基于DTW距离的KNN算法实现股票高相似筛选案例
使用DTW算法简单实现曲线的相似度计算-CSDN博客
前文中股票高相关k线筛选问题的延伸。基于github上的代码迁移应用到股票高相关预测上。
这里给出一个相关完整的代码实现案例。
1、数据准备
假设你已经有了一些历史股票的k线数据。如果数据能打标哪些股票趋势是上涨的、下跌的会更好。假设这是你目前正在研究的股票k线图:

其他支股票的k-线图如下:
plt.figure(figsize=(11,7))
colors = ['#D62728','#2C9F2C','#FD7F23','#1F77B4','#9467BD','#8C564A','#7F7F7F','#1FBECF','#E377C2','#BCBD27']for i, r in enumerate([0,27,65,100,145,172]):plt.subplot(3,2,i+1)plt.plot(x_train[r][:100], label=labels[y_train[r]], color=colors[i], linewidth=2)plt.xlabel('time sequece')plt.legend(loc='upper left')plt.tight_layout()
接下来要使用基于dtw距离计算的knn近邻算法来找出与目标股票ta高相关的Top10支股票,并将他们的k-线图与ta股票的k-线图进行可视化对比呈现。
2、训练KnnDtw算法模型
import sys
import collections
import itertools
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import mode
from scipy.spatial.distance import squareformplt.style.use('bmh')
%matplotlib inlinetry:from IPython.display import clear_outputhave_ipython = True
except ImportError:have_ipython = Falseclass KnnDtw(object):"""K-nearest neighbor classifier using dynamic time warpingas the distance measure between pairs of time series arraysArguments---------n_neighbors : int, optional (default = 5)Number of neighbors to use by default for KNNmax_warping_window : int, optional (default = infinity)Maximum warping window allowed by the DTW dynamicprogramming functionsubsample_step : int, optional (default = 1)Step size for the timeseries array. By setting subsample_step = 2,the timeseries length will be reduced by 50% because every seconditem is skipped. Implemented by x[:, ::subsample_step]"""def __init__(self, n_neighbors=5, max_warping_window=10000, subsample_step=1):self.n_neighbors = n_neighborsself.max_warping_window = max_warping_windowself.subsample_step = subsample_stepdef fit(self, x, l):"""Fit the model using x as training data and l as class labelsArguments---------x : array of shape [n_samples, n_timepoints]Training data set for input into KNN classiferl : array of shape [n_samples]Training labels for input into KNN classifier"""self.x = xself.l = ldef _dtw_distance(self, ts_a, ts_b, d = lambda x,y: abs(x-y)):"""Returns the DTW similarity distance between two 2-Dtimeseries numpy arrays.Arguments---------ts_a, ts_b : array of shape [n_samples, n_timepoints]Two arrays containing n_samples of timeseries datawhose DTW distance between each sample of A and Bwill be comparedd : DistanceMetric object (default = abs(x-y))the distance measure used for A_i - B_j in theDTW dynamic programming functionReturns-------DTW distance between A and B"""# Create cost matrix via broadcasting with large intts_a, ts_b = np.array(ts_a), np.array(ts_b)M, N = len(ts_a), len(ts_b)cost = sys.maxsize * np.ones((M, N))# Initialize the first row and columncost[0, 0] = d(ts_a[0], ts_b[0])for i in np.arange(1, M):cost[i, 0] = cost[i-1, 0] + d(ts_a[i], ts_b[0])for j in np.arange(1, N):cost[0, j] = cost[0, j-1] + d(ts_a[0], ts_b[j])# Populate rest of cost matrix within windowfor i in np.arange(1, M):for j in np.arange(max(1, i - self.max_warping_window),min(N, i + self.max_warping_window)):choices = cost[i - 1, j - 1], cost[i, j-1], cost[i-1, j]cost[i, j] = min(choices) + d(ts_a[i], ts_b[j])# Return DTW distance given window return cost[-1, -1]def _dist_matrix(self, x, y):"""Computes the M x N distance matrix between the trainingdataset and testing dataset (y) using the DTW distance measureArguments---------x : array of shape [n_samples, n_timepoints]y : array of shape [n_samples, n_timepoints]Returns-------Distance matrix between each item of x and y withshape [training_n_samples, testing_n_samples]"""# Compute the distance matrix dm_count = 0# Compute condensed distance matrix (upper triangle) of pairwise dtw distances# when x and y are the same arrayif(np.array_equal(x, y)):x_s = np.shape(x)dm = np.zeros((x_s[0] * (x_s[0] - 1)) // 2, dtype=np.double)p = ProgressBar(shape(dm)[0])for i in np.arange(0, x_s[0] - 1):for j in np.arange(i + 1, x_s[0]):dm[dm_count] = self._dtw_distance(x[i, ::self.subsample_step],y[j, ::self.subsample_step])dm_count += 1p.animate(dm_count)# Convert to squareformdm = squareform(dm)return dm# Compute full distance matrix of dtw distnces between x and yelse:x_s = np.shape(x)y_s = np.shape(y)dm = np.zeros((x_s[0], y_s[0])) dm_size = x_s[0]*y_s[0]p = ProgressBar(dm_size)for i in np.arange(0, x_s[0]):for j in np.arange(0, y_s[0]):dm[i, j] = self._dtw_distance(x[i, ::self.subsample_step],y[j, ::self.subsample_step])# Update progress bardm_count += 1p.animate(dm_count)return dmdef predict(self, x):"""Predict the class labels or probability estimates for the provided dataArguments---------x : array of shape [n_samples, n_timepoints]Array containing the testing data set to be classifiedReturns-------2 arrays representing:(1) the predicted class labels (2) the knn label count probability"""dm = self._dist_matrix(x, self.x)# Identify the k nearest neighborsknn_idx = dm.argsort()[:, :self.n_neighbors]# Identify k nearest labelsknn_labels = self.l[knn_idx]# Model Labelmode_data = mode(knn_labels, axis=1)mode_label = mode_data[0]mode_proba = mode_data[1]/self.n_neighborsreturn mode_label.ravel(), mode_proba.ravel()class ProgressBar:"""This progress bar was taken from PYMC"""def __init__(self, iterations):self.iterations = iterationsself.prog_bar = '[]'self.fill_char = '*'self.width = 40self.__update_amount(0)if have_ipython:self.animate = self.animate_ipythonelse:self.animate = self.animate_noipythondef animate_ipython(self, iter):
# print('\r', self,)
# sys.stdout.flush()self.update_iteration(iter + 1)def update_iteration(self, elapsed_iter):self.__update_amount((elapsed_iter / float(self.iterations)) * 100.0)self.prog_bar += ' %d of %s complete' % (elapsed_iter, self.iterations)def __update_amount(self, new_amount):percent_done = int(round((new_amount / 100.0) * 100.0))all_full = self.width - 2num_hashes = int(round((percent_done / 100.0) * all_full))self.prog_bar = '[' + self.fill_char * num_hashes + ' ' * (all_full - num_hashes) + ']'pct_place = (len(self.prog_bar) // 2) - len(str(percent_done))pct_string = '%d%%' % percent_doneself.prog_bar = self.prog_bar[0:pct_place] + \(pct_string + self.prog_bar[pct_place + len(pct_string):])def __str__(self):return str(self.prog_bar)
模型训练、预测
m = KnnDtw(n_neighbors=1, max_warping_window=10)
m.fit(x_train[::10], y_train[::10]) # 做数据采样,每10个元素采样
label, proba = m.predict(x_test[::10])模型评估
from sklearn.metrics import classification_report, confusion_matrix
print(classification_report(label, y_test[::10],target_names=[l for l in labels.values()]))conf_mat = confusion_matrix(label, y_test[::10])fig = plt.figure(figsize=(6,6))
width = np.shape(conf_mat)[1]
height = np.shape(conf_mat)[0]res = plt.imshow(np.array(conf_mat), cmap=plt.cm.summer, interpolation='nearest')
for i, row in enumerate(conf_mat):for j, c in enumerate(row):if c>0:plt.text(j-.2, i+.1, c, fontsize=16)
cb = fig.colorbar(res)
plt.title('Confusion Matrix')
_ = plt.xticks(range(6), [l for l in labels.values()], rotation=90)
_ = plt.yticks(range(6), [l for l in labels.values()])3、为目标股票ta筛选Top10高相似的股票
3.1 计算股票的dtw距离,并筛选出Top10高相关股票
m._dtw_distance(x_train[1], x_train[1112])x_similaritys = {}
# 选定一支目标股票
ta = x_test[0]
# 分别计算其他200支股票与目标股票的相关性系数
for stock_id, stock_data in enumerate(x_test[1:200]):dtw_dist = m._dtw_distance(ta, stock_data)if stock_id not in x_similaritys.keys() and stock_id!=0:x_similaritys[stock_id] = dtw_dist#选出与目标股票Top10相似的股票k线
res = sorted(x_similaritys.items(), key=lambda x: x[1])
print("与目标股票Ta高相关的10支股票为:")
for stock_id,dtw_dist in res[:10]:print("股票id:",stock_id," , DTW距离: ",dtw_dist)

3.2 可视化Top10高相似股票曲线
# 绘制TopN股票趋势曲线
plt.figure(figsize=(11, 11))
for i, (stock_id,dtw_dist) in enumerate(res[:10]):
# print(i, stock_id,dtw_dist)plt.subplot(5,2,i+1)plt.plot(x_test[0][:100], label="stock-0", color=colors[0], linewidth=2)plt.plot(x_test[stock_id][:100], label="stock-%d"%stock_id, color=(0.2/(i+1),0.1/(i+1),0.7-0.2/(i+1)-0.1/(i+1)), linewidth=2)plt.xlabel('time')plt.legend(loc='upper left')plt.tight_layout()
红色的是目标股票Ta的k-线图,与之高相似的10支股票的k-线图为蓝色曲线,分别呈现在10个子图中,做为对比可视化,能更直观的对两支股票的走势作出差异对比。方便交付给投资者对比查看股票走势。
Done
相关文章:
基于DTW距离的KNN算法实现股票高相似筛选案例
使用DTW算法简单实现曲线的相似度计算-CSDN博客 前文中股票高相关k线筛选问题的延伸。基于github上的代码迁移应用到股票高相关预测上。 这里给出一个相关完整的代码实现案例。 1、数据准备 假设你已经有了一些历史股票的k线数据。如果数据能打标哪些股票趋势是上涨的、下跌…...

GD32 - IIC程序编写
一、初始化 理论知识链接: IIC理论知识 二、代码实现 1、SDA和SCL设置成开漏输出模式 开漏输出的作用: 因为IIC总线是一种双向的通信协议,需要使用开漏输出实现共享总线。开漏输出类似于一种线与的方式,即无论总线上哪个设备…...

将项目部署到docker容器上
通过docker部署前后端项目 前置条件 需要在docker中拉去jdk镜像、nginx镜像 docker pull openjdk:17 #拉取openjdk17镜像 docker pull nginx #拉取nginx镜像部署后端 1.打包后端项目 点击maven插件下面的Lifecycle的package 对后端项目进行打包 等待打包完成即可 2.将打…...

免费【2024】springboot宠物美容机构CRM系统设计与实现
博主介绍:✌CSDN新星计划导师、Java领域优质创作者、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和学生毕业项目实战,高校老师/讲师/同行前辈交流✌ 技术范围:SpringBoot、Vue、SSM、HTML、Jsp、PHP、Nodejs、Python、爬虫、数据可视化…...

搞懂数据结构与Java实现
文章链接:搞懂数据结构与Java实现 (qq.com) 代码链接: Java实现数组模拟循环队列代码 (qq.com) Java实现数组模拟栈代码 (qq.com) Java实现链表代码 (qq.com) Java实现哈希表代码 (qq.com) Java实现二叉树代码 (qq.com) Java实现图代码 (qq.com)...

Stable Diffusion 图生图
区别于文生图,所谓的图生图,俗称的垫图,就是比文生图多了一张参考图,由参考一张图来生成图片,影响这个图片的要素不仅只靠提示词了,还有这个垫图的因素,这个区域就上上传垫图的地方,…...

语言转文字
因为工作原因需要将语音转化为文字,经常搜索终于找到一个免费的好用工具,记录下使用方法 安装Whisper 搜索Colaboratory 右上方链接服务 执行 !pip install githttps://github.com/openai/whisper.git !sudo apt update && sudo apt install f…...

ref函数
Vue2 中的ref 首先我们回顾一下 Vue2 中的 ref。 ref 被用来给元素或子组件注册引用信息。引用信息将会注册在父组件的 $refs 对象上。如果在普通的 DOM 元素上使用,引用指向的就是 DOM 元素;如果用在子组件上,引用就指向组件实例࿱…...

7/30 bom和dom
文档对象mox 浏览器对象模型...
)
【Golang 面试 - 进阶题】每日 3 题(五)
✍个人博客:Pandaconda-CSDN博客 📣专栏地址:http://t.csdnimg.cn/UWz06 📚专栏简介:在这个专栏中,我将会分享 Golang 面试中常见的面试题给大家~ ❤️如果有收获的话,欢迎点赞👍收藏…...

MySQL,GROUP BY子句的作用是什么?having和where的区别在哪里说一下jdbc的流程
GROUP BY 子句的作用是什么 GROUP BY 字段名 将数据按字段值相同的划为一组,经常配合聚合函数一起使用。 having和where的区别在哪里 where是第一次检索数据时候添加过滤条件,确定结果集。而having是在分组之后添加结果集,用于分组之后的过…...

1._专题1_双指针_C++
双指针 常见的双指针有两种形式,一种是对撞指针,一种是左右指针。对撞指针:一般用于顺序结构中,也称左右指针。 对撞指针从两端向中间移动。一个指针从最左端开始,另一个从最右端开始,然后逐渐往中间逼近…...

Spring集成ES
RestAPI ES官方提供的java语言客户端用以组装DSL语句,再通过http请求发送给ES RestClient初始化 引入依赖 <dependency><groupId>org.elasticsearch.client</groupId><artifactId>elasticsearch-rest-high-level-client</artifactId> </d…...

力扣高频SQL 50题(基础版)第二十六题
文章目录 力扣高频SQL 50题(基础版)第二十六题1667.修复表中的名字题目说明实现过程准备数据实现方式结果截图总结 力扣高频SQL 50题(基础版)第二十六题 1667.修复表中的名字 题目说明 表: Users ----------------…...

WIFI 接收机和发射机同步问题+CFO/SFO频率偏移问题
Synchronization Between Sender and Receiver & CFO Correction 解决同步问题和频率偏移问题是下面论文的关键,接下来结合论文进行详细解读 解读论文:Verification and Redesign of OFDM Backscatter 论文pdf:https://www.usenix.org/s…...

ubuntu安装并配置flameshot截图软件
参考:flameshot key-bindins 安装 sudo apt install flameshot自定义快捷键 Settings->Keyboard->View and Customize Shortcuts->Custom Shortcuts,输入该快捷键名称(自定义),然后输入command(…...

【Linux】CentOS更换国内阿里云yum源(超详细)
目录 1. 前言2. 打开终端3. 确保虚拟机已经联网4. 备份现有yum配置文件5. 下载阿里云yum源6. 清理缓存7. 重新生成缓存8. 测试安装gcc 1. 前言 有些同学在安装完CentOS操作系统后,在系统内安装比如:gcc等软件的时候出现这种情况:(…...

Leetcode49. 字母异位词分组(java实现)
今天我来给大家分享的是leetcode49的解题思路,题目描述如下 如果没有做过leetcode242题目的同学,可以先把它做了,会更好理解异位词的概念。 本道题的大题思路是: 首先遍历strs,然后统计每一个数组元素出现的次数&#…...

OpenJudge | 字符串中最长的连续出现的字符
总时间限制: 1000ms 内存限制: 65536kB 描述 求一个字符串中最长的连续出现的字符,输出该字符及其出现次数,字符串中无空白字符(空格、回车和tab),如果这样的字符不止一个,则输出第一个 输入 首先输入N…...

11day-C++list容器使用
这里写目录标题 1. list的介绍及使用1.1 list的介绍1.2.1 list的构造1.2.2 list iterator的使用1.2.3 list capacity1.2.4 list element access1.2.5 list modifiers1.2.6 list的迭代器失效 2. list的模拟实现2.1 list的反向迭代器 1. list的介绍及使用 1.1 list的介绍 list的…...
)
椭圆曲线密码学(ECC)
一、ECC算法概述 椭圆曲线密码学(Elliptic Curve Cryptography)是基于椭圆曲线数学理论的公钥密码系统,由Neal Koblitz和Victor Miller在1985年独立提出。相比RSA,ECC在相同安全强度下密钥更短(256位ECC ≈ 3072位RSA…...

Linux简单的操作
ls ls 查看当前目录 ll 查看详细内容 ls -a 查看所有的内容 ls --help 查看方法文档 pwd pwd 查看当前路径 cd cd 转路径 cd .. 转上一级路径 cd 名 转换路径 …...

React Native在HarmonyOS 5.0阅读类应用开发中的实践
一、技术选型背景 随着HarmonyOS 5.0对Web兼容层的增强,React Native作为跨平台框架可通过重新编译ArkTS组件实现85%以上的代码复用率。阅读类应用具有UI复杂度低、数据流清晰的特点。 二、核心实现方案 1. 环境配置 (1)使用React Native…...

Keil 中设置 STM32 Flash 和 RAM 地址详解
文章目录 Keil 中设置 STM32 Flash 和 RAM 地址详解一、Flash 和 RAM 配置界面(Target 选项卡)1. IROM1(用于配置 Flash)2. IRAM1(用于配置 RAM)二、链接器设置界面(Linker 选项卡)1. 勾选“Use Memory Layout from Target Dialog”2. 查看链接器参数(如果没有勾选上面…...

初学 pytest 记录
安装 pip install pytest用例可以是函数也可以是类中的方法 def test_func():print()class TestAdd: # def __init__(self): 在 pytest 中不可以使用__init__方法 # self.cc 12345 pytest.mark.api def test_str(self):res add(1, 2)assert res 12def test_int(self):r…...

虚拟电厂发展三大趋势:市场化、技术主导、车网互联
市场化:从政策驱动到多元盈利 政策全面赋能 2025年4月,国家发改委、能源局发布《关于加快推进虚拟电厂发展的指导意见》,首次明确虚拟电厂为“独立市场主体”,提出硬性目标:2027年全国调节能力≥2000万千瓦࿰…...
)
GitHub 趋势日报 (2025年06月06日)
📊 由 TrendForge 系统生成 | 🌐 https://trendforge.devlive.org/ 🌐 本日报中的项目描述已自动翻译为中文 📈 今日获星趋势图 今日获星趋势图 590 cognee 551 onlook 399 project-based-learning 348 build-your-own-x 320 ne…...

MacOS下Homebrew国内镜像加速指南(2025最新国内镜像加速)
macos brew国内镜像加速方法 brew install 加速formula.jws.json下载慢加速 🍺 最新版brew安装慢到怀疑人生?别怕,教你轻松起飞! 最近Homebrew更新至最新版,每次执行 brew 命令时都会自动从官方地址 https://formulae.…...

在树莓派上添加音频输入设备的几种方法
在树莓派上添加音频输入设备可以通过以下步骤完成,具体方法取决于设备类型(如USB麦克风、3.5mm接口麦克风或HDMI音频输入)。以下是详细指南: 1. 连接音频输入设备 USB麦克风/声卡:直接插入树莓派的USB接口。3.5mm麦克…...
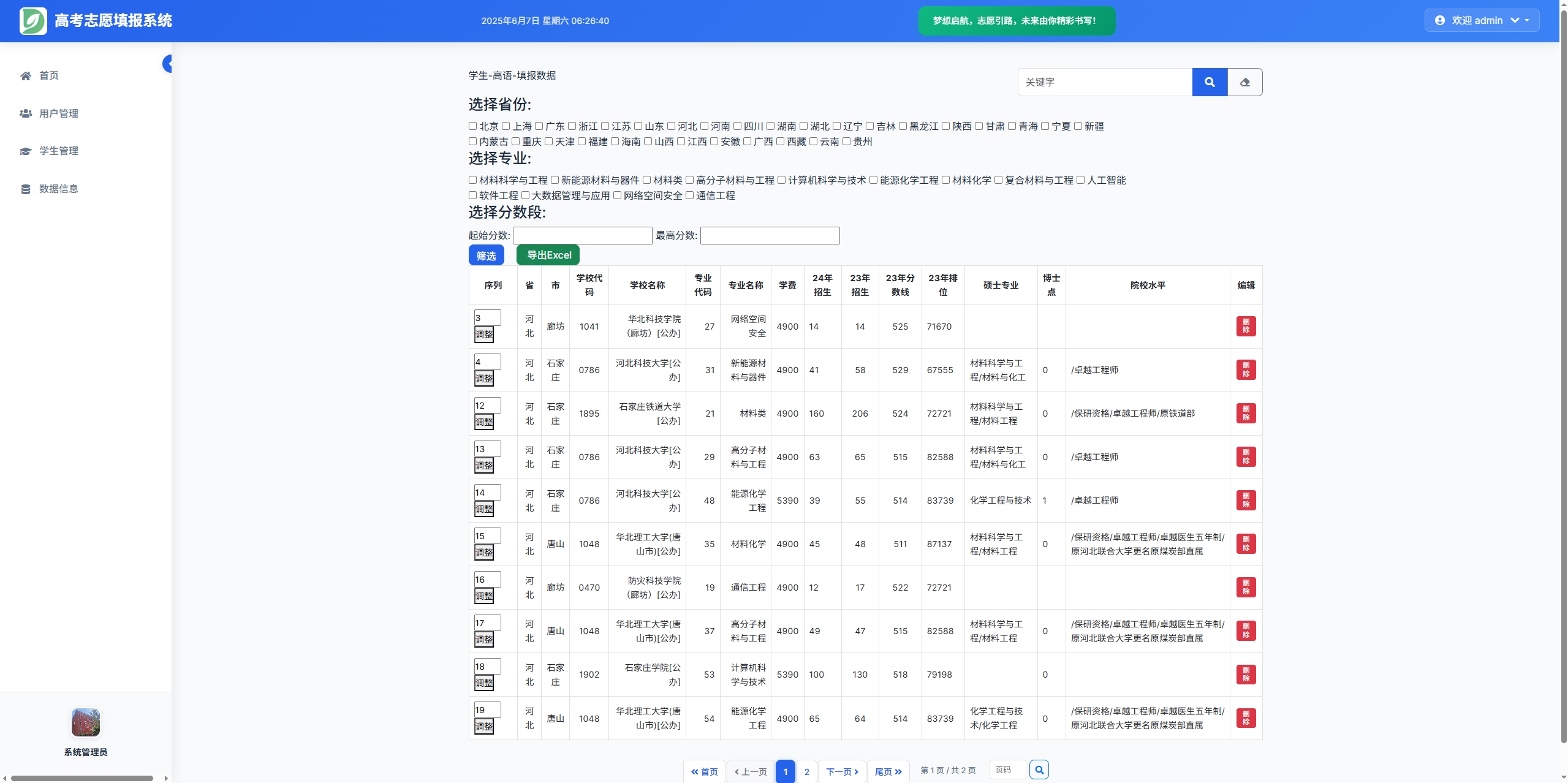
高考志愿填报管理系统---开发介绍
高考志愿填报管理系统是一款专为教育机构、学校和教师设计的学生信息管理和志愿填报辅助平台。系统基于Django框架开发,采用现代化的Web技术,为教育工作者提供高效、安全、便捷的学生管理解决方案。 ## 📋 系统概述 ### 🎯 系统定…...