汽车长翅膀:GPU 是如何加速深度学习模型的训练和推理过程的?
编者按:深度学习的飞速发展离不开硬件技术的突破,而 GPU 的崛起无疑是其中最大的推力之一。但你是否曾好奇过,为何一行简单的“.to(‘cuda’)”代码就能让模型的训练速度突飞猛进?本文正是为解答这个疑问而作。
作者以独特的视角,将复杂的 GPU 并行计算原理转化为通俗易懂的概念。从 CPU 与 GPU 的设计哲学对比,到 CUDA 编程的核心要素,再到具体的代码实现,文章循序渐进地引领读者把握 GPU 并行计算的精髓。特别是文中巧妙的比喻 —— 将 CPU 比作法拉利,GPU 比作公交车,这一比喻生动形象地诠释了两种处理器的特性。
这篇文章不仅回答了"为什么",更指明了"如何做",在当前人工智能技术飞速发展的背景下,理解底层技术原理的重要性不言而喻。这篇文章虽为入门级别的技术内容介绍,但也提到了更高级的优化技术和工具库,指明了进一步的学习方向,具有一定的学习和参考价值。
作者 | Lucas de Lima Nogueira
编译 | 岳扬

Image by the author with the assistance of AI (https://copilot.microsoft.com/images/create)
现如今,当我们提及深度学习时,人们自然而然地会联想到通过 GPU 来增强其性能。
GPU(图形处理器,Graphical Processing Units)起初是为了加速图像(images)及 2D、3D 图形(graphics)的渲染而生。但凭借其强大的并行运算能力,GPU 的应用范围迅速拓展,已扩展至深度学习(deep learning)等应用领域。
GPU 在深度学习模型中的应用始于 2000 年代中后期,2012 年 AlexNet 的横空出世更是将这种趋势推向高潮。 AlexNet,这款由 Alex Krizhevsky、Ilya Sutskever 和 Geoffrey Hinton 共同设计、研发的卷积神经网络,在 2012 年的 ImageNet Large Scale Visual Recognition Challenge (ILSVRC) 上一鸣惊人。这一胜利具有里程碑式的意义,它不仅证实了深度神经网络在图像分类领域(image classification)的卓越性能,同时也彰显了使用 GPU 训练大型模型的有效性。
在这一技术突破之后,GPU 在深度学习模型中的应用愈发广泛,PyTorch 和 TensorFlow 等框架应运而生。
如今,我们只需在 PyTorch 中轻敲 .to(“cuda”),即可将数据传递给 GPU,从而加速模型的训练。但在实践中,深度学习算法究竟是如何巧妙地利用 GPU 算力的呢?让我们一探究竟吧!
深度学习的核心架构,如神经网络、CNNs、RNNs 和 transformer,其本质都围绕着矩阵加法(matrix addition)、矩阵乘法(matrix multiplication)以及对矩阵应用函数(applying a function a matrix)等基本数学操作展开。因此,优化这些核心运算,便是提升深度学习模型性能的关键所在。
那么,让我们从最基础的场景说起。想象一下,你需要对两个向量执行相加操作 C = A + B。
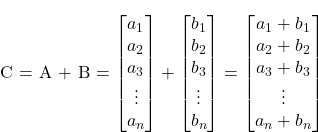
可以用 C 语言简单实现这一功能:

不难发现,传统上,计算机需逐一访问向量中的各个元素(elements),在每次迭代中按顺序对每对元素进行加法运算。但有一点需要注意,各对元素间的加法操作互不影响,即任意一对元素的加法不依赖于其它任何一对。那么,若我们能同时执行这些数学运算,实现所有元素对(pairs of elements)的并行相加,效果会如何呢?
直接做法是借助 CPU 的多线程功能,并行执行所有数学运算。但在深度学习领域,我们需要处理的向量规模巨大,往往包含数百万个元素。通常情况下,普通 CPU 只能同时处理十几条线程。此时,GPU 的优势便凸显出来!目前的主流 GPU 能够同时运行数百万个线程,极大地提高了处理大规模向量中数学运算的效率。
01 GPU vs. CPU comparison
虽然从单次运算(single operation)的处理速度来看,CPU 或许略胜 GPU 一筹,但 GPU 的优势在于其卓越的并行处理能力。究其根源,这一情况源于两者设计初衷的差异。CPU 的设计侧重于高效执行单一序列的操作(即线程(thread)),但一次仅能同时处理几十个;相比之下,GPU 的设计目标是实现数百万个线程的并行运算,虽有所牺牲单个线程的运算速度,却在整体并行性能上实现了质的飞跃。
打个比方,你可以将 CPU 视作一辆炫酷的法拉利(Ferrari)跑车,而 GPU 则如同一辆宽敞的公交车。倘若你的任务仅仅是运送一位乘客,毫无疑问,法拉利(CPU)是最佳选择。然而,如若当前的运输需求是运送多位乘客,即使法拉利(CPU)单程速度占优,公交车(GPU)却能一次容纳全部乘客,其集体运输效率远超法拉利多次单独接送的效率。由此可见,CPU 更适于处理连续性的单一任务,而 GPU 则在并行处理大量任务时展现出色的效能。

Image by the author with the assistance of AI (https://copilot.microsoft.com/images/create)
为了实现更出色的并行计算能力,GPU 在设计上倾向于将更多晶体管资源(transistors)投入到数据处理中,而非数据缓存(data caching)和流控机制(flow contro),这与 CPU 的设计思路大相径庭。CPU 为了优化单一线程的执行效率和复杂指令集的处理,特意划拨了大量的晶体管来加强这些方面的性能。
下图生动地描绘了 CPU 与 GPU 在芯片资源分配上的显著差异。
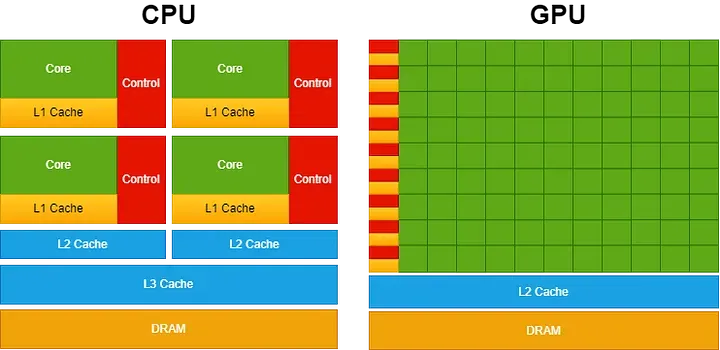
Image by the author with inspiration from CUDA C++ Programming Guide
(https://docs.nvidia.com/cuda/pdf/CUDA_C_Programming_Guide.pdf)
CPU 配备了高性能内核(powerful cores)与更为精妙的缓存内存架构(cache memory architecture)(消耗了相当多的晶体管资源),这种设计方案能够极大地优化顺序任务的执行速度。而图形处理器(GPU)则着重于内核(cores)数量,以实现更高的并行处理能力。
现在已经介绍完这些基础知识,那么在实际应用中,我们应如何有效利用并行计算的优势呢?
02 Introduction to CUDA
当我们着手构建深度学习模型时,很可能会倾向于采用诸如 PyTorch 或 TensorFlow 这类广受欢迎的 Python 开发库。尽管如此,一个不争的事实是,这些库的核心代码都是 C/C++ 代码。另外,正如我们先前所提及的,利用 GPU 加快数据的处理速度往往是一种主流优化方案。此时,CUDA 的重要作用便凸显出来!CUDA 是统一计算设备架构(Compute Unified Device Architecture)的缩写,是英伟达(NVIDIA)为使 GPU 能够在通用计算领域大放光彩而精心打造的平台。与 DirectX 被游戏引擎用于图形运算(graphical computation)不同,CUDA 使开发人员能够将英伟达(NVIDIA)的 GPU 计算能力集成到通用软件中,而不仅仅局限于图形渲染。
为了实现这一目标,CUDA 推出了一款基于 C/C++ 的简易接口(CUDA C/C++),帮助开发者调用 GPU 虚拟指令集(virtual intruction se)及执行特定操作(specific operations)(如在 CPU 与 GPU 间传输数据)。
在继续深入技术细节之前,我们有必要澄清几个 CUDA 编程的基础概念和专业术语:
- host:特指 CPU 及其配套内存;
- device:对应 GPU 及其专属内存;
- kernel:指代在设备(GPU)上运行的函数代码;
因此,在一份使用 CUDA 撰写的基本代码(basic code)中,程序主体在 host (CPU) 上执行,随后将数据传递给 device (GPU) ,并调用 kernels (functions) 在 device (GPU) 上并行运行。这些 kernels 由多条线程同时执行。运算完成后,结果再从 device (GPU) 回传至 host (CPU) 。
话说回来,让我们再次聚焦于两组向量相加这个具体问题:

借助 CUDA C/C++,编程人员能够创建一种被称为 kernels 的 C/C++ 函数;一旦这些 kernels 被调用, N 个不同的 CUDA 线程会并行执行 N 次。
若想定义这类 kernel,可运用 __global__ 关键字作为声明限定符(declaration specifier),而若欲设定执行该 kernel 的具体 CUDA 线程数目,则需采用 <<<...>>> 来完成:

每个 CUDA 线程在执行 kernel 时,都会被赋予一个独一无二的线程 ID,即 threadIdx,它可以通过 kernel 中的预设变量获取。上述示例代码将两个长度(size)均为 N 的向量 A 和 B 相加,并将结果保存到向量 C 中。值得我们注意的是,相较于循环逐次处理成对加法的传统串行方式,CUDA 的优势在于其能够并行利用 N 个线程,一次性完成全部加法运算。
不过,在运行上述这段代码前,我们还需对其进行一次修改。切记,kernel 函数的运行环境是 device (GPU) ,这意味着所有相关数据均须驻留于 device 的内存之中。 要达到这一要求,可以借助 CUDA 提供的以下内置函数:

直接将变量 A、B 和 C 传入 kernel 的做法并不适用于本情况,我们应当使用指针。在 CUDA 编程环境下,host 数组(比如示例中的 A、B 和 C)无法直接用于 kernel 启动(<<<…>>>)。鉴于 CUDA kernels 的工作空间为 device 的内存(device memory),故需向 kernel 提供 device 指针(device pointers)(d_A、d_B 和 d_C),以确保其能在 device 的内存上运行。
除此之外,我们还需通过调用 cudaMalloc 函数在 device 上划分内存空间,并运用 cudaMemcpy 实现 host 和 device 之间的数据传输。
至此,我们可在代码中实现向量 A 和 B 的初始化,并在程序结尾处清理 CUDA 内存(cuda memory)。

另外,调用 kernel 后,务必插入 cudaDeviceSynchronize(); 这一行代码。该函数的作用在于协调 host 线程与 device 间的同步,确保 host 线程在继续执行前,device 已完成所有先前提交的 CUDA 操作。
此外,CUDA 的错误检测机制同样不可或缺,这种检测机制能协助我们及时发现并修正 GPU 上潜在的程序缺陷(bugs)。倘若忽略此环节,device 线程(CPU)将持续运行,而 CUDA 相关的故障排查则将变得异常棘手,很难识别与 CUDA 相关的错误。
下面是这两种技术的具体实现方式:

要编译和运行 CUDA 代码,首先需要确保系统中已装有 CUDA 工具包(CUDA toolkit)。紧接着,使用 nvcc —— NVIDIA CUDA 编译器完成相关代码编译工作。

然而,当前的代码尚存优化空间。在前述示例中,我们处理的向量规模仅为 N = 1000,这一数值偏小,难以充分展示 GPU 强大的并行处理能力。特别是在深度学习场景下,我们时常要应对含有数以百万计参数的巨型向量。然而,倘若尝试将 N 的数值设为 500000,并采用 <<<1, 500000>>> 的方式运行 kernel ,上述代码便会抛出错误。因此,为了完善代码,使之能顺利执行此类大规模运算,我们亟需掌握 CUDA 编程中的核心理念 —— 线程层级结构(Thread hierarchy)。
03 Thread hierarchy(线程层级结构)
调用 kernel 函数时,采用的是 <<<number_of_blocks, threads_per_block>>> 这种格式(notation)。因此,在上述示例中,我们是以单个线程块的形式,启动了 N 个 CUDA 线程。然而,每个线程块所能容纳的线程数量都有限制,这是因为所有处于同一线程块内的线程,都被要求共存于同一流式多处理器核心(streaming multiprocessor core),并共同使用该核心的内存资源。
欲查询这一限制数量的具体数值,可通过以下代码实现:

就作者当前使用的 GPU 而言,其单一线程块最多能承载 1024 个线程。因此,为了有效处理示例中提及的巨型向量(massive vector),我们必须部署更多线程块,以实现更大规模的线程并发执行。 同时,这些线程块被精心布局成网格状结构(grids),如下图所展示:

https://handwiki.org/wiki/index.php?curid=1157670 (CC BY-SA 3.0)
现在,我们可以通过以下途径获取线程 ID:
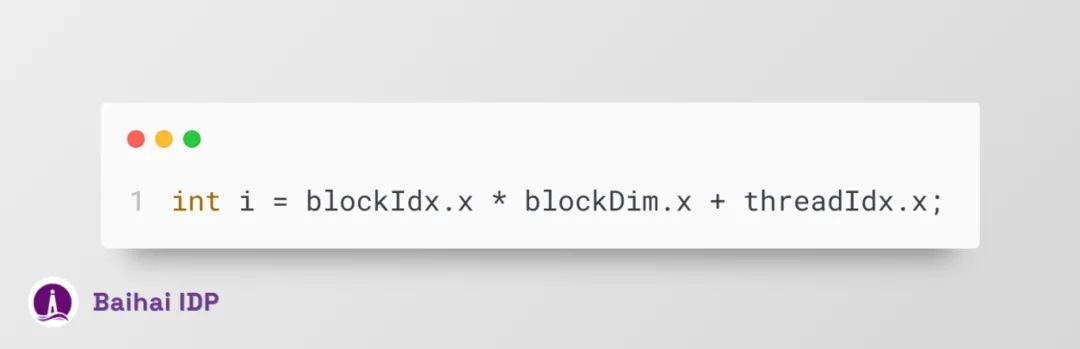
于是,该代码脚本更新为:

04 性能对比分析
下表展示了在处理不同大小向量的加法运算时,CPU 与 GPU 的计算性能对比情况。
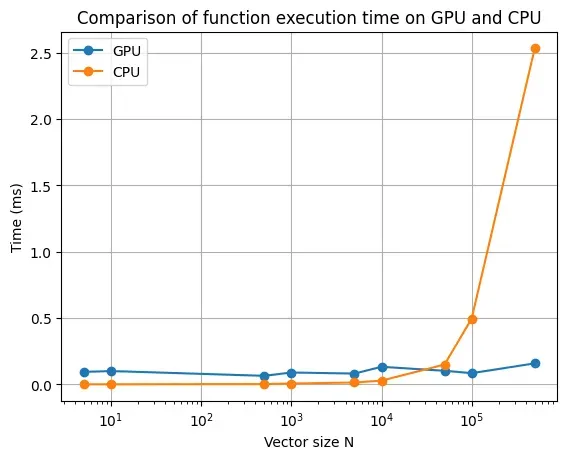
Image by the author
显而易见,GPU 的处理效能优势,唯有在处理大规模向量时方能得以凸显。此外,切勿忽视一件事,此处的时间对比仅仅考量了 kernel/function 的执行耗时,而未将 host 和 device 间数据传输所需的时间纳入考虑范围。尽管在大多数情况下,数据传输的时间开销微不足道,但就我们目前仅执行简易加法运算(simple addition operation)的情形而言,这部分时间消耗却显得相对可观。因此,我们应当铭记,GPU 的计算性能,仅在面对那些既高度依赖计算能力又适合大规模并行处理的任务时,才能得以淋漓尽致地展现。
05 多维线程处理(Multidimensional threads)
现在,我们已经知道如何提升简单数组操作(simple array operation)的性能了。然而,在处理深度学习模型时,必须要处理矩阵和张量运算(matrix and tensor operations)。在前文的示例中,我们仅使用了内含 N 个线程的一维线程块(one-dimensional blocks)。然而,执行多维线程块(multidimensional thread blocks)(最高支持三维)同样也是完全可行的。因此,为了方便起见,当我们需要处理矩阵运算时,可运行一个由 N x M 个线程组成的线程块。还可以通过 row = threadIdx.x 来确定矩阵的行索引,而 col = threadIdx.y 则可用来获取列索引。此外,为了简化操作,还可以使用 dim3 变量类型定义 number_of_blocks 和 threads_per_block。
下文的示例代码展示了如何实现两个矩阵的相加运算。

此外,我们还可以将此示例进一步拓展,实现对多个线程块的处理:

此外,我们也可以用同样的思路将这个示例扩展到三维运算(3-dimensional operations)操作的处理。
上文已经介绍了处理多维数据(multidimensional data)的方法,接下来,还有一个既重要又容易理解的概念值得我们学习:如何在 kernel 中调用 functions。 一般可以通过使用 __device__ 声明限定符(declaration specifier)来实现。这种限定符定义了可由 device (GPU)直接调用的函数(functions)。因此,这些函数仅能在 __global__ 或其他 __device__ 函数中被调用。下面这个示例展示了如何对一个向量进行 sigmoid 运算(这是深度学习模型中极其常见的一种运算方式)。

至此,我们已经掌握了 CUDA 编程的核心概念,现在可以着手构建 CUDA kernels 了。对于深度学习模型而言,其实质就是一系列涉及矩阵(matrix)与张量(tensor)的运算操作,包括但不限于求和(sum)、乘法(multiplication)、卷积(convolution)以及归一化(normalization )等。举个例子,一个基础的矩阵乘法算法,可以通过以下方式实现并行化:
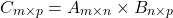

我们可以注意到,在 GPU 版本的矩阵乘法算法中,循环次数明显减少,从而显著提升了运算处理速度。下面这张图表直观地展现了 N x N 矩阵乘法在 CPU 与 GPU 上的性能对比情况:
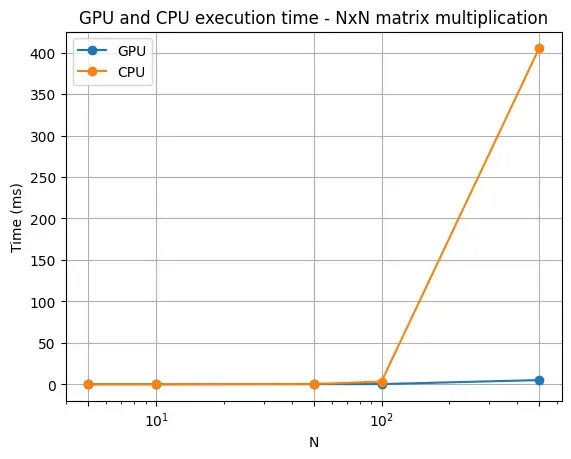
Image by the author
我们会发现,随着矩阵大小(matrix size)的增大,GPU 在处理矩阵乘法运算时的性能提升幅度更大。
接下来,让我们聚焦于一个基础的神经网络模型,其核心运算通常表现为 y = σ(Wx + b),如下图所示:
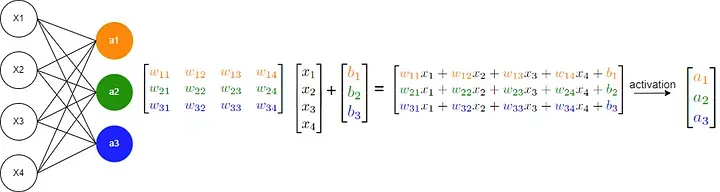
Image by the author
上述运算主要涉及矩阵乘法(matrix multiplication)、矩阵加法(matrix addition)以及对数组施加函数变换(applying a function to an array)。如若你已掌握这些并行化处理技术,意味着你现在完全具备了从零构建、并在 GPU 上构建神经网络的能力!
06 Conclusion
本文我们探讨了通过 GPU processing (译者注:使用 GPU进行数据处理和计算。)提升深度学习模型效能的入门概念。不过,有一点还需要指出,本文所介绍的内容仅仅是皮毛,背后还隐藏着很多很多更深层次的东西。PyTorch 和 Tensorflow 等框架实现了诸多高级性能优化技术,涵盖了 optimized memory access、batched operations 等复杂概念(其底层利用了基于 CUDA 的 cuBLAS 和 cuDNN 等库)。 但愿这篇文章能够让各位读者对使用 .to(“cuda”) 方法,在 GPU 上构建、运行深度学习模型时的底层原理,有个初步的了解。
Thanks so much for reading! 😊
Lucas de Lima Nogueira
https://www.linkedin.com/in/lucas-de-lima-nogueira/
END
原文链接:
https://towardsdatascience.com/why-deep-learning-models-run-faster-on-gpus-a-brief-introduction-to-cuda-programming-035272906d66
相关文章:
汽车长翅膀:GPU 是如何加速深度学习模型的训练和推理过程的?
编者按:深度学习的飞速发展离不开硬件技术的突破,而 GPU 的崛起无疑是其中最大的推力之一。但你是否曾好奇过,为何一行简单的“.to(‘cuda’)”代码就能让模型的训练速度突飞猛进?本文正是为解答这个疑问而作。 作者以独特的视角&…...

怀旧必玩!重返童年,扫雷游戏再度登场!
Python提供了一个标准的GUI(图形用户界面)工具包:Tkinter。它可以用来创建各种窗口、按钮、标签、文本框等图形界面组件。 而且Tkinter 是 Python 自带的库,无需额外安装。 Now,让我们一起来回味一下扫雷小游戏吧 扫…...

Avalonia中的路由事件
文章目录 一、路由事件的基本概念事件路由机制事件的生命周期二、创建路由事件定义路由事件触发路由事件处理路由事件三、使用路由事件的场景用户输入控件交互动画和样式数据绑定和验证四、路由事件的优缺点优点:缺点:五、总结在Avalonia中,路由事件是处理用户交互和控件之间…...

ubuntu20.04安装RabbitMQ +Erlang
ubuntu20.04安装RabbitMQ 3.11.19Erlang 25.3.1_ubuntu20.04.6 安装 rabbitmq-CSDN博客 LINUX下载编译libpng_linux libpng下载-CSDN博客 Ubuntu20.04 安装 Nginx 软件报错:libgd3 缺少 libpng12-0 依赖 Ubuntu安装RabbitMq(保姆级教学,直…...

【word转pdf】【最新版本jar】Java使用aspose-words实现word文档转pdf
【aspose-words-22.12-jdk17.jar】word文档转pdf 前置工作1、下载依赖2、安装依赖到本地仓库 项目1、配置pom.xml2、配置许可码文件(不配置会有水印)3、工具类4、效果 踩坑1、pdf乱码2、word中带有图片转换 前置工作 1、下载依赖 通过百度网盘分享的文…...

分布式:RocketMQ/Kafka总结(附下载链接)
文章目录 下载链接思维导图 本文总结的是关于消息队列的常见知识总结。消息队列和分布式系统息息相关,因此这里就将消息队列放到分布式中一并进行处理关联 下载链接 链接: https://pan.baidu.com/s/1hRTh7rSesikisgRUO2GBpA?pwdutgp 提取码: utgp 思维导图...

Air780EP模块 LuatOS开发-MQTT接入阿里云应用指南
简介 本文简单讲述了利用LuatOS-Air进行二次开发,采用一型一密、一机一密两种方式认证方式连接阿里云。整体结构如图 关联文档和使用工具:LuatOS库阿里云平台 准备工作 Air780EP_全IO开发板一套,包括天线SIM卡,USB线 PC电脑&…...

【算法】插入区间
难度:中等 题目: 给你一个 无重叠的 ,按照区间起始端点排序的区间列表 intervals,其中 intervals[i] [starti, endi] 表示第 i 个区间的开始和结束,并且 intervals 按照 starti 升序排列。同样给定一个区间 newInte…...
)
C++ 代码实现socket 类使用TCP/IP进行通信 (windows 系统)
C 代码实现socket 类使用TCP/IP进行通信 (windows 系统) TCP客户端通信常规步骤: 1.初始换socket环境 2.socket()创建TCP套接字。 3.connect()建立到达服务器的连接。 4.与客户端进行通信,recv()/send()接受/发送信息࿰…...

前后端分离项目部署,vue--nagix发布部署,.net--API发布部署。
目录 Nginx免安装部署文件包准备一、vue前端部署1、修改http.js2、npm run build 编译项目3、解压Nginx免安装,修改nginx.conf二、.net后端发布部署1、编辑appsetting.json,配置跨域请求2、配置WebApi,点击发布3、配置文件发布到那个文件夹4、配置发布相关选项5、点击保存,…...

【BUG】已解决:UnicodeDecodeError: ‘utf-8’ codec can’t decode bytes in position 10
UnicodeDecodeError: ‘utf-8’ codec can’t decode bytes in position 10 目录 UnicodeDecodeError: ‘utf-8’ codec can’t decode bytes in position 10 【常见模块错误】 【解决方案】 欢迎来到英杰社区https://bbs.csdn.net/topics/617804998 欢迎来到我的主页&#x…...

C++ | QQ后端暑期实习面试
tcp三次握手,四次挥手 断点续传 文件断点续传是一种机制,允许在网络传输中的文件传输过程中出现断开连接或传输中断的情况下,能够恢复传输并继续传输未完成的部分。其原理如下: 检测支持:首先,服务器端和…...

实用网站推荐
学习 前端 精简CSS格式 Font Awesome 图标库 BootCDN 加速服务 合集 AI工具集 动漫、音乐 娱乐 嗷呜动漫 奈飞同步 视频下载 B站视频解析下载 文件操作 ioDraw制作图 Convertio — 文件转换器 PDF处理 LOGO...
Linux |Nethogs 监控网络使用情况
引言 互联网上为 Linux 系统提供了许多开源的网络监控工具。例如,你可以利用 iftop 命令来监测网络带宽的消耗,使用 netstat 或 ss 命令来获取网络接口的统计信息,或者通过 top 命令来查看系统中正在运行的进程。 然而,如果你真正…...

大语言模型训练过程中,怎么实现算力共享,采用什么分片规则和共享策略
目录 大语言模型训练过程中,怎么实现算力共享,采用什么分片规则和共享策略 一、算力共享的实现 二、分片规则与共享策略 三、总结 DeepSpeed、Megatron-LM是什么 DeepSpeed ZeRO技术一般不实现调参的 ZeRO技术的实现方式 ZeRO与调参的关系 NCCL是什么 一、NCCL概…...

JCR一区级 | Matlab实现TTAO-Transformer-LSTM多变量回归预测
JCR一区级 | Matlab实现TTAO-Transformer-LSTM多变量回归预测 目录 JCR一区级 | Matlab实现TTAO-Transformer-LSTM多变量回归预测效果一览基本介绍程序设计参考资料 效果一览 基本介绍 1.【JCR一区级】Matlab实现TTAO-Transformer-LSTM多变量回归预测,三角拓扑聚合…...
数列 c++详解)
斐波那契数列(Fibonacci)数列 c++详解
Fibonacci数列是一个在数学和计算机科学中非常著名的数列。这个数列以其特殊的递推关系而闻名,也因其在自然界中的多次出现而引人注目。 定义: Fibonacci数列的定义如下: F(0) 0F(1) 1对于 n > 1,F(n) F(n-1) F(n-2) 也就…...

第三届人工智能、物联网和云计算技术国际会议(AIoTC 2024,9月13-15)
第三届人工智能、物联网与云计算技术国际会议(AIoTC 2024)将于2024年9月13日-15日在中国武汉举行。 本次会议由华中师范大学伍伦贡联合研究院与南京大学联合主办、江苏省大数据区块链与智能信息专委会承办、江苏省概率统计学会、江苏省应用统计学会、Sir Forum、南京理工大学、…...

家具购物小程序的设计
管理员账户功能包括:系统首页,个人中心,用户管理,家具分类管理,家具新品管理,订单管理,系统管理 微信端账号功能包括:系统首页,家具新品,家具公告࿰…...
—— token是做什么用的?)
测试面试宝典(三十四)—— token是做什么用的?
Token 在软件系统中通常具有多种重要用途。 首先,它用于身份验证和授权。用户登录成功后,系统会生成一个唯一的 token 并返回给客户端,客户端后续的请求携带这个 token 来证明其身份和访问权限,避免了每次请求都需要重新输入用户…...

大型活动交通拥堵治理的视觉算法应用
大型活动下智慧交通的视觉分析应用 一、背景与挑战 大型活动(如演唱会、马拉松赛事、高考中考等)期间,城市交通面临瞬时人流车流激增、传统摄像头模糊、交通拥堵识别滞后等问题。以演唱会为例,暖城商圈曾因观众集中离场导致周边…...

深入理解JavaScript设计模式之单例模式
目录 什么是单例模式为什么需要单例模式常见应用场景包括 单例模式实现透明单例模式实现不透明单例模式用代理实现单例模式javaScript中的单例模式使用命名空间使用闭包封装私有变量 惰性单例通用的惰性单例 结语 什么是单例模式 单例模式(Singleton Pattern&#…...

跨链模式:多链互操作架构与性能扩展方案
跨链模式:多链互操作架构与性能扩展方案 ——构建下一代区块链互联网的技术基石 一、跨链架构的核心范式演进 1. 分层协议栈:模块化解耦设计 现代跨链系统采用分层协议栈实现灵活扩展(H2Cross架构): 适配层…...

VTK如何让部分单位不可见
最近遇到一个需求,需要让一个vtkDataSet中的部分单元不可见,查阅了一些资料大概有以下几种方式 1.通过颜色映射表来进行,是最正规的做法 vtkNew<vtkLookupTable> lut; //值为0不显示,主要是最后一个参数,透明度…...

【配置 YOLOX 用于按目录分类的图片数据集】
现在的图标点选越来越多,如何一步解决,采用 YOLOX 目标检测模式则可以轻松解决 要在 YOLOX 中使用按目录分类的图片数据集(每个目录代表一个类别,目录下是该类别的所有图片),你需要进行以下配置步骤&#x…...

NFT模式:数字资产确权与链游经济系统构建
NFT模式:数字资产确权与链游经济系统构建 ——从技术架构到可持续生态的范式革命 一、确权技术革新:构建可信数字资产基石 1. 区块链底层架构的进化 跨链互操作协议:基于LayerZero协议实现以太坊、Solana等公链资产互通,通过零知…...

代理篇12|深入理解 Vite中的Proxy接口代理配置
在前端开发中,常常会遇到 跨域请求接口 的情况。为了解决这个问题,Vite 和 Webpack 都提供了 proxy 代理功能,用于将本地开发请求转发到后端服务器。 什么是代理(proxy)? 代理是在开发过程中,前端项目通过开发服务器,将指定的请求“转发”到真实的后端服务器,从而绕…...
:观察者模式)
JS设计模式(4):观察者模式
JS设计模式(4):观察者模式 一、引入 在开发中,我们经常会遇到这样的场景:一个对象的状态变化需要自动通知其他对象,比如: 电商平台中,商品库存变化时需要通知所有订阅该商品的用户;新闻网站中࿰…...

MFC 抛体运动模拟:常见问题解决与界面美化
在 MFC 中开发抛体运动模拟程序时,我们常遇到 轨迹残留、无效刷新、视觉单调、物理逻辑瑕疵 等问题。本文将针对这些痛点,详细解析原因并提供解决方案,同时兼顾界面美化,让模拟效果更专业、更高效。 问题一:历史轨迹与小球残影残留 现象 小球运动后,历史位置的 “残影”…...

CRMEB 中 PHP 短信扩展开发:涵盖一号通、阿里云、腾讯云、创蓝
目前已有一号通短信、阿里云短信、腾讯云短信扩展 扩展入口文件 文件目录 crmeb\services\sms\Sms.php 默认驱动类型为:一号通 namespace crmeb\services\sms;use crmeb\basic\BaseManager; use crmeb\services\AccessTokenServeService; use crmeb\services\sms\…...