【分布式】分库分表知识点大全
为什么要分库分表
随着业务量的增加导致数据库中数据量的增加,可能拖慢查询的性能,影响业务的可用性;如果数据库采用读写分离,可能会导致从库的延迟较大,主库进行写操作后,从库因为延迟无法及时同步,会导致出现数据不一致的情况。
分表:应对大数据量。当单表的数据达到百万级时,sql 的执行性能就较差了;当超过千万级时,sql 的执行性能急剧下降,所以要保持 sql 的执行性能,就必须采用分表。
分库:应对高并发。一个健康的单数据库并发最好维持到 1000 个连接左右,超过就可能造成宕机崩溃。采用分库就可以提高数据库的并发能力。
分库分表的原则
在进行分库分表时,我们最好遵循一下原则:
- 优先进行 MySQL 调优,能不分就不分
数据量能稳定在千万级,近几年不会到达亿级,其实是不用着急拆的,先尝试MySQL调优,优化读写性能。只有在MySQL调优已经无法解决慢查询问题时,才可以考虑分库分表。
- 分片的数量尽量少
分片就是将数据存储在多个数据库实例中,在分库中就是将数据拆分到多个独立的数据库中,在分表中就是将一个大表拆分成多个小表,每个小表存储数据的一部分。
如果实例太多,分的太细,那么查询一个 sql 可能要跨越多个分区,降低查询的性能。
- 数据的分布要尽量均匀
数据应该尽量均匀的分布在多个分片中,原因同上,这就涉及到分片建的选择了。
分表方案
分表的应用场景是单表数据量增长速度过快,影响了业务接口的响应时间,但是 MySQL 实例的负载并不高,这时候只需要分表,不需要分库(拆分实例)。
一张表的大小由 字段数量 × 记录数量 构成,也就是说如果表太大,那么要么是表的记录太多,要么就是表的字段太多。这就产生了两种分表方案:
- 垂直分表(拆分字段)
- 水平分表(拆分记录)
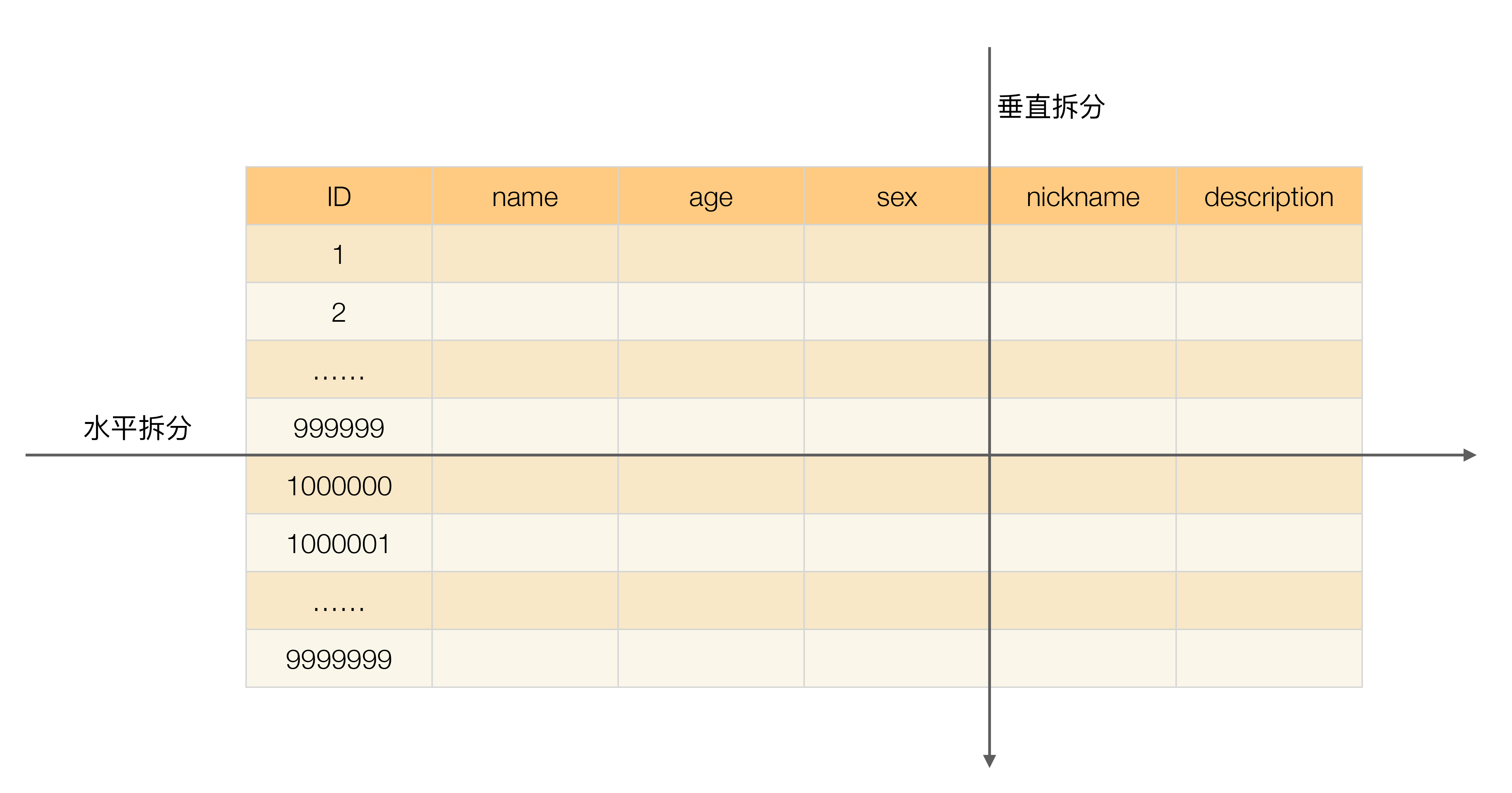
垂直分表
以订单表 orders 为例,按照字段进行拆分,这里面需要考虑一个问题,如何拆分字段才能表上的DML性能最大化。
- 常规的垂直分表方案就是冷热分离拆分(将使用频率高字段放到一张表里,剩下使用频繁低的字段放到另一张表里)。
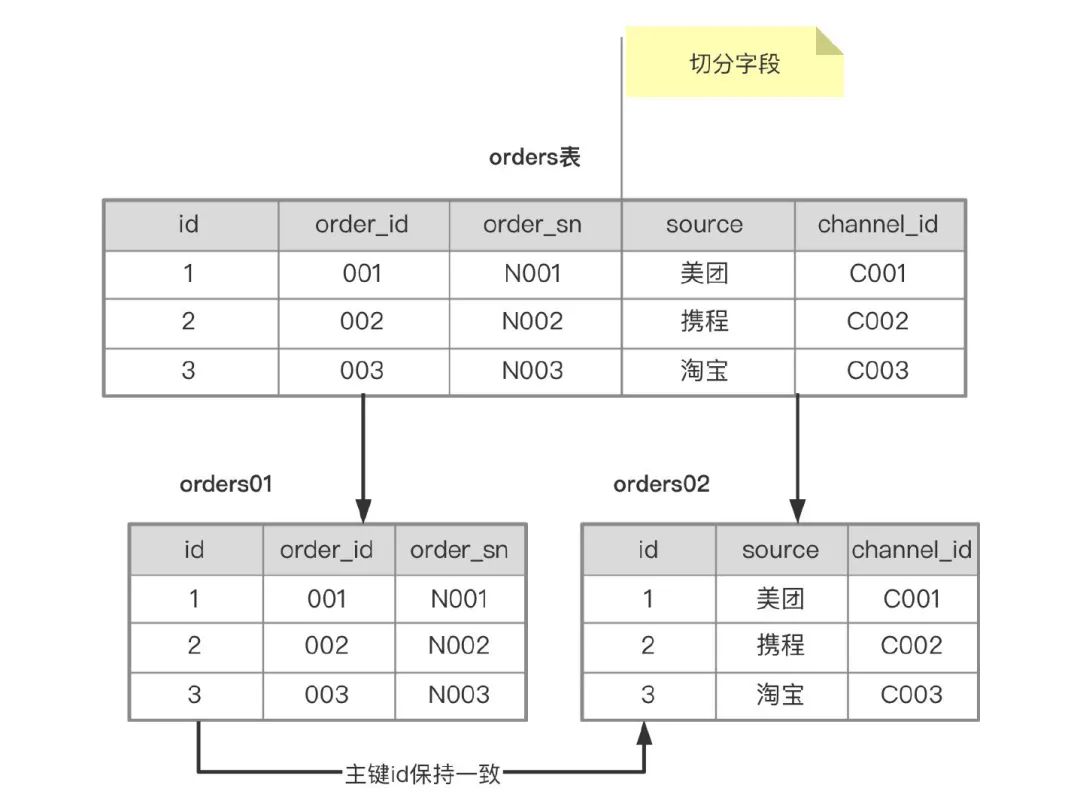
什么情况下可以使用冷热分离?
- **数据走到终态后只有读没有写的需求。**例如订单完结后基本只会读不会改。
- **用户能接受新旧数据分开查询。**比如有些电商网站默认只让查询3个月内的订单,如果要查询3个月前的订单,还需要访问其他的页面。
orders 表通过拆分之后,就变成了 orders01 和 orders02 两张表,在磁盘上就会存储两个数据文件 orders01.ibd 和 orders02.ibd,orders 表最大尺寸就是 4TB 了,拆分完之后,该怎么查询呢?举个例子:

分析下上面的 SQL,select 后面的列分别位于两张表中(order_id,order_sn在orders01中,source在orders02中),上面的SQL可以查询重写为如下形式。

一般数据库中间件就会自动实现查询重写,但是每次解析SQL时都需要根据原表名 + 字段名去获取需要的子表,然后再改写 SQL,执行 SQL 返回结果,这种代码改造量太大,而且容易出错。
业务场景举例:
- 邮件系统:邮件系统中最近邮件是用户经常访问和修改的,三个月前的邮件或已归档的邮件不经常访问的。可以将用户的收件箱、发件箱里最近三个月的邮件放在一个库里(热库),之前的邮件或者已读的邮件放在另一个库里(冷酷)。
- **日志系统:**在大型应用中,日志数据是非常庞大的,但并不是所有日志都需要经常查询或分析。可以将最近一段时间的活动日志存放在热库中,而将过去的历史日志存放在冷库中,以减轻热库的负载和优化查询性能。
- 社交媒体平台:社交媒体平台上的用户数据量通常很大,但是只有少部分用户是活跃的,并且只有少量用户的数据会频繁访问和更新,如果所有用户都放在同一个库里,势必会影响活跃用户的查询效率。可以将活跃用户的个人信息、好友关系等存放在热库中,而将不活跃用户的数据存放在冷库中,以提升热库的性能和减少冷库的存储成本。
- **电商平台:**电商平台上的商品数据也可以进行冷热分离。热库中存放热门商品的基本信息和库存等,以支持频繁的查询和更新操作,而将不活跃或下架的商品信息存放在冷库中,以减少热库的负载和优化查询性能。
- 客服工单:在我们日常操作时,经常能看到查询历史工单时会有个“近三个月工单”的选项,实际业务场景中,用户基本只会关注近三个月工单,而且这些工单也会经常需要进行修改、删除的操作,而对很早期的历史订单基本就没有修改、删除的需求,只有少量的查询需求。
- 还可以根据业务的层面来进行拆分:将混合业务拆分为独立业务。
业务场景举例:
- **电商网站:**一个典型的混合业务,包含用户信息、订单信息、商品信息等。可以将用户信息、订单信息和商品信息分别拆分到不同的库或表中,以减少数据冗余并提高访问效率。
- 社交媒体平台:包含用户信息、好友关系、动态信息等。可以将用户信息和好友关系分离存储,以便更好地支持好友关系的查询和更新。
- **在线游戏:**涉及角色信息、道具信息、战斗日志等。可以将角色信息和道具信息拆分到不同的表中,以提升查询效率,并将战斗日志存储到日志数据库中,以减轻主数据库的负载。
- 物流系统:包含订单信息、配送信息、运输信息等。可以将订单信息、配送信息和运输信息分别拆分到不同的表中,以便更好地支持订单的查询和跟踪。
- 还有如果业务表中有 text 长文本类型的字段需要存储。这时可以利用垂直拆分来减少表大小,将 text 字段拆分到子表中。
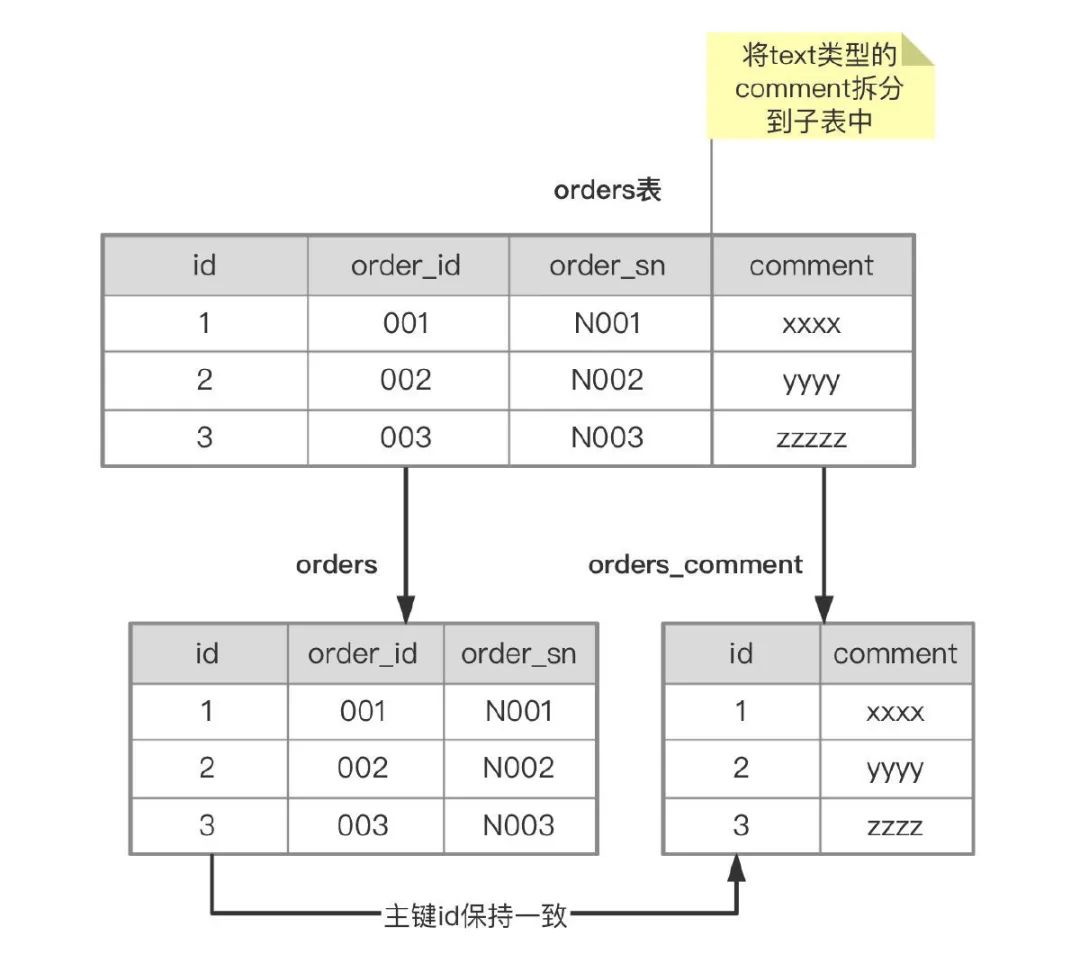
这样将 text 类型拆分放到子表中之后,原表的平均行长度就变小了,就可以存储更多的数据了。
水平分表
水平拆分表就是按照表中的记录进行分片,举个例子,目前订单表 orders 有 2000w 数据,根据业务的增长,估算一年之后会达到1亿,同时参考阿里云 RDS for MySQL 的最佳实践,单表不建议超过 500w,1亿数据分20个子表就够了。
问题来了,按照什么来拆分呢?主键id还是用户的user_id,按主键ID拆分数据很均匀,通过ID查询 orders 的场景几乎没有,业务访问 orders 大部分场景都是根据 user_id来过滤的,而且 user_id 的唯一性又很高(一个 user_id 对应的 orders 表记录不多,选择性很好),按照 user_id 来作为 Sharding key能满足大部分业务场景,拆分之后每个子表数据也比较均匀。
一般使用散列算法,让数据均匀的分摊到不同的库表中。如把原本在一台机器上的数据库存放1000万数据,分摊到n台机上,拆分这1000万的数据和后续的增量。让每个数据库资源来分摊原本需要一台数据库所提供的服务。
公式: sharding_key%N
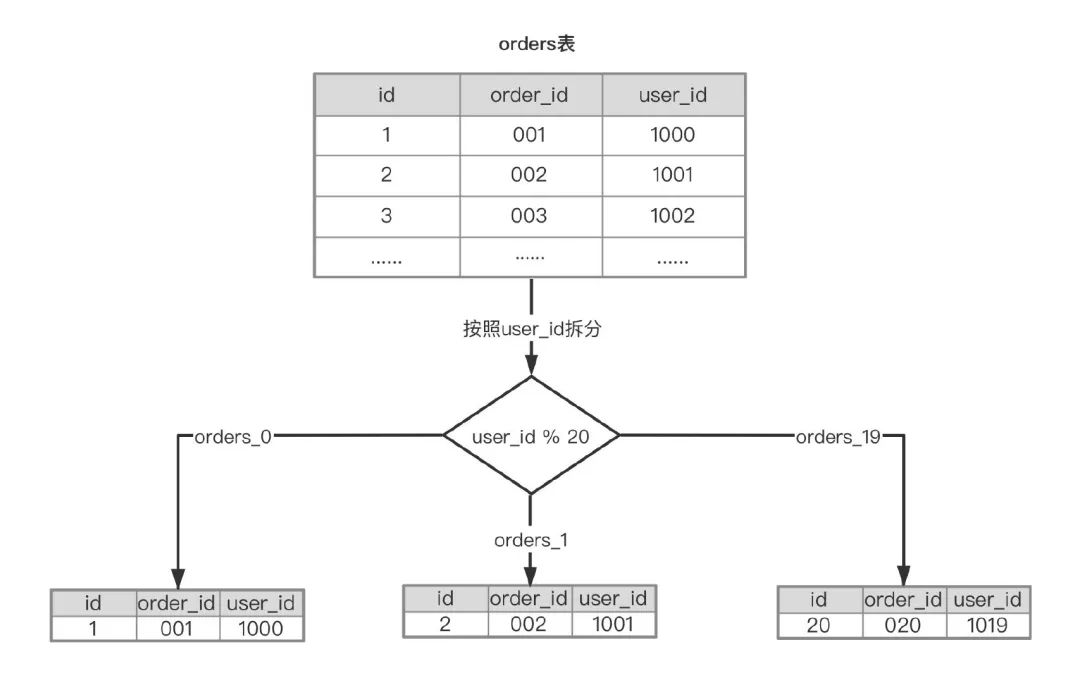
这样就将 orders 表拆分成20个子表,对应到InnoDB的存储上就是20个数据文件(orders_0.ibd,orders_1.ibd等),这时候执行SQL语句select order_id, order_sn, source from orders where user_id = 1001就能很快的定位到要查找记录的位置是在orders_1,然后做查询重写,转化为SQL语句select order_id, order_sn, source from orders_01 where user_id = 1001,这种查询重写功能很多中间件都已经实现了,常用的就是 sharding-sphere 或者 sharding-jdbc 都可以实现。
按日期分表
这种使用方式比较普遍,尤其是按照日期维度的拆分,其实在程序层面的改动很小,但是扩展性方面的收益很大。
- 日维度拆分,如test_20191021
- 月维度拆分,如test_201910
- 年维度拆分,如test_2019
例如对于账务或者计费类系统,每天晚上都会做前一天的日结或日账任务,每月的1号都会做月结或月账任务,任务执行完之后相关表的数据都已静态化了(业务层不需要这些数据),根据业务的特性,可以按月创建表,比如对于账单表 bills,就可以创建按月分表(十月份表bills_202010,202011十一月份表),出完月账任务之后,就可以归档到历史库了,用于数据仓库ETL来做分析报表,确认数据都同步到历史库之后就可以删除这些表释放空间。
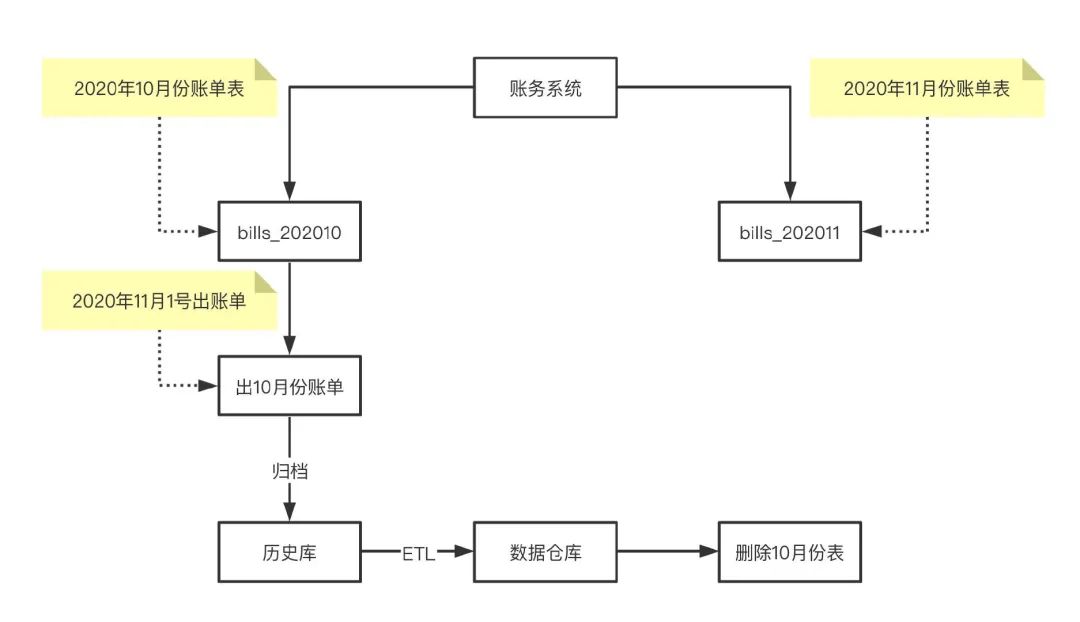
按主键范围分表
例如【1,200w】主键在一个表,【200w,400w】主键在一个表。优点是单表数据量可控。缺点是流量无法分摊,写操作集中在最后面的表。
分库方案
聊了下分表的方案,那什么时候分库呢?我们知道,MySQL 的高可用架构大多都是一主多从,所有写入操作都发生在 Master 上,随着业务的增长,数据量的增加,很多接口响应时间变得很长,经常出现 Timeout,而且通过升级 MySQL 实例配置已经无法解决问题了,这时候就要分库了。
按业务分库
举个例子,交易系统 trade 数据库单独部署在一台 RDS 实例,现在交易需求及功能越来越多,订单,价格及库存相关的表增长很快,部分接口的耗时增加,同时有大量的慢查询告警,升级 RDS 配置效果不大,这时候就需要考虑拆分业务,将库存,价格相关的接口独立出来。
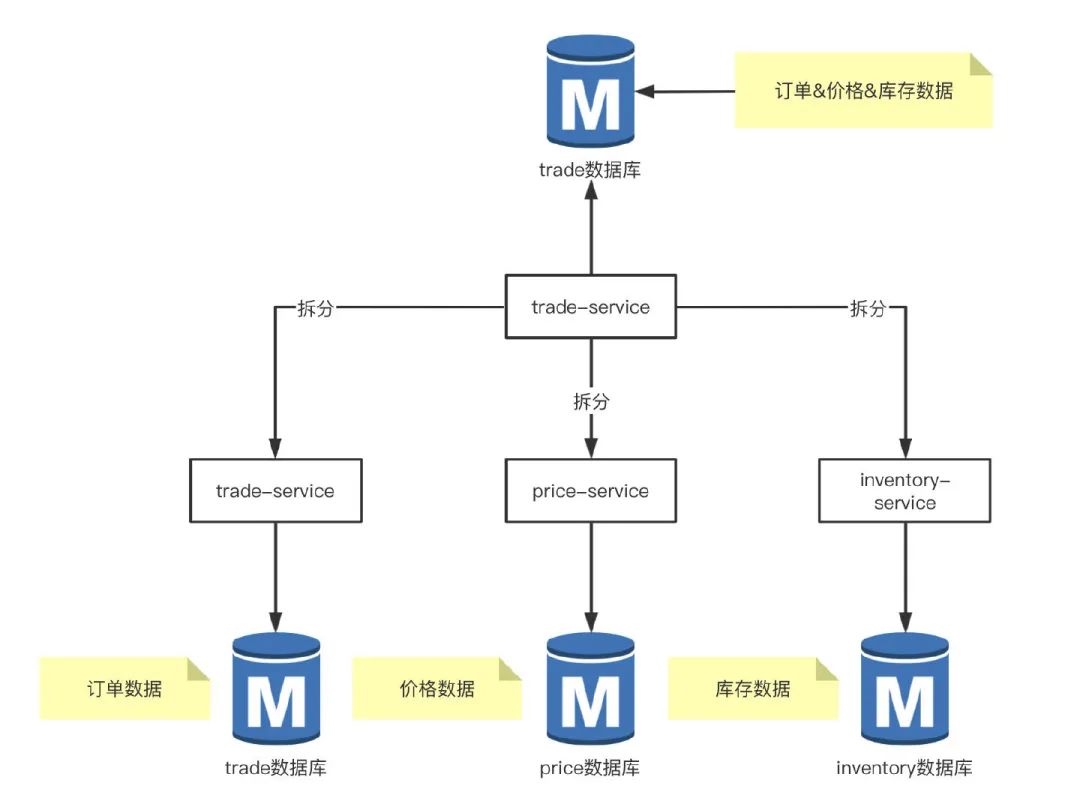
这样按照业务模块拆分之后,相应的 trade 数据库被拆分到了三个 RDS 实例中,数据库的写入能力提升,服务的接口响应时间也变短了,提高了系统的稳定性。
按表分库
上面介绍了分表方案,常见的有垂直分表和水平分表(拆分后的子表都在同一个 RDS 实例中存储),对应的分库就是垂直分库和水平分库,这里的分库其实是拆分 RDS 实例,是将拆分后的子表存储在不同的 RDS 实例中,垂直分库实际业务用的很少,就不介绍了,主要介绍下水平分库。
举个例子,交易数据库的订单表 orders 有2亿多数据,RDS 实例遇到了写入瓶颈,普通的 insert 都需要50ms,时常也会收到 CPU 使用率告警,这时就要考虑分库了。根据业务量增长趋势,计划扩容一台同配置的RDS实例,将订单表 orders 拆分20个子表,每个 RDS 实例10个。
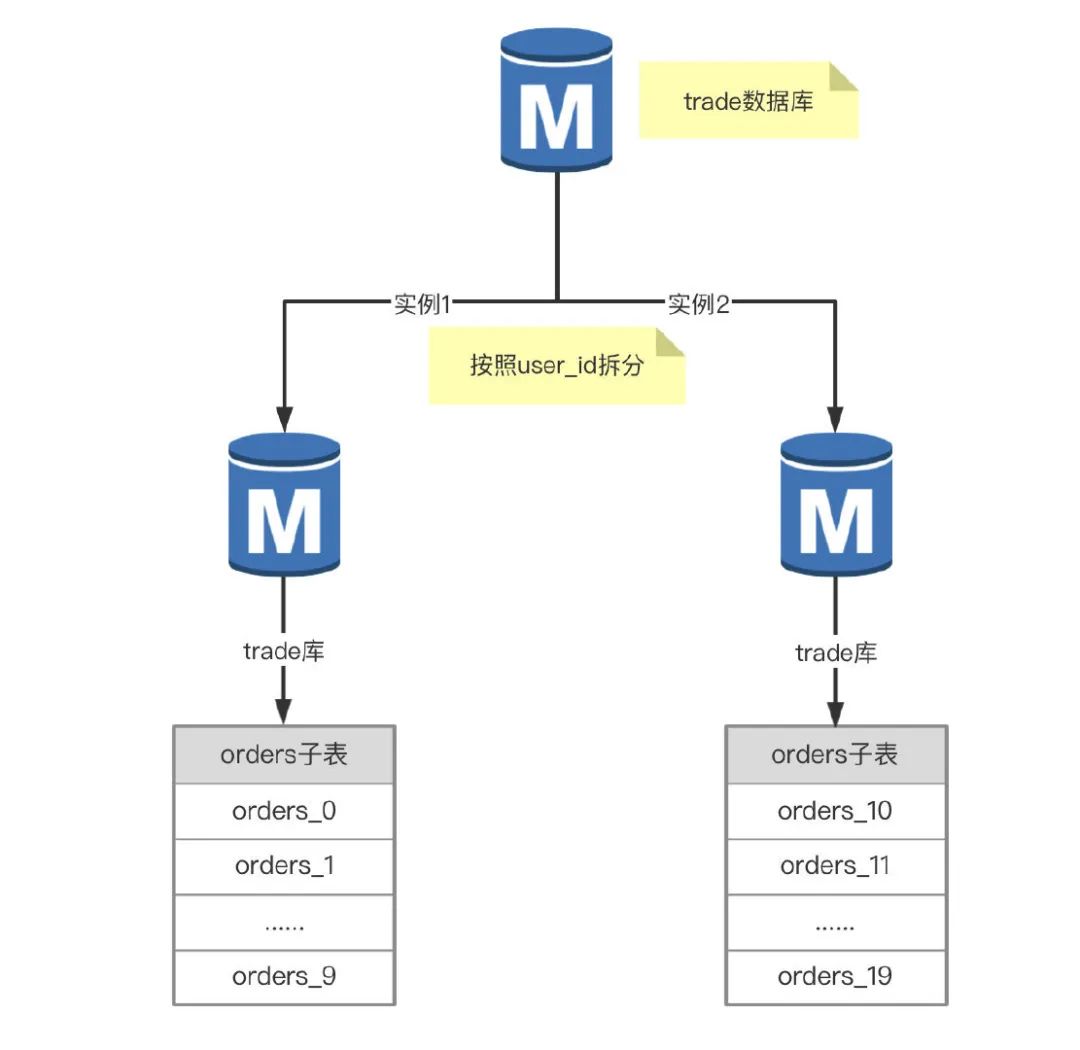 这样解决了订单表 orders 太大的问题,查询的时候要先通过分区键 user_id 定位是哪个 RDS 实例,再定位到具体的子表,然后做 DML操作,问题是代码改造的工作量大,而且服务调用链路变长了,对系统的稳定性有一定的影响。其实已经有些数据库中间件实现了分库分表的功能,例如常见的 mycat,阿里云的 DRDS 等。
这样解决了订单表 orders 太大的问题,查询的时候要先通过分区键 user_id 定位是哪个 RDS 实例,再定位到具体的子表,然后做 DML操作,问题是代码改造的工作量大,而且服务调用链路变长了,对系统的稳定性有一定的影响。其实已经有些数据库中间件实现了分库分表的功能,例如常见的 mycat,阿里云的 DRDS 等。
分片键的选择
选择最佳的分表字段是一个需要仔细考虑的问题。最佳的分表字段应该是能够让数据分布均匀、频繁查询的字段以及不可变的字段。通过选择最佳的分表字段,可以提高系统的性能和查询效率。
常用字段:
- **主键ID:**频繁查询并且唯一,非常适合作分表字段。例如,在用户表中,用户ID作为分表字段是一个不错的选择,因为用户ID是唯一的,而且在查询用户信息时经常会用到。
- **时间字段:**如果业务需要按时间范围查询数据,那么选择时间字段作为分表字段是合理的。例如,在日志表中,可以选择时间戳字段作为分表字段,以便按天、按月或按年分割数据,方便查询和维护。
- **地理信息字段:**如果业务需要按地区查询数据,那么选择地理信息字段作为分表字段是合适的。例如,在订单表中,可以选择订单地区字段作为分表字段,以便将订单数据按地区进行拆分,方便查询和扩展。
- **关联字段:**如果业务需要频繁进行关联查询,那么选择订单号等关联字段作为分表字段。例如,在订单表中,可以选择订单号作为分表字段,因为订单号唯一且包含业务信息,并且日常查询、关联查询都是根据订单号查询的,很少根据id查询,方便查询和维护。
选择分表字段的原则:
\1. 数据分布均匀
最佳的分表字段应该是能够让数据分布均匀的字段,这样可以避免某个表的数据过多,导致查询效率降低。在用户表中,如果以地区作为分表字段,可能会导致某些地区的数据过多,而某些地区的数据过少。
2. 频繁查询的字段
尽量选择查询频率最高的字段(例如主键id),然后根据表拆分方式选择字段。在一个订单表中,如果经常需要根据用户ID查询订单信息,那么以用户ID作为分表字段是一个不错的选择。
3. 不可变字段
最佳的分表字段还应该是不可变的字段,这样可以避免在数据迁移时出现问题。在一个商品表中,如果选择以商品名称作为分表字段,那么当商品名称发生变化时,就需要将数据移动到不同的表中,这样会增加系统的复杂度。
查询重写
修改代码里的查询、更新语句,以便让其适应分库分表后的情况。通常查询重写是通过一些工具来自动实现,比如 jdbc sharding,mycat 等
查询语句改造:
- **单库查询改为跨库查询:**对于需要查询的字段,需要明确指定查询的库和表,以避免查询到错误的数据。例如,原来的查询语句 “SELECT * FROM users WHERE id = 1” 可以修改为 “SELECT * FROM db.table_name WHERE id = 1”,其中 db 为目标数据库,table_name 为目标表。
- **单表查询改为跨表查询:**例如投诉记录表根据哈希取余的方式分成10个表,如果id%1=0,则查0号表complaint_records_0。
可能出现的问题
- 分布式全局唯一 ID
MySQL InnoDB的表都是使用自增的主键ID,分库分表之后,数据表分布不同的分片上,如果使用自增 ID 作为主键,就会出现不同分片上的主机 ID 重复现象,可以利用 Snowflake 算法生成唯一ID。
- 分片键的选择
选择分片键时,需要先统计该表上的所有的 SQL,尽量选择使用频率且唯一值多的字段作为分片键,既能做到数据均匀分布,又能快速定位到数据位置,例如user_id,order_id等。
相关文章:
【分布式】分库分表知识点大全
为什么要分库分表 随着业务量的增加导致数据库中数据量的增加,可能拖慢查询的性能,影响业务的可用性;如果数据库采用读写分离,可能会导致从库的延迟较大,主库进行写操作后,从库因为延迟无法及时同步&#…...

FreeRTOS中的定时器:xTimerCreate ,xTimerStart ,xTimerStop
1. 创建定时器 定时器的创建使用 xTimerCreate 函数。该函数有以下参数: pcTimerName:定时器的名字,主要用于调试。xTimerPeriodInTicks:定时器的周期,以系统节拍计时。uxAutoReload:定时器是否自动重载。如…...

【网络安全】文件上传黑白名单及数组绕过技巧
不安全的文件上传(Unsafe FileUpload) 不安全的文件上传是指Web应用程序在处理用户上传的文件时,没有采取足够的安全措施,导致攻击者可能利用这些漏洞上传恶意文件,进而对服务器或用户造成危害。 目录 一、文件上传…...

4.2、存储管理-页式存储
页式存储和段氏存储会考 页式存储几乎必考,段氏存储可能会考 页式存储 页式存储是操作系统的一种存储管理方式。 因为我们的程序往往是远远大于内存的,所以程序在执行的时候,是不会一次性把所有内容都装入到内存中,它会把程序分…...

60个常见的 Linux 指令
常见60个Linux指令 1.ssh 登录到计算机主机2.ls 列出目录内容3.pwd 当前终端会话所在的完整路径4.cd 切换当前工作目录5.touch 创建空文件或更新文件的时间戳6.echo 终端输出文本或变量值7.nano 在终端中编辑文件8.vim 文本编辑器9.cat 查看、连接和创建文件10.shred 安全删除敏…...

DockerRedis基础
目录 Docker 部署MySQL 镜像和容器 解析命令 Docker基础 常见命令 命令别名 数据卷 命令 自定义镜像 Dockerfile 网络 自定义网络设置静态IP Redis概述 NoSQL(非关系型数据库) Redis Redis命令行客户端 Redis数据结构 Redis通用命令&…...

oracle读写时相关字符集详解
服务器端操作系统(Oracle linux)字符集 服务器端数据库字符集 客户端操作系统(Oracle linux)字符集 客户端工具sqlplus字符集 结论1:客户端工具sqlplus的会话,使用的字符集,是数据库字符集。…...

OverlayFS 文件系统介绍
引言 OverlayFS(Overlay Filesystem)是 Linux 内核中的一种联合文件系统(Union Filesystem),它通过叠加多个目录形成一个单一的文件系统视图。作为 Docker 的默认存储驱动之一,OverlayFS 在提高性能和简化容…...
)
【C++】用Lua绑定C/C++对象,实现对脚本调用(依赖LuaBridge实现)
【C++】使用LuaBridge为Lua绑定C/C++对象,实现对脚本调用 问题: 如何在C++实现对如下脚本读取,在不改变代码的情况下实现修改脚本打开不同链接? <?xml version="1.0" encoding="utf-8"?> <root><script src="lua:lua_demo&quo…...

Java面试——Tomcat
优质博文:IT_BLOG_CN 一、Tomcat 顶层架构 Tomcat中最顶层的容器是Server,代表着整个服务器,从上图中可以看出,一个Server可以包含至少一个Service,用于具体提供服务。Service主要包含两个部分:Connector和…...

2024年7月个人工作生活总结
本文为 2024年7月工作生活总结。 研发编码 “康威定律(Conway’s Law)”思考 康威定律是 50 年前(1967 年)由 梅尔文康威 提出的,最初的说法如下: Any organization that designs a system (defined broa…...

快速方便地下载huggingface的模型库和数据集
快速方便地下载huggingface的模型库和数据集 方法一:用于使用 aria2/wgetgit 下载 Huggingface 模型和数据集的 CLI 工具特点Usage 方法二:模型下载【个人使用记录】保持目录结构数据集下载不足之处 方法一:用于使用 aria2/wgetgit 下载 Hugg…...

JAVA小白学习日记Day10
1.线程锁 使用Runnable接口和Lambda表达式: 在 EasyThreadA 类的 mainA 方法中,通过创建 Runnable 实例 run,并使用Lambda表达式。 EasyThreadA::method 绑定到 run 上。然后创建两个线程 a 和 b,分别启动它们,它们会…...

分布式相关理论详解
目录 1.绪论 2.什么是分布式系统,和集群的区别 3.CAP理论 3.1 什么是CAP理论 3.2 一致性 3.2.1 计算机的一致性说明 1.事务中的一致性 2.并发场景下的一致性 3.分布式场景下的一致性 3.2.2 一致性分类 3.2.3 强一致性 1.线性一致性 a) 定义 a) Raft算法…...

Linux基础知识之Shell命令行及终端中的快捷键
1.察看历史命令快捷键 按键 操作 ctrl p 返回上一次输入命令字符 ctrl n 返回下一次输入命令字符 ctrl r 输入单词甚至词组搜索匹配历史命令 alt p 输入字符查找与字符相接近的历史命令 alt . 向之前执行的命令的最后一个参数轮循, 并将之添加到当前光标之后…...
研究生选择学习Android开发的利与弊?
在开始前刚好我有一些资料,是我根据网友给的问题精心整理了一份「Android的资料从专业入门到高级教程」, 点个关注在评论区回复“888”之后私信回复“888”,全部无偿共享给大家!!!产品经理可以学学Axure快…...

怎么评价程序员40岁了竟然还在撸代码?
怎么评价外卖员40岁了竟然还在送外卖? 怎么评价滴滴司机40岁了竟然还在跑滴滴? 怎么评价老师40岁了竟然还在教书?难道程序员的本职工作不是敲代码吗?无论你是管理层还是螺丝钉,工业环境下怎么可能一行代码都不敲呢&…...

SQL优化(一)基础概念
基数(cardinality) 表中某个列的唯一键的数量叫做基数,主键列的基数就是表中数据的总行数。 可以用select count(distinct 列名) from 表名来计算基数。 基数的高低影像列的数据分布。 例如:先用Scott账户创建一个测试表test …...

【C++高阶】哈希:全面剖析与深度学习
目录 🚀 前言一: 🔥 unordered系列关联式容器1.1 unordered_map1.2 unordered_set 二: 🔥 哈希的底层结构 ⭐ 2.1 哈希概念⭐ 2.2 哈希冲突⭐ 2.3 哈希函数⭐ 2.4 哈希冲突解决2.4.1 🌄闭散列2.4.2 &#x…...

PHP西陆招聘求职系统小程序源码
🔥【职场新宠】西陆招聘求职系统,你的职场加速器🚀 🎉【开篇安利:一站式求职新体验】🎉 还在为找工作焦头烂额吗?是时候告别传统招聘网站的繁琐与低效了!今天给大家种草一个超赞的…...

业务系统对接大模型的基础方案:架构设计与关键步骤
业务系统对接大模型:架构设计与关键步骤 在当今数字化转型的浪潮中,大语言模型(LLM)已成为企业提升业务效率和创新能力的关键技术之一。将大模型集成到业务系统中,不仅可以优化用户体验,还能为业务决策提供…...

SkyWalking 10.2.0 SWCK 配置过程
SkyWalking 10.2.0 & SWCK 配置过程 skywalking oap-server & ui 使用Docker安装在K8S集群以外,K8S集群中的微服务使用initContainer按命名空间将skywalking-java-agent注入到业务容器中。 SWCK有整套的解决方案,全安装在K8S群集中。 具体可参…...

应用升级/灾备测试时使用guarantee 闪回点迅速回退
1.场景 应用要升级,当升级失败时,数据库回退到升级前. 要测试系统,测试完成后,数据库要回退到测试前。 相对于RMAN恢复需要很长时间, 数据库闪回只需要几分钟。 2.技术实现 数据库设置 2个db_recovery参数 创建guarantee闪回点,不需要开启数据库闪回。…...

前端倒计时误差!
提示:记录工作中遇到的需求及解决办法 文章目录 前言一、误差从何而来?二、五大解决方案1. 动态校准法(基础版)2. Web Worker 计时3. 服务器时间同步4. Performance API 高精度计时5. 页面可见性API优化三、生产环境最佳实践四、终极解决方案架构前言 前几天听说公司某个项…...

DIY|Mac 搭建 ESP-IDF 开发环境及编译小智 AI
前一阵子在百度 AI 开发者大会上,看到基于小智 AI DIY 玩具的演示,感觉有点意思,想着自己也来试试。 如果只是想烧录现成的固件,乐鑫官方除了提供了 Windows 版本的 Flash 下载工具 之外,还提供了基于网页版的 ESP LA…...

【Java_EE】Spring MVC
目录 Spring Web MVC 编辑注解 RestController RequestMapping RequestParam RequestParam RequestBody PathVariable RequestPart 参数传递 注意事项 编辑参数重命名 RequestParam 编辑编辑传递集合 RequestParam 传递JSON数据 编辑RequestBody …...

今日科技热点速览
🔥 今日科技热点速览 🎮 任天堂Switch 2 正式发售 任天堂新一代游戏主机 Switch 2 今日正式上线发售,主打更强图形性能与沉浸式体验,支持多模态交互,受到全球玩家热捧 。 🤖 人工智能持续突破 DeepSeek-R1&…...

c#开发AI模型对话
AI模型 前面已经介绍了一般AI模型本地部署,直接调用现成的模型数据。这里主要讲述讲接口集成到我们自己的程序中使用方式。 微软提供了ML.NET来开发和使用AI模型,但是目前国内可能使用不多,至少实践例子很少看见。开发训练模型就不介绍了&am…...

汇编常见指令
汇编常见指令 一、数据传送指令 指令功能示例说明MOV数据传送MOV EAX, 10将立即数 10 送入 EAXMOV [EBX], EAX将 EAX 值存入 EBX 指向的内存LEA加载有效地址LEA EAX, [EBX4]将 EBX4 的地址存入 EAX(不访问内存)XCHG交换数据XCHG EAX, EBX交换 EAX 和 EB…...

GC1808高性能24位立体声音频ADC芯片解析
1. 芯片概述 GC1808是一款24位立体声音频模数转换器(ADC),支持8kHz~96kHz采样率,集成Δ-Σ调制器、数字抗混叠滤波器和高通滤波器,适用于高保真音频采集场景。 2. 核心特性 高精度:24位分辨率,…...