.fun.php->getip()存在ip伪造漏洞 2、ad_js.php sql注入漏洞 Exp:view-source:http://127.0.0.3/bluecms/ad_js.php?ad_id12%20UNION%20SELECT1,2,3,4,5,6,database() 3、…...

谷粒商城实战笔记-59-商品服务-API-品牌管理-使用逆向工程的前后端代码
文章目录 一, 使用逆向工程生成的代码二,生成品牌管理菜单三,几个小问题 在本次的技术实践中,我们利用逆向工程的方法成功地为后台管理系统增加了品牌管理功能。这种开发方式不仅能快速地构建起功能模块,还能在一定程度…...

如何利用Jenkins自动化管理、部署数百个应用
目录 1. Jenkins 安装与部署步骤 1.1 系统要求 1.2 安装步骤 1.2.1 Windows 系统 1.2.2 CentOS 系统 1.3 初次配置 2. Gradle 详细配置方式 2.1 安装 Gradle 2.1.1 Windows 系统 2.1.2 CentOS 系统 2.2 配置 Jenkins 中的 Gradle 3. JDK 详细配置方式 3.1 安装 JD…...

Java之归并排序
归并排序 归并排序(Merge Sort)算法,使用的是分治思想。分治,顾名思义,就是分而治之,将一个大问题分解成小的子问题来解决。小的子问题解决了,大问题也就解决了。 核心源码: mergeSort(m->n) merge(mergeSort(m-&g…...

了解ChatGPT API
要了解如何使用 ChatGPT API,可以参考几个有用的资源和教程,这些资源能帮助你快速开始使用 API 进行项目开发。下面是一些推荐的资源: OpenAI 官方文档: 访问 OpenAI 的官方网站可以找到 ChatGPT API 的详细文档。这里包括了 API …...

多云管理“拦路虎”:深入解析网络互联、身份同步与成本可视化的技术复杂度
一、引言:多云环境的技术复杂性本质 企业采用多云策略已从技术选型升维至生存刚需。当业务系统分散部署在多个云平台时,基础设施的技术债呈现指数级积累。网络连接、身份认证、成本管理这三大核心挑战相互嵌套:跨云网络构建数据…...

C++初阶-list的底层
目录 1.std::list实现的所有代码 2.list的简单介绍 2.1实现list的类 2.2_list_iterator的实现 2.2.1_list_iterator实现的原因和好处 2.2.2_list_iterator实现 2.3_list_node的实现 2.3.1. 避免递归的模板依赖 2.3.2. 内存布局一致性 2.3.3. 类型安全的替代方案 2.3.…...

DAY 47
三、通道注意力 3.1 通道注意力的定义 # 新增:通道注意力模块(SE模块) class ChannelAttention(nn.Module):"""通道注意力模块(Squeeze-and-Excitation)"""def __init__(self, in_channels, reduction_rat…...

【ROS】Nav2源码之nav2_behavior_tree-行为树节点列表
1、行为树节点分类 在 Nav2(Navigation2)的行为树框架中,行为树节点插件按照功能分为 Action(动作节点)、Condition(条件节点)、Control(控制节点) 和 Decorator(装饰节点) 四类。 1.1 动作节点 Action 执行具体的机器人操作或任务,直接与硬件、传感器或外部系统…...

MySQL 8.0 OCP 英文题库解析(十三)
Oracle 为庆祝 MySQL 30 周年,截止到 2025.07.31 之前。所有人均可以免费考取原价245美元的MySQL OCP 认证。 从今天开始,将英文题库免费公布出来,并进行解析,帮助大家在一个月之内轻松通过OCP认证。 本期公布试题111~120 试题1…...

CVE-2020-17519源码分析与漏洞复现(Flink 任意文件读取)
漏洞概览 漏洞名称:Apache Flink REST API 任意文件读取漏洞CVE编号:CVE-2020-17519CVSS评分:7.5影响版本:Apache Flink 1.11.0、1.11.1、1.11.2修复版本:≥ 1.11.3 或 ≥ 1.12.0漏洞类型:路径遍历&#x…...

【VLNs篇】07:NavRL—在动态环境中学习安全飞行
项目内容论文标题NavRL: 在动态环境中学习安全飞行 (NavRL: Learning Safe Flight in Dynamic Environments)核心问题解决无人机在包含静态和动态障碍物的复杂环境中进行安全、高效自主导航的挑战,克服传统方法和现有强化学习方法的局限性。核心算法基于近端策略优化…...

离线语音识别方案分析
随着人工智能技术的不断发展,语音识别技术也得到了广泛的应用,从智能家居到车载系统,语音识别正在改变我们与设备的交互方式。尤其是离线语音识别,由于其在没有网络连接的情况下仍然能提供稳定、准确的语音处理能力,广…...

从物理机到云原生:全面解析计算虚拟化技术的演进与应用
前言:我的虚拟化技术探索之旅 我最早接触"虚拟机"的概念是从Java开始的——JVM(Java Virtual Machine)让"一次编写,到处运行"成为可能。这个软件层面的虚拟化让我着迷,但直到后来接触VMware和Doc…...
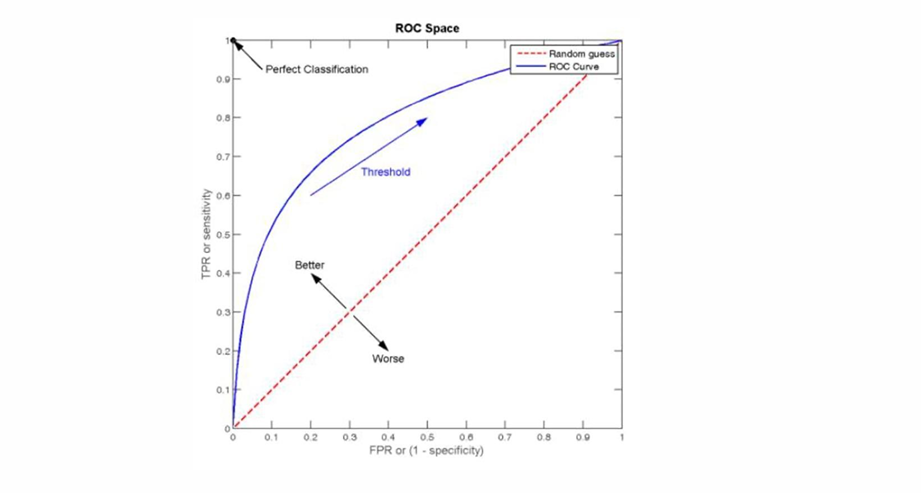
自然语言处理——文本分类
文本分类 传统机器学习方法文本表示向量空间模型 特征选择文档频率互信息信息增益(IG) 分类器设计贝叶斯理论:线性判别函数 文本分类性能评估P-R曲线ROC曲线 将文本文档或句子分类为预定义的类或类别, 有单标签多类别文本分类和多…...