北京大学:利用好不确定性,8B小模型也能超越GPT-4
大模型有一个显著的特点,那就是不确定性——对于特定输入,相同的LLM在不同解码配置下可能生成显著不同的输出。
比如问一问chatgpt“今天开心吗?”,可以得到两种不同的回答。
常用的解码策略有两种,一个是贪婪解码,即永远选择概率最高的下一个token,另一种就是采样方法,根据概率分布随机选择下一个token,常常使用温度参数平衡响应质量和多样性。
那么,这两种方式哪个更好呢?北大的一篇论文给出了答案:

贪婪解码在大多数任务中通常优于采样方法。
另外作者还发现,LLMs的这种不确定性具有巨大潜力。通过采用“Best-of-N”策略,从多个采样响应中挑选最优答案的方式,Llama-3-8B-Instruct在MMLU、GSM8K和HumanEval上均超越GPT-4-Turbo。
这是否可以说明,即使小模型单次回答可能不够准确,但多试几次,从里面挑最好的,也能找到正确答案。就像多猜几次谜语,总有一次能猜对一样。一起来看看论文中怎么说的吧~
论文标题:
The Good, The Bad, and The Greedy: Evaluation of LLMs Should Not Ignore Non-Determinism
论文链接:
https://arxiv.org/pdf/2407.10457
代码链接:
https://github.com/Yifan-Song793/GoodBadGreedy
实验设置
基准测试
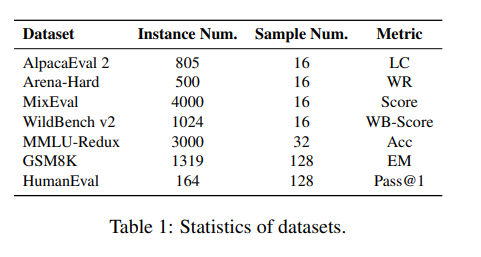
本文选择了多个基准测试如下表所示进行实验, 评测模型在通用指令跟随、知识、数学推理、编码等方面的能力。
模型选择
选择开源模型Llama-3-Instruct、Yi-1.5-Chat、Qwen-2-Instruct和Mistral以及闭源模型GPT-4-Turbo作为对比。还测试了同系列中不同规模的模型,如Qwen-2和Yi-1.5。为了更深入地分析,本文还评估了使用不同对齐方法训练的模型,以研究对齐技术的效果,包括DPO、KTO、IPO、ORPO、RDPO和SimPO等对齐方法。
方法选择
本文的目标是在不同的解码配置下比较LLMs的性能。作者选择了贪婪解码和采样生成(temperature=1.0,top-p=1.0)作为主要比较。
实验结果
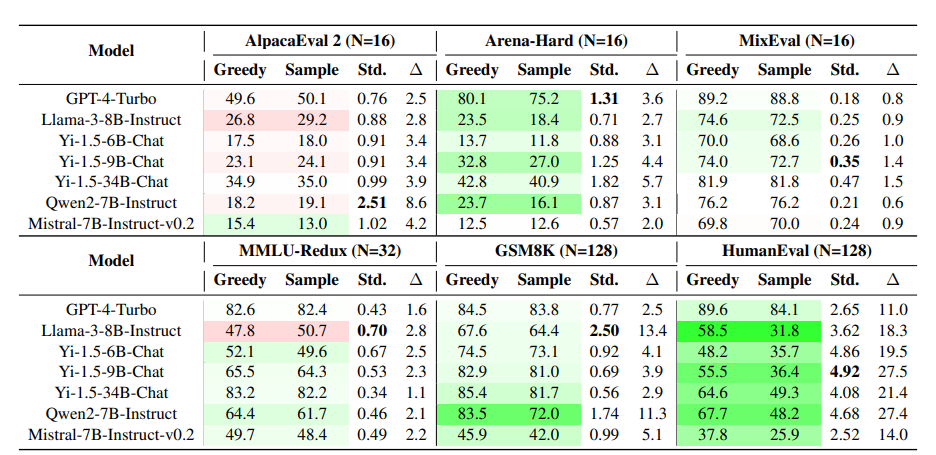
下表展示了实验结果,其中贪婪解码超过采样平均值的分数用绿色突出显示,而低于采样解码的用红色标记。
从以上结果中可以总结出一些问题的答案。
贪婪解码和采样之间的性能差距有何不同?
贪心解码和采样方法之间始终存在性能差距。这种差距在专有模型和开源模型中都很明显,并且在多个基准测试中都有体现,包括指令执行、语言理解、数学推理和代码生成。
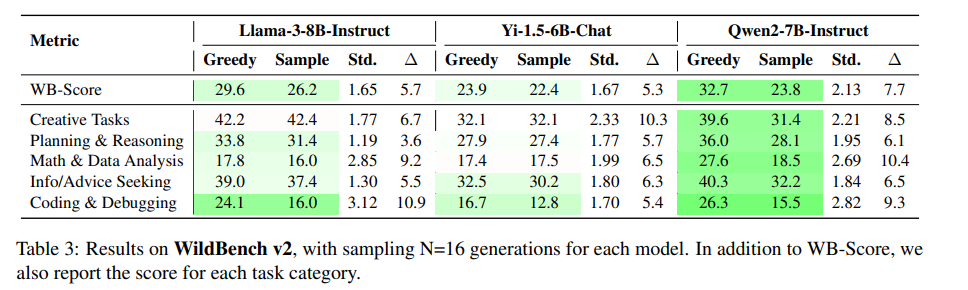
在WildBench测试中,各任务类别的性能差距也很显著,如下表所示。不同的解码配置甚至可能改变模型排名。例如,在Arena-Hard测试中,Qwen2-7B使用贪心解码时略优于Llama-3-8B;但使用采样解码时,Llama-3-8B可能超过Qwen2-7B。
什么时候贪婪解码比采样更好,反之亦然?为什么?
-
对于大多数评估任务和模型,贪心解码的表现优于采样。
-
对于包含相对简单的开放式创意任务的AlpacaEval,采样生成的响应更好。与GSM8K和HumanEval这类需要LLM解决特定数学或编程问题的推理任务不同,AlpacaEval中50%的实例是信息查询类任务,且为开放式基准测试,没有确定的答案,其实例与难度比Arena-Hard和WildBench更简单。
哪个基准在非确定性方面最一致/最不一致?
MixEval和MMLU在稳定性上表现尤为突出,这体现在无论是使用贪心解码还是采样方法,其性能差异很小,且不同采样间的结果波动也很低。这种高度稳定性主要得益于它们答案空间的严格限制:MMLU采用多项选择题形式,而MixEval则通过真实数据基准测试要求LLM给出简短答案,从而进一步压缩了输出范围。
相比之下,GSM8K和HumanEval在处理非确定性生成任务时显得不够稳定,最佳与最差采样结果之间的性能差异可能超过10分,显示出较大的波动性。
不同模型之间的表现有何差距?
GPT-4-Turbo在多种任务上展示了稳定的性能,贪心解码与采样方法间的性能差异微乎其微,同时采样质量也有所增强。
然而,开源LLMs则展现出与众不同的特性。例如,Mistral-7B-Instruct-v0.2在AlpacaEval和Arena-Hard等开放式指令任务上,其行为模式与其他模型截然相反。同样地,Llama3-8B-Instruct在MMLU任务中,通过采样实现的性能甚至超越了贪心解码,这一表现也与众不同。
这些现象引发了对未来研究领域的深刻思考:
-
为何特定模型在特定任务上会展现出如此不同的行为?
-
这些独特性是否能为构建更稳健的LLM提供新的思路?
这些问题强调了深入探究LLM内部工作机制的重要性,这类研究有望显著提升我们对不同模型及其训练方式如何影响模型行为的理解。
各种因素如何影响非确定性?
那么各种因素又是如何影响非确定性的,这里作者调整缩放、对齐和解码参数进行实验。
Scaling对非确定性的影响
有人可能会认为,较大的LLMs在解码时的不确定性会更低,从而导致采样时的性能差异较小。但从作者的实验结果来看,并非如此。作者使用Yi-1.5-Chat和Qwen2-Instruct系列来观察从0.5B到34B参数的性能差异。

参数扩展并不会导致较低的采样方差。Qwen2-7B-Instruct在AlpacaEval和HumanEval上的方差高于其较小的对应模型。并且不同大小的模型在不同任务上的性能差异显著,无法得出统一的结论。
对齐对非确定性的影响
对齐方法(如DPO)通过学习偏好数据来增强LLM。作者使用Llama-3-8B-Instruct作为训练起点,评估了DPO、KTO和SimPO等对齐方法的效果。如下图所示,应用这些方法后,贪婪解码和采样性能均受到影响。

在AlpacaEval、MMLU、GSM8K和HumanEval等任务中,标准差有所下降,这表明对齐可能会减少采样输出的多样性。然而,需注意,并非所有对齐方法都能始终如一地提高模型性能。例如,KTO和SimPO在MMLU上导致性能下降。此外,SimPO在MixEval基准上效果有限。
温度对非确定性的影响
对于采样生成,温度控制采样过程的随机性,较低的值使模型更具确定性,而较高的值使模型更随机。作者评估不同温度对非确定性生成的影响。
如上图所示,在AlpacaEval任务中,较高的温度会略微提高性能。在多项选择题的问答任务中,温度变化对性能的影响不显著。
值得注意的是,当温度极端升高至如1.5时,LLM在需要推理和代码生成的任务(如GSM8K和HumanEval)上显著受阻,模型解答问题变得困难。相反,在开放式指令任务(如AlpacaEval和ArenaHard)中,即便温度较高,模型依然能保持相对良好的表现。
重复对生成的影响
除了控制贪婪搜索和采样的参数,还有一个关键参数——重复惩罚,它也会影响生成过程。
重复惩罚通过调整新词是否重复出现在提示和已生成文本中的概率来工作。具体来说,值大于1.0时,模型倾向于使用更多新词;小于1.0时,则促进词语的重复。默认情况下,该参数设为1.0,以保持平衡。

如上图所示,大多数情况下建议保持默认值以获得最佳性能。但在AlpacaEval任务中,略微提高重复惩罚(如1.2)可能因GPT评审偏好简短答案而带来性能提升。
对于MixEval和MMLU,由于都鼓励简洁输出,重复惩罚的影响较小。而GSM8K数学推理任务则不同,最佳表现出现在重复惩罚设为0.9时,因数学推理常需重复问题中的数字和条件,过高设置反而降低性能。
非确定性生成中的表面模式
作者还对比了不同生成配置下各类任务的生成长度。如下图所示,贪心解码产生的响应比采样平均值短的情况用蓝色突出显示,反之则用紫色标记。
可以观察到贪婪解码生成的文本通常比采样生成的略短。在Yi系列模型处理AlpacaEval和GSM8K任务时,这一模式出现了变化,两种生成方法产生的响应长度几乎相当。
下图展示了Qwen2-7B-Instruct在GSM8K上贪婪解码与采样生成的效果差异。

结果显示,贪婪解码在解决GSM8K问题上表现显著优于采样生成(83.5% vs. 72.0%)。贪婪解码能有效且准确地解答问题,而采样生成则在多次尝试中错误率激增,达到89%,这表明采样方法可能在一定程度上削弱了LLMs的推理能力。

LLMs的不确定性有何潜力
当前对LLMs的评估常局限于单一输出,这限制了对其全面能力的洞察。作者采用“Best-of-N”策略,即从多个采样响应中挑选最优答案。利用ArmoRM和FsfairX等先进奖励模型,对Llama-3-8B-Instruct的响应进行评分并排序,选取最高分作为输出。同时,设立“oracle”基准,以最佳响应为上限,评估策略潜力。
可以看到“Best-of-N”策略极大提升了LLMs性能,尤其是oracle选择下,Llama-3-8B-Instruct在MMLU、GSM8K和HumanEval上均超越GPT-4-Turbo。这凸显了小规模LLMs的强劲实力。
因此未来可以从两条路径强化小规模LLMs:
-
通过概率校准和优化偏好来提升答案质量;
-
利用集成学习或自一致性等策略,从多个候选答案中精准挑选最佳项。
结语
这篇文章给了我们一个重要的提示:当我们想要提升大模型的实力,或者更准确地评估它们的性能时,别忘了考虑解码方式这个关键因素。利用大模型自带的“不确定性”,我们可以找到更多创新的方法来推动技术进步。所以,不妨在设计和评估模型时,多琢磨琢磨解码方式,也许会带来意想不到的效果~
相关文章:
北京大学:利用好不确定性,8B小模型也能超越GPT-4
大模型有一个显著的特点,那就是不确定性——对于特定输入,相同的LLM在不同解码配置下可能生成显著不同的输出。 比如问一问chatgpt“今天开心吗?”,可以得到两种不同的回答。 常用的解码策略有两种,一个是贪婪解码&am…...

哪些云服务商已通过了等保2.0合规性评估?
已通过等保2.0合规性评估的云服务商 根据最新的搜索结果,以下是已通过等保2.0合规性评估的云服务商: 阿里云:阿里云的“电子政务云平台系统”是全国首个通过等保2.0国标测评的云平台,显示了其在云计算领域的安全合规能力。华为云…...

PHP在线加密系统源码
历时半年,它再一次迎来更新[飘过] 刚刚发的那个有点问题,重新修了一下 本次更新内容有点多 1. 更新加密算法(这应该是最后一次更新加密算法了,以后主要更新都在框架功能上面了) 2. 适配php56-php74 3. 取消批量加…...
OpenCV学习笔记 比较基于RANSAC、最小二乘算法的拟合
一、RANSAC算法 https://skydance.blog.csdn.net/article/details/134887458https://skydance.blog.csdn.net/article/details/134887458 二、最小二乘算法 https://skydance.blog.csdn.net/article/details/115413982...

前端JS特效第53集:带声音的烟花模拟绽放特效插件
带声音的烟花模拟绽放特效插件,先来看看效果: 部分核心的代码如下(全部代码在文章末尾): <!DOCTYPE html> <html lang"en" > <head><meta charset"UTF-8"><title>Firework Simulator v2&…...

好展位,抢先订!2025浙江(玉环)机械展
2025第18届浙江(玉环)机械工业展览会 时间地点:2025年4月25-28日 玉环会展中心 近年来,随着玉环工业经济的蓬勃发展,汽摩配件、阀门水暖五金产业、铜加工、眼镜配件、金属加工生产等行业,如同贪婪的巨人&…...

Java面试八股之Spring如何解决循环依赖
Spring如何解决循环依赖 在Spring框架中,循环依赖问题通常发生在两个或多个Bean相互依赖的情况下。Spring为了解决循环依赖问题,采用了不同的策略,这些策略主要取决于Bean的作用域以及依赖注入的方式。下面是一些关键点: 单例Be…...

如何为 SQL Server 设置强密码以增强安全性?
为 SQL Server 设置强密码是增强数据库安全性的重要步骤。以下是一些关键步骤和最佳实践: 1. 使用复杂密码 长度:密码应至少为 12 个字符。字符类型:包括大写字母、小写字母、数字和特殊字符(如 !#$%^&*())。避免…...

C语言实现三子棋
通过一段时间的学习,我们已经能够较为熟练地使用分支语句,循环语句,创建函数,创建数组,创建随机数等。之前我们做过一个扫雷游戏,今天让我们再尝试创作一个三子棋游戏吧~ 一、三子棋游戏的思路 三子棋的游…...

昇思25天学习打卡营第XX天|RNN实现情感分类
希望代码能维持开源维护状态hhh,要是再文件整理下就更好了,现在好乱,不能好fork tutorials/application/source_zh_cn/nlp/sentiment_analysis.ipynb MindSpore/docs - Gitee.com...

linux深度学习环境配置(cuda,pytorch)
显卡驱动 首先查看linux服务器是否存在显卡驱动,可以输入以下命令 nvidia-smi如果没有直接显示下面的画面 则进行下面的步骤: ubuntu-drivers devices sudo ubuntu-drivers autoinstall上述步骤的意思是直接在线安装 然后重启linux服务器 reboot发现…...
 | SpringBoot集成Slf4j日志门面)
SpringBoot教程(十九) | SpringBoot集成Slf4j日志门面
SpringBoot教程(十九) | SpringBoot集成Slf4j日志门面 一、概述二、前言三、引入依赖 (不需要额外引入了)四、自定义Logback的配置文件(一般都需配置)情况一:不配置任何关于logback的配置文件情况二:配置关…...

科普文:深入理解ElasticSearch体系结构
概叙 Elasticsearch是什么? Elasticsearch(简称ES)是一个分布式、可扩展、实时的搜索与数据分析引擎。ES不仅仅只是全文搜索,还支持结构化搜索、数据分析、复杂的语言处理、地理位置和对象间关联关系等。 官网地址:…...
预测模型及其Python和MATLAB实现)
极限学习机(ELM)预测模型及其Python和MATLAB实现
### 一、背景 在机器学习和数据挖掘领域,预测模型旨在从过往数据中学习规律,以便对未知数据进行预测。随着数据量的激增和计算能力的提升,各种算法不断涌现。其中,极限学习机(Extreme Learning Machine, ELM࿰…...

基于Python的哔哩哔哩国产动画排行数据分析系统
需要本项目的可以私信博主,提供完整的部署、讲解、文档、代码服务 随着经济社会的快速发展,中国影视产业迎来了蓬勃发展的契机,其中动漫产业发展尤为突出。中国拥有古老而又璀璨的文明,仅仅从中提取一部分就足以催生出大量精彩的…...

Java导出Excel给每一列设置不同样式示例
Excel导出这里不讲,方法很多,原生的POI可以参照 Java原生POI实现的Excel导入导出(简单易懂) 这里只说怎么给Excel每一列设置不同的样式,比如下面这样的 直接上代码 Overridepublic void exportTemplate(HttpServletRe…...
2.1、matlab绘图汇总(图例、标题、坐标轴、线条格式、颜色和散点格式设置)
1、前言 在 MATLAB 中进行绘图是一种非常常见且实用的操作,可以用来可视化数据、结果展示、分析趋势等。通过 MATLAB 的绘图功能,用户可以创建各种类型的图形,包括线图、散点图、柱状图、曲线图等,以及三维图形、动画等复杂的可视化效果。 在绘图之前,通常需要先准备好要…...

Datawhale AI夏令营 AI+逻辑推理 Task2总结
Datawhale AI夏令营 AI逻辑推理 Task2总结 一、大语言模型解题方案介绍 1.1 大模型推理介绍 推理是建立在训练完成的基础上,将训练好的模型应用于新的、未见过的数据,模型利用先前学到的规律进行预测、分类和生成新内容,使得AI在实际应…...

linux常使用的命令
关机命令 shutdown halt poweroff reboot grep 选项 参数 -l 显示所有包含关键字的文件名 -n 在匹配之前加上行号 -c 只显示匹配的行数 -v 显示不匹配的行 管道符 “|” 左边的输出作为右边的输入 例如:我们找个文件包含abc 但是不含有def的文件 grep …...

Ubuntu系统U盘安装与虚拟机安装
一、Ubuntu系统U盘安装 准备工作 下载Ubuntu镜像文件:从Ubuntu官方网站下载最新的LTS(长期支持)版本镜像文件(ISO),以确保系统的稳定性和长期支持。准备U盘:选择一个容量至少为8GB的U盘,并确保U盘中的数据已备份,因为接下来的操作会格式化U盘。制作启动U盘: Windows…...

观成科技:隐蔽隧道工具Ligolo-ng加密流量分析
1.工具介绍 Ligolo-ng是一款由go编写的高效隧道工具,该工具基于TUN接口实现其功能,利用反向TCP/TLS连接建立一条隐蔽的通信信道,支持使用Let’s Encrypt自动生成证书。Ligolo-ng的通信隐蔽性体现在其支持多种连接方式,适应复杂网…...

XCTF-web-easyupload
试了试php,php7,pht,phtml等,都没有用 尝试.user.ini 抓包修改将.user.ini修改为jpg图片 在上传一个123.jpg 用蚁剑连接,得到flag...
: K8s 核心概念白话解读(上):Pod 和 Deployment 究竟是什么?)
云原生核心技术 (7/12): K8s 核心概念白话解读(上):Pod 和 Deployment 究竟是什么?
大家好,欢迎来到《云原生核心技术》系列的第七篇! 在上一篇,我们成功地使用 Minikube 或 kind 在自己的电脑上搭建起了一个迷你但功能完备的 Kubernetes 集群。现在,我们就像一个拥有了一块崭新数字土地的农场主,是时…...

css实现圆环展示百分比,根据值动态展示所占比例
代码如下 <view class""><view class"circle-chart"><view v-if"!!num" class"pie-item" :style"{background: conic-gradient(var(--one-color) 0%,#E9E6F1 ${num}%),}"></view><view v-else …...

React第五十七节 Router中RouterProvider使用详解及注意事项
前言 在 React Router v6.4 中,RouterProvider 是一个核心组件,用于提供基于数据路由(data routers)的新型路由方案。 它替代了传统的 <BrowserRouter>,支持更强大的数据加载和操作功能(如 loader 和…...

【项目实战】通过多模态+LangGraph实现PPT生成助手
PPT自动生成系统 基于LangGraph的PPT自动生成系统,可以将Markdown文档自动转换为PPT演示文稿。 功能特点 Markdown解析:自动解析Markdown文档结构PPT模板分析:分析PPT模板的布局和风格智能布局决策:匹配内容与合适的PPT布局自动…...

IoT/HCIP实验-3/LiteOS操作系统内核实验(任务、内存、信号量、CMSIS..)
文章目录 概述HelloWorld 工程C/C配置编译器主配置Makefile脚本烧录器主配置运行结果程序调用栈 任务管理实验实验结果osal 系统适配层osal_task_create 其他实验实验源码内存管理实验互斥锁实验信号量实验 CMISIS接口实验还是得JlINKCMSIS 简介LiteOS->CMSIS任务间消息交互…...

Redis数据倾斜问题解决
Redis 数据倾斜问题解析与解决方案 什么是 Redis 数据倾斜 Redis 数据倾斜指的是在 Redis 集群中,部分节点存储的数据量或访问量远高于其他节点,导致这些节点负载过高,影响整体性能。 数据倾斜的主要表现 部分节点内存使用率远高于其他节…...

VM虚拟机网络配置(ubuntu24桥接模式):配置静态IP
编辑-虚拟网络编辑器-更改设置 选择桥接模式,然后找到相应的网卡(可以查看自己本机的网络连接) windows连接的网络点击查看属性 编辑虚拟机设置更改网络配置,选择刚才配置的桥接模式 静态ip设置: 我用的ubuntu24桌…...

【Go语言基础【12】】指针:声明、取地址、解引用
文章目录 零、概述:指针 vs. 引用(类比其他语言)一、指针基础概念二、指针声明与初始化三、指针操作符1. &:取地址(拿到内存地址)2. *:解引用(拿到值) 四、空指针&am…...