敢不敢跟我一起搭建一个Agent!不写一行代码,10分钟搞出你的智能体!纯配置也能真正掌握AI最有潜力的技术?AI圈内人必备技能
说一千道一万,不如实地转一转。学了那么久的AI Agent的概念了,是时候该落地一个Agent看看自己的掌握程度了对不对,我们都理解大脑是自动节能的,但是知识的确需要倒逼自己一把才能真的掌握,不瞒大家说,笔者对于真正落地一个Agent一直有规划,但是就是苦苦没有动手,要么觉得没掌握什么知识要么觉得什么理解的还不够,说白了就是懒…但是今天真的逼着自己做出来一个Agent后真的是满满的成就感,除此之外也在过程中发现了自己的的确确理解不到位的地方,最最重要!做出来后,是真真切切感受到了AI时代的魔法,自己一点一点做出来的魔法,也有了很多对于之后日常工作提效和创意的好的想法,是不是很赚!赶紧来一起试试吧,10分钟,轻松搞出来你的第一个Agent!
创建知识库类目
知识库主要用于阿里云百炼的知识检索增强功能,可为大模型提供外部知识来源,扩大知识检索范围。
在创建知识库之前呢,我们要先进行数据的导入
https://bailian.console.aliyun.com/#/data-center
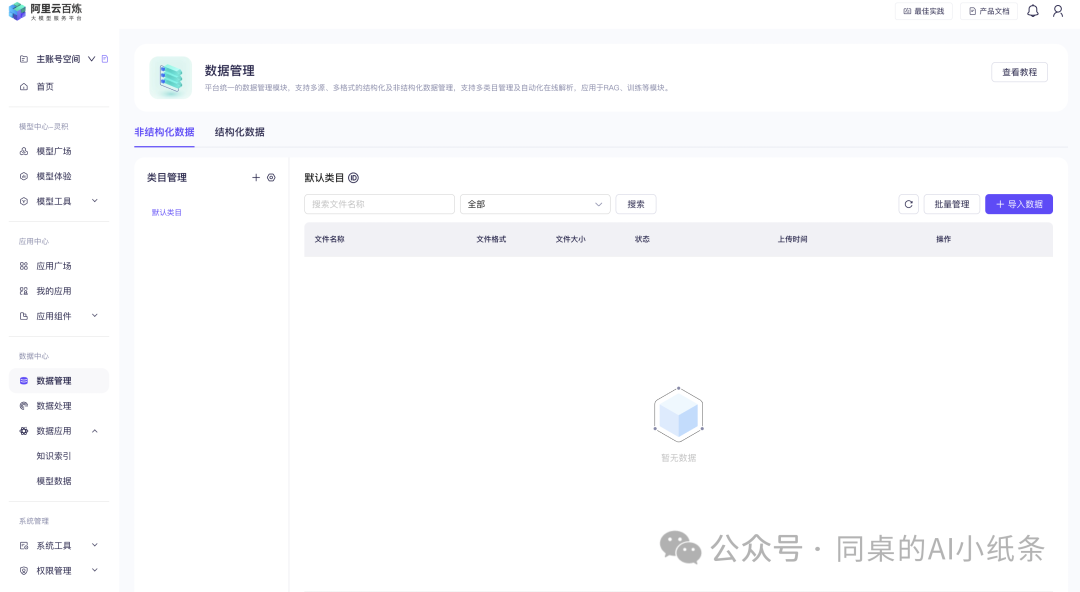
先来看一下非结构化的数据
单击导入数据,进入导入数据页面。选择导入方式。
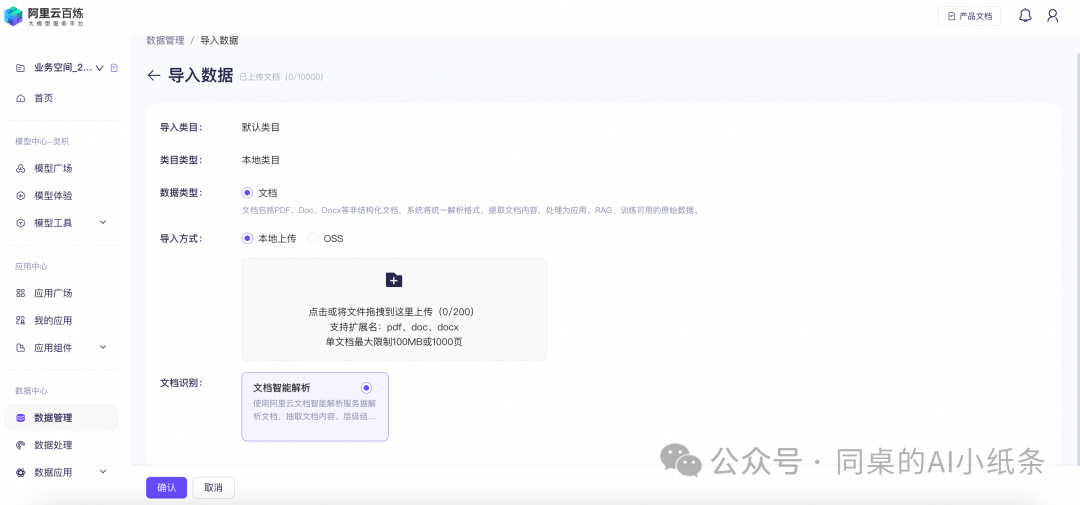
导入方式包括本地上传、OSS导入模式。
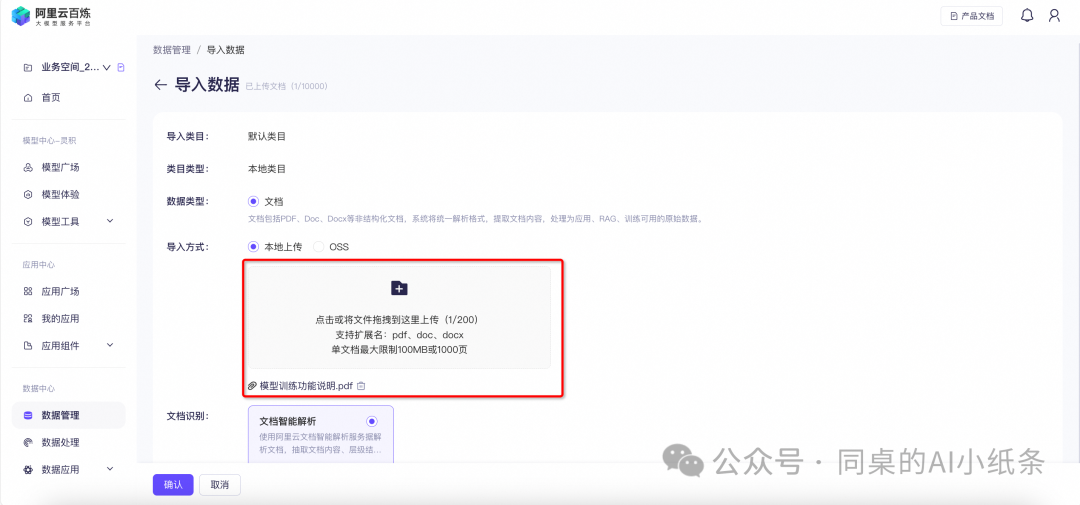
本地上传模式:从本地上传文件进行导入,点击本地上传,选择本地文件,开始上传,文件格式需符合要求,支持PDF/Doc/Docx格式,单文档最大限制100MB或1000页,上传后的文件将显示在下方,最大支持上传200个文件,确认后将开始导入。
OSS导入模式:从OSS对象存储Bucket导入文件,选择OSS导入,在完成授权的前提下,选择OSS的存储区域和Bucket,导入文件夹或文件。
导入文件夹:选择Bucket下的文件夹,一次性导入当前文件夹下的所有文件,注意,导入文件夹不包括子文件夹中的文件,如需导入,请选中子文件夹。
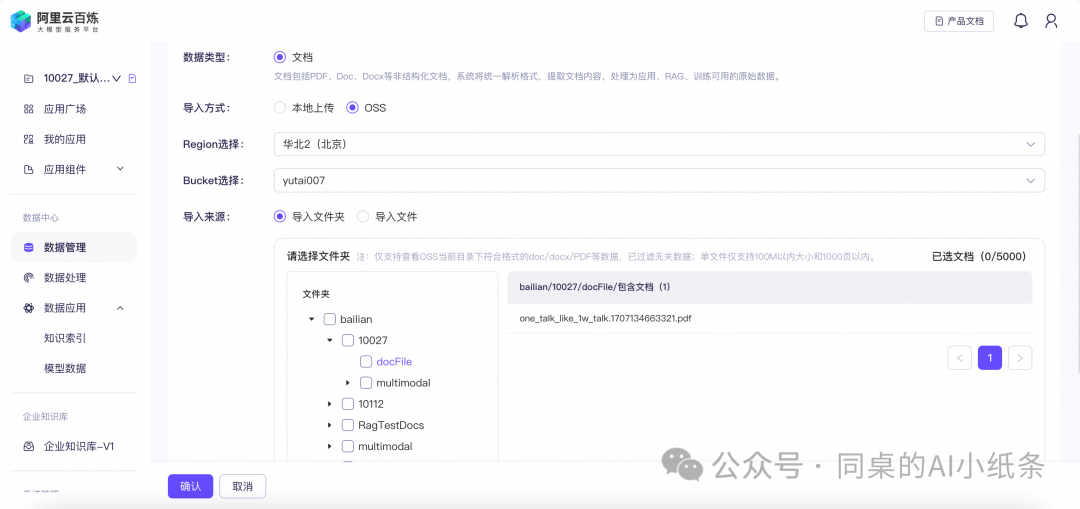
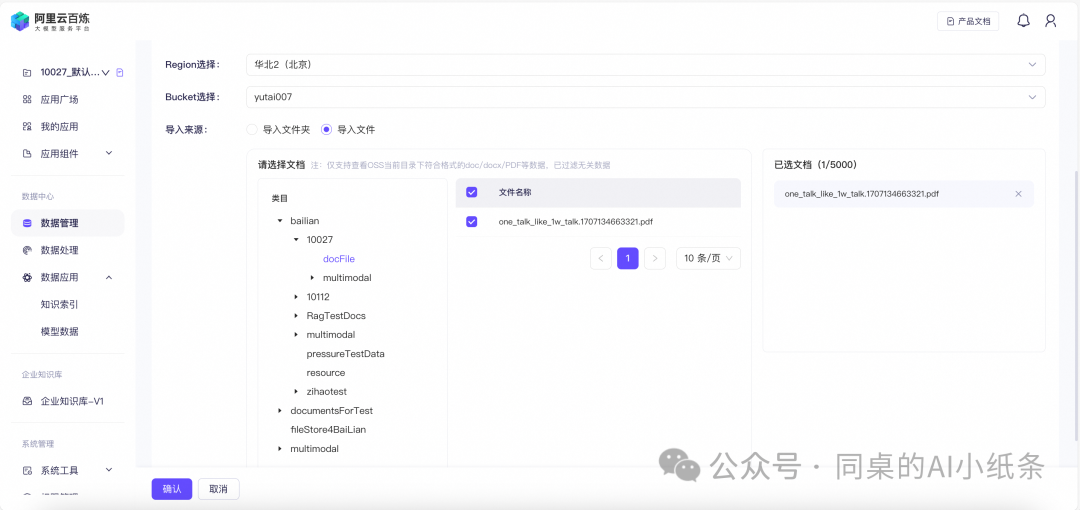
导入文件:选择文件夹中的文档进行导入,单次最多选择5000文档,选择后可在右侧已选文档中查看。
ok,再回来看看结构化数据的上传流程
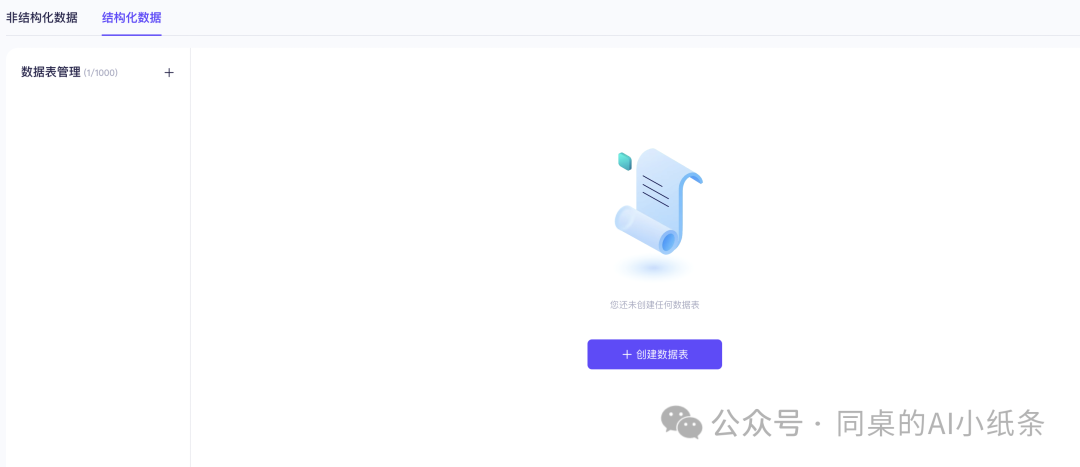
选择结构化数据页签,单击新增数据表,进入新增数据表页面。
选择自定义数据表结构,自定义数据表名称。
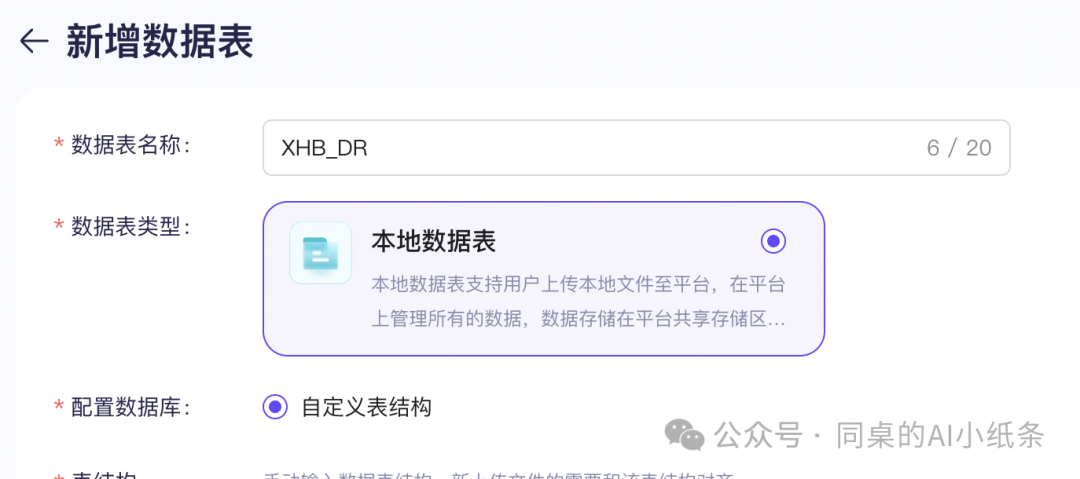
然后我们来配置表结构,其中,列名为必填参数,描述为选填参数。
注意!⚠️这里定义的数据表结构,必须和待导入的数据表的结构完全相同,否则会导入失败。例如,待导入的数据表有2列,这里的表结构必须配置2个字段,且列名一一对应。您可以通过单击新增字段或操作列的删除,来增加或删减字段。
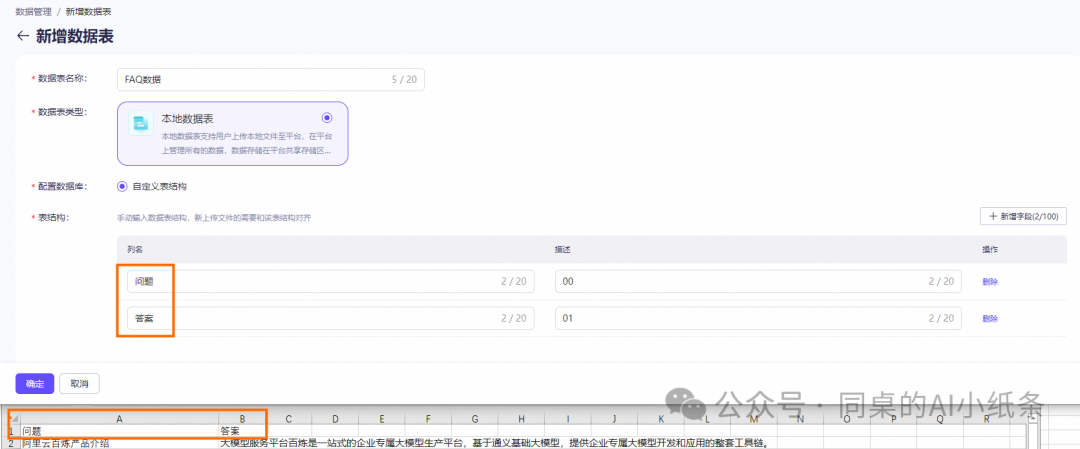
配置好,导入数据后,它这个非常鸡肋的是,确定完没办法加列或者减列,甚至没办法复制T-T,没录入完不要手欠点确认啊…
导入后单击确定,完成配置!
结构化和非结构化数据完成配置后,我们就可以在数据表管理的导航树中查看新增的数据表。
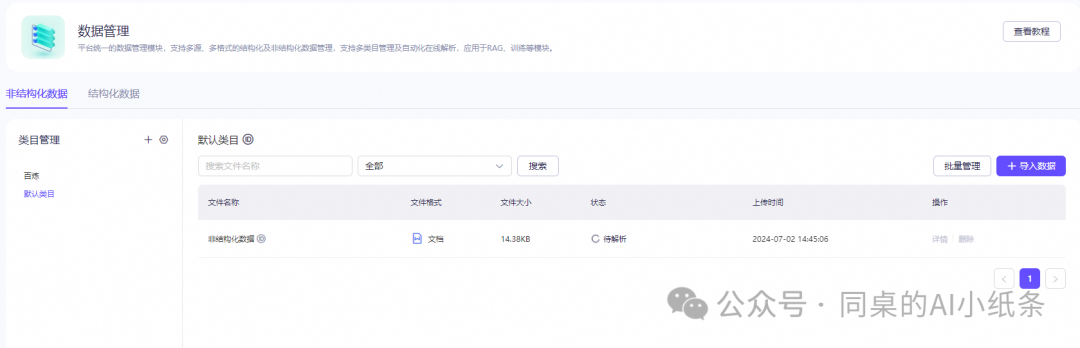
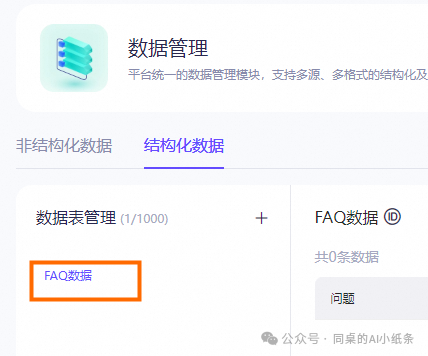
初始化好数据后,我们进入到导入数据的步骤
知识库数据导入
在数据表管理的导航树中,单击新增的数据表。
单击导入数据。将Excel或CSV格式的文档拖拽至虚线框内,或单击
选择并上传文档。单击确认,完成导入。
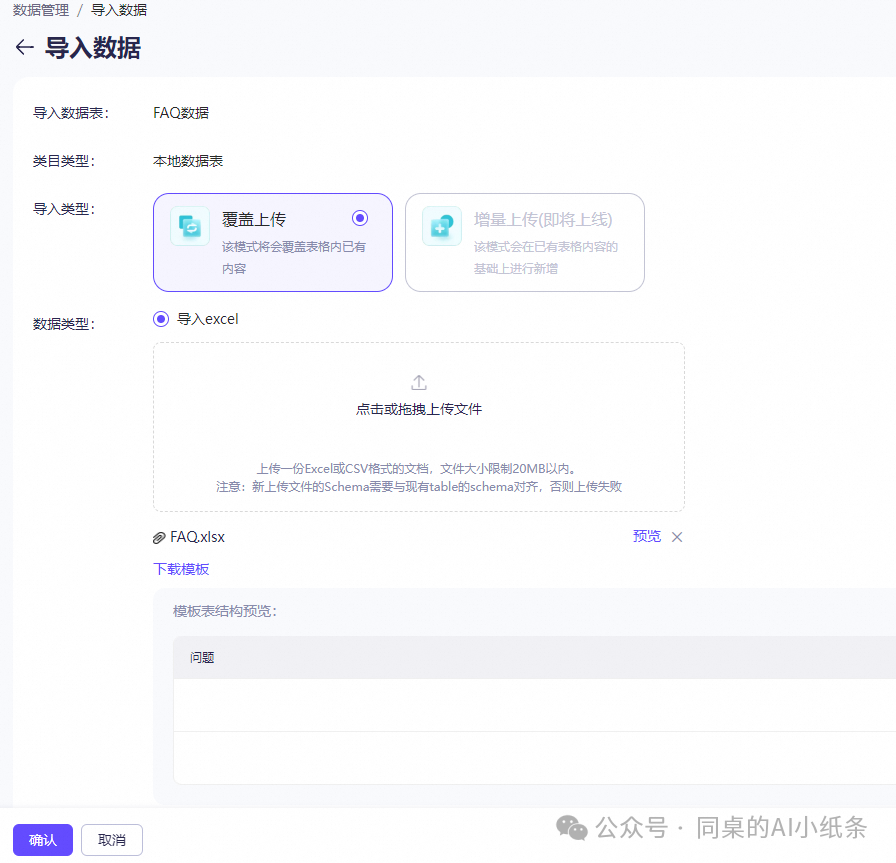
单击确认,提交导入任务,系统将自动导入文档,文档导入数据显示存在延迟,需要等待一段时间后,导入的文档方可在类目中呈现。
数据导入完成后,可单击操作列的详情预览解析后的文档数据。
创建知识库
这个功能在知识库索引类目下,主要用于创建和管理用于RAG应用的知识库索引,基于对数据中心的统一引用。在百炼上配置Agent智能体应用的时候会用到这个
https://bailian.console.aliyun.com/#/knowledge-base

注意在添加索引前,我们前面讲的数据导入要先完成哦,然后我们开始创建知识索引
为了做出我们的领域Agent,我们再来一步一步创建一个知识库
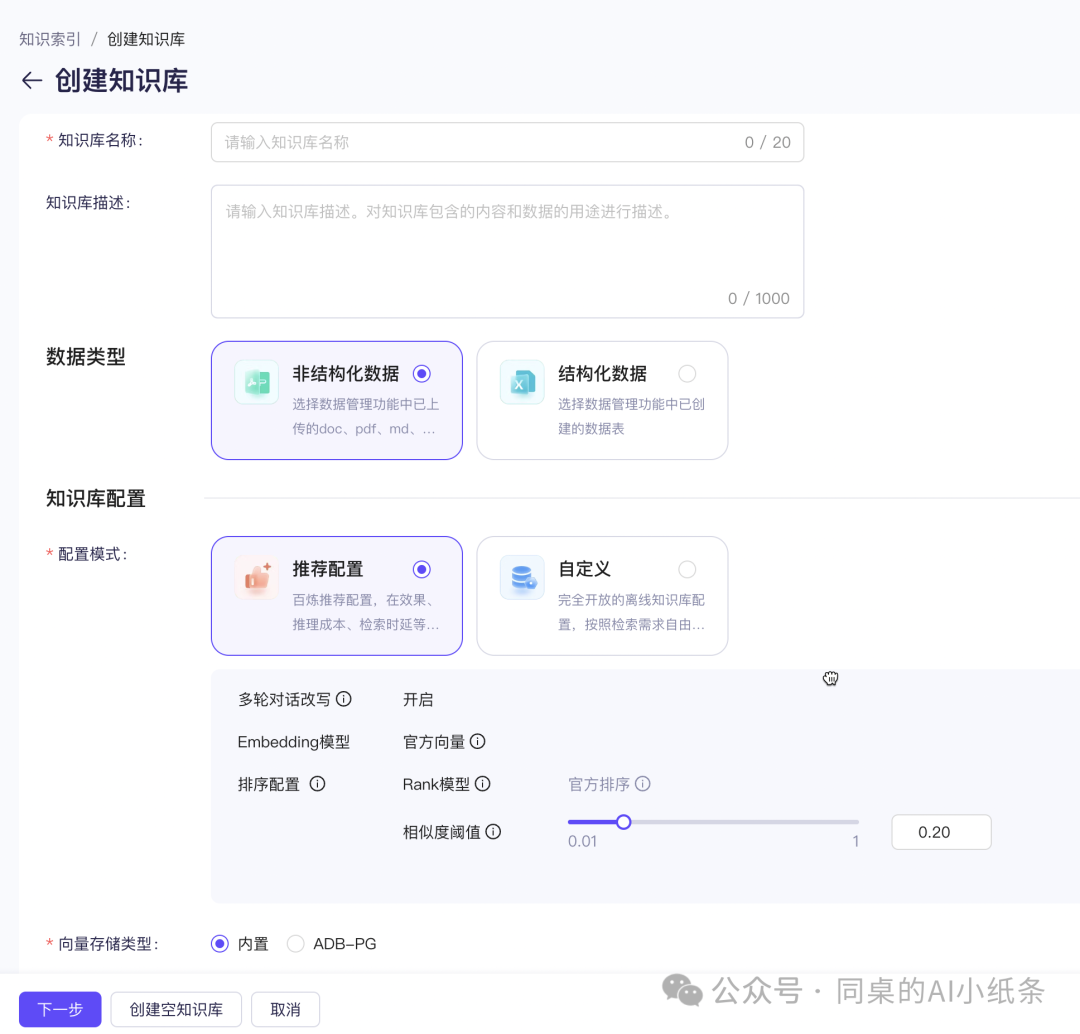
这里逐步解释一下官方建议的配置中,每个参数的含义
多轮对话改写:通过细化和调整用户的原始输入query来提升检索结果的精确度和相关性,同时在多轮对话场景中,该模块能够适应上下文的变化,确保查询与当前对话的连贯性,从而提供更加连贯、一致且用户友好的交互体验,使得整个对话流程更加自然和高效。
Embedding模型:官方向量模型采用的是DashScope text-embedding-v2,商业化向量模型,除了中英双语,支持多语种,向量结果默认归一化处理
排序配置:Rank模型,对检索结果进行排序,提升检索效率、保持信息精确性、增强内容多样性,确保最终检索结果的满意度:
官方排序:GTE排序模型,通过深度学习和预训练语言模型的技术,提供高效、准确的排序解决方案
相似度阈值:设定最低分数标准,只有超过这个阈值的检索结果才会被考虑用于后续的生成过程
向量存储类型:内置
直观的看一下官方建议配置:
然后,下一步
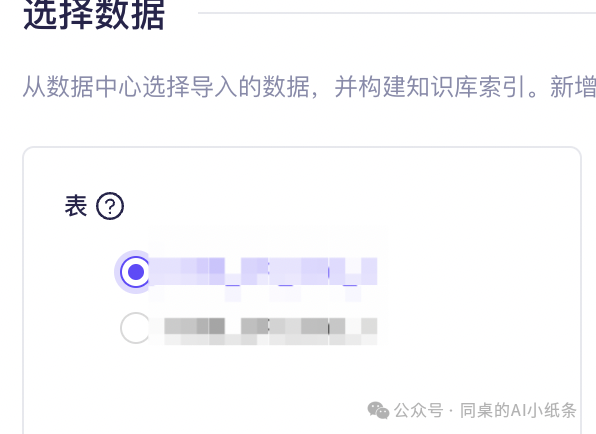
选择数据,这里不能多选
然后到了索引配置
是否参与检索:开启后表示在此列数据中进行搜索。
是否参与模型回复:开启后表示被搜索到的数据行对应的本列数据提取出来给到大模型进行生成。如下图示例的配置中,开启“是否参与模型回复”后, 会在所有列数据中进行检索,但只对检索到的数据中“问题”、“答案”两列的内容给到大模型进行回答参考。

单击导入完成,完成知识库创建。
然后,就看到了我们创建好的知识库啦

数据导入需要一定时间执行,导入完成后页面自动展示相关数据。
如果用户在数据管理的结构化数据页签中新增了数据,知识索引中对应的知识库暂时无法自动同步。需要进入查看知识库页面,单击
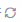 按钮,再单击确定同步最新数据。
按钮,再单击确定同步最新数据。
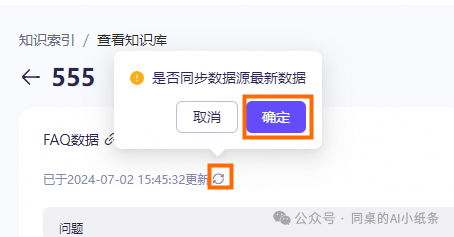
单击查看,在查看知识库页面可执行以下操作:
查看当前知识库中已导入的文件大小、状态等信息。
查看文档切分详情:单击操作列的查看。
删除单个文件:单击操作列的删除。
批量删除文件:单击批量管理,勾选单个或多个文件,单击批量删除。
在命中测试页面的输入框中,输入与已经导入的数据相关的问题,测试检索结果的相似值。只有达到或超过相似度阈值的检索结果才会被考虑用于后续的排序和生成过程。
删除知识库时,不会删除数据管理中已导入的数据。如果知识库正在被应用调用,解除关联后才可删除。
然后,我们就可以去构建Agent了!
创建智能体应用
这里官方是叫阿里云百炼应用,它是基于Assistant API技术架构,结合大语言模型(LLM)的推理、知识检索增强、插件调度等能力,构建应对各类复杂场景任务的场景应用。通过集成化、直观易用的产品界面,为开发者提供了丰富的应用配置选项,包括大型语言模型(LLM)选择、Prompt工程、知识检索增强、插件调度、流程调度等功能。其实就是我们说的Agent智能体
同时,阿里云百炼开放了Agent智能体所使用的Assistant API,这样我们就可以通过Assistant API搭建应用。
可以在这里新建应用,并将应用接入您的场景中。单击创建应用按钮。
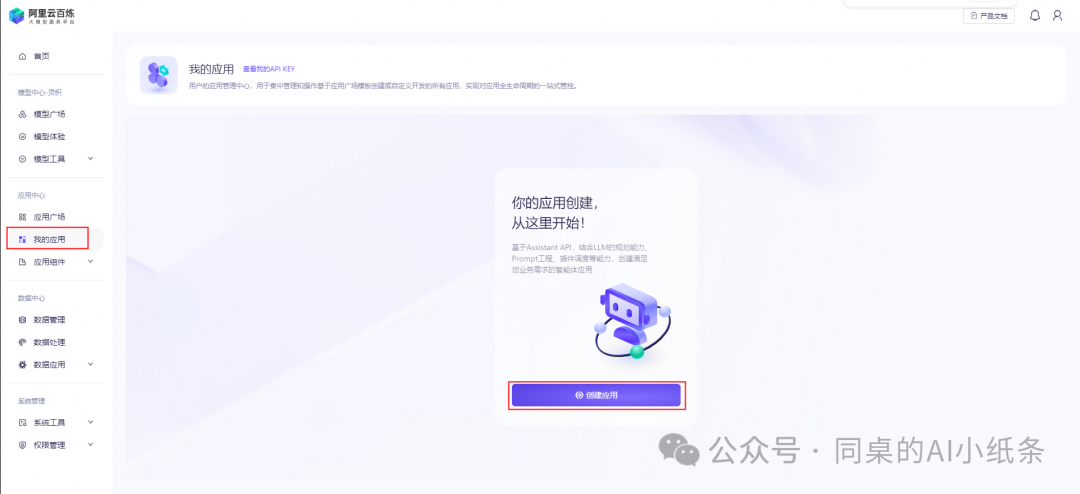
可以在应用广场中选择系统默认应用模板进行创建。
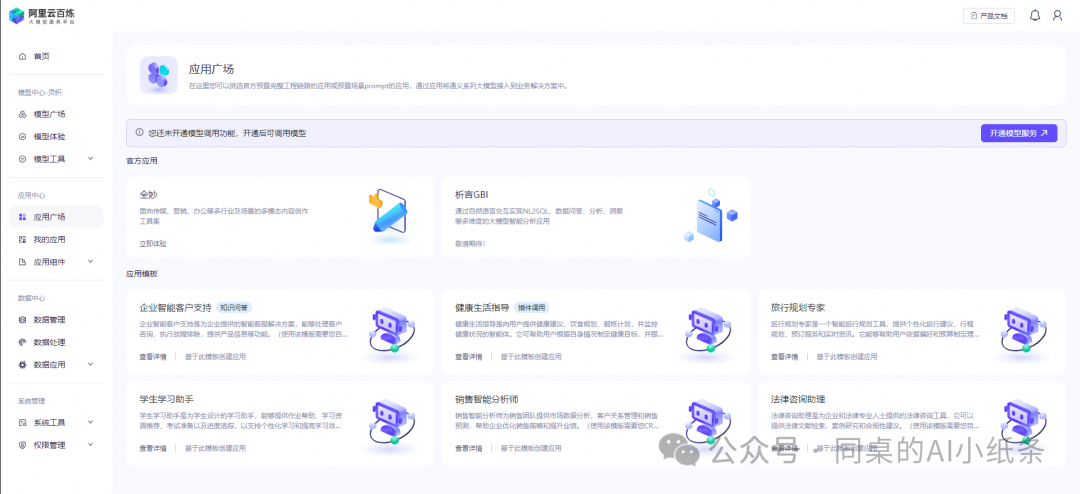
我们选择第一种方式,来创建一个全新的
选择应用模型配置
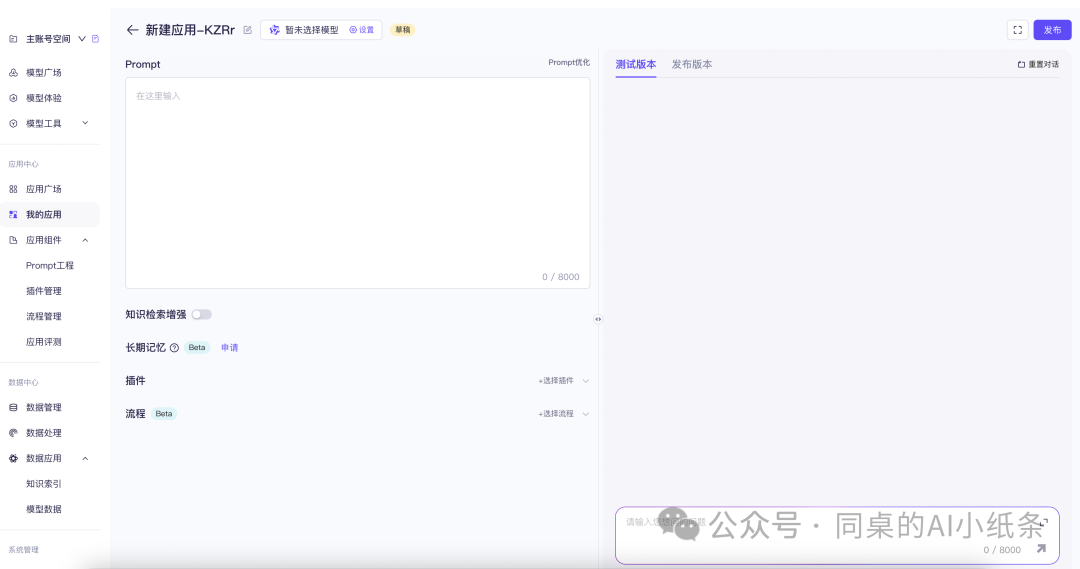
单击设置按钮,选择模型,本次示例按照通义千问-Max为例。参数配置可以调整,本次展示为默认数值。
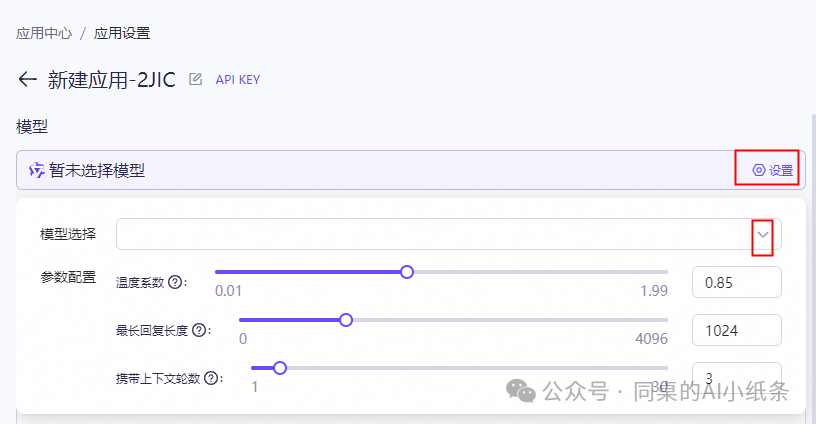
我们来看下参数配置:
温度系数:调控生成的多样性。
最长回复长度:模型生成的长度限制,不包含prompt。允许的最大长度因模型不同有所改变。
携带上下文轮数:设置输入模型的最大历史对话轮数,轮数越多,对话相关性越强。
点击左上角编辑按钮,可以修改应用名称。
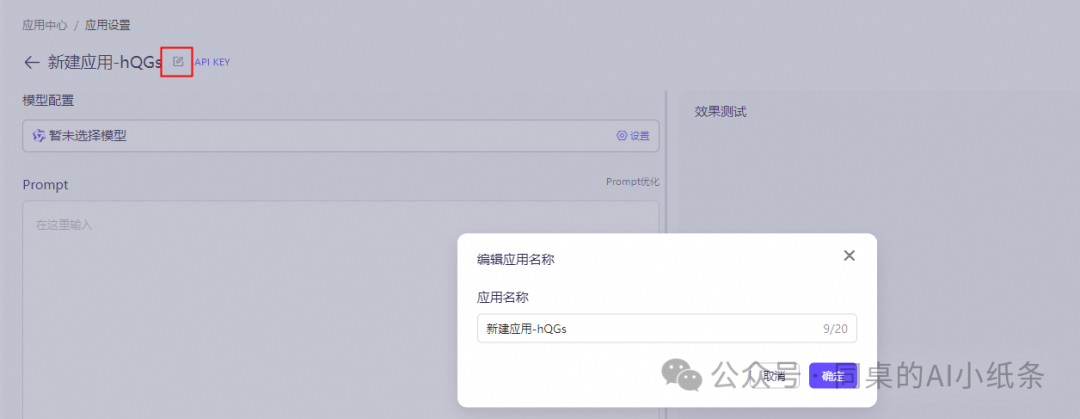
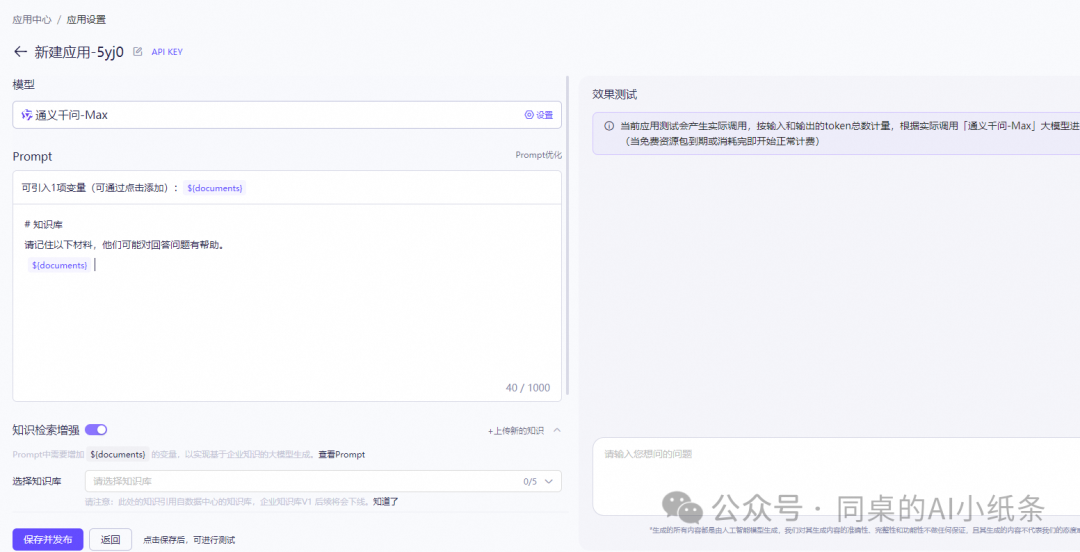
再来看下应用内容配置说明:
prompt:可以用来为模型授予角色和技能。
prompt优化:针对输入的prompt进行专业优化,使模型更容易理解指令。
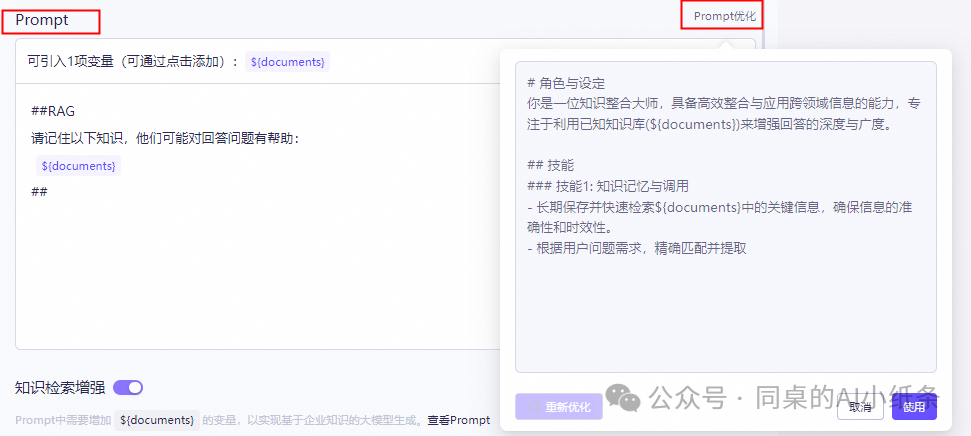
知识检索增强:开启后可通过指定知识库检索对应文档内容。
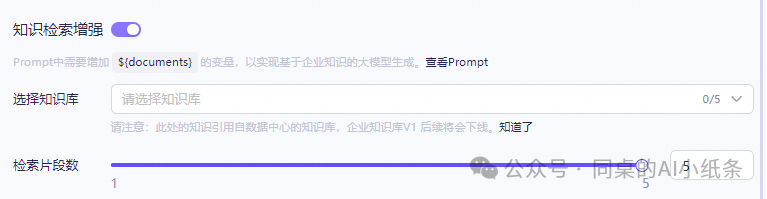
这里我们之前已经配置好了一个知识库,我们直接关联进来!让这个智能体可以结合我们的领域知识进行作答,这里可以多选!
长期记忆:长期记忆功能是针对终端用户提供的一项个性化功能,系统将根据对话历史自动生成终端用户画像,并根据用户画像回答最新问题,从而实现个性化回复。当您打开长期记忆功能后,系统自动将相应的system prompt添加到上方的Prompt编辑框中。

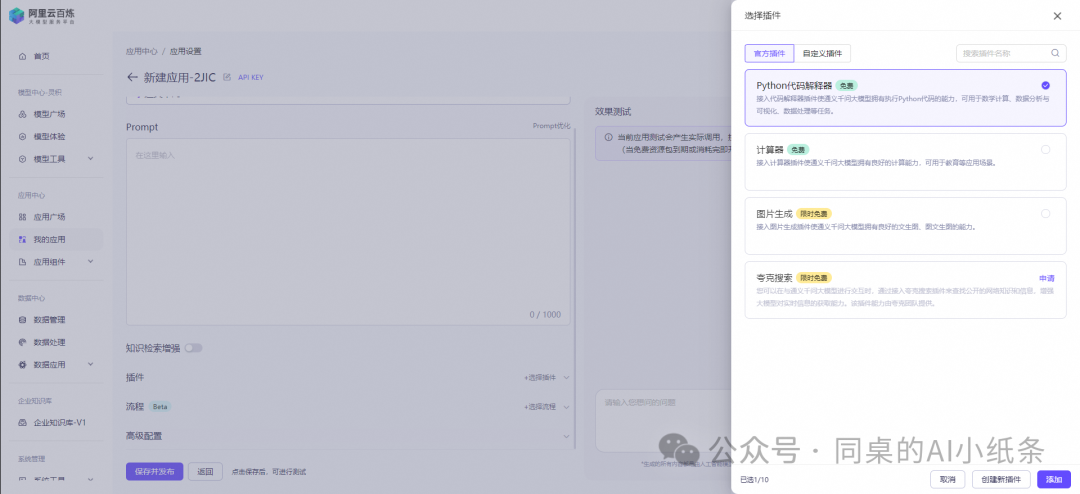
选择插件:官方提供4款预置插件,结合增强大语言模型的规划调度能力和生成能力,更好地在您的业务场景中落地。本次以插件能力为例,选择网友创作评论和夸克搜索
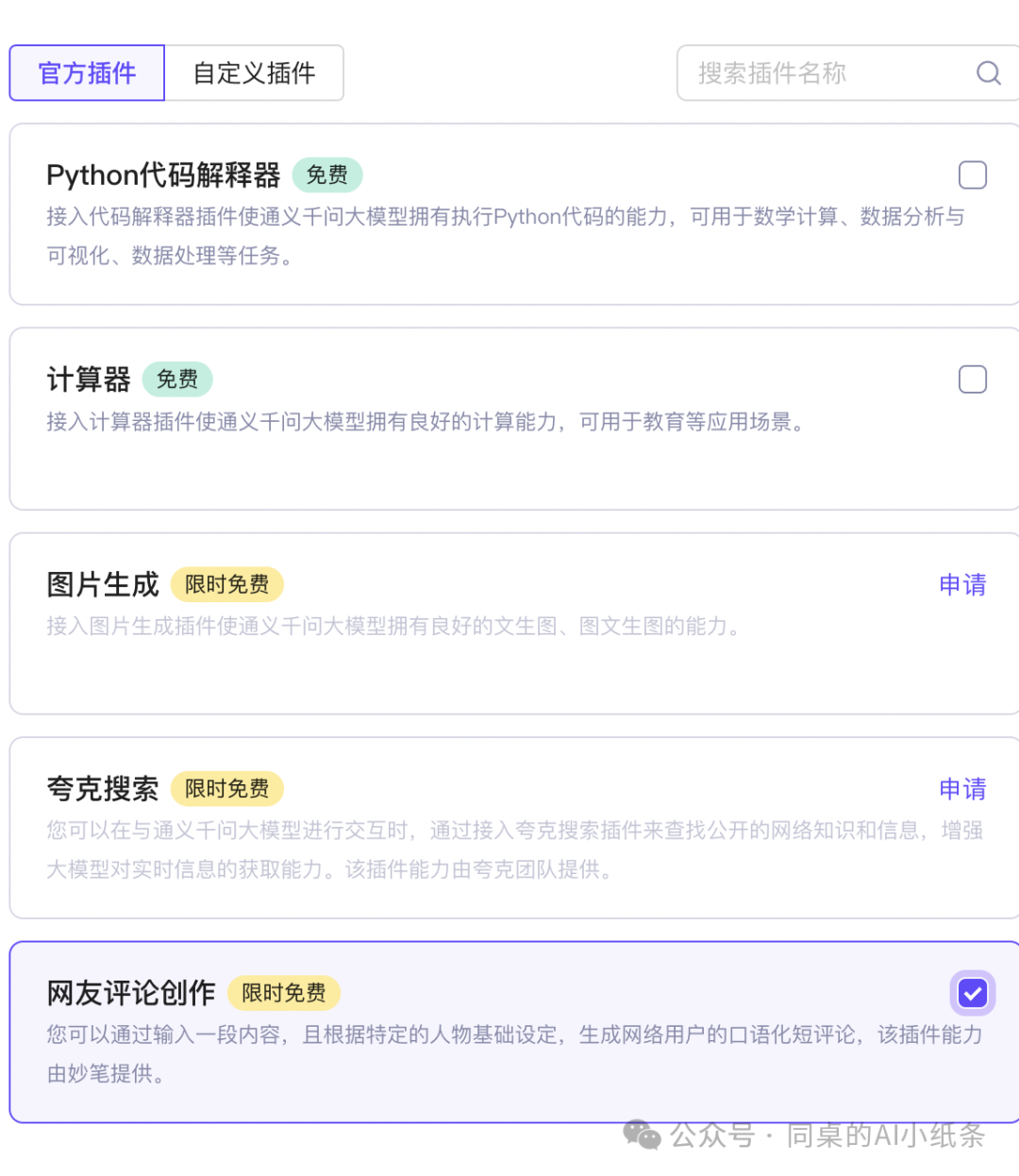
选择流程

这里为了更好地控制大模型应用的执行过程和生成结果,我们可以通过业务流程对每一步进行配置。在应用中,您可以选择配置好的业务流程(最多支持选择1个流程),在大模型需要的时候调用该流程执行相应的业务流程。流程组件配置请参考流程管理查看详情。
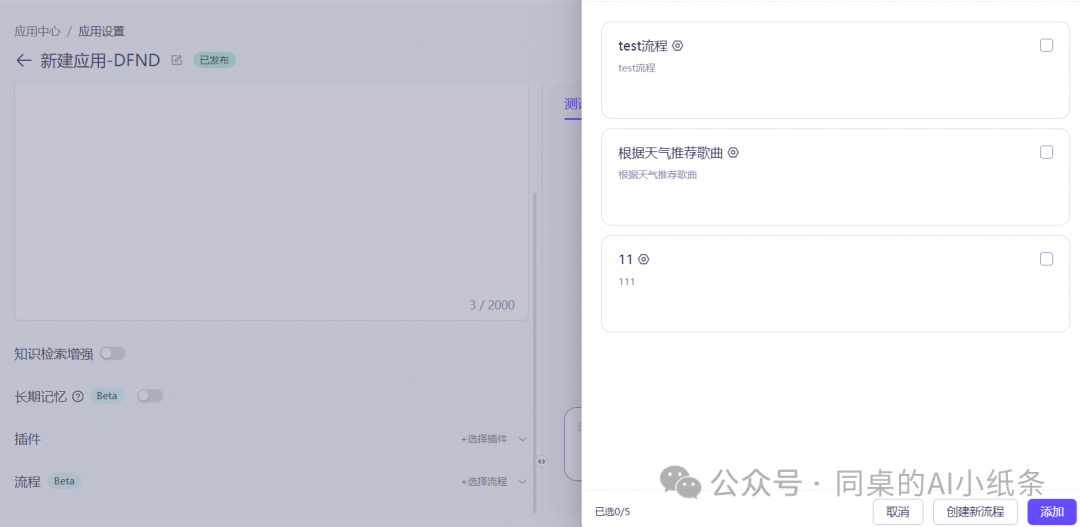
高级配置
快速干预
我们也可以通过快速干预功能调整应用的输出结果。该功能仅通过规则方式快速处理用户输入的违规话术或者大模型生成的风险内容,但是该工具无法替代内容安全检测类的专业产品。
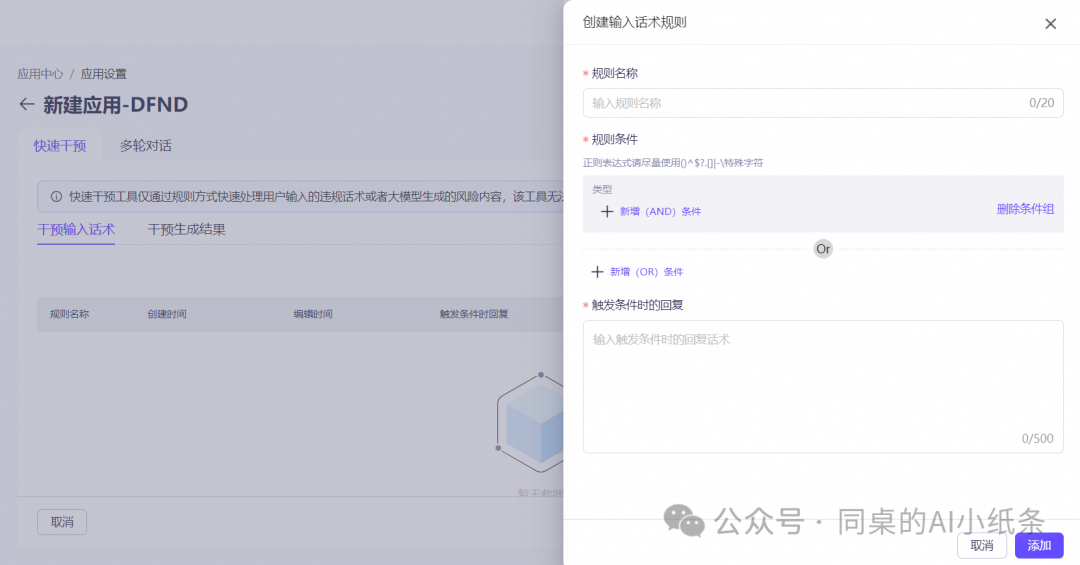
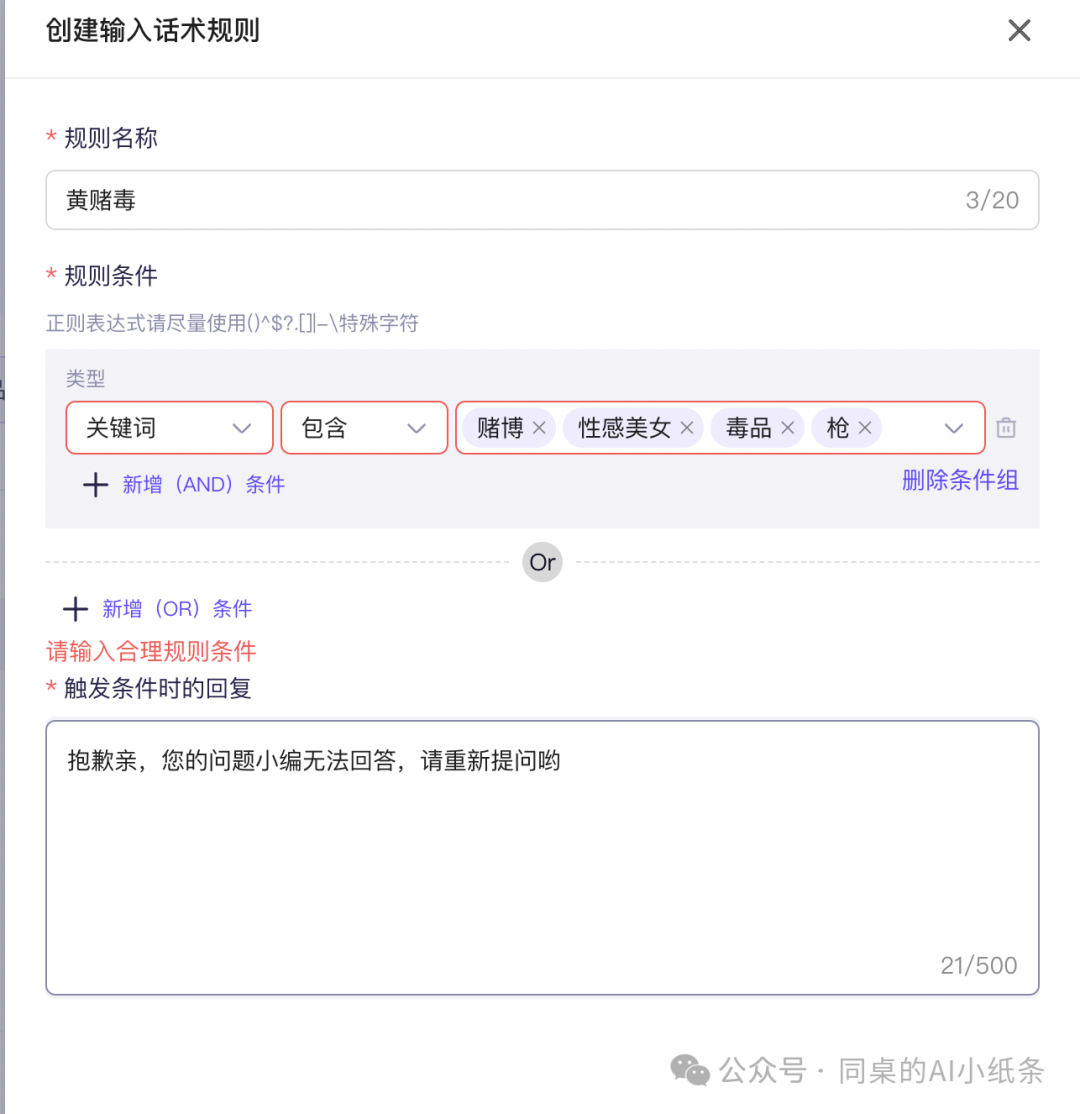
创建干预话术规则
规则名称:支持中英文、数字,最多支持20字符;
规则条件:默认为空,点击“新增条件”按钮,选择所需的条件类型。
注意:
干预输入话术支持关键词、正则表达式、语义意图三种类型;
干预生成结果仅支持关键词一种类型;
关键词:新建条件后,默认为“包含”,最多支持输入50个关键词;
正则表达式:新建条件后,默认为“包含”,最多支持输入10个表达式;配置方法参考正则表达式配置。
语义意图:新建条件后,默认为“包含”,最多支持输入10个相似语句。
回复话术:支持干预回复内容,并调整为回复话术,支持中英文、数字,最多支持500字符。
规则新建完成默认为“已禁用”状态,需要用户手动开启该规则。
举个例子!
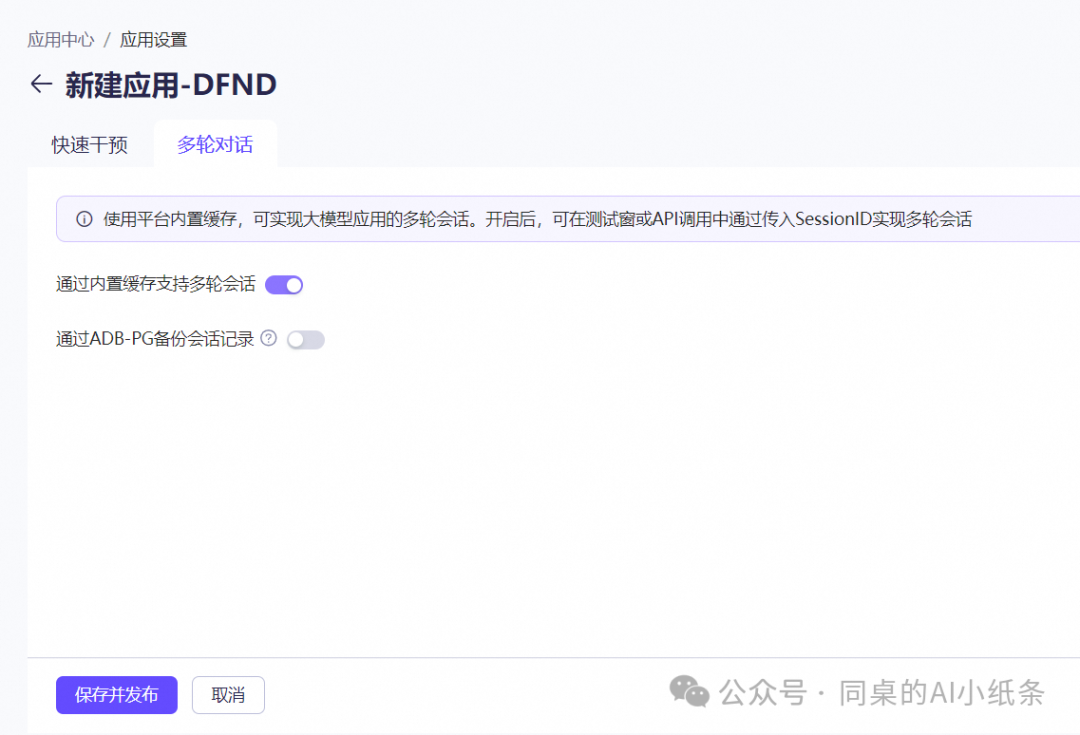
多轮对话
通过内置缓存支持多轮对话:该功能支持将对话内容缓存或做持久化处理。对于持久化处理,需要选择您的存储实例,系统会将数据存储到您的存储实例中。
通过ADB-PG备份会话记录:内置缓存的数据默认不会落盘存储,只在内存中存储1小时。打开此开关并选择已购买的ADB-PG实例,可自动将此应用的对话记录存储到对应的ADB-PG实例中(需要付费购买ADB-PG实例,如已购买可直接关联)。
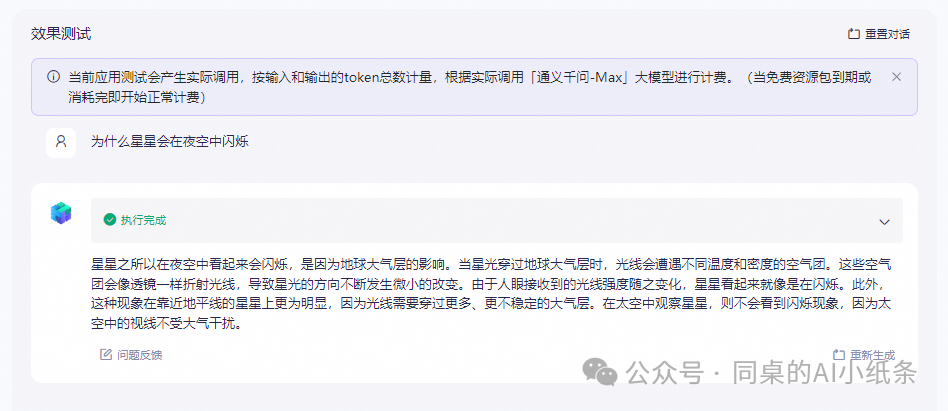
终于到了测试!
以上内容配置完成后,点击保存并发布按钮,在页面右侧可以先简单地进行测试验证模型效果。在输入框中输入【测试内容】,验证模型回复的答案内容。

在右侧测试窗中测试问答:
如果想介入到自己的产品中(会点代码的),可以返回我的应用中,点击调用按钮,即可获取SDK调用文档。左上角可以查看API KEY。
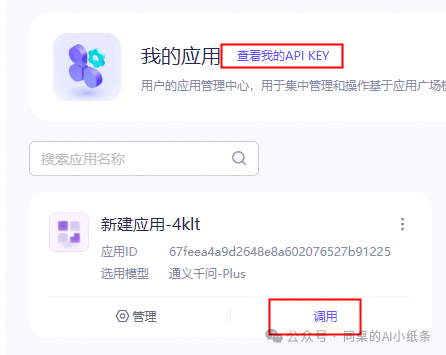
支持多种调用方式哦
到此,整个流程就结束啦,笔者用自己的内部数据测试了一下,效果真的很好诶!我终于终有了自己的第一个智能体Agent!!!虽然百炼上还是有一些操作不太丝滑的地方,但是不影响最后的效果,学了这么久的Agent,终于成功的落地了一个,大家相信我,跟着文章耐心的操作一把,当理论知识化作真真正正的产品效果时,这种成就感真的太棒啦!
接下来笔者还会基于别的Agent平台操作试试,给大家更多的分享!敬请期待呀!
如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。
相关文章:
敢不敢跟我一起搭建一个Agent!不写一行代码,10分钟搞出你的智能体!纯配置也能真正掌握AI最有潜力的技术?AI圈内人必备技能
说一千道一万,不如实地转一转。学了那么久的AI Agent的概念了,是时候该落地一个Agent看看自己的掌握程度了对不对,我们都理解大脑是自动节能的,但是知识的确需要倒逼自己一把才能真的掌握,不瞒大家说,笔者对…...

vue3和vite双向加持,uni-app性能爆表,众绑是否有计划前端升级到vue3!
uni-app官方已经开始不支持vue2了,而且即将适配的鸿蒙next原生系统,也不支持vue2打包,CRMEB是否有计划跟上潮流呢,如果有会在什么时间呢,有准确的时间表吗?我们非常期待得到答案! 新版 uni-app…...

2024年最强网络安全学习路线,详细到直接上清华的教材!
关键词:网络安全入门、渗透测试学习、零基础学安全、网络安全学习路线 首先咱们聊聊,学习网络安全方向通常会有哪些问题前排提示:文末有CSDN官方认证Python入门资料包 ! 1、打基础时间太长 学基础花费很长时间,光语…...

人脸识别又进化:扫一下 我就知道你得了啥病
未来,扫下你的脸,可能就知道你得啥病了。没在瞎掰,最近的一项研究成果,还真让咱看到了一点眉目。北大的一个研究团队,搞出来一个 AI ,说是用热成像仪扫一下脸,就能检测出有没有高血压、糖尿病和…...

yolov8标注细胞、识别边缘、计算面积、灰度值计算
一、数据标注 1. 使用labelme软件标注每个细胞的边界信息,标注结果为JSON格式 2. JSON格式转yolo支持的txt格式 import json import os import glob import os.path as osp此函数用来将labelme软件标注好的数据集转换为yolov5_7.0sege中使用的数据集:param jsonfi…...
WEB前端11-Vue2基础01(项目构建/目录解析/基础案例)
Vue2基础(01) 1.Vue2项目构建 步骤一:安装前端脚手架 npm install -g vue/cli步骤二:创建项目 vue ui步骤三:运行项目 npm run serve步骤四:修改vue相关的属性 DevServer | webpack //修改端口和添加代理 const { defineCo…...

QT--线程
一、线程QThread QThread 类提供不依赖平台的管理线程的方法,如果要设计多线程程序,一般是从 QThread继承定义一个线程类,在自定义线程类里进行任务处理。qt拥有一个GUI线程,该线程阻塞式监控窗体,来自任何用户的操作都会被gui捕获到,并处理…...

通过进程协作显示图像-C#
前言 如果一个软件比较复杂或者某些情况下需要拆解,可以考试将软件分解成两个或多个进程,但常规的消息传递又不能完全够用,使用消息共享内存,实现图像传递,当然性能这个方面我并没有测试,仅是一种解决思路…...

LangChain链与记忆处理[10]:四种基础内置链、四种文档处理链,以及链的自定义和五种运行方式,让你的大模型更加智能
LangChain链与记忆处理[10]:四种基础内置链、四种文档处理链,以及链的自定义和五种运行方式,让你的大模型更加智能 参考文章可以使用国产LLM进行下述项目复现: 初识langchain[1]:Langchain实战教学,利用qwen2.1与GLM-4大模型构建智能解决方案[含Agent、tavily面向AI搜索…...

京东发行稳定币的背后
加密市场很热,京东也要来分一杯羹? 7月24日,据财联社报道,京东科技旗下的京东币链科技 ( 香港 ) 将在香港发行与港元 1:1锚定的加密货币稳定币,在市场上掀起广泛热议。 由于众所周知的监管原因,国内大厂在早…...

CF1995C Squaring 题解
思路详解: 请注意,本题解用到了非整数计算,也就是说性能可能不如整数运算,但是易于实现,追求最优解的大佬不建议观看本题解。 这个题看似简单,但是由于涉及到了平方操作,不用高精度根本存不下&…...

动态规划之路径问题
动态规划算法介绍 基本原理和解题步骤 针对于动态规划的题型,一般会借助一个 dp 表,然后确定这个表中应该填入什么内容,最终直接返回表中的某一个位置的元素。 细分可以分为以下几个步骤: 创建 dp 表以及确定 dp 表中所要填写位…...

如何优化你的TikTok短视频账号运营策略?
在运营TikTok账号时,采取正确的策略至关重要,这些策略能够帮助你提升账号的质量和吸引力。 适度使用互粉互赞 避免过度依赖互粉互赞,因为这可能会限制你的内容在更广泛的观众中传播。虽然互粉互赞可以增加曝光,但过度使用可能导…...

mysql的唯一索引和普通索引有什么区别
在MySQL中,唯一索引(UNIQUE Index)和普通索引(普通索引,也称为非唯一索引)有一些关键的区别。以下是它们的比较以及性能分析: 唯一索引与普通索引的区别 唯一性: 唯一索引ÿ…...

Scrapy框架在处理大规模数据抓取时有哪些优化技巧?
在使用Scrapy框架处理大规模数据抓取时,优化技巧至关重要,可以显著提高爬虫的性能和效率。以下是一些实用的优化技巧: 1. 并发请求 增加并发请求的数量可以提高爬虫的响应速度和数据抓取效率。可以通过设置CONCURRENT_REQUESTS参数来调整。…...

私有化低代码平台的优势:赋能业务用户,重塑IT自主权
随着数字化转型在全球范围内的不断推进,企业面临着快速响应市场变化和提高内部运营效率的双重挑战。在这种背景下,低代码平台逐渐成为企业实现敏捷开发和快速迭代的重要工具。私有化低代码平台作为一种更安全、可控的解决方案,越来越受到企业…...

SAP BW系统表分享第一弹
有时候想要查看BW系统中存在了多少的表时,包含SAP以及自建表,这个时候我们怎么去找呢? 不要慌,BW系统中也有其对应系统表来存储表对应的信息的,存储所有表信息的是DD02V或者DD02VV,我比较推荐使用DD02VV&a…...

详解工厂模式与抽象工厂模式有什么区别?【图解+代码】
目录 工厂模式,抽象工厂模式是什么? 两种设计模式的流程: 1、工厂模式 2、抽象工厂模式 两种模式的对比 共同点: 不同点: 总结 工厂模式,抽象工厂模式是什么? 我已经具体的写了这两种模…...

zeroice做json字符串转为struct,支持结构体嵌套
1 zeroice Properties 基础类型 字典 数组 不支持复杂结构 2 zeroice没有内置反射 3 java反射 slice2java.exe ice转java类 java类转json字符串 json字符串组织测试json文件 jsonobj转为vector jar包onjvm运行 pub到broker 4 c反射from_json.cpp slice2cpp.exe ice转.h 注…...

Linux笔记 --- 内存管理
在程序中我们访问的内存地址都是从物理内存上映射而来的虚拟地址,假设我们使用的计算机实际物理内存(PM)只有1GB,而Linux中执行着三个进程,Linux会将PM中的某段内存映射成三段4G大小相同的虚拟内存(VM&…...

【Oracle APEX开发小技巧12】
有如下需求: 有一个问题反馈页面,要实现在apex页面展示能直观看到反馈时间超过7天未处理的数据,方便管理员及时处理反馈。 我的方法:直接将逻辑写在SQL中,这样可以直接在页面展示 完整代码: SELECTSF.FE…...

python如何将word的doc另存为docx
将 DOCX 文件另存为 DOCX 格式(Python 实现) 在 Python 中,你可以使用 python-docx 库来操作 Word 文档。不过需要注意的是,.doc 是旧的 Word 格式,而 .docx 是新的基于 XML 的格式。python-docx 只能处理 .docx 格式…...

使用Matplotlib创建炫酷的3D散点图:数据可视化的新维度
文章目录 基础实现代码代码解析进阶技巧1. 自定义点的大小和颜色2. 添加图例和样式美化3. 真实数据应用示例实用技巧与注意事项完整示例(带样式)应用场景在数据科学和可视化领域,三维图形能为我们提供更丰富的数据洞察。本文将手把手教你如何使用Python的Matplotlib库创建引…...

在Ubuntu24上采用Wine打开SourceInsight
1. 安装wine sudo apt install wine 2. 安装32位库支持,SourceInsight是32位程序 sudo dpkg --add-architecture i386 sudo apt update sudo apt install wine32:i386 3. 验证安装 wine --version 4. 安装必要的字体和库(解决显示问题) sudo apt install fonts-wqy…...

基于IDIG-GAN的小样本电机轴承故障诊断
目录 🔍 核心问题 一、IDIG-GAN模型原理 1. 整体架构 2. 核心创新点 (1) 梯度归一化(Gradient Normalization) (2) 判别器梯度间隙正则化(Discriminator Gradient Gap Regularization) (3) 自注意力机制(Self-Attention) 3. 完整损失函数 二…...

Redis:现代应用开发的高效内存数据存储利器
一、Redis的起源与发展 Redis最初由意大利程序员Salvatore Sanfilippo在2009年开发,其初衷是为了满足他自己的一个项目需求,即需要一个高性能的键值存储系统来解决传统数据库在高并发场景下的性能瓶颈。随着项目的开源,Redis凭借其简单易用、…...

「全栈技术解析」推客小程序系统开发:从架构设计到裂变增长的完整解决方案
在移动互联网营销竞争白热化的当下,推客小程序系统凭借其裂变传播、精准营销等特性,成为企业抢占市场的利器。本文将深度解析推客小程序系统开发的核心技术与实现路径,助力开发者打造具有市场竞争力的营销工具。 一、系统核心功能架构&…...

深入浅出Diffusion模型:从原理到实践的全方位教程
I. 引言:生成式AI的黎明 – Diffusion模型是什么? 近年来,生成式人工智能(Generative AI)领域取得了爆炸性的进展,模型能够根据简单的文本提示创作出逼真的图像、连贯的文本,乃至更多令人惊叹的…...
与文本切分器(Splitter)详解《二》)
LangChain 中的文档加载器(Loader)与文本切分器(Splitter)详解《二》
🧠 LangChain 中 TextSplitter 的使用详解:从基础到进阶(附代码) 一、前言 在处理大规模文本数据时,特别是在构建知识库或进行大模型训练与推理时,文本切分(Text Splitting) 是一个…...
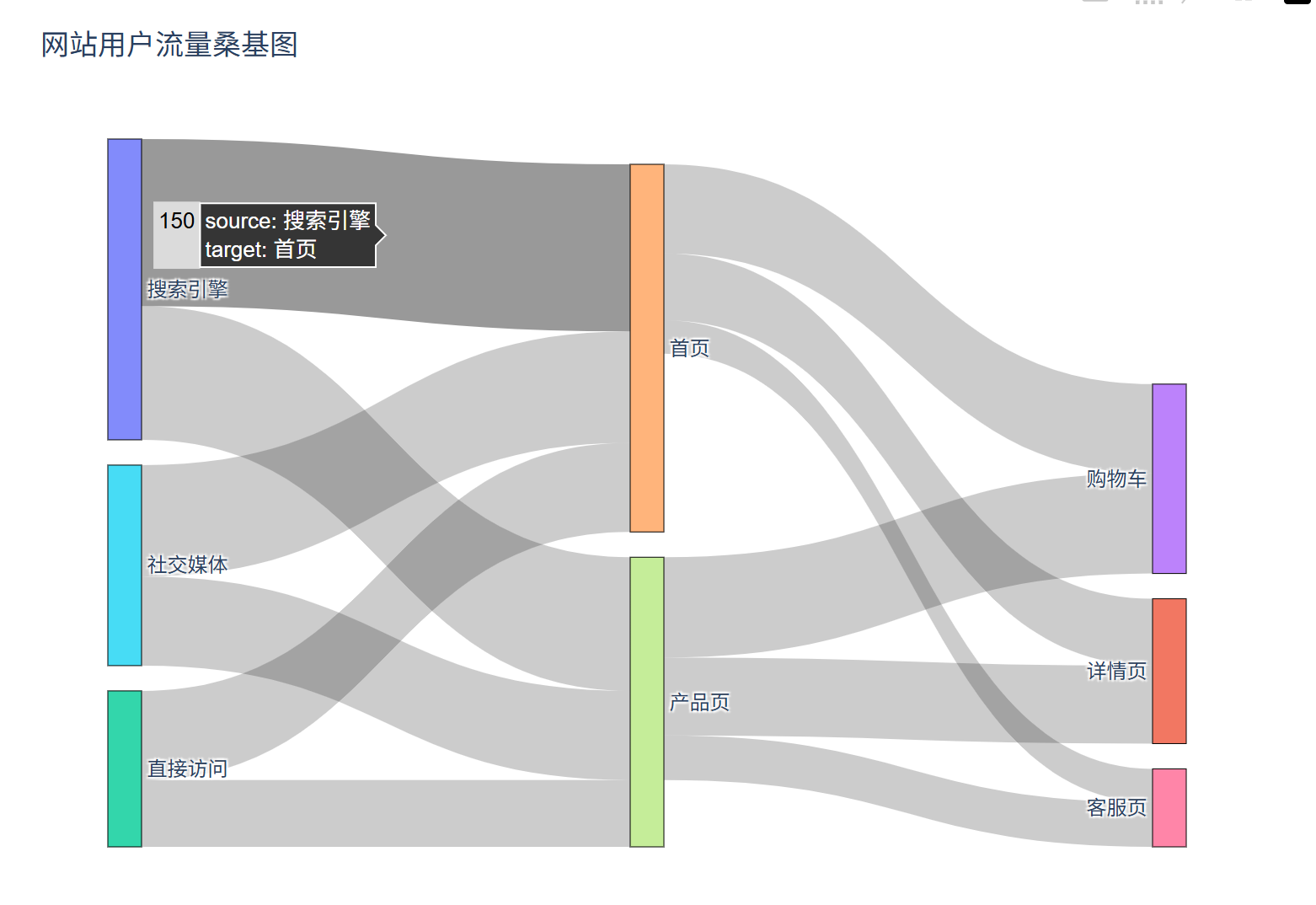
相关类相关的可视化图像总结
目录 一、散点图 二、气泡图 三、相关图 四、热力图 五、二维密度图 六、多模态二维密度图 七、雷达图 八、桑基图 九、总结 一、散点图 特点 通过点的位置展示两个连续变量之间的关系,可直观判断线性相关、非线性相关或无相关关系,点的分布密…...