【Linux】(26) 详解磁盘与文件系统:从物理结构到inode机制
目录
1.认识磁盘、
1.1 理论
1.2 磁盘的物理结构
CHS 寻址
1.3 磁盘的逻辑抽象结构
2. inode 结构
1.Boot Block 启动块
2.Super Block(超级块)
3.Group Descriptor Block(块组描述符)
4.Data Blocks (数据块)
5.Inode Table (inode表)
stat
示例
6.Bitmap 位图
思考:
3.文件系统
3.1 增/删/查/改 一个文件
3.2 理解目录
dentry 缓存:
Preface:
文件系统是一种用于在存储设备上组织数据的方法。Ext2是Linux操作系统中使用的一种文件系统,全称是Second Extended File System(第二扩展文件系统)
尽管Ext2在许多现代Linux系统中已被更新版本的文件系统(如Ext3和Ext4)所取代,它仍然在某些场景下被使用,尤其是在需要快速读写性能且不介意缺少日志功能的场合。
由于Ext2不支持日志功能,因此在系统崩溃时可能会丢失数据或在恢复时需要更长时间。现在,Ext4文件系统已经成为大多数Linux发行版的默认文件系统,因为它提供了更好的性能和更多的功能。
前面我们学习到了一个被打开的文件,那如果一个文件没有被打开呢??
我们可以知道它将在磁盘中进行存储,可以通过如下角度进行思考:
- 路径问题
- 存储问题
- 获取的问题(属性+文件内容)
- 效率
引出了我们的学习路线:
- 认识硬件--磁盘
- 对硬件进行抽象理解
- 文件系统
1.认识磁盘
1.1 理论
磁盘上存储文件属性+内容
- 文件的内容--数据块
- 文件属性--inode
sum: Linux 文件在磁盘中存储,是将属性和内容分开存的
当下磁盘存储的运用场景
1.现在电脑上装的都是SSD了
- SSD代表固态硬盘(Solid State Drive),是一种使用闪存芯片作为存储介质的电脑存储设备。目前个人电脑或工作站等设备普遍采用SSD作为主要的存储介质。SSD相比传统的机械硬盘(HDD,Hard Disk Drive)有更快的读写速度、更低的功耗和更小的噪音,同时因为没有机械运动部件,所 以更耐震动,故障率也相对较低。
2.公司服务器长时间存储还是使用磁盘,进行存储分级:冷热分离
- 在公司或企业的服务器存储解决方案中,尽管SSD在性能上有明显优势,但出于成本和容量考虑,长时间存储大量数据通常还是使用机械硬盘(HDD)。HDD的成本较低,存储容量较大,适合用来存储那些不经常访问但需要长期保存的数据。
- 存储分级:这是指根据数据的访问频率和重要性将存储分为不同的级别。通常分为热存储(hot storage)和冷存储(cold storage)。
- 热存储:用于存储经常访问的数据,这些数据需要快速访问,因此通常使用SSD或快速的磁盘阵列。
- 冷存储:用于存储不经常访问的数据,这些数据可以存储在成本更低的存储介质上,如大容量HDD或更便宜的云存储服务。
意义:优化了成本和性能,确保经常访问的数据能够快速访问,而不常用的数据则以较低的成本进行存储
机械硬盘在计算机系统中的两个特点:它是一种包含机械运动部件的设备,同时也是连接到计算机主机的外部硬件设备
- 磁盘是一个机械设备:
-
- 这里的“磁盘”通常指的是机械硬盘(HDD,Hard Disk Drive),它是由多个机械部件组成的存储设备。在个人电脑或服务器中,尽管还有其他可能包含机械部件的设备(如光盘驱动器、软盘驱动器等),但在现代计算机系统中,机械硬盘往往是唯一的主要机械存储设备。这是因为其他类型的存储设备,如固态硬盘(SSD)、内存条(RAM)、U盘等,都不包含机械运动部件。
- 也是一个外设:
-
- “外设”是外部设备的简称,指的是连接到计算机主机的硬件设备,用于扩展计算机的功能。磁盘(如HDD)作为存储设备,通常被视为计算机的外设,因为它位于计算机主机的机箱外部(或者至少是可分离的),并通过数据传输接口(如SATA、SAS等)与主板连接。尽管它是计算机运行所必需的组成部分,但它并不直接集成在主板上,因此被分类为外设。
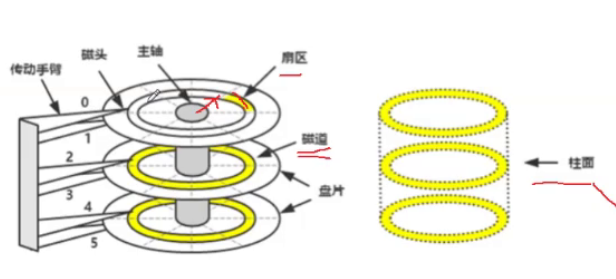
1.2 磁盘的物理结构
可以先根据下面的图片,有一个直观的感受

最后一张图的磁盘,类似于三张两面都光的光盘

磁盘作为计算机中唯一的机械部件,通常由一个或多个旋转的盘片组成,每个盘片有两个面,每个面上有一层磁性材料。通过主轴连接,磁盘上附有磁头。数据存储的基本单位是扇区(Sector),传统上每个扇区大小为512字节,但近年来逐渐过渡到4096字节的大扇区。
主轴下面有马达,一秒钟两万转都有可能
物理结构:
- 磁头是一面一个,左右摆动,两个整体移动的,有磁头停靠点
- 磁头和盘面不接触,所以物理上不适用于笔记本,开机状态移来移去,磁头刮花了磁盘,属于硬件问题
- 机械磁盘要在无尘环境下,灰尘落上去就像一座大山,可能会把数据都磨没了
磁盘存储:
- 所有的数据都在盘片上以二进制存储,磁头通过充放电写入
- 内存掉电易失设备,磁盘永久性存储介质
- 通过充放电/强弱/波,在磁盘上写入 01 数据,像吸铁石的 N S 级
- 高温消磁
- 大型互联网公司淘汰磁盘,国家规定不能数据泄露,磁盘擦除并不完全,局部数据的残留也可以被恢复,磁盘上的影子数据也挺危险的,解决方法:和厂商协商,调用接口去除~
磁盘的存储构成
- 磁盘被访问的最基本单元是扇区---大小有可能 512 字节/ 4KB
- 我们可以把磁盘看作由无数个扇区构成的存储介质
3. 第一步:定位一个扇区:哪一面(哪个磁头),哪一个磁道(纵向上形成柱面),哪一个扇区
4. 磁头摆动:定位磁道和柱面的过程
盘片转动:定位扇区的过程
5. 软件寻址,相关内容还是尽量放在一起,因为运动越少,效率越高
CHS 寻址
三个参数:Cylinder(柱面)Header(磁头)Sector(扇区)==》CHS 寻址方式
1.3 磁盘的逻辑抽象结构
我们可以类比于磁带,将扇区线性来看

将一个圆延展开来进行扇形分区(struct 来实现):存储 LBA 信息
随着技术发展,出现了逻辑块地址(LBA)的概念,它可以解决CHS寻址的局限性。LBA将磁盘上的所有扇区视为一个线性序列,操作系统可以通过LBA直接定位到扇区,而无需关心具体的磁头、柱面和扇区信息。
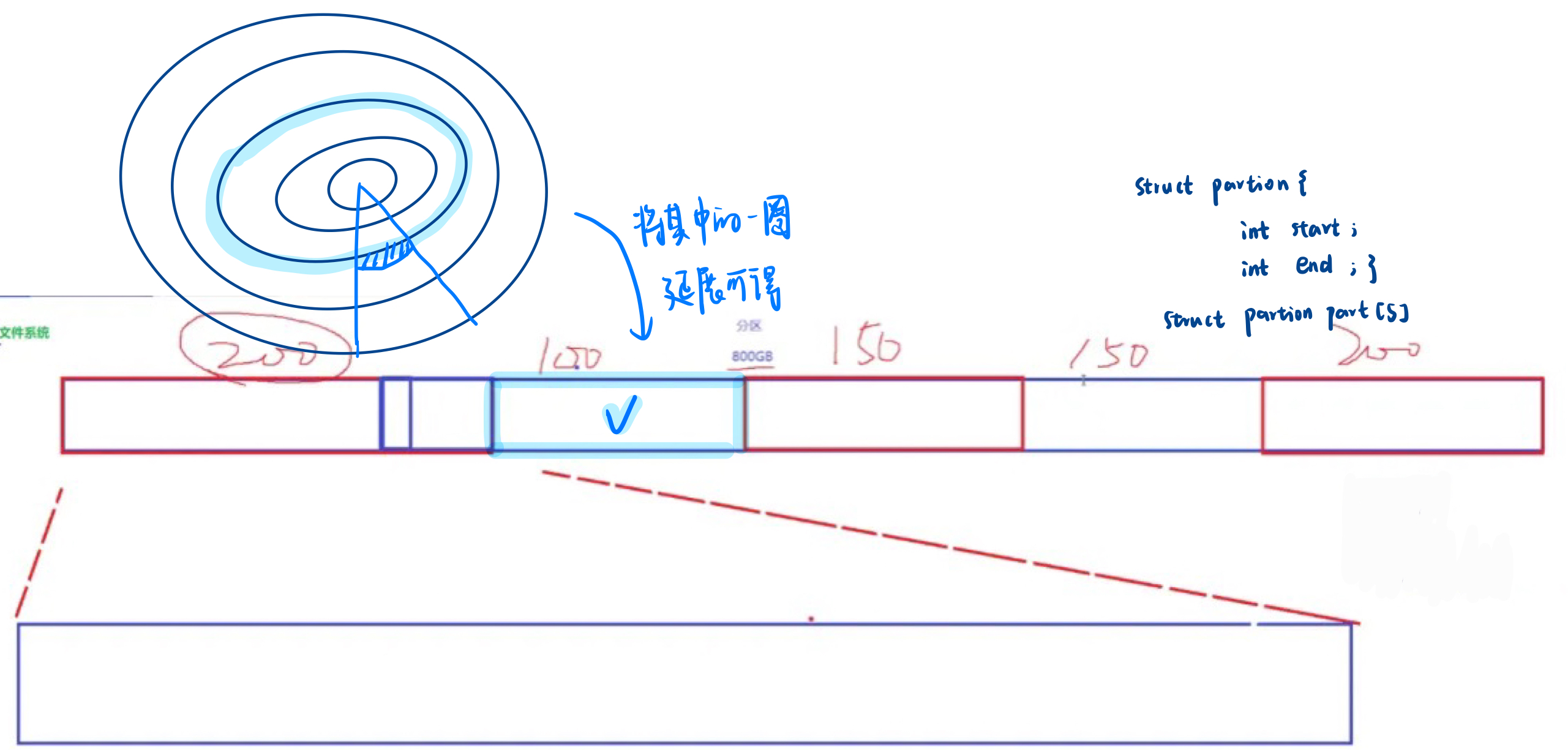
可以借助上图了解,基于对磁盘的理解建模的过程
磁盘对扇区一视同仁的划分,管理好了 10 G 的一个扇形,就能管理好 800 G--分治的思想 化大为小
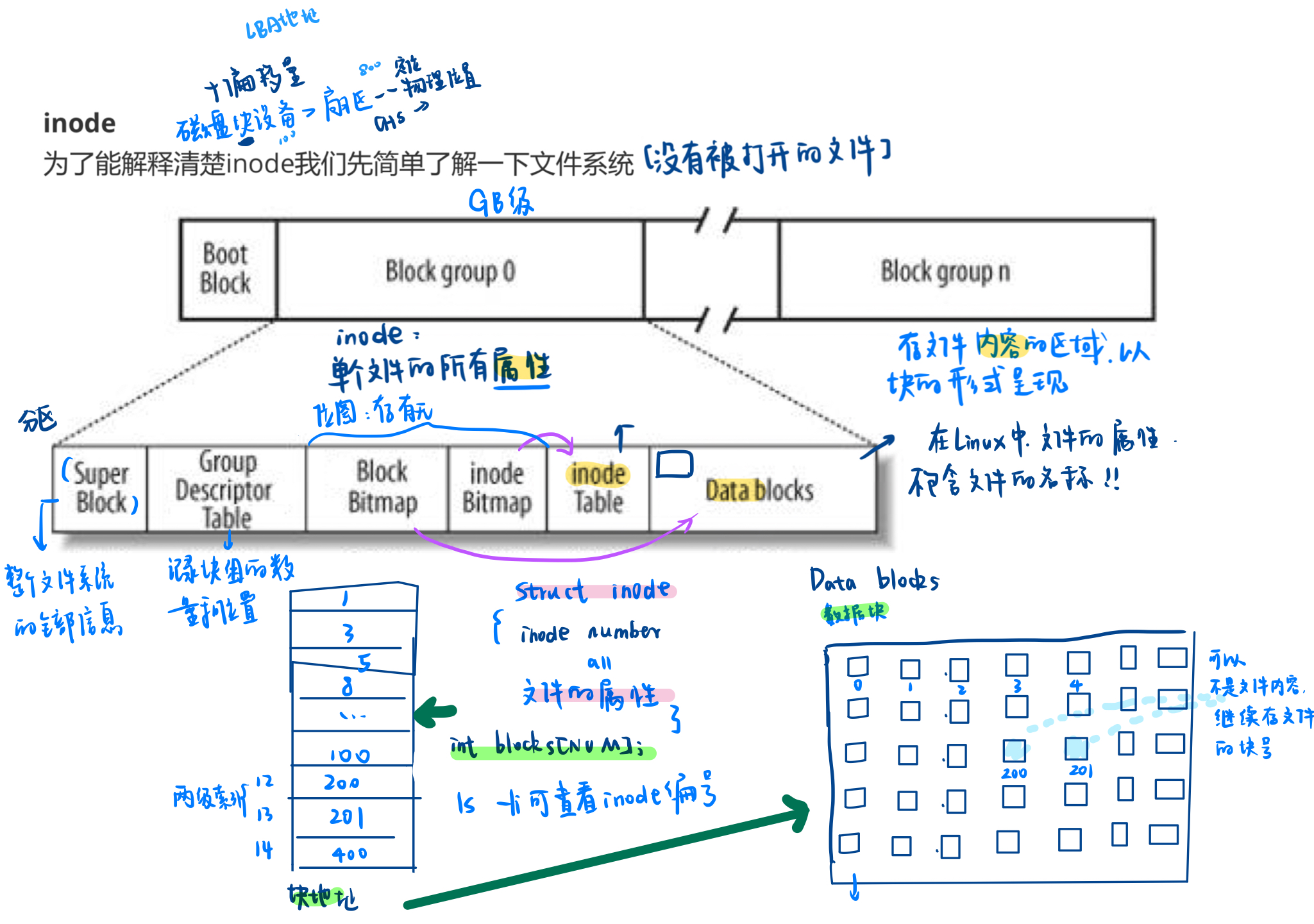
2. inode 结构
1.Boot Block 启动块
文件系统不仅需要存储文件内容,还需要存储文件的元数据,如文件大小、所有者、权限等。这些元数据存储在索引节点(inode)中。
结合上部分,先来看一下这个 10G 的分区
在Linux文件系统中,Boot Block(启动块)是一个非常重要的组成部分,尤其是在传统的磁盘驱动器中。Boot Block位于磁盘的最前端,通常是磁盘的第一个扇区,也被称作主引导记录(Master Boot Record, MBR)。
Boot Block的功能
- 引导加载:当计算机启动时,BIOS会读取磁盘的第一个扇区(即Boot Block),并将控制权传递给该扇区中的主引导程序。
- 分区检测:主引导程序会检查分区表,确定启动分区的位置。
- 操作系统加载:主引导程序会根据分区表中的信息选择一个活动分区,并加载该分区上的引导加载程序(如GRUB或LILO)。
Boot Block的示例
- 对于一个传统的MBR分区布局,Boot Block(即MBR)的结构如下:
- 主引导程序:占据MBR的前446字节。
- 分区表:接下来的64字节(每个分区条目16字节,共4个)。
- 引导签名:最后两个字节
0xAA55。对于现代系统的变化
对于使用GUID分区表(GPT)的现代系统,Boot Block的概念略有不同。在GPT分区方案中,磁盘的第一个扇区(通常称为保护MBR)通常包含一个简单的MBR,用于兼容旧版BIOS系统。真正的引导加载程序和GPT分区表位于磁盘的其他位置。
如何查看Boot Block
尽管查看Boot Block的内容通常不是日常管理任务的一部分,但如果需要,可以使用特定的工具来进行。例如,使用dd命令可以从磁盘复制第一个扇区:
sudo dd if=/dev/sda of=mbr bs=512 count=1这将把磁盘/dev/sda的第一个扇区(即Boot Block)复制到文件mbr中。随后,可以使用十六进制编辑器或特定的工具来查看该扇区的内容。
总结
Boot Block是磁盘上非常重要的一个区域,它包含了启动系统所需的关键信息。无论是传统的MBR还是现代的GPT,Boot Block都扮演着启动过程中的关键角色。
2.Super Block(超级块)
超级块是文件系统中的一种特殊的数据结构,它包含了整个文件系统的全局信息。这些信息包括但不限于:
- 文件系统类型(如ext2、ext3、ext4等)。
- 文件系统块大小(例如1024字节、2048字节或4096字节)。
- 文件系统的总块数和可用块数。
- 文件系统的总inode数和可用inode数。
- 文件系统的挂载时间、上次写入时间、上次检查时间等。
- 文件系统的特征标志(例如是否有日志功能等)。
超级块对于文件系统的正确操作至关重要。如果超级块损坏,可能导致文件系统无法被识别或挂载。大多数文件系统都会在不同的位置保存多个超级块副本,以防止单点故障。
3.Group Descriptor Block(块组描述符)
在某些文件系统中,如ext2、ext3和ext4,文件系统被分割成多个块组,以提高性能和简化管理。每个块组都包含一个块组描述符,该描述符包含了该块组的一些重要信息,例如:
- 该块组内的数据块总数。
- 该块组内的可用数据块数量。
- 该块组内的inode总数。
- 该块组内的可用inode数量。
- 该块组的块位图和inode位图的位置。
- 该块组的inode表的位置。
块组描述符使得文件系统能够快速访问每个块组的状态信息,而无需每次都访问超级块。这对于大型文件系统尤其有用,因为它减少了对超级块的访问频率,提高了性能。
总结一下:
- Super Block:包含整个文件系统的全局信息,如总块数、总inode数等。
- Group Descriptor Block:针对文件系统中的每个块组,包含该块组内的数据块和inode的数量和位置等信息。
这些信息对于文件系统的管理和维护至关重要,确保了文件系统能够正确地处理文件和目录的存储、检索和删除等操作。
4.Data Blocks (数据块)
数据块是文件系统中用于存储文件实际内容的基本单位。每个文件的内容都分布在磁盘上的一个或多个数据块中。数据块的大小取决于文件系统的配置,通常为1024字节、2048字节或4096字节等。
特点
- 可变大小:数据块的大小在文件系统创建时被定义,并且在整个文件系统的生命周期中保持不变。
- 非连续存储:文件的内容不一定存储在连续的数据块中,而是可以分散在磁盘的不同位置。
- 间接寻址:文件的内容通过inode中的指针来间接寻址,这些指针指向文件的数据块。
用途
- 存储文件内容:每个文件的实际内容(如文本、图像、音频等)都存储在数据块中。
- 高效利用磁盘空间:通过允许文件内容分散存储,文件系统可以更高效地利用磁盘空间。
5.Inode Table (inode表)
inode是文件系统中的一个数据结构,用于存储文件的元数据。每个文件都有一个与之对应的inode。inode表则是inode的集合,它包含了文件系统中所有inode的列表。
特点
- 固定大小:每个inode的大小通常是固定的,通常是128字节或256字节。
- 元数据存储:inode中存储了文件的元数据,包括文件的大小、创建时间、修改时间、权限、所有者等。
- 文件内容的指针:inode中包含指向文件数据块的指针,这些指针告诉系统文件内容存储在哪里。
用途
- 存储文件元数据:inode存储了文件的重要属性,如权限、所有者、大小等。
- 文件内容的间接寻址:inode通过指针间接指向文件的内容,这意味着文件名和文件内容是分离的。
- inode与文件名的关联:文件名不在inode中存储,而是存储在目录项中。目录项将文件名与inode编号关联起来,以便通过文件名找到对应的inode。
stat
用法查看文件具体信息
stat [OPTION]... FILE...- FILE:可以是一个文件名或目录名。
- OPTION:可以是多个选项,用于定制输出信息。
选项
-c或--format:指定输出格式,可以使用特定的格式化字符串来自定义输出结果。-f或--file-system:显示文件所在文件系统的统计信息,而不是文件本身的统计信息。-L:递归地显示符号链接的目标的统计信息。-l:显示符号链接本身的统计信息,而不是链接的目标。-t或--time=WORD:指定输出的时间戳类型,WORD可以是atime、mtime或ctime。-h或--human-readable:以人类易读的格式显示文件大小(例如,1K 234M 2G 等)。
使用场景
- 文件调试:当需要了解文件的具体信息时,比如权限、所有者等。
- 脚本编写:在编写 shell 脚本时,可以利用
stat获取文件的详细信息,进行条件判断或动态生成文件列表。 - 系统监控:监控文件的访问、修改或状态改变时间,用于安全审计或性能分析。
stat 命令是 Linux 系统管理员和开发者不可或缺的工具之一,它提供了文件系统的深入视图,有助于更好地理解和管理文件和文件系统。
会显示 acm(时间戳)
下面解释一下文件的三个时间:
- Access 最后访问时间
- Modify 文件内容最后修改时间
- Change 属性最后修改时间
示例
实现操作的融会贯通:
1. 查看文件example.txt的inode信息
stat example.txt这个命令将显示文件example.txt的inode信息,包括inode编号、文件大小、权限等。
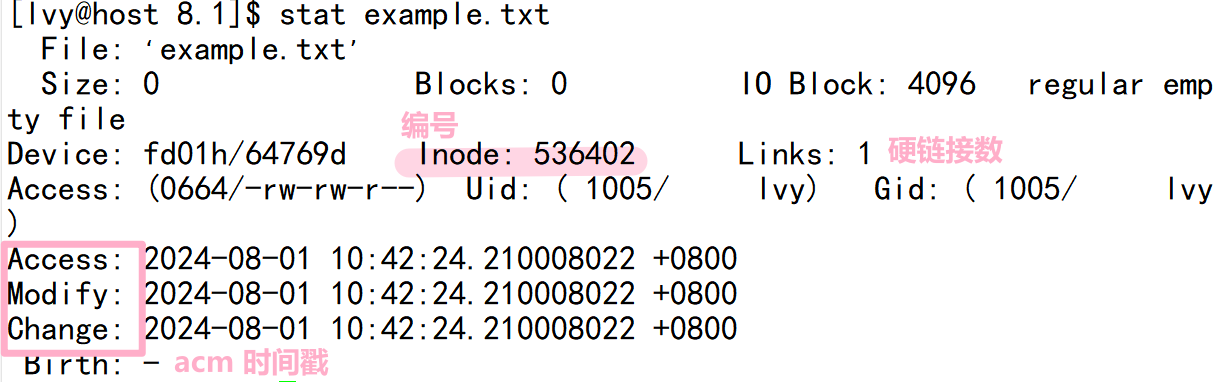
2. 查找文件example.txt的inode编号
回顾:ls -l 做的就是读取存储在磁盘上的文件信息,然后把它们显示出来
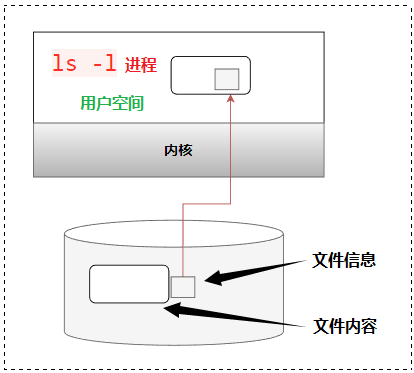
ls -i example.txt这个命令将显示文件example.txt的inode编号。
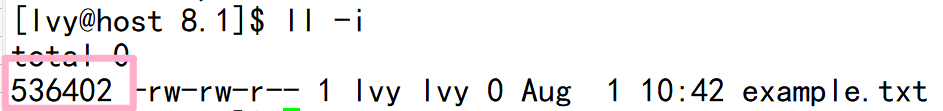
3. 查看文件example.txt的内容
cat example.txt这个命令将输出文件example.txt的内容到标准输出。
4. 假设需要直接访问数据块200(通常不建议这样做,因为它绕过了文件系统)
首先,需要确定文件系统的设备文件,比如/dev/sda1。然后使用dd命令读取数据块。以下是一个示例命令,假设每个数据块大小为4096字节,数据块200的偏移量计算方式为200 * 4096。
dd if=/dev/sda1 bs=4096 skip=200 count=1 of=data_block_200.bin这里:
if指定输入文件(文件系统设备)。bs设置块大小(这里为4096字节)。skip指定跳过的块数(这里为200)。count指定复制的块数(这里为1)。of指定输出文件(这里将数据块内容输出到data_block_200.bin)。
5. 假设需要修改文件权限
chmod 644 example.txt这个命令将设置文件example.txt的权限,使得所有者有读写权限,组和其他用户只有读权限。
6. 假设需要修改文件所有者
chown user:group example.txt这个命令将更改文件example.txt的所有者为user,所属组为group。
注意:
- 直接访问数据块的操作通常不应该在正常操作中进行,因为它可能破坏文件系统结构。
- 在执行这些操作之前,请确保备份重要数据,避免数据丢失。
- 这些命令可能需要root权限才能执行。
- 文件系统的具体实现可能会有所不同,上述命令是在一般情况下的示例。
总结
- Data Blocks:存储文件的实际内容。
- Inode Table:存储各种文件各自的 inode 元数据,包括文件内容所在的数据块的指针。
通过这种方式,文件系统可以有效地管理文件的内容和元数据,同时也提供了灵活的方式来处理文件的存储和检索。
6.Bitmap 位图
inode Bitmap (属性)位图:
比特位的内容 inode 是否有效的
Block Bitmap (文件内容)位图
和块号联系起来,申请和释放有关,内容块是否存在
思考:
- 删一个文件的时候,用不用把块内容清空呢? 不用清空原始数据,直接把管理 位图清零 即可
- inode 理论上连续的,但是还存在删除后的加入(搜索到空位就添加)
- inode 和 data block 都有对应的编号,可以找到对应的扇区
- super block 整个文件的基本信息,不是每个块组都存有,零零星星的存在,确立了稳健性
- ❗格式化: 每一个分区在被使用之前,都必须提前先将部分文件系统的属性信息提前设置进对应的分区中,方便我们后续使用这个分区或者分组,所以格式化就是把前四个重新设置,后面两个清空
3.文件系统
3.1 增/删/查/改 一个文件
系统做了些什么?
❗ 思路:
Linux 系统中,一个文件,一个 inode ,每个 inode 都有自己的编号(不能跨分区),文件名不属于 inode 内的文件属性!
通过路径能确定 200G ,存到 10G 的块里面了,找组后,在 inode map 里面找空的块
把文件误删了,是把位图删了,删除=允许被覆盖
✔️ 步骤:
系统会执行一系列底层操作来完成这些任务。下面是每个操作涉及的主要步骤:
新建文件

创建一个新文件,操作系统主要会做如下四个操作:
① 存储属性:内核找到一个空闲的结点 (这里是 263466),内核把文件信息记录到其中。
② 存储数据:该文件需要存储在三个磁盘块,内核找到了三个空闲块,300,500,800。将内核缓冲区的第一块数据复制到 300,下一块复制到 500,最后复制到 800……
③ 记录分配情况:文件内容按顺序 300,500,800 存放,内核在 inode 上的磁盘分布区记录了上述块列表。
④ 添加文件名到目录:新的文件名 abc。Linux 在当前目录中记录该文件,通过内核将入口 (263466, abc) 添加到目录文件,文件名和 inode 之间的对应关系将文件名和文件的内容及属性链接起来。
删除文件
- 查找 inode:通过文件名找到对应的 inode。
- 释放 inode 引用:减少 inode 的链接计数。
- 删除目录项:从父目录中删除指向该 inode 的条目。
- 回收资源:如果 inode 的链接计数降为 0,则回收 inode 和其关联的数据块。
- 更新文件系统元数据:更新文件系统的其他元数据,比如文件系统的块使用情况。
我怎么知道一个文件的 inode 编号?
ls -i 可查看,but 使用者基本不关心 inode ,用的是文件名
3.2 理解目录
目录也是文件,也有自己的 inode ,目录也要有自己的属性
目录有内容吗??要不要有数据块?里面放什么呢?
要,该目录下,文件的文件名 和 对应文件的 inode 的映射关系
❗ 所以我们现在就能解释, 为什么同一个目录下不能有同名文件?
ll 查看时,先找到目录的 inode, 目录内容中存储了文件的 inode,找到对应文件的 inode,就可以访问文件内容啦,例如说删除文件实际上是删除文件名与 inode 的关联,也就是从目录项中移除该文件名。这个操作需要对目录进行写操作,因为目录项(包含文件名)存储在磁盘上,并且需要被修改。但是我们限制了这一操作
目录下,没有 w ,我们无法删除文件,没有 r,我们无法查看文件是为什么?
因为想读取,目录不让读,拿什么查找到 inode,还有没有 x 无法 cd,都是通过对目录中 对文件 inode 的访问设置来管理的
目录是文件,也有 inode 编号,那么是如何管理的呢?
往上会一直访问到根目录,相当于是一个递归的实现
dentry 缓存:
- 目录项对象:dentry代表文件系统中的一个目录项,即一个文件或目录的名称与其inode(索引节点)之间的关联。
- 路径解析:当用户或程序请求访问一个文件或目录时,文件系统需要解析路径名,dentry缓存可以快速地定位到对应的inode,从而避免了每次都从磁盘读取目录信息
有绝对路径的话,不就可以从根目录往下拿到对应的 inode 了,为什么还要递归?
递归是我们从内部讲起的,就说要一路找上去,实际拿着文件路径从左到右解析就行,因为我们的任何一个文件,在进程内部都有路径,按照路径,应用层是知道文件和路径的
相关文章:
【Linux】(26) 详解磁盘与文件系统:从物理结构到inode机制
目录 1.认识磁盘、 1.1 理论 1.2 磁盘的物理结构 CHS 寻址 1.3 磁盘的逻辑抽象结构 2. inode 结构 1.Boot Block 启动块 2.Super Block(超级块) 3.Group Descriptor Block(块组描述符) 4.Data Blocks (数据块) 5.Inode…...

8.1 字符串中等 43 Multiply Strings 38 Count and Say
43 Multiply Strings【默写】 那个难点我就没想先解决,原本想法是先想其他思路,但也没想出。本来只想chat一下使用longlong数据类型直接stoi()得不得行,然后就看到了答案,直接一个默写的大动作。但这道题确实考察的是还原乘法&…...

upload-labs靶场:1—10通关教程
目录 Pass-01(JS 验证) Pass-02(MIME) Pass-03(黑名单绕过) Pass-04(.htaccess 绕过) Pass-05(大小写绕过) Pass-06(空格绕过) …...
)
Hive3:一键启动、停止、查看Hive的metastore和hiveserver2两个服务的脚本(好用)
脚本内容 #!/bin/bash # 一键启动、停止、查看Hive的metastore和hiveserver2两个服务的脚本 function start_metastore {# 启动Hive metastore服务hive --service metastore >/dev/null 2>&1 &for i in {1..30}; doif is_metastore_running; thenecho "Hiv…...

遗传算法与深度学习实战——生命模拟及其应用
遗传算法与深度学习实战——生命模拟及其应用 0. 前言1. 康威生命游戏1.1 康威生命游戏的规则1.2 实现康威生命游戏1.3 空间生命和智能体模拟 2. 实现生命模拟3. 生命模拟应用小结系列链接 0. 前言 生命模拟是进化计算的一个特定子集,模拟了自然界中所观察到的自然…...

大数据|使用Apache Spark 删除指定表中的指定分区数据
文章目录 概述方法 1: 使用 Spark SQL 语句方法 2: 使用 DataFrame API方法 3: 使用 Hadoop 文件系统 API方法 4: 使用 Delta Lake使用注意事项常见相关问题及处理结论 概述 Apache Spark 是一个强大的分布式数据处理引擎,支持多种数据处理模式。在处理大型数据集时…...

OSPF动态路由协议实验
首先地址划分 一个骨干网段分成三个,r1,r2,r5三个环回网段 ,总共要四个网段 192.168.1.0/24 192.168.1.0/26---骨干网段 192.168.1.0/28 192.168.1.16/28 192.168.1.32/28 备用 192.168.1.64/28 192.168.1.64/26---r1环回 192.1…...
的理解)
tcp中accept()的理解
源码 参数理解 NAMEaccept, accept4 - accept a connection on a socketSYNOPSIS#include <sys/types.h> /* See NOTES */#include <sys/socket.h>int accept(int sockfd, struct sockaddr *addr, socklen_t *addrlen);#define _GNU_SOURCE …...
让我们逐行重现 GPT-2:第 1 部分
欢迎来到雲闪世界。Andrej Karpathy 是人工智能 (AI) 领域的顶尖研究人员之一。他是 OpenAI 的创始成员之一,曾领导特斯拉的 AI 部门,目前仍处于 AI 社区的前沿。 在第一部分中,我们重点介绍如何实现 GPT-2 的架构。虽然 GPT-2 于 2018 年由 …...

第十九天内容
上午 1、构建vue发行版本 2、java环境配置 jdk软件包路径: https://download.oracle.com/java/22/latest/jdk-22_linux-x64_bin.tar.gz 下午 1、安装tomcat软件 tomcat软件包路径: https://dlcdn.apache.org/tomcat/tomcat-10/v10.1.26/bin/apache-to…...
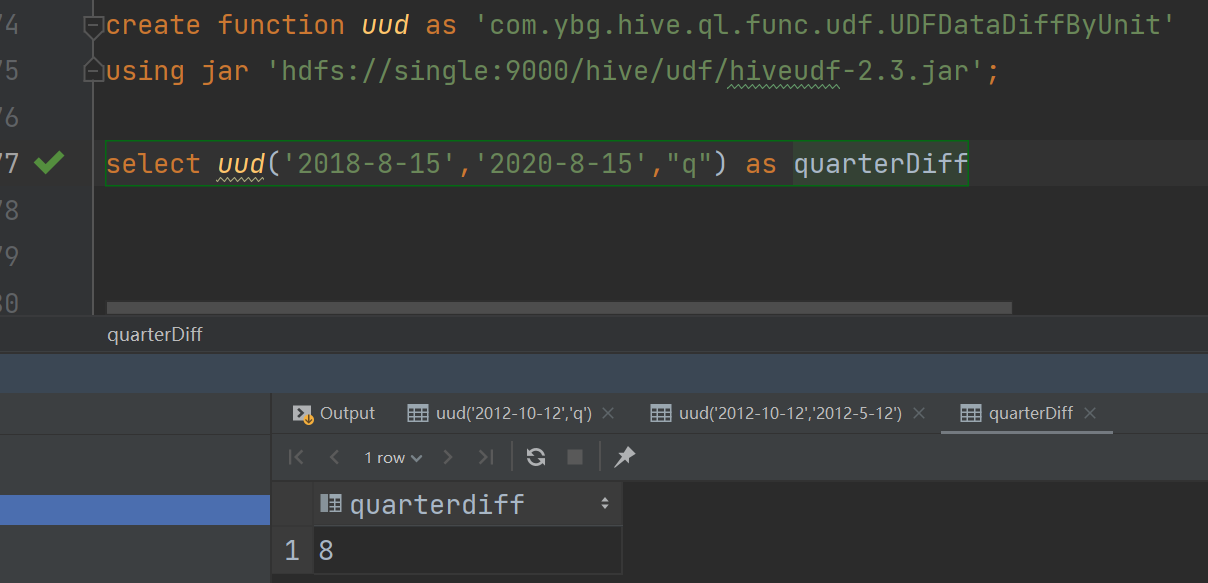
Hive之扩展函数(UDF)
Hive之扩展函数(UDF) 1、概念讲解 当所提供的函数无法解决遇到的问题时,我们通常会进行自定义函数,即:扩展函数。Hive的扩展函数可分为三种:UDF,UDTF,UDAF。 UDF:一进一出 UDTF:一进多出 UDAF:…...

jdk1.8中HashMap为什么不直接用红黑树
最开始使用链表的时候,空间占用比较少,而且由于链表短,所以查询时间也没有太大的问题。可是当链表越来越长,需要用红黑树的形式来保证查询的效率。 参考资料: https://blog.51cto.com/u_13294304/3075723...

消息推送只会用websocket、轮询?试试SSE,轻松高效。
SSE介绍 HTTP Server-Sent Events (SSE) 是一种基于 HTTP 的服务器推送技术,它允许服务器向客户端推送数据,而无需客户端发起请求。以下是 HTTP SSE 的主要特点: 单向通信: SSE 是一种单向通信协议,服务器可以主动向客户端推送数据,而客户端只能被动接收数据。 持久连接: SS…...

Spring-Retry 框架实战经典重试场景
Spring-Retry框架是Spring自带的功能,具备间隔重试、包含异常、排除异常、控制重试频率等特点,是项目开发中很实用的一种框架。 1、引入依赖 坑点:需要引入AOP,否则会抛异常。 xml <!-- Spring-Retry --> <dependency&…...

人工智能在医疗领域的应用与挑战
随着人工智能技术的不断发展,其在医疗领域的应用也越来越广泛。从辅助诊断到治疗决策,人工智能正在逐步改变着传统的医疗模式。然而,人工智能在医疗领域的应用也面临着诸多挑战,如数据隐私、伦理道德等问题。本文将探讨人工智能在…...
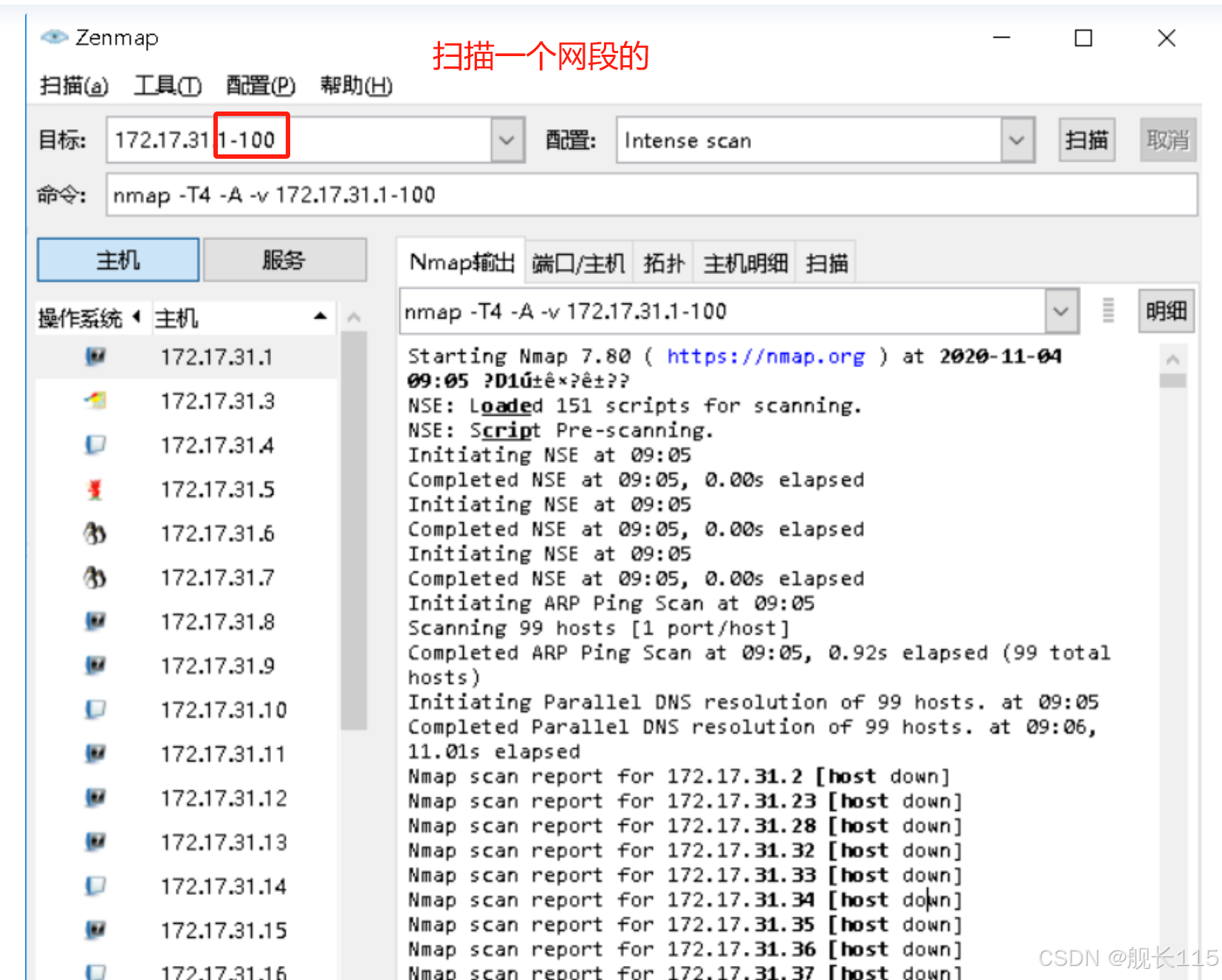
Windows下nmap命令及Zenmap工具的使用方法
一、Nmap简介 nmap是一个网络连接端扫描软件,用来扫描网上电脑开放的网络连接端。确定哪些服务运行在哪些连接端,并且推断计算机运行哪个操作系统(这是亦称 fingerprinting)。它是网络管理员必用的软件之一,以及用以评…...

深入了解-什么是CUDA编程模型
CUDA(Compute Unified Device Architecture,统一计算架构)是NVIDIA推出的一种面向GPU的并行计算平台和编程模型。它允许开发者利用NVIDIA的GPU进行通用目的的并行计算,从而加速应用程序的运行速度。CUDA编程模型为开发者提供了强大…...

111111111111111111
11111111111111111111...

环境如何搭建部署Nacos
这里我使用的是Centos7, Nacos 依赖 Java环境来运行。如果您是从代码开始构建并运行Nacos,还需要为此配置 Maven环境,请确保是在以下版本环境中安装使用 ## 1、下载安装JDK wget https://download.oracle.com/java/17/latest/jdk-17_linux-x6…...

什么是 5G?
什么是 5G? 5G 是第五代无线蜂窝技术,与以前的网络相比,它提供了更高的上传和下载速度、更一致的连接以及更高的容量。5G 比目前流行的 4G 网络更快、更可靠,并有可能改变我们使用互联网访问应用程序、社交网络和信息的方式。例如…...

【人工智能】神经网络的优化器optimizer(二):Adagrad自适应学习率优化器
一.自适应梯度算法Adagrad概述 Adagrad(Adaptive Gradient Algorithm)是一种自适应学习率的优化算法,由Duchi等人在2011年提出。其核心思想是针对不同参数自动调整学习率,适合处理稀疏数据和不同参数梯度差异较大的场景。Adagrad通…...
-----深度优先搜索(DFS)实现)
c++ 面试题(1)-----深度优先搜索(DFS)实现
操作系统:ubuntu22.04 IDE:Visual Studio Code 编程语言:C11 题目描述 地上有一个 m 行 n 列的方格,从坐标 [0,0] 起始。一个机器人可以从某一格移动到上下左右四个格子,但不能进入行坐标和列坐标的数位之和大于 k 的格子。 例…...

linux 错误码总结
1,错误码的概念与作用 在Linux系统中,错误码是系统调用或库函数在执行失败时返回的特定数值,用于指示具体的错误类型。这些错误码通过全局变量errno来存储和传递,errno由操作系统维护,保存最近一次发生的错误信息。值得注意的是,errno的值在每次系统调用或函数调用失败时…...

相机从app启动流程
一、流程框架图 二、具体流程分析 1、得到cameralist和对应的静态信息 目录如下: 重点代码分析: 启动相机前,先要通过getCameraIdList获取camera的个数以及id,然后可以通过getCameraCharacteristics获取对应id camera的capabilities(静态信息)进行一些openCamera前的…...

Java多线程实现之Thread类深度解析
Java多线程实现之Thread类深度解析 一、多线程基础概念1.1 什么是线程1.2 多线程的优势1.3 Java多线程模型 二、Thread类的基本结构与构造函数2.1 Thread类的继承关系2.2 构造函数 三、创建和启动线程3.1 继承Thread类创建线程3.2 实现Runnable接口创建线程 四、Thread类的核心…...

DingDing机器人群消息推送
文章目录 1 新建机器人2 API文档说明3 代码编写 1 新建机器人 点击群设置 下滑到群管理的机器人,点击进入 添加机器人 选择自定义Webhook服务 点击添加 设置安全设置,详见说明文档 成功后,记录Webhook 2 API文档说明 点击设置说明 查看自…...

NPOI Excel用OLE对象的形式插入文件附件以及插入图片
static void Main(string[] args) {XlsWithObjData();Console.WriteLine("输出完成"); }static void XlsWithObjData() {// 创建工作簿和单元格,只有HSSFWorkbook,XSSFWorkbook不可以HSSFWorkbook workbook new HSSFWorkbook();HSSFSheet sheet (HSSFSheet)workboo…...

云原生周刊:k0s 成为 CNCF 沙箱项目
开源项目推荐 HAMi HAMi(原名 k8s‑vGPU‑scheduler)是一款 CNCF Sandbox 级别的开源 K8s 中间件,通过虚拟化 GPU/NPU 等异构设备并支持内存、计算核心时间片隔离及共享调度,为容器提供统一接口,实现细粒度资源配额…...
:LeetCode 142. 环形链表 II(Linked List Cycle II)详解)
Java详解LeetCode 热题 100(26):LeetCode 142. 环形链表 II(Linked List Cycle II)详解
文章目录 1. 题目描述1.1 链表节点定义 2. 理解题目2.1 问题可视化2.2 核心挑战 3. 解法一:HashSet 标记访问法3.1 算法思路3.2 Java代码实现3.3 详细执行过程演示3.4 执行结果示例3.5 复杂度分析3.6 优缺点分析 4. 解法二:Floyd 快慢指针法(…...

__VUE_PROD_HYDRATION_MISMATCH_DETAILS__ is not explicitly defined.
这个警告表明您在使用Vue的esm-bundler构建版本时,未明确定义编译时特性标志。以下是详细解释和解决方案: 问题原因: 该标志是Vue 3.4引入的编译时特性标志,用于控制生产环境下SSR水合不匹配错误的详细报告1使用esm-bundler…...