logstash 全接触
- 简述什么是Logstash ?
Logstash是一个开源的集中式事件和日志管理器。它是 ELK(ElasticSearch、Logstash、Kibana)堆栈的一部分。在本教程中,我们将了解 Logstash 的基础知识、其功能以及它具有的各种组件。
Logstash 是一种基于过滤器/管道模式的工具,用于收集、处理和生成日志或事件。它有助于集中和实时分析来自不同来源的日志和事件。
Logstash 是用运行在 JVM 上的 JRuby 编程语言编写的,因此可以在不同的平台上运行 Logstash。它从几乎所有类型的来源收集不同类型的数据,如日志、数据包、事件、事务、时间戳数据等。数据源可以是社交数据、电子商务、新闻文章、CRM、游戏数据、网络趋势、金融数据、物联网、移动设备等
- 简述Logstash 一般特性 ?
Logstash 可以从不同来源收集数据并发送到多个目的地。
Logstash 可以处理所有类型的日志数据,例如 Apache 日志、Windows 事件日志、网络协议数据、标准输入数据等等。
Logstash 还可以处理 http 请求和响应数据。
Logstash 提供了多种过滤器,可帮助用户通过解析和转换数据来发现数据中的更多含义。
Logstash 还可用于处理物联网中的传感器数据。
Logstash 是开源的,可在 Apache 许可版本 2.0 下使用。
- 简述Logstash优势和缺陷 ?
(1)Logstash 优势
以下几点说明了Logstash的各种优势。
Logstash 提供正则表达式模式序列来识别和解析任何输入事件中的各种字段。
Logstash 支持用于提取日志数据的各种 Web 服务器和数据源。
Logstash 提供了多个插件来解析日志数据并将其转换为任何用户所需的格式。
Logstash 是集中式的,因此可以轻松处理和收集来自不同服务器的数据。
Logstash 支持许多数据库、网络协议和其他服务作为日志记录事件的目标源。
Logstash 使用 HTTP 协议,这使用户可以升级 Elasticsearch 版本,而无需在锁定步骤中升级 Logstash。
(2)Logstash 的缺点
以下几点解释了 Logstash 的各种缺点。
Logstash 使用 http,这会对日志数据的处理产生负面影响。
使用 Logstash 有时会有点复杂,因为它需要对输入的日志数据有很好的理解和分析。
过滤器插件不是通用的,因此用户可能需要找到正确的模式序列以避免解析错误。
- 解释Logstash 和 Elasticsearch的关系 ?
Logstash 提供了输入输出 Elasticsearch 插件来读写日志事件到 Elasticsearch。 Elasticsearch 公司也推荐将 Elasticsearch 作为输出目的地,因为它与 Kibana 兼容。 Logstash 通过 http 协议将数据发送到 Elasticsearch。
Elasticsearch 提供批量上传功能,有助于将来自不同来源或 Logstash 实例的数据上传到集中式 Elasticsearch 引擎。 ELK 与其他 DevOps 解决方案相比具有以下优势-
ELK 堆栈更易于管理,并且可以扩展以处理 PB 级事件。
ELK 堆栈架构非常灵活,并且提供与 Hadoop 的集成。 Hadoop 主要用于归档目的。 Logstash 可以使用flume 直接连接到Hadoop,Elasticsearch 提供了一个名为es-hadoop 的连接器来连接Hadoop。
ELK 拥有总成本远低于其替代品。
- 简述Logstash 和 Kibana的关系 ?
Kibana 不直接与 Logstash 交互,而是通过数据源,即 ELK 堆栈中的 Elasticsearch。 Logstash 从每个来源收集数据,Elasticsearch 以非常快的速度对其进行分析,然后 Kibana 提供有关该数据的可操作见解。
Kibana 是一个基于 Web 的可视化工具,可帮助开发人员和其他人在 Elasticsearch 引擎中分析 Logstash 收集的大量事件的变化。这种可视化可以轻松预测或查看输入源的错误或其他重要事件的趋势变
- 请说明列举Logstash 安装步骤和大概过程 ?
要在系统上安装 Logstash,我们应该按照以下步骤操作-
步骤 1-检查计算机中安装的 Java 版本;它应该是 Java 8,因为它与 Java 9 不兼容。可以通过以下方式检查-
在 Windows 操作系统 (OS) 中(使用命令提示符)-
java-version
在 UNIX 操作系统中(使用终端)-
e c h o echo echoJAVA_HOME
步骤 2-从 https://www.elastic.co/downloads/logstash下载 Logstash
对于 Windows 操作系统,下载 ZIP 文件。
对于 UNIX 操作系统,下载 TAR 文件。
对于 Debian 操作系统,请下载 DEB 文件。
对于 Red Hat 和其他 Linux 发行版,请下载 RPN 文件。
APT 和 Yum 实用程序还可用于在许多 Linux 发行版中安装 Logstash。
步骤 3-Logstash 的安装过程非常简单。让我们看看如何在不同平台上安装 Logstash。
注意-不要在安装文件夹中放置任何空格或冒号。
Windows 操作系统-解压缩 zip 包并安装 Logstash。
UNIX OS-在任何位置提取 tar 文件并安装 Logstash。
t a r – x v f l o g s t a s h − 5.0.2. t a r . g z 使用适用于 L i n u x 操作系统的 A P T 实用程序 − 下载并安装公共签名密钥 − tar –xvf logstash-5.0.2.tar.gz 使用适用于 Linux 操作系统的 APT 实用程序- 下载并安装公共签名密钥- tar–xvflogstash−5.0.2.tar.gz使用适用于Linux操作系统的APT实用程序−下载并安装公共签名密钥− t a r – x v f l o g s t a s h − 5.0.2. t a r . g z 使用适用于 L i n u x 操作系统的 A P T 实用程序 − 下载并安装公共签名密钥 − tar –xvf logstash-5.0.2.tar.gz 使用适用于 Linux 操作系统的 APT 实用程序- 下载并安装公共签名密钥- tar–xvflogstash−5.0.2.tar.gz使用适用于Linux操作系统的APT实用程序−下载并安装公共签名密钥− t a r – x v f l o g s t a s h − 5.0.2. t a r . g z 使用适用于 L i n u x 操作系统的 A P T 实用程序 − 下载并安装公共签名密钥 − tar –xvf logstash-5.0.2.tar.gz 使用适用于 Linux 操作系统的 APT 实用程序- 下载并安装公共签名密钥- tar–xvflogstash−5.0.2.tar.gz使用适用于Linux操作系统的APT实用程序−下载并安装公共签名密钥− t a r – x v f l o g s t a s h − 5.0.2. t a r . g z 使用适用于 L i n u x 操作系统的 A P T 实用程序 − 下载并安装公共签名密钥 − tar –xvf logstash-5.0.2.tar.gz 使用适用于 Linux 操作系统的 APT 实用程序- 下载并安装公共签名密钥- tar–xvflogstash−5.0.2.tar.gz使用适用于Linux操作系统的APT实用程序−下载并安装公共签名密钥− t a r – x v f l o g s t a s h − 5.0.2. t a r . g z 使用适用于 L i n u x 操作系统的 A P T 实用程序 − 下载并安装公共签名密钥 − tar –xvf logstash-5.0.2.tar.gz 使用适用于 Linux 操作系统的 APT 实用程序- 下载并安装公共签名密钥- tar–xvflogstash−5.0.2.tar.gz使用适用于Linux操作系统的APT实用程序−下载并安装公共签名密钥− t a r – x v f l o g s t a s h − 5.0.2. t a r . g z 使用适用于 L i n u x 操作系统的 A P T 实用程序 − 下载并安装公共签名密钥 − tar –xvf logstash-5.0.2.tar.gz 使用适用于 Linux 操作系统的 APT 实用程序- 下载并安装公共签名密钥- tar–xvflogstash−5.0.2.tar.gz使用适用于Linux操作系统的APT实用程序−下载并安装公共签名密钥− wget-qO-https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add-
保存存储库定义-
e c h o " d e b h t t p s : / / a r t i f a c t s . e l a s t i c . c o / p a c k a g e s / 5. x / a p t s t a b l e m a i n " ∣ s u d o t e e − a / e t c / a p t / s o u r c e s . l i s t . d / e l a s t i c − 5. x . l i s t 运行更新 − echo "deb https://artifacts.elastic.co/packages/5.x/apt stable main" | sudo tee-a /etc/apt/sources.list.d/elastic-5.x.list 运行更新- echo"debhttps://artifacts.elastic.co/packages/5.x/aptstablemain"∣sudotee−a/etc/apt/sources.list.d/elastic−5.x.list运行更新− e c h o " d e b h t t p s : / / a r t i f a c t s . e l a s t i c . c o / p a c k a g e s / 5. x / a p t s t a b l e m a i n " ∣ s u d o t e e − a / e t c / a p t / s o u r c e s . l i s t . d / e l a s t i c − 5. x . l i s t 运行更新 − echo "deb https://artifacts.elastic.co/packages/5.x/apt stable main" | sudo tee-a /etc/apt/sources.list.d/elastic-5.x.list 运行更新- echo"debhttps://artifacts.elastic.co/packages/5.x/aptstablemain"∣sudotee−a/etc/apt/sources.list.d/elastic−5.x.list运行更新− e c h o " d e b h t t p s : / / a r t i f a c t s . e l a s t i c . c o / p a c k a g e s / 5. x / a p t s t a b l e m a i n " ∣ s u d o t e e − a / e t c / a p t / s o u r c e s . l i s t . d / e l a s t i c − 5. x . l i s t 运行更新 − echo "deb https://artifacts.elastic.co/packages/5.x/apt stable main" | sudo tee-a /etc/apt/sources.list.d/elastic-5.x.list 运行更新- echo"debhttps://artifacts.elastic.co/packages/5.x/aptstablemain"∣sudotee−a/etc/apt/sources.list.d/elastic−5.x.list运行更新− e c h o " d e b h t t p s : / / a r t i f a c t s . e l a s t i c . c o / p a c k a g e s / 5. x / a p t s t a b l e m a i n " ∣ s u d o t e e − a / e t c / a p t / s o u r c e s . l i s t . d / e l a s t i c − 5. x . l i s t 运行更新 − echo "deb https://artifacts.elastic.co/packages/5.x/apt stable main" | sudo tee-a /etc/apt/sources.list.d/elastic-5.x.list 运行更新- echo"debhttps://artifacts.elastic.co/packages/5.x/aptstablemain"∣sudotee−a/etc/apt/sources.list.d/elastic−5.x.list运行更新− e c h o " d e b h t t p s : / / a r t i f a c t s . e l a s t i c . c o / p a c k a g e s / 5. x / a p t s t a b l e m a i n " ∣ s u d o t e e − a / e t c / a p t / s o u r c e s . l i s t . d / e l a s t i c − 5. x . l i s t 运行更新 − echo "deb https://artifacts.elastic.co/packages/5.x/apt stable main" | sudo tee-a /etc/apt/sources.list.d/elastic-5.x.list 运行更新- echo"debhttps://artifacts.elastic.co/packages/5.x/aptstablemain"∣sudotee−a/etc/apt/sources.list.d/elastic−5.x.list运行更新− e c h o " d e b h t t p s : / / a r t i f a c t s . e l a s t i c . c o / p a c k a g e s / 5. x / a p t s t a b l e m a i n " ∣ s u d o t e e − a / e t c / a p t / s o u r c e s . l i s t . d / e l a s t i c − 5. x . l i s t 运行更新 − echo "deb https://artifacts.elastic.co/packages/5.x/apt stable main" | sudo tee-a /etc/apt/sources.list.d/elastic-5.x.list 运行更新- echo"debhttps://artifacts.elastic.co/packages/5.x/aptstablemain"∣sudotee−a/etc/apt/sources.list.d/elastic−5.x.list运行更新− sudo apt-get update
现在可以使用以下命令进行安装-
s u d o a p t − g e t i n s t a l l l o g s t a s h 在 D e b i a n L i n u x 操作系统上使用 Y U M 实用程序 − 下载并安装公共签名密钥 − sudo apt-get install logstash 在 Debian Linux 操作系统上使用 YUM 实用程序- 下载并安装公共签名密钥- sudoapt−getinstalllogstash在DebianLinux操作系统上使用YUM实用程序−下载并安装公共签名密钥− s u d o a p t − g e t i n s t a l l l o g s t a s h 在 D e b i a n L i n u x 操作系统上使用 Y U M 实用程序 − 下载并安装公共签名密钥 − sudo apt-get install logstash 在 Debian Linux 操作系统上使用 YUM 实用程序- 下载并安装公共签名密钥- sudoapt−getinstalllogstash在DebianLinux操作系统上使用YUM实用程序−下载并安装公共签名密钥− s u d o a p t − g e t i n s t a l l l o g s t a s h 在 D e b i a n L i n u x 操作系统上使用 Y U M 实用程序 − 下载并安装公共签名密钥 − sudo apt-get install logstash 在 Debian Linux 操作系统上使用 YUM 实用程序- 下载并安装公共签名密钥- sudoapt−getinstalllogstash在DebianLinux操作系统上使用YUM实用程序−下载并安装公共签名密钥− s u d o a p t − g e t i n s t a l l l o g s t a s h 在 D e b i a n L i n u x 操作系统上使用 Y U M 实用程序 − 下载并安装公共签名密钥 − sudo apt-get install logstash 在 Debian Linux 操作系统上使用 YUM 实用程序- 下载并安装公共签名密钥- sudoapt−getinstalllogstash在DebianLinux操作系统上使用YUM实用程序−下载并安装公共签名密钥− s u d o a p t − g e t i n s t a l l l o g s t a s h 在 D e b i a n L i n u x 操作系统上使用 Y U M 实用程序 − 下载并安装公共签名密钥 − sudo apt-get install logstash 在 Debian Linux 操作系统上使用 YUM 实用程序- 下载并安装公共签名密钥- sudoapt−getinstalllogstash在DebianLinux操作系统上使用YUM实用程序−下载并安装公共签名密钥− s u d o a p t − g e t i n s t a l l l o g s t a s h 在 D e b i a n L i n u x 操作系统上使用 Y U M 实用程序 − 下载并安装公共签名密钥 − sudo apt-get install logstash 在 Debian Linux 操作系统上使用 YUM 实用程序- 下载并安装公共签名密钥- sudoapt−getinstalllogstash在DebianLinux操作系统上使用YUM实用程序−下载并安装公共签名密钥− rpm–import https://artifacts.elastic.co/GPG-KEY-elasticsearch
在"/etc/yum.repos.d/"目录下的带有.repo后缀的文件中添加以下文本。例如,logstash.repo
[logstash-5.x]
name = Elastic repository for 5.x packages
baseurl = https://artifacts.elastic.co/packages/5.x/yum
gpgcheck = 1
gpgkey = https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled = 1
autorefresh = 1
type = rpm-md
现在可以使用以下命令安装 Logstash-
$ sudo yum install logstash
步骤 4-转到 Logstash 主目录。在 bin 文件夹内,在 Windows 的情况下运行 elasticsearch.bat 文件,或者可以使用命令提示符和终端执行相同的操作。在 UNIX 中,运行 Logstash 文件。
我们需要指定输入源、输出源和可选过滤器。为了验证安装,可以通过使用标准输入流 (stdin) 作为输入源和标准输出流 (stdout) 作为输出源,使用基本配置运行它。也可以使用 –e 选项在命令行中指定配置。
在 Windows 中-
cd logstash-5.0.1/bin
Logstash-e ‘input { stdin { } } output { stdout {} }’
在 Linux 中-
c d l o g s t a s h − 5.0.1 / b i n cd logstash-5.0.1/bin cdlogstash−5.0.1/bin c d l o g s t a s h − 5.0.1 / b i n cd logstash-5.0.1/bin cdlogstash−5.0.1/bin ./logstash-e ‘input { stdin { } } output { stdout {} }’
注意-在 Windows 的情况下,可能会收到一个错误,指出 JAVA_HOME 未设置。为此,请将其在环境变量中设置为"C:\Program Files\Java\jre1.8.0_111"或安装 java 的位置。
步骤 5-Logstash Web 界面的默认端口为 9600 到 9700,在 logstash-5.0.1\config\logstash.yml 中定义为 http.port,它将选择给定范围内的第一个可用端口。
我们可以通过浏览 http://localhost:9600 来检查 Logstash 服务器是否已启动并正在运行,或者端口是否不同,然后请检查命令提示符或终端。我们可以看到分配的端口为"成功启动 Logstash API 端点 {:port ⇒ 9600}。它将返回一个 JSON 对象,其中包含有关已安装 Logstash 的信息,方式如下- {
“host”:“manu-PC”,
“version”:“5.0.1”,
“http_address”:“127.0.0.1:9600”,
“build_date”:“2016-11-11T22:28:04+00:00”,
“build_sha”:“2d8d6263dd09417793f2a0c6d5ee702063b5fada”,
“build_snapshot”:false
}
- 解释Logstash内部架构和组织方式 ?
【Logstash 服务架构】
Logstash 处理来自不同服务器和数据源的日志,它充当托运人。托运人用于收集日志,这些日志安装在每个输入源中。像 Redis、Kafka 或 RabbitMQ 这样的代理是为索引器保存数据的缓冲区,可能有多个代理作为故障转移实例。
像 Lucene 这样的索引器用于索引日志以获得更好的搜索性能,然后输出存储在 Elasticsearch 或其他输出目的地。输出存储中的数据可用于 Kibana 和其他可视化软件。
【Logstash 内部架构】
Logstash 管道由三个组件 输入、过滤器和 输出组成。输入部分负责指定和访问 Apache Tomcat Server的日志文件夹等输入数据源。
【执行模型】
(1)每个Input启动一个线程,从对应数据源获取数据
(2)Input会将数据写入一个队列:默认为内存中的有界队列(意外停止会导致数据丢失)。为了防止数丢失Logstash提供了两个特性:
Persistent Queues:通过磁盘上的queue来防止数据丢失
Dead Letter Queues:保存无法处理的event(仅支持Elasticsearch作为输出源)
(3)Logstash会有多个pipeline worker, 每一个pipeline worker会从队列中取一批数据,然后执行filter和output(worker数目及每次处理的数据量均由配置确定)
- 简述Logstash可以通过哪些方式获取日志输入 ?
Logstash 从以下来源获取输入-
STDIN
Syslog
Files
TCP/UDP
Microsoft Windows 事件日志
Websocket
Zeromq
Customized extensions
- 请简述Logstash如何使用 Apache Tomcat 7 服务器收集日志?
在文件插件的路径设置中使用正则表达式模式从日志文件中获取数据。这在其名称中包含"访问"并添加了 apache 类型,这有助于将集中目标源中的 apache 事件与其他事件区分开来。最后,输出事件将显示在 output.log 中。
input {
file {
path => “C:/Program Files/Apache Software Foundation/Tomcat 7.0/logs/access”
type => “apache”
}
}
output {
file {
path => “C:/tpwork/logstash/bin/log/output.log”
}
}
输出.log
可以在输出事件中看到,添加了一个类型字段,并且该事件出现在消息字段中。
{
“path”:“C:/Program Files/Apache Software Foundation/Tomcat 7.0/logs/
localhost_access_log.2016-12-25.txt”,
“@timestamp”:“2016-12-25T10:37:00.363Z”,“@version”:“1”,“host”:“Dell-PC”,
“message”:“0:0:0:0:0:0:0:1–[25/Dec/2016:18:37:00 +0800] “GET /
HTTP/1.1” 200 11418\r”,“type”:“apache”,“tags”:[]
}
{
“path”:“C:/Program Files/Apache Software Foundation/Tomcat 7.0/logs/
localhost_access_log.2016-12-25.txt”,“@timestamp”:“2016-12-25T10:37:10.407Z”,
“@version”:“1”,“host”:“Dell-PC”,
“message”:“0:0:0:0:0:0:0:1-munish [25/Dec/2016:18:37:02 +0800] “GET /
manager/html HTTP/1.1” 200 17472\r”,“type”:“apache”,“tags”:[]
}
{
“path”:“C:/Program Files/Apache Software Foundation/Tomcat 7.0/logs/
localhost_access_log.2016-12-25.txt”,“@timestamp”:“2016-12-25T10:37:10.407Z”,
“@version”:“1”,“host”:“Dell-PC”,
“message”:“0:0:0:0:0:0:0:1–[25/Dec/2016:18:37:08 +0800] “GET /docs/
HTTP/1.1” 200 19373\r”,“type”:“apache”,“tags”:[]
}
{
“path”:“C:/Program Files/Apache Software Foundation/Tomcat 7.0/logs/
localhost_access_log.2016-12-25.txt”,“@timestamp”:“2016-12-25T10:37:20.436Z”,
“@version”:“1”,“host”:“Dell-PC”,
“message”:“0:0:0:0:0:0:0:1–[25/Dec/2016:18:37:10 +0800] “GET /docs/
introduction.html HTTP/1.1” 200 15399\r”,“type”:“apache”,“tags”:[]
}
- 简述Logstash的过滤器机制 ?
ogstash 在输入和输出之间的管道中间使用过滤器。 Logstash 度量的过滤器操作和创建诸如 Apache-Access 之类的事件。许多过滤器插件用于管理 Logstash 中的事件。此处,在 Logstash 聚合过滤器的示例中,我们过滤数据库中每个 SQL 事务的持续时间并计算总时间。
安装聚合过滤器插件
使用 Logstash-plugin 实用程序安装聚合过滤器插件。 Logstash 插件是 Logstash 中 bin 文件夹 中 Windows 的批处理文件。
logstash-plugin install logstash-filter-aggregate
logstash.conf
在此配置中,可以看到三个"if"语句,用于 初始化、递增、和 生成事务的总持续时间,即 sql_duration。聚合插件用于添加 sql_duration,存在于输入日志的每个事件中。
input {
file {
path => “C:/tpwork/logstash/bin/log/input.log”
}
}
filter {
grok {
match => [
“message”, “%{LOGLEVEL:loglevel}-
%{NOTSPACE:taskid}-%{NOTSPACE:logger}-
%{WORD:label}(-%{INT:duration:int})?”
]
}
if [logger] == “TRANSACTION_START” {
aggregate {
task_id => “%{taskid}”
code => “map[‘sql_duration’] = 0”
map_action => “create”
}
}
if [logger] == “SQL” {
aggregate {
task_id => “%{taskid}”
code => “map[‘sql_duration’] ||= 0 ;
map[‘sql_duration’] += event.get(‘duration’)”
}
}
if [logger] == “TRANSACTION_END” {
aggregate {
task_id => “%{taskid}”
code => “event.set(‘sql_duration’, map[‘sql_duration’])”
end_of_task => true
timeout => 120
}
}
}
output {
file {
path => “C:/tpwork/logstash/bin/log/output.log”
}
}
输出.log
如配置文件中指定的,记录器所在的最后一个‘if’语句——TRANSACTION_END,打印总事务时间或sql_duration。这已在 output.log 中以黄色突出显示。 {
“path”:“C:/tpwork/logstash/bin/log/input.log”,“@timestamp”: “2016-12-22T19:04:37.214Z”,
“loglevel”:“INFO”,“logger”:“TRANSACTION_START”,“@version”: “1”,“host”:“wcnlab-PC”,
“message”:“8566-TRANSACTION_START-start\r”,“tags”:[]
} {
“duration”:320,“path”:“C:/tpwork/logstash/bin/log/input.log”,
“@timestamp”:“2016-12-22T19:04:38.366Z”,“loglevel”:“INFO”,“logger”:“SQL”,
“@version”:“1”,“host”:“wcnlab-PC”,“label”:“transaction1”,
“message”:" INFO-48566-SQL-transaction1-320\r",“taskid”:“48566”,“tags”:[]
} {
“duration”:200,“path”:“C:/tpwork/logstash/bin/log/input.log”,
“@timestamp”:“2016-12-22T19:04:38.373Z”,“loglevel”:“INFO”,“logger”:“SQL”,
“@version”:“1”,“host”:“wcnlab-PC”,“label”:“transaction1”,
“message”:" INFO-48566-SQL-transaction1-200\r",“taskid”:“48566”,“tags”:[]
} {
“sql_duration”:520,“path”:“C:/tpwork/logstash/bin/log/input.log”,
“@timestamp”:“2016-12-22T19:04:38.380Z”,“loglevel”:“INFO”,“logger”:“TRANSACTION_END”,
“@version”:“1”,“host”:“wcnlab-PC”,“label”:“end”,
“message”:" INFO-48566-TRANSACTION_END-end\r",“taskid”:“48566”,“tags”:[]
}
- 简述Logstash 如何转换日志 ?
Logstash 提供了各种插件来转换已解析的日志。这些插件可以在日志中 添加、删除、和 更新字段,以便在输出系统中更好地理解和查询。
我们正在使用 Mutate 插件 在输入日志的每一行中添加一个字段名称 user。
安装 Mutate 过滤器插件
安装mutate过滤器插件;我们可以使用以下命令。
Logstash-plugin install Logstash-filter-mutate
logstash.conf
在这个配置文件中,Mutate Plugin 被添加到 Aggregate Plugin 之后以添加一个新字段。
input {
file {
path => “C:/tpwork/logstash/bin/log/input.log”
}
}
filter {
grok {
match => [ “message”, “%{LOGLEVEL:loglevel}-
%{NOTSPACE:taskid}-%{NOTSPACE:logger}-
%{WORD:label}(-%{INT:duration:int})?” ]
}
if [logger] == “TRANSACTION_START” {
aggregate {
task_id => “%{taskid}”
code => “map[‘sql_duration’] = 0”
map_action => “create”
}
}
if [logger] == “SQL” {
aggregate {
task_id => “%{taskid}”
code => “map[‘sql_duration’] ||= 0 ;
map[‘sql_duration’] += event.get(‘duration’)”
}
}
if [logger] == “TRANSACTION_END” {
aggregate {
task_id => “%{taskid}”
code => “event.set(‘sql_duration’, map[‘sql_duration’])”
end_of_task => true
timeout => 120
}
}
mutate {
add_field => {
“user” => “lidihuo.com”
}
}
}
output {
file {
path => “C:/tpwork/logstash/bin/log/output.log”
}
}
输出.log
可以看到输出事件中有一个名为"user"的新字段。 {
“path”:“C:/tpwork/logstash/bin/log/input.log”,
“@timestamp”:“2016-12-25T19:55:37.383Z”,
“@version”:“1”,
“host”:“wcnlab-PC”,
“message”:“NFO-48566-TRANSACTION_START-start\r”,
“user”:“lidihuo.com”,“tags”:[“_grokparsefailure”]
} {
“duration”:320,“path”:“C:/tpwork/logstash/bin/log/input.log”,
“@timestamp”:“2016-12-25T19:55:37.383Z”,“loglevel”:“INFO”,“logger”:“SQL”,
“@version”:“1”,“host”:“wcnlab-PC”,“label”:“transaction1”,
“message”:" INFO-48566-SQL-transaction1-320\r",
“user”:“lidihuo.com”,“taskid”:“48566”,“tags”:[]
} {
“duration”:200,“path”:“C:/tpwork/logstash/bin/log/input.log”,
“@timestamp”:“2016-12-25T19:55:37.399Z”,“loglevel”:“INFO”,
“logger”:“SQL”,“@version”:“1”,“host”:“wcnlab-PC”,“label”:“transaction1”,
“message”:" INFO-48566-SQL-transaction1-200\r",
“user”:“lidihuo.com”,“taskid”:“48566”,“tags”:[]
} {
“sql_duration”:520,“path”:“C:/tpwork/logstash/bin/log/input.log”,
“@timestamp”:“2016-12-25T19:55:37.399Z”,“loglevel”:“INFO”,
“logger”:“TRANSACTION_END”,“@version”:“1”,“host”:“wcnlab-PC”,“label”:“end”,
“message”:" INFO-48566-TRANSACTION_END-end\r",
“user”:“lidihuo.com”,“taskid”:“48566”,“tags”:[]
}
- 简述Logstash有哪些输出类型 ?
Logstash 提供了多个插件来支持各种数据存储或搜索引擎。日志的输出事件可以发送到输出文件、标准输出或 Elasticsearch 等搜索引擎。 Logstash 支持三种类型的输出,分别是-
标准输出:它用于生成过滤后的日志事件作为命令行界面的数据流。下面是一个将数据库事务的总持续时间生成到 stdout 的示例。
文件输出:Logstash 还可以将过滤器日志事件存储到输出文件中。我们将使用上述示例并将输出存储在文件中,而不是 STDOUT。
空输出:这是一个特殊的输出插件,用于分析输入和过滤插件的性能。
- 简述Logstash如何将数据写入ElasticSearch ?
1:在bin目录下新建conf目录,在conf目录下新建jdbc.conf文件,写入以下内容
input {
file {
path => “E:\files\xx\xx.json” //json文件在本地的位置
start_position => “beginning”
sincedb_path => “/xxx” //这部分是定义的文件目录路径,如果没定义的话,默认目录是在:logstash-6.2.4\data\plugins\inputs\file
codec => json {
charset => “UTF-8” //设置json的编码格式
}
}
}
output {
elasticsearch {
hosts => “http://localhost:9200”
index => “xx” //索引名
document_type => “doc” //文档名
}
stdout{
}
}
2、 执行conf文件:
logstash -f conf/jdbc.conf
- 简述Logstash如何将数据写入MySQL?
MySQL官方JDBC驱动程序
[root@ ]#wget https://cdn.mysql.com//Downloads/Connector-J/mysql-connector-java-5.1.49.zip
[root@ ]#unzip mysql-connector-java-5.1.49.zip
[root@ ]#cp mysql-connector-java-5.1.49/mysql-connector-java-5.1.49-bin.jar /etc/logstash/jdbc/
安装jdbc插件
[root@ ]#bin/logstash-plugin install logstash-output-jdbc
logstash配置
input {
stdin{}
}
filter{
grok {
match => {
“message” => “%{WORD:name} %{NUMBER:age} %{WORD:address}”
}
}
}
output {
jdbc {
driver_jar_path => “/etc/logstash/jdbc/mysql-connector-java-5.1.49-bin.jar”
driver_class => “com.mysql.jdbc.Driver”
connection_string => “jdbc:mysql://127.0.0.1:3306/testdb?user=root&password=20c0dc7315fe8db65cbab532818e0e7a”
statement => [ “INSERT INTO logstash (name, age, address) VALUES(?, ?, ?)”, “name”, “age”, “address” ]
}
}
- 简述Logstash读取Nginx日志 ?
参考分析仅举一个简单的例子:
logstash收集单个日志到文件
[root@web01 ~]#cd /etc/logstash/conf.d/
[root@web01 /etc/logstash/conf.d]#vim message_file.conf
input {
file {
path => “/var/log/messages”
start_position => “beginning”
}
}
output {
file {
path => “/tmp/messages_%{+YYYY-MM-dd}”
}
}
[root@web01 /etc/logstash/conf.d]#vim message_file.conf
#输入插件
input {
#文件模块
file {
#日志类型
type => “message-log”
#日志路径
path => “/var/log/messages”
#第一次收集日志从头开始
start_position => “beginning”
}
}
#输出插件
output {
#文件模块
file {
#输出路径
path => “/tmp/message_%{+yyyy.MM.dd}.log”
}
}
#检测语法
[root@web01 ~]#logstash -f /etc/logstash/conf.d/message_file.conf -t
#启动
[root@web01 ~]#logstash -f /etc/logstash/conf.d/message_file.conf &
测试日志收集
#实时监控收集到的日志
[root@web01 ~]#tail -f /tmp/messages_2020-12-04
#手动添加一台日志
[root@web01 ~]#echo 111 >> /var/log/messages
- 简述Logstash 和Filebeat 关系 ?
logstash 和filebeat都具有日志收集功能,filebeat更轻量,占用资源更少,但logstash 具有filter功能,能过滤分析日志。一般结构都是filebeat采集日志,然后发送到消息队列,redis,kafaka。然后logstash去获取,利用filter功能过滤分析,然后存储到elasticsearch中。
- logstash和filebeat都是可以作为日志采集的工具,目前日志采集的工具有很多种,如fluentd, flume, logstash,betas等等。甚至最后我决定用filebeat作为日志采集端工具的时候,还有人问我为什么不用flume,logstash等采集工具。
- logstash出现时间要比filebeat早许多,随着时间发展,logstash不仅仅是一个日志采集工具,它也是可以作为一个日志搜集工具,有丰富的input|filter|output插件可以使用。常用的ELK日志采集方案中,大部分的做法就是将所有节点的日志内容上送到kafka消息队列,然后使用logstash集群读取消息队列内容,根据配置文件进行过滤。上送到elasticsearch。logstash详细信息可前往https://www.elastic.co/
- logstash是使用Java编写,插件是使用jruby编写,对机器的资源要求会比较高,网上有一篇关于其性能测试的报告。之前自己也做过和filebeat的测试对比。在采集日志方面,对CPU,内存上都要比前者高很多。LogStash::Inputs::Syslog 性能测试与优化
- filebeat也是elastic.公司开发的,其官方的说法是为了替代logstash-forward。采用go语言开发。代码开源。elastic/beats filebeat是beats的一个文件采集工具,目前其官方基于libbeats平台开发的还有Packetbeat, Metricbeat, Winlogbeat。filebeat性能非常好,部署简单。
从关系上看filebeat 是替代 Logstash Forwarder 的下一代 Logstash 收集器,为了更快速稳定轻量低耗地进行收集工作,它可以很方便地与 Logstash 还有直接与 Elasticsearch 进行对接,它们之间的逻辑与拓扑可以参看 Beats 基础,具体的使用可以查看下列的架构,这个也是很多大牛推荐的架构。
- 简述Logstash worker设置 ?
worker相关配置在logstash.yml中,主要包括如下三个:
1 pipeline.workers:
该参数用以指定Logstash中执行filter和output的线程数,当如果发现CPU使用率尚未达到上限,可以通过调整该参数,为Logstash提供更高的性能。建议将Worker数设置适当超过CPU核数可以减少IO等待时间对处理过程的影响。实际调优中可以先通过-w指定该参数,当确定好数值后再写入配置文件中。
2 pipeline.batch.size:
该指标用于指定单个worker线程一次性执行flilter和output的event批量数。增大该值可以减少IO次数,提高处理速度,但是也以为这增加内存等资源的消耗。当与Elasticsearch联用时,该值可以用于指定Elasticsearch一次bluck操作的大小。
3 pipeline.batch.delay:
该指标用于指定worker等待时间的超时时间,如果worker在该时间内没有等到pipeline.batch.size个事件,那么将直接开始执行filter和output而不再等待。
- Logstash读取Redis中的数据 ?
简单的case,就是怎么在logstash进行配置,讲多个日志数据流,通过redis缓存接收,再导出到elasticsearch索引。
假设有两组日志数据由日志端写入redis缓存,两组日志标记其类型为redis-data-A和redis-data-B,则编写logstash配置文件如下
input {
redis {
host => “127.0.0.1”
type => “redis-data-A”
data_type => “list”
key => “listA”
}
redis {
host => “127.0.0.1”
type => “redis-data-B”
data_type => “list”
key => “listB”
}
}
output {
if [type] == “redis-data-A” {
elasticsearch {
host => localhost
index => “logstash_event_a-% {
+YYYY.MM.dd
}
”
}
stdout {
codec => rubydebug
}
}
if [type] == “redis-data-B” {
elasticsearch {
host => localhost
index => “logstash_event_b-% {
+YYYY.MM.dd
}
”
}
stdout {
codec => rubydebug
}
}
}
以上logstash的配置文件含义为:
1、在input处,设置两组redis输入数据,通过type指定两组数据的类型
2、在output处,通过if [type] == “”,设置条件输出,当满足type = redis-data-A,将数据导出到elasticsearch,索引格式为”logstash_event_a-% {
+YYYY.MM.dd
}
”。如果type == redis-data-B,则导出到另一个索引里。
测试,使用redis-cli命令连接redis服务,尝试在两个队列listA和listB,输入数据。listA只输入英文字符,listB只输入数字。
打开 kibana,进入其首页,点击红框所示的标准界面
点击最右上角的齿轮按钮,配置dashborad读取redis-data-A日志数据的索引,即以logstash_event_a-开头的索引数据(同样的方法可以设置logstash_event_b-开头的):
点击保存后,dashboard页面刷新,可以看到显示的message内容,还有type里记录的redis-data-A,表示我们成功获取到了此类日志的数据,全是英文字符,且type为redis-data-A。
为了避免关闭浏览器后,下次重复以上配置,点击界面右上方的保存按钮,将这个配置保存下来。以后,只要点击打开图标,就可以找到这个配置了。
使用同样的方法查看日志数据redis-data-B,全是数字,且type为redis-data-B:
- 简述Logstash过滤器插件有哪些 ?
1、grok 插件
Grok是Logstash最主要的过滤插件,Grok是一种通过正则表达式将非结构化日志数据解析为结构化和可查询的数据的插件。以下列举几种常见的配置参数,其他配置参数详见官档。
2、mutate 插件
mutate过滤器可以讲字段执行常规变化。您可以重命名、删除、替换和修改事件中的字段。以下列举几种常见的配置参数,其他配置参数详见官档。
3、date 插件
日期过滤器用于解析字段中的日期,然后使用该日期或时间戳作为事件的日志存储时间戳。
4、kv 插件
kv插件是对键值数据进行解析,如foo=bar。
5、公共参数
所有筛选器插件都支持以下配置选项,只有筛选成功才能执行。
可以看到基本上每个插件都有公共配置参数add_field、add_tag、remove_field、remove_tag,那这些到底放在哪个插件中使用是取决于实际情况,因为只有插件过滤成功才能从事件中添加移除。另外每个插件中都有一个 tag_on_failure 参数,grok 过滤失败会在tags字段添加 _grokparsefailure,kv 过滤失败会在tags字段添加 _kv_filter_error,其他插件同理,过滤失败都会在tags字段添加响应的元素值便于判断。
- 简述Docker安装logstash的详细过程 ?
编辑docker-compose.yml,内容如下:
version: ‘3’
services:
logstash02:
image: logstash:6.4.1
hostname: logstash02
container_name: logstash02
ports:
- “5045:5045” #设置端口
environment:
XPACK_MONITORING_ENABLED: “false”
pipeline.batch.size: 10
volumes: - ./logstash/logstash.conf:/usr/share/logstash/pipeline/logstash.conf
network_mode: “host”
restart: always
./logstash/logstash.conf文件内容如下:
version: ‘3’
services:
logstash02:
image: logstash:6.4.1
hostname: logstash02
container_name: logstash02
ports:
- “5045:5045” #设置端口
environment:
XPACK_MONITORING_ENABLED: “false”
pipeline.batch.size: 10
volumes: - ./logstash/logstash.conf:/usr/share/logstash/pipeline/logstash.conf
network_mode: “host”
restart: always
然后运行docker-compose up启动logstash容器,在进行logstash测试的时候
/usr/share/logstash/bin/logstash -e ‘input { stdin{} } output { stdout{ codec => rubydebug }}’
相关文章:

logstash 全接触
简述什么是Logstash ? Logstash是一个开源的集中式事件和日志管理器。它是 ELK(ElasticSearch、Logstash、Kibana)堆栈的一部分。在本教程中,我们将了解 Logstash 的基础知识、其功能以及它具有的各种组件。 Logstash 是一种基于…...
Windows本地构建镜像推送远程仓库
下载 Docker Desktop https://smartidedl.blob.core.chinacloudapi.cn/docker/20210926/Docker-win.exe 使用本地docker构建镜像和推送至远程仓库(harbor) 1、开启docker的2375端口 2、配置远程仓库push镜像可以通过http harbor.soujer.com:5000ps&am…...

计算机毕业设计LSTM+Tensorflow股票分析预测 基金分析预测 股票爬虫 大数据毕业设计 深度学习 机器学习 数据可视化 人工智能
|-- 项目 |-- db.sqlite3 数据库相关 重要 想看数据,可以用navicat打开 |-- requirements.txt 项目依赖库,可以理解为部分技术栈之类的 |-- data 原始数据文件 |-- data 每个股票的模型保存位置 |-- app 主要代码文件夹 | |-- mod…...
最新版上帝粒子The God Particle(winmac),Cradle Complete Bundle 2024绝对可用
一。Cradle插件套装Cradle Complete Bundle 2024 Cradle 是一家音乐技术公司,致力于为个人提供所需的工具,使他们成为最好的音乐人。自发布我们的第一款插件 The Prince 以来,我们一直致力于不懈地打造可靠、有益且易于使用的产品,…...

数 据 库
数据库是什么? 如何按照和移植数据库? 如何在命令行使用SQL语句操作数据库? 如何在C / C程序中操作数据库? 1. 数据库是什么? 数据库...

智能城市管理系统设计思路详解:集成InfluxDB、Grafana和MQTTx协议(代码示例)
引言 随着城市化进程的加快,城市管理面临越来越多的挑战。智能城市管理系统的出现,为城市的基础设施管理、资源优化和数据分析提供了现代化的解决方案。本文将详细介绍一个基于开源技术的智能城市管理系统,涵盖系统功能、技术实现、环境搭建…...
 导致 Connection pool shut down 的问题)
CloseableHttpClient.close() 导致 Connection pool shut down 的问题
TL;DR; CloseableHttpClient.close() 方法默认行为是关闭 HttpClientConnectionManager如果多个 CloseableHttpClient 共用了同一个 HttpClientConnectionManager,则第一个请求执行完,其他请求就会爆 Connection pool shut down 异常备注:ht…...

centos7 docker空间不足
今天在使用docker安装镜像的时候,出现报错 查看原因,发现是分区空间不足导致的 所以考虑进行扩容 首先在vmware扩容并没有生效 因为只是扩展的虚拟空间,并不支持扩展分区大小,下面对分区进行扩容 参考: 分区扩容 主…...

C#基于SkiaSharp实现印章管理(5)
印章中最常见的特殊形状通常是五角星,空心、实心的都可能存在,本文学习并实现在印章内部绘制五角星形状。 百度五角星的绘制方法,主要分为三种: 1)五角星各点坐标固定,直接调用编程语言的绘制线条或…...
【C#】ThreadPool的使用
1.Thread的使用 Thread的使用参考:【C#】Thread的使用 2.ThreadPool的使用 .NET Framework 和 .NET Core 提供了 System.Threading.ThreadPool 类来帮助开发者以一种高效的方式管理线程。ThreadPool 是一个线程池,它能够根据需要动态地分配和回收线程…...

【Python系列】Python 中`eval()`函数的正确使用及其风险分析
💝💝💝欢迎来到我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:kwan 的首页,持续学…...

使用Spring Boot开发应用:基于请求参数MD5的缓存键及其他缓存方式
本文将介绍如何在Spring Boot应用中实现基于请求参数MD5的缓存键,以及其他常见的缓存方式。通过实际代码示例,展示如何应用这些技术优化系统性能。 1. 引入必要的依赖 首先,在Spring Boot项目中引入缓存相关的依赖。修改pom.xml文件&#x…...

typescript中interface常见3种用法
文章目录 函数类型对象类型【自命名】: (函数)对象类型 函数类型 作用:声明一个函数接口:可用于类型声明 | 不可implements 对象类型 作用:声明对象具备哪些实例接口:可用于类型 | 可implements 【自命名】&…...

windows10 安装CUDA教程
如何在windows10系统上安装CUDA? 1、查看电脑的NVIDIA版本 nvidia-smi 2、官网下载所需CUDA版本 官网地址:https://developer.nvidia.com/cuda-toolkit-archive 我们所安装的CUDA版本需要小于等于本机电脑的NVIDIA版本。推荐使用迅雷下载,速度会更快哦。 3、安装步骤...

计算机毕业设计选题推荐-某炼油厂盲板管理系统-Java/Python项目实战
✨作者主页:IT研究室✨ 个人简介:曾从事计算机专业培训教学,擅长Java、Python、微信小程序、Golang、安卓Android等项目实战。接项目定制开发、代码讲解、答辩教学、文档编写、降重等。 ☑文末获取源码☑ 精彩专栏推荐⬇⬇⬇ Java项目 Python…...

PSO求解函数最小值的MATLAB例程|MATLAB源代码
本篇文章适合PSO入门,进阶的可能会觉得太简单的。 目录 PSO例程作用运行结果代码函数解释 例程修改tips PSO Particle Swarm Optimization,粒子群优化算法,通过模拟鸟群或鱼群的行为来寻找最优解。在计算时通过对一群粒子的位置和速度进行迭…...

scrapy 爬取旅游景点相关数据(一)
配套视频可以前往B站:麦麦大数据 项目目标: 爬取的是穷游旅游景点列表 、评论数据 📊 章节: 😆 Scrapy 爬取旅游景点相关数据(一) 😆 Scrapy 爬取旅游景点相关数据(二) &…...
构建铁塔基站安全防护网:视频AI智能监控技术引领智慧化转型
一、背景现状 随着通信技术的快速发展,铁塔基站作为重要的通信基础设施,其安全、稳定、高效的运行对于保障通信网络的畅通至关重要。然而,铁塔基站大多分布在公路边、高山、野外等区域,巡检难度大,维护效率低…...

Java中的分布式缓存:Ehcache与Hazelcast
Java中的分布式缓存:Ehcache与Hazelcast 大家好,我是微赚淘客系统3.0的小编,是个冬天不穿秋裤,天冷也要风度的程序猿!今天我们将深入探讨Java中的两种分布式缓存技术:Ehcache与Hazelcast。分布式缓存可以显…...

前端开发工程师的薪资,主要取决于哪3个方面?
作者:清水束竹 从2022年开始,互联网行业的就业情况就不容乐观了。 最明显的三个表现:裁员、缩招、降薪。 其实2021-2022年年中那段时间,互联网企业出现了一波假性繁荣。 某些大厂Q大量招聘应届毕业生,宣传铺天盖地,不…...

边缘计算医疗风险自查APP开发方案
核心目标:在便携设备(智能手表/家用检测仪)部署轻量化疾病预测模型,实现低延迟、隐私安全的实时健康风险评估。 一、技术架构设计 #mermaid-svg-iuNaeeLK2YoFKfao {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg…...

Java-41 深入浅出 Spring - 声明式事务的支持 事务配置 XML模式 XML+注解模式
点一下关注吧!!!非常感谢!!持续更新!!! 🚀 AI篇持续更新中!(长期更新) 目前2025年06月05日更新到: AI炼丹日志-28 - Aud…...

Python基于历史模拟方法实现投资组合风险管理的VaR与ES模型项目实战
说明:这是一个机器学习实战项目(附带数据代码文档),如需数据代码文档可以直接到文章最后关注获取。 1.项目背景 在金融市场日益复杂和波动加剧的背景下,风险管理成为金融机构和个人投资者关注的核心议题之一。VaR&…...

iview框架主题色的应用
1.下载 less要使用3.0.0以下的版本 npm install less2.7.3 npm install less-loader4.0.52./src/config/theme.js文件 module.exports {yellow: {theme-color: #FDCE04},blue: {theme-color: #547CE7} }在sass中使用theme配置的颜色主题,无需引入,直接可…...
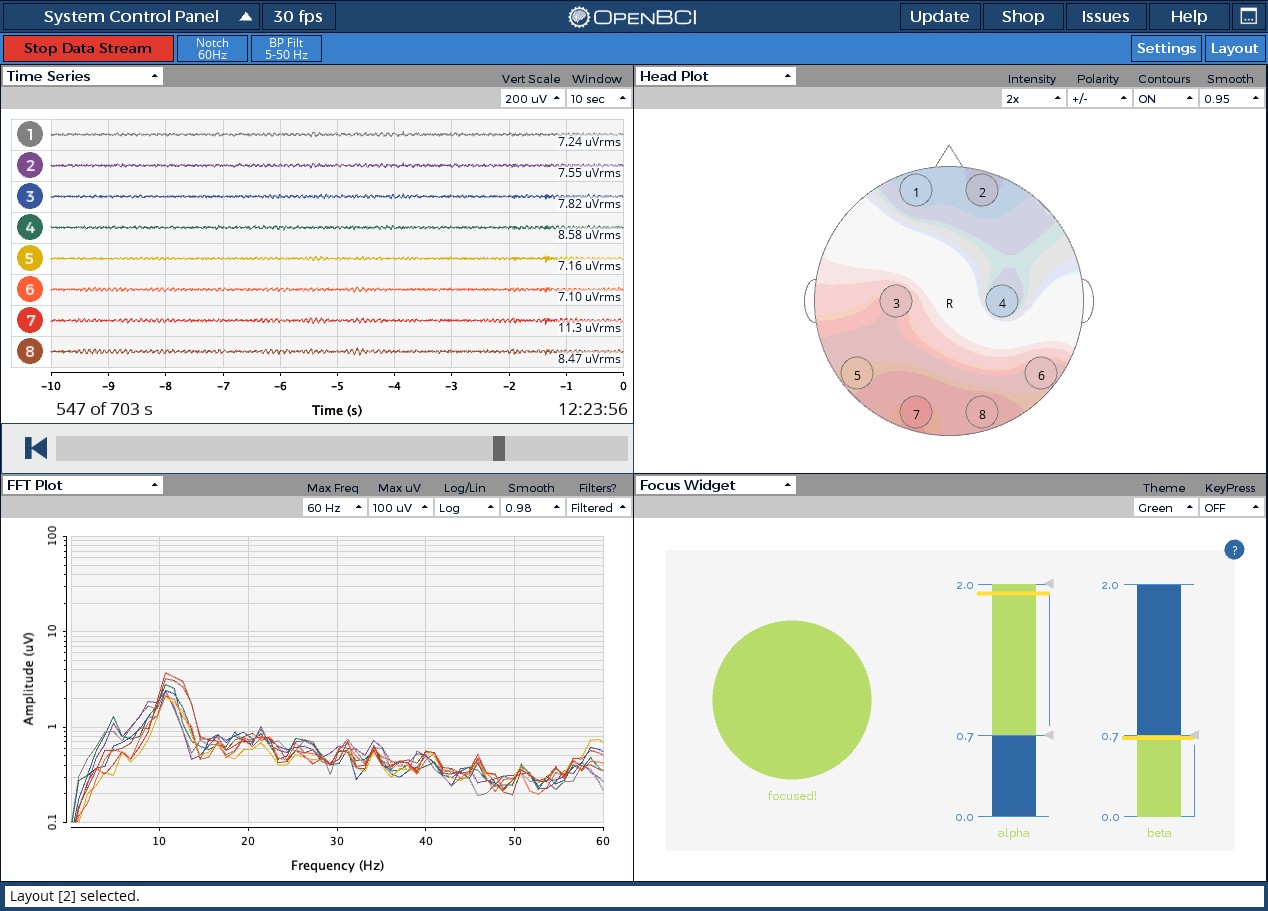
脑机新手指南(七):OpenBCI_GUI:从环境搭建到数据可视化(上)
一、OpenBCI_GUI 项目概述 (一)项目背景与目标 OpenBCI 是一个开源的脑电信号采集硬件平台,其配套的 OpenBCI_GUI 则是专为该硬件设计的图形化界面工具。对于研究人员、开发者和学生而言,首次接触 OpenBCI 设备时,往…...

tomcat入门
1 tomcat 是什么 apache开发的web服务器可以为java web程序提供运行环境tomcat是一款高效,稳定,易于使用的web服务器tomcathttp服务器Servlet服务器 2 tomcat 目录介绍 -bin #存放tomcat的脚本 -conf #存放tomcat的配置文件 ---catalina.policy #to…...

【Elasticsearch】Elasticsearch 在大数据生态圈的地位 实践经验
Elasticsearch 在大数据生态圈的地位 & 实践经验 1.Elasticsearch 的优势1.1 Elasticsearch 解决的核心问题1.1.1 传统方案的短板1.1.2 Elasticsearch 的解决方案 1.2 与大数据组件的对比优势1.3 关键优势技术支撑1.4 Elasticsearch 的竞品1.4.1 全文搜索领域1.4.2 日志分析…...

Oracle11g安装包
Oracle 11g安装包 适用于windows系统,64位 下载路径 oracle 11g 安装包...

数学建模-滑翔伞伞翼面积的设计,运动状态计算和优化 !
我们考虑滑翔伞的伞翼面积设计问题以及运动状态描述。滑翔伞的性能主要取决于伞翼面积、气动特性以及飞行员的重量。我们的目标是建立数学模型来描述滑翔伞的运动状态,并优化伞翼面积的设计。 一、问题分析 滑翔伞在飞行过程中受到重力、升力和阻力的作用。升力和阻力与伞翼面…...

pycharm 设置环境出错
pycharm 设置环境出错 pycharm 新建项目,设置虚拟环境,出错 pycharm 出错 Cannot open Local Failed to start [powershell.exe, -NoExit, -ExecutionPolicy, Bypass, -File, C:\Program Files\JetBrains\PyCharm 2024.1.3\plugins\terminal\shell-int…...