Chapter 22 数据可视化——折线图
欢迎大家订阅【Python从入门到精通】专栏,一起探索Python的无限可能!
文章目录
- 前言
- 一、Pyecharts介绍
- 二、安装Pyecharts
- 三、全局配置项
- 四、绘制折线图
前言
在大数据时代,数据可视化成为了分析和展示数据的重要手段。Pyecharts 是一个基于 Python 的强大数据可视化库,能够快速生成易于分享和交互的可视化图表。本章详细讲解了 Pyecharts 的官网资源、安装流程、全局配置项以及如何创建折线图。
本篇文章参考:黑马程序员
一、Pyecharts介绍
Pyecharts 是一个基于 Echarts 实现的 Python 可视化库,可以轻松创建交互式的图表。
①pyecharts官网
pyecharts官网提供了详细的文档和使用手册,介绍了 Pyecharts 的各种功能、API 和用法。


②pyecharts画廊官网
Pyecharts 画廊官网展示了大量实际图表的示例,包括各种复杂和多样化的图表。画廊中的图表通常是交互式的,可以在网页上直接与图表进行互动,例如缩放、筛选或者查看详细数据。


二、安装Pyecharts
Win+R 打开运行对话框,在对话框中输入cmd并回车进入命令提示符。

输入pip install pyecharts即可通过网络快速安装第三方包。

检验pyecharts是否可以正常使用,输入python并回车进入python解释器环境,接着输入import pyecharts导入pyecharts包并回车,如果没有报错即可正常使用。

三、全局配置项
Pyecharts 提供了多种全局配置选项,可以帮助我们调整图表的整体外观和行为。这些全局配置项可以在创建图表时进行设置,以改变图表的样式、颜色、标题等属性。
常见的全局配置项:
| 类别 | 配置项 | 说明 |
|---|---|---|
| 图表标题 | title | 主标题 |
| 图表标题 | subtitle | 副标题 |
| 图表标题 | subtext | 副标题详细信息 |
| 图表标题 | link | 点击标题跳转的链接 |
| 图表标题 | target | 标题链接的目标 |
| 图表标题 | textstyle_opts | 字体样式(如颜色、大小等) |
| 提示框 | is_show | 是否显示提示框 |
| 提示框 | trigger | 提示框触发方式(如 'item') |
| 提示框 | formatter | 自定义格式化函数 |
| 图例 | orient | 图例的朝向('horizontal' 或 'vertical') |
| 图例 | pos_left | 图例的左边距 |
| 图例 | pos_top | 图例的上边距 |
| 图例 | data | 显示的图例名称列表 |
| 坐标轴 | name | 坐标轴名称 |
| 坐标轴 | type | 坐标轴类型(如 'value'、'category') |
| 坐标轴 | axislabel_opts | 坐标轴标签样式 |
| 坐标轴 | split_line | 是否显示坐标轴分隔线 |
| 数据缩放 | type | 数据缩放的类型(如 'inside' 或 'slider') |
| 数据缩放 | xaxis_index | 控制哪个 X 轴的数据缩放 |
| 数据缩放 | yaxis_index | 控制哪个 Y 轴的数据缩放 |
| 背景 | backgroundColor | 图表的背景颜色 |
| 背景 | visualMap | 视觉映射配置 |
| 网格 | left | 网格的左边距 |
| 网格 | right | 网格的右边距 |
| 网格 | top | 网格的上边距 |
| 网格 | bottom | 网格的下边距 |
| 网格 | containLabel | 是否包含坐标轴的标签 |
| 其他选项 | animation | 动画关于图表的显示(开启/关闭) |
| 其他选项 | tooltip | 提示框的整体设置 |
| 其他选项 | series | 针对特定系列的设置 |
四、绘制折线图
①基本流程
- 导入必要的模块
- 创建折线图对象
- 添加 X 轴数据
- 添加 Y 轴数据
- 设置全局选项
- 渲染或生成图像
②常见方法
| 方法 | 作用 | 示例 |
|---|---|---|
Line() | 创建折线图对象 | from pyecharts.charts import Line; line = Line() |
add() | 添加数据系列 | line.add_xaxis(x_data).add_yaxis("系列名称", y_data) |
set_global_opts() | 设置全局配置,如标题、工具提示等 | line.set_global_opts(title_opts=opts.TitleOpts(title="图表标题")) |
set_series_opts() | 设置系列特定配置,如标签、样式等 | line.set_series_opts(label_opts=opts.LabelOpts(is_show=True)) |
render() | 渲染图表并保存为 HTML 文件 | line.render("line_chart.html") |
set_colors() | 自定义折线颜色 | line.set_colors(['#d48265', '#91c7ae']) |
set_tooltip() | 自定义 tooltip 的显示方式 | line.set_global_opts(tooltip_opts=opts.TooltipOpts(formatter="{b}: {c}")) |
set_xaxis() | 自定义 x 轴的名称或类型 | line.set_xaxis("自定义 X 轴名称") |
set_yaxis() | 自定义 y 轴的名称或类型 | line.set_yaxis("自定义 Y 轴名称") |
legend() | 设置图例 | line.set_series_opts(legend_opts=opts.LegendOpts(is_show=True)) |
datazoom() | 添加数据缩放控件 | line.set_global_opts(datazoom_opts=[opts.DataZoomOpts()]) |
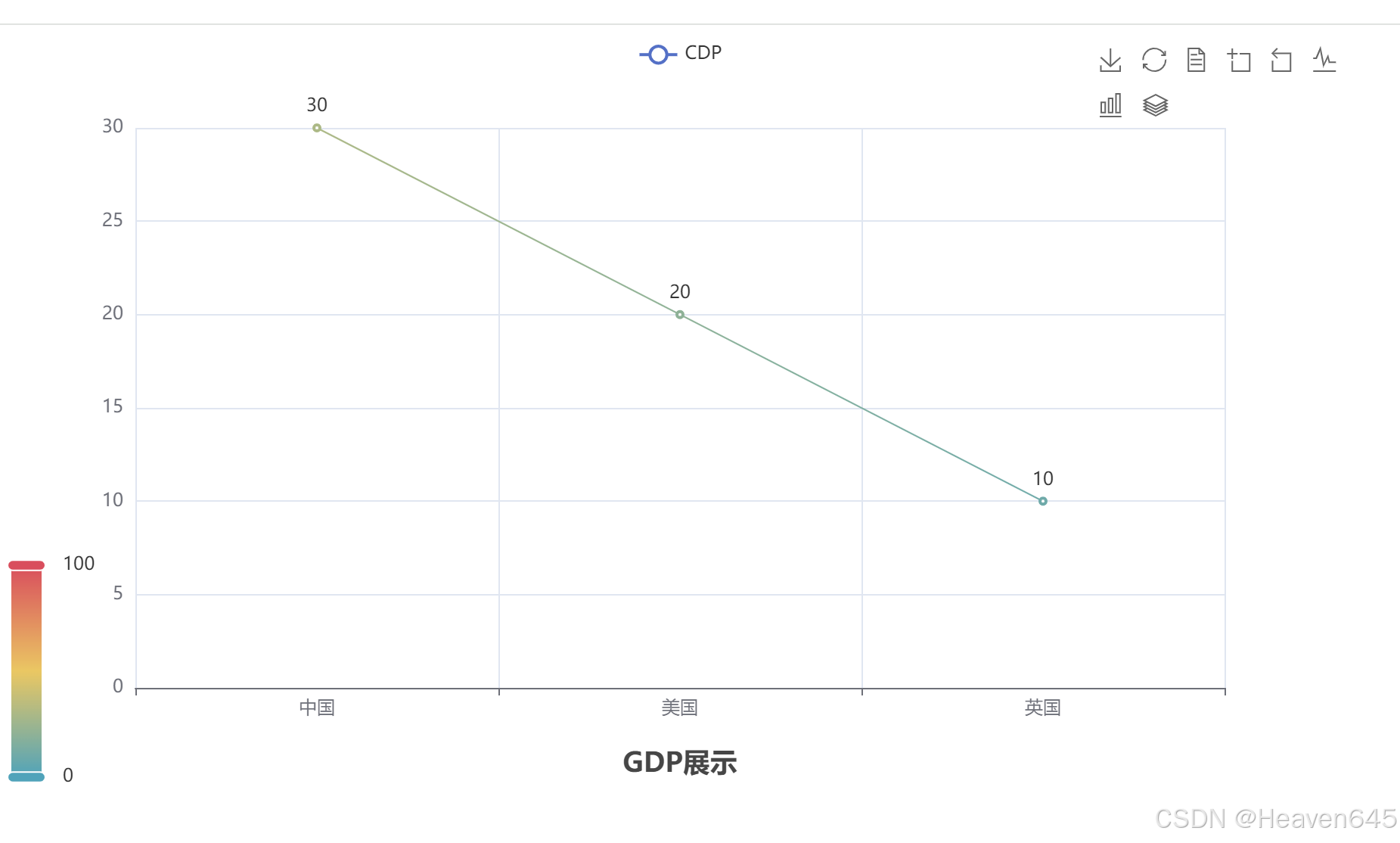
# 导包,导入Line功能构建折线图对象
from pyecharts.charts import Line
# 创建一个折线图对象
line=Line()
# 给折线图对象添加x轴的数据
line.add_xaxis(["中国","美国","英国"])
# 给折线图对象添加y轴的数据
line.add_yaxis("CDP",[30,20,10])
# 通过render方法将代码生成图像
line.render()
运行后line.render() 方法会创建并保存一个包含该折线图的HTML文件。通常情况下,这个文件会被保存在当前工作目录下,文件名默认是 render.html。

打开render.html文件,点击右上角的浏览器图标,可以在浏览器中查看创建的折线图。


进行全局配置后:
# 导包
from pyecharts.charts import Line
from pyecharts.options import TitleOpts
from pyecharts.options import LegendOpts
from pyecharts.options import ToolboxOpts
from pyecharts.options import VisualMapOpts
# 创建一个折线图对象
line=Line()
# 给折线图对象添加x轴的数据
line.add_xaxis(["中国","美国","英国"])
# 给折线图对象添加y轴的数据
line.add_yaxis("CDP",[30,20,10])
# 通过set_global_pots设置全局配置项
line.set_global_opts(# 用于配置图表的标题 title_opts=TitleOpts(title="GDP展示",# 将标题位置设置为居中显示,距底部设置为占图表可用高度的1%pos_left="center",pos_bottom="1%"),# 设置图例的可见性 legend_opts=LegendOpts(is_show=True),# 用于配置工具箱的选项 toolbox_opts=ToolboxOpts(),# 设置视觉映射的可见性 visualmap_opts=VisualMapOpts(is_show=True),
) # 通过render方法将代码生成图像
line.render()
【例题】
根据如下三个文本文件画出2020年ABC三国某疾病确诊人数对比折线图。
A国.txt文本文件内容:
jsonp_1629344292311_69436({“status”:0,“msg”:“success”,“data”:[{“name”:“A国”,“trend”:{“updateDate”:[“2.22”,“2.23”,“2.24”,“2.25”,“2.26”],“list”:[{“name”:“确诊”,“data”:[34,34,34,53,57]},{“name”:“治愈”,“data”:[0,0,3,0,0]},{“name”:“死亡”,“data”:[0,0,0,0,0]},{“name”:“新增确诊”,“data”:[23,0,0,19,4]}]}}]});
B国.txt文本文件内容:
jsonp_1629350871167_29498({“status”:0,“msg”:“success”,“data”:[{“name”:“B国”,“trend”:{“updateDate”:[“2.22”,“2.23”,“2.24”,“2.25”,“2.26”],“list”:[{“name”:“确诊”,“data”:[93,105,132,144,156]},{“name”:“治愈”,“data”:[23,24,24,26,27]},{“name”:“死亡”,“data”:[1,1,1,1,1]},{“name”:“新增确诊”,“data”:[9,12,27,12,12]}]}}]});
C国.txt文本文件内容:
jsonp_1629350745930_63180({“status”:0,“msg”:“success”,“data”:[{“name”:“C国”,“trend”:{“updateDate”:[“2.22”,“2.23”,“2.24”,“2.25”,“2.26”],“list”:[{“name”:“确诊”,“data”:[54,59,67,76,84]},{“name”:“治愈”,“data”:[468,506,620,774,969]},{“name”:“死亡”,“data”:[164,178,226,249,288]},{“name”:“新增确诊”,“data”:[533,565,809,875,846]}]}}]});
要求折线图实现下图效果:

import json
from pyecharts.charts import Line
from pyecharts.options import TitleOpts, LabelOpts# 处理数据
f_a = open("D:/A国.txt", "r", encoding="UTF-8")
a_data = f_a.read() # A国的全部内容f_b = open("D:/B国.txt", "r", encoding="UTF-8")
b_data = f_b.read() # B国的全部内容f_c = open("D:/C国.txt", "r", encoding="UTF-8")
c_data = f_c.read() # C国的全部内容# 去掉不合JSON规范的开头
a_data = a_data.replace("jsonp_1629344292311_69436(", "")
b_data = b_data.replace("jsonp_1629350871167_29498(", "")
c_data = c_data.replace("jsonp_1629350745930_63180(", "")# 去掉不合JSON规范的结尾
a_data = a_data[:-2]
b_data = b_data[:-2]
c_data = c_data[:-2]# JSON转Python字典
us_dict = json.loads(a_data)
jp_dict = json.loads(b_data)
in_dict = json.loads(c_data)# 获取trend key
us_trend_data = us_dict['data'][0]['trend']
jp_trend_data = jp_dict['data'][0]['trend']
in_trend_data = in_dict['data'][0]['trend']# 获取日期数据,用于x轴
us_x_data = us_trend_data['updateDate']
jp_x_data = jp_trend_data['updateDate']
in_x_data = in_trend_data['updateDate']# 获取确认数据,用于y轴
us_y_data = us_trend_data['list'][0]['data']
jp_y_data = jp_trend_data['list'][0]['data']
in_y_data = in_trend_data['list'][0]['data']# 生成图表
line = Line() # 构建折线图对象
# 添加x轴数据
line.add_xaxis(us_x_data) # x轴是公用的,所以使用一个国家的数据即可
# 添加y轴数据
line.add_yaxis("A国确诊人数", us_y_data, label_opts=LabelOpts(is_show=False)) # 添加A国的y轴数据
line.add_yaxis("B国确诊人数", jp_y_data, label_opts=LabelOpts(is_show=False)) # 添加B国本的y轴数据
line.add_yaxis("C国确诊人数", in_y_data, label_opts=LabelOpts(is_show=False)) # 添加C国的y轴数据# 设置全局选项
line.set_global_opts(# 标题设置title_opts=TitleOpts(title="2020年ABC三国某疾病确诊人数对比折线图", pos_left="center", pos_bottom="1%")
)# 调用render方法,生成图表
line.render("render2.html")
# 关闭文件对象
f_a.close()
f_b.close()
f_c.close()
运行后打开render2.html文件并在浏览器中查看创建的折线图:

相关文章:
Chapter 22 数据可视化——折线图
欢迎大家订阅【Python从入门到精通】专栏,一起探索Python的无限可能! 文章目录 前言一、Pyecharts介绍二、安装Pyecharts三、全局配置项四、绘制折线图 前言 在大数据时代,数据可视化成为了分析和展示数据的重要手段。Pyecharts 是一个基于 …...

管理流创建schema流程源码解析
一、简析 schema是pulsar重要的功能之一,现在就一起从源码的视角看下管理流创建schema时客户端和服务端的表现 客户端 客户端主要经历以下四个步骤 创建Schema实例 根据数据类型创建相对应的实例,例如Avro创建AvroSchema、JSON创建JSONSchema等 获取…...

【iOS】iOS内存五大分区
iOS内存五大分区 总揽 iOS中,内存主要分为五大区域:栈区,堆区,全局区/静态区,常量区和代码区。总览图如下。 这个图我觉得更好记,因为下面是低地址,上面是高地址,是比较符合日常…...

【项目实战】—— 高并发内存池
文章目录 什么是高并发内存池?项目介绍一、项目背景二、项目目标三、核心组件四、关键技术五、应用场景六、项目优势 什么是高并发内存池? 高并发内存池是一种专门设计用于高并发环境下的内存管理机制。它的原型是Google的一个开源项目tcmallocÿ…...

二叉搜索树的第 k 大的节点
题目描述 给定一棵二叉搜索树,请找出其中第 k 大的节点。 解题基本知识 二叉搜索树(Binary Search Tree)又名二叉查找树、二叉排序树。它是一棵空树,或者是具有下列性质的二叉树: 若它的左子树不空,则左子…...

利用langchain 做大模型 Few-shot Learning 提示,包括固定和向量相似的动态样本筛选
文章目录 few-shotFixed Examples 固定样本Dynamic few-shot prompting 动态样本提示辅助参考资料 few-shot 相比大模型微调,在有些情况下,我们更想使用 Few-shot Learning 通过给模型喂相关样本示例,让模型能够提升相应任务的能力。 固定样…...

基于python的百度迁徙迁入、迁出数据分析(五)
终于在第五篇文章我们进入了这个系列的正题:数据分析 这里我选择上海2024年5月1日——5月5日的迁入、迁出数据作为分析的基础,首先选择节假日的数据作为分析的原因呢,主要是节假日人们出行目的比较单一(出游、探亲)&a…...

SpringBoot 如何处理跨域请求
SpringBoot 处理跨域请求,通常是通过配置全局的 CORS(跨源资源共享)策略来实现的。CORS 是一种机制,它使用额外的 HTTP 头部来告诉浏览器,让运行在一个 origin (domain) 上的 web 应用被准许访问来自不同源服务器上的指…...

大数据技术基础编程、实验和案例----大数据课程综合实验案例
一、实验目的 (1)熟悉Linux系统、MySQL、Hadoop、HBase、Hive、Sqoop、R、Eclipse等系统和软件的安装和使用; (2)了解大数据处理的基本流程; (3)熟悉数据预处理方法; (4)熟悉在不同类型数据库之…...

微信小程序-获取手机号:HttpClientErrorException: 412 Precondition Failed: [no body]
问题: 412 异常就是你的请求参数获取请求头与服务器的不符,缺少请求体! 我的问题: 我这里获取微信手机号的时候突然给我报错142,但是代码用的是原来的代码,换了一个框架就噶了! 排查问题&am…...

大数据核心概念与技术架构简介
大数据基本概念 大数据是指无法在一定时间范围内用常规软件工具进行捕捉、管理和处理的数据集合,是具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。 大数据特征: 数据量大:一般以P(1000个TB&a…...

快排 谁在中间
原题 Whos in the Middle FJ is surveying his herd to find the most average cow. He wants to know how much milk this median cow gives: half of the cows give as much or more than the median; half give as much or less. FJ正在调查他的牛群,以找到最…...

ORA-00911: invalid character
场景: 调用接口查询oracle的数据库数据时报错ORA-00911: invalid character,但是sql语句没有问题放在navicat控制台中运行也没有问题,但是代码中跑就会报无效字符集 分析: 代码中Oracle的语法解析器比较严格,比如句…...

Pytorch实现线性回归Linear Regression
借助 PyTorch 实现深度神经网络 - 线性回归 - 第 2 周 | Coursera 线性回归预测 用PyTorch实现线性回归模块 创建自定义模块(内含一个线性回归) 训练线性回归模型 对于线性回归,特定类型的噪声是高斯噪声 平均损失均方误差函数:…...

十八次(虚拟主机与vue项目、samba磁盘映射、nfs共享)
1、虚拟主机搭建环境准备 将原有的nginx.conf文件备份 [rootserver ~]# cp /usr/local/nginx/conf/nginx.conf /usr/local/nginx/conf/nginx.conf.bak[rootserver ~]# grep -Ev "#|^$" /usr/local/nginx/conf/nginx.conf[rootserver ~]# grep -Ev "#|^$"…...

P1340 兽径管理 题解|最小生成树
题目大意 洛谷中链接 推荐文章:并查集入门 原文 约翰农场的牛群希望能够在 N N N 个草地之间任意移动。草地的编号由 1 1 1 到 N N N。草地之间有树林隔开。牛群希望能够选择草地间的路径,使牛群能够从任一 片草地移动到任一片其它草地。 牛群可在…...

Python,Maskrcnn训练,cannot import name ‘saving‘ from ‘keras.engine‘ ,等问题集合
Python版本3.9,tensorflow2.11.0,keras2.11.0 问题一、module keras.engine has no attribute Layer Traceback (most recent call last):File "C:\Users\Administrator\Desktop\20240801\代码\test.py", line 16, in <module>from mrc…...

Linux常用工具
文章目录 tar打包命令详解unzip命令:解压zip文件vim操作详解netstat详解df命令详解ps命令详解find命令详解 tar打包命令详解 tar命令做打包操作 当 tar 命令用于打包操作时,该命令的基本格式为: tar [选项] 源文件或目录此命令常用的选项及…...

AI未来的发展如何
AI(人工智能)的发展前景非常广阔,随着技术的不断进步和应用场景的不断拓展,AI将在多个领域发挥重要作用。以下是对AI发展前景的详细分析: 一、技术突破与创新 生成式AI的兴起:以ChatGPT为代表的生成式AI技…...

若依替换首页上的logo
...

ssc377d修改flash分区大小
1、flash的分区默认分配16M、 / # df -h Filesystem Size Used Available Use% Mounted on /dev/root 1.9M 1.9M 0 100% / /dev/mtdblock4 3.0M...

在 Nginx Stream 层“改写”MQTT ngx_stream_mqtt_filter_module
1、为什么要修改 CONNECT 报文? 多租户隔离:自动为接入设备追加租户前缀,后端按 ClientID 拆分队列。零代码鉴权:将入站用户名替换为 OAuth Access-Token,后端 Broker 统一校验。灰度发布:根据 IP/地理位写…...

ETLCloud可能遇到的问题有哪些?常见坑位解析
数据集成平台ETLCloud,主要用于支持数据的抽取(Extract)、转换(Transform)和加载(Load)过程。提供了一个简洁直观的界面,以便用户可以在不同的数据源之间轻松地进行数据迁移和转换。…...

Aspose.PDF 限制绕过方案:Java 字节码技术实战分享(仅供学习)
Aspose.PDF 限制绕过方案:Java 字节码技术实战分享(仅供学习) 一、Aspose.PDF 简介二、说明(⚠️仅供学习与研究使用)三、技术流程总览四、准备工作1. 下载 Jar 包2. Maven 项目依赖配置 五、字节码修改实现代码&#…...

SpringAI实战:ChatModel智能对话全解
一、引言:Spring AI 与 Chat Model 的核心价值 🚀 在 Java 生态中集成大模型能力,Spring AI 提供了高效的解决方案 🤖。其中 Chat Model 作为核心交互组件,通过标准化接口简化了与大语言模型(LLM࿰…...

高效的后台管理系统——可进行二次开发
随着互联网技术的迅猛发展,企业的数字化管理变得愈加重要。后台管理系统作为数据存储与业务管理的核心,成为了现代企业不可或缺的一部分。今天我们要介绍的是一款名为 若依后台管理框架 的系统,它不仅支持跨平台应用,还能提供丰富…...

拟合问题处理
在机器学习中,核心任务通常围绕模型训练和性能提升展开,但你提到的 “优化训练数据解决过拟合” 和 “提升泛化性能解决欠拟合” 需要结合更准确的概念进行梳理。以下是对机器学习核心任务的系统复习和修正: 一、机器学习的核心任务框架 机…...

Python第七周作业
Python第七周作业 文章目录 Python第七周作业 1.使用open以只读模式打开文件data.txt,并逐行打印内容 2.使用pathlib模块获取当前脚本的绝对路径,并创建logs目录(若不存在) 3.递归遍历目录data,输出所有.csv文件的路径…...

k8s从入门到放弃之Pod的容器探针检测
k8s从入门到放弃之Pod的容器探针检测 在Kubernetes(简称K8s)中,容器探测是指kubelet对容器执行定期诊断的过程,以确保容器中的应用程序处于预期的状态。这些探测是保障应用健康和高可用性的重要机制。Kubernetes提供了两种种类型…...

Easy Excel
Easy Excel 一、依赖引入二、基本使用1. 定义实体类(导入/导出共用)2. 写 Excel3. 读 Excel 三、常用注解说明(完整列表)四、进阶:自定义转换器(Converter) 其它自定义转换器没生效 Easy Excel在…...