【数据结构】哈希表的模拟实现
文章目录
- 1. 哈希的概念
- 2. 哈希表与哈希函数
- 2.1 哈希冲突
- 2.2 哈希函数
- 2.3 哈希冲突的解决
- 2.3.1 闭散列(线性探测)
- 2.3.2 闭散列的实现
- 2.3.3 开散列(哈希桶)
- 2.3.4 开散列的实现
- 2.4 开散列与闭散列比较

1. 哈希的概念
在我们之前所接触到的所有的数据结构中,元素关键码与其存储位置之间没有对应的关系,因此我们要想查找一个元素,必须要经过关键码的多次比较。
顺序查找时间复杂度为O(N),平衡树中为树的高度,即O(log2N),搜索的效率取决于搜索过程中元素的比较次数。
理想的搜索方法:可以不经过任何比较,一次直接从表中得到要搜索的元素。
如果构造一种存储结构,通过某种函数(hashFunc)使元素的存储位置与它的关键码之间能够建立一 一映射的关系,那么在查找时通过该函数可以很快找到该元素。
向该结构中搜索与查找一个元素时,可以直接通过关键码的值,然后通过某种函数,直接找到该元素所在的位置。
该方式即为哈希(散列)方法,哈希方法中使用的转换函数称为哈希(散列)函数,构造出来的结构称为哈希表或者称散列表
2. 哈希表与哈希函数

其中size为表中元素的大小,最初是默认是10
2.1 哈希冲突
按照上述哈希方式,向集合中插入元素14、24、34,会出现什么问题?
不同关键字通过相同哈希哈数计算出相同的哈希地址,该种现象称为哈希冲突或哈希碰撞。
把具有不同关键码而具有相同哈希地址的数据元素称为“同义词”。
发生哈希冲突该如何处理呢?
2.2 哈希函数
引起哈希冲突的一个原因可能是:哈希函数设计不够合理。
哈希函数设计原则:
- 哈希函数的定义域必须包括需要存储的全部关键码,而如果散列表允许有m个地址时,其值域必须在[0,m-1]中
- 哈希函数计算出来的地址能均匀分布在整个空间中
- 哈希函数应该比较简单
常见哈希函数
-
直接定址法- -(常用)
取关键字的某个线性函数为散列地址:Hash(Key)= A*Key + B。(例如一个字符串,其在哈希比表中的位置就可以使字符串中所有字符的和,为了避免key不同,而地址相同,可以在乘以一个A)
优点:简单、均匀
缺点:需要事先知道关键字的分布情况
使用场景:适合查找比较小且连续的情况 -
除留余数法- -(常用)
设散列表中允许的地址数为m,取一个不大于m,但最接近或者等于m的质数p作为除数,按照哈希函数:Hash(key) = key% p,将关键码转换成哈希表中的3地址 -
随机数法- -(了解)
选择一个随机函数,取关键字的随机函数值为它的哈希地址,即H(key) = random(key),其中random为随机数函数。
通常应用于关键字长度不等时采用此法
由于哈希函数比较多,这里就不一一列举了。
2.3 哈希冲突的解决
2.3.1 闭散列(线性探测)
闭散列:也叫开放定址法,当发生哈希冲突时,如果哈希表未被装满,说明在哈希表中必然还有空位置,那么可以把key存放到冲突位置中的“下一个” 空位置中去。那如何寻找下一个空位置呢?
- 线性探测
比如上述中的场景,现在需要插入元素14,先通过哈希函数计算哈希地址,hashi为4,因此14理论上应该插在该位置,但是该位置已经放了值为4的元素,即发生哈希冲突。
线性探测:从发生冲突的位置开始,依次向后探测,直到寻找到下一个空位置为止。
- 插入
通过哈希函数获取待插入元素在哈希表中的位置
如果该位置中没有元素则直接插入新元素,如果该位置中有元素发生哈希冲突,则使用线性探测找到下一个空位置,插入新元素

- 查找
例如要找key为14的元素,首先使用哈希函数计算出元素在哈希表中的地址,从该地址处依次向后比较,直到遇到空位置。

- 删除
对于删除而言,要先查找到元素,然后再将元素删除掉。那怎么删呢?将该位置的状态置为吗?
删除数据时,只需将该位置设置为删除,不能将该位置的状态设置为空,否则将影响查找功能(如果将14位置的状态置为空,在查找44时将找不到,走到空就停下了)
2.3.2 闭散列的实现
为了标明每个位置的状态,我们可以使用枚举常量来表示
//元素的状态enum State{EXIST = 0, //已有元素DELETE, //该位置元素已删除EMPTY //该位置为空};
哈希表的初步框架
namespace open_addr
{//为了后期适配map与set,这里先给两个模板参数template<class K,class T>class HashTable{//元素的状态enum State{EXIST = 0, //已有元素DELETE, //该位置元素已删除EMPTY //该位置为空};//元素的结构struct Element{T _data;State _state;};public:HashTable(size_t N = 10){_table.resize(N);for (size_t i = 0; i < N; i++){_table[i]._state = EMPTY;}}bool insert(const T& data){}size_t find(const K& key){}bool erase(const K& key){}private:vector<Element> _table;//哈希表size_t _n; //记录当前元素个数};
}

下面我们就来具体实现各项功能:
- 插入
//哈希函数template<class K>struct HashFunc{size_t operator()(const K& key){return key;}};
bool insert(const T& data){//根据哈希函数,计算位置Hash hs;size_t hashi = hs(data) % _table.size();//检查是否有哈希冲突问题while (_table[hashi]._state == EXIST){hashi++;hashi %= _table.size();//实现下标的环绕}//插入元素,修改状态_table[hashi]._data = data;_table[hashi]._state = EXIST;_n++;return true;}

当我们的元素是int时,代码可以跑通;但当元素是string时,代码就过不了了。
所以我们需要对哈希函数进行特化处理。

此时不管你是什么类型,只要提供对应的哈希函数,我们的代码就可以跑

哈希表扩容问题
如果我们的哈希表满了,那么数据进来后,就会一直死循环;而且哈希表中元素越多,哈希冲突越高,效率越低。
因此就引入了载荷因子来判断是否需要扩容来提高效率问题
散列表的载荷因子定义为: a =填入表中的元素个数 / 散列表的长度
- a是散列表装满程度的标志因子。
- 由于表长是定值,a与“填入表中的元素个数”成正比,所以,a越大,表明填入表中的元素越多,产生冲突的可能性就越大;反之,a越小,标明填入表中的元素越少,产生冲突的可能性就越小。
- 实际上,散列表的平均查找长度是载荷因子a的函数,只是不同处理冲突的方法有不同的函数。
- 对于开放定址法,荷载因子是特别重要因素,应严格限制在0.7-0. 8以下。超过0. 8,查表时的CPU缓存不命中(cache missing)按照指数曲线上升。因此,一些采用开放定址法的hash库,如Java的 系统库限制了荷载因子为0.75,超过此值将resize散列表。
扩容时,先开一个是原来旧表二倍大小的新表,然后根据旧表中的元素,寻找元素在新表中的位置,寻找位置插入。

由于再次计算位置,插入元素和不扩容时的代码一样,为了减少代码的冗余,这里我们直接开一个新的哈希表,最后交换两哈希表的表即可。
bool insert(const T& data){size_t n = _table.size();//检查是否扩容if (10 * _n / n >= 7){//直接建立一个新表HashTable<K, T, Hash> newtable;newtable._table.resize(n * 2);//复用插入的逻辑for (size_t i = 0; i < n; i++){if (_table[i]._state == EXIST)//该位置有元素才转移{newtable.insert(_table[i]._data);}}//交换新旧表swap(_table, newtable._table);}//根据哈希函数,计算位置Hash hs;size_t hashi = hs(data) % n;//检查是否有哈希冲突问题while (_table[hashi]._state == EXIST){hashi++;hashi %= n;//实现下标的环绕}//插入元素,修改状态_table[hashi]._data = data;_table[hashi]._state = EXIST;_n++;return true;}
- 查找
对于查找而言,使用哈希函数计算好位置后,从该位置向后找,直到位置的状态为空
int find(const K& key){//根据key获取表中的位置Hash hs;size_t hashi = hs(key) % _table.size();while (_table[hashi]._state != EMPTY){if (_table[hashi]._state == EXIST&& _table[hashi]._data == key){return hashi;}hashi++;hashi %= _table.size();}return -1;}
- 删除
bool erase(const K& key){int hashi = find(key);if (hashi != -1){_table[hashi]._state = DELETE;//状态设置为删除--_n;//个数减少return true;}return false;}
线性探测优点:实现非常简单,
线性探测缺点:一旦发生哈希冲突,所有的冲突连在一起,容易产生数据“堆积”,即:不同关键码占据了可利用的空位置,使得寻找某关键码的位置需要许多次比较,导致搜索效率降低。如何缓解呢?
线性探测的缺陷是产生冲突的数据堆积在一块,这与其找下一个空位置有关系,因为找空位置的方式就是挨着往后逐个去找,因此二次探测为了避免该问题,找下一个空位置的方法为: H i H_i Hi = ( H 0 H_0 H0 + i 2 i^2 i2 )% m, 或者: H i H_i Hi = ( H 0 H_0 H0 - i 2 i^2 i2 )% m。其中:i = 1,2,3…, H 0 H_0 H0是通过散列函数Hash(x)对元素的关键码 key 进行计算得到的位置,m是表的大小。
二次探测其实也只是缓解了该问题,因此我们就不实现二次探测了。
闭散列最大的缺陷就是空间利用率比较低,这也是哈希的缺陷。
//原模板
template<class K>
struct HashFunc
{size_t operator()(const K& key){return key;}
};//特化
template<>
struct HashFunc<string>
{size_t operator()(const string& key){size_t sum = 0;for (auto& e : key){sum *= 31;//这里使用了直接地址法,避免字符串的key计算后相同sum += e;}return sum;}
};
namespace open_addr
{//为了后期适配map与set,这里先给两个模板参数template<class K,class T,class Hash = HashFunc<K>>class HashTable{//元素的状态enum State{EXIST = 0, //已有元素DELETE, //该位置元素已删除EMPTY //该位置为空};//元素的结构struct Element{T _data;State _state;};public:HashTable(size_t N = 10){_table.resize(N);for (size_t i = 0; i < N; i++){_table[i]._state = EMPTY;}}bool insert(const T& data){size_t n = _table.size();//检查是否扩容if (10 * _n / n >= 7){//直接建立一个新表HashTable<K, T, Hash> newtable;newtable._table.resize(n * 2);//复用插入的逻辑for (size_t i = 0; i < n; i++){if (_table[i]._state == EXIST)//该位置有元素才转移{newtable.insert(_table[i]._data);}}//交换新旧表swap(_table, newtable._table);}//根据哈希函数,计算位置Hash hs;size_t hashi = hs(data) % n;//检查是否有哈希冲突问题while (_table[hashi]._state == EXIST){hashi++;hashi %= n;//实现下标的环绕}//插入元素,修改状态_table[hashi]._data = data;_table[hashi]._state = EXIST;_n++;return true;}int find(const K& key){//根据key获取表中的位置Hash hs;size_t hashi = hs(key) % _table.size();while (_table[hashi]._state != EMPTY){if (_table[hashi]._state == EXIST&& _table[hashi]._data == key){return hashi;}hashi++;hashi %= _table.size();}return -1;}bool erase(const K& key){int hashi = find(key);if (hashi != -1){_table[hashi]._state = DELETE;//状态设置为删除--_n;//个数减少return true;}return false;}size_t size(){return _n;}private:vector<Element> _table;//哈希表size_t _n; //记录当前元素个数};
}
2.3.3 开散列(哈希桶)
开散列法又叫链地址法(开链法),首先对关键码集合用哈希函数计算散列地址,具有相同地址的关键码归于同一子集合,每一个子集合称为一个桶,各个桶中的元素通过一个单链表链接起来,各链表的头结点存储在哈希表中。

从上图可以看出,开散列中每个桶中放的都是发生哈希冲突的元素。
2.3.4 开散列的实现
开散列与闭散列唯一的不同就是:开散列使用了链表解决哈希冲突占据其它位置的问题。
所以此时的插入和删除就要按照链表的逻辑去走。
- 插入
桶的个数是一定的,随着元素的不断插入,每个桶中元素的个数不断增多,极端情况下,可能会导致一个桶中链表节点非常多,会影响的哈希表的性能,因此在一定条件下需要对哈希表进行增容,那该条件怎么确认呢?开散列最好的情况是:每个哈希桶中刚好挂一个节点,再继续插入元素时,每一次都会发生哈希冲突,因此,在元素个数刚好等于桶的个数时,可以给哈希表增容。
由于开辟节点的消耗比较大,因此就不能使用闭散列那种方法复用插入;我们可以按照元素的值计算新的位置,对其进行重新连接,省下来开辟节点的消耗。
bool insert(const T& data){Hash hs;size_t size = _table.size();//检查扩容if (_n == size)//节点个数等于桶的数量时,进行扩容{//为了节省开销,不再重新开辟新节点,直接映射原来的节点,将原来的映射取消vector<Node*> newtable(size * 2, nullptr);size_t newsize = newtable.size();for (size_t i = 0; i < size; i++){Node* cur = _table[i];while (cur){size_t hashi = hs(cur->_data) % newsize;//元素对应的新表中的位置Node* next = cur->_next;//记录当前桶的下一个元素//头插连接到新桶cur->_next = newtable[hashi];newtable[hashi] = cur;cur = next;}_table[i] = nullptr;}swap(_table, newtable);}size_t hashi = hs(data) % _table.size();//头插连接Node* newnode = new Node(data);newnode->_next = _table[hashi];_table[hashi] = newnode;++_n;return true;}

- 查找
查找时,按照哈希函数确定位置后,遍历链表比较即可
Node* find(const K& key){Hash hs;size_t hashi = hs(key) % _table.size();Node* cur = _table[hashi];while (cur){if (cur->_data == key)return cur;cur = cur->_next;}return nullptr;}
- 删除
对于删除而言,就不能直接利用find函数了。对于链表的删除要分几种情况讨论
- 当前桶是否只有这一个元素
- 多个元素时,删除链表中的节点要连接删除节点前后的节点(要记录前驱节点)
bool erase(const K& key){Hash hs;size_t hashi = hs(key) % _table.size();Node* cur = _table[hashi];Node* prev = nullptr;while (cur){if (cur->_data == key){if (prev == nullptr)//桶中只有一个元素{_table[hashi] = nullptr;}else{prev->_next = cur->_next;//连接前驱和后继节点}delete cur;_n--;return true;}else{prev = cur;cur = cur->_next;}}return false;}
- 析构
由于此处使用的是我们自己的链表,所以最后别忘记释放节点
~HashTable(){for (size_t i = 0; i < _table.size(); i++){Node* cur = _table[i];while (cur){Node* next = cur->_next;delete cur;cur = next;}_table[i] = nullptr;}}
//原模板
template<class K>
struct HashFunc
{size_t operator()(const K& key){return key;}
};//特化
template<>
struct HashFunc<string>
{size_t operator()(const string& key){size_t sum = 0;for (auto& e : key){sum *= 31;//这里使用了直接地址法,避免字符串的key计算后相同sum += e;}return sum;}
};namespace hash_bucket
{template<class T>struct HashNode{T _data;//数据域HashNode<T>* _next;//指针域HashNode(const T& data):_data(data), _next(nullptr){}};//为了后期适配map与set,这里先给两个模板参数template<class K, class T,class Hash = HashFunc<K>>class HashTable{typedef HashNode<T> Node;public:HashTable(size_t N = 10){_table.resize(N,nullptr);}~HashTable(){for (size_t i = 0; i < _table.size(); i++){Node* cur = _table[i];while (cur){Node* next = cur->_next;delete cur;cur = next;}_table[i] = nullptr;}}bool insert(const T& data){Hash hs;size_t size = _table.size();//检查扩容if (_n == size)//节点个数等于桶的数量时,进行扩容{//为了节省开销,不再重新开辟新节点,直接映射原来的节点,将原来的映射取消vector<Node*> newtable(size * 2, nullptr);size_t newsize = newtable.size();for (size_t i = 0; i < size; i++){Node* cur = _table[i];while (cur){size_t hashi = hs(cur->_data) % newsize;//元素对应的新表中的位置Node* next = cur->_next;//记录当前桶的下一个元素//头插连接到新桶cur->_next = newtable[hashi];newtable[hashi] = cur;cur = next;}_table[i] = nullptr;}swap(_table, newtable);}size_t hashi = hs(data) % _table.size();//头插连接Node* newnode = new Node(data);newnode->_next = _table[hashi];_table[hashi] = newnode;++_n;return true;}Node* find(const K& key){Hash hs;size_t hashi = hs(key) % _table.size();Node* cur = _table[hashi];while (cur){if (cur->_data == key)return cur;cur = cur->_next;}return nullptr;}bool erase(const K& key){Hash hs;size_t hashi = hs(key) % _table.size();Node* cur = _table[hashi];Node* prev = nullptr;while (cur){if (cur->_data == key){if (prev == nullptr)//桶中只有一个元素{_table[hashi] = nullptr;}else{prev->_next = cur->_next;}delete cur;_n--;return true;}else{prev = cur;cur = cur->_next;}}return false;}private:vector<Node*> _table;size_t _n;};
}
2.4 开散列与闭散列比较
用链地址法处理溢出,需要增设链接指针,似乎增加了存储开销。事实上:由于开地址法必须保持大量的空闲空间以确保搜索效率,如二次探查法要求装载因子a <= 0.7,而表项所占空间又比指针大的多,所以使用链地址法反而比开地址法节省存储空间。
相关文章:
【数据结构】哈希表的模拟实现
文章目录 1. 哈希的概念2. 哈希表与哈希函数2.1 哈希冲突2.2 哈希函数2.3 哈希冲突的解决2.3.1 闭散列(线性探测)2.3.2 闭散列的实现2.3.3 开散列(哈希桶)2.3.4 开散列的实现 2.4 开散列与闭散列比较 1. 哈希的概念 在我们之前所接触到的所有的数据结构…...

面试经典算法150题系列-数组/字符串操作之多数元素
序言:今天是第五题啦,前面四题的解法还清楚吗?可以到面试算法题系列150题专栏 进行复习呀。 温故而知新,可以为师矣!加油,未来的技术大牛们。 多数元素 给定一个大小为 n 的数组 nums ,返回其…...

海南云亿商务咨询有限公司领航抖音电商服务
在当下这个瞬息万变的互联网时代,短视频平台尤其是抖音,正以惊人的速度重塑着消费者的购物习惯与商家的营销版图。在这场电商盛宴中,海南云亿商务咨询有限公司凭借其在抖音电商领域的深厚积累与前瞻视野,正逐步成为众多商家转型升…...

C#初级——继承
继承 继承是面向对象程序设计中最重要的概念之一。继承允许我们根据一个类来定义另一个类,不需要完全重新编写新的数据成员和成员函数,只需要设计一个新的类,继承了已有的类的成员即可。这个已有的类被称为的基类(父类࿰…...

Github 2024-07-29 开源项目日报 Top10
根据Github Trendings的统计,今日(2024-07-29统计)共有10个项目上榜。根据开发语言中项目的数量,汇总情况如下: 开发语言项目数量JavaScript项目3非开发语言项目3Python项目1TypeScript项目1C++项目1Lean项目1HTML项目1免费编程学习平台:freeCodeCamp.org 创建周期:3302 天…...

nginx反向代理和负载均衡+安装jdk-22.0.2
ps -aux|grep nginx //查看进程 nginx 代理 nginx代理是负载均衡的基础 主机:192.168.118.60 这台主机只发布了web服务,没有做代理的任何操作 修改一下index.html中的内容 echo "this is java web server" > /usr/local/nginx/htm…...

软考高级科目怎么选?软考高级含金量排序
软考既是国家职业资格考试,又是职称资格考试,含金量很高。软考的报考不设置任何条件,可以跨级考试,也就是非相关专业的人,也可以直接考高级。因此近些年报考软考、尤其是软考高级的人越来越多。 软考高级证书…...

【机器学习西瓜书学习笔记——模型评估与选择】
机器学习西瓜书学习笔记【第二章】 第二章 模型评估与选择2.1训练误差和测试误差错误率误差 欠拟合和过拟合2.2评估方法留出法交叉验证法自助法 2.3性能度量查准率、查全率与F1查准率查全率F1 P-R曲线ROC与AUCROCAUC 代价敏感错误率与代价曲线代价曲线 2.4比较检验假设检验&…...

vue3+cesium创建地图
1.我这边使用的是cdn引入形式 比较简单的方式 不需要下载依赖 在项目文件的index.html引入 这样cesium就会挂载到window对象上面去了 <!-- 引入cesium-js文件 --><script src"https://cesium.com/downloads/cesiumjs/releases/1.111/Build/Cesium/Cesium.js"…...

Zookeeper客户端和服务端NIO网络通信源码剖析
文章目录 服务端的ServerCnxFactory到底是个什么东西?ServerCnxFactory 的作用ServerCnxFactory 的实现使用 ServerCnxFactory 的示例注意事项ServerCnxFactory是什么时候完成初始化的?初始化流程代码示例详细步骤1. 创建实例2. 配置3. 启动初始化时机总结服务端基于NIO的Ser…...
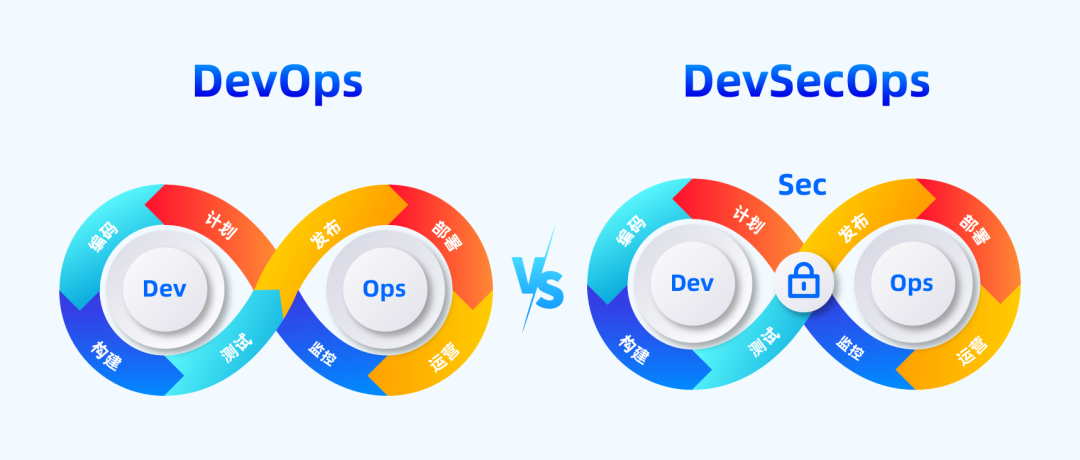
从DevOps到DevSecOps是怎样之中转变?
DevSecOps是DevOps实践的自然演进,其重点是将安全集成到软件开发和部署流程中。在DevOps和DevSecOps发展之前,企业通常在在软件部署前进行集中的安全测试,导致安全介入严重滞后,漏洞分风险无法及时修复,影响上线交付。…...

ORM与第三方数据库对接的探讨及不同版本数据库的影响
对象关系映射(Object-Relational Mapping,ORM)是一种将程序中的对象与数据库中的数据进行映射的技术,使开发者可以通过操作对象来间接操作数据库。然而,在实际应用中,ORM并不是总能完美地对接陌生的第三方数…...

Windows远程桌面无法拷贝文件问题
场景说明 Winwdows远程桌面,相比Linux方便一点就是,同是windows连接,其中复制粘贴功能,可以在两个windows无缝切换。 但最近笔者远程一台测试windows服务器时,发现无法在服务器上复制内容到本地,也无法从…...
优化数据处理效率,解读 EasyMR 大数据组件升级
EasyMR 作为袋鼠云基于云原生技术和 Hadoop、Hive、Spark、Flink、Hbase、Presto 等开源大数据组件构建的弹性计算引擎。此前,我们已就其展开了多方位、多角度的详尽介绍。而此次,我们成功接入了大数据组件的升级和回滚功能,能够借助 EasyMR …...

并发编程AtomicInteger详解
AtomicInteger 是 Java 并发包 (java.util.concurrent.atomic) 中的一个原子变量类,用于对 int 类型的变量进行原子操作。它利用底层的 CAS(Compare-And-Swap)机制,实现了无锁的线程安全。AtomicInteger 常用于需要高效、线程安全…...

ctfshow 权限维持 web670--web679
web670 <?php// 题目说明: // 想办法维持权限,确定无误后提交check,通过check后,才会生成flag,此前flag不存在error_reporting(0); highlight_file(__FILE__);$a$_GET[action];switch($a){case cmd:eval($_POST[c…...

职场生存指南
求职篇 面试潜台词分析 (1)介绍: “请做一下自我介绍?” ❌:慢吞吞的介绍:叫什么,来自学校,专业,工作了那几家公司。 问题目的:个人优势+岗位匹配度+个人身上技能标签 (2)反问: “你还有什么想问的吗?” 问题目的:对工作的好奇心+个人积极性<——岗位…...

Spring源码(八)--Spring实例化的策略
Spring实例化的策略有几种 ,可以看一下 InstantiationStrategy 相关的类。 UML 结构图 InstantiationStrategy的实现类有 SimpleInstantiationStrategy。 CglibSubclassingInstantiationStrategy 又继承了SimpleInstantiationStrategy。 InstantiationStrategy I…...

部署KVM虚拟化平台
文章目录 KVM虚拟化架构KVM组成KVM虚拟化三种模式 KVM虚拟化架构 KVM模块直接整合在Linux内核中 KVM组成 e KVM Driver虚拟机创建虚拟机内存分配虚拟CPU寄存器读写虚拟CPU运行 QEMU(快速仿真器) 模拟PC硬件的用户控件组件提供I/O设备模型及访问外设的途径 KVM虚拟化三种模式 客…...

Java对象模型深度剖析:从POJO到ENTITY
引言 在Java企业级应用开发中,对象模型是构建软件架构的核心。它们不仅帮助我们组织代码,还提升了代码的可读性和可维护性。本文将深入介绍Java中的几种关键对象模型:POJO、DTO、DAO、PO、BO、VO、QO和ENTITY,以及DO,…...

(十)学生端搭建
本次旨在将之前的已完成的部分功能进行拼装到学生端,同时完善学生端的构建。本次工作主要包括: 1.学生端整体界面布局 2.模拟考场与部分个人画像流程的串联 3.整体学生端逻辑 一、学生端 在主界面可以选择自己的用户角色 选择学生则进入学生登录界面…...

STM32F4基本定时器使用和原理详解
STM32F4基本定时器使用和原理详解 前言如何确定定时器挂载在哪条时钟线上配置及使用方法参数配置PrescalerCounter ModeCounter Periodauto-reload preloadTrigger Event Selection 中断配置生成的代码及使用方法初始化代码基本定时器触发DCA或者ADC的代码讲解中断代码定时启动…...

OkHttp 中实现断点续传 demo
在 OkHttp 中实现断点续传主要通过以下步骤完成,核心是利用 HTTP 协议的 Range 请求头指定下载范围: 实现原理 Range 请求头:向服务器请求文件的特定字节范围(如 Range: bytes1024-) 本地文件记录:保存已…...

Matlab | matlab常用命令总结
常用命令 一、 基础操作与环境二、 矩阵与数组操作(核心)三、 绘图与可视化四、 编程与控制流五、 符号计算 (Symbolic Math Toolbox)六、 文件与数据 I/O七、 常用函数类别重要提示这是一份 MATLAB 常用命令和功能的总结,涵盖了基础操作、矩阵运算、绘图、编程和文件处理等…...
 + 力扣解决)
LRU 缓存机制详解与实现(Java版) + 力扣解决
📌 LRU 缓存机制详解与实现(Java版) 一、📖 问题背景 在日常开发中,我们经常会使用 缓存(Cache) 来提升性能。但由于内存有限,缓存不可能无限增长,于是需要策略决定&am…...

【Android】Android 开发 ADB 常用指令
查看当前连接的设备 adb devices 连接设备 adb connect 设备IP 断开已连接的设备 adb disconnect 设备IP 安装应用 adb install 安装包的路径 卸载应用 adb uninstall 应用包名 查看已安装的应用包名 adb shell pm list packages 查看已安装的第三方应用包名 adb shell pm list…...

MySQL 部分重点知识篇
一、数据库对象 1. 主键 定义 :主键是用于唯一标识表中每一行记录的字段或字段组合。它具有唯一性和非空性特点。 作用 :确保数据的完整性,便于数据的查询和管理。 示例 :在学生信息表中,学号可以作为主键ÿ…...

解决:Android studio 编译后报错\app\src\main\cpp\CMakeLists.txt‘ to exist
现象: android studio报错: [CXX1409] D:\GitLab\xxxxx\app.cxx\Debug\3f3w4y1i\arm64-v8a\android_gradle_build.json : expected buildFiles file ‘D:\GitLab\xxxxx\app\src\main\cpp\CMakeLists.txt’ to exist 解决: 不要动CMakeLists.…...
Golang——7、包与接口详解
包与接口详解 1、Golang包详解1.1、Golang中包的定义和介绍1.2、Golang包管理工具go mod1.3、Golang中自定义包1.4、Golang中使用第三包1.5、init函数 2、接口详解2.1、接口的定义2.2、空接口2.3、类型断言2.4、结构体值接收者和指针接收者实现接口的区别2.5、一个结构体实现多…...

c# 局部函数 定义、功能与示例
C# 局部函数:定义、功能与示例 1. 定义与功能 局部函数(Local Function)是嵌套在另一个方法内部的私有方法,仅在包含它的方法内可见。 • 作用:封装仅用于当前方法的逻辑,避免污染类作用域,提升…...