从代码层面熟悉UniAD,开始学习了解端到端整体架构
0. 简介
最近端到端已经是越来越火了,以UniAD为代表的很多工作不断地在不断刷新端到端的指标,比如最近SparseDrive又重新刷新了所有任务的指标。在端到端火热起来之前,成熟的模块化自动驾驶系统被分解为不同的独立任务,例如感知、预测和规划,从而导致模块间信息丢失和错误累积。相比之下,端到端范式将多任务统一到一个完全可微分的框架中,从而允许以规划为导向进行优化。当然对于刚刚开始熟悉这一行的人来说,最简单也最值得接触的就是UniAD这各项目,这里最近受到优刻得的使用邀请,正好解决了我在大模型和自动驾驶行业对GPU的使用需求。UCloud云计算旗下的Compshare的GPU算力云平台。他们提供高性价比的4090 GPU,按时收费每卡2.6元,月卡只需要1.7元每小时,并附带200G的免费磁盘空间。暂时已经满足我的使用需求了,同时支持访问加速,独立IP等功能,能够更快的完成项目搭建。

而且在使用后可以写对应的博客,可以完成500元的赠金,完全可以满足个人对GPU的需求。
对应的环境搭建已经在《如何使用共享GPU平台搭建LLAMA3环境(LLaMA-Factory)》介绍过了。对于自定义的无论是LibTorch还是CUDA这些都在《Ubuntu20.04安装LibTorch并完成高斯溅射环境搭建》这篇文章提到过了。这一章节我们来看一下怎么在平台上运行以UniAD为代表的端到端模型的。
1. UniAD环境部署
统一自动驾驶框架 (UniAD) ,第一个将全栈驾驶任务整合到一个深度神经网络中的框架,并可以发挥每个子任务以及各个模块的优势,以执行安全的规划。
1.1 Miniconda 安装
首先第一步就是使用conda部署环境,在优刻得当中是没有caonda的,所以我们得先安装miniconda。通过 apt 在终端中运行以下命令确保所有系统包都是最新的。
sudo apt update
sudo apt upgrade
wget https://repo.anaconda.com/miniconda/Miniconda3-py39_4.9.2-Linux-x86_64.sh
首先使用 SHA-256 检查下载文件的完整性:
sha256sum Miniconda3-py39_4.9.2-Linux-x86_64.sh
将输出的哈希值与官方给出的哈希值进行比较,如果一致则为合法文件,可以安装。
bash Miniconda3-py39_4.9.2-Linux-x86_64.sh
安装过程中可以自定义安装路径,比如可以选择安装在 /usr/local/miniconda3,但是我们这里直接回车选择默认环境
为了能让所有用户都能使用Mniconda,要修改 /etc/profile 文件
sudo vim /etc/profile
添加如下代码:
export PATH=/home/ubuntu/miniconda3/bin:$PATH
1.2 UniAD环境安装
首先启动conda
conda create -n uniad python=3.8 -y
source activate
conda deactivate
conda activate uniad
然后安装cuda和对应的torch、torchvision、torchaudio环境。安装torch1.11.0以下版本的,不然运行uniAD会报错

pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
pip install torch==1.10.0+cu113 torchvision==0.11.0+cu113 torchaudio==0.10.0 --extra-index-url https://download.pytorch.org/whl/cu113
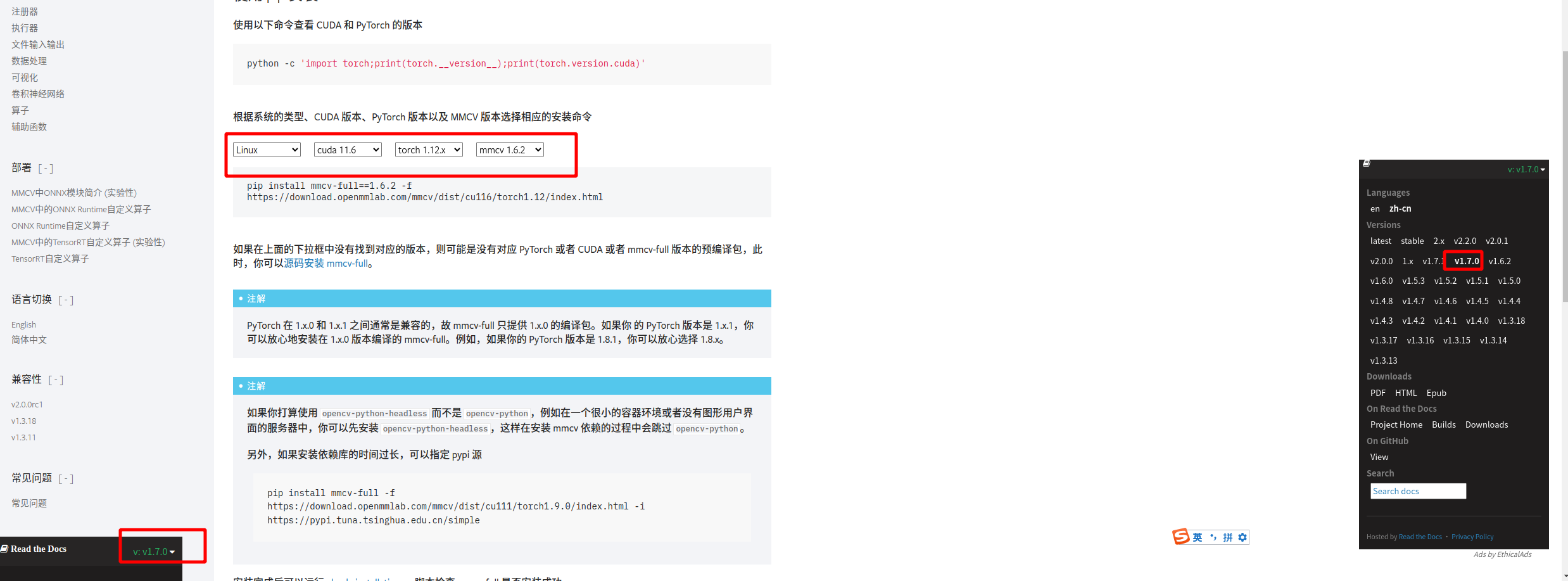
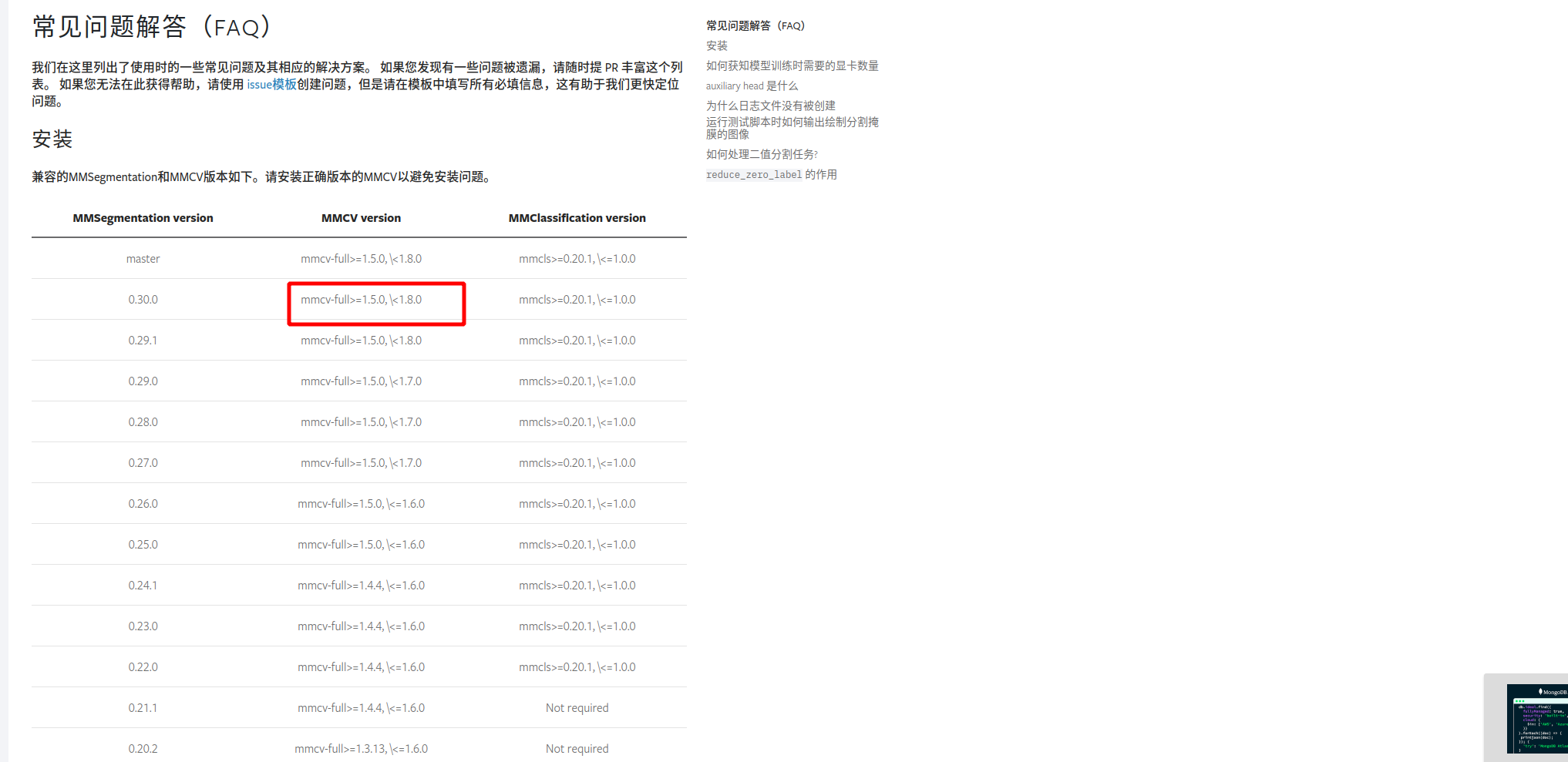
然后安装mmcv、mmdet和mmseg。首先需要判断gcc以及CUDA是否在conda环境中安装了。这部分其实可以通过网站查询:https://mmcv.readthedocs.io/zh-cn/v1.7.0/get_started/installation.html
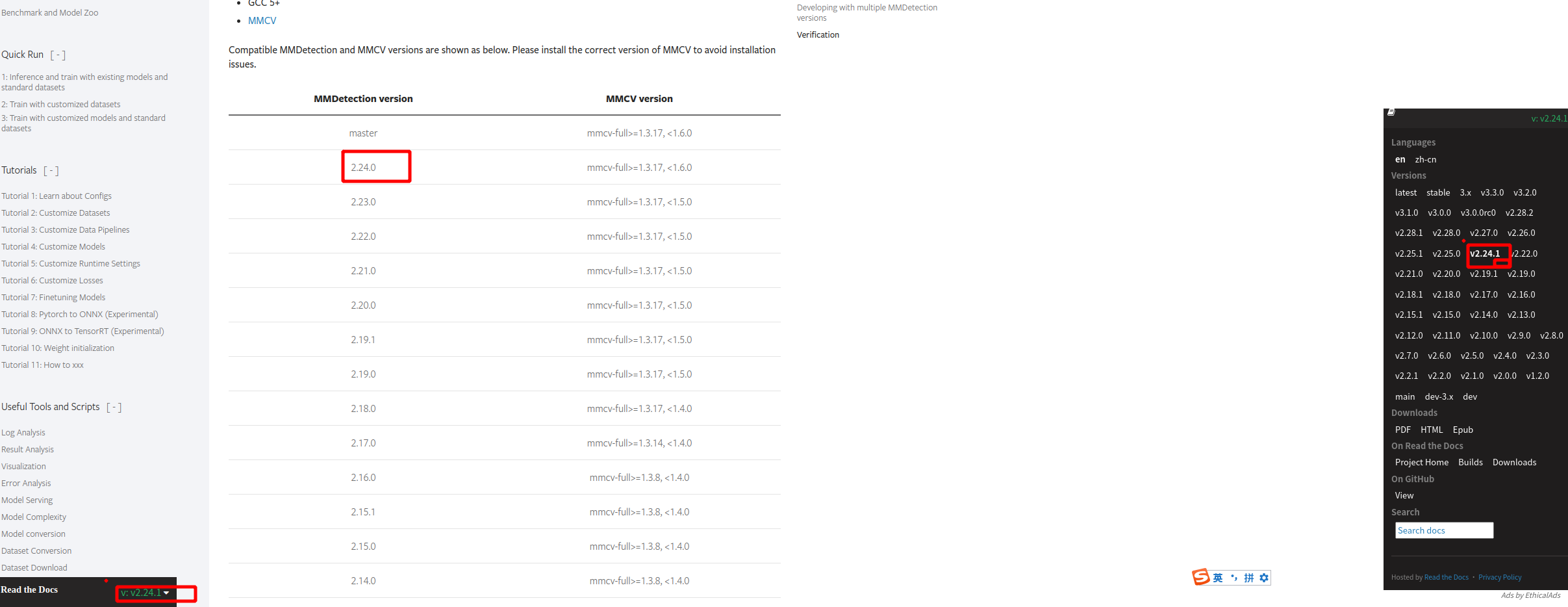
进入https://mmdetection.readthedocs.io/en/v2.24.1/get_started.html找到mmcv2.7.0对应需安装 2.24.0版mmdetection
对于mmsegmenation,在这里找到了对应的版本说明:
#如果没有安装:
# conda install -c omgarcia gcc-6 # gcc-6.2
#export PATH=YOUR_GCC_PATH/bin:$PATH
# Eg: export PATH=/mnt/gcc-5.4/bin:$PATHexport CUDA_HOME=YOUR_CUDA_PATH/
# Eg: export CUDA_HOME=/usr/local/cuda
然后安装对应版本的软件
sudo apt-get install build-essential
sudo apt install python3.7-devpip install mmcv-full==1.14.0
# If it's not working, try:
# pip install mmcv-full==1.4.0 -f https://download.openmmlab.com/mmcv/dist/cu111/torch1.9.0/index.htmlpip install mmdet==2.14.0
pip install mmsegmentation==0.14.1
1.3 UniAD代码安装编译
首先下载UniAD
git clone https://github.com/OpenDriveLab/UniAD.git
## 国内可使用魔法下载
# git clone https://mirror.ghproxy.com/https://github.com/OpenDriveLab/UniAD.git
然后切换版本,并编译mmdet3d
cd mmdetection3d
git checkout v0.17.1
pip install scipy==1.7.3
pip install scikit-image==0.20.0
pip install -v -e .
然后再编译UniAD
cd ~
git clone https://github.com/OpenDriveLab/UniAD.git
cd UniAD
pip install -r requirements.txt
2. 运行UniAD
首先需要下载一些预训练权重
mkdir ckpts && cd ckpts# Pretrained weights of bevformer
# Also the initial state of training stage1 model
wget https://github.com/zhiqi-li/storage/releases/download/v1.0/bevformer_r101_dcn_24ep.pth# Pretrained weights of stage1 model (perception part of UniAD)
wget https://github.com/OpenDriveLab/UniAD/releases/download/v1.0/uniad_base_track_map.pth# Pretrained weights of stage2 model (fully functional UniAD)
wget https://github.com/OpenDriveLab/UniAD/releases/download/v1.0.1/uniad_base_e2e.pth
然后下载一些文件,pkl文件可以在准备数据参考链接自己下载,也可以直接运行脚本生成pkl文件。
方法1
# 官方直接提供数据集nuscenes.pkl文件下载
cd UniAD/data
mkdir infos && cd infos
# train_infos
wget https://github.com/OpenDriveLab/UniAD/releases/download/v1.0/nuscenes_infos_temporal_train.pkl # val_infos
wget https://github.com/OpenDriveLab/UniAD/releases/download/v1.0/nuscenes_infos_temporal_val.pkl
方法2
我们这里可以使用脚本下载nuscenes数据集
# 2 使用nuscenes数据集生成pkl文件
cd UniAD/data
mkdir infos
./tools/uniad_create_data.sh
# This will generate nuscenes_infos_temporal_{train,val}.pkl# 本人使用nuscenes-mini生成pkl文件
python tools/create_data.py nuscenes --root-path ./data/nuscenes --out-dir ./data/infos --extra-tag nuscenes --version v1.0-mini --canbus ./data/nuscenes# 3 准备motion_anchor
cd UniAD/data
mkdir others && cd others
wget https://github.com/OpenDriveLab/UniAD/releases/download/v1.0/motion_anchor_infos_mode6.pkl
对应的目录结构为:
UniAD
├── projects/
├── tools/
├── ckpts/
│ ├── bevformer_r101_dcn_24ep.pth
│ ├── uniad_base_track_map.pth
| ├── uniad_base_e2e.pth
├── data/
│ ├── nuscenes/
│ │ ├── can_bus/
│ │ ├── maps/
│ │ │ ├──36092f0b03a857c6a3403e25b4b7aab3.png
│ │ │ ├──37819e65e09e5547b8a3ceaefba56bb2.png
│ │ │ ├──53992ee3023e5494b90c316c183be829.png
│ │ │ ├──93406b464a165eaba6d9de76ca09f5da.png
│ │ │ ├──basemap
│ │ │ ├──expansion
│ │ │ ├──prediction
│ │ ├── samples/
│ │ ├── sweeps/
│ │ ├── v1.0-test/
│ │ ├── v1.0-trainval/
│ ├── infos/
│ │ ├── nuscenes_infos_temporal_train.pkl
│ │ ├── nuscenes_infos_temporal_val.pkl
│ ├── others/
│ │ ├── motion_anchor_infos_mode6.pkl
这里只介绍nuscenes数据集,nuscenes下载地址。我们参考的是这一篇文章《Fast-BEV代码复现实践》
3. 训练/评估模型
3.1 评估示例
请确保您已经准备好环境和 nuScenes 数据集。您可以通过如下命令简单地评估预训练的第一阶段(track_map)模型来进行检查:
cd UniAD
./tools/uniad_dist_eval.sh ./projects/configs/stage1_track_map/base_track_map.py ./ckpts/uniad_base_track_map.pth 8# 对于使用 slurm 的用户:
# ./tools/uniad_slurm_eval.sh YOUR_PARTITION ./projects/configs/stage1_track_map/base_track_map.py ./ckpts/uniad_base_track_map.pth 8
如果一切准备妥当,输出结果应如下所示:
Aggregated results:
AMOTA 0.390
AMOTP 1.300
RECALL 0.489
注意:如果使用不同数量的 GPU(而不是 8 个)进行评估,结果可能会有些微差异。
3.2 GPU 要求
UniAD 分两阶段训练。第一阶段训练感知模块(例如,跟踪和地图),第二阶段初始化第一阶段训练的权重并优化所有任务模块。建议在两个阶段的训练中都使用至少 8 个 GPU。使用更少的 GPU 进行训练也是可以的,但会花费更多时间。
第一阶段训练需要大约 50 GB 的 GPU 内存,在 8 个 A100 GPU 上运行 6 个 epoch 需要大约 2 天时间。
- 提示:为了节省 GPU 内存,您可以将
queue_length=5改为3,这会略微降低跟踪性能。然后训练大约需要 30 GB 的 GPU 内存,适用于V100 GPUs(32GB 版本)。
第二阶段训练需要大约 17 GB 的 GPU 内存,在 8 个 A100 GPU 上运行 20 个 epoch 需要大约 4 天时间。
- 注意:与第一阶段相比,第二阶段需要的 GPU 内存要少得多,因为在此阶段我们冻结了 BEV 编码器以专注于学习特定任务的查询。因此,您可以在
V100 或 3090设备上运行第二阶段训练。
3.3 训练命令
# N_GPUS 是使用的 GPU 数量。建议 >=8。
./tools/uniad_dist_train.sh ./projects/configs/stage1_track_map/base_track_map.py N_GPUS# 对于使用 slurm 的用户:
# ./tools/uniad_slurm_train.sh YOUR_PARTITION ./projects/configs/stage1_track_map/base_track_map.py N_GPUS
3.4 评估命令
# N_GPUS 是使用的 GPU 数量。建议 =8。
# 如果使用不同数量的 GPU(而不是 8 个)进行评估,结果可能会有些微差异。./tools/uniad_dist_eval.sh ./projects/configs/stage1_track_map/base_track_map.py /PATH/TO/YOUR/CKPT.pth N_GPUS# 对于使用 slurm 的用户:
# ./tools/uniad_slurm_eval.sh YOUR_PARTITION ./projects/configs/stage1_track_map/base_track_map.py /PATH/TO/YOUR/CKPT.pth N_GPUS
3.5 可视化命令
# 请参见 ./tools/uniad_vis_result.sh
python ./tools/analysis_tools/visualize/run.py \--predroot /PATH/TO/YOUR/RESULTS.pkl \--out_folder /PATH/TO/YOUR/OUTPUT \--demo_video test_demo.avi \--project_to_cam True
4. nuscenes 数据集
由于nuscenes数据太大,这里只测试nuscense提供mini版本, 下载map跟mini,如下图点击红色框中US即可
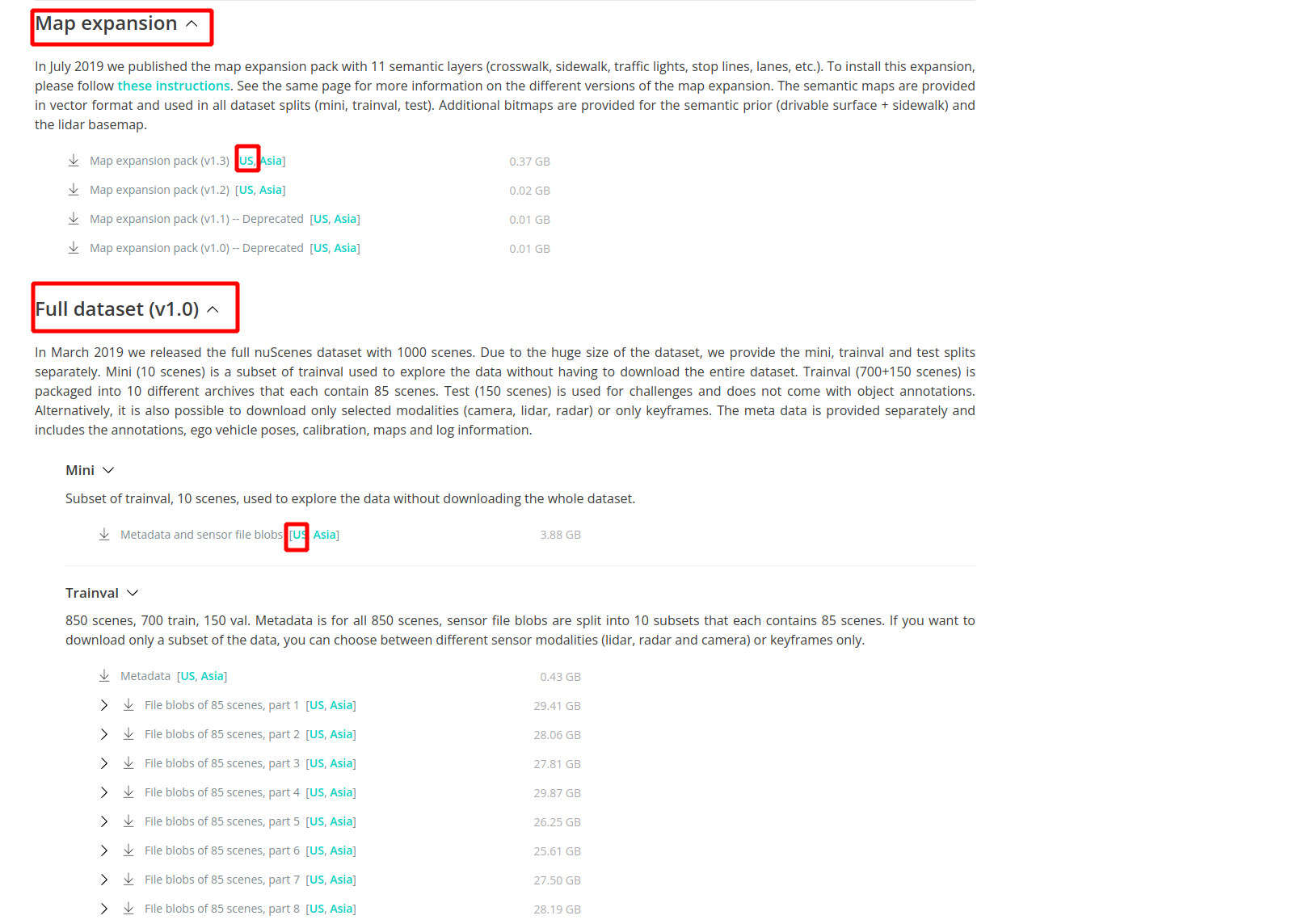
注意:map(v1.3) extensions压缩包下载后展开的三个目录basemap、expansion、prediction需要放在maps目录下,而不是和samples、sweeps等目录平级,NuScenes的train所有数据压缩包展开后,samples的最底层的每个子目录下都是34149张图片,sweeps里的子目录下的图片数量则是不等的,例如:163881、164274、164166、161453、160856、164266…等,把没有标注的test数据的压缩包在nuscenes目录下展开后,其里面samples和sweeps目录里子目录下的图片会自动拷贝到nuscenes/samples和nuscenes/sweeps下的对应子目录里去,再次统计会看到samples下的每个子目录里的图片数量变成了40157,而sweeps下的子目录里的图片数量则变成了193153、189171、189905、193082、193168、192699…
下载后得到2个压缩的文件
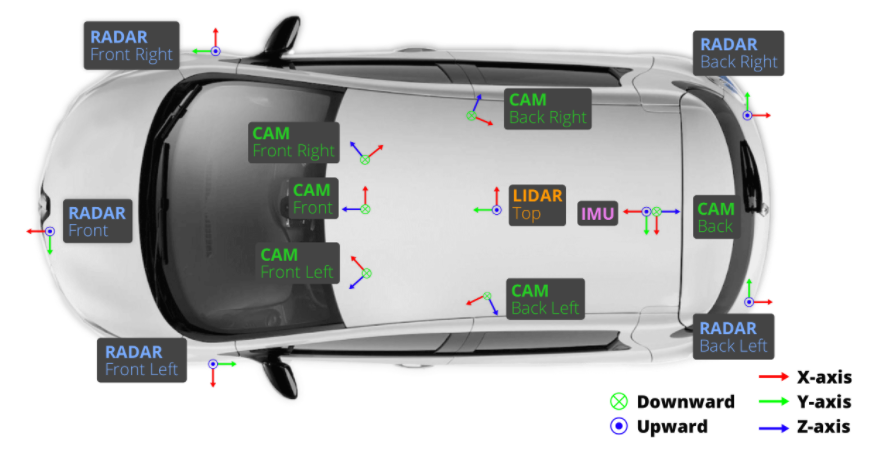
相机(CAM)有六个,分别分布在前方(Front)、右前方(Front Right)、左前方(Front Left)、后方(Back)、右后方(Back Right)、左后方(Back Left);激光雷达(LIDAR)有1个,放置在车顶(TOP);毫米波雷达有五个,分别放置在前方(Front)、右前方(Front Right)、左前方(Front Left)、右后方(Back Right)、左后方(Back Left)。
解压到当前目录。解压得到nuScenes-map-expansion-v1.3与v1.0-mini两个目录, 把nuScenes-map-expansion-v1.3中的三个文件复制到v1.0-mini/map目录下。最终得到新v1.0-mini目录,就行训练所需的数据集。这里将对应的数据信息给出来,sample和sweeps下面主要是一些传感器的信息。详细的内容可以参考:对Nuscenes数据集一无所知,手把手带你玩转Nusences数据集这一篇文章
很久没有更新过了,今天去官网看发现官方已经更新了数据结构和各个文件的组织关系,比之前版本要清晰的多,所以建议此部分直接移步官方数据标注说明。
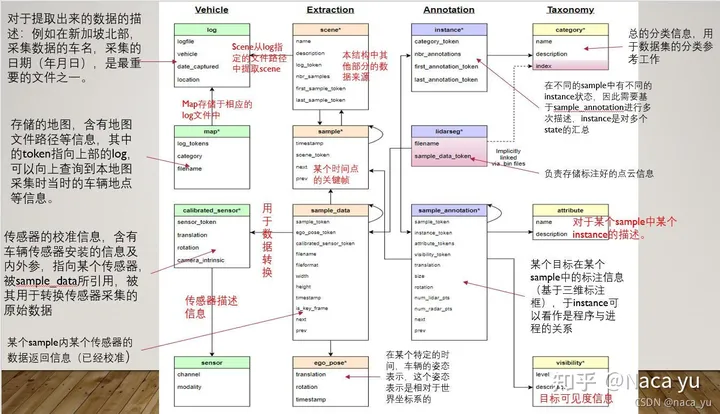
官方提供的标注数据一共有15个json文件,下面我也结合官方给的数据格式,和自己实际应用的一些经验,按自己的思路总结一下,和官方一样,直接就按照json文件来说了:
1、category.json
这个json里面是所有出现在数据集中的物体的类别,文件内容如下图所示:

包含了三个key,分别是:
(1)token: 唯一标识;
(2)name:物体类别名称 ;
(3)description :类别详细描述。
其中物体类别一共有23类,涵盖了行人、汽车、楼房、动物等等,详细类别在这里。
2、attribute.json
描述了物体本身的一些状态,比如行驶、停下等等,内容如下图:

包含三个key,分别是:
(1)token :唯一标识;
(2)name :属性名称 ;
(3)description :属性详细描述。
其中属性一共有8种,每种属性的具体名称在这里
3、visibility.json
描述一个物体可视的程度,即被遮挡、截断的程度。在kitti中就是那两个遮挡、截断的数字,nuscences中用一个百分比来表示的,内容如下图:

包含三个key,分别是:
(1)token :唯一标识;
(2)level:可视化级别,是一个百分数,越高则越清晰,即识别越简单 ;
(3)description: 详细描述。一共有4个等级,分别是0到40%,40到60%,60到80%,80到100%。
4、instance.json
以实例为单位,记录某个实例出现的帧数、初始token、结尾token等,内容如下图:
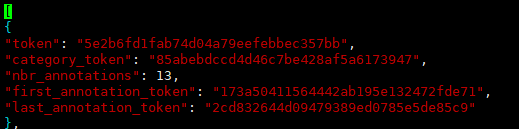
包含5个key,分别是:
(1)token:唯一表示
(2)category_token:类别标识,可以找到category.json里的对应类别
(3)nbr_annotations:出现的数量,即该实例在此数据集一共出现了多少帧
(4)fist_annotation_token:第一帧的annotation标识,在sample_annonation.json里可以找到对应标注,下同
(5)last_annotation_token:最后一帧的annotation标识
5、sensor.json
保存所有传感器的数据表,包含一些简单的传感器类型,内容如下图:
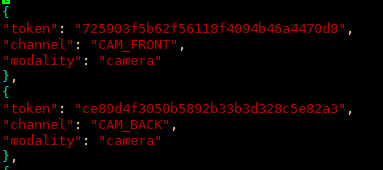
包含3个key,分别是:
(1)token:唯一标识;
(2)channel:位置;
(3)modality:类型(camera、lidar、radar)。
6、calibrated_sensor.json
一个比较大的数据表,存放了所有场景下相机的标注信息,包括了外参和内参。虽然说相机大部分场景下都是同一个,但是相机外参难免会发生微调,内参也会出现细微的变动,因此对于每一个照片,都有一个对应的相机标注,内容如下图:
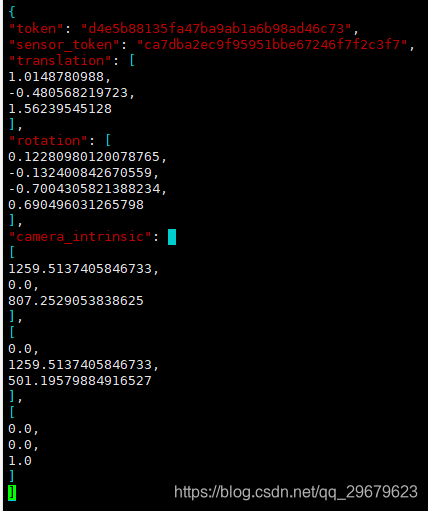
包含5个key,分别是:
(1)token:唯一标识;
(2)sensor_token:从sensor.json中对应得到相机类型;
(3)translation:相机外参,偏移矩阵,单位为米;
(4)rotation:相机外参,四元数旋转角;
(5)camera_intrinsic:相机内参(似乎只有camera会有)。
两个相机外参都是相对于ego,也就是相机所在车的坐标系的参数,即一个相对量,这里在ego_pose.json中还会提到。
7、ego_pose.json
相机所在车的标注信息,内容如下图:
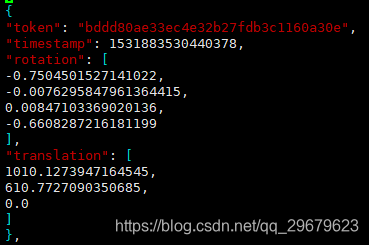
包含4个key,分别是:
(1)token:唯一标识;
(2)timestamp:Unix时间戳,应该是保存数据表时候的一个时间戳,怀疑与图片名的后缀一一对应,没有详细考证;
(3)rotation:车辆外参,四元数旋转角;
(4)translation:车辆外参,偏移矩阵,单位为米。
ego车辆,还有照片中其他车辆(sample_annotation.json)的外参,参考坐标系是世界坐标系,世界坐标系的原点是lidar或radar定义的,没有什么规律,所以要求其他车辆的相机坐标系坐标,就需要在这三个外参(ego、camera、sample)换算一下,具体方法下面会讲。
8、log.json
一些场景、日期的日志信息,大部分情况没有太大作用,内容如下图:
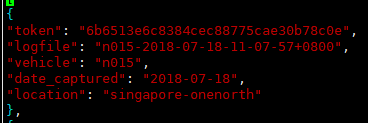
包含5个key,分别是:
(1)token:唯一标识;
(2)logfile:日志文件;
(3)vehicle:车辆名称(咱也不知道是个啥);
(4)data_captured:拍摄日期;
(5)location:拍摄地点(新加坡和波士顿)。
9、scene.json
场景数据表,Nuscenes的标注集包括850段场景视频,每个场景20s,这个表标注了该场景的一些简单描述和出现的头尾车辆token,内容如下图:
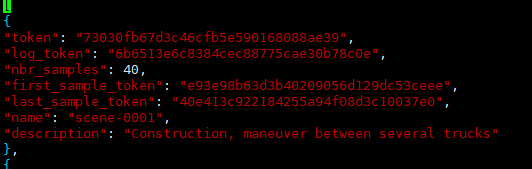
包含7个key,分别是:
(1)token:唯一标识;
(2)log_token:日志token,从log.json索引出对应日志;
(3)nbr_samples:场景中出现的sample的数量,就是该场景下一共出现过多少个标注的物体,同一物体就算一次;
(4)first_sample_token:第一个sample的token,从sample.json中可以索引出唯一sample,下同;
(5)last_sample_token:场景下的最后一个sample;
(6)name:场景名;
(7)description:场景描述。
10、sample.json
照片的标注,以照片为单位,一张照片对应一个sample,内容如下:
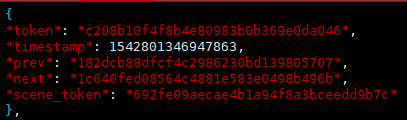
包含5个key,分别是:
(1)token:唯一标识;
(2)timestamp:时间戳;
(3)prev:上一张照片token;
(4)next:下一张照片的token;
(5)scene_token:场景标识,从scene.json中对应唯一场景。
11、sample_data.json
sample对应的简单信息,不包括标注,可以索引出同一个物体前后帧的信息,内容如下图:
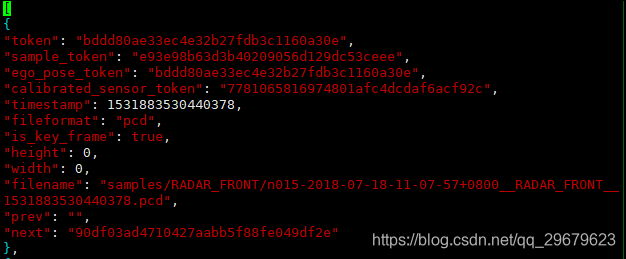
包含12个key,分别是:
(1)token:唯一标识;
(2)sample_token:可以从sample.json中索引出唯一对应的sample;
(3)ego_pose_token:对应的ego车辆的token,可以从ego_pose中索引出来,据我观察,1和3都是相同的;
(4)calibrated_sensor_token:可以从calibrated_sensor.json中索引出对应的相机外参和内参,3和4就对应索引出上文所说的ego和camera的外参,sample的外参并不在这个表里,而是在sample_annotation.json中,见下文;
(5)timestamp:时间戳;
(6)fileformat:文件格式,照片和雷达格式;
(7)is_key_frame:是否是关键帧,Nuscenes中,每秒两帧关键帧,提供标注信息;
(8)heihgt:照片像素高度,似乎只有jpg才会有,都是900;
(9)width:同上,像素宽度,都是1600;
(10)filename:照片名;
(11)prev:上一个sample_data的token,从本数据表中可以索引出对应的数据,是同一个物体的上一个标注,即上一次出现这个物体是在哪里,下同;
(12)next:下一个sample_data的token。
12、sample_annotation.json
保存了物体的标注信息,内容如下图:
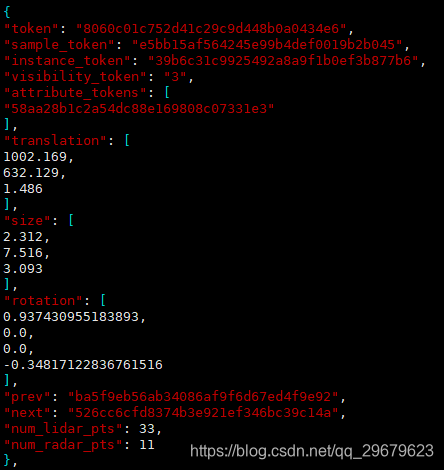
包含了12个key,分别是:
(1)token:唯一标识;
(2)sample_token:从sample.json中索引出唯一对应的sample;
(3)instance_token:从instance.json中索引出唯一对应的instance;
(4)visibility_token:从visibility.json中索引出唯一对应的visibility;
(5)attribute_token:从attribute.json中索引出唯一对应的attribute;
(6)translation:物体外参,偏移矩阵,单位为米;
(7)size:物体大小,单位为米,顺序为宽、长、高;
(8)rotation:物体外参,四元数旋转矩阵;
(9)prev:同一个物体,上一帧标注的token,在本数据表中索引出唯一对应的标注信息,下同;
(10)next:下一帧的标注token;
(11)num_lidar_pts:bbox中出现的lidar点数量,下同;
(12)num_radar_pts:bbox中出现的radar点数量。
不是搞lidar或radar的,所以11和12这两个量并不是很懂,只知道测试的时候需要保证这两个至少有一个是非零的。
13、map.json
地图相关的一些标注信息,数据集的map文件夹里面会包括map的图片,内容如下图:
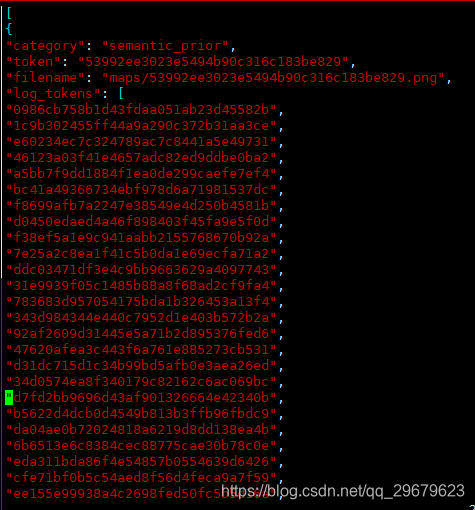
包含4个key,分别是:
(1)category:地图类别,似乎都是sematic的,因为提供的地图图片都是分割的,Nuscenes本身也包括了道路分割的数据集;
(2)token:唯一标识;
(3)filename:对应的地图文件名;
(4)log_tokens:地图中的日志文件。
14、image_annotations.json
这个表是没有出现在官方的标注格式说明中的,可以看出还是有一点冗余的,但是如果不用官方接口,自己写dataloader,还是很重要的,本表包括了2DBbox等信息,内容如下图:
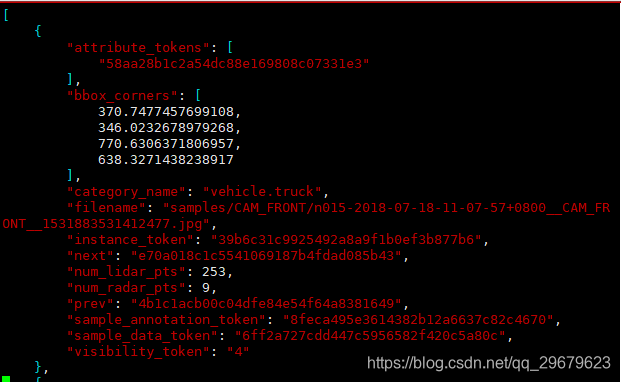
包含12个key,分别是:
(1)attribute_token:从attribute.json中索引出唯一对应的attribute;
(2)bbox_corners:2DBbox像素坐标,分别是x1,y1,x2,y2;
(3)category_name:类别名称(谢天谢地终于不用索引了);
(4)filename:图片名;
(5)instance_token:从instance.json中索引出唯一对应的instance;
(6)next:下一个物体的信息,这个应该是没有规律的,最多是按照顺序来依次记录每个出现的物体,通过这个文件可以遍历整个数据集中的所有物体;
(7)num_lidar_pts:bbox中出现的lidar点数量,下同;
(8)num_radar_pts:bbox中出现的radar点数量;
(9)prev:上一个物体,同6;
(10)sample_annotation_token:从sample_annotation.json中索引出唯一对应的sample_annotation;
(11)sample_data_token:从sample_data.json中索引出唯一对应的sample_data;
(12)visivility_token:从visibility.json中索引出唯一对应的visibility。
对于自己制作NuScene数据集可以参考:https://github.com/linClubs/nuscenes2kitti、https://github.com/linklab-uva/rosbag2nuscenes
4. 参考链接
https://blog.csdn.net/weixin_44491423/article/details/127023092
https://blog.csdn.net/h904798869/article/details/138255214
https://blog.csdn.net/XCCCCZ/article/details/134315977?spm=1001.2014.3001.5501
https://blog.csdn.net/qq_29679623/article/details/103698313
相关文章:
从代码层面熟悉UniAD,开始学习了解端到端整体架构
0. 简介 最近端到端已经是越来越火了,以UniAD为代表的很多工作不断地在不断刷新端到端的指标,比如最近SparseDrive又重新刷新了所有任务的指标。在端到端火热起来之前,成熟的模块化自动驾驶系统被分解为不同的独立任务,例如感知、…...

微信小程序-选中文本时选中checkbox
1.使用labe嵌套住checkbox标签 <label class"label-box"> <checkbox >匿名提交</checkbox> </label>2.使checkbox和label组件在同一行 .label-box{display: flex;align-items: center; }效果图 此时选中文本匿名提交,checkbox…...

[玄机]流量特征分析-蚁剑流量分析
题目网址【玄机】:https://xj.edisec.net/ AntSword(蚁剑)是一款开源的网络安全工具,常用于网络渗透测试和攻击。它可以远程连接并控制被攻击计算机,执行命令、上传下载文件等操作。 蚁剑与网站进行数据交互的过程中&a…...

2-51 基于matlab的IFP_FCM(Improved fuzzy partitions-FCM)
基于matlab的IFP_FCM(Improved fuzzy partitions-FCM),改进型FCM(模糊C均值)聚类算法,解决了FCM算法对初始值设定较为敏感、训练速度慢、在迭代时容易陷入局部极小的问题。并附带了Box和Jenkins煤气炉数据模型辨识实例。程序已调通࿰…...

Java人力资源招聘社会校招类型招聘小程序
✨💼【职场新风尚!解锁人力资源招聘新神器:社会校招类型招聘小程序】✨ 🎓【校招新体验,一键触达梦想企业】🎓 还在为错过校园宣讲会而懊恼?别怕,社会校招类型招聘小程序来救场&am…...

oracle表、表空间使用空间
文章目录 一、Oracle查询表空间占用情况二、Oracle查询表占用的空间三、Oracle查询表空间使用情况四、Oracle查询每张表占用空间五、表空间大小 TOC 一、Oracle查询表空间占用情况 oracle日常工作中查看表占用空间大小是数据库管理中的基本操作: SELECT a.tablesp…...

IDEA管理远程仓库Git
1、模拟项目 新建一个文件夹,用来这次演示 用IDEA来打开文件夹 2、创建仓库 在IDEA中给该文件夹创建本地仓库和远程仓库 在菜单栏找到VCS选择Share project on Gitee 在弹窗中输入描述信息 接下来会出现以下弹窗 点击ADD后,在gitee上会创建远程仓库 …...
【数据结构】Java实现二叉搜索树
二叉搜索树的基本性质 二叉搜索树(Binary Search Tree, BST)是一种特殊的二叉树,它具有以下特征: 1. 节点结构:每个节点包含一个键(key)和值(value),以及指…...

钉钉小程序如何通过setdate重置对象
在钉钉小程序中,通过setData方法来重置对象(即更新对象中的数据)是一个常见的操作。然而,需要注意的是,钉钉小程序(或任何小程序平台)的setData方法在处理对象更新时有一些特定的规则和最佳实践…...

DjangoRF-10-过滤-django-filter
1、安装pip install django-filter https://pypi.org/ 搜索django-filter基础用法 2、进行配置 3、进行内容调试。 4、如果碰到没有关联的字段。interfaces和projects没有直接关联字段,但是interface和module有关联,而且module和projects关联&#x…...
)
Android SurfaceFlinger——GraphicBuffer的生成(三十二)
通过前面的学习我们知道,在 SurfaceFlinger 中使用的生产者/消费者模型,Surface 做为生产者一方存在如下两个比较重要的函数: dequeueBuffer:获取一个缓冲区(GraphicBuffer),也就是 GraphicBuffer 生成。queueBuffer :把缓冲区(GraphicBuffer)放入缓冲队列中。 …...

<数据集>棉花识别数据集<目标检测>
数据集格式:VOCYOLO格式 图片数量:13765张 标注数量(xml文件个数):13765 标注数量(txt文件个数):13765 标注类别数:4 标注类别名称:[Partially opened, Fully opened boll, Defected boll, Flower] 序…...
 提升模型安全性 | 英特尔承认其13、14代 CPU 存在问题)
[240730] OpenAI 推出基于规则的奖励机制 (RBR) 提升模型安全性 | 英特尔承认其13、14代 CPU 存在问题
目录 OpenAI 推出基于规则的奖励机制(RBR)提升模型安全性英特尔承认其 13、14代 CPU 存在问题 OpenAI 推出基于规则的奖励机制(RBR)提升模型安全性 为了解决传统强化学习中依赖人工反馈的低效问题,OpenAI 开发了基于规…...

【JavaScript】展开运算符详解
文章目录 一、展开运算符的基本用法1. 展开数组2. 展开对象 二、展开运算符的实际应用1. 合并数组2. 数组的浅拷贝3. 合并对象4. 对象的浅拷贝5. 更新对象属性 三、展开运算符的高级用法1. 在函数参数中使用2. 嵌套数组的展开3. 深拷贝对象4. 动态属性名 四、注意事项和最佳实践…...

麒麟V10系统统一认证子系统国际化
在适配麒麟V10系统统一认证子系统国际化过程中, 遇到了很多的问题,关键是麒麟官方的文档对这部分也是粗略带过,遇到的问题有: (1)xgettext无法提取C源文件中目标待翻译的字符串。 (2)使用msgf…...

C语言进阶 13. 文件
C语言进阶 13. 文件 文章目录 C语言进阶 13. 文件13.1. 格式化输入输出13.2. 文件输入输出13.3. 二进制文件13.4. 按位运算13.5. 移位运算13.6. 位运算例子13.7. 位段 13.1. 格式化输入输出 格式化输入输出: printf %[flags][width][.prec][hlL]type scanf %[flags]type %[fl…...

LinuxCentos中ELK日志分析系统的部署(详细教程8K字)附图片
🏡作者主页:点击! 🐧Linux基础知识(初学):点击! 🐧Linux高级管理防护和群集专栏:点击! 🔐Linux中firewalld防火墙:点击! ⏰️创作…...

Vscode ssh Could not establish connection to
错误表现 上午还能正常用vs code连接服务器看代码,中午吃个饭关闭vscode再重新打开输入密码后就提示 Could not establish connection to xxxx 然后我用终端敲ssh的命令连接,结果是能正常连接。 解决方法 踩坑1 网上直接搜Could not establish con…...

数字陷波器的设计和仿真(Matlab+C)
目录 一、数字陷波器的模型 二、Matlab仿真 1. 示例1 2. 示例2 三、C语言仿真 1. 由系统函数计算差分方程 2. 示例代码 一、数字陷波器的模型 二、Matlab仿真 1. 示例1 clear clc f0=100;%滤掉的100Hz fs=1000;%大于两倍的信号最高频率 r=0.9; w0=2*pi*f0/fs;%转换到…...

[玄机]流量特征分析-常见攻击事件 tomcat
题目网址【玄机】:https://xj.edisec.net/ Tomcat是一个开源的Java Servlet容器,它实现了Java Servlet和JavaServer Pages (JSP) 技术,提供了一个运行这些应用程序的Web服务器环境。Tomcat由Apache软件基金会的Jakarta项目开发,是…...

React hook之useRef
React useRef 详解 useRef 是 React 提供的一个 Hook,用于在函数组件中创建可变的引用对象。它在 React 开发中有多种重要用途,下面我将全面详细地介绍它的特性和用法。 基本概念 1. 创建 ref const refContainer useRef(initialValue);initialValu…...

visual studio 2022更改主题为深色
visual studio 2022更改主题为深色 点击visual studio 上方的 工具-> 选项 在选项窗口中,选择 环境 -> 常规 ,将其中的颜色主题改成深色 点击确定,更改完成...

Spring数据访问模块设计
前面我们已经完成了IoC和web模块的设计,聪明的码友立马就知道了,该到数据访问模块了,要不就这俩玩个6啊,查库势在必行,至此,它来了。 一、核心设计理念 1、痛点在哪 应用离不开数据(数据库、No…...

鸿蒙DevEco Studio HarmonyOS 5跑酷小游戏实现指南
1. 项目概述 本跑酷小游戏基于鸿蒙HarmonyOS 5开发,使用DevEco Studio作为开发工具,采用Java语言实现,包含角色控制、障碍物生成和分数计算系统。 2. 项目结构 /src/main/java/com/example/runner/├── MainAbilitySlice.java // 主界…...
与常用工具深度洞察App瓶颈)
iOS性能调优实战:借助克魔(KeyMob)与常用工具深度洞察App瓶颈
在日常iOS开发过程中,性能问题往往是最令人头疼的一类Bug。尤其是在App上线前的压测阶段或是处理用户反馈的高发期,开发者往往需要面对卡顿、崩溃、能耗异常、日志混乱等一系列问题。这些问题表面上看似偶发,但背后往往隐藏着系统资源调度不当…...

CVE-2020-17519源码分析与漏洞复现(Flink 任意文件读取)
漏洞概览 漏洞名称:Apache Flink REST API 任意文件读取漏洞CVE编号:CVE-2020-17519CVSS评分:7.5影响版本:Apache Flink 1.11.0、1.11.1、1.11.2修复版本:≥ 1.11.3 或 ≥ 1.12.0漏洞类型:路径遍历&#x…...

Go 语言并发编程基础:无缓冲与有缓冲通道
在上一章节中,我们了解了 Channel 的基本用法。本章将重点分析 Go 中通道的两种类型 —— 无缓冲通道与有缓冲通道,它们在并发编程中各具特点和应用场景。 一、通道的基本分类 类型定义形式特点无缓冲通道make(chan T)发送和接收都必须准备好࿰…...

基于SpringBoot在线拍卖系统的设计和实现
摘 要 随着社会的发展,社会的各行各业都在利用信息化时代的优势。计算机的优势和普及使得各种信息系统的开发成为必需。 在线拍卖系统,主要的模块包括管理员;首页、个人中心、用户管理、商品类型管理、拍卖商品管理、历史竞拍管理、竞拍订单…...
的打车小程序)
基于鸿蒙(HarmonyOS5)的打车小程序
1. 开发环境准备 安装DevEco Studio (鸿蒙官方IDE)配置HarmonyOS SDK申请开发者账号和必要的API密钥 2. 项目结构设计 ├── entry │ ├── src │ │ ├── main │ │ │ ├── ets │ │ │ │ ├── pages │ │ │ │ │ ├── H…...

C++_哈希表
本篇文章是对C学习的哈希表部分的学习分享 相信一定会对你有所帮助~ 那咱们废话不多说,直接开始吧! 一、基础概念 1. 哈希核心思想: 哈希函数的作用:通过此函数建立一个Key与存储位置之间的映射关系。理想目标:实现…...