数据透视——判别分析
文章目录
- 判别分析简介
- 常用的判别分析方法
- 距离判别
- 贝叶斯判别
- 线性判别分析(LDA)
- 支持向量机(SVM)
- 总结
- 补充
在数据科学的丰富领域中,判别分析扮演着至关重要的角色。它是一种统计方法,用于预测样本数据的类别标签,基于它们的特征和已知的分类数据。判别分析的历史悠久,其根源可以追溯到20世纪初,随着时间的推移,它已经发展成为多种不同的技术和方法。
判别分析简介
判别分析最初用于生物学和遗传学,但很快在金融、医疗、市场研究和许多其他领域中找到了应用。其核心目标是找到特征空间与类别标签之间的关系,以便于对新样本进行分类。
常用的判别分析方法
判别分析方法多样,每种方法都有其特定的应用场景和优势:
-
距离判别:
- 介绍:基于样本特征与类别质心的距离进行分类,通常使用欧氏距离或曼哈顿距离。
- 特点:直观简单,但对异常值敏感。
-
贝叶斯判别:
- 介绍:使用贝叶斯定理结合先验概率和似然性进行分类,可以是朴素贝叶斯或高斯贝叶斯。
- 特点:利用先验知识,适用于特征独立假设。
-
线性判别分析(LDA):
- 介绍:寻找最佳线性组合特征,以最大化类间差异和最小化类内差异。
- 特点:适用于特征线性可分的情况,可以进行降维。
-
支持向量机(SVM):
- 介绍:通过找到最优边界,处理线性和非线性分类问题,使用核技巧处理非线性问题。
- 特点:强大的分类能力,适用于复杂数据。
-
二次判别分析(QDA):
- 介绍:与LDA类似,但允许每个类别有自己的协方差矩阵,适用于类间差异较大的情况。
- 特点:更灵活,但需要更多的数据来估计协方差矩阵。
-
主成分分析(PCA):
- 介绍:虽然主要用于降维,但也可以通过在主成分空间中应用分类器来进行判别。
- 特点:减少数据维度,去除噪声,保留数据中最重要的信息。
-
正则判别分析(RDA):
- 介绍:通过引入正则化项(如岭回归)来改进LDA,防止模型过拟合。
- 特点:适用于高维数据,提高模型泛化能力。
-
随机森林判别:
- 介绍:集成学习方法,通过构建多个决策树并结合它们的预测结果来进行分类。
- 特点:高效且准确,尤其适合大规模数据集,能够处理高维数据和非线性问题。
-
神经网络判别:
- 介绍:通过模拟人脑神经元网络结构进行非线性判别,可以自动提取特征并进行分类。
- 特点:强大的非线性映射能力,可以自动提取特征,适用于复杂模式识别。
通过这些方法,数据科学家可以根据具体问题和数据特性选择合适的判别分析技术,以实现最佳的分类效果。每种方法都有其独特的优势和局限性,理解这些差异对于在实际应用中做出明智的选择至关重要。下面主要介绍几种使用较为广泛的方法。
距离判别
介绍
距离判别是一种基于距离的分类方法,它根据样本特征与每个类别质心的距离来分配类别。
实现步骤
-
计算质心:计算每个类别的质心,公式为:
μ k = 1 N k ∑ x ∈ C k x \mu_k = \frac{1}{N_k} \sum_{x \in C_k} x μk=Nk1∑x∈Ckx
其中, μ k \mu_k μk是第 k k k 个类别的质心, N k N_k Nk 是类别 k k k中样本的数量。 -
计算距离:计算新样本与每个质心的距离,常用的距离度量包括欧氏距离和曼哈顿距离。
-
分类决策:将样本分配到具有最近质心的类别。
特点
- 简单直观。
- 对异常值敏感。
代码实例
from sklearn.datasets import make_blobs
from sklearn.metrics.pairwise import euclidean_distances# 生成模拟数据
X, y = make_blobs(n_samples=300, centers=3, cluster_std=0.60, random_state=0)# 计算质心
centroids = np.array([np.mean(X[y == i], axis=0) for i in range(len(np.unique(y)))])# 计算距离
distances = euclidean_distances(X, centroids)# 分类决策
predicted_labels = np.argmin(distances, axis=1)# 评估
accuracy = np.mean(predicted_labels == y)
print(f'Accuracy: {accuracy}')
贝叶斯判别
介绍
贝叶斯判别使用贝叶斯定理结合先验概率和特征的似然性来估计样本的后验概率,并据此进行分类。
实现步骤
-
定义先验概率:确定每个类别的先验概率。
-
计算似然概率:估计特征在每个类别下的条件概率。
-
应用贝叶斯定理:计算后验概率:
P ( C k ∣ x ) ∝ P ( x ∣ C k ) ⋅ P ( C k ) P(C_k | \mathbf{x}) \propto P(\mathbf{x} | C_k) \cdot P(C_k) P(Ck∣x)∝P(x∣Ck)⋅P(Ck) -
分类决策:选择后验概率最高的类别。
特点
- 利用先验知识。
- 对特征独立性有要求。
代码实例
from sklearn.naive_bayes import GaussianNB# 假设X_train, X_test, y_train已经准备好# 初始化并训练模型
model = GaussianNB()
model.fit(X_train, y_train)# 预测
y_pred = model.predict(X_test)# 评估
accuracy = model.score(X_test, y_test)
print(f'Accuracy: {accuracy}')
线性判别分析(LDA)
介绍
LDA寻找特征的线性组合,以最大化类间方差和最小化类内方差。
实现步骤
- 计算类别均值和协方差矩阵。
- 求解广义特征值问题:
S w − 1 S b w = λ w S_w^{-1} S_b \mathbf{w} = \lambda \mathbf{w} Sw−1Sbw=λw
其中,( S_w ) 是类内散度矩阵,( S_b ) 是类间散度矩阵。 - 选择特征向量:选择对应于最大特征值的特征向量。
- 转换特征空间:使用选定的特征向量转换数据到新的特征空间。
- 分类决策:在新的特征空间中使用线性分类器进行分类。
特点
- 适用于特征线性可分的情况。
- 可以同时进行降维和分类。
代码实例
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis# 假设X_train, X_test, y_train已经准备好# 初始化并训练模型
lda = LinearDiscriminantAnalysis()
lda.fit(X_train, y_train)# 转换特征空间
X_train_lda = lda.transform(X_train)
X_test_lda = lda.transform(X_test)# 使用线性分类器
from sklearn.linear_model import LogisticRegression
lr = LogisticRegression()
lr.fit(X_train_lda, y_train)# 预测和评估
# ...
支持向量机(SVM)
介绍
SVM通过找到数据点之间的最优边界来区分不同的类别,可以处理线性和非线性问题。
实现步骤
-
选择核函数:确定使用线性核、多项式核、RBF核等。
-
优化分类边界:求解优化问题,找到最大间隔分割数据的边界。
-
分类决策:使用找到的边界对新样本进行分类。
特点
- 强大的分类能力。
- 通过核技巧处理非线性问题。
代码实例
from sklearn.svm import SVC# 假设X_train, X_test, y_train已经准备好# 初始化并训练模型
svm = SVC(kernel='linear')
svm.fit(X_train, y_train)# 预测
y_pred = svm.predict(X_test)# 评估
accuracy = svm.score(X_test, y_test)
print(f'Accuracy: {accuracy}')
总结
判别分析是数据科学中一个多面性的工具,涵盖了从基于距离的方法到贝叶斯框架,再到线性和非线性的分类技术。每种方法都有其独特的优势和适用场景。通过深入理解这些方法的数学原理和实现步骤,数据科学家可以更有效地选择和应用最合适的工具来解决分类问题。随着技术的不断发展,判别分析将继续在数据科学领域发挥重要作用,推动知识的发现和决策的制定。
补充
在实际应用中,评估不同判别分析方法的性能是一个关键的步骤,它可以帮助我们选择最合适的模型并优化预测结果。以下是一些常用的评估指标和方法:
1. 正确率
- 定义:正确分类的样本数占总样本数的比例。
- 公式: Accuracy = T P + T N T P + T N + F P + F N \text{Accuracy} = \frac{TP + TN}{TP + TN + FP + FN} Accuracy=TP+TN+FP+FNTP+TN
- 优点:简单直观。
- 缺点:在类别不平衡的情况下可能不够敏感。
2. 混淆矩阵
- 定义:一个表格,显示了每个类别的真实值与预测值的对应关系。
- 组成:包括真正类(TP)、假正类(FP)、真负类(TN)和假负类(FN)。
- 优点:提供详细的分类结果,便于分析。
- 缺点:在多类问题中可能难以解释。
3. 精确率和召回率
- 定义:
- 精确率:预测为正类中实际为正类的比例。
- 召回率:实际为正类中被正确预测为正类的比例。
- 公式:
- Precision = T P T P + F P \text{Precision} = \frac{TP}{TP + FP} Precision=TP+FPTP
- Recall = T P T P + F N \text{Recall} = \frac{TP}{TP + FN} Recall=TP+FNTP
- 优点:适用于评估模型在特定类别上的性能。
- 缺点:一个高一个低时难以平衡。
4. F1分数
- 定义:精确率和召回率的调和平均值。
- 公式: F 1 = 2 × Precision × Recall Precision + Recall F1 = 2 \times \frac{\text{Precision} \times \text{Recall}}{\text{Precision} + \text{Recall}} F1=2×Precision+RecallPrecision×Recall
- 优点:平衡了精确率和召回率,适用于类别不平衡问题。
- 缺点:对极端值敏感。
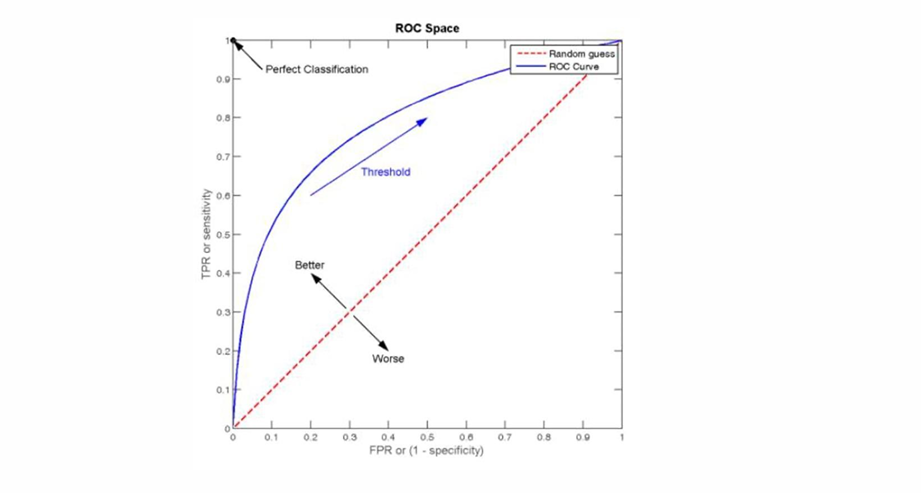
5. 接收者操作特征曲线
- 定义:描述模型在所有分类阈值下真正率(TPR)和假正率(FPR)的关系。
- 优点:直观展示模型在不同阈值下的性能。
- 缺点:只适用于二分类问题。
6. 曲线下面积
- 定义:ROC曲线下的面积,衡量模型整体性能的指标。
- 优点:提供一个综合的性能度量,适用于比较不同模型。
- 缺点:在某些情况下可能不够敏感。
7. 交叉验证
- 定义:将数据集分成多个子集,每次用一个子集作为测试集,其余作为训练集,重复这个过程多次。
- 优点:减少过拟合的风险,提供更可靠的性能估计。
- 缺点:计算成本高。
8. 贝叶斯信息准则(BIC)
- 定义:衡量模型拟合数据的能力,同时惩罚模型复杂度。
- 公式: BIC = − 2 × ln ( L ^ ) + k × ln ( n ) \text{BIC} = -2 \times \ln(\hat{L}) + k \times \ln(n) BIC=−2×ln(L^)+k×ln(n)
- 其中, L ^ \hat{L} L^ 是似然函数的最大值, k k k 是模型参数的数量, n n n 是样本数量。
- 优点:鼓励简单模型,减少过拟合。
- 缺点:对参数估计敏感。
9. 模型复杂度和过拟合
- 评估方法:比较训练集和测试集的性能,检查是否存在过拟合。
- 优点:帮助选择最合适的模型复杂度。
- 缺点:需要足够的数据进行训练和测试。
相关文章:

数据透视——判别分析
文章目录 判别分析简介常用的判别分析方法距离判别贝叶斯判别线性判别分析(LDA)支持向量机(SVM)总结 补充 在数据科学的丰富领域中,判别分析扮演着至关重要的角色。它是一种统计方法,用于预测样本数据的类别…...

书生大模型学习笔记 - 连接云端开发机
申请InternStudio开发机: 这里进去报名参加实战营即可获取 书生大模型实战营 InternStudio平台 创建开发机 SSH连接开发机: SSH免密码登录 本地创建SSH密钥 ssh-keygen -t rsa打开以下文件获取公钥 ~/.ssh/id_rsa.pub去InternStudio添加公钥 …...

Python操作符的重载
目录 1、操作符重载的基本概念1.1、常用的操作符重载方法1.1.1、算术操作符1.1.2、比较操作符1.1.3、比其他操作符 1.2、例子 2、应用场景2.1、增强代码的可读性2.2、 实现类的数学运算2.3、支持自定义的数据结构2.4、简化 API 设计2.5、实现链式操作和流式接口 3、总结 Python…...
Hash数据结构)
redis面试(三)Hash数据结构
HASH 哈希,在redis底层实现的时候,数据的结构叫做dict 这个Dict就是一个用于维护key和value映射关系的数据结构,与很多语言中的Map类型相似。 本质上也是一个数组链表的形式存在,不同的点在于,每个dict中是可以存在…...

Java基础语法
注释 注释就是在程序指定位置添加的说明性信息 简单理解,就是对代码的一种解释 注释有三种: 单行注释 格式://注释信息 多行注释 格式:/*注释信息*/ 文档注释 格式:/**注释信息*/ 注释的注意事项…...
+QBarSeries(柱状图)实战)
Qt | QChart+QChartView+QLineSeries(折线图)+QBarSeries(柱状图)实战
点击上方"蓝字"关注我们 01、QLineSeries QLineSeries 是 Qt 中的一个类,用于在图表中表示一系列的数据点。它继承自 QAbstractSeries 类,提供了绘制折线图所需的基本功能。 常用的方法包括 append(x, y):向序列中添加一个新的数据点,其中 x 和 y 分别表示横坐…...

公布一批脸书爬虫(facebook)IP地址,真实采集数据
一、数据来源: 1、这批脸书爬虫(facebook)IP来源于尚贤达猎头公司网站采集数据; 2、数据采集时间段:2023年10月-2024年7月; 3、判断标准:主要根据用户代理是否包含“facebook”和IP核实。…...

Package.Json 参数配置理解用途
"dev": "SET NODE_OPTIONS--openssl-legacy-provider & vue-cli-service serve --open" 这行命令首先设置环境变量NODE_OPTIONS,添加了--openssl-legacy-provider标志。这个标志用于解决某些情况下Node.js在Windows系统上使用OpenSSL时可能…...

k3:增加触发器,当外协单和报料单新增时,更新生产任务单的“说明”栏
外协单新增时 CREATE TRIGGER [dbo].[t_BOS257800018Entry2_update]ON [dbo].[t_BOS257800018Entry2]AFTER insert AS BEGINSET NOCOUNT ON; ------实现当外协时,生产任务单的说明有标识(240731 BY WK) declare fid_souce as int; declare…...

神奇海洋养鱼小程序游戏广告联盟流量主休闲小游戏源码
在海洋养鱼小程序中,饲料、任务系统、系统操作日志、签到、看广告、完成喂养、每日签到、系统公告、积分商城、界面设计、拼手气大转盘抽奖以及我的好友等功能共同构建了一个丰富而互动的游戏体验。以下是对这些功能的进一步扩展介绍: 饲料 任务奖励&a…...

分享几个适合普通人的AI副业变现思路
最近很多人问:看你做AI也做了有一两年了,也没见有什么产出啊?其实很多事情是长期主义,并不是一时半会儿马上就看到收益了。 正如董宇辉出名前也只是新东方默默无闻的一位老师,李佳琪曾经也只是一个化妆品销售。抱着长…...

如何使用CANoe自带的TCP/IP Stack验证TCP的零窗口探测机制
如果想利用CANoe自带的TCP/IP协议栈验证TCP的零窗口探测机制,就必须添加一个网络节点并配置独立的CANoe TCP/IP协议栈,作为验证对象。而与它进行TCP通信的对端也是一个网络节点,但不要配置TCP/IP协议栈,而是使用CAPL代码在底层组装TCP报文模拟TCP通信过程。这样可以尽量减少…...

二进制搭建 Kubernetes v1.20(中)
一、部署 CNI 网络组件 目录 一、部署 CNI 网络组件 1.flannel简介 1)UDP模式 2)VXLAN 模式 2.部署flannel 编辑 3.Calico简介 1.flannel简介 K8S 中 Pod 网络通信:●Pod 内容器与容器之间的通信 在同一个 Pod 内的容器࿰…...

Scrapy 爬取旅游景点相关数据(七):利用指纹实现“不重复爬取”
本期学习: 利用网页指纹去重 众所周知,代理是要花钱的,那么在爬取(测试)巨量网页的时候,就不可能对已经爬取过的网站去重复的爬,这样会消耗大量的时间,更重要的是会消耗大量的IP (金…...

java的对象向上转型
对象向上转型,父类对象就可以调用子类重写父类的方法,这样当父类对象需要添加新的功能时,只需要添加一个子类,在子类中对父类的功能进行扩展,而不需要更改父类代码 向上转型,格式如下 父类类型 父类对象子…...

Navicat Premium 16破解
Navicat Premium 16破解教程 1安装Navicat Premium 16 通过百度网盘分享的文件:Navicat_Premium_16_chs-x64.zip 链接:https://pan.baidu.com/s/1ryRSJ2d9s6rXI09LEmLtpw?pwdz7wo 提取码:z7wo 一直下一步即可 2破解 选择刚才安装路径&am…...

【C/C++】C语言到C++的入门知识点(主要适用于C语言精通到Qt的C++开发入门)
【C/C】C语言到C的入门知识点(主要适用于C语言精通到Qt的C开发入门) 文章目录 C语言与C的不同C中写C语言代码C语言到C的知识点Qt开发中需要了解的C基础知识namespace输入输出字符串类型class类构造函数和析构函数(解析函数)类的继…...

docker 建木 发版 (详细教程)
先创建git仓库 Git勤勉 两种方式上传-CSDN博客 把项目送上去 进入建木 可以接着这个来 dockerfile部署镜像 ->push仓库 ->虚拟机安装建木 ->自动部署化 (详细步骤)-CSDN博客 创建分组项目 开始操作 git 上钩子 前面链接里有这个教…...

什么样的人适合学习网络安全?
一、引言 在当今数字化的时代,网络安全已经成为了一个至关重要的领域。随着网络攻击的日益频繁和复杂,对于网络安全专业人才的需求也在不断增长。然而,并不是每个人都适合学习网络安全。那么,究竟什么样的人适合投身于这个充满挑…...

大厂linux面试题攻略四之Linux网络服务(二)
五、Linux网络服务-Apache优化 1.请写出工作中常见的Apache优化策略 Apache服务器优化是提升网站响应速度和稳定性的重要手段。在工作中,常见的Apache优化策略包括以下几个方面: 1. 启用压缩技术 Gzip压缩:使用Gzip压缩技术可以减少服务器…...

多模态2025:技术路线“神仙打架”,视频生成冲上云霄
文|魏琳华 编|王一粟 一场大会,聚集了中国多模态大模型的“半壁江山”。 智源大会2025为期两天的论坛中,汇集了学界、创业公司和大厂等三方的热门选手,关于多模态的集中讨论达到了前所未有的热度。其中,…...

遍历 Map 类型集合的方法汇总
1 方法一 先用方法 keySet() 获取集合中的所有键。再通过 gey(key) 方法用对应键获取值 import java.util.HashMap; import java.util.Set;public class Test {public static void main(String[] args) {HashMap hashMap new HashMap();hashMap.put("语文",99);has…...

OPenCV CUDA模块图像处理-----对图像执行 均值漂移滤波(Mean Shift Filtering)函数meanShiftFiltering()
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 在 GPU 上对图像执行 均值漂移滤波(Mean Shift Filtering),用于图像分割或平滑处理。 该函数将输入图像中的…...
相比,优缺点是什么?适用于哪些场景?)
Redis的发布订阅模式与专业的 MQ(如 Kafka, RabbitMQ)相比,优缺点是什么?适用于哪些场景?
Redis 的发布订阅(Pub/Sub)模式与专业的 MQ(Message Queue)如 Kafka、RabbitMQ 进行比较,核心的权衡点在于:简单与速度 vs. 可靠与功能。 下面我们详细展开对比。 Redis Pub/Sub 的核心特点 它是一个发后…...

初探Service服务发现机制
1.Service简介 Service是将运行在一组Pod上的应用程序发布为网络服务的抽象方法。 主要功能:服务发现和负载均衡。 Service类型的包括ClusterIP类型、NodePort类型、LoadBalancer类型、ExternalName类型 2.Endpoints简介 Endpoints是一种Kubernetes资源…...

【SSH疑难排查】轻松解决新版OpenSSH连接旧服务器的“no matching...“系列算法协商失败问题
【SSH疑难排查】轻松解决新版OpenSSH连接旧服务器的"no matching..."系列算法协商失败问题 摘要: 近期,在使用较新版本的OpenSSH客户端连接老旧SSH服务器时,会遇到 "no matching key exchange method found", "n…...
django blank 与 null的区别
1.blank blank控制表单验证时是否允许字段为空 2.null null控制数据库层面是否为空 但是,要注意以下几点: Django的表单验证与null无关:null参数控制的是数据库层面字段是否可以为NULL,而blank参数控制的是Django表单验证时字…...

小木的算法日记-多叉树的递归/层序遍历
🌲 从二叉树到森林:一文彻底搞懂多叉树遍历的艺术 🚀 引言 你好,未来的算法大神! 在数据结构的世界里,“树”无疑是最核心、最迷人的概念之一。我们中的大多数人都是从 二叉树 开始入门的,它…...
自然语言处理——文本分类
文本分类 传统机器学习方法文本表示向量空间模型 特征选择文档频率互信息信息增益(IG) 分类器设计贝叶斯理论:线性判别函数 文本分类性能评估P-R曲线ROC曲线 将文本文档或句子分类为预定义的类或类别, 有单标签多类别文本分类和多…...
Windows电脑能装鸿蒙吗_Windows电脑体验鸿蒙电脑操作系统教程
鸿蒙电脑版操作系统来了,很多小伙伴想体验鸿蒙电脑版操作系统,可惜,鸿蒙系统并不支持你正在使用的传统的电脑来安装。不过可以通过可以使用华为官方提供的虚拟机,来体验大家心心念念的鸿蒙系统啦!注意:虚拟…...