Kafka 为什么这么快的七大秘诀,涨知识了
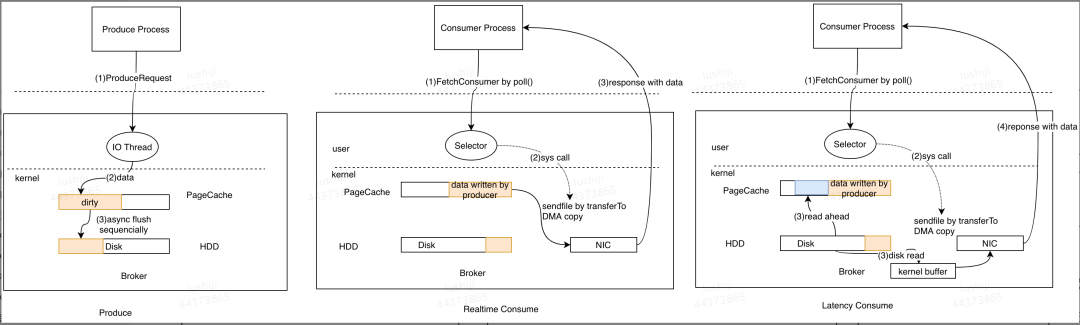
我们都知道 Kafka 是基于磁盘进行存储的,但 Kafka 官方又称其具有高性能、高吞吐、低延时的特点,其吞吐量动辄几十上百万。
在座的靓仔和靓女们是不是有点困惑了,一般认为在磁盘上读写数据是会降低性能的,因为寻址会比较消耗时间。那 Kafka 又是怎么做到其吞吐量动辄几十上百万的呢?
《Kafka 高性能架构设计 7 大秘诀》系列,已完结,今天带大家总结下 kafka 为什么这么快?提炼精华,开干。
01Kafka Reactor I/O 网络模型
Kafka Reactor I/O 网络模型是一种非阻塞 I/O 模型,利用事件驱动机制来处理网络请求。更多细节详见《Kafka 高性能 7 大秘诀之 Reactor 网络 I/O模型》
该模型通过 Reactor 模式实现,即一个或多个 I/O 多路复用器(如 Java 的 Selector)监听多个通道的事件,当某个通道准备好进行 I/O 操作时,触发相应的事件处理器进行处理。
这种模型在高并发场景下具有很高的效率,能够同时处理大量的网络连接请求,而不需要为每个连接创建一个线程,从而节省系统资源。
Reactor 线程模型如图 2 所示。
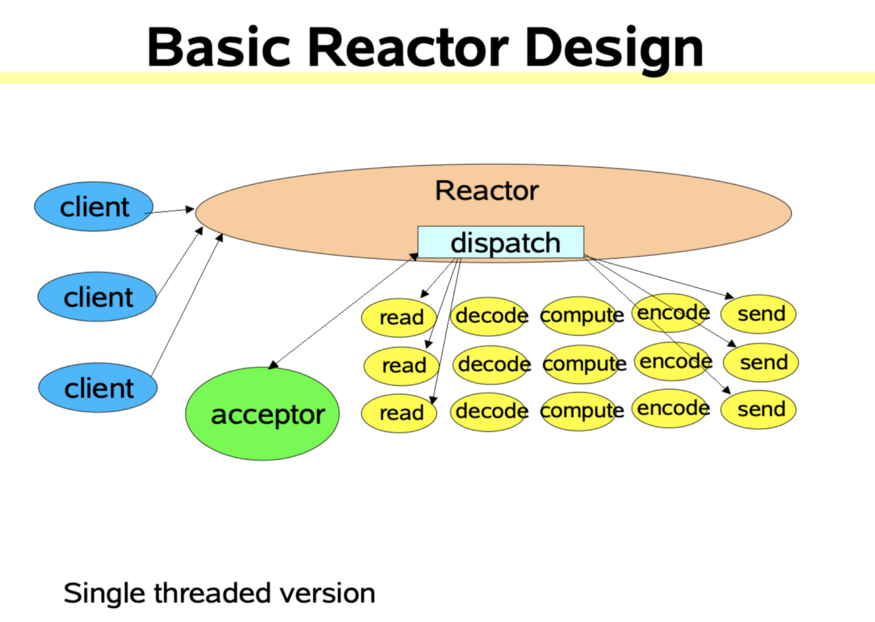
图 2
Reacotr 模型主要分为三个角色。
Reactor:把 I/O 事件根据类型分配给分配给对应的 Handler 处理。
Acceptor:处理客户端连接事件。
Handler:处理读写等任务。
Kafka 基于 Reactor 模型架构如图 3 所示。
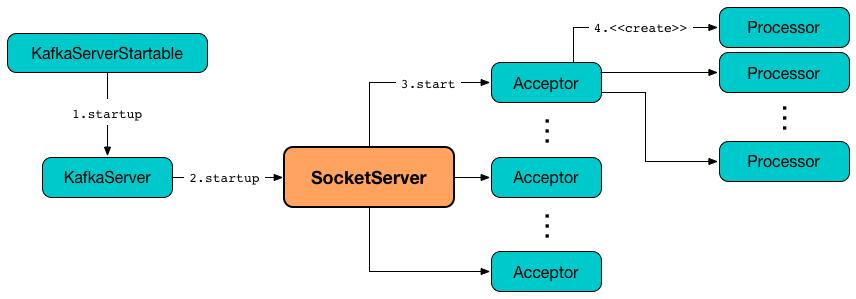
图 3
Kafka 的网络通信模型基于 NIO(New Input/Output)库,通过 Reactor 模式实现,具体包括以下几个关键组件:
SocketServer:管理所有的网络连接,包括初始化 Acceptor 和 Processor 线程。
Acceptor:监听客户端的连接请求,并将其分配给 Processor 线程。Acceptor 使用 Java NIO 的
Selector进行 I/O 多路复用,并注册 OP_ACCEPT 事件来监听新的连接请求。每当有新的连接到达时,Acceptor 会接受连接并创建一个SocketChannel,然后将其分配给一个 Processor 线程进行处理。Processor:处理具体的 I/O 操作,包括读取客户端请求和写入响应数据。Processor 同样使用
Selector进行 I/O 多路复用,注册 OP_READ 和 OP_WRITE 事件来处理读写操作。每个 Processor 线程都有一个独立的Selector,用于管理多个SocketChannel。RequestChannel:充当 Processor 和请求处理线程之间的缓冲区,存储请求和响应数据。Processor 将读取的请求放入 RequestChannel 的请求队列,而请求处理线程则从该队列中取出请求进行处理。
KafkaRequestHandler:请求处理线程,从 RequestChannel 中读取请求,调用 KafkaApis 进行业务逻辑处理,并将响应放回 RequestChannel 的响应队列。KafkaRequestHandler 线程池中的线程数量由配置参数
num.io.threads决定。
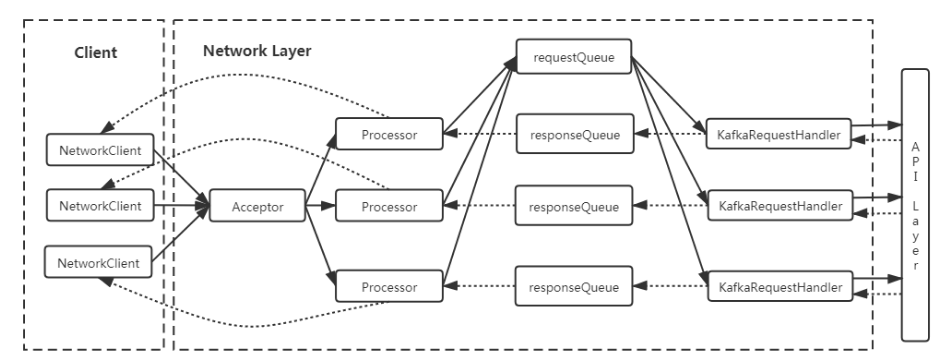
图 4
Chaya:该模型和如何提高 kafka 的性能和效率?
高并发处理能力:通过 I/O 多路复用机制,Kafka 能够同时处理大量的网络连接请求,而不需要为每个连接创建一个线程,从而节省了系统资源。
低延迟:非阻塞 I/O 操作避免了线程的阻塞等待,使得 I/O 操作能够更快地完成,从而降低了系统的响应延迟。
资源节省:通过减少线程的数量和上下文切换,Kafka 在处理高并发请求时能够更有效地利用 CPU 和内存资源。
扩展性强:Reactor 模式的分层设计使得 Kafka 的网络模块具有很好的扩展性,可以根据需要增加更多的 I/O 线程或调整事件处理器的逻辑。
02零拷贝技术的运用
零拷贝技术是一种计算机操作系统技术,用于在内存和存储设备之间进行数据传输时,避免 CPU 的参与,从而减少 CPU 的负担并提高数据传输效率。详见《Kakfa 高性能架构设计之零拷贝技术的运用》
Kafka 使用零拷贝技术来优化数据传输,特别是在生产者将数据写入 Kafka 和消费者从 Kafka 读取数据的过程中。在 Kafka 中,零拷贝主要通过以下几种方式实现:
sendfile() 系统调用:在发送数据时,Kafka 使用操作系统的 sendfile() 系统调用直接将文件从磁盘发送到网络套接字,而无需将数据复制到应用程序的用户空间。这减少了数据复制次数,提高了传输效率。
文件内存映射(Memory-Mapped Files):Kafka 使用文件内存映射技术(mmap),将磁盘上的日志文件映射到内存中,使得读写操作可以在内存中直接进行,无需进行额外的数据复制。
比如 Broker 读取磁盘数据并把数据发送给 Consumer 的过程,传统 I/O 经历以下步骤。
读取数据:通过
read系统调用将磁盘数据通过 DMA copy 到内核空间缓冲区(Read buffer)。拷贝数据:将数据从内核空间缓冲区(Read buffer) 通过 CPU copy 到用户空间缓冲区(Application buffer)。
写入数据:通过
write()系统调用将数据从用户空间缓冲区(Application) CPU copy 到内核空间的网络缓冲区(Socket buffer)。发送数据:将内核空间的网络缓冲区(Socket buffer)DMA copy 到网卡目标端口,通过网卡将数据发送到目标主机。
这一过程经过的四次 copy 如图 5 所示。
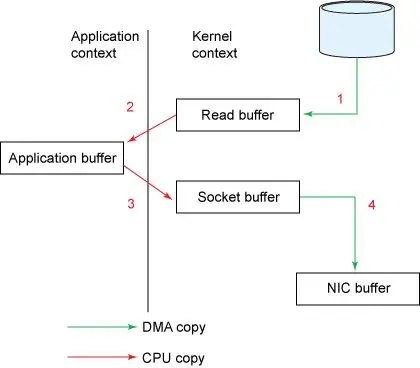
图 5
Chaya:零拷贝技术如何提高 Kakfa 的性能?
零拷贝技术通过减少 CPU 负担和内存带宽消耗,提高了 Kakfa 性能。
降低 CPU 使用率:由于数据不需要在内核空间和用户空间之间多次复制,CPU 的参与减少,从而降低了 CPU 使用率,腾出更多的 CPU 资源用于其他任务。
提高数据传输速度:直接从磁盘到网络的传输路径减少了中间步骤,使得数据传输更加高效,延迟更低。
减少内存带宽消耗:通过减少数据在内存中的复制次数,降低了内存带宽的消耗,使得系统能够处理更多的并发请求。
03Partition 并发和分区负载均衡
在说 Topic patition 分区并发之前,我们先了解下 kafka 架构设计。
03.1Kafka 架构
一个典型的 Kafka 架构包含以下几个重要组件,如图 6 所示。
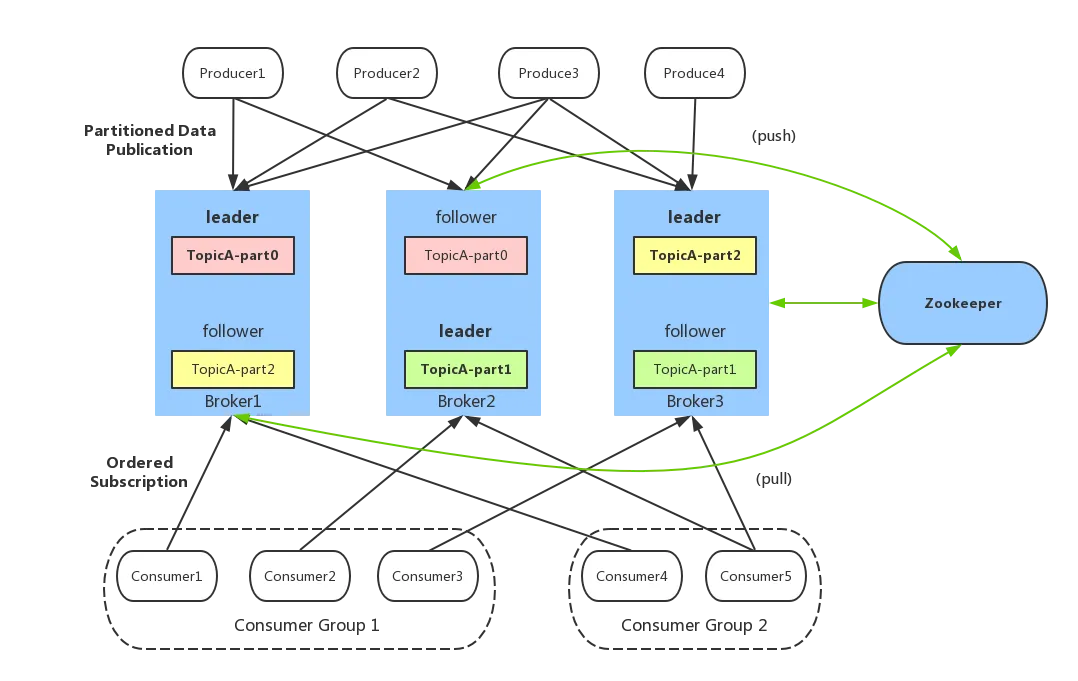
图 6
Producer(生产者):发送消息的一方,负责发布消息到 Kafka 主题(Topic)。
Consumer(消费者):接受消息的一方,订阅主题并处理消息。Kafka 有ConsumerGroup 的概念,每个Consumer 只能消费所分配到的 Partition 的消息,每一个Partition只能被一个ConsumerGroup 中的一个Consumer 所消费,所以同一个ConsumerGroup 中Consumer 的数量如果超过了Partiton 的数量,将会出现有些Consumer 分配不到 partition 消费。
Broker(代理):服务代理节点,Kafka 集群中的一台服务器就是一个 broker,可以水平无限扩展,同一个 Topic 的消息可以分布在多个 broker 中。
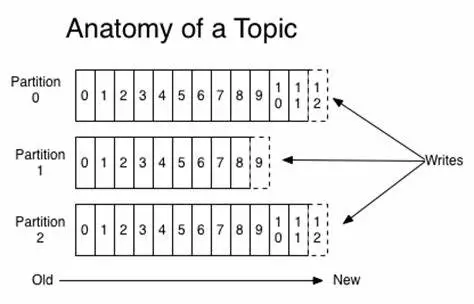
Topic(主题)与 Partition(分区) :Kafka 中的消息以 Topic 为单位进行划分,生产者将消息发送到特定的 Topic,而消费者负责订阅 Topic 的消息并进行消费。图中 TopicA 有三个 Partiton(TopicA-par0、TopicA-par1、TopicA-par2)
为了提升整个集群的吞吐量,Topic 在物理上还可以细分多个Partition,一个 Partition 在磁盘上对应一个文件夹。
Replica(副本):副本,是 Kafka 保证数据高可用的方式,Kafka 同一 Partition 的数据可以在多 Broker 上存在多个副本,通常只有 leader 副本对外提供读写服务,当 leader副本所在 broker 崩溃或发生网络一场,Kafka 会在 Controller 的管理下会重新选择新的 Leader 副本对外提供读写服务。
ZooKeeper:管理 Kafka 集群的元数据和分布式协调。
03.2Topic 主题
Topic 是 Kafka 中数据的逻辑分类单元,可以理解成一个队列。Broker 是所有队列部署的机器,Producer 将消息发送到特定的 Topic,而 Consumer 则从特定的 Topic 中消费消息。
03.3Partition
为了提高并行处理能力和扩展性,Kafka 将一个 Topic 分为多个 Partition。每个 Partition 是一个有序的消息队列,消息在 Partition 内部是有序的,但在不同的 Partition 之间没有顺序保证。
Producer 可以并行地将消息发送到不同的 Partition,Consumer 也可以并行地消费不同的 Partition,从而提升整体处理能力。
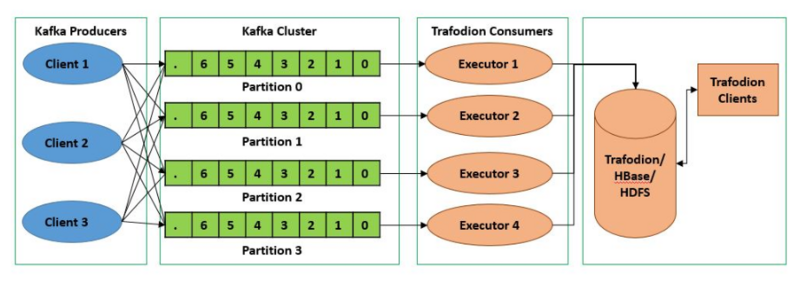
因此,可以说,每增加一个 Paritition 就增加了一个消费并发。Partition的引入不仅提高了系统的可扩展性,还使得数据处理更加灵活。
03.4Partition 分区策略
码楼:“生产者将消息发送到哪个分区是如何实现的?不合理的分配会导致消息集中在某些 Broker 上,岂不是完犊子。”
主要有以下几种分区策略:
轮询策略:也称Round-robin策略,即顺序分配。
随机策略:也称Randomness策略。所谓随机就是我们随意地将消息放置到任意一个分区上。
按消息键保序策略。
基于地理位置分区策略。
轮询策略
比如一个 Topic 下有 3个分区,那么第一条消息被发送到分区0,第二条被发送到分区1,第三条被发送到分区2,以此类推。
当生产第4条消息时又会重新开始,即将其分配到分区0,如图 5 所示。
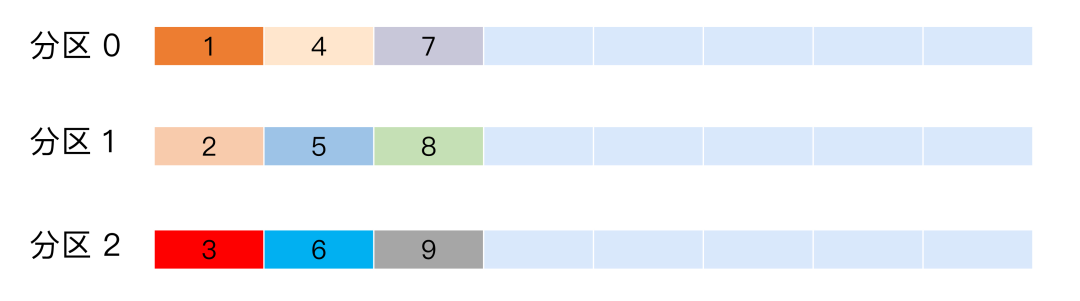
轮询策略有非常优秀的负载均衡表现,它总是能保证消息最大限度地被平均分配到所有分区上,故默认情况下它是最合理的分区策略,也是我们最常用的分区策略之一。
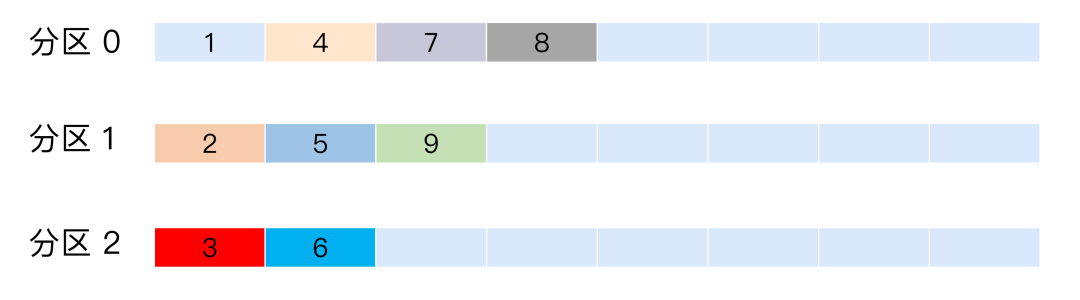
随机策略
所谓随机就是我们随意地将消息放置到任意一个分区上。如图所示,9 条消息随机分配到不同分区。
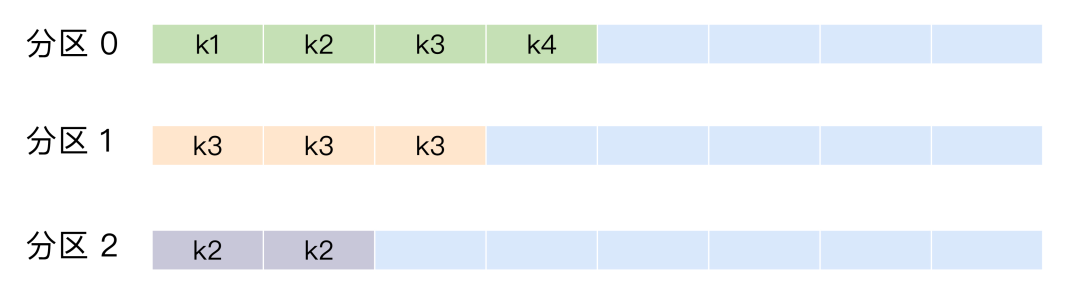
按消息键分配策略
一旦消息被定义了 Key,那么你就可以保证同一个 Key 的所有消息都进入到相同的分区里面,比如订单 ID,那么绑定同一个 订单 ID 的消息都会发布到同一个分区,由于每个分区下的消息处理都是有顺序的,故这个策略被称为按消息键保序策略,如图所示。
基于地理位置
这种策略一般只针对那些大规模的 Kafka 集群,特别是跨城市、跨国家甚至是跨大洲的集群。
我们就可以根据 Broker 所在的 IP 地址实现定制化的分区策略。比如下面这段代码:
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
return partitions.stream().filter(p -> isSouth(p.leader().host())).map(PartitionInfo::partition).findAny().get();我们可以从所有分区中找出那些Leader副本在南方的所有分区,然后随机挑选一个进行消息发送。
04Segment 日志文件和稀疏索引
前面已经介绍过,Kafka 的 Topic 可以分为多个 Partition,每个 Partition 有多个副本,你可以理解为副本才是存储消息的物理存在。其实每个副本都是以日志(Log)的形式存储。
码楼:“日志文件过大怎么办?”
为了解决单一日志文件过大的问题,kafka采用了分段(Segment)的形式进行存储。
所谓 Segment,就是当一个日志文件大小到达一定条件之后,就新建一个新的 Segment,然后在新的Segment写入数据。Topic、Partition、和日志的关系如图 8 所示。
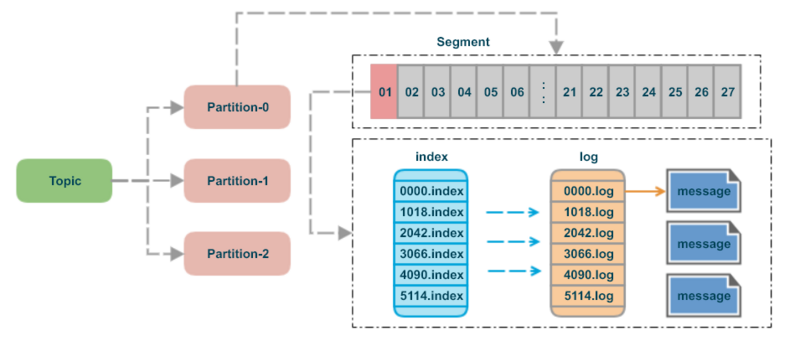
图 8
一个 segment 对应磁盘上多个文件。
.index: 消息的 offset 索引文件。.timeindex: 消息的时间索引文件(0.8版本加入的)。.log: 存储实际的消息数据。.snapshot: 记录了 producer 的事务信息。.swap: 用于 Segment 恢复。.txnindex文件,记录了中断的事务信息。
.log 文件存储实际的 message,kafka为每一个日志文件添加了2 个索引文件 .index以及 .timeindex。
segment 文件命名规则:partition 第一个 segment 从 0 开始,后续每个 segment 文件名为上一个 segment 文件最后一条消息的 offset 值。数值最大为 64 位 long 大小,19 位数字字符长度,没有数字用 0 填充。
码楼:“为什么要有
.index文件?”
为了提高查找消息的性能。kafka 为消息数据建了两种稀疏索引,一种是方便 offset 查找的 .index 稀疏索引,还有一种是方便时间查找的 .timeindex 稀疏索引。
04.1稀疏索引
Chaya:“为什么不创建一个哈希索引,从 offset 到物理消息日志文件偏移量的映射关系?”
万万不可,Kafka 作为海量数据处理的中间件,每秒高达几百万的消息写入,这个哈希索引会把把内存撑爆炸。
稀疏索引不会为每个记录都保存索引,而是写入一定的记录之后才会增加一个索引值,具体这个间隔有多大则通过 log.index.interval.bytes 参数进行控制,默认大小为 4 KB,意味着 Kafka 至少写入 4KB 消息数据之后,才会在索引文件中增加一个索引项。
哈希稀疏索引把消息划分为多个 block ,只索引每个 block 第一条消息的 offset 即可 。

Offset 偏移量:表示第几个消息。
position:消息在磁盘的物理位置。
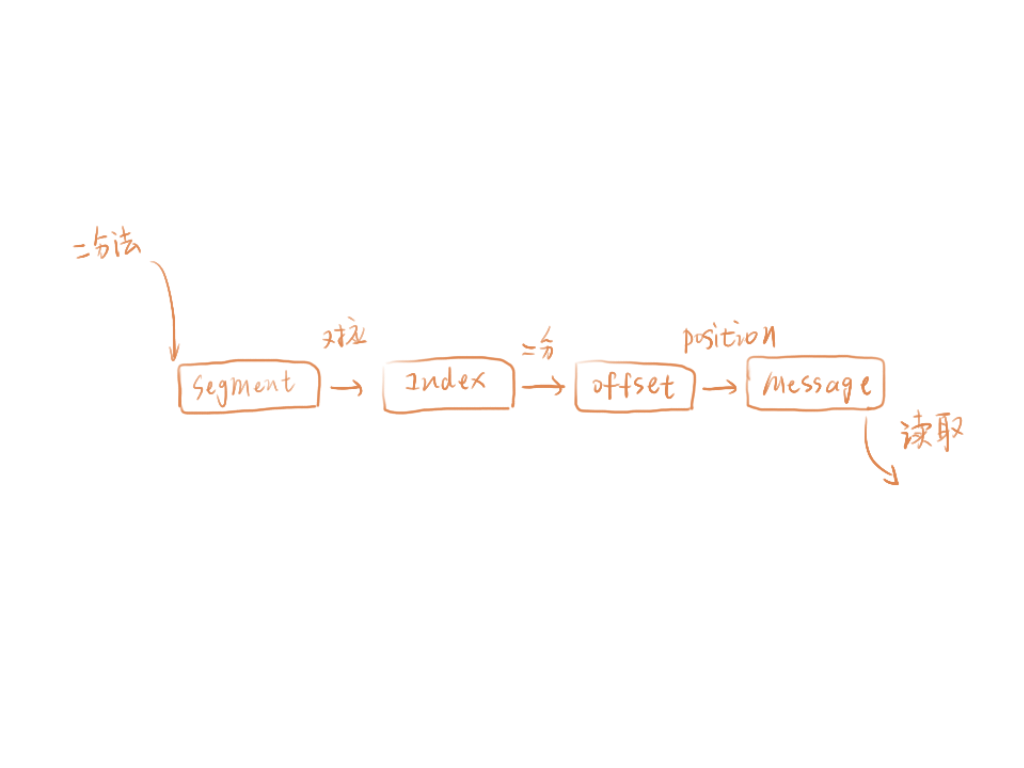
Chaya:如果消费者要查找 Offset 为 4 的消息,查找过程是怎样的?
首先用二分法定位消息在哪个 Segment ,Segment 文件命名是 Partition 第一个 segment 从 0 开始,后续每个 segment 文件名为上一个 segment 文件最后一条消息的 offset 值。
打开这个 Segment 对应的 index 索引文件,用二分法查找 offset 不大于 4 的索引条目,对应上图第二条条目,也就是 offset = 3 的那个索引。通过索引我们可以知道 offset 为 4 的消息所在的日志文件磁盘物理位置为 495。
打开日志文件,从 Position 为 495 位置开始开始顺序扫描文件,将扫描过程中每条消息的 offset 与 4 比较,直到找到 offset 为 4 的那条Message。
.timeindex 文件同理,只不过它的查找结果是 offset,之后还要在走一遍 .index 索引查找流程。
由于 kafka 设计为顺序读写磁盘,因此遍历区间的数据并对速度有太大的影响,而选择稀疏索引还能节约大量的磁盘空间。
04.2mmap
有了稀疏索引,当给定一个 offset 时,Kafka 采用的是二分查找来扫描索引定位不大于 offset 的物理位移 position,再到日志文件找到目标消息。
利用稀疏索引,已经基本解决了高效查询的问题,但是这个过程中仍然有进一步的优化空间,那便是通过 mmap(memory mapped files) 读写上面提到的稀疏索引文件,进一步提高查询消息的速度。
就是基于 JDK nio 包下的 MappedByteBuffer 的 map 函数,将磁盘文件映射到内存中。
进程通过调用mmap系统函数,将文件或物理内存的一部分映射到其虚拟地址空间。这个过程中,操作系统会为映射的内存区域分配一个虚拟地址,并将这个地址与文件或物理内存的实际内容关联起来。
一旦内存映射完成,进程就可以通过指针直接访问映射的内存区域。这种访问方式就像访问普通内存一样简单和高效。
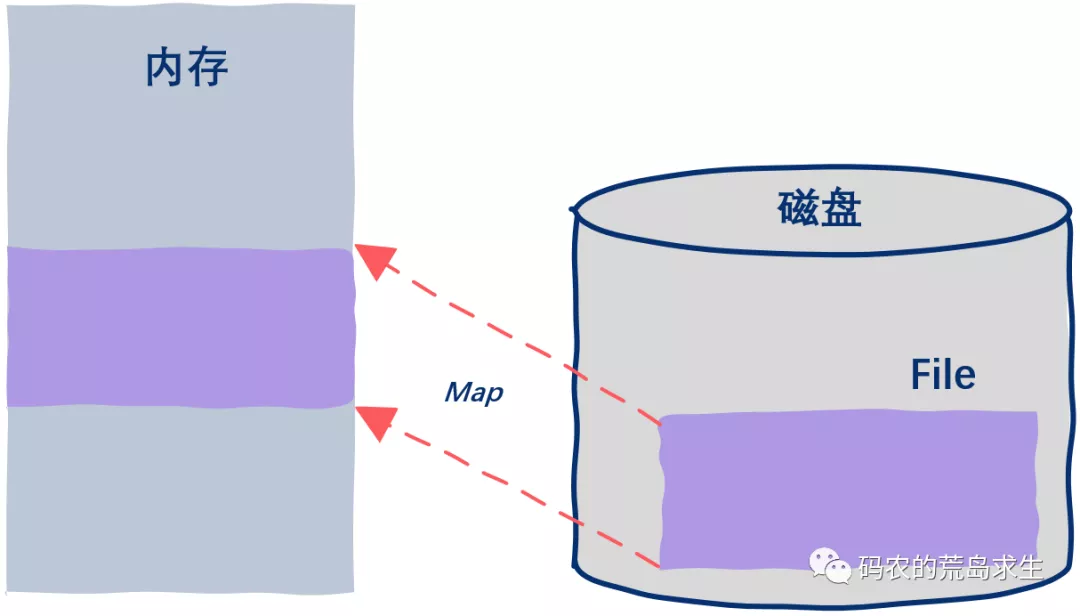
图引自《码农的荒岛求生》
05顺序读写磁盘
码楼:“不管如何,Kafka 读写消息都要读写磁盘,如何变快呢?”
磁盘就一定很慢么?人们普遍错误地认为硬盘很慢。然而,存储介质的性能,很大程度上依赖于数据被访问的模式。
同样在一块普通的7200 RPM SATA硬盘上,随机I/O(random I/O)与顺序I/O相比,随机I/O的性能要比顺序I/O慢3到4个数量级。
合理的方式可以让磁盘写操作更加高效,减少了寻道时间和旋转延迟。
码楼,你还留着课本吗?来,翻到讲磁盘的章节,让我们回顾一下磁盘的运行原理。
码楼:“鬼还留着哦,课程还没上到一半书就没了。要不是考试俺眼神好,就挂科了。”
磁盘的运行原理如图所示。
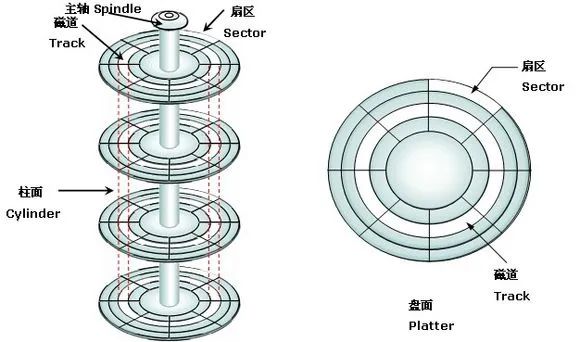
硬盘在逻辑上被划分为磁道、柱面以及扇区。硬盘的每个盘片的每个面都有一个读写磁头。
完成一次磁盘 I/O ,需要经过寻道、旋转和数据传输三个步骤。
寻道:首先必须找到柱面,即磁头需要移动到相应磁道,这个过程叫做寻道,所耗费时间叫做寻道时间。寻道时间越短,I/O 操作越快,目前磁盘的平均寻道时间一般在 3-15ms。
旋转:磁盘旋转将目标扇区旋转到磁头下。这个过程耗费的时间叫做旋转时间。旋转延迟取决于磁盘转速,通常用磁盘旋转一周所需时间的 1/2 表示。比如:7200rpm 的磁盘平均旋转延迟大约为 60*1000/7200/2 = 4.17ms,而转速为 15000rpm 的磁盘其平均旋转延迟为 2ms。
数据传输:数据在磁盘与内存之间的实际传输。
因此,如果在写磁盘的时候省去寻道、旋转可以极大地提高磁盘读写的性能。
Kafka 采用顺序写文件的方式来提高磁盘写入性能。顺序写文件,顺序 I/O 的时候,磁头几乎不用换道,或者换道的时间很短。减少了磁盘寻道和旋转的次数。磁头再也不用在磁道上乱舞了,而是一路向前飞速前行。
Kafka 中每个Partition 是一个有序的,不可变的消息序列,新的消息可以不断追加到 Partition 的末尾,在 Kafka 中 Partition 只是一个逻辑概念,每个Partition 划分为多个 Segment,每个 Segment 对应一个物理文件,Kafka 对 Segment 文件追加写,这就是顺序写文件。
每条消息在发送前会根据负载均衡策略计算出要发往的目标 Partition 中,broker 收到消息之后把该条消息按照追加的方式顺序写入 Partition 的日志文件中。
如下图所示,可以看到磁盘顺序写的性能远高于磁盘随机写,甚至比内存随机写还快。

06PageCache
Chaya:“码哥,使用稀疏索引和 mmap 内存映射技术提高读消息的性能;Topic Partition 加磁盘顺序写持久化消息的设计已经很快了,但是与内存顺序写还是慢了,还有优化空间么?”
小姑娘,你的想法很好,作为快到令人发指的 Kafka,确实想到了一个方式来提高读写写磁盘文件的性能。这就是接下来的主角 Page Cache 。
简而言之:利用操作系统的缓存技术,在读写磁盘日志文件时,操作的是内存,而不是文件,由操作系统决定什么在某个时间将 Page Cache 的数据刷写到磁盘中。
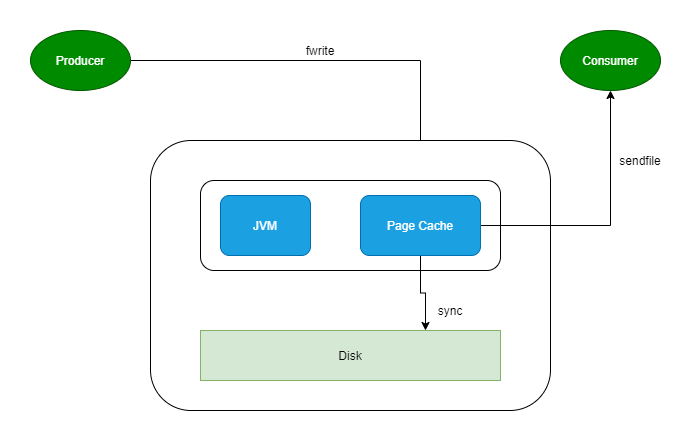
Producer 发送消息到 Broker 时,Broker 会使用
pwrite()系统调用写入数据,此时数据都会先写入page cache。Consumer 消费消息时,Broker 使用
sendfile()系统调用函数,通零拷贝技术地将 Page Cache 中的数据传输到 Broker 的 Socket buffer,再通过网络传输到 Consumer。leader 与 follower 之间的同步,与上面 consumer 消费数据的过程是同理的。
Kafka重度依赖底层操作系统提供的PageCache功能。当上层有写操作时,操作系统只是将数据写入PageCache,同时标记Page属性为Dirty。
当读操作发生时,先从PageCache中查找,如果发生缺页才进行磁盘调度,最终返回需要的数据。
于是我们得到一个重要结论:如果Kafka producer的生产速率与consumer的消费速率相差不大,那么就能几乎只靠对broker page cache的读写完成整个生产-消费过程,磁盘访问非常少。
实际上PageCache是把尽可能多的空闲内存都当做了磁盘缓存来使用。
07数据压缩和批量处理
数据压缩在 Kafka 中有助于减少磁盘空间的使用和网络带宽的消耗,从而提升整体性能。
通过减少消息的大小,压缩可以显著降低生产者和消费者之间的数据传输时间。
Chaya:Kafka 支持的压缩算法有哪些?
在Kafka 2.1.0版本之前,Kafka支持3种压缩算法:GZIP、Snappy和LZ4。从2.1.0开始,Kafka正式支持Zstandard算法(简写为zstd)。
Chaya:这么多压缩算法,我如何选择?
一个压缩算法的优劣,有两个重要的指标:压缩比,文件压缩前的大小与压缩后的大小之比,比如源文件占用 1000 M 内存,经过压缩后变成了 200 M,压缩比 = 1000 /200 = 5,压缩比越高越高;另一个指标是压缩/解压缩吞吐量,比如每秒能压缩或者解压缩多少 M 数据,吞吐量越高越好。
07.1生产者压缩
Kafka 的数据压缩主要在生产者端进行。具体步骤如下:
生产者配置压缩方式:在 KafkaProducer 配置中设置
compression.type参数,可以选择gzip、snappy、lz4或zstd。消息压缩:生产者将消息批量收集到一个
batch中,然后对整个batch进行压缩。这种批量压缩方式可以获得更高的压缩率。压缩消息存储:压缩后的
batch以压缩格式存储在 Kafka 的主题(Topic)分区中。消费者解压缩:消费者从 Kafka 主题中获取消息时,首先对接收到的
batch进行解压缩,然后处理其中的每一条消息。
07.2解压缩
有压缩,那必有解压缩。通常情况下,Producer 发送压缩后的消息到 Broker ,原样保存起来。
Consumer 消费这些消息的时候,Broker 原样发给 Consumer,由 Consumer 执行解压缩还原出原本的信息。
Chaya:Consumer 咋知道用什么压缩算法解压缩?
Kafka会将启用了哪种压缩算法封装进消息集合中,这样当Consumer读取到消息集合时,它自然就知道了这些消息使用的是哪种压缩算法。
总之一句话:Producer端压缩、Broker端保持、Consumer端解压缩。
07.3批量数据处理
Kafka Producer 向 Broker 发送消息不是一条消息一条消息的发送,将多条消息打包成一个批次发送。
批量数据处理可以显著提高 Kafka 的吞吐量并减少网络开销。
Kafka Producer 的执行流程如下图所示:
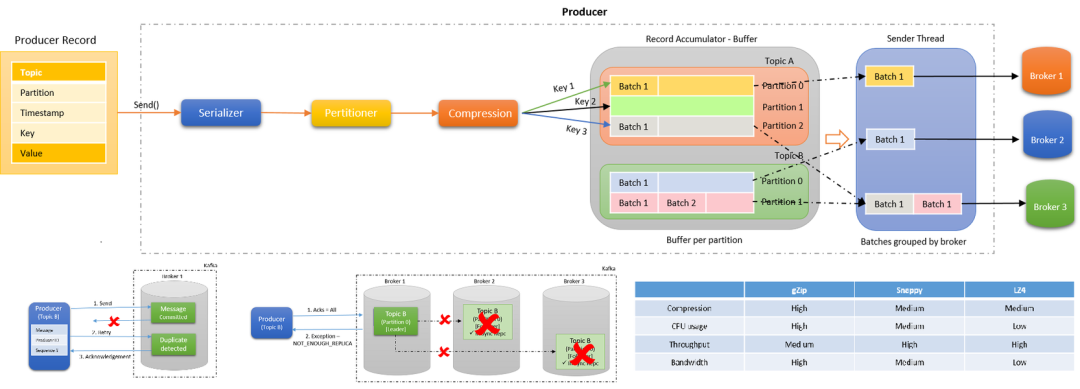
发送消息依次经过以下处理器:
Serialize:键和值都根据传递的序列化器进行序列化。优秀的序列化方式可以提高网络传输的效率。
Partition:决定将消息写入主题的哪个分区,默认情况下遵循 murmur2 算法。自定义分区程序也可以传递给生产者,以控制应将消息写入哪个分区。
Compression:默认情况下,在 Kafka 生产者中不启用压缩。Compression 不仅可以更快地从生产者传输到代理,还可以在复制过程中进行更快的传输。压缩有助于提高吞吐量,降低延迟并提高磁盘利用率。
Record Accumulator:
Accumulate顾名思义,就是一个消息累计器。其内部为每个 Partition 维护一个Deque双端队列,队列保存将要发送的 Batch批次数据,Accumulate将数据累计到一定数量,或者在一定过期时间内,便将数据以批次的方式发送出去。记录被累积在主题每个分区的缓冲区中。根据生产者批次大小属性将记录分组。主题中的每个分区都有一个单独的累加器 / 缓冲区。Group Send:记录累积器中分区的批次按将它们发送到的代理分组。批处理中的记录基于
batch.size和linger.ms属性发送到代理。记录由生产者根据两个条件发送。当达到定义的批次大小或达到定义的延迟时间时。Send Thread:发送线程,从 Accumulator 的队列取出待发送的 Batch 批次消息发送到 Broker。
Broker 端处理:Kafka Broker 接收到
batch后,将其存储在对应的主题分区中。消费者端的批量消费:消费者可以配置一次拉取多条消息的数量,通过
fetch.min.bytes和fetch.max.wait.ms参数控制批量大小和等待时间。
08无锁轻量级 offset
Offset 是 Kafka 中的一个重要概念,用于标识消息在分区中的位置。
每个分区中的消息都有一个唯一的 offset,消费者通过维护自己的 offset 来确保准确消费消息。offset 的高效管理对于 Kafka 的性能至关重要。
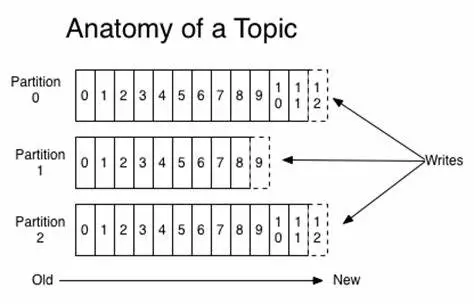
offset 是从 0 开始的,每当有新的消息写入分区时,offset 就会加 1。offset 是不可变的,即使消息被删除或过期,offset 也不会改变或重用。
Consumer需要向Kafka汇报自己的位移数据,这个汇报过程被称为提交位移(Committing Offsets)。因为Consumer能够同时消费多个partition的数据,所以位移的提交实际上是在partition粒度上进行的,即Consumer需要为分配给它的每个partition提交各自的位移数据。
提交位移主要是为了表征Consumer的消费进度,这样当Consumer发生故障重启之后,就能够从Kafka中读取之前提交的位移值,然后从相应的位移处继续消费。
在传统的消息队列系统中,offset 通常需要通过锁机制来保证一致性,但这会带来性能瓶颈。Kafka 的设计哲学是尽量减少锁的使用,以提升并发处理能力和整体性能。
08.1无锁设计思想
Kafka 在 offset 设计中采用了一系列无锁的技术,使其能够在高并发的环境中保持高效。
顺序写入:Kafka 使用顺序写入的方式将消息追加到日志文件的末尾,避免了文件位置的频繁变动,从而减少了锁的使用。
MMAP 内存映射文件:Kafka 使用内存映射文件(Memory Mapped File)来访问日志数据和索引文件。这种方式使得文件数据可以直接映射到进程的虚拟地址空间中,从而减少了系统调用的开销,提高了数据访问的效率。
零拷贝:Kafka 使用零拷贝(Zero Copy)技术,将数据从磁盘直接传输到网络,绕过了用户态的复制过程,大大提高了数据传输的效率。
批量处理:Kafka 支持批量处理消息,在一个批次中同时处理多个消息,减少了网络和 I/O 的开销。
08.2消费者 Offset 管理流程
graph TD;A[启动消费者] --> B[从分区读取消息];B --> C[处理消息];C --> D{是否成功处理?};D --> |是| E[更新 Offset];D --> |否| F[记录失败, 重新处理];E --> G[提交 Offset];G --> H[继续处理下一个消息];F --> B;H --> B;启动消费者:消费者启动并订阅 Kafka 主题的某个分区。
从分区读取消息:消费者从指定分区中读取消息。
处理消息:消费者处理读取到的消息。
是否成功处理:判断消息是否成功处理。
如果成功处理,更新 Offset。
如果处理失败,记录失败原因并准备重新处理。
更新 Offset:成功处理消息后,更新 Offset 以记录已处理消息的位置。
提交 Offset:将更新后的 Offset 提交到 Kafka,以确保消息处理进度的持久化。
继续处理下一个消息:提交 Offset 后,继续读取并处理下一个消息。
Kafka 通过无锁轻量级 offset 的设计,实现了高性能、高吞吐和低延时的目标。
09总结
Kafka 通过无锁轻量级 offset 的设计,实现了高性能、高吞吐和低延时的目标。
其 Reactor I/O 网络模型、磁盘顺序写入、内存映射文件、零拷贝、数据压缩和批量处理等技术,为 Kafka 提供了强大的数据处理能力和高效的消息队列服务。
Reactor I/O 网络模型:通过 I/O 多路复用机制,Kafka 能够同时处理大量的网络连接请求,而不需要为每个连接创建一个线程,从而节省了系统资源。
顺序写入:Kafka 使用顺序写入的方式将消息追加到日志文件的末尾,避免了文件位置的频繁变动,从而减少了锁的使用。
MMAP 内存映射文件:Kafka 使用内存映射文件(Memory Mapped File)来访问日志数据和索引文件。这种方式使得文件数据可以直接映射到进程的虚拟地址空间中,从而减少了系统调用的开销,提高了数据访问的效率。
零拷贝:Kafka 使用零拷贝(Zero Copy)技术,将数据从磁盘直接传输到网络,绕过了用户态的复制过程,大大提高了数据传输的效率。
数据压缩和批量处理:数据压缩在 Kafka 中有助于减少磁盘空间的使用和网络带宽的消耗,从而提升整体性能。;Kafka 支持批量处理消息,在一个批次中同时处理多个消息,减少了网络和 I/O 的开销。
博主简介
码哥,9 年互联网公司后端工作经验,后端架构师,InfoQ 签约作者、51CTO Top 红人,阿里云开发者社区专家博主,擅长 Redis、Spring、Kafka、MySQL 技术,在云原生微服务领域有着深入研究。

可加我微信:MageByte1024,备注「kafka」进入专属读者群,共同成长。
往期推荐
Kafka 高并发设计之数据压缩与批量消息处理
Kafka 高性能之 Page Cache 的应用哲学
Kafka 高性能 7 大秘诀之 Segment 消息存储机制的奥妙
Kafka 是什么?它的架构和原理是怎样的?
Kafka 高性能之 Partition 并发和负载均衡分配策略
Kafka 高性能 7 大秘诀之 Reactor 网络 I/O模型
Kafka 高性能 7 大秘诀之零拷贝技术
相关文章:
Kafka 为什么这么快的七大秘诀,涨知识了
我们都知道 Kafka 是基于磁盘进行存储的,但 Kafka 官方又称其具有高性能、高吞吐、低延时的特点,其吞吐量动辄几十上百万。 在座的靓仔和靓女们是不是有点困惑了,一般认为在磁盘上读写数据是会降低性能的,因为寻址会比较消耗时间。…...

一文解决3D车道线检测:最新单目3D车道线检测综述
前言 场景理解是自动驾驶中极具挑战的任务,尤其是车道检测。车道是道路分割的关键,对车辆安全高效行驶至关重要。车道检测技术能自动识别道路标记,对自动驾驶车辆至关重要,缺乏这项技术可能导致交通问题和事故。车道检测面临多种…...

稳中向好,今年新招6000人
团子校招 近日,美团宣布开启面向 2025 届的校园招聘,招聘规模达 6000 人。 虽然相比京东(宣布招聘 16000 人)稍有逊色,但 6000 这个校招规模可一点不少。 要知道,京东是重自营的传统电商,16000 …...

使用kettle开源工具进行跨库数据同步
数据库同步可以用: 1、Navicat 2、Kettle 3、自己写代码 调用码神工具跨库数据同步 -连接 4、其它 实现 这里使用Kettle来同步,主要是开源的,通过配置就可以实现了 Kettle的图形化界面(Spoon)安装参考方法 ht…...

Golang | Leetcode Golang题解之第307题区域和检索-数组可修改
题目: 题解: type NumArray struct {nums, tree []int }func Constructor(nums []int) NumArray {tree : make([]int, len(nums)1)na : NumArray{nums, tree}for i, num : range nums {na.add(i1, num)}return na }func (na *NumArray) add(index, val …...

Golang | Leetcode Golang题解之第301题删除无效的括号
题目: 题解: func checkValid(str string, lmask, rmask int, left, right []int) bool {cnt : 0pos1, pos2 : 0, 0for i : range str {if pos1 < len(left) && i left[pos1] {if lmask>>pos1&1 0 {cnt}pos1} else if pos2 <…...

【Story】《程序员面试的“八股文”辩论:技术基础与实际能力的博弈》
目录 程序员面试中的“八股文”:助力还是阻力?1. “八股文”的背景与定义1.1 “八股文”的起源1.2 “八股文”的常见类型 2. “八股文”的作用分析2.1 理论基础的评价2.1.1 助力2.1.2 阻力 3. 实际工作能力的考察3.1 助力3.2 阻力 4. 面试中的背题能力4.…...

初步了解泛型
目录 泛型的引入 泛型 泛型 泛型类 泛型的上界 泛型的引入 之前学习的数组里面是存放着整型或者自字符串中一种的数组,如果想要在一个数组里面放多种类型数据,我们该怎么去做呢?Object类或许是一个好的解决方法,因为Object类…...

【C#】.net core 6.0 webapi 使用core版本的NPOI的Excel读取数据以及保存数据
欢迎来到《小5讲堂》 这是《C#》系列文章,每篇文章将以博主理解的角度展开讲解。 温馨提示:博主能力有限,理解水平有限,若有不对之处望指正! 目录 背景读取并保存NPOI信息NPOI 插件介绍基本功能示例代码写入 Excel 文件…...

C++推荐的oj网站
洛谷 信息学奥赛一本通 C语言网 codeforces 杭电oj...

springmvc处理http请求的底层逻辑
http-nio-8088-Poller线程中在org.apache.tomcat.util.net.NioEndpoint.Poller#run这个函数里循环检测selector,若发现有SocketEvent.OPEN_READ事件则会将SelectionKey.attachment中的内容作为入参包装成runable,然后由org.apache.tomcat.util.threads.T…...

干货满满,从零到一:编程小白如何在大学成为编程大神?
✨✨ 欢迎大家来访Srlua的博文(づ ̄3 ̄)づ╭❤~✨✨ 🌟🌟 欢迎各位亲爱的读者,感谢你们抽出宝贵的时间来阅读我的文章。 我是Srlua小谢,在这里我会分享我的知识和经验。&am…...

前端-如何通过docker打包Vue服务成镜像并在本地运行(本地可以通过http://localhost:8080/访问前端服务)
1、下载安装docker,最好在vs code里安装docker的插件。 下载链接:https://www.docker.com/products/docker-desktop 🎉 Docker 简介和安装 - Docker 快速入门 - 易文档 (easydoc.net) 2、准备配置文件-dockerfile文件和nginx.conf文件 do…...

零基础学习【Mybatis】这一篇就够了
Mybatis 查询resultType使用resultMap使用单条件查询多条件查询模糊查询返回主键 动态SQLifchoosesetforeachsql片段 配置文件注解增删改查结果映射 查询 resultType使用 当数据库返回的结果集中的字段和实体类中的属性名一一对应时, resultType可以自动将结果封装到实体中 r…...
)
Shell入门(保姆级教学)
Shell是一种命令行解释器,也是一种脚本语言,广泛应用于Unix和类Unix系统中,例如Linux。它是用户与操作系统内核交互的桥梁,通过Shell可以执行系统命令、管理文件系统、处理文本数据等。本文将带你入门Shell编程,涵盖基…...

【JDK11和JDK8并行与切换】
一、JDK11安装 1、下载jdk11,点击.exe安装在:C:\Program Files\Java\jdk-11\ 2、配置JAVA_HOME 变量名为JAVA_HOME 变量值为jdk安装路径 3、配置PATH 找到系统变量里的PATH 双击或者单击后点击编辑 点击右上角的新建 新建两条 %JAVA_HOME%\bin …...

vue大数据量列表渲染性能优化:虚拟滚动原理
前面咱完成了自定义JuanTree组件各种功能的实现。在数据量很大的情况下,我们讲了两种实现方式来提高渲染性能:前端分页和节点数据懒加载。 前端分页小节:Vue3扁平化Tree组件的前端分页实现 节点数据懒加载小节:Element Tree Plu…...

昇思25天学习打卡营第1天|快速入门
目录 昇思MindSpore介绍MindSpore的API来快速实现一个简单的深度学习模型通过资料更深入的了解昇思MindSpore 昇思MindSpore介绍 今天有幸学习了昇思MindSpore,让我们来简单的了解一下它 昇思MindSpore是一个全场景深度学习框架,旨在实现易开发、高效执行…...

LinkedList 实现 LRU 缓存
LRU(Least Recently Used,最近最少使用)缓存是一种缓存淘汰策略,用于在缓存满时淘汰最久未使用的元素。 关键: 缓存选什么结构? 怎么实现访问顺序? import java.util.*;public class LRUCac…...

ubuntu安装workon
pip install virtualenvpip install virtualenvwrapper配置virtualenvwrapper。在你的shell配置文件(比如.bashrc,.bash_profile或.zshrc)中添加以下内容:export WORKON_HOME$HOME/.virtualenvs export VIRTUALENVWRAPPER_PYTHON/…...

连锁超市冷库节能解决方案:如何实现超市降本增效
在连锁超市冷库运营中,高能耗、设备损耗快、人工管理低效等问题长期困扰企业。御控冷库节能解决方案通过智能控制化霜、按需化霜、实时监控、故障诊断、自动预警、远程控制开关六大核心技术,实现年省电费15%-60%,且不改动原有装备、安装快捷、…...

ESP32读取DHT11温湿度数据
芯片:ESP32 环境:Arduino 一、安装DHT11传感器库 红框的库,别安装错了 二、代码 注意,DATA口要连接在D15上 #include "DHT.h" // 包含DHT库#define DHTPIN 15 // 定义DHT11数据引脚连接到ESP32的GPIO15 #define D…...

条件运算符
C中的三目运算符(也称条件运算符,英文:ternary operator)是一种简洁的条件选择语句,语法如下: 条件表达式 ? 表达式1 : 表达式2• 如果“条件表达式”为true,则整个表达式的结果为“表达式1”…...

在 Nginx Stream 层“改写”MQTT ngx_stream_mqtt_filter_module
1、为什么要修改 CONNECT 报文? 多租户隔离:自动为接入设备追加租户前缀,后端按 ClientID 拆分队列。零代码鉴权:将入站用户名替换为 OAuth Access-Token,后端 Broker 统一校验。灰度发布:根据 IP/地理位写…...

sqlserver 根据指定字符 解析拼接字符串
DECLARE LotNo NVARCHAR(50)A,B,C DECLARE xml XML ( SELECT <x> REPLACE(LotNo, ,, </x><x>) </x> ) DECLARE ErrorCode NVARCHAR(50) -- 提取 XML 中的值 SELECT value x.value(., VARCHAR(MAX))…...

uniapp微信小程序视频实时流+pc端预览方案
方案类型技术实现是否免费优点缺点适用场景延迟范围开发复杂度WebSocket图片帧定时拍照Base64传输✅ 完全免费无需服务器 纯前端实现高延迟高流量 帧率极低个人demo测试 超低频监控500ms-2s⭐⭐RTMP推流TRTC/即构SDK推流❌ 付费方案 (部分有免费额度&#x…...

IT供电系统绝缘监测及故障定位解决方案
随着新能源的快速发展,光伏电站、储能系统及充电设备已广泛应用于现代能源网络。在光伏领域,IT供电系统凭借其持续供电性好、安全性高等优势成为光伏首选,但在长期运行中,例如老化、潮湿、隐裂、机械损伤等问题会影响光伏板绝缘层…...
)
Typeerror: cannot read properties of undefined (reading ‘XXX‘)
最近需要在离线机器上运行软件,所以得把软件用docker打包起来,大部分功能都没问题,出了一个奇怪的事情。同样的代码,在本机上用vscode可以运行起来,但是打包之后在docker里出现了问题。使用的是dialog组件,…...
提供了哪些便利?)
现有的 Redis 分布式锁库(如 Redisson)提供了哪些便利?
现有的 Redis 分布式锁库(如 Redisson)相比于开发者自己基于 Redis 命令(如 SETNX, EXPIRE, DEL)手动实现分布式锁,提供了巨大的便利性和健壮性。主要体现在以下几个方面: 原子性保证 (Atomicity)ÿ…...

Redis:现代应用开发的高效内存数据存储利器
一、Redis的起源与发展 Redis最初由意大利程序员Salvatore Sanfilippo在2009年开发,其初衷是为了满足他自己的一个项目需求,即需要一个高性能的键值存储系统来解决传统数据库在高并发场景下的性能瓶颈。随着项目的开源,Redis凭借其简单易用、…...