MSA+抑郁症模型总结(一)(论文复现)
MSA+抑郁症模型总结(一)(论文复现)
本文所涉及所有资源均在传知代码平台可获取
文章目录
- MSA+抑郁症模型总结(一)(论文复现)
- 情感分析在多场景的应用
- 一、概述
- 二、论文地址
- 三、研究背景
- 四、主要贡献
- 五、模型结构和代码
- 多模态任务
- 单模式任务
- ULGM
- 六、数据集介绍
- 七、性能展示
- 八、复现过程
- 九、运行过程
- 模型总结
- 应用场景
- 项目特点
情感分析在多场景的应用
随着社交网络的不断发展,近年来出现了多模态数据的热潮。越来越多的用户采用媒体形式的组合(例如文本加图像、文本加歌曲、文本加视频等)。来表达他们的态度和情绪。多模态情感分析(MSA)是从多模态信息中提取情感元素进行情感预测的一个热门研究课题。传统的文本情感分析依赖于词、短语以及它们之间的语义关系,不足以识别复杂的情感信息。随着面部表情和语调的加入,多模态信息(视觉、听觉和转录文本)提供了更生动的描述,并传达了更准确和丰富的情感信息。
此外,随着近些年来生活压力的增加,抑郁症已成为现代工作环境中最常见的现象。早期发现抑郁症对避免健康恶化和防止自杀倾向很重要。无创监测应激水平在筛查阶段是有效的。许多基于视觉提示、音频馈送和文本消息的方法已用于抑郁倾向监测。
我致力于对情感计算领域的经典模型进行分析、解读和总结,此外,由于现如今大多数的情感计算数据集都是基于英文语言开发的,我们计划在之后的整个系列文章中将中文数据集(SIMS, SIMSv2)应用在模型中,以开发适用于国人的情感计算分析模型,并应用在情感疾病(如抑郁症、自闭症)检测任务,为医学心理学等领域提供帮助,此外还加入了幽默检测数据集,在未来,我也计划加入更多小众数据集,以便检测更隐匿的情感,如嫉妒、嘲讽等,使得AI可以更好的服务于社会。

一、概述
本篇文章开始,我计划使用连载的形式对经典的情感计算模型进行讲解、对比和复现,并开发不同数据集进行应用。并逐步实现集成,以方便各位读者和学者更深度地了解Multimodal Sentiment Analysis (MSA)以及他的研究重点和方向,为该领域的初学者尽量指明学习方向方法;
首先第一篇,我将介绍AAAI 2021的一篇经典MSA论文中的模型–Self_MM
二、论文地址
Learning Modality-Specific Representations with Self-Supervised Multi-Task Learning for Multimodal Sentiment Analysis
三、研究背景
近年来,多模态情感分析和抑郁检测是利用多模态数据预测人类心理状态的两个重要研究课题;多模态情感分析(MSA)和抑郁症检测(DD)引起了越来越多的关注。与单模态分析相比,多模态模型在处理社交媒体数据时更鲁棒,并取得了显着的改进。随着用户生成的在线内容的蓬勃发展,MSA已被引入许多应用,如风险管理,视频理解和视频转录。
其中,表征学习是多模态学习中一项重要而又具有挑战性的任务。有效的模态表征应包含两个方面的特征:一致性和差异性。由于统一的多模态标注,现有方法在捕获区分信息方面受到限制。然而,额外的单峰注解是高时间和人力成本的。本文设计了一个基于自监督学习策略的标签生成模块,以获得独立的单峰监督。然后,对多模态任务和单模态任务分别进行联合训练,以了解其一致性和差异性。此外,在训练阶段,作者设计了一个权重调整策略,以平衡不同子任务之间的学习进度。即引导子任务集中于模态监督之间差异较大的样本。
四、主要贡献
- 本文提出基于模态表示和类中心之间的距离的相对距离值,与模型输出正相关;
- 设计了一个基于自监督策略的单峰标签生成模块;此外,引入了一种新的权重自调整策略,以平衡不同的任务损失约束;
- 在三个baseline数据集上的实验验证了自动生成的单峰标签的稳定性和可靠性。
五、模型结构和代码
多模态情感分析和抑郁症利用多模态信号(包括文本ItI**t、音频IaI**a和视觉IvI**v)来判断情感。一般来说,MSA和DD可以被视为回归任务或分类任务。在这项工作中,我们把它作为回归任务。因此,Self-MM将ItI**t、IaI**a和IvI**v作为输入,并输出一个情感强度和抑郁程度结果ym∈R*y*m∈R。在训练阶段,为了辅助表示学习,Self-MM具有额外的三个单峰输出,其中s∈{t,a,v}s∈{t,a,v},虽然有多个输出,但我们只使用最后的预测结果。
下图为模型整体结构图;如图所示,Self-MM由一个多模态任务和三个独立的单峰子任务组成。在多模态任务和不同的单峰任务之间,作者采用硬共享策略来共享底层表征学习网络。我们将整个模型运行分为3部分讲解:多模态任务,单模态任务,ULGM模块;接下来我们将分别进行详细介绍

多模态任务
对于多模态任务,本文采用了经典的多模态情感分析架构。它包括三个主要部分:特征表示模块,特征融合模块和输出模块。在文本模态方面,由于预训练的语言模型取得了很大的成功,使用了预训练的12层BERT来提取句子表示。根据经验,最后一层中的第一个词向量被选择作为整句表示。
对于音频和视觉模式,使用预训练的ToolKits从原始数据中提取初始向量特征 Ia∈Rla×daI**a∈Rla×d**a 和 Iv∈Rlv×dvI**v∈Rlv×d**v。这里,la和lv分别是音频和视频的序列长度。然后,使用单向长短期记忆(sLSTM)来捕获时序特性。最后,采用端态隐向量作为整个序列的表示。
然后,我们将所有的单峰表示连接起来,并将它们投影到低维空间 RdmRdm 中,最后,融合表示 Fm∗F**m∗ 用于预测多模态情感。
单模式任务
对于三个单模态任务,他们共享多模态任务的模态表征。为了减少不同模态之间的维数差异,作者将它们投影到一个新的特征空间中。然后,用线性回归得到单峰结果。为了指导单峰任务的训练过程,作者设计了一个单峰标签生成模块(ULGM)来获取标签。ULGM的详细信息在下一节讲解。
最后,在m-labels和u-labels监督下,通过联合学习多模态任务和三个单峰任务。值得注意的是,这些单峰任务只存在于训练阶段。因此,我们使用 ym*y*m作为最终输出。
下面是单模态特征处理子网络的代码:
# text subnets
self.aligned = args.need_data_aligned
self.text_model = BertTextEncoder(use_finetune=args.use_finetune, transformers=args.transformers, pretrained=args.pretrained)# audio-vision subnets
audio_in, video_in = args.feature_dims[1:]
self.audio_model = AuViSubNet(audio_in, args.a_lstm_hidden_size, args.audio_out, \num_layers=args.a_lstm_layers, dropout=args.a_lstm_dropout)
self.video_model = AuViSubNet(video_in, args.v_lstm_hidden_size, args.video_out, \num_layers=args.v_lstm_layers, dropout=args.v_lstm_dropout)
ULGM
ULGM旨在基于多模态注释和模态表示生成单模态监督值。为了避免对网络参数更新造成不必要的干扰,将ULGM设计为非参数模块。通常,单峰监督值与多峰标签高度相关。因此,ULGM根据从模态表示到类中心的相对距离计算偏移,如下图所示。

Relative Distance Value。由于不同的模态表示存在于不同的特征空间中,因此使用绝对距离值不够准确。因此,我们提出了相对距离值,它与空间差异无关。
下面为ULGM模块的实现过程,包括单模态分类器的实现:
# fusion
fusion_h = torch.cat([text, audio, video], dim=-1)
fusion_h = self.post_fusion_dropout(fusion_h)
fusion_h = F.relu(self.post_fusion_layer_1(fusion_h), inplace=False)
# # text
text_h = self.post_text_dropout(text)
text_h = F.relu(self.post_text_layer_1(text_h), inplace=False)
# audio
audio_h = self.post_audio_dropout(audio)
audio_h = F.relu(self.post_audio_layer_1(audio_h), inplace=False)
# vision
video_h = self.post_video_dropout(video)
video_h = F.relu(self.post_video_layer_1(video_h), inplace=False)
# classifier-fusion
x_f = F.relu(self.post_fusion_layer_2(fusion_h), inplace=False)
output_fusion = self.post_fusion_layer_3(x_f)
# classifier-text
x_t = F.relu(self.post_text_layer_2(text_h), inplace=False)
output_text = self.post_text_layer_3(x_t)
# classifier-audio
x_a = F.relu(self.post_audio_layer_2(audio_h), inplace=False)
output_audio = self.post_audio_layer_3(x_a)
# classifier-vision
x_v = F.relu(self.post_video_layer_2(video_h), inplace=False)
output_video = self.post_video_layer_3(x_v)
下图为u-标签在不同数据集上的分布更新过程。每个子图像下的数字(#)指示时期的数量。

六、数据集介绍
1. CMU-MOSI: 它是一个多模态数据集,包括文本、视觉和声学模态。它来自Youtube上的93个电影评论视频。这些视频被剪辑成2199个片段。每个片段都标注了[-3,3]范围内的情感强度。该数据集分为三个部分,训练集(1,284段)、验证集(229段)和测试集(686段)。
2. CMU-MOSEI: 它类似于CMU-MOSI,但规模更大。它包含了来自在线视频网站的23,453个注释视频片段,涵盖了250个不同的主题和1000个不同的演讲者。CMU-MOSEI中的样本被标记为[-3,3]范围内的情感强度和6种基本情绪。因此,CMU-MOSEI可用于情感分析和情感识别任务。3. AVEC2019: AVEC2019 DDS数据集是从患者临床访谈的视听记录中获得的。访谈由虚拟代理进行,以排除人为干扰。与上述两个数据集不同的是,AVEC2019中的每种模态都提供了几种不同的特征。例如,声学模态包括MFCC、eGeMaps以及由VGG和DenseNet提取的深度特征。在之前的研究中,发现MFCC和AU姿势分别是声学和视觉模态中两个最具鉴别力的特征。因此,为了简单和高效的目的,我们只使用MFCC和AU姿势特征来检测抑郁症。数据集用区间[0,24]内的PHQ-8评分进行注释,PHQ-8评分越大,抑郁倾向越严重。该基准数据集中有163个训练样本、56个验证样本和56个测试样本。
4. SIMS/SIMSV2: CH-SIMS数据集[35]是一个中文多模态情感分析数据集,为每种模态提供了详细的标注。该数据集包括2281个精选视频片段,这些片段来自各种电影、电视剧和综艺节目,每个样本都被赋予了情感分数,范围从-1(极度负面)到1(极度正面)
七、性能展示
在情感计算任务中,可以看到Self_MM模型性能超越其他模型,证明了其有效性;

抑郁症检测任务中,Self_MM在我们的数据集AVEC2019中依旧亮眼:

八、复现过程
在准备好数据集并调试代码后,进行下面的步骤,附件已经调通并修改,可直接正常运行;
1. 下载多模态情感分析集成包
pip install MMSA
2. 进行训练
$ python -m MMSA -d mosi/dosei/avec -m lmf -s 1111 -s 1112
九、运行过程
训练过程

最终结果

模型总结
SELF-MM模型是一种多模态情感分析解决方案,结合了文本、音频和视觉信息,并利用自我监督学习策略来学习各模态的特定表示。这种方法使得模型在缺乏大量标注数据的情况下仍能有效地提取多模态信息,从而进行情感分析及其他复杂的情感理解任务。项目提供了预处理的数据集及相关下载链接,包括音频特征、文本特征和视频特征等。
应用场景
SELF-MM模型适用于多种情感分析场景,如社交媒体监控、视频对话理解和电影评论分析。通过同时分析文本、语音和视觉信息,该模型能够深入理解多模态输入,从而提升用户体验和交互性。
项目特点
- 高效的学习策略:采用自我监督多任务学习方法,无需大量标注数据即可学习到模态特定的表示。
- 全面的模态支持:模型能够处理文本、音频和视觉信息,充分考虑了多模态输入的特性。
- 易于使用的接口:项目提供清晰的代码结构和详细的配置文件,用户可以根据自己的数据路径进行设置,支持主流的预训练BERT模型的转换和应用。
- 广泛的应用范围:不仅局限于情感分析,还可扩展至其他多模态任务,如情感理解、情感生成等。
通过这些特点,SELF-MM模型不仅能提升情感分析的准确性和效率,还为多模态任务的研究和应用提供了强大的工具和支持。
文章代码资源点击附件获取
相关文章:
MSA+抑郁症模型总结(一)(论文复现)
MSA抑郁症模型总结(一)(论文复现) 本文所涉及所有资源均在传知代码平台可获取 文章目录 MSA抑郁症模型总结(一)(论文复现)情感分析在多场景的应用一、概述二、论文地址三、研究背景四…...

STM32智能农业灌溉系统教程
目录 引言环境准备智能农业灌溉系统基础代码实现:实现智能农业灌溉系统 4.1 数据采集模块 4.2 数据处理与分析模块 4.3 通信与网络系统实现 4.4 用户界面与数据可视化应用场景:农业监测与优化问题解决方案与优化收尾与总结 1. 引言 智能农业灌溉系统通…...

MySQL存储引擎和
MySQL存储引擎 在数据库中保存的是一张张有着千丝万缕关系的表,所以表设计的好坏,将直接影响着整个数据库。而在设计表的时候,最关注的一个问题是使用什么存储引擎。MySQL中的数据用各种不同的技术存储在文件(或者内存)中。这些技术中的每一种…...

Eclipse 主网向开发者开放
摘要:Eclipse 基金会宣布,Eclipse 主网已经向开发者开放。在接下来几周的时间里,Eclipse 将邀请开发者在主网上部署项目,并参加黑客马拉松活动——“Total Eclipse Challenge”。 Eclipse 是首个基于以太坊的 SVM Layer2 方案&am…...
国内NAT服务器docker方式搭建rustdesk服务
前言 如果遇到10054,就不要设置id服务器!!! 由于遇到大带宽,但是又贵,所以就NAT的啦,但是只有ipv4共享和一个ipv6,带宽50MB(活动免费会升130MB~) https://bigchick.xyz/aff.php?aff322 月付-5 循环 :CM-CQ-Monthly-5 年付-60循环:CM-CQ-Annually-60官方…...

锅总浅析链路追踪技术
链路追踪是什么?常用的链路追踪工具有哪些?它们的异同、架构、工作流程及关键指标有哪些?希望读完本文能帮您解答这些疑惑! 一、链路追踪简介 链路追踪技术(Distributed Tracing)是一种用于监控和分析分布…...

为什么阿里开发手册不建议使用Date类?
在日常编码中,基本上99%的项目都会有一个DateUtil工具类,而时间工具类里用的最多的就是java.util.Date。 大家都这么写,这还能有问题?? 当你的“默认常识”出现问题,这个打击,就是毁灭性的。 …...
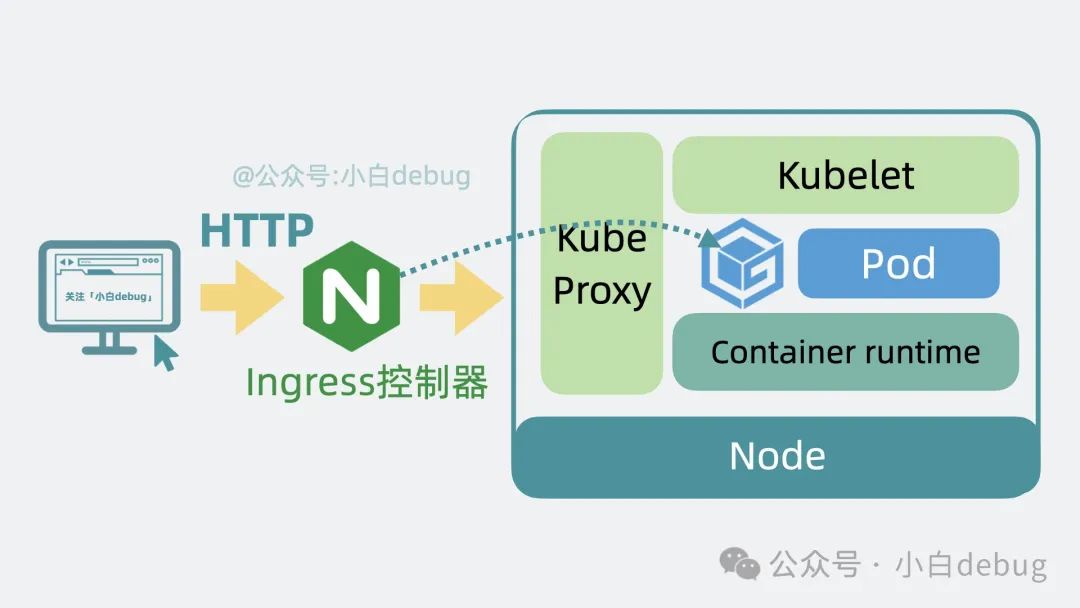
中间层 k8s(Kubernetes) 到底是什么,架构是怎么样的?
你是一个程序员,你用代码写了一个博客应用服务,并将它部署在了云平台上。 但应用服务太过受欢迎,访问量太大,经常会挂。 所以你用了一些工具自动重启挂掉的应用服务,并且将应用服务部署在了好几个服务器上,…...

【CTFWP】ctfshow-web40
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 题目介绍:题目分析:payload:payload解释:payload2:payload2解释:flag 题目介绍: …...

项目实战1(30小时精通C++和外挂实战)
项目实战1(30小时精通C和外挂实战) 01-MFC1-图标02-MFC2-按钮、调试、打开网页05-MFC5-checkbox及按钮绑定对象06--文件格式、OD序列号08-暴力破解09-CE10-秒杀僵尸 01-MFC1-图标 这个外挂只针对植物大战僵尸游戏 开发这个外挂,首先要将界面…...

百日筑基第三十六天
今日论道还算顺利,只可惜感到也没学到什么东西。晚些时候师祖问话,主要是来这边之后有什么困难之类,好像也没遇到需要他来帮我解决的困难,于是问了些修炼方法之类。...

MySQL: ALTER
正文 在数据库管理系统(DBMS)中,DDL(Data Definition Language)、DCL(Data Control Language)、和 DML(Data Manipulation Language)是三种主要的SQL(Struct…...

微前端技术预研 - bit初体验
1.关于什么是微前端以及微前端的发展, 当前主流框架以及实现技术等,可参考这篇总结(非常全面), 微前端总结:目录详见下图 本文内容主要针对bit框架的实时思路以及具体使用。 1.什么是Bit? Bit 是可组合软件的构建…...

对象关系映射---ORM
一、什么是ORM? ORM(Object Relational Mapping),即对象关系映射,是一种程序设计技术,用于在面向对象编程语言中实现对象和关系型数据库之间的映射。 二、ORM是干什么的? ORM 的主要目的是简…...
Authentication)
Django REST Framework(十七)Authentication
1.认证Authentication 在 Django REST framework (DRF) 中,可以在配置文件中配置全局默认的认证方案。常见的认证方式包括 cookie、session、和 token。DRF 提供了灵活的认证机制,可以在全局配置文件中设置默认认证方式,也可以在具体的视图类…...

FPGA开发——数码管的使用
一、概述 在我们的日常开发中,数字显示的领域中用得最多的就是数码管,这篇文章也是围绕数码管的静态显示和动态显示进行一个讲解。 1、理论 (1)数码管原理图 在对数码管进行相关控制时,其实就是对于8段发光二极管和…...
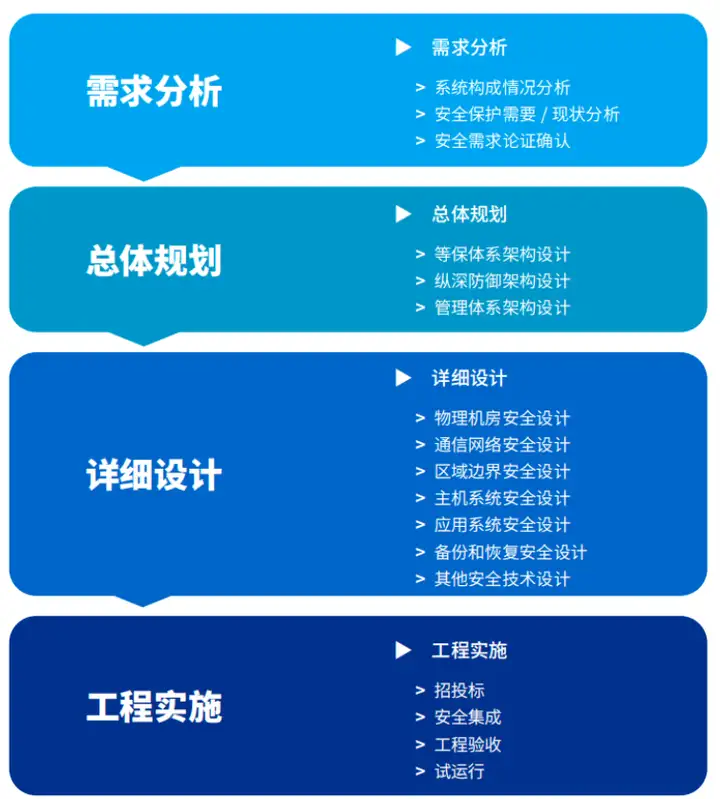
什么是网络安全等级保护测评服务?
等保测评 依据国家网络安全等级保护制度规定,按照有关管理规范和技术标准,对非涉及国家秘密的网络安全等级保护状况进行检测评估。定级协助 根据等级保护对象在国家安全、经济建设、社会生活中的重要程度,以及一旦遭到破坏、丧失功能或者数据…...

基于深度学习的多模态情感分析
基于深度学习的多模态情感分析是一个结合不同类型数据(如文本、图像、音频等)来检测和分析情感的领域。它利用深度学习技术来处理和融合多模态信息,从而提高情感分析的准确性和鲁棒性。以下是对这一领域的详细介绍: 1. **多模态情…...

Glove-词向量
文章目录 共现矩阵共线概率共线概率比词向量训练总结词向量存在的问题 上一篇文章词的向量化介绍了词的向量化,词向量的训练方式可以基于语言模型、基于窗口的CBOW和SKipGram的这几种方法。今天介绍的Glove也是一种训练词向量的一种方法,他是基于共现概率…...

Plugin ‘mysql_native_password‘ is not loaded`
Plugin mysql_native_password is not loaded mysql_native_password介绍1. 使用默认的认证插件2. 修改 my.cnf 或 my.ini 配置文件3. 加载插件(如果确实没有加载)4. 重新安装或检查 MySQL 版本 遇到错误 ERROR 1524 (HY000): Plugin mysql_native_passw…...

简易版抽奖活动的设计技术方案
1.前言 本技术方案旨在设计一套完整且可靠的抽奖活动逻辑,确保抽奖活动能够公平、公正、公开地进行,同时满足高并发访问、数据安全存储与高效处理等需求,为用户提供流畅的抽奖体验,助力业务顺利开展。本方案将涵盖抽奖活动的整体架构设计、核心流程逻辑、关键功能实现以及…...

【Redis技术进阶之路】「原理分析系列开篇」分析客户端和服务端网络诵信交互实现(服务端执行命令请求的过程 - 初始化服务器)
服务端执行命令请求的过程 【专栏简介】【技术大纲】【专栏目标】【目标人群】1. Redis爱好者与社区成员2. 后端开发和系统架构师3. 计算机专业的本科生及研究生 初始化服务器1. 初始化服务器状态结构初始化RedisServer变量 2. 加载相关系统配置和用户配置参数定制化配置参数案…...

《用户共鸣指数(E)驱动品牌大模型种草:如何抢占大模型搜索结果情感高地》
在注意力分散、内容高度同质化的时代,情感连接已成为品牌破圈的关键通道。我们在服务大量品牌客户的过程中发现,消费者对内容的“有感”程度,正日益成为影响品牌传播效率与转化率的核心变量。在生成式AI驱动的内容生成与推荐环境中࿰…...

第25节 Node.js 断言测试
Node.js的assert模块主要用于编写程序的单元测试时使用,通过断言可以提早发现和排查出错误。 稳定性: 5 - 锁定 这个模块可用于应用的单元测试,通过 require(assert) 可以使用这个模块。 assert.fail(actual, expected, message, operator) 使用参数…...

uniapp微信小程序视频实时流+pc端预览方案
方案类型技术实现是否免费优点缺点适用场景延迟范围开发复杂度WebSocket图片帧定时拍照Base64传输✅ 完全免费无需服务器 纯前端实现高延迟高流量 帧率极低个人demo测试 超低频监控500ms-2s⭐⭐RTMP推流TRTC/即构SDK推流❌ 付费方案 (部分有免费额度&#x…...
)
WEB3全栈开发——面试专业技能点P2智能合约开发(Solidity)
一、Solidity合约开发 下面是 Solidity 合约开发 的概念、代码示例及讲解,适合用作学习或写简历项目背景说明。 🧠 一、概念简介:Solidity 合约开发 Solidity 是一种专门为 以太坊(Ethereum)平台编写智能合约的高级编…...

vue3+vite项目中使用.env文件环境变量方法
vue3vite项目中使用.env文件环境变量方法 .env文件作用命名规则常用的配置项示例使用方法注意事项在vite.config.js文件中读取环境变量方法 .env文件作用 .env 文件用于定义环境变量,这些变量可以在项目中通过 import.meta.env 进行访问。Vite 会自动加载这些环境变…...

JavaScript基础-API 和 Web API
在学习JavaScript的过程中,理解API(应用程序接口)和Web API的概念及其应用是非常重要的。这些工具极大地扩展了JavaScript的功能,使得开发者能够创建出功能丰富、交互性强的Web应用程序。本文将深入探讨JavaScript中的API与Web AP…...

Git常用命令完全指南:从入门到精通
Git常用命令完全指南:从入门到精通 一、基础配置命令 1. 用户信息配置 # 设置全局用户名 git config --global user.name "你的名字"# 设置全局邮箱 git config --global user.email "你的邮箱example.com"# 查看所有配置 git config --list…...

WPF八大法则:告别模态窗口卡顿
⚙️ 核心问题:阻塞式模态窗口的缺陷 原始代码中ShowDialog()会阻塞UI线程,导致后续逻辑无法执行: var result modalWindow.ShowDialog(); // 线程阻塞 ProcessResult(result); // 必须等待窗口关闭根本问题:…...